10g (9.0.4)
Part Number B10268-01
Contents |
Home | Solution Area | Index |
| Oracle Application Server Discoverer Plus User's Guide 10g (9.0.4) Part Number B10268-01 |
|
This appendix contains the following sections:
For example:
For example:
For example:
For example:
For more information about Oracle functions in general, refer to the following Oracle publications:
The examples in the following sections use the Video Stores Tutorial supplied with Discoverer. If you do not have the Video Stores Tutorial installed, contact the Discoverer manager.
Note: If that database version that you are using does not support IF or CASE statements, you can use DECODE instead. Alternatively, you can create a PL/SQL function in the database.
For information about how to create calculations, see "How to create calculations". You can also find a worked example of creating a calculation in 'Exercise 6 - Adding Calculations' in the Oracle Application Server Discoverer Plus Tutorial.
You often use parameters to provide dynamic input to calculations. This enables other values to be entered arbitrarily for more effective analysis. In other words, to provide a different value to a calculation, you simply refresh the worksheet and enter a new value in the "Edit Parameter Values dialog".
Parameter values used in calculations are prefixed with a colon (:). For example, a parameter called Hypothetical Value would be referenced in a calculation as follows:
For more information about using parameter values in calculations, see "About using parameters to collect dynamic user input".
The examples in this section show you how to use basic functions with Discoverer to manipulate and analyze data.
Examples:
This example calculates the number of rows returned by a query using the Oracle function ROWCOUNT().

The worksheet shows the number of rows returned for each city in the central region for the year 2000.
This example calculates a 25% increase in sales.
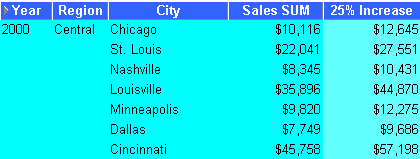
The worksheet shows a 25% increase in sales for cities in the central region.
As well as the extensive range of mathematical functions available in Discoverer, you also have access to a wide range of number and text formatting functions. This example uses a calculation to re-format City text data to upper-case

The figure above shows a worksheet containing the city names for the central region converted to upper case.
The examples in this section show you how to use the Oracle8i analytic functions with Discoverer to perform detailed data analysis.
This section contains the following topics:
Analytic functions are classified in the following categories:
When you use analytic functions, note that they have a precise definition which might not change as you drill, pivot, or sort the result set. For example, if you use the Rank function to assign ranks to sales figures partitioned by quarter, if you drill down to the month level, the rank still only applies to the quarter level.
Discoverer Plus provides easy-to-use templates for the most popular analytic functions (for more information, see "What analytic function templates are available in Discoverer").
If you want to create an analytic function that does not have a template, you can either type or paste it directly into the Calculation field on the "New Calculation dialog", or you can select it from the function list.
If you select analytic functions from the function list on the "New Calculation dialog", Discoverer copies a blank analytic function into the Calculation field. The blank analytic function contains expr prompts for missing values that tell you what information you might need to provide. The expr prompts are designed to cover most types of usage, and should be used only as a guide. In other words, you will not always need to use every expr prompt to define an analytic function.
For example, when you select the RANK analytic function in the "New Calculation dialog", Discoverer types the following text into the Calculation field:
Although you can define a complex function using both expressions (expr1 and expr2), you can often define a simple function using only the ORDER BY expression; for example:
Ranking functions compute the league table position (or rank) of an item with respect to other items in an ordered list.
Examples:
Hint: You can also use analytic function templates to quickly and easily create calculations based on ranking functions (for more information, see "How to create a new calculation using an analytic function template".
This example calculates the league table position (or rank) of a set of sales figures.
The worksheet shows the league table position of sales figures for cities in the year 2000.
This example calculates the league table position (or rank) of a set of sales figures within each region.
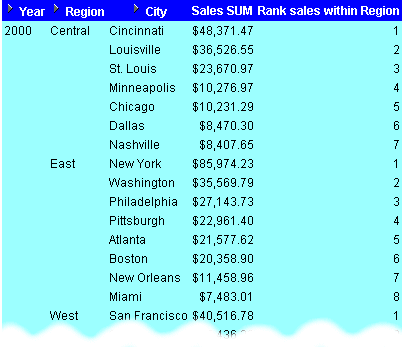
The worksheet shows the league table position of sales figures for cities grouped by region within year.
This example calculates the league table position (or rank) of a set of sales figures and displays the top three selling cities.
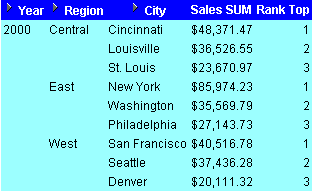
The worksheet shows a league table of the top three highest sales figures for each region within year.
This example calculates the league table position (or rank) of a set of sales figures and displays the top three and bottom three performing cities per region.
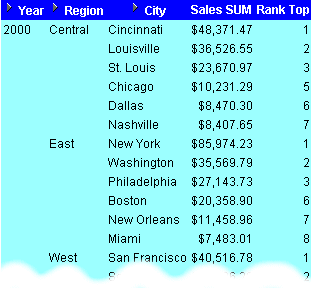
The worksheet shows a league table of the three highest and three lowest sales figures for each region within year.
Banding is a type of ranking that divides a list of values in a partition into a specified number of groups called bands (also known as buckets) and assigns each value to a band.
Examples:
Hint: You can also use analytic function templates to quickly and easily create calculations based on banding functions (for more information, see "How to create a new calculation using an analytic function template".
Two common types of banding are:
Here, the function typically takes the largest value minus the lowest value, and divides the result by the number of bands required. This value defines the range of each Band.
Values are then assigned to bands according to which range they fall into. Therefore, the number of values in each Band might differ. For example, if we have 100 values and divide them into four equi-width bands, each band might contain different numbers of values.
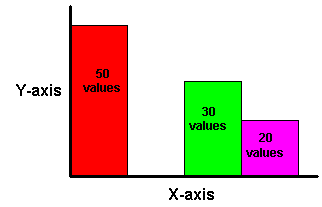
Use the GREATEST function or the CASE function to produce equi-width bands based on value.
Note: If that database version that you are using does not support IF or CASE statements, you can use DECODE instead. Alternatively, you can create a PL/SQL function in the database.
Hint: If you are using an Oracle9i database, use the WIDTH_BUCKET function to produce equi-width bands (see "Example: Producing equi-width bands using WIDTH_BUCKET").
Here, the function divides the number of values in the partition by the number of bands, which gives the number of values in each band. An equal number of values are then placed in each band. For example, if we have 100 values and divide them into four equi-height bands, each band contains 25 values.
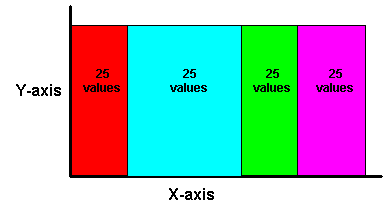
Use the NTILE function to produce equi-height bands based on rank.
This example divides sales figures into bands according to their value (e.g. for frequency analysis). For more information, see "Example: Banding by value (2)".
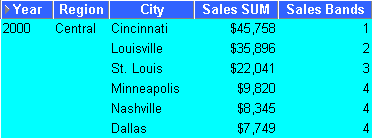
The worksheet shows equi-width bands for sales figures for cities in the central region within year.
This example divides sales figures into bands according to their value. The example creates the same results as the example in "Example: Banding by value (1)", except that it uses a CASE statement rather than the GREATEST function (e.g. for frequency analysis).
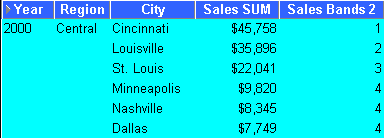
The worksheet shows equi-width bands for sales figures for cities in the central region within year.

Text description of the illustration af_bands.gif
This example divides sales figures into two bands according to their rank (e.g. for percentile analysis).
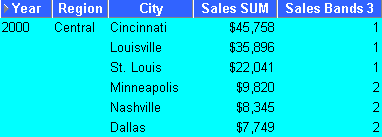
The worksheet shows equi-height bands for sales figures for cities in the central region within year.
Windowing functions are used to compute aggregates using values from other rows. For example, cumulative, moving, and centered aggregates.
Note: For more information about using row-based and time-based intervals, see "Examples of using row-based and time-based intervals".
Examples:
Hint: You can also use analytic function templates to quickly and easily create calculations based on windowing functions (for more information, see "How to create a new calculation using an analytic function template".
Two common types of windowing are:
Note: Time-based intervals are also known as logical offsets.
Time-based intervals are useful when data has missing rows. For example, you might not have seven rows for sales figures for seven days in a week, but you still want to find a weekly average.
For example, if we have a list of monthly sales figures, a logical window might compute a moving average of the previous three months (inclusive of the current month). When calculating the average, the calculation assumes a NULL value for months missing from the list. In the example below, the three-month moving average for November assumes NULL values for the missing months September and October.
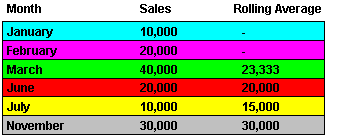
Note: Time-based intervals are also known as physical offsets.
Row-based intervals are useful when data does not have missing rows. For example, if you know that you have seven rows for sales figures for seven days in a week, you can calculate a weekly average by starting the interval six rows before the current row (inclusive).
For example, if we have a list of monthly sales figures, a physical window might compute a moving average of the previous three rows. When calculating the average, the calculation ignores months missing from the list. In the example below, the three-month moving average for November uses June, July, and November in the calculation.
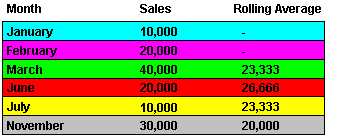
Note: For more information about using row-based and time-based intervals, see "Examples of using row-based and time-based intervals".
This example uses a time-based interval to calculate a moving three month sales average.
Note: Moving averages are also known as rolling averages.
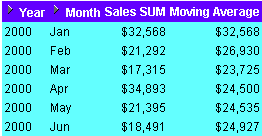
The worksheet shows a moving three month average for sales figures for months in the year 2000.
This example uses a row-based interval to calculate the cumulative value of sales.
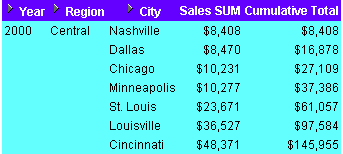
The worksheet shows a cumulative total for sales figures for cities in the central region.
This example uses a time-based interval to calculate sales figures for previous years. This enables you to compare sales figures over different years, or compare previous years' sales figures with other values, such as spending in previous years.

For each row, the worksheet shows the sales total for the previous year.
Reporting functions are used to compute aggregates.
Examples:
Hint: You can also use analytic function templates to quickly and easily create calculations based on reporting functions (for more information, see "How to create a new calculation using an analytic function template".
This example calculates annual sales.
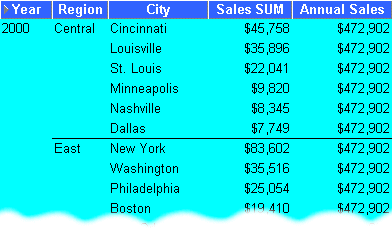
The worksheet shows the annual sales value for cities in the year 2000.
This example calculates the total annual sales by region.
.
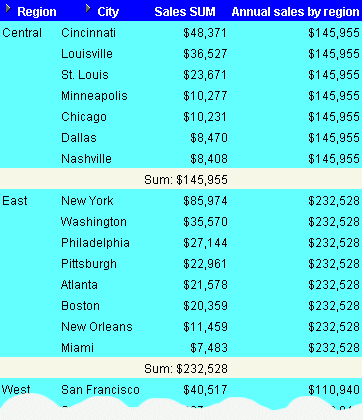
The worksheet shows the annual sales total for cities, grouped by region within year.
This example calculates the percentage of annual sales per region for each city in each year.
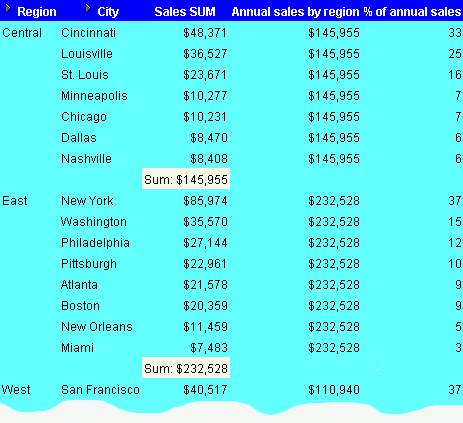
The worksheet shows sales as a percentage of annual sales, grouped by region within year.
This example calculates city sales as a percentage of total sales.
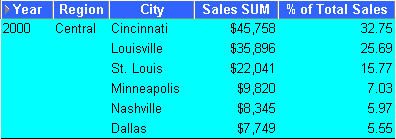
The worksheet shows the sales value for cities as a percentage of total sales.
LAG and LEAD functions are typically used to compare values in different time periods. For example, compare sales figures in 2000 with sales figures in 2001.
You can also use windowing functions to compare values over time (see "Example: Compare sales figures across time using windowing".
Hint: You can also use analytic function templates to quickly and easily create calculations based on LAG/LEAD functions (for more information, see "How to create a new calculation using an analytic function template".
Examples:
In this example, you want to compare monthly sales figures with sales figures for the same month in the previous year. For example, to look at how January 1999 sales compare with January 1998 sales.
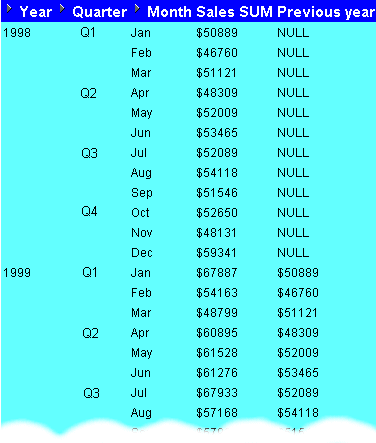
The worksheet shows contains the calculation Previous Year, which shows for each Sales SUM amount the sales amount for one year previously. For example, the Previous Year value for January 1999 is $50889, which is the Sales SUM value for January 1998.
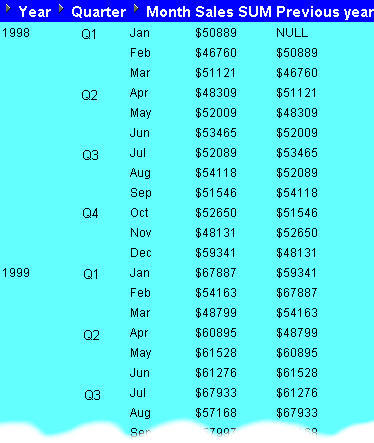
In this example, you want to calculate the percentage growth of sales across years by comparing the sales figures with sales figures for the same month in the previous year. You will do this using the comparative sales figures from example "Example: Compare sales figures across time using LAG/LEAD".
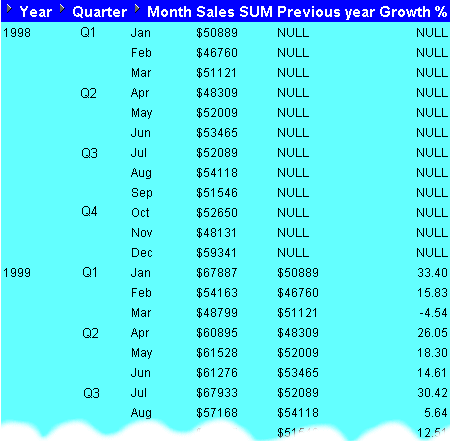
The worksheet shows contains the calculation Growth %, which shows for each month the percentage increase in sales since the previous year. For example, the Growth % value for January 1999 is 30.40% (i.e. from $50889 to $67887).
In this example, you want to create a league table of sales growth, to show which months show the highest year on year increase in sales.
You will do this using the comparative sales figures and growth figures from examples "Example: Compare sales figures across time using LAG/LEAD" and "Example: Calculate sales growth across time", and a RANK function.
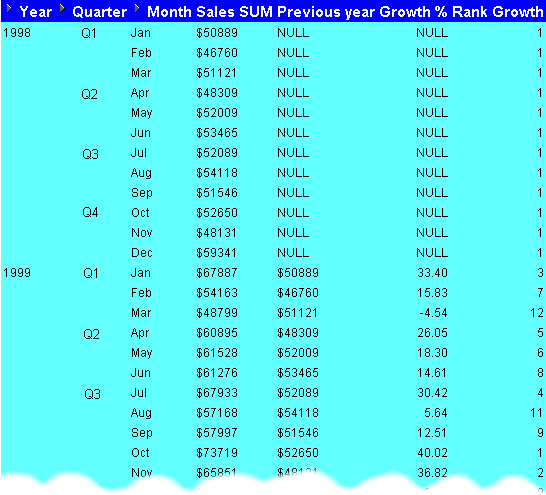
The worksheet shows the league table position of sales growth. For example, the Rank Growth value for January 1999 is 3, which means that January was the third best performing month (i.e. the sales growth for the month of January between 1998 and 1999 was the third highest in the league table).
Statistics functions are used to compute covariance, correlation, and linear regression statistics. Each function operates on an unordered set. They also can be used as windowing and reporting functions.
Examples:
"Example: Calculate linear regression"
This example computes an ordinary least-squares regression line that expresses the Profit SUM per month as a linear function of its Sales SUM. The following functions are used:
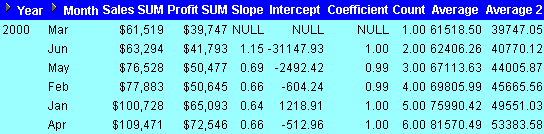
The worksheet shows for each month the slope, intercept, coefficient, count, and average values.
When you select an analytic function in the "New Calculation dialog", Discoverer types generic text into the Calculation field to help you define the function. This generic text includes:
The expressions are used as follows.
For more information about Oracle expressions, see "About getting more information".
When you use analytic functions in conditions, the way that you combine them with non-analytic functions affects the Discoverer data returned by the query. The following sequencing rules apply (for more information, see "Examples of sequencing"):
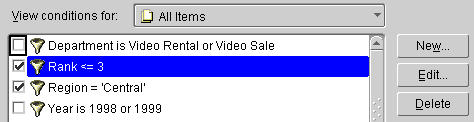
Text description of the illustration af_order.gif
To illustrate how sequencing affects the Discoverer data returned by a query, consider the following two examples:
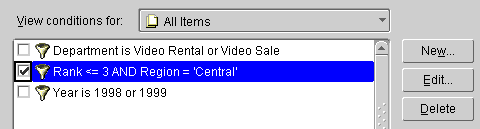
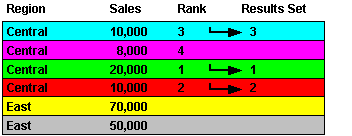
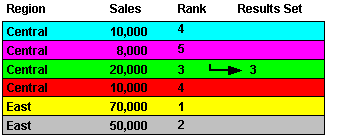
In the first scenario, we apply two single conditions: Region = `Central', and Rank <= 3 (where Rank is an analytic function).
In the second scenario, we apply a multiple condition: Region = `Central' AND Rank <= 3 (where Rank is an analytic function).
The examples in this section show you how to use the Oracle9i analytic functions with Discoverer to perform detailed data analysis.
This section contains the following topics:
Hint: You can also use analytic function templates to quickly and easily create calculations based on the most popular analytic functions (for more information, see "How to create a new calculation using an analytic function template".
For more information about Oracle9i functions, refer to the following Oracle publications:
You use inverse percentile functions to work out what value computes to a certain percentile (i.e. the cumulative distribution of a set of values). For example, to calculate the median (i.e. middle value in a series) profit value.
Examples:
Inverse percentile functions can be used as window reporting functions and aggregate functions.
Two inverse percentile functions are available:
Note: Inverse percentile functions do the opposite of the CUME_DIST function, which works out the cumulative distribution of a set of values.
PERCENTILE_CONT and PERCENTILE_DISC might return different results, depending on the number of rows in the calculation. For example, if the percentile value is 0.5, PERCENTILE_CONT returns the average of the two middle values for groups with even number of elements. In contrast, PERCENTILE_DISC returns the value of the first one among the two middle values. For aggregate groups with an odd number of elements, both functions return the value of the middle element.
This example computes the median profit value for cities using the PERCENTILE_DISC function as a reporting aggregate function.
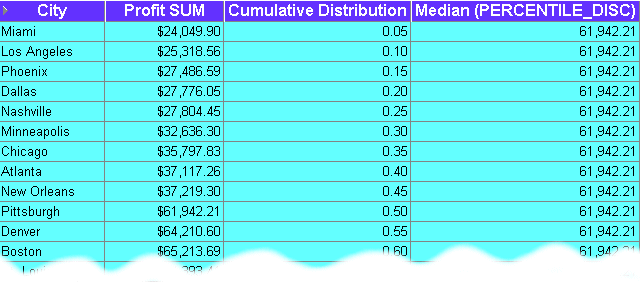
The worksheet shows the median profit value for cities. The median profit value (i.e. 0.50 in the Cumulative Distribution column) is $61,942,21 (i.e. the value for Pittsburgh, which has the value 0.50 in the Cumulative Distribution column).
This example computes the median profit value for cities using the PERCENTILE_CONT function as a reporting aggregate function.
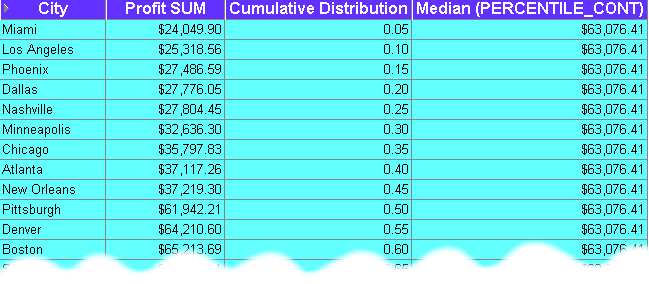
The worksheet shows the median profit value for cities. The median profit value is $63,076.41, which is the average profit value for the 0.50 and 0.55 percentile. In other words, the value for Pittsburgh plus the value for Denver, divided to two ($61,942.21 + $64,210.60)/2. For more information about how this function is calculated, see "About differences between PERCENTILE_CONT and PERCENTILE_DISC".
You use hypothetical rank and distribution functions for 'what-if?' analysis. These functions work out the position of a value if the value was inserted into a set of other values. For example, where would a person who generated sales of $1,200,000 be positioned in a league table of sales peoples' performance.
Note: You can also calculate the hypothetical values of the following:
Examples:
This example calculates the hypothetical rank of profit values in relation to profit values for departments and regions. For example, to answer the question, how would a sales value of $500.00 be positioned in a league table of values for the Video Sale department in each region?
Note: This example uses a parameter to provide dynamic input to the calculation (for more information see "About using parameters to provide dynamic input to calculations").
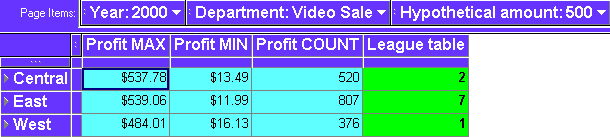
Notice that because the hypothetical amount ($500) is greater than the Profit MAX amount in the West region ($484.01), the amount $500 has the hypothetical rank of number 1 for the West region.
You use the Oracle9i WIDTH_BUCKET function to divide values into groups (sometimes called bands or buckets) according to their value (for more information, see "About banding"). For example, to group data for a bar graph.
Hint: You can also use the GREATEST and the CASE functions to calculate equi-width bands (see "Example: Banding by value (1)" and "Example: Banding by value (2)".
Examples:
This example divides profit figures into three bands according to their value.
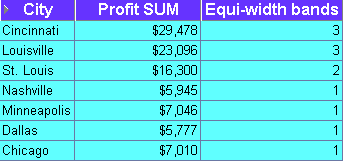
The worksheet shows equi-width bands for profit values for cities. The first band (0 to 9,999) contains Nashville, Minneapolis, Dallas, and Chicago. The second band (10,000 to 19,999) contains St. Louis. The third band (20,000 to 30,000) contains Cincinnati and Louisville.
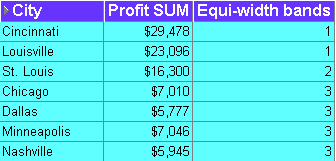
The worksheet shows equi-width bands for profit values for cities. The first band (20,000 to 30,000) contains Cincinnati and Louisville. The second band (10,000 to 19,999) contains St. Louis. The third band (0 to 9,999) contains Chicago, Dallas, Minneapolis, and Nashville.
You use FIRST/LAST aggregate functions to find the first or last value within an ordered group. This enables you to order data on one column but return another column. For example, to find the average sales transaction amount for the region with the largest number of sales transactions in a period.
Examples:
Using FIRST/LAST functions maximizes Discoverer performance by avoiding the need to perform self-joins or sub-queries.
Note: You can use FIRST/LAST functions with the following:
This example finds the largest sales transaction amount for the city with the most sales transactions in a period.
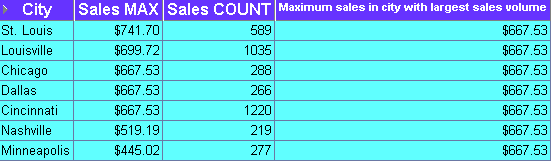
The worksheet shows the largest sales transaction value in the city with the largest number of sales transactions. Cincinnati has the largest number of sales transactions (1220). The largest sales transaction for Cincinnati is $667.53.
This example calculates the average sales transaction amount for the city with the smallest number of sales transactions in a period.
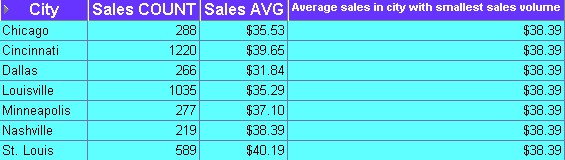
The worksheet shows the average sales transaction value in the city with the smallest number of sales transactions. Nashville has the smallest number of transactions in the period (219). Therefore, the calculation returns the average transaction value for Nashville ($38.39).
The examples in this section show you how to use analytic functions with row-based and time-based intervals to get the best results with Discoverer. For example, you might was to create a calculation that returns the value of the previous row, or the value one year previously.
Note: Using row-based and time-based intervals is also known as windowing. For more information about windowing, see "About windowing". For more examples of using windowing in Discoverer, see "Windowing function examples".
The examples use analytic functions created using Discoverer's analytic functions templates. Each example shows how selecting intervals in the Restart calculation at each change in list on the analytic function template dialogs affects the calculation. For example, you might specify 1 Month Before Current Value as the interval, to compare sales in one month with sales in another month. For more information about creating calculation formulas using analytic function templates, see "How to create a new calculation using an analytic function template".
Note: If you are entering analytic function text in the Calculation field manually, you can specify an interval by adding a PARTITION BY clause to the formula. For more information about creating calculation formulas manually, see "How to create calculations".
This section contains the following examples:
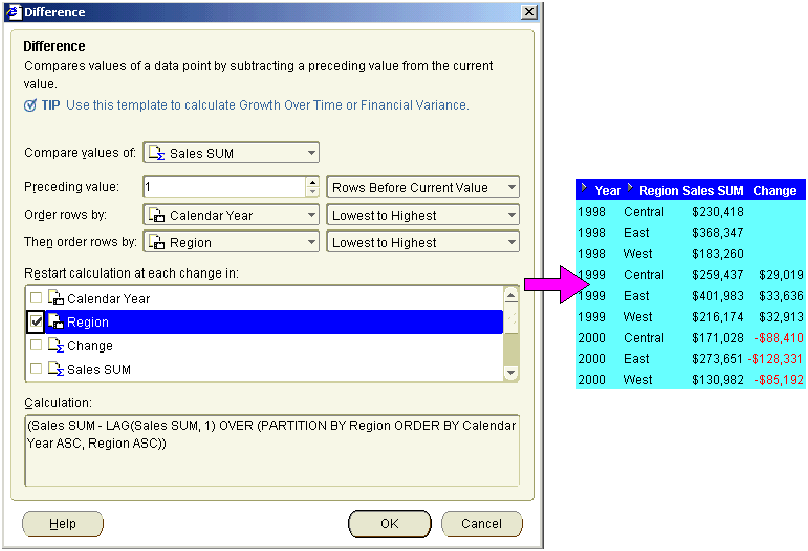
This example uses a difference calculation based on a row-based interval. The example worksheet displays the Year, Region, and Sales SUM items. To return the previous row's value for each sales value, add a calculation called 'Change' to the worksheet using the "Difference dialog", as follows:
The example worksheet shows the Change item containing the difference formula. For example, the Change column for the West region in 2000 is -$142,670. This value is derived from the West region value for 2000 (i.e. 130,982) minus the East region value for 2000 (i.e. 273,651).
Note: Positive values are shown in black. Negative values are shown in red.
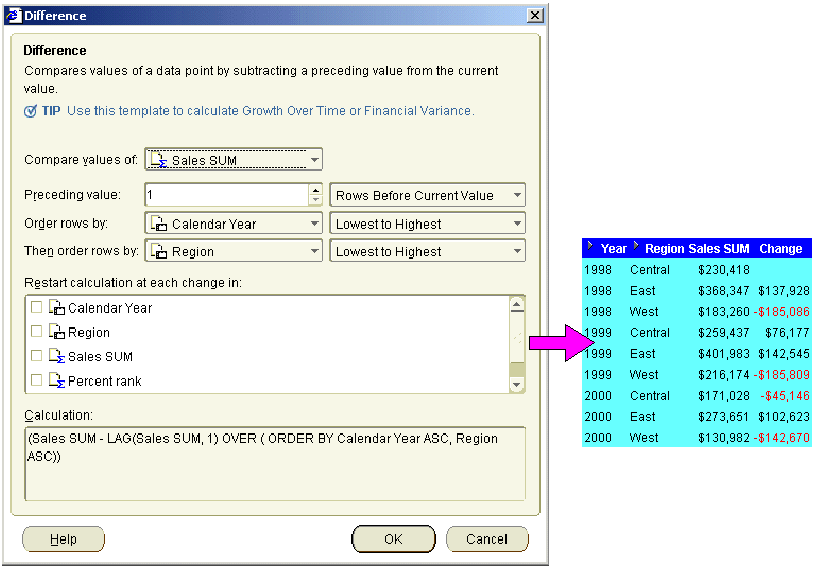
Note: If you selected the Region check box in the Restart calculation at each change in list, you would always compare each value with the Sales SUM value for the same region in the previous year.
The example worksheet below shows the Change item containing the difference formula where the Region check box in the Restart calculation at each change in list is selected. In other words:
Note: When you choose a row-based interval and select the Region check box in the the Restart calculation at each change in list, you compare values with values from the previous year. You can also compare values with values from a previous year using a time-based interval (for more information about using time-based intervals, see "Example: Creating a Difference calculation using a time-based interval").
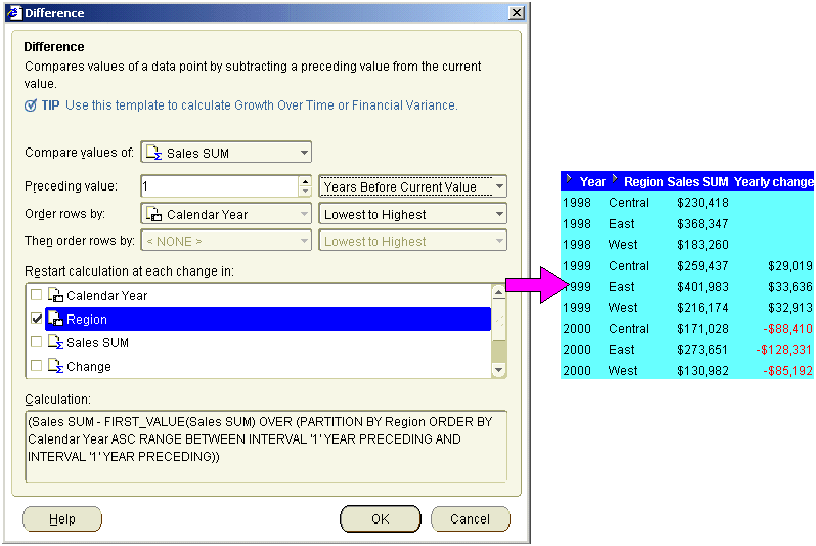
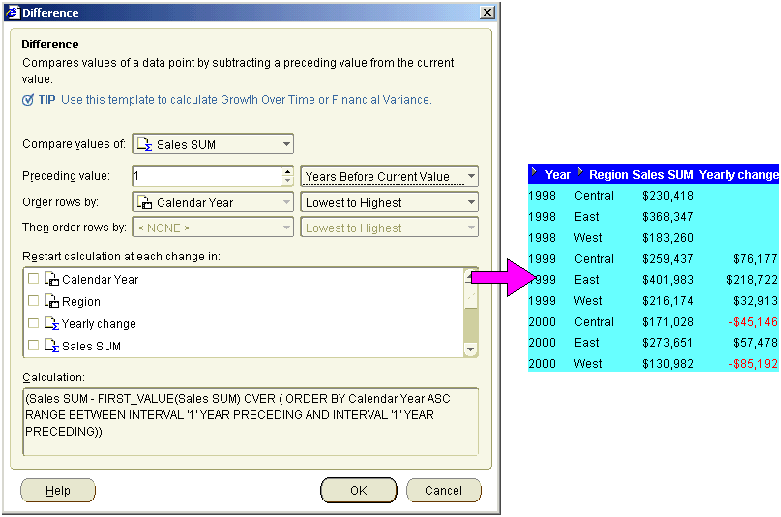
This example uses a difference calculation based on a time-based interval. The example worksheet displays the Year, Region, and Sales SUM items. To calculate the change in sales from the previous year, add a calculation called Yearly change to the worksheet using the "Difference dialog", as follows:
The example worksheet shows the Yearly change item containing the difference formula. For example, you can see in the Yearly change column that Sales SUM value for the West region in 2000 is $85,192 less that the West region in 1999.
Note: Positive values are shown in black. Negative values are shown in red.
Note: If you did not select the Region check box in the Restart calculation at each change in list, you would always compare each value with the Sales SUM value for the last region in the previous year.
The example worksheet below shows the Yearly change item containing the preceding value formula where the Region check box in the Restart calculation at each change in list is cleared. In other words:
This example uses a preceding value calculation based on a time-based interval. The example worksheet displays the Year, Region, and Sales SUM items. To return the previous year's value for each sales value, add a calculation called Previous year to the worksheet using the "Preceding Value dialog", as follows:
The example worksheet shows the Previous year item containing the preceding value formula. For example, you can see in the Previous year value for the West region in 2000 is $216,174, which is the same as the Sales SUM value for 1999 in the West region.
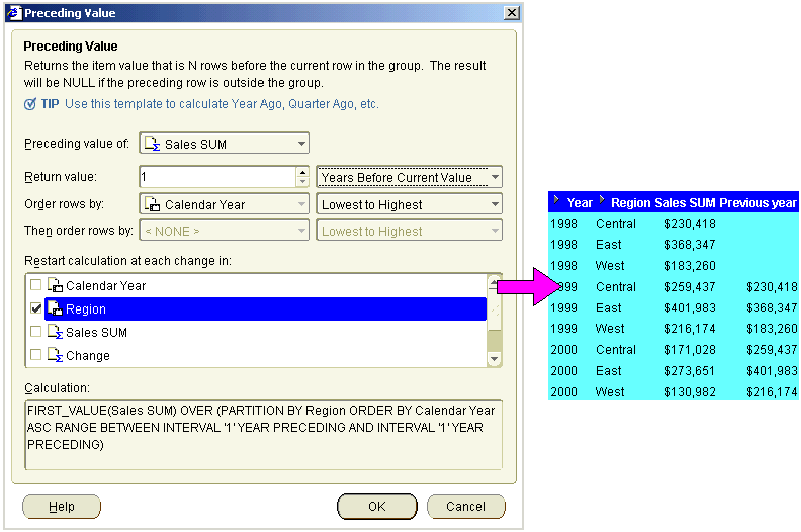
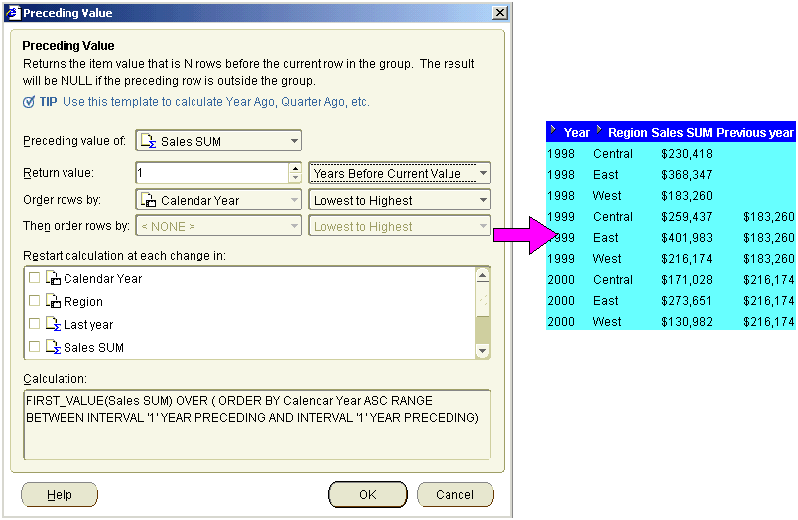
Note: If you did not select the Region check box in the Restart calculation at each change in list, you would always return the Sales SUM value for the last region in the previous year.
The example worksheet below shows the Previous year item containing the preceding value formula where the Region check box in the Restart calculation at each change in list is cleared. In other words, the Previous year value for the West, East, and Central regions in 2000 is $216,174, which is the same as the Sales SUM value for 1999 in the West region.
|
|
 Copyright © 1999, 2003 Oracle Corporation. All Rights Reserved. |
|