Release 11g (11.1.1)
Part Number E13881-01
Contents
Previous
Next
| Oracle Fusion Middleware Report Designer's Guide for Oracle Business Intelligence Publisher Release 11g (11.1.1) Part Number E13881-01 | Contents | Previous | Next |
This appendix covers the following topics:
This section describes techniques available to improve performance when your report generates very large PDF output files. The techniques discussed in this chapter are:
This section describes how to reuse static, repeating content in your PDF report output to reduce the overall PDF file size. This section contains the following topics:
What Is Static Content Reuse?
Limitations of This Feature
Defining Reusable Content in an RTF Template
Example
If your report contains static content and the placement of that content in the report is also fixed (for example, a set of instructions on the back of a Federal W-2 form), you can use this feature of BI Publisher to reduce the size of the generated PDF file.
Using the W-2 form as an example, the report has the following expected output:
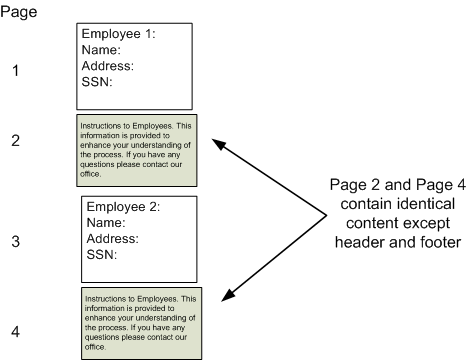
For each employee, specific content is rendered, but the back (or second) page of each contains an identical set of instructions.
This set of instructions can be defined as reusable static content. When content is identified as reusable static content, BI Publisher will include the static content in the generated PDF document only once and reference it in other places when needed, thereby reducing the overall output file size.
This feature has the following limitations:
The static content to be reused in the generated report must fit onto one page of the generated PDF output.
The contents of the report before the static content must have a fixed height. For example, the W-2 form has a fixed set of fields that occur before the static content is to be rendered. The reusable static contents are placed in the same position from the page origin for each occurrence.
This feature can only be used with RTF templates generating PDF output.
To define the static content to be reused, use the following tags around the content in your template as follows:
<?reusable-static-content:?>…. static content here …
<?end reusable-static-content?>Inserting these tags around the static content signals BI Publisher to include this content only once in the generated file and then reference it in the same position for each occurrence.
The following example illustrates an implementation of this feature. The sample report generates one occurrence per employee. The generated report will have employee-specific information on the front page of each occurrence, and static instructions that will print on the back of each occurrence. A section break will occur after each employee to reset page numbering.
The following illustrates this template structure:

When generating PDF output, BI Publisher does not limit the size of the output file. However, when the size of the file approaches 2 GB, Adobe Acrobat Reader may no longer be able to open or handle the file.
BI Publisher provides a feature to split a large PDF output file into smaller, more manageable files, while still maintaining the integrity of the report as one logical unit.
When PDF output splitting is enabled for a report, the report is split into multiple files generated in one zip file. The output type is PDFZ. For easy access to the component files, BI Publisher also generates an index file that specifies from and to elements contained in each component PDF file.
To enable this feature, the report designer must set up the report using the methods described in this section.
This feature is supported only for PDF output that is generated from an RTF template or a PDF template.
Data set input to the report must be flat XML data (that is, ROWSET/ROW). The data set cannot be hierarchical or concatenated.
The data set must be sorted by the element designated as the "repeat" element (as described below).
To enable report splitting, the report designer must determine the following:
Select a "repeat" element that will serve as the counter.
Determine how many instances of the repeat element will occur per PDF file.
Select which data elements to include in the generated index file.
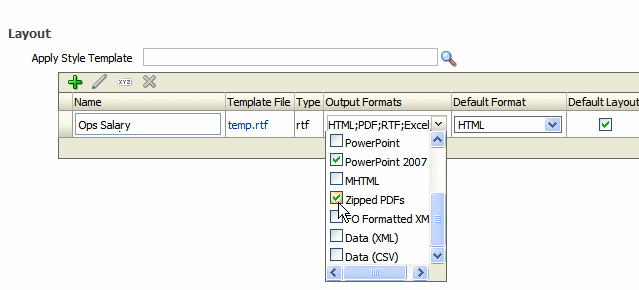
After uploading the template to the report definition, enable Zipped PDFs as an output type:
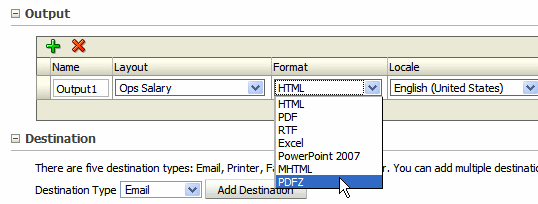
When scheduling the report, select PDFZ as the output type.
This section describes how to enable PDF splitting for reports generated from RTF templates. This section includes the following topics:
Entering the Commands in Your RTF Template
Examples
When you design your template to use this feature, you must add commands to specify the following:
What element in the data will be repeated (using the simple for-each command)
How many occurrences of the element will be included in each PDF file
What information (data elements) to include in the index file
To achieve this, the following two commands must be entered in your template within the for-each loop of the element by which you want the document to split:
<?catalog-index-info:name;element_name?>
where
name is the name you choose that will be used in the index file to identify the from and to records included in each document.
element_name is the XML tag name of the element that will provide the value for name that you identify above.
The catalog-index-info command defines the construction of the index file that is created.
<?if:position() mod n = 0?><?document-split:?><?end if?>
where
n is the number of records you want included per PDF file.
This command must be placed within the for-each loop of the element that is to be counted. This command instructs BI Publisher to split the document after the next page break when the number of records equals the value you have suppled for n.
Each time the document-split is performed, the name-value pairs defined in the catalog-index-info command will be written to the index files.
This example is based on the following XML data:
<DATA_DS>
<G_EMP>
<DEPARTMENT_NAME>Sales</DEPARTMENT_NAME>
<FIRST_NAME>Ellen</FIRST_NAME>
<LAST_NAME>Abel</LAST_NAME>
<HIRE_DATE>1996-05-11T00:00:00.000-07:00</HIRE_DATE>
<SALARY>11000</SALARY>
</G_EMP>
<G_EMP>
<DEPARTMENT_NAME>Sales</DEPARTMENT_NAME>
<FIRST_NAME>Sundar</FIRST_NAME>
<LAST_NAME>Ande</LAST_NAME>
<HIRE_DATE>2000-03-24T00:00:00.000-08:00</HIRE_DATE>
<SALARY>6400</SALARY>
</G_EMP>
<G_EMP>
<DEPARTMENT_NAME>Shipping</DEPARTMENT_NAME>
<FIRST_NAME>Mozhe</FIRST_NAME>
<LAST_NAME>Atkinson</LAST_NAME>
<HIRE_DATE>1997-10-30T00:00:00.000-08:00</HIRE_DATE>
<SALARY>2800</SALARY>
</G_EMP>
<G_EMP>
<DEPARTMENT_NAME>IT</DEPARTMENT_NAME>
<FIRST_NAME>David</FIRST_NAME>
<LAST_NAME>Austin</LAST_NAME>
<HIRE_DATE>1997-06-25T00:00:00.000-07:00</HIRE_DATE>
<SALARY>4800</SALARY>
</G_EMP>
...
</DATA_DS>In this example, the output PDF report includes a document for each employee. You want a new PDF file generated for each department. You want the index to list the FIRST_NAME and LAST_NAME from each record that is included in the PDF file.
To achieve this output, enter the following in your template
<?for-each-group:ROW;./DEPARTMENT_NAME?>
<?for-each:current-group()?>
<?catalog-index-info:'First Name';FIRST_NAME?>
<?catalog-index-info:'Last Name';LAST_NAME?>
...
<?end for-each?>
<?document-split:?>
<?end for-each-group?>This section describes the commands required in a PDF template to split the output into multiple PDF files.
To enable this feature for a PDF template, enter the following three form fields in your template with the specified commands in the "Tooltip" field:
| Form Field Name | Tooltip Command |
|---|---|
| REPEAT-ELEMENT | <?repeat-element:element name?> where element_name is the XML tag name of the repeating element that will be counted. Example: <?repeat-element:emp_id?> |
| CATALOG-INDEX-INFO | <?catalog-index-info:'Name';element_name?> where 'Name' is the label that will appear in the index file for the element_name that you specify. The index will generate a "From" and "To" listing for each file in the zipped set. Example: <?catalog-index-info:'Last Name';LAST_NAME?> Note that you can include multiple occurrences of the catalog-index-info command to include multiple data elements in the index file. |
| SPLIT-COUNT | <?split-count:n?> where n is the number of occurrences of the repeat-element that will trigger the creation of a new file. Example: <?split-count:10000?> |
![]()
Copyright © 2004, 2010, Oracle and/or its affiliates. All rights reserved.