| Bookshelf Home | Contents | Index | PDF | |
|
Siebel Deployment Planning Guide > High Availability Deployment Planning > About High Availability Deployment OptionsHigh availability means that a user can access key system services even when the underlying hardware or software for those services fails. For example, if a user synchronization session was interrupted by a failure of the server to which it was connected, the user can reconnect to the system and restart the synchronization process without any data loss. To achieve high availability, the system must automatically replace lost services and distribute loads among services to assure acceptable response times. When the system cannot replace a lost service, this is called a single point of failure. High availability planning and deployment are designed to eliminate these single points of failure. In a Siebel Business Applications deployment, a service (for the purposes of this discussion) is one of the following:
To eliminate single points of failure, some form of redundancy is required. Clustered servers are an example. When one service fails, other resources are available to take over for the failed service. To be successful, this process must be:
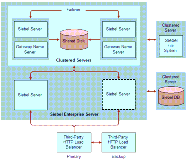
There are cases where full, automatic failover may not be possible. For example, results of the failure may need to be manually cleaned up. This guide does not cover all scenarios, and customers are advised to review environment-specific requirements before finalizing high availability planning. The options available for high availability deployment consist of the following techniques: Scalable Services (Load Balancing)Load balancing distributes workload across multiple servers. Each server runs an instance of the service you want to load-balance. Load balancing also provides failover. If one server fails, then requests are automatically routed to the remaining servers. Application Object Managers (AOMs) are the server components for which load balancing is most frequently provided. Distributing workload across AOMs indirectly distributes workload across the other server components that AOMs call, in a form of indirect load balancing. Resilient Processing (Distributed Services)Resilient processing, also called distributed services, is used for tasks initiated by the Siebel Server. (Load balancing is used for tasks initiated by users.) Multiple instances of a component run on the same Siebel Server, or the same component can run on multiple Siebel Servers. If one instance of the component fails, then another instance on the same server or on a different server takes over processing subsequent requests. For more information, see About Resilient Processing. Server ClustersServer clusters consist of two or more physical servers linked together so that if one server fails, resources such as physical disks, network addresses, and applications can be switched over to the other server. Server clusters can provide resilience when a particular Siebel operation can only take place on one server, either because of the type of process (such as Siebel Gateway Name Server or Siebel Remote) or because of hardware constraints. Figure 5 illustrates an example of server load balancing and server clustering in a Siebel Enterprise Server. |
 |
|
| Siebel Deployment Planning Guide | Copyright © 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices. | |