Release 8.1.5
A68003-01
Library |
Product |
Contents |
Index |
| Oracle8i Application Developer's Guide - Fundamentals Release 8.1.5 A68003-01 |
|
![]()
![]()
This chapter covers the following topics:
The last decade has seen a tremendous increase in the use of query, reporting, and on-line analytical processing (OLAP) tools, often in conjunction with data warehouses and data marts. Enterprises exploring new markets and facing greater competition expect these tools to provide the maximum possible decision-making value from their data resources.
Oracle expands its long-standing support for analytical applications in Oracle8i release 8.1.5 with the CUBE and ROLLUP extensions to SQL. Oracle also provides optimized performance and simplified syntax for Top-N queries. These enhancements make important calculations significantly easier and more efficient, enhancing database performance, scalability and simplicity.
ROLLUP and CUBE are simple extensions to the SELECT statement's GROUP BY clause. ROLLUP creates subtotals at any level of aggregation needed, from the most detailed up to a grand total. CUBE is an extension similar to ROLLUP, enabling a single statement to calculate all possible combinations of subtotals. CUBE can generate the information needed in cross-tab reports with a single query. To enhance performance, both CUBE and ROLLUP are parallelized: multiple processes can simultaneously execute both types of statements.
Enhanced Top-N queries enable more efficient retrieval of the largest and smallest values of a data set. This chapter presents concepts, syntax, and examples of CUBE, ROLLUP and Top-N analysis.
One of the key concepts in decision support systems is "multi-dimensional analysis": examining the enterprise from all necessary combinations of dimensions. We use the term "dimension" to mean any category used in specifying questions. Among the most commonly specified dimensions are time, geography, product, department, and distribution channel, but the potential dimensions are as endless as the varieties of enterprise activity. The events or entities associated with a particular set of dimension values are usually referred to as "facts." The facts may be sales in units or local currency, profits, customer counts, production volumes, or anything else worth tracking.
Here are some examples of multi-dimensional requests:
All the requests above constrain multiple dimensions. Many multi-dimensional questions require aggregated data and comparisons of data sets, often across time, geography or budgets.
To visualize data that has many dimensions, analysts commonly use the analogy of a data "cube," that is, a space where facts are stored at the intersection of n dimensions. Figure 20-1 shows a data cube and how it could be used differently by various groups. The cube stores sales data organized by the dimensions of Product, Market, and Time.
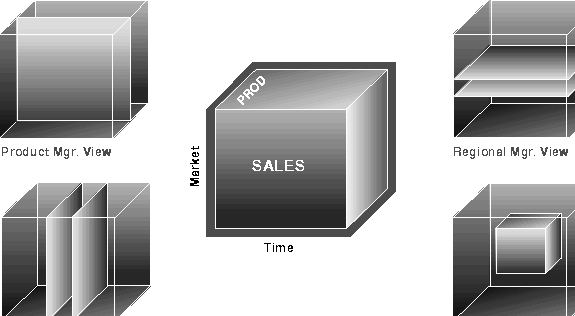
We can retrieve "slices" of data from the cube. These correspond to cross-tabular reports such as the one shown in Table 20-1. Regional managers might study the data by comparing slices of the cube applicable to different markets. In contrast, product managers might compare slices that apply to different products. An ad hoc user might work with a wide variety of constraints, working in a subset cube.
Answering multi-dimensional questions often involves huge quantities of data, sometimes millions of rows. Because the flood of detailed data generated by large organizations cannot be interpreted at the lowest level, aggregated views of the information are essential. Subtotals across many dimensions are vital to multi-dimensional analyses. Therefore, analytical tasks require convenient and efficient data aggregation.
Not only multi-dimensional issues, but all types of processing can benefit from enhanced aggregation facilities. Transaction processing, financial and manufacturing systems--all of these generate large numbers of production reports needing substantial system resources. Improved efficiency when creating these reports will reduce system load. In fact, any computer process that aggregates data from details to higher levels needs optimized performance.
To leverage the power of the database server, powerful aggregation commands should be available inside the SQL engine. New extensions in Oracle provide these features and bring many benefits, including:
Oracle8i provides all these benefits with the new CUBE and ROLLUP extensions to the GROUP BY clause. These extensions adhere to the ANSI and ISO proposals for SQL3, a draft standard for enhancements to SQL.
To illustrate CUBE, ROLLUP, and Top-N queries, this chapter uses a hypothetical videotape sales and rental company. All the examples given refer to data from this scenario. The hypothetical company has stores in several regions and tracks sales and profit information. The data is categorized by three dimensions: Time, Department, and Region. The time dimensions are 1996 and 1997, the departments are Video Sales and Video Rentals, and the regions are East, West, and Central.
Table 20-1 is a sample cross-tabular report showing the total profit by region and department in 1997:
|
1997 |
|||
| Region |
Department |
||
| Video Rental Profit | Video Sales Profit | Total Profit | |
| Central |
82,000 |
85,000 |
167,000 |
| East |
101,000 |
137,000 |
238,000 |
| West |
96,000 |
97,000 |
193,000 |
| Total |
279,000 |
319,000 |
598,000 |
Consider that even a simple report like Table 20-1, with just twelve values in its grid, needs five subtotals and a grand total. The subtotals are the shaded numbers, such as Video Rental Profits across regions, namely, 279,000, and Eastern region profits across department, namely, 238,000. Half of the values needed for this report would not be calculated with a query that used a standard SUM() and GROUP BY. Database commands that offer improved calculation of subtotals bring major benefits to querying, reporting and analytical operations.
ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause, so its syntax is extremely easy to use. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
ROLLUP appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT ... GROUP BY ROLLUP(grouping_column_reference_list)
ROLLUP's action is straightforward: it creates subtotals which "roll up" from the most detailed level to a grand total, following a grouping list specified in the ROLLUP clause. ROLLUP takes as its argument an ordered list of grouping columns. First, it calculates the standard aggregate values specified in the GROUP BY clause. Then, it creates progressively higher-level subtotals, moving from right to left through the list of grouping columns. Finally, it creates a grand total.
ROLLUP will create subtotals at n+1 levels, where n is the number of grouping columns. For instance, if a query specifies ROLLUP on grouping columns of Time, Region, and Department ( n=3), the result set will include rows at four aggregation levels.
This example of ROLLUP uses the data in the video store database.
SELECT Time, Region, Department, sum(Profit) AS Profit FROM sales GROUP BY ROLLUP(Time, Region, Dept)
As you can see in Table 20-2, this query returns the following sets of rows:
GROUP BY without using ROLLUP
Table 20-2 ROLLUP Aggregation across Three Dimensions
The NULL values returned by ROLLUP and CUBE are not always the traditional NULL value meaning "value unknown." Instead, a NULL may indicate that its row is a subtotal. For instance, the first NULL value shown in Table 20-2 is in the Department column. This NULL means that the row is a subtotal for "All Departments" for the Central region in 1996. To avoid introducing another non-value in the database system, these subtotal values are not given a special tag.
See the section "GROUPING Function" for details on how the NULLs representing subtotals are distinguished from NULLs stored in the data.
The result set in Table 20-1 could be generated by the UNION of four SELECT statements, as shown below. This is a subtotal across three dimensions. Notice that a complete set of ROLLUP-style subtotals in n dimensions would require n+1 SELECT statements linked with UNION ALL.
SELECT Time, Region, Department, SUM(Profit) FROM Sales GROUP BY Time, Region, Department UNION ALL SELECT Time, Region, '' , SUM(Profit) FROM Sales GROUP BY Time, Region UNION ALL SELECT Time, '', '', SUM(Profits) FROM Sales GROUP BY Time UNION ALL SELECT '', '', '', SUM(Profits) FROM Sales;
The approach shown in the SQL above has two shortcomings compared to using the ROLLUP operator. First, the syntax is complex, requiring more effort to generate and understand. Second, and more importantly, query execution is inefficient because the optimizer receives no guidance about the user's overall goal. Each of the four SELECT statements above causes table access even though all the needed subtotals could be gathered with a single pass. The ROLLUP extension makes the desired result explicit and gathers its results with just one table access.
The more columns used in a ROLLUP clause, the greater the savings versus the UNION approach. For instance, if a four-column ROLLUP replaces a UNION of 5 SELECT statements, the reduction in table access is four-fifths or 80%.
Some data access tools calculate subtotals on the client side and thereby avoid the multiple SELECT statements described above. While this approach can work, it places significant loads on the computing environment. For large reports, the client must have substantial memory and processing power to handle the subtotaling tasks. Even if the client has the necessary resources, a heavy processing burden for subtotal calculations may slow down the client in its performance of other activities.
Use the ROLLUP extension in tasks involving subtotals.
ROLLUP of year/month/day or country/state/city.
ROLLUP query executes in parallel.
Note that the subtotals created by ROLLUP are only a fraction of possible subtotal combinations. For instance, in the cross-tab shown in Table 20-1, the departmental totals across regions (279,000 and 319,000) would not be calculated by a ROLLUP(Time, Region, Department) clause. To generate those numbers would require a ROLLUP clause with the grouping columns specified in a different order: ROLLUP(Time, Department, Region). The easiest way to generate the full set of subtotals needed for cross-tabular reports such as those needed for Figure 20-1 is to use the CUBE extension.
CUBE enables a SELECT statement to calculate subtotals for all possible combinations of a group of dimensions. It also calculates a grand total. This is the set of information typically needed for all cross-tabular reports, so CUBE can calculate a cross-tabular report with a single SELECT statement. Like ROLLUP, CUBE is a simple extension to the GROUP BY clause, and its syntax is also easy to learn.
CUBE appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT ... GROUP BY CUBE (grouping_column_reference_list)
CUBE takes a specified set of grouping columns and creates subtotals for all possible combinations of them. In terms of multi-dimensional analysis, CUBE generates all the subtotals that could be calculated for a data cube with the specified dimensions. If you have specified CUBE(Time, Region, Department), the result set will include all the values that would be included in an equivalent ROLLUP statement plus additional combinations. For instance, in Table 20-1, the departmental totals across regions (279,000 and 319,000) would not be calculated by a ROLLUP(Time, Region, Department) clause, but they would be calculated by a CUBE(Time, Region, Department) clause. If there are n columns specified for a CUBE, there will be 2n combinations of subtotals returned. Table 20-3 gives an example of a three-dimension CUBE.
This example of CUBE uses the data in the video store database.
SELECT Time, Region, Department, sum(Profit) AS Profit FROM sales GROUP BY CUBE (Time, Region, Dept)
Table 20-3 shows the results of this query.
Just as for ROLLUP, multiple SELECT statements combined with UNION statements could provide the same information gathered through CUBE. However, this may require many SELECT statements: for an n-dimensional cube, 2n SELECT statements are needed. In our 3-dimension example, this would mean issuing 8 SELECTS linked with UNION ALL.
Consider the impact of adding just one more dimension when calculating all possible combinations: the number of SELECT statements would double to 16. The more columns used in a CUBE clause, the greater the savings versus the UNION approach. For instance, if a four-column CUBE replaces a UNION of 16 SELECT statements, the reduction in table access is fifteen-sixteenths or 93.75%.
CUBE in any situation requiring cross-tabular reports. The data needed for cross-tabular reports can be generated with a single SELECT using CUBE. Like ROLLUP, CUBE can be helpful in generating summary tables. Note that population of summary tables is even faster if the CUBE query executes in parallel.
CUBE is especially valuable in queries that use columns from multiple dimensions rather than columns representing different levels of a single dimension. For instance, a commonly requested cross-tabulation might need subtotals for all the combinations of month/state/product. These are three independent dimensions, and analysis of all possible subtotal combinations will be commonplace. In contrast, a cross-tabulation showing all possible combinations of year/month/day would have several values of limited interest, since there is a natural hierarchy in the time dimension. Subtotals such as profit by day of month summed across year would be unnecessary in most analyses.
The examples in this chapter show ROLLUP and CUBE used with the SUM() operator. While this is the most common type of aggregation, the extensions can also be used with all the other functions available to Group by clauses, for example, COUNT, AVG, MIN, MAX, STDDEV, and VARIANCE. COUNT, which is often needed in cross-tabular analyses, is likely be the second most helpful function.
Two challenges arise with the use of ROLLUP and CUBE. First, how can we programmatically determine which result set rows are subtotals, and how do we find the exact level of aggregation of a given subtotal? We will often need to use subtotals in calculations such as percent-of-totals, so we need an easy way to determine which rows are the subtotals we seek. Second, what happens if query results contain both stored NULL values and "NULL" values created by a ROLLUP or CUBE? How does an application or developer differentiate between the two?
To handle these issues, Oracle 8i introduces a new function called GROUPING. Using a single column as its argument, Grouping returns 1 when it encounters a NULL value created by a ROLLUP or CUBE operation. That is, if the NULL indicates the row is a subtotal, GROUPING returns a 1. Any other type of value, including a stored NULL, will return a 0.
GROUPING appears in the selection list portion of a SELECT statement. Its form is:
SELECT ... [GROUPING(dimension_column)...] ... GROUP BY ... {CUBE | ROLLUP}
This example uses grouping to create a set of mask columns for the result set shown in Table 20-3. The mask columns are easy to analyze programmatically.
SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING (Time) as T, GROUPING (Region) as R, GROUPING (Department) as D FROM Sales GROUP BY ROLLUP (Time, Region, Department)
Table 20-4 shows the results of this query.
A program can easily identify the detail rows above by a mask of "0 0 0" on the T, R, and D columns. The first level subtotal rows have a mask of "0 0 1", the second level subtotal rows have a mask of "0 1 1", and the overall total row have a mask of "1 1 1".
Table 20-5 shows an ambiguous result set created using the CUBE extension.
| Time | Region | Profit |
|---|---|---|
|
1996 |
East |
200,000 |
|
1996 |
[NULL] |
200,000 |
|
[NULL] |
East |
200,000 |
|
[NULL] |
[NULL] |
190,000 |
|
[NULL] |
[NULL] |
190,000 |
|
[NULL] |
[NULL] |
190,000 |
|
[NULL] |
[NULL] |
390,000 |
In this case, four different rows show NULL for both Time and Region. Some of those NULLs must represent aggregates due to the CUBE extension, and others must be NULLs stored in the database. How can we tell which is which? GROUPING functions, combined with the NVL and DECODE functions, resolve the ambiguity so that human readers can easily interpret the values.
We can resolve the ambiguity by using the GROUPING and other functions in the code below.
SELECT decode(grouping(Time), 1, 'All Times', Time) as Time, decode(grouping(region), 1, 'All Regions', 0, null)) as Region, sum(Profit) AS Profit from Sales group by CUBE(Time, Region)
This code generates the result set in Table 20-6. These results include text values clarifying which rows have aggregations.
| Time | Region | Profit |
|---|---|---|
|
1996 |
East |
200,000 |
|
1996 |
All Regions |
200,000 |
|
All Times |
East |
200,000 |
|
[NULL] |
[NULL] |
190,000 |
|
[NULL] |
All Regions |
190,000 |
|
All Times |
[NULL] |
190,000 |
|
All Times |
All Regions |
390,000 |
To explain the SQL statement above, we will examine its first column specification, which handles the Time column. Look at the first line of the in the SQL code above, namely,
decode(grouping(Time), 1, 'All Times', Time) as Time,
The Time value is determined with a DECODE function that contains a GROUPING function. The GROUPING function returns a 1 if a row value is an aggregate created by ROLLUP or CUBE, otherwise it returns a 0. The DECODE function then operates on the GROUPING function's results. It returns the text "All Times" if it receives a 1 and the time value from the database if it receives a 0. Values from the database will be either a real value such as 1996 or a stored NULL. The second column specification, displaying Region, works the same way.
The GROUPING function is not only useful for identifying NULLs, it also enables sorting subtotal rows and filtering results. In the example below (Table 20-7), we retrieve a subset of the subtotals created by a CUBE and none of the base-level aggregations. The HAVING clause constrains columns which use GROUPING functions.
SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING (Time) AS T, GROUPING (Region) AS R, GROUPING (Department) AS D FROM Sales GROUP BY CUBE (Time, Region, Department) HAVING (D=1 AND R=1 AND T=1) OR (R=1 AND D=1) OR (T=1 AND D=1)
Table 20-7 shows the results of this query.
| Time | Region | Department | Profit |
|---|---|---|---|
|
1996 |
[NULL] |
[NULL] |
526,000 |
|
1997 |
[NULL] |
[NULL] |
598,000 |
|
[NULL] |
Central |
[NULL] |
316,000 |
|
[NULL] |
East |
[NULL] |
442,000 |
|
[NULL] |
West |
[NULL] |
366,000 |
|
[NULL] |
[NULL] |
[NULL] |
1,124,000 |
Compare the result set of Table 20-7 with that in Table 20-3 to see how Table 20-7 is a precisely specified group: it contains only the yearly totals, regional totals aggregated over time and department, and the grand total.
This section discusses the following topics.
The ROLLUP and CUBE extensions work independently of any hierarchy metadata in your system. Their calculations are based entirely on the columns specified in the SELECT statement in which they appear. This approach enables CUBE and ROLLUP to be used whether or not hierarchy metadata is available. The simplest way to handle levels in hierarchical dimensions is by using the ROLLUP extension and indicating levels explicitly through separate columns. The code below shows a simple example of this with months rolled up to quarters and quarters rolled up to years.
SELECT Year, Quarter, Month, SUM(Profit) AS Profit FROM sales GROUP BY ROLLUP(Year, Quarter, Month)
This query returns the rows in Table 20-8.
CUBE and ROLLUP do not restrict the GROUP BY clause column capacity. The GROUP BY clause, with or without the extensions, can work with up to 255 columns. However, the combinatorial explosion of CUBE makes it unwise to specify a large number of columns with the CUBE extension. Consider that a 20-column list for CUBE would create 220 combinations in the result set. A very large CUBE list could strain system resources, so any such query needs to be tested carefully for performance and the load it places on the system.
The HAVING clause of SELECT statements is unaffected by the use of ROLLUP and CUBE. Note that the conditions specified in the HAVING clause apply to both the subtotal and non-subtotal rows of the result set. In some cases a query may need to exclude the subtotal rows or the non-subtotal rows from the HAVING clause. This can be achieved by using the GROUPING function together with the HAVING clause. See Table 20-7 and its associated SQL for an example.
Top-N queries ask for the n largest or smallest values of a column. An example is "What are the top ten best selling products in the U.S.?" Of course, we may also want to ask "What are the 10 worst selling products?" Both largest-values and smallest-values sets are considered Top-N queries.
Top-N queries use a consistent nested query structure with the elements described below.
ORDER BY clause to ensure that the ranking is in the desired order. For results retrieving the largest values, a DESC parameter is needed.
The high-level structure of these queries is:
SELECT column_list ROWNUM FROM (SELECT column_list FROM table ORDER BY Top-N_column) WHERE ROWNUM <= N
To illustrate the concepts here, we extend the scenario used in our earlier examples. We will now access the name of the sales representative associated with each sale, stored in the "name" column. and the sales commission earned on every sale. The SQL below returns the top 10 sales representatives ordered by dollar sales, with sample data shown in Table 20-9:
select ROWNUM AS Rank, Name, Region, Sales from (select Name, Region, sum(Sales) AS Sales from Sales GROUP BY Name, Region order by sum(Sales) DESC) WHERE ROWNUM <= 10
This example can be augmented to show the sales representatives' ranks both for sales and commissions in a single query. We now extend our query to include the sales commission earned on every sale, stored in the "commission" column. The extra information requires another layer of nested subquery. Although interpreting several layers of queries can be challenging, the SQL below has been formatted to clarify the meaning.
Below is the SQL needed for our scenario, with the sample results shown in Table 20-10. To understand the query, please step through the code following the number sequence shown at the left edge:
4) SELECT ROWNUM as SalesRank, Name, Region, SalesDollars, CommRank from 2) (SELECT Name, Region, SalesDollars, ROWNUM AS CommRank from 1) ( SELECT Name, Region, sum(Sales) AS SalesDollars, sum(commission) FROM Sales GROUP BY Name, Region ORDER BY sum(Commission) DESC ) 3) ORDER BY Sales DESC ) 5) WHERE ROWNUM <=10
Note that the results in Table 20-10 show how commission ranks are not identical to sales ranks in this data set: some representatives had higher or lower commission rates tied to specific sales.
Joint Technical Committee ISO/IEC JTC 1, Information Technology. ISO Working Draft Database Language SQL --Part 2: Foundation (SQL/Foundation), Document ID: ISO/IEC FCD 9075-2:199x, September 1997.