|
SP - Using Inverse Functions to Improve Query Performance
This page last changed on Jun 30, 2008.
edocs Home > BEA AquaLogic Data Services Platform 3.0/3.2/3.01 Documentation
Using Inverse Functions to Improve Query Performance
This topic introduces the concept of inverse functions, and explains how you can use reverse transformations to improve query performance. Topic MapOverviewWhen designing and implementing data services, one of the principal goals is to provide a set of abstractions that enable client applications to see and manipulate integrated enterprise data in a clean, unified, meaningful, canonical form. Doing so invariably requires transforming data, which can include restructuring and unifying the schemas and the instance-level data formats of the disparate data sources. In such cases, names may be reformatted, addresses normalized, and differences in units reconciled, among other operations, to provide application developers (the consumers of data services) with a natural and easily manipulable view of the underlying data. Such transformations, while highly useful to the end consumers of the data, can lead to performance challenges when retrieving underlying data. When the resulting data is queried, it is crucial for performance that much of the query processing (especially for selections and joins) be pushable to the underlying sources, particularly to relational data sources. This requires updates to the transformed view of the data to be translatable back into appropriate source updates. Unfortunately, if data transformations are written in a general-purpose programming language, such as Java, both of these requirements can be difficult. This is because, unlike user-written XQuery functions, such general-purpose functions are opaque to the ALDSP query and update processors. The Inverse Function SolutionTo solve this issue, ALDSP enables data service developers to register inverse functions with the system, enabling you to define and use general user-defined data transformations without sacrificing query pushdown and updatability. Using this information, ALDSP is able to perform a reverse transformation of the data when analyzing query predicates or attempting to decompose updates into underlying data source updates. This means that you can use inverse functions to retain the benefits of high-performance data processing for your logical data without giving up application-oriented convenience data functions. In addition, inverse functions enable automated updates without the need to create Java update overrides.
Understanding Invertible FunctionsThe thing to keep in mind when creating inverse functions is that the functions you create need to be truly invertible. For example, in the following case date is converted to a string value: public static String dateToString(Calendar cal) { SimpleDateFormat formatter; formatter = new SimpleDateFormat("MM/dd/yyyy hh:mm:ss a"); return formatter.format(cal.getTime()) ; } However, notice that the millisecond value is not in the return string value. You get data back but you have lost an element of precision. By default, all values projected are used for optimistic lock checking, so a loss of precision can lead to a mismatch with the database's original value and thus an update failure. Instead the above code should have retained millisecond values in its return string value, thus ensuring that the data you return is exactly the same as the original value. How Inverse Functions Can Improve PerformanceHere are some additional scenarios where inverse functions can improve performance, especially when large amounts of data are involved:
You can use inverse functions in these and other situations to improve performance, especially when processing sizable amounts of data. A Closer LookConsider the case of a logical data service that has a fullname operation that concatenates firstname and lastname elements. It is clear that performance would be adversely affected when running the fullname operation against large data sets. The ideal would be to have a function or functions which decomposed fullname into its indexed components, passes the components to the underlying database, gets the results and reconstitutes the returned results to match the requirements of the fullname operation. In fact, that is the basis of inverse functions. Of course there are no XQuery functions to magically deconstruct a concatenated string. Instead you need to define, as part of your data service development process, custom functions that inverse engineer fullname. In many cases complimentary inverse functions are needed. For example, fahrenheitToCentigrade() and centigradeToFahenheit() would be inverses of each other. Complimentary inverse functions are also needed to support fullname. In addition to creating inverse functions, you also need to identify inverse functions when defining the data service. Related TopicsConceptsHow TosReferenceedocs Home > BEA AquaLogic Data Services Platform 3.0/3.2 Documentation > ALDSP 3.2 New Features Documentation Examining the Inverse Functions SampleThis topic describes how to define and configure inverse functions using the sample dataspace and Java function library as an example.
Topic Map
OverviewYou need to complete the following actions to use inverse functions:
Creating the Underlying Java FunctionsThe inverse functions sample includes logic to perform transformations between:
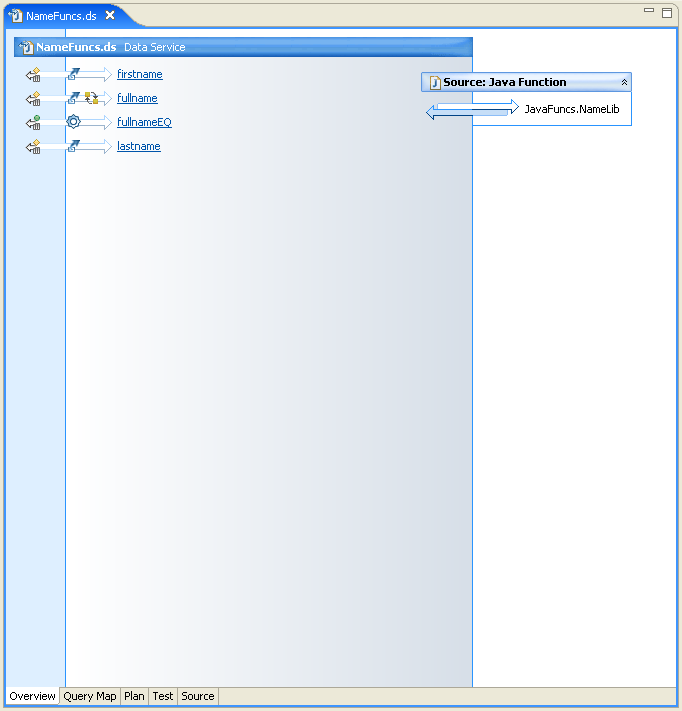
The string manipulation logic to manipulate first and last names needed by the inverse function is in the following Java file in the JavaFunctionLib project: JavaFunctionLib/JavaFuncs/NameLib.java This file defines three string manipulation functions. package JavaFuncs; public class NameLib { public static String fullname(String fn, String ln) { return (fn == null || ln == null) ? null : (fn + " " + ln); } public static String firstname(String name) { try { int sepidx = name.indexOf(' '); if (sepidx < 0) return null; return name.substring(0, sepidx); } catch (Exception e) { return null; } } public static String lastname(String name) { try { int sepidx = name.indexOf(' '); if (sepidx < 0) return null; return name.substring(sepidx+1, name.length()); } catch (Exception e) { return null; } } public static void main(String[] args) { String first = "John"; String last = "Doe"; String full = "John Doe"; System.out.println(fullname(first, last)); System.out.println(firstname(full)); System.out.println(lastname(full)); System.out.println(firstname(first)); System.out.println(lastname(first)); } } Notice that the function fullname() simply concatenates the first and last names. In contrast, the firstnname() and lastname() functions deconstruct the resulting full name using the required space in the full name string as the marker identifying the separation between first and last names. Or, put another way, the fullname() function is the invertible of firstname() and lastname(). Similar functions are available in the DeptLib and EmpIdLib packages supporting transformations between department names and numbers, and employee IDs and names respectively. Creating the Physical Data Services Based on the FunctionsAfter you have compiled the Java functions, you can create a physical data service from the resulting class file. In the sample, physical data services were created using the NameLib.class, DeptLib.class, and EmpIdLib.class files.
In the sample, the resulting operations corresponding to the string manipulation logic reside in the NameFunc.ds data service, as illustrated by the following: NameFunc.ds Data Service
Adding Comparison Logic to the Data ServiceAs is often the case, some additional programming logic is needed. In the case of the sample, a function, fullnameEQ(), compares names and returns a Boolean value indicating whether the names are identical. declare function f1:fullnameEQ($full1 as xs:string?, $full2 as xs:string?) as xs:boolean? {
(f1:firstname($full1)eq f1:firstname($full2)) and (f1:lastname($full1) eq f1:lastname($full2))
};
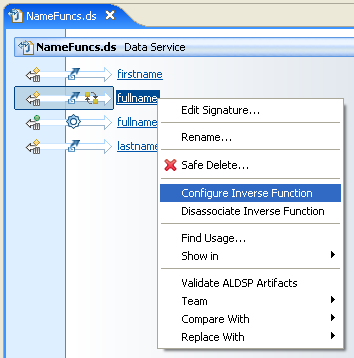
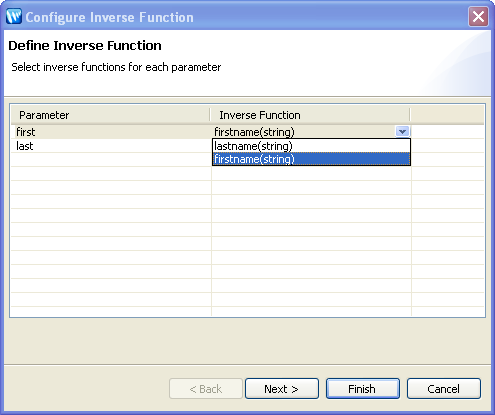
Configuring the Inverse FunctionsYou need to configure the inverse functions to perform the reverse transformation of the data. In this particular case, this means that you need to identify an inverse function for each parameter in the fullname() function.
To association the parameters of a function with inverse functions:
A dialog appears enabling you to select the inverse functions for each parameter.
Associating Custom Conditional Logic with Functions
Associating a particular conditional (such as "is greater-than") with a transformational function allows the XQuery engine to substitute the custom logic for a simple conditional. As is always the case with AquaLogic Data Services Platform, the original basis of the function does not matter. It could be created in your data service, or externally in a Java or other routine. In this example the transformational function, fullnameEQ, is in the Java-based physical data service.
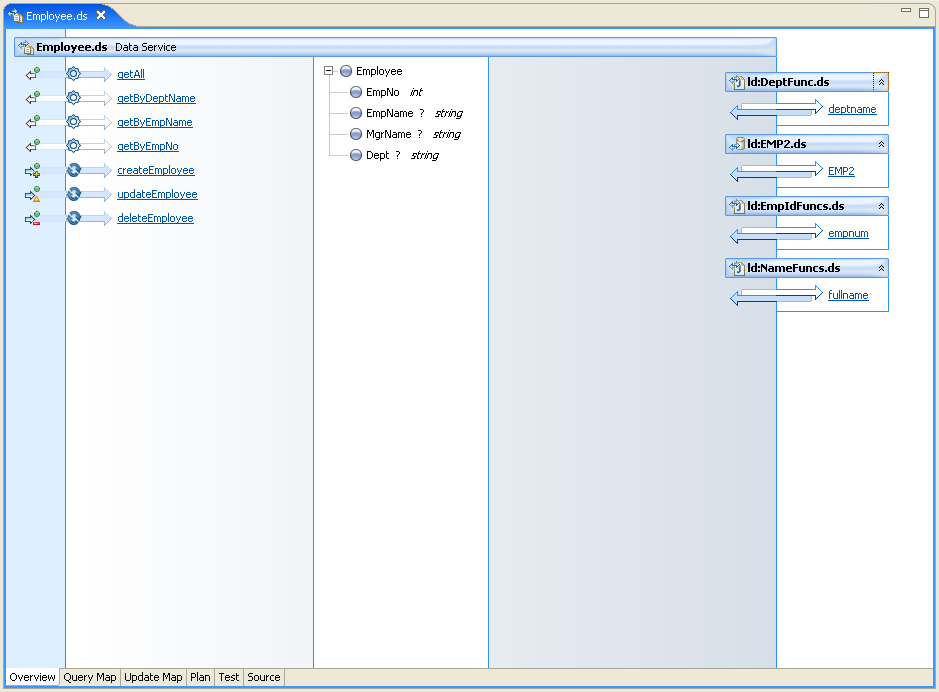
Create the Data ServiceThe final step is to build the data service that contains the operations to create, read, update, and delete the data. In the sample dataspace, this data service, Employee.ds, includes operations such as createEmployee, getAll, updateEmployee, and deleteEmployee. The data service also includes operations such as getByDeptName, getByEmpName, and getByEmpNo. The following shows the overview of the Employee.ds data service.
The data service uses XML types associated with the Employee.xsd schema. This schema could have been created through the XQuery Editor, through the ALDSP schema editor, or through a third-party editing tool. The getAll() operation returns all employee records, as shown in the following listing: declare function ns1:getAll() as element(ns1:Employee)* {
for $EMP2 in emp2:EMP2()
return
<tns:Employee>
<EmpNo>{emp1:empnum($EMP2/EmpId)}</EmpNo>
<EmpName?>{nam:fullname($EMP2/FirstName, $EMP2/LastName)}</EmpName>
<MgrName?>{fn:data($EMP2/MgrName)}</MgrName>
<Dept?>{dep:deptname($EMP2/Dept)}</Dept>
</tns:Employee>
};
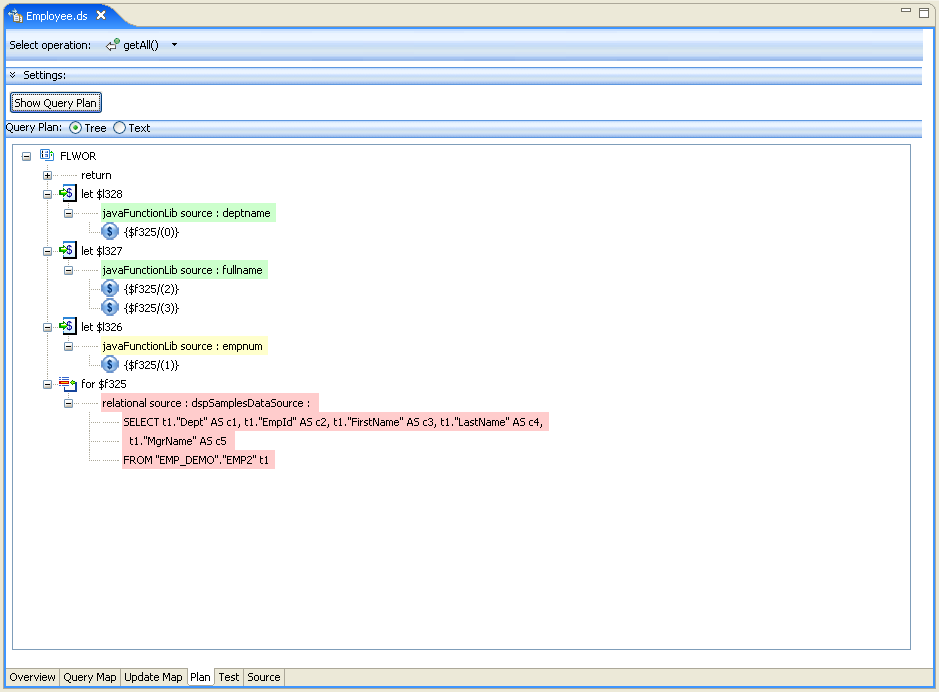
Examining the query plan for the getAll() operation, as shown in the following, you can see that predicates are being pushed despite data transformations, because of the use of inverse functions. Query Plan for the getAll Operation
The case is the same for the other read methods getByDeptName(), getByEmpName(), and getByEmpNo(). Examining the corresponding query plans, you can see that predicates are being pushed regardless of the specific transformations because of the corresponding inverse functions.
Related TopicsConceptsHow TosReferenceedocs Home > BEA AquaLogic Data Services Platform 3.0/3.2 Documentation > ALDSP 3.2 New Features Documentation How To Set Up the Inverse Functions SampleThis topic describes how to import and configure the ALDSP inverse functions sample dataspace project. Topic Map
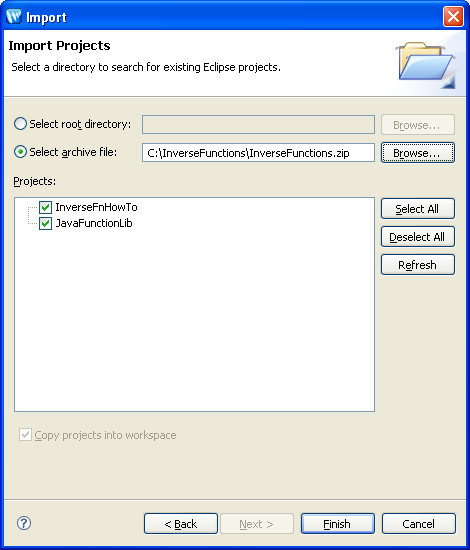
RequirementsYou can install and work with the inverse function sample on any system with ALDSP 3.2 (server 10.1) or ALDSP 3.0 or 3.01 (server 9.2) installed. The inverse function sample is available as a ZIP file from: It is recommended that the ZIP file be extracted into an ALDSP directory such as: <ALDSP_HOME>/user_projects/workspaces/default/InverseFunctionSample
Importing the Dataspace ProjectThe inverse functions sample consists of two projects:
To import the dataspace project:
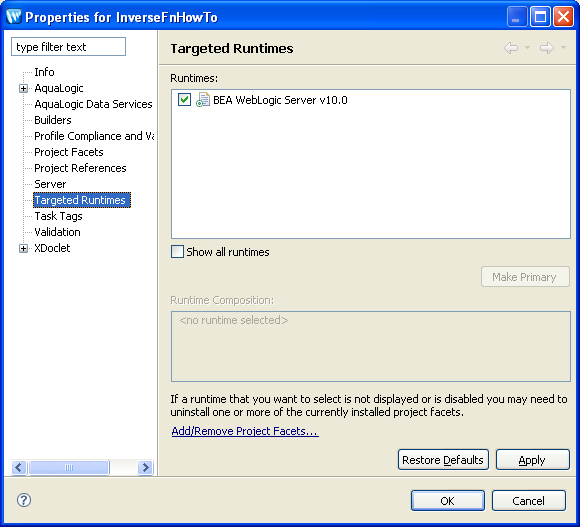
Assigning a Targeted RuntimeBefore examining the inverse functions sample, you need to start an ALDSP-enabled server and assigned a targeted runtime server to the project. To assign a targeted runtime:
Related topicsConceptsReferenceedocs Home > BEA AquaLogic Data Services Platform 3.0/3.2 Documentation > ALDSP 3.2 New Features Documentation Exploring the Inverse Functions SampleThis topic describes the components that comprise the inverse functions sample. Topic Map
Exploring the SampleThe inverse functions sample consists of two projects. Inverse Function Sample Projects
Inverse Function Projects
Exploring the ProjectsThis section describes the principal entities within the two projects that comprise the inverse functions sample. Exploring the InverseFnHowTo Dataspace ProjectThe following table describes the data services defined in the InverseFnHowTo dataspace project:
Exploring the JavaFunctionLib ProjectThe following table describes the data services defined in the JavaFunctionLib project:
Related TopicsConceptsHow Tos |
| Document generated by Confluence on Jul 03, 2008 12:12 |