| Oracle® XML DB開発者ガイド 11gリリース2 (11.2) B70200-03 |
|


 前 |
 次 |
頻繁に問い合せるXMLデータの特定部分に着目できるよう当該XMLデータに対して索引を作成し、パフォーマンスを向上できます。この章では、これを実現するためのガイドラインを示します。スキーマに基づくか否かにかかわらず、また、使用されるXMLType記憶域モデル(バイナリXML、非構造化、ハイブリッド、または構造化)に関係なく、XMLTypeデータに索引付けするための様々な方法について説明します。
この章の内容は次のとおりです。
|
注意: ここで示す実行計画は、説明のためのみに使用しています。ここで示す例を実際の環境で実行しても、実行計画が同一になるわけではありません。 |
|
関連項目:
|
表6-1は、XMLデータの索引付けに関連するいくつかの基本的なユーザー・タスクの参照先を示します。
表6-1 基本的なXML索引付けタスク
| 操作の詳細 | 参照先 |
|---|---|
|
オブジェクト・リレーショナル形式で格納された |
「オブジェクト・リレーショナル形式で格納されたXMLTypeデータの索引付け」、「ガイドライン: Ordered Collection表に対する索引の作成」 |
|
|
|
|
特定の表または列に対する |
|
|
指定された |
|
|
|
|
表6-2は、構造化コンポーネントを含むXMLIndex索引付けに関連するいくつかのユーザー・タスクの参照先を示します。
表6-2 構造化コンポーネントを含むXMLIndex索引に関連するタスク
| 操作の詳細 | 参照先 |
|---|---|
|
構造化コンポーネントが含まれる |
|
|
|
|
|
構造化コンポーネントが含まれる |
「XMLIndex構造化コンポーネントのデータ型に関する考慮事項」 |
|
|
|
|
|
|
表6-3は、非構造化コンポーネントを含むXMLIndex索引付けに関連するいくつかのユーザー・タスクの参照先を示します。
表6-3 非構造化コンポーネントを含むXMLIndex索引に関連するタスク
| 操作の詳細 | 参照先 |
|---|---|
|
非構造化コンポーネントが含まれる |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
パス表の指定による、非構造化コンポーネントが含まれる |
|
|
|
|
|
|
|
|
パス表の |
|
|
パス表の |
|
|
パス表の |
|
|
パス表の |
|
|
|
「XMLIndexパスのサブセット化: 索引付けするパスの指定」 |
|
|
「XMLIndexパスのサブセット化: 索引付けするパスの指定」 |
|
|
「XMLIndexパスのサブセット化: 索引付けするパスの指定」 |
|
|
「XMLIndexパスのサブセット化: 索引付けするパスの指定」 |
表6-4は、XMLIndex索引付けに関連するその他のユーザー・タスクの参照先を示します。
表6-4 XMLIndex索引に関連するその他のタスク
| 操作の詳細 | 参照先 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
コストベース・オプティマイザに対する表または索引に関する統計の収集 |
|
|
Oracle Textの |
|
|
|
|
|
XMLデータの全文検索におけるOracle Textの |
|
|
Oracle Textの |
|
データベース索引では、表データに対するアクセスを高速化することにより、パフォーマンスが向上します。索引の使用は、更新が少ないオンライン・トランザクション処理(OLTP)環境に特に適しています。
XMLデータを索引付けする基本的な方法は、XMLIndexを使用することです。Oracle Text CONTEXT索引を使用して、XMLIndexの使用を補完することもできます。
表の1列または複数の列、またはファンクション式に対して索引を作成できます。XMLデータには独自のファイングレイン構造がありますが、その構造は、XMLデータが格納されるデータベース表の構造に必ずしも反映されるとはかぎりません。このような理由から、XMLデータに効果的に索引付けする方法は、他の大部分のデータベース・データに対する索引付けとは多少異なります。
構造化XML記憶域では、要素や属性などのXMLオブジェクトは、オブジェクト・リレーショナル列および表に対応しているため、これらの列および表に対してBツリー索引を作成する方法は、対応するXMLオブジェクトに効果的に索引付けする場合に最適です。この場合、記憶域モデルはXMLデータのファイングレイン構造を直接反映するため、構造化XMLデータの索引付けにおいて特別な問題は生じません。「オブジェクト・リレーショナル形式で格納されたXMLTypeデータの索引付け」を参照してください。
非構造化、ハイブリッドおよびバイナリXML記憶域では、標準的な索引(Bツリー、ビットマップ)を使用してデータベース列に索引付けすると、多くの場合、XML文書の特定部分にアクセスする際に問題が生じます。XML文書を含むXMLType列がCLOBインスタンスとして格納されると、その文書内の細部が列の索引にアクセスできなくなります。つまり、列の索引に関しては、文書全体が単独のユニットとして機能することになります。ハイブリッド記憶域では、XML文書の一部が分割され、オブジェクト・リレーショナル形式(構造化記憶域)で格納されますが、1つ以上のXMLフラグメントがCLOBインスタンス(非構造化記憶域)として格納されます。このような場合は、通常、XML SchemaのcomplexTypeまたは複合要素をCLOB記憶域にマッピングします。これは、通常はフラグメント全体が1つの単位としてアクセスされるためです。標準的な索引の場合、索引付けの単位としても機能します。
XMLIndexは通常のXML固有の索引により、XMLデータの内部構造に索引付けします。その主な目的の1つとして、非構造化、ハイブリッドおよびバイナリXML記憶域によって課される索引付けの制限を克服することがあげられます。
非構造化コンポーネントを含むXMLIndex索引では、文書のXMLタグに索引付けし、それをターゲットとするXPath式に基づいて文書のフラグメントを識別します。また、スカラー・ノードの値に対して索引付けすることで、単独の値または値の範囲に基づく高速参照も可能にします。さらに、索引付けする各ノードに対し、文書の階層情報(親と子、祖先と子孫、および兄弟の関係)を記録します。この索引コンポーネントは、構造が少ない文書または可変構造を持つ文書からXMLフラグメントを抽出する問合せで特に便利です。
構造化コンポーネント含むXMLIndex索引では、ほとんどの部分が構造化されていないXMLデータでも、高度に構造化された予測可能な部分に索引付けします。この索引コンポーネントは、構造化コンテンツのアイランドを投影および使用する問合せで特に便利です。
要素や属性などのXMLノードにアクセスする以外にも、XMLテキスト・ノード内の特定の節に対して高速アクセスを提供する必要があることがあります。Oracle Text索引は全文文字列に対して索引付けすることで、この目的を達成します。Oracle TextのCONTEXT索引では、XMLの全文検索を実行するためのOracle SQL関数containsを使用できます。構造化記憶域では、XPathリライトにより、ora:contains XPath関数を使用する問合せが、contains SQL関数を使用する問合せにリライトされることが多いため、このようなケースでもOracle Text索引が使用されます。
全文索引は、特に、XML要素とテキストノード・コンテンツが混在する、文書中心のアプリケーションにおいて有用です。全文検索は、構造化XML検索と組み合せる(XPath式によって識別されるXML文書の一定部分に対して検索を限定する)ことによってさらに強力に、焦点を絞って行えるようになります。
1つのケースで複数の索引が該当する場合は、どの索引が使用されるでしょうか。パフォーマンスを最大化する索引(複数可)は、コストベースの最適化によって決定されます。Oracle Text索引はテキストにのみ適用されるため、XMLデータではテキスト・ノードを意味します。テキスト・ノードがターゲットとされ、対応するOracle Text索引が定義されている場合は、Oracle Text索引が使用されます。特定のコンテキストにおいて他の索引も適している場合は、これらも使用されます。ただし、索引が定義されており、特定の状況下において適しているように見えても、その索引が必ずしも使用されるとはかぎりません。コストベース・オプティマイザが費用効率を発揮できないと判断した索引は使用されません。
Oracle Database 11gリリース1(11.1)以前のリリースでは、XMLTypeデータにおいてCTXXPath索引の使用が適していることもありました。Oracle Database 11gリリース2(11.2)以前のリリースでは、XMLTypeデータにおいてファンクション索引の使用が適していることもありました。これらの索引付け方式は、XMLTypeデータで使用しないことをお薦めします。
Oracle Database 11gリリース2(11.2)以前のリリースでは、XPath式が単一ノードをターゲットにしている場合、XMLTypeデータにおいてファンクション索引の使用が適していることもありました。かわりに、XMLIndexの構造化コンポーネントを使用することをお薦めします。これにより、ファンクション索引のメンテナンス操作に関連するオーバーヘッドを軽減し、オプティマイザで索引を適切に選択できる状況が増えます。その結果、既存のDML文の変更が不要になります。
さらに、構造化記憶域では、Oracle SQL関数extractValue(非推奨)で索引を定義すると、XPathリライトにより、(extractValueに対してファンクション索引ではなく)基礎のオブジェクトに対してBツリー索引が自動的に作成されることがあります。XPathのターゲットは単一の要素または属性である必要があります。XMLQueryに適用されるXMLCastに対しても、同様のショートカットが存在します。
XMLデータの索引付けに使用されていたもう1つの索引CTXXPathは、Oracle Database 11gリリース1 (11.1)で非推奨になりました。CTXXPath索引はXMLIndexに置き換えられ、旧データベース・リリースでのみ使用されることになります。XMLフラグメントの抽出には使用されず、等価述語の事前フィルタとしてのみ機能します。事前フィルタリングを実行後、XPath式は関数として評価されます(つまり、XPathリライトの利点は活用されません)。
|
注意: CTXSYS.CTXXPath索引は、Oracle Database 11gリリース1 (11.1)で非推奨になりました。CTXXPathによって提供されていた機能は、XMLIndexで提供されるようになります。
|
XMLノードに対応する基礎となるデータベース列に対してBツリー索引を作成することで、オブジェクト・リレーショナル形式(構造化記憶域)で格納されたXMLデータを効果的に索引付けできます。
索引付けされるデータが単一の場合、つまりXMLインスタンス文書で一度のみ発生する可能性がある場合、表面的上ファンクション索引を作成するショートカットを使用できます。この場合、索引を定義する式はファンクション・アプリケーションで、単一データをターゲットとするXPath式の引数を使用します。ショートカットはXMLQueryに適用されるXMLCastに対して定義され、もう1つのショートカットはOracle SQL関数extractValueに対して定義されます(非推奨)。
多くの場合、Oracle XML DBでは、基礎となるオブジェクト・リレーショナル表または列に対して適切な索引が自動的に作成されますが、CREATE INDEX文が示すように、ターゲットとなるXMLTypeデータに対して、ファンクション索引は作成されません。
extractValueショートカットの場合、作成される索引はBツリー索引です。XMLQueryに適用されるXMLCastの場合、作成される索引は、ファンクション式から得られるスカラー値に対するファンクション索引です。これについては、「繰り返し使用しないtext()ノードまたは属性値の索引付け」で説明します。
索引付けされるデータがコレクションの場合、このようなショートカットを使用できません。手動でBツリー索引を作成する必要があります。これについては、「繰り返し使用する(コレクション)要素の索引付け」で説明します。
サンプル・データベース・スキーマOEの表purchaseorderはオブジェクト・リレーショナルに格納されます。各発注書には単一のReference要素が含まれます。つまりこの要素は単一です。したがって、ショートカットを使用して、基礎となるオブジェクト・リレーショナル・データに索引を作成できます。
例6-1に、Reference要素のテキスト・コンテンツをターゲットとし、XMLQueryに適用されるXMLCastを使用して、表面上ファンクション索引を作成しようとするCREATE INDEX文を示します(この要素のコンテンツはテキストのみのため、要素をターゲットにすることは、ノード・テストtext()を使用してテキスト・ノードをターゲットにすることと同じです)。
例6-2は、同じデータをターゲットにし、Oracle SQL関数extractValue(非推奨)を使用して表面上ファンクション索引を作成します。
例6-1 単一の要素でXMLCASTおよびXMLQUERYを使用したCREATE INDEX
CREATE INDEX po_reference_ix ON purchaseorder
(XMLCast(XMLQuery ('$p/PurchaseOrder/Reference' PASSING po.OBJECT_VALUE AS "p"
RETURNING CONTENT)
AS VARCHAR2(128)));
例6-2 単一の要素でEXTRACTVALUEを使用したCREATE INDEX
CREATE INDEX po_reference_ix ON purchaseorder (extractValue(OBJECT_VALUE, '/PurchaseOrder/Reference'));
実際、例6-1と例6-2では、ターゲットとなるXMLTypeデータに対してファンクション索引は作成されません。かわりに、Oracle XML DBによってCREATE INDEX文がリライトされ、基礎となるスカラー・データに対して索引が作成されます。
これらのショートカットのいずれかを使用するとき、CREATE INDEX文は前述のように基礎となるスカラー・データ上に索引を作成できない場合があります。そのかわり、実際には参照されるXMLTypeデータにファンクション索引を作成します。(これは索引の値がスカラーである場合でも当てはまります)。
このような場合は、索引を削除し、同じXPathをターゲットとする構造化コンポーネントを含むXMLIndex索引をかわりに作成します。一般的に、XMLTypeデータに対してはファンクション索引を使用しないことをお薦めします。
これは使用される格納方法にかかわらず、XMLTypeデータの一般的なルールです。ファンクション索引のかわりに構造化コンポーネントでXMLIndexを使用します。このルールはOracle Database 11gリリース 2 (11.2)から適用されます。このルールを守ることにより、ファンクション索引のメンテナンス操作に関連するオーバーヘッドを軽減し、オプティマイザで索引を適切に選択できる状況が増えます。
構造化記憶域では、コレクションはXMLTypeインスタンスのOrdered Collection Table(OCT)として格納されるため、メンバーに直接アクセスできます。構造化記憶域モデルは、XMLデータのファイングレイン構造を直接反映するため、各コレクション・メンバーをターゲットとする索引を作成できます。
このような索引は、手動で作成する必要があります。Oracle SQL関数extractValue(非推奨)に対して表面上ファンクション索引を作成する場合に、Bツリー索引を自動的に作成する専用の機能は、コレクションに適用されません(extractValueに渡されるXPath式は、単一要素をターゲットにする必要があります)。
コレクションに対してBツリー索引を作成するには、コレクションの管理に使用するSQLオブジェクトの構造を理解する必要があります。その情報に基づき、従来のオブジェクト・リレーショナルSQLコードを使用して、適切なSQLオブジェクト属性に対して索引を直接作成できます。この方法の例は、「ガイドライン: Ordered Collection表に対する索引の作成」を参照してください。
この項の内容は次のとおりです。
構造化(オブジェクト・リレーショナル)記憶域では、Bツリー索引を効果的に使用できます。基礎となるオブジェクトを直接ターゲット化することで、焦点がより明確に絞られます。ただし、バイナリXMLまたはCLOB記憶域を使用して格納されているXML文書、またはオブジェクト・リレーショナル記憶域に埋め込まれたCLOBインスタンスに格納されたXMLフラグメントの詳細な構造(要素および属性)を指定する場合、通常は効果を発揮しません。これは、XMLIndex(非構造化およびハイブリッド記憶域)の特殊ドメインです。
XMLIndexは一般的に、文書の一部に対してアクセスする場合に使用されるため、これらの部分を1つ以上のCLOBインスタンスにパックします。それでも、文書内のこれらの部分に対して問い合せる必要が生じることもあります。このような場合に、XMLIndexが役立ちます。
また、関連する文書構造とデータ型に対する特定の知識がなく、XML Schemaにxsd:any要素が含まれている場合にも使用されます。これらの要素に対応するデータはCLOBインスタンスに格納され、XMLIndexを使用して、アクセス速度を高められます。
XMLIndexはドメイン索引で、XMLデータのドメイン用に特化して設計されています。これは論理的索引です。XMLIndex索引は、SQL/XML関数XMLQuery、XMLTable、XMLExistsおよびXMLCastに対して使用できます。
XMLIndexには、他の索引付け方式に比べ、次のような利点があります。
XMLIndex索引は、問合せのどの部分においても効果があります。つまり、WHERE句での使用に限定されません。これは、XMLデータで使用される他の種類の索引では考えられません。
非構造化コンポーネントを含むXMLIndex索引では、SELECTリスト・データとFROMリスト・データの両方に対するアクセスを高速化でき、特にXMLフラグメント抽出において有用です。ファンクション索引とCTXXPath索引は両方とも非推奨になったため、文書のフラグメントの抽出には使用できません。
XMLIndex索引は、XML Schemaに基づくデータ、またはスキーマに基づかないデータに対して使用できます。非構造化記憶域、ハイブリッド記憶域またはバイナリXML記憶域で使用できます。Bツリー索引は、オブジェクト・リレーショナル形式(構造化記憶域)で格納されるXML Schemaに基づくデータに対してのみ使用でき、CLOBインスタンスに格納されるXML Schemaに基づくデータに対しては効果的ではありません。
XMLIndex索引は、コレクション(文書内に複数回出現するノード)をターゲットとするXPath式による検索において使用できます。ファンクション索引の場合とは異なります。
問合せに使用されるXPath式に関する事前の知識は不要です。XMLIndex索引の非構造化コンポーネントは、汎用性に富んでいます。ファンクション索引の場合とは異なります。
問合せに使用されるXPath式が事前にわかっている場合は、頻繁に問合せされる構造化された固定のデータ・アイランドをターゲットとする構造化XMLIndexコンポーネントを使用することで、パフォーマンスを向上できます。
XMLIndex索引(索引の作成とメンテナンス)は、複数のデータベース処理により、並列的に実行できます。これは、非推奨になったファンクション索引およびCTXXPATH索引の場合とは異なります。
XMLIndexを使用して半構造化脚注 1 のXMLデータ(一般的にほとんどまたはまったく固定構造を持たないデータ)を索引付けします。バイナリXMLまたはCLOBベース記憶域を使用して格納されたデータに適用されます。これには、オブジェクト・リレーショナル記憶域(ハイブリッド記憶域)に埋め込まれたCLOBインスタンスに格納されたXMLデータも含まれます。
それでも、半構造化XMLデータには、予測可能な構造化データ・アイランドが含まれることがあります。そのため、XMLIndex索引は、そのようなアイランドの索引付け用の構造化コンポーネントと、ほとんど構造を持たないまたは可変構造のデータの索引付け用の非構造化コンポーネントの2つのコンポーネントを持つことができます。
構造化コンポーネントは、構造化コンテンツのアイランドを投影および使用する問合せで使用すると役立ちます。非構造化コンポーネントは、XMLフラグメントを抽出する問合せで使用すると役立ちます。1つのXMLIndex索引に、必ずしも両方のコンポーネントが含まれている必要はありません。
構造化コンポーネントとは異なり、非構造化コンポーネントは汎用的で、比較的ターゲットを限定しません。特定のXPathサブセットにのみ適用されるように非構造化コンポーネントを制限することもできますが、そのパス表索引ノードの内容のスカラー型が異なる場合は、異なるデータ型を処理するようにVALUE列に対して複数の2次索引を作成する必要があることがあります(「VALUE列に対する2次索引」を参照)。また、非構造化コンポーネントのみを使用した場合、構造化アイランドを投影する問合せに対してプローブやそのパス表の自己結合が何度も行われるために、効率が悪くなることがあります。
一方、構造化コンポーネントは、ほとんど構造を持たない問合せや、XMLフラグメントを抽出する問合せには適していません。構造化データ・アイランドの索引付けには構造化コンポーネントを使用し、ほとんど構造を持たないデータの索引付けには非構造化コンポーネントを使用してください。
図6-1は第1章の図1-5と同じです。最後の行はXMLIndexがXMLデータの様々なユースケースに適用できるかどうかを示します。XMLIndexが半構造化XMLデータ(格納されているかどうかに関係なくに)適していることを示します(最後の3列)。構造化コンポーネントでのXMLIndex索引は、構造化アイランドを含むドキュメント中心データに有用です(4列目)。
XMLコンテンツの固定の構造化アイランドを投影する問合せに対しては、周囲のデータが比較的構造化されていない場合でも、XMLIndex索引の構造化コンポーネントを作成して使用します。
構造化XMLIndexコンポーネントは、このようなアイランドをリレーショナル形式で編成します。この場合、これはSQL/XML関数XMLTableと類似しており、構造化コンポーネントの定義に使用する構文も類似しています。索引付けデータの格納に使用するリレーショナル表はデータ型を認識し、各列は異なるスカラー・データ型を持つことができます。
したがって、XMLIndex索引の構造化コンポーネントを作成することは、XMLデータの構造化部分をリレーショナル形式へ分解することと考えることができます。これは、次のような点でXMLTypeのオブジェクト・リレーショナル形式の記憶域モデルとは異なります。
構造化索引コンポーネントは、指定されたデータの特定の部分(頻繁に問い合せる部分)を明示的に分解します。オブジェクト・リレーショナル形式のXMLType記憶域の場合は、XMLType表または列全体が自動的に分解されます。
XMLIndex索引の構造化コンポーネントは、XML Schemaに基づくデータにもXML Schemaに基づかないデータにも適用できます。オブジェクト・リレーショナル形式のXMLType記憶域は、XML Schemaに基づくデータにのみ適用できます。
構造化XMLIndexコンポーネントに対して分解されたデータは、XMLTypeデータ自体の記憶域モデルとしてではなく索引として、XMLTypeデータとともに格納されます。
構造化XMLIndexコンポーネントに対しては、同じデータを、データ型が異なる列として何度も投影できます。
XMLIndex索引の構造化コンポーネントに使用する索引コンテンツ表は索引の一部ですが、通常のリレーショナル表なので、標準的なリレーショナル索引(主キーおよび外部キー制約を満たす索引を含む)を使用すれば、これらの表にも索引を作成できます。また、Oracle Text CONTEXT索引などのドメイン索引を使用して索引を作成することもできます。
また、XMLIndex索引の構造化コンポーネントは、汎化ファンクション索引として考えることもできます。ファンクション索引は、リレーショナル列を1つのみ持つ構造化XMLIndexコンポーネントのようなものです。
特定のアプリケーションに対して複数のファンクション索引を作成することを予定している場合、かわりに構造化XMLIndex索引を使用することを考慮してください。また、構造化索引コンポーネントの列にBツリー索引も作成します。
|
注意:
|
XMLIndex構造化コンポーネントの索引コンテンツ表は通常のリレーショナル表ですが、読取り専用の表でもあるため、表の列を追加または削除したり、表の行を変更(挿入、更新または削除)したりすることはできません。
したがって、通常はリレーショナル索引コンテンツ表は無視してかまいません。DESCRIBEしたり、(2次)索引を作成する以外、それらにアクセスできません。それらに関する統計を明示的に収集する必要はありません。XMLIndex索引自体、またはXMLIndex索引が定義されている実表に関する統計のみ収集する必要があります。索引コンテンツ表に関する統計は透過的に収集され保持されます。
XMLIndex構造化コンポーネントに使用されるリレーショナル表では、SQLデータ型が使用されます。問合せ内で使用されるXQuery式では、XMLデータ型(XML Schemaデータ型およびXQueryデータ型)が使用されます。
一貫性や型チェックを保証するために、XQueryの入力規則の部分式のデータ型が自動的に変わることがあります。たとえば、XPath式/PurchaseOrder/LineItem[@ItemNumber = 25]を使用して問合せされる文書がXML Schemaに基づいていない場合、部分式@ItemNumberは型なしとなり、XQueryの比較演算子=によって自動的にxs:doubleにキャストされます。XMLIndex構造化コンポーネントを使用してこのデータに索引を作成するには、SQLデータ型としてBINARY_DOUBLEを使用する必要があります。
これは通例です。構造化コンポーネントを含むXMLIndex索引を問合せに適用するには、データ型が対応している必要があります。表6-5に、対応するデータ型を示します。
表6-5 XMLIndexでのXMLデータ型とSQLデータ型の対応
| XMLデータ型 | SQLデータ型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意: XMLデータ型がxs:dateまたはxs:dateTimeの場合、索引を作成する問合せ対象のデータにタイムゾーン・コンポーネントが含まれていないことがわかっていれば、SQLデータ型DATEまたはTIMESTAMPを使用するとパフォーマンスを高めることができます。データにタイムゾーン・コンポーネントが含まれている可能性がある場合は、SQLデータ型TIMESTAMP WITH TIMEZONEを使用する必要があります。 |
対象となるXMLデータ型とSQLデータ型に1対1の組込みの対応関係がない場合は、問合せに対して索引が取得されるように、(表6-5に従って)両者を対応させる必要があります。これには、次の2つの方法があります。
索引を問合せに対応させる: 構造化索引コンポーネント内の列を、XMLデータ型と対応するように定義(または再定義)します。たとえば、索引付けの対象となる問合せにXMLデータ型xs:doubleを使用するには、対応するSQLデータ型BINARY_DOUBLEを使用するように索引を定義します。
問合せを索引に対応させる: 問合せ内で、XQuery式の関連部分を、索引コンテンツ表に使用するSQLデータ型と対応するデータ型に明示的にキャストします。
例6-3および例6-4に、問合せ内でXQuery式をキャストして、索引コンテンツ表に使用するSQLデータ型に一致させる方法を示します。
例6-3 問合せデータと索引データを対応させる: SQLのキャスト
SELECT count(*) FROM purchaseorder WHERE XMLCast(XMLQuery('$p/PurchaseOrder/LineItem/@ItemNumber' PASSING OBJECT_VALUE AS "p" RETURNING CONTENT) AS INTEGER) = 25;
例6-4 問合せデータと索引データを対応させる: XQueryのキャスト
SELECT count(*) FROM purchaseorder
WHERE XMLExists('$p/PurchaseOrder/LineItem[xs:decimal(@ItemNumber) = 25]'
PASSING OBJECT_VALUE AS "p");
この2つの例では、数字25はどちらも受注品目番号ですが、それぞれ異なる役割を果しています。例6-3では25はデータ型INTEGERのSQL数値であり、例6-4では25はデータ型xs:decimalのXQuery数値です。
例6-3では、XMLQueryの結果がSQLのINTEGER型にキャストされ、SQLの値25と比較されます。例6-4では、属性ItemNumberの値がXMLデータ型xs:decimalに(XQuery内で)キャストされます。これはXQueryの値25と比較され、索引に使用されるSQLデータ型(INTEGER)に対応します。このように、この例では2つの異なる種類のデータ型の変換が行われますが、どちらも型が索引コンテンツ表と一致するように問合せデータが変換されます。
Bツリー索引は、個々のXML要素または属性を表す特定のデータベース列や、構造化ドキュメントの特定部分に適用されるXMLIndex構造化コンポーネントに対して定義します。これに対し、XMLIndex索引の非構造化コンポーネントは、デフォルトで非常に汎用性に富んでいます。索引付けに使用する特定のXPath式や使用しない特定のXPath式を限定することにより焦点を絞り込んだ場合を除き、非構造化XMLIndexコンポーネントはXMLデータのすべての使用可能なXPath式に適用されます。
XMLIndex索引の非構造化コンポーネントは、次の3つの論理部分で構成されます。
XMLIndex索引の非構造化コンポーネントは、パス表と、そのパス表の一連の(ローカルの)2次索引を使用します。これらは前述の論理部分を実装します。2つの2次索引が自動的に作成されます。
pikey索引: パスおよび順序の両方の論理索引を実装します。
値索引: 論理値の索引を実装します。
これらの2つの索引を変更したり、追加の2次索引を作成できます。パス表とその2次索引はすべて、XMLIndex索引が作成される実表の所有者によって所有されます。
pikey索引は、パスと順序の関係を処理し、ほとんどの場合で最適なパフォーマンスが得られます。値索引を取得すべきときに取り出されない場合は、パスおよび順序の関係で個別の索引をpikey索引のかわりに使用できます。このような(オプション)の索引は、それぞれパスID索引および順序キー索引と呼ばれます。特定の場合の要件でpikey索引が不十分の場合は、最適な結果を得るためにOracleサポートに問い合せてください。
パス表では、XML文書で索引付けされる1つのノードに対して1行が使用されます。索引付けされたノードごとに、パス表には次のものが格納されます。
文書を格納する表に対応するROWID。
対応する文書のフラグメントへの高速アクセスを提供するロケータ。XML Schemaに基づくデータのバイナリXML記憶域については、データ型情報も格納します。
文書におけるノードの階層的な位置を記録するための順序キー。これは、図書目録やインターネット・プロトコルSNMPで使用されるような、デューイ10進分類キーのようなものです。このようなシステムでは、3.21.5というキーは、文書のルート・ノードの3番目の子の21番目の子の5番目の子というノード位置を表します。
ノードに対するXPathパスを表す識別子。
ノードの有効なテキスト値。
表6-6 XMLIndexのパス表
| 列 | データ型 | 説明 |
|---|---|---|
|
|
|
ノードのXPathパスに対する一意の識別子です。 |
|
|
|
XMLデータを格納するために使用される表のROWIDです。 |
|
|
|
ノードの階層的な位置を識別するための、10進数の順序キーです。(ドキュメントの順序は保持されます。) |
|
|
|
フラグメント位置情報です。フラグメント抽出に使用されます。XML Schemaに基づくデータのバイナリXML記憶域では、データ型情報もここに格納されます。 |
|
|
|
ノードの有効テキスト値。 |
pikey索引では、パス表の列PATHID、RIDおよびORDER_KEYを使用して、パスと順序の索引を表します。オプションのパスID索引では、列PATHIDおよびRIDを使用して、パス索引を表します。値索引は、VALUE列に対する索引です。
例6-5では、2つの発注書のパス表の内容を見ていきます。
例6-5 2つの発注書のパス表の内容
<PurchaseOrder> <Reference>SBELL-2002100912333601PDT</Reference> <Actions> <Action> <User>SVOLLMAN</User> </Action> </Actions> . . . </PurchaseOrder> <PurchaseOrder> <Reference>ABEL-20021127121040897PST</Reference> <Actions> <Action> <User>ZLOTKEY</User> </Action> <Action> <User>KING</User> </Action> </Actions> . . . </PurchaseOrder>
これらの発注書を格納するXMLType表または列のXMLIndex索引には、XML文書で索引付けされたノードに対し、1行ずつ使用するパス表が含まれます。仮に、XPath式に従ってノードに索引付けする際、システムによって次のPATHIDが割り当てられるとします。
| PATHID | 索引付けされたXPath |
|---|---|
1 |
/PurchaseOrder |
2 |
/PurchaseOrder/Reference |
3 |
/PurchaseOrder/Actions |
4 |
/PurchaseOrder/Actions/Action |
5 |
/PurchaseOrder/Actions/Action/User |
結果として作成されるパス表は、次のようになります(LOCATOR列は示されません)。
| PATHID | RID | ORDER_KEY | VALUE |
|---|---|---|---|
1 |
R1 |
1 |
SBELL-2002100912333601PDTSVOLLMAN |
2 |
R1 |
1.1 |
SBELL-2002100912333601PDT |
3 |
R1 |
1.2 |
SVOLLMAN |
4 |
R1 |
1.2.1 |
SVOLLMAN |
5 |
R1 |
1.2.1.1 |
SVOLLMAN |
1 |
R2 |
1 |
ABEL-20021127121040897PSTZLOTKEYKING |
2 |
R2 |
1.1 |
ABEL-20021127121040897PST |
3 |
R2 |
1.2 |
ZLOTKEYKING |
4 |
R2 |
1.2.1 |
ZLOTKEY |
5 |
R2 |
1.2.1.1 |
ZLOTKEY |
4 |
R2 |
1.2.2 |
KING |
5 |
R2 |
1.2.2.1 |
KING |
パス表の列に2次索引を作成した場合でも、パス表そのものは通常は無視できます。パス表には、それをDESCRIBEしたり、(2次)索引を作成したりする以外はアクセスできません。パス表に関する統計を明示的に収集する必要はありません。統計は、XMLIndex索引、またはXMLIndex索引が定義されている実表についてのみ収集する必要があります。統計は収集され、パス表と2次索引に透過的に保持されます。
VALUE列の2次索引は、一致する文字列に関する述語を有するWHERE句のXPath式で使用されます。次に例を示します。
/PurchaseOrder[Reference/text() = "SBELL-2002100912333601PDT"]
列VALUEには、要素または属性ノードの有効テキスト値が格納されます。索引付けの際、コメントおよび処理命令は無視されます。
属性では、有効テキスト値は属性値です。
単純な要素(子のない要素)では、有効テキスト値は、要素のすべてのテキスト・ノードを連結したものになります。
複雑な要素(子のある要素)では、有効テキスト値は、(1)要素そのもののテキスト・ノードを連結したもの、(2)単純要素のすべての子孫の有効テキスト値になります。(これは再帰的定義です。)
ただし、有効テキスト値は4000バイト(単純な要素または属性の場合)および80バイト(複雑な要素の場合)に制限(切捨て)されます。
VALUE列のサイズは、VARCHAR2(4000)に固定されています。索引の作成または更新時における超過分(4000バイトを超える分)は切り捨てられますが、当該行のLOCATOR値はフラグ付けされるため、必要に応じて完全な値を実表から取得することは可能です。
VALUE列に対する4000バイトの上限に加え、当該列に対して作成される2次索引のキーのサイズにも制限があります。これは、Bツリー索引とファンクション索引にも該当します。XMLIndexの制限ではありません。索引キーのサイズの限界は、データベースのブロック・サイズの関数です。VALUEに対してどの程度の索引付けがなされるかは、この制限値によって決定します。
つまり、有効テキスト値の最初の4000バイトのみがVALUE列に格納され、VALUE列の最初のNバイトに対してのみ索引が作成されるということです。ここでNとは、索引キーのサイズの制限を表します(N < 4000)。索引キーのサイズの制限が課されることにより、VALUE列の索引は、有効テキスト値の事前フィルタとしてのみ機能します。
たとえば、データベースのブロック・サイズにより、VALUE列の索引を800バイト以内に抑え、有効テキスト値のうち最初の800バイト分のみを索引付けするとします。有効テキスト値の最初の800バイト分に対してXMLIndexを使用してテストを実行し、そのテキスト接頭辞が問合せ値に一致した場合のみ、残りの有効テキスト値がテストされます。
VALUE列の2次索引は、substr SQL関数(サブストリング等価性)です。この関数を使用して、テキスト接頭辞をテストするためです。このファンクション索引は、VALUE列に対するXMLIndexの実装の一環として自動的に作成されます。
たとえば、問合せのWHERE句のXPath式/PurchaseOrder[Reference/text() = :1]は、実質的に、次のようなテストにリライトされることがあります。
substr(VALUE, 1 800) = substr(:1, 1, 800) AND VALUE = :1;
この結合は2つの部分から構成され、左から右に向かって処理されます。1つ目のテストでは、substr関数の索引を事前フィルタとして使用し、冒頭800バイトがバインド変数:1の冒頭800バイトに一致しないテキストを削除します。
索引は、1つ目のテストでのみ使用されます。VALUE列の完全な値は索引付けされません。1つ目のテストで事前フィルタリングを実行した後、2つ目のテストで有効テキスト値全体をチェックします。つまり、VALUE列の完全な値と、:1の値の等価性を確認します。このチェックでは索引は使用されません。
テキストの冒頭800バイトのみが索引付けされる場合でも、問合せパフォーマンスでは、最大4000バイトをVALUE列に格納することが重要になります。これにより、CLOBインスタンスのXML文書内の深い部分からデータを抽出することなく、データに迅速かつ直接的にアクセスできるようになるからです。有効テキスト値が4000バイトを超える場合は、WHERE句結合の2つ目のテストにおいて、実表データにアクセスする必要があります。
VALUE列に対する4000バイト上限も、索引キーのサイズも、問合せ結果には何の影響も与えません。これらはパフォーマンスにのみ影響を与えます。
|
注意: VALUEに対して作成されたOracle Text CONTEXT索引は、VALUE列が切り捨てられることがあるために、間違った結果を戻す可能性があります。 |
前述したように、XMLIndexはXML Schemaに基づくデータで使用できます。XML Schemaが特定の要素または属性に対してdefaultValue値を指定し、特定の文書が当該の要素または属性に対して値を指定しない場合、defaultValue値がVALUE列で使用されます。
XMLIndex索引を作成する際、VALUE列に対して2次索引を指定しない場合でも、VALUE列に対してデフォルトの2次索引が作成されます。このデフォルト索引には、デフォルトのプロパティがあります。具体的には、これはtext(文字列値)データでのみ使用される索引です。
ただし、異なる種類のVALUE索引を作成できます。たとえば、数値の索引が問合せの大半に適している場合は、数値の索引を作成できます。VALUE列に対し、複数の2次索引を作成できます。特定の種類の索引は、それが適切な場合にのみ使用されます。たとえば、数値の索引は、VALUE列が数値である場合にのみ使用されます。その他の値の場合は無視されます。パス表の列の2次索引は、その他の2次索引と同様に扱われます。つまり、これらの索引は変更、削除、不使用としてマーキングするなどが可能です。
|
関連項目:
|
次のタイプのXPath式は、XMLIndexにより索引付けされません。
ora:contains以外のXPath関数の適用。特に、ユーザー定義のXPath関数は索引付けされません。
child、descendant、およびattribute以外の軸(parent、ancestor、following-sibling、preceding-sibling、following、preceding、およびancestor-or-selfの各軸)。
共用体演算子|(垂直バー)を使用する式。
例6-6に示すように、索引タイプをXDB.XMLIndexと宣言して、XMLIndex索引を作成します。
例6-6 XMLType非構造化記憶域でのXMLIndex索引の作成
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex;
これにより、XMLTypeのpo_clob表に、po_xmlindex_ixという名前のXMLIndex索引が作成されます。索引に含まれるのは非構造化コンポーネントのみで、構造化コンポーネントは含まれません。
XMLIndex索引に構造化コンポーネントを含めるように指定するには、PARAMETERS句にstructured_clauseを含めます。非構造化コンポーネントを含めるように指定するには、PARAMETERS句にpath_table_clauseを含めます。この操作は、XMLIndex索引を作成または変更する場合に可能です。例6-6に示すように、structured_clauseとpath_table_clauseのいずれも指定しない場合は、非構造化コンポーネントのみが含まれます。
XMLIndex索引に非構造化コンポーネントと構造化コンポーネントの両方が含まれる場合は、ALTER INDEXを使用していずれかのコンポーネントを削除できます。
例6-7に示すように、特定のXMLType表(または列)のXMLIndex索引の名前を取得できます。また、適宜DBA_INDEXESまたはALL_INDEXESからINDEX_NAMEを選択することも可能です。
例6-7 特定の表にあるXMLIndex索引の名前の取得
SELECT INDEX_NAME FROM USER_INDEXES WHERE TABLE_NAME = 'PO_CLOB' AND ITYP_NAME = 'XMLINDEX'; INDEX_NAME --------------- PO_XMLINDEX_IX 1 row selected.
例6-8に示すように、XMLIndex索引は、他の索引と同様に名前変更または削除できます。この名前変更では、XMLIndex索引の名前のみが変更されます。この処理ではパス表の名前は変更されません。パス表は、個別に名前を変更できます。
同様に、REBUILDなどのALTER INDEXオプションを使用し、他の索引プロパティも変更できます。この点においては、XMLIndexも他の索引タイプと同じです。
XMLIndexのALTER INDEX文のRENAME句は、XMLIndexそのものに対してのみ適用されます。パス表および2次索引の名前を変更するには、これらのオブジェクトの名前を決定し、適切なALTER TABLE文またはALTER INDEX文を直接使用する必要があります。同様に、2次索引の物理プロパティを取得したり、他のなんらかの方法で変更を加えたりする場合は、例6-13の方法に従って2次索引の名前を取得する必要があります。
例6-6に、非構造化記憶域にXMLIndex索引を作成する方法を示します。
この項では、(構造化コンポーネントも含まれるかどうかに関係なく)非構造化コンポーネントが含まれるXMLIndex索引で実行可能な操作について説明します。詳細は、「XMLIndex非構造化コンポーネント」を参照してください。
XMLIndex索引に非構造化コンポーネントを含めるには、XMLIndex索引の作成または変更時に、PARAMETERS句でpath_table_clauseを使用します。詳細は「path_table_clause ::=」を参照してください。
構造化コンポーネントを指定しない場合、パス表を指定しなくても、索引に非構造化コンポーネントが含まれます。ただし、一般的にはパス表を指定することをお薦めします。これにより他のXMLIndex操作で参照できる、ユーザー指向の認識可能な名前が含まれるようになります。
例6-9に、非構造化コンポーネントを含むXMLIndex索引の作成時に、パス表(my_path_table)の名前を付ける方法を示します。
例6-9 XMLIndex索引のパス表への名前付け
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex
PARAMETERS ('PATH TABLE my_path_table');
パス表に名前を付けなかった場合、名前はCREATE INDEXに与えた索引名に基づき、システムによって自動的に生成されます。例6-10に、例6-6で作成したXMLIndex索引を使用した例を示します。
例6-10 XMLIndexパス表のシステム生成名の決定
SELECT PATH_TABLE_NAME FROM USER_XML_INDEXES WHERE TABLE_NAME = 'PO_CLOB' AND INDEX_NAME = 'PO_XMLINDEX_IX'; PATH_TABLE_NAME ------------------------------ SYS67567_PO_XMLINDE_PATH_TABLE 1 row selected.
デフォルトでは、パス表と2次索引の記憶域オプションは、XMLIndex索引が作成された実表の記憶域プロパティから生成されます。例6-11で示すように、索引の作成時にPARAMETERS句を使用すると、異なる記憶域オプションを指定できます。CREATE INDEX(およびALTER INDEX)のPARAMETERS句は、一重引用符(')で囲む必要があります。
例6-11 XMLIndex索引の作成時における記憶域オプションの指定
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex
PARAMETERS
('PATH TABLE po_path_table
(PCTFREE 5 PCTUSED 90 INITRANS 5
STORAGE (INITIAL 1k NEXT 2k MINEXTENTS 3 BUFFER_POOL KEEP)
NOLOGGING ENABLE ROW MOVEMENT PARALLEL 3)
PIKEY INDEX po_pikey_ix (LOGGING PCTFREE 1 INITRANS 3)
VALUE INDEX po_value_ix (LOGGING PCTFREE 1 INITRANS 3)');
XMLIndexは論理的なドメイン索引であり、物理索引ではないため、すべての物理属性はゼロ(0)またはNULLになります。
XMLIndex索引に非構造化コンポーネントと構造化コンポーネントの両方が含まれる場合は、ALTER INDEXを使用して非構造化コンポーネントを削除できます。これを実行するには、パス表を削除します。例6-12に、これを示します。(この場合は、構造化コンポーネントも含むことを前提とします。例6-20では、索引に構造化コンポーネントと非構造化コンポーネントの両方が含まれるようになります。)
例6-11では、パス表に対する記憶域オプションの指定に加え、パス表に対する2次索引にも名前を付けています。
パス表の名前と同様、パス表の列の2次索引の名前は、PARAMETERS句で指定しないかぎり、索引名をベースとして使用して自動的に生成されます。例6-13にこれを示します。これらの名前をパブリック・ビューUSER_IND_COLUMNSで決定する方法も示します。また、pikey索引で3つの列を使用することも示します。
例6-13 XMLIndex索引の2次索引の名前付け
SELECT INDEX_NAME, COLUMN_NAME, COLUMN_POSITION FROM USER_IND_COLUMNS
WHERE TABLE_NAME IN (SELECT PATH_TABLE_NAME FROM USER_XML_INDEXES
WHERE INDEX_NAME = 'PO_XMLINDEX_IX')
ORDER BY INDEX_NAME, COLUMN_NAME;
INDEX_NAME COLUMN_NAME COLUMN_POSITION
------------------------------ ------------ ---------------
SYS67563_PO_XMLINDE_PIKEY_IX ORDER_KEY 3
SYS67563_PO_XMLINDE_PIKEY_IX PATHID 2
SYS67563_PO_XMLINDE_PIKEY_IX RID 1
SYS67563_PO_XMLINDE_VALUE_IX SYS_NC00006$ 1
4 rows selected.
この項では、例6-11で作成したXMLIndexに対し、2次索引を追加で作成します。
XMLIndex索引のパス表のVALUE列に対し、2次索引をいくつでも追加で作成できます。ファンクション索引やOracle Text索引など、様々な種類が可能です。
問合せの処理時に、指定の索引が指定の要素に対して使用されるかどうかは、その索引が当該値に対して適切であるかどうかや、その索引の使用が費用効率に優れているかどうかによって決まります。
例6-14では、SQL関数substrを使用して、パス表のVALUE列にファンクション索引を作成します。問合せにおいて、XML要素のテキスト・ノードに対してsubstrがよく使用される場合は便利な方法です。
テキスト・ノードが数値を表す要素が多数ある場合、VALUE列に対して数値索引を作成すると有効です。ただし、例6-14と同じような方法で数値索引を直接作成すると、要素値のいずれかが数値ではない場合にORA-01722エラー(無効な数値)が発生します。これを例6-15に示します。
例6-15 パス表のVALUE列に対する、数値索引の直接作成
CREATE INDEX direct_num_ix ON po_path_table (to_binary_double(VALUE));
CREATE INDEX direct_num_ix ON po_path_table (to_binary_double(VALUE))
*
ERROR at line 1:
ORA-01722: invalid number
ここで必要となるのは、数値の要素に対して使用されるが、数値を持たない要素に対しては無視される索引です。特に、DBMS_XMLINDEXパッケージのcreateNumberIndexプロシージャは、この目的でのみ存在するものです。このプロシージャに、データベース・スキーマの名前、XMLIndex索引、および作成される数値索引を渡します。数値索引の作成は、例6-16に示します。
例6-16 createNumberIndexプロシージャによる、VALUE列に対する数値索引の作成
CALL DBMS_XMLINDEX.createNumberIndex('OE', 'PO_XMLINDEX_IX', 'API_NUM_IX');
このような索引は数値を持たない要素を無視するよう設計されているため、この索引が数値を持たない要素を検出することはありません。非数値要素がある場合に、なんらかの理由によりXMLIndex索引が問合せで使用されなければ、ORA-01722エラーが発生します。ただし、索引が使用されると非数値データは無視されるため、エラーは発生しません。ここでも、索引の使用により結果セットが変わることはありません。結果はまったく同じですが、索引を使用すると、誤ったデータの検出を防ぐことはできます。
日付値の索引の作成は、数値索引の作成と似ています。この場合は、DBMS_XMLINDEX.createDateIndexプロシージャを使用します。例6-17に、これを示します。
例6-17 createDateIndexプロシージャによる、VALUE列に対する日付索引の作成
CALL DBMS_XMLINDEX.createDateIndex('OE', 'PO_XMLINDEX_IX', 'API_DATE_IX',
'dateTime');
例6-18では、Oracle TextのCONTEXT索引をVALUE列に作成します。これは、XML要素のテキスト値に対する全文問合せにおいて便利です。XPath関数ora:containsを使用するXPath述語は、VALUE列のcontains Oracle SQL関数の使用にあわせてリライトされます。CONTEXT索引がVALUE列に対して定義されている場合、述語の評価時に使用されます。Oracle Text索引は、他のすべてのVALUE列の索引に依存しません。
例6-18 パス表のVALUE列に対するOracle Text CONTEXT索引の作成
CREATE INDEX po_otext_ix ON po_path_table (VALUE)
INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS('TRANSACTIONAL');
例6-19の問合せは、XMLIndex索引のパス表に対して作成されたすべての2次索引を示します。作成された索引は、明確に太字で示されます。特に注意する必要があるのは、VALUE列に作成されたファンクション索引などは、この例のように表示されない点です。これらの索引の列名は、SYS_NC00007$などのシステム生成名になります。そのため、WHERE句でCOLUMN_NAME = 'VALUE'を使用して問合せを実行しても、これらの列を見ることはできません。
例6-19 XMLIndexのパス表上にある、すべての2次索引の表
SELECT c.INDEX_NAME, c.COLUMN_NAME, c.COLUMN_POSITION, e.COLUMN_EXPRESSION FROM USER_IND_COLUMNS c LEFT OUTER JOIN USER_IND_EXPRESSIONS e ON (c.INDEX_NAME = e.INDEX_NAME) WHERE c.TABLE_NAME IN (SELECT PATH_TABLE_NAME FROM USER_XML_INDEXES WHERE INDEX_NAME = 'PO_XMLINDEX_IX') ORDER BY c.INDEX_NAME, c.COLUMN_NAME; INDEX_NAME COLUMN_NAME COLUMN_POSITION COLUMN_EXPRESSION -------------------- ------------ --------------- ---------------------- API_DATE_IX SYS_NC00009$ 1 SYS_EXTRACT_UTC(SYS_XMLCONV("V ALUE",3,8,0,0,181)) API_NUM_IX SYS_NC00008$ 1 TO_BINARY_DOUBLE("VALUE") FN_BASED_IX SYS_NC00007$ 1 SUBSTR("VALUE",1,100) PO_OTEXT_IX VALUE 1 PO_PIKEY_IX ORDER_KEY 3 PO_PIKEY_IX PATHID 2 PO_PIKEY_IX RID 1 PO_VALUE_IX SYS_NC00006$ 1 SUBSTRB("VALUE",1,1599) 8 rows selected.
|
関連項目:
|
XMLIndex索引に構造化コンポーネントを含めるには、XMLIndex索引の作成または変更時に、PARAMETERS句でstructured_clauseを使用します(「structured_clause ::=」を参照)。
structured_clauseでは、索引付けの対象となる構造化アイランドを指定します。キーワードGROUPを使用して、各構造化アイランドを指定します。このためアイランドの構文は構造グループに一致します。明示的にグループを指定しない場合、事前定義済グループDEFAULT_GROUPが使用されます。ALTER INDEXの場合、GROUPキーワードの前に変更操作キーワードを指定します。新しいグループ(アイランド)を作成する場合はADD_GROUPを、グループを削除する場合はDROP_GROUPを指定します。
単に複数のXMLIndex索引を使用するのではなく、1つの索引内で複数のグループを使用する理由を考えてみます。その理由は、XMLIndexがドメイン索引であること、そして特定のデータベース列に対しては特定タイプのドメイン索引を1つしか作成できないことです。
構造グループを定義する(つまり、構造化アイランドに索引を作成する)ための構文は、SQL/XML関数XMLTableを起動するための構文と似ています。リレーショナル列を定義するにはキーワードXMLTableおよびCOLUMNSを使用し、コレクションを処理するにはXMLTableのマルチレベル連鎖を使用します。
例6-20に、非構造化コンポーネントのみを含むXMLIndex索引を作成する方法を示します。PARAMETERS句でパス・ノードに明示的に名前付けしているため、非構造化コンポーネントが作成されます。
例6-20では、ALTER INDEXを使用して、po_itemという名前の構造化コンポーネント(グループ)を追加します。この構造グループには、キーワードXMLTableで指定された2つのリレーショナル表が含まれます。
例6-20 XMLIndex索引: 構造化コンポーネントの追加
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE)
INDEXTYPE IS XDB.XMLIndex PARAMETERS ('PATH TABLE path_tab');
BEGIN
DBMS_XMLINDEX.registerParameter(
'myparam',
'ADD_GROUP GROUP po_item
XMLTable po_idx_tab ''/PurchaseOrder''
COLUMNS reference VARCHAR2(30) PATH ''Reference'',
requestor VARCHAR2(30) PATH ''Requestor'',
username VARCHAR2(30) PATH ''User'',
lineitem XMLType PATH ''LineItems/LineItem'' VIRTUAL
XMLTable po_index_lineitem ''/LineItem'' PASSING lineitem
COLUMNS itemno BINARY_DOUBLE PATH ''@ItemNumber'',
description VARCHAR2(256) PATH ''Description'',
partno VARCHAR2(14) PATH ''Part/@Id'',
quantity BINARY_DOUBLE PATH ''Part/@Quantity'',
unitprice BINARY_DOUBLE PATH ''Part/@UnitPrice''');
END;
/
ALTER INDEX po_xmlindex_ix PARAMETERS('PARAM myparam');
最上位の表po_idx_tabには、reference、requestor、usernameおよびlineitemの列があります。lineitem列の型はXMLTypeです。この列はコレクションを表しているため、2番目のXMLTable構造体に渡されて、2番目のレベルのリレーショナル表po_index_lineitemを構成します。この表には、列itemno、description、partno、quantityおよびunitpriceが含まれます。
XMLType列にはキーワードVIRTUALが必要です。このキーワードは、XMLType列自体が生成されないことを指定します。つまり、そのデータは、対応するXMLTable表により指定されたリレーショナル列の形式でのみ、XMLIndex索引に格納されます。
1つのXMLTable内に複数のXMLType列を作成することはできません。1つのXMLTable内に複数のXMLType列を入れる場合は、追加のグループを定義する必要があります。
例6-20にも、PARAMETERS句での登録済パラメータ文字列の使用を示します。これはPL/SQLのプロシージャDBMS_XMLINDEX.registerParameterを使用して、myparamという名前のパラメータ文字列を登録します。次にALTER INDEXを使用して、文字列myparamに含まれるように索引パラメータを更新します。
XMLIndex索引に非構造化コンポーネントと構造化コンポーネントの両方が含まれる場合は、ALTER INDEXを使用して構造化コンポーネントを削除できます。これを行うには、構造化コンポーネントを構成するすべての構造グループを削除します。例6-21に、例6-20で追加された構造化コンポーネントを削除する方法を示します。この場合は、その構造グループpo_itemのみを削除します。
「XMLIndex構造化コンポーネント」の項で説明したように、XMLIndex索引の構造化コンポーネントに使用する表は通常のリレーショナル表なので、標準的なリレーショナル索引を使用すれば、これらの表にも索引を作成できます。
例6-22および例6-23にこれを示します。例6-22では、例6-20のXMLIndex索引に対し、索引コンテンツ表(構造化フラグメント)のreference列にBツリー索引を作成します。例6-23では、description列に対してOracle TextのCONTEXT索引を作成し、そのコンテンツに対して全文問合せを使用します。
例6-23 XMLIndex索引コンテンツ表に対するOracle Text CONTEXT索引
CREATE INDEX idx_tab_desc_ix ON po_index_lineitem (description)
INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ('transactional');
SELECT XMLQuery('/PurchaseOrder/LineItems/LineItem'
PASSING OBJECT_VALUE RETURNING CONTENT)
FROM po_clob
WHERE XMLExists('/PurchaseOrder/LineItems/LineItem
[ora:contains(Description, "Picnic") > 0]'
PASSING OBJECT_VALUE)
AND XMLExists('/PurchaseOrder[User="SBELL"]' PASSING OBJECT_VALUE);
例6-24に、XMLIndex索引の作成を示します。この索引には、構造化コンポーネントのみが含まれ(パス表句は含まれない)、XMLNAMESPACES句を使用して名前空間を指定します。索引データを圧縮し、表領域SYSAUXを使用することを指定します。この例では、XML Schemaに基づかないデータを含むバイナリXML表po_binxmlを想定しています。
例6-24 構造化コンポーネントのみを含むXMLIndexおよび名前空間の使用
CREATE INDEX po_struct ON po_binxml (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex
PARAMETERS ('XMLTable po_ptab
(TABLESPACE "SYSAUX" COMPRESS FOR OLTP)
XMLNAMESPACES (DEFAULT ''http://www.example.com/po''),
''/purchaseOrder''
COLUMNS orderdate DATE PATH ''@orderDate'',
id BINARY_DOUBLE PATH ''@id'',
items XMLType PATH ''items/item'' VIRTUAL
XMLTable li_tab
(TABLESPACE "SYSAUX" COMPRESS FOR OLTP)
XMLNAMESPACES (DEFAULT ''http://www.example.com/po''),
''/item'' PASSING items
COLUMNS partnum VARCHAR2(15) PATH ''@partNum'',
description CLOB PATH ''productName'',
usprice BINARY_DOUBLE PATH ''USPrice'',
shipdat DATE PATH ''shipDate''');
|
関連項目:
|
特定のXMLIndex索引を使用できるかどうかは、問合せのコンパイル時にOracle Databaseにより決定されます。つまり、索引に対する問合せにその問合せをリライトできるかどうかによって決まります。
非構造化XMLIndexコンポーネントの場合、問合せ内のXPath式が、XMLIndex索引付けに使用するよう指定したパスのサブセットであることをコンパイル時に断定できない場合、索引の非構造化コンポーネントは使用されません。
たとえば、索引付けの際にパス/PurchaseOrder/LineItems//*が含まれる場合、/PurchaseOrder/LineItems/LineItem/Descriptionを含む問合せでは索引を使用できますが、//Descriptionを含む問合せは索引を使用できません。後者は、/PurchaseOrder/LineItemsの子ではない潜在的なDescription要素と一致し、そのDescription要素がデータに出現するかどうかはコンパイル時に判断できません。
特定のXMLIndex索引が問合せの解決に使用されたかどうかを把握するには、問合せの実行計画を検証します。
索引の非構造化コンポーネントが使用される場合、そのパス表、順序キー、またはパスIDが実行計画において参照されます。実行計画は、ドメイン索引が使用されていることを直接的に示すことはありません。XMLIndex索引を名前で参照することもありません。例6-25および例6-27を参照してください。
索引の構造化コンポーネントが使用される場合、その索引コンテンツ表の1つ以上が実行計画において呼び出されます。例6-28および例6-29を参照してください。
|
関連項目:
|
例6-25に、例6-9で作成したXMLIndex索引が特定の問合せで使用される様子を示します。ここで示す実行計画のMY_PATH_TABLEへの参照は、XMLIndex索引(例6-9で作成)が問合せで使用されることを示します。同様に、LOCATOR、ORDER_KEY、およびPATHIDの各列への参照も、同じことを示します。
例6-25 XMLIndex非構造化コンポーネントが使用されるかどうかの確認
SET AUTOTRACE ON EXPLAIN
SELECT XMLQuery('/PurchaseOrder/Requestor' PASSING OBJECT_VALUE RETURNING CONTENT) FROM po_clob
WHERE XMLExists('/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]' PASSING OBJECT_VALUE);
XMLQUERY('/PURCHASEORDER/REQUESTOR'PASSINGOBJECT_VALUERETURNINGCONTENT)
-----------------------------------------------------------------------
<Requestor>Sarah J. Bell</Requestor>
1 row selected.
Execution Plan
. . .
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 28 (4)| 00:00:01 |
| 1 | SORT GROUP BY | | 1 | 3524 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID | MY_PATH_TABLE | 2 | 7048 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 2 (0)| 00:00:01 |
| 4 | NESTED LOOPS | | 1 | 24 | 28 (4)| 00:00:01 |
| 5 | VIEW | VW_SQ_1 | 1 | 12 | 26 (0)| 00:00:01 |
| 6 | HASH UNIQUE | | 1 | 5046 | | |
| 7 | NESTED LOOPS | | 1 | 5046 | 26 (0)| 00:00:01 |
|* 8 | TABLE ACCESS BY INDEX ROWID| MY_PATH_TABLE | 1 | 3524 | 24 (0)| 00:00:01 |
|* 9 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_VALUE_IX | 73 | | 1 (0)| 00:00:01 |
|* 10 | TABLE ACCESS BY INDEX ROWID| MY_PATH_TABLE | 1 | 1522 | 2 (0)| 00:00:01 |
|* 11 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 1 (0)| 00:00:01 |
| 12 | TABLE ACCESS BY USER ROWID | PO_CLOB | 1 | 12 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(SYS_XMLI_LOC_ISNODE("SYS_P0"."LOCATOR")=1)
3 - access("SYS_P0"."RID"=:B1 AND "SYS_P0"."PATHID"=HEXTORAW('76E2') )
8 - filter("SYS_P4"."VALUE"='SBELL-2002100912333601PDT' AND "SYS_P4"."PATHID"=HEXTORAW('4F8C') AND
SYS_XMLI_LOC_ISNODE("SYS_P4"."LOCATOR")=1)
9 - access(SUBSTRB("VALUE",1,1599)='SBELL-2002100912333601PDT')
10 - filter(SYS_XMLI_LOC_ISNODE("SYS_P2"."LOCATOR")=1)
11 - access("SYS_P4"."RID"="SYS_P2"."RID" AND "SYS_P2"."PATHID"=HEXTORAW('4E36') AND
"SYS_P2"."ORDER_KEY"<"SYS_P4"."ORDER_KEY")
filter("SYS_P4"."ORDER_KEY"<SYS_ORDERKEY_MAXCHILD("SYS_P2"."ORDER_KEY") AND
SYS_ORDERKEY_DEPTH("SYS_P2"."ORDER_KEY")+1=SYS_ORDERKEY_DEPTH("SYS_P4"."ORDER_KEY"))
. . .
例6-26に示すように、このような実行計画からパス表の名前から、XMLIndex索引の名前を取得できます。(これは例6-10の問合せとほぼ反対のケースです。)
例6-26 パス表名からのXMLIndex索引名の取得
SELECT INDEX_NAME FROM USER_XML_INDEXES WHERE PATH_TABLE_NAME = 'MY_PATH_TABLE'; INDEX_NAME ------------------------------ PO_XMLINDEX_IX 1 row selected.
XMLIndexは、SELECTリスト、FROMリスト、および問合せのWHERE句のXPath式で使用でき、SQL/XML関数XMLQuery、XMLTable、XMLExistsおよびXMLCastにおいて有用です。ファンクション索引(および非推奨になったCTXXPath索引)とは異なり、XMLIndex索引は、文書内のXMLフラグメントからデータを抽出する際に使用できます。
例6-27に、これを示します。
例6-27 XMLIndexを使用したXMLフラグメントからのデータ抽出
SET AUTOTRACE ON EXPLAIN
SELECT li.description, li.itemno
FROM po_clob, XMLTable('/PurchaseOrder/LineItems/LineItem'
PASSING OBJECT_VALUE
COLUMNS "DESCRIPTION" VARCHAR(40) PATH 'Description',
"ITEMNO" INTEGER PATH '@ItemNumber') li
WHERE XMLExists('/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]'
PASSING OBJECT_VALUE);
DESCRIPTION ITEMNO
---------------------------------------- ----------
A Night to Remember 1
The Unbearable Lightness Of Being 2
Sisters 3
3 rows selected.
Execution Plan
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1546 | 30 (4)|00:00:01 |
|* 1 | FILTER | | | | | |
|* 2 | TABLE ACCESS BY INDEX ROWID | MY_PATH_TABLE | 1 | 3524 | 3 (0)|00:00:01 |
|* 3 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 2 (0)|00:00:01 |
|* 4 | FILTER | | | | | |
|* 5 | TABLE ACCESS BY INDEX ROWID | MY_PATH_TABLE | 1 | 3524 | 3 (0)|00:00:01 |
|* 6 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 2 (0)|00:00:01 |
| 7 | NESTED LOOPS | | | | | |
| 8 | NESTED LOOPS | | 1 | 1546 | 30 (4)|00:00:01 |
| 9 | NESTED LOOPS | | 1 | 24 | 28 (4)|00:00:01 |
| 10 | VIEW | VW_SQ_1 | 1 | 12 | 26 (0)|00:00:01 |
| 11 | HASH UNIQUE | | 1 | 5046 | | |
| 12 | NESTED LOOPS | | 1 | 5046 | 26 (0)|00:00:01 |
|* 13 | TABLE ACCESS BY INDEX ROWID| MY_PATH_TABLE | 1 | 3524 | 24 (0)|00:00:01 |
|* 14 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_VALUE_IX | 73 | | 1 (0)|00:00:01 |
|* 15 | TABLE ACCESS BY INDEX ROWID| MY_PATH_TABLE | 1 | 1522 | 2 (0)|00:00:01 |
|* 16 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 1 (0)|00:00:01 |
| 17 | TABLE ACCESS BY USER ROWID | PO_CLOB | 1 | 12 | 1 (0)|00:00:01 |
|* 18 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 1 (0)|00:00:01 |
|* 19 | TABLE ACCESS BY INDEX ROWID | MY_PATH_TABLE | 1 | 1522 | 2 (0)|00:00:01 |
----------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(:B1<SYS_ORDERKEY_MAXCHILD(:B2))
2 - filter(SYS_XMLI_LOC_ISNODE("SYS_P2"."LOCATOR")=1)
3 - access("SYS_P2"."RID"=:B1 AND "SYS_P2"."PATHID"=HEXTORAW('28EC') AND "SYS_P2"."ORDER_KEY">:B2 AND
"SYS_P2"."ORDER_KEY"<SYS_ORDERKEY_MAXCHILD(:B3))
filter(SYS_ORDERKEY_DEPTH("SYS_P2"."ORDER_KEY")=SYS_ORDERKEY_DEPTH(:B1)+1)
4 - filter(:B1<SYS_ORDERKEY_MAXCHILD(:B2))
5 - filter(SYS_XMLI_LOC_ISNODE("SYS_P5"."LOCATOR")=1)
6 - access("SYS_P5"."RID"=:B1 AND "SYS_P5"."PATHID"=HEXTORAW('60E0') AND "SYS_P5"."ORDER_KEY">:B2 AND
"SYS_P5"."ORDER_KEY"<SYS_ORDERKEY_MAXCHILD(:B3))
filter(SYS_ORDERKEY_DEPTH("SYS_P5"."ORDER_KEY")=SYS_ORDERKEY_DEPTH(:B1)+1)
13 - filter("SYS_P10"."VALUE"='SBELL-2002100912333601PDT' AND "SYS_P10"."PATHID"=HEXTORAW('4F8C') AND
SYS_XMLI_LOC_ISNODE("SYS_P10"."LOCATOR")=1)
14 - access(SUBSTRB("VALUE",1,1599)='SBELL-2002100912333601PDT')
15 - filter(SYS_XMLI_LOC_ISNODE("SYS_P8"."LOCATOR")=1)
16 - access("SYS_P10"."RID"="SYS_P8"."RID" AND "SYS_P8"."PATHID"=HEXTORAW('4E36') AND
"SYS_P8"."ORDER_KEY"<"SYS_P10"."ORDER_KEY")
filter("SYS_P10"."ORDER_KEY"<SYS_ORDERKEY_MAXCHILD("SYS_P8"."ORDER_KEY") AND
SYS_ORDERKEY_DEPTH("SYS_P8"."ORDER_KEY")+1=SYS_ORDERKEY_DEPTH("SYS_P10"."ORDER_KEY"))
18 - access("PO_CLOB".ROWID="SYS_ALIAS_4"."RID" AND "SYS_ALIAS_4"."PATHID"=HEXTORAW('3748') )
19 - filter(SYS_XMLI_LOC_ISNODE("SYS_ALIAS_4"."LOCATOR")=1)
Note
-----
- dynamic sampling used for this statement (level=2)
例6-27の問合せの実行計画は、パス表を参照することにより、XMLIndexが使用されることを示します。Oracle内部SQL関数sys_orderkey_depthが使用されることも示します。「非構造化コンポーネントを含むXMLIndexを使用するためのガイドライン」を参照してください。
例6-28に、例6-20で作成したXMLIndex索引が2つのWHERE句述語を使用する問合せに対して選択されることを示す実行計画を示します。非構造化XMLIndexコンポーネントのみが含まれる場合、WHERE内に2つの異なるパスがあるため、この問合せに対してパス表の自己結合が行われます。
例6-28 2つの述語を使用する問合せに対する構造化XMLIndexコンポーネントの使用
EXPLAIN PLAN FOR
SELECT XMLQuery('/PurchaseOrder/LineItems/LineItem' PASSING OBJECT_VALUE RETURNING CONTENT)
FROM po_clob
WHERE XMLExists('/PurchaseOrder/LineItems/LineItem
[ora:contains(Description, "Picnic") > 0]' PASSING OBJECT_VALUE)
AND XMLEXists('/PurchaseOrder[User="SBELL"]' PASSING OBJECT_VALUE);
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 189 | 22 (14)| 00:00:01 |
| 1 | SORT GROUP BY | | 1 | 3524 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID| PATH_TAB | 2 | 7048 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | SYS67840_PO_XMLINDE_PIKEY_IX | 1 | | 2 (0)| 00:00:01 |
|* 4 | HASH JOIN SEMI | | 1 | 189 | 22 (14)| 00:00:01 |
| 5 | NESTED LOOPS | | 13 | 637 | 4 (25)| 00:00:01 |
| 6 | SORT UNIQUE | | 13 | 351 | 3 (0)| 00:00:01 |
|* 7 | TABLE ACCESS FULL | PO_IDX_TAB | 13 | 351 | 3 (0)| 00:00:01 |
|* 8 | INDEX UNIQUE SCAN | SYS_C006004 | 1 | 22 | 0 (0)| 00:00:01 |
|* 9 | TABLE ACCESS FULL | PO_INDEX_LINEITEM | 13 | 1820 | 17 (6)| 00:00:01 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(SYS_XMLI_LOC_ISNODE("SYS_P0"."LOCATOR")=1)
3 - access("SYS_P0"."RID"=:B1 AND "SYS_P0"."PATHID"=HEXTORAW('3748') )
4 - access("SYS_ALIAS_1"."SYS_NC_OID$"="SYS_ALIAS_3"."OID")
7 - filter("SYS_ALIAS_2"."USERNAME"='SBELL')
8 - access("SYS_ALIAS_1"."SYS_NC_OID$"="SYS_ALIAS_2"."OID")
9 - filter(SYS_XMLCONTAINS("SYS_ALIAS_3"."DESCRIPTION",'Picnic')>0)
Note
-----
- dynamic sampling used for this statement (level=2)
- Unoptimized XML construct detected (enable XMLOptimizationCheck for more information)
30 rows selected.
例6-28で、パス表名path_tabが存在することは、索引の非構造化索引コンポーネントが使用されることを示しています。索引コンテンツ表po_idx_tabが存在することは、構造化索引コンポーネントが使用されることを示しています。
例6-29に、同じXMLIndex索引が、マルチレベルのXMLTable連鎖を使用する問合せに対して取得されることを示す実行計画を示します。非構造化XMLIndexコンポーネントのみが含まれる場合、2つのXMLTableファンクション・コールに2つの異なるパスがあるため、この問合せに対してもパス表の自己結合が行われます。
例6-29 マルチレベル連鎖を使用する問合せに対する構造化XMLIndexコンポーネントの使用
EXPLAIN PLAN FOR
SELECT po.reference, li.*
FROM po_clob p,
XMLTable('/PurchaseOrder' PASSING p.OBJECT_VALUE
COLUMNS reference VARCHAR2(30) PATH 'Reference',
lineitem XMLType PATH 'LineItems/LineItem') po,
XMLTable('/LineItem' PASSING po.lineitem
COLUMNS itemno BINARY_DOUBLE PATH '@ItemNumber',
description VARCHAR2(256) PATH 'Description',
partno VARCHAR2(14) PATH 'Part/@Id',
quantity BINARY_DOUBLE PATH 'Part/@Quantity',
unitprice BINARY_DOUBLE PATH 'Part/@UnitPrice') li
WHERE po.reference = 'SBELL-20021009123335280PDT';
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 17 | 20366 | 11 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 17 | 20366 | 11 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 1 | 539 | 3 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | PO_IDX_TAB | 1 | 529 | 3 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | SYS_C006320 | 1 | 10 | 0 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | SYS69412_69421_PKY_IDX | 17 | | 1 (0)| 00:00:01 |
| 7 | TABLE ACCESS BY INDEX ROWID| PO_INDEX_LINEITEM | 17 | 11203 | 8 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("SYS_ALIAS_8"."REFERENCE"='SBELL-20021009123335280PDT')
5 - access("SYS_ALIAS_8"."OID"="P"."SYS_NC_OID$")
6 - access("SYS_ALIAS_8"."KEY"="SYS_ALIAS_9"."PKEY")
Note
-----
- dynamic sampling used for this statement
25 rows selected.
この実行計画は、リレーショナル索引コンテンツ表po_idx_tabおよびpo_index_lineitemへの直接アクセスを示しています。パス表path_tabへのアクセスはまったくありません。
XMLIndex索引の使用を無効にするには、次のいずれかの方法を使用できます。
オプティマイザ・ヒント/*+ NO_XML_QUERY_REWRITE */を使用
オプティマイザ・ヒント/*+ NO_XMLINDEX_REWRITE */を使用
ヒントNO_XML_QUERY_REWRITEおよびNO_XMLINDEX_REWRITEでは、すべてのXMLIndex索引の使用が無効になります。NO_XML_QUERY_REWRITEは、XMLIndexの使用を無効にする他に、XQueryの最適化もすべて無効にします(XMLIndexはXPathリライトの一部です)。
例6-30に、これらのオプティマイザ・ヒントの使用方法を示します。
例6-30 オプティマイザ・ヒントを使用したXMLIndexの無効化
SELECT /*+ NO_XMLINDEX_REWRITE */ count(*) FROM po_clob WHERE XMLExists('$p/*' PASSING OBJECT_VALUE AS "p"); SELECT /*+ NO_XML_QUERY_REWRITE */ count(*) FROM po_clob WHERE XMLExists('$p/*' PASSING OBJECT_VALUE AS "p");
|
注意: NO_INDEXオプティマイザ・ヒントは、XMLIndexには適用されません。 |
|
関連項目:
|
非構造化コンポーネントを含むXMLIndex索引は、非常に汎用性が高いという利点があります。索引付けするXPathの位置を指定する必要もなければ、問合せされるXPath式に関する事前の知識も必要ありません。デフォルトでは、非構造化XMLIndex索引では、XMLデータのすべての使用可能なXPath位置に索引が作成されます。
ただし、問い合せる可能性の高いXPath式を認識している場合は、XMLIndexの索引付けの焦点を絞り、パフォーマンスを高めることもできます。索引付けされたノードが少ないほど、索引付けに必要な領域も削減されるため、DML操作中の索引のメンテナンスが向上します。索引付けされたノードの数が少ないほどDDLのパフォーマンスが向上し、パス表が小さいほど問合せのパフォーマンスも向上します。
索引付けされるXMLフラグメントに対応する一連のXPath式(パス)をプルーニングし、可能なすべてのパスのサブセットを指定することで、索引付けの焦点を絞れます。これを行うには、他に2通りの方法があります。
除外: 可能なすべてのXPath式を含めるというデフォルト動作を実行した後に、索引付けに不要なものを除外します。
包含: 索引付けに使用する空白のXPath式の包含セットにパスを追加します。
CREATE INDEXを使用してXMLIndex索引を作成するとき、またはALTER INDEXを使用して索引を修正するときに、パスのサブセット化を指定できます。いずれの場合でも、文のPARAMETERS句のPATHSパラメータで、サブセット化情報を提供します。除外の場合は、キーワードEXCLUDEを使用します。包含の場合は、ALTER INDEXのときはキーワードINCLUDEを使用し、CREATE INDEXのときはキーワードを使用しません(含めるパスをリストします)。また、PATHSパラメータによってターゲット化されるノードに対し、名前空間マッピングも指定できます。
ALTER INDEXの場合、キーワードINCLUDEまたはEXCLUDEの後にキーワードADDまたはREMOVEを付加すると、キーワードの後に続くパスのリストを包含リストや除外リストに追加するか削除するかを指定できます。たとえば、この文では、索引付けから除外するパスのリストにパス/PurchaseOrder/Referenceを追加します。
ALTER INDEX po_xmlindex_ix REBUILD
PARAMETERS ('PATHS (EXCLUDE ADD (/PurchaseOrder/Reference))');
すべてのパスが含まれるようにXMLIndex索引を変更するには、キーワードINDEX_ALL_PATHSを使用します。「alter_index_paths_clause ::=」を参照してください。
|
注意: 構造化および非構造化コンポーネントの両方を持つXMLIndex索引を作成した場合、デフォルトで、構造化コンポーネント内で索引付けされているノードはすべて、非構造化コンポーネント内でも索引付けされます。つまり、非構造化コンポーネントから自動的に除外されません。非構造化XMLIndexの索引付けを適用しないようにするには、パスのサブセット化を明示的に使用してそれらを除外する必要があります。 |
この項では、XPath式のサブセットに対し、XMLIndex索引を定義する方法を例示します。
例6-31 CREATE INDEXによるXMLIndexパスのサブセット化
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLINDEX
PARAMETERS ('PATHS (INCLUDE (/PurchaseOrder/LineItems//*
/PurchaseOrder/Reference))');
この文では、次に示すように、最上位要素であるPurchaseOrderおよびその子に対してのみ索引付けする索引を作成します。
すべてのLineItems要素およびその子孫
すべてのReference要素
索引に使用される一連の空白のパスに対し、指定のパスを含めていきます。
例6-32 ALTER INDEXによるXMLIndexパスのサブセット化
ALTER INDEX po_xmlindex_ix REBUILD
PARAMETERS ('PATHS (INCLUDE ADD (/PurchaseOrder/Requestor
/PurchaseOrder/Actions/Action//*))');
この文では、索引付けに使用されたパスに対し、2つのパスを追加します。これらのパスは、Requestor要素と、Action要素の子孫(およびその祖先)に対して索引付けします。
例6-33 名前空間接頭辞を使用したXMLIndexパスのサブセット化
XMLIndex索引付けに使用されるXPath式で名前空間接頭辞が使用される場合、NAMESPACE MAPPING句をPATHSリストで使用して接頭辞を指定できます。次に例を示します。
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex
PARAMETERS ('PATHS (INCLUDE (/PurchaseOrder/LineItems//* /PurchaseOrder/ipo:Reference)
NAMESPACE MAPPING (xmlns="http://xmlns.oracle.com"
xmlns:ipo="http://xmlns.oracle.com/ipo"))');
XMLIndexパスのサブセット化には、次のルールが適用されます。
パスはchild軸およびdescendant軸のみを参照し、さらに、要素ノードおよび属性ノード、またはその名前(ワイルドカードを使用可能)のみをテストする必要があります。特に、パスには述語を含めないでください。
パス除外とパス包含を一度に指定できません。いずれかの方法を指定する必要があります。
パス除外(包含)によって索引が作成された場合は、パス除外(包含)によってのみ修正が可能です。索引の修正は、パスのサブセット化をさらに制限するか、さらに拡張するかのいずれかです。たとえば、特定のパスを含める索引を作成した後に、特定のパスを除外するよう修正することはできません。
以降に、非構造化コンポーネントを含むXMLIndexを使用するためのガイドラインを示します。これらのガイドラインは、ここで説明する2つの方法によって同じ結果セットが戻される場合にのみ該当します。
祖先要素の接頭辞として//を付加しないでください。たとえば、同じ結果セットを戻す場合、/a/b//cではなく、//cを使用します。
祖先要素の接頭辞として/*を付加しないでください。たとえば、同じ結果セットを返す場合、/a/*/*ではなく、/*/*/*を使用します。
WHERE句では、XMLQueryのXMLCastではなく、XMLExistsを使用します。これにより最適化が可能になり、パス表VALUE列に対して副問合せが実際に起動されます。たとえば、次のように記述します。
SELECT count(*) FROM purchaseorder p
WHERE
XMLExists('$p/PurchaseOrder/LineItems/LineItem/Part[@Id="715515011020"]'
PASSING OBJECT_VALUE AS "p");
次のように記述しないでください。
SELECT count(*) FROM purchaseorder p
WHERE XMLCast(XMLQuery('$p/PurchaseOrder/LineItems/LineItem/Part/@Id'
PASSING OBJECT_VALUE AS "p" RETURNING CONTENT)
AS VARCHAR2(14))
= "715515011020";
可能な場合、SELECT句では、count(XMLCast(XMLQuery(...))ではなく、count(*)を使用します。たとえば、発注書のLineItem要素にDescriptionの子が1つしかないことがわかっている場合は、次のように記述します。
SELECT count(*) FROM po_clob, XMLTable('//LineItem' PASSING OBJECT_VALUE);
次のように記述しないでください。
SELECT count(li.value)
FROM po_clob p, XMLTable('//LineItem' PASSING p.OBJECT_VALUE
COLUMNS value VARCHAR2(30) PATH 'Description') li;
問合せのFROMリストで使用されるXPath式の数は、なるべく少なくしてください。たとえば、次のように記述します。
SELECT li.description
FROM po_clob p,
XMLTable('PurchaseOrder/LineItems/LineItem' PASSING p.OBJECT_VALUE
COLUMNS description VARCHAR2(256) PATH 'Description') li;
次のように記述しないでください。
SELECT li.description
FROM po_clob p,
XMLTable('PurchaseOrder/LineItems' PASSING p.OBJECT_VALUE) ls,
XMLTable('LineItems/LineItem' PASSING ls.OBJECT_VALUE
COLUMNS description VARCHAR2(256) PATH 'Description') li;
仮想表(XMLTable SQL/XML関数などで作成)の内部をドリルダウンするために、問合せでXPath式を使用する場合は、sys_orderkey_depth Oracle SQL関数を使用してパス表の順序キーの2次索引を作成します。このような問合せを次に例示します。選択により仮想的な明細項目表li内のDescription要素にナビゲートします。
SELECT li.description
FROM po_clob p,
XMLTable('PurchaseOrder/LineItems/LineItem' PASSING p.OBJECT_VALUE
COLUMNS description VARCHAR2(256) PATH 'Description') li;
このような問合せはsys_orderkey_depth関数によって評価されます。この関数は、order-key値の深度を戻します。順序索引は2列を使用するため、必要となる索引は、ORDER_KEY列およびRID列、およびORDER_KEY値に対して適用されたsys_orderkey_depth関数のコンポジット索引です。次に例を示します。
CREATE INDEX depth_ix ON my_path_table (RID, sys_orderkey_depth(ORDER_KEY), ORDER_KEY);
以降に、構造化コンポーネントを含むXMLIndexを使用するためのガイドラインを示します。
構造化コンポーネントを含むXMLIndexを使用して、リレーショナル列としてXMLデータを投影および索引付けします。ファンクション索引は使用しないでください。XMLとの使用は非推奨です。「ファンクション索引」を参照してください。
構造化コンポーネントが含まれるXMLIndex索引と問合せの間のデータ型の対応の確認。「XMLIndex構造化コンポーネントのデータ型に関する考慮事項」を参照してください。
XMLTypeデータに関してリレーショナル・ビューを作成する場合(SQL関数XMLTableなどを使用して)、同じリレーショナル列をターゲットとする、構造化されたコンポーネントを持つXMLIndex索引を作成することも考慮してください。第19章「XMLTypeビュー」を参照してください。
フラグメント抽出と値のフィルタリング(検索)の両方に単一のXQuery式を使用するかわりに、SELECT句でSQL/XML関数XMLQueryを使用し、WHERE句のフラグメントおよびXMLExistsを抽出して値をフィルタリングします。
こうすることで、Oracle XML DBがフラグメント抽出の機能的に、あるいはストリーミング評価を使用して評価できます。値のフィルタリングの場合、こうするとOracle XML DBが適切な構造のコンポーネントを持つXMLIndex索引を取得できます。
問合せの結果の順序を設定するには、SQLのORDER BY句とSQL/XML関数XMLTableを使用します。XQueryのorder by句は使用しないでください。構造化されたコンポーネントを含むXMLIndex索引を使用する場合は、特に使用を避けてください。
レンジ・パーティション化またはリスト・パーティション化を使用して、XMLType表や、XMLType列が含まれる表をパーティション化する場合、その表にXMLIndex索引を作成することもできます。XMLIndex索引を作成するときにキーワードLOCALを使用すると、索引とその記憶域表すべてが、実表に関連してローカルに同一レベル・パーティション化されます。
キーワードLOCALを使用しない場合は、パーティション化された表にXMLIndex索引を作成できません。また、表をハッシュ・パーティション化する場合は、表にXMLIndex索引を作成できません。
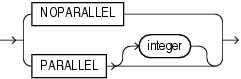
XMLIndex索引の作成または修正時にPARALLEL句(程度は任意)を使用し、索引の作成とメンテナンスを並列的に行えます。実表がパーティション化されている場合や、並列度が有効になっている場合は、これによりDML操作(INSERT、UPDATE、DELETE)と索引DDL操作(CREATE、ALTER、REBUILD)の両方のパフォーマンスを向上させることができます。
索引に並列度を指定すると、問合せサーバー・プロセスそれぞれに個別に記憶域パラメータが適用されるため、記憶域の消費も多くなります。たとえば、INITIAL値が5M、並列度が12で作成された索引は、作成時に少なくとも60Mの記憶域を消費します。
CREATE INDEXおよびALTER INDEXのPARALLEL句の構文は、他のドメイン索引のものと同じです。
{ NOPARALLEL | PARALLEL [ integer ] }
例6-34では、並列度10でXMLIndex索引を作成します。実表がパーティション化されている場合、この索引は同一レベル・パーティション化されます。
例6-34 XMLIndex索引の並列的な作成
CREATE INDEX po_xmlindex_ix ON sale_info (sale_po_clob) INDEXTYPE IS XDB.XMLIndex
LOCAL PARALLEL 10;
例6-34では、パス表と2次索引は、XMLIndex索引そのものと同じ並列度(10)を継承して作成されます。パス表と2次索引に対して個別のPARALLEL句を使用し、異なる並列度を設定することも可能です。例6-35に、これを示します。ここでも、キーワードLOCALにより、実表がパーティション化されている場合、この索引は同一レベル・パーティション化されます。
例6-35 XMLIndexの内部オブジェクトに対する、異なるPARALLEL度の使用
CREATE INDEX po_xmlindex_ix ON sale_info (sale_po_clob) INDEXTYPE IS XDB.XMLIndex
LOCAL PARAMETERS ('PATH TABLE po_path_table (PARALLEL 10)
PIKEY INDEX po_pikey_ix
VALUE INDEX po_value_ix (PARALLEL 5)') NOPARALLEL;
例6-35ではNOPARALLELが指定されているため、XMLIndex索引そのものが連続して作成されます。2次索引po_pikey_ixも連続で移入されます。これは、2次索引に対して明示的に並列度が指定されておらず、XMLIndex索引から並列度が継承されるためです。パス表そのものは並列度を10として作成され2次索引値の列po_value_ixは、明示的な並列度指定を反映し、並列度5として移入されます。
XMLIndex索引、パス表、またはその2次索引に対して指定した並列度は、後続のDML操作および問合せにおいて使用されます。
XMLIndexの並列度を指定できる位置は、PARAMETERS句のカッコ付きの式の中とその後の2箇所です。
|
関連項目:
|
この機能は、非構造化コンポーネントのみが含まれるXMLIndex索引に適用されます。構造化コンポーネントが含まれるXMLIndex索引に非同期メンテナンスを指定すると、エラーが発生します。
デフォルトでは、XMLIndex索引はDML操作のたびに更新(メンテナンス)されますので、実表と常に同期化されます。状況によっては、このようなことは必要なく、従来の索引の使用が許可される場合があります。そのような場合、索引メンテナンスのコストを遅延するよう決定し、コミット時のみまたはデータベースの負荷が軽減されているある時期に実行できます。これにより、DMLのパフォーマンスを向上させることができます。また、索引の同期化を行う際に、非同期索引行のバルク・ロードを有効にすると、索引メンテナンスのパフォーマンスを向上させることができます。
DML操作では従来の索引を使用しても、パフォーマンス以外には影響がありません。ただし、問合せ結果に影響を与えることもあります。問合せ時に索引が最新の状態でない場合は、問合せ結果も最新でない可能性があります。実表の1列のみがXMLTypeデータ型であったとしても、その表のすべての問合せには、XMLIndex列のXMLIndex索引の最終同期時のデータベース・データが反映されます。
CREATE INDEX文またはALTER INDEX文のPARAMETERS句を使用し、索引メンテナンスの遅延を指定できます。
XMLIndex索引の同期化を遅延しても、次のデータベース操作により、索引が自動的に同期化されるので注意が必要です。
索引に対するDDL操作: ALTER INDEXまたは2次索引の作成
実表に対するDDL操作: ALTER TABLEまたは他の索引の作成
表6-7に、同期化オプションと、オプションの指定に使用されるASYNC句の構文をまとめます。ASYNC句は、CREATE INDEXのPARAMETERS句またはXMLIndexのALTER INDEX文で使用されます。
表6-7 索引の同期化
| 同期化するタイミング | ASYNC句の構文 |
|---|---|
|
常時 |
これがデフォルトの動作です。前の |
|
コミット時 |
|
|
定期的 |
|
|
手動、オン・デマンド |
PL/SQLプロシージャ |
ASYNC構文のオプションのパラメータであるSTALEは、将来に備えて用意されているものであり、明示的に指定する必要はありません。ALWAYSが使用されていれば、値は常にFALSEになります。それ以外の場合の値はTRUEです。このルールに反して明示的なSTALE値を指定すると、エラーが発生します。
例6-36では、明日から毎週月曜日の午後3時に同期化されるXMLIndex索引を作成します。
例6-36 XMLIndexに対する遅延同期の指定
CREATE INDEX po_xmlindex_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS XDB.XMLIndex
PARAMETERS ('ASYNC (SYNC EVERY "FREQ=HOURLY; INTERVAL = 1")');
例6-37では、例6-36で作成された索引を手動で同期化します。
例6-37 SYNCINDEXを使用したXMLIndex索引の手動同期化
EXEC DBMS_XMLINDEX.SyncIndex('OE', 'PO_XMLINDEX_IX', REINDEX => TRUE);
XMLIndex索引の同期化が遅延されると、索引に対する最終同期化以降、実表に対して加えられたすべてのDML変更(挿入、更新、削除)は、DML操作当たり1行ずつ、保留中の表に記録されます。この表の名前は、静的なパブリック・ビューUSER_XML_INDEXES、ALL_XML_INDEXES、およびDBA_XML_INDEXESのPEND_TABLE_NAME列の値です。
この表を検証すると、指定のXMLIndex索引を同期化させる最適な時期を決定できます。保留中の表の行数が多くなると、同期化が必要な索引も多くなります。
保留中の表のサイズが大きい場合、SyncIndexのコール時にパラメータREINDEXをTRUEに設定すると、例6-37に示すようにパフォーマンスを向上できます。REINDEXがTRUEの場合は、すべての2次索引が削除され、保留中の表データを一括ロードした後に再作成されます。
|
関連項目:
|
Oracle Databaseのコストベース・オプティマイザにより、使用される索引(ある場合)も含め、所定の問合せをどのように評価すると最も費用効率が高いかが決定します。これを正確に実行するには、様々なデータベース・オブジェクトの統計を収集する必要があります。
XMLIndexについては、通常はXMLIndex索引が定義されている実表に関する統計のみ収集する必要があります(DBMS_STATS.gather_table_statsプロシージャなどを使用)。これにより、XMLIndex索引自体、パス表とその2次索引、および構造化コンポーネント・コンテンツ表とその2次索引に関する統計が自動的に収集されます。
実表の統計を削除すると(DBMS_STATS.delete_table_statsプロシージャを使用)、他のオブジェクトに関する統計も削除されます。同様に、XMLIndex索引に関する統計を収集すると(DBMS_STATS.gather_index_statsプロシージャを使用)、パス表とその2次索引、および構造化コンポーネント・コンテンツ表とその2次索引に関する統計も収集されます。
例6-38では、実表po_clobに関する統計を収集します。XMLIndex索引、パス表、および2次パス表索引に関する統計が自動的に収集されます。
例6-38 XMLIndexオブジェクトに関する統計の自動収集
CALL DBMS_STATS.gather_table_stats(USER, 'PO_CLOB', ESTIMATE_PERCENT => NULL);
標準的なデータベース索引に関する情報は、静的なパブリック・ビューUSER_INDEXES、ALL_INDEXES、およびDBA_INDEXESにあります。XMLIndex索引に関する同様の情報も、静的なパブリック・ビューUSER_XML_INDEXES、ALL_XML_INDEXES、およびDBA_XML_INDEXESにあります。
表6-8で、これらの各ビューの列について説明します。
表6-8 XMLIndexの静的なパブリック・ビュー
| 列名 | 型 | 説明 |
|---|---|---|
|
|
|
非同期索引の更新の仕様です。「XMLIndex索引の非同期(遅延)メンテナンス」を参照してください。 |
|
|
|
パスのサブセット化:
|
|
|
|
|
|
|
|
索引の所有者です。 |
|
|
|
索引のコンポーネントのタイプは、 |
|
|
|
索引の作成に使用された 非構造化 構造化コンポーネントが存在する場合、 |
|
|
|
|
|
|
|
最後に行われた索引の同期以降の、実表のDML操作を記録する表の名前です。「XMLIndex索引の非同期(遅延)メンテナンス」を参照してください。 |
|
|
|
索引が定義されている実表の名前です。 |
|
|
|
索引が定義されている実表の所有者です。 |
これらのビューでは、XMLIndex索引に関する情報が提供されますが、XMLIndex索引で収集される統計に関する情報を提供するカタログ・ビューはありません。この統計情報は、次のビュー間で配信されます。
USER_INDEXES、ALL_INDEXES、DBA_INDEXES: 列LAST_ANALYZEDでは、XMLIndex索引の最終分析日が提供されます。
USER_TAB_STATISTICS、ALL_TAB_STATISTICS、DBA_TAB_STATISTICS: 列TABLE_NAMEでは、XMLIndex索引の構造化コンポーネントおよび非構造化コンポーネントの情報が提供されます。構造化コンポーネントまたは非構造化コンポーネントの情報については、パス表またはXMLTable表の名前をTABLE_NAMEとしてそれぞれ使用して問い合せます。
USER_IND_STATISTICS、ALL_IND_STATISTICS、DBA_IND_STATISTICS: 列INDEX_NAMEでは、XMLIndex索引の2次索引のそれぞれの情報が提供されます。指定された2次索引に関する情報については、その2次索引の名前をINDEX_NAMEとして使用して問い合せます。
この項では、XMLIndexでのSQL文CREATE INDEXおよびALTER INDEXのPARAMETERS句の使用方法と構文を示します。
|
関連項目:
|
CREATE INDEXまたはALTER INDEX文のPARAMETERS句に使用する文字列値には、1000文字の制限があります。この制限を回避するには、パッケージDBMS_XMLINDEX内のPL/SQLプロシージャregisterParameterおよびmodifyParameterを使用できます。
これらのプロシージャごとに、(長さ制限のない)パラメータの文字列と、その文字列の登録に使用する識別子を指定します。次に索引PARAMETERS句で、リテラル文字列ではなく、キーワードPARAMで始まる識別子を指定します。
識別子は、CREATE INDEXまたはALTER INDEX文で使用する前に、登録しておく必要があります。
XMLIndex_parameters_clause ::=
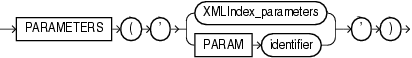
XMLIndex_parameters ::=

XMLIndex_parameter_clause ::=
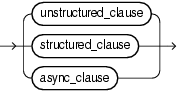
unstructured_clause ::=
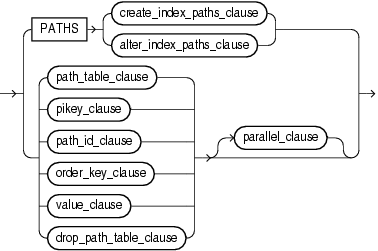
create_index_paths_clause ::=

alter_index_paths_clause ::=

namespace_mapping_clause ::=
path_table_clause ::=
pikey_clause ::=
path_id_clause ::=

order_key_clause ::=

value_clause ::=

drop_path_table_clause ::=

parallel_clause ::=
structured_clause ::=
async_clause ::=

groups_clause ::=
group_clause ::=

XMLIndex_xmltable_clause ::=
構文要素XML_namespaces_clauseおよびXQuery_stringは、SQL/XML関数XMLTableの場合と同じです。
column_clause ::=

構文要素column_clauseは、SQL/XML関数XMLTableのXML_table_columnと似ていますが同じではありません。
alter_index_group_clause ::=
add_column_clause :==
add_column_options :==

構文要素XML_namespaces_clauseは、SQL/XML関数XMLTableの場合と同じです。「Oracle XML DBのXMLTABLE SQL/XML関数」を参照してください。
drop_column_clause :==
drop_column_options :==

XMLIndex索引を作成するとき、XMLIndex_parameters_clauseがなければ、新しい索引には非構造化コンポーネントのみが含まれます。XMLIndex_parameters_clauseがあってもPARAMETERS引数が空('')であれば結果は同じで、索引には非構造化コンポーネントのみが含められます。
XMLIndex_parametersを使用する際には、次の点を考慮する必要があります。
XMLIndex_parametersでは、XMLIndex_parameter_clauseを1種類当たり最大1回しか使用できません。たとえば、PATHS句を最大で1回、path_table_clauseを最大で1回などです。
XMLIndexを作成するとき、structured_clauseがなければ、新しい索引には非構造化コンポーネントのみが含められます。structured_clauseが存在すれば、新しい索引には構造化コンポーネントのみが含められます。
PATHS句を使用する際には、次の点を考慮する必要があります。
CREATE INDEX文では、PATHS句を最大で1回使用できます。つまり、create_index_paths_clauseの後に、PATHSを最大で1回使用できます。
create_index_paths_clause句はCREATE INDEXでのみ、また、alter_index_paths_clause句はALTER INDEXでのみ使用されます。
create_index_paths_clauseおよびalter_index_paths_clauseを使用する際には、次の点を考慮する必要があります。
INDEX_ALL_PATHSキーワードは、すべてのパスが含まれた状態で索引を再構築します。このキーワードは、alter_index_paths_clauseでのみ使用でき、create_index_paths_clauseでは使用できません。
索引に対するパスの明示的なリストには、ワイルドカードおよび//を使用できます。
XPaths_listは1つ以上のXpaths式で構成されるリストです。それぞれのリストには、child軸、descendant軸、名前テスト、およびワイルドカード(*)構造のみが含まれます。
create_index_paths_clauseからXPaths_listが省略されていると、すべてのパスが索引付けされます。
XPaths_listのXPath式で使用される一意の名前空間接頭辞に対し、対応する名前空間情報を提供するには、標準的なXML名前空間宣言が必要です。
索引を削除した後で必要に応じて作成しなおすと、構文に直接反映されない方法で索引を変更できます。たとえば、パスを含めることで定義される索引を、パスを除外することで定義される索引に変更する場合は、索引を削除した後で、EXCLUDEを使用して作成しなおします。
pikey_clause、path_id_clauseおよびorder_key_clauseの各句は、構文的にそれぞれ省略可能です。pikey索引は、pikey_clauseを指定しない場合でも作成されます。パスID索引または順序キー索引を作成するには、path_id_clauseまたはorder_key_clauseをそれぞれ指定する必要があります。
value_clauseを使用する際には、次の点を考慮する必要があります。
VALUE列は、VARCHAR2(4000)として作成されています。
value_clause句がキーワードVALUEでのみ構成される場合は、通常のデフォルト属性によって値索引が作成されます。
path_id_clause句がキーワードPATH IDでのみ構成される場合は、通常のデフォルト属性によってパスID索引が作成されます。
order_key_clause句がキーワードORDER KEYでのみ構成される場合は、通常のデフォルト属性によって順序キー索引が作成されます。
ASYNC句を使用する際には、次の点を考慮する必要があります。
この機能は、非構造化コンポーネントのみが含まれるXMLIndex索引のみで使用します。構造化コンポーネントが含まれるXMLIndex索引にASYNC句を指定すると、エラーが発生します。
ALWAYSとは、各DML文に対して自動同期が行われることを意味します。
MANUALとは、自動同期が行われないことを意味します。DBMS_XMLINDEX.SyncIndexを使用して、索引を手動同期させる必要があります。
EVERY repeat_intervalとは、repeat_intervalの間隔で索引を自動同期させることを意味します。repeat_intervalの構文は、PL/SQLパッケージDBMS_SCHEDULERと同じであり、二重引用符(")で囲む必要があります。EVERYを使用するには、CREATE JOB権限が必要です。
ON COMMITとは、コミット操作の直後に索引を同期させることを意味します。コミットは、同期が完了するまでは戻されません。同期は個別の処理として実行されるため、データがコミットされてから、索引の変更がコミットされるまで短い間隔が生じることがあります。
STALEはオプションです。値がTRUEの場合は、問合せ結果が失効している可能性があります。値がFALSEの場合は、問合せ結果は常に最新です。デフォルト値と、明示的に指定可能な唯一の値は次のとおりです。
ALWAYSの場合、STALEはTRUEです。
ALWAYS以外のASYNCオプションの場合、STALEはFALSEです。
groups_clause句はCREATE INDEXでのみ、alter_index_group_clause句はALTER INDEXでのみ使用されます。
XMLIndex_xmltable_clauseを使用する際には、次の点を考慮する必要があります。
XMLIndex_xmltable_clause内のXQuery_string式では、XQuery関数ora:view(非推奨)、fn:docまたはfn:collectionを使用できません。
特定のXMLIndex_xmltable_clauseにデータ型XMLTypeのcolumn_clauseが複数含まれる場合、Oracle XML DBでエラーが発生します。このような2つの仮想列を定義した場合と同じ結果にするには、個別にgroup_clauseを追加する必要があります。
XMLIndex_xmltable_clauseではPASSING句はオプションです。この句が存在しない場合、次のようにXMLType列が暗黙的に渡されます。
パラメータ句の最初のXMLIndex_xmltable_clauseでは、索引付けされるXMLType列が暗黙的に渡されます。(XMLType表に索引を作成する場合、疑似列OBJECT_VALUEが渡されます。)
それ以降の各XMLIndex_xmltable_clauseについては、その前のXMLIndex_xmltable_clauseのVIRTUAL XMLType列が暗黙的に渡されます。
XMLIndex索引でXMLTableのマルチレベル連鎖を使用する場合、あるレベルのXMLTable表は、その前のレベルのXMLType列に対応します。構文の説明で、キーワードVIRTUALはオプションとして示されています。実際には、これはXMLType列でのみ使用され、その場合は必須です。XMLType列以外に使用するとエラーになります。VIRTUALは、XMLType列自体が生成されないことを指定します。つまり、そのデータは、対応するXMLTable表により指定されたリレーショナル列の形式でのみ、索引に格納されます。
XMLType列にOracle Text索引を作成できます。Oracle TextのCONTEXT索引では、XMLの全文検索を実行するためのOracle SQL関数containsを使用できます。構造化記憶域では、XPathリライトによりora:contains XPath関数がcontains SQL関数にリライトされることが多いため、このようなケースでもOracle Text索引が使用されます。
Oracle Text索引を作成するには、CREATE INDEXを使用します。そのとき、例6-39で示すように、CTXSYS.CONTEXTとしてINDEXTYPEを指定します。
例6-39 Oracle Text索引の作成
CREATE INDEX po_otext_ix ON po_clob (OBJECT_VALUE) INDEXTYPE IS CTXSYS.CONTEXT;
XMLType列に対して、containsやscoreなどのOracle Text操作を実行することもできます。例6-40に、Oracle SQL関数containsを使用したOracle Text検索を示します。
例6-40 SQL関数CONTAINを使用したXMLデータの検索
SELECT DISTINCT XMLCast(XMLQuery('$p/PurchaseOrder/ShippingInstructions/address'
PASSING po.OBJECT_VALUE AS "p" RETURNING CONTENT)
AS VARCHAR2(256)) "Address"
FROM po_clob po
WHERE contains(po.OBJECT_VALUE,
'$(Fortieth) INPATH (PurchaseOrder/ShippingInstructions/address)') > 0;
Address
------------------------------
1200 East Forty Seventh Avenue
New York
NY
10024
USA
1 row selected.
この問合せの実行計画は、次の2つの方法で、Oracle Text CONTEXT索引が使用されることを示しています。
索引がドメイン索引として明示的に参照されます。
述語情報内のOracle SQL関数containsが参照されます。
PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------- Plan hash value: 274475732 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 7 | 14098 | 10 (10)| 00:00:01 | | 1 | HASH UNIQUE | | 7 | 14098 | 10 (10)| 00:00:01 | | 2 | TABLE ACCESS BY INDEX ROWID| PO_CLOB | 7 | 14098 | 9 (0)| 00:00:01 | |* 3 | DOMAIN INDEX | PO_OTEXT_IX | | | 4 (0)| 00:00:01 | -------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("CTXSYS"."CONTAINS"(SYS_MAKEXML('2B0A2483AB140B35E040578C8A173FEC',523 3,"XMLDATA"),'$(Fortieth) INPATH (PurchaseOrder/ShippingInstructions/address)')>0) 20 rows selected.
Oracle Textの索引付けは、この章で説明するその他の索引付けに完全に直交しています。contains Oracle SQL関数またはora:contains XPath関数が使用されると、Oracle Text索引を全文検索で使用できます。
例6-41に、同じXMLデータに対してXMLIndex索引とOracle Text索引の両方が定義されているケースを示します。問合せは、例6-40と同じです。Oracle Text索引が、例6-9のXMLIndexパス表のVALUE列に作成されます。
例6-41 Oracle Text索引およびXMLIndex索引の使用
CREATE INDEX po_otext_ix ON my_path_table (VALUE) INDEXTYPE IS CTXSYS.CONTEXT; EXPLAIN PLAN FOR SELECT DISTINCT XMLCast(XMLQuery('$p/PurchaseOrder/ShippingInstructions/address' PASSING po.OBJECT_VALUE AS "p" RETURNING CONTENT) AS VARCHAR2(256)) "Address" FROM po_clob po WHERE contains(po.OBJECT_VALUE, '$(Fortieth) INPATH (PurchaseOrder/ShippingInstructions/address)') > 0; ------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 7 | 14098 | 3 (34)| 00:00:01 | | 1 | SORT GROUP BY | | 1 | 3524 | | | |* 2 | TABLE ACCESS BY INDEX ROWID| MY_PATH_TABLE | 2 | 7048 | 3 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | SYS67616_PO_XMLINDE_PIKEY_IX | 1 | | 2 (0)| 00:00:01 | | 4 | HASH UNIQUE | | 7 | 14098 | 3 (34)| 00:00:01 | |* 5 | TABLE ACCESS FULL | PO_CLOB | 7 | 14098 | 2 (0)| 00:00:01 | ------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter(SYS_XMLI_LOC_ISNODE("SYS_P0"."LOCATOR")=1) 3 - access("SYS_P0"."RID"=:B1 AND "SYS_P0"."PATHID"=HEXTORAW('6F7F') ) 5 - filter("CTXSYS"."CONTAINS"(SYS_MAKEXML(0,"SYS_ALIAS_1"."XMLDATA"),'$(Fortieth) INPATH (PurchaseOrder/ShippingInstructions/address)')>0) Note ----- - dynamic sampling used for this statement (level=2) - Unoptimized XML construct detected (enable XMLOptimizationCheck for more information) 24 rows selected.
例6-41の実行計画では、XMLIndex索引とOracle Text索引の両方を参照しており、両方が使用されていることを示しています。
XMLIndex索引は、パス表MY_PATH_TABLEと、その順序キー索引SYS78942_PO_XMLINDE_ORDKEY_IXによって示されます。
Oracle Text索引は、述語情報のcontains Oracle SQL関数への参照によって示されます。
脚注の凡例
脚注 1: このマニュアルでは、「構造化」と「非構造化」は一般にXMLType記憶域オプションを指します。データの性質を指すことはそれほど多くありません。「ハイブリッド」は、ある種の埋込みCLOB記憶域を持つオブジェクト・リレーショナル記憶域を示します。「半構造化」は、記憶域に関係なく、XMLコンテンツを指します。非構造化記憶域はCLOBベースの記憶域で、構造化記憶域はオブジェクト・リレーショナル記憶域です。