Release 2 (8.1.6)
A81353-01
Library |
Product |
Contents |
Index |
| Oracle8i Java Developer's Guide Release 2 (8.1.6) A81353-01 |
|
![]()
![]()
JServer runs standard Java applications. However, by integrating Java classes within the database server, your environment is different from a typical Java development environment. This chapter describes the basic differences for writing, installing, and deploying Java applications within Oracle8i.
As discussed in Chapter 1, the Oracle8i JServer platform is a standard, compatible Java environment, which will execute any 100% pure Java application. It has been implemented by Oracle to be compatible with the Java Language Specification and the Java virtual machine specification. It supports the standard Java binary format and the standard Java APIs. In addition, Oracle8i adheres to standard Java language semantics, including dynamic class loading at runtime. However, unlike other Java environments, the JServer is embedded within the Oracle8i RDBMS and, therefore, introduces a number of new concepts. This section gives an overview of the differences between Sun Microsystems's JDK environment and the environment that occurs when you combine Java within the Oracle8i database.
In your standard Java environment, you run a Java application through the interpreter by executing java <classname>. This causes the application to execute within a process on your operating system.
With the Aurora JVM, you must load the application into the database, publish the interface, and then run the application within a database session. This book discusses how to run your Java applications within the database. Specifically, see the following sections on instructions for Java in the database:
In addition, certain features, included within standard Java, change when you run your application within a database session. These are covered in the following sections:
Once you are familiar with this chapter, see Chapter 3, "Invoking Java in the Database" for directions on how to set up your client, and examples for invoking different types of Java applications.
In incorporating Java within the Oracle8i database, your Java application exists within the context of a database session. JServer sessions are entirely analogous to traditional Oracle sessions. Each JServer session maintains the client's Java state across calls within the session.
As demonstrated in Figure 2-1, each Java client starts up a database session as the environment for executing Java within the database. Garbage collection, session memory, and call memory exist solely for each client within its session.
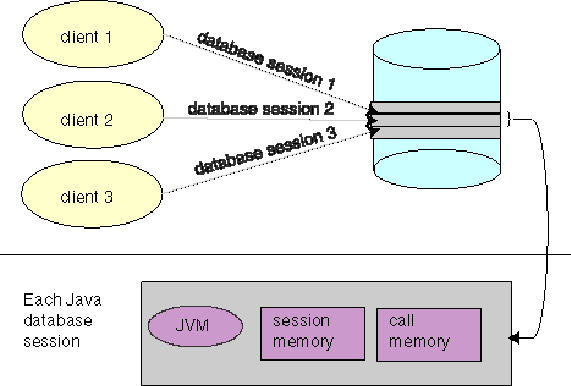
Within the context of a session, the client performs the following:
Within a single session, the client has its own Java environment, which is separate from every other client's environment. It appears to the client as if a separate, individual JVM was invoked for each session, although the implementation is vastly more efficient than this seems to imply. Within a session, the Aurora JVM manages the scalability for you within the database. Every call executed from a single client is managed within its own session--separately from other clients. The Aurora JVM maximizes sharing read-only data between clients and emphasizes a minimum amount of per-session incremental footprint to maximize performance for multiple clients.
The underlying server environment hides the details associated with session, network, state, and other shared resource management issues from Java server code. Static variables are all local to the client. No client can access another client's static variables, because the memory is not available across session boundaries. Each client executes its calls within its own session, so each client's activities are separate from any other client. During a call, you can store objects in static fields of different classes, and you can expect this state to be available for your next call. The entire state of your Java program is private to you and exists for your entire session.
The Aurora JVM manages the following within the session:
When you connect to Oracle8i, you start a database session. A session ends when one of the following events occurs:
oracle.aurora.vm.OracleRuntime.exitSession() method.
For the current Oracle8i release, we offer three Java APIs--Java stored procedures, CORBA distributed objects, and Enterprise JavaBeans (EJBs).
In addition, you can access SQL data through SQLJ or JDBC. See Chapter 3, "Invoking Java in the Database" for examples of each Java API.
In Sun Microsystems's JDK environment, you develop Java applications with a main() method, which is called by the interpreter when the class is run. The main() method is invoked when you execute java <classname> on the command-line. This command starts the java interpreter and passes the desired classname to be executed to the interpreter. The java interpreter loads the class and starts the execution by invoking main(). However, Java applications within the database do not start their execution from a main() method.
After loading your Java application within the database (see "Loading Classes"), you can execute your Java code by invoking any static method within the loaded class. The class or methods must be published for you to execute them (see "Publishing"). Your only entry point is no longer always assumed to be main(). Instead, when you execute your Java application, you specify a method name within the loaded class as your entry point.
For example, in a normal Java environment, you would start up the Java object on the server by executing the following:
java myprogram
where myprogram is the name of a class that contains a main() method. In myprogram, main() immediately calls mymethod for processing incoming information.
In Oracle8i, you load the myprogram.class file into the database and publish mymethod as an entry-point. Then, the client or trigger can invoke mymethod explicitly.
Java 2 is, for the most part, compatible with JDK 1.1. Sun Microsystems changed certain features, such as the security feature, in Java 2. These changes are documented at the following Sun Microsystems's web site:
http://java.sun.com/products/jdk/1.2/compatibility.html
The following sections discuss how the changes made within Java 2 affected Oracle8i:
The level of your development environment determines your interoperability with the server. If your development environment is Java 2-based, any code compiled and debugged on your system can be loaded and executed on the database. However, if you are developing applications in a JDK 1.1 development environment, you can only use JDK 1.1 classes. This application can be loaded and executed in the database, which is Java 2-based, with a few exceptions that are discussed in this section. Of course, you always have the option to code your Java 2-based application on your system, load it into the database, and use the Java 2 compiler that exists on the database.
Even though 8.1.5 was JDK 1.1-based, JDBC 2.0 support was added to 8.1.5 in an Oracle-specific package-- oracle.jdbc2. However, the current version of Oracle8i supports Java2, so JDBC 2.0 exists in its intended package--java.sql. If you have JDBC programs that used the oracle.jdbc2 package for JDBC 2.0 APIs, you must modify these programs before executing with JDBC 2.0 drivers.
With the addition of Java 2 in Oracle8i, the JDBC 2.0 support exists in the java.sql package, which is contained in the JDK core libraries. You can continue to use the oracle.jdbc2 package, and not needing to change your client code, by continuing to use oracle.jdbc2 within classes111.zip.
The following client applications can interoperate with 8.1.6:
oracle.jdbc2. This application imports the oracle.jdbc2 package within classes111.zip.
java.sql. This application imports the java.sql package contained within the classes12.zip, not the oracle.jdbc2 package.
The steps to port your Java application to Java 2 are as follows:
oracle.jdbc2 with java.sql in your programs.
The oracle.jdbc2 package contains the JDBC 2.0 implementation that Oracle implemented in the JDK 1.1 drivers. Because those classes and interfaces are available in Java 2, oracle.jdbc2 is not included in classes12.zip.
getTypeMap() method of Connection has been changed from java.util.Dictionary to java.util.Map. Modify your application accordingly. No change is necessary if you are using java.util.Hashtable, because Hashtable implements java.util.Map.
For more information, See Chapter 4 in the Oracle8i JDBC Developer's Guide and Reference.
Java 2 security is implemented in 8.1.6. The JDK 1.1 security sandbox is no longer applicable within Oracle8i. To use the Java 2 security permissions without modifying your code, you can manage these permissions through the PL/SQL package--DBMS_JAVA. To execute any of the Java 2 security methods, such as doPrivileged, you must have a Java 2 environment when compiling and running the application.
See "Security" for more information on Java 2 security.
Oracle8i JServer updated its ORB implementation to Visigenic 3.4. This version is compatible with both JDK 1.1 and Java 2.
Sun Microsystems's Java 2 contains an ORB implementation; JDK 1.1 did not. Thus, when you imported the Visigenic libraries and invoked the CORBA methods, it always invoked the Visigenic implementation. With Java 2, if you invoke the CORBA methods without any modifications--as discussed below--you will invoke Sun Microsystems's CORBA implementation, which can cause unexpected results.
The following lists the three methods for accessing CORBA server objects in Oracle8i from your client and the recommendations for bypassing Sun Microsystems's CORBA implementation:
If you are using JNDI on the client to access CORBA objects that reside in the server, no code changes are required. However, you must regenerate your CORBA stubs and skeletons.
If your client environment uses JDK 1.1, you do not need to change your existing code. You will need to regenerate your stubs and skeletons.
If your client environment has been upgraded to Java 2, you can initialize the ORB through the oracle.aurora.jndi.orb_dep.Orb.init method. This method guarantees that when you initialize the ORB, it will initialize only a single ORB instance. That is, if you use the Java 2 ORB interface, it returns you a new ORB instance each time you invoke the init method. Aurora's init method initializes a singleton ORB instance. Each successive call to init returns an object reference to the existing ORB instance.
In addition, the Aurora ORB interface manages the session-based IIOP connection.
There are several init methods, each with a different parameter list. The following describes the syntax and parameters for each init method.
public com.visigenic.vbroker.orb.ORB init(); public org.omg.CORBA.ORB init(Properties props); public org.omg.CORBA.ORB init(String[] args, Properties props);
| Parameter | Description |
|---|---|
|
Properties props |
ORB system properties. |
|
String[] args |
Arguments that are passed to the ORB instance. |
The following example shows a client instantiating an ORB using the Aurora Orb class.
// Create the client object and publish it to the orb in the client
// Substitute Aurora's Orb.init for OMG ORB.init call
// old way: org.omg.CORBA.ORB orb = org.omg.CORBA.ORB.init ();
com.visigenic.vbroker.orb.ORB orb = oracle.aurora.jndi.orb_dep.Orb.init();
If your client receives a reference to an object that is created in a session, it can invoke a method on that object within the session. However, since all clients must authenticate, you must provide a username and password to the database. If the server requires client-side authentication in the form of SSL_CREDENTIALS, you can provide the client's username, password, and role, which is passed on the connect handshake within the ORB.init method.
public org.omg.CORBA.ORB init(String un, String pw, String role, boolean ssl, java.util.Properties props);
If you have implemented a pure CORBA client--that is, you do not use JNDI--you need to set the following properties before the ORB initialization call. These properties direct the call to the Aurora implementation, rather than the Java 2 implementation. This ensures the behavior that you expect. The behavior expected from the Visigenic ORB is as follows:
ORB.init more than once, only a single ORB instance is created. If you do not set these properties, be aware that each invocation of ORB.init will create a new ORB instance.
| Property | Assign Value |
|---|---|
|
org.omg.CORBA.ORBClass |
com.visigenic.vbroker.orb.ORB |
|
org.omg.CORBA.ORBSingletonClass |
com.visigenic.vbroker.orb.ORB |
The following example shows how to set up the OMG properties for directing the OMG CORBA init method to the Visigenic implementation.
System.getProperties().put("org.omg.CORBA.ORBClass",
"com.visigenic.vbroker.orb.ORB"); System.getProperties().put("org.omg.CORBA.ORBSingletonClass",
"com.visigenic.vbroker.orb.ORB");
Or you can set the properties on the command line, as follows:
java -Dorg.omg.CORBA.ORBClass=com.visigenic.vbroker.orb.ORB
-Dorg.omg.CORBA.ORBSingletonClass=com.visigenic.vbroker.orb.ORB
The tools provided with Oracle8i, such as publish, have been modified to work with either a JDK 1.1 or Java 2 environment. However, any CORBA or EJB code that has been generated or loaded with the 8.1.5 version of any tool, will not succeed. Make sure that you always use the 8.1.6 version of all tools. This rule applies to your CORBA stubs and skeletons. You must regenerate all stubs and skeletons with the 8.1.6 IDL compiler.
In Sun Microsystems's Java development environment, Java source code, binaries, and resources are stored as files in a file system.
.java files.
.class files.
.properties or .ser files held within the file system hierarchy, which are loaded or used at runtime.
In addition, when you execute Java, you specify a CLASSPATH, which is a set of a file system tree roots containing your files. Java also provides a way to group these files into a single archive form--a ZIP or JAR file.
Both of these concepts are different within the database. The following describes how JServer handles Java classes and locates dependent classes:
To summarize, we use the terms call and session during our discussions. Although these terms are not Java terms, they are server terms that apply to the Oracle8i JServer platform. The Aurora memory manager preserves Java program state throughout your session (that is, between calls). The JServer uses the Oracle database to hold Java source, classes, and resources within a schema--Java schema objects. You can use a resolver to specify how Java, when executed in the server, locates source code, classes, and resources.
For your Java methods to be executed, you must do the following:
Compilation of your source can be performed in one of the following ways:
javac.
loadjava to compile the source.
If you decide to compile through
Note:
loadjava, you can specify compiler options. See "Specifying Compiler Options" for more information.
You can compile your Java with a conventional Java compiler, such as javac. After compilation, you load the compiled binary into the database, rather than the source itself. This is a better option, because it is normally easier to debug your Java code on your own system, rather than debugging it on the database.
When you specify the -resolve option on loadjava for a source file, the following occurs:
JServer logs all compilation errors both to loadjava's logfile and the USER_ERRORS view. For more information on the USER_ERRORS view, see the Oracle8i Reference for a description of this table.
When you load the Java source into the database without the -resolve option, JServer will compile the source at runtime. The source file is loaded into a source schema object.
JServer logs all compilation errors both to loadjava's logfile and the USER_ERRORS view. For more information on the USER_ERRORS view, see the Oracle8i Reference for a description of this table.
There are two ways to specify options to the compiler.
loadjava command line. You can specify the encoding option through loadjava. The online option is defaulted, unless you override it within the JAVA$OPTIONS table. If you run loadjava with of the resolve option, you can specify encoding on the command line.
JAVA$OPTIONS. Every time you compile, the compiler uses these options. However, any specified compiler options on the loadjava command override the options defined in this table.
You must create this table yourself if you wish to specify compiler options this way. See "Compiler Options Specified in a Database Table" for instructions to create the JAVA$OPTIONS table.
The following sections describe your compiler options:
When compiling a source schema object for which there is neither a JAVA$OPTIONS entry nor a command line value for an option, the compiler assumes a default value as follows:
encoding = latin1
online = true: See the Oracle8i SQLJ Developer's Guide and Reference for a description of this option, which applies only to Java sources that contain SQLJ constructs.
debug = true: This option is equivalent to javac -g.
The following describes the loadjava compiler options:
encoding--Identifies the source file encoding for the compiler. This option overrides any matching value in the JAVA$OPTIONS table. The values are identical to the javac -encoding option. This option is relevant only when loading a source file.
online--This option is valid for SQLJ only. Setting this option to TRUE enables online semantics-checking. Semantics-checking is performed relative to the schema in which the source is loaded. If the online option is set to FALSE, offline checking is performed.
Each JAVA$OPTIONS row contains the names of source schema objects to which an option setting applies; you can use multiple rows to set the options differently for different source schema objects.
You can set JAVA$OPTIONS entries by means of the following functions and procedures, which are defined in the database package DBMS_JAVA:
PROCEDURE set_compiler_option(name VARCHAR2, option VARCHAR2, value VARCHAR2);
FUNCTION get_compiler_option(name VARCHAR2, option VARCHAR2) RETURNS VARCHAR2;
PROCEDURE reset_compiler_option(name VARCHAR2, option VARCHAR2);
The parameters for these methods are described below:
| Parameter | Description |
|---|---|
|
name |
The |
|
option |
The |
A schema does not initially have a JAVA$OPTIONS table. To create a JAVA$OPTIONS table, use the DBMS_JAVA package's java.set_compiler_option procedure to set a value. The procedure will create the table if it does not exist. Specify parameters in single quotes. For example:
SQL> execute dbms_java.set_compiler_option('x.y', 'online', 'false');
Table 2-1 represents a hypothetical JAVA$OPTIONS database table. The pattern match rule is to match as much of the schema name against the table entry as possible. The schema name with a higher resolution for the pattern match is the entry that applies. Because the table has no entry for the encoding option, the compiler uses the default or the value specified on the command line. The online option shown in the table matches schema object names as follows:
a.b.c.d matches class and package names beginning with a.b.c.d; the packages and classes are compiled with online = true.
a.b matches class and package names beginning with a.b. The name a.b does not match a.b.c.d; therefore, the packages and classes are compiled with online = false.
online = true.
Table 2-1 Example JAVA$OPTIONS Table
|
JAVA$OPTIONS Entries |
Match Examples | ||
|---|---|---|---|
| Name | Option | Value | |
|
|
|
|
|
|
|
|
|
|
|
(empty string) |
|
|
|
JServer provides a dependency management and automatic build facility that will transparently recompile source programs when you make changes to the source or binary programs upon which they depend. Consider the following cases:
public class A { B b; public void assignB () {b = new B()} } public class B { C c; public void assignC () {c = new C()} } public class C { A a; public void assignA () {a = new A()} }
The system tracks dependencies at a class level of granularity. In the preceding example, you can see that classes A, B, and C depend on one another, because A holds an instance of B, B holds an instance of C, and C holds an instance of A. If you change the definition of class A by adding a new field to it, the dependency mechanism in Oracle8i flags classes B and C as invalid. Before you use any of these classes again, Oracle8i attempts to resolve them again and recompile, if necessary. Note that classes can be recompiled only if source is present on the server.
The dependency system enables you to rely on Oracle8i to manage dependencies between classes, to recompile, and to resolve automatically. You must only force compilation and resolution yourself only if you are developing and you want to find problems early. The loadjava utility also provides the facilities for forcing compilation and resolution if you do not want to allow the dependency management facilities to perform this for you.
Many Java classes contain references to other classes, which is the essence of reusing code. A conventional Java virtual machine searches for classes, ZIP, and JAR files within the directories specified in the CLASSPATH. In contrast, the Aurora Java virtual machine searches database schemas for class objects. With Oracle8i, you load all Java classes within the database, so you might need to specify where to find the dependent classes for your Java class within the database.
All classes loaded within the database are referred to as class schema objects and are loaded within certain schemas. All JVM classes, such as java.lang.*, are loaded within PUBLIC. If your classes depend upon other classes you have defined, you will probably load them all within your own schema. For example, if your schema is SCOTT, the database resolver (the database replacement for CLASSPATH) searches the SCOTT schema before PUBLIC. The listing of schemas to search is known as a resolver spec. Resolver specs are per-class, whereas in a classic Java virtual machine, CLASSPATH is global to all classes.
When locating and resolving the interclass dependencies for classes, the resolver marks each class as valid or invalid, depending on if all interdependent classes are located or not. If the class that you load contains a reference to a class that is not found within the appropriate schemas, the class is listed as invalid. Unsuccessful resolution at runtime produces a "class not found" exception. Furthermore, runtime resolution can fail for lack of database resources if the tree of classes is very large.
For each interclass reference in a class, the resolver searches the schemas specified by the resolver spec for a valid class schema object that satisfies the reference. If all references are resolved, the resolver marks the class valid. A class that has never been resolved, or has been resolved unsuccessfully, is marked invalid. A class that depends on a schema object that becomes invalid is also marked invalid.
To make searching for dependent classes easier, Oracle8i provides a default resolver and resolver spec that searches first the definer's schema and then PUBLIC. This covers most of the classes loaded within the database. However, if you are accessing classes within a schema other than your own or PUBLIC, you must define your own resolver spec.
PUBLIC:
loadjava -resolve
loadjava-resolve -resolver "((* SCOTT)(* OTHER)(* PUBLIC))"
The -resolver option specifies the objects to search within the schemas defined. In the example above, all class schema objects are searched within SCOTT, OTHER, and PUBLIC. However, if you wanted to search for only a certain class or group of classes within the schema, you could narrow the scope for the search. For example, to search only for the classes "my/gui/*" within the OTHER schema, you would define the resolver spec as follows:
loadjava -resolve -resolver '((* SCOTT) ("my/gui/*" OTHER) (* PUBLIC))'
The first parameter within the resolver spec is for the class schema object; the second parameter defines the schema to search for these class schema objects.
You can specify a special option within a resolver spec that allows an unresolved reference to a non-existent class. Sometimes, internal classes are never used within a product. For example, some ISVs do not remove all references to internal test classes from the JAR file before shipping. In a normal Java environment, this is not a problem, because as long as the methods are not called, Sun Microsystems's JVM ignores them. However, the Oracle8i resolver tries to resolve all classes referenced within the JAR file--even unused classes. If the reference cannot be validated, the classes within the JAR file are marked as invalid.
To ignore references, you can specify the "-" wildcard within the resolver spec. The following example specifies that any references to classes within "my/gui" are to be allowed even if it is not present within the resolver spec schema list.
loadjava -resolve -resolver '((* SCOTT) (* PUBLIC) ("my/gui/*" -))'
In addition, you can define that all classes not found are to be ignored. Without the wildcard, if a dependent class is not found within one of the schemas, your class is listed as invalid and cannot be run. However, this is also dangerous, because if there is a dependent class on a used class, you mark a class as valid that can never run without the dependent class. In this case, you will receive an exception at runtime.
To ignore all classes not found within SCOTT or PUBLIC, specify the following resolver spec:
loadjava -resolve -resolver "((* SCOTT) (* PUBLIC) (* -))"
According to the JVM specification, .class files are subject to verification before the class they define is available in a JVM. In JServer, the verification process occurs at class resolution. The resolver might find one of the following problems and issue the appropriate Oracle error code:
The resolver also issues warnings, as defined below:
This type of resolver marks your class valid regardless of whether classes it references are present. Because of inheritance and interfaces, you might want to write valid Java methods that use an instance of a class as if it were an instance of a superclass or of a specific interface. When the method being verified uses a reference to class A as if it were a reference to class B, the resolver must check that A either extends or implements B. For example, consider the potentially valid method below, whose signature implies a return of an instance of B, but whose body returns an instance of A:
B myMethod(A a) { return a; }
The method is valid only if A extends B or A implements the interface B. If A or B have been resolved using a "-" term, the resolver does not know that this method is safe. It will replace the bytecodes of myMethod with bytecodes that throw an Exception if myMethod is ever called.
The resolver ensures that the class definitions of A and B are found and resolved properly if they are present in the schemas they specifically identify. The only time you might consider using the alternative resolver is if you must load an existing JAR file containing classes that reference other non-system classes not included in the JAR file.
For more information on class resolution and loading your classes within the database, see Appendix A, "Tools".
This section gives an overview of the main points you should understand when loading your classes into the database. It discusses various options for the loadjava tool, but does not go into all the details. See "loadjava" for complete information.
Unlike a conventional Java virtual machine, which compiles and loads from files, the Aurora Java virtual machine compiles and loads from database schema objects.
You must load all classes or resources into the database to be used by other classes within the database. In addition, at loadtime, you define who can execute your classes within the database.
The loadjava tool performs the following for each type of file:
The dropjava tool performs the reverse of the loadjava tool: it deletes schema objects that correspond to Java files. You should always use dropjava to delete a Java schema object created with loadjava. Dropping with SQL DDL commands will not update auxiliary data maintained by loadjava and dropjava.
|
Note: More options for loadjava are available. However, this section discusses only the major options. See "loadjava" for complete information. Also, dropjava is discussed in full . |
You must abide by certain rules when loading classes into the database, which are detailed in the following sections:
After loading, you can access the USER_OBJECTS view in your database schema to verify that your classes and resources loaded properly. For more information, see "Checking Java Uploads".
You cannot have two different definitions for the same class. This rule affects you in two ways:
class file or its .java file, but not both.
JServer tracks whether you loaded a class file or a source file. If you wish to update the class, you must load the same type of file that you originally loaded. If you wish to update the other type, you must drop the first before loading the second. For example, if you loaded x.java as the source for class y, to load x.class, you must first drop x.java.
x.java defines class y and you want to move the definition of y to z.java. If x.java has already been loaded, loadjava rejects any attempt to load z.java (which also defines y). Instead, do either of the following:
You must have the following SQL database privileges to load classes:
CREATE PROCEDURE and CREATE TABLE privileges to load into your schema.
CREATE ANY PROCEDURE and CREATE ANY TABLE privileges to load into another schema.
The loadjava tool accepts .class, .java, .properties, .sqlj, .ser, .jar, or .zip files. The JAR or ZIP files can contain source, class, and data files. When you pass loadjava a JAR or ZIP file, loadjava opens the archive and loads its members individually. There is no JAR or ZIP schema object. If the JAR or ZIP content has not changed since the last time it was loaded, it is not reloaded; therefore, there is little performance penalty for loading JAR or ZIP files. In fact, loading JAR or ZIP files is the simplest way to use loadjava.
When you are loading your classes, you can grant execution rights to another user through an option for loadjava. There are two methods for defining who can execute your class:
The classes that define a Java application are stored within the Oracle8i RDBMS under the SQL schema of their owner. By default, classes that reside in one user's schema are not executable by other users, because of security concerns. You can allow other users (schemas) the right to execute your class through the loadjava -grant option.
You can specify that the user evaluated for execution rights is either the invoker or the definer. Invoker's and definer's rights are SQL concepts that are applicable to your Java classes. In SQL, when you execute under definer's rights, you execute with the user identifier for the schema that loaded the PL/SQL. With invoker's rights, your SQL executes with the user identifier for the schema that actually invokes the PL/SQL. This applies to the Java classes in that the schema that is evaluated for JVM security permission to execute is based on whether the class was loaded under invoker's or definer's rights.

With the example in Figure 2-2, which class, A or B, is checked when the method in class C is executed? This depends on invoker's or definer's rights.
loadjava -definer.
For information on JVM security permissions, see Chapter 5, "Security and Performance".
You can query the database view USER_OBJECTS to obtain information about schema objects--including Java sources, classes, and resources--that you own. This allows you, for example, to verify that sources, classes, or resources that you load are properly stored into schema objects.
Columns in USER_OBJECTS include those contained in Table 2-2 below.
An OBJECT_NAME in USER_OBJECTS is the short name. The full name is stored as a short name if it exceeds 31 characters. See "Shortened Class Names" for more information on full and short names.
If the server uses a short name for a schema object, you can use the LONGNAME() routine of the server DBMS_JAVA package to receive it from a query in full name format, without having to know the short name format or the conversion rules.
SQL*Plus> SELECT dbms_java.longname(object_name) FROM user_objects WHERE object_type='JAVA SOURCE';
This routine shows you the Java source schema objects in full name format. Where no short name is used, no conversion occurs, because the short name and full name are identical.
You can use the SHORTNAME() routine of the DBMS_JAVA package to use a full name as a query criterion, without having to know whether it was converted to a short name in the database.
SQL*Plus> SELECT object_type FROM user_objects WHERE object_name=dbms_java.shortname('known_fullname');
This routine shows you the OBJECT_TYPE of the schema object of the specified full name. This presumes that the full name is representable in the database character set.
SVRMGR> select * from javasnm; SHORT LONGNAME ---------------------------------------------------------------------- /78e6d350_BinaryExceptionHandl sun/tools/java/BinaryExceptionHandler /b6c774bb_ClassDeclaration sun/tools/java/ClassDeclaration /af5a8ef3_JarVerifierStream1 sun/tools/jar/JarVerifierStream$1
STATUS is a character string that indicates the validity of a Java schema object. A source schema object is VALID if it compiled successfully; a class schema object is VALID if it was resolved successfully. A resource schema object is always VALID, because resources are not resolved.
The following SQL*Plus script accesses the USER_OBJECTS view to display information about uploaded Java sources, classes, and resources.
COL object_name format a30 COL object_type format a15 SELECT object_name, object_type, status FROM user_objects WHERE object_type IN ('JAVA SOURCE', 'JAVA CLASS', 'JAVA RESOURCE') ORDER BY object_type, object_name;
You can optionally use wildcards in querying USER_OBJECTS, as in the following example.
SELECT object_name, object_type, status FROM user_objects WHERE object_name LIKE '%Alerter';
This routine finds any OBJECT_NAME entries that end with the characters: Alerter.
For more information about USER_OBJECTS, see the Oracle8i Java Stored Procedures Developer's Guide.
Oracle8i enables clients and SQL to invoke Java methods loaded within the database, once published. You publish either the object itself or individual methods, depending on the type of Java application it is, as shown below:
Oracle8i furnishes all core Java class libraries on the server, including those associated with presentation of user interfaces (java.awt and java.applet). It is, however, inappropriate for code executing in the server to attempt to bring up or materialize a user interface in the server. Imagine thousands of users worldwide exercising an Internet application that executes code that requires someone to click on a dialog presented on the server hardware. You can write Java programs that reference and use java.awt classes as long as you do not attempt to materialize a user interface.
When building applets, you test them using the java.awt and the Peer implementation, which is a platform-specific set of classes for support of a specific windowing system. When the user downloads an applet, it dynamically loads the proper client Peer libraries, and the user sees a display appropriate for the operating system or windowing system in use on the client side. Oracle8i takes the same approach. We provide an Oracle-specific Peer implementation that throws an exception, oracle.aurora.awt.UnsupportedOperation, if you execute Java code on the Oracle8i server that attempts to materialize a user interface.
Oracle8i's lack of support for materializing user interfaces in the server means that we do not pass the Java 2 Compatibility Kit tests for java.awt, java.awt.manual, and java.applet. In the Oracle RDBMS, all user interfaces are supported only on client applications, although they might be displayed on the same physical hardware that supports the server--for example, in the case of Windows NT. Because it does not make sense for the server to support user interfaces, we exclude these tests from our complete Java Compatibility Kit testing.
A similar issue exists for vendors of Java-powered embedded devices and in handheld devices (known as Personal Java). Future releases of Java and the Java Compatibility Kit will provide improved factorization of user interface support so that vendors of Java server platforms can better address this issue.
Each Java source, class, and resource is stored in its own schema object in the server. The name of the schema object is derived from the fully qualified name, which includes relevant path or package information. Dots are replaced by slashes. These fully qualified names (with slashes)--used for loaded sources, loaded classes, loaded resources, generated classes, and generated resources--are referred to in this chapter as schema object full names.
Schema object names, however, have a maximum of only 31 characters, and all characters must be legal and convertible to characters in the database character set. If any full name is longer than 31 characters or contains illegal or non-convertible characters, the Oracle8i server converts the full name to a short name to employ as the name of the schema object, keeping track of both names and how to convert between them. If the full name is 31 characters or less and has no illegal or inconvertible characters, then the full name is used as the schema object name.
Because Java classes and methods can have names exceeding the maximum SQL identifier length, Oracle8i uses abbreviated names internally for SQL access. Oracle8i provides a method within the DBMS_JAVA package for retrieving the original Java class name for any truncated name.
FUNCTION longname (shortname VARCHAR2) RETURN VARCHAR2
This function returns the longname from a Java schema object. An example is to print the fully qualified name of classes that are invalid for some reason.
select dbms_java.longname (object_name) from user_objects where object_type = 'JAVA CLASS' and status = 'INVALID';
In addition, you can specify a full name to the database by using the shortname() routine of the DBMS_JAVA package, which takes a full name as input and returns the corresponding short name. This is useful when verifying that your classes loaded by querying the USER_OBJECTS view.
FUNCTION shortname (longname VARCHAR2) RETURN VARCHAR2
Refer to the Oracle8i Java Stored Procedures Developer's Guide. for a detailed example of the use of this function and ways to determine which Java schema objects are present on the server.
The Java Language Specification provides the following description of Class.forName():
Given the fully-qualified name of a class, this method attempts to locate, load, and link the class. If it succeeds, a reference to the Class object for the class is returned. If it fails, a ClassNotFoundException is thrown.
Class lookup is always on behalf of a referencing class through a ClassLoader. The difference between the JDK implementation and JServer's implementation is the method on which the class is found:
CLASSPATH.
Class.forName(), the resolver of the currently executing class (this) is used to locate the class. See "Resolving Class Dependencies" for more information on resolvers.
You can receive unexpected results if you try to locate a class with an unexpected resolver. For example, if a class X in schema X requests a class Y in schema Y to look up class Z, you can experience an error if you expected class X's resolver to be used. Because class Y is performing the lookup, the resolver associated with class Y is used to locate class Z. In summary, if the class exists in another schema and you specified different resolvers for different classes--as would happen by default if they are in different schemas-- you might not find the class.
You can solve this resolver problem as follows:
ClassLoader in the Class.forName method.
classForNameAndSchema method.
ClassForName.lookupClass.
JServer uses resolvers for locating classes within schemas. Every class has a specified resolver associated with it. Each class can have a different resolver associated with it. Thus, the locating of classes is dependent on the definition of the associated resolver. The ClassLoader knows which resolver to use based upon the class specified. When you supply a ClassLoader to Class.forName(), your class is looked up in the schemas defined within the resolver of the class. The syntax for this variant of Class.forName is as follows:
Class forName (String name, boolean initialize, ClassLoader loader);
The following examples show how to supply the class loader of either the current class instance or the calling class instance.
You can retrieve the class loader of any instance through the Class.getClassLoader method. The following example retrieves the class loader of the class represented by instance x.
Class c1 = Class.forName (x.whatClass(), true, x.getClass().getClassLoader());
You can retrieve the class of the instance that invoked the executing method through the oracle.aurora.vm.OracleRuntime.getCallerClass method. Once you retrieve the class, invoke the Class.getClassLoader method on the returned class. The following example retrieves the class of the instance that invoked the workForCaller method. Then, its class loader is retrieved and supplied to the Class.forName method. Thus, the resolver used for looking up the class is the resolver of the calling class.
void workForCaller() {ClassLoader c1 =
oracle.aurora.vm.OracleRuntime.getCallerClass().getClassLoader(); ... Class c = Class.forName (name, true, c1);
You can resolve the problem of where to find the class by either supplying the resolver, which knows the schemas to search, or by supplying the schema in which the class is loaded. If you know in which schema the class is loaded, you can use the classForNameAndSchema method. JServer provides a method in the DbmsJava class, which takes in both the name of the class and the schema that the class resides in. This method locates the class within the designated schema.
The following example shows how you can save the schema and class names in the save method. Both names are retrieved and the class is located using the DbmsJava.classForNameAndSchema method.
import oracle.aurora.rdbms.ClassHandle; import oracle.aurora.rdbms.Schema; import oracle.aurora.rdbms.DbmsJava; void save (Class c1) {ClassHandle handle = ClassHandle.lookup(c1); Schema schema = handle.schema(); writeNmae (schema.getName()); writeName (c1.getName());} Class restore() {String schemaName = readName(); String className = readName(); return DbmsJava.classForNameAndSchema (schemaName, className);}
You can supply a single String, containing both the schema and class names, to the oracle.aurora.util.ClassForName.lookupClass method. When invoked, this method locates the class in the specified schema. The string must be in the following format:
"<schema>:<class>"
For example, to locate com.package.myclass in schema SCOTT, you would execute the following:
oracle.aurora.util.ClassForName.lookupClass("SCOTT:com.package.myclass");
When you de-serialize a class, part of the operation is to lookup a class based on a name. In order to ensure that the lookup is successful, the serialized object must contain both the class and schema names.
JServer provides the following classes for serializing and deserializing objects:
This class extends java.io.ObjectOutputStream and adds schema names in the appropriate places.
This class extends java.io.ObjectInputStream and reads streams written by DbmsObjectOutputStream. This class can be used on any environment. If used within JServer, the schema names are read out and used when performing the class lookup. If used on a client, the schema names are ignored.
The following example shows several methods for looking up a class.
lookupWithClassLoader. This method supplies a class loader to the Class.forName method in the from variable. The class loader specified in the from variable defaults to this class.
ForName with the designated class name followed by lookupWithClassLoader. The ForName method sets the from variable to the specified class. The lookupWithClassLoader method uses the class loader from the specified class.
ForName method without any parameters. It sets the from variable to the calling class. Then, invoke the lookupWithClassLoader to locate the class using the resolver of the calling class.
lookupWithSchema method. This provides the class and schema name to the classForNameAndSchema method.
import oracle.aurora.vm.OracleRuntime;
import oracle.aurora.rdbms.Schema;
import oracle.aurora.rdbms.DbmsJava;
public class ForName {
private Class from;
/* Supply an explicit class to the constructor */
public ForName(Class from) {
this.from = from;
}
/* Use the class of the code containing the "new ForName()" */
public ForName() {
from = OracleRuntime.getCallerClass();
}
/* lookup relative to Class supplied to constructor */
public Class lookupWithClassLoader(String name) throws ClassNotFoundException
{
/* A ClassLoader uses the resolver associated with the class*/
return Class.forName(name, true, from.getClassLoader());
}
/* In case the schema containing the class is known */
static Class lookupWithSchema(String name, String schema) {
Schema s = Schema.lookup(schema);
return DbmsJava.classForNameAndSchema(name, s);
}
}
Operating system resources are a limited commodity on any computer. Because Java is targeted at providing a computing platform as well as a programming language, it contains platform-independent classes and frameworks for accessing platform-specific resources. The Java class methods access operating system resources through the JVM. Java has potential problems with this model, because programmers rely on the garbage collector to manage all resources, when all that the garbage collector manages is Java objects, not the operating system resources that the Java object holds on to.
In addition, because the Aurora JVM is embedded in the database, your operating system resources, which are contained within Java objects, can be invalidated if they are maintained across calls within a session.
The following sections discusses these potential problems:
In general, your operating system resources contain the following:
|
memory |
Aurora manages memory internally, allocating memory as you create new objects and freeing objects as you no longer need them. The language and class libraries do not support a direct means to allocate and free memory. "Automated Storage Management" discusses garbage collection. |
|
files |
Java contains classes that represent file resources. Instances of these classes hold on to your operating system's file constructs, such as file handles, which can become invalid between calls in a session. |
|
sockets |
Java contains classes that represent socket resources. Instances of these classes hold on to socket constructs, some of which can become invalid between calls in a session. See "Sockets" for information specific to maintaining sockets across calls. |
|
threads |
Threads are discouraged within the Aurora JVM because of scalability issues. However, you can have a multi-threaded application within the database. "Threading in JServer" discusses in detail the Aurora's JVM threading model. |
By default, a Java user does not have direct access to most operating system resources. A system administrator may give permission to a user to access these resources by modifying the JVM security restrictions. The JVM security enforced upon system resources conforms to Java 2 security. See "Security" for more information.
You access operating system resources using the standard core Java classes and methods. Once you access a resource, the time that it remains active (usable) varies according to the type of resource.
| Resource | Lifetime |
|---|---|
|
Files |
The system closes all files left open when a database call ends. |
|
Memory |
Memory is garbage collected as described in "Automated Storage Management". |
|
Threads |
All threads are terminated when a call ends. |
|
Objects that depend on operating system resources |
Regardless of the usable lifetime of the object (for example, the defined lifetime for a thread object), the Java object can be valid for the duration of the session. This can occur, for example, if the Java object is stored in a static class variable or a class variable references it directly or indirectly. If you attempt to use one of these Java objects after its usable lifetime is over, Aurora throws an exception. This is true for the following examples: |
|
Sockets |
See "Sockets" more information. |
Imagine that memory is divided up into two realms: Java object memory and operating system constructs. The Java object memory realm contains all objects and variables. Operating system constructs include resources that the operating system allocates to the object when it asks. These resources include files, sockets, and so on.
Basic programming rules dictate that you close all memory--both Java objects and operating system constructs. Java programmers incorrectly assume that all memory is freed by the garbage collector. The garbage collector was created to collect all unused Java object memory. However, it does not close any operating system constructs. All operating system constructs must be closed by the program before the Java object is collected.
For example, whenever an object opens a file, the operating system creates the file and gives the object a file handle. If the file is not closed, the operating system will hold the file handle construct open until the call ends or JVM exits. This can cause you to run out of these constructs earlier than necessary. There are a finite number of handles within each operating system. To guarantee that you do not run out of handles, close your resources before exiting the method. This includes closing the streams attached to your sockets. You should close the streams attached to the socket before closing the socket.
So why not expand the garbage collector to close all operating system constructs? For performance reasons, the garbage collector cannot examine each object to see if it contains a handle. Thus, the garbage collector collects Java objects and variables, but does not issue the appropriate operating system methods for freeing any handles.
Example 2-6 shows how you should close the operating system constructs.
public static void addFile(String[] newFile) { File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i);/*closing the file, which frees up the operating system file handle*/in.close();}
If you do not close the in file, eventually the File object will be garbage collected. However, even if the File object is garbage collected, the operating system still believes that the file is in use, because it was not closed.
You should close resources that are local to a single call when the call ends. However, for static objects that hold on to operating system resources, you must be aware of how these resources are affected after the call ends.
The JVM automatically closes any open operating system constructs--in Example 2-7, the file handle--when the call ends. This can affect any operating system resources within your Java object. For example, if you have a file opened within a static variable, the file handle is closed at the end of the call for you. So, if you hold on to the File object across calls, the next usage of the file handle throws an exception.
In Example 2-7, class Concat enables multiple files to be written into a single file, outFile. On the first call, outFile is created. The first input file is opened, read, input into outFile, and the call ends. Because outFile is statically defined, it is moved into session space between call invocations. However, the file handle--that is, the FileDescriptor--is closed at the end of the call. The next time you call addFile, you will get an exception.
public class Concat { static File outFile = new File("outme.txt"); FileWriter out = new FileWriter(outFile); public static void addFile(String[] newFile) { File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i); in.close(); } }
There is a workaround. To make sure that your handles stay valid, you should close your files, buffers, and so on, at the end of every call; reopen the resource at the beginning of the next call. Another option is to use the database, rather than using operating system resources. For example, try to use database tables, rather than a file. Or simply do not store operating system resources within static objects expected to live across calls; use operating system resources only within objects local to the call.
Example 2-8 shows how you can perform concatenation, as in Example 2-7, without compromising your operating system resources. The addFile method opens the outme.txt file within each call, making sure that anything written into the file is appended to the end. At the end of each call, the file is closed. Two things occur:
File object no longer exists outside of a call.
outme.txt file, is reopened for each call. If you had made the File object a static variable, the closing of outme.txt within each call would ensure that the operating system resource is not compromised.
public class Concat { public static void addFile(String[] newFile) {/*open the output file each call; make sure the input*//*file is written out to the end by making it "append=true"*/FileWriter out = new FileWriter("outme.txt", TRUE);File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i); in.close();/*close the output file between calls*/out.close();} }
Sockets are used in setting up a connection between a client and a server. For each database connection, sockets are used at either end of the connection. Your application does not set up the connection; the connection is set up by the underlying networking protocol: Net8's TTC or IIOP. See "Configuring JServer" for information on how to configure your connection.
You might also wish to set up another connection--for example, connecting to a specified URL from within one of the classes stored within the database. To do so, instantiate sockets for servicing the client and server sides of the connection.
java.net.Socket() constructor creates a client socket.
java.net.ServerSocket() constructor creates a server socket.
A socket exists at each end of the connection. The server-side of the connection that listens for incoming calls is serviced by a ServerSocket. The client-side of the connection that sends requests is serviced through a Socket. You can use sockets as defined within the JVM with the following restriction: a ServerSocket instance within an MTS server cannot exist across calls.
The Aurora JVM implements a non-preemptive threading model. With this model, the JVM runs all Java threads on a single operating system thread. It schedules them in a round-robin fashion and switches between them only when they block. Blocking occurs when you, for example, invoke the Thread.yield() method or wait on a network socket by invoking mySocket.read().
| Advantages of JServer's Threading Model | Disadvantages |
|---|---|
Oracle chose this model because any Java application written on a single-processor system works identical to one written on a multi-processor system. Also, the lack of concurrency among Java threads is not an issue because Aurora is embedded in the database, which provides a higher degree of concurrency than any conventional JVM.
There is no need to use threads within the application logic because the Oracle server preemptively schedules the session JVMs. If you must support hundreds or thousands of simultaneous transactions, start each one in its own JVM. This is exactly what happens when you create a session on the JServer. The normal transactional capabilities of the Oracle database server accomplish coordination and data transfer between the Java virtual machines. This is not a scalability issue, because in contrast to the 6 to 8 MB memory footprint of the typical Java virtual machine, the Oracle server can create thousands of Java virtual machines, with each one taking less than 40 KB.
Threading is managed within Aurora by servicing a single thread until it completes or blocks. If the thread blocks, by yielding or waiting on a network socket, the JVM will service another thread. However, if the thread never blocks, it is serviced until completed.
The Aurora JVM has added the following features for better performance and thread management:
oracle.aurora.vm.DeadlockError exception.
oracle.aurora.vm.LimboError exception is thrown.
In the single-threaded execution case, the call ends when one of the following events occurs:
System.exit(), oracle.aurora.vm.OracleRuntime.exitCall(), or oracle.aurora.vm.OracleRuntime.exitSession() method is invoked.
If the initial thread creates and starts other Java threads, the rules about when a call ends are slightly more complicated. In this case, the call ends in one of the following two ways:
System.exit(), oracle.aurora.vm.OracleRuntime.exitCall(), or oracle.aurora.vm.OracleRuntime.exitSession() method.
When a call ends because of a return and/or uncaught exceptions, Aurora throws a ThreadDeathException in all daemon threads. The ThreadDeathException essentially forces threads to stop execution.
When a call ends because of a call to System.exit(), oracle.aurora.vm.OracleRuntime.exitCall(), or oracle.aurora.vm.oracleRuntime.exitSession(), Aurora ends the call abruptly and terminates all threads, but does not throw ThreadDeathException.
During the execution of a single call, a Java program can recursively cause more Java code to be executed. For example, your program can issue a SQL query using JDBC or SQLJ that in turn causes a trigger written in Java to be invoked. All the preceding remarks regarding call lifetime apply to the top-most call to Java code, not to the recursive call. For example, a call to System.exit() from within a recursive call will exit the entire top-most call to Java, not just the recursive call.
