| Oracle® Airlines Data Model実装およびオペレーション・ガイド 11gリリース2 (11.2) B72456-01 |
|


 前 |
 次 |
この章では、Oracle Airlines Data Modelの物理データ・モデルのカスタマイズの一般情報および物理モデルの基盤レイヤーのカスタマイズの詳細情報について説明します。この章では、次の項目について説明します。
Oracle Airlines Data Modelのデフォルト物理データ・モデルは、おおよそ次のように定義されます。
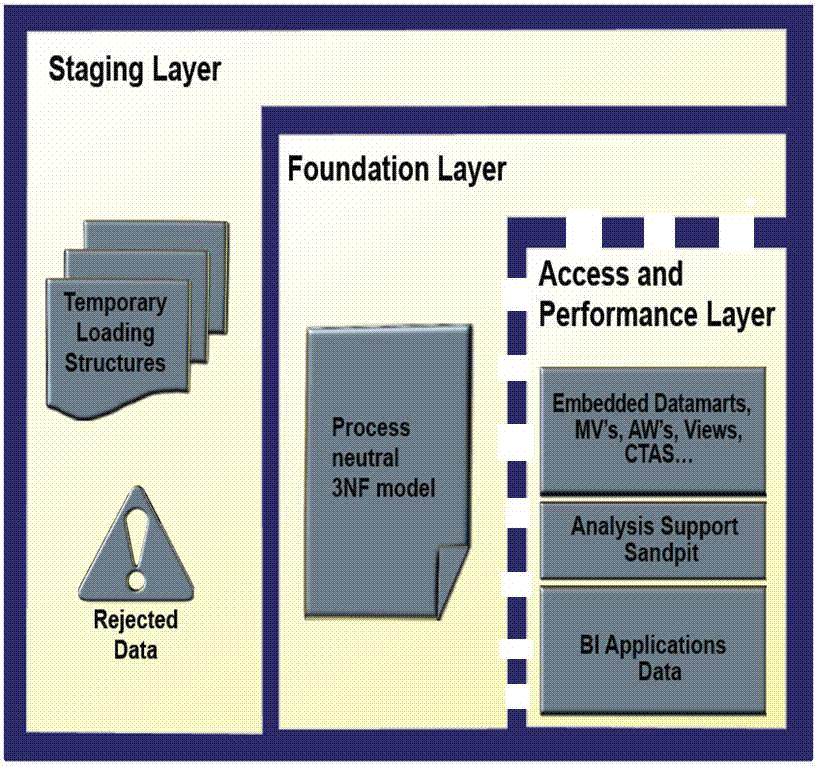
Oracle Airlines Data Modelのデフォルトの物理モデルは、「従来のデータ・ウェアハウスのレイヤー」に示されているようにマルチスキーマの従来のデータ・ウェアハウスの特性を共有しますが、「デフォルトのOracle Airlines Data Modelウェアハウスのレイヤー」に示されているように単一のスキーマのすべてのデータ構造を定義します。
従来のデータ・ウェアハウスのレイヤー
以前から、データ・ウェアハウス環境に3つのレイヤーが定義されます。
ステージング・レイヤー。OLTPシステムおよび他のデータ・ソースからデータ・ウェアハウス自体にデータを移動する場合、このレイヤーを使用します。一時的なロード構造および拒否されたデータで構成されます。ステージング・レイヤーを使用すると、ビジネス・ユーザーに影響を与えることなくオペレーティング・システムからデータ・ウェアハウスへのデータの迅速な抽出、変換およびロード(ETL)を実行できます。このレイヤーで、ほとんどの複雑なデータ変換およびデータ品質処理が発生します。ステージング・レイヤーの設計の最も基本的なアプローチは、ソース・オペレーティング・システムに存在するスキーマと同じスキーマを使用することです。
|
注意: 基盤レイヤーに直接挿入される前にデータがソース・システムから抽出され、すべてのデータ変換処理が即座に実行されるため、一部の実装でこのレイヤーは必要ありません。 |
基盤レイヤーまたは統合レイヤー。このレイヤーは、以前から第3正規形(3NF)スキーマとして実装されています。3NFスキーマは、アプリケーションとは独立した中立的なスキーマ設計で、通常多数の表があります。データの冗長性なしで各トランザクションの詳細なレコードを保存し、属性およびデータ要素間のすべてのリレーションシップの豊富なエンコーディングを使用できます。通常、ユーザーは、データを確実に理解して、詳細な構造を確実に操作する必要があります。このレイヤーでは、データの具体化が開始されますが、アクセスおよびパフォーマンス・レイヤーに変換される前にデータが使用可能になるので、特に時間に依存する場合にエンドユーザー・アプリケーションでこのレイヤーのデータにアクセスすることは珍しくありません。
アクセス・レイヤー。このレイヤーは、データのフラット化されたビューまたは次元ビューを示すスノーフレークまたはスター・スキーマとして以前から定義されています。
デフォルトのOracle Airlines Data Modelウェアハウスのレイヤー
Oracle Airlines Data Modelウェアハウス環境も3つのレイヤーから構成されます。ただし、図2-1「Oracle Airlines Data Modelウェアハウスのレイヤー」に点線で示されているように、Oracle Airlines Data Modelでは、基盤レイヤーおよびアクセス・レイヤーの定義は、単一のスキーマに結合されます。
Oracle Airlines Data Modelウェアハウスのレイヤーは、次のとおりです。
ステージング・レイヤー。従来のデータ・ウェアハウス環境のように、Oracle Airlines Data Modelウェアハウス環境でステージング・レイヤーを使用できます。このレイヤーの定義は顧客ごとに異なるため、この領域の定義はOracle Airlines Data Modelの一部として提供されません。
基盤レイヤーおよびアクセス・レイヤー。これらのレイヤーの物理オブジェクトは、単一のスキーマのoadm_sysスキーマに定義されます。
基盤レイヤー。Oracle Airlines Data Modelの基盤レイヤーは、3NF(つまり、DWB_接頭辞を持つ表)でデータを表示する実表で定義されます。このレイヤーには、oadm_sysスキーマ(つまり、DWR_、DWL_、DWC_接頭辞を持つ表)で定義される参照表、検索表および制御表も含まれます。
アクセス・レイヤー。Oracle Airlines Data Modelのアクセス・レイヤーは、ディメンション表(DWM_接頭辞を使用して定義されます)、導出表および集計表(DWD_およびDWA_接頭辞を使用して定義されます)、キューブ(CB$接頭辞を使用して定義されます)およびビュー(_VIEW接尾辞を使用して定義されるビュー)で定義されます。これらの構造は、基盤レイヤーのデータの要約またはフラット化された視点を示します。
このレイヤーは、導出表(DWD_)に格納されるデータ・マイニング・モデルの結果も含みます。
|
参照: oadm_sysスキーマの詳細は、『Oracle Airlines Data Modelリファレンス』を参照してください。 |
Oracle Airlines Data Model物理データ・モデルの開始点は、3NF論理データ・モデルです。物理データ・モデルは、論理モデルをできるだけミラー化し、(ただし、表または列の構造の変更が必要になる場合があります)データベース・オブジェクト(表、キューブ、ビューなど)を定義します。
Oracle Airlines Data Modelのデフォルトの物理モデルをカスタマイズするには、次の手順に従います。
「物理モデルをカスタマイズする前に答える質問」に記載されている質問に答えます。
「デフォルトの物理モデルの特性」に記載され、詳細が『Oracle Airlines Data Modelリファレンス』に示されているOracle Airlines Data Modelの論理および物理モデルの特性についてよく理解します。
必要に応じて、Oracle Airlines Data Modelの物理モデルのFoundationレベルを変更します。カスタマイズがいつ必要になるかについての説明は、「Oracle Airlines Data Modelの基盤レイヤーをカスタマイズする際の一般的な変更シナリオ」を参照してください。
物理構造を定義する場合:
3NF形式の基盤レイヤーを保持します。
「物理構造を設計する場合の一般的な推奨事項」の情報を使用して、物理オブジェクトを設計する場合を説明します。
「物理モデルをカスタマイズする場合の規則」に記載されているOracle Airlines Data Modelのデフォルトの物理モデルを作成する場合に使用する規則に従います。
|
ヒント: oadm_sysスキーマへのパッチとして物理データ・モデルに行う変更をパッケージ化します。 |
第3章「アクセス・レイヤーのカスタマイズ」の説明に従って、Oracle Airlines Data Modelの物理モデルのアクセス・レイヤーを変更します。
物理モデルを設計する場合、論理データ・モデルが物理データ・モデルと1対1ではないことに注意してください。論理データ・モデルを物理レイヤーに変換する場合、ロード、問合せおよびメンテナンス要件を検討します。たとえば、物理データ・モデルを設計する前に、次の質問に答えます。
論理データ・モデルの全範囲または範囲の一部のみを含む物理データ・モデルが必要ですか。
「Oracle Airlines Data Modelの基盤レイヤーをカスタマイズする際の一般的な変更シナリオ」では、ビジネス・ニーズがOracle Airlines Data Model論理モデルと同じ論理モデルにならない場合の物理データ・モデルの変更の概要を説明します。
ソース・データ・プロファイルの結果は何ですか。
各表のデータ・ロード頻度は何ですか。
どれだけ大きい表がありますか、それはどの表ですか。
どうすれば表と列にアクセスできますか。共通結合は何ですか。
データ・バックアップ戦略は何ですか。
Oracle Airlines Data Modelの物理モデルを開発する場合、次に示すような規則に従いました。物理モデルをカスタマイズする場合、継続してこれらの規則に従います。
定義する物理オブジェクトの名前を付けるには、次のガイドラインに従います。
物理オブジェクトの名前を付ける場合、Oracle Databaseスキーマ内のオブジェクトの名前を付けるネーミング・ガイドラインに従います。次に例を示します。
表および列の名前は文字で始める必要があり、30文字以下の英数字のみで使用できます。スペースや"!"などの一部の特殊文字および予約語は使用できません。
表名は、ビューおよびシノニムで共有するスキーマ内で一意である必要があります。
列名は、表内で一意である必要があります。
物理モデリング・ステージで略称を使用することが一般的ですが、論理モデルのエンティティ名に対応する物理オブジェクトの名前をできるだけ使用します。プログラマおよびユーザーの混乱を避けるため、一貫性のある略称を使用します。
列の名前を付ける場合、可能であればショート名を使用します。列のショート名は、SQLコマンド解析に必要な時間を削減します。
Oracle Airlines Data Modelで提供されるoadm_sysスキーマは、次の表に示されている接頭辞および接尾辞を使用して、オブジェクト・タイプを識別します。
| プリフィクスまたはサフィックス | 次のオブジェクトの名前に使用 |
|---|---|
CB$ |
OLAPキューブのマテリアライズド・ビュー。このマテリアライズド・ビューは、OLAPサーバーによって自動的に作成されます。
注意: このオブジェクトのレポートまたは問合せを実行しないでください。かわりに、対応する |
DMV_ |
データ・マイニング・モデルのソース・データとして使用されるマテリアライズド・ビュー |
DWA_ |
集計表。 |
DWB_ |
ベース・トランザクション・データ(3NF)表。 |
DWC_ |
制御表。 |
DWD_ |
導出表 -- データ・マイニング結果表を含む。 |
DWL_ |
検索表。 |
DWM_ |
アクセス・レイヤーのファクト表内のディメンション表(つまり、DWD_またはDWA_)。 |
DWV_ |
時間ディメンションのリレーショナル・ビュー。 |
DWR_ |
基盤レイヤーのファクト表内でディメンション表として使用される参照データ表(つまり、DWB_表)。 |
_H |
特定のエンティティの最新データおよび履歴データの両方を格納するために使用される従来のデータ・ウェアハウス表。(「履歴(_H)表の使用」を参照してください。) |
_VIEW |
OLAPキューブ、ディメンションまたは階層のリレーショナル・ビュー。 |
定義する新しい表、ビューおよびキューブに対して、これらの接頭辞および接尾辞を使用します。
|
参照: デフォルトOracle Airlines Data Modelのオブジェクトの詳細は、『Oracle Airlines Data Modelリファレンス』を参照してください。 |
デフォルトOracle Airlines Data Modelの物理データ・モデルは、Operational Data Store (ODS)およびデータ・ウェアハウスの両方として機能するように設計されました。この二重の機能をサポートするために、論理エンティティが2つの異なる物理表タイプとして実装されています。
tablename_H表は従来のデータ・ウェアハウス表です。これらの表は、エンティティの最新データおよび履歴データの両方を格納するために設計されています。これらは、アクセス・レイヤー・オブジェクト(つまり、導出表、集計表およびOLAPキューブ)のデータを提供する表です。_H表に新規データが移入される場合、データは表に追加され、データは上書きされることはありません。
tablename表は、ODS表です。これらの表は、エンティティの最新データのみを格納するように設計されています。これらは、リアルタイム(または、ほぼリアルタイム)の問合せを行う際にアプリケーションによってアクセスされる表です。これらの表に新規データが移入される場合、新規データによって表内の既存のデータは上書きされます。
たとえば、論理エンティティであるサービスを表す物理表を調べると、DWR_SERVICEとDWR_SERVICE_Hの2つの表があります。DWR_SERVICE表の機能は、最新データを保持することであり、一方、DWR_SERVICE_Hの機能は、最新データと履歴データの両方を保持することです。
ドメインは、列に使用できる一連の値です。データベースに加えて外部キー、チェック制約またはアプリケーションでドメインを適用できます。モデル間の各ドメインの次のような規格を定義します。
'YYYY-MM-DD'などの日時タイプ。
様々な状況の数値。
様々な状況の文字列の長さ。
キーや説明などのコード値定義。
Oracle Airlines Data Modelの物理モデルのカスタマイズの最初の手順は、物理データ・モデルの基盤レイヤーのカスタマイズです。「デフォルトのOracle Airlines Data Modelウェアハウスのレイヤー」で示されているように、物理モデルの基盤レイヤーはOracle Airlines Data Modelの3NF論理モデルをミラー化するので、論理モデル・ニーズとOracle Airlines Data Modelのデフォルトの論理モデルの違いを反映するため、基盤レイヤーのカスタマイズを選択できます。また、パフォーマンスを向上するには、基盤レイヤーの物理オブジェクトのカスタマイズが必要な場合があります(たとえば、一部の基盤レイヤー表の圧縮を選択する場合があります)。
基盤レイヤーに変更を加える場合、次の点に注意してください。
基盤レイヤー・オブジェクトを変更して論理モデル設計を反映する場合、できるだけ変更は少なくします。「Oracle Airlines Data Modelの基盤レイヤーをカスタマイズする際の一般的な変更シナリオ」は、これに関連して行う最も一般的なカスタマイズ変更の概要を説明しています。
新しい基盤レイヤーを定義する場合またはパフォーマンスの向上のために既存の基盤レイヤー・オブジェクトを再設計する場合、「物理構造を設計する場合の一般的な推奨事項」および「物理モデルをカスタマイズする場合の規則」に従います。
基盤レイヤー・オブジェクトの変更は、アクセス・レイヤー・オブジェクトにも影響する場合があります。
|
注意: Oracle Airlines Data Modelを慎重に変更してください。Oracle Airlines Data Modelの物理モデルの基盤レイヤーは、柔軟性および拡張性を実現する一連の汎用構造が中心にあります。広範囲の追加、削除または変更を行う前に、Oracle Airlines Data Modelのすべての機能を理解し、基盤レイヤーのデフォルトのオブジェクトを使用して要件を処理できないことを確認します。 |
物理データ・モデルの基盤レイヤーをカスタマイズする場合、複数の一般的な変更シナリオがあります。
既存の構造への追加
Oracle Airlines Data Modelの物理データ・モデルのデフォルトの基盤レイヤーでサポートされていないビジネス・エリアまたはプロセスを確認する場合、新しい表および列を追加します。
追加を行う場合の冗長構造の作成を回避するには、Oracle Airlines Data Modelの物理データ・モデルのデフォルトの基盤レイヤー(および基礎となる論理データ・モデル)を慎重に調査します。これらの追加でビジネス価値に高い付加価値が得られる場合、今後リリースされるOracle Airlines Data Modelへの追加を検討するため、Oracle Airlines Data Model開発チームに追加内容を通知します。
既存の構造の削除
レガシー・システムのビジネス要件と一致しないモデルの領域がある場合、これらの構造を保持してウェアハウスの該当する部分を移入しない方が安全です。
物理データ・モデルの基盤レイヤーの表を削除すると、モデルの他の部分に必要なリレーションシップまたはそれに基づくアプリケーションを破棄できます。初期実装中に一部の表が不要な場合がありますが、これらの構造を後で使用する可能性があります。この可能性がある場合、ここで構造を保持すると後の作業が少なくなります。表を削除する場合、完全な分析を実行してエンティティからのすべてのリレーションシップを確認します。
既存の構造への変更
状況によって、Oracle Airlines Data Modelの物理データ・モデルの基盤レイヤーの一部の構造は、使用される対応する構造と完全に一致しない場合があります。変更を実装する前に、変更によるOracle Airlines Data Modelのデータベース設計への影響を確認します。また、新しい設計に基づいたアプリケーションの影響を確認します。
たとえば、Oracle Airlines Data Modelが様々な航空サービスをどのようにサポートするか、サンプルの顧客がフィットギャップ分析中に何を検出するか、およびその顧客が検出されたギャップに合せてOracle Airlines Data Modelをどのように拡張するかを見てみましょう。
航空会社サービスをサポートするエンティティ
航空会社サービスをサポートするOracle Airlines Data Modelの論理モデルに提供されているエンティティは、次のとおりです。
AIRPORT: 空港(AIRPORT)とは、1つ以上のフライトの出発地または到着地として機能する、IATAによって認識されている場所を指します。このエンティティには、空港のある都市、国、地域など、空港の詳細が格納されます。
FLIGHT: このエンティティには、フライトの情報(所属する航空会社、フライト番号など)が格納されます。
AIRCRAFT: このエンティティには、航空機のタイプが格納されます(例: ボーイング737)。
AIRCRAFT VERSION: このエンティティには、フライトに使用される航空機バージョンの詳細が格納されます。たとえば、航空機タイプがボーイング737の場合、バージョンはボーイング737-800です。
CARRIER: このエンティティには、航空会社の詳細(航空会社コード、説明など)が格納されます。
CARRIER TYPE: このエンティティには、航空会社タイプの詳細(航空路線、鉄道、道路輸送、船便など)が格納されます。
フィットギャップ分析中に検出された差異
フィットギャップ分析中に、Oracle Airlines Data Modelで提供されている論理モデルではサポートされない次のニーズが検出されたとします。
ある会社は、航空分野において複数のサービスを提供しています。言い換えると、その会社では、Oracle Airlines Data Modelの標準論理モデルで表される空港を追跡するだけではなく、空港アクティビティのカテゴリ(つまり、空港カテゴリ)別に空港を定義する必要もあります。たとえば、これらの空港カテゴリは、商業サービス空港、主要空港、貨物サービス空港、救援空港、一般航空空港などです。
航空業務において、航空会社は、様々なサービスを運用するために使用する空港カテゴリ(商業、貨物、救援または一般空港など)の履歴を管理する必要があります。
差異をサポートするための論理および物理モデルの拡張
差異をサポートするには、次の方法で論理および物理モデルを拡張する必要があります。
空港カテゴリの詳細を格納するには、論理モデルを変更する必要があります。これを行う従来の方法は、この情報を保持する別のエンティティを追加することです。たとえば、AIRPORTエンティティと1:M関係を持つAIRPORT CATEGORYという名前のエンティティを追加できます。次に、対応する方法で物理データ・モデルを拡張します。物理モデルを拡張する手順の詳細は、例2-1「Oracle Airlines Data Modelの物理データ・モデルの拡張による複数のAIRPORTカテゴリのサポート」に示されています。
各空港カテゴリから行われる航空業務の履歴を管理するには、対応する区間エンティティのフライト・スケジュールとAIRPORTエンティティ間の既存の関係に基づいて同じものを見つけられます。
例2-1 Oracle Airlines Data Modelの物理データ・モデルの拡張による複数のAIRPORTカテゴリのサポート
Oracle Airlines Data Modelの基盤レイヤーの設計を拡張し、複数のAIRPORTカテゴリをサポートするには、次の手順を実行します。
次の文を実行して、空港の複数カテゴリ情報を保持するためのDWL_ARPRT_CTGRSという名前の新しい表を作成します。
CREATE TABLE DWL_ARPRT_CTGRS
(
ARPRT_CTGRS_ID INTEGER NOT NULL ,
ARPRT_CTGRS_NM VARCHAR2(50) NULL ,
ARPRT_CTGRS_DESC VARCHAR2(500) NULL ,
ARPRT_CTGRS_CD CHAR(18) NULL ,
DWFEED_ID INTEGER NULL ,
SRC_SYS_ID VARCHAR2(30) NULL ,
SRC_SYS_CRTD_TMSTMP TIMESTAMP NULL ,
SRC_SYS_UPD_TMSTMP TIMESTAMP NULL ,
SRC_SYS_DEL_IND VARCHAR2(1) NULL
);
ALTER TABLE DWL_ARPRT_CTGRS ADD CONSTRAINT XPKARPRT_CTGRS PRIMARY KEY (ARPRT_CTGRS_ID);
次の文を実行して、DWL_ARPRT_CTGRSの履歴情報を保持するDWL_ARPRT_CTGRS_Hという名前の新しい表を作成します。
CREATE TABLE DWL_ARPRT_CTGRS_H
(
ARPRT_CTGRS_ID INTEGER NOT NULL ,
ARPRT_CTGRS_NM VARCHAR2(50) NULL ,
ARPRT_CTGRS_DESC VARCHAR2(500) NULL ,
ARPRT_CTGRS_CD CHAR(18) NULL ,
DWFEED_ID INTEGER NULL ,
SRC_SYS_ID VARCHAR2(30) NULL ,
SRC_SYS_CRTD_TMSTMP TIMESTAMP NULL ,
SRC_SYS_UPD_TMSTMP TIMESTAMP NULL ,
SRC_SYS_DEL_IND VARCHAR2(1) NULL ,
ETL_BATCH_ID INTEGER NULL ,
ETL_BATCH_CRTD_BY VARCHAR2(60) NULL ,
ETL_BATCH_CRTD_TMSTMP TIMESTAMP NULL ,
ETL_BATCH_UPD_BY VARCHAR2(60) NULL ,
ETL_BATCH_UPD_TMSTMP TIMESTAMP NULL ,
DATA_MVT_STS_CD VARCHAR2(25) NULL ,
VLD_FRM TIMESTAMP NULL ,
VLD_UPTO TIMESTAMP NULL ,
CURR_STS VARCHAR2(1) NULL ,
DWL_ARPRT_CTGRS_H_SKEY INTEGER NOT NULL
);
次の文を発行して、ARPRT_CTGRS_IDという名前の列をDWR_AIP表に追加します。
ALTER TABLE DWR_AIP ADD COLUMN ARPRT_CTGRS_ID INTEGER NULL;
データ・アクセスおよびパフォーマンスのベスト・プラクティスに従って、Oracle Airlines Data Modelで提供されるoadm_sysスキーマが設計および定義されました。新しい物理オブジェクトを追加する場合、これらのプラクティスを引き続き使用します。この項では、次の物理設計の側面の決定がデフォルトのOracle Airlines Data Modelに行われた方法について説明します。
表領域は、使用中のオペレーティング・システム内の物理構造である1つ以上のデータファイルで構成されます。
推奨: 表領域の定義
可能であれば、論理的なビジネス・ユニットを表すため、表領域を定義します。
非常に大きいOracle Airlines Data Modelウェアハウスを大幅に改善するには、非常に大きいデータ・ファイルを使用します。
表で使用される表領域とパーティションの変更
Oracle Airlines Data Model表で使用する表領域およびパーティションを変更できます。行う作業は、Oracle Airlines Data Model表にパーティションがあるかどうかによって決まります。
パーティションのない表(つまり、検索表および参照表)の場合、表の既存の表領域を変更できます。
デフォルトでは、Oracle Airlines Data Modelはパーティション表を時間隔パーティションとして定義します。これは、新規データが到着したときのみパーティションが作成されることを意味します。
したがって、パーティションのあるOracle Airlines Data Model表(つまり、実表、導出表および集計表)で、現在の表領域ではなく新しい表領域に新しい時間隔パーティションを生成する場合は、次の文を発行します。
ALTER TABLE table_name MODIFY DEFAULT ATTRIBUTES TABLESPACE new_tablespace_name;
table_nameで指定された表に新規データが挿入されると、tablespace new_tablespace_nameで指定された表領域に新しいパーティションが自動的に作成されます。
パーティションのある表(つまり、実表、導出表および集計表)の場合は、新しい表領域に新しい時間隔パーティションが生成されることを指定できます。
パーティションのないOracle Airlines Data Model表(つまり、検索表と参照表)で、表の既存の表領域を変更するには、次の文を発行します。
ALTER TABLE table_name MOVE TABLESPACE new_tablespace_name;
実行する必要がある主な決定は、データを圧縮するかどうかです。表の圧縮を使用すると、ディスクおよびメモリーの使用率が削減され、多くの場合に読取り専用操作のスケールアップ・パフォーマンスが向上します。また、表の圧縮は、ディスクのデータの取得に必要なラウンド・トリップの数を最小化して、問合せ実行を高速化できます。ただし、データの圧縮は、データのロード速度でパフォーマンスが低下します。Oracle Airlines Data Modelの実表のほとんどは、圧縮された表です。
推奨: データの圧縮
通常、データの圧縮を選択します。通常、全体のパフォーマンスの改善は、圧縮のコストを上回ります。
圧縮を使用する場合、ロードして最適な圧縮率を達成する前に、データのソートを検討してください。受信データをソートする最も簡単な方法は、CTASまたはIAS文にORDER BY句を使用してロードします。多数の異なる値(1,000から10,000)を含むNOT NULL列(数値以外を推奨)のORDER BYを指定します。
Oracle Databaseは、次のタイプの圧縮を提供します。
標準の圧縮を使用する場合、Oracle Databaseは、データベース・ブロックの重複値を削除して、データを圧縮します。標準の圧縮は、ダイレクト・パス操作(CTASまたはIAS)にのみ有効です。あらゆる従来のDML操作(更新など)を使用してデータを変更する場合、変更を行うためにデータベース・ブロック内のデータの圧縮が解除され、圧縮されないでディスクに書き込まれます。
特にリレーショナル・データに設計された圧縮アルゴリズムを使用すると、圧縮表にアクセスするSQL問合せのパフォーマンスの低下がほとんど発生しない方法で、Oracle Databaseはデータを効果的に圧縮します。
Oracle Airlines Data Modelは、すべての実表、導出表および集計表に圧縮機能を利用します。これにより、格納されるデータ量とメモリー使用率が削減され(メモリー・ブロック当たりのデータが増えます)、問合せのパフォーマンスが向上します。
CREATE TABLE文のCOMPRESS句を使用して表の圧縮を指定するか、次に示すようにALTER TABLE文を使用して既存の表に対して圧縮を有効にできます。
alter table <tablename> move compress;
OLTP圧縮は、拡張圧縮オプションのコンポーネントです。OLTP圧縮を使用する場合、標準の圧縮と同じように、Oracle Databaseは、データベース・ブロックの重複値を削除して、データを圧縮します。ただし、標準の圧縮と異なり、OLTP圧縮は、INSERTおよびUPDATEなどの従来のDMLを含むすべてのタイプのデータ操作中にデータの圧縮を維持できます。
|
参照: OLTP表の圧縮機能の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
|
Oracle By Example: Oracle Advanced Compressionの詳細は、ストレージ・コストを節約する表圧縮の使用に関するOBEチュートリアルを参照してください。チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
HCCはストレージ形式で使用可能で、一連のHybrid Columnar圧縮行の格納に使用される圧縮ユニットと呼ばれる論理構成を使用して圧縮を実現します。データがロードされると、一連の行が列の表現にピボットされて圧縮されます。行のセットの列データが圧縮されると、圧縮ユニットに格納されます。従来のDMLがHCCを使用した表に発行されると、変更を行うために必要なデータの圧縮が解除され、ブロックレベルの圧縮アルゴリズムを使用してデータがディスクに書き込まれます。
|
ヒント: データ・セットが従来のDMLを使用して頻繁に変更される場合、HCCの使用は推奨しません。かわりに、OLTP圧縮の使用をお薦めします。 |
HCCは、問合せパフォーマンスまたは圧縮率に焦点を当てた様々なレベルの圧縮を提供します。問合せ用に最適化されたHCCを使用すると、少ない圧縮アルゴリズムがデータに適用され、パフォーマンスに影響をほとんど与えないで適切な圧縮を実現します。ただし、アーカイブ用の圧縮は、問合せパフォーマンスの潜在的な影響に関係なく、ディスクの圧縮の最適化を試行します。
|
関連項目: HCCの説明は、『Oracle Database概要ガイド』を参照してください。 |
スーパータイプは、1つ以上のサブタイプのリレーションシップを持つ汎用エンティティ・タイプです。
サブタイプは、組織にとってわかりやすく、他のサブグループと区別して一般的な属性またはリレーションシップを共有するエンティティ・タイプのエンティティのサブグループです。
サブタイプは、すべてのスーパータイプ属性を継承します。
サブタイプには、他のサブタイプと異なる属性があります。
たとえば、デフォルトのOracle Airlines Data Modelでは、表DWB_PRTY_INTRATN (パーティ・インタラクション)は、DWB_PRTY_INTRATN_CALL (パーティ・インタラクション - 電話)およびDWB_PRTY_INTRATN_EML (パーティ・インタラクション - 電子メール)を含む多くのサブタイプを持つスーパータイプです。
推奨: スーパータイプおよびサブタイプ・エンティティの表
次の理由のため、スーパータイプおよびすべてのサブタイプのエンティティの個別の表を作成します。
データベース・レベルで適用されるデータ整合性(NOT NULL列制約の使用)
リレーションシップを正確にモデル化して適用できます(1つのサブタイプのみに適用されるリレーションシップを含む)。
物理モデルは、論理データ・モデルと非常に似ています。
論理データ・モデルと物理データ・モデルを関係付けて、論理データ・モデルの拡張機能と変更をサポートすることが容易になります。
物理データ・モデルは、実際のビジネス・ルールを反映します(たとえば、1つのサブタイプのみに必要な属性またはリレーションシップが存在する場合など)。
主キーの作成のサロゲート・キー方法には、ソース・システムから自然キー・コンポーネントを取得し、一意のキー値を自然キー・コンポーネントの一意の各組合せに割り当てるプロセス(ソース・システム識別子を含む)でマップすることが含まれます。作成される主キー値は完全に非インテリジェントで、通常最大パフォーマンスおよびストレージ効率性のための数値のデータ型です。
サロゲート・キーのメリットは次のとおりです。
一意性の確認: データ分散
ソース・システムの独立
番号変更処理
重複する範囲
主キーおよび結合の最もパフォーマンスが高いデータ型の数値のデータ型の使用
サロゲート・キーのデメリットは次のとおりです。
ETL中の割当てが必要
再処理およびデータ品質修正が複雑で高負荷
パフォーマンスに影響するため、問合せでは使用不可
業務系ビジネス・インテリジェンスには、業務系システムに結合するための自然キーが必要
整合性制約は、データベースに関連したビジネス・ルールを規定し、表中の無効な情報を防止するために使用されます。最も一般的なタイプの制約は、次のとおりです。
通常サロゲート・キー列で定義され、レコード識別子の一意性を確認するPRIMARY KEY制約。通常、ENFORCED ENABLED RELYモードを指定することをお薦めします。
特定の列(または列のセット)が一意であることを確認するUNIQUE制約。緩やかに変化するディメンションの場合、ビジネス・キーおよび有効期間開始日の列の一意制約を追加して、同じビジネス・キー・レコードの複数のバージョン(サロゲート・キーに基づく)の追跡を許可することをお薦めします。
NULL値が許可されないことを確認するNOT NULL制約。クエリー・リライト・シナリオの場合、主キー制約の他に主キー列のインラインの明示的なNOT NULL制約を使用することをお薦めします。
表間の関係がデータで参照されることを確認するFOREIGN KEY制約。通常データ・ウェアハウス環境で、外部キー制約はRELY DISABLE NOVALIDATEノードにあります。
Oracle Databaseでは、SQL問合せを最適化するときに、制約が使用されます。制約は、問合せの最適化に多くの点で効果的ですが、マテリアライズド・ビューのクエリー・リライトに特に重要です。ある特定の状況では、制約はデータベースの領域を必要とします。このような制約は、基礎となる一意索引の形式になっています。
多くのリレーショナル・データベース環境とは異なり、データ・ウェアハウスのデータは通常、抽出、変換、ロード(ETL)プロセス中の、制御された状況下で追加または変更されます。
索引は、表またはクラスタに関連付けられたオプションの構造体です。データ・ウェアハウス環境では、従来のBツリー索引に加えて、ビットマップ索引がきわめて一般的です。
ビットマップ索引は、セット指向の操作に最適化された索引構造です。また、スター型変換など、最適化された一部のデータ・アクセス方法にも必要になります。通常、ビットマップ索引のサイズは、表内の索引付けされたデータの何分の1かの大きさで済みます。
Bツリー索引は、カーディナリティが高いデータ(顧客名や電話番号など、固有な値を多く持つデータ)に対して最も効果的です。ただし、大規模な表を従来のBツリー索引で完全に索引付けすると、索引が、表にあるデータの数倍の大きさになる場合があるため、ディスク領域の点で非常にコストが高くなります。Bツリー索引は、明示的に圧縮して格納することで、領域を大幅に節約することが可能です。この際、各索引ブロックにはより多くのキーが格納され、I/Oの削減およびパフォーマンスの向上にもつながります。
推奨: 索引とパーティション索引
カスタマイズされたOracle Airlines Data Modelビットマップ索引でほとんどの索引を作成します。
一意の列またはカーディナリティが非常に高い他の列(つまり、ほとんどの一意である列)にのみ、Bツリー索引を使用します。Bツリー索引は圧縮して格納します。
索引をパーティション化します。索引は、パーティション化できるという点では表と同じですが、パーティション化方法は表の構造に依存しません。索引をパーティション化すると、リフレッシュ時にデータ・ウェアハウスを管理しやすくなり、問合せのパフォーマンスが改善されます。
通常、ローカルとしてパーティション表の索引を指定します。パーティション表のビットマップ索引は、常にローカルである必要があります。パーティション表のBツリー索引は、ローカルまたはグローバルにできます。ただし、データ・ウェアハウス環境で、ローカル索引はグローバル索引よりも一般的です。ローカル索引では満たせない特定の要件(非パーティション化キーの一意索引や、パフォーマンス要件など)がある場合のみ、グローバル索引を使用します。
パーティション化により、表、索引および索引構成表をより細かい単位に細分化できるようになります。データベース・オブジェクトの単位をパーティションと呼びます。各パーティションには独自の名前があり、独自の記憶特性を持つことができます。データベース管理者の視点からすると、パーティション・オブジェクトには、まとめて管理することも個別に管理することも可能な複数の単位があります。このため、管理者は、パーティション・オブジェクトをかなり柔軟に管理できます。ただし、アプリケーションの視点から、パーティション表は非パーティション表と同じです。SQL DMLコマンドを使用してパーティション表にアクセスする場合、変更は必要ありません。
次のトピックで説明するように、パーティション化によって、管理性、可用性およびパフォーマンスが向上し、多様なアプリケーションに大きなメリットがもたらされます。
|
Oracle By Example: Oracle Databaseの様々なパーティション化技術を理解するには、Oracle Database 11gのパーティションの操作に関するOBEチュートリアルを参照してください。チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
レンジ・パーティション化により、大量のデータの管理性および可用性を向上できます。
2年分の売上データまたは100TBが表に格納されている事例を検討します。1日の最後に、新しいバッチのデータを表にロードして、最も古い日のデータを削除する必要があります。Sales表を日単位でレンジ・パーティション化する場合、パーティション交換ロードを使用して、新しいデータをロードできます。これは、エンド・ユーザー問合せにほとんど影響しない1秒以内の操作です。
また、レンジ・パーティション化により、問合せに応答するための必要なデータのみスキャンすることを確認できます。ビジネス・ユーザーが週単位(たとえば、週ごとの売上合計など)で売上データに主にアクセスすると想定する場合、日単位でこの表をレンジ・パーティション化すると、全体の表ではなく7つのパーティションのみをスキャンしてビジネス・ユーザーの問合せに応答するため、データに最も効率的な方法でアクセスできます。関係ないパーティションのスキャンを回避する機能は、パーティション・プルーニングと呼ばれます。
パフォーマンスのため、ハッシュによるサブパーティション化を主に使用します。Oracle Databaseは、線形ハッシング・アルゴリズムを使用して、サブパーティションを作成します。
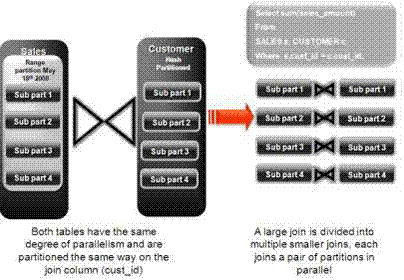
ハッシュ・パーティション化の主なパフォーマンスの利点は、パーティション・ワイズ結合です。パーティション・ワイズ結合では、結合がパラレルで実行されるときにパラレル実行サーバー間で交換されるデータ量が最小限に抑えられ、問合せのレスポンス時間が短縮されます。レスポンス時間は大幅に短縮され、CPUとメモリー・リソースの使用率が改善されます。クラスタ化されたデータ・ウェアハウスで、大規模な結合操作で優れたスケーラビリティを実現するために重要なインターコネクト(IPC)でのデータ・トラフィックを制限して、レスポンス時間が大幅に短縮されます。パーティション・ワイズ結合は、結合する表のパーティション・スキームによってフルまたはパーシャルになります。
図2-2「結合パフォーマンスのパーティション化」に示すように、フル・パーティション・ワイズ結合は、2つの大きい表の結合を複数の小さい結合に分割します。小さい各結合は、結合される表ごとに、パーティションのペアの結合を実行します。フル・パーティション・ワイズ結合方法を選択するオプティマイザには、両方の表を結合キーでパーティション化する必要があります。つまり、同じパーティション化方法を使用した同じ列でパーティション化する必要があります。フル・パーティション・ワイズ結合のパラレル実行はシリアル実行と似ていますが、一度に1つのパーティション・ペアを結合するかわりに複数のパーティション・ペアを複数のパラレル問合せサーバーで結合する点が異なります。パラレルで結合するパーティションの数は、並列度(DOP)によって決定されます。
推奨: ハッシュ・パーティションの数
ハッシュ・パーティション間でデータを確実に均等に分散するには、ハッシュ・パーティションの数を2の累乗(たとえば、2、4、8など)にすることを強くお薦めします。表に使用するハッシュ・パーティションの数を決定する場合に従う優れた経験則として、2 X # CPUs(2の累乗まで丸める)があります。
システムに12個のCPUがある場合、ハッシュ・パーティションに適切な数は32です。クラスタ化されたシステムで、同じルールが適用されます。それぞれに4個のCPUを使用した3つのノードがある場合、ハッシュ・パーティションの適切な数は32です。ただし、各ハッシュ・パーティションのサイズが少なくとも16MBであることを確認してください。多くの小さいパーティションは、パラレル問合せで効率的なスキャン率ではありません。したがって、CPU数の使用でハッシュ・パーティションのサイズが小さくなりすぎる場合、かわりに環境のOracle RACノードの数(2の累乗まで丸めます)を使用します。
パラレル実行により、データベース・タスクをパラレル化または小さい作業単位に分割できるため、複数のプロセスを同時に実行できます。パラレル化を使用すると、TB単位のデータを時間単位や日単位ではなく、数分以内でスキャンして処理できます。
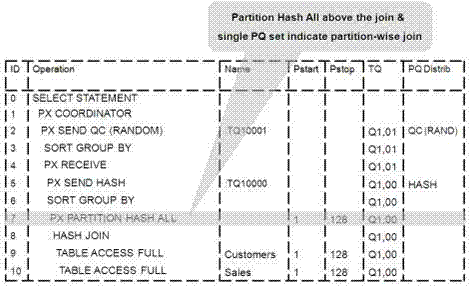
図2-3「2つの表間のフル・パーティション・ワイズ結合のパラレル実行」に、SalesおよびCustomersの2つの表間のフル・パーティション・ワイズ結合のパラレル実行を示します。両方の表の並列度およびパーティション数は同じです。日付フィールドでレンジ・パーティション化され、cust_idフィールドでハッシュを使用してサブパーティション化されます。図に示すように、各パーティション・ペアがデータベースから読み取られ、直接結合されます。
データの再分散が必要ないため、特にノード間でIPC通信を最小化します。次の図に、この結合を確認する実行計画を示します。
パラレルでパーティション・ワイズ結合を実行する場合に最適なパフォーマンスを取得するには、結合に使用する並列度よりも大きい各表のパーティションの数を指定します。パラレル・サーバーよりも多くのパーティションがある場合、各パラレル・サーバーに結合するパーティションの1つのペアが提供され、パラレル・サーバーが結合を完了すると、結合する別のペアのパーティションがリクエストされます。すべてのペアが処理されるまで、このプロセスが繰り返されます。この方法により、動的にロード・バランスできます(たとえば、並列度32の128個のパーティションなど)。
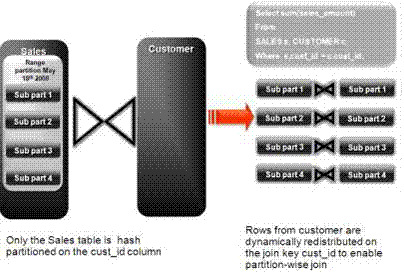
結合している1つの表のみをパーティション化するとどうなるのでしょうか。この場合、オプティマイザはパーシャル・パーティション・ワイズ結合を選択できます。フル・パーティション・ワイズ結合とは異なり、1つの表のみが結合キーでパーティション化されている場合にパーシャル・パーティション・ワイズ結合を適用できます。したがって、パーシャル・パーティション・ワイズ結合は、フル・パーティション・ワイズ結合よりも一般的です。パーシャル・パーティション・ワイズ結合を実行するために、Oracle Databaseによって、パーティション表のパーティション化戦略に基づいて、もう一方の表が動的に再パーティション化されます。
もう一方の表が再パーティション化された後は、フル・パーティション・ワイズ結合と同様に実行されます。再分散操作には、パラレル実行サーバー間での行の交換が伴います。データをノード境界で再パーティション化する必要があるため、この操作は、Oracle RAC環境のインターコネクト・トラフィックにつながります。
図2-4「パーシャル・パーティション・ワイズ結合」に、パーシャル・パーティション・ワイズ結合を示します。図2-3と同じ例を使用しますが、顧客表がパーティション化されない点が異なります。結合操作を実行する前に、顧客表の行が結合キーで動的に再分散されます。
パラレル問合せは、Oracle Databaseの最もよく使用されているパラレル実行機能です。パラレル実行により、大きな問合せの経過時間を大幅に短縮できます。セッション全体のパラレル化を有効にするには、次の文を実行します。
alter session enable parallel query;
INSERT、UPDATE、DELETEなどのデータ操作言語(DML)操作は、Oracle Databaseでパラレル化できます。パラレル実行により大きなDML操作を高速化でき、データ・ウェアハウス環境ではパラレル実行が特に有効です。DML文のパラレル化を有効にするには、次の文を実行します。
alter session enable parallel dml;
INSERT、UPDATE、DELETEなどのDML文を発行すると、Oracle Databaseは一連のルールを適用してその文をパラレル化できるかどうかを判断します。ルールは、文がDML INSERT文であるか、DML UPDATEまたはDELETE文であるかによって異なります。
次のルールは、DML UPDATEおよびDELETE文のパラレル化の方法を決定するときに適用されます。
Oracle Databaseはパーティション表に対するUPDATEおよびDELETE文をパラレル化できますが、パラレル化できるのは複数パーティションが関係する場合だけです。
パーティション化されていない表に対して、または操作が単一パーティションにのみ影響する場合は、UPDATEまたはDELETE操作をパラレル化できません。
次のルールは、DML INSERT文のパラレル化の方法を決定するときに適用されます。
VALUES句を使用する標準INSERTはパラレル化できません。
Oracle Databaseは、INSERT . . . SELECT . . . FROM文のみパラレル化できます。
表のパラレル化の設定は、オプティマイザに影響します。したがって、パラレル問合せを使用する場合は、次の文を発行して表レベルでのパラレル化も有効にします。
alter table <table_name> parallel 32;