



|
|
This chapter provides an overview of BEA AquaLogic Data Services Platform. It covers the following topics:
| Note: | AquaLogic Data Services Platform was formerly named Liquid Data. Some artifacts of the original name remain in the product, installation path, and components. |
Information resources are often the most important assets of an enterprise. Availability of accurate and timely formation can make or break an enterprise's ability to execute on its essential functions — from day-to-day operations to the marketing and delivery of products or services to strategic planning.
It is a fact of life, however, that as enterprises evolve, their data resources tend to become increasingly fragmented. Corporate acquisitions and mergers, new technologies, and changing IT strategies all contribute to data lakes and puddles, in which pockets of information become isolated by physical and technical boundaries. In a typical enterprise information pools in databases and files, within applications, or externally, supplied on-the-fly by business partners, vendors, and clients as Web services or XML documents. Figure 1-1 illustrates this fragmentation of data.
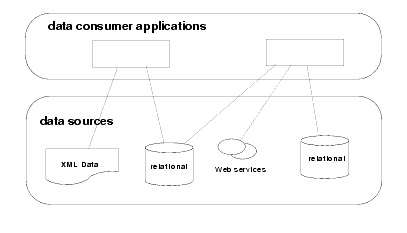
As a consequence, integrated information becomes so expensive to create that it is — except for the highest priority needs — effectively unavailable to the decision makers, employees, and customers when they need it. And as for those highest priority projects, developers must cope with a daunting variety of data access mechanisms and APIs. Resulting applications tends to be dominated by data management logic, making them intolerant to changes in the data layer.
When changes do occur, the applications must be revised and retested, because their business logic is embedded with the data access code. In sum, when it comes to developing applications, the costs of information fragmentation are quantifiable and significant. By many estimates, up to 70% of the time required to develop an enterprise application goes into data access programming.
Other costs may be more difficult to gauge but are certainly as significant — from hampered decision making and poor responsiveness to the high cost of integration talent.
A data service is a query-based access layer that facilitates the ability of calling applications to access and manage disparate data.
AquaLogic Data Services Platform (AquaLogic Data Services Platform) is the AquaLogic component dedicated to developing and deploying integrated data services. Data services give consumers an easy-to-use, uniform model for accessing heterogeneous, distributed data.
AquaLogic Data Services Platform significantly simplifies the task of creating and deploying reusable data services. It provides tools and frameworks for rapidly generating physical data services based on existing data sources and for creating view-like logical data services.
Most data in an organization exists as queryable data or application data. From the perspective of the data consumer, AquaLogic Data Services Platform presents a sensible, uniform model for getting and using information. The application simply retrieves or updates its data by calling one of the data service's public APIs. The backend data may come from legacy applications, relational databases, Web services, and so forth. Thus data services can be viewed as a layer integrated between the data consumer and the data sources, as illustrated in Figure 1-2.
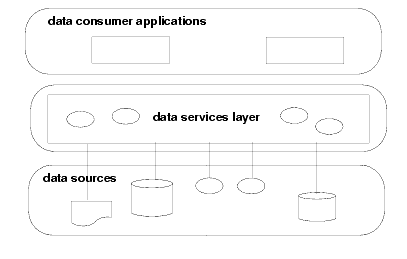
AquaLogic Data Services Platform is a virtual data layer in the sense that, except for caching, data is not kept in any AquaLogic Data Services Platform or WebLogic component. Instead, data services dynamically retrieve data from the physical data sources. Dynamic access ensures that applications have access to current (that is, real time) information.
A data service represents a unit of information in the enterprise data model. Like a Web service, it exposes an API public interface in the form of one or more accessor functions. A data service accessor function typically returns data in the form of the data service's complex datatype. The function uses XQuery to acquire, transform, and aggregate data from external sources.
Returned data is poured into an XML data shape defined as the XML type of the data service. Because an individual data service represents a relatively small unit of information, response time is generally superior. Other features — such as caching and query optimization — help to ensure the optimal performance of the data services layer.
AquaLogic Data Services Platform insulates data consumers from the complexity of disparate data sources. It encapsulates the details of data integration logic and gives consumers a sensible, coherent model for accessing and updating data. Data access and business or presentation logic are effectively decoupled, resulting in applications that are easier to develop and maintain, without data access plumbing code.
As it does for reading data, AquaLogic Data Services Platform gives client applications a unified interface for updating data. AquaLogic Data Services Platform allows client applications to modify and update data from heterogeneous, distributed sources as if it were a single entity. The complexity of propagating changes to diverse data sources is handled by AquaLogic Data Services Platform.
From the data service implementor's point of view, the task of building a library of update-capable data services is considerably eased by the AquaLogic Data Services Platform update framework. For relational sources, AquaLogic Data Services Platform can propagate changes to the data source automatically. For other sources or to customize relational updates, you can use the AquaLogic Data Services Platform update framework artifacts and APIs to quickly implement customized, update-capable services. Either way, data consumers are isolated from the details of updating the data sources.
A Service-Oriented Architecture (SOA) is an IT environment architectural style. In this architecture, business processes are delivered as a set of loosely-bound services. Web services provide an implementation of SOA. A web service is a modular, self-describing component that can be used in a platform-independent way.
To appreciate SOA it is helpful to consider that, traditionally, applications are built as monolithic units. They impose platform dependencies on users and are not easily adaptable to new types of interactions. Web services break the monolithic model into multiple reusable components that can interact with other independent components and services in meaningful ways. For example, instead of having a single financial application, an organization may deploy one or more services that expose the business activities of the application as modular, self-contained, callable processes. That way other systems (such as Human Resource services or applications) can easily leverage financial computing resources for its current or future needs. In this way SOA can be viewed either as breaking down barriers between applications or eliminating the need for them entirely.
With SOA the IT infrastructure operates in an integrated, organic fashion like a virtual application that spans the organization.
SOA is considered a loosely coupled — not completely decoupled — architecture because, while the service provider has no knowledge of the interfaces or business concerns of its consumers, the consumers do include explicit references to the service provider interface, in the form of service calls.
The benefits of loose coupling include simplified data access, reusability, and adaptability. New services can be exposed and used without requiring extensive changes to existing applications. The result is a service layer that is highly adaptive and change tolerant.
Data services fit perfectly into the SOA picture by providing a data abstraction layer between data users and the underlying data sources. Thus the application developer can count on working with a uniform, well-defined SOA-based data access interface. The need for data access specialists capable of establishing connections to back-end data is greatly reduced. The application simply calls a public function and good things happen.
Simply put, AquaLogic Data Services Platform disentangles the data provider from the applications that use the data.
Other benefits of AquaLogic Data Services Platform include:
A data model typically organizes data in a way that represents business entities. With AquaLogic Data Services Platform, you can define the data model that makes sense for your organization. Business entities common to most organizations include, for example, products, orders, and customers. A data service Customer object can have all of the attributes that are relevant to a customer in the deployed environment, such as contact information, shipping preferences, payment information, and so on. The underlying data sources for the elements that make up the Customer object are only of interest when the underlying structure or availability of that data changes. The data service can also specify security, caching, and other policies.
The policies relevant to the data are applied to the data consistently, without requiring developers to implement them in the various applications they develop.
To help you get from a complex, distributed physical data landscape into a sensible data model, AquaLogic Data Services Platform supports a visual, model-driven approach to developing data services. Modeling provides a graphical representation of the data resources in your environment, providing a bird's eye view of a large system, or giving you a way to break a larger problem into smaller pieces.
The result is real-time access to externally persisted data through a logical data model (as illustrated in Figure 1-3) while providing a single point for applying data service policies, such as security and caching, on information used across applications and services.
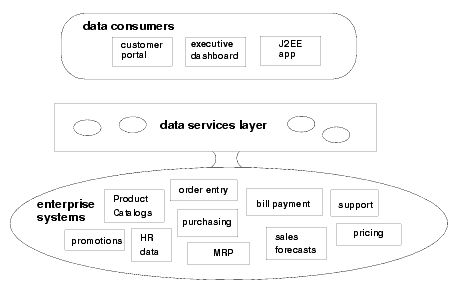
In SOA, services are conventionally thought of in terms of processes. However, most SOA initiatives actually start with data. By its nature, data has broader, more generalized usage than typically does a business process. Data consumers can use the same piece of data in different ways. Once you have developed the data model for your enterprise data, the data types, as encapsulated by data services, can be reused by numerous data consuming applications.
The data model represented by a AquaLogic Data Services Platform deployment is captured by metadata. In AquaLogic Data Services Platform, metadata serves several purposes:
The metadata browser, a component of the AquaLogic Data Services Platform Console, provides an easy-to-use interface for searching and browsing through metadata.
A data service encapsulates the logic for normalizing, transforming, and integrating disparate data. A client application or process uses a data service by calling one of its public functions. A data service can have any number of public functions, each of which returns data in the form of the data shape described by the XML Schema associated with the data service.
Logic is encapsulated in a data service in the form of queries written in the XML Query (XQuery) language. XQuery 1.0, an emerging W3C standard specification, is a SQL-like language specifically intended for working with structured, XML data. As a declarative language, XQuery lends itself to compiler-based optimization techniques, freeing developers from having to learn extensive rules and techniques for writing optimized query functions.
Those familiar with SQL should find XQuery easy to learn since they have many features in common. AquaLogic Data Services Platform provides an XQuery Editor that allows you to create XQueries through graphical gestures using an easy-to-use IDE tool.
Once the AquaLogic Data Services Platform application has been deployed to a WebLogic Server, clients can use it to access real-time data. AquaLogic Data Services Platform supports several data clients:
In all cases AquaLogic Data Services Platform supports data access through Java interfaces (AquaLogic Data Services Platform Mediator API and Workshop Data Service control) or through Web services that act as wrappers for the data services.
As an additional option, the AquaLogic Data Services Platform JDBC driver gives SQL clients (such as reporting and database tools) and JDBC applications a traditional, database-oriented view of the data layer. To users of the JDBC driver, the set of data served by AquaLogic Data Services Platform appears as a single virtual database. Note that, given the two-dimensional view of data inherent in SQL, SQL access is supported only for data services that provide a flat view of data.
The following are the basic steps for managing a data service in a SOA environment:
In a SOA environment instead of developers having to understand how to connect to and use numerous data sources — along with the business or presentation logic that needs to be implemented once the data is acquired — development tasks are be divided in ways that naturally correspond to the roles that often exist in an organization:
This section provides a compendium of links to technical and product information related to BEA AquaLogic Data Services Platform. These documents are subject to revision on a frequent basis and may reflect earlier versions of the product in some aspects.


|