Release 1 (9.0.1)
Part Number A88876-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Application Developer's Guide - Fundamentals Release 1 (9.0.1) Part Number A88876-02 |
|
![]()
![]()
This chapter describes how Oracle processes Structured Query Language (SQL) statements. Topics include the following:
Although some Oracle tools and applications simplify or mask the use of SQL, all database operations are performed using SQL, to take advantage of the security and data integrity features built into Oracle.
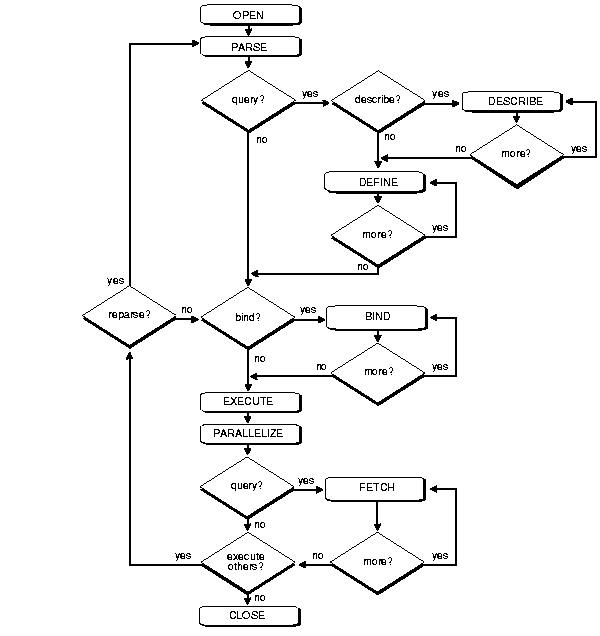
Table 7-1 outlines the stages commonly used to process and execute a SQL statement. In some cases, these steps might be executed in a slightly different order. For example, the DEFINE stage could occur just before the FETCH stage, depending on how your code is written.
For many Oracle tools, several of the stages are performed automatically. Most users do not need to be concerned with, or aware of, this level of detail. However, you might find this information useful when writing Oracle applications.
|
See Also:
Refer to Oracle9i Database Concepts for a description of each stage of SQL statement processing for each type of SQL statement. |
The Federal Information Processing Standard for SQL (FIPS 127-2) requires a way to identify SQL statements that use vendor-supplied extensions. Oracle provides a FIPS flagger to help you write portable applications.
When FIPS flagging is active, your SQL statements are checked to see whether they include extensions that go beyond the ANSI/ISO SQL92 standard. If any non-standard constructs are found, then the Oracle Server flags them as errors and displays the violating syntax.
The FIPS flagging feature supports flagging through interactive SQL statements submitted using Enterprise Manager or SQL*Plus. The Oracle Precompilers and SQL*Module also support FIPS flagging of embedded and module language SQL.
When flagging is on and non-standard SQL is encountered, the following message is returned:
ORA-00097: Use of Oracle SQL feature not in SQL92 level Level
Where level can be either ENTRY, INTERMEDIATE, or FULL.
In general, only application designers using the programming interfaces to Oracle are concerned with which types of actions should be grouped together as one transaction. Transactions must be defined properly so that work is accomplished in logical units and data is kept consistent. A transaction should consist of all of the necessary parts for one logical unit of work, no more and no less. Data in all referenced tables should be in a consistent state before the transaction begins and after it ends. Transactions should consist of only the SQL statements or PL/SQL blocks that comprise one consistent change to the data.
A transfer of funds between two accounts (the transaction or logical unit of work), for example, should include the debit to one account (one SQL statement) and the credit to another account (one SQL statement). Both actions should either fail or succeed together as a unit of work; the credit should not be committed without the debit. Other non-related actions, such as a new deposit to one account, should not be included in the transfer of funds transaction.
In addition to determining which types of actions form a transaction, when you design an application, you must also determine if you can take any additional measures to improve performance. You should consider the following performance enhancements when designing and writing your application. Unless otherwise noted, each of these features is described in Oracle9i Database Concepts.
BEGIN_DISCRETE_TRANSACTION procedure to improve the performance of short, non-distributed transactions.
SET TRANSACTION command with the USE ROLLBACK SEGMENT parameter to explicitly assign a transaction to an appropriate rollback segment. This can eliminate the need to dynamically allocate additional extents, which can reduce overall system performance.
SET TRANSACTION command with the ISOLATION LEVEL set to SERIALIZABLE to get ANSI/ISO serializable transactions.
ANALYZE command to collect statistics that can be used by Oracle to implement a cost-based approach to SQL statement optimization. You can supply additional "hints" to the optimizer as needed.
DBMS_APPLICATION_INFO.SET_ACTION procedure before beginning a transaction to register and name a transaction for later use when measuring performance across an application. You should specify what type of activity a transaction performs so that the system tuners can later see which transactions are taking up the most system resources.
MAX_OPEN_CURSORS can often reduce the frequency of parsing and improve performance.
To commit a transaction, use the COMMIT command. The following two statements are equivalent and commit the current transaction:
COMMIT WORK; COMMIT;
The COMMIT command lets you include the COMMENT parameter along with a comment (less than 50 characters) that provides information about the transaction being committed. This option is useful for including information about the origin of the transaction when you commit distributed transactions:
COMMIT COMMENT 'Dallas/Accts_pay/Trans_type 10B';
|
See Also:
For additional information about committing in-doubt distributed transactions, see Oracle8 Distributed Database Systems. |
To roll back an entire transaction, or to roll back part of a transaction to a savepoint, use the ROLLBACK command. For example, either of the following statements rolls back the entire current transaction:
ROLLBACK WORK; ROLLBACK;
The WORK option of the ROLLBACK command has no function.
To roll back to a savepoint defined in the current transaction, use the TO option of the ROLLBACK command. For example, either of the following statements rolls back the current transaction to the savepoint named POINT1:
SAVEPOINT Point1; ... ROLLBACK TO SAVEPOINT Point1; ROLLBACK TO Point1;
|
See Also:
For additional information about rolling back in-doubt distributed transactions, see Oracle8 Distributed Database Systems. |
To define a savepoint in a transaction, use the SAVEPOINT command. The following statement creates the savepoint named ADD_EMP1 in the current transaction:
SAVEPOINT Add_emp1;
If you create a second savepoint with the same identifier as an earlier savepoint, the earlier savepoint is erased. After creating a savepoint, you can roll back to the savepoint.
There is no limit on the number of active savepoints for each session. An active savepoint is one that has been specified since the last commit or rollback.
The following series of SQL statements illustrates the use of COMMIT, SAVEPOINT, and ROLLBACK statements within a transaction:
No privileges are required to control your own transactions; any user can issue a COMMIT, ROLLBACK, or SAVEPOINT statement within a transaction.
By default, the consistency model for Oracle guarantees statement-level read consistency, but does not guarantee transaction-level read consistency (repeatable reads). If you want transaction-level read consistency, and if your transaction does not require updates, then you can specify a read-only transaction. After indicating that your transaction is read-only, you can execute as many queries as you like against any database table, knowing that the results of each query in the read-only transaction are consistent with respect to a single point in time.
A read-only transaction does not acquire any additional data locks to provide transaction-level read consistency. The multi-version consistency model used for statement-level read consistency is used to provide transaction-level read consistency; all queries return information with respect to the system control number (SCN) determined when the read-only transaction begins. Because no data locks are acquired, other transactions can query and update data being queried concurrently by a read-only transaction.
Changed data blocks queried by a read-only transaction are reconstructed using data from rollback segments. Therefore, long running read-only transactions sometimes receive a "snapshot too old" error (ORA-01555). Create more, or larger, rollback segments to avoid this. You can also issue long-running queries when online transaction processing is at a minimum, or you can obtain a shared lock on the table before querying it, preventing any other modifications during the transaction.
A read-only transaction is started with a SET TRANSACTION statement that includes the READ ONLY option. For example:
SET TRANSACTION READ ONLY;
The SET TRANSACTION statement must be the first statement of a new transaction; if any DML statements (including queries) or other non-DDL statements (such as SET ROLE) precede a SET TRANSACTION READ ONLY statement, an error is returned. Once a SET TRANSACTION READ ONLY statement successfully executes, only SELECT (without a FOR UPDATE clause), COMMIT, ROLLBACK, or non-DML statements (such as SET ROLE, ALTER SYSTEM, LOCK TABLE) are allowed in the transaction. Otherwise, an error is returned. A COMMIT, ROLLBACK, or DDL statement terminates the read-only transaction; a DDL statement causes an implicit commit of the read-only transaction and commits in its own transaction.
PL/SQL implicitly declares a cursor for all SQL data manipulation statements, including queries that return only one row. For queries that return more than one row, you can explicitly declare a cursor to process the rows individually.
A cursor is a handle to a specific private SQL area. In other words, a cursor can be thought of as a name for a specific private SQL area. A PL/SQL cursor variable enables the retrieval of multiple rows from a stored procedure. Cursor variables allow you to pass cursors as parameters in your 3GL application. Cursor variables are described in PL/SQL User's Guide and Reference.
Although most Oracle users rely on the automatic cursor handling of the Oracle utilities, the programmatic interfaces offer application designers more control over cursors. In application development, a cursor is a named resource available to a program, which can be specifically used for parsing SQL statements embedded within the application.
There is no absolute limit to the total number of cursors one session can have open at one time, subject to two constraints:
OPEN_CURSORS found in the parameter file (such as INIT.ORA).
Explicitly creating cursors for precompiler programs can offer some advantages in tuning those applications. For example, increasing the number of cursors can often reduce the frequency of parsing and improve performance. If you know how many cursors may be required at a given time, then you can make sure you can open that many simultaneously.
After each stage of execution, the cursor retains enough information about the SQL statement to re-execute the statement without starting over, as long as no other SQL statement has been associated with that cursor. This is illustrated in Figure 7-1. Notice that the statement can be re-executed without including the parse stage.
By opening several cursors, the parsed representation of several SQL statements can be saved. Repeated execution of the same SQL statements can thus begin at the describe, define, bind, or execute step, saving the repeated cost of opening cursors and parsing.
To understand the performance characteristics of a cursor, a DBA can retrieve the text of the query represented by the cursor using the V$SQL catalog view. Because the results of EXPLAIN PLAN on the original query might differ from the way the query is actually processed, the DBA can get more precise information by examining the V$SQL_PLAN and V$SQL_PLAN_STATS catalog views. The V$SQL_PLAN_ENV catalog view shows what parameters have changed from their default values, which might cause the EXPLAIN PLAN output to differ from the actual execution plan for the cursor.
Closing a cursor means that the information currently in the associated private area is lost and its memory is deallocated. Once a cursor is opened, it is not closed until one of the following events occurs:
Cancelling a cursor frees resources from the current fetch.The information currently in the associated private area is lost but the cursor remains open, parsed, and associated with its bind variables.
|
See Also:
For more information about cancelling cursors, see Oracle Call Interface Programmer's Guide. |
Oracle always performs necessary locking to ensure data concurrency, integrity, and statement-level read consistency. You can override these default locking mechanisms. For example, you might want to override the default locking of Oracle if:
The automatic locking mechanisms can be overridden at two different levels:
The following sections describe each option available for overriding the default locking of Oracle. The initialization parameter DML_LOCKS determines the maximum number of DML locks allowed.
Although the default value is usually enough, you might need to increase it if you use additional manual locks.
A transaction explicitly acquires the specified table locks when a LOCK TABLE statement is executed. A LOCK TABLE statement manually overrides default locking. When a LOCK TABLE statement is issued on a view, the underlying base tables are locked. The following statement acquires exclusive table locks for the EMP_TAB and DEPT_TAB tables on behalf of the containing transaction:
LOCK TABLE Emp_tab, Dept_tab IN EXCLUSIVE MODE NOWAIT;
You can specify several tables or views to lock in the same mode; however, only a single lock mode can be specified for each LOCK TABLE statement.
You can also indicate if you do or do not want to wait to acquire the lock. If you specify the NOWAIT option, then you only acquire the table lock if it is immediately available. Otherwise an error is returned to notify that the lock is not available at this time. In this case, you can attempt to lock the resource at a later time. If NOWAIT is omitted, then the transaction does not proceed until the requested table lock is acquired. If the wait for a table lock is excessive, then you might want to cancel the lock operation and retry at a later time; you can code this logic into your applications.
|
Note:
A distributed transaction waiting for a table lock can time-out waiting for the requested lock if the elapsed amount of time reaches the interval set by the initialization parameter |
LOCK TABLE Emp_tab IN ROW SHARE MODE; LOCK TABLE Emp_tab IN ROW EXCLUSIVE MODE;
ROW SHARE and ROW EXCLUSIVE table locks offer the highest degree of concurrency. You might use these locks if:
LOCK TABLE Emp_tab IN SHARE MODE;
SHARE table locks are rather restrictive data locks. You might use these locks if:
SHARE locks on the table either commit or roll back.
SHARE table locks on the same table, also allowing them the option of transaction-level read consistency.
For example, assume that two tables, EMP_TAB and BUDGET_TAB, require a consistent set of data in a third table, DEPT_TAB. For a given department number, you want to update the information in both of these tables, and ensure that no new members are added to the department between these two transactions.
Although this scenario is quite rare, it can be accommodated by locking the DEPT_TAB table in SHARE MODE, as shown in the following example. Because the DEPT_TAB table is rarely updated, locking it probably does not cause many other transactions to wait long.
LOCK TABLE Dept_tab IN SHARE MODE; UPDATE Emp_tab SET sal = sal * 1.1 WHERE deptno IN (SELECT deptno FROM Dept_tab WHERE loc = 'DALLAS'); UPDATE Budget_tab SET Totsal = Totsal * 1.1 WHERE Deptno IN (SELECT Deptno FROM Dept_tab WHERE Loc = 'DALLAS'); COMMIT; /* This releases the lock */
LOCK TABLE Emp_tab IN SHARE ROW EXCLUSIVE MODE;
You might use a SHARE ROW EXCLUSIVE table lock if:
FOR UPDATE), which might make UPDATE and INSERT statements in the locking transaction wait and might cause deadlocks.
LOCK TABLE Emp_tab IN EXCLUSIVE MODE;
You might use an EXCLUSIVE table if:
You can automatically acquire any type of table lock on tables in your schema. To acquire a table lock on a table in another schema, you must have the LOCK ANY TABLE system privilege or any object privilege (for example, SELECT or UPDATE) for the table.
Letting Oracle control table locking means your application needs less programming logic, but also has less control, than if you manage the table locks yourself.
Issuing the command SET TRANSACTION ISOLATION LEVEL SERIALIZABLE or ALTER SESSION ISOLATION LEVEL SERIALIZABLE preserves ANSI serializability without changing the underlying locking protocol. This technique allows concurrent access to the table while providing ANSI serializability. Getting table locks greatly reduces concurrency.
Table locks are also controlled by the ROW_LOCKING and SERIALIZABLE initialization parameters. By default, SERIALIZABLE is set to FALSE and ROW_LOCKING is set to ALWAYS. In almost every case, these parameters should not be altered. They are provided for sites that must run in ANSI/ISO compatible mode, or that want to use applications written to run with earlier versions of Oracle. Only these sites should consider altering these parameters, as there is a significant performance degradation caused by using other than the defaults.
|
See Also:
Oracle9i SQL Reference for details about the |
The settings for these parameters should be changed only when an instance is shut down. If multiple instances are accessing a single database, then all instances should use the same setting for these parameters.
Three combinations of settings for SERIALIZABLE and ROW_LOCKING, other than the default settings, are available to change the way locking occurs for transactions. Table 7-1 summarizes the nondefault settings and why you might choose to execute your transactions in a particular way.
Table 7-2 illustrates the difference in locking behavior resulting from the three possible settings of the SERIALIZABLE option and ROW_LOCKING initialization parameter, as shown in Table 7-1.
You can override default locking with a SELECT statement that includes the FOR UPDATE clause. This statement acquires exclusive row locks for selected rows (as an UPDATE statement does), in anticipation of updating the selected rows in a subsequent statement.
You can use a SELECT... FOR UPDATE statement to lock a row without actually changing it. For example, several triggers in Chapter 15, "Using Triggers", show how to implement referential integrity. In the EMP_DEPT_CHECK trigger (see "Foreign Key Trigger for Child Table"), the row that contains the referenced parent key value is locked to guarantee that it remains for the duration of the transaction; if the parent key is updated or deleted, referential integrity would be violated.
SELECT... FOR UPDATE statements are often used by interactive programs that allow a user to modify fields of one or more specific rows (which might take some time); row locks are acquired so that only a single interactive program user is updating the rows at any given time.
If a SELECT... FOR UPDATE statement is used when defining a cursor, the rows in the return set are locked when the cursor is opened (before the first fetch) rather than as they are fetched from the cursor. Locks are only released when the transaction that opened the cursor is committed or rolled back, not when the cursor is closed.
Each row in the return set of a SELECT... FOR UPDATE statement is locked individually; the SELECT... FOR UPDATE statement waits until the other transaction releases the conflicting row lock. If a SELECT... FOR UPDATE statement locks many rows in a table, and if the table experiences a lot of update activity, it might be faster to acquire an EXCLUSIVE table lock instead.
When acquiring row locks with SELECT... FOR UPDATE, you can specify the NOWAIT option to indicate that you are not willing to wait to acquire the lock. If you cannot acquire then lock immediately, an error is returned to signal that the lock is not possible at this time. You can try to lock the row again later.
By default, the transaction waits until the requested row lock is acquired. If the wait for a row lock is too long, you can code logic into your application to cancel the lock operation and try again later.
As described on "Choosing a Locking Strategy", a distributed transaction waiting for a row lock can time-out waiting for the requested lock if the elapsed amount of time reaches the interval set by the initialization parameter DISTRIBUTED_LOCK_TIMEOUT.
You can use Oracle Lock Management services for your applications by making calls to the DBMS_LOCK package. It is possible to request a lock of a specific mode, give it a unique name recognizable in another procedure in the same or another instance, change the lock mode, and release it. Because a reserved user lock is the same as an Oracle lock, it has all the features of an Oracle lock, such as deadlock detection. Be certain that any user locks used in distributed transactions are released upon COMMIT, or an undetected deadlock can occur.
|
See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference has detailed information on the |
User locks can help to:
The following Pro*COBOL precompiler example shows how locks can be used to ensure that there are no conflicts when multiple people need to access a single device.
***************************************************************** * Print Check * * Any cashier may issue a refund to a customer returning goods. * * Refunds under $50 are given in cash, above that by check. * * This code prints the check. The one printer is opened by all * * the cashiers to avoid the overhead of opening and closing it * * for every check. This means that lines of output from multiple* * cashiers could become interleaved if we don't ensure exclusive* * access to the printer. The DBMS_LOCK package is used to * * ensure exclusive access. * ***************************************************************** CHECK-PRINT * * Get the lock "handle" for the printer lock. MOVE "CHECKPRINT" TO LOCKNAME-ARR. MOVE 10 TO LOCKNAME-LEN. EXEC SQL EXECUTE BEGIN DBMS_LOCK.ALLOCATE_UNIQUE ( :LOCKNAME, :LOCKHANDLE ); END; END-EXEC. * * Lock the printer in exclusive mode (default mode). EXEC SQL EXECUTE BEGIN DBMS_LOCK.REQUEST ( :LOCKHANDLE ); END; END-EXEC. * We now have exclusive use of the printer, print the check. ... * * Unlock the printer so other people can use it * EXEC SQL EXECUTE BEGIN DBMS_LOCK.RELEASE ( :LOCKHANDLE ); END; END-EXEC.
Oracle provides two facilities to display locking information for ongoing transactions within an instance:
|
(Lock and Latch Monitors) |
The Monitor feature of Enterprise Manager provides two monitors for displaying lock information of an instance. Refer to Oracle Enterprise Manager Administrator's Guide for complete information about the Enterprise Manager monitors. |
|
|
The |
By default, the Oracle Server permits concurrently executing transactions to modify, add, or delete rows in the same table, and in the same data block. Changes made by one transaction are not seen by another concurrent transaction until the transaction that made the changes commits.
If a transaction A attempts to update or delete a row that has been locked by another transaction B (by way of a DML or SELECT... FOR UPDATE statement), then A's DML command blocks until B commits or rolls back. Once B commits, transaction A can see changes that B has made to the database.
For most applications, this concurrency model is the appropriate one, because it provides higher concurrency and thus better performance. But some rare cases require transactions to be serializable. Serializable transactions must execute in such a way that they appear to be executing one at a time (serially), rather than concurrently. Concurrent transactions executing in serialized mode can only make database changes that they could have made if the transactions ran one after the other.
The ANSI/ISO SQL standard SQL92 defines three possible kinds of transaction interaction, and four levels of isolation that provide increasing protection against these interactions. These interactions and isolation levels are summarized in Table 7-3.
The behavior of Oracle with respect to these isolation levels is summarized below:
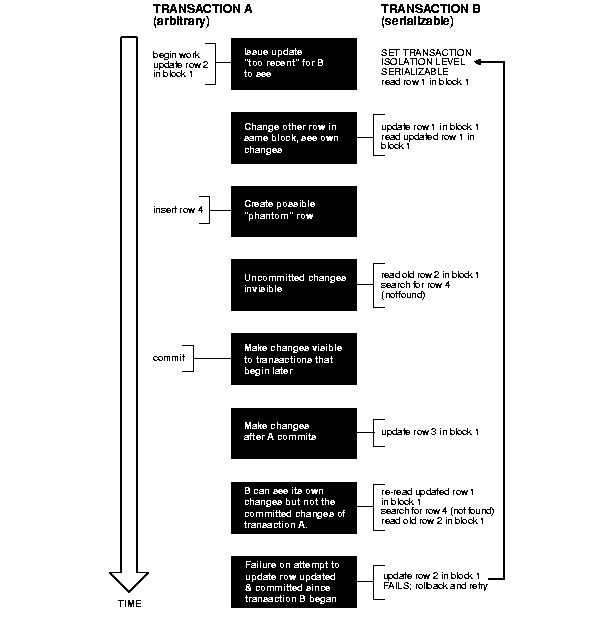
Figure 7-3 shows how a serializable transaction (Transaction B) interacts with another transaction (A, which can be either SERIALIZABLE or READ COMMITTED).
When a serializable transaction fails with an ORA-08177 error ("cannot serialize access"), the application can take any of several actions:
Oracle stores control information in each data block to manage access by concurrent transactions. To use the SERIALIZABLE isolation level, you must use the INITRANS clause of the CREATE TABLE or ALTER TABLE command to set aside storage for this control information. To use serializable mode, INITRANS must be set to at least 3.
You can change the isolation level of a transaction using the ISOLATION LEVEL clause of the SET TRANSACTION command, which must be the first command issued in a transaction.
Use the ALTER SESSION command to set the transaction isolation level on a session-wide basis.
|
See Also:
Oracle9i Database Reference for the complete syntax of the |
Oracle stores control information in each data block to manage access by concurrent transactions. Therefore, if you set the transaction isolation level to serializable, then you must use the ALTER TABLE command to set INITRANS to at least 3. This parameter causes Oracle to allocate sufficient storage in each block to record the history of recent transactions that accessed the block. Higher values should be used for tables that will undergo many transactions updating the same blocks.
Because Oracle does not use read locks, even in SERIALIZABLE transactions, data read by one transaction can be overwritten by another. Transactions that perform database consistency checks at the application level should not assume that the data they read will not change during the execution of the transaction (even though such changes are not visible to the transaction). Database inconsistencies can result unless such application-level consistency checks are coded carefully, even when using SERIALIZABLE transactions. Note, however, that the examples shown in this section are applicable for both READ COMMITTED and SERIALIZABLE transactions.
Figure 7-3 shows two different transactions that perform application-level checks to maintain the referential integrity parent/child relationship between two tables. One transaction checks that a row with a specific primary key value exists in the parent table before inserting corresponding child rows. The other transaction checks to see that no corresponding detail rows exist before deleting a parent row. In this case, both transactions assume (but do not ensure) that data they read will not change before the transaction completes.
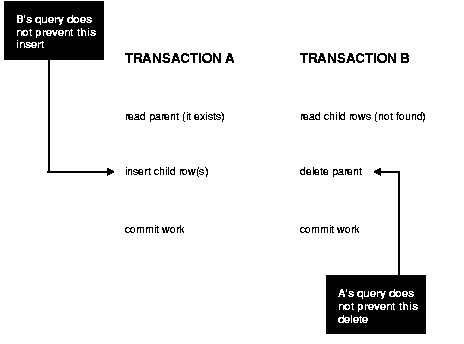
The read issued by transaction A does not prevent transaction B from deleting the parent row, and transaction B's query for child rows does not prevent transaction A from inserting child rows. This scenario leaves a child row in the database with no corresponding parent row. This result occurs even if both A and B are SERIALIZABLE transactions, because neither transaction prevents the other from making changes in the data it reads to check consistency.
As this example shows, sometimes you must take steps to ensure that the data read by one transaction is not concurrently written by another. This requires a greater degree of transaction isolation than defined by SQL92 SERIALIZABLE mode.
Fortunately, it is straightforward in Oracle to prevent the anomaly described above:
SELECT FOR UPDATE to query and lock the parent row and thereby prevent transaction B from deleting the row.
Referential integrity can also be enforced in Oracle using database triggers, instead of a separate query as in Transaction A above. For example, an INSERT into the child table can fire a BEFORE INSERT row-level trigger to check for the corresponding parent row. The trigger queries the parent table using SELECT FOR UPDATE, ensuring that parent row (if it exists) remains in the database for the duration of the transaction inserting the child row. If the corresponding parent row does not exist, the trigger rejects the insert of the child row.
SQL statements issued by a database trigger execute in the context of the SQL statement that caused the trigger to fire. All SQL statements executed within a trigger see the database in the same state as the triggering statement. Thus, in a READ COMMITTED transaction, the SQL statements in a trigger see the database as of the beginning of the triggering statement's execution, and in a transaction executing in SERIALIZABLE mode, the SQL statements see the database as of the beginning of the transaction. In either case, the use of SELECT FOR UPDATE by the trigger correctly enforces referential integrity.
Oracle gives you a choice of two transaction isolation levels with different characteristics. Both the READ COMMITTED and SERIALIZABLE isolation levels provide a high degree of consistency and concurrency. Both levels reduce contention, and are designed for deploying real-world applications. The rest of this section compares the two isolation modes and provides information helpful in choosing between them.
A useful way to describe the READ COMMITTED and SERIALIZABLE isolation levels in Oracle is to consider:
An operation (a query or a transaction) is transaction set consistent if its read operations all return data written by the same set of committed transactions. When an operation is not transaction set consistent, some reads reflect the changes of one set of transactions, and other reads reflect changes made by other transactions. Such an operation sees the database in a state that reflects no single set of committed transactions.
Oracle transactions executing in READ COMMITTED mode are transaction set consistent on a per-statement basis, because all rows read by a query must be committed before the query begins.
Oracle transactions executing in SERIALIZABLE mode are transaction set consistent on a per-transaction basis, because all statements in a SERIALIZABLE transaction execute on an image of the database as of the beginning of the transaction.
In other database systems, a single query run in READ COMMITTED mode provides results that are not transaction set consistent. The query is not transaction set consistent, because it may see only a subset of the changes made by another transaction. For example, a join of a master table with a detail table could see a master record inserted by another transaction, but not the corresponding details inserted by that transaction, or vice versa. Oracle's READ COMMITTED mode avoids this problem, and so provides a greater degree of consistency than read-locking systems.
In read-locking systems, at the cost of preventing concurrent updates, SQL92 REPEATABLE READ isolation provides transaction set consistency at the statement level, but not at the transaction level. The absence of phantom protection means two queries issued by the same transaction can see data committed by different sets of other transactions. Only the throughput-limiting and deadlock-susceptible SERIALIZABLE mode in these systems provides transaction set consistency at the transaction level.
Table 7-4 summarizes key similarities and differences between READ COMMITTED and SERIALIZABLE transactions.
Choose an isolation level that is appropriate to the specific application and workload. You might choose different isolation levels for different transactions. The choice depends on performance and consistency needs, and consideration of application coding requirements.
For environments with many concurrent users rapidly submitting transactions, you must assess transaction performance against the expected transaction arrival rate and response time demands, and choose an isolation level that provides the required degree of consistency while performing well. Frequently, for high performance environments, you must trade-off between consistency and concurrency (transaction throughput).
Both Oracle isolation modes provide high levels of consistency and concurrency (and performance) through the combination of row-level locking and Oracle's multi-version concurrency control system. Because readers and writers do not block one another in Oracle, while queries still see consistent data, both READ COMMITTED and SERIALIZABLE isolation provide a high level of concurrency for high performance, without the need for reading uncommitted ("dirty") data.
READ COMMITTED isolation can provide considerably more concurrency with a somewhat increased risk of inconsistent results (due to phantoms and non-repeatable reads) for some transactions. The SERIALIZABLE isolation level provides somewhat more consistency by protecting against phantoms and non-repeatable reads, and may be important where a read/write transaction executes a query more than once. However, SERIALIZABLE mode requires applications to check for the "can't serialize access" error, and can significantly reduce throughput in an environment with many concurrent transactions accessing the same data for update. Application logic that checks database consistency must take into account the fact that reads do not block writes in either mode.
When a transaction runs in serializable mode, any attempt to change data that was changed by another transaction since the beginning of the serializable transaction causes an error:
ORA-08177: Can't serialize access for this transaction.
When you get this error, roll back the current transaction and execute it again. The transaction gets a new transaction snapshot, and the operation is likely to succeed.
To minimize the performance overhead of rolling back transactions and executing them again, try to put DML statements that might conflict with other concurrent transactions near the beginning of your transaction.
This section gives a brief overview of autonomous transactions and what you can do with them.
|
See Also: For detailed information on autonomous transactions, see PL/SQL User's Guide and Reference and Chapter 15, "Using Triggers". |
At times, you may want to commit or roll back some changes to a table independently of a primary transaction's final outcome. For example, in a stock purchase transaction, you may want to commit a customer's information regardless of whether the overall stock purchase actually goes through. Or, while running that same transaction, you may want to log error messages to a debug table even if the overall transaction rolls back. Autonomous transactions allow you to do such tasks.
An autonomous transaction (AT) is an independent transaction started by another transaction, the main transaction (MT). It lets you suspend the main transaction, do SQL operations, commit or roll back those operations, then resume the main transaction.
An autonomous transaction executes within an autonomous scope. An autonomous scope is a routine you mark with the pragma (compiler directive) AUTONOMOUS_TRANSACTION. The pragma instructs the PL/SQL compiler to mark a routine as autonomous (independent). In this context, the term routine includes:
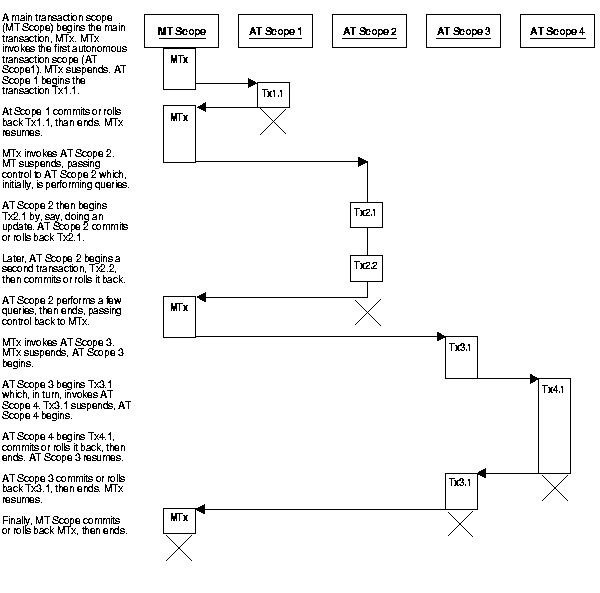
Figure 7-4 shows how control flows from the main routine (MT) to an autonomous routine (AT) and back again. As you can see, the autonomous routine can commit more than one transaction (AT1 and AT2) before control returns to the main routine.
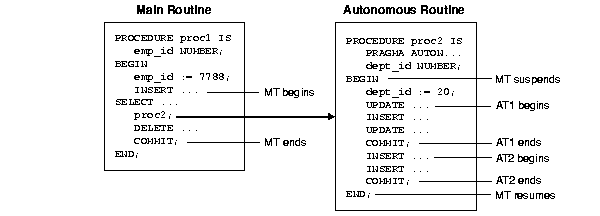
When you enter the executable section of an autonomous routine, the main transaction suspends. When you exit the routine, the main transaction resumes. COMMIT and ROLLBACK end the active autonomous transaction but do not exit the autonomous routine. As Figure 7-4 shows, when one transaction ends, the next SQL statement begins another transaction.
A few more characteristics of autonomous transactions:
Figure 7-5 illustrates some of the possible sequences autonomous transactions can follow.
The two examples in this section illustrate some of the ways you can use autonomous transactions.
As these examples illustrate, there are four possible outcomes that can occur when you use autonomous and main transactions. The following table presents these possible outcomes. As you can see, there is no dependency between the outcome of an autonomous transaction and that of a main transaction.
| Autonomous Transaction | Main Transaction |
|---|---|
|
Commits |
Commits |
|
Commits |
Rolls back |
|
Rolls back |
Commits |
|
Rolls back |
Rolls back |
In this example, a customer enters a buy order. That customer's information (such as name, address, phone) is committed to a customer information table--even though the sale does not go through.
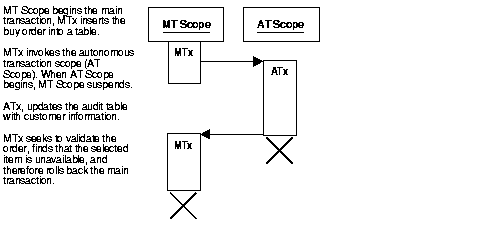
In the following banking application, a customer tries to make a withdrawal from his or her account. In the process, a main transaction calls one of two autonomous transaction scopes (AT Scope 1, and AT Scope 2).
The following diagrams illustrate three possible scenarios for this transaction.
There are sufficient funds to cover the withdrawal and therefore the bank releases the funds
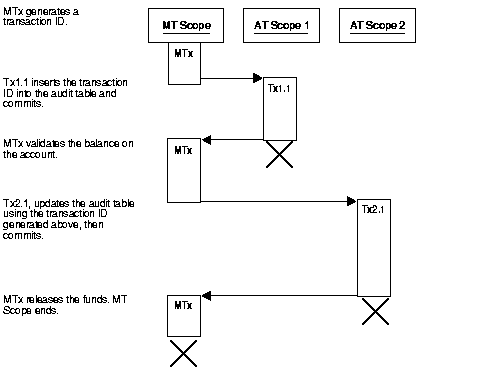
There are insufficient funds to cover the withdrawal, but the customer has overdraft protection. The bank therefore releases the funds.
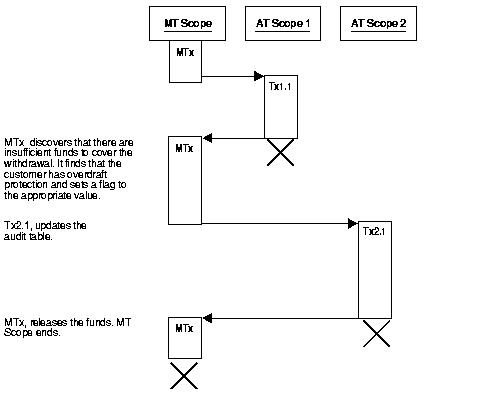
There are insufficient funds to cover the withdrawal, the customer does not have overdraft protection, and the bank therefore withholds the requested funds.
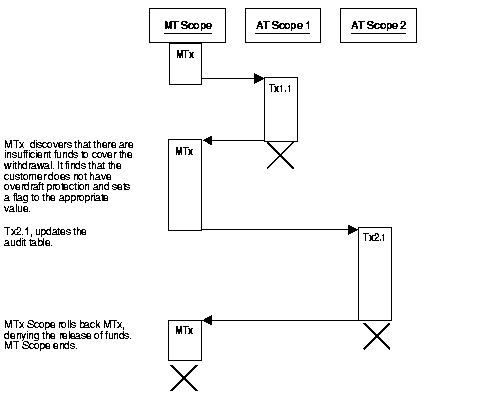
|
Note: This section is provided here to round out your general understanding of autonomous transactions. For a more thorough understanding of autonomous transactions, see PL/SQL User's Guide and Reference. |
To define autonomous transactions, you use the pragma (compiler directive) AUTONOMOUS_TRANSACTION. The pragma instructs the PL/SQL compiler to mark the procedure, function, or PL/SQL block as autonomous (independent).
You can code the pragma anywhere in the declarative section of a procedure, function, or PL/SQL block. But, for readability, code the pragma at the top of the section. The syntax follows:
PRAGMA AUTONOMOUS_TRANSACTION;
In the following example, you mark a packaged function as autonomous:
CREATE OR REPLACE PACKAGE Banking AS FUNCTION Balance (Acct_id INTEGER) RETURN REAL; -- add additional functions and/or packages END Banking; CREATE OR REPLACE PACKAGE BODY Banking AS FUNCTION Balance (Acct_id INTEGER) RETURN REAL IS PRAGMA AUTONOMOUS_TRANSACTION; My_bal REAL; BEGIN --add appropriate code END; -- add additional functions and/or packages... END Banking;
You cannot use the pragma to mark all subprograms in a package (or all methods in an object type) as autonomous. Only individual routines can be marked autonomous. For example, the following pragma is illegal:
CREATE OR REPLACE PACKAGE Banking AS PRAGMA AUTONOMOUS_TRANSACTION; -- illegal FUNCTION Balance (Acct_id INTEGER) RETURN REAL; END Banking;
When a long-running transaction is interrupted by an out-of-space error condition, your application can suspend the statement that encountered the problem and resume it after the space problem is corrected. This capability is known as resumable storage allocation. It lets you avoid time-consuming rollbacks, without the need to split the operation into smaller pieces and write your own code to track its progress.
Queries, DML operations, and certain DDL operations can all be resumed if they encounter an out-of-space error. The capability applies if the operation is performed directly by a SQL statement, or if it is performed within a stored procedure, anonymous PL/SQL block, SQL*Loader, or an OCI call such as OCIStmtExecute().
Operations can be resumed after these kinds of error conditions:
Certain storage errors cannot be handled using this technique. In dictionary-managed tablespaces, you cannot resume an operation if you run into the limit for rollback segments, or the maximum number of extents while creating an index or a table. Oracle encourages users to use locally managed tablespaces and automatic undo management in combination with this feature.
When an operation is suspended, your application does not receive the usual error code. Instead, perform any logging or notification by coding a trigger to detect the AFTER SUSPEND event and call the functions in the DBMS_RESUMABLE package to get information about the problem. Using this package, you can:
DBMS_RESUMABLE.SPACE_ERROR_INFO function. For details about this function, see Oracle9i Supplied PL/SQL Packages and Types Reference.
SET_TIMEOUT procedure.
Within the body of the trigger, you can perform any notifications, such as sending a mail message to alert an operator to the space problem.
Alternatively, the DBA can periodically check for suspended statements using the data dictionary views DBA_RESUMABLE, USER_RESUMABLE, and V$_SESSION_WAIT.
When the space condition is corrected (usually by the DBA), the suspended statement automatically resumes execution. If it is not corrected before the timeout period expires, the operation causes a SERVERERROR exception.
To reduce the chance of out-of-space errors within the trigger itself, you must declare it as an autonomous transaction so that it uses a rollback segment in the SYSTEM tablespace. If the trigger encounters a deadlock condition because of locks held by the suspended statement, the trigger is aborted and your application receives the original error condition, as if it was never suspended. If the trigger encounters an out-of-space condition, the trigger and the suspended statement are rolled back. You can prevent the rollback through an exception handler in the trigger, and just wait for the statement to be resumed.
|
See Also:
Oracle9i Database Reference for details on the |
This trigger handles applicable storage errors within the database. For some kinds of errors, it aborts the statement and alerts the DBA that this has happened through a mail message. For other errors that might be temporary, it specifies that the statement should wait for eight hours before resuming, with the expectation that the storage problem will be fixed by then.
CREATE OR REPLACE TRIGGER suspend_example AFTER SUSPEND ON DATABASE DECLARE cur_sid NUMBER; cur_inst NUMBER; err_type VARCHAR2(64); object_owner VARCHAR2(64); object_type VARCHAR2(64); table_space_name VARCHAR2(64); object_name VARCHAR2(64); sub_object_name VARCHAR2(64); msg_body VARCHAR2(64); ret_value boolean; error_txt varchar2(64); mail_conn utl_smtp.connection; BEGIN SELECT DISTINCT(sid) INTO cur_sid FROM v$mystat; cur_inst := userenv('instance'); ret_value := dbms_resumable.space_error_info(err_type, object_owner, object_type, table_space_name, object_name, sub_object_name); IF object_type = 'ROLLBACK SEGMENT' THEN INSERT INTO sys.rbs_error ( SELECT sql_text, error_msg, suspend_time FROM dba_resumable WHERE session_id = cur_sid AND instance_id = cur_inst); SELECT error_msg into error_txt FROM dba_resumable WHERE session_id = cur_sid AND instance_id = cur_inst; msg_body := 'Subject: Space error occurred: Space limit reached for rollback segment '|| object_name || ' on ' || to_char(SYSDATE, 'Month dd, YYYY, HH:MIam') || '. Error message was: ' || error_txt; mail_conn := utl_smtp.open_connection('localhost', 25); utl_smtp.helo(mail_conn, 'localhost'); utl_smtp.mail(mail_conn, 'sender@localhost'); utl_smtp.rcpt(mail_conn, 'recipient@localhost'); utl_smtp.data(mail_conn, msg_body); utl_smtp.quit(mail_conn); dbms_resumable.abort(cur_sid); ELSE dbms_resumable.set_timeout(3600*8); END IF; COMMIT; END;
By default, operations on the database use the most recent committed data available. If you want to query the database as it was at some time in the past, you can do so with the flashback query feature. It lets you specify either a time or a system change number (SCN) and query using the committed data from the corresponding time.
Some potential applications of flashback query are:
The flashback query mechanism relies on automatic undo management to maintain the necessary undo data. The DBA requests that undo data be kept for a specified period of time. Depending on the available storage capacity, the database might not always be able to keep all the requested undo data. If you use flashback queries, you might need to familiarize yourself with automatic undo management to understand its capabilities and limitations.
Other features are available to recover lost data. The unique feature of flashback query is that you can see the data as it was in the past, then choose exactly how to process the information; you might just want to do an analysis rather than undoing the changes.
Before you can perform flashback queries, enlist the help of your DBA. Ask them to:
UNDO_RETENTION initialization parameter to a value that represents how far in the past you might want to query. The value depends on your needs. If you only need to recover data immediately after a mistaken change is committed, the parameter can be set to a small value. If you need to recover deleted data from days before, you might need several worth of data.
UNDO_MANAGEMENT=AUTO.
UNDO tablespace, with enough space to keep the required data. The more often the data is updated, the more space is required.
EXECUTE privilege on the DBMS_FLASHBACK package to users, roles, or applications that need to perform flashback queries.
To use the flashback query feature in an application, use these coding techniques:
DBMS_FLASHBACK package around any queries that apply to data at a past time:
DBMS_FLASHBACK.DISABLE. You can fetch results from past data from the cursor, then issue INSERT or UPDATE statements against the current state of the database.
MINUS or UNION to show differences in the data or combine past and current data.
DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER. You can store the returned number, and later use it to perform flashback queries against the data at that point in time. Perform a COMMIT before calling this procedure, so that the database is in a consistent state to which you can return.
PCTFREE, INITTRANS, MAXTRANS, and so on. Operations such as adding new extents, constraints or partitions are also exempted from this restriction.
DBMS_RESUMABLE.ENABLE_AT_TIME is mapped to an SCN value. Currently, the SCN-time mapping is recorded every 5 minutes after database startup. Thus it might appear as if the specified time is being rounded down by up to 5 minutes.
For example, assume that the SCN values 1000 and 1005 are mapped to the times 8:41 and 8:46 AM respectively. A flashback query for a time anywhere between 8:41:00 and 8:45:59 AM is mapped to SCN 1000; a flashback query for 8:45 AM is mapped to SCN 1005.
Due to this time-to-SCN mapping, a flashback query for a time immediately after creation of a table may result in an ORA-1466 error. An SCN-based flashback query therefore gives you a more precise way to retrieve a past snapshot of data.
DELETE.
ENABLE /DISABLE pairs. You can call DISABLE multiple times in succession, although this introduces a little extra overhead, as shown in the following examples.
SELECT /*+ FULL(employees) */ * FROM employees;
The flashback query mechanism is flexible enough to be used in many situations. You can:
To find out someone's salary at year-end 2000 through a flashback query:
EXECUTE DBMS_FLASHBACK.ENABLE_AT_TIME('01-JAN-2001'); SELECT salary FROM employee WHERE empid = 41863; EXECUTE DBMS_FLASHBACK.DISABLE;
Remember that a date with no time represents the very beginning of that day. Because of the limited amount of mapping data that is stored for times, such a query might only be able to look back a few days in the past. To look back farther, you need to store the SCN at the time of interest. Even then, the data might be unavailable if the saved undo data does not extend back that far.
This example makes an incorrect update, commits the changes, then immediately recovers the old information using a flashback query:
UPDATE employee SET salary = salary - 1000; DELETE FROM employee WHERE salary = COMMIT; -- Those updates and deletes were in error. We need to recover the data. -- Use the data as it existed approximately 15 minutes ago. -- This requires confidence that the data has not changed during that interval. EXECUTE DBMS_FLASHBACK.ENABLE_AT_TIME(SYSDATE - (15/(24*60)); FOR item IN (SELECT * FROM employee WHERE ...) LOOP -- Within the loop we can see the old data. If we want to put it back -- into the current table, we must disable flashback query inside -- the loop. ... END LOOP;
A more reliable method of specifying the flashback point uses the SCN directly:
DECLARE old_scn NUMBER := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER; BEGIN UPDATE employee SET salary = salary - 1000; DELETE FROM employee WHERE salary = 60000; COMMIT; -- Those updates and deletes were in error. We need to recover the data. -- Use the data as it existed immediately before the update and delete. EXECUTE DBMS_FLASHBACK.ENABLE_AT_SYSTEM_CHANGE_NUMBER(old_scn); FOR item IN (SELECT * FROM employee WHERE ...) LOOP ... END LOOP;
The following example illustrates how this can be done for a case where the deletion of a senior employee triggers the deletion of all the reports under him. Using flashback query, we can recover and re-insert the missing employees.
rem keep_scn is a temporary table to store scns that we are interested in. create table keep_scn (scn number); set echo on create table employee ( employee_no number(5) primary key, employee_name varchar2(20), employee_mgr number(5) constraint mgr_fkey references employee on delete cascade, salary number, hiredate date ); rem Now populate the company with employees. insert into employee values (1, 'Dennis Potter', null, 1000000, '5-jul-91'); insert into employee values (10, 'Margaret O'Neil', 1, 500000, '12-aug-94'); insert into employee values (20, 'Charles Evans', 10, 250000, '13-dec-97'); insert into employee values (100, 'Roger Smith', 20, 200000, '3-feb-96'); insert into employee values (200, 'Juan Hernandez', 100, 150000, '22-mar-98'); insert into employee values (210, 'Jonathan Takeda', 100, 100000, '11-apr-97'); insert into employee values (220, 'Nancy Schoenfeld', 100, 100000, '18-sep-95'); insert into employee values (300, 'Edward Ngai', 210, 75000, '4-nov-96'); insert into employee values (310, 'Amit Sharma', 210, 65000, '3-may-95'); commit; rem Show the entire org select lpad(' ', 2*(level-1)) || employee_name Name from employee connect by prior employee_no = employee_mgr start with employee_no = 1 order by level; execute dbms_flashback.disable; rem Store this snapshot for later access through FlashBack. declare I number; begin I := dbms_flashback.get_system_change_number; insert into keep_scn values (I); commit; rem Now Roger decides it's time to retire but the HR department does rem the transaction incorrectly delete from employee where employee_name = 'Roger Smith'; commit; rem Notice that all of Roger's employees are now gone. select lpad(' ', 2*(level-1)) || employee_name Name from employee connect by prior employee_no = employee_mgr start with employee_no = 1 order by level; rem Well, lets put back Roger's organization now. declare restore_scn number; begin select scn into restore_scn from keep_scn; dbms_flashback.enable_at_system_change_number (restore_scn); end; / rem First show Roger's org. select lpad(' ', 2*(level-1)) || employee_name Name from employee connect by prior employee_no = employee_mgr start with employee_no = (select employee_no from employee where employee_name = 'Roger Smith') order by level; declare rogers_emp number; rogers_mgr number; cursor c1 is select employee_no, employee_name, employee_mgr, salary, hiredate from employee connect by prior employee_no = employee_mgr start with employee_no = (select employee_no from employee where employee_name = 'Roger Smith'); c1_rec is c1 % ROWTYPE; begin select employee_no, employee_mgr into rogers_emp, rogers_mgr from employee where employee_name = 'Roger Smith'; rem Open c1 with FlashBack enabled. open c1; rem Disable FlashBack now. dbms_flashback.disable; loop rem Note that all the DML operations inside the loop are performed rem with FlashBack disabled. fetch c1 into c1_rec; exit when c1%NOTFOUND; for c1_rec in c1 loop if (c1_rec.employee_mgr = rogers_emp) then insert into employee values (c1_rec.employee_no, c1_rec.employee_name, rogers_mgr, c1_rec.salary, c1_rec.hiredate); else if (c1_rec.employee_no != rogers_emp) then insert into employee values (c1_rec.employee_no, c1_rec.employee_name, c1_rec.employee_mgr, c1_rec.salary, c1_rec.hiredate); end if; end if; end loop; end; / execute dbms_flashback. disable;
To compare today's data with yesterday's using a flashback query:
DECLARE old_value NUMBER; new_value NUMBER; BEGIN EXECUTE DBMS_FLASHBACK.ENABLE_AT_TIME(SYSDATE - 1); SELECT ... INTO old_value FROM ...; DBMS_FLASHBACK.DISABLE; SELECT ... INTO new_value FROM ...; DBMS_OUTPUT.PUT_LINE('Value from one day ago: ' || old_value); DBMS_OUTPUT.PUT_LINE('Value from today: ' || new_value); DBMS_OUTPUT.PUT_LINE('Percentage change over past day: ' || (old_value / (new_value - old_value)) * 100); END;
To store a system change number so that it can be used later for flashback queries:
DECLARE scn NUMBER; BEGIN -- We make a set of updates so that the data is at a known state. INSERT ...; UPDATE ...; DELETE ...; COMMIT; -- We can use this saved SCN to return to this known state later. scn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER; INSERT INTO ... VALUES (scn, SYSDATE, 'State of the system after ...'); END;
Although you can use an implicit cursor loop and call DBMS_FLASHBACK.DISABLE multiple times within the loop body, doing so results in some extra overhead. It is more efficient to use an explicit cursor:
-- Most efficient technique. Open the cursor, disable flashback, then use -- the older data in DML statements on the current table. EXECUTE DBMS_FLASHBACK.ENABLE_AT_TIME(SYSDATE - 1); OPEN c FOR 'SELECT * FROM employees WHERE ...'; DBMS_FLASHBACK.DISABLE; LOOP FETCH ...; EXIT WHEN c%NOTFOUND; INSERT ...; END LOOP;
You can also use an implicit cursor, although this is slightly less efficient:
-- Less efficient technique. To allow DML statements against the current -- table within the loop body, DISABLE must be called for each loop iteration. EXECUTE DBMS_FLASHBACK.ENABLE_AT_TIME(SYSDATE - 1); -- The FOR loop is examining data values from the past. FOR c in (SELECT * FROM employees WHERE ...') LOOP DBMS_FLASHBACK.DISABLE; -- Because flashback is disabled within the loop body, we can access the -- present state of the data, and issue DML statements to undo the changes -- or store the old data. INSERT ...; END LOOP;
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|