Normalize No Data |
「Normalize No Data」プロセッサでは、データの属性に存在する様々なタイプの空白値をNull値または独自に選択した特定の値に正規化できます。これは、非データ値を一貫して処理するために重要です。たとえば、空白文字のみが格納された属性がある場合、他のプロセッサ(マッチ・プロセッサによる比較など)では、これらの値がNULL値に正規化されていないかぎり非データとして処理されません。
「Normalize No Data」プロセッサでは、スナップショット取得時またはリーダーのいずれかで使用された非データ処理と同じ機能(Nullに正規化する場合)を実行できますが、実行できるのは1つのプロセス内のみです。これは、プロファイリング時にソースに存在する様々なタイプの非データを把握しておく必要がある一方で、後続のプロセッサでは引き続き空白値(Null)として処理する場合や、空白文字のみの構成になるまで値をノイズ除去または切り取るなど、他の変換を介して属性内に空白値が生じ、これらをNullとして処理する必要がある場合に便利です。
「Normalize No Data」プロセッサは、空白文字のみが格納された属性値があることをパターン・プロファイリングで検出し、結果的に使用するデータがないとみなす必要がある場合に使用します。後続のプロセッサには、これらの値をNullとして処理することが保証されます。たとえば、マッチ・プロセッサによる比較で、Null文字列とデータ値を比較した場合は、非データの比較結果が返されます。
あるいは、元からNull(正規化前)であった値と区別するために、非データ値を独自に選択した値に明確に変換できます。
非データ値をNullまたは特定の値に正規化する任意の数の文字列または文字列配列属性。
配列属性を入力すると、変換はすべての配列要素に適用され、単一の配列属性が出力されます。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
No data handling reference data |
参照データ(「No Data Handling」カテゴリ) |
非データ文字として処理する文字のセットをリストします。これらの文字と空の文字列ですべて構成される値がNullまたは指定の値に正規化されます。 |
*No Data Handling |
|
Normalize no data to |
選択(Null値/カスタム文字列) |
非データ値をNullまたは選択したカスタム文字列値(後述のオプションで指定)のどちらに正規化するかを決定します。 |
Null値 |
|
Custom string |
自由形式テキスト |
Null値に正規化しない場合に非データ値を正規化するカスタム文字列値。 |
なし |
各入力属性ごとに、次のようになります。
|
データ属性 |
タイプ |
目的 |
値 |
|
[Attribute Name].NoDataNormalized |
導出 |
非データ値が正規化された後の新しい属性値を保持します。 |
元の属性にNull、空の文字列または非データ文字のみが含まれていた場合に、指定の参照データ・リストを使用して、元の属性がNull値またはカスタム文字列に変換された値。 |
なし
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
「Normalize No Data」トランスフォーマでは、処理に関するサマリー統計は表示されません。
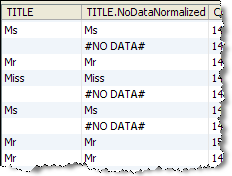
データ・ビューには、各入力属性とともに、右側に新しく正規化された属性が表示されます。
なし
この例では、「No Data Normalizer」を使用して、「TITLE」属性のすべての空白値をカスタム文字列「#NO DATA#」に正規化します。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.