| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
変換ノードは、データ・ノードで識別された表(複数可)で1つ以上の変換を実行します。変換は、「コンポーネント」ペインの「変換」セクションで使用できます。評価と適用データノードは、構築データを準備する方法と同じ方法で準備する必要があります。
集計とは、複数の値を1つの値に集約するプロセスです。たとえば、複数の州の売上を、複数の州で構成される地域の売上に集計できます。
集計を実行するには、集計ノードを使用します。次の各項で、集計ノードについて説明します。
集計を定義するには、集計対象のデータ・ソース・ノードおよび列を特定する必要があります。
集計対象のノードを特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにすることができます。
「コンポーネント」ウィンドウが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。「変換」セクションを展開します。
「集計」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
データ・ソース・ノードを集計ノードに接続します。
データ・ソース・ノードを右クリックして「接続」をクリックします。
集計ノードへラインを描画してもう一度クリックします。
集計ノードを右クリックして「編集」をクリックします。
集計ノードを右クリックして「実行」をクリックします。「ワークフロー・ジョブ」で、ノードの実行をモニターします。「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、集計ノードを右クリックして「データの表示」を選択し、集計の結果を表示します。
集計ノードの集計要素は、「集計ノードの編集」ダイアログ・ボックスで定義および編集が可能です。
集計ノードを編集するには、次の手順を実行します。
ノードをダブルクリックするか、右クリックして「編集」をクリックします。
グループ化基準列またはグループ化基準式を選択するには、「編集」をクリックします。「グループ化の編集」ダイアログ・ボックスが開きます。
次を定義できます。
「集計ウィザード」を使用するには、 をクリックします。集計の定義ウィザードが開きます。集計を1つずつ追加できます。
をクリックします。集計の定義ウィザードが開きます。集計を1つずつ追加できます。
すでに定義されている集計列を編集するには、集計要素を選択して をクリックします。「集計要素の編集」ダイアログ・ボックスが開きます。
をクリックします。「集計要素の編集」ダイアログ・ボックスが開きます。
集計列を削除するには、 をクリックします。
をクリックします。
集計列を追加するには、 をクリックします。「列集計の追加」ダイアログ・ボックスが開きます。
をクリックします。「列集計の追加」ダイアログ・ボックスが開きます。
カスタム集計(式)を追加するには、 をクリックします。「カスタム集計の追加」ダイアログ・ボックスが開きます。
をクリックします。「カスタム集計の追加」ダイアログ・ボックスが開きます。
集計の定義が完了したら、「OK」をクリックします。
デフォルトのタイプ: 列
次のタイプに変更可: 「式」
タイプが「列」の場合、「使用可能な属性」リストで1つ以上の列を選択します。名前またはデータ型でリストを検索できます。矢印を使用して、選択した列を「選択された属性」リストに移動します。
タイプが「式」の場合、「式」ボックスに適切な式を入力します。
式を検証するには、「検証」をクリックします。
完了後、「OK」をクリックします。
集計の定義ウィザードを使用して、集計を定義できます。
集計を定義するには、次の手順を実行します。
集計に使用する「関数」を定義します。使用可能な関数は、集計する列のデータ型によって異なります。
たとえば、1つ以上の数値の列を集計する場合は、SUMを選択できます。
「次へ」をクリックします。
集計する「列」を1つ以上選択します。選択した関数と互換性のあるデータ型を持つ列を選択する必要があります。
たとえば、関数がSUMの場合、数値データ型の列を選択する必要があります。
「次へ」をクリックします。
オプションで、集計の「サブ・グループ化」列を選択します。「サブ・グループ化」列を指定すると、ネストした表が作成されます。
たとえば、顧客ごとに製品ごとの販売額を計算するために、サブ・グループ化を使用できます。ネストした表は、データ型DM_NESTED_NUMERICALSの列を持ちます。
「タイプ」を「式」に変更することで、「サブ・グループ化」式を選択できます。式を定義したら、「検証」をクリックして式を検証します。
「次へ」をクリックします。
列のデフォルト名を確認します。名前は変更できます。
必要に応じて、定義を確認します。「戻る」をクリックして変更を実行できます。
完了後、「終了」をクリックします。
集計の個別要素を定義または変更できます。個別要素を定義または変更するには、次の手順を実行します。
「出力」では、名前を指定できます。名前を指定するには、「自動生成」の選択を解除して名前を入力します。デフォルトでは、「自動生成」が選択されています。
「出力」は、集計の結果を保持する列の名前です。
集計対象の列を選択または変更します。
列に適用する関数を選択します。使用可能な関数は、列のデータ型によって異なります。
「編集」をクリックして、新しい「サブ・グループ化」列を定義します。「グループ化の編集」ダイアログ・ボックスが開きます。
終了したら、「OK」をクリックします。
列の集計方法を定義できます。
属性を追加するには:
をクリックします。
名前を指定するには、「自動生成」の選択を解除して名前を入力します。デフォルトでは、「自動生成」が選択されています。
「出力」は、集計の結果を保持する列の名前です。
集計する列をリストから選択します。
列に適用する関数を選択します。使用可能な関数は、列のデータ型によって異なります。たとえば、数値に対して平均(AVG)を指定できます。
「サブ・グループ化」列を定義するには、「編集」をクリックします。「グループ化の編集」ダイアログ・ボックスが開きます。「サブ・グループ化」列の定義は必須ではありません。
完了後、「OK」をクリックします。
カスタム集計を追加するには、をクリックして次の手順を実行します。
「出力」は、集計の結果を保持する列の名前です。名前を指定します。
「式」は、追加する式です。式を定義するには、をクリックして「式ビルダー」を開きます。
この式は、顧客が購入したすべての製品を計算し、結果をネストされたデータ型にキャストします。
CAST (COLLECT (TO_CHAR (PROD_ID)) AS ODMR_NESTED_VARCHAR2)
「サブ・グループ化」列を定義するには、「編集」をクリックします。「グループ化の編集」ダイアログ・ボックスが開きます。
「サブ・グループ化」列の定義は必須ではありません。
式を検証するには、「検証」をクリックします。
完了後、「OK」をクリックします。
「プロパティ」ペインを表示するには、ノードを選択します。「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
集計ノードの「プロパティ」ペインには、次のセクションがあります。
デフォルトの設定では、結果の表示を最適化するためのキャッシュは生成されません。
キャッシュを生成できます。キャッシュを生成する場合は、サンプリング・サイズを次のいずれかに指定します。
行数。デフォルトは2000行
パーセント。デフォルトは60%
集計ノードのコンテキスト・メニューには、次のエントリが含まれます。
編集。詳細は、「集計ノードの編集」。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合のみ表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
変換ノードが有効な状態の場合、データを表示できます。
データを表示するには、ノードを右クリックして、コンテキスト・メニューから「データの表示」を選択します。データ・ビューアが開きます。
データ・ビューアには次のタブがあります。
「データ」タブには、データのサンプルが表示されます。データ・ビューアは、キャッシュで定義されたサンプリングからのデータまたはソース表に遡るノード系統から取得されたデータの行のグリッド表示を提供します。
表示は、次で制御されます。
リフレッシュ: 表示をリフレッシュするには をクリックします。
をクリックします。
表示: キャッシュされたデータまたは実際のデータのいずれかを選択できます。
ソート: 「ソートする列の選択」ダイアログ・ボックスが表示されます。
フィルタ: データを選択するためのWHERE句を入力できます。
「ソートする列の選択」ダイアログ・ボックスでは、次を実行できます。
ソート対象の複数の列を選択します。
列の順序を決定します。
列による昇順または降順を決定します。
「NULLS FIRST」を指定して、NULL値が実際のデータ値に先行して表示されるようにします。
ソート順序は、クリアするまで維持されます。
列ヘッダーもソート対応であり、ソートの選択に対して一時的なオーバーライドを提供します。
「列」タブは、ノードからの出力であるすべての列のリストです。このタブ内の表示は、次の条件に応じて異なります。
ノードが未実行である場合、データベースにより提供される表またはビュー構造が表示されます。
ノードが正常に実行済である場合、サンプリングされた表の構造が表示されます。これは、ノードの指定時に定義されたサンプリングに基づきます。
各列の次の値が表示されます。
名前
データ型
マイニング型
長さ
精度
スケール(浮動小数点用)
列ID
表示される列を制限する複数のフィルタリング・オプションがあります。(または)/(および)の接尾辞を指定したフィルタ設定を使用すると、スペースで区切られた複数の文字列を入力できます。たとえば、「名前/データ型/マイニング型(いずれか)」が選択されている場合、フィルタ文字列A Bでは、「名前」、「データ型」または「マイニング型」が文字AまたはBで始まるすべての列が生成されます。
「SQL」タブでは、「SQLの詳細」テキスト領域に、「データ」タブ内に表示されている実際のビューにより提供されているデータを生成したSQLコードが表示されます。
SQLは、実際のデータにアクセスするために必要な系統に応じて親ノードからのSQLが含まれる、積み重ね型の式にすることができます。
次のタスクを実行できます。
適切なSQLインタフェース内でのSQL問合せのコピーおよび実行。次のオプションが有効です。
すべて選択([Ctrl]+[A])
コピー([Ctrl]+[C])
テキストの検索。検索コントロールは、一致したテキストをハイライトし、前方検索および後方検索を実行する標準の検索コントロールです。
式ビルダーは、フィルタの制約など、SQL式の入力および検証に役立ちます。式とは、データを変換したり制限を指定するSQL文または句です。式ビルダーには使用可能な列が表示され、関数と一般に使用される演算子の選択肢が提供され、式が検証されます。
式ビルダーで式を構築して検証するには、次の手順に従います。
「カスタム変換の追加」ダイアログ・ボックスでをクリックします。「式ビルダー」ダイアログ・ボックスが開きます。
「式ビルダー」ダイアログ・ボックスには、次のコンポーネントが含まれています。
「属性」タブ: ソース・データ内の属性(列)がリストされます。「式」ボックスで作成している問合せに属性を挿入したり、選択した文字を置換するには、現在の文字位置で属性をダブルクリックします。
「関数」タブ: 一般的に使用されるSQL関数が、フォルダに分割されてリストされます。フォルダをダブルクリックして、そこにリストされている関数を表示します。式の現在の文字位置に関数を挿入したり、選択した文字を置換するには、関数をダブルクリックします。
「式」ボックス: 作成する式が「式」ボックスに表示されます。式は、次のいずれかの方法で作成できます。
「式」ボックスに式を直接入力します。
属性および関数を、それぞれ「属性」タブおよび「関数」タブでダブルクリックしてこれらを追加します。
演算子を式に追加するには、演算子をクリックします。
一般的に使用される演算子が、「式」ボックスの下にリストされています。記号で示されている適切な演算子をクリックします。「式」ボックスに、直接演算子を入力することも可能です。表7-1は、入力できる演算子を示しています。
「検証結果」テキスト領域(読取り専用): 検証結果が表示されます。
検証: 「式」ボックス内の式を検証するには、「検証」をクリックします。結果は、「検証結果」に表示されます。
式の作成が完了したら、「OK」をクリックします。
式ビルダーには、文字、数値および日付のデータに適用できる様々な関数が含まれています。欠損値処理も含めて、データ・マイニングに必要な通常のデータ前処理の大半をサポートする関数が用意されています。使用可能な関数のリストを参照するには、該当するカテゴリを開いてください。
関数は、次のカテゴリに分類されています。
文字: concatenate、trim、length、substringなどが含まれます。
変換: 文字、日付、数字などに変換します。
日付: 翌日の計算、タイムスタンプの挿入、切捨て、丸めおよびその他の日付操作を実行します。
数値: 絶対値、ceiling、floor、三角関数、双曲線関数、対数、指数関数などが含まれます
分析: 分析関数を実行します。
NULL値の置換: 日付、文字および数値用。
関数の表記法は、SQL関数の表記法です。
|
関連項目: 『Oracle Database SQL言語リファレンス』 |
「列のフィルタ」は、列が後続のワークフロー計算で使用されないように、フィルタ処理で列を除外します。たとえば、Null値が94%を超える列を除外または無視できます。
オプションで、重要な属性を識別できます。
「列のフィルタ」は、実行後に分析を必要とします。変換により、推奨が提示されます。受け入れる推奨項目を決定できます。
「列のフィルタ」はパラレルに実行できます。
次の各項で、フィルタ列ノードについて説明します。
フィルタ列を定義する前に、データ・ソース・ノードを特定し、重要な属性を見つけるかどうかを決定する必要があります。フィルタ列を定義するには、次の手順を実行します。
フィルタ対象のノードを特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにすることができます。
「コンポーネント」ペインで「変換」セクションを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「列のフィルタ」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
データ・ソース・ノードをフィルタ列ノードに接続します。
データ・ソース・ノードを右クリックして「接続」を選択します。
フィルタ列ノードへラインを描画してもう一度クリックします。
フィルタ列ノードを右クリックして「編集」をクリックします。
フィルタ列ノードを右クリックして「実行」をクリックします。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」で「Data Miner」に移動して「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、フィルタ列ノードを右クリックして「データの表示」を選択し、フィルタされた列の結果を表示します。
ヒントを確認した後、必要に応じて追加の列をフィルタ処理で除外できます。
フィルタ列ノードにより実行されるフィルタを定義または編集できます。次のタスクを実行できます。
フィルタ列ノードの初回編集時に、列を除外します。
フィルタ列ノードの初回編集時に、「フィルタ列設定の定義」を編集または表示します。
重要な属性を計算します。「設定」をクリックして、「属性重要度」を有効にします。
ヒントを評価して、フィルタ処理で除外する列を決定します。フィルタ列ノードの実行後に、追加情報をヒントの形式で使用できます。
デフォルトでは、すべての列が出力用に選択されているため、すべての列がワークフローの次のノードに渡されます。
列を除外するには、 をクリックします。矢印が取り消されたことが
をクリックします。矢印が取り消されたことが により示されます。除外された列は無視され、渡されなくなります。
により示されます。除外された列は無視され、渡されなくなります。
設定を表示または変更するには、「設定」をクリックします。「フィルタ列設定の定義」ダイアログ・ボックスが開きます。
「列のフィルタ」の設定を、ここで作成および編集できます。次の3種類の設定があります。
データ品質: NULL値の割合、一意な値の割合および定数の割合に関して「列のフィルタ」の設定を可能にします。「データ品質」のデフォルト値は、プリファレンスで指定されます。デフォルトのモデルを変更できます。次のデータ品質の基準を指定できます。
% Nullが次の値以下: データ・ソースの列内のNull値の最大許容パーセンテージを示します。Null値の割合が多い列は無視することをお薦めします。デフォルト値は95%です。
%一意が次の値以下: データ・ソースの列内で一意な値の最大許容パーセンテージを示します。列に多数の一意値が含まれている場合、モデル構築に有用な情報が含まれていない可能性があります。デフォルト値は95%です。
%定数が次の値以下: データ・ソースの列内の定数値の最大許容パーセンテージを示します。列内の大部分の値が同じである場合、その列はモデル構築に有用でない可能性があります。
属性重要度: 重要な属性を識別するための属性重要度モデルの構築を可能にします。
デフォルトでは、この設定はOFFになっています。「列のフィルタ」は、「属性重要度」を計算しません。
サンプリング: 統計の計算用のランダム・サンプルのデフォルト・サイズに従った「列のフィルタ」の設定を可能にします。サンプリングのデフォルト値は、プリファレンスで指定されます。デフォルトを変更することも、サンプリングをオフにすることも可能です。デフォルトのサンプル・サイズは2000レコードです。
フィルタ列ノードの実行後に、次のタスクを実行できます。
ヒントの表示: ヒントを表示するには、フィルタ列ノードをダブルクリックします。列のフィルタ詳細ノードの編集ダイアログ・ボックスに、データ品質チェックに適合しなかった属性を示すヒントが表示されます。詳細は、をクリックしてください。
データ品質に関するサマリー情報が表示されます。
値は、データ・ビューア内にグラフィカルに示されます。
属性重要度を指定した場合:
「ヒント」に、最小の重要度値を持たない属性が示されます。
各列の重要度が表示されます。
列の除外: 属性の「出力」列に移動してをクリックします。「出力」列のアイコンがに変わります。選択された列は無視または除外され、これは列が後続のノード用ではないことを意味します。ノードを再度実行する必要はありません。
推奨の受入れ:
推奨が複数の場合、属性を選択して をクリックします。
をクリックします。
すべての推奨の場合、[Ctrl]を押しながら[A]を押してをクリックします。
推奨される出力設定の適用: ヒントがある属性は渡されません。ヒントがない属性は変更されず、渡されます。
表またはビューの作成ノード: このノードの出力はデータ・フローです。結果が含まれる表を作成するには、表またはビューの作成ノードを使用します。
ノードの実行後に、「列の詳細の編集」ダイアログ・ボックス内に列フィルタの詳細レポートが生成されます。グリッドの各列には、データ品質情報が要約されています。
デフォルト設定では、「属性重要度」と「データ品質」の両方が表示されます。
「属性重要度」が選択されている場合、次が表示されます。
ランク
重要度
「データ品質」が選択されている場合、次の列が表示されます。
% Null
%一意
%定数
グリッド内の「ヒント」列は、データ品質に適合しない、最小重要度値を満たさないデータ・セット内の列を示します。
棒グラフにより、値が視覚的に提示されます。
たとえば、Null値の割合が「% Nullが次の値以下」で指定された値より大きい場合、NULL値の割合が超過していることを示すヒントが生成されます。ある列のNULL値の割合が非常に大きい場合、その列を除外することをお薦めします。
データ・セットが多数の属性を持つ場合、すべての属性が予測モデルに寄与するとはかぎりません。一部の属性は単にノイズを加えるのみの場合があり、これらは実際にモデルの予測値の精度を損います。Oracle Data Minerは、ターゲット値のデータ・マイニングにおける重要度で属性をランク付けします。次に、ターゲット値の特定に重要ではない属性をフィルタ処理で除外できます。
使用する属性を少なくすることは、必ずしも予測の精度を損ねることにはなりません。使用する属性の数が多すぎると、モデルに影響を与え、そのパフォーマンスや精度が低下する場合があります。最小数の属性を使用したマイニングにより、計算時間を大幅に削減でき、より優れたモデルを構築することが可能になります。
次の事項が属性重要度に適用されます。
属性重要度は分類において最も有用です。
「列のフィルタ」における属性重要度のターゲットは、構築を計画している分類モデルのターゲットと同じである必要があります。
属性重要度では、各属性のランクおよび重要度が計算されます。
属性のランクは、整数です。
属性の重要度は実数であり、負の場合もあります。
属性重要度に対して次の値を指定します。
ターゲット: 重要な属性を見つける対象の値。通常は、分類問題のターゲットです。
重要度カットオフ: 0から1.0までの数値です。この値は、受け入れる重要度の最小値を特定します。属性の重要度が負の数である場合、その属性はターゲットと関連付けられないため、カットオフは負にできません。デフォルトのカットオフは0です。属性のランクまたは重要度により、モデルの構築に使用する属性を選択できます。
上位N: 属性の最大数です。デフォルトは100です。
属性重要度の計算用の「サンプル手法」を選択します。デフォルトは「システム決定」です。「層別」または「ランダム」も選択できます。
「システム決定」は、層別カットオフ値を持ち、そのデフォルト値は10です。
選択された列の個別の数がカットオフ値を超えている場合、ランダム・サンプリングが使用されます。
選択された列の個別の数がカットオフ値以下である場合、層別サンプリングが使用されます。
ターゲットのサンプリングの特定の組合せにより、パフォーマンスの問題が発生する可能性があります。パフォーマンスに問題がある場合は、警告が表示されます。
属性重要度モデルを表示するには、選択された「属性重要度」を使用してフィルタ列ノードを構築します。ノードを右クリックして、「データの表示」を選択します。結果は、新しい「フィルタ列の詳細」タブに表示されます。ビューアには、次のタブがあります。
属性重要度: 重要度が0以上の属性がリストされます。属性は、最小ランク(最重要)から最大ランクまでランク順にリストされます。このタブには、各属性のデータ型も表示されます。青色のバーがランクを示しています。任意の列ヘッダーをクリックして、列をソートできます。
列をフィルタ処理するには、つまり表示される列を数を制限するには、 を使用します。
を使用します。
フィルタ定義をクリアするには、をクリックします。名前、タイプ、ランクまたは重要度でも検索できます。
データ: 重要な属性が重要度順にリストされます(最重要が先頭)。各属性のランクおよび重要度について、値がリストされます。重要度値が0以上の属性のみがリストされます。
列: 「属性重要度」により作成される、属性名、ランクおよび重要度値の列が表示されます。
SQL: これは、詳細を生成するSQLです。
属性重要度に対して次の値を指定します。
ターゲット: 重要な属性を見つける対象の値。通常は、分類問題のターゲットです。
重要度カットオフ: 0から1.0までの数値です。この値は、受け入れる重要度の最小値を特定します。属性の重要度が負の数である場合、その属性はターゲットと関連付けられないため、カットオフは負にできません。デフォルトのカットオフは0です。属性のランクまたは重要度により、モデルの構築に使用する属性を選択できます。
上位N: 属性の最大数です。デフォルトは100です。
属性重要度の計算用の「サンプル手法」を選択します。デフォルトは「システム決定」です。「層別」または「ランダム」も選択できます。
「システム決定」手法は、層別カットオフ値を持ち、そのデフォルト値は10です。
選択された列の個別の数がカットオフ値を超えている場合、ランダム・サンプリングが使用されます。
選択された列の個別の数がカットオフ値以下である場合、層別サンプリングが使用されます
ターゲットのサンプリングの特定の組合せにより、パフォーマンスの問題が発生する可能性があります。パフォーマンスに問題がある場合は、警告が表示されます。
「プロパティ」ペインを表示する手順:
フィルタ列ノードを選択します。
「プロパティ」タブに、ノードの「プロパティ」ペインが表示されます。「プロパティ」タブが表示されていない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
フィルタ列ノードのプロパティには、次のセクションがあります。
列:データ・ソースの列が表示されます。ノードの実行後に、ヒントが表示されます。
フィルタ: 「フィルタ列設定の定義」で作成された仕様。
フィルタ列ノードのコンテキスト・メニューには、次のエントリが含まれます。
編集。詳細は、「フィルタ列ノードの編集」を参照してください。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
「フィルタ列の詳細」では、「属性重要度」の結果で構成されるデータ・フローを作成します。各属性について、ランクおよび重要度の値がリストされます。
|
注意: 「フィルタ列の詳細」は、「設定」で選択された属性重要度を持つフィルタ列ノードに接続されている必要があります。それ以外の場合、フィルタ列の詳細ノードは無効となります。 |
「フィルタ列の詳細」はパラレルに実行できます。
この項は次のトピックで構成されています:
フィルタ列の詳細ノードを作成する前に、「設定」で「属性重要度」が選択されているフィルタ列ノードを特定する必要があります。
フィルタ列の詳細ノードを作成する手順:
フィルタ対象のノードを特定または作成します。属性重要度が計算されているフィルタ列ノードのみを接続できます。
「コンポーネント」ペインで「変換」セクションを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「フィルタ列の詳細」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
フィルタ列ノードをフィルタ列の詳細ノードに接続します。
フィルタ列ノードを右クリックして「接続」を選択します。
フィルタ列の詳細ノードへラインを描画してもう一度クリックします。
フィルタ列の詳細ノードを右クリックして「編集」を選択できます。このリリースでは、選択するオプションはありません。
フィルタ列の詳細ノードを右クリックして「実行」を選択します。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、フィルタ列の詳細ノードを右クリックして「データの表示」を選択し、結果を表示します。
このノードの出力は、データ・フローです。結果が含まれる表を作成するには、表またはビューの作成ノードを使用します。
|
注意: 「フィルタ列の詳細」は、「属性重要度」の結果のみで構成されています。データ品質に関する情報は含まれていません。 |
使用可能なオプションは、「属性重要度」オプションのみです。
フィルタ列の詳細ノードのプロパティを表示する手順:
フィルタ列の詳細ノードを選択します。
「プロパティ」タブに、ノードのプロパティが表示されます。「プロパティ」タブが表示されていない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
フィルタ列ノードのプロパティには、次のセクションがあります。
フィルタ列の詳細ノードのコンテキスト・メニューには、次のオプションが含まれます。
編集。詳細は、「フィルタ列の詳細ノードの編集」を参照してください。
データの表示。詳細は、「属性重要度ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
フィルタ行ノードでは、行を記述するSQL文を指定して行を選択できます。
たとえば、CUST_GENDERがFであるすべての行を選択するには、次のように指定します。
CUST_GENDER = 'F'
SQL式を直接記述することも、式ビルダーを使用することも可能です。
フィルタ行はパラレルに実行できます
この項は次のトピックで構成されています:
前提条件:
データ・ソース・ノードを特定します。フィルタ対象のノードを特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにすることができます。
フィルタ行ノードを定義するには、次の手順を実行します。
「コンポーネント」ペインで「変換」セクションを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「行のフィルタ」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
データ・ソース・ノードをフィルタ行ノードに接続します。
カーソルをデータ・ソース・ノードに移動します。
データ・ソース・ノードを右クリックして「接続」を選択します。
フィルタ行ノードへラインをドラッグしてもう一度クリックします。
フィルタ行ノードを右クリックして「編集」を選択します。「行のフィルタの編集」ダイアログ・ボックスを使用して、フィルタを定義します。
フィルタ行ノードを右クリックして「実行」を選択します。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、フィルタ行ノードを右クリックして「データの表示」を選択し、「行のフィルタ」の結果を表示します。
「行のフィルタの編集」ダイアログ・ボックスでは、フィルタ行ノードで実行されるフィルタを定義または編集します。
「行のフィルタの編集」ダイアログ・ボックスには、次の2つのタブがあります。
フィルタは、選択する行を記述した1つ以上のSQL式です。
フィルタを作成または編集するには、次の手順を実行します。
をクリックして、「式ビルダー」を開きます。
フィルタリングに使用するSQL問合せを記述します。
式の指定後に、それを削除できます。それを選択して、をクリックします。
完了後、「OK」をクリックします。Data Minerにより、式が検証されます。
SQL式を入力するか、式ビルダーを使用してそれを定義します。フィルタ行ノードのプロパティを表示する手順:
フィルタ行ノードを選択します。
「プロパティ」タブに、ノードのプロパティが表示されます。「プロパティ」タブが表示されていない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
フィルタ行ノードの「プロパティ」タブには、次のセクションがあります。
フィルタ: 「行のフィルタの編集」を使用して作成したSQL式。をクリックして、「プロパティ」内で式を変更できます。
列:出力データ列。各列に対して、名前、別名(該当する場合)およびデータ型がリストされます。
フィルタ行ノードのコンテキスト・メニューには、次のオプションが含まれます。
編集。詳細は、「行のフィルタの編集」を参照してください。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
「結合」ノードでは、2つ以上のデータ・ソース・ノードからのデータを、新しいデータ・ソースに結合します。
理論的には、結合ノードとは、2つ以上の表、ビューまたはマテリアライズド・ビューの行を結合する問合せです。たとえば、結合ノードは表またはビューを組み合せて(FROM句で指定)、指定した条件に一致する行のみを選択し(WHERE句)、投影を使用して2つの列からデータを取得します(SELECT文)。
「結合」はパラレルに実行できます。
この項では、次の項目について説明します。
結合ノードでは、2つ以上のデータ・ソース・ノードおよび少なくとも1つの出力列を指定する必要があります。
「結合」は、非常に低速になる場合があります。結合入力を索引付き表としてマテリアライズする場合、結合はより高速になります。
「結合」の出力は、データ・フローです。それを表またはビューとしてマテリアライズする場合、それを表またはビュー作成ノードに接続します。
2つ以上のデータ・ソース・ノードを結合するには、次の手順を実行します。
結合対象のノードを少なくとも2つ特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにできます。
「コンポーネント」ペインで「変換」ノードを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「結合」ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。これにより、結合ノードがワークフローに追加されます。
結合するデータ・ソース・ノードを結合ノードに接続します。
結合するいずれかのノードにカーソルを移動します。
ノードを右クリックして「接続」を選択します。
結合ノードへラインを描画してもう一度クリックします。
結合対象のすべてのノードが結合ノードに接続されるまで繰り返します。
結合ノードを右クリックして「編集」を選択します。「結合ノードの編集」オプションを使用して、結合ノードを定義します。
結合ノードを右クリックして「実行」を選択します。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、結合ノードを右クリックして「データの表示」を選択し、結合の結果を表示します。
結合の定義と結果の表示は、結合ノードのプロパティからも行えます。
結合ノードは次のどちらかの方法で定義できます。
結合ノードをダブルクリックするか、ノードを右クリックして「編集」をクリックします。「結合」タブをクリックします。
ノードを選択します。「プロパティ」ペインで「結合」タブを選択します。をクリックします。
いずれの場合でも、「結合ノードの編集」ダイアログ・ボックスが開きます。
「結合」タブが表示されていない場合は、それをクリックします。「結合ノードの編集」ダイアログ・ボックスでは、次のタスクを実行できます。
新しい結合列を追加するには、をクリックします。「結合列の編集」ダイアログ・ボックスが開きます。
「結合列の編集」ダイアログ・ボックスで、「データソース」—「ソース1」および「ソース2」を選択します。いずれのソース内の列も、名前またはデータ型で検索できます。
「ソース1」でエントリを1つ選択して、対応するエントリを「ソース2」で選択します。
「追加」をクリックします。Data Minerにより適切な結合タイプが選択されます。
「列1」(「ソース1」から)、「列2」(「ソース2」から)および「結合タイプ」がグリッドに表示されます。このグリッドは、「列1」、「列2」または「結合タイプ」で検索できます。
完了後、「OK」をクリックします。
「結合」で列を選択するには、「列」タブをクリックして、「列の編集」ダイアログ・ボックスを表示します。
「結合」のフィルタを定義するには、「フィルタ」タブを選択して適切なSQL式を入力します。SQLワークシート(SQL Developerの一部)を使用してフィルタを記述することも可能です。
いずれかのデータ・ノードが結合ノードに接続されなくなった場合など、結合の問題が発生した場合は、次のように情報インジケータが表示されます。
「問題の解決」をクリックします。「解決」ダイアログ・ボックスが開きます。

デフォルト設定では、表示された列のリストに対して「自動設定」を使用します。列を選択するには、次のいずれかの方法で結合詳細の編集内の「列」タブに移動します。
結合ノードを右クリックして「編集」を選択します。「列」をクリックします。
結合ノードを選択します。「プロパティ」ペインで「列」タブを選択します。
変更を行うには、「自動設定」の選択を解除します。次のタスクを実行できます。
列のリストの編集: 「「出力データ列の編集」ダイアログ」ボックスを開いて をクリックします。
をクリックします。
出力からの列の削除: 列を選択してをクリックします。
ノードを実行していない場合は、それを再度実行する必要があります。
デフォルト設定では、出力内の両方の表からのすべての列が含まれます。
出力から列を除外するには、次の手順を実行します。
列を「選択された属性」リストから「使用可能な属性」リストに移動します。
「OK」をクリックします。
データ・ソース・ノードが結合ノードから切断されると、そのノードのすべての結合仕様が保持され、「無効」としてマークされます。結合ノードを実行する前に、問題を解決する必要があります。「解決」ダイアログ・ボックスには、結合の問題を解決する方法が2つ表示されます。
削除: すべての無効なエントリを、すべての指定(「適用」および「データ」)から削除します。
解決: 未割当てノードと欠落ノードの関連付けを可能にするグリッドが表示されます。欠落ノードがグリッドにリストされ、アクションが提示されます。
結合ノードのプロパティを表示する手順:
結合ノードを選択します。
「プロパティ」ペインに、ノードのプロパティが表示されます。「プロパティ」ペインが表示されていない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
結合ノードの「プロパティ」ペインには、次のセクションがあります。
結合: 結合を定義します。
列: 「結合」の出力列が表示されます。
各列に対して、名前、ノード、別名(該当する場合)およびデータ型がリストされます。最大1000列が表示されます。
「フィルタ」では、式ビルダーを使用してフィルタ条件を定義して、結果をフィルタ処理します。をクリックして、「式ビルダー」を開きます。
結合ノードのコンテキスト・メニューには、次のエントリが含まれます。
編集。詳細は、「結合ノードの編集」を参照してください。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
JSON (JavaScript Object Notation)は一種のデータ・フォーマットであり、ユーザーが一連の値、リストおよびキーと値のペアのマッピングを複数のシステムにわたって格納および通信することを可能にします。Oracle Data Miner (SQL Developer 4.1)でのJSONデータ・フォーマットのサポートは、JSON問合せノードにより実現されます。
JSON問合せノードは、JSONデータ・フォーマットをリレーショナル・フォーマットに投影します。それは、データ・ソース・ノードなどの入力データ・プロバイダ・ノードを1つのみサポートします。JSON問合せノードでは、次のタスクを実行できます。
ソース・データ内の任意のJSON属性を選択して、それをリレーショナル・データとして投影します。
ソース・データ内のリレーショナル列を選択して、それをリレーショナル・データとして投影します。
JSONデータ上の集計列を定義します。
出力データのプレビュー。
ユーザー指定に基づいてJSON問合せを構成します。
|
注意: JSON問合せノードは、SQL Developer 4.1がOracle Database 12.1.0.2に接続されている場合にサポートされます。 |
JSON問合せノードは、データ・ソース・ノードなどの入力プロバイダ・ノードに接続されている必要があります。ノードを正常に実行するには、入力提供ノードにJSONデータが含まれている必要があります。
JSON問合せノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動して、「変換」を展開します。
「コンポーネント」ペインが表示されていない場合は、SQL Developerメニュー・バーで「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
「変換」セクションで、JSON問合せノードをクリックします。
JSON問合せノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。これにより、JSON問合せノードがワークフローに追加されます。
|
注意: ワークフロー内に、JSONデータが含まれているデータ・ソース・ノードが存在することを確認してください。 |
接続を作成するノード(たとえばデータ・ソース・ノード)を右クリックして、コンテキスト・メニューで「接続」をクリックします。
選択したノードからJSON問合せノードへラインを描画してもう一度クリックします。これにより、JSON問合せノードがデータ・ソース・ノードに接続されます。
「JSON問合せノードの編集」ダイアログ・ボックスでは、擬似JSON型の入力列のみを操作できます。「JSON問合せノードの編集」ダイアログ・ボックスを開く手順:
JSON問合せノードをダブルクリックします。
ノードを右クリックして「編集」をクリックします。
「JSON問合せノードの編集」は、次のタブで構成されています。
「JSON」タブでJSONデータを選択できます。「列」ドロップダウン・リストには、JSONデータ(擬似JSONデータ型)が含まれる入力列のみがリストされます。ドロップダウン・リストから入力列を1つ選択します。選択した入力列のデータ構造が「構造」タブに表示されます。
「JSON」タブは次で構成されています。
「構造」タブには、選択した列のJSONデータ構造が表示されます。構造またはデータ・ガイド表が、データ・ソース・ノードなどの親ソース・ノード内で生成されている必要があります。構造が見つからない場合、それを通知するメッセージが表示されます。
データ構造に関する次の情報が表示されます。
JSON属性: 生成されたJSON構造が階層形式で表示されます。インポートする1つ以上の属性を選択できます。親属性を選択した場合、すべての子属性が自動的に選択されます。
JSONデータ型: JSONデータから得られた、すべての属性のJSONデータ型が表示されます。
ネストされていない: 配列内のすべての属性が、リレーショナル・フォーマットにネストされていません。デフォルトでは、「ネストされていない」オプションは有効です。配列属性の「ネストされていない」オプションが無効である場合、次のようになります。
この属性は表示されますが、選択できません。
出力に対して配列属性が選択されている場合、出力列には配列のJSON表現が含まれます。
「データ」タブには、JSON構造の作成に使用されているJSONデータが表示されます。テキスト・パネルでは、データが読取り専用モードで表示されます。コピーおよび貼付け操作用にテキストを選択できます。
表示するデータを問合せできます。データを問い合せるには、 をクリックします。
をクリックします。
「追加出力」タブでは、ソース・データ内のリレーショナル列を出力用に選択できます。「集計」タブで集計定義により使用されている入力列は、出力のリストに自動的に追加されます。
ここでは、次のタスクを実行できます。
リレーショナル列の追加: 「出力データ列の編集」ダイアログでリレーショナル列を追加するには、をクリックします。
リレーショナル列の削除: 削除するリレーショナル列を選択してをクリックします。
「「出力データ列の編集」ダイアログ」ボックスでは、データ・ソース内の使用可能なすべてのリレーショナル列がリストされます。出力に追加する1つ以上の列を選択できます。列を追加するには、次の手順を実行します。
「使用可能な属性」リストで、出力に含める列を選択します。
右矢印をクリックして、属性を「選択された属性」リストに移動します。出力から任意の列を除外するには、属性を選択して左矢印をクリックします。
「OK」をクリックします。これで、出力に列が含まれ、列が「追加出力」タブにリストされます。
「集計」タブでは、JSON属性上の集計列の定義を定義できます。「集計」タブでは、次の2つのセクションに情報が表示されます。
「グループ化基準属性」セクション: ここでは、グループ化基準属性が、属性カウントとともにリストされます。次のタスクを実行できます。
JSONパスの表示: 属性名とコンテキスト情報を表示するには、「JSONパス」をクリックします。たとえば、$."customers"."cust_id"などです。
有効化されていない場合、属性名のみが表示されます。
属性の編集と追加: 「グループ化の編集」ダイアログ・ボックスにグループ化基準属性を追加するには、をクリックします。
属性の削除: 削除する属性を選択してをクリックします。
「集計属性」セクション: ここでは、集計列が列カウントとともに表示されます。
JSONパスの表示: 属性名とコンテキスト情報を表示するには、「JSONパス」をクリックします。たとえば、$."customers"."cust_id"などです。
有効化されていない場合、属性名のみが表示されます。
集計列の定義: 集計の追加ボックスで集計列を定義するには、をクリックします。
集計列の削除: 選択した列を削除するには、をクリックします。
「集計ダイアログの追加」ボックスでは、JSON属性に対して関数を定義できます。このダイアログ・ボックスには、階層ビューでJSON構造が表示されます。複数の属性を選択して、それに集計関数を適用できます。
|
注意: オブジェクトおよび配列タイプの属性は選択できません。 |
次のタスクを実行できます。
集計関数の定義:
JSON属性を選択します。[Ctrl]キーを押しながら関数を定義する属性をクリックすると、複数の属性を選択できます。
選択した属性に対して関数を選択および適用するには、 をクリックします。適用可能な関数がリストされます。適用する関数を選択します。
をクリックします。適用可能な関数がリストされます。適用する関数を選択します。
または、「関数」列で対応する行をクリックします。適用可能な関数がドロップダウン・リスト内にリストされます。適用する関数を選択します。このオプションを使用すると、一度に1つの属性にのみ関数を定義できます。
「OK」をクリックします。
集計定義のクリア: 属性を選択して をクリックします。定義された関数に加え、出力と「サブ・グループ化」エントリも削除されます。
をクリックします。定義された関数に加え、出力と「サブ・グループ化」エントリも削除されます。
サブ・グループ化要素の編集: 属性を選択して をクリックします。「サブ・グループ化の編集」ダイアログ・ボックスが開きます。
をクリックします。「サブ・グループ化の編集」ダイアログ・ボックスが開きます。
検索: 属性名の一部に基づいて属性を見つけるには をクリックします。
をクリックします。
「サブ・グループ化の編集」ダイアログ・ボックスでは、選択したJSON属性に「サブ・グループ化」属性を追加できます。属性を追加するには、次の手順を実行します。
上部ペインで、「使用可能な属性」フォルダを展開します。
「サブ・グループ化」属性として追加する属性を選択します。選択した属性は下部ペインにリストされ、そこには追加した属性のカウントも表示されます。
「OK」をクリックします。
「グループ化の編集」ダイアログ・ボックスには、JSON属性コレクションの上にリレーショナル列が表示されます。リレーショナル列を、最上位レベルのグループ化基準の一部として追加できます。リレーショナル列を追加するには、次の手順を実行します。
上部ペインで、「使用可能な属性」フォルダを展開します。
追加する列を選択します。選択した列が、下部ペインにリストされます。
「OK」をクリックします。
「プレビュー」タブでは、ノード出力のプレビューが可能です。出力は、次の2つのタブに表示されます。
「出力列」タブでは、ヘッダー内の列がグリッド・フォーマットで表示されます。「JSONパス」をクリックすると、ソース属性名が表示されます。
「JSONパス」をクリックすると、ソース属性名がコンテキスト情報とともに表示されます。たとえば、$."customers"."cust_id"などです。
「JSONパス」をクリックしない場合は、属性名のみが表示されます。たとえば、cust_idなどです。
列の次の詳細が「出力列」タブに表示されます。
名前: 出力列の名前が表示されます
データ型: 出力列のデータ型が表示されます
データソース: 属性名のソースが表示されます
JSONパス: 属性ソースが表示されます
集計: 集計に使用される集計関数が表示されます
グループ化基準: グループ化基準属性が表示されます
サブ・グループ化: 集計で使用されるサブ・グループ化属性が表示されます
「出力データ」タブでは、結果の上位N行が表示されます。問合せには、最新のユーザー指定が反映されます。問合せ結果は、グリッド・フォーマットで表示されます。
「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
JSON問合せノードの「プロパティ」ペインには、次のセクションがあります。
「プロパティ」ペインの「出力」セクションには、出力列が読取り専用モードで表示されます。
「キャッシュ」セクションには、出力データのキャッシュを生成するオプションがあります。キャッシュ出力を生成するには、次の手順を実行します。
「出力データのキャッシュ生成による結果表示の最適化」を選択して、キャッシュ出力を生成します。
「サンプリング・サイズ」フィールドで、次のオプションを選択します。
行数(デフォルト): デフォルトのサンプリング・サイズは2000です。矢印を使用して、別の数を設定します。
パーセント: ポインタを移動してパーセンテージを設定します。
「詳細」セクションには、ノードの名前、およびノードについてのコメントが表示されます。このフィールドでは、名前の変更およびコメントの追加が可能です。
ノード名
ノード・コメント
サンプル・ノードでは、次のいずれかの方法でのデータのサンプリングが可能です。
ランダム・サンプル: データ・セットの各要素が選択される機会を等しく持つ場合のサンプル。
上位Nサンプル: 最初のN個の値を選択するデフォルトのサンプル。
層別サンプル: 次のように作成されるサンプル。
最初に、データ・セットは、分断されたサブセットまたは層に分割されます。
各サブセットからサンプルがランダムに取得されます。
この手法は、ターゲット値の分布が大幅に偏っている場合に使用される。
たとえば、マーケティング・キャンペーンに対する反応のポジティブ・ターゲット値が、そのキャンペーン期間の1%以下の場合などで使用されます。
ネストしたデータのサンプリングは、ケースIDを使用すると最適に実行されます。
サンプル・ノードはパラレルに実行できます。
この項の内容は次のとおりです。
ネストしたデータのサンプリングは、ケースIDを必要とする場合があります。ケースIDを指定しない場合、密度および深度が非常に高いネストした列に対するサンプル操作が失敗する可能性があります。1行当たりのネストしたデータの量が、特定の列または行に対する最大値である30,000を超過すると、失敗する可能性があります。
また、ケースIDにより、Data Minerが密度および深度の高いデータ上で層別ソートを実行することが可能になります。
サンプルを指定するには、データ・ソース・ノードおよびサンプルの詳細を特定する必要があります。
サンプリング対象のノードを特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにすることができます。
「コンポーネント」ペインで「変換」セクションを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「サンプル」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
データ・ソース・ノードをサンプル・ノードに接続します。
カーソルをデータ・ソース・ノードに移動します。
データ・ソース・ノードを右クリックして、コンテキスト・メニューから「接続」を選択します。
サンプル・ノードへラインをドラッグしてもう一度クリックします。
サンプル・ノードをダブルクリックするか、サンプル・ノードを右クリックして「編集」をクリックします。「サンプル・ノードの編集」ダイアログ・ボックスが開きます。
「サンプル・ノードの編集」ダイアログ・ボックスでサンプルを定義します。
サンプル・ノードを右クリックして「実行」をクリックします。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、サンプル・ノードを右クリックして「データの表示」を選択し、サンプリングの結果を表示します。
この設定は、作成するサンプルのタイプおよびサンプルのサイズを示します。「サンプル・ノードの編集」ダイアログ・ボックスでは、サンプルを定義および編集できます。
サンプル・ノードの設定を編集するには、次の手順を実行します。
「サンプル・ノードの編集」ダイアログ・ボックスを開きます。
サンプル・ノードをダブルクリックするか、サンプル・ノードを右クリックして「編集」を選択します。
ノードを選択して、サンプル・ノードの「プロパティ」ペインの「設定」タブに移動します。
「サンプル・ノードの編集」ダイアログ・ボックスでは、次の詳細を指定および編集できます。
ランダム・サンプルに対して次を指定します。
シード: デフォルトのシードは2345です。
別の整数を指定できます。
ケースID(オプション): ドロップダウン・リストからケースIDを選択します。
シードおよびケースIDを指定すると、サンプルは再現可能になります。
「上位N」に対しては、その他の指定項目はありません。
層別サンプルに対して次を指定します。
列: 層化用の列を選択します。
シード: デフォルトのシードは12345です。
別の整数を指定できます。
ケースID(オプション): ドロップダウン・リストからケースIDを選択します。
シードおよびケースIDを指定すると、サンプルは再現可能になります。
分布: サンプルがどのように作成されるかを指定します。3つのオプションがあります。
オリジナル: サンプル内の選択された列の分布は、データ・ソース内の分布と同じです。
たとえば、列GENDERにケースの95%の値としてMがある場合、サンプルでは、GENDERの値はM (ケースの95%)になります。
平均化: 列の値の分布は、データ・ソース内の分布とは関係なくサンプル内で均等です。
列がGENDERでGENDERがMとFの2つの値を持つ場合、GENDERの値は50%の確率でMです。
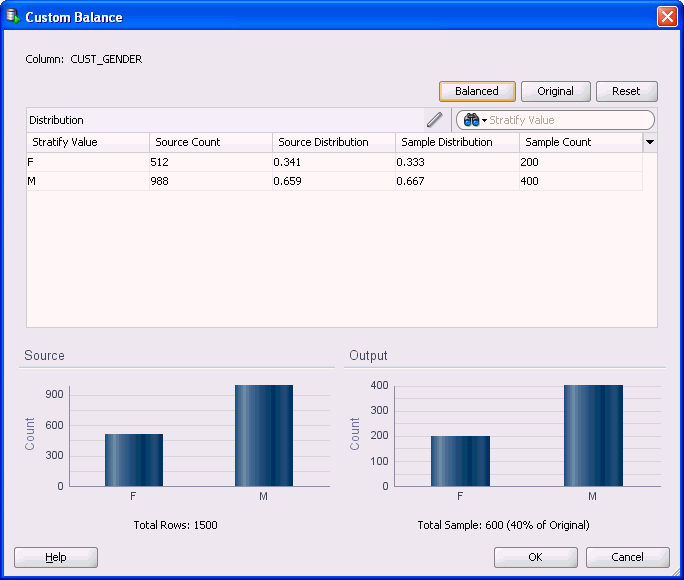
カスタム: サンプル内の列の値の分布を定義します。カスタム分布を定義する前に、ノードを1回実行する必要があります。「編集」をクリックして、「カスタム平均化」ダイアログ・ボックスを開きます。
「層別」ダイアログ・ボックスでは、選択された列の値のヒストグラムがウィンドウの底部に表示されます。
詳細を表示するには、「表示」をクリックして「カスタム平均化」ダイアログ・ボックスを表示します。
「カスタム平均化」ダイアログ・ボックスでは、選択された列がどのように分散されるかを正確に指定できます。
カスタム分布を作成する前に、ノードを実行して統計を収集する必要があります。ノードの実行後に、カスタム分布を選択して「表示」を選択し、それを編集します。「カスタム平均化」ダイアログが開きます。
層別属性の各値に対してカスタム・エントリを作成することも、「オリジナル」または「平均化」をクリックして開始点を準備することも可能です。「リセット」をクリックして、元の値にリセットできます。
カスタム値を作成するには、変更する属性を選択してをクリックします。
「サンプル・カウント」列内の値をカスタム値に変更します。[Enter]を押します。新しいサンプルが、出力として画面下部に表示されます。必要に応じて何度でも値を変更できます。作業を終了後、「OK」をクリックします。
サンプル・ノードのプロパティを表示する手順:
サンプル・ノードを選択します。
「プロパティ」ペインに、ノードのプロパティが表示されます。
「プロパティ」ペインが表示されていない場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」を選択します。
サンプル・ノードの「プロパティ」ペインには、次のセクションがあります。
設定: 次を指定できます。
サンプル・ノードのコンテキスト・メニューには、次のオプションが含まれます。
編集。詳細は、「サンプル・ノードの編集」を参照してください。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
変換ノードでは、サンプリングされたデータまたはすべてのデータを使用して統計を計算できます。これらの統計を、複数の変換のうちの1つを定義するためのガイドとして使用できます。
次の各項で、変換ノードについて説明します。
変換ノードでは、サンプリングされたデータまたはすべてのデータを使用して統計を計算できます。これらの統計を、複数の変換のうちの1つを定義するためのガイドとして使用できます。
次の変換がサポートされています。
使用可能な変換は、属性のデータ型によって異なります。たとえば、正規化は文字データ上では実行できません。
変換は、列単位で定義します。変換を定義したら、複数の列を同じ方法で変換できます。
変換ノードはパラレルに実行できます。
変換ノードを使用するには、それをデータ・フロー、つまりデータ・ソース・ノードまたは属性を生成するフィルタリング・ノードなどのその他のノードに接続します。次に、変換する属性を選択します。
ビニングは、次の変換を行います。
連続変数から質的変数へ。
連続値から連続値へ。たとえば、年齢を1から10の10グループに変換できます。
多くの値の質的な値から少ない変数の質的変数へ。
たとえば、給与は連続変数です。給与を10個のビンに分割する場合は、給与を、10個の給与の範囲を表す値を持つ質的変数に変換します。
数値、およびVARCHAR2とCHARの文字型の両方をビニングできます。
欠損値変換では、欠損値の処理方法を指定できます。
データ値は、様々な理由で欠損します。
データ値が測定されなかった、つまりそれがNull値を持っている場合。
データ値が回答されなかった場合。
データ値が既知ではなかった場合。
データ値が失われた場合。
データ・マイニング・アルゴリズムは、欠損値の処理方法において様々です。
欠損値を無視し、欠損値を含むすべてのレコードを省略します。
欠損値を最頻値または平均値で置き換えます。
既存値から欠損値を推測します。
正規化では、[–1.0,1.0]や[0.0,1.0]などの量的な値を、x_new = (x_old-shift)/scaleなどのように特定の範囲に変換します。正規化は、量的属性に対してのみ適用されます。
Oracle Data Minerでは、次の種類の正規化を指定できます。
最小/最大: 変換「x_new = (x_old-min)/(max-min)」を使用して各属性を正規化します
線形目盛: 変換x_new = (x_old-shift)/scaleを使用して各属性を正規化します
Z-スコア: データから計算される平均および標準偏差を使用して、量的属性を正規化します。変換
x_new = (x-平均)/標準偏差
カスタム: 正規化方法をユーザーが定義します。
正規化により、最小/最大正規化、スケール正規化およびZ-スコア正規化を実行する変換が提供されます。
|
注意: 文字データは正規化できません。 |
変換ノードは、日付および時間の次のデータ型に対して限定されたサポートを提供します。
DATE
TIMESTAMP
TIMESTAMP_WITH_TIMEZONE
TIMESTAMP_WITH_LOCAL_TIMEZONE
日付および時間の属性は、等幅およびカスタム・ビニングを使用してビニングできます。統計処理または値処理を使用して、統計値および欠損値の変換を適用できます。
変換を指定するには、データ・ソース・ノード、または表作成ノードなどのデータを提供するその他のノードを特定し、変換の詳細を指定する必要があります。
変換対象のノードを特定または作成します。データ・ソース・ノードを含む、データ・フローを提供する任意のノードをこのノードにすることができます。
「コンポーネント」ペインで「変換」セクションを展開します。
「コンポーネント」ペインが開いていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「変換」をクリックします。カーソルをワークフローに移動してもう一度クリックします。
データ・ソース・ノードを変換ノードに接続します。
カーソルをデータ・ソース・ノードに移動します。
データ・ソース・ノードを右クリックして「接続」を選択します。
変換ノードへラインをドラッグしてもう一度クリックします。
変換ノードをダブルクリックするか、そのノードを右クリックして「編集」をクリックします。「変換ノードの編集」ダイアログ・ボックスを使用して、変換を定義します。
変換ノードを右クリックして「実行」を選択します。「ワークフロー・ジョブ」で、ノードの実行をモニターします。
「ワークフロー・ジョブ」が開いていない場合は、「表示」に移動して「Data Miner」をクリックします。「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
ノードの実行が完了したら、変換ノードを右クリックして「データの表示」を選択し、変換の結果を表示します。
「変換ノードの編集」ダイアログ・ボックスを使用して、変換ノードの定義および編集を実行できます。このダイアログ・ボックスは次の2つのタブで構成されています。
変換
統計
「変換」タブには、各列の統計が表示されます。統計を非表示にするには、「統計情報の表示」の選択を解除します。
|
注意: 統計を表示するには、ノードを実行する必要があります。 |
「変換」タブでは、次のタスクを実行できます。
変換の定義: 元の列、つまり変換されていない列を1つ以上選択します。をクリックします。
1つまたは少数の列を選択すると、「変換を追加」ダイアログ・ボックスが開きます。それ以外の場合は、「分割適用ウィザード」が開きます。
カスタム変換の定義: 元の列、つまり変換されていない列を1つ以上選択します。をクリックします。
「カスタム変換の追加」ダイアログ・ボックスが開きます。ここで、カスタム変換の追加を行うことができます。
デフォルトの動作では、元の列を無視して、変換された列を出力として使用します。「出力」列に表示される値には、次が示されます。
: 含まれている列
: 無視されている列
「出力」列の値の変更: 「出力」列に示されているアイコンをクリックして、「変換を追加」ダイアログ・ボックス内の値を編集します。
変換された列の編集: 変換された列のみを編集できます。たとえば、AGE_BINを編集できますがAGEは編集できません。変換を編集するには、変換された列を1つ以上選択してをクリックします。1つまたは少数の列を選択すると、「変換の編集」ダイアログ・ボックスが開きます。
変換の削除: 変換された列を1つ以上選択してをクリックします。
列のフィルタリング: 表示される列を制限するには、をクリックします。次の基準で検索できます。
「出力」列
変換
「ソース」列
フィルタ定義のクリア: フィルタ定義をクリアするには、をクリックします。
変換の効果の表示: 変換の効果を表示する手順:
ノードを実行します。
ノードの実行の完了後に、ノードをダブルクリックします。
元の列と変換済列を比較するヒストグラムを表示するには、変換済の列を選択します。
列に、それに適用される変換がある場合、列のリストに新しい行が生成されます。各列には名前が必要であるため、新しい行の名前は古い列の名前および実行された変換のタイプに基づきます。ユーザーは通常、列を変換した後、新しい列に含まれている変換ノードの出力のみを必要とします。元の列には、それが出力列の1つとして渡されないようにするために設定されるオプションがあります。たとえば、AGEをビニングしてAGE_BINを作成している場合、AGEは渡されず、AGE_BINが渡されます。
変換を追加する手順:
「変換ノードの編集」ダイアログ・ボックスで、をクリックします。「変換を追加」ダイアログ・ボックスが開きます。
カスタム変換を追加するには、をクリックします。
「変換タイプ」フィールドで、変換タイプ、つまり定義する変換のタイプを選択します。デフォルトのタイプは、「ビニング」です。
「変換を追加」ダイアログ・ボックス内のフィールドは、選択した変換タイプに応じて異なります。
完了後、「OK」をクリックします。
ビニングは、次の目的で使用できる変換タイプです。
連続値を不連続値に変換します。
多数の不連続値を持つ変数を、少数の不連続値を持つ変数に変換します。
デフォルトの変換タイプは、「ビニング」です。
サポートされるビニングのタイプは、列のデータ型によって異なります。
量的データ型NUMBERの場合、サポートされるビニングのタイプは次のとおりです。
等幅のビニング(数) (デフォルト)
質的データ型VARCHAR2の場合、サポートされるビニングのタイプは次のとおりです。
日付および時間データ型のDATE、TIMESTAMP、TIMESTAMP WITH LOCAL TIMEZONEおよびTIMESTAMP WITH TIMEZONEの場合、サポートされるビニングのタイプは次のとおりです。
等幅のビニング(数) (デフォルト)
|
注意: ビン数には、2を指定する必要があります。 |
この選択肢は、指定した同じサイズのビン数に値の範囲を分割することによって、量的属性のビンを決定します。次のフィールドを編集します。
ビン件数: ビン件数を、2以上の任意の数に変更できます。デフォルトの件数は10に設定されています。
ビン・ラベル: リストから別のビン・ラベル・スキームを選択します。デフォルトは「範囲」に設定されています。
作業を終了後、「OK」をクリックします。
この選択肢は、各ビンにほぼ同数のケースが含まれるように属性をビンに分割します。次のフィールドを編集します。
ビン件数: ビン件数を、2以上の任意の数に変更できます。デフォルトの件数は10に設定されています。
ビン・ラベル: リストから別のビン・ラベル・スキームを選択できます。デフォルトは「範囲」に設定されています。
作業を終了後、「OK」をクリックします。
「トップNのビニング」タイプは、質的属性をビニングします。各属性のビンの定義は、データから計算される値の発生頻度に基づいて計算されます。
N (ビンの数)を指定します。各ビン(bin_1、…、bin_N)には、頻度が上位にある値が含まれます。最後のbin_Nには、残りのすべての値が含まれます。
「ビン件数」を、3以上の任意の数に変更できます。デフォルトの件数は10に設定されています。
作業を終了後、「OK」をクリックします。
「カスタム」ビニングでは、カスタム・ビンを定義できます。
ビンを定義するには、「ビン割当て」をクリックしてデフォルトのビンを変更します。
デフォルト・ビンの生成後に、生成されたビンを次の複数の方法で変更できます。
ビン名の編集: 範囲ラベルの場合。
ビンの削除: それを選択してをクリックします。
ビンの追加: をクリックします。
ビンの編集: ビンを選択してをクリックします。
次のオプションを選択します。
ビニング・タイプ: デフォルトのタイプは、ビニング対象属性のデータ型によって異なります。
属性のデータ型が数値型である場合、デフォルトのビニング・タイプは等幅のビニングです。
属性のデータ型が文字型である場合、デフォルトのビニング・タイプは「トップNのビニング」です。
数値の場合、ビニング・タイプを変更できます。
ビン件数: デフォルトの件数は10です。これを、2より大きい任意の整数に変更できます。
ビン・ラベル: 数値に対するデフォルトのビン・ラベルは「範囲」です。ビン・ラベルを「数」に変更できます。
NULLの変換: NUMBERデータ型を生成するビニング変換に対して「NULLの変換」チェック・ボックスが選択されている場合、Null値は最後のビンに配置されます。たとえば、AGE列にNull値があり、「ビン・ラベル」値が番号と等しく、ビン数が10の等幅ビニングが要求された場合、Null値は11番ビンに入れられます。
このオプションには、次の条件が適用されます。
選択が解除されている場合、Null値は生成された変換SQLから除外されます。
|
注意: 変換後にVARCHAR2データ型を生成するビニング変換のみに適用されます。 |
このフィールドは、変換後に数値データ型を生成するビニング変換の場合は編集できません。
レガシー・ワークフローの場合、このフィールドはデフォルトで選択され、対応するフィールドには値Null binが含まれています。
作業を終了後、「OK」をクリックします。生成されたビンを変更する「カスタム」表示に戻ります。
ビンを編集する方法は、属性のデータ型によって異なります。
数値の場合: グリッドで下限を編集します。下限を持たないビンは編集できません。前のビンの下限値より小さい値または後続のビンの下限値より大きい値は追加できません。
文字の場合: 「カスタム・カテゴリ型ビンの編集」ダイアログ・ボックスには次の2つの列があります。
ビン: ビンの追加、選択したビンの削除および選択したビンの名前の変更が可能です。
ビン割当て: 選択したビンの値を削除できます。
ビンの編集が完了したら、「OK」をクリックします。カスタムのカテゴリ型ビンを編集している場合、初めに「OK」を2回クリックします(1回は「カスタム・カテゴリ型ビンの編集」ダイアログ・ボックスを閉じるため)。
次のビンを追加できます。
カテゴリ型: 「カスタム・カテゴリ型ビンの編集」を開いてをクリックします。新しいビンは、変更可能なデフォルト名を持ちます。「ビン割当て」列で、ビンに値を追加します。
数値型: ビンを選択してをクリックします。ビンの名前変更および値の範囲の追加が可能です。
「欠損値」は、欠損した値を適切な値に置き換える変換タイプです。
「欠損値」変換を指定するには、次の手順を実行します。
「変換タイプ」フィールドで、「欠損値」オプションを選択します。
「欠損値」フィールドで、次のオプションを選択します。
統計: 統計的な手法により欠損値を置き換えます。「統計」は、欠損値のデフォルトの処理です。適用可能な統計タイプは、列のデータ型によって異なります。
量的な列の場合、欠損値を「平均」(デフォルト)、「中間」、「最小」、「最大」を使用して置き換えることができます。
カテゴリ型の列の場合、欠損値を「モード」(デフォルト)を使用して置き換えることができます。
値: 欠損値を指定した値で置き換えます。Oracle Data Minerでは、変更可能なデフォルト価が提供されます。
統計が使用できない場合、デフォルト値は0です。
統計を使用できる場合、デフォルト値は次のとおりです。
平均(数値型の列の場合)
モード(カテゴリ型の列の場合)
これらの両方の処理は、データまたは時間のデータ型DATE、TIMESTAMP、TIMESTAMP_WITH_LOCAL_ TIMEZONEおよびTIMESTAMP_WITH_TIMEZONEを持つ属性に適用可能です。
完了後、「OK」をクリックします。
正規化では、[–1.0,1.0]や[0.0,1.0]などの量的な値を、x_new = (x_old-shift)/scaleなどのように特定の範囲に変換します。正規化の結果は、通常、絶対値が1.0以下の値となります。
|
注意: 正規化は、量的な列に対してのみ適用されます。したがって、量的な属性のみを正規化できます。 |
列を正規化するには、次の手順を実行します。
「変換タイプ」フィールドで、「正規化」オプションを選択します。
「正規化のタイプ」フィールドで、ドロップダウン・リストからタイプを選択します。Oracle Data Minerでは、次のタイプの正規化をサポートしています。
最小/最大: 変換x_new = (x_old-min)/(max-min)を使用して列を正規化します。デフォルトはmin-maxです。
Z-スコア: データから計算される平均および標準偏差を使用して、量的な列を正規化します。変換x_new = (x-平均)/標準偏差を使用して各列を正規化します。
線形目盛: 変換x_new = (x-0)/ max(abs(max), abs(min))を使用して各列を正規化します。
手動: 変換x_new = (x_old-shift)/scaleのshiftおよびscaleを指定して正規化を定義します。「手動」を選択した場合、次を指定します。
シフト
スケール
完了後、「OK」をクリックします。
外れ値は、通常のデータの個体群から離れているデータ値です。つまり、それは極値です。正規分布では、外れ値は通常、平均値からの標準偏差が少なくとも3である。外れ値は、通常、極値ではない値と置き換えられるか、NULLと置き換えられます。
|
注意: 外れ値の処理は、量的な列に対してのみ定義できます。 |
「外れ値」変換を定義する手順:
「変換タイプ」フィールドで、「外れ値」オプションを選択します。
「外れ値のタイプ」フィールドで、次のいずれか1つのオプションを選択します。
標準偏差: これは、デフォルトの「外れ値」タイプです。この外れ値タイプの場合、標準偏差を入力して、次のフィールドで外れ値を定義します。
シグマの倍数: これは、外れ値を定義する標準偏差の個数です。
デフォルトは3、つまり標準偏差3個分です。
標準偏差3個分とは、外れ値が平均- 3 *標準偏差より小さいか、平均+ 3 *標準偏差より大きいことを意味します。
パーセント: 外れ値が下位パーセンテージおよび上位パーセント内の値であることを指定できます。デフォルトでは、外れ値が下位5%または上位5%であると指定しています。次のフィールドに値を入力して、デフォルトを変更できます。
下位のパーセント値
上位のパーセント値
値: 外れ値が下位値より小さい値または上位値より大きい値になるように、下位値および上位値を指定できます。
これらの値を変更できますが、上位値は下位値よりも大きい値である必要があります。
下位値: 統計が使用可能な場合、デフォルトは-3*標準偏差です。
統計が使用できない場合、デフォルトは0です。
上位値: 統計が使用可能な場合、デフォルトは+3*標準偏差です。
統計が使用できない場合、デフォルトは1です。
「置換後」フィールドでオプションを選択して、外れ値の置換方法を指定します。オプションは、次のとおりです。
Null (デフォルト)
エッジ値
例:
列分布の平均が10で
標準偏差が10の場合、
外れ値は次のようになります。
-5、つまり平均-3*標準偏差より小さい値
25、つまり平均+3*標準偏差より大きい値
外れ値=-10。-10をNullまたはエッジ値の-5で置換できます。
完了後、「OK」をクリックします。
この選択肢は、少なくとも1つの変換が存在しないと表示されません。
この選択肢は、複数の変換の追加または編集を行う場合に使用されます。
複数の列の変換を同時に定義または編集できます。既存の変換を、1つ以上の列に適用することも可能です。
複数の変換の変換を追加または編集する手順:
変換ノードをダブルクリックします。変換エディタが開きます。
複数の列に対して同じ変換を定義するには、列を選択します。データ型が異なっていても互換性がある場合、それらの列を選択できます。たとえば、CHARとVARCHARは文字であり、互換性のあるデータ型です。すべての列に適用される変換が存在しない場合、メッセージが表示されます。をクリックします。
分割適用ウィザードが開きます。
すべての列に適用する「変換」タイプを選択します。
選択した変換タイプに関連する特定の詳細を指定します。
「次へ」をクリックします。
「統計の生成」をクリックします。
「終了」をクリックします。
すでに列を変換している場合は、同じ変換を複数の別の列に対して定義できます。
AGEをビニングしてAGE_BINを作成したと仮定します。同じ方法で複数列をビニングするには、AGEおよび同じ方法でビニングする複数の列を選択します。をクリックします。
分割適用ウィザードが開きます。
「変換タイプ」に<既存を使用>を選択します。AGE_BINが、変換済列としてリストされます。その他の値は変更できません。
「次へ」をクリックします。出力列の名前を変更できます。
「完了時に統計を生成」を選択します。
「終了」をクリックします。
複数の変換を同時に編集するには、複数の変換を選択してをクリックします。
分割適用ウィザードが開きます。変換を編集し、「終了」をクリックします。
「カスタム変換の追加」ダイアログ・ボックスでは、カスタム変換を定義できます。新しい属性のデフォルトの名前はEXPRESSIONです。この名前は変更できます。
「カスタム変換の追加」ダイアログ・ボックスでは、次のタスクを実行できます。
式の追加: をクリックします。式ビルダーが開きます。式ビルダーを使用して、式を定義します。
式を検証します。
「OK」をクリックします。
カスタム変換を編集します。
カスタム変換の削除: をクリックします。
分割適用ウィザードでは、複数の列の変換を同時に定義または編集できます。ウィザードの初めのステップは、「変換を追加」ダイアログ・ボックスと似ています。
カスタム変換は選択できません。
「変換の選択」セクションで、次の操作を行います。
変換: 変換タイプを選択します。
選択した変換タイプに関連する詳細を指定します。
「次へ」をクリックします。
「列の選択」セクションで、変換された列の名前を指定します。名前は変更せずにそのまま使用することも、変更することも可能です。使用可能な変換は、選択したすべての列で実行可能な変換です。これは、オプションのセクションです。
「終了」をクリックします。
「変換の編集」ダイアログ・ボックスは、「変換を追加」ダイアログ・ボックスと似ています。
ノードが実行されると、「編集」ダイアログに、変換されていない列および変換されたバージョンの両方の情報が表示されます。
「ヒストグラム」タブには、変換されていない属性および変換された属性の両方のヒストグラムが、2つのセットのヒストグラムに表示されます。タブの左側は、変換されていない列のヒストグラムです。タブの右側は、変換された列のヒストグラムです。
「統計」タブには、変換されたデータおよび元のデータの統計が表示されます。
|
注意: データを変換した場合、変換済データは、元のデータのデータ型とは異なるデータ型を持つ場合があります。たとえば、AGEはNUMBER型を持ち、AGE_BINはVARCHAR2型を持ちます。 |
式を編集するには、次の手順を実行します。
属性を選択し、をクリックします。「式ビルダー」が開きます。
式ビルダーを使用して式を変更します。
式を検証します。
「OK」をクリックします。
式を削除するには、をクリックします。
「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
変換ノードの「プロパティ」ペインには、次のセクションがあります。
変換: 変換の定義方法を指定します。これらの値を変更できます。
グリッドに変換の概要が示されます。各列に対して、名前(データ型)、変換および出力が表示されます。AGEをビニングしてAGE_BINを作成している場合、AGEは出力として使用されず、後続ノードに渡されません。
ヒストグラム: ヒストグラムで使用されるビンの数を指定します。数値型、カテゴリ型および日付の各データ型に対して作成されるヒストグラムに、異なる数のビン数を指定できます。デフォルトでは、すべてのデータ型に10個のビンです。
変換ノードのコンテキスト・メニューには、次のオプションが含まれます。
編集。詳細は、「変換ノードの編集」を参照してください。
データの表示。詳細は、「データ・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。