Release 2 (9.0.2)
Part Number A95881-01
Home |
Solution Area |
Contents |
Index |
| Oracle9iAS Containers for J2EE Enterprise JavaBean Developer's Guide and Reference Release 2 (9.0.2) Part Number A95881-01 |
|
EJB clustering offers improved scalability and high-availability through the following circumstances:
The methods for providing load balancing and clustering for failover are different for HTTP requests than for EJB communications because Web components use different protocols than EJB components. This chapter discusses EJB clustering; the instructions for setting up the HTTP failover and load balancing environment is detailed in Oracle9i Application Server Performance Guide.
The following is discussed in this chapter:
To create an EJB cluster, you specify OC4J nodes that are to be involved in the cluster, configure each of them with the same multicast address, username, and password, and deploy the EJB to be clustered to each of the nodes in the cluster.
Unlike HTTP clustering, OC4J nodes included in an EJB cluster are not currently grouped in an island and do not have a load balancer as a front-end. Instead, the EJB client container stubs discover--either statically or dynamically--all the OC4J nodes in the EJB cluster, shuffle the destination addresses, and choose one from this group for the connection. Thus, the only method for load balancing and failover is a random methodology.
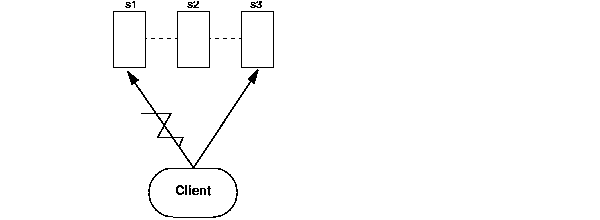
As Figure 7-1 demonstrates, the client container stubs chose server "s1" for its EJB connection. However, sometime during the conversation, the connection went down. At this point, the client container stubs shuffle the remaining OC4J node addresses and choose another server to connect to for the failover. In this example, server "s3" from the OC4J cluster resumes the conversation.
The client container stubs discover the OC4J server addresses by one of the following methods:
The JNDI addresses of all OC4J nodes that should be contacted for load balancing and failover are provided in the lookup URL, and each address is separated by a comma. For example, the following URL definition provides the client container with three OC4J nodes to use for load balancing and failover.
java.naming.provider.url=ormi://s1:23791/ejbsamples,
ormi://s2:23793/ejbsamples, ormi://s3:23791/ejbsamples;
The JNDI addresses of all OC4J nodes that can be contacted for load balancing and failover are dynamically discovered during the first JNDI lookup. The client must perform a lookup with a "lookup:" prefix, as follows:
ic.lookup("lookup:ormi://s1:23971/ejbsamples");
During the JNDI lookup, server "s1" contacts the other OC4J nodes in the cluster, which are identified as a cluster if they all have the same multicast address (host/port), and retrieves their ormi addresses. These addresses are sent back to the client container. From this point forward, the client container shuffles these addresses for any load balancing or failover needs.
However, the client container never tries to rediscover these addresses. Therefore, if you remove a node from the cluster and add another one during the connection, the client container will be unaware of it until the next time the client re-discovers the cluster nodes through the "lookup:" method.
The state of all beans are replicated at the end of every method call to all nodes in the cluster. This option is the most reliable in that the state of the bean is replicated to all nodes in the cluster, using a JMS multicast topic to all nodes in the cluster--which uses the same multicast address. This state stays in the topic until it is needed. Then when a method call comes in on the alternate node, the latest state for the bean is found in the JMS topic, reinstated, and the bean invocation continues.
These methods have different repercussions for each of the EJB types, which are discussed in the following sections:
Stateless session beans do not require any state to be replicated among nodes in a cluster. Thus, the only use of the clustering methods that stateless session beans have is load balancing between nodes. Both the dynamic and state cluster discovery methods can be used for stateless session beans. Failover defaults to the remote invocation handler by redirecting a request.
Stateful session beans require state to be replicated among nodes. In fact, stateful session beans must send all their state between the nodes, which can have a noticeable effect on performance. Thus, the following replication modes are available to you to decide on how to manage the replication performance cost:
setAttribute method of the HTTPSession object. Oracle offers a similar method through a new OC4J-specific class: com.evermind.server.ejb.statefulSessionContext. Although this option is a performant and reliable mechanism, it does not comply with the J2EE specification. Thus, if you provide this within your server code, you cannot port this application to any non-Oracle J2EE server.
The state of the entity bean is saved in a persistent storage, such as a database. Thus, when the client loses the connection to one node in the cluster, it can switch to another node in the cluster without worrying about replication of the entity bean state. However, to ensure that the state is updated from the persistent storage when the load balancing occurs, the entity bean that changes state notifies other nodes that their state is no longer in synch. That is, that their state is "dirty". At this point, nothing is done. If failover occurs and the client accesses another node for this entity bean, then the bean notices that its cache is dirty and resynchronizes its cache to the "READ_COMMITTED" state within the database.
If you have a servlet that invokes an EJB, you must include both the HTTP and EJB clustering. For HTTP clustering options, see the HTTP clustering white paper. The type of EJB clustering you choose is based on the EJB type. If you do not configure for both types, you will not have the proper state replication for the type for which you did not configure.
If the HTTP invokes an EJB that is colocated, the EJBReference cannot be replicated to another node unless EJB clustering has been enabled. Instead, a null pointer will be copied to the other node. So, you must provide for both types of clustering in order for all of the correct information to be replicated.
To enable the OC4J nodes for EJB clustering, you must perform the following steps:
When you are configuring each OC4J node included in the EJB cluster, you must configure each node with an identical multicast address (host and port number), username, and password. However, each node in the cluster should also include its own unique identifier within the cluster. You can test a network for multicast ability by pinging the following hosts:
ping 224.0.0.1.
ping 224.0.0.2.
Modify the rmi.xml file and add the <cluster> tag to configure the multicast address, username, password, and identifier for the OC4J node, as follows:
<cluster host=<multi_host> port=<multi_port> username=<multi_user> password=<multi_pwd> />
where each variable should be the following:
multi_host: The multicast host used for the EJB cluster that communicates among the nodes in the cluster. The IP addresses that you can use for multicast are between 224.0.0.0 and 239.255.255.255. You must specify this variable.
multi_port: The multicast port used for the EJB cluster for communication among the nodes in the cluster.
multi_user/multi_pwd- The username and password used to authenticate itself to other nodes in the cluster. If the username and password are different for other nodes in the cluster, they will fail to communicate. You can have multiple username and password combinations within a multicast address. Those with the same username/password combinations will be considered a unique cluster.
For example, the following cluster definition identifies a cluster on mulitcast address of host=230.0.0.1, port=9127, username=mult1, and password=hwdr:
<cluster host="230.0.0.1" port="9127"
username="mult1" password="hwdr"/>
You can specify the node identifier number as follows:
server.xml file with the <cluster> tag, as follows:
<cluster id="123"/>
Modify the orion-ejb-jar.xml file to add the configuration for stateful session beans and entity beans require for state replication. The following sections offer more details:
You configure the replication type for the stateful session bean within the bean deployment descriptor. Thus, each bean can use a different type of replication.
Set the replication attribute of the <session-deployment> tag in the orion-ejb-jar.xml file to "VMTermination". This is shown below:
<session-deployment replication="VMTermination" .../>
Set the replication attribute of the <session-deployment> tag in the orion-ejb-jar.xml file to "endOfCall". This is shown below:
<session-deployment replication="EndOfCall" .../>
No static configuration is necessary when using the stateful session context to replicate information across the clustered nodes. To replicate the desired state, set the information that you want replicated and execute the setAttribute method within the StatefulSessionContext class in the server code. This enables you to designate what information is replicated and when it is replicated. The state indicated in the parameters of this method is replicated to all nodes in the cluster that share the same multicast address, username, and password.
Configure the clustering for the entity bean within its bean deployment descriptor.
Modify the orion-ejb-jar.xml file to add the clustering-schema attribute to the <entity-deployment> tag, as follows:
<entity-deployment ... clustering-schema="asynchronous-cache" .../>
Deploy the EJB application to all nodes in the cluster. If you do not do so, the client container shuffles through the nodes in the cluster until it finds a node with the EJB deployed on it. This will affect your performance.
You can either deploy the application to each node individually using the -cluster option of the admin.jar tool or you can use Oracle Enterprise Manager (OEM), which can deploy your application for you to multiple nodes.
Use the following syntax with the admin.jar tool:
java -jar admin.jar ormi://myhost admin welcome
-deploy -file bmpapp.ear -deploymentName bmpapp -cluster
The client container designates randomly within the nodes in the cluster where to direct the client request. As discussed above, the container discovers the nodes within the cluster through one of the following methods:
The JNDI addresses of all OC4J nodes that should be contacted for load balancing and failover are supplied in the lookup URL, and each address is separated by a comma. For example, the following URL definition provides the client container with three OC4J nodes to use for load balancing and failover.
java.naming.provider.url=ormi://s1:23791/ejbsamples,
ormi://s2:23793/ejbsamples, ormi://s3:23791/ejbsamples;
The JNDI addresses of all OC4J nodes that can be contacted for load balancing and failover are dynamically discovered during the first JNDI lookup. The client must perform a lookup with a "lookup:" prefix, as follows:
ic.lookup("lookup:ormi://s1:23971/ejbsamples");
During the JNDI lookup, server "s1" contacts the other OC4J nodes in the cluster, which are identified as a cluster if they all have the same multicast address (host/port), and retrieves their ormi addresses. These addresses are sent back to the client container. From this point forward, the client container shuffles these addresses for any load balancing or failover needs.
The client container never tries to rediscover these addresses, though. Therefore, if you remove a node from the cluster and add another one during the connection, the client container will be unaware of it until the next JNDI lookup.
If you configure for load balancing, it balances the load at the connection level. However, if you want load balancing to occur on each JNDI lookup, configure the LoadBalanceOnLookup property to true in the JNDI properties before retrieving the InitialContext, as follows:
env.put("LoadBalanceOnLookup", "true");
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|