Release 2 (9.2)
Part Number A95298-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i OLAP Developer's Guide to the OLAP DML Release 2 (9.2) Part Number A95298-01 |
|
Aggregating Data, 11 of 12
Maintenance of an analytic workspace must usually be done within a restrictive batch window. For this reason, many DBAs perform partial aggregations rather than full aggregations each time they refresh the data. When all of the data is pre-aggregated, this does not present a problem. However, when partial aggregations are performed on data that uses both pre-aggregation and runtime aggregation, then steps must be taken to ensure that the results are correct. Errors in the data occur when the status list generated by the PRECOMPUTE keyword is outdated.
The PRECOMPUTE clause produces a status list that:
AGGREGATE command which data should be pre-calculated, andAGGREGATE function what the AGGREGATE command has doneIf you never use the AGGREGATE command with the AGGREGATE function, you do not need the information.
You should read this information to address the following circumstances:
PRECOMPUTE clause in a RELATION command in an aggregation map.PRECOMPUTE clauses: When you use the PRECOMPUTE keyword in an aggregation map, that PRECOMPUTE clause can be data-dependent instead of simply identifying dimension values or levels.Incremental data loading refers to the process of loading new input data into an existing analytic workspace and then aggregating that data. This usually happens on a regular basis, whether it is on a monthly, weekly, or even daily basis.
For example, suppose you design a new analytic workspace. It contains two variables: sales and units. Suppose that when you build the analytic workspace for the first time, you have input data for one year for both variables. Because sales and units contain exactly the same dimensions in exactly the same order in their definitions, you define one aggregation map that will be shared by both sales and units. You load that input data into the analytic workspace, then use the AGGREGATE command to roll up that input data.
You know that you will be getting new input data for sales and units on the first day of every month. For example, suppose it is March 1. On this day, you expect to receive the sales data and units data for the previous month of February. Your responsibility is to load the February data into the existing analytic workspace and aggregate that input data. This is an incremental data load. The next incremental data load will take place on April 1, and so on.
Typically, when you aggregate this new data, you will use a LIMIT command to ensure that only the new input data will be aggregated. For example, to aggregate only the new input data that you have loaded for February, you might use the following commands:
LIMIT month TO 'FEB99' AGGREGATE sales units USING salesunits.aggmap
This is acceptable as long as you do not change any of the PRECOMPUTE clauses in the aggregation map. If you do, then you must pre-aggregate all of the data.
If you change a PRECOMPUTE clause, then the status list will change. This means that although the data that is produced by the AGGREGATE command after you change the PRECOMPUTE clause will be correct, Oracle OLAP may not be able to return the data that is requested by a user using the AGGREGATE function. The status list might indicate that a value has already been calculated when in fact it has not.
If you make any changes to any PRECOMPUTE clause in one or more RELATION commands in an aggregation map, then you must pre-aggregate all of the data. Otherwise, the AGGREGATE function will use a PRECOMPUTE status list that is out of synchronization with the data, and thus may not generate all of the required values.
Use the following procedure to be sure the data will be aggregated correctly:
PRECOMPUTE clauses in your aggregation map.ALL. (You can use one ALLSTAT command, or a LIMIT TO ALL command for every dimension in the aggregation map.)AGGREGATE command.FUNCDATA keyword when you execute the AGGREGATE command in Step 4.)The clause that follows the PRECOMPUTE keyword is like a LIMIT command. You have the flexibility to specify the limit expression using the values of the data. For example, you can specify the five areas with the lowest sales figures in a time period. The RELATION command might look like this:
RELATION geography.parentrel PRECOMPUTE (BOTTOM 5 BASEDON sales)
Data-dependent limit expressions can vary in their results. In other words, the "bottom five" areas in the analytic workspace that you build in February will not necessarily be the same "bottom five" areas after performing an incremental data load in March. Furthermore, the "bottom five" areas in your March will not necessarily be the same "bottom five" areas after the April incremental data load.
In this situation, the PRECOMPUTE status list is out of synchronization, and the AGGREGATE function may not calculate a needed value because the status list indicates that it was precomputed.
Instead of using a data-dependent PRECOMPUTE clause, you can either:
As you load and aggregate incremental data over the course of time, the status list that is generated by the PRECOMPUTE keyword remains constant when you use one of these methods. However, the five stores in the limit expression or valueset remains the same, regardless of whether or not they still represent the stores with the lowest sales figures.
To keep the limit phrase current, take the following steps:
AGGREGATE function.Refer to "Incremental Data Loading" for the general guidelines you should follow.
If you have changed the input data or your hierarchies, then replace any data that has been aggregated with NA values. These are the steps that you might take: Limit the dimensions to the input data, create a new variable, copy the data from the original variable to the new variable, delete the original variable, and rename the new variable to the name of the original variable.
Instead of using data-dependent PRECOMPUTE clauses, use specific dimension values in the PRECOMPUTE clause. After loading the data, issue a data-dependent LIMIT command to identify the dimension values. Then list those values in the PRECOMPUTE clause. For example,
LIMIT time TO '2001' LIMIT channel TO 'TOTALCHANNEL' LIMIT product TO 'TOTALPROD' LIMIT geography TO BOTTOM 5 BASED ON sales STATUS geography The current status of GEOGRAPHY is: BOGOTA, BORDEAUX, EDINBURGH, KYOTO, BRUSSELS
You would then change the PRECOMPUTE clause to list these areas:
RELATION geography.parentrel PRECOMPUTE ('BOGOTA' 'BORDEAUX' 'EDINBURGH' - 'KYOTO' 'BRUSSELS')
If you want to use data-dependent PRECOMPUTE clauses, create and use a valueset with the PRECOMPUTE clause.
A valueset can be used to store a list of values. For example, the following commands create a valueset for the geography dimension. After performing an incremental update, you would need to update the valueset, but you would not need to edit the aggregation map.
The following commands create a valueset for geography:
DEFINE lowsales.geog VALUESET geography LIMIT time TO '2001' LIMIT channel TO 'TOTALCHANNEL' LIMIT product TO 'TOTALPROD' LIMIT lowsales.geog TO BOTTOM 5 BASED ON sales
The VALUES function returns the status list of the valueset:
SHOW VALUES(lowsales.geog) BOGOTA BORDEAUX EDINBURGH BRUSSELS KYOTO
This RELATION command uses the valueset:
RELATION geography.parentrel PRECOMPUTE (lowsales.geog)
Once you have defined a hierarchy and you have aggregated data, if you move one or more dimension values to a different parent in the hierarchy, then you have changed the hierarchy.
For example, suppose your geography hierarchy has input data for stores. The store data rolls up into cities. The cities roll up into regions, and so on.
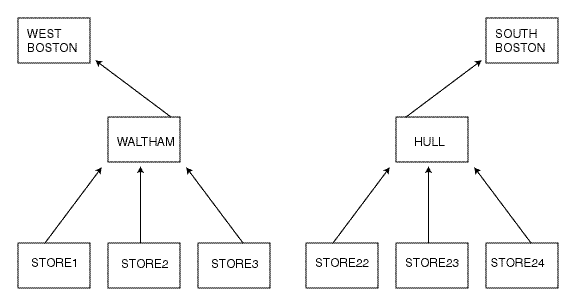
You define your dimensions and variables. You define the hierarchies for your dimensions. You load data and roll it up. Several months later, after you have loaded and rolled up incremental data, one of the stores changes location. For example, STORE22 closes its location in Hull, Massachusetts and then reopens at a new location in Waltham, Massachusetts. Therefore, STORE22 now is part of the WEST BOSTON region instead of SOUTH BOSTON region.
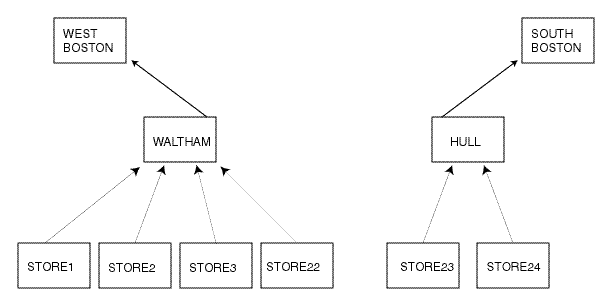
Therefore, you must move the STORE22 dimension value so that its data will roll up to different dimension values in the higher levels of the hierarchy. For example, you must move STORE22 from the HULL path to the WALTHAM path.
When you move one or more dimension values so that their data rolls up in a different path in the hierarchy, you have changed the hierarchy.
Suppose that you receive the most recent month's worth of data for STORE22. You load that data and aggregate it.
Today you find out that last month the store moved to a new city, as well as a new region. This means that you have already aggregated the STORE22 data into HULL, when the STORE22 data now should be aggregated into WALTHAM.
The problem is that you not only need to change the hierarchy, but you need to correct the data so that the STORE22 data aggregates into WALTHAM instead of HULL.
When you change a hierarchy, you can re-aggregate the data in the analytic workspace (after you have changed the hierarchy) in one of two ways:
The advantage of a partial aggregation is that it takes a shorter period of time to complete than a full aggregation. However, the advantage of performing a full rollup is that you know the results will be correct.
Therefore, if you move one or two dimension values in your hierarchy, and you have a small window of time to roll up the analytic workspace, you can perform a partial aggregation; otherwise, perform a full aggregation.
Follow these steps to aggregate the data for the former parents and the current parents of the dimension value that moved in the hierarchy.
STORE22 is the dimension value whose data now aggregates to WALTHAM instead of HULL.STORE22 was previously grouped with STORE23 and STORE24; either one qualifies as a previous sibling of STORE22.geography dimension to STORE22 and STORE23.
LIMIT time TO 'STORE22' 'STORE23'
sales variable.
AGGREGATE sales USING sales.agg
By identifying the dimension value that has moved, you can recalculate its new ancestors (such as WALTHAM). By identifying a previous sibling of the dimension value that has moved, you can recalculated its previous ancestors (such as HULL).
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|


