| Oracle® Retail Predictive Application Server Administration Guide for the Classic Client Release 14.1 E59120-01 |
|

 Previous |
 Next |
| Oracle® Retail Predictive Application Server Administration Guide for the Classic Client Release 14.1 E59120-01 |
|
Previous |
Next |
There are a number of key concepts and processes that are critical to the hierarchy management process:
Hierarchy structures are loaded into a domain using the loadHier utility.
RPAS uses integer indexing for simplified hierarchy administration. A set number of hierarchy positions, based on bit size, is allocated to each dimension. The pre-allocation of positions reduces the need for updating the measure data structures.
The length of position names is 24 characters or less by default. RPAS provides the ability to increase this length using the dimensionMgr utility.
Position names must consist of only the following characters: a-z, A-Z, 0-9, _, &, $, and %. Position names cannot start with _. Any uppercase letters are converted to lowercase letters by the application. Position names cannot be an empty string.
RPAS provides the ability to have placeholder positions in the domain that can be used when loading new hierarchy positions.
RPAS can automatically handle the movement of positions and their corresponding data between local domains when their parent-child relationships change and cause such a scenario. This is only applicable in a global domain environment.
Positions at the partition level in a global domain environment can be moved between local domains using the reconfigGlobalDomainPartitions utility.
New local domains can be added to an existing global domain environment using the reconfigGlobalDomainPartitions utility.
The loadHier utility is used to load and refresh a hierarchy. loadHier supports comma separated value (CSV) or fixed width flat files for loading. The load file should have a .dat file extension when a flat file is loaded and a .csv.dat file extension when a CSV file is loaded. When using a fixed width file, the width of fields (number of characters) is specified in a configuration file before a domain is built. The width of fields can be increased after a domain has been built using the dimensionMgr utility or by changing a property in the Configuration Tools and patching the domain. The utility also allows a simple compression method that can skip duplicated values line by line.
|
Note: The following information concerns hierarchy loading with intraday:
|
To manage the addition, removal, and reclassification of positions in a hierarchy, RPAS uses a methodology called integer indexing. It is used to manage multidimensional data at the storage level. For more information, see "Integer Indexing".
The loadHier utility supports both the loading of hierarchy positions and purging data in parallel. When RPAS deletes a partition position through purging, RPAS adjusts the cache data in parallel to maintain the correct position or domain mapping.
RPAS allows for multiple input files to be loaded for the same hierarchy. The extra input files should be named with a secondary extension (for example, ' msgs.dat.1'). The extra input files can be loaded only with the main input file. For example, you cannot load 'msgs.dat.1' in a separate loadHier call. Multiple files are often used when the hierarchy load data comes from different sources.
RPAS automatically generates a backup copy of hierarchy files prior to performing a load for a hierarchy. If any type of error occurs during the load process, the hierarchy is restored from the backup copy. Note that in cases where the -loadAll argument is used to load multiple hierarchies at once, any hierarchies already loaded prior to the error will not be reverted; only the hierarchy in which the error was encountered will be restored.
The loadHier utility stops with an error if the loadHierBk directory exists in the data directory of the domain, which indicates that a non-recoverable error may have occurred in the previous run. If this occurs, contact My Oracle Support at http://www.oracle.com/support/contact.html. The My Oracle Support team can best determine whether to delete the loadHierBk directory or copy the loadHierBk content back to the domain.
To optimize performance while moving or cleaning data during the hierarchy purging or reclassification processes, the -excludeMeasList or -includeMeasList argument can be specified. Both arguments specify a full path to an XML file, in the following format, which contains a list of measures to either be excluded or included:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
</rpas>
<measures>meas1,meas2,meas3…,measN</measures>
</rpas>
|
Note: It is important to specify the measures with care, especially when using the-includeMeasList option. This is because no data moves for those measures not included in the list; such data is lost when loadHier completes. |
When working with a domain sharing data through a RPAS Data Mart, loadhier also updates the ITT tables of the RDM to reflect the changes introduced in the hierarchy load. Additionally, loadhier is used on a domain integrated through a RPAS Data Mart, the RDM status tables are updated to reflect the fact that a hierarchy load is in progress. See the "Domain Integration and the RPAS Data Mart" section for more information on the hierarchy load process in an integrated environment.
loadHier -d domainPath -load hierName -loadAll {-purgeAge purgeage}{-purgeAll hierarchy1} {-noClean}{-loglevel level} {-defaultDomain ldom#, ldom#}{-excludeMeasList listName | -includeMeasList listName} {-includeUdd}
Table 7-1 provides descriptions of the arguments used by the loadHier utility.
Table 7-1 loadHier Utility Arguments
| Argument | Description |
|---|---|
|
-d domainPath |
Indicates the domain in which to load the hierarchy data. |
|
-load hierName |
Indicates the name of the hierarchy to load and refresh. |
|
-loadAll |
Loads all hierarchy input files (with a .dat file extension) that are located in the input directory of the domain. Including this argument disables the reshaping process until all files have been loaded. |
|
-purgeAge purgeage |
Specifies the purgeage during loadHier.If not specified, loadHier gets purgeage from domain. In global domains, -purgeAge supports the purge of partition positions when the purgeage is reached. |
|
-purgeAll hierarchy1, hierarchy2 |
Purges formal, informal, and user-defined positions in the listed hierarchies. It cannot be used on a partition hierarchy or any system hierarchy. |
|
-noClean |
Prevents the removal of input files and temporary data files that are generated during the hierarchy load process. Input files remain in the input directory of the domain after the process is completed. This option is often used for debugging or troubleshooting. |
|
-logLoadedPositions |
Enables the logging of successfully loaded input file lines into a loaded[HIERNAME].dat file under the processed directory. |
|
-maxProcesses count |
If specified, some parts of loadHier will run in parallel, meaning that it will use a maximum of the defined processes, which are specified by count. |
|
-forceInputRollups |
Enforces new hierarchy rollup changes. New rollup changes override or dominate existing hierarchy rollups if they conflict with the rollups specified in the input file. This allows you to load a hierarchy file that reclassifies one or more upper level positions while removing one or more discontinued base-level positions that roll up to the reclassified position. |
|
-forceNAConsistency |
Forces NA consistency when the current NA value is different from the originally defined NA value for the measure. |
|
-includeUdd |
Loads user-defined positions back to the domain. The data file must be in CSV format with a headerline. The name of the data file should follow the current standard: <hierarchy name>.csv.dat. All user-defined dimensions must be in the data file. Any missing user-defined dimensions cause an error. All loaded positions will have formal status after running -includeUdd. |
|
-defaultDomain ldom#, ldom#, |
Specifies comma-separated default domain paths that are used for accommodating new partitions. The domain paths can point to existing local domains or to new (non-existing) local domain. The local domain names are specified by a fully qualified path. To specify more than one local domain, separate local domain paths with a comma.Example: loadHier -defaultDomain ldom1, ldom2, ldom3 |
|
-excludeMeasList listName or -includeMeasList listName |
Optimizes performance while moving or cleaning data during the hierarchy purging or reclassification processes:
|
|
-headerLine |
Specifies the column order base on the header line. If not specified, the order is based on the start property of the dimension. This option is only applicable to the loading of CSV files; it has no effect on the loading of fixed-width files. |
When using -defaultDomain, loadHier adds the new partition positions to the specified default domains one by one. The list of default domains is performed in the given order until each new partition position is added.
Example:
For a global domain that consists of two local domains, ldom0 and ldom1, using the following loadHier command:
loadHier ... -defaultDomain ldom1,ldom2,ldom3 ...
In this call, three new partition positions (part1, part2, and part3) are in the input file. When the loadHier finishes, there will be two new local domains, ldom2 and ldom3, with the following new partition positions included in them:
ldom1 --> part1 ldom2 --> part2 ldom3 --> part3
In the previous example, if only two new partition positions (part1 and part2) are added, when the loadHier finishes there will only be one new local domain, ldom2. New partition positions will be located as follows:
ldom1 --> part1 ldom2 --> part2
Using the same example, if five partition positions (part1, part2, part3, part4 and part5) are added, when the loadHier finishes there will be two new local domains, ldom2 and ldom3. New partition positions will be located as follows:
ldom1 --> part1,part4 ldom2 --> part2,part5 ldom3 --> part3
To enable translation of position labels for the desired dimensions using the RPAS Configuration Tools, check the box in the Translate column of the Dimension definition tools. Building or patching the domain with this configuration builds the necessary infrastructure in the domain to manage translations for those dimensions. However, label translations must be separately loaded.
Position label translations are loaded in dimension specific translation measures for every language that is used by the users. If translated labels are not loaded using these measures, workbooks show position names wherever a label has to be shown. Note that for a translatable dimension, RPAS never uses or shows the position labels from the hierarchy load file but always refers to the labels in dimension specific translation measures. This implies that if a domain is patched to make a dimension translatable but the translation measures were not loaded, RPAS users will see position names instead of position labels from the load file.
Dimension specific position translation measures are named as r_<dim name>label, where <dim name> must be replaced with the name of the translated dimension. For example, if the sku dimension is translated, load the r_skulabel measure with translations. These measures must be loaded after loading the hierarchy because RPAS can only load translations for already loaded positions.
The position label translation measure load files have three columns. The first column has the position names, the second column has the language identifier, and the third column has the translation for the language specified in that row.
For example, a translation measure file for the sku dimension is named r_skulabel.csv.ovr and has the content formatted, as shown below. Note that in the following example, the same file contains labels in four languages.
10006782,ENGLISH,White Nike Running Shoe size 11 10006782,CHINESE_SIMPLIF,白色耐克?鞋大小白色耐克跑鞋大小11 10006782,FRENCH,Taille blanche 11 de chaussure de course de Nike 10006782,ITALIAN,Formato bianco 11 del pattino corrente di Nike 10004523,ENGLISH,Black leather shoe size 8 10004523,CHINESE_SIMPLIF,黑皮鞋大小黑皮鞋大小8 10004523,FRENCH,Taille noire 8 de chaussure en cuir 10004523,ITALIAN,Formato nero 8 del pattino di cuoio
Alternatively, you can manually enter or alter translated labels using the Translations workbook in the Administration tab. In this workbook, a worksheet is available for each dimension that has translations enabled. You can manually enter translated strings for the language of interest. After they are committed, these translations are available for every new workbook.
It is possible that, because of errors that occurred when translation files were prepared, translated labels for some positions may not be loaded. In a situation where RPAS is unable to look up the label for the locale of the machine on which the RPAS client is being run, RPAS looks for a non-empty label string for the English language. If it fails to find a non-empty label string for the English language, it uses or shows the loaded position name of the position.
|
Note: For the fixed-width format of translation measure load files, RPAS limits the labels to 80 bytes (RPAS uses UTF-8 encoding). For CSV format files, there is no limit. To avoid the complexity of calculating starting positions for fixed-width format files and the limitation of translation string length, it is recommended that CSV files be used. |
Integer indexing refers to the RPAS methodology for managing multidimensional data at the storage level. It aims at eliminating some of the inefficiencies around the addition, removal, and reclassification of positions in a hierarchy.
In the earlier versions of RPAS, string identifiers were constructed and used for internal addressing of the multidimensional data. Integer Indexing changes this mechanism in the sense that the data is internally referenced and stored by integer identifiers that are calculated from the dimension size and measure intersection.
Integer index calculation and management is entirely internal to RPAS. From a domain administrator's point of view, loading and exporting hierarchy and measure data is achieved through external names consistent with earlier versions of RPAS.
One major advantage of integer indexing is its impact on reducing the complexity of operations around managing position placeholders (buffers). The number of positions that a dimension can hold is defined by a bit size, which typically provides significant space for including new positions. For instance, a SKU dimension at 24 bits can include in excess of 16 million products. This provides significant growth space for adding new products.Compared to the earlier versions of RPAS, integer indexing can improve the hierarchy load performance as it eliminates the need for running the frequent rebuffering processes and completely eliminates the reshaping process.
Note the following definitions:
Index: An identifier that allows for random access to the multidimensional data. In RPAS, it is a numerical value that identifies a position in a given dimension. Prior to integer indexing, RPAS used string-type position identifiers and referred to them as internal names. Internal names were internally generated by RPAS. They were often different from the Position IDs provided in the hierarchy input files.
Position ID: The name provided in the input hierarchy files. RPAS maps the position ID to an internally generated integer index.
Consider the following example in which some items are loaded into the Product hierarchy. These items are externally identified by the position names and labels (as shown in the second and third columns in Table 7-2). The table represents the SKU dimension in the product hierarchy. Integer indexes, names, and position labels are the three major pieces of information associated with a dimension.
Table 7-2 Example 1
| Integer Index | Position Name | Position Label |
|---|---|---|
|
0 |
SKU1234 |
blue sweatpants |
|
1 |
SKU2345 |
white sweatpants |
|
2 |
SKU3456 |
green sweatpants |
|
3 |
SKU4567 |
purple sweatpants |
|
4 |
SKU5678 |
yellow sweatpants |
|
5 |
SKU6789 |
pink sweatpants |
|
6 |
SKU7890 |
orange sweatpants |
|
7 |
||
|
8 |
||
|
9 |
When the green sweatpants item is loaded into the domain, its position ID, SKU3456, is mapped to an available integer index, which is 2. After these items are loaded, RPAS uses the integer indexes to look up those items instead of their item IDs. Therefore, if you performed a query for green sweatpants, RPAS first identifies that the integer index of the green sweatpants is 2. Then, it searches for instances of 2 in the array. The reason that RPAS searches for 2 instead of SKU3456 is because searching for an integer is faster than searching for a string.
Here is what happens if you delete the blue and white sweatpants from your domain because they are discontinued. Rather than delete these position IDs from the dimension, RPAS marks them as inactive. By keeping these position IDs in the dimension, RPAS maintains the position ID to integer index mapping. This way, the green sweatpants are still mapped to the integer index 2.
Table 7-3 Example 2
| Integer Index | Position Name | Position Label | Position Status |
|---|---|---|---|
|
0 |
SKU1234 |
blue sweatpants |
Inactive |
|
1 |
SKU2345 |
white sweatpants |
Inactive |
|
2 |
SKU3456 |
green sweatpants |
|
|
3 |
SKU4567 |
purple sweatpants |
|
|
4 |
SKU5678 |
yellow sweatpants |
|
|
5 |
SKU6789 |
pink sweatpants |
|
|
6 |
SKU7890 |
orange sweatpants |
|
|
7 |
|||
|
8 |
|||
|
9 |
As you delete items from the domain, the dimension begins to have gaps in it where inactive items are using integer indexes. This is not an issue unless you want to add more position IDs than the dimension has room for. When this happens, you need to reindex the dimension first.
For example, add five more colors of sweatpants to the dimension. This dimension has ten integer indexes, so it can hold ten total position IDs. As the dimension is now, it has only three available integer indexes (7, 8, and 9) even though there are five indexes that are not being used (0, 1, 7, 8 and 9). To use the 0 and 1 integer indexes that the inactive sweatpants are mapped to, use the reindexDomain utility to defragment the dimension. This removes the blue and white sweatpants and allows you to use the 0 and 1 integer indexes for the new sweatpants. For more details about reindexDomain and defragging, see "Reindexing Domains Using reindexDomain".
Table 7-4 Example 3
| Integer Index | Position Name | Position Label | Position Status |
|---|---|---|---|
|
0 |
SKU3456 |
green sweatpants |
|
|
1 |
SKU4567 |
purple sweatpants |
|
|
2 |
SKU5678 |
yellow sweatpants |
|
|
3 |
SKU6789 |
pink sweatpants |
|
|
4 |
SKU7890 |
orange sweatpants |
|
|
5 |
|||
|
6 |
|||
|
7 |
|||
|
8 |
|||
|
9 |
However, a different result occurs if you add 15 new SKUs instead of 5. Even if you defragment the dimension, there is room for only 5 new SKUs. In this instance, you need to add more room to the dimension by increasing the dimension's bit size. There are two ways to increase the bit size: through the configuration and patching process or through the dimensionMgr utility. (For more information about dimensionMgr, see "Setting Properties for Dimensions Using dimensionMgr".)
To change the bit size after a domain has been built or upgraded to 13.3, complete one of the following sets of steps:
Update the configuration and patch the domain. See "Upgrading and Patching Domains" for instructions. To change the bit size, see the ”Defining Dimension Properties” in the Oracle Retail Predictive Application Server Configuration Tools User Guide.
Run the reindexDomain utility. See "Reindexing Domains Using reindexDomain" for instructions.
Or,
Run the dimensionMgr utility to update the bit size. See "Setting Properties for Dimensions Using dimensionMgr" for instructions.
Run the reindexDomain utility. See "Reindexing Domains Using reindexDomain" for instructions.
Use the reindexDomain utility to compress, increase, or decrease the set of physical address space (or indexes) of the multidimensional arrays. The process of compressing and defragmenting the physical IDs makes the domain load and run faster.
Compression is achieved by removing the gaps that develop due to hierarchy operations like purge and delete. Gaps essentially block certain physical IDs within an address space and prevent them from being used to store data in the individual dimension arrays. After the gaps are removed, the dimension space of the multidimensional array is recreated.
Increasing or decreasing the multidimensional array's address space is also achieved by increasing or decreasing the bit size of the dimension arrays and then recreating the dimension space of the array with the reindexDomain utility. In addition to defragmenting, increasing, and decreasing the number of indexes, the reindexDomain utility also updates any measure array affected. The update is similar to the dimension data because they are reindexed and defragmented. An affected measure is one that has a dimension that was reindexed in its base intersection.
|
Note: While working with a global domain, the reindexDomain utility runs from the master domain and spawns subprocesses across subdomains if more than one process is used.Domain reindexing should not invalidate existing workbooks.After the reindexing process, the workbook refresh and build operations may run more slowly. Users who try to open a workbook that was built before the reindexing process should be prompted and informed about the potential slow performance.A workbook is old if its dimregistry version is older than the domain dimregistry version.Workbook commit and refresh processes will use external name dimension maps if the workbook is old. |
When operating on a domain that shares data through a RPAS Data Mart, reindexDomain also updates the ITT tables of the RDM to reflect changes made as a result of the reindex process. See the "Domain Integration and the RPAS Data Mart" section for more information on domain operations in an integrated environment
reindexDomain -d <domainPath> {Commands} {Options}
There are three unique ways to use the reindexDomain utility: reindex, analyze, and domain properties. These are described in the following sections:
The reindexing options allow you to reindex the entire domain, dimensions within a hierarchy, a specified list of dimensions, or prepend calendar dimension positions.
Table 7-5 reindexDomain: Reindexing
| Example | Description |
|---|---|
reindexDomain -d <domainPath> |
Reindexes the entire domain. Checks the reindex condition. |
reindexDomain -d <domainPath> -hier <hierName> |
Reindexes all dimensions of the specified hierarchy. |
reindexDomain -d <domainPath> -dimSpec <Dim1,Dim2,..> |
Reindexes the comma separated list of dimensions. |
reindexDomain -d <domainPath> -hier CLND -prepend |
Creates a new DimRegistry by allocating space to prepend calendar dimensions' positions. The input to this process comes from |
Two options can be used with these usages:
-force: Forces reindexing at domain/hierarchy/dimension level. It does not check the reindexing condition.
-processes max: Specifies the number of processes to run in parallel.
The analysis option of the reindexDomain utility allow you to analyze the dimensions of a hierarchy or a CSV list of dimensions.
Table 7-6 reindexDomain: Analysis
| Example | Description |
|---|---|
reindexDomain -d <domainPath> -analyze -hier <hierName> |
Analyses the dimensions of the hierarchy and prints a report. |
reindexDomain -d <domainPath> -analyze -dimSpec <Dim1, ...> |
Analyses the CSV list of dimensions and prints a report. |
The report consists of the following information:
DimName
DimRegistry BitSize
DimInfo BitSize
Capacity
Maximum Physical Id
Maximum Logical Id
Threshold
Action Required
The reindexDomain utility can be used to review the domain properties by appending the -prop argument.
Table 7-7 reindexDomain: Domain Properties
| Example | Description |
|---|---|
reindexDomain -d <domainPath> -prop |
Prints the following domain properties:
|
Table 7-8 provides descriptions of the arguments used by the reindexDomain utility.
Table 7-8 reindexDomain Arguments
| Argument | Description |
|---|---|
|
-d |
Specifies the path to the global or non-partitioned domain. This argument is required for all reindex usages. |
|
-hier |
Reindexes all the dimensions of the specified hierarchy. When used with the -analyze argument, the -hier argument specifies which hierarchies should be analyzed. |
|
-dimSpec |
Reindexes the comma separated list of dimensions. When used with the -analyze argument, the -dimSpec argument specifies which dimensions should be analyzed. |
|
-force |
Forces the reindexDomain utility to reindex the entire domain whether it needs it or not. This argument overrides the logic that checks whether reindexing is necessary. |
|
-prepend |
Creates a new DimRegistry by allocating space to prepend calendar dimensions' positions. The input to this process comes from clndprepend.xml file. The loadHier utility generates the clndpreprend.xml file when you load the calendar hierarchy that has positions been prepended. After loadHier generates this file, it displays a message, stating that reindexDomain needs to be run first. The clndprepend.xml must exist in the master domain root. After you run the reindexDomain utility, you must run the loadHier utility again to complete the prepending the calendar hierarchy process. You can also generate clndprepend.xml manually without using loadHier. Use this argument only when you are prepending the calendar hierarchy. |
|
-processes max |
Specifies the number of processes to run in parallel. |
|
-analyze |
Checks whether reindexing is necessary for hierarchies or dimensions. This argument returns details about the dimension name, bit size, number of available and used position IDs, the threshold ratio, and whether reindexing is necessary. |
|
-prop |
Shows the domain properties. The properties are dimregistry_version and reindexing_in_progress, where the dimension registry number and the progress indicates whether a reindex is currently running. For more information about these domain properties, see Version and ReindexStatus. |
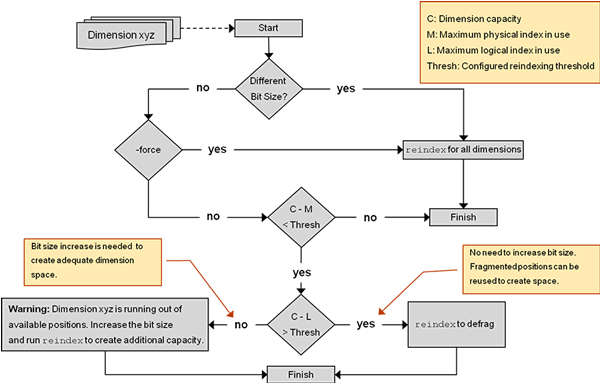
To know whether you should reindex a domain, run the reindexDomain utility with the -analyze option to generate a status report. (Detailed instructions for using the analyze option are described in "Run Reports".) RPAS calculates how much space is left in the array with the following equation:
(C-M) < Thresh
Where:
C equals the maximum number of position IDs that the array has been allocated to hold. C is the dimension or BitSize cardinality, which is computed with the following equation:
C = 2BitSize
BitSize is used to compute the cardinality of a dimension. The BitSize can be represented by up to a 4-byte unsigned long integer, which gives a maximum of four gigs of address space. Since four gigs is very large, the BitSize is specified at configuration time. The BitSize is determined based on the current size of the dimension and expected increase in future. If the user does not specify BitSize for a dimension at configuration time, then the RPAS Configuration Tools provides a default BitSize of 8 for that dimension.
For domains that were converted to 13.3.0, you must ensure that the hierarchy.xml file contains an entry for all dimensions along with the bit sizes.
M equals the number of used position IDs in the dimension. This is across all position IDs currently assigned to the dimension positions. The maximum number of utilized physical IDs can differ from the maximum number of utilized logical IDs if the hierarchy is subjected to deletions and additions.
Thresh is the threshold value you set for a dimension. The threshold is an integer that represents the number of unused position IDs that you want to be available in the dimension array. When the dimension array no longer has this specified amount of free space, RPAS reindexes the dimension array. The threshold is part of the configuration and is configured as a dimension attribute.
The threshold can be specified per dimension and can be configured to any initial value. The default value is 10 percent of the BitSize cardinality for a particular dimension. This value helps determine what approach you need to take:
Increase the address space of a dimension after reindexing the dimension arrays
Compress the domain arrays without increasing the BitSize
Both
L is the maximum utilized logical ID, which is the logical ID value of the last position in a dimension. The domain sequence generator displays this number, which is incremented as new positions are added to the dimension.
For example, if you have a dimension with the following characteristics:
C: Dimension or BitSize Cardinality for the dimension: 16 (where Bitsize is 4)
M: Maximum Utilized Position IDs: 9
Thresh: Threshold: 10
L: Maximum Utilized Logical ID: 4
The calculation produces the following:
(C-M) < Thresh
(16 - 9) < 10
7 < 10
Since 7 (the number of available position IDs) is less than 10 (the threshold of required available position IDs), the report returns a a message that states the dimension needs to be defragmented.
RPAS also checks the C - L > or < Thresh condition. If C - L > Thresh, then the report returns a message that states not to increase the BitSize, but to defragment the dimension to recover unused address space. In the example above, C - L (16 - 4 =12) is less than the threshold (10). Therefore, the available address space is sufficient after the dimension is defragmented.
If you have a dimension with the following characteristics:
C: Dimension or BitSize Cardinality for the dimension: 16 (where Bitsize is 4)
M: Maximum Utilized Position IDs: 9
Thresh: Threshold: 10
L: Maximum Utilized Logical ID: 7
The calculation produces the following:
(C-M) < Thresh
(16-9) < 10
7 < 10
(C-L) < Thresh
(16-7) < 10
9 < 10
Since 9 is less than 10, the report returns a message that states that defragmenting alone will not help, but that a BitSize increase is required to create additional address space.
Before calculating this equation, RPAS validates the inputs. The main inputs to this utility are the domain path, hierarchy names, and dimension names. Validation logic checks the syntax of the command and verifies all inputs
Three reports that you can run with the reindexDomain can help you determine if you should reindex your domain. Depending on the results of these reports, RPAS may recommend that you need to reindex the dimension, that you need to increase its bit size and then reindex, or that you do not need to do either of these because the cost of reindexing outweighs the benefit. To find out which one of these is the case, run the following commands:
This command analyzes one or more dimensions to check whether reindexing is necessary. You can use either the -hier argument or the -dimspec argument.
If the -hier argument is used, the command analyzes all dimensions in the specified hierarchy to check whether reindexing is necessary:
reindexDomain -d [domainPath] -analyze -hier [hierName]
If the -dimspec argument is used, the command analyzes all the dimensions in the CSV list to check whether reindexing is necessary:
reindexDomain -d [domainPath] -analyze -dimSpec [comma seperated dim names]
The command returns the reindexing details. The following is an example of the returned details:
Dim Name : splr DimRegistry BitSize: 8 DimInfo BitSize: 8 Capacity (C): 256 MaxPhyId (M): 3 MaxLogId (L): 3 Threshold: (T): 25 Action Required : No action required for this dimension at this stage
To see the DimRegistry version and reindex status, run the following argument:
reindexDomain -d [domainPath] -prop
It returns details about the following two domain properties:
dimregistry_version reindex_in_progress
These two domain properties can be set using the domainprop utility. But when reindexDomain is run, these two properties are set automatically. Therefore, there is no need to set them separately unless you want to see their values before using the reindexDomain utility.
dimregistry_version: This domain property stores the current version number of the dim registry. A dim registry defines the version of the indexes. The version number is reset with a new value when reindexing is performed. For instance, if SKU123's index is 15, but then reindexing causes that same SKU to be at index 2, then the dimregistry_version is incremented. The new version is created and stored in the domain at the same level as the previous version. Each version can be identified physically as it is named after its version number. The path up to the version is the same across all versions so that data can be processed from one version to another.
reindex_in_progress: This domain property stores the status of the last run reindex process. It is set to TRUE when the reindexing starts and to FALSE when it successfully completes. When the process aborts in the middle, the status remains TRUE to indicate that reindexing needs to be restarted. As long as the status is TRUE, the domain cannot be used for any purpose other than reindexing.
|
Note: After the reindexing process starts, the domain must not be used for any other purpose until the process finishes successfully. If the process aborts in the middle, then the reindexing process must be restarted and completed successfully.Only an administrator should run this utility. |
The sections below describe the various scenarios and steps needed for reindexing.
This checks whether the reindex condition is met by at least one dimension in the domain. If so, the reindexDomain utility stops further checks and reindexes the entire domain. If reindex condition is not met by any of the dimensions, the utility exits.
It is recommended that you do not reindex the entire domain. Instead, you should reindex on a hierarchy-by-hierarchy or dimension-by-dimension basis.
reindexDomain -d <domainPath>
By using the reindexDomain with the -force option, you can reindex the entire domain. The -force option overrides the logic that checks whether reindexing is necessary and reindexes the entire domain.
reindexDomain -d <domainPath> -force
Reindexes one or more dimensions. Use either the -hier argument or the -dimSpec argument
When used with the -dimSpec argument, the utility reindexes only those dimensions in the CSV list that meet the reindex condition. If listing more than one dimension, use commas to separate them.
reindexDomain -d <domainPath> -dimSpec <comma seperated dim names>
When used with -hier argument, if at least one dimension in the hierarchy meets the reindex condition, the utility reindexes all the dimensions in the specified hierarchy.
reindexDomain -d <domainPath> -hier <hierName>
|
Note: You can use the-force option with both the -hier and the -dimSpec arguments. |
This is a unique case where you need to add calendar positions before the current start of the calendar. This scenario must be handled differently from scenarios where you add calendar positions at the end of the calendar. This is because the DimRegistry for calendar dimensions must make space at the beginning for the new positions to be added. Here is what happens during the process of prepending positions to calendar dimensions:
The loadHier utility detects during its first run that clnd.dat has positions to be prepended. It generates an XML file (clndPrepend.xml) that contains the dimensions to be prepended and the number of new positions to be prepended for each dimension. The loadHier utility then displays an error message, stating that the reindexDomain utility must be run first before prepending the calendar dimensions.
Here is an example of the clndPrepend.xml file:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?> - <clnd> - <prepend> <dimension>day</dimension> <prependsize>1457</prependsize> </prepend> - <prepend> <dimension>mnth</dimension> <prependsize>48</prependsize> </prepend> - <prepend> <dimension>qrtr</dimension> <prependsize>16</prependsize> </prepend> - <prepend> <dimension>ssn</dimension> <prependsize>8</prependsize> </prepend> - <prepend> <dimension>week</dimension> <prependsize>208</prependsize> </prepend> - <prepend> <dimension>year</dimension> <prependsize>4</prependsize> </prepend> </clnd>
The reindexDomain utility is run with syntax added specifically for prepending calendar dimensions:
reindexDomain -d <domainPath> -hier CLND -prepend
The reindexDomain domain reads the clndPrepend.xml file and creates a new version of the DimRegistry with space allocated to prepend the calendar dimensions by shifting the physical IDs by an offset equal to the number of new positions. The reindexDomain utility then reindexes all the arrays in the domain that have these calendar dimensions.
After running reindexDomain, run the loadHier utility again to complete the process of prepending the calendar dimensions. During both the first and second runs of loadHier, the loadHier utility checks whether calendar dimensions are ready to be prepended or not. The DimRegistry interface is modified to verify this condition.
If you want to avoid using loadHier for generating the clndPrepend.xml file, then you can manually generate the file and place it under the domain root. Ensure that you use the same syntax as the one loadHier generates, as shown in the previous example.
This table does not contain a comprehensive list of scenarios that can occur. It only lists some examples of the reindexDomain functionality.
Table 7-9 Change of Bit Size Scenarios
| Scenario | Utility Option | Result |
|---|---|---|
|
Increase/Decrease Bit Size for SKU dimension |
- |
Reindexes SKU dimension and create a new dimRegistry version. |
|
Increase/Decrease Bit Size for SKU and Store dimensions |
|
Reindexes SKU and Store dimensions only. The Class dimension does not meet any reindex condition. A new dimRegistry version is created. |
|
Increase/Decrease Bit Size for SKU dimension |
- |
Reindexes all dimensions in the product hierarchy and creates a new dimRegistry version. For SKU dimension, the bit size change is applied to the dimension and measures. |
|
Increase/Decrease Bit Size for SKU |
|
Reindexes all the dimensions in the entire domain and creates a new dimRegistry version. For the SKU dimension, the bit size change is applied to the dimension and measures. |
Table 7-10 -force Option Scenarios
| Scenario | Utility Option | Result |
|---|---|---|
|
No bit size change or any fragmentation |
|
Reindexes the SKU dimension and creates a new dimRegistry version. |
|
Bit size change for SKU, fragmentation in CLSS, no fragmentation in STR |
|
Reindexes by changing the bit size for the SKU dimension and defragmenting CLSS and STR. Creates a new version of dimRegistry. |
|
Bit size change for SKU and fragmentation in CLSS and STR |
|
Reindexes all dimensions in the product hierarchy and creates a new dimRegistry version. SKU dimension has bit size change applied. STR dimension and location hierarchy are not affected. |
|
Bit size change for SKU, fragmentation in CLSS, no fragmentation in STR |
|
Reindexes all the dimensions in the entire domain and creates a new dimRegistry version. For the SKU dimension, the bit size change is applied to the dimension and measures. |
Table 7-11 Fragmentation Check Scenarios
| Scenario | Utility Option | Result |
|---|---|---|
|
Fragmentation in SKU dimension but does not meet reindex condition. In this case, |
|
Nothing happens. |
|
Fragmentation in SKU dim - does not meet the reindex condition (here |
|
Only the STR dimension will get reindexed. A new dimRegistry version is created. |
|
Fragmentation in SKU dimension but does not meet reindex condition. In this case, |
|
Nothing happens. |
|
Fragmentation in SKU, CLSS and STR but none meet reindex condition. In this case, all three have |
|
Nothing happens. |
|
Fragmentation in SKU dimension where |
|
Reindexes the SKU dimension and creates a new dimRegistry version. This condition means that there is fragmentation in the SKU dimension over the threshold and defragmenting can generate enough address space to resolve the initial reindex condition of |
|
Fragmentation in SKU dimension with |
|
Only the SKU dimension is reindexed. A new dimRegistry version is created. |
|
Fragmentation in CLSS dimension with |
|
All dimensions in the product hierarchy are reindexed. A new dimRegistry version is created. |
|
Fragmentation in both the SKU and STR dimensions. Both dimensions have |
|
All dimensions in the product hierarchy are reindexed. Nothing happens in the location hierarchy or to the STR dimension. A new dimRegistry version is created. |
|
Fragmentation in the STR dimension with |
|
All dimensions in the entire domain are reindexed. A new dimRegistry version is created. |
|
Fragmentation in the SKU dimension with |
|
No reindexing of SKU takes place as it does not resolve the issue since a bit size increase is needed. A message is provided through the utility indicating a bit size increase is required. |
|
Fragmentation in the SKU dimension with |
|
No reindexing takes place on either SKU or STR. SKU requires a bit size increase. A message is provided through the utility indicating a bit size increase for SKU is required. |
|
Fragmentation of all dimensions in the product hierarchy were |
|
No reindexing, but a message is provided through the utility, stating that all dimensions in the product hierarchy need an increase in bit size. |
|
Fragmentation for the SKU and STR dimension where both have |
|
No reindexing, but a message is provided through the utility, stating that the SKU and STR dimensions need an increase in bit size. |
Because the RPAS Btree dimension arrays undergo continuous updates and changes as a result of adding and deleting existing positions, over time, measure arrays become full of stale data. This stale data is created when positions are deleted, but the associated index remains. This results in wasted space and inefficient operations. The measure arrays containing any data for these positions should be updated to reflect these deletions. Deleting positions marks the hierarchy data for the corresponding dimensions as changed, but it does not clean up the associated data from the measure arrays. The optimizeDomain utility cleans this stale data from the measure arrays.
When this utility is run in a global domain environment, it is centrally administrated. This means it runs over the master domain and spawns parallel processes over the local domains.
For example, consider a measure called meas1 that exists at intersection sku_str_week. When a user adds a DPM position skudpm1 through an RPAS client, it is assigned to an integer index in the meas1 data array in addition to being assigned within the dimension's array. When this DPM position is deleted, the position is flagged as inactive, but the integer index cannot be reused until the dimension is reindexed. The measure array also still contains the data associated with the inactive position. This measure array needs to be updated too in order to remove the stale data.
|
Note: The reindex process cleans data, but there are times when a reindex is not needed but data needs to be cleaned. That is when optimizeDomain should be run. |
The same also holds true for formal positions that are purged during a normal hierarchy patch. The measures arrays need to be updated for this set of positions because they may be pointing to stale data too.
Another issue is that, over time, existing arrays in RPAS databases may become fragmented, resulting in wasted space and a possible degradation in efficiency on array operations. This occurs because the RPAS Btree array stores data in chunks of disk memory called pages. Deleting data from the array causes empty spaces or holes to develop in these pages. These holes contain no data, yet they still increase the overall size of the array. Over time, these holes become larger and more frequent, and array operations suffer degraded performance as a result. Also, the pages begin to acquire large amounts of unused space, causing an inefficient disk usage and a larger than optimal domain size.
|
Notes: While reclassifying a position from one subdomain to another, data associated with the reclassified positions is moved to the new subdomain. But it is also cleaned from the source subdomain. Therefore, the reclass operation in loadHier does not cause stale data.No matter what option is specified, when an array is picked to be processed by optimizeDomain, that array is both cleaned and defragmented after a successful run. |
The optimizeDomain utility is used to correct these two issues. It is recommended that after a full hierarchy purge you run the optimizeDomain utility with the
-cleanOnly argument to remove all stale data from the domain.
optimizeDomain -d [domainpath] [options]
Table 7-12 provides descriptions of the arguments used by the optimizeDomain utility.
Table 7-12 optimizeDomain Usage
| Argument | Description |
|---|---|
|
|
Defines the path to the domain that you want to optimize. If no options are specified, by default, optimizeDomain defragmentss and cleans the entire measure set that have arrays that have a BTree density ratio lower than the threshold (80%). A BTree density ratio is the ratio of the populated positions in the array to the total available BTree pages in the array. The density threshold value (80%) is not configured. |
|
|
Selectively defragments the domain data based on database fragmentation. Note: |
|
|
Cleans the stale data in the domain. Note: |
|
|
Forces the utility to defragment the entire measure arrays set. This must be used in combination with the |
|
|
Defines the path to exclude list XML file. Optimize performance by excluding this list of measures while defragmenting or cleaning. This option cannot be used with |
|
|
Defines the path to include list XML file. Optimize performance by including only this list of measures while defragmenting or cleaning. This option cannot be used with |
|
|
Returns a non-zero value if any of the databases or arrays fail to defragment or clean. The optimizeDomain process still runs to completion. The default behavior is to log a warning and continue. |
|
|
Defines the maximum number of processes to run in parallel. |
In this example, the measures list and corresponding BTree density ratios. SKU dimension have some positions purged from the domain and marked for cleaning.
Table 7-13 SKU Positions Purged
| Meas1 | Meas2 | Meas3 | Meas4 | |
|---|---|---|---|---|
|
Base Intersection |
SKU |
SKU |
STR |
STR |
|
Density Ratio |
60% |
90% |
60% |
90% |
Here is the list of measures that are processed based on the specified command.
Table 7-14 Processed Measures
| Meas1 | Meas2 | Meas3 | Meas4 | |
|---|---|---|---|---|
|
No specified options |
X |
X |
X |
|
|
-includeMeas List Meas1, Meas3, Meas4 |
X |
X |
||
|
-excludeMeasList Meas1,Meas3 |
X |
|||
|
-defragOnly |
X |
X |
||
|
-cleanOnly |
X |
X |
||
|
-defragOnly -force or -force |
X |
X |
X |
X |
|
-defragOnly -includeMeasList Meas1,Meas4 |
X |
|||
|
-defragOnly -excludeMeasList Meas1 |
X |
|||
|
-cleanOnly -includeMeasList Meas1,Meas4 |
X |
|||
|
-cleanOnly - excludeMeasList Meas1 |
X |
Using the RPAS Configuration Tools and RPAS utilities, you can add new dimensions to hierarchies in existing domains. This process is described at a high level in this section. Each step is described in greater detail in the following sections.
|
Caution: Due to its invasive impact, adding new dimensions is different from the normal domain patch process. It is a multi-step process and requires careful user intervention. |
To add new dimensions to an existing hierarchy, use the Configuration Tools to open and modify the existing configuration so that the new configuration includes the additional dimensions.
|
Note: This process can be used only for non-partitioned hierarchies. It cannot be used to delete dimensions. |
After the configuration has been modified, use the Reports Generator in the Configuration Tools to generate a hierarchy.xml report. For more information about creating this report, see the "Report Generator" section in the Oracle Retail Predictive Application Server Configuration Tools User Guide.
Export measure data for all measures that have one of the dimensions of the modifying hierarchies. See "Exporting Measure Data".
Export all hierarchy data from the hierarchy, including all DPM positions and user-defined dimension rollup information. Repeat this step for each hierarchy being modified. See "Exporting Hierarchy Data".
Purge all positions from the hierarchies. See "Purging Hierarchy Data".
Use the hierarchyMgr utility with the new hierarchy.xml to add the new dimensions. Repeat this step for each hierarchy being modified. See "Adding New Dimensions".
Create a new data file, or update the old one, to contain positions for the newly added dimensions. Load it back to the domain. If the original hierarchy contains user-defined dimensions, the format of the data file must be in CSV format with a header line indicating all user-defined dimension position and label columns and using the -includeUdd switch. Perform one execution for each modified hierarchy. See "Reloading Formal Hierarchy Data".
Optional: Informalize previous DPM positions. See "Informalizing DPM Positions".
Reload measure data to the domain. See "Reloading Measure Data".
Use the exportMeasure utility to export all measures for hierarchies. It exports only measures that have storage in the domain (db property).
exportMeasure -d [domain path] -hier [hierarchy1, hierarchy2] -outDir [outputDirectory]
To enter multiple hierarchies, separate them with commas, for example, -hier loc,clnd. This exports all hierarchy measures that have storage in the domain.
If the output directory that you specify does not exist, it will be created. One output file is created for each HBI (higher based intersection) measure. (In a global domain, the HBI measures are stored in the master domain because the measure's base intersection is above the partition dimension. Forced non-HBI measures are measures that should be HBI measures and stored in the master domain, but the RPAS application has forced these measures to be stored across the local domains.) In addition, one file is created for each non-HBI or FnHBI measure per subdomain. The file names contain an internal subdomain index, for example, sales.0.csv.rpl, sales.1.csv.rpl, and so on.
For more information about exportMeasure, see "Exporting Measure Data Using exportMeasure".
Use the exportHier utility to include user-defined dimensions. Export each hierarchy individually.
exportHier -d [domain path] -hier [hierarchy] -datFile [datFile] -udd [-listInformal fileName]
Use the -udd argument to export the user-defined definitions. The -udd argument can only be used with the -onlyFormal or -onlyInformal options. It cannot be used with -fixedWidth option. User-defined dimensions can only be exported in CSV format.
If the -listInformal argument is used, exportHier also creates a file with the fileName, which contains a list of informal positions in the domain in a format that can be used by the informalPositionMgr. This option cannot be used with the -onlyFormal option.
For more information about exportHier, see "Exporting Hierarchy Data Using exportHier".
Use the loadHier utility with the -purgeAll argument to purge the hierarchy data. The -purgeAll argument purges formal, informal, and user-defined positions in the listed hierarchies. It cannot be used on a partition hierarchy or any system hierarchy.
loadHier -d [domain path] -purgeAll [hierarchy1,hierarchy2]
Use the -purgeAll argument to purge hierarchies. Specify multiple hierarchies by using CSV format (-purgeAll loc,clnd). For more information about loadHier, see "Loading Hierarchies Using loadHier".
Use the hierarchyMgr utility to add new dimensions. The hierarchyMgr utility parses the hierarchy.xml file and determines where to add the new dimensions. All start and width properties of all dimensions in the hierarchy are refreshed to be consistent with the new hierarchy.xml.
hierarchyMgr -d [domain path] -h [hierName] -addLevels hierarchy.xml
One or more dimensions can be added to any existing hierarchy except for partitioned or system hierarchies. Only one hierarchy can be parsed at a time. The original meta, hmaint, and language databases are backed up and can be restored if a failure occurs.
|
Note:
|
Use loadHier to load the hierarchy that was purged. The user-defined dimensions included in the input hierarchy file are also loaded.
loadHier -d [domain path] -load [hierarchy] [-includeUdd]
or
loadHier -d [domain path] -loadAll [-includeUdd]
Use the -load argument to load one hierarchy at a time. Use the -loadAll argument to load all hierarchies that have an input file in the input directory of the domain.
Use the -includeUdd argument to load user-defined positions back to the domain. The data file must be in CSV format with a header line. The name of the data file should follow the current standard: <hierarchy name>.csv.dat.
All user-defined dimensions must be in the data file. Any missing user-defined dimensions can cause an error. All loaded positions are in formal status. See the "Informalizing DPM Positions" section for information on how to convert the status of previous DPM positions to informal.
For more information about loadHier, see "Loading Hierarchies Using loadHier".
Use informalPositionMgr to informalize DPM positions.
informalPositionMgr -d domainPath -hier hierName -operation informalize -file inputFile
Use the -file argument to enter the input file to be processed. The inputFile is the list file exported by exportHier with -listInformal.
For more information, see "Informal Position Manager".
Use loadmeasure to load all measure files located in the specified input directory.
loadmeasure -d [domain path] -inDir [inputDirectory]
Only .rpl files can be used with this option, and only the CSV format with a header line is supported. The exported files have one measure per file.
For more information, see "Loading Measure Data Using loadmeasure".
Here is an example of a script that adds new hierarchy dimensions.
#!/bin/ksh
# ----------------------------------------------------------------------------
#
# This is a sample script demostrates different steps to add levels to an
# existing domain
#
# ----------------------------------------------------------------------------
DOMPATH=$TEST_GLOBAL_DOMAIN
# Need to be full path.
MEAS_STORAGE_DIR="C:/tak/patchHierScript/measdata"
OLD_HIER_DATA_DIR="c:/tak/patchHierScript/oldhier"
NEW_HIER_DATA_DIR="c:/tak/patchHierScript/newhier"
# can be comma separated list. If multiple is intended, exportHier, hierarchyMgr,
# and loadHier needs to be called in a loop.
# ex. HIERS="loc,clnd"
HIERS="loc"
mkdir -p $MEAS_STORAGE_DIR
mkdir -p $OLD_HIER_DATA_DIR
# Inside NEW_HIER_DATA_DIR, there should be new hierarchy xml file and new hierarchy data file.
IFS=","
# ----------------------------------------------------------------------------
# Step one, export all positions.
# ----------------------------------------------------------------------------
exportMeasure -d $DOMPATH -hier $HIERS -outDir $MEAS_STORAGE_DIR
if [ $? -ne 0 ]; then
echo "exportMeasure for exporing $HIERS hierarchy"
exit 1
fi
# ----------------------------------------------------------------------------
# Step two, export all hierarchy data and informal position list. One hierarchy
# at a time.
# ----------------------------------------------------------------------------
for h in "$HIERS"; do
exportHier -d $DOMPATH -hier $h -datFile $OLD_HIER_DATA_DIR/$h.csv.dat -udd -listInformal $OLD_HIER_DATA_DIR/$h.informal.lst
if [ $? -ne 0 ]; then
echo "exportHier failed for $h"
exit 2
fi
done
# ---------------------------------------------------------------------------
# Step 3, purge the hierarchies.
# ---------------------------------------------------------------------------
loadHier -d $DOMPATH -purgeAll $HIERS
if [ $? -ne 0 ]; then
echo "Unable to purge $HIERS."
exit 3
fi
# BEGIN MODIFICATION and DATA LOADING.
# ---------------------------------------------------------------------------
# Step 4, patch the hierarchy (add levels) one hierarchy at a time.
# ---------------------------------------------------------------------------
for h in $HIERS; do
hierarchyMgr -d $DOMPATH -h $h -addLevels $NEW_HIER_DATA_DIR/hierarchy.xml
if [ $? -ne 0 ]; then
echo "hierarchMgr failed for $h"
exit 4
fi
done
# --------------------------------------------------------------------------
# Step 5, Load the hierarchy data back. The structure reflect the
# new hierarchy structure.
#
# NOTE 1:
# Data should be updated to include positions of the newly added dimensions
#
# NOTE 2:
# Even though reclass is supported by loadHier, measure data is going
# to be loaded assuming old position is still in the original subdomain.
# Position reclassification is not recommended and may cause measure data lost.
# --------------------------------------------------------------------------
for h in $HIERS; do
# copy the data file to input directory of the domain
cp $NEW_HIER_DATA_DIR/$h.csv.dat $DOMPATH/input/
loadHier -d $DOMPATH -load $h -includeUdd
if [ $? -ne 0 ]; then
echo "loadHier failed while loading $h hierarchy"
exit 5
fi
done
# --------------------------------------------------------------------------
# Step 6, Set the previously DPM position back to DPM
# --------------------------------------------------------------------------
for h in $HIERS; do
informalPositionMgr -d $DOMPATH -hier $h -file $OLD_HIER_DATA_DIR/$h.informal.lst -operation informalize
if [ $? -ne 0 ]; then
echo "informalPositionMgr failed while informalizing positions in $h hierarchy"
exit 6
fi
done
#
# --------------------------------------------------------------------------
# Step 7, load measure data that exported with exportMeasure back to the
# domain.
# --------------------------------------------------------------------------
loadmeasure -d $DOMPATH -inDir $MEAS_STORAGE_DIR
if [ $? -ne 0 ]; then
echo "Unable to purge load measure data in $MEAS_STORAGE_DIR. Please check the logs in output directory"
exit 7
fi
# Completed
The transferData utility allows you to load measure data into one domain by using a second domain as the data source. While this can be achieved with the exportMeasure and loadmeasure utilities, the transferData utility is more efficient since it uses a single process to load a data file into the destination domain.
The transferData utility works by copying the source measure data to the destination measure data along any matching external position names between the source and destination measures. This includes any informal positions that have matching names in the destination. You can choose to exclude informal positions' data from being copied to the destination if you want.
|
Note: You cannot use the transferData utility for forced non-HBI (higher based intersection) measures. Forced non-HBI measures are measures that should be HBI measures and stored in the master domain, but the RPAS application has forced these measures to be stored across the local domains. For these measures, you must transfer data using export and import utilities as described in "Adding New Dimensions to Hierarchies". |
The measure names do not need to be identical in both domains. However, the source and destination measures must conform in intersection and data type.
The measures to be transferred are identified with the -measMap argument. The format of the argument is a colon-separated list of source measure name, destination measure name, and an optional mask measure name:
src1:dest1[:mask1]
Multiple measure groups can be specified in pairings if separated by a comma:
src1:dest1[:mask1],src2:dest2[:mask2]
For a complete example, see "transferData Usage".
The transferData utility can run in parallel when the destination domain is a global domain. The -processes argument determines how many child processes to spawn to perform the processing. This makes the transferData task faster when used in a global domain destination.
The transferData utility validates several components before transferring data. It validates that the source and destination domains exist, that the source and destination measures exist, and that the source and destination measures have conforming intersections and data types.
After it has validated everything, the transferData utility opens the source measure in read mode and opens the destination measure in write mode; this prevents data integrity issues. It iterates over positions in the source measure, pulls the values, and writes them to the destination measure.
The transferData utility cannot be used to transfer the data of a measure shared through a RPAS Data Mart. If transferData is called on a shared measure, transferData will exit with an error message identifying the shared measure.
See the section on transferFactData for information on transferring the content of a shared measure between a domain and a RPAS Data Mart.
You can use a mask measure to restrict the transfer of a range of positions from the source measure. This mask measure is a boolean measure, located in the source domain, that is at the same intersection of the source/destination measure pair or higher than that intersection.
|
Note: It should be noted that the mask measure should have an NA value of FALSE for optimal performance. The transferData utility will stop and inform the user if this is not the case. |
In addition, you can use the -clearDest flag with or without a mask option. These combinations are described as follows:
Clears the destination arrays. Changes the destination array's NA value to the source measure's NA value at the beginning of the process. Loops over the source arrays and populates the destination.
Does not clear the destination arrays. Does not change the destination array's NA value. Loops over the source arrays and copies to the corresponding destination.
Does not clear the destination arrays. Does not change the destination array's NA value. Loops over the mask and copies the source values (populated or unpopulated) to the corresponding destination cells.
Does not clear the destination arrays. Does not change the destination array NA value. Loops over the mask and copies the populated source values to the corresponding destination cells. It does not copy unpopulated source values.
Table 7-15 illustrates the results of the mask and flag combinations.
Table 7-15 Mask and Flag Combinations and Outcomes
| No Mask, -clearDest Flag | No Mask, No Flag | Mask, -clearDest Flag | Mask, No Flag | |
|---|---|---|---|---|
|
Clears destination arrays |
Yes |
No |
No |
No |
|
Changes the destination array's NA value to the source measure's NA value |
Yes |
No |
No |
No |
|
Populates the destination arrays |
Yes |
Yes |
Yes, populated and unpopulated source values |
Yes, only populated source values |
transferdata -d destDomain -src srcDomain -measMap "src1:dest1[:mask1],src2:dest2[:mask2]" {-processes n} {-clearDest} {-noInformal}
Table 7-16 provides descriptions of the arguments used by the transferData utility.
Table 7-16 transferData Utility Arguments
| Argument | Description |
|---|---|
|
-d pathToDestDomain |
Specifies the path to the domain containing the destination measure. This is required. |
|
-src pathToSrcDomain |
Specifies the path to the domain containing the source measure. This is required. |
|
-measMap |
Indicates the comma-separated list of source to destination to mask mappings (src:dest:[:mask]), where src is the name of the measure to be copied from the source domain, dest is the name of the measure to be written to in the destination domain, and mask is the name of the mask measure to be used, if any. A one-to-one relationship must exist between source measures and destination measures. |
|
-processes max |
Defines the maximum number of processes to run in parallel in a global domain setup. |
|
-clearDest |
When used with a mask option, ensures that the destination measures array is not cleared and its NA value is not changed. The utility copies the populated and unpopulated data from the source measure positions that are populated in the mask. When used without a mask option, the transferData utility clears the destination arrays and changes the destination array's NA value to the source NA value at the beginning of the process. After that, the populated measure positions from the source array |
|
-noInformal |
Ensures that only formal positions that have a matching external name in the destination measure are copied over. |
The following sections describe the four scenarios for using the transferData utility.
When the source and destination domains are simple domains, the data is copied from the source domain to the destination domain.
When the source is a simple domain and the destination is a global domain, and the destination measure is a non-HBI measure, then the data is copied to the local domains of the destination. HBI measure data is copied to the master domain. Since the destination domain is a global domain, the data is transferred in parallel.
When the source is a global domain, for non-HBI measures, the subdomain data array is copied to the destination. HBI measure data is copied from the master domain to the destination domain.
Since the destination domain is a global domain, the data is transferred in parallel. However, each subprocess visits each source subdomain when transferring a non-HBI measure. This means that you do not have to run transferData over each local domain, but only on the master domain once.
Global-to-global transferring follows this process:
The transferData utility maps the source's external position names to the destination's external position names.
The utility scans the source.
The utility writes the values into the destination measure.
The transferData utility always runs in parallel when the destination domain is a global domain and the -processes option is set to a number greater than 1. When the source domain is a global domain and the source measure is a non-HBI measure, every subprocess running on each local domain of the destination domain visits every local domain on the source, even when the source local domain has no common position with that particular destination local domain. However, if there is no common position, the subprocesses visits should occur quickly.
Sometimes, a retailer has a master file of hierarchy data that needs to be loaded into multiple domains. Some of these domains may be missing one or more levels from the master hierarchy, mostly because the planning levels in these domains are higher than the lowest level in the master and the domains do not need to have all the lower levels. For example, a retailer may have one domain for Merchandise Financial Planning where the lowest level is Category and another for Item Planning where the lowest level is Item. The hierarchies in these two domains have their relevant hierarchy load data in one master file, but using loadhier, the retailer cannot load just what is relevant to the domain from the master. System integrators need to write custom scripts to parse out irrelevant columns from the master file to prepare load files suited for individual domains.
The filterHier utility does the filtering of columns for the system integrators so that they do not need to write custom scripts. The utility analyzes the target domain and trims down the master file to only those columns that are needed by the target domain. The utility acts on CSV formatted files and requires the input file to contain a header line containing the names of the columns, for example, SKU,SKU_label,STCO,STCO_label. The output of the utility is a .csv.dat file that can be subsequently used by the loadHier utility.
filterHier -d domainPath -input inputPath [COMMAND] {OPTIONS}
Table 7-17 provides descriptions of the arguments used by the filterHier utility.
Table 7-17 filterHier Utility Arguments
| Argument | Description |
|---|---|
|
-d domainPath |
Indicates the domain in which to load the hierarchy data. |
|
-input inputpath |
Indicates the path to the folder where the master files are located. |
|
-filter hiername |
Filters the hierarchy named in the parameter to the command. |
|
-filterAll |
Filters all hierarchies in the input directory that are relevant to the target domain. |
|
-compress |
Creates a compressed .csv.dat output file.RPAS provides a simple, proprietary compression technique to help reduce the file size and file I/O time during loads. This technique simply replaces a column's value with a '?' character to indicate that the column's value for the row matches that of the row above. The compressed file continues to print out '?' characters for a column until a change is encountered.This kind of compression is useful for hierarchy files where the lowest level positions are grouped by the higher level positions. In such cases, the output file will print out '?' characters for higher level positions until a change is encountered, thus significantly reducing the file size.Note that compressed files should not be split up or reprocessed in ways that change the order of rows. |
This utility combines one or more input files into an output file that can be imported into the target domain using loadHier. The input files must be csv data containing a comma-separated header line listing the name of each column. Column names must be in the format DIM,DIM_label.
Example: SKU,SKU_label,STCO,STCO_label,SIZ1,SIZ1_label
The input files must have the extension .hdr.csv.dat. Optional extensions are allowed at the end of the file.
Example: prod.hdr.csv.dat.foo1
The columns in the output file are arranged to match the hierarchy format of the target domain. Any dimensions from the input files that are not present in the output domain are filtered out.
The output file is a properly formatted .csv.dat file, and is located in the input directory of the target domain.
The following error conditions may occur during the operation of filterHier:
Dimension Not Found: If a dimension that exists in the domain is not found in the header, the input file will be skipped.
No Usable Input Files: If filterHier cannot find a usable input file, it will exit with error.
Parse Error in Data: If one or more data rows contain an error, filterHier will display an error specifying which lines contain an error and continue processing the rest of the file.
Conflicting Base Positions: If a base position has multiple definitions in the input files, the first definition will be used and all others will be skipped.
Position repartitioning is the automated process of moving positions and all corresponding measure data between local domains. This functionality is only available (and relevant) in global domain environments. Positions must be moved between local domains when they are assigned a new parent that exists in a different local domain. Note that moving positions at the partitioning level is a manual process and requires the use of the reconfigGlobalDomainPartitions utility.
For example, imagine Style1 belongs to Sub-Class1 in LocalDomain1. If Style1 is reassigned to be a child of Sub-Class2, which is located in LocalDomain2, RPAS will move the Style1 position, Style1's children (if any), and all corresponding data to LocalDomain2. This process is often referred to as reclassification by RPAS customers. RPAS refers to this functionality as position repartitioning because it technically does not handle the many complex functional requirements of true reclassification as most retailers define the term to mean.
After repartitioning, default parameters for Curve and RDF are not automatically loaded in new subdomains. To load these parameters, the following scripts, which are located in the RPAS_HOME/bin directory, need to be executed:
loadCurveParameters.ksh: Used to load Curve parameters after a repartition.
loadRdfParameters.ksh: Used to load RDF parameters after a repartition.
These scripts are used to load RDF and Curve parameters to a subdomain created as a result of repartitioning. These parameters are usually loaded during a full installation by the plug-ins, but when performing a patchinstall, the parameters are not loaded by default. These parameters include default required method, default source, spreading profile, and others.
You must run these scripts after repartitioning a domain on the new partition.
It is common for many customers to regularly add, remove, or change the parent-child relationships for positions in hierarchies, most commonly for positions in the product hierarchy. While this movement and reassignment of positions is normally handled automatically within the loadHier utility, a special process must be followed for positions at the partition level of a global domain environment.
The RPAS utility reconfigGlobalDomainPartitions is used for the following activities in a global domain environment:
Adding a new position along the partition dimension and allocate it to an existing or new local domain.
Removing an existing position from the partition dimension.
Removing local domains (this is automatic if all partition-level positions in a local domain are removed or moved).
Moving an existing partition position from one local domain to an existing or new local domain.
Runs loadHier to apply the position addition or removal to the hierarchy.
|
Note: This utility can only be used on a master domain of a global domain set. |
The following processes must be followed to add, remove, or move positions at the partition level in a global domain environment:
The administrator must be notified in advance that positions at the partition level are being added, removed, or moved.
The administrator must run the utility reconfigGlobalDomainPartitions by specifying the subdomain to which the positions do or will belong.
This utility calls the loadHier utility at the end of the reconfiguration process to apply the hierarchy changes to the domain. When positions are added (using the
-add argument) an updated hierarchy file must be available in the input directory when the reconfigGlobalDomainPartitions utility is called. Otherwise the utility will fail. Updated hierarchy files are not required to remove (using the -remove argument) or move positions (using the -move argument).
|
Note: The use of this utility is only required for positions at the partition level. Positions below the partition level can be added, removed, or moved between local domains by loading a modified hierarchy input file with these changes. |
When operating on a domain integrated with an RPAS Data Mart, reconfigureGlobalDomainPartitions updates the ITT tables of the RDM to reflect the changes made as a result of its execution. Additionally, reconfigureGlobalDomainPartitions updates the RDM status tables to reflect the fact that a reconfigure operation is in progress. See the "Domain Integration and the RPAS Data Mart" section for more information on domain operations in an integrated environment.
reconfigGlobalDomainPartitions -d pathToMasterDomain -remove posName1, posName2, ... reconfigGlobalDomainPartitions -d pathToMasterDomain -add posName1,posName2, ... -sub pathToSubDomain reconfigGlobalDomainPartitions -d pathtoMasterDomain -move posName1,posName2, ... -sub pathToSubDomain reconfigGlobalDomainPartitions -d pathToMasterDomain -input pathToInputDir
Table 7-18 provides descriptions of the arguments used by the reconfigGlobalDomainPartitions utility.
Table 7-18 reconfigGlobalDomainPartitions Utility Arguments
| Argument | Description |
|---|---|
|
-d pathToMasterDomain |
Specifies the path to the master domain in a global domain environment. |
|
-add posName1, posName2, … |
Adds one or more positions at the partition level to a specified local domain. The path to the local domain must follow the list of positions to add, using the -sub argument. If the specified path is to a local domain that does not yet exist, the system will create a new local domain with the specified positions at the partition level. This argument cannot be used with -remove or -input. |
|
-remove posName1, posName2, ... |
Removes the designated positions from the local domain to which the positions belong. The path to the local domain does not need to be specified with this argument. The local domain will be deleted if all the positions at the partition level in a local domain are removed. This argument cannot be used with -add or -input. |
|
-move posName1, posName2, ... |
Moves the specified positions at the partition level from the current domain in which the positions are located to the specified local domain. This argument requires specification of the -sub argument. To move positions, all dimensions below the partition level must be enabled for dummy positions. |
|
-sub pathToSubDomain |
Specifies the path to the local domain to which positions are being added or the destination local domain for positions being moved. When a new domain path is specified using -sub option, a new local domain is created. This argument is required for the -add argument and -move argument. |
|
-input pathToInputDir |
Specifies the path to the input directory that contains an xml configuration file (reconfigpartdim.xml) to specify positions to either add or move. The file must have all the information to run the process including the command name, position names to add or move, and paths to the local domains. This option is useful for adding or moving positions to multiple local domains. This argument does not handle both adding and moving in the same call. This argument cannot be used with -add or -remove. |
|
-maxProcesses count |
If specified, some parts of reconfig utility will run in parallel, using up to the given number of processes. |
|
-forceInputRollups |
Prevents this utility from failing in instances where there is a rollup conflict in the input file provided to the utility. This argument enforces new hierarchy rollup changes so that they dominate existing hierarchy rollups in case they conflict with the rollups specified in the input file. |
When using the -input argument, the file must be in a particular format and must contain the add or move commands, the path to each local domain to which positions are being added or the destination for positions being moved, and the list of positions for each local domain. The file must be XML and named reconfigpartdim.xml.
|
Note: The -input argument only supports the addition or movement of positions. |
Here is the required format of the input file:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<rpas>
<command name="command_name">
<subdomain>
<subpath>path_to_local_domain_1</subpath>
<subpositions>sample_pos_1</subpositions>
</subdomain>
<subdomain>
<subpath>path_to_local_domain_2</subpath>
<subpositions>sample_pos_2,sample_pos_3</subpositions>
</subdomain>
</command>
</rpas>
|
Note: The entries in bold are the parameters that must be specified in the input file. |
Table 7-19 provides descriptions of the arguments used by the input file.
Table 7-19 Arguments Used by the input File
| Argument | Description |
|---|---|
|
command_name |
Valid values are add or move. |
|
path_to_local_domain |
Indicates the path to the local domain to which positions are added or moved. |
|
sample_pos |
Indicates one or more positions that are being added or moved to the designated local domains. |
Note the following:
Position names are separated by commas and must be valid external position names without the prefix of a dimension (for example, 0102,0144,0152,0160).
The utility backs up the required data and automatically restores the domains to the original state in case of failure.
In a single call to the utility without using the -input argument, positions can only be added or removed or moved. That is, the -add, -remove, and -move arguments cannot be mixed in the same call.
Multiple positions can be added or moved to a single local domain in a single call to the utility using the -add or -move option, respectively.
Multiple positions can be added or moved to multiple local domains in a single call to the utility using the -input option.
When positions are added at the partition level, an updated hierarchy file must be available in the input directory when running this utility as the loadhier utility is called after adding positions. If the updated hierarchy file is not present in the input directory when attempting to add positions, the utility will fail.
No updated hierarchy file is required when moving or removing positions. If a hierarchy file is in the input directory, the utility will back up this file.
RPAS provides the ability to change the name of a position using an RPAS utility named renamePositions. Positions that are to be renamed should be included in a hierarchy data file. After the hierarchy data files have been updated and placed in the designated location, an administrator must run the renamePositions utility.
|
Note: The renamePositions utility cannot be used to rename any RPAS system objects such as dimensions, workbooks, hierarchies, and so on. |
When executing on a domain that shares data through an RPAS Data Mart, it may be necessary to run rename positions on all domains interacting with the RPAS Data Mart. If the call to renamePositions affects positions used in sharing data between domains, all domains must be updated by renamePositions using the same input file to reflect the change in position names.
When renaming:
Positions of on-shared dimensions, run only on domain in question.
Informal positions of shared dimensions, run only on domain in question.
Formal positions of shared dimensions, run on all domains using the dimension in question.
renamePositions -d domainPath -hier hierName {-input inputDirectory} {-log logFileName} {-dryRun}
The renamePositions utility renames positions in a specified hierarchy. It looks for a file named hierName.rn.dat (for example, prod.rn.dat) in the domain's input directory when -input is not specified.
The input file is a CSV text file with three columns. Tab-delimited fields are not supported in the input file. This is consistent with other domain utilities in which tab-delimited fields are not supported. One line is required per rename request. Each line consists of a dimension name, the old position name, and a new position name. For example:
sku,10000_old,10000_new
The utility ignores any line not formatted this way, empty lines, and lines with a specified dimension that does not exist for the specified hierarchy.
The input file is not case sensitive, and all names are converted to lower case before the positions are renamed. Old position names that are specified but that do not actually exist are ignored. New position names cannot be names that are already in use. Lines with invalid position names are ignored and added to the log file. The old position name and new position name should not be prefixed with the name of the dimension.
The width property of the dimension is enforced. The width attribute in the domain must be greater than or equal to the maximum length of the new names in the input file. If the width of the new name is greater than the width attribute of the corresponding dimension, RPAS prints an error in the log file and ignores the record.
Dimensions specified in the input file should belong to the hierarchy that is specified in arguments. Otherwise, the record is ignored, and RPAS prints an error in the log file.
|
Note: If you want to swap position names (a->b, b->a), then you must perform these two separate operations: (a->tempa,b->tempb) and (tempa->b, tempb->a). |
Table 7-20 provides descriptions of the arguments used by the renamePositions utility.
Table 7-20 Arguments Used by the renamePositions Utility
| Argument | Description |
|---|---|
|
-d domainPath |
Specifies the full path to the domain. |
|
-hier hierName |
Specifies the hierarchy in which positions are being renamed. |
|
-input inputDirectory |
Specifies the input directory where the input file with positions to rename is located. Optional. Utility looks for hierarchy data files with "rn" between hierarchy name and .dat extension (for instance, prod.rn.dat). |
|
-log logFileName |
Generates a log file to file name other than default. The default file name is hierRename.log. Optional. This argument can be used to name the log file other than the default, which is created as hierRename.log in the current directory. |
|
-dryRun |
Does not apply changes, but generates a report that identifies changes that would be applied. This argument generates a log file. |
The dattrmgr utility is a command-line utility used to manage the dimension attributes in a domain including both static and dynamic attributes. It can be run only on the master domain or simple domains. This utility provides the user the option to register new dimension attributes or unregister dimension attributes that are already registered in the domain. There is also a report option to list out all the static and dynamic dimension attributes that are present in a domain. The report option also prints out the saved split definitions and workbooks where the dimension attributes are used.
dattrmgr -d pathToDomain [COMMAND [OPTIONS]]
Table 7-21 provides descriptions of the arguments used by the dattrmgr utility.
Table 7-21 Arguments Used by the dattrmgr Utility
| Argument | Description |
|---|---|
|
-d pathToDomain |
Specifies the directory in which to run the utility. All arguments except -version require -d pathToDomain. |
|
-register measName |
Name of a registered one-dimensional measure in the domain. This measure is used to register the dimension attribute. |
|
-dattname attrName |
Optional parameter that can be used with -register to specify the name of the dimension attribute. If this is not supplied, the measure name is used for the dimension attribute name. |
|
-dattlabel attrLabel |
Optional parameter that can be used with -register to specify the label of the new dimension attribute. If this is not supplied, the measure label is used as the label of the new dimension attribute. |
|
-report |
Lists all the static and dynamic dimension attributes that are present in the domain. Also prints out the saved split definitions and workbooks where the dimension attributes are used. |
|
-version |
Prints the version of the utility. |
Here is a sample output of the -report option. Note that the same split definition may be used in multiple workbooks and there may be split definitions that are not used in any workbooks. The split definition ID is printed under saved splits and also under workbooks.
Name : attr1
Label : measA
Dim : sku
Meas : measa
:
Saved splits :
:
id : splt_dm001
Label : split1
User : adm
:
id : splt_dm3
Label : split3
User : adm
:
Workbooks :
:
id : t0000000000
Label : 1
Split id : splt_dm001
:
id : t0000000002
Label : 3
Split id : splt_dm3
--------------------------
Name : datt_1
Label : dynAttr1
Dim : stco
Meas : datt_1
:
Saved splits :
:
id : splt_dm2
Label : split2
User : adm
:
Workbooks :
:
id : t0000000001
Label : 2
Split id : splt_dm2
--------------------------
The dimension manager utility is used for setting a number of parameters for dimensions and positions. Multiple command arguments are allowed.
dimensionMgr -d pathToDomain -dim dimensionName [COMMAND] {Options}
Table 7-22 provides descriptions of the arguments used by the dimensionMgr utility.
|
Note: This utility includes arguments that are not documented in this guide as it is recommended that those operations be configured using the Configuration Tools to ensure consistency between the configuration and the domain. |
Table 7-22 dimensionMgr Utility Arguments
| Argument | Description |
|---|---|
|
|
Specifies the path to the domain. |
|
|
Specifies the name of the dimension to which the settings will apply. |
|
|
Specifies a new dimension label. |
|
|
Enables Dynamic Position Maintenance (DPM) for the specified dimension (-dim dimensionName). Using this argument not only enables DPM for the specified dimension, but for all dimensions that roll up to it. DPM cannot be enabled for any dimension in an RPAS-internal hierarchy (DATA, META, RGPS, ADMU, ADMW, MSGS, LNGS). |
|
|
Enables the specified dimension to use translated labels. When enabling translated labels, the numeric parameter passed in the argument (width) defines the field width for the translated values in the data file, which is loaded using the loadMeasure utility. |
|
|
Displays the properties of the specified dimension. The dimension properties indicate whether DPM and translation are enabled for the dimension and whether the dimension is image-enabled. Here is the full list of properties that the
|
|
|
Sets the width of position names for the specified dimension. After you have created a position name, you can only increase its width; you cannot decrease the width. |
|
bitSize |
Changes the bit size for the dimension, but does not actually update the dimension arrays. You must run reindexDomain for the dimension data and measure arrays to be updated. |
|
reindexThreshold |
Sets a new reindex threshold for the dimension. |
To change the label of a dimension, use the dimensionMgr utility. It is not restricted to partitioned hierarchies.
dimensionMgr -d domainPath -dim dimName -label newLabel
The exportHier utility is used to export all the positions in a hierarchy, including their rollup relations. The exportHier utility cannot be run on local domains. It must be run only on the master domain or simple domains. By default, the utility assumes that the file has a CSV flat file format with fixed-width format as an optional argument. The utility exports all hierarchy positions, but the file may be specified to include only formal or informal positions. The resulting file can then be used as a .DAT file with loadHier.
exportHier -d domainPath -hier hier_name -datFile dat_file [-fixedWidth]
[-onlyFormal | -onlyInformal][-upperCase]
Table 7-23 provides descriptions of the arguments used by the exportHier utility.
Table 7-23 Arguments Used by the exportHier Utility
| Argument | Description |
|---|---|
|
- |
Specifies the path to the domain. |
|
- |
Indicates the name of a hierarchy in the domain from which the .DAT file is generated. |
|
- |
Indicates the path/location where the .DAT file is created. This .DAT file can then be used with loadHier to load the hierarchy into a domain. |
|
- |
Indicates that the output .DAT file is a fixed-width file instead of a comma-separated value (CSV) file format. |
|
- |
Exports only formal positions to the .DAT file. If this is option is specified, informal positions will be skipped. |
|
- |
Exports only informal positions to the .DAT file. If this is option is specified, formal positions will be skipped. |
|
|
Generates a header line for CSV export. The line contains fields to identify the dimension and its label column. |
|
-udd |
Exports the user-defined definitions. It can only be used with the |
|
- |
Creates a file with the fileName, which contains a list of the informal positions in the domain in a format that can be used by the informalPositionMgr. This option cannot be used with the |
|
- |
Converts the position names to all uppercase before writing the output data file. Without this argument, position names are in lowercase since they are stored in lowercase in the domain. |
Informal Position Manager is a domain utility that maintains informal positions for any dimension in a domain. Informal positions are those created with the Dynamic Position Manager (DPM). Formal positions are those created with the loadHier utility. This utility can convert positions from formal to informal or from informal to formal. It can also remove informal positions, create informal positions in bulk, and copy data slices between positions in measures.
The three main areas of use for informalPositionMgr are described in the following sections:
Informalizing, formalizing, and removing informal positions all have similar command line options.
informalPositionMgr -d domainPath -hier hierName -operation [remove | formalize | informalize | load] [-dir inputDir | -file inputFile] [-retain]
Table 7-24 provides descriptions of the arguments used in basic operations of the informalPositionMgr utility.
Table 7-24 Arguments Used by the informalPositionMgr Utility: Basic Operations
| Argument | Description |
|---|---|
|
-d domainPath |
Indicates the domain to run the utility. |
|
-hier hierName |
Specifies the hierarchy to operate on. |
|
-operation informalize | formalize |remove | load |
Specifies one of the three basic operations: informalize, formalize, or remove. You can use only one of these operations at a time.
In a domain sharing data through a RPAS Data Mart, informalPositionMgr cannot informalize formal positions of a shared hierarchy. |
|
-file inputFile or
|
Use one and only one of these arguments to specify the input files to use during the operation specified.
All files that match the naming patterns below are processed:
For example: The format of the above files except load files has one position on each line. The position has a dimension name and a position name that are comma delimited. There is no header line: dimName1, positionName1 dimName2, positionName2 The format of load files is the same as that of the load files for loadHier. |
|
-retain |
Use if you do not want to move the input files to the processed subdirectory after a successful run. |
The following errors result the described behavior.
Table 7-25 informalPositionMgr Error Handling
| Error | Behavior |
|---|---|
|
Input file does not exist |
A log error is generated and the operation stops. |
|
Any dimension specified in the input file is not DPM enabled or does not exist |
A log error is generated and the operation stops. |
|
One or more positions does not exist |
Log warnings are generated, the line is skipped, and the operation continues. |
|
Selecting to convert a position to informal that is already informal OR Selecting to convert a position to formal that is already formal |
No action is taken on that position, a warning message is logged, and the operation continues. |
|
Selecting to convert a position to informal in a shared dimension. |
No action is taken on that position. A warning message is logged, and the operation continues. |
This feature allows the user to create a number of informal positions on any DPM-enabled dimension. These positions are automatically named and labeled. However, the user must provide applicable rollup and spread information so that these new positions can be properly placed in the hierarchy.
informalPositionMgr -d domainPath -create -dim dimName -n posCount -rollups dim1:pos1,dim2:pos2,... [-spreads dimA:ratioA,dimB:ratioB,...]
For bulk creation of informal positions, the position names and labels are auto-generated. To ensure the names are unique, a prefix and sequence number is used and the width and label width attributes of the dimension should be at least 10. If the width or label width is less than 10, bulk creation is not allowed, and an exception is thrown.
If the dimension specified by option -dim is above the root dimension, informal positions are added to the lower levels. The numbers of spread positions for lower level dimensions are defined by the -spreads option. Note that the spread ratio determines the number of children for each position at the level immediately above the specified dimension. If it is not specified, the default is 1.
If these new descendent positions roll up to other alternate dimensions, there are a few options to handle the rollups. If those dimensions are DPM-enabled, you can either specify the rollup positions (in the -rollups option) or let the program create single rollup position for you. This repeats recursively for those new positions. If any of those affected dimensions are not DPM-enabled, the rollup positions must be specified.
Table 7-26 provides descriptions of the arguments used by the create bulk positions functionality of the informalPositionMgr utility.
Table 7-26 Arguments Used by the informalPositionMgr Utility: Create Bulk Positions
| Argument | Description |
|---|---|
|
-d domainPath |
Indicates the domain to run the utility. |
|
-create |
Batch creates new positions with auto-generated names. |
|
|
Specifies the dimension to operate on. |
|
|
Specifies the rollup positions for the auto-generated positions. You should include the direct rollups for the new positions and rollups for the descendents of these new positions on alternate branches, if applicable. |
|
|
Specifies the spread counts for the auto-generated positions. This is optional. It defaults to 1 if not specified. |
|
|
Use to enter the number of positions to create on the specified dimension. |
The following sections provide some examples of creating informal positions in bulk on the product hierarchy. Figure 7-2 displays a product hierarchy with alternative branches and four DPM-enabled dimensions (STYL, STCO, SKU, and SZ12).
To create informal positions on the STYL dimension, you must specify rollups for SCLS, CLR, and SPLR. You have the following two options for SZ12:
Option 1
Specify the rollup for SZ12.
informalPositionMgr -d domainPath -create -dim STYL -n 100 -rollups SCLS:scls1001,CLR:clrwhite,SPLR:splr100,SZ12:sz12null -spreads STCO:2,SKU:5
This command creates the following:
The 100 new informal positions on the STYL dimension. These positions all roll up to SCLS:scls1001.
Since the spread ratio for STCO dimension is 2, then 200 new informal positions are created at the STCO level, and every two of them roll up to one STYLE position that was created in step 1. These new informal positions all roll up to CLR:clrwhite on the alternate branch.
Similarly, 1000 new informal positions are created at the SKU level, and every 5 of them roll up to one STCO position that was created in step 2. They all roll up to SPLR:splr100 and SZ12:sz12null on the two alternate branches.
Option 2
Specify the rollups for SIZ1 and SIZ2. A new position is automatically created on SZ12. You can specify spread ratios for STCO and SKU. If you do not specify the spread ratio, it defaults to 1.
informalPositionMgr -d domainPath -create -dim STYL -n 100 -rollups SCLS:scls1001,CLR:clrwhite,SPLR:splr100,SIZ1:siz1null,SIZ2:siz2lt02 -spreads STCO:2,SKU:5
This command creates the following:
The 100 new informal positions on the STYL dimension. These positions all roll up to SCLS:scls1001.
One new informal position at the SZ12 level, which rolls up to SIZ1:siz1null and SIZ2:siz2lt02.
Since the spread ratio for STCO dimension is 2, then 200 new informal positions are created at the STCO level, and every two of them roll up to one STYL position created in step 1. These new informal positions all roll up to CLR:clrwhite on the alternate branch.
Similarly, 1000 new informal positions are created at the SKU level and every 5 of them roll up to one STCO position created in step 3. They all roll up to SPLR:splr100 and the new SZ12 position created in step 2.
To create informal positions on SZ12 dimension, you must specify rollups for SIZ1, SIZ2, and SPLR and specify the spread ratio for SKU. For the DPM-enabled dimension STCO, you have the following two options:
Option 1
Specify a rollup position.
informalPositionMgr -d domainPath -create -dim SZ12 -n 10 -rollups SPLR:splr100,SIZ1:siz1null,SIZ2:siz2lt02,STCO:stco2000 -spreads SKU:5
This command creates the following:
The 10 new informal positions on the SZ12 dimension. These positions all roll up to SIZ1:siz1null and SIZ2:siz2lt02.
Since the spread ratio for SKU dimension is 5, then 50 new informal positions are created at the SKU level, and every 5 of them roll up to one position at the SZ12 level, which was created in step 1. These new informal positions all roll up to SPLR:splr100 and STCO:stco2000.
Option 2
Create a rollup position and specify a rollup position on CLR and rollup position on STYL (or create recursively until the non-DPM enabled dimension is reached).
informalPositionMgr -d domainPath -create -dim SZ12 -n 10 -rollups SPLR:splr100,SIZ1:siz1null,SIZ2:siz2lt02,SCLS:scls1001,CLR:clrwhite, -spreads SKU:5
This command creates the following:
The 10 new informal positions on the SZ12 dimension. These positions all roll up to SIZ1:siz1null and SIZ2:siz2lt02.
One new informal position at the STYL level, which rolls up to SCLS:scls1001.
One new informal position at the STCO level, which rolls up to CLR:clrwhite, and the new position at STYL level, which was created in step 2.
Since the spread ratio for SKU dimension is 5, then 50 new informal positions are created at the SKU level, and every 5 of them roll up to one position at the SZ12 level which was created in step 1. These new informal positions all roll up to SPLR:splr100 and the new STCO position created in step 3.
When the bulk creation feature is used, the names and labels of the new positions are created with the following name conventions:
Position name: {dimName}{dpm}{seq#}
The width is an attribute of the dimension. For auto-generated position names, the minimum width required is 10.
For width = 10, {4 char dimName}d{5 char seq#}
For width = 11, {4 char dimName}d{6 char seq#}
For width = 12, {4 char dimName}d{7 char seq#}
For width = 13, {4 char dimName}dp{7 char seq#}
For width >= 14, {4 char dimName}dpm{7 char seq#}
If the dimName is less than four characters, an underscore is appended, for example: sku_. Each dimension uses its own persistent sequence generator in the domain with a unique label DPM_{dimName}. For a global domain, the sequence generators are in the master domain.
Position label: Follows the same convention as that of position name, but uses the label width attribute of the domain.
This feature allows you to copy data slices from one position to those of another. It is useful when you want to merge informal positions with existing formal positions. An inclusive or exclusive measure list can be specified. A Boolean type mask measure can be used to enable selective copying of data slices.
When operating on a domain that shares data through an RPAS Data Mart, if informalPositionMgr is used to copy a slice of data involving a dimension shared in the RDM, the slice of data will also to be copied within the RDM.
informalPositionMgr -d domainPath -copy -file inputXMLFile [-retain]
Table 7-27 provides descriptions of the arguments used by the data slice copying functionality of the informalPositionMgr utility.
Table 7-27 Arguments Used by the informalPositionMgr Utility: Data Slice Copying
| Argument | Description |
|---|---|
|
-d domainPath |
Indicates the domain to run the utility. |
|
-copy |
Copies data slices within measures. |
|
-retain |
Use if you do not want to move the input file to the processed subdirectory after a successful run. |
|
-file inputXMLFile |
Specifies the XML file that contains the configuration settings for the copying operations. |
Table 7-28 shows the available settings for the XML input file. This file defines the configuration settings for the copying operation.
Table 7-28 XML Input File Settings
| Section | Attribute | Description | Required | Format |
|---|---|---|---|---|
|
copy |
Settings for copying operation. |
|||
|
copy |
removeSource |
Removes source data slices after copying. |
Yes |
”true” or ”false” |
|
measures |
A list of measures. |
No |
Comma delimited measure names |
|
|
measures |
option |
The measure list is inclusive or exclusive. |
Yes, if the measures section exists |
”include” or ”exclude” |
|
mask |
Mask measure. |
No |
One Boolean type measure name |
|
|
positionMap |
Position mapping for the copying operation. |
Yes |
||
|
positionMap |
dim |
The dimension of the mapped positions. |
Yes |
Dimension name |
|
positions |
Two positions. The first one is the position to copy from. The second one is the one to copy to. |
Yes |
Comma delimited |
Here is a sample XML Input File Schema in XSD format file.
<?xml version=”1.0” encoding=”UTF-8”?>
<xsd:schema attributeFormDefault=unqualified” elementFormDefault=”qualified”
version=”1.0” xmlns:xsd=http://www.w3.org/2001/XMLSSchema”>
<xsd:element name=”rpas” type=”rpasType” />
<xsd:complexType name=”rpasType”>
<xsd:sequence>
<xsd:element name=”copy” type=”copyType” />
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name=”copyType”>
<xsd:sequence>
<xsd:element name=”measure” type=”measuresType” />
<xsd:element name=”mask” type=”xsd:string” />
<xsd:element name=”positionMap” type=”positionMapType” />
<xsd:sequence>
<xsd:attribute name=”removesource” type=”xsd:boolean” />
</xsd:complexType>
<xsd:complexType name=”positionMapType”>
<xsd:sequence>
<xsd:element maxOccurs=”unbounded” name=”positions” type=”xsd:string” />
</xsd:sequence>
<xsd:attribute name=”dim” type=”xsd:string” />
</xsd:complexType>
<xsd:complexType name=”measuresType”>
<xsd:attribute name=”option” type=”xsd:string” />
<xsd:complexType>
</xsd:schema>
Here is a sample XML Input file.
<?xml version=”1.0” encoding=”UTF-8”?>
<rpas>
<copy removeSource=”true”>
<measures option=”include”>
r_ex_demoa, r_ex_demob, r_ex_democ
</measures>
<mask>maskMeasure</mask>
<positionMap dim=”sku”>
<positions>sku_10000010, sku_10000008</positions>
<positions>sku_22200001, sku_22200002</positions>
</positionMap>
</copy>
</rpas>
Here are the steps to merge informal positions to formal positions in a domain.
Create the XML input file by specifying the position pairs to merge. Optionally, you can specify the measures to update and a mask measure.
Create the mask measure if you want to use a filter to protect some data slices from being modified. For example if you want to leave elapsed data alone, you can create a calendar based mask measure and set all the elapsed cells to false.
Run informalPositionMgr with -copy option to copy the data slices.
Create an input file for the removal of informal positions you no longer need.
Run informalPositionMgr with -operation remove to remove those informal positions.
The pqdMgr utility is a command-line utility used to add and delete Position Query Definitions (PQDs) using XML-formatted position lists. A position list is a multi-level listing of positions along a non-Calendar RPAS hierarchy. For example, along the product hierarchy, a position list could be a single-level listing of SKUs or it could be a multi-level list of classes, styles, and SKUs. A PQD is used to represent a set of selected positions in a particular hierarchy. Each PQD is identified by a unique name. A user can load the PQD instead of performing manual selections on a two-tree wizard.
This utility can be used to load PQDs in master, local, and non-partitioned domains. PQDs are not shared across local domains. Loading a PQD into a global domain does not affect any local domain. Similarly, loading a PQD into a local domain does not impact the master or other local domains.
The input file must be in the following XML file format. This example shows loading and deleting lists for world and user access levels.
<? xml version="1.0" encoding="UTF-8" ?>
<pqdlists>
<pqdlist name="list_name" hier="hierarchy_name">
<access level="user">
<comma_separated_user_names>
</access>
<dimension name="dimension_name">
<pos>
<position_external_name>
</pos>
</dimension>
</pqdlist>
<pqdlist name="list_name" hier="hierarchy_name">
<access level="world">
</access>
<dimension name="dimension_name">
<pos>
<position_external_name>
</pos>
</dimension>
</pqdlist>
<pqdlist name="list_name" hier="hierarchy_name" operation="delete">
<access level="world">
</access>
</pqdlist>
<pqdlist name="list_name" hier="hierarchy_name" operation="delete">
<access level="user">
<comma_separated_list_of_users>
</access>
</pqdlist>
</pqdlists>
pqdMgr -d domainPath -load xmlFile pqdMgr -d domainPath -delete xmlFile pqdMgr -d domainPath -deleteAll pqdMgr -d domainPath -validate xmlFile pqdMgr -d domainPath -export outFile [-user userName|-world]
Table 7-29 provides descriptions of the arguments used by the pqdMgr utility.
Table 7-29 Arguments Used by the pqdMgr Utility
| Argument | Description |
|---|---|
|
-d domainpath |
Specifies the path to the domain. |
|
-load xmlFile |
Loads position lists from an input XML file. Position lists with an operation attribute of delete are ignored. |
|
-delete xmlFile |
Deletes PQDs as specified in the input XML file with an operation attribute of delete. Position lists with an operation attribute of load are ignored. |
|
-deleteAll |
Deletes all PQD lists from the domain. |
|
-validate xmlFile |
Validates the XML file and report any errors. No impact on the existing PQD files in the domain. |
|
-export outFile [-user userName|-world] |
Exports existing PQDs in the domain for a user or world access level. The file specified by outFile is overwritten. Requires one of the following options:
|
Note the following:
Input files are validated before loading. All dimensions, hierarchies, and user names provided in the input file must be consistent with the existing hierarchies and registered users in the domain. The utility fails (return a non-zero error code) if it finds such inconsistencies in the input file. The errors are reported to the standard output.
Multiple list operations are allowed in the XML input file.
The supported operations are load and delete. If no operation is specified for a list, the default is load.
The name list_name must be unique within an access level and, if the access level is user, for the user name.
Each list definition consists of the list name, hierarchy, and access level. One or more dimension definitions are allowed. One or more position definitions are allowed for each dimension. Only external names are allowed to describe positions.
When specifying an access level of user, a single user name or a comma-separated list of user names is required. A PQD file is created for each user name in the list.
For the access level of world, the PQD file that is created is saved in the following path:
<domain_root>/wizardPQD/<hierarchy_name>/_world/<list_name>
For the access level of user, the PQD file that is created is saved in the following path:
<domain_root>/wizardPQD/<hierarchy_name>/<user_name>/<list_name>