Release 2 (9.0.2) for UNIX
Part Number A97380-01
Home |
Contents |
Index |
| Oracle9i Application Server Performance Guide Release 2 (9.0.2) for UNIX Part Number A97380-01 |
|
This chapter discusses Oracle9i Application Server performance and tuning concepts.
This chapter contains the following sections:
To maximize Oracle9i Application Server performance, all components need to be monitored, analyzed, and tuned. In the chapters of this guide, the tools used to monitor performance and the techniques for optimizing the performance of Oracle9iAS components, such as Oracle HTTP Server and Oracle9iAS Containers for J2EE (OC4J) are described.
Following are performance terms used in this book:
The ability to handle multiple requests simultaneously. Threads and processes are examples of concurrency mechanisms.
A number generated from a string of text with an algorithm. The hash value is substantially smaller than the text itself. Hash numbers are used for security and for faster access to data.
The time that one system component spends waiting for another component in order to complete the entire task. Latency can be defined as wasted time. In networking contexts, latency is defined as the travel time of a packet from source to destination.
The ability of a system to provide throughput in proportion to, and limited only by, available hardware resources. A scalable system is one that can handle increasing numbers of requests without adversely affecting response time and throughput.
Performance must be built in. You must anticipate performance requirements during application analysis and design, and balance the costs and benefits of optimal performance. This section introduces some fundamental concepts:
"Performance Targets" for a discussion on performance requirements and determining what parts of the system to tune.
See Also:
Because response time equals service time plus wait time, you can increase performance in this area by:
Figure 1-1 illustrates ten independent sequential tasks competing for a single resource as time elapses.
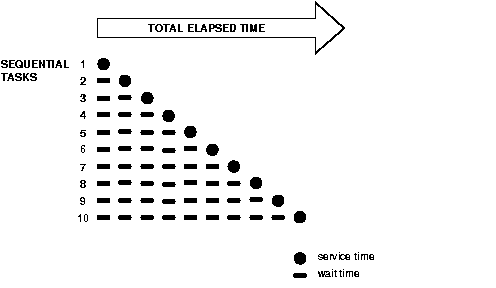
In the example shown in Figure 1-1, only task 1 runs without waiting. Task 2 must wait until task 1 has completed; task 3 must wait until tasks 1 and 2 have completed, and so on. Although the figure shows the independent tasks as the same size, the size of the tasks will vary.
In parallel processing with multiple resources, more resources are available to the tasks. Each independent task executes immediately using its own resource and no wait time is involved.
The Oracle HTTP Server processes requests in this fashion, allocating client requests to available httpd processes. The MaxClients parameter specifies the maximum number of httpd processes simultaneously available to handle client requests. When the number of processes in use reaches the MaxClients value, the server refuses connections until requests are completed and processes are freed.
System throughput is the amount of work accomplished in a given amount of time. You can increase throughput by:
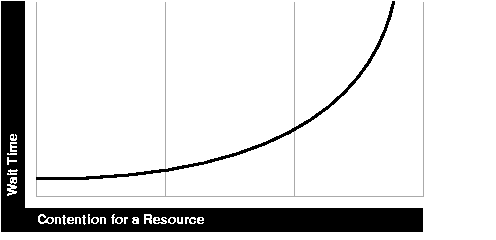
While the service time for a task may stay the same, wait time will lengthen with increased contention. If many users are waiting for a service that takes one second, the tenth user must wait 9 seconds. Figure 1-2 shows the relationship between wait time and resource contention. In the figure, the graph illustrates that wait time increases exponentially as contention for a resource increases.
Resources such as CPU, memory, I/O capacity, and network bandwidth are key to reducing service time. Adding resources increases throughput and reduces response time. Performance depends on these factors:
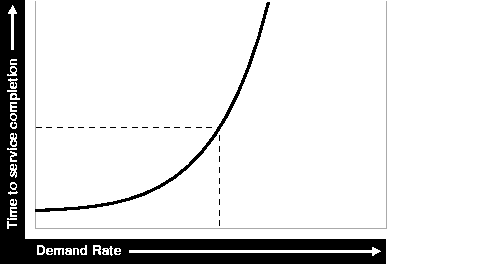
Figure 1-3 shows the relationship between time to service completion and demand rate. The graph in the figure illustrates that as the number of units requested rises, the time to service completion increases.
To manage this situation, you have two options:
Excessive demand increases response time and reduces throughput, as illustrated by the graph in Figure 1-4.
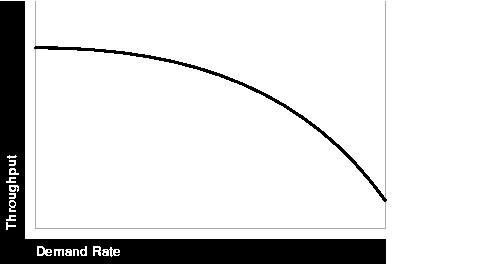
If the demand rate exceeds the achievable throughput, then determine through monitoring which resource is exhausted and increase the resource, if possible.
Performance problems can be relieved by making adjustments in the following:
Reducing the resource (CPU, memory) consumption of each request can improve performance. This might be achieved by pooling and caching.
Rescheduling or redistributing the work will relieve some problems.
Increasing or reallocating resources (such as CPUs) relieves some problems.
Whether you are designing or maintaining a system, you should set specific performance goals so that you know how and what to optimize. If you alter parameters without a specific goal in mind, you can waste time tuning your system without significant gain.
An example of a specific performance goal is an order entry response time under three seconds. If the application does not meet that goal, identify the cause (for example, I/O contention), and take corrective action. During development, test the application to determine if it meets the designed performance goals.
Tuning usually involves a series of trade-offs. After you have determined the bottlenecks, you may have to modify performance in some other areas to achieve the desired results. For example, if I/O is a problem, you may need to purchase more memory or more disks. If a purchase is not possible, you may have to limit the concurrency of the system to achieve the desired performance. However, if you have clearly defined goals for performance, the decision on what to trade for higher performance is easier because you have identified the most important areas.
Application developers, database administrators, and system administrators must be careful to set appropriate performance expectations for users. When the system carries out a particularly complicated operation, response time may be slower than when it is performing a simple operation. Users should be made aware of which operations might take longer.
With clearly defined performance goals, you can readily determine when performance tuning has been successful. Success depends on the functional objectives you have established with the user community, your ability to measure whether or not the criteria are being met, and your ability to take corrective action to overcome any exceptions.
Ongoing performance monitoring enables you to maintain a well tuned system. Keeping a history of the application's performance over time enables you to make useful comparisons. With data about actual resource consumption for a range of loads, you can conduct objective scalability studies and from these predict the resource requirements for anticipated load volumes.
Achieving optimal effectiveness in your system requires planning, monitoring, and periodic adjustment. The first step in performance tuning is to determine the goals you need to achieve and to design effective usage of available technology into your applications. After implementing your system, it is necessary to periodically monitor and adjust your system. For example, you might want to ensure that 90% of the users experience response times no greater than 5 seconds and the maximum response time for all users is 20 seconds. Usually, it's not that simple. Your application may include a variety of operations with differing characteristics and acceptable response times. You need to set measurable goals for each of these.
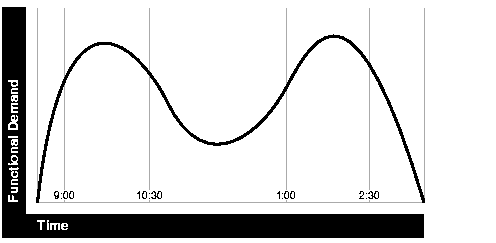
You also need to determine variances in the load. For example, users might access the system heavily between 9:00am and 10:00am and then again between 1:00pm and 2:00pm, as illustrated by the graph in Figure 1-5. If your peak load occurs on a regular basis, for example, daily or weekly, the conventional wisdom is to configure and tune systems to meet your peak load requirements. The lucky users who access the application in off-time will experience better response times than your peak-time users. If your peak load is infrequent, you may be willing to tolerate higher response times at peak loads for the cost savings of smaller hardware configurations.
Performance spans several areas:
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|