

|
|
|
|
|
|
Scaling CORBA Java Server Applications
Using the JDBC Bankapp sample application as an example, this topic demonstrates scaling a WebLogic Enterprise CORBA Java application to increase its processing capability. This topic includes the following sections:
Before you begin, be sure to read Scaling WebLogic Enterprise Applications, for a comprehensive introduction to tuning and scaling WebLogic Enterprise applications. For information about building and running the JDBC Bankapp sample application, see the Bankapp Sample Using JDBC in the WebLogic Enterprise online documentation.
Note: Some of the Bankapp examples in this topic include sample code that is not implemented in the sample Bankapp files that ship with WebLogic Enterprise.
About Scaling the JDBC Bankapp Sample Application
This topic includes the following sections:
The primary design goal of the JDBC Bankapp sample application is to significantly increase the number of client applications it can accommodate by:
How the Application Has Been Scaled
To accommodate these design goals, the JDBC Bankapp sample application has been scaled by:
This makes these objects available on a per-client application (and not per-process) basis, thereby accommodating a parallel processing capability.
The sections that follow describe how the JDBC Bankapp sample application uses replicated server processes and server groups, object state management, and factory-based routing to meets it scalability goals.
Scaling with Object State Management
This section describes how object state management is used with the Teller objects in the Bankapp sample application to increase the application's scalability. For an introduction to object state management, see Using Object State Management.
For example, the Bankapp sample Teller object could use the method activation policy. The method activation policy assigned to this object means that the object is activated whenever a client request arrives for it. The Teller object remains in memory only for the duration of one client invocation, which is appropriate in cases where the Process-Entity design pattern is recommended. For more information about the Process-Entity design pattern, see the technical article Process-Entity Design Pattern.
As the number of clients issuing requests on the Teller object increases, WebLogic Enterprise can:
Scaling by Replicating Server Processes and Server Groups
This topic includes the following sections:
This topic describes how the BankApp server application was scaled by replicating server processes and server groups. For an introduction to this topic, see Replicating Server Processes and Server Groups.
Replicating Server Processes in the Bankapp Application
Figure 3-1 shows the Bankapp server application replicated in the BANK_GROUP1 group. The replicated servers are running on a single machine.
Figure 3-1 Replicated Servers in the Bankapp Sample
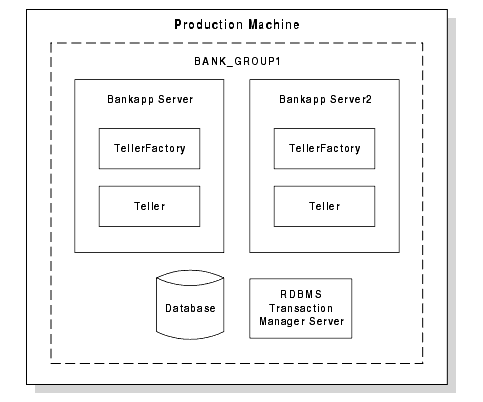
When a request arrives for this group, WebLogic Enterprise has several server processes available that can process the request, and WebLogic Enterprise can choose the server process that is the least busy.
In Figure 3-1, note the following:
Replicating Server Groups in the Bankapp Application
Figure 3-2 shows the Bankapp sample application groups replicated on another machine, as specified in the application's UBBCONFIG file.
Figure 3-2 Replicating Server Groups Across Machines
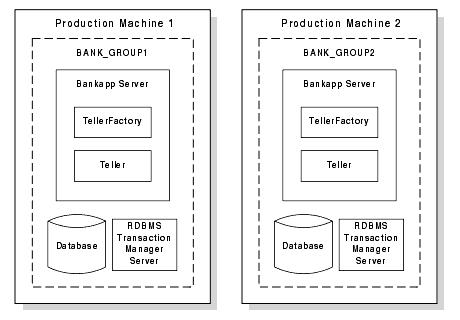
Note: In the simple example shown in Figure 3-2, the content of the databases on Production Machines 1 and 2 is identical. Each database contains all of the account records for all of the account IDs. Only the processing is distributed, based on the ATM (atmID field). A more realistic example would distribute the data and processing based on ranges of bank account IDs.
For more information about how the Bankapp sample application uses factory-based routing to distribute the application's processing load across multiple machines, see Scaling with Factory-based Routing.
Configuring Replicated Server Processes and Groups in the Bankapp Application
Listing 3-1 shows excerpts from the GROUPS and SERVERS sections of the UBBCONFIG file for a Bankapp sample application.
Note: These configuration settings are not used with the Bankapp sample provided with the WebLogic Enterprise software.
Listing 3-1 Excerpts from GROUPS and SERVERS Section of UBBCONFIG
*RESOURCES
IPCKEY 55432
DOMAINID simple
MASTER SITE1
MODEL SHM
LDBAL Y
*MACHINES
"TRIXIE"
LMID = SITE1
APPDIR = "c:\bankapp\jdbc\."
TUXCONFIG = "c:\bankapp\jdbc\.\tuxconfig"
TUXDIR = "c:\m3dir"
MAXCLIENTS = 10
*GROUPS
SYS_GRP
LMID = SITE1
GRPNO = 1
BANK_GROUP1
LMID = SITE1
GRPNO = 2
BANK_GROUP2
LMID = SITE1
GRPNO = 3
*SERVERS
# By default, restart a server if it crashes, up to 5 times
# in 24 hours.
#
DEFAULT:
RESTART = Y
MAXGEN = 5
# Start the Tuxedo System Event Broker. This event broker
# must be started before any servers providing the
# NameManager Service.
#
TMSYSEVT
SRVGRP = SYS_GRP
SRVID = 1
# TMFFNAME is a M3 provided server that runs the
# object-transactional management services. This includes the
# NameManager and FactoryFinder services.
# The NameManager service is a M3-specific service
# that maintains a mapping of application-supplied names to
# object references.
# Start the NameManager Service (-N option). This name
# manager is being started as a Master (-M option).
#
TMFFNAME
SRVGRP = SYS_GRP
SRVID = 2
CLOPT = "-A -- -N -M"
# Start a slave NameManager Service
#
TMFFNAME
SRVGRP = SYS_GRP
SRVID = 3
CLOPT = "-A -- -N"
# Start the FactoryFinder (-F) service
#
TMFFNAME
SRVGRP = SYS_GRP
SRVID = 4
CLOPT = "-A -- -N -F"
# Start the JavaServer in Bank_Group1
#
JavaServer
SRVGRP = BANK_GROUP1
SRVID = 5
CLOPT = "-A -- -M 10 BankApp.jar TellerFactory_1"
SYSTEM_ACCESS=FASTPATH
RESTART = N
# Start the JavaServer in Bank_Group2
#
JavaServer
SRVGRP = BANK_GROUP2
SRVID = 6
CLOPT = "-A -- -M 10 BankApp.jar TellerFactory_1"
SYSTEM_ACCESS=FASTPATH
RESTART = N
# Start the listener for IIOP clients
#
# Specify the host name of your server machine as
# well as the port. A typical port number is 2500
#
ISL
SRVGRP = SYS_GRP
SRVID = 7
CLOPT = "-A -- -n //TRIXIE:2468"
*SERVICES
*INTERFACES
"IDL:beasys.com/BankApp/Teller:1.0"
FACTORYROUTING=atmID
*ROUTING
atmID
TYPE = FACTORY
FIELD = "atmID"
FIELDTYPE = LONG
RANGES = "1-5:BANK_GROUP1,
6-10: BANK_GROUP2,
*:BANK_GROUP1
Scaling with Factory-based Routing
This topic includes the following sections:
This topic describes how the BankApp server application was scaled using factory-based routing. For an introduction to factory-based routing, see Using Factory-based Routing (CORBA only).
About Factory-based Routing in the Bankapp Application
You can use factory-based routing to expand the load-balancing and scalability features of WebLogic Enterprise. In the Bankapp sample application, you can use factory-based routing to send requests to a subset of ATMs to one machine, and requests for another subset of ATMs to another machine. As you increase your application's processing capability, you can easily modify the factory-based routing in your application to add more machines.
The primary design consideration regarding implementing factory-based routing in the Bankapp sample application is in choosing the value on which routing is based. The following sections describe how factory-based routing works in the JDBC Bankapp sample application. Client application requests to the Teller object are routed based on a teller number:
Configuring Factory-based Routing in the UBBCONFIG File
The UBBCONFIG file must specify the following data in the INTERFACES and ROUTING sections, as well as how groups and machines are identified.
Listing 3-2 Sample INTERFACES Section
*INTERFACES
"IDL:beasys.com/BankApp/Teller:1.0"
FACTORYROUTING = atmID
Listing 3-2 shows the fully qualified Interface Repository ID for an interface in the extended Bankapp sample in which factory-based routing is used. The FACTORYROUTING identifier specifies the name of the routing value, atmID.
Table 3-1 Parameters Specified in the ROUTING Section
Parameter Description TYPE Specifies the type of routing. In the Bankapp sample, the type of routing is factory-based routing. Therefore, this parameter is defined as FACTORY. FIELD Specifies the name that the factory inserts in the routing value. In the extended Bankapp sample, the field parameter is atmID. FIELDTYPE Specifies the data type of the routing value. In the Bankapp sample, the field type for atmID is LONG. RANGES Specifies the values that are routed to each group.
Listing 3-3 shows the ROUTING section of the UBBCONFIG file used in the Bankapp sample application.
Listing 3-3 Sample ROUTING Section
*ROUTING
atmID
TYPE = FACTORY
FIELD = "atmID"
FIELDTYPE = LONG
RANGES = "1-5:BANK_GROUP1,
6-10: BANK_GROUP2,
*:BANK_GROUP1
Listing 3-3 shows that Teller object references for ATMs in one range are routed to one server group, and Teller object references for ATMs in other ranges are routed to other groups. As shown in Figure 3-2, BANK_GROUP1 and BANK_GROUP2 reside on different production machines.
Implementing Factory-based Routing in a Factory
Factories implement factory-based routing in the way in which the invocation to the com.beasys.Tobj.TP.create_object_reference method is implemented.
Listing 3-4 shows the Java binding for this operation.
Listing 3-4 Java Binding for create_object_reference
public static org.omg.CORBA.Object
create_object_reference(java.lang.String interfaceName,
java.lang.String stroid,
org.omg.CORBA.NVList criteria)
throws InvalidInterface,
InvalidObjectId
The criteria specifies a list of named values that can be used to provide factory-based routing for the object reference. The use of factory-based routing is optional and is dependent on this argument. Instead of using factory-based routing, you can pass a value of 0 (zero) for this argument. To implement factory-based routing in a factory, you need to build the NVlist.
As stated previously, the TellerFactory object in the Bankapp sample application specifies the value atmID. This value must exactly match the following information in the UBBCONFIG file:
Note: Listing 3-5 is not part of the Bankapp sample code, but is included here to illustrate factory-based routing. The TellerFactory object inserts the bank account number into the NVlist using the following code.
Listing 3-5 Sample of Factory-Based Routing
// Put the atmID (which is the routing criteria)
// into a CORBA NVList. The atmID comes from the
// tellerName that is passed in as an input parameter;
// tellerName should have the form: Teller<atmID>
int atmID = Integer.parseInt (tellerName.substring(6));
any.insert_long(atmID);
// Create the NVlist and add the atmID to the list.
org.omg.CORBA.NVList criteria = TP.orb().create_list(1);
criteria.add_value("atmID", any, 0);
// Create the object reference.
org.omg.CORBA.Object teller_oref =
TP.create_object_reference(
BankApp.TellerHelper.id(), // Repository ID
tellerName, // Object ID
criteria // Routing Criteria
);
When you implement factory-based routing in a factory, WebLogic Enterprise generates an object reference. The following example shows how the client application gets an object reference to a Teller object when factory-based routing is implemented:
When the client application subsequently invokes an object using the object reference, WebLogic Enterprise routes the request to the group specified in the object reference.
Note: If you use the process-entity design pattern, you should use caution in how you implement factory-based routing. The object can service only those entities that are contained in the group's database.
Additional Design Considerations
This topic includes the following sections:
About the Additional Design Considerations
When designing the Teller object, you should ensure that:
These objects must have unique object IDs (OIDs) and must be method-bound (that is, they must have the method activation policy assigned to them).
Instantiating the Teller Object
Because the extended Bankapp server is now replicated, the WebLogic Enterprise domain must have be able to differentiate among multiple instances of the Teller object. For example, if there are two Bankapp server processes running in a group, WebLogic Enterprise must be able to distinguish between a Teller object running in the first Bankapp server process and a Teller object running in the second Bankapp server process. To distinguish multiple instances of these objects, each object instance must be unique.
To make each Teller object unique, the factories for those objects must change the way in which they make object references to them. For example, when the TellerFactory object in the original Bankapp sample application created an object reference to the Teller object, the com.beasys.Tobj.TP::create_object_reference method specified an OID that consisted only of the string tellerName. However, in the extended Bankapp sample application discussed in this chapter, the same create_object_reference method uses a generated unique OID instead.
As a result of giving each Teller object a unique OID, multiple instances of these objects may be running simultaneously in the WebLogic Enterprise domain. This characteristic is typical of the stateless object model, and is an example of how the WebLogic Enterprise domain can be highly scalable while it offers high performance.
Finally, because unique Teller objects need to be brought into memory for each client request on them, it is critical that these objects be deactivated when the invocations on them are completed so that any object state associated with them does not remain idle in memory. The Bankapp server application addresses this issue by assigning the method activation policy to the Teller object in the XML-based Server Description File.
Ensuring That Account Updates Occur in the Correct Server Group
The primary scalability advantage of using replicated server groups is being able to distribute processing across multiple machines. However, if your application interacts with a database, which is the case with the JDBC Bankapp sample application, it is critical that you consider the impact of these multiple server groups on the database interactions.
In many cases, you may have one database associated with each machine in your deployment. If your server application is distributed across multiple machines, you must consider how you set up your databases.
The JDBC Bankapp sample application uses factory-based routing to send one set of requests to one machine, and another set to the other machine. How factory-based routing is implemented in the TellerFactory object depends on how references to Teller objects are created.
Scaling the Application Further
In the future, the system administrator of the Bankapp sample application may want to add capacity to the WebLogic Enterprise domain. For example, the bank may eventually have a large increase in automated teller machines (ATMs). This can be done without modifying or rebuilding the application.
The system administrator can continually add capacity by:
The system administrator must modifying the UBBCONFIG file to specify the additional groups, the server processes that run in those groups, and the machines on which they run.
For example, instead of routing to the four groups shown earlier in this chapter, the system administrator can modify the routing rules in the UBBCONFIG file to partition the application further among the new groups added to the WebLogic Enterprise domain. Any modification to the routing tables must be consistent with any changes or additions made to the server groups and machines configured in the UBBCONFIG file.
Note: If you add capacity to an application that uses a database, you must also consider the impact on how the database is set up, particularly when you are using factory-based routing. For example, if the Bankapp sample application is distributed across six machines, the database on each machine must be set up appropriately and in accordance with the routing tables in the UBBCONFIG file.

|

|

|
|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|