|
|
BEA Aqualogic Data Services Platform services provide a framework for creation and maintenance of functions that access and transform available data. You can use the XQuery Editor to create such functions.
A valid query function is always associated with a return type. In Source View a return type is described for each function. It typically matches the XML type — or schema — that defines the shape of your data service.
Once created, your query functions can be called by client applications. Details on the various methods of invoking AquaLogic Data Services Platform functions can be found in the AquaLogic Data Services Platform Client Application Developer's Guide.
You can also use the XQuery Editor to create standalone, queries that can be run in Test View (see Testing Query Functions and Viewing Query Plans).
Topics discussed in this chapter include:
Using the XQuery Editor you can create query functions using an intuitive, drag-and-drop approach. During the creation process you can easily move back and forth between the editor to Source View.
The XQuery Editor relies on data services functions for the metadata necessary to represent various types of data. (For detailed information on importing metadata see Obtaining Enterprise Metadata.)

A data service may represent a physical data source or it may represent logical data that has previously been created. Data service and custom XQuery library functions are both represented from the Data Services Palette (Figure 6-2), a WebLogic Workshop pane available when XQuery Editor View is active.
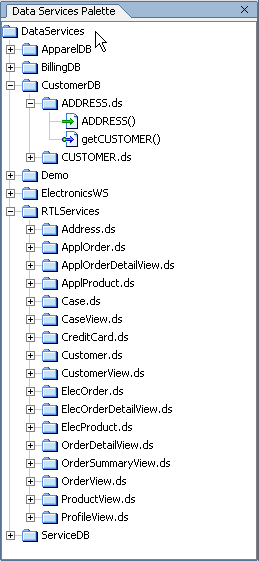
Notice in Figure 6-2 that there are two different type of function representations: Functions represent by a straight (green) arrow are read functions, while functions represented by a more stylized (blue) arrow are navigation functions.
Essentially you create a query function by:
As you work graphically you are automatically creating an XQuery in Source View.
Once created, you can execute your function using Test View (see Testing Query Functions and Viewing Query Plans). When you execute your query function, underlying data sources are accessed and the results appear. If you have appropriate permissions, data can be updated directly after the query is run.
Metadata representations of source are available to the XQuery Editor from the Data Services Palette. The Data Services Palette lists available data services and their read and relationship functions. Any such function can be dragged into the XQuery Editor work area where it will be transformed into a for clause.
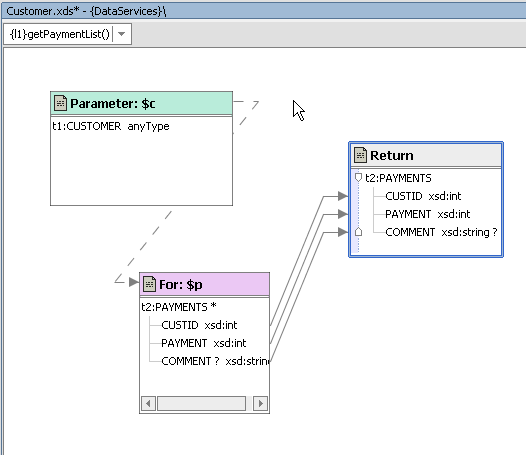
Read functions and Web services often have input parameters. For example, the logical data service Customer (customer.ds) can be represented in the XQuery Editor by its read functions: getCustomer() and getPaymentList( ). If you drag the getCustomer( ) item from the Data Services Palette to the XQuery Editor, the source representation shown in Figure 6-3 appears in the work area.
In some cases you may want to use a physical or logical data source representation several times in a query.
See Obtaining Enterprise Metadata and Designing Data Services for details on creating physical and logical data services.
When you create a new function in your data service and then click on the name of your new function (Figure 6-1), you will automatically be placed in the XQuery Editor. Alternatively, click the XQuery Editor View tab and select your function from the drop-down menu. Initially your XQuery will have only a return type, assuming that your data service is associated with an XML type (see Associating an XML Type).
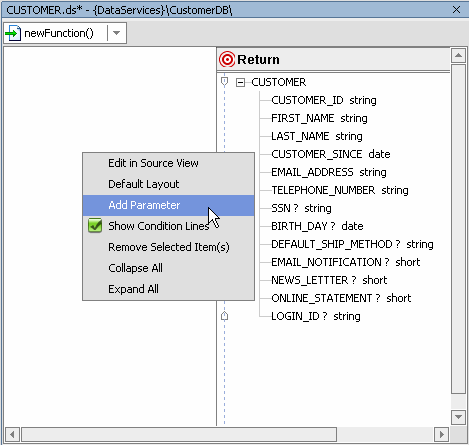
Several right-click menu options are available when you click in any unoccupied part of the work area.
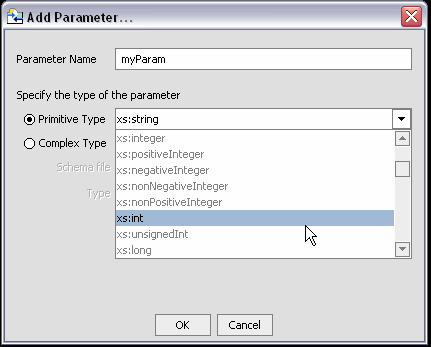
Adds a simple or complex parameter to your work area. Complex parameters require you to select a schema file and global type. See Parameter Nodes.
|
|
Creating a data service — as you will if you follow the steps in this section — is a good way to get the feel of working with the XQuery Editor, as well as other aspects of data services.
| Tip: | Changes made in the XQuery Editor are immediately reflected in Source View. |
The goal of this exercise is to quickly create a logical data service, including creating an XML type for your data service, using the XQuery Editor. The basic steps are:
| Tip: | The quickest way to change something you have done in the XQuery Editor is to use the Edit  Undo command (or Ctrl-Z). Prior to saving your application you can undo any number of previous steps. Thus it is often preferable to use Undo rather than redrawing mappings, zone settings, or conditions. Undo command (or Ctrl-Z). Prior to saving your application you can undo any number of previous steps. Thus it is often preferable to use Undo rather than redrawing mappings, zone settings, or conditions. |
In the sample it is assumed that you have the RTLApp sample installed and running, as well as its server.
In this section you create a new data service-enabled project and import metadata for the data sources you plan to use in your logical data service.
In this section you create a logical data service that provides client applications with the ability to retrieve customer-order information. In this section you will:
Here are the specific steps involved:
Data Service.| Note: | At this point your data service has no XML type (schema). |
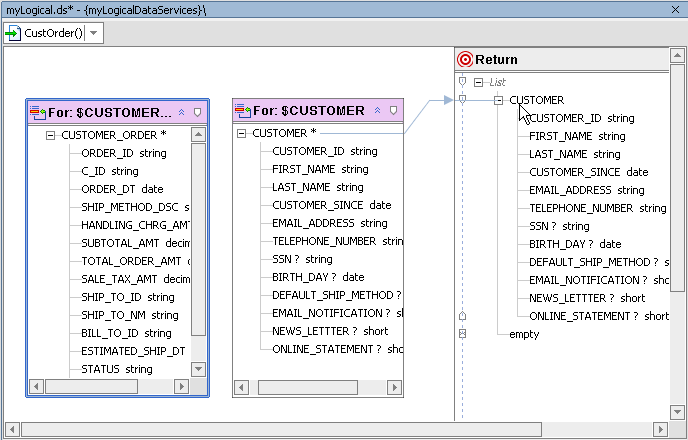
The existence of the two incomplete for clauses, $CUSTOMER and $CUSTOMER_ORDER, is accounted for by the return type's two empty elements.
Next, you need to populate your function's return type. CUSTOMER_ORDER should be set up as a child of CUSTOMER so that information will be return in the following shape:
Customer1
..
Order1
..
Order2
..
Customer2
..
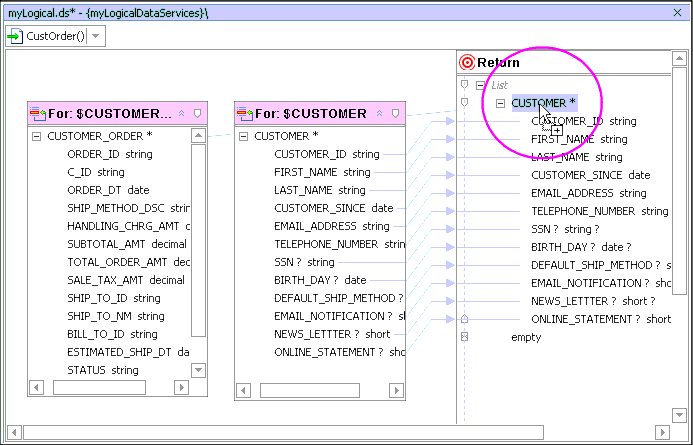
As the returned document is to list all customer orders associated with a specific customer, you need to create a subordinate complex element. One way to do this is to simply add the CUSTOMER_ORDER type as a subordinate to CUSTOMER, as shown in the next step.
The CUSTOMER_ORDER elements will appear as subordinate to CUSTOMER (Figure 6-9).
If you try to run a query at this point it will fail for several reasons:
Similarly, if you attempt to map source elements to CUSTOMER_ORDER, you will not be successful. This is because the implicit assumption behind the mapping of a complex element is that all the child elements are mapped to the return type.
ns0:customer
Now the default name for your new schema matches the name of your data service; the default namespace is the qualified name (qname) of the root element of your return type.
Although there are several ways to go about accomplishing the same task. It is also important to be aware that there were points along the way where an effort to build or deploy your application would not have been successful because the query or the return type was not fully formed. Thus the order in which steps are accomplished can be significant.
The following terms and concepts are introduced in this section:
AquaLogic Data Services Platform supports multiple data sources including:
For details on importing data source metadata from these sources into AquaLogic Data Services Platform-based projects see Obtaining Enterprise Metadata.
The XQuery Editor uses XML schema representations as:
For more information see XML Types and Return Types.
Using the XQuery Editor, query functions can be built up graphically using a combination of graphical gestures and functions, including:
The following topics describe XQuery clauses as rendered in the XQuery Editor. (For information on the XQuery engine used by AquaLogic Data Services Platform and specific uses of XQuery in Source View see the AquaLogic Data Services Platform XQuery Developer's Guide. This document also contains references to the most up-to-state XQuery W3C specifications.)
Query functions always map to a single return type. If your data service is associated with a return type, that type will appear in the Return node.
The return type can be thought of as extending the XML type to in support of:
When you click on a simple element in the return type, the expression on that element's constructor appears.
A for clause node represents a named XQuery for clause construct. For and let clause nodes are always based data service functions.
By default, whenever you add a data service to the XQuery Editor work area, it is represented in a for node. The for node typically represents looping over a query function using either:
A for node, representing a parameterized query function, provides both Input and Output sections. As you would expect, parameters are mapped to the Input elements while Output elements either serve as input to other nodes or to the return type.

Table 6-16 shows options available when you right-click on the title of a for or let node.
Opens the data service that is represented by the node. The data service is opened to the current function in XQuery Editor View. However, if the function represents a physical data service (termed external in Source View), then the function definition in Source View appears. You can use the back arrow to return to your initial data service.
|
|
Relationship functions associated with the data service are listed. Selecting a relationship function allows your for or let node to serve as input for the relationship. See Adding Relationship Functions to an Existing Data Service for an illustration and code sample.
|
|
For and let clauses (see Let Statement Nodes) have many interchangeable characteristics.
The following code shows the conversion of the DataServices/RTLServices/Case/getCaseByCustID() function expression from a for clause:
declare function ns1:getCaseByCustID($cust_id as xs:string) as element(ns0:CASE)* {
for $x0 in ns1:getCase()
where $cust_id eq $x0/CustomerID
return $x0
};declare function ns1:getCaseByCustID($cust_id as xs:string) as element(ns0:CASE)* {
let $x0 := ns1:getCase()
where $cust_id eq $x0/CustomerID
return $x0
};A let clause binds a sequence of elements (graphically contained in a node) to a variable that in turn becomes available to the FLWR expression.
Options available for use with for clauses are also available for let clauses. See For and Let Node Options.
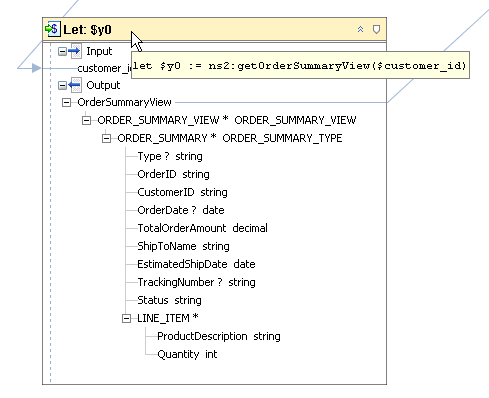
When examining a let clause, you can read the assign string (:=) as the "be bound to". For example, in the following let clause:
let $x := (1, 2, 3)
Can be read as "let the variable named x be bound to the sequence containing the items 1, 2, and 3."
See also Converting Between For and Let Clauses.
Parameter nodes enable you to associate a parameter with a for or let clause. Parameter nodes are created in the XQuery Editor work area (Figure 6-4). Three right-click menu options are available: Rename, Delete, and View Source.
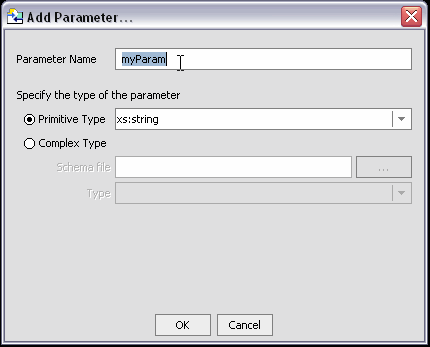
You can create parameters that range from simple data elements to elements of any complexity.
You can create a simple type parameter by selecting the type from the drop-down list and clicking Ok.
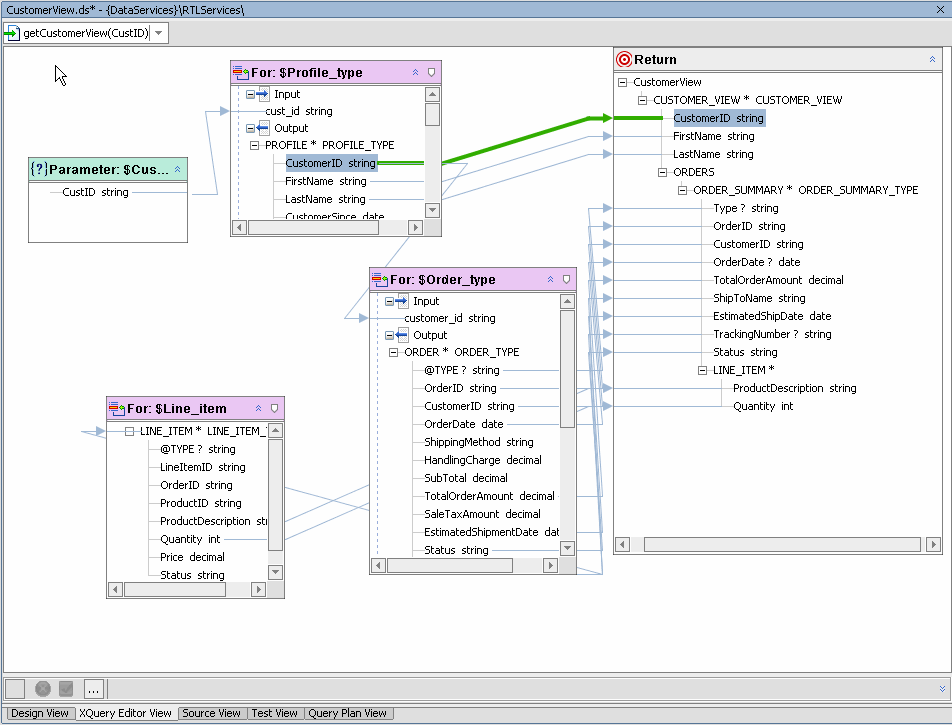
The act of mapping a parameter to a for or a let node containing an Input creates a parameterized query and also establishes a where condition. In Figure 6-20 the customer_id string parameter is dragged over the element in the ADDRESS node which is to be associated with the parameter through a where clause.
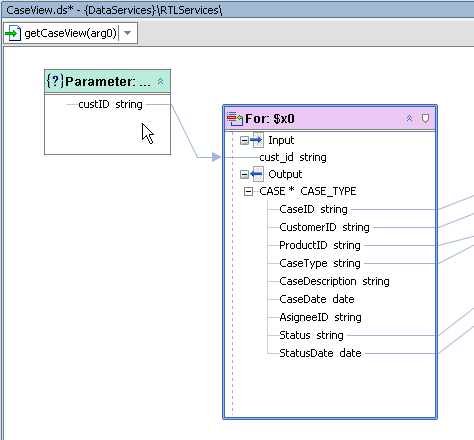
The corresponding Source View code highlights the parameter:
declare function ns5:getCaseView($custID as xs:string) as element(ns6:CaseView) {
<ns6:CaseView>
{
<CASE_VIEW>
<CASES>{
for $Case in ns7:getCaseByCustID($custID)
return <CASE>
<CaseID> {fn:data($Case/CaseID)} </CaseID>
<CustomerID>{fn:data($Case/CustomerID)}</CustomerID>
<CaseType> {fn:data($Case/CaseType)} </CaseType>
<ProductID> {fn:data($Case/ProductID)} </ProductID>
<Status> {fn:data($Case/Status)} </Status>
<StatusDate> {fn:data($Case/StatusDate)} </StatusDate>
</CASE>
}
</CASES>
</CASE_VIEW>
}
</ns6:CaseView>
};
When you invoke your function from an application — or execute your function in Test View — you will supply a value for your parameter.
Complex parameters are established by identifying a schema and a global element. Some schemas have only one global element.

The resulting parameter can be associated with any for or let node. See also Parameterized Input.
You can use the parameter dialog to create a where clause condition simply by dragging the simple or complex parameter over an element in a for or let clause. In Figure 6-22 the newly created parameter productID is mapped to PRODUCT_ID. Since the $PRODUCT for node is selected, the where clause is in scope.
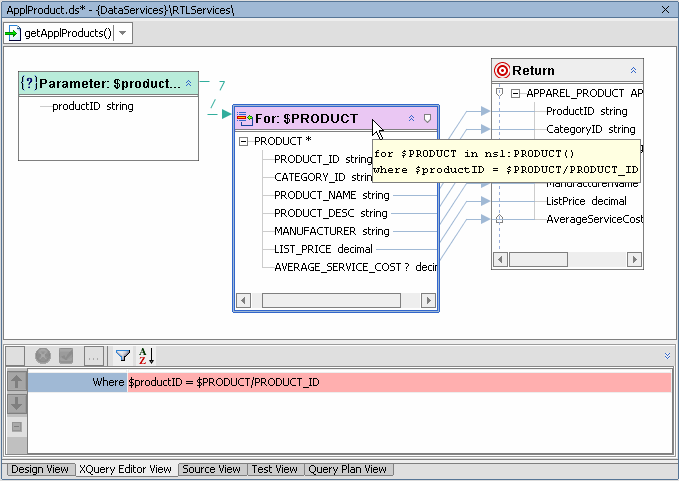
There are several ways to add relationship functions to existing data services. The recommended way is to use the right-click menu option available from for and let nodes, since this will created more appropriately nested clauses than simply dragging a relationship function from the Data Services Palette into the work area.
For example, if you want to create a logical data service that was a union of customer order and order line items, you could start with a customer order and add the related line item data.
Figure 6-23 takes the RTLApp DataServices/ApparelDB/CUSTOMER_ORDER() function and shows the process of adding the related getCUSTOMER_ORDER_LINE_ITEM() function.
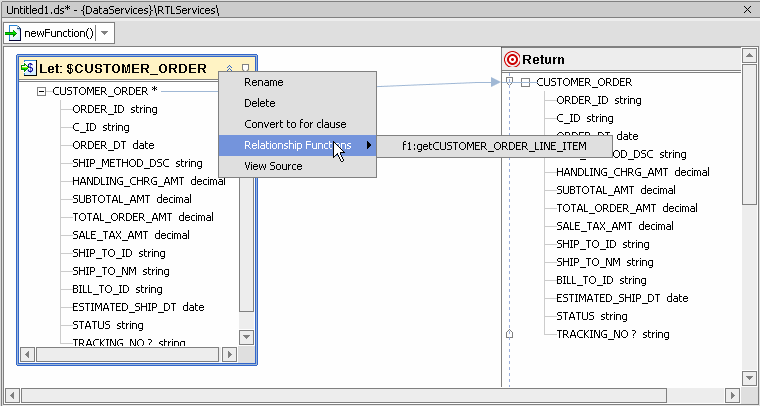
The function initially appears as:
declare function tns:newFunction() as element(ns30:CUSTOMER_ORDER9)* {
for $CUSTOMER_ORDER in ns28:CUSTOMER_ORDER()
return $CUSTOMER_ORDER
};Adding the relationship function changes it to:
declare function tns:newFunction() as element(ns30:CUSTOMER_ORDER9)* {
for $CUSTOMER_ORDER in ns28:CUSTOMER_ORDER()
for $CUSTOMER_ORDER_LINE_ITEM in ns28:getCUSTOMER_ORDER_LINE_ITEM($CUSTOMER_ORDER)
return $CUSTOMER_ORDER
};To complete this simple example you would need to add elements from the related data service to your return type and complete your mappings, as well as any transformations.
The Group By node represents a single group by clause with zero or more grouping expressions. The top part of the Group By node defines variables available to the generated group by expression. The bottom part defines the grouping expression itself.
Group By expressions are often used with aggregation functions such as grouping customers by total sales. A for or let clause supports multiple group by elements.
You can generate a Group By node by right-clicking on any element in a for or let node and selecting Create Group By from the right-click menu.
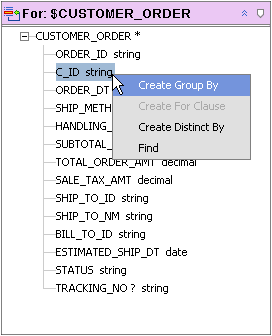
In Figure 6-24 output will be grouped by the C_ID (customer ID) element. Once a GroupBy node is created, mappings to target objects — such as the return type — are done through the new node.
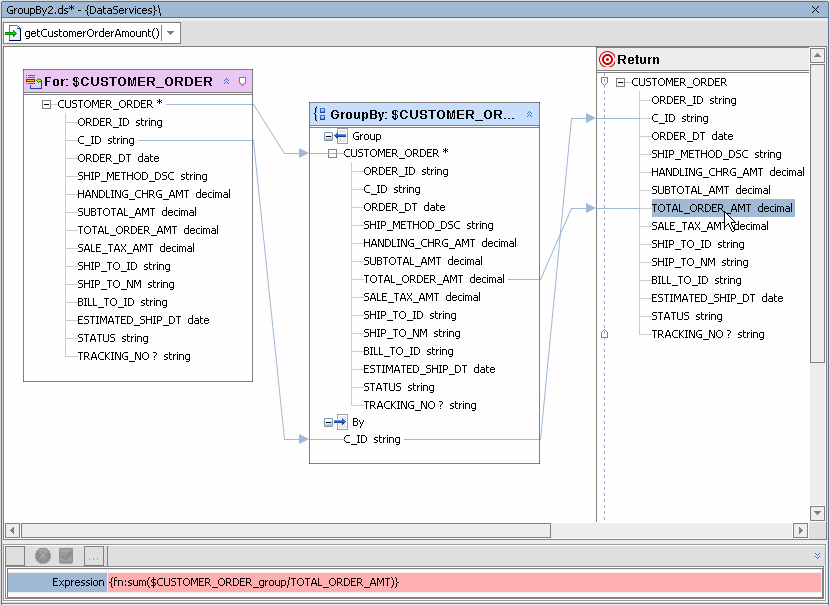
The default name of the group by node will be a unique name based on the local name of the for/let node. Thus the CUSTOMER_ORDER for clause becomes the basis for CUSTOMER_ORDER_group0. Group By nodes cannot be renamed from the XQuery Editor.
As seen in Figure 6-25, any node mappings are automatically transferred to the Group By node.
declare function tns:getCustomerOrderAmount() as element(ns5:CUSTOMER_ORDER)* {
for $CUSTOMER_ORDER in ns6:CUSTOMER_ORDER()
group $CUSTOMER_ORDER as $CUSTOMER_ORDER_group by $CUSTOMER_ORDER/C_ID as $C_ID_group
return
<ns5:CUSTOMER_ORDER>
<ORDER_ID></ORDER_ID>
<C_ID>{fn:data($C_ID_group)}</C_ID>
<ORDER_DT></ORDER_DT>
<SHIP_METHOD_DSC></SHIP_METHOD_DSC>
<HANDLING_CHRG_AMT></HANDLING_CHRG_AMT>
<SUBTOTAL_AMT></SUBTOTAL_AMT>
<TOTAL_ORDER_AMT>{fn:sum($CUSTOMER_ORDER_group/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
<SALE_TAX_AMT></SALE_TAX_AMT>
<SHIP_TO_ID></SHIP_TO_ID>
<SHIP_TO_NM></SHIP_TO_NM>
<BILL_TO_ID></BILL_TO_ID>
<ESTIMATED_SHIP_DT></ESTIMATED_SHIP_DT>
<STATUS></STATUS>
<TRACKING_NO?></TRACKING_NO>
</ns5:CUSTOMER_ORDER>
};If you delete a Group By node any mappings from the parent node will need to be redrawn.
In the example you can add additional grouping expressions simply by dragging new elements over the "By" separator, (Figure 6-26).
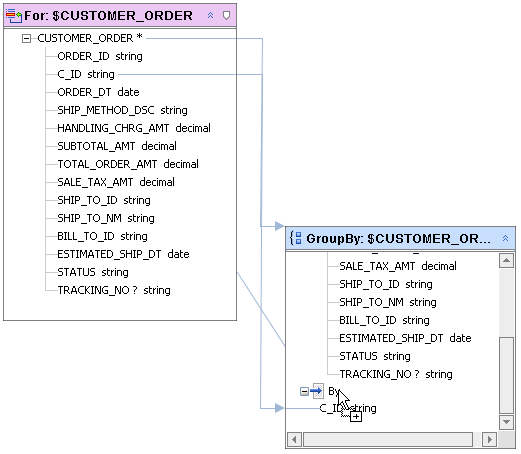
The act of dragging the element over an existing group by expression, adds a second group by expression, as shown in Figure 6-27.
The effect of adding the second group by in the above example is to group total orders by their status value.
<ORDER_ID/>
<C_ID>CUSTOMER0</C_ID>
<TOTAL_ORDER_AMT>1173.2</TOTAL_ORDER_AMT>
<STATUS>CLOSED</STATUS>
</ns0:CUSTOMER_ORDER5>
<ns0:CUSTOMER_ORDER5 xmlns:ns0="ld:DataServices/ApparelDB/CUSTOMER_ORDER5">
<ORDER_ID/>
<C_ID>CUSTOMER0</C_ID>
<TOTAL_ORDER_AMT>436.3</TOTAL_ORDER_AMT>
<STATUS>OPEN</STATUS>
</ns0:CUSTOMER_ORDER5>
<ns0:CUSTOMER_ORDER5 xmlns:ns0="ld:DataServices/ApparelDB/CUSTOMER_ORDER5">
<ORDER_ID/>
You can create additional multiple Group By expressions to enable creation of logic such as:
In order to do this you need to introduce an additional for or let clause to establish the parent-child structure that will support the needed logic.
To creating a second-level group by:
And, when you mouse over the new child element, it will be highlighted, indicating that it is a zone unto itself.
You can use Test View to verify your work.
The Distinct By node represents a single distinct by clause.
Several types of conditions can be graphically applied to for and let clauses. You can create these conditions using a multifunction editor that appears at the bottom of XQuery Editor work area. (Figure 6-28).
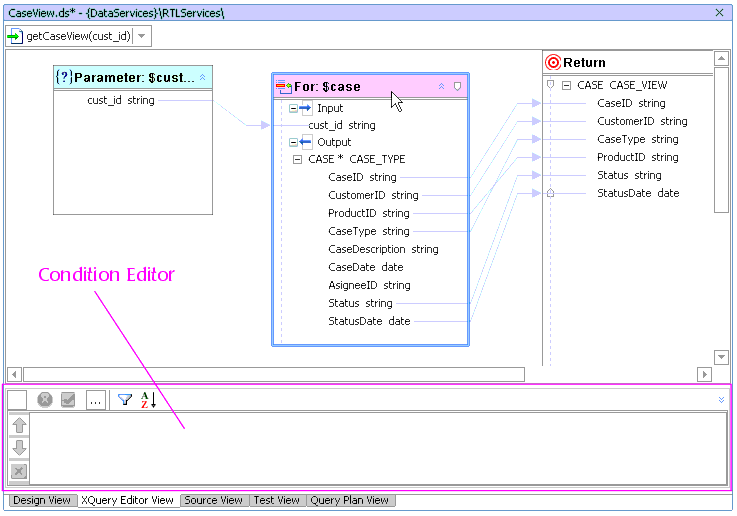
To add or modify constraints for a for or let node first select the node, then click anywhere in the multifunction editor. Everything but your selected expression will become unavailable, as indicated by the "grayed out" appearance of unselected objects.
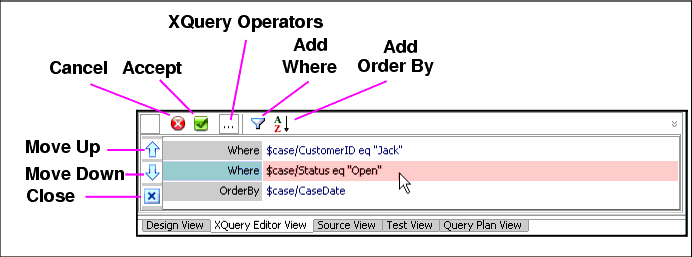
Figure 6-29 provides a closer look at the multifunction dialog which includes the ability to:
Functions from the XQuery Function Palate can be dragged into the multifunction box and then edited.
The where clause places a condition on a for and/or let clause. A where clause can be any query expression, including another FLWR expression. The where clause typically filters the number of matches in a FLWR loop.
A common use of the where clause is to specify a join between two sources. For example, consider the following query:
<results>
{
for $x in (1, 2, 3), $y in (2, 3, 4)
where $x eq $y
return
<matches>{$x}</matches>
}
</results>
The where clause in this query filters (or joins or constraints) the results that match two sequences specified in the for clause. In this case, the numbers 2 and 3 match, and the query returns the following results:
<results>
<matches>2</matches>
<matches>3</matches>
</results>
To effect this in the XQuery Editor you would select the for or let clause to which the where condition applies. Then, in the where condition field, you enter:
$x eq $y
You can type in the name of an element or drag it from the a node in the work area into the multifunction editor.
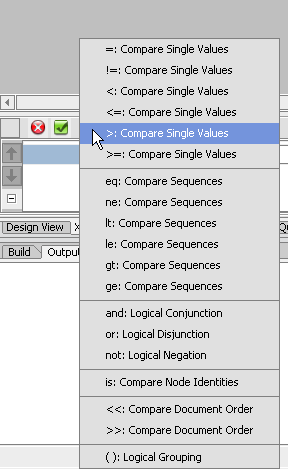
The eq XQuery operator can be entered directly or selected from the conditional pop-up list (Figure 6-30).
Here is a more complete example involving an XQuery function (see Using XQuery Functions). It involves finding all customers whose first name is Jack.
The following example illustrates the use of a where clause in the multifunction editor:
Windows Data Services Palette) select the CUSTOMER() function from the CustomerDB/CUSTOMER data service; drag it into the work area.You can create a valid XML type (schema file) for your new data service by associating your return type with your data service. The name of the global element in your return type or the alias assigned to the namespace or both needs to be changed because there already is a schema named CUSTOMER that was based on the physical data source you started with. (For details on Save and Associate see Creating a Simple Data Service Function.)
If you change the name field CUSTOMER to CUSTOMER_WHERE and click Ok you will notice that the name of the complex element in your return type will change.
$CUSTOMER/FIRST_NAME eq "Jack"
Notice that the clause becomes red whenever your expression is invalid.
See also Using the Parameter Dialog to Create a WHERE Clause.
The order by clause indicates output order for a given set of data.
Unless otherwise specified, the order data appears will follow the XML tree. This is known as the document order. The order by keyword indicates that the content should be sorted in ascending order by the identified element(s).
XQuery keywords such as descending are supported. For example, an XQuery can be written that orders the customers by last name in descending order:
for $customer in document('customers.xml')//customer
order by last_name descending
return
<customer>
{$customer/first_name}
{$customer/last_name}
</customer>
...In the XQuery Editor you would select the for or let clause to which the order by condition applies and in the order by condition field enter:
last_name descending
You can type in the name of an element or drag it from the work area into the multifunction editor Figure 6-29.
Join conditions are represented as equality relationships in where clauses. Therefore you can create such an equality relationship by dragging and dropping the eq function onto a row in the Conditions tab and then selecting two source elements/attributes into the same row.
AquaLogic Data Services Platform contains a full set of built-in XQuery functions. Most XQuery functions in the XQuery Function Palette are standard XQuery functions supported by the W3C. However, there are several BEA-specific functions as well as several extensions to the language. (For details on the BEA implementation of the 1.0 XQuery engine see XQuery Developer's Guide. For more detailed information on standard XQuery functions, see the W3C XQuery 1.0 and XPath 2.0 Functions and Operators specification.)
The functions available from the XQuery Functions palette help you create conditions around for and let clauses. XQuery functions can be used in several contexts:
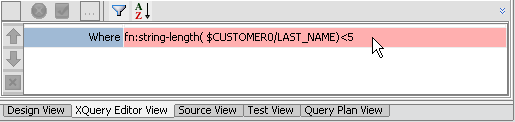
To create a where clause condition that filters customers a query returns you can follow these steps:
Windows XQuery Function Palette).Where fn:string-length($CUSTOMER/LAST_NAME)<5 as the predicate so the string appears as:Where fn:string-length($i/ORDERID)>5If you mouse over the title of your for clause, you can see that the condition has been associated with the fragment. You can also verify this change in source view.
When you run the function only records with LAST_NAMEs shorter than five characters will appear.
Automatic type casting generally ensures that input parameters used in functions and mappings are appropriate to the function in which they are used.
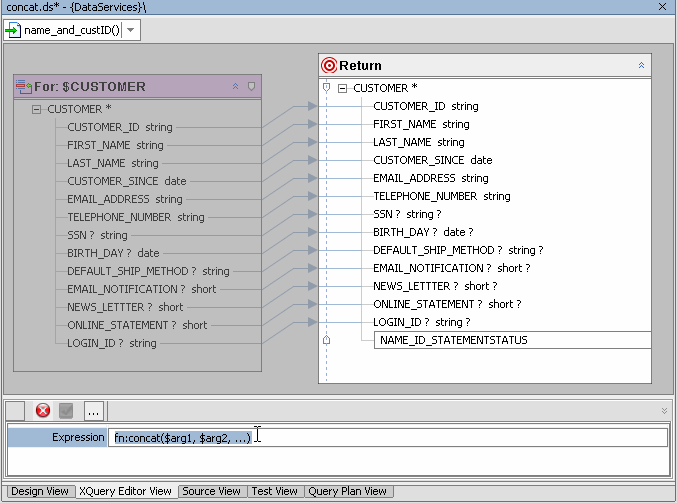
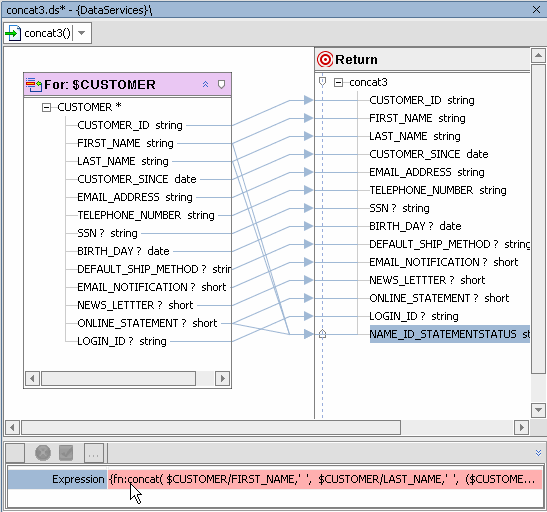
There are many transformational XQuery functions. In the following example the concat() function is used to quickly enrich data returned from a physical data service by adding functionality to the expression associated with an element returned by the function.
When your editing is complete, the XQuery function will appear as:
{fn:concat( $CUSTOMER/FIRST_NAME, ' ',$CUSTOMER/LAST_NAME,' | ',($CUSTOMER/ONLINE_STATEMENT cast as xs:string),' (online=1; printed=0)')}Notice also (Figure 6-35) how the new functionality is reflected in the source-to-target mapping.
<NAME_ID_STATEMENTSTATUS>
Jack Black | 1 (online=1; printed=0)
</NAME_ID_STATEMENTSTATUS>
The Expression editor is most commonly used to edit return type expressions. For example, if the return type contains:
ORDERID xsd:int
The editor can be used to limit the scope of the expression to a single customer:
Expression>{fn:data($o/ORDERID)} eq "1001"Prototypes of functions available from the XQuery Function Palette can be dragged into the editor or you can use the build-in line editor to enter them yourself.

Operation of the Expression editor is similar to that for the multifunction box. When you select a element other workspace artifacts are grayed out. However, you can drag elements from any part of the work area into the Expression Editor.
XQuery operators are available as a drop down list, as shown in Figure 6-30, or you can simply type them in.
If you think of selected data elements as nouns (what you want to work on), the functions as verbs (the action), then the mapping among the data elements creates a logical sentence that expresses the query.
Results and query performance can change significantly depending on how you:
Although you can simply type in an XQuery and run it from Test View, the more common way to create a query is build it up through the following operations:
| Note: | Some operations are not deterministic. For example if a node has elements mapped to a return type, deleting the node before removing the mappings may create error conditions. Instead you can use Undo and then delete the mappings or you can make the necessary changes in Source View. |
Mapping elements involves establishing a visual relationship between data source elements and the return type or an intermediary node requiring input parameters.
There are two types of schema elements: simple and complex. Complex elements contain elements and/or attributes.

To expand a complex element, click on the plus sign (+) to the left of its name. (If you double click on the name itself, you will enter edit mode.)
As shown in Creating a Simple Data Service Function, the XQuery Editor automatically generates queries based on graphical mappings into a return type.
The XQuery Editor supports two types of mappings: value mappings and complex element mappings. Value mappings map (assign) only the value of an element or attribute from a source to the value of its target element or attribute. Element mappings allow mapping source elements (simple or complex) to target.
In order to map an element to a return type, that element needs to be in scope. If the element you are attempting to map is not in scope, a message will appear indicated that the mapping is invalid (see XX). Invalid mappings occur whenever the underlying for or let statement would not be able to validly handle the association of the data element(s) with the return type schema.
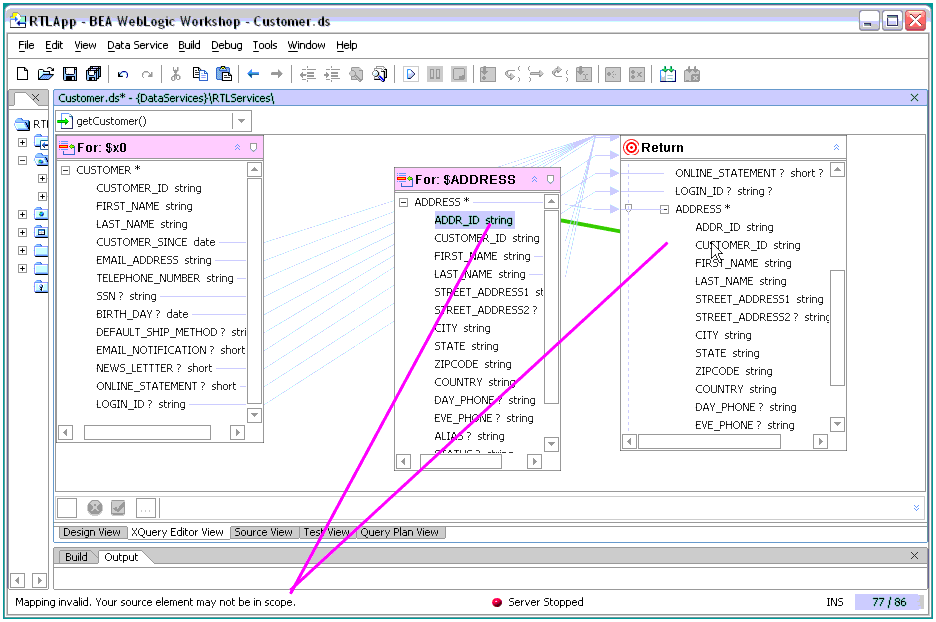
For more information on element scoping and other related issues see XML Types and Return Types and Editing XML Types and Return Types.
A questionmark symbol [?] next to an element name represents an optional element, meaning that it is not required by the query. Primary keys are never optional.
You can rapidly map complex elements from source to your return type. This known as an induced mapping is useful where all or part of the return type should match source representations.
There are many situations when you will find it convenient to map elements into your type, including:
If the match is not exact, mapping a complex element to your return type will be appended.
There are several benefits of mapping or projecting elements:
Figure 6-39 shows the results of the mapping of a complex element to a return type.

| Note: | You cannot map multiple elements to a single target element. |
Three source-to-return type gesture mappings are available — value mappings, overwrite mappings, and append mappings.
The following code expresses the results of an induced mapping:
declare function tns:newFunction() as element(ns5:CREDIT_CARD)* {
for $CREDIT_CARD in tns:getCreditCard()
return
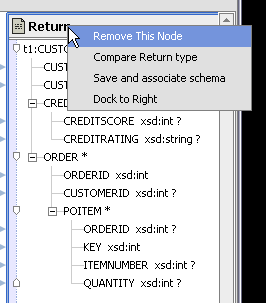
$CREDIT_CARDIn many cases an induced mapping is insufficient either for further building your query function or running it. You can always expand an induced mapping by right-clicking on the element in the return type and selecting the only available option: Expand Complex Elements.
In the above case the source would be correspondingly modified:
declare function tns:newFunction() as element(ns5:CREDIT_CARD)* {
for $CREDIT_CARD in tns:getCreditCard()
return
<ns5:CREDIT_CARD>
<CreditCardID>{fn:data($CREDIT_CARD/CreditCardID)}</CreditCardID>
<CustomerID>{fn:data($CREDIT_CARD/CustomerID)}</CustomerID>
<CustomerName>{fn:data($CREDIT_CARD/CustomerName)}</CustomerName>
<CreditCardType>{fn:data($CREDIT_CARD/CreditCardType)}</CreditCardType>
<CreditCardBrand>{fn:data($CREDIT_CARD/CreditCardBrand)}</CreditCardBrand>
<CreditCardNumber>{fn:data($CREDIT_CARD/CreditCardNumber)}</CreditCardNumber>
<LastDigits>{fn:data($CREDIT_CARD/LastDigits)}</LastDigits>
<ExpirationDate>{fn:data($CREDIT_CARD/ExpirationDate)}</ExpirationDate>
<Status?>{fn:data($CREDIT_CARD/Status)}</Status>
<Alias?>{fn:data($CREDIT_CARD/Alias)}</Alias>
<AddressID>{fn:data($CREDIT_CARD/AddressID)}</AddressID>
</ns5:CREDIT_CARD>
};| Note: | Any changes you make to a return type should be propagated to your data services XML type using the Save and Associate XML Type right-click option, available from the return type titlebar. |
You can delete mappings between elements by selecting the mapping line (link) and pressing Delete. Alternatively, use the Delete key.
The shape of the information returned by your query is determined by its return type. Using a combination of mapping techniques and return type options you can:
You should only modify a return type if you intend to propagate the change to the data service's XML type using the Save and Associate XML Type command, described in Creating a Simple Data Service Function.
You can edit your return type by right-clicking any element. Editing options for a type in the XQuery Editor are somewhat different options described in Editing an XML Type. For example, in a return type you can create zones automatically add for clauses to your query, allowing for a "master-detail" arrangement of results.
| Caution: | While it is possible to modify a return type and run a query in an manner, problems will likely arise when your application calls a query with a mismatch between the return clause and the XML type of the data service. |
Table 6-41 describes notable return type editing options.
|
If the elements are in a zone the query will return them in a master-detail arrangement. See Setting Zones in Your Return Type.
|
|
A special option, Expand Complex Mappings, is becomes available for use with Induced mappings. See Complex Element Mappings to a Return Type for details.
There are several things to keep in mind when making changes to a return type:
Save All command in WebLogic Workshop.
You can add a complex child element to a return type by selecting a schema and identifying a global element (a type). Complex child elements incorporate data service schemas (.xsd file) into the return type.
To add a complex global element to your return type:
| Note: | When you add a complex child element it will be place at the end of its peers in the return type. |
In AquaLogic Data Services Platform return types zones identify how query results will be arranged. Adding or changes zones through the XQuery Editor is the same as adding or changing the order of subordinate for statements in Source View. (For a detailed example of building a logical data service that makes use of zones to create a nested master-detail arrangement of data see Creating a Simple Data Service Function.
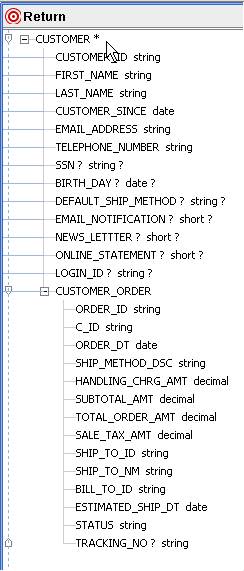
For example in Figure 6-42 the CUSTOMER_ORDER elements for a particular customer will be grouped under that customer.

By default, return types have only a single zone. However, without additional zones elements simply repeat in their natural order. In the simple example shown in Figure 6-42 this would mean that if a customer had more than one order, both the customer information and the order information would be repeated it your report until all matching orders had appeared.
The following slightly simplified XML illustrates a single-zone approach.
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERNAME>Supermart</CUSTOMERNAME>
<ORDER>
<ORDERID>632</ORDERID>
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERNAME>Supermart</CUSTOMERNAME>
<ORDER>
<ORDERID>888</ORDERID>
<CUSTOMERID>987655</CUSTOMERID>
..
Notice the repetition of CUSTOMERNAME and CUSTOMERID.
XQuery source for a similar function clearly shows why this is:
for $CUSTOMER in ns0:CUSTOMER()
for $CUSTOMER_ORDER in ns1:CUSTOMER_ORDER()
where $CUSTOMER/CUSTOMER_ID = $CUSTOMER_ORDER/C_ID
return <ns2:CUSTOMER7>
<CUSTOMER_ID>{fn:data($CUSTOMER/CUSTOMER_ID)}</CUSTOMER_ID>
<LAST_NAME>{fn:data($CUSTOMER/LAST_NAME)}</LAST_NAME>
<ns1:CUSTOMER_ORDER>
<ORDER_ID>{fn:data($CUSTOMER_ORDER/ORDER_ID)}</ORDER_ID>
<C_ID>{fn:data($CUSTOMER_ORDER/C_ID)}</C_ID>
<TOTAL_ORDER_AMT>{fn:data($CUSTOMER_ORDER/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
</ns1:CUSTOMER_ORDER>
</ns2:CUSTOMER7>
If you were, however, to create a repeatable zone around the CUSTOMER_ORDER element, a subordinate for clause will be introduced in Source View.
for $CUSTOMER in ns0:CUSTOMER()
return <ns2:CUSTOMER7>
<CUSTOMER_ID>{fn:data($CUSTOMER/CUSTOMER_ID)}</CUSTOMER_ID>
<LAST_NAME>{fn:data($CUSTOMER/LAST_NAME)}</LAST_NAME>{
for $CUSTOMER_ORDER in ns1:CUSTOMER_ORDER()
where $CUSTOMER/CUSTOMER_ID = $CUSTOMER_ORDER/ORDER_ID
return
<ns1:CUSTOMER_ORDER>
<ORDER_ID>{fn:data($CUSTOMER_ORDER/ORDER_ID)}</ORDER_ID>
<C_ID>{fn:data($CUSTOMER_ORDER/C_ID)}</C_ID>
<TOTAL_ORDER_AMT>{fn:data($CUSTOMER_ORDER/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
</ns1:CUSTOMER_ORDER>
}
</ns2:CUSTOMER7>
Specifically the highlighted where clause in the second code fragment mandates that all orders be collected under a single instance of customer.
To create a zone simply right-click on an element and select Mark as Zone. Once created, the zone will appear highlighted whenever you move your cursor into areas under its control (Figure 6-42).
In XQuery for, let, and group by clauses can enclose other for, let, or group by clauses. Similarly, nodes representing these constructs can be associated with return type zones using the create zone icon in the titlebar of the node (see Figure 6-10 in the XQuery Editor example at the beginning of this chapter). Simply drag the icon over an existing zone to associate the node with the zone.
To verify that the operation is successful mouse-over the zone icon after the association is complete. If successful, the appropriate zone will be highlighted (see Figure 6-42). Alternatively, look at Source View to verify that your operation has been successful or simply run your query under Test View.
| Note: | The order in which you create zones and other aspects of your XQuery in the XQuery Editor can be significant. For example, zones should be created before creating a where clause associating two nodes. |
To remove a zone, right-click on the parent element in the zone and select the Remove Zone option.
You can make changes in your function's return type and, optimally, bring your data service into conformance with the changes that you have made.
Several right-click menu options are available for managing the return type, including:
Notice in the following example that two new child elements have been added to the return type.
Elements differences detected when comparing the return type with the content of the XML type are shown in red. This includes elements you have deleted from the return type as well as those you have added to the return type.
The addition of DESCRIPTION to the return type is shown in blue in Figure 6-45.
The arrows to the left of changed items indicate whether the change is originating locally in the return type () or in the data service's XML type ( ).
This command can also be used to save the revised return type to a schema, schema location, target Namespace, or root name that is different than that used by the containing data service.
When you are building a return type from data service functions it is sometimes necessary to change either the namespace or the root name prior to using the Save and Associate Schema command. This is because the qualified name of your return type will initially be the same as the function used to create the return type.


|