Release 1 (9.0.1)
Part Number A89867-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Concepts Release 1 (9.0.1) Part Number A89867-02 |
|
![]()
![]()
This chapter is an overview Cache Fusion and how the Global Cache Service (GCS) operates.
Topics in this chapter include:
Chapter 6, "Coordination by the Global Enqueue Service" for information on the Global Enqueue Service
See Also:
Cache Fusion is a new technology that uses a high speed interprocess communication (IPC) interconnect to provide cache to cache transfers of data blocks between instances in a cluster. This eliminates disk I/O (which is inherently slow, since it is a mechanical process) and optimizes read/write concurrency. Block reads take advantage of the speed of IPC and an interconnecting network. Cache Fusion also relaxes the requirements of data partitioning.
Cache Fusion addresses these types of concurrency between instances, each of which is discussed in the following sections:
Concurrent reads on multiple nodes occur when two instances need to read the same data block. Real Application Clusters easily resolves this situation because multiple instances can share the same blocks for read access without cache coherency conflicts.
Concurrent reads and writes on different nodes are the dominant form of concurrency in Online Transaction Processing (OLTP) and hybrid applications. A read of a data block that was recently modified can be either for the current version of the block or for a read-consistent previous version. In both cases, the block will be transferred from one cache to the other.
Concurrent writes on different nodes occur when the same data block is modified frequently by processes on different instances.
The main features of the cache coherency model used in Cache Fusion are:
The GCS tracks the location and status (mode and role) of data blocks, as well as the access privileges of various instances. Oracle uses the GCS for cache coherency when the current version of a data block is in one instance's buffer cache and another instance requests that block for modification. It is also used for reading blocks.
Following the initial acquisition of exclusive resources in subsequent transactions multiple transactions running on a single Real Application Clusters instance can share access to a set of data blocks without involvement of the GCS as long as the block is not transferred out of the local cache. If the block has to be transferred out of the local cache, then the Global Resource Directory is updated by the GCS.
Data blocks are the most often required database resources. The GCS manages all types of data blocks.
The GCS ensures cache coherency by requiring that instances acquire a resource cluster-wide before modifying or reading a database block. Thus, the GCS synchronizes global cache access, allowing only one instance at a time to modify a block. The GCS coordination of the buffer caches located on separate nodes provides cache coherency to Real Application Clusters. The GCS ensures the status of data blocks cached in any mode in the cluster is globally visible and maintained.
Oracle's multi-versioning architecture distinguishes between current data blocks and one or more consistent read (CR) versions of a block. A data block can reside in many buffer caches under shared resources. The current block contains changes for all committed and yet-to-be-committed transactions. A consistent read (CR) version of a block represents a consistent snapshot of the data at a previous point in time. Consistent read versions are produced by applying rollback segment information. Both current and consistent read blocks are managed by the GCS
To transfer data blocks among database caches, buffers are shipped by means of a high speed IPC interconnect. Just as in a single instance system, disk writes are only required for cache replacement. A past image (PI) of a block is kept in memory before the block is sent and if it is a dirty block. In the event of failure, Oracle can reconstruct the current version of the block by reading PIs.
GCS resources track the transmission of blocks through the system. The same block can exist in multiple caches as a result of block transfers. The block can be held in different modes depending on whether a resource holder intends to modify data or merely read them.
It is important to understand that a resource is identified by these factors:
Resource modes are generally determined by the holder, as part of a request for a data block. The resource modes determine whether the holder can modify the block. Table 5-1 compares the null (N) mode, shared (S) mode, and exclusive (X) mode.
Oracle assigns GCS resource roles to the holder. They supplement the user-requested modes based on the knowledge of the global state of the blocks by the resource management system. The roles are either local or global:
All GCS resources effectively have the local role if they only exist in one cache. Roles are mutually exclusive. If a data block was changed in one instance and subsequently transferred to another instance, the buffer containing the data is considered globally dirty. That is, the resource has the global role.
When running a single instance in exclusive mode, all concurrency control is done within the instance. With Real Application Clusters in shared mode, synchronization is accomplished by the GCS or Global Enqueue Service (GES).
A block is initially acquired in local role, with no past images (PIs) present. Only after a block has been changed (or becomes a dirty block) and another instance requests it, does the node that dirtied the block begin to keep PIs. The resource then becomes global.
The exclusive current copy of a data block can only exist in the cache of the instance that last modified it. There might also be PIs of the block in other caches. These PIs represent earlier versions of the block with modifications that have not been written to disk, and can be used for consistent reads in the cluster.
When a block is requested for modification for a current read, the instance that last modified a data block sends the block by using a high speed IPC interconnect and retains a PI. Writes to disks are only triggered by cache replacements and checkpoints. The write protocol is largely asynchronous. This reduces the I/O requirements of an Real Application Cluster node to those comparable to a single instance.
Consider when an instance intends to initiate a write of a data block, and the resource has a global role, and it does not have the current buffer, only a PI. Under these circumstances the instance informs the GCS. The GCS then forwards the write request to the instance where the current (or most recent) version of the block is held.
The holder of the current version writes the block to disk. Then, upon completion, the holder sends a completion message to the GCS. Finally, all instances with PI buffers for the written block free their PI buffers.
The GCS always mediates global operations at the cache layer and tracks the latest global state of resources.
To guarantee coherent and accurate access to cached data, the cluster database controls access to shared resources. This includes resources such as data blocks or data structures used for other purposes such as instance management, data dictionary access, and recovery synchronization.
When Oracle reads a data block into memory, Oracle opens a GCS resource to coordinate concurrent access to the resource from multiple instances. Oracle opens or converts the resource in different modes and roles depending on whether:
Oracle closes GCS resources when the block access mode is down-converted to NULL, and there no PI, or when Oracle flushes the buffer from the cache due to cache replacement.
By default, a resource is allocated for each data block in a cache. Due to Cache Fusion and the virtual elimination of immediate disk writes that occur when other instances make modification requests, the performance overhead of concurrency on shared data between instances is diminished. This reduces the tuning and administrative effort for Real Application Clusters environments.
|
Note:
Cache Fusion only works with the default resource control scheme. If you override Cache Fusion and set |
The new architecture for global resource control and Oracle's breakthrough Cache Fusion technology simplify the performance tuning and administration of Real Application Clusters environments. The importance of configuring accurate resource allocations to provide optimal performance, as well as the planning of sufficient capacity for Global Cache Service and Global Enqueue Service (GES) resources has been largely reduced. If you use the default resource control scheme, you do not need special initialization parameter settings to configure resources in Real Application Clusters.
The GCS assigns and opens resources for each database block read into the buffer cache. Oracle closes resources when the resources do not manage any more buffers or when buffered blocks are written to disks due to cache replacement and free buffer requests.
When Oracle closes a resource, it returns it to a free list from which Oracle can assign new resources. The size of the free list is by default equal to the size of the buffer cache. Oracle allocates the free list from the shared pool.
There are no special considerations for global enqueues. Their number is calculated automatically at startup and Oracle records the calculated values in the alert.log file. You do not need to set initialization parameters.
Generally, global enqueues have different uses and semantics than GCS resources. Global enqueues are used by the different kernel layers such as the row cache, the library cache and so on, to coordinate access to a variety of objects.
This section describes how Cache Fusion controls resource assignments. The topics in this section are:
There are three concurrency control concepts that need to be distinguished: buffer state, resource mode, and resource role:
The buffer state of a block relates directly to the access mode of the block and the role assigned to the instance in relation to the block. For example, if a buffer is in exclusive current (XCUR) state, you know that an instance owns the resource in exclusive mode. In addition, if the data block is read from disk and cached in only one instance, the role is local.
There can be only one block buffered in XCUR state in the cluster at any time. To perform modifications on a block, a process must assign an XCUR buffer state to the buffer containing the data block.
If another instance requests reading the same block in its most current version, for example, then Oracle changes the access mode from exclusive to shared, sends the block and keeps a PI buffer if the buffer contained a dirty block. It sends a current read version of the block to the requesting instance. At this point, the first instance has the current block, the changes made to it, and the requesting instance also has the current block in shared mode. The role of the resource becomes global. There can be multiple shared current (SCUR) versions of this block cached at any time.
To see a buffer's state, query the STATUS column of the V$BH dynamic performance view. The V$BH view provides information about each buffer header as shown in Table 5-2.
Figure 5-1 shows how buffer states and block access modes change as instances perform various operations on a given buffer. The block access mode appears in parentheses.
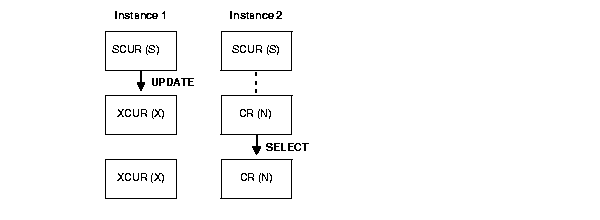
In Figure 5-1, the two instances begin with blocks in shared current mode and with shared resources. When Instance 1 performs an update on the block, its access mode on the block changes to exclusive mode (X). The shared resource owned by instance 2 converts to null mode (N). Meanwhile, the block state in instance 1 becomes XCUR, and in instance 2 it becomes CR. These block access modes are compatible.
When one process owns a resource in a given mode, another process requesting a resource in any particular mode succeeds or fails as shown in Table 5-3.
| Mode Requested: Mode Owned | Null | S | X |
|
Null |
Succeed |
Succeed |
Succeed |
|
S |
Succeed |
Succeed |
Fail |
|
X |
Succeed |
Fail |
Fail |
The following scenarios illustrate the key points of Cache Fusion processing. These scenarios, which illustrate key concepts and do not address all possible configurations, are described in the following sections:
The scenario shown in Figure 5-2 assumes that one instance has read a data block into its cache. The data block is protected by a resource in shared mode (S) and its role is local (L). This indicates that the block only exists in the local cache of this instance.
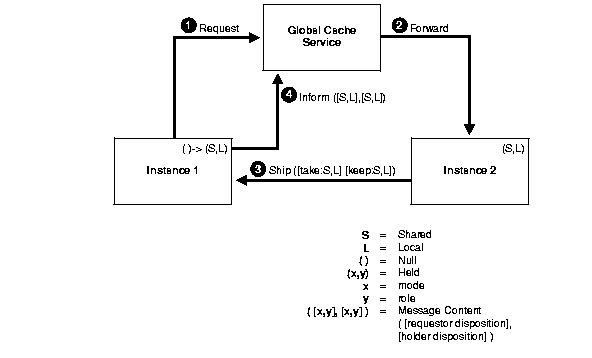
Note that the block and the mode and role information is transferred cache-to-cache through the high speed IPC interconnect without any disk I/O.
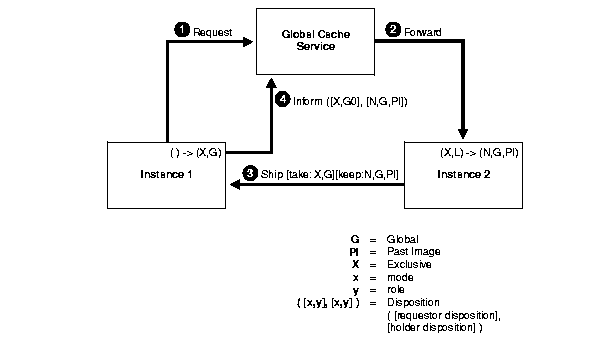
The scenario shown in Figure 5-3 assumes that the data block has been changed (or dirtied) by one instance and held in exclusive mode (X). Furthermore, this scenario assumes that the block has only been accessed by the instance that changed it. That is, only one copy of it exists cluster-wide. In other words, the block is in a local role (L).
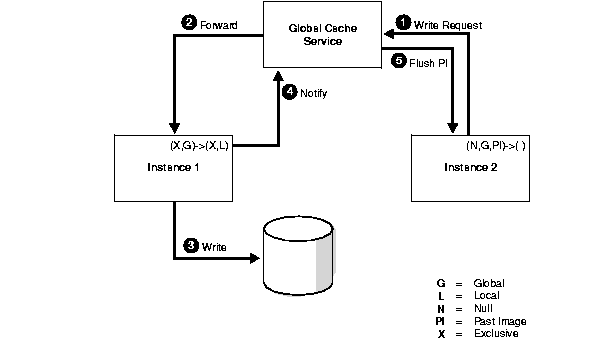
The scenario shown in Figure 5-4 illustrates how an instance can checkpoint at any time or replace buffers in the cache due to free buffer requests. Because multiple versions of the data block with changes could exist in the caches of instances in the cluster, a write protocol mediated by the GCS must ensure that the current version of the data is written to disk. It must also ensure that all existing previous versions are purged from the other caches. A write request for a data block can originate in any instance that has the current or previous version of the block.
In this scenario, assume that the instance holding a PI buffer in null mode requests that the buffer be written.
Oracle9i Real Application Clusters Deployment and Performance for additional information on System Change Numbers
See Also:
This section describes the basic concepts of how the GCS grants and coordinates resource requests. The topics in this section are:
The GCS tracks block access requests within your Real Application Clusters environment, granting requests for resources whenever possible. The GCS also tracks requests for resources that are not currently available. Access rights are granted when these resources later become available. The GCS maintains an inventory of block access requests and status of resources.
There are three situations where processes are interrupted or notified to handle a request for a data block:
The usual flow of a Cache Fusion request is that a block request is made to the GCS and forwarded to the instance in which the data is cached. From there, the buffer is sent directly to the requestor, which is interrupted and completes the request. One key part of request completion is that the requestor informs the GCS that it has received the block. This is called a block arrival interrupt. It also informs the GCS that is taking it in a particular mode and role. This is called the assume notification. Informing the GCS is an asynchronous task. (That is, it is not blocking.)
On the holding side, an interrupt occurs when the resource requested by another instance is held in a conflicting mode. When this occurs, processes on the holding instance are interrupted. Processes on the holding instance are interrupted in order to release or downgrade their access privileges and send the block. This is called a blocking notification or blocking interrupt.
In some cases the GCS determines that resource is not available in any other instance in the cluster and grants permission to access the block directly. Upon request completion the requesting process will then read the block from disk. If the GCS can make the decision to grant the request locally (that is, without sending messages) the request will be completed immediately. Otherwise, an acquisition interrupt is sent to the requesting process.
The Global Enqueue Service (GES) uses a similar notification mechanism. There, only completion interrupts and blocking interrupts are used.
All requests for cluster-wide access to a resource are maintained in grant queues and convert queues. While requests are in progress and until they are completed, the requests remain in a convert queue. These queues are managed by the GCS and GES.
The GCS maintains two queues for resource requests:
|
Granted queue |
The GCS tracks resource requests that have been granted in the granted queue. |
To communicate the statuses of resource requests, the GCS uses two types of interrupts (also known as wake up calls):
The following figures show how the GCS handles resource requests. In Figure 5-5, shared request 1 has been granted on the resource to process 1, and shared request 2 has been granted to process 2. As mentioned, the GCS tracks the resources in the granted queue. When a request for an exclusive block access mode is made by process 2, it must wait in the convert queue.
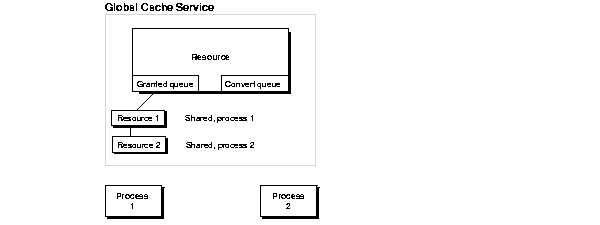
Figure 5-6 shows the GCS sending a blocking interrupt to Process 1, the owner of the shared resource, notifying it that a request for an exclusive resource is waiting. When the shared resource is relinquished by Process 1, Oracle converts the access mode NULL or releases it.
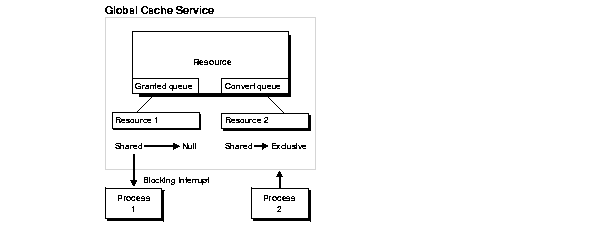
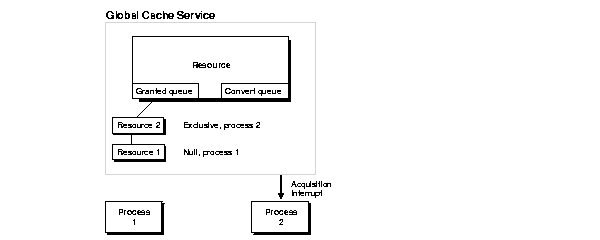
An acquisition interrupt is then sent to alert Process 2, the requestor of the exclusive resource. The GCS grants the exclusive resource and converts it to the granted queue. Figure 5-7 illustrates this.
Real Application Clusters recovery is optimized to execute certain steps in parallel. Data blocks become available immediately after they are recovered. Database recovery and resource space reconfiguration are divided into two phases and can be executed in parallel. Generally, the recovery process allows a high degree of parallelism and hence better availability and scalability.
When an instance expires and the failure is detected by another Oracle instance in the cluster, Oracle performs the following recovery steps:
In summary, the recovered database or recovered portions of the database become available earlier, and before the completion of the entire recovery sequence. This makes the system more available and recovery more scalable.
In the rare occurrence of multiple simultaneous instance failures, neither the PI buffers nor the current buffer for a data block can be found in any of the surviving instances' caches. Then a log merge of the failed instances must be performed. The performance penalty of a log merge is proportional to the number of failed instances and the size of the redo logs for each instance. The size of the log to be read can be controlled by checkpoint features.
With its advanced design, Real Application Clusters recovery is able to handle multiple simultaneous failures and sequential failures. The shared cache server is also resilient to instance failures or crashes during recovery.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|