11gリリース1(11.1)
E05765-03
 目次 |
 索引 |
| Oracle Database 概要 11gリリース1(11.1) E05765-03 |
|

この章では、Oracleデータベース・システムのプロセスと、Oracleデータベース・システムで使用可能な各種構成について説明します。
この章の内容は、次のとおりです。
Oracle Databaseに接続されたすべてのユーザーは、Oracle Databaseインスタンスにアクセスするために、2つのコード・モジュールを実行する必要があります。
これらのコード・モジュールは、プロセスによって実行されます。プロセスは制御のスレッド、つまり一連の処理を実行できるオペレーティング・システムのメカニズムです。(オペレーティング・システムによっては、ジョブまたはタスクという用語を使用します)。プロセスには、通常、実行するプライベート・メモリー領域があります。
この項の内容は、次のとおりです。
マルチ・プロセスOracle(マルチユーザーOracleとも呼ばれる)は、Oracleコードの各部分とユーザーのためのその他のプロセスを実行するために、複数のプロセスを使用します。ユーザー用プロセスは、接続中のユーザーごとに個別のプロセスの場合や、複数のユーザーが共有する1つ以上のプロセスの場合があります。データベースの主な利点の1つが、複数のユーザーが同時に必要とするデータを管理できることにあるため、多くのデータベース・システムはマルチユーザー・システムです。
Oracle Databaseインスタンスの各プロセスは、特定のジョブを実行します。Oracle Databaseとデータベース・アプリケーションの処理を複数のプロセスに分割することにより、1つのデータベース・インスタンスに複数のユーザーおよびアプリケーションが同時に接続でき、優れたシステム・パフォーマンスを維持できます。
Oracle Databaseシステムのプロセスは、次の2つの大きなグループに分類できます。
プロセスの構造は、オペレーティング・システムおよびOracle Databaseオプションの選択に応じて、Oracle Databaseの構成ごとに異なります。接続ユーザー用のコードは、専用サーバーまたは共有サーバーとして構成できます。
専用サーバーの場合は、それぞれのユーザーについて、データベース・アプリケーションを実行するプロセス(ユーザー・プロセス)と、Oracleデータベース・サーバー・コードを実行するプロセス(専用サーバー・プロセス)が異なります。
共有サーバーの場合は、データベース・アプリケーションを実行するプロセス(ユーザー・プロセス)と、Oracleデータベース・サーバー・コードを実行するプロセスが異なります。Oracleデータベース・サーバー・コードを実行する各サーバー・プロセス(共有サーバー・プロセス)は、マルチ・ユーザー・プロセスとして機能します。
図9-1に、専用サーバー構成を示します。接続ユーザーごとに専用のユーザー・プロセスが生成され、Oracle Databaseで複数のバックグラウンド・プロセスが実行されています。
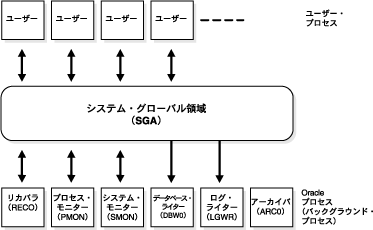
図9-1では、Oracle Databaseと同じコンピュータで複数の同時実行ユーザーがアプリケーションを実行しています。このような特別の構成は、通常、メインフレームまたはミニコンピュータで稼働します。
|
関連項目
|
Oracle Databaseでは、ユーザーがアプリケーション・プログラム(Pro*Cプログラムなど)またはOracleのツール製品(Oracle Enterprise ManagerやSQL*Plusなど)を実行するとき、ユーザー・プロセスを作成してユーザーのアプリケーションを実行します。
接続およびセッションという用語は、ユーザー・プロセスという用語と密接に関連していますが、意味的には大きな差異があります。
接続とは、ユーザー・プロセスとOracle Databaseインスタンスとの通信経路のことです。通信経路は、使用可能なプロセス間通信メカニズム(1台のコンピュータでユーザー・プロセスとOracle Databaseの両方を実行する場合)、またはネットワーク・ソフトウェア(データベース・アプリケーションとOracle Databaseを別々のコンピュータで実行し、ネットワークを介して通信する場合)を使用して確立されます。
セッションとは、ユーザー・プロセスによるユーザーとOracle Databaseインスタンスとの特定の接続です。たとえば、ユーザーは、SQL*Plusを開始するときに、有効なユーザー名とパスワードを入力する必要があります。そうすることにより、そのユーザーのためのセッションが確立されます。セッションは、ユーザーが接続した時点から、接続を切断するかデータベース・アプリケーションを終了する時点まで続きます。
同じユーザー名を使用して、1人のOracle Databaseユーザーのセッションを複数作成し、それらを同時に存在させることができます。たとえば、SCOTT/TIGERというユーザー名/パスワードを持つユーザーが、同じOracle Databaseインスタンスに複数回接続できます。
共有サーバーのない構成では、Oracle Databaseは、各ユーザー・セッションに対して1つのサーバー・プロセスを作成します。しかし、共有サーバーを使用すると、多くのユーザー・セッションで1つのサーバー・プロセスを共有できます。
この項では、Oracleデータベース・サーバー・コードを実行する2種類のプロセス(サーバー・プロセスとバックグラウンド・プロセス)について説明します。また、Oracle Databaseプロセスに関するデータベース・イベントが記録されるトレース・ファイルとアラート・ログについても説明します。
この項の内容は、次のとおりです。
Oracle Databaseでは、インスタンスに接続されたユーザー・プロセスの要求を処理するために、サーバー・プロセスが作成されます。アプリケーションとOracle Databaseが同一のコンピュータで実行している場合は、ユーザー・プロセスとそれに対応するサーバー・プロセスを1つのプロセスに結合して、システムのオーバーヘッドを軽減できる場合もあります。ただし、アプリケーションとOracle Databaseがそれぞれ別のコンピュータで実行している場合は、ユーザー・プロセスは常に専用のサーバー・プロセスを通じてOracle Databaseと通信します。
各ユーザー・アプリケーションのために作成されたサーバー・プロセス(または、結合されたユーザー/サーバー・プロセスのサーバー部)は、次の1つ以上の操作を実行できます。
パフォーマンスを最大化し、多数のユーザーに対処するために、マルチプロセスOracle Databaseシステムでは、バックグラウンド・プロセスと呼ばれる追加のOracle Databaseプロセスを使用します。
An Oracle Database instance can have many background processes; not all are always present.バックグラウンド・プロセスには、多数の種類があります。バックグラウンド・プロセスの詳細は、V$BGPROCESSビューを参照してください。Oracle Databaseインスタンスには、次のようなバックグラウンド・プロセスがあります。
多くのオペレーティング・システムでは、インスタンスが起動するときに、バックグラウンド・プロセスが自動的に作成されます。
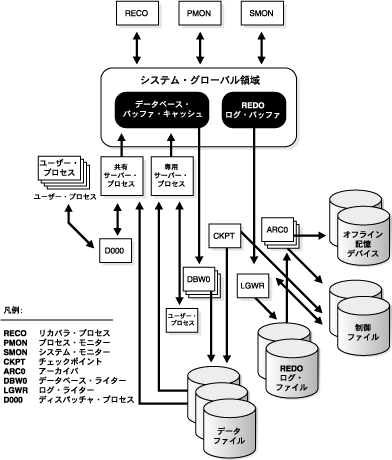
図9-2に、Oracleデータベースの各部分とそれぞれのバックグラウンド・プロセスとの相互作用を示します。その後、各プロセスについて説明します。
|
関連項目
|
アーカイバ・プロセス(ARCn)は、ログ・スイッチの発生後、REDOログ・ファイルを指定のストレージ・デバイスにコピーします。また、トランザクションのREDOデータを収集し、そのデータをスタンバイの宛先に転送できます。ARCnプロセスは、データベースがARCHIVELOGモードに設定され、自動アーカイブが使用可能になっている場合にのみ存在します。
データのバルク・ロード中など、アーカイブに伴う大量のワークロードが予想される場合は、初期化パラメータLOG_ARCHIVE_MAX_PROCESSESを使用してアーカイバ・プロセスの最大数を増加できます。ALTER SYSTEM文では、このパラメータの値を動的に変更し、ARCnプロセス数を増減させることができます。
|
関連項目
|
Oracle Databaseでは、チェックポイントが発生すると、チェックポイントの詳細を記録するためにすべてのデータファイルのヘッダーを更新する必要があります。この処理は、CKPTプロセスによって実行されます。CKPTプロセスは、ブロックをディスクに書き込みません。この書込みは、常にDBWnが実行します。
Oracle Enterprise ManagerのSystem_Statisticsモニターによって表示されるDBWRチェックポイントの統計には、完了したチェックポイント要求の数が示されます。
データベース・ライター・プロセス(DBWn)は、バッファの内容をデータファイルに書き込みます。DBWnプロセスは、データベース・バッファ・キャッシュ内の変更された(使用済)バッファをディスクに書き込みます。ほとんどのシステムでは1つのデータベース・ライター・プロセス(DBW0)があれば十分ですが、追加プロセス(DBW1〜DBW9およびDBWa〜DBWj)を構成して、システムでデータを頻繁に変更する場合に書込みのパフォーマンスを改善できます。これらの追加DBWnプロセスは、ユニプロセッサ・システムでは効果がありません。
データベース・バッファ・キャッシュ内のバッファが変更されると、そのバッファには使用済のマークが付きます。コールド・バッファとは、LRUアルゴリズムに従って最近使用されたことがないバッファです。DBWnプロセスは、ユーザー・プロセスが新規ブロックをキャッシュに読み取るために使用できるクリーンなコールド・バッファを検出できるように、使用済のコールド・バッファをディスクに書き込みます。ユーザー・プロセスによってバッファが使用済の状態になると、使用可能バッファの数が減少します。使用可能バッファの数が少なすぎると、ディスクからキャッシュにブロックを読み取る必要があるユーザー・プロセスは、使用可能バッファを検出できません。ユーザー・プロセスが使用可能バッファを常に検出できるように、DBWnはバッファ・キャッシュを管理します。
使用済のコールド・バッファをディスクに書き込むことにより、DBWnは、使用頻度の高いバッファをメモリー内に保ちながら、使用可能バッファを検索するときのパフォーマンスを向上させます。たとえば、頻繁にアクセスされる小さな表または索引の一部であるブロックは、それらをディスクから再び読み取らなくても済むように、キャッシュ内に置かれます。LRUアルゴリズムは、バッファの内容をディスクに書き込むときに、すぐに使用されそうなデータが書き込まれてしまわないように、より頻繁にアクセスされるブロックをバッファ・キャッシュ内に保持します。
DBWnプロセスの個数は、初期化パラメータDB_WRITER_PROCESSESで指定します。DBWnプロセスの最大数は20です。起動時にユーザーが最大数を設定しない場合は、Oracle DatabaseによりCPU数とプロセッサ・グループ数に基づいてDB_WRITER_PROCESSESの設定方法が決まります。
DBWnプロセスは、次のような場合に使用済バッファをディスクに書き込みます。
どの場合でも、効率を向上させるためにDBWnはバッチ(マルチブロック)書込みを実行します。マルチブロック書込みで書き込まれるブロックの数は、オペレーティング・システムによって異なります。
|
関連項目
|
ジョブ・キュー・プロセスは、バッチ処理で使用します。ジョブ・キュー・プロセスはユーザー・ジョブを実行します。ジョブ・キュー・プロセスは、ジョブをPL/SQL文またはOracle Databaseインスタンスのプロシージャとしてスケジュールするために使用するスケジューラ・サービスであると考えることができます。開始日と間隔を指定すると、ジョブ・キュー・プロセスは、指定された間隔でジョブの実行を試行します。
ジョブ・キュー・プロセスは動的に管理されます。このため、ジョブ・キューのクライアントは、必要なときに、より多くのジョブ・キュー・プロセスを使用できます。新規プロセスが使用するリソースは、そのプロセスがアイドル状態になると解放されます。
動的ジョブ・キュー・プロセスは、指定された間隔で多数のジョブを同時に実行できます。ジョブ・キュー・プロセスは、ユーザー・ジョブがCJQプロセスにより割り当てられると、それを実行します。ジョブ・キュー・プロセスは、次のように機能します。
JOB$表から、実行する必要があるジョブを定期的に選択します。選択された新規ジョブは、時間順に並べ替えられます。
初期化パラメータJOB_QUEUE_PROCESSESは、1つのインスタンスで同時に実行できるジョブ・キュー・プロセスの最大数を示します。ただし、クライアントは、すべてのジョブ・キュー・プロセスがジョブの実行に使用可能であると想定することはできません。
ログ・ライター・プロセス(LGWR)は、REDOログ・バッファ管理、つまりディスク上のREDOログ・ファイルへのREDOログ・バッファの書込みを行います。LGWRは、最後の書込み以後にバッファにコピーされたREDOエントリすべてを、REDOログ・ファイルに書き込みます。
REDOログ・バッファは循環バッファです。LGWRがREDOログ・バッファからREDOログ・ファイルにREDOエントリを書き込んだ後、サーバー・プロセスはディスクに書き込まれたREDOログ・バッファのエントリ上に新しいエントリをコピーできます。REDOログへのアクセスが頻繁なときにも、新しいエントリを書き込めるよう常にバッファ内の領域を空けておくため、LGWRが行う書込みは通常は非常に高速になります。
LGWRは、バッファの1つの連続した部分をディスクに書き込みます。LGWRは、次のものを書き込みます。
LGWRは、ミラー化されたアクティブなREDOログ・ファイルのグループにも同時に書き込みます。グループ内のファイルのいずれかが破損している場合や使用できない場合、LGWRはそのグループ内の他のファイルへの書込みを続け、このエラーのログをLGWRトレース・ファイルやシステム・アラート・ログに記録します。グループ内のすべてのファイルが破損している場合や、アーカイブされていないためにグループ全体が使用できない場合、LGWRは機能を続行できません。
ユーザーがCOMMIT文を発行すると、LGWRはREDOログ・バッファ内にコミット・レコードを入れ、トランザクションのREDOエントリとともにそれを即時にディスクに書き込みます。対応するデータ・ブロックの変更は、それらをより効率的に書き込めるようになるまで延期されます。これを高速コミット・メカニズムと呼びます。トランザクションのコミット・レコードを含むREDOエントリのアトミックな書込みは、トランザクションがコミットされたかどうかを判別する1つのイベントです。Oracle Databaseでは、データ・バッファがまだディスクに書き込まれていない場合でも、コミットしたトランザクションに対する成功コードが戻されます。
ユーザーがトランザクションをコミットすると、そのトランザクションにはシステム変更番号(SCN)が割り当てられます。Oracle Databaseでは、このシステム変更番号は、該当するトランザクションのREDOエントリとともにREDOログに記録されます。SCNは、Real Application Clustersおよび分散データベースでリカバリ操作を同期させることができるように、REDOログに記録されます。
アクティビティが高いときには、LGWRはグループ・コミットを使用してREDOログ・ファイルに書き込むこともあります。たとえば、ユーザーがトランザクションをコミットする場合を考えます。LGWRは、トランザクションのREDOエントリをディスクに書き込む必要がありますが、その際、他のユーザーはCOMMIT文を発行します。ただし、LGWRは前の書込み操作を完了するまで、他のユーザーのトランザクションをREDOログ・ファイルに書き込んでコミットすることはできません。最初のトランザクションのエントリをREDOログ・ファイルに書き込んだ後、待機中の(まだコミットされていない)トランザクションのREDOエントリのリスト全体を1回の操作でディスクに書き込むことができるため、トランザクションのエントリを個々に処理するときよりも、必要となるI/Oを低減できます。したがって、Oracle Databaseでは、ディスクI/Oが最小化され、LGWRのパフォーマンスが最大化されます。コミットの要求が高い頻度で続くと、REDOログ・バッファからの(LGWRによる)毎回の書込みに複数のコミット・レコードが含まれることがあります。
|
関連項目
|
ユーザー・プロセスが失敗すると、プロセス・モニター(PMON)がプロセスをリカバリします。PMONは、データベース・バッファ・キャッシュをクリーン・アップしたり、ユーザー・プロセスが使用していたリソースを解放します。たとえば、アクティブ・トランザクション表の状態をリセットしてロックを解除し、アクティブ・プロセスのリストからプロセスIDを削除します。
PMONは、ディスパッチャ・プロセスとサーバー・プロセスの状態を定期的にチェックし、実行を停止したプロセスがあれば再起動します(ただし、Oracle Databaseが意図的に終了させたプロセスは除きます)。また、PMONは、インスタンスおよびディスパッチャ・プロセスに関する情報をネットワーク・リスナーに登録します。
SMONと同じように、PMONは、処理が必要かどうかを定期的にチェックし、別のプロセスで起動する必要が検出された場合にコールできます。
キュー・モニター・プロセスは、メッセージ・キューを監視するOracle Streams Advanced Queuingのオプションのバックグラウンド・プロセスです。最大10個のキュー・モニター・プロセスを構成できます。これらのプロセスは、ジョブ・キュー・プロセスと同様に、プロセスの障害がインスタンス障害の原因とならない点で他のOracle Databaseバックグラウンド・プロセスと異なります。
リカバラ・プロセス(RECO)は、分散データベース構成で使用されるバックグラウンド・プロセスであり、分散トランザクションに関連する障害を自動的に解決します。ノードのRECOプロセスは、インダウト分散トランザクションにかかわる他のデータベースに自動的に接続されます。RECOプロセスは、関係するデータベース・サーバー間の接続を再確立するときに、すべてのインダウト・トランザクションを自動的に解決し、解決されるインダウト・トランザクションに対応する行を各データベースの保留中のトランザクション表からすべて削除します。
RECOプロセスがリモート・サーバーとの接続に失敗した場合、RECOは決められた間隔で自動的に再接続しようとします。ただし、RECOが次の接続を試行するまで待機する時間は増えていきます(指数関数的に増加します)。RECOプロセスは、インスタンスが分散トランザクションを許可している場合にのみ存在します。同時分散トランザクションの数に制限はありません。
システム・モニター・プロセス(SMON)は、インスタンスの起動時に必要に応じてリカバリを実行します。また、SMONは、使用されなくなった一時セグメントをクリーン・アップする操作と、ディクショナリ管理表領域内で連続した使用可能エクステントを1つに結合する操作を受け持ちます。ファイル読取りエラーやオフライン・エラーが原因で、インスタンス・リカバリ時に終了済トランザクションがスキップされた場合、SMONはその表領域やファイルがオンラインに戻った時点でトランザクションをリカバリします。SMONは、処理が必要かどうかを定期的にチェックします。他のプロセスは、必要性が検出された場合にSMONをコールできます。
Real Application Clustersでは、あるインスタンスのSMONプロセスは、障害が発生したCPUまたはインスタンスについてもインスタンス・リカバリを実行できます。
他にも実行されているバックグラウンド・プロセスがいくつかあります。次のSQL問合せを発行して、システムで実行中のバックグラウンド・プロセスを表示できます。
SELECT * FROM V$BGPROCESS WHERE PADDR != '00' ORDER BY NAME;
次のようなバックグラウンド・プロセスが含まれる場合があります。
oradebugコマンドを実行します。
さらにFBDAは、領域、編成、および保存に対するフラッシュバック・データ・アーカイブを自動的に管理し、記録済トランザクションのアーカイブがどの程度発生するかを追跡します。
Oracle Database 11gからは、問題を防止、検出、診断および解決するための高度な障害診断性インフラストラクチャが含まれるようになりました。特にターゲットとなる問題は、データベース・コードの不具合、メタデータの破損、顧客データの破損などが原因の重大なエラーです。
致命的なエラーが発生すると、それに対してインシデント番号が割り当てられ、エラーに対する診断データ(トレース・ファイルなど)が即座に取得され、この番号がタグ付けされます。その後、データは自動診断リポジトリ(ADR)(データベースの外部にあるファイル・ベースのリポジトリ)に保存され、後でインシデント番号を使用して取り出して分析できます。
それぞれのサーバーとバックグラウンド・プロセスは、対応付けられたトレース・ファイルに書き込むことができます。プロセスによって内部エラーが検出されると、エラーについての情報がそのプロセスのトレース・ファイルに書き込まれます。内部エラーが発生して情報がトレース・ファイルに書き込まれた場合、管理者はOracleサポート・サービスに連絡してください。
バックグラウンド・プロセスに対応付けられているすべてのトレース・ファイルのファイル名には、そのトレース・ファイルを生成したプロセスの名前が含まれます。唯一の例外は、ジョブ・キュー・プロセス(Jnnn)が生成するトレース・ファイルです。
トレース・ファイル内の追加情報は、アプリケーションやインスタンスをチューニングするための手引きにもなります。バックグラウンド・プロセスは、該当する場合は、いつもトレース・ファイルにこの情報を書き込みます。
また、各データベースには、alert.logがあります。データベースのアラート・ログは、次のようなメッセージとエラーの履歴ログです。
CREATE/ALTER/DROP DATABASE/TABLESPACEと、Oracle Enterprise ManagerまたはSQL*Plus文のSTARTUP、SHUTDOWN、ARCHIVE LOG、およびRECOVERなど。
Oracle Databaseでは、オペレータのコンソール上に情報を表示するかわりに、アラート・ログを使用してこれらのイベントの記録を保管します。(多くのシステムではコンソール上にもこの情報が表示されます。)管理操作が成功すると、タイムスタンプとともに「completed」というメッセージがアラート・ログに書き込まれます。
共有サーバー・アーキテクチャでは、それぞれの接続に対する専用サーバー・プロセスが必要ありません。ディスパッチャが、複数の受信ネットワーク・セッション要求を共有サーバー・プロセスのプールに導きます。サーバー・プロセスの共有プールにあるアイドル状態の共有サーバー・プロセスは、共通キューからの要求をピックアップします。このことは、少数の共有サーバーで、多数の専用サーバーと同じ量の処理を行えることを意味します。また、各ユーザーに必要なメモリーの量が比較的少ないため、メモリー管理やプロセス管理も容易であり、多くのユーザーをサポートできます。
共有サーバー・システムでは、次に示すように、様々なプロセスが多数必要です。
共有サーバー・プロセスでは、Oracle Net ServicesまたはSQL*Netバージョン2が必要です。
インスタンスが起動されると、ネットワーク・リスナー・プロセスは、ユーザーがOracle Databaseへの接続に使用する通信経路をオープンして確立します。その後、各ディスパッチャ・プロセスは、接続要求をリスニングするアドレスをリスナー・プロセスに割り当てます。データベース・クライアントで使用するネットワーク・プロトコルごとに、最低1つ以上のディスパッチャ・プロセスを構成し起動する必要があります。
ユーザー・プロセスが接続を要求すると、リスナーはその要求を調べてユーザー・プロセスが共有サーバー・プロセスを使用できるかどうかを決定します。使用できる場合には、リスナー・プロセスは負荷が最も軽いディスパッチャ・プロセスのアドレスを戻し、ユーザー・プロセスはディスパッチャに直接接続します。
ディスパッチャと通信できないユーザー・プロセスもあるため、ネットワーク・リスナー・プロセスはそれらをディスパッチャに接続できません。この場合、つまりユーザー・プロセスが専用サーバーを要求すると、リスナーは専用サーバーを作成して適切な接続を確立します。
Oracle Databaseの共有サーバー・アーキテクチャでは、アプリケーションのスケーラビリティが向上し、データベースへのクライアントの同時接続数が増加します。このアーキテクチャでは、アプリケーション自体を一切変更することなく、既存のアプリケーションをスケールアップできます。
この項の内容は、次のとおりです。
ユーザーからの要求は、ユーザーのSQL文の一部である単一のプログラム・インタフェース・コールです。ユーザーがコールすると、そのディスパッチャが要求を要求キューに入れ、次に使用可能な共有サーバー・プロセスがそこから要求を取り出します。
要求キューはSGA内に存在し、インスタンスのディスパッチャ・プロセスすべてに共通です。共有サーバー・プロセスは、共通の要求キューをチェックして新しい要求がないかどうかを調べ、先入れ先出し方式に基づいて新しい要求をピックアップします。1つの共有サーバー・プロセスがキュー内の要求を1つピックアップし、その要求を完了するのに必要なデータベースに対するコールをすべて出します。
サーバーは要求を完了すると、コール・ディスパッチャのレスポンス・キューに応答を入れます。各ディスパッチャには、SGA内に固有のレスポンス・キューがあります。ディスパッチャは、完了した要求を適切なユーザー・プロセスに戻します。
たとえば、注文入力システムでは、それぞれの事務担当のユーザー・プロセスがディスパッチャに接続し、事務担当が出したそれぞれの要求がそのディスパッチャに送られ、そしてディスパッチャがその要求を要求キューに入れます。次に使用可能な共有サーバー・プロセスは、要求をピックアップして処理し、レスポンス・キューに応答を入れます。事務担当の要求が完了しても、事務担当はディスパッチャに接続されたままですが、その要求を処理した共有サーバー・プロセスは解放されるため、別の要求で使用できます。1人の事務担当が顧客と話し合っている間に、別の事務担当は同じ共有サーバー・プロセスを使用できます。
図9-3に、ユーザー・プロセスがプログラム・インタフェースを介してディスパッチャと通信する方法と、ディスパッチャがユーザー要求を共有サーバー・プロセスに伝達する方法を示します。

この項の内容は、次のとおりです。
ディスパッチャ・プロセスは、ユーザー・プロセスが限定された数のサーバー・プロセスを共有できるようにすることで、共有サーバー構成をサポートします。共有サーバーでは、共有サーバー・プロセスの数がユーザーの数より少なくてすみます。そのため、特にクライアント・アプリケーションとサーバーが別々のコンピュータ上で稼働するようなクライアント/サーバー環境では、共有サーバーによってより多くのユーザーをサポートできます。
1つのデータベース・インスタンスに対し、複数のディスパッチャ・プロセスを作成できます。ただし、Oracle Databaseで使用する各ネットワーク・プロトコルごとに、少なくとも1つのディスパッチャを作成する必要があります。データベース管理者は、オペレーティング・システムの制限とプロセス当たりの接続数に応じて、ディスパッチャ・プロセスを適切な数だけ起動する必要があります。また、インスタンスの実行中にディスパッチャ・プロセスを追加および削除できます。
共有サーバー構成では、ネットワーク・リスナー・プロセスがクライアント・アプリケーションからの接続要求を待機し、それぞれのクライアント・アプリケーションをディスパッチャ・プロセスにルーティングします。クライアント・アプリケーションをディスパッチャに接続できない場合、リスナー・プロセスは専用サーバー・プロセスを起動し、クライアント・アプリケーションを専用サーバーに接続します。リスナー・プロセスは、Oracle Databaseインスタンスの一部ではなく、Oracle Databaseと連携するネットワーキング・プロセスの一部です。
共有サーバー構成では、各共有サーバー・プロセスは複数のクライアント要求を処理します。共有サーバー・プロセスには専用サーバー・プロセスと同じ機能がありますが、特定のユーザー・プロセスとは対応付けられていません。共有サーバー・プロセスは、共有サーバー構成におけるクライアント要求に対してサービスを提供します。
共有サーバー・プロセスのPGAには、ユーザーに関係した(すべての共有サーバー・プロセスからアクセス可能であることが必要な)データは含まれません。共有サーバー・プロセスのPGAには、スタック領域とプロセス固有の変数のみが含まれています。
セッション関連の情報はすべてSGA内に入れられます。各共有サーバー・プロセスは、サーバーがどのセッションからの要求でも処理できるように、すべてのセッションのデータ領域にアクセスできる必要があります。セッションのデータ領域ごとに、SGA内に領域が割り当てられます。ユーザーのプロファイル内のリソース制限PRIVATE_SGAを必要な領域の容量に設定すると、セッションが割り当てることのできる領域の容量を制限できます。
Oracle Databaseは、要求キューの長さに基づいて、共有サーバー・プロセスの数を動的に調整します。作成できる共有サーバー・プロセスの数は、初期化パラメータSHARED_SERVERSとMAX_SHARED_SERVERSの値で指定した範囲です。
|
関連項目
|
インスタンスの停止、インスタンスの起動、およびメディア・リカバリを含む、特定の管理アクティビティは、ディスパッチャ・プロセスに接続されている間は実行できません。ディスパッチャ・プロセスに接続されている間にこれらのアクティビティを実行しようとすると、エラー・メッセージが出されます。
これらのアクティビティは、一般的には管理者権限を使用して接続しているときに実行されます。共有サーバーにより構成されたシステムで管理者権限を使用して接続する場合は、ディスパッチャ・プロセスではなく専用サーバー・プロセスを使用することを接続文字列で明言してください(SERVER=DEDICATED)。
図9-4では、専用サーバー・アーキテクチャを使用して、Oracle Databaseが2台のコンピュータで実行されています。この構成では、データベース・アプリケーションが1台のコンピュータのユーザー・プロセスによって実行され、対応付けられたOracleデータベース・サーバーがもう1台のコンピュータ上のサーバー・プロセスによって実行されます。
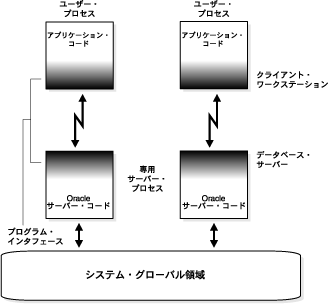
ユーザー・プロセスとサーバー・プロセスは、相互に分離した別のプロセスです。ユーザー・プロセスごとに作成された別々のサーバー・プロセスは、このサーバー・プロセスが対応付けられたユーザー・プロセスのためにのみ活動するため、専用サーバー・プロセス(またはシャドウ・プロセス)と呼ばれます。
この構成では、ユーザー・プロセス数とサーバー・プロセス数の比率が1対1に維持されます。ユーザーが活発にデータベース要求をしていない場合でも、専用サーバー・プロセスはそのまま残ります(ただし、活動していない状態の場合、オペレーティング・システムによってはページアウトされることもあります)。
図9-4では、ユーザー・プロセスとサーバー・プロセスが、ネットワークで接続された別々のコンピュータで実行されています。専用サーバー・アーキテクチャは、同じコンピュータ上でクライアント・アプリケーションとOracleデータベース・サーバー・コードの両方が実行される場合にも使用されますが、この2つのプログラムが1つのプロセスで実行されている場合は、ホスト・オペレーティング・システムはその2つの分離を維持できません。UNIXはそのようなオペレーティング・システムの一例です。
専用サーバー構成では、ユーザー・プロセスとサーバー・プロセスは異なるメカニズムを使用して通信します。
データベース常駐接続プーリング(DRCP)は、一般的なWebアプリケーション使用のシナリオにおいて、データベース・サーバー内で接続プールを提供します。DRCPは、プールされたサーバーを作成するために、データベース・セッションと組み合せたサーバー・フォアグラウンドから構成される専用サーバーをプールします。
通常、Webアプリケーションは、データベースへの接続を取得し、その接続を短時間使用した後、接続を解放します。DRCPでは、複数のWebアプリケーションのスレッドおよびプロセスが、サーバー・プールを共有して接続ニーズを満たすことができます。
DRCPは、中間層プロセス内のスレッド間で接続を共有する、中間層接続プールを補完します。また、DRCPは、複数の中間層プロセスにわたってデータベース接続を共有できるようにします。これらの中間層プロセスは、中間層ホストが同一の場合と異なる場合があります。
DRCPは、多数のクライアント接続のサポートに必要な主要データベース・リソースを大幅に削減できます。DRCPは、データベース・サーバーに必要なメモリーの量を削減し、データベース・サーバーおよび中間層両方のスケーラビリティを向上させます。すぐに利用できるサーバーのプールにより、クライアント接続を再作成するコストも削減されます。
DRCPは、中間層接続プーリングを実行できないPHPやApacheサーバーなど、マルチプロセスのシングルスレッド・アプリケーション・サーバーを含むアーキテクチャに特に有効です。DRCPを使用すると、データベースは同時接続数を数万にまで増やすことができます。
プールされたサーバーのモデルは、Oracleに接続するためのデフォルトとして使用されている専用モデルに密接に従っています。プールされたサーバー・モデルは、短時間サーバーを必要とする接続のすべてにサーバーを専用とすることによるオーバーヘッドを排除します。DRCPでは、プールされたサーバーを取得して、同じような他の接続のために、自発的にそのサーバーを解放できます。プールされたサーバーは、接続によって取得されると、プールへ解放されるまでは、その接続に対しては基本的に専用サーバーへと変わります。データベース常駐接続プールから接続を取得したクライアントは、接続ブローカと呼ばれるOracleバックグラウンド・プロセスに接続します。接続ブローカはプール機能を実装しており、プールされたサーバーをクライアント・プロセスからのインバウンド接続間で多重化します。
クライアントがバックエンド・データベース処理を実行する必要がある場合、接続ブローカはプールから、プールされたサーバーを選択してクライアントに割り当てます。その後クライアントは、要求が処理されるまでプールされたサーバーに直接接続します。サーバーでのクライアント要求の処理が終了すると、サーバーはプールに戻され、クライアント接続は接続ブローカ・プロセスにリストアされます。図9-5は、データベース常駐接続プーリングを示しています。
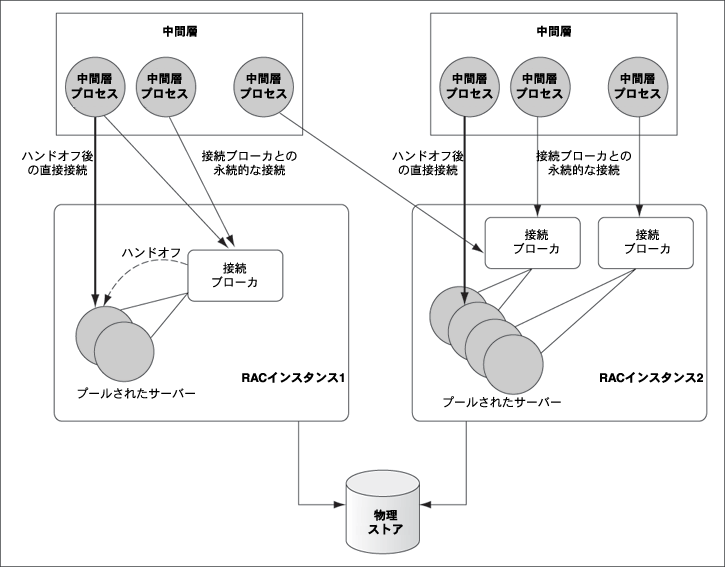
データベース常駐接続プーリングを使用すると、データベース側のメモリー不足を考慮せずに、中間層ハードウェアの自由自在な拡張が可能になります。これは、専用サーバー・プロセスの比較的小さなプールによって、より多くの中間層のプロセスを処理できるためです。
デフォルトの接続プール名は、SYS_DEFAULT_CONNECTION_POOLです。データベース常駐接続プーリングを使用するには、データベース管理者は、明示的にプールを起動する必要があります。次に例を示します。
SQL*PlusにSYSDBAとしてログインします。
次のコマンドを実行します。
SQL> EXECUTE DBMS_CONNECTION_POOL.START_POOL('SYS_DEFAULT_CONNECTION_POOL');
共有プールに接続するには、データベース接続文字列中のサーバー・タイプがPOOLEDに設定されている必要があります。次に例を示します。
ServerPool = (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp) (HOST=somehost) (PORT=1521))(CONNECT_DATA=(SERVICE_NAME=testdb)(SERVER=POOLED)))
簡単な接続ネーミング・メソッドを使用して共有プールに接続することもできます。POOLEDキーワードをデータベース・サービス名で使用する必要があります。次に例を示します。
CONNECT joeuser@myhost.example.com:1521/mydb:POOLED Enter password: password
この項の内容は、次のとおりです。
接続クラスは、アプリケーションに必要な接続タイプの論理名を定義します。2人の異なるユーザーは、接続またはセッションをユーザー間で共有できません。たとえば、ユーザーHR向けに作成されたセッションは、HRの以降の要求に対してのみ割り当てられます。接続クラスは、任意のユーザーのセッション間でさらに分離を可能にします。接続クラスは、同じデータベース・ユーザーとして接続している異なるアプリケーションが、アプリケーションに対応する論理名を使用して、セッションを識別できるようにします。これにより、DRCPでは、特定の接続クラスに属すセッションが、接続クラスを越えて共有されることはありません。
セッション純粋度は、アプリケーションに新しいセッションが必要か(PURITY=NEW)、プールされたセッションを再利用するようにアプリケーション・ロジックで設定されているか(PURITY=SELF)を指定します。プールされたセッションの再利用が可能なアプリケーションの場合、要求された接続クラスを持つ空きセッションがそのアプリケーションに割り当てられます。
接続クラスおよびセッション純粋度は、DRCP接続の属性としてクライアントで指定されます。接続クラスのデフォルト値は、username.SHAREDです。デフォルトでは、純粋度がSELFである場合に同じusernameを持つセッションが共有されます。
純粋度のデフォルト値は、NEWです。異なるアプリケーション・シナリオでは、デフォルトが異なる可能性があります。アプリケーションによるDRCPの使用方法の詳細は、それぞれのアプリケーション・マニュアルを参照してください。
プログラム・インタフェースとは、データベース・アプリケーションとOracle Databaseの間のソフトウェア・レイヤーです。プログラム・インタフェースには次のような機能があります。
Oracleコードはサーバーとして機能し、データ・ブロックから行をフェッチするなど、アプリケーション(クライアント)のためにデータベース・タスクを実行します。Oracleコードには、Oracle Databaseソフトウェアとオペレーティング・システム固有のソフトウェアの両方のコード部分が含まれます。
この項の内容は、次のとおりです。
プログラム・インタフェースは、次の要素から構成されます。
ユーザー側とOracle Database側のプログラム・インタフェースは、どちらもドライバのような仕組みでOracleソフトウェアを実行します。
Oracle Net Servicesは、クライアント・アプリケーション・プログラムとOracleデータベース・サーバーが通信ネットワーク内の別々のコンピュータに存在することを可能にするプログラム・インタフェース部分です。
ドライバとは、通常はネットワークを介してデータを転送するソフトウェアの一部です。ドライバは、接続、切断、エラーの通知、エラーのテストなどの操作を実行します。ドライバは、通信プロトコルに固有であり、必ずデフォルトのドライバが存在します。
複数のドライバ(非同期またはDECnetドライバなど)をインストールし、その1つをデフォルト・ドライバとして選択しますが、各ユーザーは接続の時点で必要なドライバを指定すると、他のドライバを使用できます。プロセスが異なる場合は、異なるドライバを使用できます。1つのプロセスは、異なるOracle Net Servicesドライバを使用した単一または複数のデータベース(ローカルまたはリモートのどちらでも)に同時接続できます。
ユーザー側をOracle Database側のプログラム・インタフェースに接続する最下位層のソフトウェアは、ホスト・オペレーティング・システムによって提供される通信ソフトウェアです。たとえば、DECnet、TCP/IP、LU6.2、ASYNCなどです。通信ソフトウェアはOracleから提供されることもありますが、通常、ハードウェア・ベンダーまたはサード・パーティのソフトウェア・サプライヤから別途、購入します。
|
 Copyright © 1993, 2008 Oracle Corporation. All Rights Reserved. |
|