| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
Data Minerワークフローは、モデルの構築、テスト、適用などのデータ・マイニング操作を定義するメカニズムです。これらの操作は、ワークフローを構成するノードで定義されます。1つのプロジェクトで複数のワークフローを作成できます。この章の内容は次のとおりです。
ワークフローには、表やモデルなどのデータのソースを1つ以上含める必要があります。たとえば、Naive Bayesモデルを構築するには、まず、データ・ソース・ノードを使用して入力を識別する必要があります。その後、分類ノードを作成して、モデルを構築およびテストします。
ワークフローを使用すると、次のことが可能です。
データ・マイニング・プロセスの構築、分析およびテスト
データ・ソースの識別および調査
モデルの構築および適用
予測問合せの作成
この項の内容は次のとおりです。
ワークフローは、次の手順で作成され、実行されます。
空のワークフローを作成します。
ワークフローにノードを追加します。
ワークフローでノードを接続します。
ノードを実行します。
結果を確認します。
必要に応じて、手順を繰り返します。
ワークフローは、相互に接続されるノードで構成される方向付きグラフです。ワークフローに関するノードを示すために使用する特定の用語があります。
たとえば、N1とN2の2つのノードで構成されたワークフローを考えます。N1はN2に接続されているものとします。
親ノードおよび子ノード: ノードN1はN2の親ノードであり、ノードN2はN1の子ノードです。親ノードは、実行時に子ノードが必要とする情報を提供します。新しいデータに適用する前に、モデルを構築する必要があります。
下位および上位: N1から始まり最終的にN2に接続するワークフロー接続がある場合、ノードN2はN1の下位と呼ばれます。N1は、N2の上位と呼ばれます。N1は、常にN2よりもルート・ノードの近くにあります。
ルート・ノード: 親ノードを持たないノードは、ルート・ノードと呼ばれます。すべてのワークフローに少なくとも1つのルート・ノードがあります。親ノードには、複数のルート・ノードがある場合があります。
|
注意: 親ノードは、子ノードよりもルート・ノードの近くにあります。 |
兄弟: ノードに複数の子ノードがある場合、子ノードは兄弟とみなされます。
アップストリーム: 親ノードは、子ノードのアップストリームと呼ばれます。
ワークフローのサムネイル・ビューには、ワークフロー全体のビューが表示されます。サムネイルは、大規模なワークフローで特に役に立ちます。
サムネイル・ビューアを開くには、「ビュー」に移動して「サムネイル」をクリックします。または、[Ctrl]を押しながら[Shift]と[T]を押して、サムネイル・ビューアを開きます。
「サムネイル」ビューで、次のことが可能です。
ワークフロー内の特定のノードにナビゲートできます。
ワークフローのズーム・レベルを変更できます。
ワークフローで現在表示されているノードを変更できます。
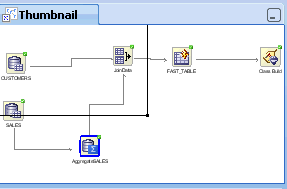
「サムネイル」ビューには、長方形が表示されます。ビューアの内側をクリックして、その周りで長方形を移動させると、ワークフロー・エディタの表示のフォーカスが変わります。また、長方形のサイズを変更して、より詳細なレベルで制御できます。
「サムネイル」ビューでモデルを表示するときに、モデルがツリーを生成すると、「サムネイル」ビューが自動的に開いて、ツリーの全体の形を示すビューが表示されます。また、「サムネイル」ビューには、モデル・ビュー全体での位置も表示されます。
「コンポーネント」ペインには、ワークフローに追加できるコンポーネントがリストされます。ワークフローにコンポーネントを追加するには、「コンポーネント」ペインからワークフローにコンポーネントをドラッグ・アンド・ドロップします。
ワークフローをロードすると、「コンポーネント」ペインが自動的に開きます。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
「コンポーネント」ペインには、次が含まれます。
「コンポーネント」には、次の2つのタブがあります。
お気に入り: コンポーネントを「お気に入り」リストに追加するには、コンポーネントを右クリックして、「お気に入りに追加」を選択します。
最近使用: 最近使用したコンポーネントをリストします。
「すべてのページ」では、使用可能なコンポーネントが1つのリストに一覧表示されます。
プロパティによって、ワークフロー全体またはワークフロー内のノードの情報を表示したり、変更することができます。
|
注意: Oracle Data Minerの以前のリリースでは、「プロパティ」タブは「プロパティ・インスペクタ」でした。 |
ノードのプロパティを表示するには、ノードを右クリックし、「プロパティに移動」を選択します。
ワークフローまたはそのノードの1つを選択すると、それぞれのプロパティが「プロパティ」ペインに表示されます。たとえば、データ・ソース・ノードを選択すると、データ・ソース・ノードのプロパティが「プロパティ」ペインに表示されます。
次の中から、ノードおよびワークフローに対して複数のタスクを実行できます。
「プロパティ」コンテキスト・メニュー:
「プロパティ」ペイン:
ワークフローを使用して、次のタスクを実行できます。ただし、ワークフローの前提条件を満たしていることを確認する必要があります。
ワークフローを使用してタスクを実行する前に、次のワークフローの前提条件を満たしていることを確認します。
データベースへの接続を作成し、確立します。
ワークフローを作成するプロジェクトを作成します。
ワークフローを作成する前に、ワークフローの前提条件を満たしていることを確認します。
空のワークフローを作成するには、次の手順を実行します。
「Data Miner」タブで、左側のペインの「接続」を展開します。
「Data Miner」タブが開かない場合は、「ツール」をクリックして「Data Miner」を選択します。
ワークフローを作成するプロジェクトを選択します。
プロジェクトを右クリックして、コンテキスト・メニューから「新規ワークフロー」を選択します。「ワークフローの作成」ダイアログ・ボックスが開きます。
「名前」フィールドに、ワークフローの一意の名前を入力します。
「OK」をクリックします。これで、空のワークフローが作成されます。
ワークフローを削除するには、次の手順を実行します。
「Data Miner」タブで、「プロジェクト」を展開して、削除するワークフローを選択します。
右クリックして、「削除」をクリックします。
ワークフローまたはプロジェクトの名前を変更するには、次の手順を実行します。
「Data Miner」タブのワークフローまたはプロジェクトの名前を右クリックして、「名前変更」を選択します。
ワークフローの名前変更ダイアログ・ボックスまたは「プロジェクトの名前変更」ダイアログ・ボックスが開きます。「変更後の名前」フィールドに新しい名前を入力します。
プロジェクトの場合、新しい名前はプロジェクト名の制限を満たしている必要があります。ワークフローの場合、新しい名前はワークフロー名の制限を満たしている必要があります。
「OK」をクリックします。
ワークフローを作成した後に、次のタスクを実行できます。
ワークフローのロード: 「Data Miner」タブで、プロジェクトを展開してワークフロー名をダブルクリックします。ワークフローが新しいタブで開きます。
ワークフローのクローズ: ワークフローがロードされ、表示されているタブを閉じます。
ワークフローの保存: 「ファイル」に移動して、「保存」をクリックします。ワークフローを変更した場合は、終了時に保存されます。
ワークフローを作成すると、ワークフローは「Data Miner」タブの「プロジェクト」の下にリストされます。
次のいずれかのタスクを実行するには、プロジェクトの下のワークフローを右クリックして、コンテキスト・メニューから次のオプションを選択します。
新規ワークフロー: 現在のプロジェクトに新しいワークフローを作成します。
削除: プロジェクトからワークフローを削除します。
名前変更: ワークフロー名を変更します。
エクスポート: ワークフローをエクスポートします。
インポート: ワークフローをインポートします。
ワークフローをエクスポートするには、次の手順を実行します。
「Data Miner」タブで、「接続」を展開して、ワークフローを作成したプロジェクトをクリックします。
エクスポートするワークフローを右クリックして、「エクスポート」をクリックします。「保存」ダイアログ・ボックスが開きます。
「保存」ダイアログ・ボックスで、ワークフローをエクスポートする場所にナビゲートして、「保存」をクリックします。ワークフローが、XMLファイルとして保存されます。
|
注意: ワークフローを保存するデフォルト・ディレクトリは、ドキュメントを保存するためのシステムのデフォルト・ディレクトリです。このディレクトリを変更できます。 |
ワークフローをプロジェクトにインポートできます。ワークフローをインポートする前に、ワークフローのインポート要件を満たしていることを確認します。
ワークフローをインポートするには、次の手順を実行します。
「Data Miner」タブで、ワークフローをインポートするプロジェクトを右クリックして、「ワークフローのインポート」をクリックします。「オープン」ダイアログ・ボックスが表示されます。
「開く」ダイアログ・ボックスで、ワークフローのXMLファイルの場所にナビゲートします。
「開く」をクリックします。システムは、指定されたファイルにワークフローがあることを検証して、ワークフローのバージョン番号を特定します。「ワークフローのインポート」ダイアログ・ボックスが開きます。一度に選択してインポートできるワークフローは1つのみです。
「ワークフローのインポート」ダイアログ・ボックスで、新しいワークフローの名前を指定し、名前の競合を処理する次のオプションを1つ選択します。
必要に応じてモデルと出力表の名前を変更
競合が発生しても既存のモデルと出力表の名前を維持
「ワークフローのインポート」ダイアログ・ボックスでは、インポートするワークフローの名前および名前の競合を処理する方法を指定できます。デフォルトのワークフロー名は、ワークフローのファイル名です。次の操作が必要な場合があります。
競合を避けるために名前を少し変更します。
有効なワークフロー名にするために名前を編集します。新しいワークフローの名前は、新しい接続で一意である必要があります。
また、ワークフロー・ノードおよび出力表の名前において名前の競合を処理する方法を選択する必要もあります。デフォルトは、「必要に応じてモデルと出力表の名前を変更」です。
「競合が発生しても既存のモデルと出力表の名前を維持」を選択できます。このオプションを選択する場合、競合を自分で解決する必要があります。
インポートを開始するには、「OK」をクリックします。
ワークフローのインポート要件は、次のとおりです。
エクスポートしたワークフローでデータ・ソースとして使用されるすべての表およびビューは、新しいアカウントにある必要があります。
表またはビューは、新しいアカウントでも古いアカウントのときと同じ名前である必要があります。
データ・ソース・ノードを再定義する必要がある場合があります。
ワークフローにモデル・ノードが含まれる場合、ワークフローがインポートされるアカウントに、使用するすべてのモデルが含まれている必要があります。モデル・ノードは、データ・ソース・ノードと同じ方法で再定義される必要がある場合があります。
ワークフローを実行するための権限が必要です。
ワークフローは、互換性の要件を満たしている必要があります。
ワークフローがエクスポートされるアカウントは、エクスポートされるワークフローでエンコードされます。
次に例を示します。
ワークフローはアカウントDMUSERからエクスポートされ、ワークフローにはデータMINING_DATA_BUILDを含むデータ・ソース・ノードがあるとします。
異なるアカウント(つまり、DMUSERではないアカウント)にスキーマをインポートして、ワークフローを実行しようとすると、ワークフローはDMUSER.MINING_DATA_BUILD_Vを検索するため、データ・ソース・ノードは失敗します。
この問題の解決方法:
データ・ソース・ノードMINING_DATA_BUILD_Vを右クリックして、「データ定義ウィザード」を選択します。
使用できる表またはビューにDMUSER.MINING_DATA_BUILD_Vが存在しないことを示すメッセージが表示されます。
「OK」をクリックして、現在のアカウントのMINING_DATA_BUILD_Vを選択します。これで問題が解決されます。
ワークフローのインポートおよびエクスポートの互換性要件は、次のとおりです。
Oracle Database 11gリリース2 (11.2.0.1.2)より前のバージョンのOracle Data Minerを使用してエクスポートしたワークフローは、以降のバージョンのOracle Data Minerにインポートできません。
以前のバージョンのOracle Data Minerからエクスポートしたワークフローには、無効なXMLが含まれている場合があります。ワークフローのXMLファイルに無効なXMLが含まれている場合、インポートは終了されます。
Oracle Data Minerのバージョンを確認するには、次の手順を実行します。
「ヘルプ」に移動して、「バージョン」をクリックします。
「拡張」タブをクリックします。
「Data Miner」を選択します。
ワークフローにインポートされるスキーマは、ワークフローで使用されるすべての表またはビューを持つわけではない場合があります。Data Minerはこの問題を検出すると、表が欠損していることを示す「表選択の失敗」メッセージを生成します。別の表を選択できます。
別の表を選択するには、「はい」をクリックします。データ・ソースの定義ウィザードが開きます。ウィザードを使用して、表および属性を選択します。
ワークフロー名のすぐ下にある、ワークフロー上部の境界でアイコンとして複数のコントロールを使用できます。次のタスクを実行できます。
ワークフロー・ノードのズームインおよびズームアウト: それぞれ アイコンおよび
アイコンおよび アイコンをクリックします。
アイコンをクリックします。
ノード・サイズの制御: パーセントのドロップダウン・リストをクリックして、サイズを選択します。デフォルト・サイズは100%です。
イベント・ログの表示:  アイコンをクリックします。
アイコンをクリックします。
選択したノードの実行:  アイコンをクリックします。実行するノードを選択すると、三角形が緑色になります。
アイコンをクリックします。実行するノードを選択すると、三角形が緑色になります。
実行中のワークフローの取消し:  アイコンをクリックします。
アイコンをクリックします。
「プロパティ」ペインで、ワークフロー全体またはワークフローのノードに関する情報を表示して変更できます。ノードのプロパティを表示するには、次の手順を実行します。
ノードを右クリックし、「プロパティに移動」を選択します。対応する「プロパティ」ペインが開きます。たとえば、データ・ソース・ノードを選択すると、「プロパティ」ペインにデータ・ソース・ノードの詳細が表示されます。
「検索」フィールドを使用して、プロパティの項目を検索します。
 アイコンをクリックして、表示する項目のエディタを開きます。
アイコンをクリックして、表示する項目のエディタを開きます。
コンテキスト・メニューのオプションを使用して、その他のタスクを実行します。
ワークフローを表示するには、「Data Miner」タブのワークフロー名をダブルクリックします。ワークフローは、「Data Miner」タブと「コンポーネント」ペインの間にあるタブで開きます。複数のワークフローを開く場合、各ワークフローは異なるタブで開きます。一度にアクティブになるワークフローは1つのみです。
ワークフローのコンテキスト・メニューを表示するには、ワークフロー・タブを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
閉じる: 選択したタブを閉じます。
すべて閉じる: すべてのワークフロー・タブを閉じます。
その他を閉じる: 現在のタブ以外のすべてのタブを閉じます。
最大化: ワークフローを最大化します。「Data Miner」タブ、「コンポーネント」ペインおよびその他の項目は表示されません。以前のサイズに戻すには、選択をもう一度クリックします。
最小化: 「プロパティ」タブをメニューに最小化します。以前のサイズに戻すには、「プロパティ」タブを右クリックして「ドッキング」をクリックします。
垂直分割: アクティブなエディタまたはビューアを2つのドキュメントに分割します。2つのドキュメントは垂直方向に分割されます。分割を元に戻すには、選択をもう一度クリックします。
水平分割: アクティブなエディタまたはビューアを2つのドキュメントに分割します。2つのドキュメントは水平方向に分割されます。分割を元に戻すには、選択をもう一度クリックします。
新規ドキュメント・タブ・グループ: 現在アクティブなエディタまたはビューアを独自のタブ・グループに追加します。この操作を元に戻すには、「エディタ・タブ・グループを閉じる」を使用します。
ドキュメント・タブ・グループの縮小: すべてのエディタまたはビューアを1つのタブ・グループに縮小します。「新規エディタ・タブ・グループ」の後にのみ表示されます。
フローティング: 「プロパティ」タブを移動可能なペインに変換します。
ドッキング: 浮動ウィンドウの場所を設定します。または、[Alt]を押しながら[Shift]と[D]を押します。
クローン: プロパティの新しいインスタンスを作成します。
コンテンツの凍結: コンテンツを凍結します。プロパティの凍結を解除するには、この選択をもう一度クリックします。
イベント・ログの表示によって、ワークフローの実行の進捗状況を表示できます。また、ワークフローの作成にかかった時間も表示できます。
Oracle Data Minerは、Oracle Schedulerを使用してワークフローの実行をスケジュールします。Oracle Schedulerの概要は、『Oracle Database管理者ガイド』を参照してください
モデル構築は、リソース集中処理型にすることができます。Oracle Data MinerサーバーのMAX_NUM_THREADSパラメータにより、パラレル構築の数が制御されます。MAX_NUM_THREADSは、サーバーで実行されるすべてのワークフローでの最大モデル構築数を指定します。
デフォルト値は10です。そのため、デフォルトでは、10個のモデルをすべてのワークフローで同時に構築できます。リポジトリ表ODMRSYSには、MAX_NUM_THREADSパラメータがあります。ODMR$REPOSITORY_PROPERTIES、ここで値を指定できます。
MAX_NUM_THREADSの値を増やす場合は、段階的に増やします。ネットワーク接続が切断されていても、ワークフローが実行されているように見えることがあります。
パラレル・モデル構築動作を制御するために、次のパラメータが使用されます。
THREAD_WAIT_TIME。デフォルトは5です。MAX_NUM_THREADSに達すると、パラレル・モデル構築数がMAX_NUM_THREADSを下回るまで、構築プロセスがキューに入れられます。この設定(秒数)により、パラレル・モデル構築数のチェック間隔が決まります。
MAX_THREAD_WAIT。デフォルトはNULLです。キューに入っている構築プロセスのタイムアウト(秒数)。NULLの場合、タイムアウトは発生しません。
Data Minerサーバーへのネットワーク接続がワークフローの実行中に中断された場合、ワークフロー・エディタは、ワークフローが無期限に実行されていることを示す場合があります。一方で、「ワークフロー・ジョブ」ウィンドウは、接続がダウンしていることを示す場合があります。
Data Minerは、接続が切断されたことを示すメッセージを表示します。適当な期間で接続が回復されない場合は、ワークフロー・エディタを閉じて、再度開きます。
|
注意: 「ワークフロー・ジョブ」ウィンドウを使用して、接続を監視します。 |
ワークフローは、次の条件でロックされます。
ノードの実行中、ワークフローはロックされ、そのノードは編集できません。ワークフローの実行中に、既存の結果が表示されることがあります。また、別のワークフローに移動して、それを編集または実行することもできます。
ユーザーがワークフローを開くと、他のユーザーが変更できないようにワークフローはロックされます。
ワークフローの実行中、ツールバーのアニメーション(環状の矢印のループ)により、ワークフローが実行されていることが示されます。
ロックされたワークフローを開くと、ツールバーに「ロック済」と表示され、ワークフローが実行されている場合、実行インジケータは次のようになります。

他のユーザーによってワークフローがロックされず、自分がロックしている場合、ロック・アイコンはツールバーから削除されます。
ロックされたワークフローのロック解除: ワークフローが完了したのにロックされたままになっている場合は、「ロック済」をクリックしてワークフローのロックを解除します。
ワークフローのリフレッシュ: ロックしたワークフローの実行が停止したら、 アイコンをクリックしてワークフローをリフレッシュできます。また、ロックの上でクリックすることで、ロックの取得を試行することもできます。
アイコンをクリックしてワークフローをリフレッシュできます。また、ロックの上でクリックすることで、ロックの取得を試行することもできます。
Data Miner 4.1を使用すると、ワークフローによって生成されたすべてのオブジェクトを再作成するスクリプトをワークフローから生成できます。Data Minerの以前のリリースでは、変換ノードのスクリプトのみを生成できました。
ワークフローによって生成されたすべてのオブジェクトを再作成するスクリプトによって、ワークフロー全体の動作をレプリケートすることもできます。このようなスクリプトは、アプリケーション統合またはワークフローの軽量デプロイの基盤を提供し、ターゲットおよび本番システムでのData Minerリポジトリのインストールおよびワークフローは必要ありません。
Data Miner 4.1は、次の2つのタイプのデプロイメントを提供します。
データを生成するすべてのノードには、コンテキスト・メニューに「SQLを保存」オプションがあります。
「SQLを保存」オプションにより、SQLスクリプトが生成されます。生成されるSQLは、SQL*Plusスクリプトを使用して作成したり、標準SQLスクリプトとして作成することができます。スクリプト形式の利点は、パラメータで表およびモデルの参照をオーバーライドできることです。
「SQLを保存」オプションを使用すると、生成するスクリプトの種類とスクリプトを保存する場所を選択できます。
オブジェクト生成スクリプトにより、オブジェクトを作成するスクリプトが生成されます。オブジェクトを生成するスクリプトは、次を参照してください。
生成されたスクリプトは、次の方法で実行できます。
Oracle Enterprise Managerジョブとして、SQLスクリプトまたはオペレーティング・システム・コマンドのいずれかとして。
Oracle Schedulerのジョブとして:
SQLスクリプトをコールする外部ジョブ
環境: 実行時の管理にOracle Enterprise Managerを使用するか、またはPL/SQLを使用します。
SQL*PLusまたはSQLワークシートを使用してスクリプトを実行します。スクリプトを実行するには、Oracle Data Minerリポジトリがインストールされていることを確認します。
ワークフロー・スクリプトの要件には、次の特定の要件が含まれています。
スクリプト・ファイルがUTF8文字セットを使用して生成されていない場合、スクリプトに、適切に処理されない文字セットに基づく文字が含まれることがあります。
|
注意: すべてのスクリプト・ファイルがUTF8文字セットを使用して生成されていることを確認します。 |
スクリプトには、スクリプトによって作成されたパブリック・オブジェクトにオブジェクト名を提供する変数定義があります。マスター・スクリプトは、すべての基礎スクリプトを順番にコールする役割を果します。そのため、変数定義は、マスター・スクリプトで定義される必要があります。
変数オブジェクト・タイプ: 表またはビュー、モデルなどのスクリプトに入力されるオブジェクト名を変更できます。デフォルトでは、これらの名前は、表またはビュー、およびモデルの元の名前です。
生成されるすべてのスクリプトは、同じディレクトリに配置する必要があります。
この種類のデプロイメントでは、次のような複数の一般的なスクリプトが生成されます。
マスター・スクリプト: すべての必要なスクリプトを適切な順序で開始します。このスクリプトは、次の作業を実行します。
スクリプトのバージョンが、インストールされたData Minerリポジトリのバージョンと互換性があるかどうかを確認します。
ワークフロー・スクリプトによって作成されたすべての基礎オブジェクトのエントリを含む、ワークフローのマスター表を作成します。
スクリプトの操作を理解するために必要な、主要な使用情報に対応する生成済のドキュメントが含まれています。
クリーンアップ・スクリプト: ワークフロー・スクリプトによって作成されたすべてのオブジェクトを削除します。クリーンアップ・スクリプトは、次のオブジェクトを削除します。
データの参照用に生成された表などの非表示オブジェクト。
構築ノードによって作成されたモデル名などのパブリック・オブジェクト。
表作成ノードによって作成された表。
ワークフロー・ダイアグラム・イメージ: スクリプトの生成時にワークフローのイメージ(.pngファイル)を作成します。ワークフロー全体が表示されます。
生成されるその他のスクリプトは、チェーン内のノードによって異なります。表4-1に、ノードおよび対応するスクリプト機能を示します。
表4-1 ノードおよびスクリプト機能
| ノード | スクリプト機能 |
|---|---|
|
ノードの出力を反映するビューを作成します。 |
|
フィルタ列ノード |
その他の変換タイプ・ノードなど、フィルタ列ノードの出力を反映するビューを作成します。
|
|
テキストの構築ノード |
テキストの変換ごとに、次のオブジェクトが作成されます。
テキストの構築ノードの出力を反映するビューを作成します。これは、テキストの適用ノードと基本的に同じ出力になります。 |
|
分類構築ノード |
モデルは、モデル構築の仕様ごとに作成されます。 マスター・テスト結果表は、モデルごとに作成されたテスト結果表のリストを格納するために生成されます。 行の診断がオンになっている場合、GLMモデル行の診断表が作成されます。 各モデル・テストでは、パフォーマンス、パフォーマンス・マトリックス、ROC (2項分類のみ)の各テスト結果に表が1つ生成されます。 各モデル・テストには、ターゲット値(最大ターゲット値は100)ごとのリストおよび収益の各テストに表が1つあります。 |
|
回帰構築ノード |
モデルは、モデル構築の仕様ごとに作成されます。 行の診断がオンになっている場合、GLMモデル行の診断表が作成されます。 マスター・テスト結果表は、モデルごとに作成されたテスト結果表のリストを格納するために生成されます。 各モデル・テストでは、パフォーマンス・テストと残差テストの各結果に表が1つ生成されます。 |
|
モデルは、モデル構築の仕様ごとに作成されます。 |
|
テスト・ノード(分類) |
マスター・テスト結果表は、モデルごとに作成されたテスト結果表のリストを格納するために生成されます。 行の診断がオンになっている場合、GLMモデル行の診断表が作成されます。 各モデル・テストでは、パフォーマンス、パフォーマンス・マトリックス、ROC (2項分類のみ)の各テスト結果に表が1つ生成されます。 各モデル・テストには、ターゲット値(最大ターゲット値は100)ごとのリフトおよび利益のそれぞれに表が1つあります。 |
|
テスト・ノード(回帰) |
行の診断がオンになっている場合、GLMモデル行の診断表が作成されます。 マスター・テスト結果表は、モデルごとに作成されたテスト結果表のリストを格納するために生成されます。 各モデル・テストでは、パフォーマンスおよび残差のそれぞれについて表が1つ生成されます。 |
|
スクリプトは生成されません。これらのノードは、メタデータに対する参照ノードです。 |
Oracle Enterprise Manager (OEM)を使用すると、データベース管理者はOEMアプリケーションを通じてジョブを定義できます。ジョブは、Oracle SchedulerではなくOEMを通して実行されます。ジョブは、OEMから手動で実行できます。ジョブの実行は監視できます。結果は、成功または報告される失敗のいずれかになります。
ジョブの定義では、生成されたスクリプト・ファイルを直接開くことができます。
ジョブの定義では、完全なファイル・パスを使用して、スクリプト・ファイルとしてマスター・スクリプトの起動を定義する必要があります。
ジョブは、スケジュールどおりまたはオンデマンドで実行できます。
マスター・スクリプト内で実行されるすべてのスクリプトには、完全修飾されたパス名が必要です。
Enterprise Managerの詳細は、Oracle Enterprise Managerのドキュメント・セット『Oracle Database 2日でデータベース管理者』、または接続するデータベースの『Oracle Database 2日で』ドキュメントを参照してください。
生成されたスクリプトは、Data Minerリポジトリ・オブジェクトにアクセスする必要があります。Data Minerリポジトリは、スクリプトが実行されるシステムにインストールされている必要があります。スクリプトは、リポジトリ・バージョンをチェックし、リポジトリがソース・システムのバージョンと同じかそれ以降のバージョンであることを確認します。
ワークフローは、リンクによって接続される1つ以上のノードで構成されます。ノードは、ワークフローでのデータ・マイニング操作を定義します。表4-2に示すノードのカテゴリを「コンポーネント」ペインで使用できます。
すべてのノードには名前が必要で、コメントがある場合があります。
名前の割当ては、一意であることを確実にするためにすべて確認されます。
Oracle Data Minerは、デフォルトのノード名を生成します。特定タイプの新規ノードが作成される場合、デフォルト名はノード・タイプに基づいています(分類ノードのClass Buildなど)。その名前のノードがすでに存在する場合、名前に1を追加して一意にします。そのため、Class Buildが存在する場合、ノードにはClass Build 1という名前が付けられます。Class Build 1が存在する場合は2が追加され、3つ目の分類ノードの名前はClass Build 2となり、以降も同様に処理されます。各ノード・タイプは、個別に処理されます。たとえば、フィルタ列ノードには、分類ノードの手順とは異なる独自の手順があります。
デフォルト名は、次の要件を満たす名前に変更できます。
ノード名は、ワークフロー内で一意である必要があります。
ノード名に/ (スラッシュ)文字を含めることはできません。
ノード名は、1文字以上の長さにする必要があります。31文字以上の長さにすることはできません。
ノード名を変更するには、プロパティの「詳細」タブで変更するか、ワークフローで名前を選択して新しい名前を入力します。
ノードのコメントは任意です。コメントを入力する場合、4000文字を超える長さにすることはできません。
表4-2に、様々なノードのカテゴリを示します。
ノードは、そのステータスを示す状態に常に関連付けられています。表4-3に、ノードの状態を示します。
表4-3 ノードの状態
| ノードの状態 | 説明 | グラフィカル・インジケータ |
|---|---|---|
|
|
ノードが完全に定義されておらず、実行できないことを示します。 ほとんどのノードを有効になるように接続する必要があります。つまり、入力を定義する必要があります。データ・ノードを有効になるように接続する必要はありません。 |
|
|
|
ノードを実行しようとしましたがエラーが発生したことを示します。複数のモデルの構築など複数のタスクを実行するノードでは、1つの失敗によってノードのステータスが すべての問題を修正して、 問題が標準的な仕様の検証に起因するものではなくサーバー実行時の失敗の場合、変更によって |
|
|
|
ノードは適切に定義されており、実行できることを示します。
|
グラフィカル・インジケータなし |
|
|
ノードの実行が正常に完了したことを示します。 |
|
|
|
ノードの実行が完了したが、予想した結果にならなったことを示します。 |
|
任意のノードを使用して次のタスクを実行できます。
ノードを作成したり、ワークフローにノードを追加します。実行の準備が整っているノードでは、データ・ソース・ノードの表またはビュー、または分類ノードのターゲットなどの情報を指定する必要がある場合があります。情報を指定するには、ノードを編集します。実行するには、ワークフローのノードを接続する必要があります。たとえば、データ・ノードを構築ノードに接続することによって構築ノードの入力を指定します。
ノードをワークフローに追加するには、次の手順を実行します。
次のようにして、ノードを編集できます。
「エディタ」ダイアログ・ボックスを使用します。
プロパティを使用します。
ノードの「エディタ」ダイアログ・ボックスを表示するには、次の手順を実行します。
ノードをダブルクリックするか、ノードを右クリックして「編集」を選択します。
「エディタ」ダイアログ・ボックスが開きます。必要に応じてノードを編集し、「OK」をクリックします。
データ・ソース・ノードなどの一部のノードでは、ノードがワークフローで削除される場合または入力ノードがノードに接続される場合に、「エディタ」ダイアログ・ボックスが自動的に表示されます。
ノードの「プロパティ」ペインは、ワークフローのノードが選択されると開くペインです。このペインをドッキングできます。
「プロパティ」ペインによってノードを編集するには、次の手順を実行します。
編集するノードをクリックします。ノードの「プロパティ」ペインが右下のペインに表示されます。
アイコンをクリックして、ノードを編集します。その他すべての編集について、「プロパティ」ペインのそれぞれのセクションをクリックします。
すべてのノードの「プロパティ」ペインに、「詳細」という名前の共通セクションが1つあります。このセクションには、ノード名とコメントが表示されます。プロパティの他のセクションは、ノードのタイプによって異なります
対応する「編集」ダイアログ・ボックスが開きます。必要に応じてノードを編集し、「OK」をクリックします。
1つ以上のノードをコピーして、同じワークフローまたは別のワークフローに貼り付けることができます。コピーおよび貼付けでは、元のノードに属するマイニング・モデルまたは結果は維持されません。モデル名は一意である必要があるため、開始点として元の名前を使用して、一意の名前をモデルに割り当てます。
たとえば、コピーされた構築ノードをワークフローに貼り付ける場合、貼付け操作によって、元のノードと同じ設定を持つ新しい構築ノードが作成されます。ただし、モデルまたはテスト結果は、ノードが実行されるまで存在しません。
詳細は、「親の検証」を参照してください。
1つ以上のノードを実行することによって、ワークフローで指定されたタスクを実行します。ノードが1つ以上の親ノードの出力に依存する場合、実行中のノードに必要な出力がない場合にのみ親ノードが自動的に実行されます。ノードを選択して、ワークフローのツールバーでクリックすることによって、1つ以上のノードを実行することもできます。
|
注意: ノードは常に実行できるわけではありません。祖先ノードが「無効」状態で出力がない場合、それに依存する子ノードは実行できません。 |
ワークフロー内の各ノードには、「ノードの状態」で説明するように、ステータスを示す状態があります。
コンテキスト・メニューの次のオプションをクリックすることによって、ノードを実行できます。
データ・ソース・ノード、表の更新ノード、モデル・ノードなどのノードは、定義についてデータベース・リソースに依存します。データベース・リソースが変更された場合は、ノード定義のリフレッシュが必要になることがあります。
ノードをリフレッシュするには、次の手順を実行します。
リフレッシュするノードをクリックします。
右側のペインで、「プロパティ」に移動して、適切なセクションをクリックします。
データ: データ・ソース・ノードの場合
モデル: モデル・ノードの場合
列: 表の更新ノードの場合
アイコンをクリックします。Data Minerは、データベースに接続して、属性またはモデルを検証します。属性またはモデルのステータスは、次のいずれかに設定されます。
有効: 右上隅にマークがないノードによって示されます。
無効: ノードの右上隅の マークまたは
マークまたは マークによって示されます。
マークによって示されます。
その他の可能性がある検証エラー・シナリオは、次のとおりです。
ソース表が存在しない: エラー・メッセージが、ソース表または属性がないことを示します。次のオプションがあります。
別の表を選択するか、欠損した属性を置換します。
「取消」をクリックすることによって、ノードを以前の状態のままにします。
モデルが無効である: プロパティ・モデル・ツールバーのモデルのリフレッシュ・ボタンをクリックして、ノードを有効にします。モデル・ノードの場合、モデルが無効であると検出されると、ノードは「無効」になります。モデル・ノードは、ノードを有効にするまで実行できません。
モデルが存在しない: モデル・ノードが実行されていて、モデルがないとサーバーが判断した場合、ノードは「エラー」に設定されます。欠損したモデルを置換した後に、モデルを再実行できます。
ワークフローは、方向を示すグラフです。つまり、順番に接続されるノードで構成されます。各リンクは、ソース・ノードをターゲット・ノードに接続します。ワークフローを作成するには、ノードを接続またはリンクします。2つのノードを接続する場合は、ノード間の関係を示します。たとえば、モデル構築のデータを指定するには、データ・ソース・ノードをモデル構築ノードにリンクします。
次のオプションを使用して、ノードをリンクできます。
コンテキスト・メニューの「接続」オプション
「リンクしているノード」オプションを使用して2つのノードを接続するには、次の手順を実行します。
「コンポーネント」ペインで、「リンクしているノード」セクションを展開します。
「リンク」をクリックします。ソース・ノードにカーソルを移動して、クリックします。ソース・ノードから、表示されているリンクをターゲット・ノードにドラッグし、再度クリックします。
リンクが有効な場合は、ターゲット・ノードをクリックするとリンクが作成されます。
リンクが無効な場合、線は終了しません。リンクを完了せずにリンク・プロセスを終了するには、[Esc]を押すか、「コンポーネント」ペイン内でクリックします。
ノードの接続ダイアログ・ボックスを使用して2つのノードをリンクするには、次の手順を実行します。
「コンポーネント」ペインで、「リンクしているノード」セクションを展開します。
「リンク」アイコンをクリックして、[Enter]を押します。これによって、新規リンクのソースおよびリンク先の選択ダイアログ・ボックスが開きます。
「ソース・リスト」でソース・ノードを選択し、「宛先リスト」でターゲット・ノードを選択します。
「ソース・リスト」には、ワークフローのすべてのノードがリストされます。「宛先リスト」には、選択したノードに対して許可されるターゲット・ノードがリストされます。
「OK」をクリックします。
「ダイアグラム」メニューの「接続」オプションを使用するには、次の手順を実行します。
ワークフローのソース・ノードを選択します。
Data Minerのメニュー・バーで、「ダイアグラム」をクリックして、「接続」を選択します。
ソース・ノードからターゲット・ノードにカーソルを移動して、再度クリックします。
リンクが有効な場合は、ターゲット・ノードをクリックするとリンクが作成されます。
リンクが無効な場合、線は終了しません。リンクを完了せずにリンク・プロセスを終了するには、[Esc]を押します。
次の方法で、ワークフロー・ノードの位置を変更できます。
ドラッグ: ノードをドラッグするには、ノードをクリックします。マウス・ボタンを押したまま、ノードを目的の位置にドラッグします。ノードへのリンクが、自動的に位置変更されます。
矢印キーを使用した調整: 少しずつ位置を調整するには、ノードを選択します。[Shift]キーと[Ctrl]キーを押したままにします。矢印キーを使用して、ノードを移動します。
コンテキスト・メニューのオプションは、ノードのタイプによって異なります。ノードを右クリックして、ノードのコンテキスト・リストを表示します。コンテキスト・メニューに含まれるものは、次のとおりです。
データの表示。データ・ノードに適用できます。詳細は、「データ・ソース・ノード・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
「接続」オプションを使用すると、「コンポーネント」ペインのオプションを使用せずにノードをリンクできます。
ノードを接続するには、次の手順を実行します。
ノードを右クリックして、「接続」をクリックします。または、「ダイアグラム」に移動して、「接続」をクリックします。
カーソルを使用して、このノードからターゲット・ノードに線を描きます。
クリックして、接続を確立します。次の点に注意してください。
有効な接続のみを作成できます。
2つのノード間で1つの接続のみを作成できます。
[Esc]キーを押すことによって、接続を削除できます。
ノードには、デフォルトのアルゴリズムおよび設定があります。ノードを編集する場合は、デフォルトのアルゴリズムおよび設定を変更します。次の方法のいずれかで、ノードを編集できます。
Data Minerは、現在のノードのすべての親ノードを検証します。ノードの親ノードを検証するには、ノードを右クリックして、「親の検証」を選択します。
ノードが「準備完了」、「完了」および「エラー」状態の場合は、親ノードを検証できます。すべての親ノードは、完了済の状態である必要があります。
Data Minerサーバーは、非同期的にワークフローを実行します。クライアントを接続する必要はありません。ワークフローで指定されたタスクは、そのワークフローで1つ以上のノードを実行することによって実行されます。
1つのノードを実行する場合: ノードを右クリックして、「実行」を選択します。
複数のノードを同時に実行する場合: [Ctrl]キーを押しながら個々のノードをクリックして、ノードを選択します。選択したノードを右クリックして、「実行」を選択します。
ノードが1つ以上の親ノードの出力に依存する場合、実行中のノードに必要な出力がない場合にのみ親ノードが自動的に実行されます。
「実行の強制」オプションは、完了している1つ以上のノードを再実行します。「実行の強制」は、モデルをもう一度構築する前に、既存のモデルを削除します。
複数のノードを選択するには、[Ctrl]キーを押しながらノードをクリックします。
ワークフローの任意の場所で、ノードの「実行の強制」を使用できます。ワークフロー内のノードの場所に応じて、「実行の強制」を使用してノードを実行するための次の選択肢があります。
選択されたノード
選択されたノードと子(ノードに子ノードがある場合に使用可能)
子ノードのみ(ノードに1つ以上の子ノードがある場合に使用可能)
選択されたノードと親(ノードに親ノードがある場合に使用可能)
ワークフローで指定されたタスクを実行するSQLスクリプトを作成することによって、ノードまたはワークフローをデプロイできます。「デプロイ」によって生成されたスクリプトは、ディレクトリに保存されます。
|
注意: デプロイする前にノードを実行する必要があります。 |
ワークフロー全体の動作をレプリケートするスクリプトを生成できます。このようなスクリプトは、アプリケーション統合の基礎として、またはData Minerリポジトリとワークフローをターゲットおよび本番システムにインストールする方法よりも軽量のデプロイメントとして機能します。
ワークフローまたはワークフローの一部をデプロイするには、次の手順を実行します。
ノードを右クリックして、「デプロイ」を選択します。
次のデプロイメント・オプションのいずれかを選択します。
選択したノードと依存ノード
選択したノード、依存ノード、子ノード
選択したノードと接続ノード
デプロイメント・オプションを選択すると、SQLスクリプトの生成ウィザードが開きます。ウィザードで、次の詳細を入力します。
保存されるSQLは、現在のノードとデータ・プロバイダであるすべての親ノードによって生成されるSQLで構成されます。系統は、表やテーブルなどの永続化された項目を表すノードが検出されると終了します。
「ターゲット・データベースのバージョン」ドロップダウン・リストからスクリプトが実行されるOracle Databaseのバージョンを選択して、「次へ」をクリックします。デフォルト・バージョンは、11.2.0.1.0です。
スクリプトが格納されるディレクトリを選択します。ディレクトリを参照して、スクリプトのディレクトリを作成できます。「終了」をクリックします。
「参照」をクリックします。既存のディレクトリを参照するか、 アイコンをクリックして、スクリプトに新しいディレクトリを作成できます。
アイコンをクリックして、スクリプトに新しいディレクトリを作成できます。
新しいディレクトリを作成したら、「OK」をクリックします。
「選択」をクリックして、ディレクトリを選択します。
選択したオブジェクト(ノードまたは接続)を削除します。
または、オブジェクトを選択して、キーボードの[Delete]を押すことによってオブジェクトを削除することもできます。
1つ以上のノードをコピーして、同じワークフローまたは別のワークフローに貼り付けることができます。ノードをコピーして貼り付けるには、次の手順を実行します。
コピーするノードを選択します。複数のノードを選択するには、[Ctrl]キーを押しながらノードをクリックします。
選択したノードが強調表示されます。この例では、「分類」が選択されています。他のノードは選択されていません。
右クリックして、コンテキスト・メニューから「コピー」を選択します。または、[Ctrl]を押しながら[C]を押して、選択したノードをコピーすることもできます。
|
注意: ノードのコピーおよび貼付けでは、元のノードのマイニング・モデルまたは結果は維持されません。 |
「貼付け」オプションは、ワークフローでコピーされたオブジェクトを貼り付けます。オブジェクトを貼り付けるには、ワークフローを右クリックして、「貼付け」をクリックします。または、[Ctrl]を押しながら[V]を押します。
「拡張貼付け」オプションによって、ノード名およびモデル名を維持できます。貼付けのデフォルトの動作では、名前の衝突を避けるためにノード名およびモデル名が変更されます。
「拡張貼付け」オプションに移動するには、ワークフローを右クリックして、「拡張貼付け」をクリックします。または、[Ctrl]を押しながら[Shift]と[V]を押します。
|
注意: モデル名が一意ではない場合、再作成されるときにモデルがオーバーライドされることがあります。 |
「適用チェーンの生成」によって、変換を実行するノードの仕様を含む新しいノードが作成されます。手順で実行される変換が複数ある場合(たとえばサンプルの後にカスタム変換が続く場合など)、手順での変換ごとに「適用チェーンの生成」を選択する必要があります。個々のノードを接続し、それらを適切なデータ・ソースに接続する必要があります。
「適用チェーンの生成」によって、新しいデータが既存のデータと同じ方法で準備されていることを確認するために使用できる変換手順を作成できます。たとえば、適用データが構築データと同じ方法で準備されていることを確認するには、このオプションを使用します。
「適用チェーンの生成」オプションは、すべてのノードに有効なわけではありません。たとえば、構築ノードの仕様はコピーされません。
このオプションを使用すると、ワークフロー内のすべてのノードを選択できます。選択したノードおよびリンクは、濃い青色の枠線で強調表示されます。
このオプションは、「イベント・ログの表示」ダイアログ・ボックスを開きます。イベント・ログには、現在の接続内のイベントに関する情報が表示されます。エラー、警告および情報メッセージが表示されます。
このオプションは、実行時にノードの実行が失敗した場合にのみ表示されます。イベント・ログが開き、エラーのリストが表示されます。エラーを選択すると、正確なメッセージと詳細が表示されます。
このオプションは、検証エラーがある場合にのみ表示されます。たとえば、相関ノードがデータ・ソース・ノードに接続されていない場合、「検証エラーの表示」を選択すると、「ビルド・データ入力ノードが接続されていません」という検証エラーが表示されます。
または、マウスをノード上に移動することによって検証エラーを表示することもできます。エラーは、ツールチップに表示されます。
「SQLを保存」オプションは、選択したノードのSQLスクリプトを生成します。
ノードを右クリックして、「SQLを保存」をクリックします。
次のいずれかのオプションを選択して、生成されたSQLスクリプトを保存します。
SQLをクリップボードへ
SQLをファイルへ
SQLスクリプトをクリップボードへ
SQLスクリプトをファイルへ
ファイルに保存する場合、システムにはデフォルトの場所が用意されています。参照してこの場所を変更できます。スクリプト用のフォルダを作成することもできます。
保存されるSQLには、現在のノードとデータ・プロバイダであるすべての親ノードによって生成されたSQLが含まれます。SQLの系統は、表やモデルなどの永続するオブジェクトを表すノードが検出されると終了します。
生成されるスクリプトは、ノードのすべての動作を生成するわけではありません。スクリプトはオブジェクトを作成しません。たとえば、表作成ノードの「SQLを保存」を選択する場合、表を作成するスクリプトは生成されません。かわりに、作成された表を問い合せるスクリプトが生成されます。
このオプションは、他のノードへのリンクがある場合に有効になります。
「ナビゲート」によって、このノードから使用可能なリンクのコレクションが表示されます。リンクの1つを選択すると、リンクが選択され、選択されたリンクが強調表示されます。リンク自体にコンテキスト・メニュー・オプションがあるため、右クリックして「ナビゲート」オプションを続行できます。矢印キーを使用して、次のノードに進むこともできます。
データ・ノードを実行すると、データ・ソース・ノード・ビューアが開きます。
リストからモデルを選択して、そのモデルのモデル・ビューアを開きます。表示する前に、モデルが正常に作成されている必要があります。
分類モデルおよび回帰モデルについてのみ、モデルを選択して、そのモデルのテスト結果を表示します。
分類モデルおよび回帰モデルについて、このオプションは、問題解決に最適なモデルを選択できるように、正常に作成されたすべてのモデルのテスト結果を表示します。
Oracle Data Minerは、ワークフローで仕様を使用してSQL問合せを作成します。これらの問合せはOracle Databaseに渡され、実行されます。
パラレル問合せまたはパラレル処理では、複数プロセスが同時に機能して、単一のSQL文を実行します。複数プロセス内で作業を分割すると、Oracle Databaseでは、より迅速に文を実行できます。たとえば、1つのプロセスで4つの四半期分をすべて処理するのではなく、4つのプロセスが1年のそれぞれの四半期を分担して処理するとします。
パラレル処理の利点は、次のとおりです。
データ・ウェアハウスなどの大規模データベースでの、データ処理集中型の操作におけるレスポンス時間が短縮されます。
文の処理が複数のシステムに分割される場合に、対称型マルチプロセッシング(SMP)のパフォーマンスが向上します。特定タイプのOLTPおよびハイブリッド・システムにも、パラレル処理による利益があります。
Oracle RACシステムでは、特定サービスのサービス配置によってパラレル処理が制御されます。つまり、パラレル・プロセスはサービスが構成されているノードで実行されます。デフォルトでは、Oracle Databaseは、データベースへの接続に使用されるサービスを提供するインスタンスでのみパラレル・プロセスを実行します。これは、パラレル・リカバリやGV$問合せの処理などの他のパラレル操作には影響しません。
パラレル処理は、データベース管理者(DBA)によって構成される必要があります。Oracle Databaseでのパラレル処理の詳細は、次を参照してください。
パラレル処理の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』または『Oracle Database VLDBおよびパーティショニング・ガイド』を参照してください。
Oracle RAC環境でのパラレル処理に関する考慮事項については、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』を参照してください。
この項では、パラレル処理のいくつかの一般的なユースケースを示します。
ユースケースの前提は、次のとおりです。
モデルの入力ソースはパラレルで定義された表で、介在するワークフロー・ノードがこの状態を変更する表を生成しない場合、モデルはワークフロー設定を変更せずにパラレルで作成されます。
入力ソースがパラレルで定義されていない場合は、次のようにパラレルでモデルを構築できます。
分類モデルおよび回帰モデル: ワークフローのパラレル処理をオンにします。分類および回帰の設定は、「パラレル」オプションを使用して入力を表に分割するためのものです。
すべてのモデル: ワークフローのパラレル処理をオンにします。構築ノードの前に表作成ノードを挿入します。作成した表をモデルへの入力として使用します。
パラレル処理およびその他の手法を使用して、変換の実行を迅速にすることができます。
ワークフローのパラレル処理をオンにする: サンプル入力の形式を持つすべてのノードにいくつかの利点があります。サンプル・サイズが小さい場合、Oracle Databaseはパラレル問合せを生成しないことがあります。ただし、複雑な問合せはパラレル処理をトリガーできます。
表作成ノードを追加する: コストのかかる変換の後に表作成ノードを追加して、繰り返しの問合せコストを削減できます。
表作成ノードに索引を追加する: 表作成ノードに索引を追加して、ダウンストリームの結合パフォーマンスを向上できます。
パラレルで、グラフ・ノードを実行できます。その他のノードがパラレルでなくても、パフォーマンスが向上する場合があります。
パラレルでグラフ・ノードを実行するには、次の手順を実行します。
ワークフロー全体にパラレル処理を設定します。
グラフ・ノード以外のすべてのノードのパラレル処理をオフにします。
グラフ・ノードを実行します。これで、グラフ・ノードのサンプル・データがパラレルで生成されます。グラフ・ノードのサンプルが小さかったり、問合せが単純な場合、問合せがパラレルにならないことがあります。
1回のみノード上でパラレル処理を実行して、パラレル処理によってパフォーマンスが向上するかどうかを確認できます。パラレル処理を実行するには、次の手順を実行します。
ワークフロー全体にパラレル処理を設定します。
ワークフローを実行します。パフォーマンスをメモします。
ワークフローのパラレル処理をオフにします。
デフォルトでは、パラレル処理はすべてのノード・タイプに対して「オフ」に設定されています。パラレル処理がプリファレンスで「オン」に設定されていても、ユーザーは特定のワークフローまたはノードのセクションをオーバーライドできます。
ノードまたはワークフローのパラレル処理を設定するには、次の手順を実行します。
ノードを右クリックして、コンテキスト・メニューから「パラレル問合せ」を選択します。「選択したノードの設定の編集」ダイアログ・ボックスが開きます。
「OK」をクリックします。
「選択したノードの設定の編集」ダイアログ・ボックスには、ワークフローを構成するすべてのノードが示されます。ここでは、次のことが可能です。
パラレル処理を設定します。
選択したノード: パラレル問合せを実行するノードに対する「パラレル」列のチェック・ボックスをクリックします。
すべてのノード: 「すべて」をクリックして、ワークフロー内のすべてのノードのパラレル処理を選択します。
なし: 「なし」をクリックして、すべてのノードの選択を解除し、パラレル処理をオフにします。
並列度の指定: ノードを選択してをクリックします。
少なくとも1つのノードのパラレル処理を指定すると、次の表示がワークフローのタイトル・バーに示されます。

パラレル問合せは、選択したノードでオン、オン(すべてのノードに対して)またはオフのいずれかになります。「パラレル問合せ」ボックスをクリックすると、「選択したノードの設定の編集」ダイアログ・ボックスを開くことができます。
パラレル処理のプリファレンスの編集:  をクリックして、パラレル処理のプリファレンスを編集します。
をクリックして、パラレル処理のプリファレンスを編集します。
デフォルトの並列度はシステムによって決定されます。値を指定するには、次の手順を実行します。
「ノードのパラレル設定の編集」ダイアログ・ボックスで、「パラレル問合せオン」オプションをクリックして、選択したノードのパラレル処理をオンにします。
「程度値」オプションをクリックして、より高い値を選択します。デフォルト値は1です。
「OK」をクリックします。設定が、ノードの「パラレル」列と「並列度」列に表示されます。
パラレル問合せのプリファレンスを編集するには、次の手順を実行します。
「選択したノードの設定の編集」ダイアログ・ボックスで、ノードを選択してをクリックします。
次のオプションのいずれかを選択します。
ノードのデフォルト設定の編集: ノードの設定を編集します。「プリファレンス」ダイアログ・ボックスが開き、すべてのノードがリストされます。ここでノードを選択して、編集できます。
デフォルト設定の変更: ノードの設定をデフォルトに戻します。
「OK」をクリックします。