Release 1 (9.0.1)
Part Number A88878-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Application Developer's Guide - Object-Relational Features Release 1 (9.0.1) Part Number A88878-01 |
|
![]()
![]()
The other chapters in this book discuss the topics that you need to get started with Oracle objects. The topics in this chapter are of interest once you start applying object-relational techniques to large-scale applications or complex schemas.
The chapter contains these topics:
Oracle automatically maps the complex structure of object types into the simple rectangular structure of tables.
An object type is like a tree structure, where the branches represent the attributes. Attributes that are objects sprout subbranches for their own attributes.
Ultimately, each branch ends at an attribute that is a built-in type (such as NUMBER, VARCHAR2, or REF) or a collection type (such as VARRAY or nested table). Each of these leaf-level attributes of the original object type is stored in a table column.
The leaf-level attributes that are not collection types are called the leaf-level scalar attributes of the object type.
In an object table, Oracle stores the data for every leaf-level scalar or REF attribute in a separate column. Each VARRAY is also stored in a column, unless it is too large (see "Internal Layout of VARRAYs"). Oracle stores leaf-level attributes of nested table types in separate tables associated with the object table. You must declare these tables as part of the object table declaration (see "Internal Layout of Nested Tables").
When you retrieve or change attributes of objects in an object table, Oracle performs the corresponding operations on the columns of the table. Accessing the value of the object itself produces a copy of the object, by invoking the default constructor for the type, using the columns of the object table as arguments.
Oracle stores the system-generated object identifier in a hidden column. Oracle uses the object identifier to construct REFs to the object.
When a table is defined with a column of an object type, Oracle adds hidden columns to the table for the object type's leaf-level attributes. Each object-type column also has a corresponding hidden column to store the NULL information for the column objects (that is, the atomic nulls of the top-level and the nested objects).
A substitutable column or object table has a hidden column not only for each attribute of the column's object type but also for each attribute added in any subtype of the object type. These columns store the values of those attributes for any subtype instances inserted in the substitutable column.
For example, a substitutable column of Person_typ will have associated with it a hidden column for each of the attributes of Person_typ, namely: ssn, name, address. It will also have hidden columns for attributes of the subtypes of Person_typ: for example, the attributes deptid and major (for Student_typ) and numhours (for PartTimeStudent_typ).
When a subtype is created, hidden columns for attributes added in the subtype are automatically added to tables containing a substitutable column of any of the new subtype's ancestor types. These retrofit the tables to store data of the new type. If, for some reason, the columns cannot be added, creation of the subtype is rolled back.
When a subtype is dropped with the VALIDATE option to DROP TYPE, all such hidden columns for attributes unique to the subtype are automatically dropped as well if they do not contain data.
A substitutable column also has associated with it a hidden type discriminant column. This column contains an identifier, called a typeid, that identifies the most specific type of each object in the substitutable column. Typically, a typeid (RAW) is one byte, though it can be as big as four bytes for a large hierarchy.
You can find the typeid of a specified object instance using the function--SYS_TYPEID. For example, suppose that the substitutable object table persons contains three rows, as follows:
CREATE TABLE persons OF Person_typ; INSERT INTO persons VALUES (Person_typ(1243, 'Bob', '121 Front St')); INSERT INTO persons VALUES (Student_typ(3456, 'Joe', '34 View', 12, 'HISTORY')); INSERT INTO persons VALUES (PartTimeStudent_typ(5678, 'Tim', 13, 'PHYSICS', 20));
The following query gets typeids of object instances stored in the table:
SELECT name, SYS_TYPEID(VALUE(p)) typeid FROM persons p; NAME TYPEID ---- ------ Bob 01 Joe 02 Tim 03
The catalog views USER_TYPES, DBA_TYPES and ALL_TYPES contain a TYPEID column (not hidden) that gives the typeid value for each type. You can join on this column to get the type names corresponding to the typeids in a type discriminant column.
When Oracle constructs a REF to a row object, the constructed REF is made up of the object identifier, some metadata of the object table, and, optionally, the ROWID.
The size of a REF in a column of REF type depends on the storage properties associated with the column. For example, if the column is declared as a REF WITH ROWID, Oracle stores the ROWID in the REF column. The ROWID hint is ignored for object references in constrained REF columns.
If column is declared as a REF with a SCOPE clause, the column is made smaller by omitting the object table metadata and the ROWID. A scoped REF is 16 bytes long.
If the object identifier is primary-key based, Oracle may create one or more internal columns to store the values of the primary key depending on how many columns comprise the primary key.
The rows of a nested table are stored in a separate storage table. Each nested table column has a single associated storage table, not one for each row. The storage table holds all the elements for all of the nested tables in that column. The storage table has a hidden NESTED_TABLE_ID column with a system-generated value that lets Oracle map the nested table elements back to the appropriate row.
You can speed up queries that retrieve entire collections by making the storage table index-organized. Include the ORGANIZATION INDEX clause inside the STORE AS clause.
A nested table type can contain objects or scalars:
COLUMN_VALUE that contains the scalar values.
For more information, see Nested Table Storage.
All the elements of a VARRAY are stored in a single column. Depending upon the size of the array, it may be stored inline or in a BLOB. See Storage Considerations for Varrays for details.
Using the SYS_TYPEID function, you can build an index on the hidden type discriminant column that every substitutable column has. The type discriminant column contains typeids that identify the most specific type of every object instance stored in the substitutable column. This information is used by the system to evaluate queries that use the IS OF predicate to filter by type, but you can access the typeids for your own purposes using the SYS_TYPEID function.
For example, the following statement creates a bitmap index on the type discriminant column underlying the substitutable author column of table books. Function SYS_TYPEID is used to reference the type discriminant column:
CREATE BITMAP INDEX typeid_i ON books (SYS_TYPEID(author));
You can build an index on attributes of any of the types that can be stored in a substitutable column. Attributes of subtypes can be referenced in the CREATE INDEX statement by using the TREAT function to filter out types other than the desired subtype (and its subtypes); you then use the dot notation to specify the desired attribute.
For example, the following statement creates an index on the major attribute of all student authors in the books table. The declared type of the author column is Person_typ, of which Student_typ is a subtype, so the column may contain instances of Person_typ, Student_typ, and subtypes of either one:
CREATE INDEX major_i ON books (TREAT(author AS Student_typ).major);
Student_typ is the type that first defined the major attribute: the Person_typ supertype does not have it. Consequently, all the values in the hidden column for the major attribute are values for Student_typ or PartTimeStudent_typ authors (a Student_typ subtype). This means that the hidden column's values are identical to the values returned by the TREAT expression, which returns major values for all students, including student subtypes: both the hidden column and the TREAT expression list majors for students and nulls for authors of other types. The system exploits this fact and creates index major_i as an ordinary btree index on the hidden column.
Values in a hidden column are identical to the values returned by a TREAT expression like the one above only if the type named as the target of the TREAT function (Student_typ, above) is the type that first defined the attribute. If the target of the TREAT function is a subtype that merely inherited the attribute, as in the example below, the TREAT expression will return non-null major values for the subtype (part-time students) but not for its supertype (other students).
CREATE INDEX major_func_i ON books (TREAT(author AS PartTimeStudent_typ).major);
Here the values stored in the hidden column for major may be different from the results of the TREAT expression. Consequently, an ordinary btree index cannot be created on the underlying column.
In a case like this, Oracle treats the TREAT expression like any other function-based expression and tries to create the index as a function-based index on the result. However, creating a function-based index requires some privileges and session settings beyond those required to create a btree index.
The following example, like the previous one, creates a function-based index on the major attribute of part-time students, but in this case the hidden column for major is associated with a substitutable object table persons:
CREATE INDEX major_func_i2 ON persons p (TREAT(VALUE(p) AS PartTimeStudent_typ).major);
Every row object in an object table has an associated logical object identifier (OID). By default, Oracle assigns each row object a unique system-generated OID, 16 bytes in length. Oracle provides no documentation of or access to the internal structure of object identifiers. This structure can change at any time.
The OID column of an object table is a hidden column. Once it is set up, you can ignore it and focus instead on fetching and navigating objects through object references.
The OID for a row object uniquely identifies it in an object table. Oracle implicitly creates and maintains an index on the OID column of an object table. In a distributed and replicated environment, the system-generated unique identifier lets Oracle identify objects unambiguously .
In an environment where a locally unique identifier can be assumed to be globally unique (in other words, where the table is not distributed or replicated), you can use the primary key value of a row object as its object identifier. Doing this saves the 16 bytes of storage for each object that a system-generated identifer requires.
Primary-key based identifiers also make it faster and easier to load data into an object table. By contrast, system-generated object identifiers need to be remapped using some user-specified keys, especially when references to them are also stored.
Changing a user-defined type is called type evolution. You can make the following changes to a user-defined type:
FINAL and INSTANTIABLE properties
Changes to a type affect things that reference the type. For example, if you add a new attribute to a type, data in a column of that type must be presented so as to include the new attribute.
Schema objects that directly or indirectly reference a type and are affected by a change to it are called dependents of the type. A type can have these kinds of dependents:
How a dependent schema object is affected by a change to a type depends on the dependent object and on the nature of the change to the type.
All dependent program units, views, operators and indextypes are marked invalid when a type is modified. The next time one of these invalid schema objects is referenced, it is revalidated using the new type definition. If the object recompiles successfully, it becomes valid and can be used again. (Depending on the change to the type, function-based indexes may be dropped or disabled and need to be rebuilt.)
If a type has dependent tables, then, for each attribute added to a type, one or more internal columns are added to the table depending on the new attribute's type. New attributes are added with NULL values. For each dropped attribute, the columns associated with that attribute are dropped. For each modified attribute, the length, precision, or scale of its associated column is changed accordingly.
These changes mainly involve updating the tables' metadata (information about a table's structure, describing its columns and their types) and can be done quickly. However, the data in those tables must be updated to the format of the new type version as well. Updating this data can be time-consuming if there is a lot of it, so Oracle provides options in the ALTER TYPE command to let you choose whether to convert the table data all at once or leave it as is to be converted piecemeal as it is updated.
The CASCADE option for ALTER TYPE propagates a type change to dependent types and tables. CASCADE itself has options (see "ALTER TYPE Options for Type Evolution") that let you choose whether to convert table data to the new type format as part of the propagation: the option INCLUDING TABLE DATA converts the data; the option NOT INCLUDING TABLE DATA does not convert it. By default, the CASCADE option converts the data. In any case, table data is always returned in the format of the latest type version. If the table data is stored in the format of an earlier type version, Oracle converts the data to the format of the latest version before returning it, even though the format in which the data is actually stored is not changed until the data is rewritten.
The definition of the latest type can be retrieved from the system view USER_SOURCE. You can view definitions of all versions of a type in the USER_TYPE_VERSIONS view.
The following example changes Person_typ by adding one attribute and dropping another. The CASCADE keyword propagates the type change to dependent types and tables, but the phrase NOT INCLUDING TABLE DATA prevents conversion of the related data.
CREATE TYPE person_typ AS OBJECT ( first_name VARCHAR(30), last_name VARCHAR(30), age NUMBER(3)); CREATE TABLE person_tab of person_typ; INSERT INTO person_tab VALUES (person_typ (`John', `Doe', 50)); SELECT value(p) FROM person_tab p; VALUE(P)(FIRST_NAME, LAST_NAME, AGE) ---------------------------------------------- PERSON_TYP('John', 'Doe', 50) ALTER TYPE person_typ ADD ATTRIBUTE (dob DATE), DROP ATTRIBUTE age CASCADE NOT INCLUDING TABLE DATA; -- The data of table person_tab has not been converted yet, but -- when the data is retrieved, Oracle returns the data based on -- the latest type version. The new attribute is initialized to NULL. SELECT value(p) FROM person_tab p; VALUE(P)(FIRST_NAME, LAST_NAME, DOB) ---------------------------------------------- PERSON_TYP('John', 'Doe', NULL)
During SELECT statements, even though column data may be converted to the latest type version, the converted data is not written back to the column. If a certain user-defined type column in a table is retrieved often, you should consider converting that data to the latest type version to eliminate redundant data conversions. Converting is especially beneficial if the column contains a VARRAY attribute since a VARRAY typically takes more time to convert than an object or nested table column.
You can convert a column by issuing an UPDATE statement to set the column to itself. For example:
UPDATE dept_tab SET emp_array_col = emp_array_col;
You can convert all columns in a table by using ALTER TABLE UPGRADE DATA.
For example:
ALTER TYPE person_typ ADD ATTRIBUTE (photo BLOB) CASCADE NOT INCLUDING TABLE DATA; ALTER TABLE dept_tab UPGRADE INCLUDING DATA;
Only structural changes to a type affect dependent data. Changes that are confined to a type's method definition or behavior (for example, to the type body, where the type's methods are implemented) do not.
These possible changes to a type are structural:
FINAL to NOT FINAL or from NOT FINAL to FINAL.
These changes result in new versions of the altered type and all its dependent types and require the system to add, drop, or modify internal columns of dependent tables as part of the process of converting to the new version.
When you make any of these kinds of changes to a type that has dependent types or tables, the effects of propagating the change are not confined only to metadata but affect data storage arrangements. You must choose whether to let the schema object conversions at the storage level happen as data is rewritten for unrelated reasons, or to initiate the conversions for their own sake for particular columns, particular tables, or globally.
You may also need to make other changes. For example, if a new attribute is added to a type, and the type body invokes the type's constructor, then each constructor in the type body must be modified to specify a value for the new attribute. Similarly, if a new method is added, then the type body must be replaced to add the implementation of the new method. The type body can be modified by using the CREATE OR REPLACE TYPE BODY statement.
Below are the steps required to make a change to a type:
Assume we have the following schema:
CREATE TYPE Person_typ AS OBJECT ( name CHAR(20), ssn CHAR(12), address VARCHAR2(100)); CREATE TYPE Person_nt IS TABLE OF Person_typ; CREATE TYPE dept_typ AS OBJECT ( mgr Person_typ, emps Person_nt); CREATE TABLE dept OF dept_typ;
ALTER TYPE statement to alter the type.
The default behavior of an ALTER TYPE statement without any option specified is to check if there is any object dependent on the target type. The statement aborts if any dependent object exists. Optional keywords allow cascading the type change to dependent types and tables.
In the following code, conversion of table data is deferred by adding the phrase NOT INCLUDING TABLE DATA.
-- Add new attributes to Person_typ and propagate the change -- to Person_nt and dept_typ ALTER TYPE Person_typ ADD ATTRIBUTE (picture BLOB, dob DATE) CASCADE NOT INCLUDING TABLE DATA;
CREATE OR REPLACE TYPE BODY to update the corresponding type body to make it current with the new type definition.
ALTER TABLE dept UPGRADE INCLUDING DATA;
Adding a new attribute to a supertype also increases the number of attributes in all its subtypes because these inherit the new attribute. Inherited attributes always precede declared (locally defined) attributes, so adding a new attribute to a supertype causes the ordinal position of all declared attributes of any subtype to be incremented by one recursively. The mappings of the altered type must be updated to include the new attributes. OTT and JPUB do this. If you use some other tool, you must be sure that the type headers are properly synchronized with the type definition in the server; otherwise, unpredictable behavior may result.
When the system executes an ALTER TYPE statement, it first validates the requested type change syntactically and semantically to make sure it is legal. The system performs the same validations as for a CREATE TYPE statement plus some additional ones. For example, it checks to be sure an attribute being dropped is not used as a partitioning key. If the new spec of the target type or any of its dependent types fails the type validations, the ALTER TYPE statement aborts. No new type version is created, and all dependent objects remain unchanged.
If dependent tables exist, further checking is done to ensure that restrictions relating to the tables and any indexes are observed. Again, if the ALTER TYPE statement fails the check of table-related restrictions, then the type change is aborted, and no new version of the type is created.
When multiple attributes are added in a single ALTER TYPE statement, they are added in the order specified. Multiple type changes can be specified in the same ALTER TYPE statement, but no attribute name or method signature can be specified more than once in the statement. For example, adding and modifying the same attribute in a single statement is not allowed.
For example:
CREATE TYPE mytype AS OBJECT (attr1 NUMBER, attr2 NUMBER); ALTER TYPE mytype ADD ATTRIBUTE (attr3 NUMBER), DROP ATTRIBUTE attr2, ADD ATTRIBUTE attr4 NUMBER CASCADE;
The resulting definition for mytype becomes:
(attr1 NUMBER, attr3 NUMBER, attr4 NUMBER);
The following ALTER TYPE statement, which attempts to make multiple changes to the same attribute (attr5), is invalid:
-- invalid ALTER TYPE statement ALTER TYPE mytype ADD ATTRIBUTE (attr5 NUMBER, attr6 CHAR(10)), DROP ATTRIBUTE attr5;
Below are other notes on validation constraints, table restrictions, and assorted information about the various kinds of changes that can be made to a type.
CASCADE option removes the method from the target type and all subtypes. However, if a method is overridden in a subtype, the CASCADE will fail and roll back. For the CASCADE to succeed, you must first drop each override from the subtype that defines it and only then drop the method from the supertype.
You can consult the USER_DEPENDENCIES table to find all the schema objects, including types, that depend on a given type.
INVALIDATE option to drop a method that has overrides, but the overrides in the subtypes must still be dropped manually. The subtypes will remain in an invalid state until they are explicitly altered to drop the overrides. (Until then, an attempt to recompile the subtypes for revalidation will produce the error, "Method does not override.")
Unlike CASCADE, INVALIDATE bypasses all the type and table checks and simply invalidates all schema objects dependent on the type. The objects are revalidated the next time they are accessed. This option is faster than using CASCADE, but you must be certain that no problems will be encountered revalidating dependent types and tables. Table data cannot be accessed while a table is invalid; if a table cannot be validated, its data remains inaccessible.
NOT FINAL to FINAL is allowed only if the target type has no subtypes.
INSTANTIABLE to NOT INSTANTIABLE is allowed only if the type has no table dependents.
FINAL to NOT FINAL affects dependent tables and so requires schema object conversion of columns and tables because a new column must be added for the TypeId now that the type can have subtypes.
NOT INSTANTIABLE to INSTANTIABLE is allowed anytime. This change does not affect tables.
The INVALIDATE option of the ALTER TYPE statement lets you alter a type without propagating the type change to dependent objects. In this case, the system does not validate the dependent types and tables to ensure that all the ramifications of the type change are legal. Instead, all dependent schema objects are marked invalid. The objects, including types and tables, are revalidated when next referenced. If a type cannot be revalidated, it remains invalid, and any tables referencing it become inaccessible until the problem is corrected.
A table may fail validation because, for example, adding a new attribute to a type has caused the number of columns in the table to exceed the maximum allowable number of 1000, or because an attribute used as a partitioning or clustering key of a table was dropped from a type.
To force a revalidation of a type, users can issue the ALTER TYPE COMPILE statement. To force a revalidation of an invalid table, users can issue the ALTER TABLE UPGRADE statement and specify whether the data is to be converted to the latest type version. (Note that, in a table validation triggered by the system when a table is referenced, table data is always updated to the latest type version: you do not have the option to postpone conversion of the data.)
If a table is unable to convert to the latest type version, then INSERT, UPDATE and DELETE statements on the table are not allowed and its data becomes inaccessible. The following DDLs can be executed on the table, but all other statements which reference an invalid table are not allowed until the table is successfully validated:
All PL/SQL programs containing variables defined using %ROWTYPE of a table or %TYPE of a column or attribute from a table are compiled based on the latest type version. If the table fails the revalidation, then compiling any program units that reference that table will also fail.
Below is a synopsis of the options in the ALTER TYPE statement for altering the attribute or method definition of a type:
Figure 6-1 graphically summarizes the options for ALTER TYPE INVALIDATE and their effects. In the figure, T1 is a type, and T2 is a dependent type. Also see the notes beneath the figure.
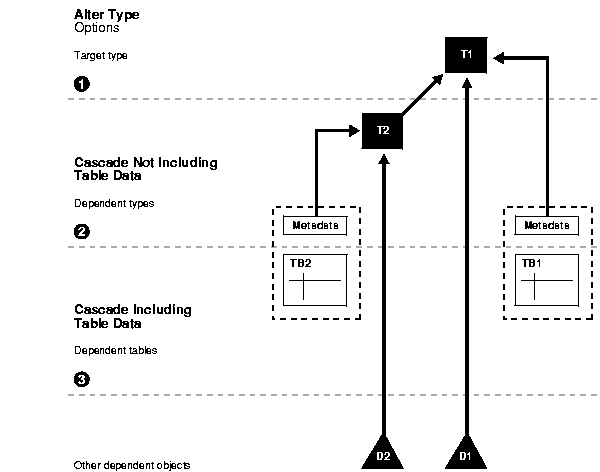
Notes on the figure:
You can use ALTER TABLE to convert table data to the latest version of referenced types. For example, the following statement converts the data in table benefits to the latest type version.
ALTER TABLE benefits UPGRADE INCLUDING DATA;
The ALTER TABLE statement contains the following options for converting table data to the latest type version:
The following sections introduce tips and techniques for using OCI effectively by showing common operations performed by an OCI program that uses objects.
To enable object manipulation, the OCI program must be initialized in object mode. The following OCI code initializes a program in object mode:
err = OCIInitialize(OCI_OBJECT, 0, 0, 0, 0);
When the program is initialized in object mode, the object cache is initialized. Memory for the cache is not allocated at this time; instead, it is allocated only on demand.
The OCIObjectNew() function creates transient or persistent objects. A transient object's lifetime is the duration of the session in which it was created. A persistent object is an object that is stored in an object table in the database. The OCIObjectNew() function returns a pointer to the object created in the cache, and the application should initialize the new object by setting the attribute values directly. The object is not created in the database yet; it will be created and stored in the database when it is flushed from the cache.
When OCIObjectNew() creates an object in the cache, it sets all the attributes to NULL. The attribute null indicator information is recorded in the parallel null indicator structure. If the application sets the attribute values, but fails to set the null indicator information in the parallel null structure, then upon object flush the object attributes will be set to NULL in the database.
If you want to set all of the attributes to NOT NULL during object creation, you can use the OCI_OBJECT_NEW_NOTNULL attribute of the environment handle using the OCIAttrSet() function. When set, this attribute creates a non-null object. That is, all the attributes are set to default values provided by Oracle and their null status information in the parallel null indicator structure is set to NOT NULL. Using this attribute eliminates the additional step of changing the indicator structure. You cannot change the default values provided by Oracle. Instead, you can populate the object with your own default values immediately after object creation.
When OCIObjectNew() is used to create a persistent object, the caller must identify the database table into which the newly created object is to be inserted. The caller identifies the table using a table object. Given the schema name and table name, the OCIObjectPinTable() function returns a pointer to the table object. Each call to OCIObjectPinTable() results in a call to the server to fetch the table object information. The call to the server happens even if the required table object has been previously pinned in the cache. When the application is creating multiple objects to be inserted into the same database table, Oracle Corporation recommends that the table object be pinned once and the pointer to the table object be saved for future use. Doing so improves performance of the application.
Before you can update an object, the object must be pinned in the cache. After pinning the object, the application can update the desired attributes directly. You must make a call to the OCIObjectMarkUpdate() function to indicate that the object has been updated. Objects which have been marked as updated are placed in a dirty list and are flushed to the server upon cache flush or when the transaction is committed.
You can delete an object by calling the OCIObjectMarkDelete() function or the OCIObjectMarkDeleteByRef() function.
You can control the size of the object cache by using the following two OCI environment handle attributes:
OCI_ATTR_CACHE_MAX_SIZE controls the maximum cache size
OCI_ATTR_CACHE_OPT_SIZE controls the optimal cache size
You can get or set these OCI attributes using the OCIAttrGet() or OCIAttrSet() functions. Whenever memory is allocated in the cache, a check is made to determine whether the maximum cache size has been reached. If the maximum cache size has been reached, the cache automatically frees (ages out) the least-recently used objects with a pin count of zero. The cache continues freeing such objects until memory usage in the cache reaches the optimal size, or until it runs out of objects eligible for freeing. The object cache does not limit cache growth to the maximum cache size. The servicing of the memory allocation request could cause the cache to grow beyond the specified maximum cache size. The above two parameters allow the application to control the frequency of object aging from the cache.
Pinning is the process of retrieving an object from the server to the client cache, laying it in memory, providing a pointer to it for an application to manipulate, and marking the object as being in use. The OCIObjectPin() function de-references the given REF and pins the corresponding object in the cache. A pointer to the pinned object is returned to the caller and this pointer is valid as long as the object is pinned in the cache. This pointer should not be used after the object is unpinned because the object may have aged out and therefore may no longer be in the object cache.
The following are examples of OCIObjectPin() and OCIObjectUnpin() calls:
status = OCIObjectPin(envh, errh, empRef,(OCIComplexObject*)0, OCI_PIN_RECENT, OCI_DURATION_TRANSACTION, OCI_LOCK_NONE, (dvoid**)&emp); /* manipulate emp object */ status = OCIObjectUnpin(envh, errh, emp);
The empRef parameter passed in the pin call specifies the REF to the desired employee object. A pointer to the employee object in the cache is returned in the emp parameter.
You can use the OCIObjectPinArray() function to pin an array of objects in one call. This function de-references an array of REFs and pins the corresponding objects in the cache. Objects that are not already cached in the cache are retrieved from the server in one network round-trip. Therefore, calling OCIObjectPinArray() to pin an array of objects improves application performance. Also, the array of objects you are pinning can be of different types.
When pinning an object, you can use the pin option argument to specify whether the recent version, latest version, or any version of the object is desired. The valid options are explained in more detail in the following list:
OCI_PIN_RECENT pin option instructs the object cache to return the object that is loaded into the cache in the current transaction; in other words, if the object was loaded prior to the current transaction, the object cache needs to refresh it with the latest version from the database. Succeeding pins of the object within the same transaction would return the cached copy and would not result in database access. In most cases, you should use this pin option.
OCI_PIN_LATEST pin option instructs the object cache to always get the latest copy of the object. If the object is already in the cache and not-locked, the object copy is refreshed with the latest copy from the database. On the other hand, if the object in the cache is locked, Oracle assumes that it is the latest copy, and the cached copy is returned. You should use this option for applications that must display the most recent copy of the object, such as applications that display stock quotes, current account balance, etc.
OCI_PIN_ANY pin option instructs the object cache to fetch the object in the most efficient manner; the version of the returned object does not matter. The pin any option is appropriate for objects which do not change often, such as product information, parts information, etc. The pin any option also is appropriate for read-only objects.
When pinning an object, you can specify the duration for which the object is pinned in the cache. When the duration expires, the object is unpinned automatically from the cache. The application should not use the object pointer after the object's pin duration has ended. An object can be unpinned prior to the expiration of its duration by explicitly calling the OCIObjectUnpin() function. Oracle supports two pre-defined pin durations:
OCI_DURATION_SESSION) lifetime is the duration of the database connection. Objects that are required in the cache at all times across transactions should be pinned with session duration.
OCI_DURATION_TRANS) lifetime is the duration of the database transaction. That is, the duration ends when the transaction is rolled back or committed.
When pinning an object, the caller can specify whether the object should be locked using lock options. When an object is locked, a server-side lock is acquired, which prevents any other user from modifying the object. The lock is released when the transaction commits or rolls back. The following list describes the available lock options:
OCI_LOCK_NONE lock option instructs the cache to pin the object without locking.
OCI_LOCK_X lock option instructs the cache to pin the object only after acquiring a lock. If the object is currently locked by another user, the pin call with this option waits until it can acquire the lock before returning to the caller. Using the OCI_LOCK_X lock option is equivalent to executing a SELECT FOR UPDATE statement.
OCI_LOCK_X_NOWAIT lock option instructs the cache to pin the object only after acquiring a lock. Unlike the OCI_LOCK_X option, the pin call with OCI_LOCK_X_NOWAIT option will not wait if the object is currently locked by another user. Using the OCI_LOCK_X_NOWAIT lock option is equivalent to executing a SELECT FOR UPDATE WITH NOWAIT statement.
Depending upon how frequently objects are updated, you can choose which locking options from the previous section to use.
If objects are updated frequently, you can use the pessimistic locking scheme. This scheme presumes that contention for update access is frequent. Objects are locked before the object in the cache is modified, ensuring that no other user can modify the object until the transaction owning the lock performs a commit or rollback. The object can be locked at the time of pin by choosing the appropriate locking options. An object that was not locked at the time of pin also can be locked by the function OCIObjectLock(). The locking function OCIObjectLockNoWait() does not wait to acquire the lock if another user holds a lock on the object.
If objects are updated infrequently, you can use the optimistic locking scheme. This scheme presumes that contention for update access is rare. Objects are fetched and modified in the cache without acquiring a lock. A lock is acquired only when the object is flushed to the server. Optimistic locking allows for a higher degree of concurrent access than pessimistic locking. To use optimistic locking most effectively, the Oracle object cache detects if an object is changed by any other user since it was fetched into the cache. By turning on the object change detection mode, object modifications are made persistent only if the object has not been changed by any other user since it was fetched into the cache. This mode is activated by setting OCI_OBJECT_DETECTCHANGE attribute of the environment handle using the OCIAttrSet() function.
Changes made to the objects in the object cache are not sent to the database until the object cache is flushed. The OCICacheFlush() function flushes all changes in a single network round-trip between the client and the server. The changes may involve insertion of new objects into the appropriate object tables, updating objects in object tables, and deletion of objects from object tables. If the application commits a transaction by calling the OCITransCommit() function, the object cache automatically performs a cache flush prior to committing the transaction.
Complex Object Retrieval (COR) can significantly improve the performance of applications that manipulate graphs of objects. COR allows applications to pre-fetch a set of related objects in one network round-trip, thereby improving performance. When pinning the root object(s) using OCIObjectPin() or OCIObjectPinArray(), you can specify the related objects to be pre-fetched along with the root. The pre-fetched objects are not pinned in the cache; instead, they are put in the LRU list. Subsequent pin calls on these objects result in a cache hit, thereby avoiding a round-trip to the server.
The application specifies the set of related objects to be pre-fetched by providing the following information:
REF to the root object
REF attributes should be de-referenced and which resulting object should be pre-fetched. The depth defines the boundary of objects pre-fetched. The depth level is the shortest number of references that need to be traversed from the root object to a related object.
For example, consider a purchase order system with the following properties:
REF to a customer object, and a collection of REFs that point to line item objects.
Suppose you want to calculate the total cost of a particular purchase order. To maximize efficiency, you want to fetch only the objects necessary for the calculation from the server to the client cache, and you want to fetch these objects with the least number of calls to the server possible.
If you do not use COR, your application must make several server calls to retrieve all of the necessary objects. However, if you use COR, you can specify the objects that you want to retrieve and exclude other objects that are not required. To calculate the total cost of a purchase order, you need the purchase order object, the related line item objects, and the related stock item objects, but you do not need the customer objects.
Therefore, as shown in Figure 6-2, COR enables you to retrieve the required information for the calculation in the most efficient way possible. When pinning the purchase order object without COR, only that object is retrieved. When pinning it with COR, the purchase order and the related line item objects and stock item objects are retrieved. However, the related customer object is not retrieved because it is not required for the calculation.
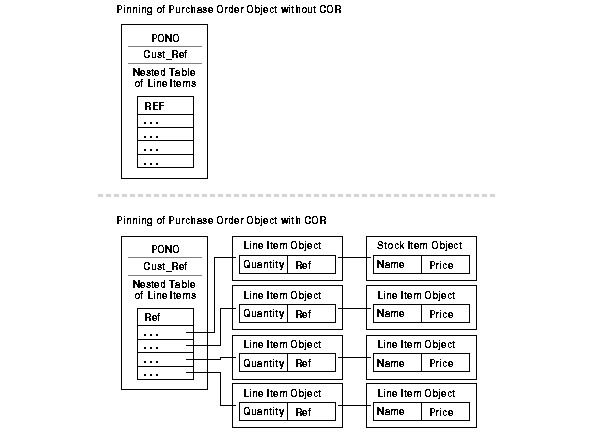
For a demonstration of how to use OCI with Oracle objects, see the cdemocor1.c file in $ORACLE_HOME/rdbms/demo.
We can pin and navigate objects synthesized from object views in the OCI Object Cache similar to the way we do this with object tables. We can also create new view objects, update them, delete them and flush them from the cache. The flush performs the appropriate DML on the view (such as insert for newly created objects and updates for any attribute changes). This fires any INSTEAD-OF triggers on the view and stores the object persistently.
There is a minor difference between the two approaches with regard to getting the reference to a newly created instance in the object cache.
In the case of object views with primary key based reference, the attributes that make up the identifier for the object need to be initialized before the OCIObjectGetObjectRef call can be called on the object to get the object reference. For example, to create a new object in the OCI Object cache for the purchase order object, we need to take the following steps:
.. /* Initialize all the settings including creating a connection, getting a environment handle etc. We do not check for error conditions to make the example eaiser to read. */ OCIType *purchaseOrder_tdo = (OCIType *) 0; /* This is the type object for the purchase order */ dvoid * purchaseOrder_viewobj = (dvoid *) 0; /* This is the view object */ /* The purchaseOrder struct is a structure that is defined to have the same attributes as that of PurchaseOrder_objtyp type. This can be created by the user or generated automatically using the OTT generator. */ purchaseOrder_struct *purchaseOrder_obj; /* This is the null structure corresponding to the purchase order object's attributes */ purchaseOrder_nullstruct *purchaseOrder_nullobj; /* This is the variable containing the purchase order number that we need to create */ int PONo = 1003; /* This is the reference to the purchase order object */ OCIRef *purchaseOrder_ref = (OCIRef *)0; /* Pin the object type first */ OCITypeByName( envhp, errhp, svchp, (CONST text *) "", (ub4) strlen( "") , (CONST text *) "PURCHASEORDER_OBJTYP" , (ub4) strlen("PURCHASEORDER_OBJTYP"), (CONST char *) 0, (ub4)0, OCI_DURATION_SESSION, OCI_TYPEGET_ALL, &purchaseOrder_tdo); /* Pin the table object - in this case it is the purchase order view */ OCIObjectPinObjectTable(envhp, errhp, svchp, (CONST text *) "", (ub4) strlen( "" ), (CONST text *) "PURCHASEORDER_OBJVIEW", (ub4 ) strlen("PURCHASEORDER_OBJVIEW"), (CONST OCIRef *) NULL, OCI_DURATION_SESSION, &purchaseOrder_viewobj); /* Now create a new object in the cache. This is a purchase order object */ OCIObjectNew(envhp, errhp, svchp, OCI_TYPECODE_OBJECT, purchaseOrder_tdo, purchaseOrder_viewobj, OCI_DURATION_DEFAULT, FALSE, (dvoid **) *purchaseOrder_obj); /* Now we can initialize this object, and use it as a regular object. But before getting the reference to this object we need to initialize the PONo attribute of the object which makes up its object identifier in the view */ /* Initialize the null identifiers */ OCIObjectGetInd( envhp, errhp, purchaseOrder_obj, purchaseOrder_nullobj); purchaseOrder_nullobj->purchaseOrder = OCI_IND_NOTNULL; purchaseOrder_nullobj->PONo = OCI_IND_NOTNULL; /* This sets the PONo attribute */ OCINumberFromInt( errhp, (CONST dvoid *) &PoNo, sizeof(PoNo), OCI_NUMBER_SIGNED, &( purchaseOrder_obj->PONo)); /* Create an object reference */ OCIObjectNew( envhp, errhp, svchp, OCI_TYPECODE_REF, (OCIType *) 0, (dvoid *) 0, (dvoid *) 0, OCI_DURATION_DEFAULT, TRUE, (dvoid **) &purchaseOrder_ref); /* Now get the reference to the newly created object */ OCIObjectGetObjectRef(envhp, errhp, (dvoid *) purchaseOrder_obj, purchaseOrder_ ref); /* This reference may be used in the rest of the program ..... */ ... /* We can flush the changes to the disk and the newly instantiated purchase order object in the object cache will become permanent. In the case of the purchase order object, the insert will fire the INSTEAD-OF trigger defined over the purchase order view to do the actual processing */ OCICacheFlush( envhp, errhp, svchp, (dvoid *) 0, 0, (OCIRef **) 0); ...
Oracle has three special SQL datatypes that enable you to dynamically encapsulate and access type descriptions, data instances, and sets of data instances of any other SQL type, including object and collection types. You can also use these three special types to create anonymous (that is, unnamed) types, including anonymous collection types.
The three SQL types are implemented as opaque types. In other words, the internal structure of these types is not known to the database: their data can be queried only by implementing functions (typically 3GL routines) for the purpose. Oracle provides both an OCI and a PL/SQL API for implementing such functions.
The three generic SQL types are:
Each of these three types can be used with any built-in type native to the database as well as with object types and collection types, both named and unnamed. The types provide a generic way to work dynamically with type descriptions, lone instances, and sets of instances of other types. Using the APIs, you can create a transient ANYTYPE description of any kind of type. Similarly, you can create or convert (cast) a data value of any SQL type to an ANYDATA and can convert an ANYDATA (back) to a SQL type. And similarly again with sets of values and ANYDATASET.
The generic types simplify working with stored procedures. You can use the generic types to encapsulate descriptions and data of standard types and pass the encapsulated information into parameters of the generic types. In the body of the procedure, you can detail how to handle the encapsulated data and/or type descriptions of whatever type.
You can also store encapsulated data of a variety of underlying types in one table column of type ANYDATA or ANYDATASET. For example, you can use ANYDATA with Advanced Queuing to model queues of heterogenous types of data. You can query the data of the underlying datatypes like any other data.
Corresponding to the three generic SQL types are three OCI types that model them. Each has a set of functions for creating and accessing the respective type:
OCIType, corresponding to SYS.ANYTYPE
OCIAnyData, corresponding to SYS.ANYDATA
OCIAnyDataSet, corresponding to SYS.ANYDATASET
Oracle Call Interface Programmer's Guide for the
See Also:
OCIType, OCIAnyData, and OCIAnyDataSet APIs and details on how to use them. See Oracle9i Supplied PL/SQL Packages and Types Reference for information about the interfaces to the ANYTYPE, ANYDATA, and ANYDATASET types and about the DBMS_TYPES package, which defines constants for built-in and user-defined types, for use with ANYTYPE, ANYDATA, and ANYDATASET.
Oracle provides a number of pre-defined aggregate functions such as MAX, MIN, SUM for performing operations on a set of records. These pre-defined aggregate functions can be used only with scalar data. However, you can create your own custom implementations of these functions, or define entirely new aggregate functions, to use with complex data--for example, with multimedia data stored using object types, opaque types, and LOBs.
User-defined aggregate functions are used in SQL DML statements just like Oracle's own built-in aggregates. Once such functions are registered with the server, Oracle simply invokes the aggregation routines that you supplied instead of the native ones.
User-defined aggregates can be used with scalar data as well. For example, it may be worthwhile to implement special aggregate functions for working with complex statistical data associated with financial or scientific applications.
User-defined aggregates are a feature of the Extensibility Framework. You implement them using ODCIAggregate interface routines.
|
See Also:
Oracle9i Data Cartridge Developer's Guide for information on using the |
Partitioning addresses the key problem of supporting very large tables and indexes by allowing you to decompose them into smaller and more manageable pieces called partitions. Oracle extends partitioning capabilities by letting you partition tables that contain objects, REFs, varrays, and nested tables. Varrays stored in LOBs are equipartitioned in a way similar to LOBs.
The following example partitions the purchase order table along zip codes (ToZip), which is an attribute of the ShipToAddr embedded column object. For the purposes of this example, the LineItemList nested table was made a varray to illustrate storage for the partitioned varray.
Assuming that the LineItemList is defined as a varray:
CREATE TYPE LineItemList_vartyp as varray(10000) of LineItem_objtyp; CREATE TYPE PurchaseOrder_typ AS OBJECT ( PONo NUMBER, Cust_ref REF Customer_objtyp, OrderDate DATE, ShipDate DATE, OrderForm BLOB, LineItemList LineItemList_vartyp, ShipToAddr Address_objtyp, MAP MEMBER FUNCTION ret_value RETURN NUMBER, MEMBER FUNCTION total_value RETURN NUMBER ); CREATE TABLE PurchaseOrders_tab of PurchaseOrder_typ LOB (OrderForm) store as (nocache logging) PARTITION BY RANGE (ShipToAddr.zip) (PARTITION PurOrderZone1_part VALUES LESS THAN ('59999') LOB (OrderForm) store as ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)) VARRAY LineItemList store as LOB ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)), PARTITION PurOrderZone6_part VALUES LESS THAN ('79999') LOB (OrderForm) store as ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)) VARRAY LineItemList store as LOB ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)), PARTITION PurOrderZoneO_part VALUES LESS THAN ('99999') LOB (OrderForm) store as ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)) VARRAY LineItemList store as LOB ( storage (INITIAL 10 MINEXTENTS 10 MAXEXTENTS 100)));
Parallel query is supported on the objects synthesized in views.
To execute queries involving joins and sorts (using the ORDER BY, GROUP BY, and SET operations) in parallel, a MAP function is needed. In the absence of a MAP function, the query automatically becomes serial.
Parallel queries on nested table columns are not supported. Even in the presence of parallel hints or parallel attributes for the view, the query will be serial if it involves the nested table column.
Parallel DML is not supported on views with INSTEAD-OF trigger. However, the individual statements within the trigger may be parallelized.
Collection types do not map directly to a native type or structure in languages such as C++ and Java. An application using those languages must access the contents of a collection through Oracle interfaces, such as OCI.
Generally, when the client accesses a nested table explicitly or implicitly (by fetching the containing object), Oracle returns the entire collection value to the client process. For performance reasons, a client may wish to delay or avoid retrieving the entire contents of the collection. Oracle handles this case for you by using a locator instead of the real nested table value. When you really access the contents of the collection, they are automatically transferred to the client.
A nested table locator is like a handle to the collection value. It attempts to preserve the value or copy semantics of the nested table by containing the database snapshot as of its time of retrieval. The snapshot helps the database retrieve the correct instantiation of the nested table value at a later time when the collection elements are fetched using the locator. The locator is scoped to a session and cannot be used across sessions. Since database snapshots are used, it is possible to get a "snapshot too old" error if there is a high update rate on the nested table. Unlike a LOB locator, the nested table locator is truly a locator and cannot be used to modify the collection instance.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|