| Oracle® Database Backup and Recovery Basics 10g Release 1 (10.1) Part Number B10735-01 |
|






|
View PDF |
| Oracle® Database Backup and Recovery Basics 10g Release 1 (10.1) Part Number B10735-01 |
|
|
View PDF |
This chapter provides a general overview of backup and recovery concepts, the files in an Oracle database related to backup and recovery, and the tools available for making backups of your database, recovering from data loss or other error, and maintaining records of your backups.
This chapter includes the following topics:
In general, backup and recovery refers to the various strategies and procedures involved in protecting your database against data loss and reconstructing the database after any kind of data loss.
A backup is a copy of data from your database that can be used to reconstruct that data. Backups can be divided into physical backups and logical backups.
Physical backups are backups of the physical files used in storing and recovering your database, such as datafiles, control files, and archived redo logs. Ultimately, every physical backup is a copy of files storing database information to some other location, whether on disk or some offline storage such as tape.
Logical backups contain logical data (for example, tables or stored procedures) exported from a database with an Oracle export utility and stored in a binary file, for later re-importing into a database using the corresponding Oracle import utility..
| See also:
Oracle Database Utilities for more details about importing and exporting data using Oracle export and import utilities. |
Physical backups are the foundation of any sound backup and recovery strategy. Logical backups are a useful supplement to physical backups in many circumstances but are not sufficient protection against data loss without physical backups.
Unless otherwise specified, the term "backup" as used in the backup and recovery documentation refers to physical backups, and to backup part or all of your database is to take some kind of physcial backup. The focus in the backup and recovery documentation set will be almost exclusively on physical backups.
While there are several types of problem that can halt the normal operation of an Oracle database or affect database I/O operations, only two typically require DBA intervention and media recovery: media failure, and user errors.
Other failures may require DBA intervention to restart the database (after an instance failure) or allocate more disk space (after statement failure due to, for instance, a full datafile) but these situations will not generally cause data loss or require recovery from backup.
User errors occur when, either due to an error in application logic or a manual mis-step, data in your database is changed or deleted incorrectly. Data loss due to user error includes such missteps as dropping important tables or deleting or changing the contents of a table. While user training a nd careful management of privileges can prevent most user errors, your backup strategy determines how gracefully you recover the lost data when user error does cause data loss.
A media failure is the failure of a read or write of a disk file required to run the database, due to a physical problem with the disk such as a head crash. Any database file can be vulnerable to a media failure.
The appropriate recovery from a media failure depends on the files affected and the types of backup available.
For performing backup and recovery based on physical backups, you have two solutions available:
Both methods are supported by Oracle Corporation and are fully documented. Recovery Manager is, however, the preferred solution for database backup and recovery. It can perform the same types of backup and recovery available through user-managed methods more easily, provides a common interface for backup tasks across different host operating systems, and offers a number of backup techniques not available through user-managed methods.
Most of the backup and recovery documentation set will focus on RMAN-based backup and recovery. User-managed backup and recovery techniques are covered in the later chapters of Oracle Database Backup and Recovery Advanced User's Guide.
Whether you use RMAN or user-managed methods, you can supplement your physical backups with logical backups of schema objects made using data export utilities. Data thus saved can later be imported to re-create this data after restore and recovery. However, logical backups are for the most part beyond the scope of the backup and recovery documentation.
The physical structures of the database and the role each plays in the database recovery process are what determine the forms of backup and recovery available through user-managed techniques and through RMAN.
The files and other structures that make up an Oracle database store data and safeguard it against possible failures. This section introduces each of the physical structures that make up an Oracle database and their role in the reconstruction of a database from backup. This section contains these topics:
An Oracle database consists of one or more logical storage units called tablespaces. Each tablespace in an Oracle database consists of one or more files called datafiles, physical files under the host operating system in which the database is running.
A database's data is collectively stored in the datafiles that constitute each tablespace of the database. The simplest Oracle database would have one tablespace, stored in one datafile. The datbase manages the storage space in the datafiles of a database in units called data blocks. A data block is the smallest unit of data used by a database. Data blocks are the smallest units of storage that the database can use or allocate.
Modified or new data is not written to datafiles immediately. Updates are buffered in memory and written to datafiles at intervals. If a database has not gone through a normal shutdown (that is, if it is open, or exited abnormally, as in an instance failure or a SHUTDOWN ABORT) then there are typically changes in memory that have not been written to the datafiles. Datafiles that were restored from backup, or were not closed during a consistent shutdown, are typically not completely up to date.
Copies of the datafiles of a database are a critical part of any backup.
| See also:
Oracle Database Concepts for more detail about the structure and contents of datafiles and data blocks. |
Redo logs record all changes made to a database's data files. With a complete set of redo logs and an older copy of a datafile, the database can reapply the changes recorded in the redo logs to re-create the database at any point between the backup time and the end of the last redo log. Each time data is changed in the database, that change is recorded in the online redo log first, before it is applied to the datafiles. An Oracle database requires at least two online redo log groups, and in each group there is at least one online redo log member, an individual redo log file where the changes are recorded.
At intervals, the database rotates through the online redo log groups, storing changes in the current online redo log while the groups not in use can be copied to an archive location, where they are called archived redo logs (or, collectively, the archived redo log). You can run your database in ARCHIVELOG mode (in which this archiving of redo log files is enabled) or NOARCHIVELOG mode (in which redo log files are simply overwritten).
Preserving the archived redo log is a major part of most backup strategies, as they contain a record of all updates to datafiles. Backup strategies often involve copying the archived redo logs to disk or tape for longer-term storage. Running in NOARCHIVELOG mode limits your data recovery options.
| See also:
Oracle Database Administrator's Guide for more details about the online redo logs, Oracle Database Administrator's Guide for more details about archived redo logs, and "Deciding Between ARCHIVELOG and NOARCHIVELOG Mode" for a discussion of the implications of archiving or discarding your redo log files. |
The control file contains a crucial record of the physical structures of the database and their status. Several types of information stored in the control file are related to backup and recovery:
The recovery process for datafiles is in part guided by status information in the control file, such as the database checkpoints, current online redo log file, and the datafile header checkpoints for the datafiles. Loss of the control file makes recovery from a data loss much more difficult.
| See also:
Oracle Database Concepts for more information about control files. |
In general, when data in a datafile is updated, "before images" of that data are written into undo segments. If a transaction is rolled back, this undo information can be used to restore the original datafile contents.
In the context of recovery, the undo information is used to undo the effects of uncommitted transactions, once all the datafile changes from the redo logs have been applied to the datafiles. The database is actually opened before the undo is applied.
You should not have to concern yourself with undo segments or manage them directly as part of your backup and recovery process.
Reconstructing the contents of all or part of a database from a backup typically involves two phases: retrieving a copy of the datafile from a backup, and reapplying changes to the file since the backup from on the archived and online redo logs, to bring the database to the desired SCN (usually the most recent one).
To restore a datafile or control file from backup is to retrieve the file onto disk from a backup location on tape, disk or other media, and make it available to the database server.
To recover a datafile (also called performing recovery on a datafile), is to take a restored copy of the datafile and apply to it changes recorded in the database's redo logs. To recover a whole database is to perform recovery on each of its datafiles.
Figure 1-1 illustrates the basic principle of backing up, restoring, and recovering a database. Most of the data recovery procedures supported by the Oracle database are variations on the process described here.
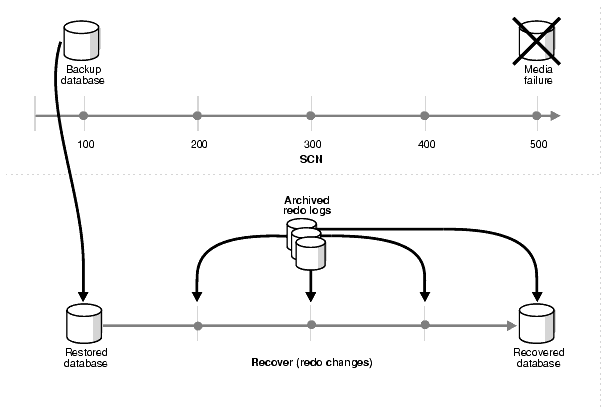
Text description of the illustration brbsc002.gif
In this example a full backup of a database (copies of its datafiles and control file) is taken at SCN 100. Redo logs generated during the operation of the database capture all changes that occur between SCN 100 and SCN 500. Along the way, some logs fill and are archived. At SCN 500, the datafiles of the database are lost due to a media failure. The database is then returned to its transaction-consistent state at SCN 500, by restoring the datafiles from the backup taken at SCN 100, then applying the transactions captured in the archived and online redo logs and undoing the uncomitted transactions.
The preceding scenario outlined the basics of the restore-and-recovery process. Several variants on this scenario are important to your backup and recovery work.
This section contains the following topics:
Datafile media recovery (often simply called media recovery) is the most basic form of user-initiated data recovery. It can be used to recover from a lost or damaged current datafile, SPFILE or control file. It can also recover changes that were recorded in the redo logs but not in the datafiles for a tablespace that went offline without the OFFLINE NORMAL option. Datafile media recovery can be performed whether you use Recovery Manager or user-managed backup and recovery. (For user-managed backup and recovery, it is in fact the main option available.)
Like crash recovery, datafile media recovery is intended to restore database integrity. However, there are a number of important differences between the two:
The need to restore a datafile from backup is not detected automatically. The first step in performing media recovery is to manually restore the datafile by copying it from a backup. Once a datafile has been copied from backup, however, the database does automatically detect that this datafile is out of date and must undergo media recovery.
Several situations force you to perform media recovery:
OFFLINE NORMAL option.For a datafile to be available for media recovery, one of two things must be true:
or
A datafile that needs media recovery cannot be brought online until media recovery has been completed. A database cannot be opened if any of the online datafiles needs media recovery.
You can manage the expected duration of media recovery as part of your backup and recovery strategy. It is affected by, for example, the frequency of backups and parallel recovery parameters.
Complete recovery is recovering a database to the most recent point in time, without the loss of any committed transactions. Generally, the term "recovery" refers to complete recovery.
Occasionally, however, you need to return a database to its state at a past point in time. For example, to undo the effect of a user error, such as dropping or deleting the contents of a table, you may want to return the database to its contents before the delete occurred. In incomplete recovery, also known as point-in-time recovery, the goal is to restore the database to its state at some previous target SCN or time. Point-in-time recovery is one possible response to a data loss caused by, for instance, a user error or logical corruption that goes unnoticed for some time.
Point-in-time recovery is also your only option if you have to perform a recovery and discover that you are missing an archived log covering time between the backup you are restoring from and the target SCN for the recovery. Without the missing log, you have no record of the updates to your datafiles during that period. Your only choice is to recover the database from the point in time of the restored backup, as far as the unbroken series of archived logs permits, then perform an OPEN RESETLOGS and abandon all changes in or after the missing log. (If you discover that you have lost archived logs and your database is still up, you should do a full backup immediately.)
|
Note: If only one tablespace is affected by the data loss, you have the option of performing point-in-time recovery on that tablespace instead of the entire database. Tablespace point-in-time recovery (often abbreviated TSPITR) is an advanced technique documented in Oracle Database Backup and Recovery Advanced User's Guide. |
The crash recovery process is a special form of recovery, which happens the first time an Oracle database instance is started after a crash (or SHUTDOWN ABORT). In crash recovery, the goal is to bring the datafiles to a transaction-consistent state, preserving all committed changes up to the point when the instance failed.
Unlike the forms of recovery performed manually after a data loss, crash recovery uses only the online redo log files and current online datafiles, as left on disk after the instance failure. Archived logs are never used during crash recovery, and datafiles are never restored from backup.
The database applies any pending updates in the online redo logs to the online datafiles of your database. The result is that, whenever the database is restarted after a crash, the datafiles reflect all committed changes up to the moment when the failure occurred. (After the database opens, any changes that were part of uncommitted transactions at the time of the crash are rolled back.)
The duration of crash recovery is a function of the number of instances needing recovery, amount of redo generated in the redo threads of crashed instances since the last checkpoint, and user-configurable factors such as the number and size of redo log files, checkpoint frequency, and the parallel recovery setting.You can set parameters in the database server that can tune the duration of crash recovery. You can also tune checkpointing to optimize recovery time.
|
Note: Crash recovery in a Real Application Cluster (RAC) database takes place when all instances in the cluster have failed. The related process of instance recovery takes place when some but not all instances fail. For more information on crash and instance recovery in the context of RAC, refer to Real Application Clusters Quick Start. |
As noted earlier, using RMAN gives you access to several data backup and recovery techniques and features not available at all with user-managed backup and recovery. The most noteworthy are:
A complete list of feature differences between RMAN and user-managed backup and recovery can be found in "Feature Comparison of Backup Methods".
RMAN also reduces the administration work associated with your backup strategy. RMAN keeps an extensive record of metadata about backups, archived logs, and its own activities, known as the RMAN repository. In restore operations, RMAN can use this information to eliminate the need for you to identify backup files for use in restores in most situations. You can also generate reports of backup activity using the information in the repository.
Primary storage for RMAN repository information is in the control file of the production database. You can also set up an independent recovery catalog, a schema that stores RMAN repository information for one or many databases in a separate recovery catalog database.
The remainder of this book, Oracle Database Backup and Recovery Basics, focuses on using RMAN to implement your backup and recovery strategy.
There are several ways of distinguishing among physical backups, according to the state the database was in when the backup was created, what parts of the database were actually backed up, and how the resulting backup was stored.
Physical backups can also be divided into consistent and inconsistent backups. Consistent backups are those created when the database is in a consistent state, that is, when all changes in the redo log have been applied to the datafiles. A database restored from a consistent backup can be opened immediately, without undergoing media recovery. However, a consistent backup can only be created after the database has been shut down normally, that is, not after a crash or a SHUTDOWN ABORT.
For reasons of availability, the Oracle database is designed to work equally well with an inconsistent backup, a backup taken while the database is open. When a database is restored from an inconsistent backup, it must undergo media recovery, so that the database can apply any pending changes from the online and archived redo log before the database is opened again. Because archived logs are required, using inconsistent backups requires that your database be run in ARCHIVELOG mode.
Full backups are backups which include datafiles in their entirety. Full backups can be created with Recovery Manager or with operating system-level file copy commands. Incremental backups are based on the idea of making copies only of changed data blocks in a data file. In recovery, extracting entire changed blocks from an incremental backup can substitute for applicationof redo for individual datafile updates during the time covered by the backup, shortening recovery times considerably. Incremental backups can only be created with RMAN.
| See Also:
"Full and Incremental Datafile Backups" for more details about the different ways to back up datafiles. |
The results of an Oracle database backup created through RMAN can be either image copies or backup sets. An image copy is a bit-for-bit identical copy of a database file. These can be created using operating system commands such as cp in Unix or COPY in Windows. RMAN can also create image copy backups, although in the process, RMAN will check the contents for corruption, something that native operating-system file copy utilities cannot do. RMAN records image copies it creates in the RMAN repository, so that it can use them when restoring your database. If you create image copies outside of RMAN, you can catalog them manually into the RMAN repository.
RMAN can also store its backups in an RMAN-exclusive format called a backup set. A backup set is a collection of files called backup pieces, each of which may contain the backup of one or several database files. A backup task performed in RMAN can create one or more backup sets, which are recorded in the RMAN repository. Backup sets are also the only form in which RMAN can write backups to media manager devices like tape libraries. Backup sets are only created and accessed through Recovery Manager.
| See Also:
"RMAN Backup Formats: Image Copies and Backup Sets" for more details about image copies and backup sets. |
In planning your database backup and recovery strategy, you must try to anticipate the errors that will arise, and put in place the backups needed to recover from them.While there are several types of problem that can halt the normal operation of an Oracle database or affect database I/O operations, only two typically require DBA intervention and media recovery: media failure, and user errors. Instance failures, network failures, failures of Oracle database background processes and failure of a statement to execute due to, for instance, exhaustion of some resource such as space in a datafile may require DBA intervention, and might even crash a database instance, but will not generally cause data loss or the need to recover from backup.
This section contains these topics:
Database operation after a media failure of online redo log files or control files depends on whether the online redo log or control file is protected by multiplexing, as recommended. When an online redo log or control file is multiplexed, multiple copies of the file are maintained on the system. Multiplexed files should be stored on separate disks.
If a media failure damages a disk containing one copy of a multiplexed online redo log, then the database can usually continue to operate without significant interruption. Damage to a nonmultiplexed online redo log causes database operation to halt and may cause permanent loss of data.
Damage to any control file, whether it is multiplexed or not, halts database operation when the database attempts to read or write to the damaged control file (which happens frequently, for example at every checkpoint and log switch).
Media failures that affect datafiles can be divided into two categories: read errors and write errors. In a read error, the instance cannot read a datafile and an operating system error is returned to the application, along with an error indicating that the file cannot be found, cannot be opened, or cannot be read. The database continues to run, but the error is returned each time an unsuccessful read occurs. At the next checkpoint, a write error will occur when the database attempts to write the file header as part of the standard checkpoint process.
The effect of a datafile write error depends upon which tablespace the datafile is in.
If the instance cannot write to a datafile in the SYSTEM tablespace, an undo tablespace (if the database is in automatic undo management mode, which is the preferred choice in Release 10g), or a datafile in a tablespace containing active rollback segments (if in manual undo management mode), then the database issues an error and shuts down the instance. All files in the SYSTEM tablespace and all datafiles containing rollback segments must be online in order for the database to operate properly.
If the instance cannot write to a datafile other than those in the preceding list, then the result depends on whether the database is running in ARCHIVELOG mode or not.
In ARCHIVELOG mode, the database records an error in the database writer trace file and takes the affected datafile offline. (All other datafiles in the tablespace containing this datafile remain online.) You can then rectify the underlying problem and restore and recover the affected tablespace.
In NOARCHIVELOG mode, the database writer background process DBWR fails, and the instance fails, the cause of the problem determines the required response. If the problem is temporary (for example, a disk controller was powered off), then crash recovery usually can be performed using the online redo log files. In such situations, the instance can be restarted without resorting to media recovery. However, if a datafile is permanently damaged, then you must restore a consistent backup of the database.
Recovery is not needed on any read-only tablespace during crash or instance recovery. During startup, recovery verifies that each online read-only datafile does not need media recovery. That is, the file was not restored from a backup taken before it was made read-only. If you restore a read-only tablespace from a backup taken before the tablespace was made read-only, then you cannot access the tablespace until you complete media recovery.
Typically, a user error like dropping a table or deleting rows from a table requires one of the following responses:
The recovery options available to you will be a function of your backup strategy. For example, if you are running in NOARCHIVELOG mode then you have limited point-in-time recovery options.
See Also:
|
The components that creates different backup and recovery-related files have no knowledge of each other or of the size of the file systems where they store their data. With Automatic Disk-Based Backup and Recovery, you can create a flash recovery area, which automates management of backup-related files. Choose a location on disk and an upper bound for storage space, and set a retention policy that governs how long backup files are needed for recovery, and the database manages the storage used for backups, archived redo logs, and other recovery-related files for your database within that space. Files no longer needed are eligible for deletion when RMAN needs to reclaim space for new files. If you do not use a flash recovery area, you must manually manage disk space for your backup-related files and balance the use of space among the different types of files. Oracle Corporation recommends that you enable a flash recovery area to simplify your backup management.
When choosing a backup and recovery solution, find one that is appropriate for the database environment. For example, if you manage only databases of release 8.0 or higher, then you can use RMAN to manage your backup and recovery requirements. Releases older than 8.0 will have to be managed using some method besides RMAN.
Table 1-1 describes the version and system requirements for different database backup and recovery methods.
Besides being limited by system requirements, the backup and recovery solution you choose should be driven by the features that you want. Table 1-2 compares the features of the different backup methods.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

