Parse |
「Parse」プロセッサは、データを理解して構造を改善するための強力なツールです。手動で構成したビジネス・ルールおよび人工知能の両方を適用して、1つまたは複数の属性内のデータの意味を分析して理解できます。さらに、ルール内でその意味を使用して、データを検証し、必要に応じてデータを再構築できます。たとえば、「Parse」を使用すると、誤って住所属性に取得された氏名データを認識でき、必要に応じて、そのデータを異なる構造の新しい属性にマップできます。
「Parse」プロセッサは、任意のタイプのデータを認識して変換するように構成できます。EDQにおけるパースの詳細は、「パースの概念ガイド」を参照してください。
このトピックでは、「Parse」プロセッサの使用方法と機能について説明します。
「Parse」プロセッサには多様な用途があります。たとえば、「Parse」を使用して次のことができます。
「Parser」は複数のステップで実行されます。各ステップの詳細は、後述する「構成」の項を参照してください。ここでは、パーサーの処理を要約して説明します。
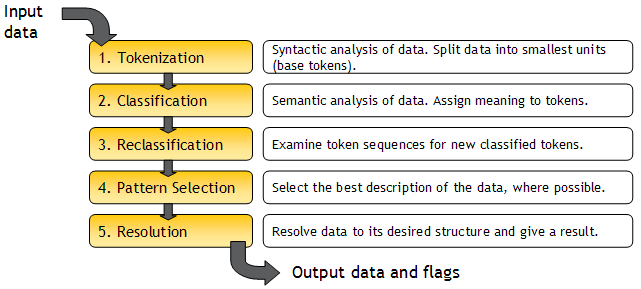
「Parse」プロセッサが全体としてどのように機能するかを理解するには、次のレコードの例が役立ちます。この例では、「Title」、「Forenames」および「Surname」の3つの属性から個人の氏名をパースします。
入力レコードの例
次のレコードが入力されます。
![]()
トークン化
トークン化では、レコードを次のようにトークン化し、「Mr」、「Bill」、「Archibald」および「SCOTT」の各トークンを認識して、これらにトークン・タグ<A>を割り当てます。また、「Bill」と「Archibald」の間のスペースもトークンとして認識し、これにトークン・タグ<_>を割り当てます。トークン化では常に、ベース・トークンの単一パターンが出力されます。この場合、パターンは次のようになります(「Tokenization」ビュー)。
![]()
分類
分類では、氏名と敬称のリストを使用する分類ルールによって、レコードのトークンを分類します。一部の氏名は複数のリストに含まれるため、一部のトークンは複数の方法で分類されます。たとえば、トークン「Archibald」は<possible forename>と<possible surname>の両方に分類され、トークン「SCOTT」は<possible forename>と<valid surname>の両方に分類されます。その結果、次の「Classification」ビューに示すように、分類では複数の分類パターンが出力されます。

再分類
前述したように、この時点でデータの説明が複数存在します。ここで、トークン「Archibald」は「valid forename」(有効な名)の後に続き、ミドル・ネームを表すことは確実であるため、次の再分類ルールを「Forenames」属性に適用することを決定します。
![]()
このルールは「Forenames」属性内のパターン「<valid forename>(<possible forename>)」に適用されるため、前述の2番目と4番目の分類パターンに影響します。「Reclassification」ビューには、次の4つのパターン、つまり、データの4つの可能な説明が表示されます。

|
注意: 「Reclassification」ビューには、選択プロセスへの入力として事前選択されたパターンのみが表示されます。事前選択は選択プロセスの最初のステップ(構成不可)で、未分類トークンが多く含まれるパターンを除外するステップです。事前選択プロセスでは、最初に、それまでに生成されたすべてのパターンを調べて、1つのパターンに含まれる未分類トークンの最小数を決定します。次に、未分類トークンがこの数より多いパターンが除外されます。前述の例では、未分類トークンが含まれるパターンはないため、未分類トークンの最小数はゼロです。したがって、ゼロより多い未分類トークンが含まれるパターンはないため、事前選択プロセスで除外されるパターンはありません。 |
選択
選択では、4つの候補から最適なパターンを選択します。この場合、前述の1番目のパターンはすべてのトークン分類の結果が「valid」であるため、最適であることがわかります。したがって、デフォルトの選択ルールを使用して各パターンをスコア付けすると、1番目のパターンが選択されて「Selection」ビューに表示されます。
![]()
解決
選択されたパターンがレコードの最適な説明であることを確認した後、そのパターンを出力属性に解決し、結果を割り当てることができます。これを行うには、前述の選択されたパターンを右クリックして「Resolve」を選択し、完全マッチ解決ルールを追加します。
(実行された分類に従って)デフォルトの出力割当てを使用し、パターンに「Pass」結果を割り当て、「Comment」に「Known name format」(一般的な氏名書式)と入力します。

このルールを使用して「Parse」を再実行した後、ルールによって入力レコードが解決されたことを確認できます。
![]()
最後に、レコードにドリルダウンすると、解決ルールに従ってデータが出力属性に正しく割り当てられていることを確認できます。
![]()
「Parse」はいくつかのサブプロセッサで構成される高度なプロセッサで、各サブプロセッサはパースの異なるステップを実行し、個別に構成する必要があります。「Parse」は次のサブプロセッサで構成されており、次に説明するように、それぞれ個別の機能を実行します。
各ステップの詳細、および構成手順については、サブプロセッサをクリックしてください。
詳細オプション
一部の結果ビューが不要な場合に最適なパフォーマンスを得るために、パーサーには2つの実行モードがあります。
次の2つのモードがあります。
「Parse and Profile」(デフォルト・モード)は、最初にデータをパースするときに使用する必要があります。これは、パーサーによって出力される「Token Checks」および「Unclassified Tokens」結果ビューが、分類で使用されるリストを作成および追加してパース・ルールを定義する過程で役立つためです。
「Parse」モードは、パーサーの分類構成が完了し、パフォーマンスの最適化が必要な場合に使用します。このモードで実行すると、「Token Checks」および「Unclassified Tokens」ビューは作成されないことに注意してください。
すべてのオプションは各サブプロセッサ内で構成できます。
出力データ属性は「Resolve」サブプロセッサで構成できます。
|
フラグ属性 |
目的 |
可能性のある値 |
|
[Attribute name].SelectedPattern |
レコードに対して選択されたトークン・パターンを示します。 |
選択されたトークン・パターン |
|
[Attribute name].BasePattern |
トークン化によって出力された、レコードのベース・トークン・パターンを示します(このパターンを生成するためにパーサーを使用する場合)。 |
ベース・トークン・パターン |
|
ParseResult |
レコードに対するパーサーの結果を示します。 |
Unknown/Pass/Review/Fail |
|
ParseComment |
レコードの解決ルールに関するユーザー指定のコメントを追加します。 |
レコードを解決した解決ルールに関するコメント |
「Parse」プロセッサの結果は、ダッシュボードに公開できます。
次の結果解釈がデフォルトで使用されます。
|
結果 |
|
|
Pass |
合格 |
|
Review |
警告 |
|
Fail |
アラート |
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
「Parse」プロセッサでは、次に示す結果のビューが作成されます。すべてのビューは、プロセス内の「Parse」プロセッサをクリックして表示できます。また、「Parse」プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
「Base Tokenization」ビュー(「Tokenize」で作成)
このビューには、「Tokenize」サブプロセッサの結果が表示され、すべての入力属性間で重複しないベース・トークン・パターンがすべて表示されます。パターンは頻度別に編成されます。
|
注意: 各レコードのベース・トークン・パターンは1つのみです。複数のレコードが同じベース・トークン・パターンになります。 |
|
統計 |
意味 |
|
For each input attribute |
入力属性内のベース・トークンのパターン ビュー内の行は、すべての属性間で重複しない各ベース・トークン・パターンに対応することに注意してください。 |
|
すべての入力属性間で重複しないベース・トークン・パターンが含まれるレコードの数 |
|
|
% |
すべての入力属性間で重複しないベース・トークン・パターンが含まれるレコードのパーセント |
「Token Checks」ビュー(「Classify」で作成)
このビューには、「Classify」サブプロセッサの結果が表示され、各入力属性内の各トークン・チェックの結果が表示されます。
|
統計 |
意味 |
|
Attribute |
トークン・チェックが適用された属性 |
|
Classifier |
トークンの分類に使用されたトークン・チェックの名称 |
|
Valid |
トークン・チェックによって「Valid」と分類された各トークンの数 |
|
Possible |
トークン・チェックによって「Possible」と分類された各トークンの数 |
「Valid」または「Possible」統計をドリルダウンすると、分類された各トークン、およびそれらのトークンを含むレコードの数のサマリーが表示されます。再度ドリルダウンすると、それらのトークンを含むレコードが表示されます。
「Unclassified Tokens」ビュー(「Classify」で作成)
|
統計 |
意味 |
|
Attribute |
入力属性 |
|
Unclassified Tokens |
その属性内の未分類トークンの合計数 |
「Unclassified Tokens」をドリルダウンすると、すべての未分類トークンとその頻度のリストが表示されます。再度ドリルダウンすると、それらのトークンを含むレコードが表示されます。
「Classification」ビュー(「Classify」で作成)
このビューには、分類の後(ただし、再分類の前)に生成されたすべてのトークン・パターンのリストが表示されます。1つの入力レコードに対して、可能なパターンが複数ある場合があります。
|
統計 |
意味 |
|
For each input attribute |
属性内のトークンのパターン ビュー内の行は、すべての属性間で重複しない各トークン・パターンに対応することに注意してください。 |
|
Count |
このトークン・パターンがデータの可能な説明であるレコードの数。このビューでは、同じレコードに対して複数の可能なトークン・パターンが存在したり、1つのトークン・パターンが複数のレコードを説明する場合があることに注意してください。 |
|
% |
「Count」値を、データ・セット内の可能な全トークン・パターンに対するパーセントとして表した値。 |
「Reclassification Rules」ビュー(「Reclassify」で作成)
このビューには、すべての再分類ルールのリスト、およびそれらのルールがデータにどのように影響したかが表示されます。
|
統計 |
意味 |
|
再分類ルールのID。このIDは自動的に割り当てられます。このIDはルール間に依存関係がある場合に役立ちます。後述する「Precedents」統計を参照してください。 |
|
|
Rule Name |
再分類ルールの名称 |
|
Attribute |
再分類ルールが適用された属性 |
|
Look for |
ルールを照合するのに使用されるトークン・パターン |
|
Reclassify as |
再分類ルールのターゲット・トークン |
|
Result |
再分類ルールの分類レベル(「valid」または「possible」) |
|
Records affected |
ルールの影響を受けたレコードの数 |
|
Patterns affected |
ルールの影響を受けた分類パターンの数 |
|
Precedents |
このルールが動作する前に先行する他の再分類ルールの数。たとえば、あるルールで<A>を<B>に再分類し、別のルールで<B>を<C>に再分類する場合、1番目のルールは2番目のルールより先行しています。レコードに影響しなかった再分類ルールでも先行するルールが存在する場合があります。これらは論理的に計算されるためです。 |
「Reclassification」ビュー(「Reclassify」で作成)
このビューには、再分類の後(ただし、選択の前)に生成されたすべてのトークン・パターンのリストが表示されます。1つの入力レコードに対して、可能なパターンが複数ある場合があります。ビューには、データ・セット全体で可能なすべてのパターンとその頻度が表示されます。その後に、「Select」ステップで、各入力レコードの最適パターンが選択されます。
|
注意: このビュー内のデータ自体を使用して、選択するパターンを決定できます。つまり、データ・セット内での出現回数を評価して、レコードのパターンが選択されるように「Select」ステップを構成できます。「Select」サブプロセッサの構成を参照してください。 |
|
統計 |
意味 |
|
For each input attribute |
属性内のトークンのパターン ビュー内の行は、すべての属性間で重複しない各トークン・パターンに対応することに注意してください。 |
|
Count |
このトークン・パターンがデータの可能な説明であるレコードの数。このビューでは、同じレコードに対して複数の可能なトークン・パターンが存在したり、1つのトークン・パターンが複数のレコードを説明する場合があることに注意してください。 |
|
% |
「Count」値を、データ・セット内の可能な全トークン・パターンに対するパーセントとして表した値。 |
「Selection」ビュー(「Select」で作成)
「Select」ステップが完了すると、各入力レコードに対してトークン・パターンが選択されています。
このビューには、データ・セット内の選択されたパターンとその出現頻度が表示されます。
|
注意: 複数のあいまいなパターンがあるために、パターン選択でレコードを説明する1つのトークン・パターンを選択できない場合は、そのあいまいなパターンとともに、あいまいなパターンが同じレコード(つまり、複数の可能なパターンが同じで、パターン選択で1つを選択できなかったレコード)の数が表示されます。 |
|
統計 |
意味 |
|
For each input attribute |
属性内のトークンのパターン ビュー内の行は、すべての属性間で重複しない各トークン・パターンに対応することに注意してください。 |
|
トークン・パターンを解決した完全マッチ解決ルール(ある場合)の数値識別子 |
|
|
トークン・パターンを解決したファジー・マッチ解決ルール(ある場合)の数値識別子 |
|
|
Count |
このトークン・パターンがデータの最適な説明として選択されたレコードの数 |
|
% |
このトークン・パターンが選択されたレコードのパーセント |
「Resolution Rule」ビュー(「Resolve」で作成)
このビューには、各解決ルールによって実行された解決のサマリーが表示されます。これは、ルールが要求どおりに機能していることをチェックする際に役立ちます。
|
統計 |
意味 |
|
ID |
構成時に設定されたルールの数値識別子 |
|
Rule |
ルールのタイプ(完全一致ルールまたはファジー・マッチ・ルール) |
|
Result |
ルールの結果(「Pass」、「Review」または「Fail」) |
|
Comment |
ルールのコメント |
|
Count |
このルールを使用して解決されたレコードの数。結果ブラウザで「Additional Information」ボタンをクリックすると、この値がパーセントとして表示されます。 |
「Result」ビュー(「Resolve」で作成)
|
統計 |
意味 |
|
Pass |
結果が「Pass」のレコードの合計数 |
|
Review |
結果が「Review」のレコードの合計数 |
|
Fail |
結果が「Fail」のレコードの合計数 |
|
Unknown |
「Parse」が結果を割り当てることができなかったレコードの数 |
「Parse」プロセッサからは、次の出力フィルタが使用可能です。
この例では、「Parse」の完全な構成を使用して、1つの「NAME」属性のデータを理解し、構成された氏名を出力します。
「Base Tokenization」ビュー

「Token Checks」ビュー

「Classification」ビュー

「Unclassified Tokens」ビュー

「Reclassification Rules」ビュー

「Reclassification」ビュー

「Selection」ビュー

「Resolution Rule」ビュー

「Results」ビュー

「Pass」結果のドリルダウン

Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.