| Oracle® Retail Predictive Application Server Administration Guide for the Classic Client Release 14.1 E59120-01 |
|

 Previous |
 Next |
| Oracle® Retail Predictive Application Server Administration Guide for the Classic Client Release 14.1 E59120-01 |
|
Previous |
Next |
This chapter explains the processes involved in RPAS data management. It includes the following sections:
The loadmeasure utility is used to load measure data from text files into the domain. The administrator must specify the measure names and the path to the domain that contains the measures.
The loadmeasure utility supports the use of fixed width and CSV (comma-separated variable) files for loading measure data. RPAS recommends the use of CSV files to reduce the size of the load file and to reduce disk I/O time.
To load measure data, system administrators must copy or create one or more load files in the input folder of the domain directory. The administrator can then call loadmeasure to load data.
Example:
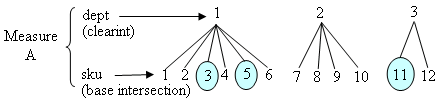
Measure A has a base intersection of SKU and a clearint of dept.
If there is data for only a few SKUs (3, 5, and 11) in the incoming file, and SKUs 3 and 5 roll up to dept1 while sku11 rolls up to dept3, the data in all of the SKUs that rolls into dept1 and dept3 will be cleared.
The base intersection is SKU.
The clearint is dept.
Data is present for SKUs 3, 5, and 11; these fall under dept 1 and dept3.
Data are cleared for dept1 (SKUs 1, 2, 3, 4, 5, 6) and dept3 (SKUs 11, and 12).
Data for SKUs in dept2 (7, 8, 9, and 10) are untouched.
System integrators must pay close attention to file naming. If a file name has not specifically been configured in the domain configuration, the file must be named the same as the measure name, with the appropriate extension depending on the type of the load.
For example, if the measure is named "rsal" and does not have a filename configured in the domain configuration, then the basic filename will also be "rsal". This name should be appended with one of the following extensions to indicate the type of load. If the load is an overlay, then the filename should be rsal.ovr; if it is an increment the file name should be rsal.inc, and so on. If a CSV file is being used, then the load type extension should be prefixed with the .csv extension; for example, rsal.csv.ovr and rsal.csv.inc.
RPAS supports the following types of loads (identified by file name extension):
.ovr (Overlay): Existing values in the measure are overlaid with the values in the input file. Any values not included in the input file are not changed in the measure.
|
Note: For string type measures, an empty cell in the ovr file is treated as a valid string; as a result, the loadmeasure utility overwrites the previously loaded string with an empty string.For other measure types, an empty cell in the ovr file is treated as invalid data. It is discarded and the previously loaded value is retained. |
.rpl (Replace): The existing measure is cleared and the values in the input file are taken as the new values for the measure. Existing values for cells that do not exist in the load file are switched to NA. In other words, all data at the base intersection for the measure are removed before cells are populated with the data from the incoming file.
.inc (Increment): Increment mode should only be used with numeric measures in which the load file contains incremental values. Therefore, if a cell had a value of 2 and the .inc file provided a value of 3 for the cell, the new value for the cell will be 5 (2 incremented with 3).
.clr (Clear): Clear mode is a variation of replace mode. It is used when measure data is loaded in parts or staggered in time, so that data for all positions grouped by an aggregate level position is replaced if one or more positions for that group of positions are being loaded.
In other words, data at the base intersection of a measure is partially cleared based on incoming data and the clearint attribute for the measure. The clearint attribute defines an intersection above the base intersection. All cells at the base intersection that are descended from a given position at the clearint level will be removed if data exists in the incoming file for at least one of those descending positions.
For example, assume that there are four regions, each with several stores, and the data is loaded region by region or for a subset of regions at a time. When loading data, ensure that data for a region is completely replaced with the new load if the load file has data for one or more stores from that region; however, other regions should be left untouched. This is made possible by clear loads where the clear intersection (clearint) property of a measure specifies the aggregate level at which to group positions for completely replacing the data. In this example, the clear intersection is at the region level. Clear intersection does not have to be performed along one hierarchy, but can be performed at the intersection of multiple hierarchies.
However, if you load multiple .clr files with region as the clear intersection, and data for one of those regions is in multiple files, then the last loaded .clr file for that region will replace any information that the previous .clr files loaded for that particular region.
The loadmeasure utility allows more than one load file to be present in the input folder at the same time for the same measure. If more than one load file is present in the input folder at the same time, each will be loaded. Since RPAS has a strict naming convention for measure file names, in order to add more than one load file at the same time, integrators must append the filenames as described above with file-distinguishing extensions.
For example, with the file names rsal.csv.ovr.1 and rsal.csv.ovr.2, RPAS does not care about the form of the multi-file extension. The extensions can be anything, number or text, and RPAS will still load them.
|
Note:
|
The loadmeasure utility also allows multiple types of load files to be present in the input directory at the same time. RPAS loads .rpl files first, then .clr, .ovr, and .inc files. Since .rpl files completely erase existing measure data and then load the given data, you should not have multiple .rpl files at the same time.
The loadmeasure utility allows multiple measures to be loaded from a single file. You can load measures from "CSV Files" or "Fixed Width Files".
|
Note: See the ”Data Interface Tool” section of the RPAS Configuration Tools User Guide for more information. |
If a CSV file is used for loading measure data, loadmeasure will use the order that measures were specified on the command line to determine the order of columns in the CSV format. For example, if a file named multiple is used to load measures A, B, and C, where the call to loadmeasure listed the -measure argument as A,C,B, then when using the CSV file multiple.csv.ovr, loadmeasure will assume that after the dimension columns, the first column is A, then C, and then B, because that is the order they were passed in the call to loadmeasure.
It is not necessary to load all measures in a multiple measures file. If a file contains more columns than the call to loadmeasure requires, the trailing columns are ignored. If a line in the file does not contain enough columns to hold values for all measures specified, the line will be skipped. For example, if a file containing three measures (after the dimension positions), but only one measure is specified in the command line, only the first measure field will be used and the rest of the line is ignored.
|
Note: Even though it is not required to specify all measures contained in the multi-measure CSV file in a single loadmeasure command, there is no way to skip data columns in the CSV file. |
With a fixed width file, a single measure's data can be loaded from a file containing multiple measures.
The loadmeasure utility supports loading measure data from an intersection lower than the base intersection of the measure. The load intersection has to be pre-specified in the configuration (loadint property) and the load time aggregation (loadagg property) method must also be specified. See the RPAS Configuration Tools User Guide for information on setting up measure properties.
When loadmeasure loads data from below the base intersection, all low-level data corresponding to a cell at the base intersection must be available in the load file for RPAS to be able to correctly aggregate the low-level data to the base level. A mistake in the values of a subset of cells that aggregate up to one cell at the base level can only be corrected by reloading the data for all low-level cells that correspond to the cell at the base level. If any low-level cells are missing, RPAS replaces their value with NA.
To perform a lower level load, RPAS first aggregates the data and then applies the appropriate load type to update the measure value, overwriting the existing value with the aggregate of the input cells if .ovr files were used, or incrementing the existing value with the aggregate of the input cells if .inc files were used.
RPAS supports the notion of stage-only measures. For stage-only measures, loadmeasure queues the loaded data in an intermediate staging area, but does not load it into the measure until it is called with the -applyloads parameter. For stage-only measures, loadmeasure should be called twice, once to stage the measures and then with the -applyloads parameter to subsequently load the staged data in the measure arrays. The loadmeasure utility cannot simultaneously stage loads and apply the staged loads.
Measure staging should be performed when measure data can arrive from different sources, in different load formats, and staggered in time, when system administrators want to queue all these loads up and apply them at once while honoring the data arrival queue. Measure staging can be performed while the system is online as it does not cause measure data-related contention (it has the potential to cause metadata-related contention). When staging measure data, loadmeasure splits the data and purges the data files if data purging is enabled; it does not purge measure data until the loads are applied. This staging time preprocessing significantly reduces the load time when the loads are actually applied.
|
Note: The replace (.rpl) format cannot be used for staging. Furthermore, data loads from below the base intersection of the measure cannot be staged. |
The loadmeasure utility provides the ability to automatically run scripts before and after the utility is executed. These are referred to as preprocessing and post-processing scripts.
When leadmeasure is called, the utility checks for the existence of scripts named pre<measurename>.sh in the ./scripts directory of the domain. If scripts exist, they will be run prior to the execution of the utility. Similarly, after the utility has completed running, the utility checks for the existence of scripts named post<measurename>.sh and executes them.
When multiple measures are loaded in a single call, only the preprocessing script for the first listed measure has any effect on the data.
System administrators can purge old measure data during a load. When the base intersection of a measure involves the Calendar hierarchy, the setting for the purgeage measure property defines how and when existing data gets purged to an NA value. If purgeAge has not been set, the data never gets purged. If a purge age of zero or more has been set, data is purged for all dates before RPAS_TODAY - purgeage days. That is, if purgeage is 5, then at data load time, all data that is older than 5 days before RPAS_TODAY will be purged.
The loadmeasure utility cannot be used to load measure data for a measure that is shared through an RPAS Data Mart. If one of the measures passed to loadmeasure is a shared measure, loadmeasure will exit with an error message identifying the shared measure.
See the section on loadFactData for information on loading data into shared measures.
In a global domain environment, loadmeasure is centralized and can only be called in the master domain. The loadmeasure utility loads one or more input files that can contain data from one or all of the local domains within the given global domain environment. The utility then splits the input files and loads them into the required domain (which is the local domain to which the position belongs), or the master domain if the measure has a base intersection above the partition level. The split only occurs once in the case of multiple measures. Local domains will be checked for files even if there is no file in the global domain. The utility can be run in parallel in a global domain environment.
loadmeasure -d pathToDomain -measure measureName{,measureName,…} {-applyloads}{-processes max} {-noClean} {-forcePurge}{-splitOnly | -noSplit} {-defrag} {-loglevel level} {-recordLogLevel level} {-inDir inputDirectory}
Table 8-1 provides descriptions of the arguments used by the loadmeasure utility.
Table 8-1 Arguments Used by the loadmeasure Utility
| Argument | Description |
|---|---|
|
-d pathToDomain |
Specifies the domain in which to load the measure. |
|
-measure measureNames |
Specifies the name of the measures to load.Measure names must be lowercase (for example, measurename1, measurename2, measurename3).If more than one measure is specified, all the measures must be in the same input file. |
|
-applyloads |
Applies any staged loads for the named measure. If the measure is registered to be a stage-only measure, loadmeasure will put the load in a staging area but will not update the measure until loadmeasure is called again with this argument. Upon the use of this argument, loadmeasure applies all loads that have been queued up in the staging area. It clears out the staged loads unless the measure's loadsToKeep property has been set to a non-zero number. In that case, it does not clear out the latest loadsToKeep loads. Note that only .ovr, .inc, and .clr loads can be staged. .rpl loads cannot be staged. Additionally, staging is only allowed for base intersection loads. RPAS cannot stage loads where load intersection is below the base intersection of the measure. This argument must not be used for measures that are not stage-only. |
|
-processes max |
Specifies the maximum number of child processes for parallel splitting of files and loading of measures across local domains in a global domain environment. For instance, if you specify five as the maximum number of processes, then up to five child processes can run concurrently in the split or load operations. If this argument is omitted or if only one process is specified, the application will perform all processing in a single process and no child processes will be created. This only specifies the number of child processes. The controlling process is not included (max + 1 is the actual number of processes). |
|
-noClean |
Prevents the input files from being moved to the processed directory. This option is used when a single file is used to load multiple measures, but not all measures from the file are loaded at once. The use of this option instructs loadmeasure to leave the load file behind for subsequent loading of unloaded measures. The user might want to use this option to perform intermediate processing between loads of measures available from the same file. |
|
-forcePurge |
Forces the purge routine to run even if no new data is loaded. This purges old measure data. This option can be applied to stage-only measures without having to apply loads. When a measure has the Calendar hierarchy in its base intersection, the setting for the purgeAge measure property defines how and when existing data gets purged to a NA value. If purgeAge has not been set, the data never gets purged. If a purge age of zero or more has been set, data is purged for all dates that are before RPAS_TODAY -purgeAge days. That is, if purgeAge is five, at data load time all data that is more than five days before RPAS_TODAY will be purged. This option does not require you to load any new data. |
|
-loglevel level |
Sets the logger verbosity level. Possible values: all, profile, audit, information, warning, error, or none. |
|
-noSplit |
Loads the pre-split input files (created by -splitOnly) into the local domains. This option should only be used in global domain environments. |
|
-splitonly |
Causes the input files in the global domain to be split across the local domains, but does not do any further processing of the input files. Subsequently, loadmeasure can be used with the -noSplit argument to load these pre-split input files into the local domains. File-splitting is a fairly time consuming activity and can consume up to 80 percent of the load time. System integrators may be able to improve batch performance by breaking away file-splitting from actual measure loading. This is useful if a multi-measure file is being used in such a way that subsets of measures are loaded at different steps in a batch process. The file can be split with multiple processes by specifying the -processes argument. This option should only be used in global domain environments. |
|
-defrag |
Defragments the domain at the end of the measure loading process to reduce the physical size of the domain. This space-saving is achieved by replacing the existing fragmented pages with copied, fully populated BTree database pages. |
|
-recordLogLevel level |
Sets a logging level for record loading issues. Issues such as parsing errors, missing positions, and data conversion errors are evaluated for every record in the measure load file. By default, these are logged as errors in the log file of the loadmeasure utility. However, customers might want to downgrade the logging level for such record loading issues. They can do that by using the -recordLogLevel level argument. The standard log levels, error, warning, information, and profile, can be used as parameters to this argument. When logging, loadmeasure compares this logging level to the utility's logging level (set using -loglevel). If the utility's logging level is less verbose than the record logging level, then record issues will not be logged. If utility's logging level is at same or higher verbosity as the record logging level, the record issues will be logged with the log indicator as set using this argument. |
|
|
Only .rpl files can be used with this option, and only the CSV format with header line is supported. The header line is used to map the columns to dimensions and measures (for example: SKU,STR,DAY,Sales). Enter one measure per input file. The name of the measure is extracted from the file name; for example, sales.csv.rpl corresponds to measure sales. The input data must be at the base intersection of the measure. If the measure is normally partitioned (non-HBI), a sub-domain index may be used for further performance optimization by avoiding the data-splitting step. For measures that may contain duplicate positions in different sub-domains (FnHBI measures), the sub-domain index is required. In either case, the name of the file is used to figure the sub-domain index (for example, sales.0.csv.rpl corresponds to the first local domain; sales.1.cvs.rpl corresponds to the second local domain, and so on). Note: The sub-domain index is designed to be used in conjunction with exportMeasure -hier only. Manual name-indexing of the files is not recommended. The filename property of the measure is not considered with the -inDir option. |
A configuration and backend process may also be used to support the load of image paths for one or more positions of a dimension at a time. The paths of the images must be stored in a measure called r_images_<dimension name> where <dimension name> must be replaced with the RPAS Name of the image-enabled dimension (for example, r_images_sku if loading image paths for the sku dimension). This measure is single-dimensional, defined on the image enabled dimension. An .ovr file is required with position names and the image paths for those positions formatted according to the RPAS measure load formats. The loadMeasure utility is then used to load this data into the domain.
|
Note: See the RPAS Configuration Tools User Guide and the "Position Images" section in the RPAS User Guide for the Classic Client for more information on Image Display. |
Example
loadmeasure -d <domain path> -measure r_images_sku
where <domain path> is the path to the domain.
The exportMeasure utility is a command-line utility that may be used to export domain or workbook measure data from RPAS in either a CSV or a fixed-width file format. A single measure, or multiple measures, may be exported based a specified intersection. If the measure's base intersection is not the same as the export intersection, the measure's default aggregation method will be used to aggregate data to an intersection higher than base, or replication will be used for spreading measure data if the data is required at an intersection lower than base. This utility:
Supports export of data in a user-specified range, which can be a single mask measure, a range specified on Calendar dimension, or a combination of the two.
Supports multiple processes for better performance in a global domain environment.
|
Note: The exportMeasure utility allows multiple measures to be exported into the same file when multiple measure names are provided. The same measure name cannot be specified more than once (using comma separation) in a single call; therefore, a measure can be exported only once per file. |
The exportMeasure utility cannot be used to export the data contained within a shared measure in a domain integrated with an RPAS Data Mart. If one or more of the measures passed to exportMeasure is shared through an RPAS Data Mart, exportMeasure will exit with an error message identifying the shared measure.
exportMeasure -d pathToDomain -out outFile [COMMAND] [OPTIONS]
Table 8-2 provides descriptions of the arguments used by the exportMeasure utility.
Table 8-2 Arguments Used by the exportMeasure Utility
| Argument | Description |
|---|---|
|
-d pathToDomain |
Specifies the path to the domain. |
|
- |
Specifies the output file name. It is required and must be a valid file name including the path. |
|
- |
If specified, exportMeasure exports data from the specified workbook (wbname). A valid workbook name must be used. |
|
- |
Specifies the intersection at which to export measures. If the measure's base intersection is higher than the export intersection, replication is used to spread the measure down to the export intersection. If the measure's base intersection is lower than the export intersection, the measure's default method (defagg) is used for aggregation. The export intersection must be either at, above, or below the base intersection of the measure. The export intersection cannot have some dimensions above the dimension in the base intersection of the measure and some below. The RPAS dimension names in an intersection should be four characters in length. If a RPAS dimension name is less than four character long, then an underscore character ("_") must be used as a filler at the end of a dimension name. |
|
- |
Specifies a mask measure, which must be a valid Boolean measure registered. In the current measure store, its baseintx must be at same export intx. |
|
- |
Specifies a range of positions along the innermost dimension. Only values in the range are considered for export. |
|
- |
Defines the maximum number of processes to run in parallel. |
|
- |
Appends new output to the current output file. If not specified, the current output file will be erased and replaced with new data. |
|
- |
If run in a global domain environment and exporting intersection below partition dimension, and have processes set greater than 1, specifying nomerge will stop exportMeasure from merging multiple output files created from each local domain to the master output file. Output files created from local domain are stored at masterdomain/output/exportMeasure[TS] folder, where [TS] represents a timestamp. Files are named as out000X.txt, where 000X is the index of the local domain. |
|
- |
Specifies that the output file should be in the compressed CSV format. |
|
|
Exports all measures for hierarchies. It exports only measures that have storage in the domain. Multiple hierarchies can be specified in a comma-separated list. |
|
|
Updates the output directory. If the output directory does not exist, the utility creates one. The measure names are used to generate the output file names. A CSV file with a header line can identify the dimensions of the base intersection and the name of the measure that is generated for each file. The files always have a csv.rpl extension (e.g. sales.csv.rpl). Old files are overwritten. One output directory is created for each HBI measure. In addition, one file is created for each non-HBI or FnHBI measure per sub-domain. The file names contain an internal sub-domain index, for example |
|
- |
Converts the position names to all uppercase before writing the output data file. Without this argument, position names are in lowercase since they are stored in lowercase in the domain. |
|
-meas "measSpec, measSpec …" |
Must specify one. measSpec is measName.modifier. The -meas argument may be repeated to export multiple measure arrays to the same output file. modifier include the following: .precision<double>, specifies the precision for numeric measure .format<formatString>, specifies the user defined export format The examples below provide valid measure specifications given MeasNameA is a valid real type measure. Examples:
-meas MeasNameA
-meas MeasNameA.precision(0.0001)
-meas MeasNameA.format("%13.2f").precision(0.01)
-meas MeasNameA.precision(0.01).format("%13.2f")
For specifying date and time, the following formats are supported: %Y: four-digit year %y: two-digit year %m: month %d: day %B: full name of the month %b: three character abbreviation for the month %H: hour %M: minute %S: second %s: milli-second The examples below provide valid measure specifications given MeasNameB is a valid date/time type measure. Examples:
-meas MeasNameB
-meas MeasNameB.format("%Y%m%d")
-meas MeasNameB.format("%d%B%Y%H%M%S")
|
Use exportData to export measure data from RPAS into text files. Each line that is exported contains the position name for the exported dimension followed by the value in the cell for each array being exported.
|
Note: More than one array may be exported and more than one dimension in each array can be exported. |
The utility may be invoked by specifying all parameters on the command line or by specifying an array that contains a list of the parameters.
When running this utility in a global domain environment, the utility must only be called to export data from the master domain. The utility extracts the data from either the local domains or the master domain depending on where the data resides, which in turn depends on the level at which the global domain environment is partitioned.
The exportData utility cannot be used to export the data contained within a shared measure in a domain integrated with an RPAS Data Mart. If one or more of the measures passed to exportData is shared through an RPAS Data Mart, exportData will exit with an error message identifying the shared measure.
The parameters specify what arrays and dimensions are exported and how to format the data. It is best to specify the arrays first. An array specification begins with -array followed by the array information. This includes the array name, formatting string, NA cell value, and NA cell value formatting string. The formatting string for both the cell value and NA value is based on the C language printf function formats. See the documentation on the printf for more information on the possible values. The -array parameter can be repeated as needed to export more than one array into the same export file. Remember that the order in which the arrays appear in the -array parameter is the order that they appear in the export file.
After the arrays have been specified, the administration must specify the dimensions to be exported within the arrays. The -dim parameter is used to specify a dimension in an array. The -dim parameter is followed by the dimension name, a convert option, the formatting string (just like an array), and the order the dimension appears in the export file. Because arrays are not required to contain identical dimensions, it is important to list all dimensions in all arrays with the -dim parameter. This makes it possible to track dimensions across arrays and line the data up correctly. If a dimension in an array is not to be in the export file, set the last value of this parameter to 0. The conversion option specifies either the number of characters to be removed from the position name or it specifies an array that contains the real position name. If an array name is given, this array must be a vector. The function will go to this array and use the original position name to jump to the cell of the same position name. It will then get the cell value and use that as the position name in the export.
It is possible to specify the number of decimal places when exporting numeric measures of data type real. This setting is defined in the specifications for measures, arrays, and dimensions (measSpec, arraySpec, and dimSpec). The format is %[.precision]type where [.precision] is the number of decimal places and type is the
letter f. For example, the setting %.2f exports numbers with two decimal places. Other settings are provided below.
If all parameters are contained in an array, after the export file name and source database name, the -params parameter is used to specify the database name and array name that contains all of the parameters needed for the export.
|
Note: Either the -array, -meas, or -params parameters must be specified when using this utility. |
exportData -d domainPath -out outputFile -params db array exportData -d domainPath -out outputFile -array \"arraySpec\" {options} exportData -d domainPath -out outputFile -meas <measspec> | -array <arrayspec> | -params <paramspec> -wb <wbName> {options}
Table 8-3 provides descriptions of the arguments used by the exportData utility.
Table 8-3 Arguments Used by the exportData Utility
| Argument | Description |
|---|---|
|
- |
Specifies the domain that contains the data that to export. |
|
- |
Specifies the file that will contain the exported data. The outputFile is relative to the domain unless the full path is specified. |
|
- |
Specifies the measures to export. measSpec must be quoted, and the format is
The -meas argument can be repeated to export multiple measure arrays to the same output file. Measures are exported at the base intersection. |
|
- |
Specifies the array to export. arraySpec must be quoted, and the format is
The -array argument can be repeated to export multiple arrays to the same output file. The order in which arrays are listed is the order in which they will be exported. Note: This argument cannot be used in a global domain environment and can only be used in simple domains. This argument cannot be used with -useLoadFormat. |
|
- |
Instead of specifying all parameters on the command line, this parameter allows the parameters to be read from an array.
|
|
- |
Used after specifying any of the command arguments: -array, -meas, or -params. |
|
- |
Specifies that output is appended at end of output file. The default is to overwrite output file. |
|
- |
Specifies the dimension to be exported.
If the value is 0, then the dimension is not exported. The -dim parameter can be repeated. The -dim parameter is not allowed with the -useLoadFormat. When using with the -wide parameter, the -dim parameter should not be used for the innermost dimension. |
|
- |
Controls whether a line of data is exported based on having NAs in a cell.
|
|
- |
When arrayna is specified using the -skipNA parameter, this option specifies the export array that is checked to determine if data is exported. |
|
- |
Causes the data to be exported wide, which means the innermost dimension will go across the row instead of each cell on a separate line. This is most useful when the innermost dimension is time. The -range parameter can be used in conjunction with wide format (-wide) to specify a range along the innermost dimension. The -dim parameter should not be used for the innermost dimension when -wide is being used. |
|
- |
Used to limit the export to positions in the range. The range can only be specified for the innermost dimension. May be used in conjunction with the -wide parameter. |
|
- |
Specifies the YYYYMMDD format for dates. |
|
- |
Causes the utility to avoid exporting values that differ from the NA value by the specified value. Any values smaller than the precision value are not exported. For example, consider a measure with the NA value of zero and a precision value of 0.01. A value of 0.0034 would not be exported while a value of 0.34 would be exported. The precision value must be less than one. If a value greater than one is provided the utility returns a warning. |
|
- |
Defines the maximum number of processes to run in parallel. |
|
- |
Enables the use of the NA value of the array instead of the NA value specified in measSpec or arraySpec. |
|
- |
Converts the position names to all uppercase before writing the output data file. Without this argument, position names are in lowercase since they are stored in lowercase in the domain. |
|
- |
Controls the display of measures used as a mask in -naArray option. The default is to not display the mask NA measure value. However, if this option is specified, then the NA Array measure values are also exported. |
|
- |
Enables the use of the format as specified by the measure property. The level at which the data is stored in the domain is used. The -dim parameter is not allowed with the -useLoadFormat. |
Use the format specified by the measure's loading format to export the measure. This loading format includes Start and Width, which defines the column that corresponds to this measure's data in the measure load file. The measure is exported into the same column in the output file. If the full measure export specifications are not provided, including the cellFormat, naValue and naFormat, the default format will be used. The default export formats for each type of measure are as follows:
Integer: %<width>.0f
Real: %<width>f
String: %<width>s
Date: %Y%m%d
Boolean: TRUE or FALSE as string
All values are exported right aligned, as in the measure loading file.
If users provide full measure specifications, then user-specified cellFormat, naValue, and naFormat will be used rather than the default format.
Users can either use the default format by specifying the measure name only or give the full specifications. Partial measure specifications are not permitted.
If users specify multiple measures to be exported into the same file, each of these measures will occupy a column in the file defined by its start and width attributes. If two measures occupy the same column, exportData will throw an exception with an error message saying "overlapping measures in the output file" and exit. If a measure's column is overlapping with the columns occupied by the position names, exportData will throw an exception with an error message saying "measure column is overlapping with position columns" then exit. Basically, if the measure cannot be exported correctly, exportData will not try to export it but simply exit and alert user with a proper exception.
The -dim and -array parameters are not allowed if -useLoadFormat is used. All dimensions in the measure's base intersection are exported by default. The external position name is exported to the export file, in the order specified by the hierarchy's order attribute, usually in the order of CLND, PROD, and LOC. The position names are left aligned in the export file.
The mapData utility is used to move data from one domain to another. Specifically, it copies data from an existing domain, database, or array to a new domain, database or array.
Before this utility is run, the new hierarchy must be loaded in the destination domain. After mapData has copied data, administrators can purge the source domain by calling loadHier with a purge age of 0. Tasks such as hierarchy loading, hierarchy purging, and the validation of source and destination domains are performed outside of this utility.
|
Note: This utility does not update buffer positions. |
mapdata -d SrcPath -dest destPath [-db dbName [-array arrayName]]
{-db dbName {-array arrayName}} {-loglevel}
Table 8-4 provides descriptions of the arguments used by the mapData utility.
Table 8-4 Arguments Used by the mapdata Utility
| Argument | Description |
|---|---|
|
-d SrcPath |
Specifies the path to the source domain. |
|
-dest DestPath |
Specifies the path to the destination domain. |
|
-db dbName |
Applies mapdata only on the given database. Must be a valid file. If this argument is not specified, the entire domain will be included in the operation. |
|
-array arrayName |
Applies mapdata only on the given array. The database in which the array resides must be specified with the -db argument. |
The updateArray utility moves data from a source array to a destination array. The destination array must contain the superset of dimensions in both source arrays. The source array's dimensions may be at the same or higher level, as mapped by the dimension dictionary. If a dimension in the source array is at a higher level, the results are spread across the lower level dimension in the destination. If there are extra dimensions in the destination array, the results are replicated across these extra dimensions. The NA value of the destination array remains unchanged.
To limit the scope of the update, a mask array and an innermost range may be specified. If a mask array is given, the update is limited to cells in the source array for which the corresponding mask cell is on. If an innermost range is given for source or destination array, the update is limited to cells that are within the start and end of this range on the innermost dimension. If the source and destination arrays are not in the same domain, the measure store associated with the source domain is used to find hierarchy information.
|
Note: This utility does not update buffer positions. |
updateArray -destArray dbPath.arrayName {-srcArray dbPath.arrayName}{-destDomain domainPath {-srcDomain domainPath} {-maskDomain domainPath} {-maskArray dbPath.arrayName} {-updateMethod method} {-srcRange first:last} {-destRange first:last} {-srcScalar scalarCell} {-version} {-loglevel level} updateArray -argFile filename {-version} {-loglevel level}
Table 8-5 provides descriptions of the arguments used by the updateArray utility.
Table 8-5 Arguments Used by the updateArray Utility
| Argument | Description |
|---|---|
|
- |
Specifies the destination array where the data is copied. Required. dbPath is relative to destDomain. |
|
- |
Optional argument. Default is no source array. Note: This parameter cannot be used with -srcScalar scalarCell. |
|
- |
Optional argument. Default is current working directory. |
|
- |
Optional argument. Default is current working directory. |
|
- |
Optional argument. Default is current working directory. |
|
- |
Optional argument. Default is OVERLAY. The following update methods are available:
|
|
- |
Optional argument. Default is no range. Defines range along innermost dimension of source array. |
|
- |
Optional argument. Default is no range. Defines range along innermost dimension of destination array. The position names of the innermost dimension are the range value. For example, if the range values is one week, the range should be specified as -srcRange WEEK200811011:WEEK200811022 -destRange WEEK200811011:WEEK200811022 |
|
- |
Optional argument. Default is NA cell. Format for scalar cell is one of:
Note: This parameter cannot be used with -srcArray dbPath.arrayName. |
The scanDomain utility is a domain utility used for detecting data loss and repairing data corruption in an RPAS database.
Data loss occurs when an RPAS process is abnormally terminated. This can happen when an external mechanism, such as a power failure, causes a sudden termination of an RPAS process. Data loss can also occur due to unexpected program breakdown.
Data corruption can occur if an external program modifies the RPAS database files or an unforeseen defect occurs in the processes using the RPAS database (an extremely rare event).
The scanDomain utility can detect both corruption and data loss, but it can only fix corruption. This utility can operate on global, non-partitioned, and local domains. It supports parallelization when repairing databases in a domain.
While the utility is attempting to perform a repair of the databases, it can use the command line option (-backup) to enable backing up the original databases. While running in detection mode (-detectDataLoss or -detectCorruption option), the utility does not change any of the RPAS databases, and therefore, it does not create such backups.
In detection mode, the utility prints a list of databases with data loss or data corruption to the screen. The output can be directed to a file.
scanDomain -version scanDomain -d domainPath [-detectDataLoss ] [-detectCorruption] [-loglevel level] [-noheader] scanDomain -d domainPath -repairCorruption [-backup][-processes maximumNumberOfProcesses] [-loglevel level] [-noheader] scanDomain -d domainPath -listUnusedData outputFile [-processes maximumNumberOfProcesses] [-loglevel level] scanDomain [-?|-help|-usage]
If the user intends to detect both corruption and data loss, it is more efficient to run the utility once with both the -detectDataLoss and -detectCorruption options. The user can run two consecutive commands for detecting corruption and data loss, although this is less efficient.
When running scanDomain to detect unused data, the user sees a list of databases that may not be needed by the domain. This information includes:
User directories for users who are not registered in the domain
Measure databases whose corresponding measures have been removed from the domain
Other databases not referenced by the domain (for example, measure load databases, backup databases, and temporary databases)
The data contained in the specified databases may not be needed by the domain. If the user can confirm that the data is actually unnecessary, then the user can remove those databases before proceeding with the upgrade.
Table 8-6 provides descriptions of the arguments used by the scanDomain utility.
Table 8-6 Arguments Used by the scanDomain Utility
| Argument | Description |
|---|---|
|
-version |
Prints the version of the utility. |
|
-d domainPath |
Specifies the path to a global, non-partitioned, or local domain. Required. |
|
-detectDataLoss |
Checks for data loss in the specified domain. |
|
-detectCorruption |
Checks for database corruption in the specified domain. |
|
-repairCorruption |
Repairs the database corruption in the specified domain. Note: This argument cannot be used with -detectDataLoss or -detectCorruption. |
|
-backup |
Backs up database files before attempting to repair them. Optional. Note: This argument can only be used with -repairCorruption. |
|
-listUnusedData |
Lists potentially unused data in the domain. Information about this unused data is output to a file whose location is passed as the outputFile argument. |
|
-processes maximumNumberOfProcesses |
Specifies the maximum number of processes to be started to repair Btree database corruptions. Optional. Note: This argument can only be used with -repairCorruption. |
|
-loglevel level |
Sets the logger verbosity level. Possible values: all, profile, debug, audit, information, warning, error, or none. Optional. |
|
-noheader |
Disables the timestamp header. Optional. |
|
-?|-help|-usage |
Obtains the usage text. Optional. |
Discrepancies in the metadata of a domain can cause serious problems during domain operations, and such discrepancies can be difficult to correct. The fixDomain utility analyzes a domain in order to detect problems in the metadata of a domain and can be used to attempt to fix any detected problems.
By default, fixDomain runs in report-only mode. Users should run fixDomain in this mode first in order to detect discrepancies in the metadata. Should any problems be discovered, fixDomain provides functionality to fix certain problems in the metadata of the domain.
The measure array present in the measure's database can have an NA value which is different from the NA value of the measure in the measure's property. The array NA value can change depending on the state of the array. The NA value of the array is calculated based on the current value of populated cells in the array and hence this is not constant. The syncNAValue utility is used to set a measure's array NA value to its measure NA value.
The synchNAValue cannot be used to modify the array NA value of a measure shared through an RPAS Data Mart. If synchNAValue is called with the optional -m argument and the specified measure is a shared measure, synchNAValue will exit with an error message stating that the measure is shared. If it is called without the optional -m argument, synchNAValue will skip any shared measures within the domain.
syncNAValue -d [domainpath] [options]
Table 8-7 provides descriptions of the arguments used by the syncNAValue utility.
Table 8-7 Arguments Used by the syncNAValue Utility
| Argument | Description |
|---|---|
|
-d domainPath |
Specifies the path to the domain where the utility needs to be run. This is a required argument. SyncNAValue can also be run from sub-domains. Caution: If syncNaValue is run with the -d option and without any additional arguments, it changes the array NA value to the measure NA value for every measure registered in the domain. |
|
-m measName |
Optional argument to run syncNaValue on a single measure only instead of all measures in the domain. |
|
-report |
Optional argument to print out all measures whose array NA value is different from its measure NA value. This option does not update any measure arrays. If used along with the -m option, it prints the measure array information even if the array and measure NA values are the same. |
Usage Examples
In the following examples, it is assumed that syncNAValue is run from the domain path:
syncNAValue -d . -report syncNAValue -d . syncNAValue -d . -m measA syncNAValue -d . -m measA -report