Release 1 (9.0.1)
Part Number A89867-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Concepts Release 1 (9.0.1) Part Number A89867-02 |
|
![]()
![]()
This chapter describes the scalability features of Real Application Clusters. Topics in this chapter include:
You can implement Real Application Clusters by using several features that enhance application performance and maintain high availability levels. These features:
The Database Configuration Assistant (DBCA) automatically configures most of these features for you.
|
See Also:
Oracle9i Net Services Administrator's Guide for information for manually configuring scalability features |
If tasks can run independently of one another, then Real Application Clusters can distribute them to different nodes. This permits you to achieve scale up. In essence, scale up is more processes run through the database in the same amount of time. The number of nodes used, however, depends upon the purpose of the system.
If processes can run faster, then the system accomplishes more work. The parallel execution feature, for example, permits scale up. With parallel execution, a system might maintain the same response time if the data queried increased tenfold, or if more users could be served. Real Application Clusters without the parallel execution feature also provides scale up, but does this by running the same query sequentially on different nodes.
With a mixed workload of Decision Support System (DSS), Online Transaction Processing (OLTP), and reporting applications, you can achieve scale up by running multiple programs on different nodes. You can also achieve speed up by rewriting the batch programs and separating their transactions into a number of parallel streams to take advantage of multiple CPUs.
Real Application Clusters also offers improved flexibility by overcoming memory limitations so you can use it to accommodate thousand of users. You can allocate or deallocate instances as necessary. For example, as database demand increases, you can temporarily allocate more instances. Then you can deallocate the instances and use them for other purposes once they are no longer required. This feature is useful in Internet-based computing environments.
You can measure the performance goals of cluster database processing in two ways:
The concept of scale up is the factor that expresses how much more work can be done in the same time period by a larger system. With added hardware, a formula for scale up holds the time constant, and measures the increased size of the job that can be done.
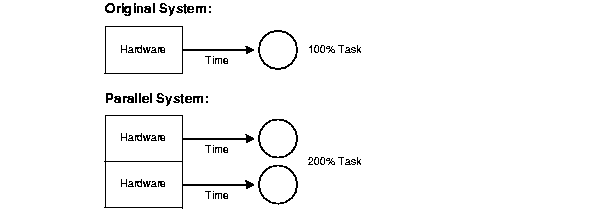
If transaction volumes grow and you have good scale up, you can keep response time constant by adding hardware resources such as CPUs.
You can measure scale up using this formula:
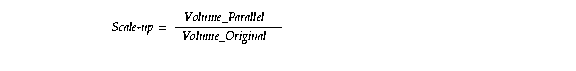
Where:
|
|
is the transaction volume processed in a given amount of time on a parallel system. |
For example, if the original system processes 100 transactions in a given amount of time and the parallel system processes 200 transactions in this amount of time, then the value of scale up would be equal to 2. A value of 2 indicates the ideal of linear scale up: when twice as much hardware can process twice the data volume in the same amount of time.
The concept of speed up is the extent that more hardware can perform the same task in less time than the original system. With added hardware, speed up holds the task constant and measures time savings. Figure 9-2 shows how each parallel hardware system performs half of the original task in half the time required to perform it on a single system.
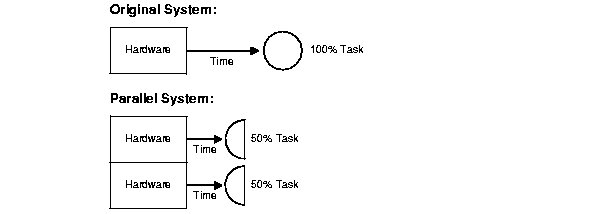
Speed up can be calculated with the formula:
Speed Up = Time1 volume / volume - Time2 volume / volume
(Where the volume of work is the same n transactions.)
Note that you might not experience direct, linear speed up. Instead, speed up could be more logarithmic. That is, assume the system can perform a task of size x in a time duration of n. But for a task of size 2x, the system might require a time duration of 3n.
This section describes applications that benefit from Real Application Clusters. It includes the following topics:
The applications in the transaction systems category include e-business as well as more traditional online transaction processing (OLTP) systems. Transaction systems are characterized by the use of relatively short transactions that update the database with the capture of specific information such as Internet purchases, credit card purchases, or telephone order purchases. In general, the transaction must be completed within a short response time. The greatest challenge is to scale up transaction systems to support many concurrent transactions.
Transaction systems benefit from Real Application Clusters by scale up. Cache Fusion enables updates to occur from multiple instances with minimal overhead, due to concurrency control. Well-designed applications that scale well on a single system with a single instance of Oracle9i will be able to scale in a clustered configuration with Real Application Clusters. As transaction systems are required to handle more transactions as more users are added to the system, additional capacity can be added by simply adding nodes to the cluster. However, poorly designed systems will not scale well and may experience a degradation of performance.
Data warehousing applications that infrequently update, insert, or delete data are often appropriate for using the Real Application Clusters. Query-intensive applications and other applications with low update activity can access the database through different instances with little additional overhead.
If the data blocks are not modified, then multiple nodes can read the same block into their buffer caches and perform queries on the block without additional I/O or enqueue operations.
Decision support applications are good candidates for using Real Application Clusters because they only occasionally modify data, as in a database of financial transactions that is mostly accessed by queries during the day and is updated during off-peak hours. Decision support systems usually benefit from scale up and may experience speed up as well.
Real Application Clusters provides the framework for parallel execution to operate between nodes. Oracle parallel execution behaves the same way with or without Real Application Clusters. The only difference is that Real Application Clusters enables parallel execution to distribute portions of statements among nodes so that the nodes execute on behalf of a single query. The server sub-divides the statement into smaller operations that run against a common database residing on shared disks. Because parallel execution is performed by the server, this parallelism can occur at a low level of server operation.
If Oracle does not process a statement in parallel, then Oracle reads disks serially with one I/O stream. In this case, a single CPU scans all rows in a table. With the statement parallelized, disks are read in parallel with multiple I/Os.
Several CPUs can each scan a part of the table in parallel and aggregate the results. Parallel execution benefits not only from multiple CPUs but also from greater I/O bandwidth availability.
Oracle parallel execution can run with or without Real Application Clusters. Without Real Application Clusters parallel execution cannot perform multinode parallelism. Real Application Clusters optimizes the Oracle9i Enterprise Edition running on clustered hardware using a parallel cache architecture to avoid shared memory bottlenecks in OLTP and DSS applications.
Successful implementation of cluster database processing and parallel databases requires optimal scalability on these levels:
Interconnects are key to hardware scalability. That is, every system must have some means of connecting the CPUs, whether this is a high speed bus or a low speed Ethernet connection. Bandwidth and latency of the interconnect then determine the scalability of the hardware.
Most interconnects have sufficient bandwidth. A high bandwidth might, in fact, disguise high latency.
Hardware scalability depends heavily on very low latency. Resource coordination traffic is characterized by a large number of very small messages in the LMD process.
Consider an example of a highway and the difference between conveying a hundred passengers on a single bus, compared to one hundred individual cars. In the latter case, efficiency depends largely upon the ability of cars to quickly enter and exit the highway. Even if the highway has 5 lanes so multiple cars can pass, if there is only a one-lane entrance ramp, there can be a bottleneck getting onto the fast highway.
Other operations between nodes, such as parallel execution, rely on high bandwidth.
In Real Application Clusters, client/server connections are established by using several subcomponents. A client submits a connection request to a listener process that resides on the destination node in the cluster. A listener process is a process that manages incoming connection requests. The listener grants a client/server connection by way of a particular node based on several factors depending on how you configure the connection options.
The shared server enables enhanced scalability in that for a given amount of memory it enables you to support a larger number of users than when you use dedicated servers. The incremental costs of memory as you add a user is less than when you use a dedicated server. In addition to improving the scalability of the number of users, shared server offers additional benefits.
An increasing number of Oracle9i features require the shared server. You need the shared server if you use the following database features:
Oracle9i Net Services Administrator's Guide for shared server configuration information for Real Application Clusters environments
See Also:
An important feature of the shared server process is service registration. This feature provides the listener with the service names, instance names and network addresses of the database, as well as the current state and load of all instances and shared server dispatchers. With this information, the listener can forward client connection requests to the appropriate dispatchers and dedicated servers.
Because this information is registered with the listener, you do not need to configure the listener.ora file with this static information about a database service. Service registration also extends benefits to connection load balancing that is a feature of the shared server.
The connection load balancing feature provides exceptional benefits in Real Application Clusters environments where there are multiple instances and dispatchers. Connection load balancing improves performance by balancing the number of active connections among various instances and shared server dispatchers for the same service. Note that if your application is partitioned that you may not want to use this feature.
Because of service registration's ability to register with remote listeners, a listener is always aware of all instances and dispatchers regardless of their location. This way, a listener can send an incoming client request for a specific service to the least-loaded instance and least-loaded dispatcher.
Service Registration also facilitates connect-time failover and client load balancing that you can use with or without a shared server.
Service registration enables listeners to know whether an instance is up at all times. This enables you to use connect-time failover when multiple listeners support a service. Do this by configuring a client to failover client requests to a different listener if the first listener connection fails. The reconnection attempts continue until the client successfully connects to a listener. If an instance is down, then a listener returns a network error.
When more than one listener supports a service, a client can randomly send connection requests to the various listeners. The random nature of the connection requests distributes the load to avoid overburdening a single listener.
In addition to load balancing, clients can also specify that their connection request automatically fails over to a different listener if a connection cannot be made with the listener chosen at random. A connection could fail either because the specified listener is not up or because the instance is not up and the listener therefore cannot accept the connection.
|
See Also:
Oracle9i Net Services Administrator's Guide for configuration information on the features described in this section |
The ultimate scalability of your system also depends upon the scalability of the operating system. This section explains how to analyze this factor.
Software scalability can be an important issue if one node is a shared memory system (that is, a system where multiple CPUs connect to a symmetric multiprocessor single memory). Methods of synchronization in the operating system can determine the scalability of the system. In asymmetrical multiprocessing, for example, only a single CPU can handle I/O interrupts. Consider a system where multiple user processes request resources from the operating system.
An important distinction in Real Application Clusters architecture is internal versus external parallelism; this has a strong effect on scalability. The key difference is whether the Object-Relational Database Management System (ORDBMS) parallelizes the query, or an external process parallelizes the query.
The resource affinity capability of Real Application Clusters can improve performance by ensuring that nodes mainly access local, rather than remote, devices. An efficient synchronization mechanism enables better speed up and scale up.
Application design is key to taking advantage of the scalability of the other elements of the system.
No matter how scalable the hardware, software, and database might be, a table with only one row that every node is updating will synchronize on one data block. It is best to use sequences to improve scalability, for example by using the SQL command INSERT INTO ORDERS VALUES.
You can preallocate and cache sequence numbers to improve scalability. However you might not be able to scale some applications due to business rules. In such cases, you must determine the cost of the rule.
Clients must be connected to server machines in a scalable manner. This means that your network must also be scalable!
Oracle9i Real Application Clusters Deployment and Performance for information on designing databases and application analysis, and on the sequence number generator
Note:
See Also:
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|