| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
モデル・ノードでは、構築するモデルおよびワークフローに追加するモデルを指定します。「コンポーネント」ペインの「モデル」セクションに、モデル・ノードが含まれています。「コンポーネント」ペイン内のモデルは次のとおりです。
使用可能なモデルのタイプは次のとおりです。
異常検出ノード: 1クラス・サポート・ベクター・マシン(SVM)を使用して異常検出モデルを構築します。
相関ノード: マーケット・バスケット分析用のモデルを構築します。
分類ノード: 同じターゲット、ケースID、コストおよび分割(該当する場合)の設定を使用して分類モデルを構築し、テストします。このモデルでは、サポート・ベクター・マシン(SVM)、Naive Bayes (NB)、ディシジョン・ツリー(DT)、および一般化線形モデル(GLM)の分類アルゴリズムを使用します。
クラスタリング・ノード: クラスタリング・アルゴリズムのk-Means、O-Clusterおよび期待値の最大化(EM)を使用してクラスタリング・モデルを構築します。EMには、Oracle Database 12c以上が必要です。
特徴抽出ノード: 特徴抽出アルゴリズムのNon-Negative Matrix Factorization、主成分分析(PCA)および特異値分解(SVD)を使用して特徴抽出モデルを構築します。PCAおよびSVDには、Oracle Database 12c以上が必要です。
モデル・ノード: 現在のワークフローでは構築されなかったモデルをワークフローに追加します。このノードには入力データがありません。
モデル詳細ノード: モデル構築ノード、モデル・ノードまたはモデルを生成する任意のノードからモデルの詳細を抽出します。
回帰ノード: 同じターゲット、ケースID、コストおよび分割(該当する場合)の設定を使用して、回帰モデルの集合を構築およびテストします。このモデルは、回帰アルゴリズムSVMおよびGLMを使用します。
モデルの構築に使用されるデータは適切に準備されている必要があります。アルゴリズムごとに必要な入力が異なります。たとえば、Naive Bayesにはビニングされたデータが必要です。
ADPでは、アルゴリズムの要件に従って作成データが変換され、モデルに変換の指示が組み込まれて、モデルの適用時にテスト・データまたはスコアリング・データを変換する際にその指示が使用される。
Oracle Database 12cに接続している場合、ADPによりテキスト・データが準備されます。
|
関連項目: 『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』 |
次のいくつかの例は、ADPによって数値データがどのように準備されるかを示しています。
ビニングされたデータを必要とするアルゴリズム(Naive Bayesなど)の場合、ADPは監視ありビニングを実行します。監視ありビニングは、予測子内の適切なカット位置を特定するためにターゲットを考慮に入れる特殊なビニング方法です。
正規化されているデータが必要なアルゴリズム(サポート・ベクター・マシンなど)の場合、数値データが正規化されます。
変換されていないデータを扱うことができるアルゴリズム(ディシジョン・ツリーなど)の場合、数値データを使用して、監視ありビニングと同様の方法でツリー内のスプリッタを特定できます。
Oracle Data Minerでは、モデルを構築する際に必ずしもデータ・ソースのすべての列を使用するとはかぎりません。モデル構築ノードでは、一連の経験則を使用して、モデル構築プロセスから列を除外するかどうか、または単にマイニング型を数値型からカテゴリ型に変更するかが決定されます。
モデル構築に特定の列を使用ない理由がいくつかあります。有用な情報が含まれていない列は、通常使用されません。
モデルを構築するために入力として使用される属性の正確なリストは、モデルの構築に使用されるアルゴリズムごとに異なります。あるアルゴリズムが特定のデータ型をサポートしない場合、Oracle Data Minerは、そのデータ型の属性を入力として使用しません。
分類モデルなどのターゲットを持つモデルの場合は、ターゲットをテキストにすることはできません。
同じマイニング型がすべてのモデルに使用されます。
Oracle Database 12cに接続している場合、構築ノードの編集時にテキスト属性の特性を指定できます。
モデルのデータの使用方法は、次の場所で表示および変更できます。
構築ノードを編集するには、次の手順を実行します。
ノードをダブルクリックするか、ノードを右クリックして「編集」を選択します。
「入力」タブをクリックします。「入力」タブでは、すべてのモデルに対してデフォルトで「入力を自動的に判定(ヒューリスティックを使用)」フィールドが選択されています。Oracle Data Minerは、入力に使用する属性およびその属性の特性を決定します。また、Oracle Data Minerはマイニング型を決定し、すべての属性に対して自動データ準備が実行されることを指定します。
モデルの実行後に、Oracle Data Minerは、属性の除外やマイニング型の変更など、これが行った変更を示すルールを生成します。経験則の詳細情報を表示するには、「表示」をクリックします。
|
注意: これらの手順を使用して、相関モデルのデータの使用方法を表示および編集できません。 |
Oracle Data Minerでは、有用な情報を提供しない属性は使用されません。たとえば、ほぼ不変の属性は入力に適さないと考えられます。
ノードの実行後に、使用された経験則がルールに示されます。詳細情報を表示するには、「表示」をクリックします。
入力を手動で指定するには、入力を自動的に判定(経験則を使用)の選択を解除します。次の変更が可能です。
属性を無視する場合: 属性を入力として使用しない場合は、「入力」列に移動して出力アイコン をクリックします。無視アイコン
をクリックします。無視アイコン を選択して、「OK」をクリックします。属性は使用されません。これは無視されます。
を選択して、「OK」をクリックします。属性は使用されません。これは無視されます。
同様に、無視した属性を使用するには、「入力」列内のをクリックしてを選択します。属性がモデル構築に使用されます。
属性のマイニング型を変更する場合: 「マイニング型」列に移動してドロップダウン・リストからオプションを選択します。
数値型
カテゴリ型
テキストのマイニング型は、「テキスト」および「テキスト・カスタム」です。列レベルのテキスト指定を作成するには、「テキスト・カスタム」を選択します。
手動でデータを準備する場合: デフォルトで、すべての属性に対して自動データ準備(ADP)が実行されます。ある属性について自動データ準備の実行が不要な場合は、「自動準備」列で該当の属性に対応するチェック・ボックスの選択を解除します。「自動準備」をオフにする場合は、その属性のデータ準備に対して責任を持つ必要があります。
|
注意: ある属性のマイニング型が「テキスト」または「テキスト・カスタム」である場合、ADPの選択を解除できません。 |
Oracle Data Minerにより選択されている列および選択されている各列に割り当てられているマイニング型を表示にするには、次の手順を実行します。
|
注意: これらの手順を使用して、相関モデルのデータの使用方法を表示および編集できません。 |
データ・ソース・ノードをモデル・ノードに接続します。
モデル・ノードを右クリックして「実行」を選択します。
次のいずれかの方法で、「詳細設定」ダイアログ・ボックスを開きます。
モデル構築の完了後に、モデル・ノードを右クリックして「編集」を選択します。
「編集」ダイアログ・ボックスが開きます。「拡張」をクリックします。
モデル構築の完了後に、モデル・ノードを右クリックして「詳細設定」を選択します。
「詳細設定」には、次の2つのグリッドがあります。
「モデル設定」グリッド: 上部のグリッドには、ノードにより構築されたモデルがリストされます。
ダイアログ・ボックスの下部は、次のタブ表示です。
データの使用方法: 「データの使用方法」タブには、モデル構築に対して選択された列、各列でモデル構築に使用されたマイニング型、データ型、入力、自動データ準備およびルールに関する情報が表示されます。
ルール(経験則)の詳細情報を表示するには、「表示」をクリックします。
アルゴリズム設定
パフォーマンス設定
モデル構築の入力として使用された列を表示するには、モデルを選択します。「データの使用方法」タブでは、モデル構築ルールで使用された属性により、属性に適用された経験則が示されます。たとえば、マイニング型が変更されている可能性があります。詳細を確認するには「表示」をクリックします。
データの使用方法の情報は、モデルごとに変更できますが、複数のモデルのデータの使用方法を同時に変更することも可能です。
複数のモデルのデータの使用方法を変更するには、[Ctrl]キーを押しながら複数のモデルをクリックして選択します。変更を行い、「OK」をクリックします。選択されているすべてのモデルに対して、データの使用方法の変更が行われます。
|
注意: 自動データ準備をオフにすることも可能です。これはお薦めしません。自動データ準備をオフにした場合、各アルゴリズムに対して入力が正しく準備されていることを保証する必要があります。 |
Oracle Database 12cに接続している場合、「モデル構築の編集」ダイアログ・ボックスの「テキスト」でテキスト特性を指定できます。
「テキスト」タブでテキスト特性を指定する場合、テキスト・ノードを使用する必要はありません。
|
注意: Oracle Database 11gリリース2 (11.2)以前に接続している場合は、テキスト・ノードを使用します。「テキスト」タブは、Oracle Database 11gリリース2以前では使用できません。 |
テキストは、CHAR、VARCHAR2、BLOB、CLOB、NCHARまたはNVARCHAR2のいずれのデータ型でも使用可能です。
データ・マイニング用のテキスト特性を確認または指定するには、構築ノードをダブルクリックするか、ノードを右クリックしてコンテキスト・メニューから「編集」を選択します。「テキスト」タブをクリックします。
「テキスト」タブを使用すると、次を変更できます。
カテゴリ型のカットオフ値: 列がテキストまたはカテゴリのどちらのマイニング型とみなされるかを決定するために使用されるカットオフを制御できます。カットオフ値は整数です。これは、10以上4000以下である必要があります。デフォルト値は200です。
デフォルトの変換タイプ: 列レベル・テキスト設定のデフォルトの変換タイプを指定します。値は次のとおりです。
トークン(デフォルト): 「トークン」が選択されている場合、デフォルト設定は次のとおりです。
言語: ドキュメントで使用される言語を指定します。デフォルトは「英語」です。この値を変更するには、ドロップダウン・リストからオプションを選択します。複数の言語を選択できます。
ステミング: デフォルトでは、このオプションは選択されていません。
一部の言語ではステミングはサポートされません。選択されている言語が英語、オランダ語、フランス語、ドイツ語、イタリア語またはスペイン語である場合、ステミングは自動的に有効になっています。
ステミングが有効である場合、ステミングされた語句がサポート対象言語に対して戻されます。そうでない場合は、元の語句が戻されます。
ストップリスト: 使用するストップリストを指定します。デフォルト設定では、デフォルトのストップリストを使用します。ストップリストは追加または編集が可能です。
複数の言語を選択し、選択されているストップリストが「デフォルト」である場合、その言語のデフォルトのストップワードがリポジトリからデフォルトのストップリストに追加されます。重複したストップワードは追加されません。
トークン: すべてのドキュメントにわたるトークンの最大数を指定します。デフォルトは3000です。
テーマ: 「テーマ」が選択されている場合、デフォルト設定は次のとおりです。
言語: ドキュメントで使用される言語を指定します。デフォルトはアラビア語です。この値を変更するには、ドロップダウン・リストから値を選択します。複数の言語を選択できます。
ストップリスト: 使用するストップリストを指定します。デフォルト設定では、デフォルトのストップリストを使用します。ストップリストは追加または編集が可能です。
複数の言語を選択し、選択されているストップリストが「デフォルト」である場合、その言語のデフォルトのストップワードがデフォルトのストップリストに追加されます(リポジトリから)。重複したストップワードは追加されません。
テーマ: すべてのドキュメントにわたるテーマの最大数を指定します。デフォルトは3000です。
ストップリスト・エディタを開くには、「ストップリスト」をクリックします。ストップリストは、表示、編集および作成が可能です。
すべてのテキスト列に対して同じストップリストを使用できます。
モデル構築ノードのプロパティは、次のいずれかの方法で表示できます。
ノードを選択して「表示」に移動し、「プロパティ」をクリックします。必要に応じて「プロパティ」タブをクリックします。
ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
モデル・ノードの「プロパティ」には、次のセクションがあります。
以前のリリースでは、「プロパティ」はプロパティ・インスペクタと呼ばれていました。
「モデル」セクションには、ノードで定義されているモデルのリストが表示されます。デフォルト設定では、ノードでサポートされているアルゴリズムごとに1つのモデルが構築されます。
各モデルに対して、モデルの名前、構築情報、アルゴリズムおよびコメントがグリッド内にリストされます。「構築」列には、最新の構築成功日時、またはモデルが構築されていないか正常に構築されなかったかが示されます。
リスト内のモデルを追加、削除または表示できます。モデルが後続のノードに渡されたかどうかを示すこともできます。
リストからモデルを削除するには、それを選択して をクリックします。
をクリックします。
モデルを追加するには、 をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
正常に構築されたモデルを表示するには、モデルを選択して をクリックします。
をクリックします。
分類モデルは「プロパティ」ペインからチューニングできます。
「モデル設定」グリッドの「出力」列では、後続ノードへのモデルの受渡しを制御します。デフォルト設定では、すべてのモデルが後続ノードに渡されます。
モデルを無視するには、つまり後続ノードに渡さないようにするには、 をクリックします。出力アイコンが無視アイコンに置き換わります。
をクリックします。出力アイコンが無視アイコンに置き換わります。
無視を取り消すには、「無視」アイコンを再度クリックします。出力アイコンになります。
「モデルの追加」ダイアログ・ボックスでは、モデルをノードに追加できます。
モデルをノードに追加するには、次の手順を実行します。
「アルゴリズム」フィールドで、ドロップダウン・リストからアルゴリズムを選択します。たとえば、クラスタリング・ノードにモデルを追加する場合、使用可能なアルゴリズムはk-MeansおよびO-Clusterです。
デフォルトのモデル名が表示されます。デフォルトのモデルを変更できます。
「コメント」フィールドにコメントを追加します(該当する場合)。これはオプションのフィールドです。
「OK」をクリックします。
ターゲットを持つモデル(分類および回帰)では、ターゲットがリストされます。ノード内のすべてのモデルは、同じターゲットを持ちます。このセクションには、次の項目が表示されます。
ターゲット: ターゲットが表示されます。ターゲットを変更するには、ドロップダウン・リストから新しいターゲットを選択します。
ケースID: このノードで定義されたモデルのケースIDが表示されます。ノード内のすべてのモデルは、同じケースIDを持ちます。ケースIDを編集するには、ドロップダウン・リストから別のケースIDを選択します。
トランザクションID: 相関モデルに対してのみ表示されます。トランザクションIDを変更するには、「編集」をクリックします。
項目ID: 相関モデルに対してのみ表示されます。値を変更するには、ドロップダウン・リストからオプションを選択します。
項目値: 相関モデルに対してのみ表示されます。値を変更するには、ドロップダウン・リストからオプションを選択します。
「テスト」セクションは、分類および回帰モデルに対して表示されます。これらのモデルのみ、テストが可能です。
「テスト」セクションでは、テストの実行方法を定義します。デフォルトでは、すべてのモデルがテストされます。ノード内のすべてのモデルは、同じ方法でテストされます。
「詳細」セクションには、ノード名およびノードに関するコメントが表示されます。このセクションから、ノード名の変更およびコメントの編集が可能です。新しいノード名およびコメントは、「ノード名およびノードのコメント」の要件を満たす必要があります。
異常検出ノードでは、1クラスSVMアルゴリズムを使用して、不正行為などの発生頻度が低い事象を検出する1つ以上モデルが構築されます。
異常検出には、次の2つの方法があります。
異常検出モデルを構築して適用します。
予測問合せノードの1つである、異常検出問合せを使用します。
異常検出構築は、パラレルに実行できます。
次の項では、異常検出ノードについて説明します。
初めにワークフローを作成し、次にデータ・ソース・ノードを特定または作成します。モデル・ノードの入力は、変換ノードやデータ・ノードを含む、出力としてデータを生成する任意のノードです。
異常検出ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、「ワークフロー・エディタ」をクリックします。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「異常検出」をクリックします。
異常検出ノードを「ワークフロー」ペインにドラッグ・アンド・ドロップします。
|
注意: ノードに関連付けられたデータがないことがGUIに表示されます。 |
構築用にデータを提供するノードに移動します。右クリックして「接続」をクリックします。異常検出ノードへ線までドラッグし、再度クリックします。
ケースIDの指定、データの使用方法の編集およびアルゴリズム設定の変更も可能です。これらのいずれかのタスクを実行するには、ノードを右クリックして「編集」を選択します。
これでノードは構築準備ができました。ノードを右クリックして、「実行」をクリックします。
異常検出ノードの編集ダイアログ・ボックスで、構築するモデルの特性を指定または変更できます。
異常検出ノードの編集ダイアログ・ボックスを開くには、異常検出ノードをダブルクリックするか、異常検出ノードを右クリックして「編集」を選択します。
異常検出ノードの編集ダイアログ・ボックスには次のタブがあります。
入力
テキスト
異常検出用の「構築」タブには、構築するモデルおよびケースIDがリストされます。次のように指定します。
「ケースID」を選択します。「ケースID」リストから属性を1つ選択します。この属性は、ケースを一意に識別する必要があります。
|
注意: ケースIDは必須ではありません。ただし、ケースIDにより構築およびテストを反復しやすくなります。ケースIDは、GLM診断情報の生成には必須です。 |
ケースIDを指定すると、ノード内のすべてのモデルが同じケースIDを持ちます。
「モデル設定」リストで、構築するモデルを指定します。次のタスクも実行できます。
モデルを追加するには、をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
モデルを編集するには、モデルを選択して をクリックします。「詳細モデル設定」ダイアログ・ボックスが開きます。
をクリックします。「詳細モデル設定」ダイアログ・ボックスが開きます。
モデルを削除するには、モデルを選択してをクリックします。
既存のモデルをコピーするには、モデルを選択して をクリックします。
をクリックします。
ノードの定義を完了するには、「OK」をクリックします。
「入力」タブでは、モデル構築の入力を指定します。
すべてのモデルに対して入力を自動的に判定(経験則を使用)がデフォルトで選択されています。Oracle Data Minerにより、入力に使用する属性が決定されます。たとえば、ほぼ不変の属性は入力に適さないと考えられます。また、Oracle Data Minerはマイニング型を決定し、すべての属性に対して自動データ準備が実行されることを指定します。
ノードの実行後に、経験則を説明するルールが示されます。詳細情報を確認するには、「表示」をクリックします。
これらの選択内容を変更できます。これを行うには、入力を自動的に判定(経験則を使用)の選択を解除します。
詳細設定を変更または表示するには、ノードを右クリックして「詳細設定」を選択します。
「詳細設定」ダイアログ・ボックスには、上部ペインの「モデル設定」セクションにすべてのモデルがリストされます。モデルを追加したりノードから削除できます。
モデルを削除するには、それを選択してをクリックします。
モデルを追加するには、 をクリックします。「モデルの追加」(AD)ダイアログ・ボックスが開きます。
をクリックします。「モデルの追加」(AD)ダイアログ・ボックスが開きます。
モデルのデータ使用方法を変更するには、上部ペインでモデルを選択します。「データの使用方法」で必要な変更を行います。
デフォルトのアルゴリズムを変更するには、上部ペインでモデルを選択します。「アルゴリズム設定」タブで必要な変更を行います。
異常検出ノードのプロパティでは、ノードで定義されているモデルに関する情報の表示および変更が可能です。
異常検出ノードのプロパティを表示するには、ノードを選択します。
「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
異常検出の「プロパティ」ペインには、次のセクションがあります。
「モデル」セクションには、ノードで定義されているモデルのリストが表示されます。デフォルトでは、1つのモデルが構築されます。
各モデルに対して、モデルの名前、構築情報、アルゴリズムおよびコメントがグリッド内にリストされます。「構築」列には、最新の構築成功日時、またはモデルが構築されていないか正常に構築されなかったかが示されます。
リスト内のモデルを追加、削除または表示できます。また、「出力列(AD)」で説明しているように、どのモデルが後続ノードに渡されるか、または渡されないかを示すことができます。
モデルを削除するには、それを選択してをクリックします。
モデルを追加するには、をクリックします。「モデルの追加」(AD)モデル・ダイアログ・ボックスが開きます。
モデルを表示するにはをクリックします。適切なモデル・ビューアが開きます。
モデルを複製するには、モデルを選択してをクリックします。
「モデル設定」グリッドの「出力」列では、後続ノードへのモデルの受渡しを制御します。デフォルトでは、すべてのモデルが後続ノードに渡されます。
モデルを無視するにはをクリックします。出力アイコンが無視アイコンに置き換わります。
無視を取り消すには、「無視」アイコンを再度クリックします。アイコンが出力アイコンに変わります。
「モデルの追加」ダイアログ・ボックスでは、ノードのモデルを追加または変更できます。アルゴリズムはすでに選択されています。モデルを追加するには、次の手順を実行します。
「アルゴリズム」フィールドには、選択されているアルゴリズムが表示されます。これを変更して、ドロップダウン・リストから別のアルゴリズムを選択できます。
「名前」フィールドに、モデルの名前を入力します。
「コメント」フィールドにコメントを追加します(該当する場合)。これはオプションのフィールドです。
「OK」をクリックします。
「構築」セクションには、ノードで定義されているモデルのケースIDが表示されます。ノード内のすべてのモデルは、同じケースIDを持ちます。
ケースIDを変更するには、リストから別の属性を選択します。
異常検出ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。異常検出ノードの編集が開きます。
詳細設定。「詳細モデル設定」が開きます。
モデルの表示。選択されているモデルの異常検出モデル・ビューアが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
相関ノードは、1つ以上の相関モデルを定義します。構築用のデータを指定するには、データ・ソース・ノードを相関ノードに接続します。
相関ノード内のすべてのモデルは、同じ入力データを持ちます。
|
注意: 相関モデル用のデータは、トランザクション形式である必要があります。 |
相関モデルは、信頼度および支持度の低いルールを非常に多く生成する場合もあれば、ルールをまったく生成しない場合もあります。
相関構築は、パラレルに実行できます。
この項では、次の項目について説明します。
デフォルトでは、相関ノードはAprioriアルゴリズムを使用して1つのモデルを構築します。Aprioriアルゴリズムでは、次のことが想定されます。
データはトランザクショナル・データです。
データには多くの欠損値があります。Aprioriアルゴリズムは、すべての欠損値をスパース・データとして解釈し、スパース・データを処理するための独自のメカニズムを持っています。
ノード内のすべてのモデルは、同じケースID、項目IDおよび項目値を持ちます。ケースIDは2列にすることができます。たとえば、データ・ソースSH.SALESの場合、CUST_IDとTIME_IDの組合せをケースIDにすることができます。
相関ノードに対しては、自動データ準備は実行されません。「アイテム値」の値としてデフォルトの<存在>以外の値を選択した場合、データの準備が必要な場合があります。
初めにワークフローを作成し、データ・ソースを特定または作成します。
|
注意: 相関モデルの構築に使用されるデータは、トランザクション形式である必要があります。 |
相関ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、「ワークフロー・エディタ」を選択します。
「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「相関」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないこと、およびそれを構築できないことがGUIに表示されます。
構築用にデータを提供するノードに移動します。ノードを右クリックして、「接続」をクリックします。相関ノードまで線をドラッグし、再度クリックします。
「アソシエーション・ビルド・ノードの編集」が開きます。
相関ノードに対して、次を指定します。
トランザクションID: をクリックして1つ以上のトランザクションIDを挿入します。
項目ID: ドロップダウン・リストからオプションを選択します。
値: 存在(デフォルト)
「OK」をクリックします。
ノードの定義が終了すると、ノードの構築準備が完了します。ノードを右クリックして、「実行」をクリックします。
相関構築ノード・エディタでは、作成するモデルの特性を指定または変更できます。相関構築ノードの編集ダイアログ・ボックスを開くには、相関ノードをダブルクリックするか、相関ノードを右クリックして「編集」を選択します。
すべてのモデル・ノードに対して次を指定します。
トランザクションID: これらは、トランザクションを一意に識別する属性の組合せです。トランザクションIDを指定するには、をクリックします。「列の選択」(AR)が開きます。1つ以上の属性を、「使用可能な属性」リストから「選択された属性」リストに移動します。「OK」をクリックします。
アイテムID: 項目を識別します。リストから属性を選択します。
アイテム値: 存在(デフォルト)。ドロップダウン・リストから属性を選択できます。これはオプションのフィールドです。
項目値列では、(リンゴ3個などの)項目数、(マッキントッシュのリンゴなどの)項目タイプなどの情報を指定できます。
リストから属性を選択する場合、その属性は10より少ない数の個別値を持っている必要があります。最大個別件数のデフォルト値は10です。相関のモデル構築プリファレンスの値を変更できます。
|
注意: 項目値の属性を指定する場合、データの準備が必要な場合があります。 |
次のタスクを実行できます。
モデルの追加: をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
モデルの削除: モデルを選択してをクリックします。
モデルの編集: モデルを選択してをクリックします。相関ノードの詳細設定のダイアログ・ボックスが開きます。ここで、モデルの設定やアルゴリズムの設定を指定できます。
既存モデルのコピー: モデルを選択してをクリックします。
この時点で、「OK」をクリックしてモデル定義を完了できます。
属性を選択するには、次の手順を実行します。
「使用可能な属性」リストで属性を1つ以上選択します。
リスト間の矢印を使用して、選択内容を「選択された属性」リストに移動します。
「OK」をクリックします。
相関ノードの詳細設定にアクセスできます。
「アソシエーション・ビルド・ノードの編集」ダイアログ・ボックスでをクリックします。
ノードを右クリックして「詳細設定」をクリックします。
このダイアログ・ボックスでは、モデルの追加または削除、および各モデルのデフォルトのアルゴリズム設定の変更が可能です。
このダイアログ・ボックスの上部ペインには、ノード内のすべてのモデルがリストされます。モデルの追加および削除が可能です。
モデルを削除するには、それを選択してをクリックします。
モデルを追加するには、をクリックします。「モデルの追加」(AR)ダイアログ・ボックスが開きます。
アルゴリズム設定を変更するには、上部ペインでモデルを1つ選択します。「アルゴリズム設定」タブで、最大ルール長、最小信頼度および最小支持度を変更できます。
|
注意: 相関モデルで非常に多数のルールが作成される場合もあれば、ルールがまったく作成されない場合もあります。 |
相関ノードを右クリックします。相関ノードのコンテキスト・メニューでは、次のオプションを使用できます。
編集。相関構築ノードの編集が開きます。
詳細設定。ARのアルゴリズム設定が開きます。
モデルの表示。選択したモデルのARモデル・ビューアが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
相関構築ノードのプロパティでは、ノードで定義されているモデルに関する情報の表示および変更が可能です。
ノードのプロパティを表示するには、ノードをクリックします。
「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
相関構築ノードの「プロパティ」ペインには、次のセクションがあります。
「モデル」セクションには、ノードで定義されているモデルのリストが表示されます。デフォルトでは、1つのモデルが構築されます。
各モデルに対して、モデルの名前、構築情報、アルゴリズムおよびコメントがグリッド内にリストされます。「構築」列には、最新の構築成功日時、またはモデルが構築されていないか正常に構築されなかったかが示されます。
リスト内のモデルを追加、削除または表示できます。また、「出力列(AR)」で説明しているように、どのモデルが後続ノードに渡されるか、または渡されないかを示すことができます。
リストからモデルを削除するには、それを選択してをクリックします。
モデルを追加するには、をクリックします。「モデルの追加」(AR)ダイアログ・ボックスが開きます。
正常に構築されているモデルを表示するには、をクリックします。適切なモデル・ビューが開きます。
モデルのコピーを作成するには、モデルを選択してをクリックします。
アルゴリズムはすでに選択されています。モデルをリストに追加するには、次の手順を実行します。
モデル名をそのまま使用するか変更します。
「コメント」フィールドにコメントを追加します(該当する場合)。これはオプションです。
「OK」をクリックします。これにより、リストに新しいモデルが追加されます。新しいモデルは、既存のモデルと同じ構築特性を持ちます。また、詳細設定のデフォルト値を持ちます。
「モデル設定」グリッドの「出力」列では、後続ノードへのモデルの受渡しを制御します。デフォルトでは、すべてのモデルが後続ノードに渡されます。次のタスクを実行できます。
モデルを無視するにはをクリックします。アイコンがに変わります。
モデルの無視を取り消すには、無視アイコンを再度クリックします。アイコンが出力アイコンに変わります。
ノード内のすべてのモデルは、同じトランザクションID、項目IDおよび項目値を持ちます。「構築」セクションには、ノードで定義されているモデルのこれらの情報が表示されます。
トランザクションID: トランザクションIDを変更するには、「編集」をクリックします。
アイテムID: ドロップダウン・リストから別の項目IDを選択できます。
アイテム値: ドロップダウン・リストから別の項目値を選択できます。
分類予測の実行には、次の2つの方法があります。
分類モデルを構築してテストします。これは、分類ノードを使用して、分類を行うための新しいデータにモデルを適用することで行います。
予測問合せの一種である予測問合せを使用します。
分類ノードでは、構築およびテストを行うための分類モデルを1つ以上定義します。構築用のデータを指定するには、データ・ソース・ノードを分類ノードに接続します。
分類ノード内のモデルは、すべて同じターゲットとケースIDを持ちます。
ターゲットは1つのみ指定できます。
分類構築は、パラレルに実行できます。
この項の内容は次のとおりです。
分類ノードのデフォルト動作は、次に関連して説明されます。
使用されるアルゴリズム: 2項ターゲットに対して、分類ノードは次の4個のアルゴリズムを使用してモデルを構築します。
ターゲットが2項ではない場合、デフォルトではGLMは構築されません。GLMモデルを明示的にノードに追加できます。
モデルは、同じ構築データおよび同じターゲットを持つ必要があります。
|
注意: 特定のモデルの作成を望まない場合は、モデルのリストからそのモデルを削除します。モデル名の左側の青色のチェック・マークにより、後続ノードで使用されるモデルが選択されます。それにより、構築するモデルは選択されません。 |
モデルのテスト: デフォルトでは、すべてのモデルがテストされます。構築データを構築データ・セットおよびテスト・データ・セットにランダムに分割することにより、テスト・データは作成されます。デフォルトの分割比率は60:40です。つまり、60%の構築と40%のテストです。Oracle Data Minerは、構築表およびテスト表の作成時に、適宜圧縮を使用します。
ノードの接続: 構築データ・ソース・ノードとテスト・データ・ソース・ノードの両方を、構築ノードに接続できます。
モデルのテスト: テスト・ノードと個別のテスト・データを使用して、分類モデルをテストできます。
テスト結果の解釈
モデルのチューニング: 分類のテスト後に、各モデルをチューニングできます。
ケースID: ケースIDはオプションです。ただし、ケースIDを指定しない場合、処理は低速になります。
分類ノードを作成する前に、初めにワークフローを作成します。次に、分類ノード用のデータ・ソースを特定または作成します。
分類ノードを作成してそれにデータを接続するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「分類」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないことがGUIに表示されます。したがって、それは構築できません。
構築用にデータを提供するノードに移動します。右クリックして「接続」をクリックします。分類ノードまで線をドラッグし、再度クリックします。
「分類ビルド・ノードの編集」ダイアログ・ボックスが開きます。ターゲットを1つ指定する必要があります。ノード内のすべてのモデルは、同じターゲットを持ちます。ターゲットをテキストにすることはできません。
テスト用の別のデータ・ソース・ノードを指定するには、2番目のデータ・ソース・ノードを構築ノードに接続します。これはオプションです。
編集操作を終了してオプションのテスト・データ・ソースを接続すると、ノードの構築準備が完了します。ノードを右クリックし、メニューから「実行」を選択します。
テスト・データ・ソースを指定した場合、ノードを実行すると、構築データ・ソースからの接続には「構築」というラベルが付き、テスト・データ・ソースからの接続には「テスト」というラベルが付きます。
Oracle Data Minerは、経験則を使用してモデル構築に使用する入力データの属性を決定し、各属性のマイニング型も決定します。
分類構築ノードの編集ダイアログ・ボックスを開くには、分類ノードをダブルクリックするか、分類ノードを右クリックして「編集」を選択します。
分類ノードの編集ダイアログには次の3つのタブがあります。
入力
テキスト
構築ノードでは、作成するモデルの特性を指定または変更できます。構築するモデルの特性を編集するには、次の手順を実行します。
「ターゲット」フィールドで、ドロップダウン・リストからターゲットを選択します。リストには、構築ノードに接続されているデータ・ソース・ノード内で指定された表またはビューの属性が含まれています。
ターゲットを1つ指定する必要があります。ノード内のすべてのモデルは、同じターゲットを持ちます。
「ケースID」フィールドで、ドロップダウン・リストから属性を1つ選択します。この属性は、ケースを一意に識別する必要があります。
ケースIDを指定すると、ノード内のすべてのモデルが同じケースIDを持ちます。
|
注意: ケースIDを指定しない場合は、表を生成する必要があるため、処理は低速になります。ケースIDは、GLM診断情報の生成には必須です。 入力データ内の列がネストされた列である場合、ケースIDは必須です。つまり、高密度および高深度(多数の名前/値ペア)の状態です。ケースIDがない場合、ソート操作に失敗する可能性があります。 |
「モデル設定」セクションで、構築するモデルを選択します。2項ターゲットを持つ分類ノードの場合、Naive Bayes (NB)、ディシジョン・ツリー(DT)、サポート・ベクター・マシン(SVM)および一般化線形モデル(GLM)のモデルがデフォルトで指定されています。
モデルを削除するには、モデルを選択してをクリックします。
モデルを編集するには、モデルを選択してをクリックします。
モデルを追加するには、をクリックします。
既存のモデルをコピーするには、コピー対象モデルを選択してをクリックします。
デフォルトでは、モデルは、構築データ・セットを分割して作成されたテスト・データ・セットを使用してテストされます。この方法でのモデルのテストを望まない場合は、分類ノードの「プロパティ」ペインの分類ノードのテストセクションに移動します。かわりに、テスト・ノードとテスト・データ・ソースを使用してモデルをテストできます。
ケースIDが指定されていない場合、Oracle Data Minerは、行番号を使用して生成されたケースIDが含まれるすべての入力データ用の表を作成します。この表は、構築の作成用およびランダム・サンプル・ビューのテスト用のソースとして使用されます。生成されたケースIDは、すべての問合せに対して不変です。これは、一貫したテスト結果が生成されることを保証します。
リストからモデルを削除するには、それを選択してをクリックします。
モデルをリストに追加するには、をクリックします。「モデルの追加」(分類)ダイアログ・ボックスが開きます。
「モデルの追加」ダイアログ・ボックスで、次の手順を実行します。
「アルゴリズム」フィールドで、アルゴリズムを選択します。
「名前」フィールドに、デフォルト名が表示されます。デフォルトを使用することも、モデル名を変更することも可能です。
「コメント」フィールドにコメントを入力できます(該当する場合)。これはオプションのフィールドです。
「OK」をクリックして、モデルをノードに追加します。
「詳細設定」ダイアログ・ボックスでは、次を検査および変更できます。
データの使用方法
アルゴリズム設定
パフォーマンス設定
詳細設定を変更または表示するには、「分類ビルド・ノードの編集」ダイアログ・ボックスでをクリックします。または、分類構築ノードを右クリックして、「詳細設定」をクリックします。
「詳細設定」ダイアログ・ボックスには、上部ペインにノード内のすべてのモデルがリストされます。ダイアログ・ボックスの上部ペインで、モデルの追加およびモデルの削除が可能です。
下部ペインで、上部ペインで選択されたモデルの次の情報を表示または編集できます。
変更可能な設定は、アルゴリズムによって異なります。
分類ノードのプロパティでは、モデル構築およびテストに関する情報を表示および変更できます。
分類モデルを構築する前に、ターゲットを指定してください。ケースIDを指定できます。ケースIDを指定しない場合、処理は低速になります。
プロパティを表示できない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
分類ノードの「プロパティ」ペインには、次のセクションがあります。
分類ノードには、ノードの実行時に構築されるモデルがリストされます。デフォルトでは、分類構築ノードは3つの分類モデルを作成します。それぞれ異なる分類アルゴリズムが使用されます。
サポート・ベクター・マシン(SVM)
Naive Bayes (NB)
ディシジョン・ツリー(DT)
一般化線形モデル(GLM)。このアルゴリズムは、ターゲットが2項の場合のみ、デフォルトとして使用されます。多クラス・ターゲットの場合、モデルを追加する場合にGLMアルゴリズムを指定することもできます。
「モデル設定」には、構築されるモデルがリストされます。
次のタスクを実行できます。
追加: モデルを追加するには、をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
削除: モデルを削除するには、それを選択してをクリックします。
テスト結果の比較: モデルがテストされた場合、2つ以上のモデルを選択して![]() をクリックすることで、テスト結果を比較できます。
をクリックすることで、テスト結果を比較できます。
表示: モデルが正常に構築された場合、モデルを選択してをクリックすることでモデルを表示できます。モデル・ビューアは、モデルの作成に使用されたアルゴリズムによって異なります。
複製: モデルをコピーするには、モデルを選択してをクリックします。
モデルのチューニング: モデルをチューニングするには、モデルを選択して をクリックします。
をクリックします。
モデルが後続のノードに渡されたかどうかを示すこともできます。
「モデル設定」グリッドの「出力」列では、後続ノードへのモデルの受渡しを制御します。デフォルトでは、すべてのモデルが後続ノードに渡されます。
モデルを無視するには、つまり後続ノードに渡さないようにするには、をクリックします。アイコンが無視アイコンに変わります
無視を取り消すには、「無視」アイコンを再度クリックします。それが出力アイコンに変わります。
「構築」セクションには、ターゲットとクラスIDが表示されます。構築ノードは、データ・ソース・ノードに接続されている必要があります。次のタスクを実行できます。
ターゲット: 「ターゲット」ドロップダウン・リストからターゲットを選択できます。
ケースID: ケースIDを変更または選択するには、「ケースID」ドロップダウン・リストから属性を1つ選択します。この属性は、ケースを一意に識別します。
ケースIDはオプションのフィールドです。ケースIDを選択しない場合、処理は低速になります。
「テスト」セクションでは、テストに使用されるデータおよび実行されるテストを指定します。
次の設定を指定できます。
テストの実施: 分類ノードをテストするには、このオプションを選択します。デフォルトの設定では、構築データを2つのサブセットにランダムに分割して構築されたテスト・データを使用して、構築されたすべてのモデルがテストされます。デフォルトでは、次のテストが実行されます。
パフォーマンス・メトリック
パフォーマンス・マトリックス
ROC曲線(バイナリ・クラスのみ)
リフトおよび利益
頻度による上位5件のターゲット・クラスのリフトおよび利益。「編集」をクリックします。「ターゲット値の選択」ダイアログ・ボックスが開きます。
モデル・チューニングに対して選択したテスト結果を生成: モデルのチューニングを計画している場合は、テスト・ノードではなく、構築ノード内でモデルをテストする必要があります。
テスト・データ: テスト・データを作成するための次のいずれかのオプションを選択します。
テストにすべてのマイニング構築データを使用
テストに分割ビルドデータを使用
テストの分割(%)
次の分割を作成: 表(デフォルト)
テストにテスト・データ・ソースを使用: 構築データを接続した後にテスト・データ・ソースを構築ノードに接続するには、このオプションを選択します。
「ターゲット値の選択」ダイアログ・ボックスには、選択したターゲット値の数が表示されます。デフォルトのオプションの「自動」では、頻度による上位5件のターゲット・クラス値が使用されます。「頻度カウント」を変更することで、ターゲット値の数を変更できます。「最低発生回数を使用」のオプションを選択することもできます。
自動: デフォルトで、頻度による上位5件のターゲット・クラス値を使用します。
頻度カウント: この値の値を変更して、ターゲット値の数を変更できます。
最低発生回数を使用
最高発生回数を使用
カスタム: 特定のターゲット値を指定するには、このオプションを使用します。次に、値を「使用可能な値」から「選択した値」に移動します。
コンテキスト・メニューを表示するには、分類ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。分類構築ノードの編集が開きます。
詳細設定。分類モデルの詳細設定が開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
クラスタリング・ノードは、k-Means、O-Clusterおよび期待値の最大化の各アルゴリズムを使用してクラスタリング・モデルを構築します。
|
注意: 期待値の最大化モデルでは、Oracle Database 12c以上が必要です。 |
データのクラスタリングには、次の2つの方法があります。
クラスタリング・モデルを構築する。分類ノードを使用します。次に、モデルを新しいデータに適用してクラスタを作成します。
予測問合せの一種であるクラスタリング問合せを使用する。
クラスタリング構築は、パラレルに実行できます。
この項では、次の項目について説明します。
クラスタリング・ノードは、次のアルゴリズムを使用して3つのモデルを構築します。
k-Meansアルゴリズム(KM)
期待値の最大化(EM)。EMには、Oracle Database 12cが必要です。
ケースIDはオプションです。
モデルはすべて同じ構築データを持ちます。
|
注意: 任意のモデルの作成を望まない場合は、モデルのリストからそのモデルを削除します。モデル名の左の青色のチェックマークにより、「適用」などの後続ノードで使用されるモデルが選択されます。それにより、構築するモデルは選択されません。 |
クラスタリング構築ノードを作成する前に、初めにワークフローを作成します。次に、データ・ソース・ノードを特定または作成します。
クラスタリング・ノードを作成してそれにデータを接続するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。
「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「クラスタリング」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないことがGUIに表示されます。したがって、それは構築できません。
構築用にデータを提供するノードに移動します。ノードを右クリックして、「接続」をクリックします。分類ノードまで線をドラッグし、再度クリックします。
クラスタリング・ノードを右クリックして、「実行」をクリックします。ノードが実行され、モデルが構築されます。
Oracle Data Minerは次のために経験則を使用します。
モデルの構築に使用される入力データの属性を決定します
各属性のマイニング型を決定します
「クラスタリングの編集」ダイアログ・ボックスを開くには、クラスタリング・ノードをダブルクリックします。または、クラスタリング・ノードを右クリックして「編集」を選択します。
クラスタリング・ノードの編集ダイアログ・ボックスには次の3つのタブがあります。
入力
テキスト
「構築」タブでは、作成するモデルの特性を指定または変更できます。構築するモデルの特性を編集するには、次の手順を実行します。
「ケースID」フィールドで、ドロップダウン・リストから属性を1つ選択します。この属性は、ケースを一意に識別する必要があります。
|
注意: ケースIDは必須ではありません。ただし、ケースIDにより構築およびテストを反復しやすくなります。 |
ケースIDを指定すると、ノード内のすべてのモデルが同じケースIDを持ちます。
「モデル設定」リストで、構築するモデルを選択します。クラスタリング・ノードでは、次のアルゴリズムを使用してモデルを構築できます。
次のタスクを実行できます。
削除: 任意のモデルを削除するには、モデルを選択してをクリックします。
追加: モデルを追加するには、をクリックします。
コピー: モデルをコピーするには、モデルを選択してをクリックします。
リストからモデルを削除するには、それを選択してをクリックします。
モデルをリストに追加するには、をクリックします。「モデルの追加」ダイアログ・ボックスが開きます。
「モデルの追加」ダイアログ・ボックスで、次の手順を実行します。
「アルゴリズム」フィールドで、KM、OCまたはEMのいずれかのアルゴリズムを選択します。EMには、Oracle Database 12cが必要です。
期待値の最大化。このオプションには、Oracle Database 12cリリース12.1が必要です。
「名前」フィールドに、デフォルト名が表示されます。デフォルト名を使用することも、モデル名を変更することも可能です。
「コメント」フィールドにコメントを入力します(該当する場合)。これは、オプションのコメントです。
「OK」をクリックして、モデルをノードに追加します。
「詳細設定」にアクセスするには、「クラスタリング・ビルド・ノードの編集」ダイアログ・ボックスでをクリックします。または、ノードを右クリックして、「詳細設定」を選択します。「詳細設定」ダイアログ・ボックスには、上部ペインにすべてのモデルがリストされます。
次のタスクを実行できます。
データの使用方法およびアルゴリズムの検査と変更
ノードへのモデルの追加
ノードからのモデルの削除
下部ペインで、上部ペインで選択されたモデルの次の項目を表示および編集できます。
「データの使用方法」タブのデータの使用方法
「アルゴリズム設定」のアルゴリズム設定
変更可能な設定は、アルゴリズムによって異なります。
クラスタリング構築ノードのプロパティでは、モデル構築に関する情報を表示および変更できます。「プロパティ」ペインを表示できない場合は、「表示」に移動して、「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
クラスタリング構築ノードのプロパティには、次のセクションがあります。
「モデル」には、ノードの実行時に構築されるモデルがリストされます。デフォルトでは、KM、OCおよびEMの各アルゴリズムを使用して2つのクラスタリング・モデルが構築されます。
「モデル設定」グリッドには、ノード内のモデルがリストされます。次のタスクを実行できます。
モデルの検索
後続ノードに渡されるモデルの指定。
「モデル設定」グリッドの「出力」列では、後続ノードへのモデルの受渡しを制御します。デフォルトでは、すべてのモデルが後続ノードに渡されます。
モデルを無視するには、つまり後続ノードに渡さないようにするには、をクリックします。出力アイコンがに変わります。
無視を取り消すには、「無視」アイコンを再度クリックします。アイコンが出力アイコンに変わります。
モデルが正常に構築された場合、モデルを選択してをクリックすることでモデルを表示できます。モデル・ビューアが開きます。モデル・ビューアは、モデルの作成に使用されたアルゴリズムによって異なります。
クラスタリング・モデルのオプションのケースIDが表示されます。ケースIDを変更するには、リストから属性を1つ選択します。
クラスタリング構築ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。相関構築ノードの編集が開きます。
詳細設定。相関ノードの詳細設定が開きます。
モデルの表示。選択したモデルの適切なビューア(KMモデル・ビューアまたはOCモデル・ビューア)を開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
イベント・ログの表示。ノードの実行に失敗した場合にのみ表示されます。
特徴抽出ノードでは、Non-negative Matrix Factorization (NMF)アルゴリズムを使用してモデルを構築します。特徴の抽出には、次の2つの方法があります。
特徴抽出ノードを使用して特徴抽出モデルを構築します。
予測問合せの一種である特徴抽出問合せを使用します。
Oracle Data MinerがOracle Database 12cに接続している場合、特徴抽出ノードはPCAおよびSVDアルゴリズムを使用してモデルを構築します。
|
注意: 主成分分析モデルおよび特異値分解モデルは、Oracle Database 12cを必要とします。 |
特徴抽出構築は、パラレルに実行できます。
この項では、次の項目について説明します。
デフォルトでは、特徴抽出ノードでは、Non-Negative Matrix Factorization (NMF)アルゴリズムを使用してモデルを1つ構築します。
Oracle Database 12cに接続している場合、ノードはデフォルトで次の2つのモデルを構築します。
NMFモデル
PCAモデル
SVDモデルを追加できます。
ノード内のすべてのモデルは同じ構築データを使用し、ケースIDを指定した場合は同じケースIDを持ちます。
特徴抽出ノードを作成する前に、初めにワークフローを作成します。次に、データ・ソース・ノードを特定または作成します。
特徴抽出ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。
「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「特徴抽出」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。特徴構築ノードがワークフローに追加されます。
ノードに関連付けられたデータがないことがGUIに表示されます。したがって、それは構築できません。
構築用にデータを提供するノードに移動します。右クリックして「接続」をクリックします。特徴抽出ノードまで線をドラッグし、再度クリックします。
ノードを編集できます。ノードを編集するには、ノードを右クリックして「編集」を選択します。「機能抽出ビルド・ノードの編集」ダイアログ・ボックスが開きます。
ノードの構築準備ができました。ノードを右クリックして、「実行」をクリックします。
Oracle Data Minerは次のために経験則を使用します。
モデル構築に使用される入力データの属性を決定します
各属性のマイニング型を決定します
特徴構築ノードを編集するには、特徴構築ノードをダブルクリックするか、このノードを右クリックして「編集」を選択します。「機能抽出ビルド・ノードの編集」ダイアログ・ボックスが開きます。特徴構築ノードをワークフローにドロップしても、同じダイアログ・ボックスが開きます。
特徴抽出構築の編集ダイアログ・ボックスには次の3つのタブがあります。
入力
テキスト
「構築」タブでは、次のタスクを実行できます。
ケースID: 特徴抽出のケースIDの指定はオプションです。ドロップダウン・リストから属性を選択することでこれを指定します。
「モデルの追加」
削除: モデルを削除するには、モデルを選択してをクリックします。
コピー: 既存のモデルをコピーするには、モデルを選択してをクリックします。
モデルを追加するには、をクリックします。「モデルの追加」(特徴抽出)ダイアログ・ボックスが開きます。
「アルゴリズム」フィールドで、アルゴリズムを選択します。デフォルトのアルゴリズムはNMFです。
「名前」フィールドに、デフォルト名が表示されます。デフォルト名をそのまま使用することも変更することも可能です。
「コメント」フィールドにコメントを入力します(該当する場合)。これはオプションのフィールドです。
「OK」をクリックします。モデルがリストに追加されます。新しいモデルは、既存のモデルと同じ構築特性を持ちます。新しいモデルは、詳細設定のデフォルト値を持ちます。
詳細設定を選択することにより、ノード内の各モデルのデータの使用方法およびアルゴリズム設定を検査および変更できます。
データの使用方法を検査および変更します。
ノード内の各モデルのアルゴリズム設定を変更します。
詳細設定を変更または表示するには、「機能抽出ビルド・ノードの編集」ダイアログ・ボックスでをクリックします。または、ノードを右クリックして、「詳細設定」を選択します。詳細設定を選択することにより、ノード内の各モデルのデータの使用方法およびアルゴリズム設定を検査および変更できます。
上部ペインに、すべてのモデルがリストされます。次のタスクを実行できます。
削除: モデルを削除するには、それを選択してをクリックします。
追加: モデルを追加するには、をクリックします。
下部ペインで、上部ペインで選択されたモデルの次の情報を表示または編集できます。
設定は、アルゴリズムによって異なります。
PCAおよびSVDは、Oracle Data MinerがOracle Database 12cに接続している場合に使用可能です。
特徴抽出ノードのプロパティでは、ノードで定義されているモデルに関する情報の表示および変更が可能です。
ノードのプロパティを表示するには、ノードをクリックします。「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
特徴抽出ノードの「プロパティ」ペインには、次のセクションがあります。
「構築」セクションには、ノードで定義されているモデルのケースIDが表示されます。ノード内のすべてのモデルは、同じケースIDを持ちます。
ケースIDは必須ではありません。
ケースIDを編集するには、リストから別の属性を選択します。
特徴抽出ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「機能抽出ビルド・ノードの編集」ダイアログ・ボックスが開きます。
詳細設定。特徴抽出の詳細設定ダイアログ・ボックスが開きます。
モデルの表示。選択したモデルのNMFモデル・ビューアが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
モデル・ノードでは、ワークフローで構築されていないモデルを、そのワークフローに追加できます。たとえば、いずれかのODM APIを使用して構築されたモデルを指定できます。
モデル・ノード内のモデルはモデルの制約を満たしている必要があります。
モデル・ノードは入力を取りません。モデル・ノードは、少なくとも一部の関数タイプについては、適用ノード、テスト・ノードなど、モデルを受け入れる任意のノードの入力にすることができます。たとえば、モデル・ノードに分類モデルまたは回帰モデルが含まれている場合、それをテスト・ノードの入力にすることができます。テスト・データは、構築データを準備する方法と同じ方法で準備する必要があります。
モデル・ノードに関するこの項では、次の項目について説明します。
モデル・ノードは、その定義にデータベース・リソースを使用します。たとえば、リソースが削除されたり再作成されるなど、データベース・リソースが変更された場合は、ノード定義のリフレッシュが必要となる可能性があります。
ワークフローにモデル・ノードを追加して、モデル・ノードにモデルを追加するには、次の手順を実行します。
「コンポーネント」ペインを開いて、「ワークフロー・エディタ」を選択します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「モデル」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
「モデル選択の編集」ダイアログ・ボックスが自動的に開きます。モデル・ノード内のモデルは、同じマイニング機能および同じターゲット(分類および回帰モデルのみ)を持つ必要があります。
「モデル選択の編集」ダイアログ・ボックスでは、モデル・ノードに含める、またはモデル・ノードからモデルを削除するための、1つ以上のモデルを選択できます。ノード内のモデルを編集するには、モデル・ノードをダブルクリックするか、モデル・ノードを右クリックして「編集」を選択します。
次のタスクを実行できます。
「使用可能な互換モデル」リストからモデルを選択し、リスト間のコントロールを使用してこれらを「選択したモデル」リストに移動します。
選択したモデルは互換性がチェックされます。モデル・ノード内のモデルはモデルの制約を満たしている必要があります。
選択したモデルは、モデル・ノードの一部になります。モデル・ノードのプロパティを使用してモデルを表示できます。
他のスキーマからのモデルを含めます。モデルを含めるには、「他のスキーマからのモデルを含める」を選択します。
次の方法を使用して、「使用可能な互換モデル」リストをフィルタ処理します。
モデル関数リストからモデル関数を選択します。オプションは、次のとおりです。
すべて
異常検出
相関ルール
回帰
クラスタリング
特徴抽出
モデルを名前、関数、アルゴリズム、ターゲット、ターゲット・データ型、作成日またはコメントでソートします。ソートを行うには、使用可能モデルのリスト内の列ヘッダーをクリックします。
モデルを追加または削除します。
モデルを「使用可能な互換モデル」リストから「選択したモデル」リストに移動して、これらを追加します。
モデルを「選択したモデル」リストから「使用可能な互換モデル」リストに移動して、これらを削除します。「モデル」タブを使用してモデルを削除することもできます。
モデル・ノードは、類似したモデルで構成されています。モデル・ノード内のモデルは、次を満たしている必要があります。
すべてのモデルの関数タイプ(分類、回帰、クラスタリング、異常検出、相関ルールまたは特徴検出)が同じである必要があります。異なる関数タイプのモデルを含めることはできません。
モデルが異なるアルゴリズムを使用して構築されていても、同じ関数タイプを持つ場合、それらのモデルを追加できます。
分類モデルまたは回帰モデルは、同じターゲット属性を持つ必要があります。ターゲット属性は、すべて同じデータ型を持つ必要があります。
CHARおよびVARCHAR2は、分類モデルでは同じデータ型とみなされます。
分類モデルは、同じターゲット値のリストを持つ必要があります。
モデル・ノードのプロパティにアクセスするには、ノードをクリックします。「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
モデル・ノードの「プロパティ」ペインでは、次が可能です。
モデル・ノードへのモデルの追加
モデル・ノードからのモデルの削除
モデル・ノード内のモデルの表示
モデル・ノードのソース・ノードの「プロパティ」ペインには、次のセクションがあります。
「モデル」セクションでは、モデルが使用するマイニング機能を示し、ノード内のすべてのモデルをグリッドにリストします。
モデルの検索、モデルの追加、およびモデルの削除が可能です。
次のタスクを実行できます。
モデルの追加: モデルを追加するには、次の手順を実行します。
をクリックします。「モデル選択の編集」ダイアログ・ボックスが開きます。
「モデル選択の編集」ダイアログ・ボックスで、ノードに追加するモデルを選択します。他のスキーマからもモデルを追加できます。ただし、追加するモデルは、すべてノード内の既存のモデルと互換性がある必要があります。
「OK」をクリックします。これでモデルがノードに追加されます。モデル・ノードの「プロパティ」ペインに移動して、モデルを表示できます。
モデルの削除: モデルを削除するには、モデルを選択してをクリックします。
モデルの表示: モデルを表示するには、モデルを選択してをクリックします。
モデルのリフレッシュ: モデルをリフレッシュするには、 をクリックします。サーバー上のデータが変更された場合、ノードのリフレッシュが必要となる場合があります。
をクリックします。サーバー上のデータが変更された場合、ノードのリフレッシュが必要となる場合があります。
モデル・ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「モデル選択の編集」ダイアログ・ボックスが開きます。
ノードで指定されたモデルが存在することの検証を実行します。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
モデル詳細ノードは、アプリケーション開発者にとって最も有用です。モデル詳細ノードは、次の機能を実行します。
モデル構築ノード、モデル・ノードまたはモデルを出力する任意のノードから、モデルの詳細を抽出します。
モデル属性と、アルゴリズムによるその処理に関する情報を表示します。出力は選択されたモデルのタイプおよび指定した特定のモデル詳細のタイプにより異なります。
モデル詳細ノードの出力は、データ・フローです。データを永続化するには、表またはビュー作成ノードを使用します。
モデル詳細ノードは、パラレルに実行できます。
モデル詳細ノードに関するこの項では、次の項目について説明します。
モデル詳細ノードの入力は、次のいずれかまたは複数です。
構築ノード(任意のモデル・タイプ)
モデル・ノード
構築ノードまたはモデル・ノード内のすべてのモデルは、同じマイニング機能タイプを持っている必要があります。たとえば、1つが分類モデルの場合、これらのすべては分類モデルである必要があります。
モデル詳細ノードの出力は、モデル詳細指定に基づくデータ・フローです。データを永続化するには、表またはビュー作成ノードを使用します。
モデル詳細ノードを作成するには、次の手順を実行します。
入力ノードまたはモデル詳細の対象ノードを特定します。入力ノードは、次のいずれかまたは複数である必要があります。
任意のモデル構築ノード
任意のモデル・ノード
|
注意: 選択されたすべてのモデルは、同じマイニング機能タイプを持っている必要があります。たとえば、いずれかのノードが分類ノードである場合、その他のすべてのノードは分類モデルを構築する必要があります。 |
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「モデル詳細」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
モデル詳細ノードは、入力を提供する構築ノードまたはモデル・ノードの近くに配置することをお薦めします。
ワークフローにカーソルを移動します。いずれかの入力ノードを右クリックし、「接続」を選択します。モデル詳細ノードへリンクをドラッグします。複数のノードを接続する必要がある場合、繰り返します。
モデル詳細のデフォルトの指定は、モデルにより異なります。デフォルトの指定を使用するには、モデル詳細ノードを右クリックして「実行」をクリックします。
モデル詳細ノードの指定を変更するには、ノードを右クリックして「編集」を選択します。または、ノードの「プロパティ」ペインで仕様を変更できます。
モデル詳細ノード・エディタでは、ノードにより提供されるモデルの詳細を表示または指定できます。「モデル詳細ノードの編集」を開くには、モデル詳細ノードをダブルクリックします。または、モデル詳細ノードを右クリックして「編集」を選択します。
次のタスクを実行できます。
自動指定: このオプションが選択されている場合(デフォルト)、システムにより指定が決定されます。出力タイプ、アルゴリズム・タイプまたは選択されたモデルは変更できません。
関数: 接続されている入力ノードの関数タイプを表示します(たとえば、分類ノードがモデル詳細に接続されている場合、関数は「分類」です)。入力ノードが接続されていない場合、それは未定義です。
モデル・タイプ: これは、「すべて」を含む、使用可能なアルゴリズムのリストです。
出力: アルゴリズムに対するモデル詳細のデフォルト出力を表示します。
列: 列をクリックして、選択されている出力タイプの列のリスト(名前とデータ型)を表示します。
追加: モデル・タイプの追加または出力タイプの編集を行うには、自動指定の選択を解除します。別のモデル・タイプを追加するには、モデル・タイプを選択してをクリックします。モデル選択詳細の編集ダイアログ・ボックスが開きます。デフォルトの指定をそのまま使用することも変更することも可能です。
モデル選択詳細の編集ダイアログ・ボックスの上部ペインには、一般情報が含まれます。
関数: 接続されている入力ノードの関数タイプを表示します(たとえば、分類ノードがモデル詳細に接続されている場合、関数は「分類」です)。入力ノードが接続されていない場合、それは未定義です。
モデル・タイプ: アルゴリズムを表示します。すでに選択されているモデルが存在する場合(「選択したモデル」にリストされます)、「モデル・タイプ」フィールドは無効になり、すでに選択したモデルと一致しています。すべてのモデルを「選択したモデル」グリッドから移動すると、「モデル・タイプ」フィールドは再び有効になります。「モデル・タイプ」が有効である場合、モデルを選択できます。デフォルトは、「すべてのモデル」です。
出力タイプ: 指定されたモデル・タイプに使用可能な出力タイプ(モデル問合せ)のリストが表示されます。各アルゴリズム選択に対する値は、次のとおりです。
ディシジョン・ツリー(初期デフォルト): 「ツリー全体」(デフォルト)、「ツリー全体のXML」、「リーフ・ノード」、「モデル・シグネチャ」
SVM分類: 「係数」(デフォルト)、「モデル・シグネチャ」
SVM回帰: 「係数」(デフォルト)、「モデル・シグネチャ」
Naive Bayes: 「ペア確度」(デフォルト)、「モデル・シグネチャ」
相関ルール: 「ルール」(デフォルト)、「グローバル詳細」、項目セット
異常検出: 「係数」(デフォルト)、「モデル・シグネチャ」
GLM分類: 「統計」(デフォルト)、「行診断」、「モデル・シグネチャ」、「グローバル詳細」
GLM回帰: 「統計」(デフォルト)、「行診断」、「モデル・シグネチャ」、「グローバル詳細」
KMまたはOCクラスタリング: 「ツリー全体」(デフォルト)、「ルール」、「属性ヒストグラム」、「重心」、「モデル・シグネチャ」
期待値の最大化(EM): 「ツリー全体」(デフォルト)、「属性ヒストグラム」、重心コンポーネント、「グローバル詳細」、「モデル・シグネチャ」、「予測」、「ルール」
EMには、Oracle Database 12c以上が必要です。
NMF: 「トランザクションの機能」(デフォルト)、「モデル・シグネチャ」
SVD: 「トランザクションの機能」(デフォルト)、「グローバル詳細」、「モデル・シグネチャ」、「予測」、特異値
SVDには、Oracle Database 12c以上が必要です。
PCA: 「トランザクションの機能」(デフォルト)、「固有値」、「グローバル詳細」、「モデル・シグネチャ」、「予測」
PCAには、Oracle Database 12c以上が必要です。
出力値は、複数のモデル・タイプに対しても使用可能です。たとえば、すべてのクラスタリング・モデルに対して「重心」を選択できます。
列: クリックして、選択されている出力タイプの列のリスト(名前とデータ型)を表示します。
ダイアログ・ボックスの下部に次が表示されます。
使用可能な互換モデル: 使用可能なモデル、つまりアルゴリズム選択に一致するモデルがリストされます。各モデルのグリッドには、モデル名、モデルの入力ノードおよびモデルの構築に使用されるアルゴリズムが表示されます。
選択したモデル: 選択したモデルがリストされます。各モデルのグリッドには、モデル名、モデルの入力ノードおよびモデルの構築に使用されるアルゴリズムが表示されます。
指定がどのように自動的に変更されるかは、自動選択がオンであるかオフであるかに応じて異なります。
デフォルトでは、自動指定が選択されています。自動指定により、最終的に次の動作が実行されます。
最初の入力ノードがモデル詳細ノード接続されると、デフォルトの優先順位で、入力ノードでモデルが検索されされます。最初のモデル・タイプが見つかると、モデルに一致するすべてノードが、デフォルトの出力タイプとともにモデル詳細の指定に追加されます。
後続の接続で、モデル詳細ノード内のタイプと一致するモデルが自動的に追加されます。モデルが自動的に追加されることを通知するメッセージが表示されます。
入力ノードが切断されると、そのノードにより提供されたすべてのモデル指定が、モデル詳細ノードから自動的に削除されます。
入力ノードが編集されると、追加されたモデルがそのノードに含まれているモデル・タイプに一致する場合、追加されたすべてのモデルが自動的にモデル詳細ノードに追加されます。入力ノードからモデルが削除されると、これらはモデル詳細ノードから削除されます。
すべてのモデルが削除されるように親ノードが編集された場合、モデル・ノードは未定義に設定されます。新しいモデルが親モデルに追加されると、多数の親ノードがモデル・ノードに接続されている可能性がある場合、デフォルトでどのモデルおよび出力タイプが選択されるかの予測が非常に困難であるため、モデル・ノードは未定義を維持します。
入力ノードが編集されて、モデル詳細ノード内の指定との一貫性がなくなるようにモデルが変更された場合、モデル指定は削除されます。
自動指定が「オフ」になっているか、選択が解除されていると、次の動作が実行されます。
モデルは自動的には追加されません。
モデル詳細ノードを編集する必要があります。
検証が通常どおり実行されるため、現在一貫性がない、または欠損しているモデルは、無効としてマークされます。また、モデルが欠損していて、そのモデルとの一致を含むノードが追加された場合、それは有効になり新しいノードと関連付けられます。
無効なモデル参照を手動で修正または削除する必要があります。
自動的に追加される指定は、次のようにモデルのマイニング機能により異なります。
分類
ディシジョン・ツリー: ツリー全体
GLM: 統計
NB: 確率
SVM: (線形カーネルのみ)係数
クラスタリング
KM: ツリー全体
OC: ツリー全体
EM: ツリー全体
回帰
GLM: 統計
SVM: (線形カーネルのみ)係数
異常検出
SVM: (線形カーネルのみ)係数
相関
Apriori: ルール
特徴抽出
NMF、SVDまたはPCA: トランザクションの機能
モデル詳細ノードのプロパティでは、詳細が抽出されたモデルを表示できます。ノードの「プロパティ」ペインを表示するには、ノードをクリックします。「プロパティ」ペインが閉じている場合は、「表示」に移動して、「プロパティ」に移動します。または、ノードを右クリックし、「プロパティに移動」をクリックします。
モデル詳細ノードの「プロパティ」には、次のセクションがあります。
「モデル」セクションには、詳細を保存するモデルがリストされます。モデルを追加したり、リストから削除できます。
「出力」タブには、モデル詳細ノードにより生成される列がリストされます。列ごとに、別名(該当する場合)とデータ型が表示されます。
デフォルトでは、結果の表示を最適化するためのキャッシュは生成されません。キャッシュを生成できます。キャッシュを生成する場合は、サンプリング・サイズを指定できます。デフォルトのサンプリング・サイズは2000行です。
モデル詳細ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「モデル詳細ノードの編集」が開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
モデル詳細出力をすべて表示するには、ノードを右クリックして「データの表示」を選択します。
出力が次の複数タブ表示で表示されます。
データ
モデル詳細を構成しているデータ。データが表す内容はモデルによって異なります。たとえば、データはツリーまたはルールを表す場合があります。
このタブの列をソートおよびフィルタ処理できます。
列
出力内の列のデータ型とマイニング型。
SQL
モデル詳細を生成するために使用されたSQL。
モデル詳細ノードに表示されるデータは特定のモデルによって異なります。
適用(スコアリング)可能なすべてのモデルは、出力としてモデル・シグネチャを持ちます。
回帰予測の実行には、次の2つの方法があります。
回帰モデルの構築とテスト: 回帰ノードを使用し、次に、分類を行うための新しいデータにモデルを適用します。
予測問合せの一種である予測問合せを使用します。
回帰ノードでは、構築およびテストを行うための回帰モデルを1つ以上定義します。構築用のデータを指定するには、データ・ソース・ノードを回帰ノードに接続します。2番目のデータ・ソースを回帰構築ノードに接続して、テスト・データを指定することも可能です。
回帰ノード内のモデルは、すべて同じターゲットとケースIDを持ちます。
ターゲットは1つのみ指定できます。
回帰構築は、パラレルに実行できます。
この項は次のトピックで構成されています:
2項ターゲットに対して、回帰ノードは次のアルゴリズムを使用して4つのモデルを構築します。
一般化線形モデル(GLM)
サポート・ベクター・マシン(SVM)
モデルは、同じ構築データおよび同じターゲットを持ちます。
デフォルトでは、すべてのモデルがテストされます。構築データを構築データ・セットおよびテスト・データ・セットにランダムに分割することにより、テスト・データは作成されます。デフォルトの分割比率は、60%が構築で40%がテストです。可能な場合、Data Minerはテスト・データ・セットおよび構築データ・セットの作成時に圧縮を使用します。
かわりに、すべての構築データをテスト・データとして使用できます。
個別のテスト・データを使用するには、テスト・データ・ソースを構築ノードに接続するか、テスト・ノードを使用します。
モデルのテスト後に、テスト結果を表示できます。
コンテキスト・メニューの「テスト結果の比較」選択肢を使用して、2つ以上の回帰モデルのテスト結果を比較できます。
ケースIDはオプションです。ただし、ケースIDを指定しない場合、処理は低速になります。
回帰ノードを作成する前に、初めにワークフローを作成します。次に、データ・ソースを特定または作成します。
回帰ノードを作成してそれにデータを接続するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで「モデル」を展開して、「回帰」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないことがGUIに表示されます。したがって、それは構築できません。
構築用にデータを提供するノードに移動します。右クリックして、「接続」をクリックします。回帰ノードまで線をドラッグし、再度クリックします。
「回帰ビルド・ノードの編集」ダイアログ・ボックスが開きます。ターゲットを指定する必要があります(ノード内のすべてのモデルが同じターゲットを持ちます)。ターゲットをテキストにすることはできません。
テスト用の別のデータ・ソース・ノードを指定するには、2番目のデータ・ソース・ノードを構築ノードに接続します。これはオプションです。
ノードの編集を終了してオプションのテスト・データ・ソースを接続すると、ノードの構築準備が完了します。ノードを右クリックして、「実行」をクリックします。
テスト・データ・ソース・ノードを指定した場合、ノードを実行すると、構築データ・ソースからの接続には「構築」というラベルが付き、テスト・データ・ソースからの接続には「テスト」というラベルが付きます。
Oracle Data Minerは次のために経験則を使用します。
モデル構築に使用される入力データの属性を決定します。
各属性のマイニング型を決定します。
回帰構築ノードの編集ダイアログ・ボックスを開くには、回帰構築ノードをダブルクリックするか、回帰構築ノードを右クリックして「編集」を選択します。
構築の編集ダイアログ・ボックスには次の3つのタブがあります。
入力
テキスト
「構築」タブでは、作成するモデルの特性を指定または変更できます。構築するモデルの特性を編集するには、次の手順を実行します。
「ターゲット」フィールドで、ドロップダウン・リストからターゲットを選択します。リストには、構築ノードに接続されているデータ・ソース・ノード内で指定された表またはビューの属性が含まれています。
ターゲットを1つ指定する必要があります。ノード内のすべてのモデルは、同じターゲットを持ちます。
「ケースID」フィールドで、ドロップダウン・リストから属性を1つ選択します。この属性は、ケースを一意に識別する必要があります。
|
注意: ケースIDは必須ではありません。ただし、ケースIDを指定しない場合、処理は低速になります。ケースIDは、GLM診断情報の生成には必須です。 |
ケースIDを指定すると、ノード内のすべてのモデルが同じケースIDを持ちます。
「モデル設定」リストで、構築するモデルを選択します。サポート・ベクター・マシン(SVM)および一般線形モデル(GLM)を構築できます。モデルを選択してクリックすることで、これらの任意のモデルを削除できます。
任意のモデルを削除するには、モデルを選択してをクリックします。
モデルを追加するには、をクリックします。「モデルの追加」(回帰)ダイアログ・ボックスが開きます。
モデルを編集するには、をクリックします。回帰モデルの詳細設定ダイアログ・ボックスが開きます。
既存のモデルをコピーするには、モデルを選択してをクリックします。
「OK」をクリックします。
デフォルトでは、構築データ・セットを分割して作成されたテスト・データ・セットを使用してモデルをテストします。この方法でのモデルのテストを望まない場合は、回帰ノードの「プロパティ」ペインの「テスト」セクションに移動します。かわりに、テスト・ノードとテスト・データ・ソースを使用してモデルをテストできます。
ノードにモデルを追加するには、次の手順を実行します。
「アルゴリズム」フィールドで、アルゴリズムを選択します。
「名前」フィールドに、デフォルト名が表示されます。デフォルトを使用することも、モデル名を変更することも可能です。
「コメント」フィールドにコメントを追加します(該当する場合)。これはオプションのフィールドです。
「OK」をクリックします。新しいモデルがノードに追加されます。
「詳細設定」ダイアログ・ボックスでは、次の操作が可能です。
ノード内の各モデルのデータの使用方法およびアルゴリズム設定の検査と変更
モデルの追加と削除
詳細設定を変更または表示するには、「回帰ビルド・ノードの編集」ダイアログ・ボックスでをクリックします。または、ノードを右クリックして、「詳細設定」を選択します。
上部パネルには、ノード内のすべてのモデルがリストされます。次の操作を実行できます。
削除: モデルを削除するには、モデルを選択してをクリックします。
追加: モデルを追加するには、をクリックします。「モデルの追加」(回帰)ダイアログ・ボックスが開きます。
下部ペインでは、上部ペインで選択されたモデルのデータの使用方法およびアルゴリズム設定を表示および変更できます。次の詳細を編集できます。
変更可能な設定は、アルゴリズムによって異なります。
回帰ノードのプロパティでは、モデル構築に関する情報の表示および変更が可能です。回帰ノードの「プロパティ」ペインを表示するには、ノードをクリックします。「プロパティ」ペインが閉じている場合は、「表示」に移動して、「プロパティ」に移動します。または、ノードを右クリックし、「プロパティに移動」をクリックします。
回帰モデルを構築する前に、次の操作を必ず実行してください。
ターゲットの指定。
ケースIDの指定。これはオプションです。ただし、ケースIDを指定しない場合、処理は低速になります。
この項では、次の項目について説明します。
「モデル」セクションには、構築されるモデルがリストされます。デフォルトでは、3つの異なるアルゴリズム(SVM、NBおよびDT)を使用して3つの回帰モデルが構築されます。モデルを追加する場合に、GLMアルゴリズムを指定することも可能です。
次のタスクを実行できます。
削除: モデルを削除するには、モデルを選択してをクリックします。
追加: モデルを追加するには、をクリックします。
テスト結果の比較: モデルがテストされた場合、テスト結果を比較できます。2つ以上のモデルを選択して![]() をクリックします。
をクリックします。
モデルの表示: モデルが正常に構築された場合、モデルを表示できます。モデルを選択してをクリックします。対応するビューアが開きます。
モデル・ステータスの表示: モデルが後続のノードに渡されたかどうかが示されます。
「構築」セクションには、次が表示されます。
ターゲット: 構築ノードがデータ・ソース・ノードに接続されている必要があります。次に、ターゲット・リストからターゲットを選択します。ターゲットを変更するには、ドロップダウン・リストから別のターゲットを選択します。
ケースID: ドロップダウン・リストから属性を選択します。この属性は、ケースを一意に識別する必要があります。ケースIDはオプションです。ケースIDが選択されていない場合、<なし>が表示されます。ただし、ケースIDが指定されていない場合は、処理が低速になります。
「テスト」セクションでは、テストに使用されるデータおよび実行するテストを指定します。デフォルトでは、テスト・データを使用して構築されたすべてのモデルがテストされます。テスト・データは、構築データをランダムに分割して作成されます。
「テスト」セクションでは、次の設定を使用できます。
テストの実施: デフォルトでは、テスト・データを使用して構築されたすべてのモデルがテストされます。テスト・データは、構築データをランダムに分割して作成されます。
デフォルトのテスト結果は、次のとおりです。
パフォーマンス・メトリック
残差
両方の選択を解除できます。
テスト・データ: テスト・データは、次のいずれかの方法で作成されます。
テストにすべてのマイニング構築データを使用
テストに分割構築データを使用
テストの分割(%)
次の分割を作成: ビュー(デフォルト)。分割により、パラレルではないビューが作成されます。
テストにテスト・データ・ソースを使用: 構築データを接続した後に個別のテスト・データ・ソースを提供してテスト・データ・ソースを構築ノードに接続するには、このオプションを選択します。または、テスト・ノードを使用してモデルをテストできます。
回帰ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「回帰ビルド・ノードの編集」ダイアログ・ボックスが開きます。
詳細設定。回帰モデルの詳細設定ダイアログ・ボックスが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示(エラーがある場合のみ表示されます)
検証エラーの表示(検証エラーがある場合のみ表示されます)
「詳細設定」ダイアログ・ボックスでは、データの使用方法およびその他のモデル指定の編集、モデルの追加とノードからの削除が可能です。
次のいずれかの方法で、「詳細設定」ダイアログ・ボックスを開くことができます。
任意のモデル・ノードを右クリックして、コンテキスト・メニューから「詳細設定」を選択します。
ノードをダブルクリックしてエディタを開きます。次に、をクリックします。
分類構築ノードの「詳細設定」の次の例に示すように、このダイアログ・ボックスには2つのペインがあります。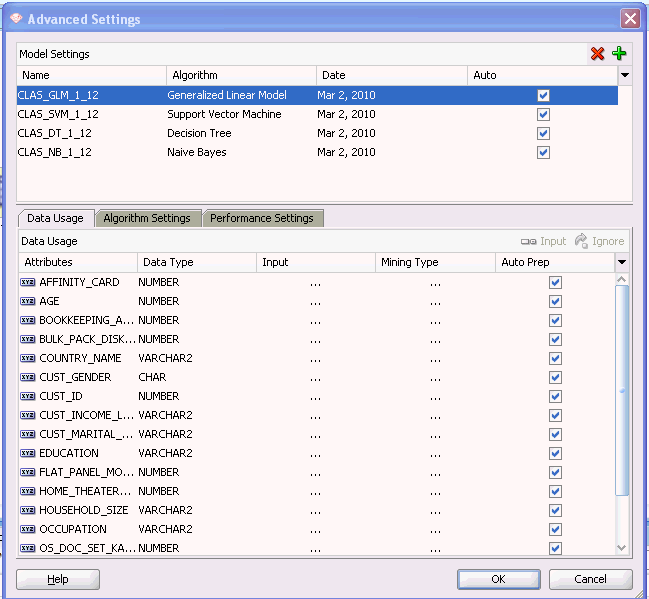
図advsettings_class.gifの説明
「詳細設定」の上部ペインでは、モデルの削除およびモデルの追加が可能です。上部ペインでモデルを選択して、データの使用方法を変更することも可能です。「詳細設定」の下部ペインには、1、2または3個のタブがあり、モデル指定を編集できます。
「詳細設定」の上部ペインには、ノード内のすべてのモデルがリストされます。「モデル設定」グリッドには、各モデルに関する次の情報が提供されます。
モデル名
アルゴリズム
最新の構築の日付
自動
データの使用方法
次により除外された列
入力および属性のマイニング型を表示するには、上部ペインでモデルを選択して「自動」の選択を解除します。「自動」が選択されている場合(デフォルト)、モデルの構築に使用される属性がシステムにより自動的に決定されます。
Data Minerは、モデルの構築に使用するために必ずしもすべての属性を選択するとはかぎりません。たとえば、属性の値の大部分が同じである場合、その属性は選択されません。
選択されている属性を確認するには、「自動」の選択を解除します。モデルを選択します。下部ペインには、選択された属性が、「入力」列にチェック・マークが付いた状態で示されます。
「自動」が選択されていない場合、「データの使用方法」タブ内のシステムによる選択をオーバーライドできます。「自動」が選択されていない場合、入力およびマイニング型も表示できます。これにより、モデル構築に使用される属性を確認でき、必要に応じてこれらを変更できます。
「モデル設定」グリッドでは、ノードに対してモデルを削除または追加できます。
削除: モデルを削除するには、モデルを選択してをクリックします。
追加: モデルをノード追加するには、をクリックします。ノードの「モデルの追加」ダイアログ・ボックスが開きます。「モデルの追加」ダイアログ・ボックスでアルゴリズムを選択して、デフォルトの名前をそのまま使用するか別の名前を指定して、オプションのコメントを追加します。
上部ペインでモデルを選択します。「詳細設定」の下部ペインの次の各タブに、関連する情報が表示されます。
これらのタブに、選択されたモデルの構築に使用される指定が表示されます。指定を変更できます。
「データの使用方法」タブは、相関ノードではサポートされません。任意の値の変更、入力として使用されない属性の確認またはマイニング型の確認を行うには、下部ペインで「表示」を選択します。
データの使用方法の情報は、複数のモデルで同時に変更できます。
「データの使用方法」タブにはデータ・グリッドが含まれています。データ・グリッドには、データ・ソース内のすべての属性がリストされます。各属性に対して、グリッドには次のリストが表示されます。
名前: これは、属性の名前です。
データ型: これは、属性のOracle Databaseデータ型です。
入力: 属性がモデルの構築に使用されるかどうかを示します。入力タイプを変更するには、「自動」をクリックします。次にアイコンをクリックして新しいアイコンを選択します。分類モデルや回帰モデルなどのターゲットを持つモデルの場合は、ターゲットが赤色のターゲット・アイコンでマークされます。
アイコンは、属性がモデルの構築に使用されることを示します。
アイコンは、属性が無視される、つまりモデルの構築に使用されないことを示します。
マイニング型: これは属性の論理型で、数値型(数値データ)、カテゴリ型(文字データ)、ネストした数値型、またはネストしたカテゴリ型、テキストまたはカスタム・テキストのいずれかです。属性の型がマイニングでサポートされない場合、列は空白になります。マイニング型はアイコンで示されます。このアイコン上にカーソルを置くと、アイコンが何を表しているか確認できます。
マイニング型を変更するには、「自動」をクリックして、次に属性の型をクリックします。リストから新しい型を選択します。マイニング型は、次のように変更できます。
数値型はカテゴリ型に変更できます。カテゴリ型への変更により、数値が文字列にキャストされます。
カテゴリ型。
ネストしたカテゴリ型およびネストした数値型は変更できません。
自動準備: 「自動準備」が選択された場合、属性上で自動データ準備が実行されます。「自動準備」が選択されていない場合、属性上で自動データ準備は実行されません。この場合、正規化など、モデルの構築に使用されるアルゴリズムで必要になる可能性のあるデータ操作を実行する必要があります。ターゲット属性に対してはデータ準備は行われません(または必要ありません)。デフォルトでは、自動データ準備が実行されます。
ルール: モデルの実行後に、「ルール」には使用された経験則が示されます。詳細を確認するには「表示」をクリックします。
属性を入力として選択しない理由が2つあります。
属性のデータ型が、モデルの構築に使用されるアルゴリズムでサポートされていないため。
たとえば、O-Clusterでは、DM_NESTED_NUMERICALSなどのネストしたデータ型はサポートされません。DM_NESTED_NUMERICALSの型の属性を使用してO-Clusterモデルを構築すると、構築に失敗します。
属性がマイニングに有用なデータを提供しないため。たとえば、不変またはほぼ不変の値を持つ属性が該当します。
この種類の属性を含めた場合、これらを除外した場合よりモデルの品質が低下します。
「アルゴリズム設定」セクションには、アルゴリズム設定の値が表示されます。設定は、モデルの構築に使用されるアルゴリズムにより決定されます。
パフォーマンス設定は、分類モデルでのみ使用できます。
「パフォーマンス設定」タブでは、分類モデル構築のパフォーマンス目標を定義します。モデルのパフォーマンス設定を表示または変更するには、上部ペインでモデルを選択します。「重み」グリッドに重みがリストされます。次のいずれかの設定を選択します。
平均化: (デフォルト)すべてのターゲット・クラス値にわたって最適な全体精度の実現を試みます。これは、選択されたアルゴリズムに応じて異なる方法で行われます。通常これは、モデル構築プロセスにおいて、出現頻度の低いターゲット値に追加の重みを提供する重み値を使用して、バイアスをかけることが求められます。
自然: バイアスをかけないモデルの構築を可能にするため、モデルはデータの本来の特徴を使用して正確なモデルを構築できるようになります。この場合、出現頻度の低いターゲット・クラス値は多くの場合、それらが平均化オプションを使用して構築されたモデルを予測する頻度と同じ頻度では予測されません。
カスタム: 各ターゲット値に一連の重みを入力できます。カスタム重みの定義を開始する1つの方法は、「重み」グリッドのすぐ上にある「平均化」または「自然」をクリックすることです。これらのいずれのオプションも、「平均化」または「自然」パフォーマンスで得られる重みと同様な重みを生成します。次に、これらの重みを異なる値に変更できます。
値を保存するには、「OK」をクリックします。
各マイニング機能は、データ・マイニング・アルゴリズムを使用して解決可能なマイニング問題の種類を表しています。データ・マイニング・モデルを作成する場合、まずマイニング機能を指定してから、その機能を実装する適切なアルゴリズムを選択する必要があります(デフォルトのアルゴリズムがない場合)。
Oracle Data Miningは、次のマイニング機能をサポートしています。
|
関連項目: 詳細は、『Oracle Data Mining概要』。 |
分類とは、ある集合内の項目をターゲットのカテゴリまたはクラスに割り当てる、つまり項目がターゲット・カテゴリに従って分類されるデータ・マイニング機能です。分類の目的は、データの各ケースのターゲット・クラスを正確に予測することです。たとえば、分類モデルを使用すれば、融資希望者を信用リスク別(低、中、高)で識別することが可能です。
分類のターゲット・カテゴリは、離散的であり、順序付けされていません。最も単純なタイプの分類問題は、2項分類です。2項分類では、ターゲット属性が取り得る値は2つのみ(たとえば「支払能力が高い」と「支払能力が低い」)です。多クラス・ターゲットは、3つ以上の値(たとえば支払能力の場合、低、中、高、不明など)を持ちます。
次の項では、分類について説明します。
分類モデルは、分類が既知である履歴データから構築されます。分類モデルを構築(トレーニング)するために、分類アルゴリズムは、予測子の値とターゲットの値の関係を見つけます。関係の検出に使用される手法は、分類アルゴリズムによって異なります。これらの関係がモデル内に集約されます。次に、このモデルはクラスの割当てが未知である別のデータ・セットに適用できます。
「アルゴリズム」設定では、モデル構築を制御します。設定は、アルゴリズムによって異なります。
構築ノードを使用して、1つ以上の分類モデルを作成します。
分類モデルはデフォルトでテストされます。
分類モデルのスコアリングまたは適用の結果は、クラスの割当ておよび割当てが正しい確率となります。たとえば、顧客を低、中、高の値に分類するモデルの場合、分類が正しい確率も予測されます。
適用ノードを使用して分類モデルのスコアリング、つまり新しいデータへのモデルの適用を行います。
Oracle Data Miningには、次の分類アルゴリズムが用意されています。
ディシジョン・ツリーは、ツリーの構築に使用されるロジックを明らかにする条件文であるルールを自動的に生成します。
Naive BayesではBayesの定理が使用されます(履歴データの値の組合せと値の頻度を数えて確率を計算する式)。
一般化線形モデルは、線形モデリングでよく使用される統計的手法です。Oracle Data Miningでは、2項分類および回帰でGLMを実装しています。
GLMでは、係数統計情報やモデルの統計情報および行の診断情報など多数の情報を利用できます。また、GLMは、予測値がある区間に収まると考えられるときのその区間の上限と下限である、信頼限界もサポートします。
サポート・ベクター・マシンは、線形回帰および非線形回帰に基づく強力な最新のアルゴリズムです。Oracle Data Miningでは、2項分類および多クラス分類に対してSVMが実装されています。
Oracle Data Miningでは、2項分類および多クラス分類に対してSVMが実装されています。
回帰は、数値を予測するデータ・マイニング機能です。利益、売上、住宅ローン金利、住宅価格、建坪、気温、距離などはすべて、回帰の手法を使用して予測することが可能です。たとえば、回帰モデルを使用すると、立地、部屋数、敷地の広さその他の要因に基づいて住宅価格を予測できます。
回帰に関するこの項では、次の項目について説明します。
回帰モデルはデフォルトでテストされます。
構築ノードを使用して、1つ以上の回帰モデルを作成します。「アルゴリズム」設定では、モデル構築を制御します。設定は、アルゴリズムによって異なります。
回帰タスクは、ターゲット値が判明しているデータセットから着手します。たとえば、住宅価格を予測する回帰モデルは、一定の期間に観測された多数の住宅のデータに基づいて作成されます。このデータには、住宅価格だけでなく、築年数、建坪、部屋数、税金、学区、商店街までの距離などのデータが含まれていることが考えられます。住宅価格をターゲット、他の属性を予測子として、各住宅のデータが1つのケースを構成します。
モデルの作成(トレーニング)プロセスでは、回帰アルゴリズムは、作成データの各ケースの予測子の関数としてターゲットの値を予測します。予測子とターゲットの関係はモデルに集約され、このモデルはターゲット値が未知である別のデータセットに適用できます。
回帰モデルのスコアリングまたは適用の結果は、クラスの割当ておよび各ケースについて割当てが正しい確率となります。たとえば、各ケースの値を予測するモデルは、値が正しい確率も予測します。
適用ノードを使用して回帰モデルのスコアリング、つまり新しいデータへのモデルの適用を行います。
Oracle Data Miningには、次の回帰アルゴリズムが用意されています。
一般化線形モデルは、線形モデリングでよく使用される統計的手法です。Oracle Data Miningでは、2項分類および回帰でGLMを実装しています。
GLMでは、係数統計情報やモデルの統計情報および行の診断情報など多数の情報を利用できます。GLMは信頼限界もサポートしています。
サポート・ベクター・マシンは、線形回帰および非線形回帰に基づく強力な最新のアルゴリズムです。
SVM回帰では、非線形回帰用のガウス・カーネルおよび線形回帰用の線形カーネルという2種類のカーネルをサポートしています。また、SVMは能動学習もサポートしています。
異常検出は、分類問題の一種です。標準の分類アルゴリズムでは、ターゲット・クラスのポジティブ例およびネガティブ例(反例)の両方が存在している必要があります。1クラス・サポート・ベクター・マシン(SVM)分類では、単一のターゲット・クラスの例のみ存在している必要があります。
モデルは、ポジティブ・クラスの既知の例と反例の未知のネガティブ・セットを区別することを学習します。目標は、例がある集合に属する場合はポジティブで、例がその集合の補集合に属する場合はネガティブまたはゼロである関数を推定することです。
|
注意: 1クラス分類問題の解決は困難な場合があります。1クラス分類プログラムの精度は通常、有意の反例を使用して作成した標準的な分類プログラムの精度とは一致しません。 |
異常検出モデルに関するこの項では、次の項目について説明します。
Oracle Data Miningでは、異常検出(AD)用の1クラス分類機能としてSVMが使用されます。SVMは異常検出で使用される場合、分類マイニング機能を持ちますが、ターゲットは使用しません。
ADモデルを構築するには、適切なデータ・ソースに接続されている異常検出ノードを使用します。
1クラスSVMモデルは、適用時に、スコアリング・データの各ケースに対して予測および確率を生成します。予測が1の場合、そのケースは典型的とみなされます。予測が0の場合、そのケースは異常とみなされます。この動作は、モデルが標準データでトレーニングされていることを反映しています。
クラスタリングでは、データ・オブジェクトの自然なグループ、つまり相互になんらかの類似性を持つオブジェクトを見つけます。つまり、あるクラスタのメンバーは、別のクラスタのメンバーよりも同じクラスタのメンバーに類似していることになります。クラスタリング分析の目的は、クラスタ間の類似度が低くなり、クラスタ内の類似度が高くなるような、質の高いクラスタを見つけることです。
次の項では、クラスタリングについて説明します。
クラスタリングは、分類と同じくデータを分割するために使用できます。クラスタリング・モデルが分類と異なるのは、事前に定義されていないグループにデータを分割する点です。分類モデルの場合は、あらかじめ定義済のクラスをターゲットとして指定し、それらのクラスに割り当てることによってデータを分割します。クラスタリング・モデルではターゲットを使用しません。
クラスタリングはデータの調査に役立ちます。ケース数が多くグループが明らかでない場合、クラスタリング・アルゴリズムを使用して、自然なグループを見つけることができます。クラスタリングは、監視ありモデルの作成対象となる同種グループを識別するためのデータの前処理手段としても有効です。
クラスタリングは、異常検出にも使用できます。データがいくつかのクラスタに分割された後に、どのクラスタにも適合しないケースを検出することが可能です。これらのケースが異常値または外れ値です。
項目が複数のクラスタに存在する可能性があり、クラスタは必ずしも分離しているとはかぎりません。
Oracle Data Miningでは階層クラスタリングを実行します。リーフ・クラスタは、アルゴリズムによって生成される最終クラスタです。階層内で上位にあるクラスタは中間クラスタです。
O-Clusterとk-Meansの相違について説明します。Oracle Data Miningでは、クラスタリング用に次のアルゴリズムがサポートされます。
期待値の最大化。Oracle Database 12c以上が必要です。
相関は、ある集合内の項目が同時に発生する確率を見つけるデータ・マイニング機能です。同時に発生する項目間の関係は、相関ルールで表されます。
相関ルールは、よく販売トランザクションの分析に使用されます。たとえば、食料品店でシリアルを購入する顧客は同時に牛乳も購入することが多いことがわかっているとします。実際に相関分析を行うと、精算時にシリアルと牛乳の両方が含まれている確率は85%である、という結果が得られることがあります。
相関モデルのこうした応用は、マーケット・バスケット分析と呼ばれています。マーケット・バスケット分析は、ダイレクト・マーケティングや販促活動、ビジネス上の傾向の把握などに役立ちます。また、店舗レイアウト、カタログのデザイン、抱合せ販売などにも活用できます。
相関モデルは、その他の分野でも重要な用途に応用されています。たとえば、E-Commerceアプリケーションにおいて、Webページのパーソナライズに相関ルールを使用することがあります。相関モデルから、ページAとページBにアクセスするユーザーは70%の確率で同じセッション内でページCにアクセスすることがわかったとします。このルールに基づいて、ページCに関心を持ちそうなユーザー向けに動的なリンクを作成することが可能です。
相関モデルでは、トランザクションで構成されるデータを分析します。
相関はトランザクションに基づきます。ケースは、マーケット・バスケットやWebセッションなどのトランザクションで構成されます。トランザクションの項目の集まりが、そのトランザクションの1つの属性です。トランザクションに関連する日付、時間、場所、ユーザーIDなどがその他の属性となります。
トランザクショナル・データで、項目の集合は、各ケースに関連付けられます。ただし、ほとんどの場合は、可能性があるすべての項目の小さなサブセットが所定のトランザクションに存在します。マーケット・バスケット内の項目は、店舗内の売上対象のほんの一部分のみを表します。
ある項目が集合内に含まれていない場合は、その値がNULLであるか、または欠損している可能性があります。集合に含まれる可能性がある項目の大部分は個々のトランザクションに存在しない確率が高いので、ほとんどの項目はNULLであるかまたは欠損していると考えられます。
情報量が多すぎると、データ・マイニングの有効性が低下する可能性があります。モデルの構築やテストのために集められたデータ属性の一部の列が、そのモデルにとって意味のある情報とならない場合もあります。実際にモデルの質や精度を落としてしまう場合もあります。
無関係な属性は、データにノイズを加えるのでモデルの精度に響きます。無関係な属性は、モデルのサイズ、およびモデルの構築とスコアリングに必要な時間とシステム・リソースが増加します。
特徴選択では、最適な属性を選択します。
特徴抽出では、属性を組み合せて、新しい削減された特徴セットを作成します。特徴選択では、最適な属性を選択します。
一部のデータ・マイニング・プロジェクトでは、最も重要な予測子を見つけることが最終目的となります。たとえば、高い信用リスクを示す顧客の主要な特徴を見つけることを目的とするモデルなどです。
属性評価は、分類モデルの作成の準備段階で使用しても効果的です。ディシジョン・ツリー・モデルと一般化線形モデルは、このタイプの前処理によってメリットを得られます。Oracle Data Miningは、これらの両方のアルゴリズム内で最適化を行うために特徴選択を実装しています。
Oracle Data Minerでは、「列のフィルタ」変換で「属性重要度」設定を提供し、Oracle Data Mining重要度関数を使用して重要な特徴を特定します。
特徴抽出は、属性を削減するプロセスです。予測における重要度に従って既存の属性をランク付けする特徴選択とは異なり、特徴抽出では実際に属性を変換します。変換された属性、つまり特徴は、元の属性の一次結合です。
特徴抽出のプロセスによって、より小さく上質な属性のセットが生成されます。特徴の最大数は、ユーザーが指定するか、アルゴリズムによって決定されます。デフォルトでは、アルゴリズムによって決定されます。
Oracle Data Miningでは、次の特徴抽出用アルゴリズムがサポートされます。
特異値分解および主成分分析。Oracle Database 12c以上が必要です。