| Oracle Data Mining概要 11g リリース2(11.2) E48231-01 |
|


 前 |
 次 |
この章では、予測データ・マイニングを自動的に実行する、Oracle Data Miningの予測分析の概要を説明します。
|
関連項目: インストール手順については、『Oracle Data Mining管理者ガイド』を参照してください。 PL/SQLの予測分析の構文については、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。 |
この章には、次の項が含まれます。
予測分析は、データ・マイニング・プロセスを単純なルーチンで実行する手法です。「1クリック・データ・マイニング」とも呼ばれるとおり、予測分析では、データ・マイニング・プロセスの単純化と自動化を実現しています。
予測分析ではプロファイルを作成し、特定の結果をもたらす要因を見つけ、最も起こりそうな結果を予測し、予測における信頼度を特定します。
予測分析ではデータ・マイニングの手法を使用しますが、データ・マイニングに関する知識は必要としません。
ユーザーは、データに対して実行する操作を指定するだけで予測分析を実行できます。マイニング・モデルを作成または使用したり、このマニュアルの第2章で説明されているマイニング機能やマイニング・アルゴリズムについて理解しておく必要もありません。
予測分析ルーチンによって、入力データが分析され、マイニング・モデルが作成されます。これらのモデルがトレーニングおよびテストされてから、ユーザーに戻される結果を生成するために使用されます。操作の完了後は、モデルおよび補助オブジェクトは保存されません。
データ・マイニング手法を直接利用する場合は、自分でモデルを作成するか、他のユーザーが作成したモデルを使用します。通常、モデルは新しいデータ(モデルのトレーニングおよびテストに使用されるデータとは異なるデータ)に適用します。予測分析ルーチンでは、トレーニングおよびテストに使用されたものと同じデータにモデルが適用されます。
Oracle Spreadsheet Add-In for Predictive Analyticsは、Microsoft Excelのスプレッドシート内で予測分析操作を行えるようにするためのアドインです。Excelのデータを分析したり、Oracleデータベース内のデータを分析できます。
図3-1は、Microsoft Excel 7.0でのEXPLAIN操作を示しています。EXPLAINにより、重要度を降順でランク付けした特定のターゲットの予測子が示されます。この例では、RELATIONSHIPが最も重要な予測子で、MARTIAL STATUSが2番目に重要な予測子です。
図3-1 Oracle Spreadsheet Add-In for Predictive AnalyticsのEXPLAIN
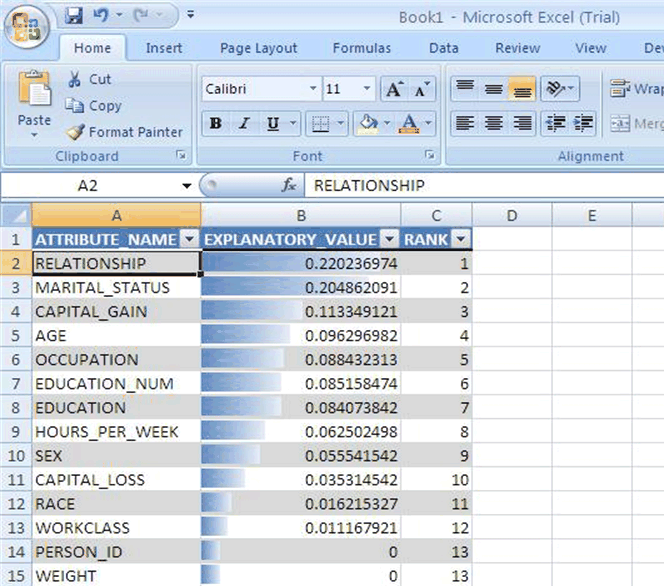
図3-2は、2項ターゲットに対するPREDICT操作を示しています。PREDICTにより、各ケースの実際の分類と予測された分類が示されます。それぞれの予測の確率と、データセットに対する全体的な予測の信頼度も表示されます。
図3-2 Oracle Spreadsheet Add-In for Predictive AnalyticsのPREDICT
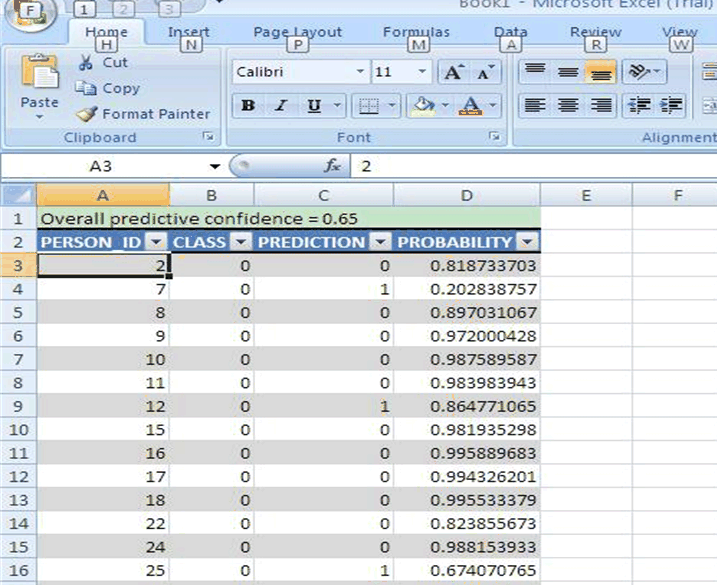
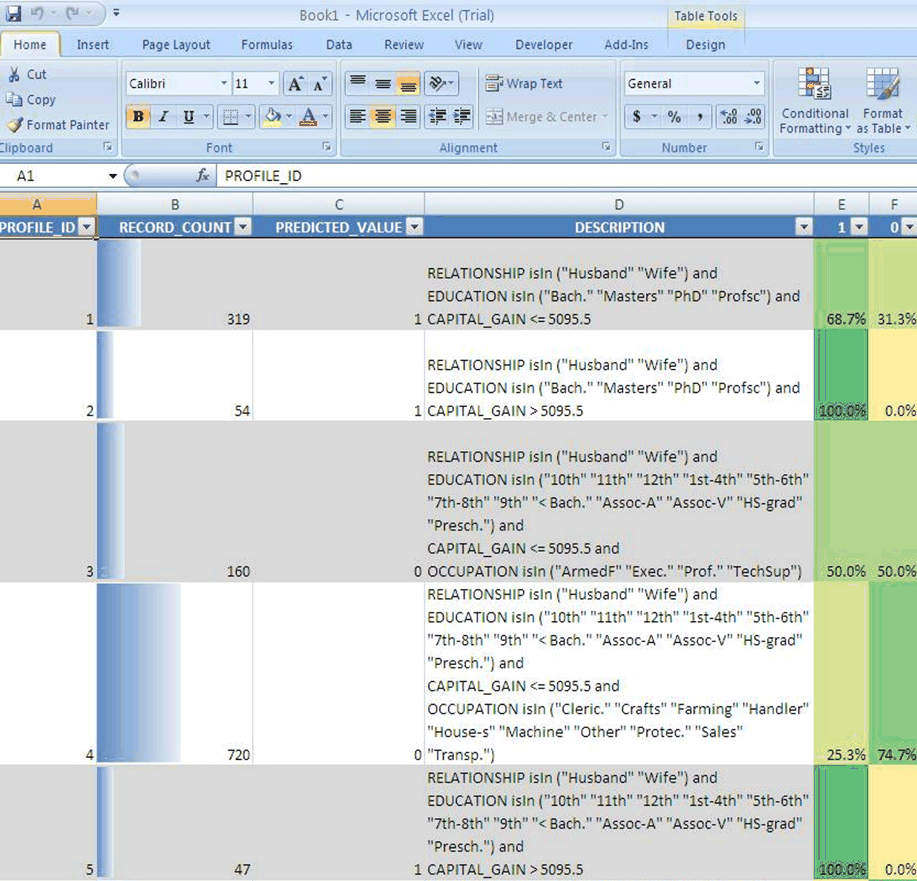
図3-3は、PROFILE操作を示しています。この例では、2項分類問題について5つのプロファイルが示されています。各プロファイルには、1つのルール、該当するケースの数およびスコアの分布が含まれています。プロファイル1によって記述されるケースは319件あります。そのメンバーは、学士号、修士号、博士号または専門職学位を持ち、キャピタル・ゲインが5095.5以下の既婚男性または既婚女性です。このグループに対するポジティブ予測の確率は68.7%、ネガティブ予測の確率は31.3%です。
図3-3 Oracle Spreadsheet Add-In for Predictive AnalyticsのPROFILE
最新版のSpreadsheet Add-Inは、Oracle Technology Networkでダウンロードできます。
Oracle Data Miningには、DBMS_PREDICTIVE_ANALYTICS PL/SQLパッケージでの予測分析が実装されています。次のSQL DESCRIBE文は、予測分析のプロシージャとそれぞれのパラメータを表示します。
SQL> describe dbms_predictive_analytics PROCEDUREEXPLAINArgument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- DATA_TABLE_NAME VARCHAR2 IN EXPLAIN_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT PROCEDUREPREDICTArgument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- ACCURACY NUMBER OUT DATA_TABLE_NAME VARCHAR2 IN CASE_ID_COLUMN_NAME VARCHAR2 IN TARGET_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT PROCEDUREPROFILEArgument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- DATA_TABLE_NAME VARCHAR2 IN TARGET_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT
例3-1に、単純なPREDICT操作を使用して、提携カードを発行した場合に消費を増やす可能性が最も高い顧客を見つける方法を示します。
現在の提携カードの使用内容と、その他の性別、教育レベル、年齢、世帯規模などの情報を含む顧客データが、MINING_DATA_APPLY_Vという名前のビューに格納されています。PREDICT操作の結果は、p_result_tblという名前の表に書き込まれます。
PREDICT操作は、予測とその予測の精度の両方を計算します。精度(予測の信頼度)は、ナイーブ・モデルによって生成される予測に対する改良度を示す測度です。分類の場合、ナイーブ・モデルは常に最も一般的なクラスを予測します。例3-1では、改良度は約50%です。
例3-1 提携カードで消費を増やす可能性が最も高い顧客の予測
DECLARE
p_accuracy NUMBER(10,9);
BEGIN
DBMS_PREDICTIVE_ANALYTICS.PREDICT(
accuracy => p_accuracy,
data_table_name =>'mining_data_apply_v',
case_id_column_name =>'cust_id',
target_column_name =>'affinity_card',
result_table_name =>'p_result_tbl');
DBMS_OUTPUT.PUT_LINE('Accuracy: ' || p_accuracy);
END;
/
Accuracy: .492433267
次の問合せは、提携カードに対して最も好意的に反応する可能性の高い顧客の性別および平均年齢を戻します。
SELECT cust_gender, COUNT(*) as cnt, ROUND(AVG(age)) as avg_age
FROM mining_data_apply_v a, p_result_tbl b
WHERE a.cust_id = b.cust_id
AND b.prediction = 1
GROUP BY a.cust_gender
ORDER BY a.cust_gender;
C CNT AVG_AGE
- ---------- ----------
F 90 45
M 443 45
この項では、Oracleによる予測分析の内部的な仕組みという、高度な内容を取り上げます。データ・マイニングについてある程度の知識があるユーザーにとっては、この情報は簡単で理解しやすいものとなっています。データ・マイニングにまだ習熟していない場合、この項を読まなくてもかまいません。予測分析を使用する際に、この情報について知っている必要はありません。
EXPLAINは、属性評価モデルを作成します。属性評価では、最小記述長アルゴリズムを使用して、ターゲット値を予測する際の属性の相対的な重要度が決定されます。EXPLAINは、予測に対する属性の影響を相対的な順序でランク付けしたリストを戻します。この情報は、属性評価モデルのモデルの詳細から導出されます。
属性評価モデルでは、新しいデータに対するスコアリングは行われません。ユーザーが指定したデータに関する情報(モデルの詳細)のみが戻されます。
属性評価については、「特徴選択および属性評価」を参照してください。
PREDICTは、分類または回帰用のサポート・ベクター・マシン(SVM)モデルを作成します。
PREDICTは、受信者操作特性(ROC)曲線を作成して、ケースごとの予測の精度を分析します。PREDICTは、2項分類モデルの確率しきい値を最適化します。確率しきい値とは、ポジティブ予測を出すためにモデルが使用する確率です。デフォルトは50%です。
PREDICTは、予測の精度(予測の信頼度)を示す値を戻します。精度は、ナイーブ予測に対する改良度です。ナイーブ予測は、質的ターゲットの場合は最も一般的なクラスとなり、量的ターゲットの場合は平均値となります。たとえば、質的ターゲットがsmall、mediumまたはlargeのいずれかの値をとり、smallがmediumまたはlargeよりも多く予測される場合、ナイーブ・モデルはすべてのケースに対してsmallを戻します。予測分析では、基準の精度として、ナイーブ・モデルの精度が使用されます。
PREDICTによって戻される精度メトリックは、ナイーブ・モデルの最大平均精度に対する改良最大平均精度の測度です。最大平均精度とは、ある確率しきい値で得られる各クラスの精度が、それ以外のしきい値で得られる精度よりも高い場合の、前者の精度の平均です。
SVMについては、第18章を参照してください。
PROFILEは、ディシジョン・ツリー・モデルを作成して、共通のターゲットを予測する属性の特徴を識別します。たとえば、データの質的ターゲットがsmall、mediumまたはlargeの値をとる場合、PROFILEは、特定の属性が通常どのようにして各サイズを予測するかを説明します。
ディシジョン・ツリー・アルゴリズムは、予測に影響する決定を記述するルールを作成します。このルールはif-then-else文としてXMLで記述され、モデルの詳細で戻されます。PROFILEは、このアルゴリズムによって生成されたモデルの詳細から導出されるXMLを戻します。
ディシジョン・ツリーについては、第11章を参照してください。
