Patterns Profiler |
「Patterns Profiler」では、任意の数の文字列属性でデータ値を分析し、文字タイプの並びに従ってパターンを割り当てます。たとえば、デフォルトの「Pattern Map」参照リストを使用すると、値「10 Lowestoft Lane」にはパターン「NN_aaaaaaaaa_aaaa」が割り当てられます。
|
注意: デフォルトの「*Pattern Map」はLatin-1エンコード・データで使用するように設計されていますが、データの文字エンコーディング(マルチバイトのUnicode(16進数)文字参照を含む)に適した新しいパターン・マップを作成できます。 |
次に、プロファイラでは、各属性で各パターンが出現した回数をカウントして、その結果を表示します。
「Patterns Profiler」を使用して、データのパターンを特定し、有効パターンと無効パターンの参照リストを作成します。この参照リストは、「Check Pattern」プロセッサを使用してデータを継続的に検証するために使用できます。
データ・パターンを分析する文字列属性。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
参照データ(「Pattern Generation」カテゴリ) |
各文字をパターン文字にマップします。 |
*Character Pattern Map |
デフォルトの標準パターン・マップにより、次のように文字がマップされます。
|
文字タイプ |
パターンの表現 |
|
英字(a-zまたはA-Z) |
a |
|
数字(0-9) |
N |
|
句読点文字(セミコロン、カンマなど) |
その文字のままで表す |
|
制御文字(改行など) |
C |
|
スペース |
_ |
「Character Pattern Map」で認識されない文字は、各パターンで疑問符(?)で表現されます。
必要に応じて、別の文字パターン・マップを使用して文字をマップできます。たとえば、「x」や「z」など出現頻度の低い文字は、出現頻度の高い文字と異なる表現にできます。
なし
|
フラグ属性 |
目的 |
可能性のある値 |
|
[Attribute name].Pattern |
属性のパターンを示します。 |
「Pattern Map」参照データで定義されたパターン |
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
「Patterns Profiler」では、分析対象の各属性に関する次の統計が表示されます。
結果ブラウザでは、各属性が個別のタブに表示されることに注意してください。
|
統計 |
意味 |
|
Pattern |
各値に対して生成されたパターン |
|
Length |
生成された各パターンの長さ、つまり、各値の文字数 |
|
Count |
パターンにマッチした属性の値を含むレコードの数 |
|
% |
パターンにマッチした属性の値を含むレコードのパーセント |
この例では、「Patterns Profiler」を使用して、顧客レコード表のすべての属性でパターンを分析します。属性ごとに、次のタイプのビューが生成されます。
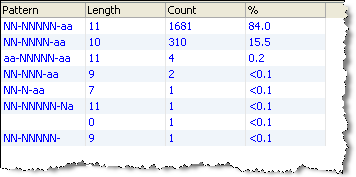
「Count」列を基準にビューをソートすると、データ内で出現頻度が最も高いパターンと最も低いパターンをすばやく把握できるため、有効パターンと無効パターンのリストを構築して「Pattern Check」で使用できます。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.