| Oracle® Airlines Data Model実装およびオペレーション・ガイド 11gリリース2 (11.2) B72456-01 |
|


 前 |
 次 |
この章では、Oracle Airlines Data Modelのアクセス・レイヤーのカスタマイズについて説明します。内容は次のとおりです。
Oracle Airlines Data Modelのアクセス・レイヤーは、ビジネス・インテリジェンス・ツールに必要なデータの計算および要約(「フラット化」)の視点を提供します。基盤レイヤーの3NFオブジェクトのデータを使用して、アクセス・レイヤー・オブジェクトが移入されます。
oadm_sysスキーマのアクセス・レイヤー・オブジェクトには、導出表および集計表、導出表および集計表のディメンションを提供する表、OLAPキューブ、およびマテリアライズド・ビューが含まれます。このレイヤーには、データ・マイニング・モデルも含まれます。これらのモデルの結果が導出表に格納されます。
アクセス・レイヤー・オブジェクトを設計およびカスタマイズする場合:
「物理構造を設計する場合の一般的な推奨事項」に示されている物理オブジェクトをカスタマイズする一般的なガイドラインに従います。
使用しているサイトのビジネス・インテリジェンス・レポートおよび問合せをサポートするため、アクセス・レイヤー・オブジェクトを設計します。第5章「レポートおよび問合せのカスタマイズ」を参照してください。
次のトピックで、アクセス・レイヤー・オブジェクトの設計およびカスタマイズの特化した情報について説明します。
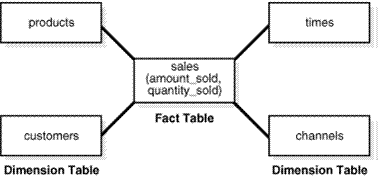
ディメンション表は、ファクト表のディメンション・データを格納する表です。Oracle Airlines Data Modelには、他の表に対してディメンションとして機能する2つのタイプの表があります。
基盤レイヤーでは、DWR_表(参照表とも呼ばれる)は、実表(DWB_)へのディメンション表として機能します。
アクセス・レイヤーでは、DWM_表(単純にディメンション表と呼ばれる)は、導出表(DWD_)および集計表(DWA_)へのディメンション表として機能します。DWM_表は、スター・スキーマのディメンション表で示されるビューと同様のデータのビューを提供します。
デフォルトOracle Airlines Data Modelは、いくつかのディメンション表を定義します。たとえば、DWR_SEGおよびDWM_SEG表は、様々なレイヤーのセグメント情報の値を格納します。
導出表は、基盤レイヤー表のデータに対する非集計計算の結果を値として含む表です。導出表には、DWD_接頭辞があります。
デフォルトのOracle Airlines Data Modelには2つの主要なタイプの導出表があり、これらの表のカスタマイズ方法はタイプごとに異なります。
計算結果を保持する表。これらの表のカスタマイズの詳細は、「計算データの新しい導出表の作成」を参照してください。
データ・マイニング・モデルの結果表。データ・マイニング・モデルのカスタマイズの詳細は、「Oracle Airlines Data Modelのデータ・マイニング・モデルのカスタマイズ」を参照してください。
|
参照: デフォルトOracle Airlines Data Modelのすべての導出表のリストは、『Oracle Airlines Data Modelリファレンス』の導出表に関する項を参照してください。データ・マイニング・モデルの結果表である導出表のみのリストは、『Oracle Airlines Data Modelリファレンス』のデータ・マイニング・モデルに関する章を参照してください。 |
フィットギャップ分析の実行中にデフォルトの導出表で示されない計算データのニーズを確認した場合、新しい表を定義してこのニーズを満たすことができます。これらの表を設計する場合、導出表にDWD_接頭辞を使用する規則に従って表の名前を付けます。
oadm_sysスキーマで定義されている導出表(DWD_)の一部は、Oracle Airlines Data Modelで定義されているデータ・マイニング・モデルの結果表です。すべてのOracle Airlines Data Modelデータ・マイニング・モデルは、マテリアライズド・ビューをソース入力として使用します。これらのマテリアライズド・ビューは、$ORACLE_HOME/oadm/pdm/miningにあるoadm_mining_init.sqlスクリプトで定義されます。異なるデータ・マイニング・モデルは異なるソース・マテリアライズド・ビューを使用します。
カスタマイズされたOracle Airlines Data Modelウェアハウスを作成する場合、次の方法でデータ・マイニング・モデルをカスタマイズできます。
「Oracle Airlines Data Modelの新しいデータ・マイニング・モデルの作成」で説明するように、新しいデータ・マイニング・モデルを作成します。
「Oracle Airlines Data Modelのデータ・マイニング・モデルの変更」で説明するように、既存のデータ・マイニング・モデルを変更します。
新しいデータ・マイニング・モデルを作成するには、次の手順を実行します。
oadm_sysスキーマに新規データ・マイニング・モデルへの入力として使用できるマテリアライズド・ビューの定義が含まれていることを確認します。必要に応じて、新しいマテリアライズド・ビューを定義します。
任意のデータ・マイニング・モデルとして新規データ・マイニング・モデルを作成します。『Oracle Data Mining概要』の手順に従います。
データ・マイニング・モデルに必要な物理表をoadm_sysスキーマに追加します。データ・マイニング・ソース表に名前を付ける際は、接頭辞DM_を使用します。データ・マイニング結果表に名前を付ける際は、接頭辞DWD_を使用します。
Oracle Airlines Data Modelデータ・マイニング・モデルをカスタマイズするには、次の手順に従います。
データ・マイニング・モデルへの入力として使用されるソース・マテリアライズド・ビューの定義を変更します。
Oracle Airlines Data Modelマイニング・パッケージを呼び出して、データ・マイニング・モデルを再度トレーニングします。
データ・マイニング・モデルが新しい定義(たとえば、新しい列の追加など)を反映していることを確認します。
例3-1 create_cust_ltv_svm_rgrsn_modelデータ・マイニング・モデルへの新規列の追加
create_cust_ltv_svm_rgrsn_modelデータ・マイニング・モデルでは、dmv_cust_ltv_srcマテリアライズド・ビューがソース入力として使用されます。新規列をcreate_cust_ltv_svm_rgrsn_modelデータ・マイニング・モデルに追加してモデルをカスタマイズするには、次の手順を実行します。
次のマテリアライズド・ビューを変更します。
dmv_bkg_fact_src
dmv_lylty_acct_bal_src
dmv_cust_profile_src
顧客生涯価値回帰データ・マイニング・モデルをトレーニングし、次の文を実行します。
pkg_oadm_mining.create_cust_ltv_svm_rgrsn
次の文を発行して結果表を問い合せて、新しい列名が問合せ結果に含まれていることを確認します。
SELECT attribute_name FROM TABLE( SELECT attribute_set FROM TABLE(DBMS_DATA_MINING.GET_MODEL_DETAILS_SVM('CUST_LTV_SVM_RGRSN')));
Oracle Airlines Data Modelの基盤レイヤーを移入し、Intra-ETLを実行して導出表を移入したら、より高度な分析および予測のための事前作成済のOracle Airlines Data Modelデータ・マイニング・モデルを利用できます。
このチュートリアルは、移入されたOracle Airlines Data Modelウェアハウスに基づく次の6か月間について、利用頻度の高い乗客である顧客の生涯価値の予測方法を示します。事前作成済のOracle Airlines Data Modelデータ・マイニング・モデルを使用すると、従来の最初から作成するマイニング・プロジェクトで行う必要があるすべてのデータ準備、トレーニング、テストおよび適用プロセスを実行することなく、顧客の予測結果を簡単かつ迅速に確認できます。
最初にデータ・マイニング・モデルを生成した後、時間の経過とともに顧客の情報、動作および使用状況が変更されます。したがって、最新の顧客および使用データに基づいて以前にトレーニングしたデータ・マイニング・モデルをリフレッシュする必要があります。このチュートリアルのプロセスに従って、データ・マイニング・モデルをリフレッシュして最新の顧客情報の予測を取得できます。
このチュートリアルでは、Oracle Airlines Data ModelマイニングAPIを使用して、顧客生涯価値予測モデルを調査する方法を示します。トレーニング・プロセスで様々なパラメータを使用する、またはより高度な方法でモデルをカスタマイズするには、マイニング設定表(接頭辞がDM_)を変更するか、Oracle Data Miner GUIツールを使用できます。
このチュートリアルは、次の手順で構成されています。
|
参照: Oracle Databaseデータ・マイニング・モデル・トレーニングおよびスコアリング(適用)プロセスの詳細は、『Oracle Data Mining概要』を参照してください。 |
このチュートリアルの開始する前に:
Oracle Data Miner 11gリリース2の使用に関するOracle by Example(OBE)チュートリアルを確認します。このチュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。
Oracle Airlines Data Modelをインストールします。
実表、参照表および検索表を移入します。
Intra-ETLを実行します。
少なくとも次の表に有効なデータが含まれていることを確認します。
DWB_LYLTY_ACCT_BAL_HIST_H DWD_BKG_FACT DWM_CLNDR DWM_FRQTFLR DWM_GEOGRY
|
注意: 実際のデータを移入しないでOracle Airlines Data Modelデータ・マイニング・モデルを学習するだけの場合、次の手順に従って、サンプル・データを使用できます。
|
このチュートリアルには、移入された有効なOracle Airlines Data Modelウェアハウスが必要です。
環境を準備するには、次の手順に従います。
SQL Developerで、oadm_sysスキーマに接続します。
|
ヒント: $ORACLE_HOME/sqldeveloperの下のOracle Databaseインストールで、SQL Developerを確認できます。 |
|
Oracle By Example: SQL Developerの使用の詳細は、Oracle SQL Developer 3.0の概要に関するチュートリアルを参照してください。このチュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
oadm_sysスキーマに接続したら、作成済のすべての表を表示できます。「表」を右クリックしてフィルタを適用し、リストを絞り込むことができます。
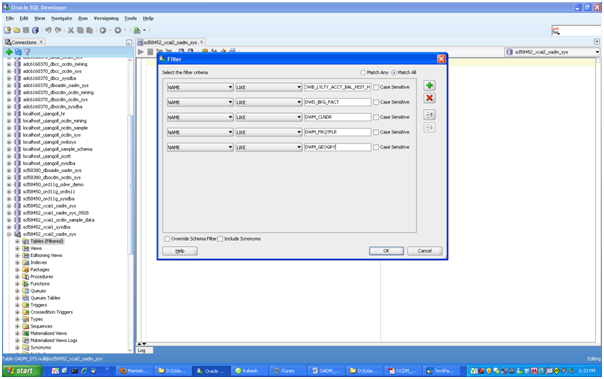
(オプション)「チュートリアルの前提条件」に示されているように、表に固有のデータを移入していない場合は、サンプル・データで試行できます。サンプル・データをダウンロードしたら、データをインポートする次の手順を実行します。
次の文を発行して、dbaをoadm_sysに付与します。
grant dba to oadm_sys
チュートリアルで必要な表のすべての外部キーを無効にします。
まず、SQL文を生成する次の文を発行します。
SELECT 'ALTER TABLE ' || table_name || ' DISABLE CONSTRAINT ' ||
CONSTRAINT_NAME ' CASCADE;' FROM all_constraints
WHERE status='ENABLED' AND owner='OADM_SYS'
AND constraint_type=
'R' and table_name IN
('DWB_LYLTY_ACCT_BAL_HIST_H','DWD_BKG_FACT','DWM_CLNDR',
'DWM_FRQTFLR','DWM_GEOGRY') ;
次に、次の表の外部キーを実際に無効にするために、前のSELECT文で生成されたSQL文を実行します。
DWB_LYLTY_ACCT_BAL_HIST_H DWD_BKG_FACT DWM_CLNDR DWM_FRQTFLR DWM_GEOGRY
サンプル・ダンプ(oadm_sample.dmp)が、デフォルトのデータ・ダンプ・ディレクトリ(DATA_PUMP_DIR)にあることを確認します。次に、次の文を発行して、サンプル・マイニング・ダンプをoadm_sysスキーマにインポートします。(passwordの部分は、oadm_sysのパスワードに置き換えてください。)
impdp oadm_sys/password directory=DATA_PUMP_DIR dumpfile=oadm_sample.dmp
content=DATA_ONLY table_exists_action=truncate
TABLES=oadm_sample.DWB_LYLTY_ACCT_BAL_HIST_H,
oadm_sample.DWD_BKG_FACT,oadm_sample.DWM_CLNDR,
oadm_sample.DWM_FRQTFLR,oadm_sample.DWM_GEOGRY
有効なデータ(固有の顧客データまたはサンプル・マイニング・データのいずれか)が含まれている表を確認します。
Oracle Airlines Data ModelマイニングAPI内のモデル・プロシージャを実行する前に、マイニング結果表DWD_CUST_MNNGが空であることを確認します。
このチュートリアルは、Oracle Airlines Data ModelマイニングAPIの2つのプロシージャを使用します。
すべてのマイニング・ソース・マテリアライズド・ビューをリフレッシュするpkg_oadm_mining.refresh_mining_source。
顧客生涯価値予測モデルを生成するpkg_oadm_mining.create_cust_ltv_svm_rgrsn。
プロシージャを使用するには、次の手順を実行します。
次のSQL文を実行して、Oracle Airlines Data Modelマイニング・ソース・マテリアライズド・ビューをリフレッシュします。
SELECT count(*) FROM dmv_cust_ltv_src; exec pkg_oadm_mining.refresh_mining_source; SELECT count(*)FROM dmv_cust_ltv_src;
次の文を実行します。
マテリアライズド・ビューのリフレッシュの前に、dmv_cust_ltv_srcマテリアライズド・ビューのレコード数を表示します。
マイニング・ソース・マテリアライズド・ビューをリフレッシュします。
マテリアライズド・ビューのリフレッシュの後に、dmv_cust_ltv_srcマテリアライズド・ビューのレコード数を表示します。
次の文を実行して、顧客生涯価値予測モデルを生成します。
SELECT count(*) FROM dwd_cust_mnng; SELECT count(*) FROM dwd_cust_ltv_svm_factor; EXEC pkg_oadm_mining. create_cust_ltv_svm_rgrsn; SELECT count(*) FROM dwd_cust_mnng; SELECT count(*) FROM dwd_cust_ltv_svm_factor;
次の文を実行します。
データ・マイニング・モデルの構築の前に、dwd_cust_mnng表のレコード数を表示します。
データ・マイニング・モデルの構築の前に、dwd_cust_ltv_svm_factor表のレコード数を表示します。
データ・マイニング・モデルをトレーニングします。
データ・マイニング・モデルの構築の後に、dwd_cust_mnng表のレコード数を表示します。
データ・マイニング・モデルの構築の後に、dwd_cust_ltv_svm_factor表のレコード数を表示します。
マイニング・ソースのマテリアライズド・ビューをリフレッシュし、データ・マイニング・モデルを構築した後、次の手順に示すように、dwd_cust_mnng表内のマイニング予測結果を確認します。
次の問合せを発行します。
SELECT frqtflr_card_key, ltv_value, ltv_band_cd FROM dwd_cust_mnng;
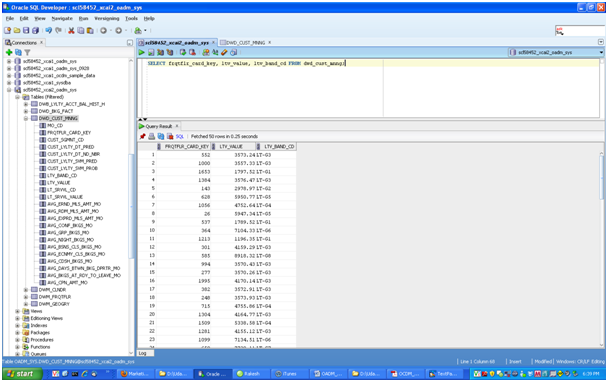
frqtflr_card_keyで識別される顧客ごとに、ltv_value列で顧客生涯価値(連続値)の予測が示されます。予測値ltv_valueをビニングすることで、ltv_band_cd列に値が移入されます。
集計表は、実表または導出表より1つ上位のレベルにデータを集計または「ロールアップ」する表です。デフォルトのOracle Airlines Data Modelの集計表には、DWA_接頭辞があります。ファクト表のディメンションはDWM_表ですが、これらの集計表は、スノーフレーク・スキーマのファクトのファクト表で示されるビューと同様のデータのビューを提供します。
デフォルトのOracle Airlines Data Modelは、複数の集計表を定義しています。たとえば、DWA_DLY_BKG_FACT表は、DWD_BKG_FACT表の値を1日、セグメントおよびトラフィック・カテゴリ・レベルで集計します。
|
参照: デフォルトOracle Airlines Data Modelのすべての集計表のリストは、『Oracle Airlines Data Modelリファレンス』の集計表に関する項を参照してください。 |
フィットギャップ分析の実行中にデフォルトの集計表で示されない集計データのニーズを確認した場合、新しいマテリアライズド・ビューを定義できます。これらの表を設計する場合、次の点を考慮します。
単一のレベルのみを集計するマテリアライズド・ビューの問合せを作成します。たとえば、長期間の集計の日次から月次のみの集計などです。
|
注意: 多くのレベル(たとえば、時間、月、四半期、年など)または異なる階層(たとえば、時間ディメンションの会計およびカレンダ階層など)を集計する必要がある場合、DWA_表を定義しないで、かわりにOLAPキューブを作成して集計を定義します。 |
「物理オブジェクトの一般的なネーミング規則」に記載された規則に従って表の名前を付け、DWA_接頭辞を使用します。
固有の長所と短所を持つ各スタイル、従来の3NFおよび次元を使用した特定のデータ・ウェアハウスに対する最適なモデリング・アプローチに関して多くの議論がよくあります。傾向として、データ・ウェアハウスは、1つのみに依存しないで各モデル・タイプの利点をさらに取り込む必要があります。これはOracle Airlines Data Modelの設計で採用されたアプローチです。Oracle Airlines Data Modelの基盤レイヤーは3NFモデルです。デフォルトのOracle Airlines Data Modelは、データの次元モデルも提供します。この次元モデルのデータは、詳細トランザクション情報を保持するのではなく、データを要約および集計する視点です。
デフォルトのOracle Airlines Data Modelの次元モデルをカスタマイズする前に、次のトピックを参照して次元モデリングについてよく理解します。
次元モデルに簡素性が備わっているのは、実在するビジネス・エンティティを表すオブジェクトを定義しているためです。分析者は、調査したいビジネス・メジャー、データに意味を与えているディメンションや属性、およびビジネスのディメンションがレベルや階層に編成されている方法がわかります。
つまり、次元モデルは次のオブジェクトを識別します。
メジャー。メジャーは、予約、パートナの収益などの定量的なビジネス・データを格納します。メジャーは、「ファクト」と呼ばれることがあります。メジャーは1つ以上のディメンションによって編成され、問合せ時に格納または計算される場合があります。
ストアド・メジャーストアド・メジャーは、リーフ・レベルでロードおよび格納されます。通常、格納されるサマリー・データの割合もあります。格納されないサマリー・データは、問合せ時に動的に集計されます。
計算済メジャー。計算済メジャーは、問合せ時に動的に計算される値のメジャーです。計算ルールのみ、データベースに格納されます。一般的な計算には、比率、差、移動和、平均などのメジャーが含まれます。計算にはディスク・ストレージ領域が必要なく、データのメンテナンスに必要な処理時間を拡張しません。
ディメンション。ディメンションは、ユーザーのビジネス上の疑問に答えられるようにデータを分類する構造です。一般的に使用されるディメンションは、Account、Airport、Flight、GeographyおよびCalendarです。ディメンションの構造は、親子リレーションシップに基づいて階層的に編成されます。これらのリレーションシップで次のことが可能です。
レベル間の移動。
ディメンションの階層では、下位レベルのドリルダウンまたは上位レベルの移動(ロールアップ)を行うことができます。通常、カレンダ年ディメンション・メンバー2005のドリルダウンは、2005年第1四半期から第4四半期の四半期に移動します。カレンダ年階層では、2005年第1四半期のドリルダウンは05年1月から05年3月の月に移動します。このようなリレーションシップにより、ユーザーは大量の多次元データを簡単に移動できます。
子値から親値の集計。
親は、子の集計を表します。下位レベルのデータ値は、上位レベルのデータ値に集計されます。ディメンションは、異なるレベルの集計のデータを効率的に操作して分析および表示するため、階層的に構造化されます。
親値から子値の割当て。
集計の反対は割当てで、予算計画や同様の適用例で頻繁に使用されます。ここで、階層の役割は、使用例の中で特に予算の「トップダウン」の割当ての特定のディメンション・メンバーの子および子孫を識別することです。
計算用のメンバーのグループ化。
シェアおよび指標計算では、階層リレーションシップ(たとえば、利用頻度の高い各乗客メンバー・レベルが寄与する合計チケット予約数の割合、特定のセグメントの飛行収益のシェア割合、販売代理店の場所の地理的地域の割合としての売上収益など)を利用します。
ディメンション・オブジェクトにより、ディメンション情報を階層形式に編成してグループ化できます。これは、制約では表すことのできない列間または列グループ(階層レベル)間の1:nの関係を表します。階層内でのレベルを上げることはデータのロールアップと呼ばれ、レベルを下げることはデータのドリルダウンと呼ばれます。
次元モデルを実装できる2つの方法があります。
スター・スキーマ構成のリレーショナル表次元モデルを実装するこの従来の方法は、「リレーショナル・スターおよびスノーフレーク表の特性」で説明します。
Oracle OLAPキューブ。Oracle Airlines Data Modelで提供される物理モデルは、Oracle OLAPキューブを使用してデータのディメンションの視点を示します。この次元モデルは、「OLAP次元モデルの特性」で説明します。
リレーショナル表の場合、次元モデルは、以前からスター・スキーマまたはスノーフレーク・スキーマとして実装されています。ディメンション表(階層、レベルおよび属性の情報を含む)は、1つ以上のファクト表に結合します。ファクト表は定量的なビジネス・メジャー(予約、パートナ収益など)を格納する大きい表で、通常ディメンション表に対する外部キーがあります。ディメンション表(検索表または参照表とも呼ぶ)には、データ・ウェアハウスの比較的静的または記述的なデータが含まれます。
ドリル・パス、階層および問合せプロファイルはデータではなくデータ・モデル自体に埋め込まれるため、スター・スキーマは物理モデルに似ています。これにより、少なくとも部分的にエンド・ユーザーにとってモデルの操作が容易になります。通常、スター・スキーマには、小さなディメンション表で囲まれた大きいファクト表があります。ディメンション表は頻繁に変更されません。ユーザーが必要とするほとんどの情報は、ファクト表にあります。したがって、スター・スキーマは、3NFモデルよりも表の結合が少なくなります。
中央から点が放射状に伸びており、ダイアグラムが星に似ているため、スター・スキーマと呼ばれます。星の中心は1つ以上のファクト表で構成されており、星の点はディメンション表です。
スノーフレーク・スキーマは、ディメンション表を複数の表にさらに正規化して分割する場合に単純なスター・スキーマを少し変化させたものです。スノーフレークはディメンションにのみ影響しファクト表には影響しないため、概念的にスター・スキーマと同等とみなされます。スノーフレーク・ディメンションは、異なる粒度のファクト表がある場合に便利で実際に必要です。月レベルの導出表または集計表(またはマテリアライズド・ビュー)は、デフォルトの(下位の)日レベルのスター・ディメンション表ではなく月レベルのスノーフレーク・ディメンション表に関連付ける必要があります。
リレーショナル表がファクト表のディメンションとして機能する場合、(必要でなくても)ディメンションとして表を宣言することをお薦めします。定義されたディメンションは大きなパフォーマンスの利点があり、より複雑なタイプのリライトの使用をサポートします。
ディメンションの構造を定義および宣言するには、CREATE DIMENSIONコマンドを使用します。LEVEL句を使用して、ディメンション・レベルの名前を識別します。
|
注意: デフォルトのOracle Airlines Data Modelでは、ディメンション表として使用されるリレーショナル表は、CREATE DIMENSIONコマンドを使用して定義されていません。 |
データ・ウェアハウスのディメンション・データのデータ品質を向上するには、ディメンション・データの変更後のディメンション・メンバー間のリレーションシップの宣言情報を検証することをお薦めします。
この検証を実行するには、DBMS_DIMENSIONパッケージのVALIDATE_DIMENSIONプロシージャを使用します。VALIDATE_DIMENSIONプロシージャでエラーが検出されると、プロシージャはエラーをDIMENSION_EXCEPTIONS表に書き込みます。VALIDATE_DIMENSIONプロシージャで識別される例外を確認するには、DIMENSION_EXCEPTIONS表の問合せを実行します。
通常の増分ディメンション・ロード・スクリプトの後処理の手順として、VALIDATE_DIMENSIONプロシージャのコールをスケジュールできます。マテリアライズド・ビューのリフレッシュを通じてデータ・モデルの導出表または集計表をリフレッシュするコール、Intra-ETLパッケージ・コールの前に、これを実行できます。
|
注意: デフォルトのOracle Airlines Data Modelで提供されているETLでは、リレーショナル・ディメンション表は検証されません。 |
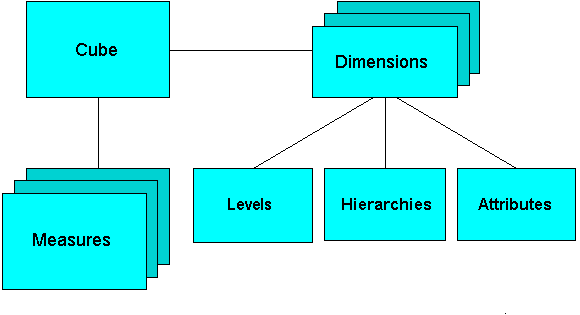
Oracle OLAPキューブは、リレーショナル・スター表と同様のデータを論理的に表しますが、データは実際に多次元配列に格納されます。ディメンション表と同様、キューブ・ディメンションはメンバーを階層、レベルおよび属性に編成します。キューブは、メジャー(ファクト)データを格納します。ディメンションは、キューブのエッジを形成します。
Oracle OLAPは、Oracle Databaseに埋め込まれたOLAPサーバーです。Oracle OLAPにより、複数のディメンションにまたがってデータを分析する際に、固有の多次元格納および高速な応答時間を実現できます。データベースでは、時系列計算、予測、加算および非加算の演算子や割当て操作による高度な集計など、多様な形で分析を行うことができます。
Oracleでは、多次元オブジェクトおよび分析をデータベースに統合することにより、両者の利点を活かし、Oracleデータベースの信頼性、可用性、セキュリティ、スケーラビリティとともに多次元分析機能を実現しています。
Oracle OLAPはOracle Databaseに完全に統合されています。これは、技術レベルでは次のことを意味します。
OLAPエンジンは、Oracle Databaseのカーネルで実行されます。
ディメンション・オブジェクトは、固有の多次元形式でOracle Databaseに格納されます。
キューブなどのディメンション・オブジェクトは、Oracleデータ・ディクショナリの主要なデータ・オブジェクトです。
データ・セキュリティは、Oracle Databaseのユーザーとロールに対して権限の付与および取消しを行う、標準的な方法で管理されます。
OLAPキューブ、ディメンションおよび階層は、リレーショナル・ビューとしてアプリケーションに公開されます。そのため、「Oracle OLAPキューブ・ビュー」および第5章「レポートおよび問合せのカスタマイズ」に示されているように、アプリケーションはSQLを使用してOLAPオブジェクトを問い合せることができます。
「キューブ・マテリアライズド・ビュー」の説明に従ってマテリアライズド・ビューになるように、Oracle OLAPキューブを拡張できます。
Oracle OLAPを使用する利点
これは組織にとって非常に有益です。Oracle OLAPでは、1つのデータベース、標準的な管理とセキュリティ、標準のインタフェースと開発ツールといった、簡略性による利点が得られます。
Oracle OLAP次元データ・モデルは、高度に構造化されています。構造とは、データ間の関係を決定し、データの問合せ方法を制御する規則のことを意味します。キューブは次元モデルの物理的な実装なので、次元問合せにあわせて高度に最適化されています。OLAPエンジンは、元々備えているこのディメンション性を利用することにより、きわめて効率的にクロスキューブ結合(行間計算の場合)、外部結合(時系列分析の場合)および索引付けを実行します。ディメンションは、メジャーに事前結合されます。キューブの基盤となるこのテクノロジは、索引付けされた多次元配列モデルをベースにしており、この多次元配列モデルが直接的なセル・アクセスを可能にしています。
OLAPエンジンによる次元オブジェクトの処理は、SQLエンジンによるリレーショナル・オブジェクトの処理と同様に行われます。ただし、OLAPエンジンは分析関数の計算に関して、次元オブジェクトは分析に関してそれぞれ最適化されているため、OLAPでは、分析関数および行関数の計算を、SQLよりもはるかに高速に実行できます。
Oracle OLAPは次元モデルにより、OracleBI Discoverer Plus OLAP、OracleBI Spreadsheet Add-In、Oracle Business Intelligence Suite Enterprise Edition、BusinessObjects EnterpriseおよびCognos ReportNetなど、ビジネス・インテリジェンス用のハイエンドなツールやアプリケーションをサポートすることが可能になっています。
Oracle OLAP次元オブジェクト
Oracle OLAP次元オブジェクトには、キューブ、メジャー、ディメンション、階層、レベルおよび属性が含まれます。OLAP次元オブジェクトの詳細は、『Oracle OLAPユーザーズ・ガイド』で説明されています。図3-2に、オブジェクト間の一般的な関係を示します。
OLAPキューブを定義する場合、Oracle OLAPは、キューブ、ディメンションおよび階層の一連のリレーショナル・ビューを自動的に生成します。
キューブ・ビュー。各キューブには、キューブ内のすべてのメジャーと計算済メジャーのデータを示すキューブ・ビューが1つあります。キューブ・ビューは、スター・スキーマまたはスノーフレーク・スキーマ内のファクト表のように使用できます。ただし、キューブ・ビューには、ディテール・レベルのデータの他にすべてのサマリー・データも含まれます。キューブ・ビューのデフォルトの名前はcube_VIEWです。
ディメンション・ビューと階層ビュー各ディメンションには、ディメンション・ビューが1つと、そのディメンションに関連付けられている各階層の階層ビューがあります。ディメンション・ビューのデフォルトの名前はdimension_VIEWです。階層ビューのデフォルトの名前はdimension_hierarchy_VIEWです。
これらのビューは、スター・スキーマにおけるファクト表とディメンション表と同様の関係にあります。キューブ・ビューはファクト表と同じ機能を持ち、階層ビューとディメンション・ビューはディメンション表と同様に機能します。通常の問合せでは、階層ビューまたはディメンション・ビューのいずれかとキューブ・ビューを結合します。
SQLアプリケーションでこれらのビューを問い合せることにより、分析担当者や意思決定者はこれらのオブジェクトの情報量に富んだ内容を表示できます。また、実表などのシステム生成ビューを使用して、ご使用のアプリケーションに必要な構造に従ったカスタム・ビューを作成できます。
マテリアライズド・ビューにするため、Oracle OLAPキューブを拡張できます。このように拡張されたキューブはキューブ・マテリアライズド・ビューと呼ばれ、CB$接頭辞を使用します。キューブ・マテリアライズド・ビューはOracle Databaseマテリアライズド・ビュー・サブシステムを介して段階的にリフレッシュでき、ソース表に対する問合せの透過的リライトの対象として使用できます。
キューブ・マテリアライズド・ビューに関連付けられたOLAPディメンションも、マテリアライズド・ビュー機能を使用して定義されます。
キューブ・マテリアライズド・ビューの必要なキューブ特性
キューブ・マテリアライズド・ビューとして設定するキューブは、次の条件を満たしている必要があります。
キューブのすべてのディメンションに、少なくとも1つのレベルと、1つのレベルベース階層が存在する。不規則階層およびスキップレベル階層はサポートされない。ディメンションがマップされている必要がある。
キューブのすべてのディメンションで同じ集計演算子(SUM、MIN、MAXのいずれか)を使用している。
ディメンションとメジャーがそれぞれ1つ以上存在する。
定義とマップが完全に行われている。たとえば、キューブに5つのメジャーがある場合、その5つすべてがソース表にマップされている。
キューブのデータ型が、NUMBER、VARCHAR2、NVARCHAR2またはDATEである。
ソースのディテール表で、ディメンションおよびRELY制約がサポートされている。これらが定義されていない場合は、リレーショナル・スキーマ・アドバイザを使用して、ディテール表に対してこれらを定義するスクリプトを生成できる。
圧縮されている。
計算済メジャーは使用できるが、キューブ・スクリプト内のより高度な分析機能は使用できない。
マテリアライズド・ビュー機能の追加
マテリアライズド・ビュー機能をOLAPキューブに追加するには、次の手順を実行します。
Analytic Workspace Managerで、oadm_sysスキーマに接続します。
キューブ・リストから、有効にするキューブを選択します。
右ペインで、「マテリアライズド・ビュー」タブを選択します。
「キューブのマテリアライズド・ビューのリフレッシュを有効化」を選択し、「適用」をクリックします。
|
注意: 予測キューブのキューブ・マテリアライズド・ビューは有効にできません。 |
|
Oracle By Example: OLAPキューブの操作の詳細は、次のOBEチュートリアルを参照してください。
チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
|
関連項目: 『Oracle OLAPユーザーズ・ガイド』 |
Oracle Airlines Data Modelのデフォルトのアクセス・レイヤーは、Oracle OLAPキューブを使用してデータのディメンションの視点を示します。
デフォルトのoadm_sysスキーマで定義されるOLAPキューブがあります。これらのキューブには、「OLAP次元モデルの特性」で説明されている一般的な特性があります。具体的に、Oracle Airlines Data ModelのOLAPキューブには次の特性があります。
すべてのデフォルトのOLAPキューブは、DWA_表のデータとともにロードされます。
Analytical Workspace Manager(AWM)クライアント・ツールを使用して、キューブが定義および作成されました。
リレーショナル・ビュー(_VIEW接尾辞を使用)は、各OLAPキューブに定義されます。
Oracle Airlines Data ModelのすべてのOLAPキューブは、キューブのマテリアライズド・ビューとして有効化できる状態にあります(つまり、CB$オブジェクト)。
|
ヒント: インストールの直後に、OLAPキューブの基になるすべてのマテリアライズド・ビューがデフォルトで無効になります。キューブ・マテリアライズド・ビューを有効にするには、「マテリアライズド・ビュー機能の追加」で概説する手順に従う必要があります。 |
Oracle Airlines Data ModelのカスタマイズしたバージョンのOLAPキューブの使用の詳細は、『Oracle OLAPユーザーズ・ガイド』および次のトピックを参照してください。
新しいOLAPキューブをoadm_sysスキーマに追加できます。一貫性のため、「Oracle Airlines Data ModelのOLAPキューブの特性」の説明に従って、これらの新しいキューブを設計および定義します。
次の手順を実行して、新しいキューブを定義します。
キューブの「最下位のリーフ」データとして使用する集計表(DWA_)があることを確認します。新しい表の作成の詳細は、「Oracle Airlines Data Modelの集計表」を参照してください。
AWMを使用して、Oracle Airlines Data Modelのカスタマイズしたバージョンの新しいキューブを定義します。『Oracle OLAPユーザーズ・ガイド』のキューブおよびディメンションを作成する指示に従います。
新しいOLAPキューブを設計および定義する場合、「OLAP次元モデルの特性」で提供されている情報および『Oracle OLAPユーザーズ・ガイド』を使用します。また、「リレーショナル・スターおよびスノーフレーク表の特性」で概説するリレーショナル・スター・スキーマ設計に慣れている場合、この知識を利用して、次に説明するようにOLAPキューブを設計できます。
ファクト表は、キューブに対応する。
ファクト表のデータ列は、メジャーに対応する。
ファクト表の外部キー制約は、ディメンション表に対応する。
ディメンション表は、ディメンションに対応する。
ディメンション表の主キーは、ベース・レベルのディメンション・メンバーに対応する。
ディメンション表の親列は、上位レベルのディメンション・メンバーに対応する。
ディメンション・メンバーの説明や特性が格納されているディメンション表の列は、属性に対応する。
また、Oracle Airlines Data Modelに含まれるサンプル・レポートを参照して、次元モデルを理解できます。
|
参照: サンプル・レポートのインストール、ならびにBusiness Intelligence Suite Enterprise EditionインスタンスでのOracle Airlines Data Model RPDおよびWebcatのデプロイの詳細は、『Oracle Airlines Data Modelインストレーション・ガイド』を参照してください。 |
|
ヒント: ソース・データを調査するときに、作成しようとしている次元モデルとの一致度がより高いリレーショナル・ビューを作成することもできます。 |
「マテリアライズド・ビュー機能の追加」の説明に従って、マテリアライズド・ビュー機能をOLAPキューブに追加します。
|
関連項目: 『Oracle OLAPユーザーズ・ガイド』、「Oracle Airlines Data Modelの新しいOracle OLAPキューブの定義」および『Oracle Airlines Data Modelリファレンス』のサンプル・レポート |
|
Oracle By Example: OLAPキューブの作成の詳細は、OLAP 11gキューブの作成に関するOBEチュートリアルを参照してください。チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
Oracle Airlines Data Modelキューブの一般的なカスタマイズは、キューブのディメンションまたはメジャーを変更します。
すべてのOracle Airlines Data Modelキューブは接頭辞がDWA_の表からデータをロードするため、1つのキューブのメジャーまたはディメンションを変更する場合は、次の手順に従う必要があります。
『Oracle Airlines Data Modelリファレンス』の情報を使用して、OLAPキューブの移入元のDWA_表を識別します。
手順1で識別したDWA_表の構造を変更します。
OLAPキューブとキューブ・マテリアライズド・ビューを変更して、新しい構造を反映します。
Oracle Airlines Data Modelの予測キューブを作成する手順は、次のとおりです。
「Oracle Airlines Data Modelの新しいOracle OLAPキューブの定義」の説明に従って、予測の結果を含むキューブを作成します。
|
注意: Oracle Airlines Data Modelの予測キューブのマテリアライズド・ビューは有効にできません。 |
『Oracle OLAP DMLリファレンス』の説明に従って、OLAP DML予測コンテキスト・プログラムを作成します。
パーティション化は物理的にキューブの内容を格納する方法です。これによって、大きいキューブのパフォーマンスが次のように向上します。
データ構造をコンパクトに保つことで、スケーラビリティが向上します。各パーティションは、小さなメジャーのように機能します。
関連するデータはまとめて格納されるため、問合せまたはメンテナンスの際に対象となるデータセットが小さくて済みます。
データ・メンテナンス時のパラレル集計が可能になります。各パーティションを別々のプロセスで集計できます。
記憶域上の古いデータの削除が容易になります。古いパーティションを削除し、新しいパーティションを追加できます。
パーティションの数は、キューブへのデータのロードやデータの集計に割当て可能なデータベース・リソースに影響します。十分なリソースが割り当てられていれば、複数のパーティションを同時に集計できます。
ソース表の分析とパーティション化方法の決定は、キューブ・パーティショニング・アドバイザによって行われます。キューブ・パーティショニング・アドバイザの推奨する方法を採用できますが、ユーザー独自のパーティション化方法を決めることもできます。
パーティション化戦略が主にライフサイクル管理を考慮して作成される場合は、時間ディメンションでキューブをパーティション化する必要があります。こうすれば、古い期間をまとめて削除し、新しい期間を新しいパーティションに追加できます。キューブ・パーティショニング・アドバイザの時間オプションを選択すると、Timeディメンションの階層とレベルをパーティション化に使用するよう推奨されます。
キューブをパーティション化するレベルは、ロード・パフォーマンスと問合せパフォーマンスのトレードオフに基づいて決定されます。
通常、非常に低いレベル(たとえば、時間ディメンションの日レベルなど)ではパーティション化しません。実行すると、非常に多くのパーティションをロード時に定義する必要があり、初期ロードまたは履歴ロードの速度が低下するためです。また、多数のパーティションの結果、アナリティック・ワークスペース接続時間が異常に長くなり、時系列ベースの計算の速度が低下する場合があります。また、四半期累積メジャー(現在までの1四半期メジャー)は、90または91のパーティションにアクセスして、1つの顧客および組織の特定の値を計算する必要があります。パーティション・ディメンションのパーティション・レベルより上位のすべてのディメンション・メンバー(デフォルト以外の階層に属するメンバーを含む)は、単一のデフォルトのテンプレートに存在します。すべての上位レベルのメンバーがデフォルトのテンプレートに格納されるため、日レベルのパーティション化は非常に重くなります。ただし、OLAPキューブ・ロード頻度が日単位の場合のDAYのパーティション化の利点は、毎日ファクト表の新しいパーティションからOLAPキューブの単一のパーティションにロードするだけで済むことです。これにより、キューブがマテリアライズド・ビュー対応でマテリアライズド・ビュー・ログを含む場合に割合ベースのリフレッシュを有効にできるので、ロード・パフォーマンスが大幅に向上します。
推奨: キューブ・パーティション化戦略
通常、異なるロードと問合せパフォーマンス要件の適切な妥協案として、パーティション・レベルとしてMONTHなどの中間レベルを使用します。月内の時系列計算(現在までの週、現在までの月など)は高速で、現在までの年などの上位レベルの計算は最大で12のパーティションを参照する必要があります。また、このように、月単位のパーティションが各月の最初の初期ロード中に一度だけ定義および作成され、その月の後続のロードのたびに再使用されます。集計プロセスが特定の日レベルのかわりに月レベルでトリガーされ、現在の月の以前にロードした日の余分な集計が毎回発生する可能性がありますが、結果は正常なロードおよび問合せパフォーマンスになります。
|
関連項目: パーティション戦略の選択の説明は、『Oracle OLAPユーザーズ・ガイド』、「Oracle Airlines Data Modelの索引とパーティション索引」および「パーティション化とマテリアライズド・ビュー」を参照してください。 |
データの次元モデルの開発中に、オブジェクト定義またはマッピングのエラーをすぐに検出して修正するため、作成後すぐに各オブジェクトをマップおよびロードすることをお薦めします。
ただし、本番環境では、できるだけ簡単で時間もかからない定期的なメンテナンスが必要です。このような場合は、データのメンテナンス方法を選択できます。キューブはメンテナンス・ウィザードを使用してリフレッシュできます。このウィザードでは、キューブを即時にリフレッシュするか、リフレッシュ処理をジョブとしてOracleジョブ・キューに送るか、またはPL/SQLスクリプトを生成します。スクリプトは手動で実行する以外にも、Oracle Enterprise Managerのスケジューラや、PL/SQLパッケージのDBMS_SCHEDULERなどのスケジューリング・ユーティリティを使用することもできます。生成したスクリプトによって、PL/SQLパッケージのDBMS_CUBEのBUILDプロシージャがコールされます。このスクリプトを編集したり、このパッケージを使用してスクリプトを始めから作成することができます。
複数のプロセスが作成処理に割り当てられている場合、パーティション化されたキューブのデータはパラレルにロードおよび集計されます。この結果は作成ログで確認できます。
さらに、それぞれのキューブに対して次のデータ・メンテナンス方法を使用できます。
カスタム・キューブ・スクリプト
キューブ・マテリアライズド・ビュー
既存のマテリアライズド・ビューをキューブに置き換えるように定義した場合は、必ずマテリアライズド・ビューを使用してデータ・メンテナンスを行います。ただし、マテリアライズド・ビュー機能を有効にすると、カスタム・キューブ・スクリプトで実行できる分析の種類が制限されます。
|
Oracle By Example: リレーショナル・スター・スキーマへの透過的なアクセスに対してキューブ・マテリアライズド・ビューを使用する方法の例は、次のOBEチュートリアルを参照してください。
チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
マテリアライズド・ビューは、スキーマ・オブジェクトとして事前に格納またはマテリアライズされた問合せ結果です。物理設計の観点からすると、マテリアライズド・ビューは表やパーティション表に似ており、透過的に使用されパフォーマンスが向上するという点で、索引のような動作をします。
以前は、サマリーを使用する場合、手動でのサマリーの作成、どのサマリーを作成するかの識別、サマリーへの索引付け、サマリーの更新、およびユーザーに対するサマリーのアドバイスに膨大な時間と労力を費やしていました。マテリアライズド・ビューの導入で、データベース管理者はサマリーと同等の1つ以上のマテリアライズド・ビューを作成します。そのため、データベース管理者の作業負荷が軽減され、ユーザーはどのサマリーが定義されているかを把握する必要がなくなっています。かわりに、エンド・ユーザーは、表やビューをディテール・データ・レベルで問い合せます。Oracleサーバーのクエリー・リライト・メカニズムにより、サマリー・テーブルを使用するようにSQL問合せが自動的にリライトされ、問合せから結果を戻すレスポンス時間が短縮されます。
マテリアライズド・ビューは、問合せを実行する前にコストの高い結合および集計操作をデータベース上で事前に計算し、その結果をデータベースに格納することで、問合せのパフォーマンスを改善します。問合せオプティマイザでは、問合せの要求を満たすのに既存のマテリアライズド・ビューが使用可能かどうか、また必要かどうかが自動的に認識されます。
デフォルトのOracle Airlines Data Modelは、マテリアライズド・ビューを定義します。デフォルトのoadm_sysスキーマでは、次の表にリストされている接頭辞を使用したオブジェクトを参照して、これらのマテリアライズド・ビューを識別できます。
| 接頭辞 | 説明 |
|---|---|
CB$ |
マテリアライズド・ビュー機能で拡張されるOLAPキューブ。
参照: デフォルトのデータ・モデルのこれらのオブジェクトのリストは、『Oracle Airlines Data Modelリファレンス』のOLAPキューブ・マテリアライズド・ビューを参照してください。 OLAPキューブの詳細は、「Oracle Airlines Data ModelのOLAPキューブの特性」を参照してください。 注意: これらのオブジェクトのレポートまたは問合せを実行 |
DMV_ |
データ・マイニング・ソース・マテリアライズド・ビュー。
参照: デフォルトのデータ・モデルのこれらのオブジェクトを確認するには、『Oracle Airlines Data Modelリファレンス』を参照してください。 |
次のトピックで、カスタマイズしたOracle Airlines Data Modelのマテリアライズド・ビューの使用および作成の詳細を説明します。
リフレッシュ・オプションは、マテリアライズド・ビューのタイプごとに異なります。
|
参照: Oracle OLAPキューブのマテリアライズド・ビューの作成の詳細は、『Oracle OLAPユーザーズ・ガイド』を参照してください。 |
データ・ウェアハウスで、通常マテリアライズド・ビューは集計を含みます。デフォルトのOracle Airlines Data Modelの_DWA表は、このタイプのマテリアライズド・ビューです。
集計を含むマテリアライズド・ビューで、高速のリフレッシュが可能です。
SELECTリストは、すべてのGROUP BY列(存在する場合)を含む必要があります。
集計列にCOUNT(*)およびCOUNT(column)が必要です。
マテリアライズド・ビュー・ログは、マテリアライズド・ビューを定義する問合せで参照されるすべての表に関して存在する必要があります。有効な集計関数は、SUM、COUNT(x)、COUNT(*)、AVG、VARIANCE、STDDEV、MIN、MAXです。また、任意のSQL値式を集計できます。
結合と集計を含むマテリアライズド・ビューの高速リフレッシュは、実表に対してDML(ダイレクト・ロードまたは従来型のINSERT、UPDATEまたはDELETE)を実行した後に可能になります。
マテリアライズド・ビューをON COMMITまたはON DEMANDでリフレッシュするように定義できます。REFRESH ON COMMITを指定した場合は、マテリアライズド・ビューのディテール表に対してDMLを実行するトランザクションがコミットされると、マテリアライズド・ビューが自動的にリフレッシュされます。
REFRESH ON COMMITを指定すると、表のコミットに時間がかかる場合があります。これは、リフレッシュ操作がコミット・プロセスの一部として実行されるためです。したがって、この方法は、多数のユーザーがマテリアライズド・ビューの実表を同時に変更する場合には適していません。
マテリアライズド・ビューに結合のみが含まれ、集計は含まれません(たとえば、sales表をtimes表およびcustomers表に結合するマテリアライズド・ビューが作成される場合など)。このタイプのマテリアライズド・ビューを作成するメリットは、コストの高い結合が事前に計算されることです。
結合のみを含むマテリアライズド・ビューの高速リフレッシュは、実表に対してDML(ダイレクト・パスまたは従来型のINSERT、UPDATEまたはDELETE)を実行した後に可能になります。
結合のみを含むマテリアライズド・ビューは、ON COMMITまたはON DEMANDでリフレッシュされるように定義できます。ON COMMITの場合、リフレッシュは、マテリアライズド・ビューにある1つのディテール表上でDMLを実行するトランザクションのコミット時に実行されます。
REFRESH FASTを指定する場合、Oracleは、問合せ定義をさらに検証して、いずれかのディテール表が変更された場合の高速リフレッシュの実行を保証します。これらの追加チェックには、次の制限が含まれます。
表がパーティション・チェンジ・トラッキングをサポートしないかぎり、マテリアライズド・ビュー・ログがディテール表ごとに存在する必要があります。また、マテリアライズド・ビュー・ログが必須の場合は、ROWID列が各マテリアライズド・ビュー・ログに存在していること。
すべてのディテール表のROWIDが、マテリアライズド・ビュー問合せ定義のSELECT構文のリストにあること。
これらの制限で満たされないものがある場合は、マテリアライズド・ビューをREFRESH FORCEとして作成し、可能なときに高速リフレッシュの効果を得ることができます。表がすべての基準を満たさなくても、他の表がすべての基準を満たしている場合は、すべての基準が満たされている他の表に関しては、マテリアライズド・ビューを高速リフレッシュできます。
最適で効率的なリフレッシュを実行する手順は、次のとおりです。
定義問合せに内部結合のように動作する外部結合が使用されていないことを確認します。このような結合が定義問合せに含まれている場合は、内部結合を使用するように定義問合せをリライトすることを検討してください。
マテリアライズド・ビューに含まれているのが結合のみである場合は、各表のROWID列(およびFROM句のリストに複数回指定されている表)を、マテリアライズド・ビューのSELECT構文のリストに指定する必要があります。
マテリアライズド・ビューのFROM句にリモート表が指定されている場合、そのFROM句の表はすべて同じサイトに配置されている必要があります。また、リモート表を含むマテリアライズド・ビューでは、ON COMMITによるリフレッシュはサポートされません。SCNベースのマテリアライズド・ビュー・ログを除き、マテリアライズド・ビューの各ディテール表のマテリアライズド・ビュー・ログはリモート・サイトに作成されている必要があり、ROWID列は、マテリアライズド・ビューのSELECT構文のリストに指定されている必要があります。
ネステッド・マテリアライズド・ビューとは、その定義が別のマテリアライズド・ビューに基づいているマテリアライズド・ビューです。ネステッド・マテリアライズド・ビューは、マテリアライズド・ビューの他に、データベース内の他のリレーションも参照する場合があります。
データ・ウェアハウスでは、通常、単一の結合上に多数の集計ビュー(たとえば、異なるディメンションに沿ったロールアップ)を作成します。これらの個別の結合と集計を含むマテリアライズド・ビューに対する増分メンテナンスは、ベースとなる結合が何度も実行される必要があるため、かなりの時間がかかります。
ネステッド・マテリアライズド・ビューを使用すると、結合のみを含む1つのマテリアライズド・ビューに基づいて複数の単一表マテリアライズド・ビューを作成できます。さらに、この種類の単一表集計マテリアライズド・ビューには最適化が実行され、リフレッシュが非常に効率的になります。
ネステッド・マテリアライズド・ビューの中には、高速リフレッシュできないタイプがあります。このようなタイプのマテリアライズド・ビューを特定するには、EXPLAIN_MVIEWを使用します。
DBMS_MVIEW.REFRESHパラメータとともにnested =TRUEパラメータを指定すると、適切な依存順序でネステッド・マテリアライズド・ビューのツリーをリフレッシュできます。
マテリアライズド・ビューに対して行う最も一般的な操作は、問合せの実行および高速リフレッシュですが、各操作には、異なるパフォーマンス要件があります。
問合せの実行では、マテリアライズド・ビュー・キー列のすべてのサブセットがアクセスされる必要があり、これらの列のサブセット上で結合および集計が行われる必要がある場合があります。したがって、最適なパフォーマンスには、各マテリアライズド・ビュー・キー列上に単一列のビットマップ索引を作成します。
結合のみを含むマテリアライズド・ビューに高速リフレッシュ・オプションを使用する場合は、ROWIDを含む列上に索引を作成して、リフレッシュ操作のパフォーマンスを向上させます。
集計を使用するマテリアライズド・ビューが高速リフレッシュ可能な場合は、CREATE MATERIALIZED VIEW文にUSING NO INDEXが指定されていないかぎり、高速リフレッシュ・プロシージャに適切な索引が作成されます。
データ・ウェアハウスに格納されているデータの量は膨大であるため、パーティション化は、データベースの設計時に非常に有効なオプションです。ファクト表のパーティション化によって、スケーラビリティの向上とシステム管理の簡素化を実現できます。また、効率的に再作成できるローカル索引を定義できるようになります。ファクト表をパーティション化することにより、マテリアライズド・ビューに対するパーティション・チェンジ・トラッキング・リフレッシュが可能になるので、マテリアライズド・ビューを高速リフレッシュできる可能性も高くなります。
マテリアライズド・ビューのパーティション化は、ファクト表のパーティション化と同じ利点があります。マテリアライズド・ビューがパーティション化されると、リフレッシュ・プロシージャは、より多くの場合にパラレルDMLを使用でき、パーティション・チェンジ・トラッキング・ベースのリフレッシュは、パーティションの切捨てを使用してマテリアライズド・ビューを効率的にメンテナンスできるようになります。
|
関連項目: 『Oracle Database VLDBおよびパーティショニング・ガイド』、「Oracle Airlines Data Modelのパーティション表」、「Oracle Airlines Data Model内の索引およびパーティション化された索引」および「Oracle Airlines Data Modelのキューブ・パーティション化戦略の選択」 |
パーティション・チェンジ・トラッキングの使用
最新の状態かどうかの追跡対象を、マテリアライズド・ビュー全体ではなく、より細かく限定でき、それによるメリットが得られます。特定のディテール表のパーティションによる影響を受けるマテリアライズド・ビュー内の行を識別する機能は、パーティション・チェンジ・トラッキングと呼ばれます。1つ以上のディテール表がパーティション化されている場合は、マテリアライズド・ビュー内で、変更されたディテール・パーティションに対応する特定の行を識別できます。これらの行はパーティションが変更されると失効しますが、他のすべての行は最新のままです。
パーティション・チェンジ・トラッキングを使用すると、特定のパーティションに対応するマテリアライズド・ビューの行を識別できます。パーティション・チェンジ・トラッキングは、ディテール表に対するパーティション・メンテナンス操作後の高速リフレッシュのサポートにも使用されます。たとえば、ディテール表のパーティションが切り捨てられるか削除されると、マテリアライズド・ビュー内で影響を受ける行が識別され、削除されます。QUERY_REWRITE_INTEGRITY = ENFORCEDまたはTRUSTEDモードのときは、マテリアライズド・ビュー全体を失効とみなすのではなく、マテリアライズド・ビューの行のうち最新のものと失効しているものが識別され、リフレッシュされる行をクエリー・リライトで使用できるようになります。
DBA_MVIEW_DETAIL_PARTITIONなどの一部のビューでは、どのパーティションが失効しているかまたは最新なのかが具体的に示されます。マテリアライズド・ビューに結合依存の式があることによって、変更対象の表のパーティション・チェンジ・トラッキングが使用可能になる場合は、部分的に失効しているマテリアライズド・ビューへのリライトは行われません。
パーティション・チェンジ・トラッキングをサポートするには、マテリアライズド・ビューが次の要件を満たしている必要があります。
マテリアライズド・ビューで参照される1つ以上のディテール表が、パーティション化されている必要があります。
パーティション表には、レンジ、リストまたはコンポジットのいずれかのパーティション化を使用する必要があります。
最上位レベルのパーティション・キーは、単一列のみで構成する必要があります。
マテリアライズド・ビューには、ディテール表のパーティション・キー列、パーティション・マーカー、ROWIDまたは結合依存の式のいずれかを含める必要があります。
GROUP BY句を使用する場合は、パーティション・キー列、パーティション・マーカー、ROWIDまたは結合依存の式をGROUP BY句に指定する必要があります。
分析ウィンドウ関数またはMODEL句を使用する場合は、パーティション・キー列、パーティション・マーカー、ROWIDまたは結合依存の式を、それぞれのPARTITION BY副次句に指定する必要があります。
データ修正の発生が可能なのは、パーティション表のみです。マテリアライズド・ビューに結合依存の式を含む表に対してパーティション・チェンジ・トラッキング・リフレッシュを実行する際は、いずれの結合依存の表についても、データ修正が発生しないようにしてください。
COMPATIBILITY初期化パラメータは9.0.0.0.0以上に設定する必要があります。
パーティション・チェンジ・トラッキングは、ビュー、リモート表または外部結合を参照するマテリアライズド・ビューのためにサポートされていません。