Release 2 (9.2)
Part Number A96566-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Recovery Manager User's Guide Release 2 (9.2) Part Number A96566-01 |
|
This chapter describes how to use Recovery Manager to perform restore and recovery operations. This chapter contains these topics:
| See Also:
"Monitoring RMAN Job Progress" to learn how to monitor restore and recovery operations |
Typically, you restore and recover a database or subset of a database in the following cases:
If you want to restore a version of the database for testing purposes, then run the DUPLICATE rather than the RESTORE command.
| See Also:
Chapter 12, "Duplicating a Database with Recovery Manager" to learn how to duplicate a database |
The basic procedure for performing restore and recovery with RMAN is as follows:
RESTORE command.RECOVER command.Because so many possible restore and recover scenarios exist, the actual recovery procedure that you should follow differs from case to case.
Note that if you use Oracle Enterprise Manager, then you can use the Recovery wizard instead of running the RESTORE and RECOVER commands through the RMAN command-line interface. You can perform the following RMAN restore and recovery tasks through the Recovery wizard:
| See Also:
Oracle Enterprise Manager Administrator's Guide to learn about RMAN restore and recovery |
Before performing recovery, identify the conditions under which you will perform the recovery. The recovery procedure differs depending on whether:
RESETLOGSThe section "Performing Basic RMAN Media Recovery" describes a typical recovery scenario. This scenario is typical in that sense that is serves as the generic template for media recovery. Obviously, this generic template can cover only some of the possible restore scenarios. The sections in this chapter other than "Performing Basic RMAN Media Recovery" describe variations. Use Table 10-1 to determine which sections you should refer to when your recovery scenario differs from the generic procedure.
| Question | If yes, then see ... | If no, then see ... |
|---|---|---|
|
Is the current control file available? |
||
|
Is the current server parameter file available? |
||
|
Are you using a recovery catalog? |
"Performing Basic RMAN Media Recovery". If using a backup control file and no catalog, refer to "Performing Recovery with a Backup Control File and No Recovery Catalog". |
|
|
Is the restore host the same as the target host? |
||
|
Will the restored database files have the same name as the original database files? |
||
|
Is the target database in an Oracle Real Application Cluster? |
||
|
Are you performing complete recovery? |
"Performing Incomplete Restore and Recovery" to recover the whole database, or Chapter 11, "Performing RMAN Tablespace Point-in-Time Recovery" for point-in-time recovery of an individual tablespace |
|
|
Are you recovering the whole database? |
"Restoring and Recovering the Whole Database in the Default Location" |
"Restoring and Recovering a Subset of the Database" if you are performing complete recovery of a database subset, or Chapter 11, "Performing RMAN Tablespace Point-in-Time Recovery" for point-in-time recovery of a database subset |
|
Were the necessary backups performed after the most recent database |
||
|
Do you need to recover whole datafiles rather than a few corrupt blocks? |
This section contains these topics:
All the procedures in this section assume the following:
Use the RESTORE and RECOVER commands to perform the recovery. The RESTORE command restores backups from disk or a media manager, but restores image copies only from disk.
If you have automatic channels configured, then RMAN allocates all channels configured for the available device types according to their parallelism settings. For example, if you configure two sbt channels and set parallelism to 1, and if you set parallelism for DISK channels to 3, then RMAN automatically allocates one sbt channel and three DISK channels. For a restore, RMAN allocates all configured channels unless the DEVICE TYPE option restricts the device type from which RMAN restores.
If you are manually allocating channels, then allocate the appropriate DISK or sbt channel when restoring files. If the appropriate device type is not allocated, then RMAN may not be able to find a backup set or copy to restore, and the RESTORE command will fail.
When and how to recover depends on the state of the database and the location of its datafiles. If possible, query fixed views to obtain the needed information.
To determine whether media recovery is necessary:
trgt:
% sqlplus 'SYS/oracle@trgt AS SYSDBA'
SELECT STATUS FROM V$INSTANCE; STATUS ------- OPEN
If the status is OPEN, then the database is open, but it is still possible that you need to restore or recover some tablespaces and their datafiles.
V$DATAFILE_HEADER view. These columns indicate the status of datafiles. Execute the following SQL script to check the datafile headers and respond according to the table that follows this example:
COL FILE# FORMAT 999 COL STATUS FORMAT A7 COL ERROR FORMAT A10 COL TABLESPACE_NAME FORMAT A10 COL NAME FORMAT A30 SELECT FILE#, STATUS, ERROR, RECOVER, TABLESPACE_NAME, NAME FROM V$DATAFILE_HEADER /
V$DATAFILE and V$TABLESPACE to obtain the tablespace names for the datafiles requiring recovery as well as status and error information. For example, run the following SQL*Plus script:
COL DF# FORMAT 999 COL DF_NAME FORMAT A30 COL TBSP_NAME FORMAT A7 COL STATUS FORMAT A7 COL ERROR FORMAT A10 COL CHANGE# FORMAT 99999999 SELECT r.FILE# AS df#, d.NAME AS df_name, t.NAME AS tbsp_name, d.STATUS, r.ERROR, r.CHANGE#, r.TIME FROM V$RECOVER_FILE r, V$DATAFILE d, V$TABLESPACE t WHERE t.TS# = d.TS# AND d.FILE# = r.FILE# /
This script produces output similar to the following:
DF# DF_NAME TBSP_NA STATUS ERROR CHANGE# TIME ---- -------------------------------- ------- ------- ---------- --------- ---------- 7 /oracle/oradata/trgt/tools01.dbf TOOLS OFFLINE OFFLINE 0 NORMAL
If media recovery is required, then the ERROR column indicates the problem that makes recovery necessary.
| See Also:
Oracle9i Database Reference for information about these views |
After determining which datafiles require recovery, you can either restore all datafiles in the database or only a subset of datafiles.
This section contains these topics:
In this scenario, you have a current control file but all datafiles are damaged or lost. You must restore and recover the whole database.
To restore and recover the database when the current control file is available:
STARTUP MOUNT
SHOW ALL to see the current configuration.RESTORE command, and recover it using the RECOVER command.This example performs recovery using automatic channels and skips the read-only history tablespace:
RESTORE DATABASE; RECOVER DATABASE # optionally, delete logs restored for recovery and limit disk space used DELETE ARCHIVELOG MAXSIZE 1M SKIP TABLESPACE history; # optionally, skip the recovery of some tablespaces
ALTER DATABASE OPEN;
In this scenario, some but not all of the datafiles are damaged. You have already determined which tablespaces are affected by following the procedure in "Preparing for Media Recovery".
The following procedure assumes that the database is open, so you must take the tablespaces to be recovered offline.
To recover a tablespace to the default location:
STARTUP MOUNT
SHOW ALL to see the current configuration.ALTER TABLESPACE ... OFFLINE IMMEDIATE.RESTORE command, and recover it with the RECOVER command.This example restores and recovers the users tablespace:
SQL 'ALTER TABLESPACE users OFFLINE IMMEDIATE'; RESTORE TABLESPACE users; RECOVER TABLESPACE users;
SQL 'ALTER TABLESPACE users ONLINE';
This section contains these topics:
RMAN can perform recovery of the whole database to a specified noncurrent time, SCN, or log sequence number. This type of recovery is called incomplete recovery because it does not completely use all of the available redo. Incomplete recovery of the whole database is also called database point-in-time recovery (DBPITR).
Incomplete recovery of the database requires you to open the database with the RESETLOGS option. Using this option gives the online redo logs a new time stamp and SCN, thereby eliminating the possibility of corrupting datafiles by the application of obsolete archived redo logs. Note that you have to recover all datafiles: you cannot recover some datafiles before the RESETLOGS and others after the RESETLOGS. In fact, Oracle prevents you from resetting the logs if a datafile is offline. The only exception is if the datafile is offline normal or read-only. You can bring files in read-only or offline normal tablespaces online after the RESETLOGS because they do not need any redo applied to them.
The easiest way to perform DBPITR is to use the SET UNTIL command (rather than specifying the UNTIL clause on the RESTORE and RECOVER commands individually) because it sets the desired time for any subsequent RESTORE, SWITCH, and RECOVER commands in the same RUN job. Note that if you specify a SET UNTIL command after a RESTORE and before a RECOVER, you may not be able to recover the database to the point in time required because the restored files may already have time stamps more recent than the set time. Hence, it is recommended that you specify the SET UNTIL command before the RESTORE command.
The database must be closed to perform database point-in-time recovery. Note that if you are recovering to a time, you should set the time format environment variables before invoking RMAN (refer to "Setting Globalization Support Environment Variables for RMAN"). The following are sample Globalization Support settings:
NLS_LANG = american_america.us7ascii NLS_DATE_FORMAT="Mon DD YYYY HH24:MI:SS"
To recover the database until a specified time, SCN, or log sequence number:
SHUTDOWN IMMEDIATE; STARTUP MOUNT;
You can also examine the alert.log to find the SCN of an event and recover to a prior SCN. Alternatively, you can determine the log sequence number that contains the recovery termination SCN, and then recover through that log. For example, query V$LOG_HISTORY to view the logs that you have archived.
RECID STAMP THREAD# SEQUENCE# FIRST_CHAN FIRST_TIM NEXT_CHANG ---------- ---------- ---------- ---------- ---------- --------- ---------- 1 344890611 1 1 20037 24-SEP-01 20043 2 344890615 1 2 20043 24-SEP-01 20045 3 344890618 1 3 20045 24-SEP-01 20046
RUN command:
NLS_LANG and NLS_DATE_FORMAT environment variables.The following example performs an incomplete recovery until November 15 at 9 a.m.
RUN { SET UNTIL TIME 'Nov 15 2001 09:00:00'; # SET UNTIL SCN 1000; # alternatively, you can specify SCN # SET UNTIL SEQUENCE 9923; # alternatively, you can specify log sequence number RESTORE DATABASE; RECOVER DATABASE; }
ALTER DATABASE OPEN RESETLOGS;
RESETLOGS are not easily usable. For example, run the following to back up the database:
SHUTDOWN IMMEDIATE STARTUP MOUNT BACKUP DATABASE; ALTER DATABASE OPEN;
RMAN can restore the server parameter file either to the default location or to a nondefault location. Also, RMAN can restore the server parameter file as a server parameter file or as a client-side initialization parameter file.
Note the following restrictions and usage notes when restoring the server parameter file:
TO clause is not used. The default location is platform-specific (for example, ?/dbs/spfile@.ora on Solaris).To restore the server parameter file:
% rman TARGET / CATALOG rman/cat@catdb
DB_NAME of the target database is unique in the catalog, then skip this step. Otherwise, set the DBID of the target database. For example:
SET DBID 676549873;
STARTUP FORCE NOMOUNT;
RESTORE SPFILE; # if you are using a catalog RESTORE SPFILE FROM AUTOBACKUP; # if in NOCATALOG mode
If restoring to a nondefault location, then you could run commands as in the following example:
RESTORE SPFILE TO '/tmp/spfileTEMP.ora'; # if you are using a catalog RESTORE SPFILE TO '/tmp/spfileTEMP.ora' FROM AUTOBACKUP; # if in NOCATALOG mode
You can restore the server parameter file as a client-side initialization parameter file with the TO PFILE 'filename' clause as in the following example:
RESTORE SPFILE TO PFILE '/tmp/initTEMP.ora';
SPFILE=new_location, where new_location is the path name of the restored server parameter file. Then, restart the instance with the client-side initialization parameter file. For example:
HOST 'echo "SPFILE=/tmp/spfileTEMP.ora" > /tmp/init.ora'; STARTUP FORCE PFILE=/tmp/init.ora; # starts instance with /tmp/spfileTEMP.ora
If you restored the server parameter file as a client-side initialization parameter file, then simply specify the path name of this restored file. For example:
STARTUP FORCE PFILE=/tmp/pfileTEMP.ora; # starts instance with /tmp/pfileTEMP.ora
If all copies of the current control file are lost or damaged, then you must restore and mount a backup control file before you can perform recovery. The procedure differs depending on whether you use a catalog. Note these usage notes and restrictions that apply to both cases:
RECOVER command after restoring a backup control file, even if no datafiles have been restored.RESETLOGS option. If you do not, then Oracle can display the following error for when attempting to sort: ORA-25153: Temporary Tablespace is Empty.RESETLOGS option after performing either complete or incomplete recovery with a backup control file.If RMAN is not able to automatically catalog a needed online or archived log, which can happen if you changed the archiving destination or format during recovery, or if you added new online log members after the backup of the control file, then RMAN reports errors similar to the following:
RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of recover command at 08/29/2001 14:23:09 RMAN-06054: media recovery requesting unknown log: thread 1 scn 86945
In this case, you must use the CATALOG command to manually add the required logs to the repository so that recovery can proceed. The cataloging procedure is described in "Cataloging Archived Logs and User-Managed Copies".
This section contains these topics:
If you use a recovery catalog and have a backup control file available, this procedure does not differ substantially from "Performing Complete Restore and Recovery". The procedure in this section assumes that you are restoring the control file to its default location. If you must restore the control file to a new location, then refer to "Restoring Control Files to a New Location" for instructions.
When you perform a restore operation using a backup control file and you use a catalog, RMAN automatically adjusts the control file to reflect the structure of the restored backup.
The following procedure assumes that you do not have more than one target database registered in the catalog with the same name. If multiple target databases are registered with the same name, then you must specify the DBID with the SET DBID command so that RMAN knows which control file to restore. The DBID is the unique numerical identifier for a database.
| See Also:
"Performing Recovery with a Backup Control File and No Recovery Catalog" to learn how to set the DBID |
To recover the database with a backup control file and a recovery catalog:
STARTUP NOMOUNT
RESTORE CONTROLFILE command to restore the control file to all default locations specified in the CONTROL_FILES initialization parameter. To restore a control file from an older backup, you can run SET UNTIL or specify the UNTIL clause on the RESTORE CONTROLFILE command.SET UNTIL command for incomplete recovery. Note that you can also specify the UNTIL clause on the RESTORE and RECOVER commands.This example restores the control file to its default location, then restores and completely recovers the database:
RESTORE CONTROLFILE; ALTER DATABASE MOUNT; RESTORE DATABASE; RECOVER DATABASE;
ALTER DATABASE OPEN RESETLOGS;
SQL "ALTER TABLESPACE temp ADD TEMPFILE ''?/oradata/trgt/temp01.dbf'' REUSE";
RESETLOGS are not easily usable. For example, run the following to back up the database:
SHUTDOWN IMMEDIATE STARTUP MOUNT BACKUP DATABASE; ALTER DATABASE OPEN;
This section assumes that you have RMAN backups of the control file, but do not use a recovery catalog. Assuming that you enabled the control file autobackup feature for the target database, you can restore an autobackup of the control file. Because the autobackup uses a default format, RMAN can restore it even though it does not have a repository available that lists the available backups. You can restore the autobackup to the default or a new location. RMAN replicates the control file to all CONTROL_FILES locations automatically.
Because you are not connected to a recovery catalog, the control file must have a record of all needed backups. If any backups are not listed in the control file, then RMAN cannot restore them. If datafile copies are located on disk but are not in the control file, however, then you can add them to the control file repository with the CATALOG command. This cataloging procedure is described in "Cataloging Archived Logs and User-Managed Copies".
Because the repository is not available when you restore the control file, run the SET DBID command to identify the target database. You should only run the SET DBID command in the following specialized circumstances:
To recover the database with an autobackup of the control file without a recovery catalog:
CONNECT TARGET /
STARTUP NOMOUNT;
SET DBID. RMAN displays the DBID whenever you connect to the target. You can also obtain it by running LIST, querying the catalog, or looking at the filenames of control file autobackup. (refer to "Restoring When Multiple Databases in the Catalog Share the Same Name: Example"). For example, run:
SET DBID 676549873;
sbt, then you must allocate one or more sbt channels. Because no repository is available, you cannot use automatic channels. If the autobackup was created on a disk channel, however, then you do not need to manually allocate a channel.UNTIL clause to a time, log sequence, or SCN before the online redo logs. If the online logs are usable, then restore and recover the database as described in "Performing Complete Restore and Recovery".In this example, the online redo logs have been lost. This example limits the restore of the control file autobackup, then performs recovery of the database to log sequence 13243, which is the most recent archived log:
RUN { # Optionally, set upper limit for eligible time stamps of control file backups # SET UNTIL TIME '09/10/2000 13:45:00'; # Specify a nondefault autobackup format only if required # SET CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '?/oradata/%F.bck'; ALLOCATE CHANNEL c1 DEVICE TYPE sbt; # manually allocate one or more channels RESTORE CONTROLFILE FROM AUTOBACKUP MAXSEQ 100 # start at sequence 100 and count down MAXDAYS 180; # start at UNTIL TIME and search back 6 months ALTER DATABASE MOUNT DATABASE; } # uses automatic channels configured in restored control file RESTORE DATABASE UNTIL SEQUENCE 13243; RECOVER DATABASE UNTIL SEQUENCE 13243; # recovers to most recent archived log
ALTER DATABASE OPEN RESETLOGS;
RESETLOGS are not easily usable. For example, enter:
SHUTDOWN IMMEDIATE STARTUP MOUNT BACKUP DATABASE; ALTER DATABASE OPEN;
In a recovery scenario, you may be unable to restore some or all database files or archived logs to their original locations. For example, if your machine uses two disk drives and the second drive fails, then you may be forced to restore the datafiles from the second drive to the first.
This section contains these topics:
If you cannot restore datafiles to the default location, then follow the generic procedure in "Restoring and Recovering a Subset of the Database", except run a SET NEWNAME command to rename each datafile before performing the restore. RMAN restores each datafile to its NEWNAME location rather than its original location.
After restoring the datafiles but before recovering them, run a SWITCH command to permanently change the filenames of the datafiles renamed by SET NEWNAME commands. The SWITCH command is equivalent to the SQL statement ALTER DATABASE RENAME FILE. If you run SWITCH DATAFILE ALL, then all datafiles for which a SET NEWNAME has been issued in this job are switched to their new name.
| See Also:
Oracle9i Recovery Manager Reference for |
To restore a tablespace to a new location and then recover it:
This example restores the datafiles in tablespace users and tools to a new location, then performs recovery:
RUN { SQL 'ALTER TABLESPACE users OFFLINE IMMEDIATE'; SQL 'ALTER TABLESPACE tools OFFLINE IMMEDIATE'; # restore the datafile to a new location SET NEWNAME FOR DATAFILE '?/oradata/trgt/users01.dbf' TO '/tmp/users01.dbf'; SET NEWNAME FOR DATAFILE '?/oradata/trgt/tools01.dbf' TO '/tmp/tools01.dbf'; RESTORE TABLESPACE users, tools; SWITCH DATAFILE ALL; # point control file to new filenames RECOVER TABLESPACE users, tools; }
SQL 'ALTER TABLESPACE users ONLINE'; SQL 'ALTER TABLESPACE tools ONLINE';
If a media failure damages the control file and you do not have multiplexed copies, then you must restore a backup. Specify a new name with RESTORE CONTROLFILE TO 'filename' when restoring a control file to a new location. The default location is the first location specified in the CONTROL_FILES initialization parameter. If the filename already exists, then Oracle overwrites the file.
After restoring the control file to a new location, run the RESTORE CONTROLFILE FROM 'filename' command to copy it to all CONTROL_FILES destinations. The RESTORE CONTROLFILE FROM 'filename' command is equivalent to running multiple COPY CONTROLFILE commands. Note that in case a media failure permanently damages some of the CONTROL_FILES locations, you can edit the server parameter file before starting the instance to specify new CONTROL_FILES locations.
To restore the control file to a new location:
STARTUP NOMOUNT
SET UNTIL command to restore a control file created before a specified date.CONTROL_FILES parameter of the parameter file.RUN { # To restore a control file created before a certain date, issue the following # SET command using a valid date for 'date_string'. You can also specify an SCN # or log sequence number. # SET UNTIL TIME = 'date_string'; RESTORE CONTROLFILE TO '/tmp/control01.ctl'; # restore to new location # replicate the control file manually to CONTROL_FILES locations RESTORE CONTROLFILE FROM '/tmp/control01.ctl'; STARTUP MOUNT; }
| See Also:
Oracle9i Recovery Manager Reference for |
RMAN restores archived redo logs with names constructed using the LOG_ARCHIVE_FORMAT and the LOG_ARCHIVE_DEST_1 parameters of the target database. These parameters combine in a port-specific fashion to derive the name of the restored archived log.
You can override the default names using the SET ARCHIVELOG DESTINATION command. This command manually stages archived logs to different locations while a database restore is occurring. During recovery, RMAN knows where to find the newly restored archived logs; it does not require them to be in the location specified in the initialization parameter file.
To restore archived redo logs:
STARTUP MOUNT
RUN command:
SET ARCHIVELOG DESTINATION.This example restores all backup archived logs to a new location:
RUN { SET ARCHIVELOG DESTINATION TO '/oracle/temp_restore'; RESTORE ARCHIVELOG ALL; # restore and recover datafiles as needed . . . }
You can also specify multiple restore destinations for archived logs, although you cannot specify these destinations simultaneously. For example, you can do the following:
RUN { # Set a new location for logs 1 through 10. SET ARCHIVELOG DESTINATION TO '/tmp'; RESTORE ARCHIVELOG FROM SEQUENCE 1 UNTIL SEQUENCE 10; # Set a new location for logs 11 through 20. SET ARCHIVELOG DESTINATION TO '?/oradata'; RESTORE ARCHIVELOG FROM SEQUENCE 11 UNTIL SEQUENCE 20; # Set a new location for logs 21 through 30. SET ARCHIVELOG DESTINATION TO '?/dbs'; RESTORE ARCHIVELOG FROM SEQUENCE 21 UNTIL SEQUENCE 30; # restore and recover datafiles as needed . . . }
Note that if you restore archived redo logs to multiple locations, then you only need to issue a single RECOVER command. RMAN finds the restored archived logs automatically and applies them to the datafiles.
This section contains these topics:
Various scenarios are possible when restoring a database to a new host. For example, you may want to:
To create a duplicate database for testing while maintaining the original database, use the DUPLICATE command instead of the RESTORE command (refer to Chapter 12, "Duplicating a Database with Recovery Manager"). RMAN automatically creates a unique database identifier for the duplicate database. This chapter covers the use of the RESTORE command only.
To test the restore of a database to a new host or to move the database to a new host, run the RESTORE command. If you perform a test restore only, then you should do the following to prevent overwriting the target records in the recovery catalog:
NOCATALOG mode when restoring the datafiles.Table 10-2 describes the impact on the RMAN repository when you are restoring or duplicating to a new host.
The basic procedure for performing incomplete recovery on a new host does not differ substantially from incomplete recovery on the original host. The principal issue is whether the path names of the database files on the new host are going to be the same as the path names of the files on the primary host.
The following table indicates which restore procedure you should use depending on the situation.
| Path Names of Restored Files | Procedure |
|---|---|
|
Same as the target database path names |
|
|
Different from target database path names |
Note the following when restoring to a new host:
CATALOG command to update the RMAN repository with the new filenames and use the CHANGE ... UNCATALOG command to uncatalog the old filenames.RESETLOGS option. Obtain the SCN for recovery termination by finding the lowest SCN among the most recent archived logs for each thread.
Start SQL*Plus and use the following query to determine the necessary SCN:
SELECT MIN(SCN) FROM (SELECT MAX(NEXT_CHANGE#) SCN FROM V$ARCHIVED_LOG GROUP BY THREAD#);
The basic procedure for recovering an Oracle Real Application Clusters database does not differ substantially from recovering a non-Oracle Real Application Clusters database as described in "Performing Basic RMAN Media Recovery". The main difference is that you must either configure or manually allocate channels that connect to each node of the cluster.
Because RMAN performs autolocation when restoring backups, datafile copies, and control file copies, it knows which channels should restore the files on each node. For example, if you create datafile copy df1.copy on node 2, then only the channel allocated on node 2 attempts to restore this file. Autolocation is enabled whenever the allocated channels have different PARMS or CONNECT settings.
To restore a database in an Oracle Real Application Clusters configuration:
SHUTDOWN IMMEDIATE STARTUP MOUNT
RUN command:
In this example, automatic channels are configured as follows:
CONFIGURE DEVICE TYPE sbt PARALLELISM 3; CONFIGURE DEFAULT DEVICE TYPE TO sbt; CONFIGURE CHANNEL 1 DEVICE TYPE sbt CONNECT 'SYS/oracle@node_1'; CONFIGURE CHANNEL 2 DEVICE TYPE sbt CONNECT 'SYS/oracle@node_2'; CONFIGURE CHANNEL 3 DEVICE TYPE sbt CONNECT 'SYS/oracle@node_3';
The following command performs complete restore and recovery:
RUN { RESTORE DATABASE; RECOVER DATABASE; }
| See Also:
Oracle9i Recovery Manager Reference to learn about the |
This section contains these topics:
You must reset the online redo logs after performing recovery with a backup control file or performing incomplete recovery. After you open a database with the RESETLOGS option, you cannot typically use the backups of the database made before the RESETLOGS was performed. Oracle Corporation strongly recommends that you take a full database backup after resetting the online redo logs.
If you experience media failure after a RESETLOGS but before performing a backup, then you may be forced to perform media recovery on a backup taken prior to the last database RESETLOGS. You should not rely on the procedure to perform media recovery through RESETLOGS as a normal recovery strategy. Rather, you should resort to it only in a worst-case scenario, such as when no backups are available from after the RESETLOGS.
After you have determined that it is necessary to perform a media recovery through a RESETLOGS, you need the following:
RESETLOGSRESETLOGSRESETLOGS SCN is the SCN at which the database was opened with the RESETLOGS option. Obtain this SCN through one of the following:
RESETLOGSRESETLOGS SCNRESETLOGS, up to the end point of media recoveryIt is impossible to perform media recovery through RESETLOGS if no backup or copy of the control file from after the RESETLOGS is available.
Recovery through a RESETLOGS occurs in two sequential phases discussed in this section:
In the first phase, you restore the database and recover it to the state it was in immediately prior to the RESETLOGS command.
RESETLOGS SCN using one of these methods:
LIST INCARNATION command and subtracting 1 from the value in the Reset SCN column. Also, note down the database incarnation keys of all incarnations as listed in the Inc Key column.alert_SID.log from the time of the RESETLOGS, and search for the word RESETLOGS. Look for a line such as this one: RESETLOGS after incomplete recovery UNTIL CHANGE 1234. Use this value as-is.RESETLOGS (either the current control file or a backup made after opening RESETLOGS), run the following query:
SELECT (RESETLOGS_CHANGE#)-1 FROM V$DATABASE;
ABORT option.LIST INCARNATION command to obtain the incarnation key of the prior incarnation (if do not already have it). If you have already registered the database incarnation made after the RESETLOGS with the RESET DATABASE command, then run the RESET DATABASE TO INCARNATION inc_key command to allow RMAN to restore backups that were taken before the RESETLOGS, where inc_key is the key of the prior incarnation.RUN command with the following subcommands:
SET UNTIL SCN resetlogs_scn command, where resetlogs_scn is the SCN obtained from the first step.RESETLOGS and then mount it.RESETLOGS. Only restore datafiles that require recoveryRESETLOGS, then take them offline by running the SQL statement ALTER DATABASE DATAFILE ... OFFLINE.V$DATAFILE to make sure that all datafiles are pointing to valid locations and only files that need to be recovered are online.RECOVER DATABASE.IMMEDIATE option.After the previous phase is complete, follow this procedure.
RESETLOGS if all copies of the current control file are lost (note that using a backup control file here requires another OPEN RESETLOGS after recovery completes)LIST INCARNATION output.RECOVER command.RESETLOGS only if you used a backup control file or performed incomplete recovery. Note that a RESETLOGS operation erases all changes from the online redo logs, so if you open RESETLOGS then you cannot restart this recovery procedure and recover to the same point.This scenario assumes that you have a database trgt that you want to recover through a RESETLOGS operation. Assume that trgt contains the database files described in Table 10-3.
For our case study, assume the scenario depicted in Figure 10-1.
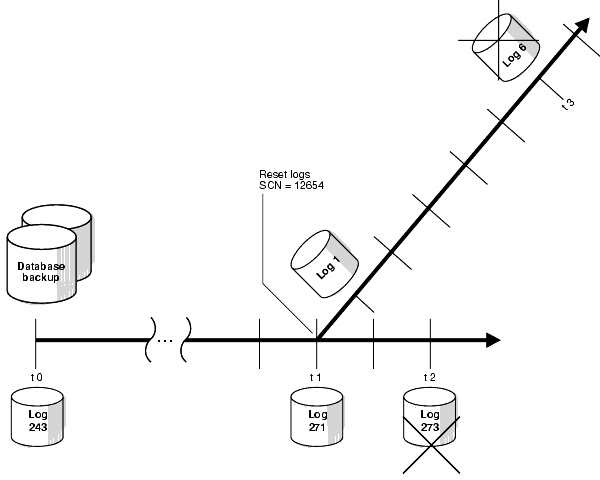
Assume that the following sequence of events occurs:
trgt at time t0.trgt database with the RESETLOGS option.RESETLOGS, the log sequence was reset to 1 and redo was generated until time t3 at which time another media failure results in the loss of datafile system01.dbf.The alert.log after the RESETLOGS for trgt appears as follows:
Starting ORACLE instance alter database mount Successful mount of redo thread 1. Tue. Nov 7 15:39:41 2001 Completed: alter database mount Tue Nov 7 15:39:43 2001 ALTER DATABASE RECOVER database until time 'Nov 07 2001 15:37:54' using backup controlfile Media Recovery Start Media Recovery Log ORA-279 signaled during: ALTER DATABASE RECOVER database until time 'Nov... Tue Nov 7 15:39:43 2000 ALTER DATABASE RECOVER CONTINUE DEFAULT Media Recovery Log /oracle/oradata/trgt/arch/archive1_271.dbf Incomplete recovery done UNTIL CHANGE 12654 Media Recovery Complete Completed: ALTER DATABASE RECOVER CONTINUE DEFAULT Tue Nov 7 15:39:44 2000 alter database open resetlogs RESETLOGS after incomplete recovery UNTIL CHANGE 12654
In the first phase, you restore the control file and system01.dbf datafile of trgt and recover the database to the state it was in immediately prior to opening with the RESETLOGS option.
V$DATABASE view to obtain the RESETLOGS SCN. For example, enter:
SQL> SELECT RESETLOGS_CHANGE# FROM V$DATABASE;
Alternatively, if you have a copy of the alert.log from when the RESETLOGS occurred, then look for a line such as this one:
RESETLOGSafterincompleterecoveryUNTILCHANGE12654.
SQL> SHUTDOWN ABORT
% cp $ORACLE_HOME/oradata/trgt/control01.ctl /tmp/control01.ctl % cp $ORACLE_HOME/oradata/trgt/control02.ctl /tmp/control02.ctl % cp $ORACLE_HOME/oradata/trgt/control03.ctl /tmp/control03.ctl
% rman TARGET / CATALOG rman/cat@catdb
STARTUP NOMOUNT
RESETLOGS was registered with RMAN, obtain the primary key of the prior incarnation by running a LIST INCARNATION command, and then reset RMAN to this incarnation. For example, run the following command, where inc_key is the key obtained from the LIST output:
LIST INCARNATION OF DATABASE trgt; RESET DATABASE TO INCARNATION inc_key;
RUN command with the following subcommands:
RESETLOGS, and then mount the control file.RESETLOGS. Only restore system01.dbf, because this is the only datafile requiring recovery.SQL 'ALTER DATABASE DATAFILE ... OFFLINE'.V$DATAFILE to ensure that all datafiles are pointing to valid locations and only files requiring recovery are online.IMMEDIATE option.For example, run the following command:
RUN { SET UNTIL SCN 12654; RESTORE CONTROLFILE; ALTER DATABASE MOUNT; RESTORE DATAFILE system01.dbf; SQL 'ALTER DATABASE DATAFILE ?/oradata/trgt/undotbs01.dbf, ?/oradata/trgt/cwmlite01.dbf, ?/oradata/trgt/drsys01.dbf, ?/oradata/trgt/example01.dbf, ?/oradata/trgt/indx01.dbf, ?/oradata/trgt/tools01.dbf, ?/oradata/trgt/users01.dbf OFFLINE'; HOST; # check V$DATAFILE to make sure everything is OK RECOVER DATABASE; SHUTDOWN IMMEDIATE; }
% cp /tmp/control01.ctl $ORACLE_HOME/oradata/trgt/control01.ctl % cp /tmp/control02.ctl $ORACLE_HOME/oradata/trgt/control02.ctl % cp /tmp/control03.ctl $ORACLE_HOME/oradata/trgt/control03.ctl
STARTUP NOMOUNT
LIST INCARNATION command). For example, enter the following, where curr_inc_key is the current incarnation key:
RESET DATABASE TO INCARNATION curr_inc_key;
ALTER DATABASE MOUNT;
RUN command with the following subcommands:
For example, run the following command to perform complete recovery:
RECOVER DATAFILE system01.dbf;
SQL 'ALTER DATABASE DATAFILE ?/oradata/trgt/undotbs01.dbf, ?/oradata/trgt/cwmlite01.dbf, ?/oradata/trgt/drsys01.dbf, ?/oradata/trgt/example01.dbf, ?/oradata/trgt/indx01.dbf, ?/oradata/trgt/tools01.dbf, ?/oradata/trgt/users01.dbf ONLINE';
ALTER DATABASE OPEN or ALTER DATABASE OPEN RESETLOGS depending on complete or incomplete recovery. For example:
ALTER DATABASE OPEN;
RESETLOGS are not easily usable. For example, enter the following to make a new database backup:
SHUTDOWN IMMEDIATE STARTUP MOUNT BACKUP DATABASE; ALTER DATABASE OPEN;
If you are in a disaster recovery scenario, then presumably you have lost the target database, the recovery catalog database, all control files, all online redo logs, and all parameter files. At minimum, you must have backups of some datafiles, some archived redo logs generated after the time of the backup, and at least one autobackup of the control file.
The basic procedure for disaster recovery is found in "Performing Recovery with a Backup Control File", with an additional first step of restoring an autobackup of the server parameter file. After the instance is started, you can restore an autobackup of the control file, mount it, then restore and recover the datafiles. Because you are restoring to a new host, you should review the considerations described in "Restoring the Database to a New Host".
The following scenario restores and recovers the database to the most recently available archived log, which in this example is log 1124 in thread 1. It assumes that:
In this scenario, you perform the following steps:
tnsnames.ora and listener.ora by means of operating system utilities.SET DBID command, as described in "Performing Recovery with a Backup Control File and No Recovery Catalog".STARTUP NOMOUNT command. RMAN attempts to start the instance with a dummy server parameter file.RESTORE SPFILE FROM AUTOBACKUP command.STARTUP FORCE NOMOUNT mode so that the instance is restarted with the restored server parameter file.CATALOG command (refer to"Cataloging Archived Logs and User-Managed Copies").SET NEWNAME commands before the restore and perform a switch after the restore to update the control file with the new locations for the datafiles (refer to"Restoring Files to a New Location").RESETLOGS mode. Only complete this last step if you are certain that no other archived logs can be applied.
|
Note: Oracle Corporation recommends that you back up the database after the |
# Start RMAN and connect to the target database % rman TARGET SYS/oracle@trgt # set the DBID for the target database SET DBID 676549873; STARTUP FORCE NOMOUNT; # rman starts instance with dummy parameter file RUN { ALLOCATE CHANNEL t1 DEVICE TYPE sbt; RESTORE SPFILE FROM AUTOBACKUP; } STARTUP FORCE NOMOUNT; RUN { # manually allocate a channel to the media manager ALLOCATE CHANNEL t1 DEVICE TYPE sbt; # Restore an autobackup of the control file. This example assumes that you have # accepted the default format for the autobackup name. RESTORE CONTROLFILE FROM AUTOBACKUP; # The set until command is used in case the database # structure has changed in the most recent backups, and you wish to # recover to that point-in-time. In this way RMAN restores # the database to the same structure that the database had at the specified time. SET UNTIL SEQUENCE 1124 THREAD 1; ALTER DATABASE MOUNT; RESTORE DATABASE; RECOVER DATABASE; } ALTER DATABASE OPEN RESETLOGS; # Reset the online logs after recovery completes
The following example of the RUN command shows the same scenario except with new filenames for the restored datafiles:
RUN { # If you need to restore the files to new locations, tell Recovery Manager # to do this using SET NEWNAME commands: SET NEWNAME FOR DATAFILE 1 TO '/dev/vgd_1_0/rlvt5_500M_1'; SET NEWNAME FOR DATAFILE 2 TO '/dev/vgd_1_0/rlvt5_500M_2'; SET NEWNAME FOR DATAFILE 3 TO '/dev/vgd_1_0/rlvt5_500M_3'; ALLOCATE CHANNEL t1 DEVICE TYPE sbt; RESTORE CONTROLFILE FROM AUTOBACKUP; SET UNTIL SEQUENCE 124 THREAD 1; ALTER DATABASE MOUNT; RESTORE DATABASE; SWITCH DATAFILE ALL; # Update the control file with new location of the datafiles. RECOVER DATABASE; } ALTER DATABASE OPEN RESETLOGS;
The BLOCKRECOVER command can restore and recover individual datablocks within a datafile. This procedure is useful when a trace file or standard output reveals that a small number of blocks within a datafile are corrupt. Block media recovery is not useful in cases where the extent of data loss or corruption is not known; in this case, use datafile recovery instead.
This section contains these topics:
See Also:
|
In this scenario, you identify the blocks that require recovery and then use any available backup to perform the restore and recovery of these blocks.
To recover datablocks using all available backups:
alert.log, trace files, or a media management interface. For example, you may see the following in a trace file:
ORA-01578: ORACLE data block corrupted (file # 8, block # 13) ORA-01110: data file 8: '/oracle/oradata/trgt/users01.dbf' ORA-01578: ORACLE data block corrupted (file # 2, block # 19) ORA-01110: data file 2: '/oracle/oradata/trgt/undotbs01.dbf'
BLOCKRECOVER command at the RMAN prompt, specifying the file and block numbers for the corrupted blocks as in the following example:
BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19;
In this scenario, you identify the blocks that require recovery, and then use only selected backups to perform the restore and recovery of these blocks.
To recover datablocks while limiting the type of backup:
alert.log, trace files, or a media management interface. For example, you may see the following in a trace file:
ORA-01578: ORACLE data block corrupted (file # 8, block # 13) ORA-01110: data file 8: '/oracle/oradata/trgt/users01.dbf' ORA-01578: ORACLE data block corrupted (file # 2, block # 19) ORA-01110: data file 2: '/oracle/oradata/trgt/undotbs01.dbf'
BLOCKRECOVER command at the RMAN prompt, specifying the file and block numbers for the corrupted blocks and limiting the backup candidates by means of the available options. For example, you can specify what type of backup should be used to restore the blocks:
# restore from backupset BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19 FROM BACKUPSET; # restore from datafile image copy BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19 FROM DATAFILECOPY;
You can indicate the backup by specifying a tag:
# restore from backupset with tag "mondayam" BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 199 FROM TAG = mondayam;
You can limit the backup candidates to those made before a certain point:
# restore using backups made before one week ago BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19 RESTORE UNTIL 'SYSDATE-7'; # restore using backups made before SCN 100 BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19 RESTORE UNTIL SCN 100; # restore using backups made before log sequence 7024 BLOCKRECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19 RESTORE UNTIL SEQUENCE 7024;
If you limit the restore of datablocks with the UNTIL clause, then RMAN must perform more recovery on the blocks. Also, the recovery phase must scan all logs for changes to the specified blocks. Hence, do not limit recovery unless necessary.
The V$DATABASE_BLOCK_CORRUPTION view indicates which blocks in a datafile were marked corrupt since the most recent BACKUP, BACKUP ... VALIDATE, or COPY command was run. After a corrupt block is repaired, the row identifying this block is deleted from the view.
You can check for logical corruption in the database by running the BACKUP (with or without VALIDATE option) and COPY commands with the CHECK LOGICAL command. If RMAN finds corrupt blocks, and if the number of blocks is below the MAXCORRUPT setting, then it populates V$DATABASE_BLOCK_CORRUPTION. A historical record of block corruptions in RMAN backups and copies is kept in V$BACKUP_CORRUPTION and V$COPY_CORRUPTION.
In this scenario, you identify the blocks that require recovery by querying V$DATABASE_BLOCK_CORRUPTION, and then instruct RMAN to recover all blocks listed in this view by means of the CORRUPTION LIST keyword.
To recover datablocks while limiting the type of backup:
V$DATABASE_BLOCK_CORRUPTION to determine whether corrupt blocks exist in the most recent backups and copies of the datafiles:
SQL> SELECT * FROM V$DATABASE_BLOCK_CORRUPTION;
V$DATABASE_BLOCK_CORRUPTION by running the BLOCKRECOVER CORRUPTION LIST command. For example, this command restores blocks from backup sets created more than 10 days ago:
BLOCKRECOVER CORRUPTION LIST FROM BACKUPSET RESTORE UNTIL TIME 'SYSDATE-10';
A restore validation executes a restore test run without actually restoring the files. You can test the restore of either the entire database or individual tablespaces, datafiles, or control files. The RESTORE ... VALIDATE and VALIDATE BACKUPSET commands test whether you can restore backups or copies. You have these options:
RESTORE ... VALIDATE tests whether RMAN can restore a specific object from a backup or copy. RMAN chooses which backups or copies to use.VALIDATE BACKUPSET tests the validity of a backup set that you specify.
| See Also:
Oracle9i Recovery Manager Reference for |
To let RMAN choose which backup sets or copies to validate:
To perform the validation, the database can be mounted or open. You do not have to take datafiles offline when validating them.
SYSTEM tablespace, and all archived logs:
RESTORE CONTROLFILE VALIDATE; RESTORE TABLESPACE SYSTEM VALIDATE; RESTORE ARCHIVELOG ALL VALIDATE;
RMAN-06026: some targets not found - aborting restore
If you see an error message stack and output similar to the following, for example, then there is a problem with the restore of the specified file:
RMAN-03009: failure of restore command on c1 channel at 12-DEC-01 23:22:30 ORA-19505: failed to identify file "oracle/dbs/1fafv9gl_1_1" ORA-27037: unable to obtain file status SVR4 Error: 2: No such file or directory Additional information: 3
If you do not see an error stack, then RMAN successfully validated the files.
To specify which backup sets to validate:
LIST commands, noting primary keys:
LIST BACKUPSET; LIST COPY;
VALIDATE BACKUPSET 1121;
validation complete message then RMAN successfully validated the restore of the specified backup set. For example:
using channel ORA_DISK_1 channel ORA_DISK_1: starting validation of archive log backupset channel ORA_DISK_1: restored backup piece 1 piece handle=/oracle/dbs/0mdg9v8l_1_1 tag=TAG20020208T155604 params=NULL channel ORA_DISK_1: validation complete
This section contains these topics:
To move the database to a new host by means of datafile copies, you must transfer the copies manually to the new machine. This example assumes that you are using a recovery catalog.
LIST command to see a listing of datafile copies and their associated primary keys, as in the following example:
LIST COPY;
% cp -r /tmp/*dbf /net/new_host/oracle/oradata/trgt
CHANGE COPY OF DATAFILE 1,2,3,4,5,6,7,8 UNCATALOG;
CATALOG DATAFILECOPY '?/oradata/trgt/system01.dbf', '?/oradata/trgt/undotbs01.dbf', '?/oradata/trgt/cwmlite01.dbf', '?/oradata/trgt/drsys01.dbf', '?/oradata/trgt/example01.dbf', '?/oradata/trgt/indx01.dbf', '?/oradata/trgt/tools01.dbf', '?/oradata/trgt/users01.dbf';
As explained in the description for SET DBID in Oracle9i Recovery Manager Reference, you must run the SET DBID command to restore the control file when the target database is not mounted and multiple databases registered in the recovery catalog share the same name. In this case, do the following steps in order:
STARTUP FORCE NOMOUNT command.SET DBID command to distinguish this connected target database from other target databases that have the same name.RESTORE CONTROLFILE command. After restoring the control file, you can mount the database to restore the rest of the database.This procedure avoids the RMAN-20005 message when you attempt to restore the control file. This message occurs because more than one target database has the same name, so RMAN requires the unique DBID to distinguishes the databases from one another.
If you have saved the RMAN output, then refer to this information to determine the database identifier, because RMAN automatically provides it whenever you connect to the database:
% rman TARGET / Recovery Manager: Release 9.2.0.0.0 connected to target database: RMAN (DBID=1231209694)
If you have not saved the RMAN output and need the DBID value of a database for a restore operation, then obtain it by querying the RC_DATABASE or RC_DATABASE_INCARNATION recovery catalog views.
Because the names of the databases that are registered in the recovery catalog are presumed nonunique in this scenario, you must use some other unique piece of information to determine the correct DBID. If you know the filename of a datafile or online redo log associated with the database you wish to restore, and this filename is unique across all databases registered in the recovery catalog, then substitute this fully specified filename for filename_of_log_or_df in the following queries. Determine the DBID by performing one of the following queries:
SELECT DISTINCT DB_ID FROM DB, DBINC, DFATT WHERE DB.DB_KEY = DBINC.DB_KEY AND DBINC.DBINC_KEY = DFATT.DBINC_KEY AND DFATT.FNAME = 'filename_of_log_or_df'; SELECT DISTINCT DB_ID FROM DB, DBINC, ORL WHERE DB.DB_KEY = DBINC.DB_KEY AND DBINC.DBINC_KEY = ORL.DBINC_KEY AND ORL.FNAME = 'filename_of_log_or_df';
To set the DBID, connect RMAN to the target database and run the following SET command, where target_dbid is the value you obtained from the previous step:
SET DBID = target_dbid;
To restore the control file to its default location and then mount it, run:
RESTORE CONTROLFILE; ALTER DATABASE MOUNT;
To restore and recover the database, run:
RESTORE DATABASE; RECOVER DATABASE # optionally, delete logs restored for recovery and limit disk space used DELETE ARCHIVELOG MAXSIZE 2M;
Assume the following situation:
trgt on January 2, 2001.RESETLOGS option on January 10, 2001. A new database incarnation was created.On January 25, you discover that you need crucial data that was dropped from the database at 8:00 a.m. on January 8, 2001. You decide to reset trgt to the prior incarnation, restore the January 2 backup, and recover to 7:55 a.m. on January 8.
|
Note: It is not possible to restore one datafile of a previous incarnation while the current database is in a different incarnation--you must restore the whole database. |
To recover the database by means of a backup from the old incarnation:
LIST command:
# obtain primary key of old incarnation LIST INCARNATION OF DATABASE trgt; List of Database Incarnations DB Key Inc Key DB Name DB ID CUR Reset SCN Reset Time ------- ------- ------- ------ --- ---------- ---------- 1 2 TRGT 1224038686 NO 1 02-JAN-01 1 582 TRGT 1224038686 YES 59727 10-JAN-01
SHUTDOWN ABORT STARTUP NOMOUNT
# reset database to old incarnation RESET DATABASE TO INCARNATION 2;
RUN command:
For example, run the following commands:
RUN { SET UNTIL TIME 'Jan 8 2001 07:55:00'; # set time to just before data was lost RESTORE CONTROLFILE; ALTER DATABASE MOUNT; # mount database after restoring control file RESTORE DATABASE; RECOVER DATABASE; }
ALTER DATABASE OPEN RESETLOGS; # this command automatically resets the database # so that this incarnation is the new incarnation
You can recover a database running in NOARCHIVELOG mode by means of incremental backups. Note that the incremental backups must be consistent, so you cannot make backups of the database when it is open.
Assume the following scenario:
trgt in NOARCHIVELOG mode.trgt to tape on Sunday afternoon.In this case, you must perform an incomplete media recovery until Friday, since that is the date of the most recent incremental backup. RMAN uses the level 0 Sunday backup as well as the Wednesday and Friday level 1 backups.
Because the online redo logs are lost, you must specify the NOREDO option in the RECOVER command. You must also specify NOREDO if the online logs are available but the redo cannot be applied to the incrementals. If you do not specify NOREDO, then RMAN searches for redo logs after applying the Friday incremental backup, and issues an error message when it does not find them. If the online logs had been available, then you could have run RECOVER DATABASE without specifying NOREDO.
After connecting to trgt and the catalog database, recover the database using the following command:
STARTUP FORCE MOUNT; RESTORE CONTROLFILE; # restore control file from consistent backup ALTER DATABASE MOUNT; RESTORE DATABASE; # restore datafiles from consistent backup RECOVER DATABASE NOREDO; # specify NOREDO because online redo logs are lost ALTER DATABASE OPEN RESETLOGS;
In this scenario, all changes generated between the Friday incremental backup and the Saturday failure are not applied.
In this scenario, the following sequence of events occurs:
ARCHIVELOG mode database.?/oradata/trgt/history01.dbf.?/oradata/trgt/history01.dbf from the operating system before you have a chance to back it up.Are you prevented from recovering the data in the lost datafile because you have no backup of the file? No. You can recover the data by creating a new datafile with the same filename as the lost datafile, then run the RECOVER command to apply the redo for this file.
For example, start RMAN, connect to the target database, and then run the following statements at the RMAN prompt:
# take the missing datafile offline # note that SQL statement is bounded by double quotes, but the datafile name has two # individual single quotes both before and after it SQL "ALTER DATABASE DATAFILE '' ?/oradata/trgt/history01.dbf '' OFFLINE"; # create a new datafile with the same name as the missing datafile SQL "ALTER DATABASE CREATE DATAFILE '' ?/oradata/trgt/history01.dbf '' "; # recover the newly created datafile RECOVER DATAFILE '?/oradata/trgt/history01.dbf'; # bring the recovered datafile back online SQL "ALTER DATABASE DATAFILE '' ?/oradata/trgt/history01.dbf '' ONLINE";
You can use the transportable tablespace feature to copy a tablespace from one database to another database. As described in Oracle9i Database Administrator's Guide, the basic method for transporting tablespaces does not make use of RMAN. Nevertheless, if you use RMAN to back up your target database, then you can also use RMAN to transport backups of a tablespace from one database into another.
In the following procedure, assume that:
users from database trgta, located on computer hosta, to database trgtb, located on computer hostbusers tablespace, which has one datafileusers datafile as /net/hostb/oracle/oradata/trgtb/users01.dbf in database trgtbtrgta:
trgta are accessible by hostb through a tape device.
| See Also:
Oracle9i Database Administrator's Guide to learn how to transport a tablespace |
To transport a tablespace into a different database:
hostb according to the instructions in the "Preparing the Auxiliary Instance for Duplication: Basic Steps".rman TARGET SYS/oracle@auxdb CATALOG rman/rman@catdb
RESTORE CONTROLFILE TO '/net/hostb/tmp/cf.f'; STARTUP FORCE MOUNT; EXIT
NOCATALOG mode, then restore and recover the auxiliary database. Perform the following steps:
UNTIL time to indicate which backup of the tablespace that you want to restore.SET NEWNAME to specify temporary filenames for the SYSTEM datafiles and the datafiles containing rollback or undo segments.SET NEWNAME to specify the filenames in the trgtb database that will be used by the datafiles in the transported tablespace.For example, run the following commands:
% rman TARGET SYS/oracle@auxdb NOCATALOG RUN { SET UNTIL ARCHIVELOG 1243 THREAD 1; # set the end recovery log ALLOCATE CHANNEL c1 DEVICE TYPE sbt; # allocate a channel if not configured # specify temporary name for SYSTEM datafile SET NEWNAME FOR DATAFILE 1 TO '/net/hostb/tmp/df1.dbf'; # specify temporary names for datafiles with undo or rollback segments SET NEWNAME FOR DATAFILE 2 TO '/net/hostb/tmp/df2.dbf'; # specify names for datafiles to be plugged into trgtb database SET NEWNAME FOR DATAFILE 8 TO '/net/hostb/oracle/oradata/trgtb/users01.dbf'; # restore and recover the datafiles RESTORE DATAFILE 1, 2, 8; RECOVER DATAFILE 1, 2, 8; }
SQL 'ALTER TABLESPACE cwmlite, drsys, example, indx, tools OFFLINE IMMEDIATE';
RESETLOGS option. For example:
ALTER DATABASE OPEN RESETLOGS;
SQL 'ALTER TABLESPACE users READ ONLY';
exp TRANSPORT_TABLESPACE=y TABLESPACES=(users) TRIGGERS=y CONSTRAINTS=n GRANTS=n FILE=expdat.dmp
sqlplus SYS/oracle@auxdb <<EOF SHUTDOWN ABORT EXIT EOF rm /net/hostb/tmp/*
imp TRANSPORT_TABLESPACE=y FILE=expdat.dmp DATAFILES=('/net/hostb/oracle/oradata/trgtb/users01.dbf') TABLESPACES=(users) TTS_OWNERS=(usera) FROMUSER=(usera) TOUSER=(userb)
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

