| Oracle® Airlines Data Modelリファレンス 11gリリース2 (11.2) B72453-01 |
|



 前 |
 次 |
この章では、Oracle Airlines Data Modelで提供されるデータ・マイニング・モデルの参照情報を提供します。
この章の内容は次のとおりです。
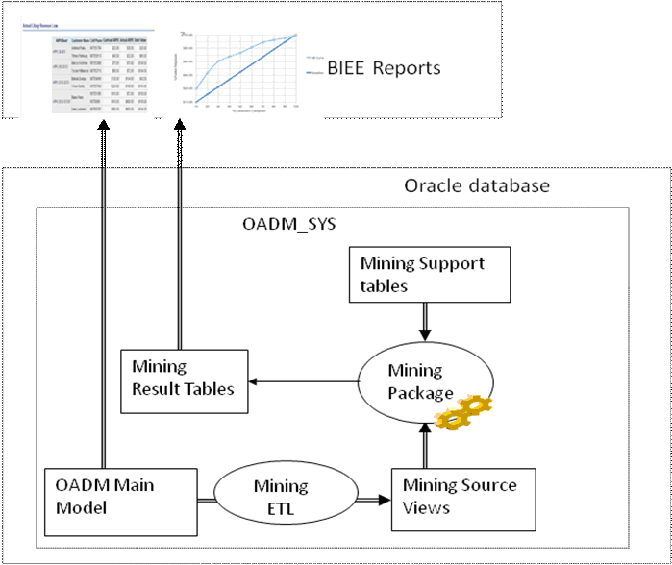
Oracle Airlines Data Modelのマイニング・モデルには、マイニング・パッケージ、マイニング・ソース表(MV)およびターゲット表が含まれます。
ソース・マテリアライズド・ビューは、Oracle Airlines Data Modelの3NFレイヤー表(実表、参照表)および分析レイヤー表(導出表、参照表)で定義されます。マイニング・パッケージのプロシージャは、ソース表からデータを取得してマイニング・モデルをトレーニングします。トレーニングされたマイニング・モデルは、同様に3NFおよび分析レイヤー表で定義される適用表(MV)に適用されます。ソース表および適用表のデータは、時間によって異なります。ターゲット表には、マイニングの結果データが含まれますが、これは、トレーニングされたモデルから導出されたルールであり、トレーニングされたモデルを適用データに適用した結果でもあります。
|
注意: Oracle Airlines Data Modelでは、データ・モデルの変更または新規のデータ・モデルはサポートされません。したがって、Oracle Airlines Data Modelで定義および提供されたデータ・モデルは変更せず、データ・モデルを作成する場合は、提供されたデータ・モデルをコピーしてください。 |
表9-2に示すように、Oracle Airlines Data Modelマイニング・モデルでは、特定の問題タイプに対して指定されたアルゴリズムが使用されます。
表9-1 Oracle Airlines Data Modelのモデルが使用するアルゴリズムのタイプ
| モデル | 問題のタイプ | データ・マイニング・モデルで使用されるアルゴリズム |
|---|---|---|
|
モデル1: 顧客セグメンテーション分析 |
クラスタリング |
K-Meansクラスタリング |
|
モデル2: 顧客ロイヤルティ分析 |
分類 |
Decision Tree (DT)、Support Vector Machine (SVM) |
|
モデル3: 顧客生涯価値分析 |
分類および回帰 |
ディシジョン・ツリー(DT)、一般化線形モデル回帰(GLMR) |
|
モデル4: 搭乗頻度の高い乗客の予測 |
分類 |
Decision Tree (DT)、Support Vector Machine (SVM) |
Oracle Airlines Data Modelは、1つのスキーマのoadm_sysで構成されます。表9-1に、マイニング・ソース表(MV)のマップ方法とマイニング・パッケージの動作方法を示します。
oadm_sysスキーマの構成は次のとおりです。
OADMメイン・モデル: これには、すべての実表、参照表、検索表、導出表および集計表が含まれます。
マイニング・モデル・パッケージ(pkg_oadm_mining): マイニング・ソース表および適用表のデータが提供されると、マイニング・パッケージは、ソース表を使用してモデルをトレーニングし、マイニング・ルールを生成し、適用データにトレーニング・モデルを適用して、予測される結果を生成します。
マイニング・モデル・ソースおよび適用表: マテリアライズド・ビューがOADMメイン・モデル表(3NFレイヤーの実表と参照表、分析レイヤーの導出表と参照表)で定義されます。
マイニング・サポート表: マイニング・サポート表は中間表であり、マイニング・モデルのトレーニング中にマイニング・パッケージで使用されます。これらのサポート表の名前には、DMという接頭辞が付きます。
マイニング結果表: マイニング結果表は、トレーニング・モデルからマイニング・ルールを保存します。これらの表は、適用データにトレーニング・モデルを適用した結果も保存します。
Oracle Miningのトレーニングおよびスコアリング(適用)プロセスの詳細は、『Oracle Data Mining概要』を参照してください。
顧客情報および顧客動作は、時間の経過とともに変化します。このため、トレーニングされたマイニング・モデルは、最新の顧客データおよび使用状況データを使用してリフレッシュできます。トレーニングされたマイニング・モデルをリフレッシュすることで、最新のデータに基づいてマイニング・モデルを再トレーニングします。再トレーニングされたマイニング・モデルと以前のトレーニング・モデルは、最新のソース・データに基づいてテストされ、最も適したものが選択されます。マイニング・モデルのリフレッシュ・プロセスは、次の3つのタスクに分類されます。
データの準備: データをロードし、マイニング・アルゴリズムによって認識される形式に変換します。また、ユーザーは、次の2つのタスクのいずれかにそれぞれ対応する2セットのデータを準備する必要があります。
トレーニング・データ
スコアリング(適用)・データ
トレーニング: 顧客の最近のデータがトレーニング・データとして使用され、アルゴリズムの使用によって、選択したトレーニング・データに基づいてモデルがトレーニングされます。
スコアリング(適用): 顧客の最新のデータがスコアリング・データとして使用され、選択したスコアリング・データにトレーニングされたマイニング・モデルが適用されて、管理下の問題のターゲット変数や管理外の問題のグルーピング/ルールが予測されます。
最新の顧客データおよび搭乗頻度の低い乗客のデータに基づいてすべてのマイニング・モデルをリフレッシュするには、pkg_oadm_mining.refresh_modelプロシージャをコールします。このプロシージャは、各モデルで次のタスクを実行します。
3NFおよび分析レイヤー表からの最新データに基づいて、すべてのソース・マテリアライズド・ビューをリフレッシュします。
新しいトレーニング・データを使用して各モデルを再度トレーニングします。新しくトレーニングされたマイニング・モデルと以前のメイン・マイニング・モデルを新しいトレーニング・データに適用して、どちらのモデルがより適切に動作するかを確認します。2つのモデルのうち最も適したものがメイン・マイニング・モデルとして選択されます。
最新の適用データに各メイン・モデルを適用します。
マイニング・モデルのリフレッシュ中に発生したエラーは、制御表のdwc_intra_etl_activityに保存されます。
表9-2 Oracle Airlines Data Modelのモデルが使用するアルゴリズムのタイプ
| モデル | 問題のタイプ | データ・マイニング・モデルで使用されるアルゴリズム |
|---|---|---|
|
モデル1: 顧客セグメンテーション分析 |
クラスタリング |
K-Meansクラスタリング |
|
モデル2: 顧客ロイヤルティ分析 |
分類 |
Decision Tree (DT)、Support Vector Machine (SVM) |
|
モデル3: 顧客生涯価値分析 |
分類および回帰 |
ディシジョン・ツリー(DT)、一般化線形モデル回帰(GLMR) |
|
モデル4: 搭乗頻度の高い乗客の予測 |
分類 |
Decision Tree (DT)、Support Vector Machine (SVM) |
表9-3に、dwd_cust_mnngデータ・マイニング結果表を示します。
表9-3 dwd_cust_mnngデータ・マイニング結果表
| 列名 | データ型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
FF_CARD_KEY |
NUMBER(38) |
搭乗頻度の高い乗客を一意に識別するための、搭乗頻度の高い乗客のカード・キー |
|
CUST_SGMNT_CD |
VARCHAR2(30) |
顧客セグメント・コード |
|
CUST_LYLTY_DT_PRED |
VARCHAR2(30) |
ディシジョン・ツリーを使用した顧客ロイヤルティ予測 |
|
CUST_LYLTY_DT_ND_NBR |
VARCHAR2(30) |
ディシジョン・ツリーを使用したツリー内の顧客ロイヤルティ予測のノード番号 |
|
CUST_LYLTY_SVM_PRED |
VARCHAR2(30) |
サポート・ベクター・マシンを使用した顧客ロイヤルティ予測 |
|
CUST_LYLTY_SVM_PROB |
NUMBER(10,8) |
サポート・ベクター・マシンを使用した顧客ロイヤルティ予測確率 |
|
LTV_BAND_CD |
VARCHAR2(30) |
生涯価値バンド・コード |
|
LTV_VALUE |
NUMBER(16,2) |
生涯価値(連続値) |
|
LT_SRVVL_CD |
VARCHAR2(30) |
生涯生存価値コード |
|
LT_SRVVL_VALUE |
NUMBER(16,2) |
生涯生存価値(連続値) |
表9-4に、dwr_cust_sgmnt結果表を示します。
表9-4 dwr_cust_sgmntデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
CUST_SGMNT_KEY |
NUMBER(30) |
順序によって生成された顧客セグメンテーション・キー |
|
CUST_SGMNT_CD |
VARCHAR2(30) |
顧客セグメンテーション・コード |
|
CUST_SGMNT_NAME |
VARCHAR2(50) |
顧客セグメンテーション名 |
|
CUST_SGMNT_DESC |
VARCHAR2(50) |
顧客セグメンテーションの説明 |
|
CUST_SGMNT_PROFILE |
VARCHAR2(4000) |
セグメントに含まれる顧客のすべての属性の平均値と最頻値によって構成される顧客セグメンテーション・プロファイル |
|
SGMNT_DISPRSN |
NUMBER(10,4) |
セグメント内の顧客の類似度を示すセグメント分散 |
|
SPRTNG_REC_CNT |
NUMBER(16) |
セグメント内の顧客の数に相当するサポート・レコード数 |
|
TREE_LVL |
NUMBER(4) |
階層型k-meansクラスタリングのツリーのレベル |
|
IS_LEAF_IND |
CHAR(1) |
リーフ・レベル・インジケータ |
表9-5に、dwd_cust_lylty_dt_rulesデータ・マイニング結果表を示します。
表9-5 dwd_cust_lylty_dt_rulesデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
ANALYSIS_NAME |
VARCHAR2(100) |
分析の名前 |
|
MODEL_NAME |
VARCHAR2(100) |
マイニング・モデル名 |
|
RULE_ID |
NUMBER(10) |
ルール識別子番号 |
|
PERFORMANCE_MEASURE |
VARCHAR2(100) |
ターゲット・メジャー列名 |
|
MEASURE_VALUE |
VARCHAR2(100) |
ターゲット・メジャー値 |
|
PROFILE |
VARCHAR2(1000) |
各ツリー・ノードのディシジョンを連結することで構成される顧客のプロファイル |
|
IS_LEAF |
CHAR(10) |
リーフ・レベル・インジケータ |
|
PREDICTION_COUNT |
NUMBER(10) |
ノードの予測と同じ予測を持つ、このノードに分類される顧客の数 |
|
RECORD_COUNT |
NUMBER(10) |
このノードに分類される顧客の数 |
|
SUPPORT |
NUMBER(10,5) |
record_countと顧客の合計数の比率 |
|
CONFIDENCE |
NUMBER(10,5) |
prediction_countとrecord_countの比率 |
|
RULE_DISPLAY_ORDER |
NUMBER(10) |
ルール表示順序 |
表9-6に、dwd_cust_lylty_svm_factorデータ・マイニング結果表を示します。
表9-6 dwd_cust_lylty_svm_factorデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
TARGET_VALUE |
VARCHAR2(100) |
ターゲット・メジャー値 |
|
ATTRIBUTE_NAME |
VARCHAR2(4000) |
|
|
ATTRIBUTE_SUBNAME |
VARCHAR2(4000) |
|
|
ATTRIBUTE_VALUE |
VARCHAR2(4000) |
|
|
COEFFICIENT |
NUMBER |
表9-7に、dwd_cust_ltv_dt_rulesデータ・マイニング結果表を示します。
表9-7 dwd_cust_ltv_dt_rulesデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
|
|
ANALYSIS_NAME |
VARCHAR2(100) |
分析の名前 |
|
MODEL_TYPE |
VARCHAR2(100) |
マイニング・モデルのタイプ |
|
MODEL_NAME |
VARCHAR2(100) |
マイニング・モデル名 |
|
RULE_ID |
NUMBER(10) |
ルール識別子番号 |
|
PERFORMANCE_MEASURE |
VARCHAR2(100) |
ターゲット・メジャー列名 |
|
MEASURE_VALUE |
VARCHAR2(100) |
ターゲット・メジャー値 |
|
PROFILE |
VARCHAR2(1000) |
各ツリー・ノードのディシジョンを連結することで構成される、搭乗頻度の低い乗客のプロファイル |
|
IS_LEAF |
CHAR(10) |
リーフ・レベル・インジケータ |
|
PREDICTION_COUNT |
NUMBER(10) |
ノードの予測と同じ予測を持つ、このノードに分類される搭乗頻度の低い乗客の数 |
|
RECORD_COUNT |
NUMBER(10) |
このノードに分類される搭乗頻度の低い乗客の数 |
|
SUPPORT |
NUMBER(10,5) |
record_countと搭乗頻度の低い乗客の合計数の比率 |
|
CONFIDENCE |
NUMBER(10,5) |
prediction_countとrecord_countの比率 |
|
RULE_DISPLAY_ORDER |
NUMBER(10) |
ルール表示順序 |
表9-8に、dwd_cust_ltv_svm_factorデータ・マイニング結果表を示します。
表9-8 dwd_cust_ltv_svm_factorデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
MODEL_NAME |
VARCHAR2(100) |
マイニング・モデル名 |
|
TARGET_COLUMN |
VARCHAR2(100) |
ターゲット・メジャー値 |
|
TARGET_COLUMN_ABBR |
VARCHAR2(30) |
ターゲット・メジャー値の略語 |
|
ATTRIBUTE_NAME |
VARCHAR2(4000) |
顧客属性名 |
|
ATTRIBUTE_SUBNAME |
VARCHAR2(4000) |
顧客属性別名(存在する場合) |
|
ATTRIBUTE_VALUE |
VARCHAR2(4000) |
顧客属性の値 |
|
COEFFICIENT |
NUMBER |
サポート・ベクター・マシン・アルゴリズムによって予測される属性係数 |
表9-9に、dwd_ffp_pred_dt_rulesデータ・マイニング結果表を示します。
表9-9 dwd_cust_lylty_svm_factorデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
|
|
ANALYSIS_NAME |
VARCHAR2(100) |
分析の名前 |
|
MODEL_TYPE |
VARCHAR2(100) |
マイニング・モデルのタイプ |
|
MODEL_NAME |
VARCHAR2(100) |
マイニング・モデル名 |
|
RULE_ID |
NUMBER(10) |
ルール識別子番号 |
|
PERFORMANCE_MEASURE |
VARCHAR2(100) |
ターゲット・メジャー列名 |
|
MEASURE_VALUE |
VARCHAR2(100) |
ターゲット・メジャー値 |
|
PROFILE |
VARCHAR2(1000) |
各ツリー・ノードのディシジョンを連結することで構成される、搭乗頻度の低い乗客のプロファイル |
|
IS_LEAF |
CHAR(10) |
リーフ・レベル・インジケータ |
|
PREDICTION_COUNT |
NUMBER(10) |
ノードの予測と同じ予測を持つ、このノードに分類される搭乗頻度の低い乗客の数 |
|
RECORD_COUNT |
NUMBER(10) |
このノードに分類される搭乗頻度の低い乗客の数 |
|
SUPPORT |
NUMBER(10,5) |
record_countと搭乗頻度の低い乗客の合計数の比率 |
|
CONFIDENCE |
NUMBER(10,5) |
prediction_countとrecord_countの比率 |
|
RULE_DISPLAY_ORDER |
NUMBER(10) |
ルール表示順序 |
表9-10に、dwd_ffp_pred_svm_factorデータ・マイニング結果表を示します。
表9-10 dwd_ffp_pred_svm_factorデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
ATTRIBUTE_NAME |
VARCHAR2(4000) |
搭乗頻度の低い乗客の属性名 |
|
ATTRIBUTE_SUBNAME |
VARCHAR2(4000) |
搭乗頻度の低い乗客の属性別名(存在する場合) |
|
ATTRIBUTE_VALUE |
VARCHAR2(4000) |
搭乗頻度の低い乗客の属性の値 |
|
COEFFICIENT |
NUMBER |
サポート・ベクター・マシン・アルゴリズムによって予測される属性係数 |
表9-11に、dwd_non_ffp_mnngデータ・マイニング結果表を示します。
表9-11 dwd_non_ffp_mnngデータ・マイニング結果表
| 名前 | 型 | 説明 |
|---|---|---|
|
MO_CD |
VARCHAR2(30) |
モデルがトレーニングされたときの月コード |
|
TRVL_DOC_NBR |
VARCHAR2(30) |
識別のために乗客によって示される旅行ドキュメント番号 |
|
FST_NM |
VARCHAR2(40) |
搭乗頻度の低い乗客の名 |
|
LAST_NM |
VARCHAR2(40) |
搭乗頻度の低い乗客の姓 |
|
FFP_DT_PRED |
VARCHAR2(10) |
ディシジョン・ツリーを使用した、搭乗頻度の低い乗客のうちで搭乗頻度の高い乗客になるという予測 |
|
FFP_DT_ND_NBR |
VARCHAR2(30) |
ディシジョン・ツリーの予測のノード番号 |
|
FFP_SVM_PRED |
VARCHAR2(10) |
サポート・ベクター・マシンを使用した、搭乗頻度の低い乗客のうちで搭乗頻度の高い乗客になるという予測 |
|
FFP_SVM_PROB |
NUMBER(10,8) |
サポート・ベクター・マシンを使用した、搭乗頻度の低い乗客のうちで搭乗頻度の高い乗客になるという予測確率 |
ビジネス問題では、顧客の人口統計や飛行履歴などに基づいて顧客を一般的な同種のグループにグループ化します。ビジネス・アナリストは、モデルによって検出された顧客グループをさらに深く理解するために各セグメントを調査し、各セグメントに名前を付けることができます。
顧客は、クラスタリング・アルゴリズムのK-Meansを使用してクラスタ化されます。検出されたクラスタリング・ルールによって、顧客のプロファイルが示されます。
次の表に、K-Meansモデルのソースとしてデータ・ウェアハウスの3NFレイヤー(実表、参照表)および分析レイヤー(導出表、参照表)から識別される列を示します。
表9-12に、モデルの入力ソース変数として識別されるマテリアライズド・ビューdmv_cust_profile_srcの列を示します。
表9-12 顧客セグメンテーションのソース: dmv_cust_profile_src
| 列名 | 説明 |
|---|---|
|
ff_card_key |
順序によって生成された一意の識別子である、搭乗頻度の高い乗客のカード・キー |
|
ff_nbr |
搭乗頻度の高い乗客の識別番号(ビジネス・キー) |
|
clndr_month_key |
収集されたデータのカレンダの月のキー |
|
gndr |
搭乗頻度の高い乗客の性別 |
|
income_lvl |
搭乗頻度の高い乗客の所得水準 |
|
marital_sts |
搭乗頻度の高い乗客の婚姻関係 |
|
edu |
搭乗頻度の高い乗客の学歴 |
|
occupation |
搭乗頻度の高い乗客の職業 |
|
age |
搭乗頻度の高い乗客の年齢 |
|
card_carr |
|
|
carr_cd |
|
|
rqst_typ |
搭乗頻度の高い乗客によるリクエスト・タイプ |
|
sts_cd |
ステータス・コード |
|
airl_mbshp_lvl |
搭乗頻度の高い乗客の航空会社のメンバーシップ・レベル |
|
airl_prorty_cd |
搭乗頻度の高い乗客の航空会社の優先度コード |
|
airl_tier_desc |
航空会社の層の説明 |
|
airl_cust_value |
航空会社の顧客値 |
|
alan_membr_lvl |
|
|
all_airl_prorty_cd |
|
|
alan_tier_desc |
|
|
cert_nbr |
|
|
alanc_cd |
|
|
stk_cntrl_nbr |
|
|
cls_bef_upgrd |
アップグレード前の予約クラス(アップグレードがある場合) |
|
miles_cr_ind |
マイル・インジケータ |
|
city_nm |
搭乗頻度の高い乗客の都市名 |
|
ctry_nm |
搭乗頻度の高い乗客の国名 |
|
cont_nm |
搭乗頻度の高い乗客の大陸名 |
|
sales_chnl_id |
搭乗頻度の高い乗客が予約を行う場合に使用する販売チャネル・インジケータ |
|
tot_ernd_miles_amt |
搭乗頻度の高い乗客が取得した合計マイル数 |
|
mo_ernd_miles_amt |
clndr_month_keyの搭乗頻度の高い乗客が取得したマイル数 |
|
tot_redeem_miles_amt |
搭乗頻度の高い乗客が引き換えた合計マイル数 |
|
mo_redeem_miles_amt |
clndr_month_keyの搭乗頻度の高い乗客が引き換えたマイル数 |
|
tot_expired_miles_amt |
搭乗頻度の高い乗客の期限切れ合計マイル数 |
|
mo_expired_miles_amt |
clndr_month_keyの搭乗頻度の高い乗客の期限切れマイル数 |
|
tot_conf_bkgs |
搭乗頻度の高い乗客が行った予約における確認済予約の合計数 |
|
mo_conf_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における確認済予約の数 |
|
tot_grp_bkgs |
搭乗頻度の高い乗客が行った予約におけるグループ予約の合計数 |
|
mo_grp_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるグループ予約の数 |
|
tot_night_bkgs |
搭乗頻度の高い乗客が行った予約における夜間予約の合計数 |
|
mo_night_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における夜間予約の数 |
|
tot_dead_bkgs |
搭乗頻度の高い乗客が行った予約における無効予約の合計数 |
|
mo_dead_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における無効予約の数 |
|
tot_bsns_cls_bkgs |
搭乗頻度の高い乗客が行った予約におけるビジネス・クラス予約の合計数 |
|
mo_bsns_cls_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるビジネス・クラス予約の数 |
|
tot_ecnmy_cls_bkgs |
搭乗頻度の高い乗客が行った予約におけるエコノミ・クラス予約の合計数 |
|
mo_ecnmy_cls_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるエコノミ・クラス予約の数 |
|
tot_cdsh_bkgs |
搭乗頻度の高い乗客が行った予約におけるコード共有予約の合計数 |
|
mo_cdsh_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるコード共有予約の数 |
|
tot_brdng_cnt |
搭乗頻度の高い乗客の搭乗フライトの合計回数 |
|
mo_brdng_cnt |
clndr_month_keyの搭乗頻度の高い乗客の搭乗フライトの回数 |
|
tot_open_bkgs |
搭乗頻度の高い乗客が行った予約におけるオープン予約の合計数 |
|
mo_open_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるオープン予約の数 |
|
tot_info_bkgs |
搭乗頻度の高い乗客が行った予約における情報予約の合計数 |
|
mo_info_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における情報予約の数 |
|
tot_avg_days_btwn_bkg_dprtr |
確定された予約とフライトの出発日の間の合計平均日数 |
|
mo_avg_days_btwn_bkg_dprtr |
clndr_month_keyの確定された予約とフライトの出発日の間の平均日数 |
|
tot_bkgs_at_rdy_to_leave |
搭乗頻度の高い乗客の出発準備ができている合計予約数 |
|
mo_bkgs_at_rdy_to_leave |
clndr_month_keyの搭乗頻度の高い乗客の出発準備ができている予約数 |
|
tot_cpn_amt |
合計クーポン数 |
|
mo_cpn_amt |
clndr_month_keyのクーポン数 |
マテリアライズド・ビューdmv_cust_profile_srcは、次の表から導出されます。
dwb_lylty_acct_bal_hist_h
dwd_bkg_fact
dwm_frequent_flyer
dwm_clndr
dwm_geogry
dwc_etl_parameter
マイニング・ルールは、次のターゲット表に保存されます。
dwr_cust_sgmnt
スコアリング結果は、ターゲット表dwd_cust_mnngの次の列に保存されます。
dwd_cust_mnng. cust_sgmnt_cd
ビジネス問題では、顧客のプロファイルを構築して、顧客の特性が航空会社に対するロイヤルティに影響を与えることを説明します。Oracle Data Miningでは、KPIは、ディシジョン・ツリー(DT)およびサポート・ベクター・マシン(SVM)という一般的な2つの分類アルゴリズムを使用してモデル化されます。この分析では、航空会社に対するロイヤルティに顧客のどのキー属性が影響を与えているかを識別します。このモデルは、顧客の様々な属性をマイニングします。
モデルからの出力には次の2つがあります。
検出ルールによって、航空会社に対する顧客ロイヤルティと顧客属性の間の相関関係が示されます。
履歴データに基づいて構築されたモデルを使用して、次の月または四半期に関して現在の基本顧客データを対象に予測を行うことができます。
ルールは、月または四半期ごとに生成されるように設計されます。したがって、ターゲットとして次の変数を使用して、すべての顧客に対して毎月1つのSVMモデルと1つのDTモデルが作成されます。
ディシジョン・ツリー(DT)のターゲット変数は次のとおりです。
乗客ロイヤルティ・コードcust_lylty_cd
サポート・ベクター・マシン(SVM)のターゲット変数は次のとおりです。
乗客ロイヤルティ・コードcust_lylty_cd
顧客ロイヤルティ・モデルでは、ソースとしてdmv_cust_loyalty_srcマテリアライズド・ビューを使用します。このマテリアライズド・ビューには、dmv_cust_profile_srcマテリアライズド・ビューのすべての列と、次の列が含まれます。
cust_rfmp_cd
cust_lylty_score
cust_lylty_cd
マイニング・ルールは、次のターゲット表に保存されます。
dwd_cust_lylty_dt_rules
dwd_cust_lylty_svm_factor
スコアリング結果は、ターゲット表dwd_cust_mnngの次の列に保存されます。
cust_lylty_dt_pred
cust_lylty_dt_nd_nbr
cust_lylty_svm_pred
cust_lylty_svm_prob
ビジネス問題では、顧客の人口統計情報、飛行履歴、サービス品質などの基準に基づいて、生涯を通じて収益価値が最も大きくなる可能性が高い顧客を識別および予測します。
この分析では、生涯価値に顧客のどのキー属性が影響を与えているかを識別します。生涯価値は、連続値です(顧客が寄与する総収益)。生涯価値は、標準的なビニング操作を使用してカテゴリ値に変換されます。分類変数は、様々な独立変数(属性)がターゲットの従属変数(KPI - 分類)に与える影響を特定または予測するために、分類モデルとしてモデル化されます。Oracle Data Mining (11gリリース2)では、分類アルゴリズムのディシジョン・ツリー(DT)を使用して、ターゲット変数のカテゴリ生涯価値および生涯生存価値がモデル化されます。
連続する生涯価値および生涯生存価値は、一般化線形モデル回帰(GLMR)の回帰アルゴリズムを使用して、回帰モデルとしてモデル化されます。
マイニング・モデルは、顧客の最新データを使用して毎月構築され、現在の基本顧客データに適用されて、生涯を通じて収益価値が最も大きくなる可能性が高い顧客が予測されます。
モデルからの出力には次の2つがあります。
生涯を通じて収益価値が最も大きくなる可能性が非常に高い顧客のプロファイルの概要を示す検出ルール。
モデルが一度トレーニングされると、顧客データを対象に予測を行うことができます。
ルールは、月ごとに生成されるように設計されます。したがって、ターゲットとして次の変数を使用して、すべての顧客に対して毎月2つのGLMRモデルと2つのDTモデルが作成されます。
ディシジョン・ツリー(DT)のターゲット変数は次のとおりです。
生涯価値コードcust_ltv_bnd
生涯生存価値コード
一般化線形モデル回帰(GLMR)のターゲット変数は次のとおりです。
生涯価値tot_cpn_amt
ライフタイム・サバイバル・バリュー
顧客ロイヤルティ・モデルでは、ソースとしてdmv_cust_ltv_srcマテリアライズド・ビューを使用します。このマテリアライズド・ビューには、dmv_cust_profile_srcマテリアライズド・ビューのすべての列と、次の列が含まれます。
cust_ltv_bnd
マイニング・ルールは、次のターゲット表に保存されます。
dwd_cust_ltv_dt_rules
dwd_cust_ltv_svm_factor
スコアリング結果は、ターゲット表dwd_cust_mnngの次の列に保存されます。
ltv_band_cd
ltv_value
lt_srvvl_cd
lt_srvvl_value
ビジネス問題では、人口統計属性、フライト使用状況、1ユーザー当たりの収益などに基づいて、FFP乗客になる可能性の高い非FFP乗客(搭乗頻度の低い乗客)を識別および予測します。
この分析では、非FFP乗客がFFPになる可能性が高いかどうかを予測する場合に重要となる非FFP乗客のキー属性も識別します。トレーニング・データは、非FFP乗客とFFP乗客の混在したものになります。FFP乗客は、過去1年間に非FFPからFFPになった乗客です。ターゲット変数は、FFP_INDであり、FFP乗客の場合は1で、非FFP乗客の場合は0です。ターゲット変数FFP_INDは、分類アルゴリズムのサポート・ベクター・マシン(SVM)とディシジョン・ツリー(DT)を使用してモデル化されます。
2つのマイニング・モデルは、最新のFFPおよび非FFPデータを使用して毎月構築され、現在の非FFP乗客に適用されて、FFP乗客になる可能性の高い乗客が予測されます。
モデルからの出力には次の2つがあります。
検出ルールによって、FFPになる可能性の高い非FFP乗客のプロファイルの概要が示されます。
モデルが一度トレーニングされると、現在の非FFP乗客を対象に予測を行うことができます。
ルールは、月ごとに生成されるように設計されます。したがって、ターゲットとして次の変数を使用して、毎月1つのSVMモデルと1つのDTモデルが作成されます。
搭乗頻度の高い乗客のインジケータff_ind
次の表に、K-Meansモデルのソースとしてデータ・ウェアハウスの3NFレイヤー(実表、参照表)および分析レイヤー(導出表、参照表)から識別される列を示します。
表9-13に、モデルの入力ソース変数として識別されるマテリアライズド・ビューdmv_ffp_pred_srcの列を示します。
表9-13 搭乗頻度の高い乗客の予測ソース: dmv_ffp_pred_src
| 列名 | 説明 |
|---|---|
|
case_id |
一意識別子 |
|
trvl_doc_typ |
旅行ドキュメント・タイプ |
|
trvl_doc_nbr |
識別のために乗客によって示される旅行ドキュメント番号 |
|
ff_nbr |
搭乗頻度の高い乗客の番号(ビジネス・キー) |
|
idfn_cd |
識別コード |
|
pax_typ |
乗客タイプ |
|
typ_cd |
タイプ・コード |
|
gndr |
乗客の性別 |
|
age |
乗客の年齢 |
|
curr_sts |
乗客の現在のステータス |
|
ff_ind |
搭乗頻度の高い乗客のインジケータ(現在FFPだが、過去に非FFPだった乗客は1、現在非FFPの乗客は0) |
|
clndr_month_key |
収集されたデータのカレンダの月のキー |
|
sales_chnl_id |
乗客が予約を行う場合に使用する販売チャネル・インジケータ |
|
tot_conf_bkgs |
搭乗頻度の高い乗客が行った予約における確認済予約の合計数 |
|
mo_conf_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における確認済予約の数 |
|
tot_grp_bkgs |
搭乗頻度の高い乗客が行った予約におけるグループ予約の合計数 |
|
mo_grp_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるグループ予約の数 |
|
tot_night_bkgs |
搭乗頻度の高い乗客が行った予約における夜間予約の合計数 |
|
mo_night_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における夜間予約の数 |
|
tot_dead_bkgs |
搭乗頻度の高い乗客が行った予約における無効予約の合計数 |
|
mo_dead_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約における無効予約の数 |
|
tot_bsns_cls_bkgs |
搭乗頻度の高い乗客が行った予約におけるビジネス・クラス予約の合計数 |
|
mo_bsns_cls_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるビジネス・クラス予約の数 |
|
tot_ecnmy_cls_bkgs |
搭乗頻度の高い乗客が行った予約におけるエコノミ・クラス予約の合計数 |
|
mo_ecnmy_cls_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるエコノミ・クラス予約の数 |
|
tot_cdsh_bkgs |
搭乗頻度の高い乗客が行った予約におけるコード共有予約の合計数 |
|
mo_cdsh_bkgs |
clndr_month_keyの搭乗頻度の高い乗客が行った予約におけるコード共有予約の数 |
|
tot_avg_days_btwn_bkg_dprtr |
確定された予約とフライトの出発日の間の合計平均日数 |
|
mo_avg_days_btwn_bkg_dprtr |
clndr_month_keyの確定された予約とフライトの出発日の間の平均日数 |
|
tot_bkgs_at_rdy_to_leave |
搭乗頻度の高い乗客の出発準備ができている合計予約数 |
|
mo_bkgs_at_rdy_to_leave |
clndr_month_keyの搭乗頻度の高い乗客の出発準備ができている予約数 |
|
tot_cpn_amt |
合計クーポン数 |
|
mo_cpn_amt |
clndr_month_keyのクーポン数 |
マイニング・ルールは、次のターゲット表に保存されます。
dwd_ffp_pred_dt_rules
dwd_ffp_pred_svm_factor
スコアリング結果は、ターゲット表dwd_non_ffp_mnngの次の列に保存されます。
ffp_dt_pred
ffp_dt_nd_nbr
ffp_svm_pred
ffp_svm_prob