Phrase Profiler |
「Phrase Profiler」では、複数の属性を分析し、共通する単語やフレーズを検索します。
すべての入力属性内で出現する単語やフレーズが頻度順に返されます。
「Phrase Profiler」を使用すると、データ内で最も頻出する重要な単語やフレーズ、およびその出現場所を簡単に検出できます。さらに、フレーズ・プロファイリングの結果を使用して、「Parse」プロセッサの構成を決定できます。たとえば、検出された単語やフレーズを、データの分類に使用する参照データ・リストに追加したり、属性内で出現する単語やフレーズを調べることにより、どのトークン・チェックをどの属性に適用するかを決定できます。
したがって、「Phrase Profiler」は、テキスト・フィールドの内容を理解するとき、特にデータの構造を改善したり変更する場合(たとえば、データを移行するため)に使用する重要なツールの1つです。
共通する単語やフレーズを分析する文字列属性。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
数値 |
データ・セット内で出現回数が少ない単語やフレーズを返しません。分析対象のレコードに対してわずかなパーセントであることを示すために、100万分の1単位で指定します。たとえば、100万レコードごとに出現回数が100未満(つまり、レコードの0.0001%)の値です。 (後述の注意を参照) |
5000(100万分の5000) |
|
|
Allowable variation(100万分の1単位) |
数値 |
2つのフレーズが他方のフレーズに相互に含まれる場合に、その頻度の許容可能な差異を指定して、重要でないフレーズ(他方のフレーズ内に含まれるフレーズ)を除外し、最上位レベル・フレーズを重要とマークできます。 (後述の注意を参照) |
5000(100万分の5000) |
|
Maximum words in a phrase |
数値 |
返されるフレーズの最大長を単語数で設定します。 |
10 注意: パフォーマンス上の理由から、このオプションの最大値は20です。 |
|
Additional word delimiter |
一般的なデリミタ文字を選択 |
単語やフレーズを区切るために使用される追加のセパレータ文字(通常のスペース文字に加えて)を定義できます。 |
なし |
|
Word delimiter regular expression |
正規表現 |
単語やフレーズを区切るために使用される正規表現を定義できます。 |
なし |
|
Ignore case? |
Yes/No |
大/小文字の相違以外は同一の単語またはフレーズを区別するかどうかを設定します。 (後述の注意を参照) |
No |
 「Ignore case」オプションに関する注意(クリックして開く)
「Ignore case」オプションに関する注意(クリックして開く)
「Cutoff frequency」および「Allowable variation」オプションに関する注意(クリックして開く)
なし
なし
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
No |
「Phrase Profiler」では、結果のサマリー・ビューが作成され、入力属性内で検出された単語やフレーズが出現頻度順に表示されます。
|
統計 |
意味 |
|
Size |
フレーズのサイズ(単語数)。 |
|
フレーズが最上位レベル・フレーズかどうかを示します。 前述の「Allowable variation」設定に関する注意を参照してください。 |
|
|
Phrase |
データ内で検出された単語またはフレーズ。 |
|
Frequency |
フレーズまたは単語の出現回数。データをドリルダウンすると、この頻度よりレコード数が少ない場合があります。これは、同じフレーズまたは単語が同じレコード内で複数回出現する場合があるためです。 |
|
[Attribute].freq |
各入力属性内でのフレーズまたは単語の出現回数。 |
なし
この例では、顧客名と住所データをパースして構造的なイシューを解決するために、データを分析します。
「Phrase Profiler」を実行して、氏名および住所属性内で最多の単語やフレーズを検索します。ここでは、次のようにオプションを構成しています。
Cutoff frequency: 5000
Allowable variation: 5000
Maximum words in a phrase: 10
Additional word delimiter: カンマ(,)
Word delimiter regular expression: 使用しない
Ignore case: No
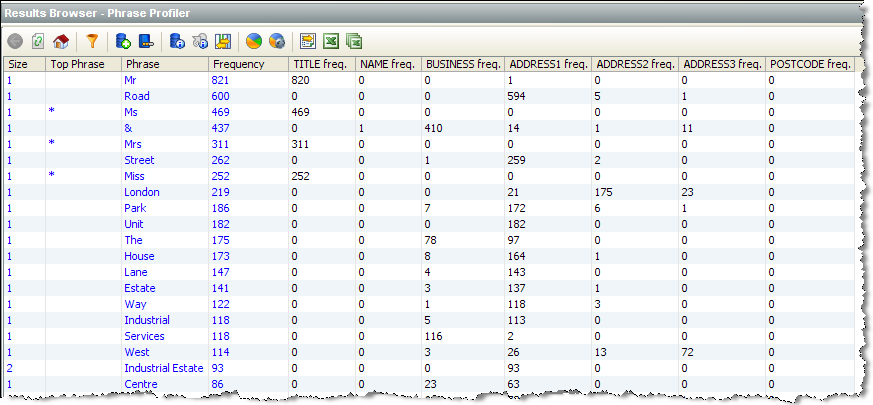
前述の情報から、単語「Mr」、「Ms」、「Mrs」および「Miss」は頻出しており、有効な敬称であることが容易に確認できるため、パースでこれらの敬称を分類するための参照データ・リストを作成できます。
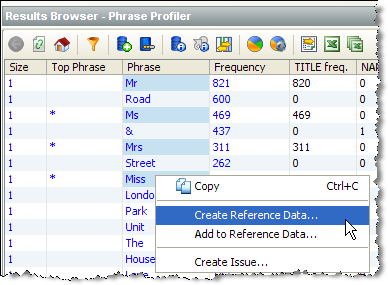
次に、「Title」属性を基準にして結果をソートし、出現している値をさらに調べることができます。
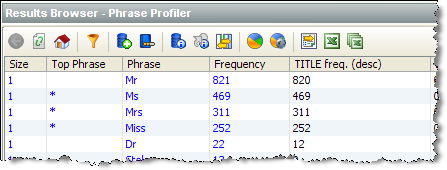
これにより、「Dr」を有効な敬称のリストに追加できます。
フレーズと単語のリストをさらに見ると、コンテキストに依存して意味があいまいなフレーズや単語がデータ内にあることを簡単に確認できます。次に例を示します。
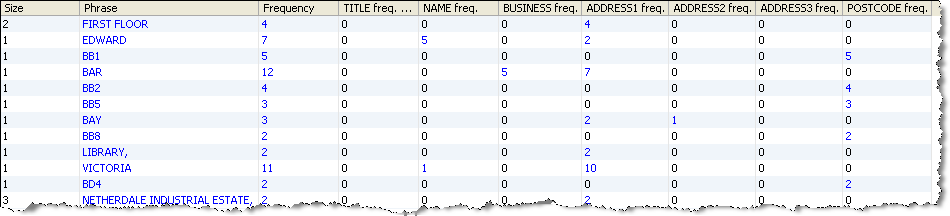
前述のリストで、「VICTORIA」と「EDWARD」が、「NAME」属性に加えて「ADDRESS1」属性にも出現しているのがわかります。この1つをドリルダウンして理由を調べます。

これにより、データをパースするとき、「VICTORIA」が「NAME」属性に出現する場合は有効な名として分類し、「ADDRESS1」属性に出現する場合はこの単語を分類しません。ただし、「Victoria Centre」を有効な建物として分類する場合は、次の3つのステップを実行します。
1. 「Victoria Centre」を含むデータを右クリックし、「Add to Reference Data」を選択します。
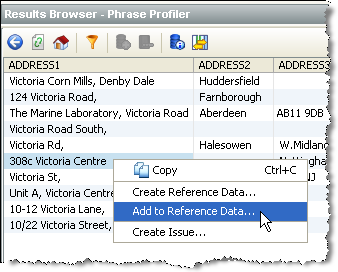
2. 値を追加する参照データ・リストを選択します。
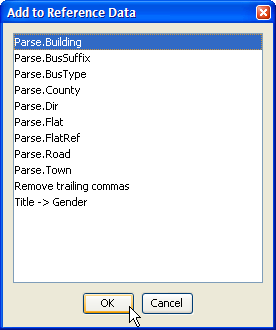
3. 参照データ・エディタで、リストのエントリを必要な値(「Victoria Centre」)に編集します。

必要な分類リストに最も重要な単語やフレーズを追加した後は、データのパースを開始でき、「Phrase Profiler」の結果はいつでも参照できます。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.