10g (9.0.4)
Part Number B10313-01
Home |
Solution Area |
Contents |
Index |
| Oracle Application Server TopLink Application Developer's Guide 10g (9.0.4) Part Number B10313-01 |
|
A database transaction is a set of operations (create, read, update, or delete) that either succeed or fail as a single operation. The database discards, or rolls back, unsuccessful transactions, leaving the database in its original state.
In OracleAS TopLink, transactions are encapsulated by the Unit of Work object. Using the Unit of Work, you can transactionally modify objects directly or by way of a Java 2 Enterprise Edition (J2EE) external transaction controller such as the Java Transaction API (JTA).
This chapter explains how to use the OracleAS TopLink Unit of Work, including:
This section describes generic database transaction concepts and how they apply to the OracleAS TopLink Unit of Work.
Transactions execute in their own context, or logical space, isolated from other transactions and database operations.
The transaction context is demarcated; that is, it has a defined structure that includes:
The degree to which concurrent (parallel) transactions on the same data are allowed to interact is determined by the level of transaction isolation configured. ANSI/SQL defines four levels of database transaction isolation as shown in Table 7-1. Each offers a trade-off between performance and resistance from the following unwanted behaviors:
Table 7-1 Transaction Isolation Levels
| Transaction Isolation Level | Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|
|
Read Uncommitted |
Yes |
Yes |
Yes |
|
Read Committed |
No |
Yes |
Yes |
|
Repeatable Read |
No |
No |
Yes |
|
Serializeable |
No |
No |
No |
As a transaction is committed, the database maintains a log of all changes to the data. If all operations in the transaction succeed, the database allows the changes; if any part of the transaction fails, the database uses the log to roll back the changes.
In OracleAS TopLink, transactions are encapsulated by the Unit of Work object. Like any transaction, a Unit of Work transaction provides:
Unit of Work operations occur within a Unit of Work context, isolated from the database until commit time. The Unit of Work executes changes on copies, or clones, of objects in its own internal cache, and if successful, applies changes to objects in the database and the session cache.
If your application is a stand-alone OracleAS TopLink application, your application demarcates transactions using the Unit of Work.
If your application includes a J2EE container that provides container-managed transactions, you can configure OracleAS TopLink to integrate with the container's transaction demarcation. The Unit of Work supports:
J2EE containers use JTA to manage transactions in the application. If your application includes a J2EE container, the Unit of Work executes as part of an external JTA transaction. The Unit of Work still manages its own internal operations, but relies on the external transaction to commit changes to the database. The Unit of Work waits for the external transaction to commit successfully before writing changes back to the session cache.
Note that because the transaction happens outside of the Unit of Work context and is controlled by the JTA, errors can be more difficult to diagnose and fix.
For more information, see "J2EE Integration".
Entity beans that use container-managed persistence can participate in either client-demarcated or container-demarcated transactions. They can demarcate transactions with the javax.transaction.UserTransaction interface. OracleAS TopLink automatically wraps invocations on entity beans in container transactions based on the transaction attributes in the EJB deployment descriptor. For more information about transactions with EJBs, see the EJB specification and your J2EE container documentation.
In transactions involving EJBs, OracleAS TopLink waits until the transaction begins its two-stage commit process before updating the database. This allows for:
OracleAS TopLink DatabaseLogin API allows you to set the transaction isolation level used when you open a connection to a database:
databaseLogin.setTransactionIsolation(DatabaseLogin.TRANSACTION_SERIALIZABLE);
However, the Unit of Work does not participate in database transaction isolation. Because the Unit of Work may execute queries outside the database transaction, the database has no control over the data and its visibility outside the transaction.
To maintain transaction isolation, each Unit of Work instance operates on its own copy (clone) of affected objects (see "Clones and the Unit of Work"). Multiple reads to the same object return the same clone and the clone's state is from when it was first accessed (registered).
Optimistic locking, optimistic read locking, or pessimistic locking can be used to ensure concurrency (see "Locking Policy").
The Unit of Work method ShouldAlwaysConformResultsInUnitOfWork allows querying to be done on object changes within a Unit of Work (see "Using Conforming Queries and Descriptors").
Changes are committed to the database only when the Unit of Work commit method is called (either directly or by way of an external transaction controller.)
This section describes:
The OracleAS TopLink Unit of Work simplifies transactions and improves transactional performance. It is the preferred method of writing to a database in OracleAS TopLink because it:
The Unit of Work is used as follows:
As each object is registered, the Unit of Work accesses the object from the Session cache or database and creates a backup clone and working clone (see "Clones and the Unit of Work").
The Unit of Work returns the working clone to the client application.
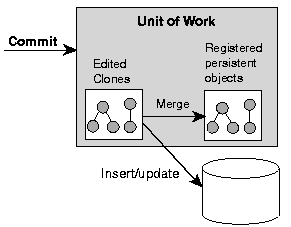
Example 7-1 shows the life cycle in code.
// The application reads a set of objects from the database. Vector employees = session.readAllObjects(Employee.class); // The application specifies an employee to edit. . . . Employee employee = (Employee) employees.elementAt(index); try { // Acquire a Unit of Work from the session. UnitOfWork uow = session.acquireUnitOfWork(); // Register the object that is to be changed. Unit of Work returns a clone // of the object and makes a backup copy of the original employee Employee employeeClone = (Employee)uow.registerObject(employee); // We make changes to the employee clone by adding a new phoneNumber. // If a new object is referred to by a clone, it does not have to be // registered. Unit of Work determines it is a new object at commit time. PhoneNumber newPhoneNumber = new PhoneNumber("cell","212","765-9002"); employeeClone.addPhoneNumber(newPhoneNumber); // We commit the transaction: Unit of Work compares the employeeClone with // the backup copy of the employee, begins a transaction, and updates the // database with the changes. If successful, the transaction is committed // and the changes in employeeClone are merged into employee. If there is an // error updating the database, the transaction is rolled back and the // changes are not merged into the original employee object. uow.commit(); } catch (DatabaseException ex) { // If the commit fails, the database is not changed. The Unit of Work should // be thrown away and application-specific action taken. } // After the commit, the Unit of Work is no longer valid. Do not use further.
The Unit of Work maintains two copies of the original objects registered with it:
After you change the working clones and the transaction is committed, the Unit of Work compares the working copy clones to the backup copy clones, and writes any changes to the database. The Unit of Work uses clones to allow parallel Units of Work (see "Nested and Parallel Units of Work") to exist, a requirement in multi-user three-tier applications.
The OracleAS TopLink cloning process is efficient in that it clones only the mapped attributes of registered objects, and stops at indirection objects unless you trigger the indirection. For more information, see "Indirection".
You can customize the cloning process using the descriptor's copy policy. For more information, see "Descriptor Copy Policy".
Never use a clone after committing the Unit of Work that the clone is from (even if the transaction fails and rolls-back). A clone is a working copy used during a transaction and as soon as the transaction is committed (successful or not), the clone must not be used. Accessing an uninstantiated clone value holder after a Unit of Work commit will raise an exception. The only time you can use a clone after a successful commit is when you use the advanced API described in "Resuming a Unit of Work After Commit".
You can use OracleAS TopLink to create a:
For information and examples on using nested and parallel Units of Work, see "Using a Nested or Parallel Unit of Work".
You can nest a Unit of Work (the child) within another Unit of Work (the parent). A nested Unit of Work does not commit changes to the database. Instead, it passes its changes to the parent Unit of Work, and the parent attempts to commit the changes at commit time. Nesting Units of Work enables you to break a large transaction into smaller isolated transactions, and ensures that:
You can modify the same objects in multiple Unit of Work instances in parallel because the Unit of Work manipulates copies of objects. OracleAS TopLink resolves any concurrency issues when the Units of Work commit.
A Unit of Work is a Session, and as such, offers the same set of database access methods as a regular session.
When called from a Unit of Work, these methods access the objects in the Unit of Work, register the selected objects automatically, and return clones.
Although this makes it unnecessary for you to call the registerObject and registerAllObjects methods, be aware of the restrictions on registering objects described in "Creating an Object" and "Associations: New Source to Existing Target Object".
As with regular sessions, you use the readObject and readAllObjects methods to read objects from the database.
You can execute queries in a Unit of Work with the executeQuery method.
When a Unit of Work transaction is committed, it either succeeds or fails and rolls back. A commit can be initiated by your application or a J2EE container.
At commit time, the Unit of Work compares the working clones and backup clones to calculate the change set (that is, to determine the minimum changes required). Changes include updates to or deletion of existing objects, and the creation of new objects. The Unit of Work then begins a database transaction, and attempts to write the changes to the database. If all changes commit successfully on the database, the Unit of Work merges the changed objects into the session cache. If any of the changes fail on the database, the Unit of Work rolls back any changes on the database, and does not merge changes into the session cache.
The Unit of Work calculates commit order using foreign key information from one-to-one and one-to-many mappings. If you encounter constraint problems during commit, verify your mapping definitions. The order in which you register objects with the registerObject method does not affect the commit order.
When your application uses JTA, the Unit of Work commit behaves differently than in a non-JTA application. In most cases, the Unit of Work attaches itself to an external transaction. If no transaction exists, the Unit of Work creates a transaction. This distinction affects commit behavior as follows:
commit call. The transaction commits the Unit of Work when the entire external transaction is complete.
commit call as a request to commit the external transaction. The external transaction then calls its own commit code on the database.
In either case, only the external transaction can call commit on the database because it owns the database connection.
For more information, see "J2EE Integration".
A Unit of Work commit must succeed or fail as a unit. Failure in writing changes to the database causes the Unit of Work to roll back the database to its previous state. Nothing changes in the database, and the Unit of Work does not merge changes into the session cache.
In a JTA environment, the Unit of Work does not own the database connection. In this case, the Unit of Work sends the rollback call to the external transaction rather than the database, and the external transaction treats the rollback call as a request to roll the transaction back.
For more information, see "J2EE Integration".
You cannot modify the primary key attribute of an object in a Unit of Work. This is an unsupported operation and doing so will result in unexpected behaviour (exceptions and/or database corruption).
To replace one instance of an object with unique constraints with another, see "Using the Unit of Work setShouldPerformDeletesFirst Method".
Throughout this chapter, the following object model and schema is used in the examples provided. The example object model appears in Figure 7-2 and the example entity-relationship (data model) diagram appears in Figure 7-3.
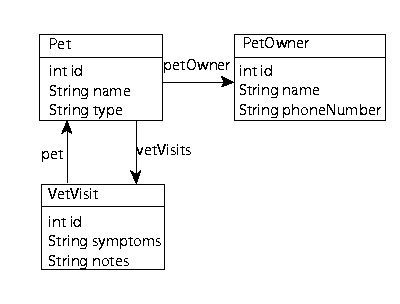
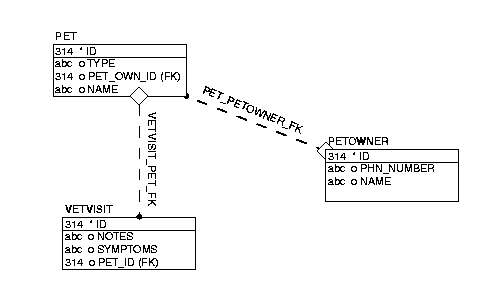
This section explores the essential Unit of Work API calls most commonly used throughout the development cycle:
For more information about the available methods for the UnitOfWork, see "Advanced Unit of Work" and the Oracle Application Server TopLink API Reference.
This example shows how to acquire a Unit of Work from a client session object.
Server server = (Server) SessionManager.getManager().getSession( sessionName, MyServerSession.class.getClassLoader() ); Session session = (Session) server.acquireClientSession(); UnitOfWork uow = session.acquireUnitOfWork();
You can acquire a Unit of Work from any session type. Note that you do not need to create a new session and login before every transaction.
The Unit of Work is valid until the commit or release method is called. After a commit or release, a Unit of Work is not valid even if the transaction fails and is rolled back.
A Unit of Work remains valid after the commitAndResume method is called as described in "Resuming a Unit of Work After Commit".
When using a Unit of Work with JTA, you can also use the advanced API getActiveUnitOfWork method as described in "J2EE Integration".
When you create new objects in the Unit of Work, use the registerObject method to ensure that the Unit of Work writes the objects to the database at commit time.
The Unit of Work calculates commit order using foreign key information from one-to-one and one-to-many mappings. If you encounter constraint problems during commit, verify your mapping definitions. The order in which you register objects with the registerObject method does not affect the commit order.
Example 7-2 and Example 7-3 show how to create and persist a simple object (without relationships) using the clone returned by the Unit of Work registerObject method.
UnitOfWork uow = session.acquireUnitOfWork();Pet pet = new Pet();Pet petClone = (Pet)uow.registerObject(pet);petClone.setId(100);petClone.setName("Fluffy");petClone.setType("Cat"); uow.commit();
Example 7-3 shows a common alternative:
UnitOfWork uow = session.acquireUnitOfWork();Pet pet = new Pet();pet.setId(100);pet.setName("Fluffy");pet.setType("Cat");uow.registerObject(pet); uow.commit();
Both approaches produce the following SQL:
INSERT INTO PET (ID, NAME, TYPE, PET_OWN_ID) VALUES (100, 'Fluffy', 'Cat', NULL)
Example 7-2 is preferred: it gets you into the pattern of working with clones and provides the most flexibility for future code changes. Working with combinations of new objects and clones can lead to confusion and unwanted results.
In Example 7-4, a Pet is read prior to a Unit of Work: the variable pet is the cache copy for that Pet. Inside of the Unit of Work, we must register the cache copy to get a working copy. We then modify the working copy and commit the Unit of Work.
// Read in any pet. Pet pet = (Pet)session.readObject(Pet.class); UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet) uow.registerObject(pet);petClone.setName("Furry"); uow.commit();
In Example 7-5, we take advantage of the fact that you can query through a Unit of Work and get back clones, saving the registration step. However, the drawback is that we do not have a handle to the cache copy.
If we wanted to do something with the updated Pet after commit, we would have to query the session to get it (remember that after a Unit of Work is committed, its clones are invalid and must not be used).
UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet) uow.readObject(Pet.class);petClone.setName("Furry"); uow.commit();
Both approaches produce the following SQL:
UPDATE PET SET NAME = 'Furry' WHERE (ID = 100)
Take care when querying through a Unit of Work. All objects read in the query are registered in the Unit of Work and therefore will be checked for changes at commit time. Rather than do a ReadAllQuery through a Unit of Work, it is better for performance to design your application to do the ReadAllQuery through a session and then only register in a Unit of Work the objects that need to be changed.
There are two ways to associate a new target object with an existing source object with 1-many and 1-1 relationships:
Deciding which approach to use depends on whether or not your code requires a reference to the cache copy of the new object after the Unit of Work is committed and on how adaptable to change you want your code to be.
Example 7-6 shows the first way of associating a new target with an existing source.
UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet)uow.readObject(Pet.class);PetOwner petOwner = new PetOwner();petOwner.setId(400);petOwner.setName("Donald Smith");petOwner.setPhoneNumber("555-1212");VetVisit vetVisit = new VetVisit();vetVisit.setId(500);vetVisit.setNotes("Pet was shedding a lot.");vetVisit.setSymptoms("Pet in good health.");vetVisit.setPet(petClone);petClone.setPetOwner(petOwner);petClone.getVetVisits().addElement(vetVisit);uow.commit();
This executes the proper SQL:
INSERT INTO PETOWNER (ID, NAME, PHN_NBR) VALUES (400, 'Donald Smith', '555-1212') UPDATE PET SET PET_OWN_ID = 400 WHERE (ID = 100) INSERT INTO VETVISIT (ID, NOTES, SYMPTOMS, PET_ID) VALUES (500, 'Pet was shedding a lot.', 'Pet in good health.', 100)
When associating new objects to existing objects, the Unit of Work treats the new object as if it was a clone. That is, after the commit:
petOwner != session.readObject(petOwner)
For a more detailed discussion of this fact, see "Using registerNewObject").
Therefore, after the Unit of Work commit, the variables vetVisit and petOwner no longer point to their respective cache objects: they point at working copy clones.
If you need the cache object after the Unit of Work commit, you must query for it or create the association with a reference to the cache object (as described in "Associating with Reference to the Cache Object").
Example 7-7 shows how to associate a new target with an existing source with reference to the cache object.
UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet)uow.readObject(Pet.class);PetOwner petOwner = new PetOwner();PetOwner petOwnerClone = (PetOwner)uow.registerObject(petOwner);petOwnerClone.setId(400);petOwnerClone.setName("Donald Smith");petOwnerClone.setPhoneNumber("555-1212");VetVisit vetVisit = new VetVisit();VetVisit vetVisitClone = (VetVisit)uow.registerObject(vetVisit);vetVisitClone.setId(500);vetVisitClone.setNotes("Pet was shedding a lot.");vetVisitClone.setSymptoms("Pet in good health.");vetVisitClone.setPet(petClone);petClone.setPetOwner(petOwnerClone);petClone.getVetVisits().addElement(vetVisitClone); uow.commit();
Now, after the Unit of Work commit:
petOwner == session.readObject(petOwner)
This means that we have a handle to the cache copy after the commit, rather than a clone.
Example 7-8 shows another way to add a new object in a Unit of Work when a bidirectional relationship exists.
// Get an employee read from the parent session of the Unit of Work. Employee manager = (Employee)session.readObject(Employee.class); // Acquire a Unit of Work. UnitOfWork uow = session.acquireUnitOfWork(); // Register the manager to get its clone Employee managerClone = (Employee)uow.registerObject(manager); // Create a new employee Employee newEmployee = new Employee(); newEmployee.setFirstName("Spike"); newEmployee.setLastName("Robertson"); /* INCORRECT: Do not associate the new employee with the original manager. This will cause a QueryException when OracleAS TopLink detects this error during commit. */ //newEmployee.setManager(manager); /* CORRECT: Associate the new object with the clone. Note that in this example, the setManager method is maintaining the bidirectional managedEmployees relationship and adding the new employee to its managedEmployees. At commit time, the Unit of Work will detect that this is a new object and will take the appropriate action. */ newEmployee.setManager(managerClone); /* INCORRECT: Do not register the newEmployee: this will create two copies and cause a QueryException when OracleAS TopLink detects this error during commit.*/ //uow.registerObject(newEmployee); /* CORRECT: In the above setManager call, if the managerClone's managedEmployees was not maintained by the setManager method, then you should call registerObject before the new employee is related to the manager. If in doubt, you could use the registerNewObject method to ensure that the newEmployee is registered in the Unit of Work. The registerNewObject method registers the object, but does not make a clone. */ uow.registerNewObject(newEmployee); // Commit the Unit of Work uow.commit();
This section describes how to associate a new source object with an existing target object with 1-many and 1-1 relationships.
OracleAS TopLink follows all relationships of all registered objects (deeply) in a Unit of Work to calculate what is new and what has changed. This is known as persistence by reachablity. In "Associations: New Target to Existing Source Object", we saw that when you associate a new target with an existing source, you can choose to register the object or not. If you do not register the new object, it is still reachable from the source object (which is a clone, hence it is registered). However, when you need to associate a new source object with an existing target, you must register the new object. If you do not register the new object, then it is not reachable in the Unit of Work and OracleAS TopLink will not write it to the database.
For example, imagine we want to create a new Pet and associate it with an existing PetOwner. The code shown in Example 7-9 will accomplish this:
UnitOfWork uow = session.acquireUnitOfWork(); PetOwner existingPetOwnerClone = (PetOwner)uow.readObject(PetOwner.class); Pet newPet = new Pet(); Pet newPetClone = (Pet)uow.registerObject(newPet); newPetClone.setId(900); newPetClone.setType("Lizzard"); newPetClone.setName("Larry"); newPetClone.setPetOwner(existingPetOwnerClone); uow.commit();
This generates the proper SQL:
INSERT INTO PET (ID, NAME, TYPE, PET_OWN_ID) VALUES (900, 'Larry', 'Lizzard', 400)
In this situation, you should register the new object and work with the working copy of the new object. If you associate the new object with the PetOwner clone without registering, it will not be written to the database. If you are in a situation where you want to associate the PetOwner clone with the new Pet object, use the advanced API registerNewObject as described in "Using registerNewObject".
If you fail to register the clone and accidentally associate the cache version of the existing object with the new object, then OracleAS TopLink will generate an error which states that you have associated the cache version of an object ("from a parent session") with a clone from this Unit of Work. You must work with working copies in units of work.
This section explains how to associate an existing source object with an existing target object with 1-many and 1-1 relationships.
As shown in Example 7-10, associating existing objects with each other in a Unit of Work is as simple as associating objects in Java. Just remember to only work with working copies of the objects.
// Associate all VetVisits in the database to a Pet from the database UnitOfWork uow = session.acquireUnitOfWork(); Pet existingPetClone = (Pet)uow.readObject(Pet.class); Vector allVetVisitClones; allVetVisitClones = (Vector)uow.readAllObjects(VetVisit.class); Enumeration enum = allVetVisitClones.elements(); while(enum.hasMoreElements()) { VetVisit vetVisitClone =(VetVisit)enum.nextElement(); existingPetClone.getVetVisits().addElement(vetVisitClone); vetVisitClone.setPet(existingPetClone); };
uow.commit();
The most common error when associating existing objects is failing to work with the working copies. If you accidentally associate a cache version of an object with a working copy you will get an error at commit time indicating that you associated an object from a parent session (the cache version) with a clone from this Unit of Work.
Example 7-11 shows another example of associating an existing source to an existing target object.
// Get an employee read from the parent session of the Unit of Work. Employee employee = (Employee)session.readObject(Employee.class) // Acquire a Unit of Work. UnitOfWork uow = session.acquireUnitOfWork(); Project project = (Project) uow.readObject(Project.class); /* When associating an existing object (read from the session) with a clone, we must make sure we register the existing object and assign its clone into a Unit of Work. */ /* INCORRECT: Cannot associate an existing object with a Unit of Work clone. A QueryException will be thrown. */ //project.setTeamLeader(employee); /* CORRECT: Instead register the existing object then associate the clone. */ Employee employeeClone = (Employee)uow.registerObject(employee); project.setTeamLeader(employeeClone); uow.commit();
To delete objects in a Unit of Work, use the deleteObject or deleteAllObjects method. When you delete an object that is not already registered in the Unit of Work, the Unit of Work registers the object automatically.
When you delete an object, OracleAS TopLink deletes the object's privately owned parts, because those parts cannot exist without the owning object. At commit time, the Unit of Work generates SQL to delete the objects, taking database constraints into account.
When you delete an object, you must take your object model into account. You may need to set references to the deleted object to null (for an example, see "Using privateOwnedRelationship").
This section explains how to delete objects with a Unit of Work, including:
Relational databases do not have garbage collection like a Java Virtual Machine (JVM) does. To delete an object in Java you just de-reference the object. To delete a row in a relational database you must explicitly delete it. Rather than tediously manage when to delete data in the relational database, use the mapping attribute privateOwnedRelationship to make OracleAS TopLink manage the garbage collection in the relational database for you.
As shown in Example 7-12, when you create a mapping using Java, use its privateOwnedRelationship method to tell OracleAS TopLink that the referenced object is privately owned: that is, the referenced object cannot exist without the parent object.
OneToOneMapping petOwnerMapping = new OneToOneMapping(); petOwnerMapping.setAttributeName("petOwner"); petOwnerMapping.setReferenceClass(com.top.uowprimer.model.PetOwner.class); petOwnerMapping.privateOwnedRelationship(); petOwnerMapping.addForeignKeyFieldName("PET.PET_OWN_ID", "PETOWNER.ID"); descriptor.addMapping(petOwnerMapping);
When you create a mapping using the Mapping Workbench, you can select the Private Owned check box under the General tab.
When you tell OracleAS TopLink that a relationship is private owned, you are telling it two things:
Do not configure private owned relationships to objects that might be shared. An object should not be the target in more than one relationship if it is the target in a private owned relationship.
The exception to this rule is the case when you have a many-to-many relationship in which a relation object is mapped to a relation table and is referenced through a one-to-many relationship by both the source and target. In this case, if the one-to-many mapping is configured as privately owned, then when you delete the source, all the association objects will be deleted.
Consider the example shown in Example 7-13.
// If the Pet-PetOwner relationship is privateOwned // then the PetOwner will be deleted at uow.commit() // otherwise, just the foreign key from PET to PETOWNER will // be set to null. The same is true for VetVisit. UnitOfWork uow = session.acquireUnitOfWork(); Pet petClone = (Pet)uow.readObject(Pet.class); petClone.setPetOwner(null); VetVisit vvClone = (VetVisit)petClone.getVetVisits().firstElement(); vvClone.setPet(null); petClone.getVetVisits().removeElement(vvClone); uow.commit();
If the relationships from Pet to PetOwner and from Pet to VetVisit are not private owned, this code produces the following SQL:
UPDATE PET SET PET_OWN_ID = NULL WHERE (ID = 150) UPDATE VETVISIT SET PET_ID = NULL WHERE (ID = 350)
If the relationships are private owned, this code produces the following SQL:
UPDATE PET SET PET_OWN_ID = NULL WHERE (ID = 150) UPDATE VETVISIT SET PET_ID = NULL WHERE (ID = 350) DELETE FROM VETVISIT WHERE (ID = 350) DELETE FROM PETOWNER WHERE (ID = 250)
If there are cases where you have objects that will not be garbage collected through private owned relationships (especially root objects in your object model) then you can explicitly tell OracleAS TopLink to delete the row representing the object using the deleteObject API. For example:
UnitOfWork uow = session.acquireUnitOfWork(); pet petClone = (Pet)uow.readObject(Pet.class); uow.deleteObject(petClone); uow.commit();
The above code generates the following SQL:
DELETE FROM PET WHERE (ID = 100)
The Unit of Work does not track changes or the order of operations. It is intended to isolate you from having to modify your objects in the order the database requires.
By default, at commit time, the Unit of Work orders all inserts and updates using the constraints defined by your schema. After all inserts and updates are done, the Unit of Work will issue the necessary delete operations.
Constraints are inferred from one-to-one and one-to-many mappings. If you have no such mappings, you can add additional constraint knowledge to OracleAS TopLink as described in "Controlling the Order of Deletes".
This section explores more advanced Unit of Work API calls and techniques most commonly used later in the development cycle, including:
For more information about integrating the Unit of Work with J2EE and external transaction controllers, see "J2EE Integration".
For more information about the available methods for the UnitOfWork, see the Oracle Application Server TopLink API Reference.
This section examines common Unit of Work problems and debugging techniques, including:
A common Unit of Work error is holding on to clones after commit. Typically the clones are stored in a static variable and the developer incorrectly thinks that this object is the cache copy. This leads to problems when another Unit of Work makes changes to the object and what the developer thinks is the cache copy is not updated (because a Unit of Work only updates the cache copy, not old clones).
Consider the error in Example 7-15. In this example we get a handle to the cache copy of a Pet and store it in the static CACHE_PET. We get a handle to a working copy and store it in the static CLONE_PET. In a future Unit of Work, the Pet is changed.
Developers who incorrectly store global references to clones from units of work often expect them to be updated when the cache object is changed in a future Unit of Work. Only the cache copy is updated.
//Read a Pet from the database, store in static CACHE_PET = (Pet)session.readObject(Pet.class); //Put a clone in a static. This is a bad idea and is a common error UnitOfWork uow = session.acquireUnitOfWork();CLONE_PET = (Pet)uow.readObject(Pet.class);CLONE_PET.setName("Hairy"); uow.commit(); //Later, the pet is changed again UnitOfWork anotherUow = session.acquireUnitOfWork();Pet petClone = (Pet)anotherUow.registerObject(CACHE_PET);petClone.setName("Fuzzy"); anotherUow.commit(); // If you incorrectly stored the clone in a static and thought it should be // updated when it's later changed, you would be wrong: only the cache copy is // updated; NOT OLD CLONES. System.out.println("CACHE_PET is" + CACHE_PET); System.out.println("CLONE_PET is" + CLONE_PET);
The two System.out calls produce the following output:
CACHE_PET isPet type Cat named Fuzzy id:100 CLONE_PET isPet type Cat named Hairy id:100
In "Modifying an Object", we noted that it is possible to read any particular instance of a class by executing:
session.readObject(Class);
There is also a readObject method that takes an object as an argument: this method is equivalent to doing a ReadObjectQuery on the primary key of the object passed in. For example, the following:
session.readObject(pet);
Is equivalent to the following:
ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Pet.class); ExpressionBuilder builder = new ExpressionBuilder(); Expression exp = builder.get("id").equal(pet.getId()); query.setSelectionCriteria(exp); session.executeQuery(query);
Also note that primary key based queries, by default, will return what is in the cache without going to the database.
Given this, we have a very quick and simple method for accessing the cache copy of an object as shown in Example 7-16.
//Here is a test to see if an object is the cache copy boolean cached = CACHE_PET == session.readObject(CACHE_PET); boolean cloned = CLONE_PET == session.readObject(CLONE_PET); System.out.println("Is CACHE_PET the Cache copy of the object: " + cached); System.out.println("Is CLONE_PET the Cache copy of the object: " + cloned);
This code produces the following output:
Is CACHE_PET the Cache copy of the object: true Is CLONE_PET the Cache copy of the object: false
The Unit of Work has several debugging methods to help you analyze performance or track down problems with your code. The most useful is printRegisteredObjects which prints all the information about objects known in the Unit of Work. Use this method to see how many objects are registered and to make sure objects you are working on are registered.
To use this method, you must have log messages enabled for the session that the Unit of Work is from. Session log messages are disabled by default. To enable log messages, use the session logMessages method. To disable log messages, use the session dontLogMessages method as shown in Example 7-17.
session.logMessages(); // enable log messages UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet)uow.readObject(Pet.class);petClone.setName("Mop Top");Pet pet2 = new Pet();pet2.setId(200);pet2.setName("Sparky");pet2.setType("Dog");uow.registerObject(pet2);uow.printRegisteredObjects(); uow.commit(); session.dontLogMessages(); // disable log messages
This example produces the following output:
UnitOfWork identity hashcode: 32373 Deleted Objects: All Registered Clones:Key: [100] Identity Hash Code:13901 Object: Pet type Cat named Mop Top id:100Key: [200] Identity Hash Code:16010 Object: Pet type Dog named Sparky id:200 New Objects:Key: [200] Identity Hash Code:16010 Object: Pet type Dog named Sparky id:200
OracleAS TopLink exceptions are instances of RuntimeException, which means that methods that throw them do not have to be placed in a try-catch statement.
However, the Unit of Work commit method is one that should be called within a try-catch statement to deal with problems that may arise.
Example 7-18 shows one way to handle Unit of Work exceptions:
UnitOfWork uow = session.acquireUnitOfWork(); Pet petClone = (Pet)uow.registerObject(newPet); petClone.setName("Assume this name is too long for a database constraint"); // Assume that the name argument violates a length constraint on the database. // This will cause a DatabaseException on commit. try {uow.commit(); } catch (TopLinkException tle) {System.out.println("There was an exception: " + tle); }
This code produces the following output:
There was an exception: EXCEPTION [ORACLEAS TOPLINK-6004]: oracle.toplink.exceptions.DatabaseException
Catching exceptions at commit time is mandatory if you are using optimistic locking because the exception raised is the indication that there was an optimistic locking problem. Optimistic locking allows all users to access a given object, even if it is currently in use in a transaction or Unit of Work. When the Unit of Work attempts to change the object, the database checks to ensure that the object has not changed since it was initially read by the Unit of Work. If the object has changed, the database raises an exception, and the Unit of Work rolls back the transaction.
For more information, see "Locking Policy".
Example shows how to use the Unit of Work newInstance method to create a new Pet object, register it with the Unit of Work, and return a clone, all in one step. If you are using a factory pattern to create your objects (and specified this in the builder), the newInstance method will use the appropriate factory.
UnitOfWork uow = session.acquireUnitOfWork();Pet petClone = (Pet)uow.newInstance(Pet.class);petClone.setId(100);petClone.setName("Fluffy");petClone.setType("Cat"); uow.commit();
This example examines how to use the registerNewObject method, including:
The registerNewObject method registers a new object as if it was a clone. At commit time, the Unit of Work creates another instance of the object to be the cache version of that object.
Use registerNewObject in situations where:
Example 7-20 shows how to register a new object with the registerNewObject method:
UnitOfWork uow = session.acquireUnitOfWork();PetOwner existingPetOwnerClone =PetOwner)uow.readObject(PetOwner.class);Pet newPet = new Pet();newPet.setId(900);newPet.setType("Lizzard");newPet.setName("Larry");newPet.setPetOwner(existingPetOwnerClone);uow.registerNewObject(newPet); uow.commit();
By using registerNewObject, the variable newPet should not be used after the Unit of Work is committed. The new object is the clone and if you need the cache version of the object, you need to query for it. If you needed a handle to the cache version of the Pet after the Unit of Work has committed, then you should use the first approach described in "Associations: New Source to Existing Target Object". In that example, the variable newPet is the cache version after the Unit of Work is committed.
At commit time, OracleAS TopLink can determine if an object is new or not. In "Associations: New Target to Existing Source Object", we saw that if a new object is reachable from a clone, you do not need to register it. OracleAS TopLink effectively does a registerNewObject to all new objects it can reach from registered objects.
When working with new objects, remember the following rules:
registerNewObject are considered to be working copies in the Unit of Work.
registerObject with a new object, the result is the clone and the argument is considered the cache version.
Example 7-21 shows how to associate new objects with the registerNewObject method:
UnitOfWork uow = session.acquireUnitOfWork();Pet newPet = new Pet();newPet.setId(150);newPet.setType("Horse");newPet.setName("Ed");PetOwner newPetOwner = new PetOwner();newPetOwner.setId(250);newPetOwner.setName("George");newPetOwner.setPhoneNumber("555-9999");VetVisit newVetVisit = new VetVisit();newVetVisit.setId(350);newVetVisit.setNotes("Talks a lot");newVetVisit.setSymptoms("Sore throat");newPet.getVetVisits().addElement(newVetVisit);newVetVisit.setPet(newPet);newPet.setPetOwner(newPetOwner);uow.registerNewObject(newPet); uow.commit();
However, after the Unit of Work, the variables newPet, newPetOwner, and newVetVisit should not be used since they were technically copies from the Unit of Work.
If we needed a handle to the cache version of these business objects we could query for them or we could have done the Unit of Work as shown in Example 7-22.
UnitOfWork uow = session.acquireUnitOfWork(); Pet newPet = new Pet(); Pet newPetClone = (Pet)uow.registerObject(newPet); newPetClone.setId(150); newPetClone.setType("Horse"); newPetClone.setName("Ed"); PetOwner newPetOwner = new PetOwner(); PetOwner newPetOwnerClone = (PetOwner)uow.registerObject(newPetOwner); newPetOwnerClone.setId(250); newPetOwnerClone.setName("George"); newPetOwnerClone.setPhoneNumber("555-9999"); VetVisit newVetVisit = new VetVisit(); VetVisit newVetVisitClone = (VetVisit)uow.registerObject(newVetVisit); newVetVisitClone.setId(350); newVetVisitClone.setNotes("Talks a lot"); newVetVisitClone.setSymptoms("Sore throat"); newPetClone.getVetVisits().addElement(newVetVisitClone); newVetVisitClone.setPet(newPetClone); newPetClone.setPetOwner(newPetOwnerClone); uow.commit();
The registerAllObjects method takes a Collection of objects as an argument and returns a Collection of clones. This allows you to register many objects at once as shown in Example 7-23:
UnitOfWork uow = session.acquireUnitOfWork(); Collection toRegister = new Vector(2); VetVisit vv1 = new VetVisit(); vv1.setId(70); vv1.setNotes("May have flu"); vv1.setSymptoms("High temperature"); toRegister.add(vv1); VetVisit vv2 = new VetVisit(); vv2.setId(71); vv2.setNotes("May have flu"); vv2.setSymptoms("Sick to stomach"); toRegister.add(vv2); uow.registerAllObjects(toRegister); uow.commit();
When OracleAS TopLink writes an object to the database, OracleAS TopLink runs an existence check to determine whether to perform an insert or an update. You can specify the default existence checking policy for a project as a whole or on a per-descriptor basis. By default, OracleAS TopLink uses the check cache existence checking policy. If you use any existence checking policy other than check cache, then you can use the way you register your objects to your advantage to reduce the time it takes OracleAS TopLink to register an object.
This section explains how to use one of the following existence checking policies to accelerate object registration:
If your existence checking policy is check database then OracleAS TopLink will check the database for existence for all objects registered in a Unit of Work. However, if you know that an object is new or existing, rather than use the basic registerObject method, you can use registerNewObject or registerExistingObject to bypass the existence check. OracleAS TopLink will not check the database for existence on objects that you have registered with these methods. It will automatically do an insert if registerNewObject is called or an update if registerExistingObject is called.
If your existence checking policy is assume existence then all objects registered in a Unit of Work are assumed to exist and OracleAS TopLink will always do an update to the database on all registered objects, even new objects that you registered with registerObject. However, if you use the registerNewObject method on the new object, OracleAS TopLink knows to do an insert in the database even though the existence checking policy says assume existence.
If your existence checking policy is assume non-existence then all objects registered in a Unit of Work are assumed to be new and OracleAS TopLink will always do an insert to the database, even on objects read from the database. However, if you use the registerExistingObject method on existing objects, OracleAS TopLink knows to do an update to the database.
Aggregate mapped objects should never be registered in an OracleAS TopLink Unit of Work (in fact, you will get an exception if you try). Aggregate cloning and registration is automatic based on the owner of the aggregate object. In other words, if you register the owner of an aggregate, the aggregate is automatically cloned. When you get a working copy of an aggregate owner, its aggregate is also a working copy.
The bottom line of working with aggregates is you should always use an aggregate within the context of its owner:
The Unit of Work unregisterObject method allows you to unregister a previously registered object from a Unit of Work. An unregistered object will be ignored in the Unit of Work and any uncommitted changes made to the object up to that point will be discarded.
In general, this method is rarely used. It can be useful if you create a new object, but then decide to delete it in the same Unit of Work (which is also not recommended).
You can declare a class as read-only within the context of a Unit of Work. Clones are neither created nor merged for such classes, thus improving performance. Such classes are ineligible for changes in the Unit of Work.
When a Unit of Work registers an object, it traverses and registers the entire object tree. If the Unit of Work encounters a read-only class, it does not traverse that branch of the tree and does not register objects referenced by the read-only class, so those classes are ineligible for changes in the Unit of Work.
For example, suppose class A owns a class B and class C extends class B. You acquire a Unit of Work in which you know only instances of A will change: you know that no class B's will be changed. Before registering an instance of B, use:
myUnitofWork.addReadOnlyClass(B.class);
Then you can proceed with your transaction: registering A objects, modifying their working copies, and committing the Unit of Work.
At commit time, the Unit of Work will not have to compare backup copy clones with the working copy clones for instances of class B (even if instances were registered explicitly or implicitly). This can improve Unit of Work performance if the object tree is very large.
Note that if you register an instance of class C, the Unit of Work does not create or merge clones for this object; any changes made to your C are not be persisted because C extends B and B was identified as read-only.
To identify multiple classes as read only, add them to a Vector and use:
myUnitOfWork.addReadOnlyClasses(myVectorOfClasses);
Note that a nested Unit of Work inherits the set of read-only classes from the parent Unit of Work. For more information on using a nested Unit of Work, see "Using a Nested or Parallel Unit of Work".
To establish a default set of read-only classes for all Units of Work, use the project method setDefaultReadOnlyClasses(Vector). After you call this method, all new Units of Work include the Vector of read-only classes.
When you declare a class as read-only, the read-only flag extends to its descriptors. You can flag a descriptor as read-only at development time, using either Java code or the OracleAS TopLink Mapping Workbench. This option improves performance by excluding the read-only descriptors from Unit of Work registration and editing.
To flag descriptors as read-only in Java code, call the setReadOnly method on the descriptor as follows:
descriptor.setReadOnly();
To flag a descriptor as read-only in the OracleAS TopLink Mapping Workbench, select the Read Only check box for a specific descriptor.
For more information, see "Working with Descriptors," in the Oracle Application Server TopLink Mapping Workbench User's Guide.
This section explains how to include new, changed, or deleted objects in queries within a Unit of Work prior to commit, including:
Because queries are executed on the database, querying though a Unit of Work will not, by default, include new, uncommitted, objects in a Unit of Work. The Unit of Work will not spend time executing your query against new, uncommitted, objects in the Unit of Work unless you explicitly tell it to.
Assume that a single Pet of type Cat already exists on the database. Examine the code shown in Example 7-24.
UnitOfWork uow = session.acquireUnitOfWork();Pet pet2 = new Pet();Pet petClone = (Pet)uow.registerObject(pet2);petClone.setId(200);petClone.setType("Cat");petClone.setName("Mouser");ReadAllQuery readAllCats = new ReadAllQuery();readAllCats.setReferenceClass(Pet.class);ExpressionBuilder builder = new ExpressionBuilder();Expression catExp = builder.get("type").equal("Cat");readAllCats.setSelectionCriteria(catExp);Vector allCats = (Vector)uow.executeQuery(readAllCats);System.out.println("All 'Cats' read through UOW are: " + allCats); uow.commit();
This produces the following output:
All 'Cats' read through UOW are: [Pet type Cat named Fluffy id:100]
If you tell the query readAllCats to include new objects:
readAllCats.conformResultsInUnitOfWork();
The output would be:
All 'Cats' read through UOW are: [Pet type Cat named Fluffy id:100, Pet type Cat named Mouser id:200]
Bear in mind that conforming will impact performance. Before you use conforming, make sure that it is actually necessary. For example, consider the alternative described in "Conforming Query Alternatives".
Sometimes, you need to provide other code modules with access to new objects created in a Unit of Work. Conforming can be used to provide this access. However, the following alternative is significantly more efficient.
Somewhere a Unit of Work is acquired from a Session and is passed to multiple modules for portions of the requisite processing:
UnitOfWork uow = session.acquireUnitOfWork();
In the module that creates the new employee:
Pet newPet = new Pet(); Pet newPetClone = (Pet)uow.registerObject(newPet); uow.setProperty("NEW PET", newPet);
In other modules where newPet needs to be accessed for further modification, it can simply be extracted from the Unit of Work's properties:
Pet newPet = (Pet) uow.getProperty("NEW PET"); newPet.setType("Dog");
Conforming queries are ideal if you are not sure if an object has been created yet or the criteria is dynamic.
However, for situations where the quantity of objects is finite and well known, this simple and more efficient solution is a very practical alternative.
OracleAS TopLink's support for conforming queries in the Unit of Work can be specified in the descriptors.
You can flag a descriptor directly to always conform results in the Unit of Work so that all queries performed on this descriptor conform its results in the Unit of Work by default. You can specify this either within code or from the OracleAS TopLink Mapping Workbench.
You can flag descriptors to always conform in the Unit of Work by calling the method on the descriptor as follows:
descriptor.setShouldAlwaysConformResultsInUnitOfWork(true);
To set this flag in the OracleAS TopLink Mapping Workbench, select the Conform Results in Unit Of Work check box for a descriptor.
In a three-tier application, the client and server exchange objects using a serialization mechanism such as RMI or CORBA.
When the client changes an object and returns it to the server, you cannot register this serialized object into a Unit of Work directly.
On the server, you must register the original object in a Unit of Work and then use the Unit of Work methods listed in Table 7-2 to merge serialized object changes into the working copy clone. Each method takes the serialized object as an argument.
Note that if your three-tier client is sufficiently complex, consider using the TopLink remote session (see "Remote Session"). It automatically handles merging and allows you to use a Unit of Work on the client.
You can merge clones with both existing and new objects. Because they do not appear in the cache and may not have a primary key, you can merge new objects only once within a Unit of Work. If you need to merge a new object more than once, call the Unit of Work setShouldNewObjectsBeCached method, and ensure that the object has a valid primary key; you can then register the object.
Example 7-25 shows one way to update the original object with the changes contained in the corresponding serialized object (rmiClone) received from a client.
update(Object original, Object rmiClone) { original = uow.registerObject(original); uow.mergeCloneWithRefereneces(rmiClone); uow.commit(); }
At commit time, a Unit of Work and its contents expire: you must not use the Unit of Work nor its clones even if the transaction failed and rolled back.
However, OracleAS TopLink offers API that enables you to continue working with a Unit of Work and its clones:
commitAndResume: commits the Unit of Work, but does not invalidate it or its clones
commitAndResumeOnFailure: commits the Unit of Work. If the commit succeeds, the Unit of Work expires. However, if the commit fails, this method does not invalidate the Unit of Work or its clones. This method enables the user to modify the registered objects in a failed Unit of Work and retry the commit.
Example 7-26 shows how to use the commitAndResume method:
UnitOfWork uow = session.acquireUnitOfWork();PetOwner petOwnerClone =(PetOwner)uow.readObject(PetOwner.class);petOwnerClone.setName("Mrs. Newowner");uow.commitAndResume();petOwnerClone.setPhoneNumber("KL5-7721"); uow.commit();
The commitAndResume call produces the SQL:
UPDATE PETOWNER SET NAME = 'Mrs. Newowner' WHERE (ID = 400)
And then the commit call produces the SQL:
UPDATE PETOWNER SET PHN_NBR = 'KL5-7721' WHERE (ID = 400)
Under certain circumstances, you may want to abandon some or all changes to clones in a Unit of Work, but not abandon the Unit of Work itself. The following options exist for reverting all or part of the Unit of Work:
revertObject: abandons changes to a specific working copy clone in the Unit of Work
revertAndResume: uses the backup copy clones to restore all clones to their original states, deregister any new objects, and reinstate any deleted objects
You can use a Unit of Work within another Unit of Work (nesting) or you can use two or more Units of Work with the same objects in parallel.
To start multiple Units of Work that operate in parallel, call the acquireUnitOfWork method multiple times on the session. The Units of Work operate independently of one another and maintain their own cache.
To nest Units of Work, call the acquireUnitOfWork method on the parent Unit of Work. This creates a child Unit of Work with its own cache. If a child Unit of Work commits, it updates the parent Unit of Work rather than the database. If the parent does not commit, the changes made to the child are not written to the database.
OracleAS TopLink does not update the database or the cache until the outermost Unit of Work is committed. You must commit or release the child Unit of Work before you can commit its parent.
Working copies from one Unit of Work are not valid in another Units of Work: not even between an inner and outer Unit of Work. You must register objects at all levels of a Unit of Work where they are used.
Example 7-27 shows how to use nested Units of Work:
UnitOfWork outerUOW = session.acquireUnitOfWork(); Pet outerPetClone = (Pet)outerUOW.readObject(Pet.class); UnitOfWork innerUOWa = outerUOW.acquireUnitOfWork(); Pet innerPetCloneA = (Pet)innerUOWa.registerObject(outerPetClone); innerPetCloneA.setName("Muffy"); innerUOWa.commit(); UnitOfWork innerUOWb = outerUOW.acquireUnitOfWork(); Pet innerPetCloneB = (Pet)innerUOWb.registerObject(outerPetClone); innerPetCloneB.setName("Duffy"); innerUOWb.commit(); outerUOW.commit();
You can add custom SQL to a Unit of Work at any time by calling the Unit of Work executeNonSelectingCall method as shown in Example 7-28.
uow.executeNonSelectingCall(new SQLCall(mySqlString));
The Unit of Work validates object references at commit time. If an object registered in a Unit of Work references other unregistered objects, this violates object transaction isolation, and causes OracleAS TopLink validation to raise an exception.
Although referencing unregistered objects from a registered object can corrupt the session cache, there are applications in which you want to disable validation. OracleAS TopLink offers API to toggle validation, as follows:
If the Unit of Work detects an error when merging changes into the session cache, it throws a QueryException. Although this exception specifies the invalid object and the reason it is invalid, it may still be difficult to determine the cause of the problem.
In this case, you can use the validateObjectSpace method to test registered objects and provide the full stack of traversed objects. This may help you more easily find the problem. You can call this method at any time on a Unit of Work.
"Deleting Objects" explained that OracleAS TopLink always properly orders the SQL based on the mappings and foreign keys in your object model and schema. You can control the order of deletes by:
It is possible to tell the Unit of Work to issue deletes before inserts and updates by calling the Unit of Work setShouldPerformDeletesFirst method.
By default, OracleAS TopLink does inserts and updates first to ensure that referential integrity is maintained.
If you are replacing an object with unique constraints by deleting it and inserting a replacement, if the insert occurs before the delete, you may raise a constraint violation. In this case, you may need to call setShouldPerformDeletesFirst so that the delete is performed before the insert.
The constraints used by OracleAS TopLink to determine delete order are inferred from one-to-one and one-to-many mappings. If you do not have such mappings, you can add constraint knowledge to OracleAS TopLink using the descriptor addConstraintDependencies(Class) method.
For example, suppose you have a composition of objects: A contains B (one-to-many, privately owned) and B has a one-to-one, non-private relationship with C. You want to delete A (and in doing so the included B's) but before deleting the B's, for some of them (not all) you want to delete the associated object C.
There are two possible solutions:
In the first option, we do not use privately-owned on the one-to-many (A to B) relationship. When deleting an A, we make sure to delete all of it's B's as well as any C instances. For example:
uow.deleteObject(existingA); uow.deleteAllObjects(existingA.getBs()); // delete one of the C's uow.deleteObject(((B) existingA.getBs().get(1)).getC());
This option produces the following SQL:
DELETE FROM B WHERE (ID = 2) DELETE FROM B WHERE (ID = 1) DELETE FROM A WHERE (ID = 1) DELETE FROM C WHERE (ID = 1)
In the second option, we keep the one-to-many (A to B) relationship privately owned and add a constraint dependency from A to C. For example:
session.getDescriptor(A.class).addConstraintDependencies(C.class);
Now the delete code would be:
uow.deleteObject(existingA); uow.deleteAllObjects(existingA.getBs()); // delete one of the C's uow.deleteObject(((B) existingA.getBs().get(1)).getC());
This option produces the following SQL:
DELETE FROM B WHERE (A = 1) DELETE FROM A WHERE (ID = 1) DELETE FROM C WHERE (ID = 1)
In both cases, the B is deleted before A and C. The main difference is that the second option will generate fewer SQL statements as it knows that it is deleting the entire set of B's related from A.
For best performance when using a Unit of Work, consider the following tips:
OracleAS TopLink J2EE integration provides support for external datasources and external transaction controllers. Together, these features provide support for JTA. This enables you to incorporate external container support into your application, and to use JTA transactions.
This section describes:
For most non-J2EE applications OracleAS TopLink provides an internal connection or pool of connections. However, most J2EE applications use external connection pooling offered by the J2EE Container JTA DataSource. For J2EE applications OracleAS TopLink integrates with the J2EE Container connection pooling.
External connection pools enable your OracleAS TopLink application to:
DataSource).
DataSource.
DataSource configured and managed directly on the server.
DataSource interface.
Configure OracleAS TopLink to use the built-in JTA integration support to take advantage of these benefits. Without JTA, external connection pools generally offer benefits only if transactions in an OracleAS TopLink application are independent of each other and any other transactions in the system. In that case, the complexities of an OracleAS TopLink connection or connection pool are unnecessary.
To configure the use of an external connection pool in the sessions.xml file:
DataSource on the server.
login tag in the sessions.xml file to specify a DataSource and the use of an external connection pool:
<data-source>jdbc/MyApplicationDS</data-source> <uses-external-connection-pool>true</uses-external-connection-pool>
To configure the use of an external connection pool in Java:
DataSource on the server.
Login to specify a DataSource and the use of an external connection pool:
login.setConnector(
new JNDIConnector(new InitialContext(), "jdbc/MyApplicationDS")
);
login.setUsesExternalConnectionPooling(true);
A transaction controller is an OracleAS TopLink class that synchronizes the session cache with the data on the database. The transaction controller manages messages and callbacks from the J2EE transaction. On commit, the transaction controller executes the Unit of Work SQL on the database, and merges changed objects into the OracleAS TopLink session cache. Because JTA transaction controllers require a JTA-enabled DataSource, configure an external transaction controller and enable OracleAS TopLink external connection pool support.
OracleAS TopLink provides transaction controllers for container-specific support, as well as a generic controllers that can be used for other specification-conforming servers.
Table 7-3 lists the custom external transaction controllers OracleAS TopLink provides.
To configure the use of an external transaction controller in the sessions.xml file:
DataSource on the server.
For more information, see the J2EE container documentation.
login tag in the sessions.xml file to specify a DataSource, the use of an external transaction controller, and the use of an external connection pool:
<data-source>jdbc/MyApplicationDS</data-source>
<uses-external-transaction-controller>
true
</uses-external-transaction-controller>
<uses-external-connection-pool>true</uses-external-connection-pool>
sessions.xml file.
For example:
<external-transaction-controller-class>
oracle.toplink.jts.oracle9i.Oracle9iJTSExternalTransactionController
</external-transaction-controller-class>
To configure the use of an external transaction controller in Java:
DataSource on the server.
For more information, see the J2EE container documentation.
Login to specify a DataSource, the use of an external transaction controller, and the use of an external connection pool:
login.setConnector(
new JNDIConnector(new InitialContext(), "jdbc/MyApplicationDS")
);
login.setUsesExternalTransactionController(true);
login.setUsesExternalConnectionPooling(true);
serverSession.setExternalTransactionController( new Oracle9iJTSExternalTransactionController() );
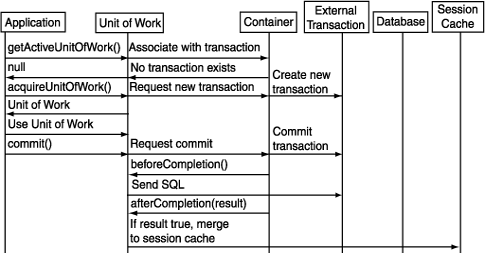
You use a Unit of Work to write to a database even in a JTA environment. To ensure that only one Unit of Work is associated with a given transaction, use the getActiveUnitOfWork method to acquire a Unit of Work as shown in Example 7-29.
The getActiveUnitOfWork method searches for an existing external transaction:
If a non-null Unit of Work is returned, use it exactly as you would in a non-JTA environment: the only exception is that you do not call the commit method (see "Using a Unit of Work When an External Transaction Exists").
If a null Unit of Work is returned, start an external transaction either explicitly through the UserTransaction interface, or by acquiring a new Unit of Work using the acquireUnitOfWork method on the client session (see "Using a Unit of Work When No External Transaction Exists").
boolean shouldCommit = false; // Read in any pet. Pet pet = (Pet)clientSession.readObject(Pet.class); UnitOfWork uow = clientSession.getActiveUnitOfWork(); if (uow == null) { uow = clientSession.acquireUnitOfWork(); // Start external transaction shouldCommit = true; } Pet petClone = (Pet) uow.registerObject(pet); petClone.setName("Furry"); if (shouldCommit) { uow.commit(); // Ask external transaction controller to commit }
When getActiveUnitOfWork returns a non-null Unit of Work, you are associated with an existing external transaction. Use the Unit of Work as usual.
As the external transaction was not started by the Unit of Work, issuing a commit on it will not cause the JTA transaction to be committed. The Unit of Work will defer to the application or container that began the transaction. When the external transaction does get committed by the container, OracleAS TopLink receives sychronization callbacks at key points during the commit.
The Unit of Work sends the required SQL to the database when it receives the beforeCompletion call back.
The Unit of Work uses the boolean argument received from the afterCompletion call back to determine if the commit was successful (true) or not (false).
If the commit was successful, the Unit of Work merges changes to the session cache. If the commit was unsuccessful, the Unit of Work discards the changes.
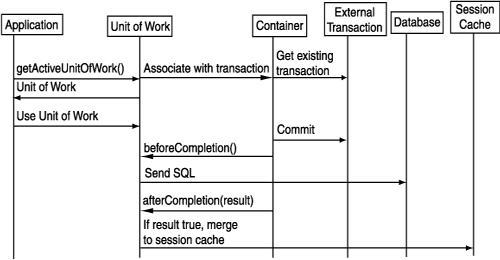
When getActiveUnitOfWork returns a null Unit of Work, there is no existing external transaction. You must start a new external transaction.
Do this either by starting an external transaction explicitly using the UserTransaction interface, or by acquiring a new Unit of Work using the acquireUnitOfWork method on the server session.
Use the Unit of Work as usual.
Once the modifications to registered objects are complete, you must commit the transaction either explicitly through the UserTransaction interface or by calling the Unit of Work commit method.
The transaction synchronization callbacks are then invoked on OracleAS TopLink and the database updates and cache merge occurs based upon those callbacks.
|
|
 Copyright © 2000, 2003 Oracle Corporation. All Rights Reserved. |
|