Release 1 (9.0.1)
Part Number A90237-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Data Warehousing Guide Release 1 (9.0.1) Part Number A90237-01 |
|
![]()
![]()
Data warehouses often contain large tables and require techniques both for managing these large tables and for providing good query performance across these large tables. This chapter discusses two key methodologies for addressing these needs: parallelism and partitioning.
These topics are discussed:
Parallel execution dramatically reduces response time for data-intensive operations on large databases typically associated with decision support systems (DSS) and data warehouses. You can also implement parallel execution on certain types of online transaction processing (OLTP) and hybrid systems. Parallel execution is sometimes called parallelism. Simply expressed, parallelism is the idea of breaking down a task so that, instead of one process doing all of the work in a query, many processes do part of the work at the same time. An example of this is when four processes handle four different quarters in a year instead of one process handling all four quarters by itself. The improvement in performance can be quite high. In this case, each quarter will be a partition, a smaller and more manageable unit of an index or table.
|
See Also:
Oracle9i Database Concepts for further conceptual information regarding parallel execution |
The most common use of parallel execution is in DSS environments. Complex queries, such as those involving joins of several tables or searches of very large tables, are often best executed in parallel.
Parallel execution is useful for many types of operations that access significant amounts of data. Parallel execution improves processing for:
You can also use parallel execution to access object types within an Oracle database. For example, use parallel execution to access LOBs (large objects).
Parallel execution benefits systems that have all of the following characteristics:
If your system lacks any of these characteristics, parallel execution might not significantly improve performance. In fact, parallel execution can reduce system performance on overutilized systems or systems with small I/O bandwidth.
|
See Also:
Chapter 21, "Using Parallel Execution" for further information regarding parallel execution requirements |
Different parallel operations use different types of parallelism. The optimal physical database layout depends on the parallel operations that are most prevalent in your application or even of the necessity of using partitions.
The basic unit of work in parallelism is a called a granule. Oracle divides the operation being parallelized (for example, a table scan, table update, or index creation) into granules. Parallel execution processes execute the operation one granule at a time. The number of granules and their size correlates with the degree of parallelism (DOP). It also affects how well the work is balanced across query server processes. There is no way you can enforce a specific granule strategy as Oracle makes this decision internally.
Block range granules are the basic unit of most parallel operations, even on partitioned tables. Therefore, from an Oracle perspective, the degree of parallelism is not related to the number of partitions.
Block range granules are ranges of physical blocks from a table. The number and the size of the granules are computed during runtime by Oracle to optimize and balance the work distribution for all affected parallel execution servers. The number and size of granules are dependent upon the size of the object and the DOP. Block range granules do not depend on static preallocation of tables or indexes. During the computation of the granules, Oracle takes the DOP into account and tries to assign granules from different datafiles to each of the parallel execution servers to avoid contention whenever possible. Additionally, Oracle considers the disk affinity of the granules on MPP systems to take advantage of the physical proximity between parallel execution servers and disks.
When block range granules are used predominantly for parallel access to a table or index, administrative considerations (such as recovery or using partitions for deleting portions of data) might influence partition layout more than performance considerations.
When Oracle uses partition granules, a query server process works on an entire partition or subpartition of a table or index. Because partition granules are statically determined by the structure of the table or index when a table or index is created, partition granules do not give you the flexibility in parallelizing an operation that block granules do. The maximum allowable DOP is the number of partitions. This might limit the utilization of the system and the load balancing across parallel execution servers.
When Oracle uses partition granules for parallel access to a table or index, you should use a relatively large number of partitions (ideally, three times the DOP), so that Oracle can effectively balance work across the query server processes.
Partition granules are the basic unit of parallel index range scans and of parallel operations that modify multiple partitions of a partitioned table or index. These operations include parallel update, parallel delete, parallel creation of partitioned indexes, and parallel creation of partitioned tables.
In conjunction with parallel execution, partitioning can improve performance in data warehouses. The following are the main design considerations for partitioning:
This section describes the partitioning features that significantly enhance data access and improve overall application performance. This is especially true for applications that access tables and indexes with millions of rows and many gigabytes of data.
Partitioned tables and indexes facilitate administrative operations by enabling these operations to work on subsets of data. For example, you can add a new partition, organize an existing partition, or drop a partition and cause less than a second of interruption to a read-only application.
Using the partitioning methods described in this section can help you tune SQL statements to avoid unnecessary index and table scans (using partition pruning). You can also improve the performance of massive join operations when large amounts of data (for example, several million rows) are joined together by using partition-wise joins. Finally, partitioning data greatly improves manageability of very large databases and dramatically reduces the time required for administrative tasks such as backup and restore.
Granularity can be easily added or removed to the partitioning scheme by splitting partitions. Thus, if a table's data is skewed to fill some partitions more than others, the ones that contain more data can be split to achieve a more even distribution. Partitioning also allows one to swap partitions with a table. By being able to easily add, remove, or swap a large amount of data quickly, swapping can be used to keep a large amount of data that is being loaded inaccessible until loading is completed, or can be used as a way to stage data between different phases of use. Some examples are current day's transactions or online archives.
Oracle offers four partitioning methods:
Each partitioning method has different advantages and design considerations. Thus, each method is more appropriate for a particular situation.
Range partitioning maps data to partitions based on ranges of partition key values that you establish for each partition. It is the most common type of partitioning and is often used with dates. For example, you might want to partition sales data into monthly partitions.
Range partitioning maps rows to partitions based on ranges of column values. Range partitioning is defined by the partitioning specification for a table or index:
PARTITION BY RANGE (column_list)
and by the partitioning specifications for each individual partition:
VALUES LESS THAN (value_list)
where:
column_list
is an ordered list of columns that determines the partition to which a row or an index entry belongs. These columns are called the partitioning columns. The values in the partitioning columns of a particular row constitute that row's partitioning key.
value_list
is an ordered list of values for the columns in the column list. Each value must be either a literal or a TO_DATE or RPAD function with constant arguments. Only the VALUES LESS THAN clause is allowed. This clause specifies a non-inclusive upper bound for the partitions. All partitions, except the first, have an implicit low value specified by the VALUES LESS THAN literal on the previous partition. Any binary values of the partition key equal to or higher than this literal are added to the next higher partition. Highest partition being where MAXVALUE literal is defined. Keyword, MAXVALUE, represents a virtual infinite value that sorts higher than any other value for the data type, including the null value.
The statement below creates a table sales_range that is range partitioned on the sales_date field.
CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) ( PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')), PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY')), PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','DD/MM/YYYY')), PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','DD/MM/YYYY')), );
Hash partitioning maps data to partitions based on a hashing algorithm that Oracle applies to a partitioning key that you identify. The hashing algorithm evenly distributes rows among partitions, giving partitions approximately the same size. Hash partitioning is the ideal method for distributing data evenly across devices. Hash partitioning is a good and easy-to-use alternative to range partitioning when data is not historical and there is no obvious column or column list where logical range partition pruning can be advantageous.
Oracle uses a linear hashing algorithm and to prevent data from clustering within specific partitions, you should define the number of partitions by a power of two (for example, 2, 4, 8).
The statement below creates a table sales_hash, which is hash partitioned on the salesman_id field. data1, data2, data3, and data4 are tablespace names.
CREATE TABLE sales_hash (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION BY HASH(salesman_id) PARTITIONS 4 STORE IN (data1, data2, data3, data4);
List partitioning enables you to explicitly control how rows map to partitions. You do this by specifying a list of discrete values for the partitioning column in the description for each partition. This is different from range partitioning, where a range of values is associated with a partition and with hash partitioning, where you have no control of the row-to-partition mapping. The advantage of list partitioning is that you can group and organize unordered and unrelated sets of data in a natural way.
CREATE TABLE sales_list (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_state VARCHAR2(20), sales_amount NUMBER(10), sales_date DATE) PARTITION BY LIST(sales_state) ( PARTITION sales_west VALUES IN('California', 'Hawaii'), PARTITION sales_east VALUES IN ('New York', 'Virginia', 'Florida'), PARTITION sales_central VALUES IN('Texas', 'Illinois'), );
Composite partitioning combines range and hash partitioning. Oracle first distributes data into partitions according to boundaries established by the partition ranges. Then Oracle uses a hashing algorithm to further divide the data into subpartitions within each range partition.
You can choose whether or not to inherit the partitioning strategy of the underlying tables. You can create both local and global indexes on a table partitioned by range, hash, or composite methods. Local indexes inherit the partitioning attributes of their related tables. For example, if you create a local index on a composite table, Oracle automatically partitions the local index using the composite method.
Oracle supports only range partitioning for global partitioned indexes. You cannot partition global indexes using the hash or composite partitioning methods.
This section describes performance issues for:
Range partitioning is a convenient method for partitioning historical data. The boundaries of range partitions define the ordering of the partitions in the tables or indexes.
Range partitioning organizes data by time intervals on a column of type DATE. Thus, most SQL statements accessing range partitions focus on timeframes. An example of this is a SQL statement similar to "select data from a particular period in time." In such a scenario, if each partition represents data for one month, the query "find data of month 98-DEC" needs to access only the December partition of year 98. This reduces the amount of data scanned to a fraction of the total data available, an optimization method called partition pruning.
Range partitioning is also ideal when you periodically load new data and purge old data. It is easy to add or drop partitions.
It is common to keep a rolling window of data, for example keeping the past 36 months' worth of data online. Range partitioning simplifies this process. To add data from a new month, you load it into a separate table, clean it, index it, and then add it to the range-partitioned table using the EXCHANGE PARTITION statement, all while the original table remains online. Once you add the new partition, you can drop the trailing month with the DROP PARTITION statement. The alternative to using the DROP PARTITION statement can be to archive the partition and make it read only, but this works only when your partitions are in separate tablespaces.
In conclusion, consider using range partitioning when:
ORDER_DATE or PURCHASE_DATE. Partitioning the table on that column enables partition pruning.
This SQL example creates the table sales for a period of two years, 1999 and 2000, and partitions it by range according to the column s_salesdate to separate the data into eight quarters, each corresponding to a partition. In the example, the partitioning granularity is not restricted to any logical range.
CREATE TABLE sales (s_productid NUMBER, s_saledate DATE, s_custid NUMBER, s_totalprice NUMBER) PARTITION BY RANGE(s_saledate) (PARTITION sal99q1 VALUES LESS THAN (TO_DATE('01-APR-1999', 'DD-MON-YYYY')), PARTITION sal99q2 VALUES LESS THAN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY')), PARTITION sal99q3 VALUES LESS THAN (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')), PARTITION sal99q4 VALUES LESS THAN (TO_DATE('01-JAN-2000', 'DD-MON-YYYY')), PARTITION sal00q1 VALUES LESS THAN (TO_DATE('01-APR-2000', 'DD-MON-YYYY')), PARTITION sal00q2 VALUES LESS THAN (TO_DATE('01-JUL-2000', 'DD-MON-YYYY')), PARTITION sal00q3 VALUES LESS THAN (TO_DATE('01-OCT-2000', 'DD-MON-YYYY')), PARTITION sal00q4 VALUES LESS THAN (TO_DATE('01-JAN-2001', 'DD-MON-YYYY')));
The way Oracle distributes data in hash partitions does not correspond to a business or a logical view of the data, as it does in range partitioning. Consequently, hash partitioning is not an effective way to manage historical data. However, hash partitions share some performance characteristics with range partitions. For example, partition pruning is limited to equality predicates. You can also use partition-wise joins, parallel index access, and parallel DML.
As a general rule, use hash partitioning for these purposes:
If you add or merge a hashed partition, Oracle automatically rearranges the rows to reflect the change in the number of partitions and subpartitions. The hash function that Oracle uses is especially designed to limit the cost of this reorganization. Instead of reshuffling all the rows in the table, Oracles uses an "add partition" logic that splits one and only one of the existing hashed partitions. Conversely, Oracle coalesces a partition by merging two existing hashed partitions.
Although the hash function's use of "add partition" logic dramatically improves the manageability of hash partitioned tables, it means that the hash function can cause a skew if the number of partitions of a hash partitioned table, or the number of subpartitions in each partition of a composite table, is not a power of two. In the worst case, the largest partition can be twice the size of the smallest. So for optimal performance, create a number of partitions and subpartitions per partition that is a power of two. For example, 2, 4, 8, 16, 32, 64, 128, and so on.
This example creates four hashed partitions for the table sales using the column s_productid as the partition key:
CREATE TABLE sales (s_productid NUMBER, s_saledate DATE, s_custid NUMBER, s_totalprice NUMBER) PARTITION BY HASH(s_productid) PARTITIONS 4;
Specify partition names only if you want some of the partitions to have different properties from those of the table. Otherwise, Oracle automatically generates internal names for the partitions. Also, you can use the STORE IN clause to assign hash partitions to tablespaces in a round-robin manner.
You should use list partitioning when you want to specifically map rows to partitions based on discrete values.
Unlike range and hash partitioning, multi-column partition keys are not supported for list partitioning. If a table is partitioned by list, the partitioning key can only consist of a single column of the table.
Composite partitioning offers the benefits of both range and hash partitioning. With composite partitioning, Oracle first partitions by range. Then within each range Oracle creates subpartitions and distributes data within them using the same hashing algorithm it uses for hash partitioned tables.
Data placed in composite partitions is logically ordered only by the boundaries that define the range level partitions. The partitioning of data within each partition has no logical organization beyond the identity of the partition to which the subpartitions belong.
Consequently, tables and local indexes partitioned using the composite method:
Use the composite partitioning method for tables and local indexes if:
Most large tables in a data warehouse should use range partitioning. Composite partitioning should be used for very large tables or for data warehouses with a well-defined need for the conditions listed above. When using the composite method, Oracle stores each subpartition on a different segment. Thus, the subpartitions may have properties that differ from the properties of the table or from the partition to which the subpartitions belong.
The following example partitions the table sales by range on the column s_saledate to create four partitions that order data by time. Then, within each range partition, the data is further subdivided into 16 subpartitions by hash on the column s_productid.
CREATE TABLE sales( s_productid NUMBER, s_saledate DATE, s_custid NUMBER, s_totalprice NUMBER) PARTITION BY RANGE (s_saledate) SUBPARTITION BY HASH (s_productid) SUBPARTITIONS 16 (PARTITION sal99q1 VALUES LESS THAN (TO_DATE('01-APR-1999', 'DD-MON-YYYY')), PARTITION sal99q2 VALUES LESS THAN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY')), PARTITION sal99q3 VALUES LESS THAN (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')), PARTITION sal99q4 VALUES LESS THAN (TO_DATE('01-JAN-2000', 'DD-MON-YYYY')));
Each hashed subpartition contains sales data for a single quarter ordered by product code. The total number of subpartitions is 4x16 or 64.
Partition pruning is an essential performance feature for data warehouses. In partition pruning, the cost-based optimizer analyzes FROM and WHERE clauses in SQL statements to eliminate unneeded partitions when building the partition access list. This enables Oracle to perform operations only on those partitions that are relevant to the SQL statement. Oracle prunes partitions when you use range, equality, and IN-list predicates on the range partitioning columns, and when you use equality and IN-list predicates on the hash partitioning columns.
Partition pruning dramatically reduces the amount of data retrieved from disk and shortens the use of processing time, improving query performance and resource utilization. If you partition the index and table on different columns (with a global, partitioned index), partition pruning also eliminates index partitions even when the partitions of the underlying table cannot be eliminated.
On composite partitioned objects, Oracle can prune at both the range partition level and at the hash subpartition level using the relevant predicates. Refer to the table sales from the previous example, partitioned by range on the column s_salesdate and subpartitioned by hash on column s_productid, and consider the following example:
SELECT * FROM sales WHERE s_saledate BETWEEN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY')) AND (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')) AND s_productid = 1200;
Oracle uses the predicate on the partitioning columns to perform partition pruning as follows:
sal99q2 and sal99q3.
s_productid=1200. The mapping between the subpartition and the predicate is calculated based on Oracle's internal hash distribution function.
In "Partition Pruning Example", the date value was fully specified as four digits for the year using the TO_DATE function, just as it was in the underlying table's range partitioning description ("Composite Partitioning Example"). While this is the recommended format for specifying date values, the optimizer can prune partitions using the predicates on s_salesdate when you use other formats, as in the following example:
SELECT * FROM sales WHERE s_saledate BETWEEN TO_DATE('01-JUL-99', 'DD-MON-RR') AND TO_DATE('01-OCT-99', 'DD-MON-RR') AND s_productid = 1200;
Although "Partition Pruning with DATE Example" uses the DD-MON-RR format, which is not the same as the base partition in "Hash Partitioning Example", the optimizer can still prune properly.
If you execute an EXPLAIN PLAN statement on the query, the PARTITION_START and PARTITION_STOP columns of the output table do not specify which partitions Oracle is accessing. Instead, you see the keyword KEY for both columns. The keyword KEY for both columns means that partition pruning occurs at run-time. It can also affect the execution plan because the information about the pruned partitions is missing compared to the same statement using the same TO_DATE function than the partition table definition.
To avoid I/O bottlenecks, when Oracle is not scanning all partitions because some have been eliminated by pruning, spread each partition over several devices. On MPP systems, spread those devices over multiple nodes.
Partition-wise joins reduce query response time by minimizing the amount of data exchanged among parallel execution servers when joins execute in parallel. This significantly reduces response time and improves the use of both CPU and memory resources. In Oracle Real Application Cluster environments, partition-wise joins also avoid or at least limit the data traffic over the interconnect, which is the key to achieving good scalability for massive join operations.
Partition-wise joins can be full or partial. Oracle decides which type of join to use.
A full partition-wise join divides a large join into smaller joins between a pair of partitions from the two joined tables. To use this feature, you must equipartition both tables on their join keys. For example, consider a large join between a sales table and a customer table on the column customerid. The query "find the records of all customers who bought more than 100 articles in Quarter 3 of 1999" is a typical example of a SQL statement performing such a join. The following is an example of this:
SELECT c_customer_name, COUNT(*) FROM sales, customer WHERE s_customerid = c_customerid AND s_saledate BETWEEN TO_DATE('01-JUL-1999', 'DD-MON-YYYY') AND (TO_DATE('01-OCT-1999', 'DD-MON-YYYY') GROUP BY c_customer_name HAVING COUNT(*) > 100;
This large join is typical in data warehousing environments. The entire customer table is joined with one quarter of the sales data. In large data warehouse applications, this might mean joining millions of rows. The join method to use in that case is obviously a hash join. You can reduce the processing time for this hash join even more if both tables are equipartitioned on the customerid column. This enables a full partition-wise join.
When you execute a full partition-wise join in parallel, the granule of parallelism, as described under "Granules of Parallelism", is a partition. As a result, the degree of parallelism is limited to the number of partitions. For example, you require at least 16 partitions to set the degree of parallelism of the query to 16.
You can use various partitioning methods to equipartition both tables on the column customerid with 16 partitions. These methods are described in these subsections.
This is the simplest method: the customer and sales tables are both partitioned by hash into 16 partitions, on the s_customerid and c_customerid columns. This partitioning method enables full partition-wise join when the tables are joined on s_customerid and c_customerid, both representing the same customer identification number. Because you are using the same hash function to distribute the same information (customer ID) into the same number of hash partitions, you can join the equivalent partitions. They are storing the same values.
In serial, this join is performed between pairs of matching hash partitions, one at a time. When one partition pair has been joined, the join of another partition pair begins. The join completes when the 16 partition pairs have been processed.
Parallel execution of a full partition-wise join is a straightforward parallelization of the serial execution. Instead of joining one partition pair at a time, 16 partition pairs are joined in parallel by the 16 query servers. Figure 5-1 illustrates the parallel execution of a full partition-wise join.
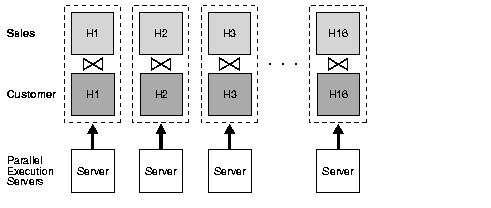
In Figure 5-1, assume that the degree of parallelism and the number of partitions are the same, in other words, 16 for both. Defining more partitions than the degree of parallelism may improve load balancing and limit possible skew in the execution. If you have more partitions than query servers, when one query server completes the join of one pair of partitions, it requests that the query coordinator give it another pair to join. This process repeats until all pairs have been processed. This method enables the load to be balanced dynamically when the number of partition pairs is greater than the degree of parallelism, for example, 64 partitions with a degree of parallelism of 16.
In Oracle Real Application Cluster environments running on shared-nothing or MPP platforms, placing partitions on nodes is critical to achieving good scalability. To avoid remote I/O, both matching partitions should have affinity to the same node. Partition pairs should be spread over all nodes to avoid bottlenecks and to use all CPU resources available on the system.
Nodes can host multiple pairs when there are more pairs than nodes. For example, with an 8-node system and 16 partition pairs, each node receives two pairs.
This method is a variation of the hash-hash method. The sales table is a typical example of a table storing historical data. For all the reasons mentioned under the heading "When to Use Range Partitioning", range is the logical initial partitioning method.
For example, assume you want to partition the sales table into eight partitions by range on the column s_salesdate. Also assume you have two years and that each partition represents a quarter. Instead of using range partitioning, you can use composite partitioning to enable a full partition-wise join while preserving the partitioning on s_salesdate. Partition the sales table by range on s_salesdate and then subpartition each partition by hash on s_customerid using 16 subpartitions per partition, for a total of 128 subpartitions. The customer table can still use hash partitioning with 16 partitions.
When you use the method just described, a full partition-wise join works similarly to the one created by the hash/hash method. The join is still divided into 16 smaller joins between hash partition pairs from both tables. The difference is that now each hash partition in the sales table is composed of a set of 8 subpartitions, one from each range partition.
Figure 5-2 illustrates how the hash partitions are formed in the sales table. Each cell represents a subpartition. Each row corresponds to one range partition, for a total of 8 range partitions. Each range partition has 16 subpartitions. Each column corresponds to one hash partition for a total of 16 hash partitions; each hash partition has 8 subpartitions. Note that hash partitions can be defined only if all partitions have the same number of subpartitions, in this case, 16.
Hash partitions are implicit in a composite table. However, Oracle does not record them in the data dictionary, and you cannot manipulate them with DDL commands as you can range partitions.
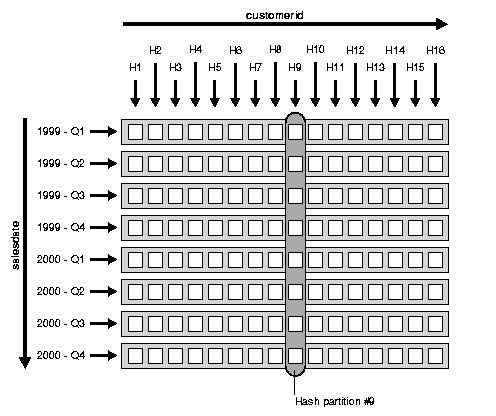
Composite-hash partitioning is effective because it lets you combine pruning (on s_salesdate) with a full partition-wise join (on customerid). In the previous example query, pruning is achieved by scanning only the subpartitions corresponding to Q3 of 1999, in other words, row number 3 in Figure 5-2. Oracle then joins these subpartitions with the customer table, using a full partition-wise join.
All characteristics of the hash-hash partition-wise join apply to the composite-hash partition-wise join. In particular, for this example, these two points are common to both methods:
sales table has 128 subpartitions, it has only 16 hash partitions.
sales table shown by the eight circled subpartitions, on the same node as hash partition 9 of the customer table.
If needed, you can also partition the customer table by the composite method. For example, you partition it by range on a postal code column to enable pruning based on postal code. You then subpartition it by hash on customerid using the same number of partitions (16) to enable a partition-wise join on the hash dimension.
You can also join range partitioned tables in a partition-wise manner, but this is relatively uncommon. This is more complex to implement because you must know the distribution of the data before performing the join. Furthermore, if you do not correctly identify the partition bounds so that you have partitions of equal size, data skew during the execution may result.
The basic principle for using range-range is the same as for using hash-hash: you must equipartition both tables. This means that the number of partitions must be the same and the partition bounds must be identical. For example, assume that you know in advance that you have 10 million customers, and that the values for customerid vary from 1 to 10,000,000. In other words, you have 10 million possible different values. To create 16 partitions, you can range partition both tables, sales on c_customerid and customer on s_customerid. You should define partition bounds for both tables in order to generate partitions of the same size. In this example, partition bounds should be defined as 625001, 1250001, 1875001, ... 10000001, so that each partition contains 625000 rows.
Finally, you can also subpartition one or both tables on another column. Therefore, the range/composite and composite/composite methods on the range dimension are also valid for enabling a full partition-wise join on the range dimension.
Oracle can perform partial partition-wise joins only in parallel. Unlike full partition-wise joins, partial partition-wise joins require you to partition only one table on the join key, not both tables. The partitioned table is referred to as the reference table. The other table may or may not be partitioned. Partial partition-wise joins are more common than full partition-wise joins.
To execute a partial partition-wise join, Oracle dynamically repartitions the other table based on the partitioning of the reference table. Once the other table is repartitioned, the execution is similar to a full partition-wise join.
The performance advantage that partial partition-wise joins have over joins in non-partitioned tables is that the reference table is not moved during the join operation. Parallel joins between non-partitioned tables require both input tables to be redistributed on the join key. This redistribution operation involves exchanging rows between parallel execution servers. This is a CPU-intensive operation that can lead to excessive interconnect traffic in Oracle Real Application Cluster environments. Partitioning large tables on a join key, either a foreign or primary key, prevents this redistribution every time the table is joined on that key. Of course, if you choose a foreign key to partition the table, which is the most common scenario, select a foreign key that is involved in many queries.
To illustrate partial partition-wise joins, consider the previous sales/customer example. Assume that s_customer is not partitioned or is partitioned on a column other than c_customerid. Because sales is often joined with customer on customerid, and because this join dominates our application workload, partition sales on s_customerid to enable partial partition-wise join every time customer and sales are joined. As in full partition-wise join, we have several alternatives:
The simplest method to enable a partial partition-wise join is to partition sales by hash on c_customerid. The number of partitions determines the maximum degree of parallelism, because the partition is the smallest granule of parallelism for partial partition-wise join operations.
The parallel execution of a partial partition-wise join is illustrated in Figure 5-3, which assumes that both the degree of parallelism and the number of partitions of sales are 16. The execution involves two sets of query servers: one set, labeled set 1 on the figure, scans the customer table in parallel. The granule of parallelism for the scan operation is a range of blocks.
Rows from customer that are selected by the first set, in this case all rows, are redistributed to the second set of query servers by hashing customerid. For example, all rows in customer that could have matching rows in partition H1 of sales are sent to query server 1 in the second set. Rows received by the second set of query servers are joined with the rows from the corresponding partitions in sales. Query server number 1 in the second set joins all customer rows that it receives with partition H1 of sales.
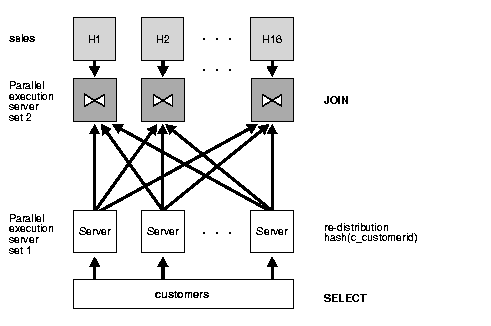
Considerations for full partition-wise joins also apply to partial partition-wise joins:
sales should preferably have affinity to only one node in order to avoid remote I/Os. Also, spread partitions over all nodes to avoid bottlenecks and use all CPU resources available on the system. A node can host multiple partitions when there are more partitions than nodes.
As with full partition-wise joins, the prime partitioning method for the sales table is to use the range method on column s_salesdate. This is because sales is a typical example of a table that stores historical data. To enable a partial partition-wise join while preserving this range partitioning, subpartition sales by hash on column s_customerid using 16 subpartitions per partition. Pruning and partial partition-wise joins can be used together if a query joins customer and sales and if the query has a selection predicate on s_salesdate.
When sales is composite, the granule of parallelism for a partial partition-wise join is a hash partition and not a subpartition. Refer to Figure 5-2 for an illustration of a hash partition in a composite table. Again, the number of hash partitions should be a multiple of the degree of parallelism. Also, on an MPP system, ensure that each hash partition has affinity to a single node. In the previous example, the eight subpartitions composing a hash partition should have affinity to the same node.
Finally, you can use range partitioning on s_customerid to enable a partial partition-wise join. This works similarly to the hash method, but a side effect of range partitioning is that the resulting data distribution could be skewed if the size of the partitions differs. Moreover, this method is more complex to implement because it requires prior knowledge of the values of the partitioning column that is also a join key.
Partition-wise joins offer benefits described in this section:
When executed in parallel, partition-wise joins reduce communications overhead. This is because, in the default case, parallel execution of a join operation by a set of parallel execution servers requires the redistribution of each table on the join column into disjoint subsets of rows. These disjoint subsets of rows are then joined pair-wise by a single parallel execution server.
Oracle can avoid redistributing the partitions because the two tables are already partitioned on the join column. This enables each parallel execution server to join a pair of matching partitions.
This improved performance from using parallel execution is even more noticeable in Oracle Real Application Cluster configurations with internode parallel execution. Partition-wise joins dramatically reduce interconnect traffic. Using this feature is for large DSS configurations that use Oracle Real Application Clusters.
Currently, most Oracle Real Application Clusters platforms, such as MPP and SMP clusters, provide limited interconnect bandwidths compared with their processing powers. Ideally, interconnect bandwidth should be comparable to disk bandwidth, but this is seldom the case. As a result, most join operations in Oracle Real Application Clusters experience high interconnect latencies without parallel execution of partition-wise joins.
Partition-wise joins require less memory than the equivalent join operation of the complete data set of the tables being joined.
In the case of serial joins, the join is performed at the same time on a pair of matching partitions. If data is evenly distributed across partitions, the memory requirement is divided by the number of partitions. There is no skew.
In the parallel case, memory requirements depend on the number of partition pairs that are joined in parallel. For example, if the degree of parallelism is 20 and the number of partitions is 100, 5 times less memory is required because only 20 joins of two partitions are performed at the same time. The fact that partition-wise joins require less memory has a direct effect on performance. For example, the join probably does not need to write blocks to disk during the build phase of a hash join.
The cost-based optimizer weighs the advantages and disadvantages when deciding whether or not to use partition-wise joins.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|