11g Release 1 (11.1.1.5.0)
Part Number E20386-01
Contents
Previous
Next
|
Oracle® Fusion
Applications Order Orchestration Implementation Guide 11g Release 1 (11.1.1.5.0) Part Number E20386-01 |
Contents |
Previous |
Next |
This chapter contains the following:
Data Collections, Order Orchestration, and Order Promising: How They Fit Together
Collecting Data for the Order Orchestration and Planning Data Repository: Explained
Data Collection Entities: Explained
Data Collection Methods for External Source Systems: Explained
Data Collection Methods for the Oracle Fusion Source System: Explained
Refreshing the Global Order Promising Engine: Explained
Manage Planning Data Collection Processes
Perform Planning Data Collections
Review Planning Collected Data
You perform data collections to populate the order orchestration and planning data repository. The collected data is used by Oracle Fusion Distributed Order Orchestration and Oracle Fusion Global Order Promising.
The following figure illustrates that the order orchestration and planning data repository is populated with data from external source systems and from the Oracle Fusion source system when you perform data collections. Oracle Fusion Distributed Order Orchestration uses some reference data directly from the repository, but the Global Order Promising engine uses an in-memory copy of the data. After data collections are performed, you refresh the Global Order Promising data store with the most current data from the data repository and start the Global Order Promising server to load the data into main memory for the Global Order Promising engine to use. When Oracle Fusion Distributed Order Orchestration sends a scheduling request or a check availability request to Oracle Fusion Global Order Promising, the Global Order Promising engine uses the data stored in main memory to determine the response.

You perform data collections to populate the order orchestration and planning data repository with data from external source systems and from the Oracle Fusion source system.
Oracle Fusion Distributed Order Orchestration uses some reference data directly from the order orchestration and planning data repository. You must perform data collections for the order orchestration reference entities even if you are not using Oracle Fusion Global Order Promising.
The Global Order Promising engine uses an in-memory copy of the data from the order orchestration and planning data repository. When Oracle Fusion Distributed Order Orchestration sends a scheduling request or a check availability request to Oracle Fusion Global Order Promising, the Global Order Promising engine uses the data stored in main memory to determine the response to send back to order orchestration. After a cycle of data collections is performed, you refresh the Global Order Promising data store with the most current data from the data repository and start the Global Order Promising server to load the data into main memory for the Global Order Promising engine to use.
The order orchestration and planning data repository provides a unified view of the data needed for order orchestration and order promising. You manage data collection processes to populate the data repository with data collected from external source systems and from the Oracle Fusion source system. You manage the data collection processes to collect the more dynamic, transaction data every few minutes and the more static, reference data on a daily, weekly, or even monthly schedule. The data collected into the data repository contains references to data managed in the Oracle Fusion Trading Community Model and to data managed in the Oracle Fusion Product Model. The data managed in these models is not collected into the order orchestration and planning data repository.
The following figure illustrates that the order orchestration and planning data repository is populated with data collected from external source systems and from the Oracle Fusion source system. The data repository does not contain data managed by the Oracle Fusion Trading Community Model and the Oracle Fusion Product Model. The data collected into the data repository references data managed in the models.
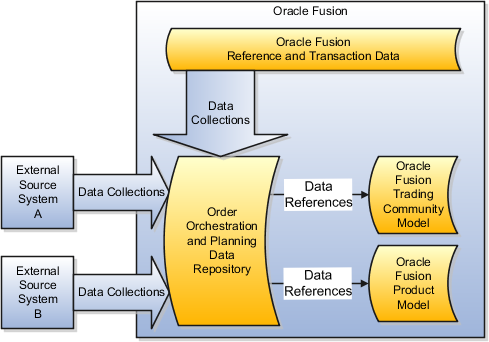
When you plan and implement your data collections, you determine which entities you collect from which source systems, the frequency of your collections from each source system, which data collection methods you will use to collect which entities from which source systems, and the sequences of your collections. Consider these categories of data when you plan your data collections:
Data collected for order promising
Data collected for order orchestration
Data not collected into the order orchestration and planning data repository
The following data is collected and stored to support order promising:
Existing supply including on-hand, purchase orders, and work orders
Capacity including supplier capacity and resource capacity
Related demands including work order demands and work order resource requirements
Planned supply including planned buy and make orders
Reference data including calendars, transit times, and routings
Important
After performing data collections, you must refresh the Order Promising engine to ensure it is using the data most recently collected.
The following data is collected and stored to support order orchestration:
Order capture and accounts receivable codes
Accounting terms and currencies
Tip
Use the Review Planning Collected Data page or the Review Order Orchestration Collected Data page to explore many of the entities and attributes collected for the order orchestration and planning data repository.
Data collected into the order orchestration and planning data repository includes attributes, such as customer codes, that refer to data not collected into the data repository. Most of the data references are to data in the Oracle Fusion Trading Community Model or in the Oracle Fusion Product Model. Some of the data references are to data outside the models, such as item organizations and inventory organizations. To manage data collections effectively, especially the sequences of your collections, you must consider the data dependencies created by references to data not collected into the data repository.
References to data in the Oracle Fusion Trading Community Model include references to the following:
Source systems
Geographies and zones
Customers
Customer sites
References to data in the Oracle Fusion Product Model include references to the following:
Items, item relationships, and item categories
Item organization assignments
Structures
For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
When you collect data for the order orchestration and planning data repository, you specify which of the data collection entities to collect data for during each collection. When you plan your data collections, you plan which entities to collect from which source systems and how frequently to collect which entities. One of the factors you include in your planning considerations is the categorizations of each entity. One way entities are categorized is as reference entities or transaction entities. You typically collect transaction entities much more frequently than reference entities.
Another way entities are categorized is as source-specific entities or global entities. For global entities the order in which you collect from your source systems must be planned because the values collected from the last source system are the values that are stored in the data repository.
When you plan your data collections, you consider the following categorizations:
Source-specific entities
Global entities
Reference entities
Transaction entities
You also consider which entities can be collected from which types of source systems using which data collection methods as follows:
Entities you can collect from the Oracle Fusion source system and from external source systems
Entities you can collect only from external source systems
When you collect data for a source-specific entity, every record from every source system is stored in the order orchestration and planning data repository. The source system association is maintained during collections. The data stored in the data repository includes the source system from which the data was collected.
For example, you collect suppliers from source system A and source system B. Both source systems contain a record for the supplier named Hometown Supplies. Two different supplier records will be stored in the data repository for the supplier named Hometown Supplies. One record will be the Hometown Supplies supplier record associated with source system A and the second record will be the Hometown Supplies supplier record associated with source system B.
The majority of the data collections entities are source-specific entities.
When you collect data for a global entity, only one record for each instance of the global entity is stored in the order orchestration and planning data repository. Unlike source-specific entities, the source system association is not maintained during collections for global entities. The data stored in the data repository for global entities does not include the source system from which the data was collected. If the same instance of a global entity is collected from more than one source system, the data repository stores the values from the last collection.
For example, you collect units of measure (UOM) from three source systems and the following occurs:
During the collection of UOM from source system A, the Kilogram UOM is collected.
This is first time the Kilogram UOM is collected. The Kilogram record is created in the data repository.
During the collection of UOMs from source system B, there is no collected UOM with the value = Kilogram
Since there was no record for the Kilogram UOM in source system B, the Kilogram record is not changed.
During the collection of UOMs from source system C, the Kilogram UOM is also collected.
Since the collections from source system C include the Kilogram UOM, the Kilogram record in the data repository is updated to match the values from source system C.
The following entities are the global entities:
Order orchestration reference objects
Units of measure (UOM) and UOM conversions
Demand classes
Currency and currency conversion classes
Shipping methods
Tip
When you collect data for global entities from multiple source systems, you must consider that the last record collected for each occurrence of a global entity is the record stored in the order orchestration and planning data repository. Plan which source system you want to be the source system to determine the value for each global entity. The source system that you want to be the one to determine the value must be the source system that you collect from last.
Reference entities are entities that define codes and valid values that are then used regularly by other entities. Units of measure and demand classes are two examples of reference entities. Reference entities are typically static entities with infrequent changes or additions. Whether an entity is reference entity or a transaction entity does not impact how it is stored in the order orchestration and planning data repository.
You consider whether an entity is a reference entity or a transaction entity when determining which collection method to use to collect data for the entity. You typically use the staging tables upload method to collect data for reference entities from external source systems. You typically used the targeted collection method to collect data for reference entities from the Oracle Fusion source system unless the reference entity is one of the entities for which the targeted collection method is not possible.
Transaction entities are the entities in the data repository that store demand and supply data. Because the data for transaction entities changes frequently, you typically use the web services upload method to collect data for transaction entities from external source systems. You typically use the continuous collection method to collect data for transaction entities from the Oracle Fusion source system.
Many of the data collection entities can be collected from both types of sources systems. For the following entities you can use any of the collections methods:
Approved supplier lists
Calendars
Calendar associations
Interlocation shipping networks
Item costs
On hand
Organization parameters
Purchase orders and requisitions
Subinventories
Suppliers
Units of measure
For the following entities you can only use the Web service upload method to collect data from external source systems:
Currencies
Order orchestration reference objects
Shipping methods
Many of the data collection entities can be only collected from external sources systems. For these entities, you can use both methods for collecting data from external source systems. Remember to consider frequency of change and volume of data in your considerations of which methods to use to collect which entities. The following are the entities you can only collect from external sources systems:
Customer item relationships
Demand classes
Planned order supplies
Routings
Resources
Resource availability
Sourcing
Supplier capacities
Work-in-process supplies
Work-in-process component demands
Work-in-process resource requirements
To populate the order orchestration and planning data repository with data collected from external source systems, you use a combination of two data collection methods. The two methods are Web service uploads and staging tables uploads.
The following figure illustrates the two data collection methods, Web service uploads and staging tables uploads, used to collect data from external source systems. The figure illustrates that both methods require programs to be written to extract data from the external source systems. For Web service uploads, you load the data from the extracted data files directly into the order orchestration and planning data repository. Any records with errors or warnings are written to the data collections staging tables. For staging table uploads, you load the data from the extracted data files into the data collections staging tables, and then you use the Staging Tables Upload program to load the data from the staging tables into the data repository.
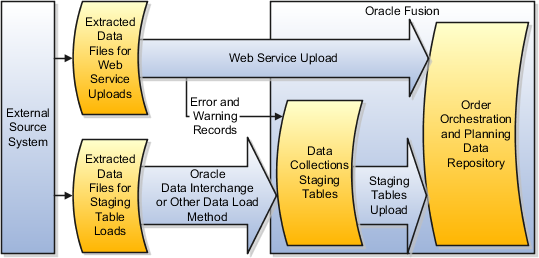
You determine which entities you collect from which source systems and at what frequency you need to collect the data for each entity. The data for different entities can be collected at different frequencies. For example, supplies and demands change frequently, so collect data for them frequently. Routings and resources, are more static, so collect data for them less frequently.
Which data collection method you use for which entity depends upon the frequency of data changes as follows:
Web service upload
Use for entities with frequent data changes.
Staging tables upload
Use for entities with more static data.
Use the Web service upload method for entities that change frequently, such as supply and demand entities. You determine the frequency of collections for each entity. For certain entities, you may implement Web services to run every few minutes. For other entities, you may implement Web services to run hourly.
To implement and manage your Web service uploads, you must design and develop the processes and procedures to extract the data in the format needed by the data collection web services. For more information regarding the data collection Web services, refer to the Oracle Enterprise Repository. For additional technical details, such as the table and column descriptions for the data collection staging tables, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
Use the staging tables upload method for entities that do not change frequently, such as routings and resources. You determine the frequency of collections for each entity. You may establish staging table upload procedures to run daily for some entities, weekly for some entities, and monthly for other entities.
To implement and manage your staging table uploads, you must develop the processes and procedures you use to extract data from an external source system. You use Oracle Data Interchange, or another data load method, to load the extracted data into the data collection staging tables. For the technical details required to develop and manage your data extracts and staging table loads, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
For the final step of the staging tables upload method, you initiate the Load Data from Staging Tables process from the Manage Data Collection Processes page or via the Enterprise Scheduling Service.
To populate the order orchestration and planning data repository with data collected from the Oracle Fusion source system, you use a combination of two data collection methods: continuous collection and targeted collection. You typically use continuous collection for entities that change frequently and targeted collection for entities that are more static.
The following figure illustrates the two data collection methods, continuous collection and targeted collection, used in combination to collect data from the Oracle Fusion source system.
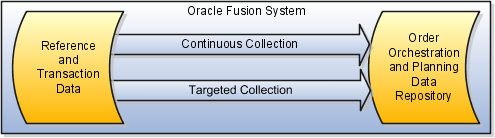
When you use the continuous collection method, you are only collecting incremental changes, and only for the entities you have included for continuous collection. Because continuous collection only collects incremental changes, you usually set up the continuous collection to run frequently, such as every five minutes.
Note
Prior to including an entity for continuous collection, you must have run at least one targeted collection for that entity.
When you collect data using the targeted collection method, you specify which entities to include in the targeted collection. For the included entities, the data in the data repository that was previously collected from the Oracle Fusion source system is deleted and replaced with the newly collected data. The data for the entities not included in the targeted collection is unchanged. You typically use the targeted collection method to collect data from entities that do not change frequently.
The Global Order Promising engine is an in-memory engine that uses an in-memory copy of the data collected into the order orchestration and planning data repository. To ensure the in-memory data reflects the latest supply and demand data collected into the data repository, you should refresh the Global Order Promising data store and start the Global Order Promising server at least once a day.
The following figure illustrates that you perform data collections to populate the order orchestration and planning data repository with current data from multiple source systems. After you complete a cycle of data collections, you refresh the Global Order Promising data store with the latest data from the data repository. After you refresh the Global Order Promising data store, you start the Global Order Promising server to load a copy of the refreshed data from the data store into main memory.
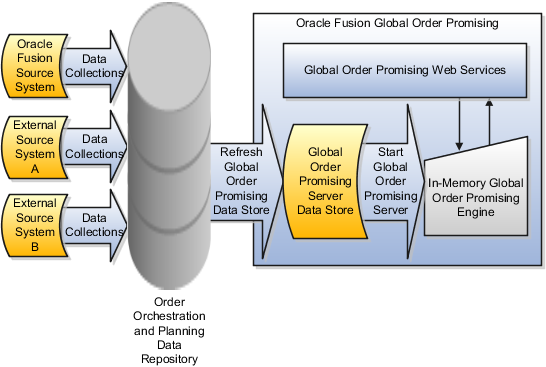
To refresh the in-memory copy of the collected data with the most recently collected data, perform these two steps:
Refresh the Global Order Promising data store.
Start the Global Order Promising server.
To refresh the Global Order Promising data store, complete these steps:
Navigate to the Schedule New Process page by following this navigation path:
Navigator
Tools
Schedule Processes
Schedule New Process
Click the more link
Select the Schedule Processes link.
Click the Submit New Request button.
In the popup window, select Job for the type.
Search for and select the process named RefreshOpDatastore.
Select the entities you want to refresh and submit the job.
To start the Global Order Promising server, you use an Oracle Fusion Global Order Promising instantiation of Oracle Enterprise Manager.
You do not need to stop the server before you start it. If the Global Order Promising server is already running when you start the Global Order Promising server, the Global Order Promising engine currently in memory continues to run until the start process is complete. The Start Global Order Promising Server process updates another engine with the current data from the Global Order Promising Server data store. When the updated engine comes up, the existing engine with the old data is automatically shut down.
Important
The Current Date attribute stored within the Global Order Promising engine is also updated when you start the Global Order Promising server. If the Global Order Promising engine is not updated at least once a day, the Global Order Promising engine may have a wrong current date, and there may be issues with promising results.
Note
You also use an Oracle Fusion Global Order Promising instantiation of Oracle Enterprise Manager to monitor performance of the Global Order Promising server, to access log files, and to stop the server when necessary.
For your data collections from the Oracle Fusion source system, you use the Manage Planning Data Collection Processes page or the Manage Orchestration Data Collection Processes page. From these pages you perform the following:
Manage your continuous collections from the Oracle Fusion source system.
Manage your collections destination server.
Perform your targeted collections from the Oracle Fusion source system.
For your data collections from external source systems, most of the management of your Web services uploads and staging tables uploads is performed external to the Oracle Fusion application pages. If you choose to perform staging tables uploads, you initiate the Perform Data Load process from the Manage Planning Data Collection Processes page, from the Manage Orchestration Data Collection Processes page, or from the Oracle Fusion Enterprise Scheduler.
To enable continuous collections, you must set up the publish data processes for the Oracle Fusion source system. The publish process performs the incremental data collections from the Oracle Fusion source system. You can start, stop, and pause the publish process. To review statistics regarding the publish process, view process statistics from the Actions menu on the Continuous Collection - Publish tab on the Manage Planning Data Collection Processes page or the Manage Orchestration Data Collection Processes page.
Note
Because continuous collections only collects net changes, you must perform at least one targeted collection for an entity before you include the entity for continuous collections.
You define the publish process parameters to determine the frequency and scope of the continuous collections publish process.
You define the frequency and scope of continuous collections by specifying the following:
Process Parameters
Process Entities
You determine how frequently the continuous collections publish process executes by specifying the frequency in minutes. The continuous collections publish process will publish incremental changes based on the frequency that was defined when the publish process was last started.
You determine which organizations will be included in the set of organizations for which data is collected by specifying an organization collection group. You can leave it blank if you want data collected from all organizations.
You determine which entities are collected during the continuous collections cycles by selecting which entities you want included in the collections. The continuous collections publish process collects incremental changes for the business entities that were included when the publish process was last started.
The collections destination server is applicable to all four data collection methods. For the continuous collections method the collections server is the subscriber to the continuous collections publish process. From the Actions menu on the Collections Destination Server tab you can access a daily statistic report with statistics regarding each of the collection methods. You also can access a data collections summary report.
The collection parameters are initially set to what was defined for the Oracle Fusion system when your planning source systems or order orchestration source systems were initially managed. You can fine tune the parameters for your data collections.
The data collection parameters affect the usage of system resources. This table define what each parameter does and provides guidelines for setting it.
|
Parameter |
What the Parameter Does |
A Typical Value for the Parameter |
|---|---|---|
|
Number of Database Connections |
Defines the maximum number of database connections the source server can create during the collection process. This controls the throughput of data being extracted into the Source Java program. |
10 |
|
Number of Parallel Workers |
Defines the maximum number of parallel workers (Java threads) used to process the extracted data. The number here directly impacts the amount of central processing units and memory used during a collection cycle. |
30 |
|
Cached Data Entries in Thousands |
During data collections, various lookup and auxiliary data are cached in the collection server to support validation. For example, currency rate may be cached in memory. This parameter controls the maximum number of lookup entries cached per lookup to prevent the server from occupying too much memory. |
10,000 |
When you collect data from multiple source systems, you often collect a variety of values for the same instance of an entity. You cross-reference data during data collections to store a single, agreed value in the order orchestration and planning data repository for each instance of an entity.
Caution
Cross-referencing data during data collections can impact the performance of your collections. For collections from external source systems, consider performing the cross-references as part of your processes to extract data into data files.
The following information explains why you might need to cross-reference your data during data collections, and what you need to do to implement cross-referencing:
Cross-reference example
Cross-reference implementation
The following table provides an example of why you might need to cross-reference your data during data collections. In the example, the Kilogram unit of measure is collected from two source systems. The source systems use a different value to represent kilogram. You decide to store kg for the value for Kilogram in the order orchestration and planning repository.
|
Source System |
Collections Entity |
Source Value |
Target Value |
|---|---|---|---|
|
System A |
Unit of measure |
kilogram |
kg |
|
System B |
Unit of measure |
k.g. |
kg |
To implement cross-referencing, you must complete the following actions:
Decide which business object to enable cross reference.
For each object, work with business analyst to decide value-to-value maps.
Use the Oracle Fusion Middleware Domain Value Map user interface to upload mappings to the corresponding domain value map.
On the Manage Planning Data Collection Processes page, enable the corresponding entity for cross-reference.
Determine an ongoing procedure for adding new values into the domain value map.
For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
The continuous collection data collection method is partially supported for item costs. Item costs are collected in the next incremental collection cycle for previously existing items when one or more item organization attributes in addition to item cost have changed.
When a new item is defined, the item cost for the new item is not collected in the next incremental collection cycle. If an existing item is not changed other than an update to the item cost, the item cost change is not picked up in the next incremental collection cycle.
Tip
If items are added frequently, item costs are changed frequently, or both, then targeted collection of item costs should be routinely performed, perhaps once a day.
To perform a data load from the data collection staging tables, you invoke the Perform Data Load from Staging Tables process. When you invoke the process, you provide values for the parameters used by the process
When you perform an upload from the staging tables, you specify values for a set of parameters for the Perform Data Load from Staging Tables process including specifying Yes or No for each of the entities you can load. For the parameters that are not just entities to select, the table below explains the name of each parameter, the options for the parameter values, and the effect of each option.
|
Parameter Name |
Parameter Options and Option Effects |
|---|---|
|
Source System |
Select from a list of source systems. |
|
Collection Type |
|
|
Group Identifier |
Leave blank or select from the list of collection cycle identifiers. Leave blank to load all staging table data for the selected collection entities. Select a specific collection cycle identifier to load data for that collection cycle only. |
|
Regenerate Calendar Dates |
|
|
Regenerate Resource Availability |
|
The parameters presented for the Perform Data Load from Staging Tables process also include a yes-or-no parameter for each of the entities you can collect using the staging tables upload method. If you select yes for all of the entities, the data collections will be performed in the sequence necessary to avoid errors caused by data references from one entity being loaded to another entity being loaded.
Important
If you do not select yes for all of the entities, you need to plan your load sequences to avoid errors that could occur because one of the entities being loaded is referring to data in another entity not yet loaded. For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
The collection cycle identifier is a unique number that identifies a specific data collection cycle, or occurrence. One cycle of a data collection covers the time required to collect the set of entities specified to be collected for a specific data collection method. The collection cycle identifier is then used in statistics regarding data collections, such as the Data Collection Summary report. The collection cycle identifier is also used for a parameter in various processes related to data collections, such as the Purge Staging Tables process and the Perform Data Load process.
This topic explains the population of the collection cycle identifier when you use collecting data from external source systems as follows:
Web Service Uploads and the Collection Cycle Identifier
Staging Tables Uploads and the Collection Cycle Identifier
When you use the Web service upload data collection method, a collection cycle identifier is included as part of the collected data. You can then use the collection cycle identifier to review statistics regarding the Web service collections, or to search for error and warning records written to the data collection staging tables.
If you use the Oracle Data Integrator tool to load your extracted data into the data collections staging tables, a collection cycle identifier is created for each load session. Each record loaded into the staging table during the load session will include the collection cycle identifier for that session.
If you populate the data collection staging tables using a method other than the Oracle Data Integrator tool, you must follow these steps to populate the collection cycle identifier.
Groupid is to be populated in column refresh_number of each data collections staging table. In one cycle of loading data into the staging tables, the column should be populated with same value. Get the group id value as follows:
SELECT ....NEXTVAL FROM DUAL;
After a cycle loading data into the data collections staging tables, insert a row as follows into table msc_cycle_status for that cycle as follows:
INSERT INTO MSC_COLL_CYCLE_STATUS
(INSTANCE_CODE, INSTANCE_ID, REFRESH_NUMBER, PROC_PHASE, STATUS, COLLECTION_CHANNEL, COLLECTION_MODE, CREATED_BY, CREATION_DATE, LAST_UPDATED_BY, LAST_UPDATE_DATE)
SELECT a.instance_code, a.instance_id, :b1, 'DONE', 'NORMAL',
'LOAD_INTERFACE', 'OTHER', 'USER', SYSTIMESTAMP, USER, SYSTIMESTAMP
FROM msc_apps_instances a
WHERE a.instance_code= :b2 ;
:b1 is instance_code for which data is loaded
:b2 is the groupid value populated in column refresh_number in all interface tables for this cycle
When you collect calendars and net resource availability from external source systems, you decide whether to collect individual dates or patterns. However, order promising requires individual calendar dates and individual resource availability dates to be stored in the order orchestration and planning data repository. If you collect calendar patterns or resource shift patterns, you must invoke concurrent processes to populate the order orchestration and planning data repository with the individual dates used by order promising.
You invoke the concurrent processes by specifying the applicable parameters when you run data collections. The concurrent processes generate the individual dates needed by order promising by using the collected patterns as input. The processes then populate the order orchestration and planning data repository with the individual calendar dates and the individual resource availability dates.
When you collect calendars from external source systems, you decide whether to collect calendar patterns or individual calendar dates. Both methods for collecting data from external source systems, Web service upload and staging tables upload, include specifying whether individual calendar dates must be generated as follows:
The Web service to upload to calendars includes a parameter to run the Generate Calendar Dates concurrent process.
You control whether the process will run. If the parameter is set to yes, then after the Web service upload completes, the process will be launched to generate and store individual calendar dates.
The parameters for the Perform Data Load from Staging Tables process also include a parameter to run Generate Calendar Dates.
You control whether the process will run. If the parameter is set to yes, then after the load from staging tables completes, the process will be launched to generate and store individual calendar dates.
In both scenarios, calendar data is not available while the Generate Calendar Dates concurrent request is processing.
When you collect calendars from the Oracle Fusion system, the Generate Calendar Dates concurrent process is run automatically.
Restriction
Only calendar strings that are exactly equal to seven days are allowed. Calendar strings with lengths other than seven are not collected. Only calendars with Cycle = 7 should be used.
When you collect net resource availability from external source systems, you decide whether to collect resource shift patterns or individual resource availability dates. Both methods for collecting data from external source systems, Web service upload and staging tables upload, include specifying whether individual resource availability dates must be generated as follows:
The Web service to upload to net resource availability includes a parameter to run the Generate Resource Availability concurrent process.
You control whether the process will run. If the parameter is set to Yes, then after the Web service upload completes, the process will be launched to generate and store individual resource availability dates.
The parameters for the Perform Data Load from Staging Tables process also include a parameter to run the Generate Resource Availability concurrent process.
You control whether the process will run. If the parameter is set to Yes, then after the load from staging tables completes, the process will be launched to generate and store individual resource availability dates.
In both scenarios, new resource availability data is not available while the Generate Resource Availability concurrent process is processing.
You cannot collect net resource availability from the Oracle Fusion source system.
To perform a targeted data collection from the Oracle Fusion system, you use the Perform Data Collection process. When you invoke the process, you provide values for the parameters used by the process.
When you perform a targeted collection, you specify the Oracle Fusion source system to be collected from and the organization collection group to collect for. When you invoke the process, the parameters also include each of the fourteen entities you can collect from the Oracle Fusion source system with yes or no for the parameter options. The table below explains the other two parameters.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
The source system presented for selection is determined by what system has been defined as the Oracle Fusion source system when the manage source systems task was performed. |
|
Organization Collection Group |
The organization collection groups presented for selection are determined by what organization groups were defined when the manage source systems task was performed for the selected source system. |
The parameters presented also include a yes-or-no parameter for each of the entities you can collect. If you select yes for all of the entities, the data collections will be performed in the sequence necessary to avoid errors caused by data references from one entity being loaded to another entity being loaded.
Important
If you do not select yes for all of your entities, you need to plan your load sequences to avoid errors that could occur because one of the entities being loaded is referring to data in another entity not yet loaded. For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
When you perform a targeted collection from the Oracle Fusion source system, you use an organization collection group to contain the collections processing to only the organizations with data that is needed for the order orchestration and planning data repository. Organization collection groups limit targeted collections from the Oracle Fusion source system to a specific set of organizations.
You perform the following actions for organization collection groups:
Define an organization collection group.
Use an organization collection group.
You define organization groups when managing source systems for the source system where the version equals Oracle Fusion. For each organization in the organization list for the Oracle Fusion source system, you can specify an organization group. You can specify the same organization group for many organizations.
You use an organization collection group when you perform a targeted collection from the Oracle Fusion source system and you want to contain the collections processing to a specific set of organizations. You specify which organization group to collect data from by selecting from the list of organization groups defined for the Oracle Fusion source system. Data will only be collected from the organizations in the organization group you specified.
For example, if only certain distribution centers in your Oracle Fusion source system are to be considered for shipments to your customers by the order promising and order orchestration processes, you could create a DC123 organization group and assign the applicable distribution centers to the DC123 organization group when managing source systems. When you perform a targeted collection for the Oracle Fusion source system, you could select DC123 for the organization collection group.
When you manage the data collection processes, you use the Process Statistics report and the Data Collection Summary report to routinely monitor your collections. When error records are reported, you query the data staging tables for further details regarding the error records. You can also review most of your collected data using the review collected data pages.
The following information sources are available for you to monitor data collections:
Process Statistics report
Data Collection Summary report
Review collected data pages
Staging table queries
You view the Process Statistics report to monitor summary of statistic for the daily collections activity for each of your source systems. This report is available on the Actions menu when managing data collection processes for either the continuous collection publish process or the collections destination server. The day starts at 00:00 based on the time zone of the collection server.
For the Oracle Fusion source system, statistics are provided for both the continuous collection and the targeted collection data collection methods. For each external source system, statistics are provided for the Web service upload and for the staging tables upload data collection methods. The following statistics are provided in the Process Statistics report:
Number of collection cycles for the current day
Average cycle time in seconds
Average number of records
Average number of data errors
Note
The process statistics provide summary information, and are not intended for detailed analysis of the collections steps. Use the Oracle Enterprise Scheduler Service log files for detailed analysis.
You view the Data Collection Summary report to monitor statistics regarding the data collection cycles for each of your source systems. The summary report shows last the results of the last 20 cycles of all collection types. This report is available on the Action menu when managing data collection processes for the collections destination server.
The Data Collection Summary report provides information for each source system. If a source system was not subject to a data collection cycle for the period covered by the summary, an entry in the report states that there are no cycles in the cycle history for that source system. For each source system that was subject to a data collection cycle for the period covered by the summary, the following information is provided for each data collection method and collected entity value combination:
The data collection method
The collection cycle number
The entity collected and, for that entity, the number of records collected, the number of records with data errors, and collection duration
Time started
Time ended
You can review most of your collected data by using the Review Planning Collected Data page or the Review Order Orchestration Collected Data page. Both pages include a list of entities from which you select to specify the entity for which you want to review collected data. The list of entities is the same on both pages. Most of the entities listed on the review collected data pages are identical to the entities you select from when you run collections, but there are a few differences.
Some of the entities on the list of entities you select from when you review collected data are a combination or a decomposition of the entities you select from when you run collections. For example, the Currencies data collection entity is decomposed into the Currencies entity and the Currency Conversions entity on the review collected data pages. For another example, the Supplies entity on the review collected data pages is a combination of data collection entities including the On Hand entity and the Purchase Orders and Requisitions entity.
A few of the data collection entities cannot be reviewed from the review collected data pages. The data collection entities that are not available for review on the review collected data pages are Resources, Resource Availability, Routings, Work-in-Process Resource Requirements, and Customer Item Relationships.
If errors or warnings have been encountered during data collections, you can submit queries against the staging tables to examine the applicable records. For more information regarding the staging tables and staging table columns, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
When you are collecting data from external source systems, the data collection processes perform many data validation checks. If the data validations fail with errors or warnings, the steps taken by the data collection processes vary slightly depending upon whether the Web service upload data collection method or the staging tables upload data collection method is used.
In both cases, records where errors are found are not loaded into the order orchestration and planning data repository. Instead records are loaded into, or remain in, the applicable staging tables with an appropriate error message. Records where only warnings are found are loaded to the data repository, and records are loaded into, or remain in, the applicable staging tables with an appropriate warning message.
The handling of errors and warnings encountered when the data collection processes validate data during collections from external source systems depends upon which data collection method is used, Web service upload or staging tables upload.
When you are running data collections using the Web services method, the following error and warning handling steps occur:
Errors: Records are loaded to the applicable staging tables instead of the data repository and are marked with the appropriate error message.
A record with an error due to mandatory missing mandatory fields, such as organization or supplier or item, is first marked as retry. After several unsuccessful retry attempts, the record will be marked as error.
Warnings: Records are loaded into the data repository and into the applicable staging tables with the appropriate warning message.
When you are running data collections using the staging tables upload method, the following error and warning handling steps occur:
Errors: Records remain in the staging tables without being loaded to the data repository and are marked with the appropriate error message.
A record with an error due to mandatory missing mandatory fields, such as organization or supplier or item, is first marked as retry. After several unsuccessful retry attempts, the record will be marked as error.
Warnings: Records are loaded into the data repository and remain in the staging tables with the appropriate warning message.
When a Planned Order Supplies record is collected, many validations occur for which an error is recorded if the validation fails.
For example, the supplier name is validated against the suppliers data in the order orchestration and planning data repository. If the supplier name is not found, the validation fails with an error condition, and the following steps occur:
The Planned Order Supplies record is not loaded into the data repository.
The Planned Order Supplies record is loaded into the applicable stating table, or remains in the applicable staging table, with an error message stating invalid supplier or invalid supplier site.
When a Planned Order Supplies record is collected, many validations occur for which a warning is recorded if the validation fails.
For example, the Firm-Planned-Type value in the record is validated to verify that the value is either 1 for firm or 2 for not firm. If the validation fails, the failure is handled as a warning, and the following steps occur:
The Planned Order Supplies record is loaded into the data repository with the Firm-Planned-Type value defaulted to 2 for not firm.
The Planned Order Supplies record is also loaded into the applicable stating table, or remains in the applicable staging table, with a warning message stating invalid firm planned type.
You use the Purge Data Repository Tables process to delete all collected data from the order orchestration and planning data repository that was collected from a specific source system. You use the Purge Staging Tables process to remove data that you no longer need in the data collections staging tables.
You use the Purge Data Repository process to delete all data for a source system from the order orchestration and planning data repository. The process enables you to delete data for a specific source system. You typically use the Purge Data Repository process when one of your source systems becomes obsolete, or when you decide to do a complete data refresh for a set of collection entities.
The Purge Data Repository process has only two parameters, both of which are mandatory. This table explains the two parameters.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
Select a source system for the list of source systems. All data for the selected system will be deleted from the data repository. |
|
Purge Global Entities |
Yes or No If you select yes, in addition to the applicable data being deleted for the source-specific entities, all data from global entities will also be deleted. If you select no, data will be deleted from the source-specific entities only. |
You use the Purge Staging Tables process to delete data from the data collection staging tables.
The following table explains the parameters you specify when you run the Purge Staging Tables process. In addition to the five parameters explained below, you specify yes or no for each of the twenty-five data collection entities.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
Select a source system for the list of source systems. Data will be deleted for this source system only. |
|
Record Type |
The record type specifies which type of records to purge as follows:
|
|
Collection Cycle ID |
Specify a value for the collection cycle identifier to purge data for a specific collection cycle only, or leave blank. |
|
From Date Collected |
Specify a date to purge data from that date only, or leave blank. |
|
To Date Collected |
Specify a date to purge data up to that date only, or leave blank. |
One of the objects in the set of objects used by the orchestration processes to determine the meaning and descriptions for names or codes, such as payment terms names, freight-on-board codes, and mode-of-transport codes.
The sales order data passed to the orchestration processes contains the names or codes, but the processes need to display the meanings or descriptions. The data to determine the meanings or descriptions for the names or codes must be collected into the order orchestration and planning data repository.
For example, sales order information is passed to the Order Orchestration processes containing a freight-on-board code equal to 65, and the order orchestration and planning data repository contains a record with freight-on-board code equal to 65. The processes use the matching codes to determine that the freight-on-board code meaning is equal to Origin, and the description is equal to Vendors responsibility.
Tip
For the full list of order orchestration reference objects, review collected data for the order orchestration reference objects, and view the list of values for the Lookup Type field.
|
Copyright © 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|