| Oracle® Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド 11gリリース2 (11.2) B61350-02 |
|



 前 |
 次 |
この章では、Oracle Warehouse Builderのデータ・プロファイリング機能、およびOracle Warehouse BuilderのETLまたはその他のETLツールを使用してこの機能を使用する方法を説明します。
この章の内容は次のとおりです。
データ・プロファイリングでは、データ・ウェアハウジングまたはその他のデータ統合シナリオでソース・データを使用する前にその品質を評価できます。
データ・プロファイリングではデータ内の内容、構造および関係を分析し、パターンおよびルール、矛盾、異常、冗長性を検出します。
データ・プロファイリングは、データ統合またはウェアハウス・シナリオにおけるあらゆるソースに適用できる他、MDMシナリオのマスター・データ・ストアに適用できます。また、データ・ディクショナリに定義された基本的メタデータ以上の情報の検出が可能なため、新規のソースが関係するあらゆるシナリオで便利に使用できます。
Oracle Warehouse Builderのデータ・プロファイリングでは、次のソース・タイプがサポートされています。
Oracleデータベース
OracleゲートウェイまたはODBCでアクセスするデータ・ソース
フラット・ファイル・ソース
フラット・ファイルをプロファイリングするには、Oracle Warehouse Builderでフラット・ファイルをインポートし、フラット・ファイルに基づいて外部表を作成してから、外部表をプロファイルする必要があります。
SAP R/3およびその他のERPアプリケーション・ソース
|
注意: データ・プロファイリングではJDBCでアクセスしたソースはサポートしません。 |
Oracle Warehouse Builderのデータ・プロファイリングおよびその他のデータ品質機能では、次の方法で、Oracle Warehouse Builder ETLから値を導出したり、Oracle Warehouse Builderに値を追加します。
Oracle Warehouse Builderのデータ品質ではデータ・ルールに基づいてデータ・クレンジング・ロジックを自動的に生成できます。クレンジング・プロセスが、他のETLマッピングと同じ機能を持つ、自動的に生成されたETLマッピングにより実装されます。データ・クレンジング・プロセスのデプロイメント、実行およびスケジューリングはその他のマッピングと同一です。Oracle Warehouse Builder ETL機能に習熟した開発者であれば、たとえば、データ・クレンジング・プロセスのパフォーマンスの調整や生成されたコードの確認などを、他のETLマッピングの場合と同様に実行できます。カスタム・データ・クレンジングおよび修正ロジックが必要な場合は、PL/SQLで実装できます。
データ・プロファイリング結果に関するメタデータは、データ・ルールとして表され、プロファイリング対象のデータ・オブジェクトにバインドできます。このようなルールは、プロファイリング対象のオブジェクトをETLで使用する任意のコンテキストで使用できます。
たとえば、Oracle Warehouse Builder ETLはETLロジックのデータ・ルールを使用して、表内の準拠行および非準拠行の別のデータ・フローを実装できます。非準拠行はデータベースで有効なデータ・クレンジング、修正および改良のロジックを使用してルーティングされ、通常のマッピング演算子を使用して転送されるか、単にエラー表に記録されます。非準拠行を処理する他のオプションに必要なすべてのロジックは、データ・ルールを使用するOracle Warehouse Builderマッピングに対して自動的に生成されます。
また、Oracle Warehouse Builderのデータ・プロファイリング機能ではOracle Warehouse Builder ETLのインフラストラクチャを使用してデータ・ソースに接続し、プロファイリング対象のデータにアクセスし、プロファイリング・ワークスペースと呼ばれるスクラッチ領域に中間のプロファイリング結果を移動します。
Oracle Warehouse Builderのデータ・プロファイリングおよびデータ品質は、任意のサード・パーティのETLソリューションまたはハンドコードされたETLソリューションと併用できます。このようなシナリオの使用モデルは次のとおりです。
既存のETLソリューションをそのままにする
Oracle Warehouse Builderで、データ・ソースに接続するためのワークスペースおよびロケーションを作成します。
データ・プロファイルを作成し、プロファイリングするオブジェクトを追加し、プロファイリング・パラメータを設定します。
プロファイリング・ジョブの実行
データ・プロファイル・エディタで結果を確認
プロファイリング結果に基づいてデータ・ルールを導出し、データのパターンをより適切に理解して文書化します。
これらのタスクの実行方法の詳細は、「データ・プロファイリングの実行」を参照してください。
Oracle Warehouse Builderのデータ・クレンジングおよび修正機能をサード・パーティのETLソリューションと併用することもできます。データ・クレンジングと修正の詳細は、第21章「データ・ルールによるデータ整備とデータ修正」を参照してください。データ監査の詳細は、第20章「データ監査およびデータ・ルールによる品質の監視」を参照してください。
データ・プロファイル・エディタでは、Oracle Warehouse Builderのデータ・プロファイリング、データ・ルールおよびデータ・クレンジング機能のほとんどの主要なユーザー・インタフェースを提供します。データ・プロファイル・エディタで、次のことを実行できます。
データ・プロファイリング、つまり、選択したオブジェクトの属性分析および構造分析を設定して実行します。
プロファイル分析およびソース表ルールに基づく新しいターゲット・スキーマを生成します。このターゲット・スキーマはすべてのデータがプロファイルのオブジェクトに適用されているデータ・ルールに準拠しています。
データ・ルール戦略および選択したクレンジング戦略に基づいてデータ修正を実行するマッピングおよび変換を自動的に生成します。
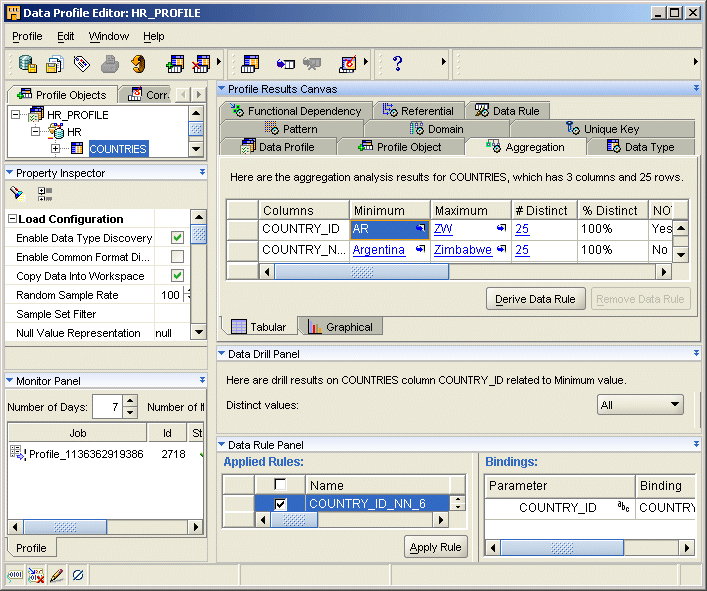
図18-1に、データ・プロファイル・エディタを示します。
データ・プロファイル・エディタには、次のユーザー・インタフェースがあります。
メニュー・バー
ツールバー
オブジェクト・ツリー
プロパティ・インスペクタ
モニター・パネル
プロファイル結果キャンバス
データ・ドリル・パネル
データ・ルール・パネル
各パネルの内容の詳細は、オンライン・ヘルプを参照してください。
データ・プロファイリングはリソース集中型であるため、特に大容量のデータではプロファイル実行時間がきわめて長くなる場合があります。1つまたはすべてのソース・システムの全体の内容のプロファイリングは、有効なプロファイリング結果を生成するうえで最も効率的な方法ではない可能性があります。初回の限定的なデータ・プロファイリングでは、次にプロファイルする内容を決定するうえで使用する検出を生成する反復的なアプローチは、プロファイリング対象が大規模で複雑なソースのセットに対応する必要がある場合に、より効果的な可能性があります。
次のガイドラインでは、データ・プロファイリング結果の有効性を向上させるとともに、プロファイリングの時間と手間を削減できます。
多数のダウンストリーム・オブジェクトに影響するソースまたは影響されるオブジェクトがシステムの最重要の出力であるソースをプロファイリングします。たとえば、ソース表に多数のダウンストリームのビジネス・インテリジェンス・レポートの内容に影響するデータを含む場合、その表のプロファイリングを検討します。特定の列のみをダウンストリーム・ターゲットで使用する場合、属性セットを使用してそれらの列にプロファイリングを限定することを検討します。
|
ヒント: Oracle Warehouse Builderのデータ系統機能およびデータ影響分析機能を使用して、システム内で大きな影響を受けるソースを識別します。詳細は、『Oracle Warehouse Builderインストレーションおよび管理ガイド』を参照してください。 |
エラーの可能性のあるデータを含む可能性が高いソースをプロファイリングします。たとえば、手動で入力されている顧客および発注データは、仕入先からダウンロードした製品データよりエラーを含む可能性が高くなります。
特に最初のデータ品質が不明なソースでは、任意の既存システムに新しいソースを統合する前にそのソースをプロファイリングします。
ソースのドキュメントがある場合、このドキュメントに基づいてデータ・ルールを定義し、そのルールに準拠するデータに絞ってプロファイリングします。準拠するデータがない場合は、より全体的なプロファイリングを検討します。
重要な結果を提供する可能性が低いプロファイリング・タイプを無効にします。たとえば、初回のプロファイリングの引渡しをドメイン検出のみに限定して実行したり、機能の依存性の検出などより高度で演算が集中するプロファイリング・タイプの前に実行することをお薦めします。
最初は、ソースのコンテンツ全体をプロファイリングするのではなく、プロファイリングをデータのランダム・サンプリングに制限します。データ・ルールの最初のセットを識別したら、それらのルールへの準拠性についてすべての行をプロファイリングできます。
たとえば、5つの表CUSTOMERS、REGIONS、ORDERS、PRODUCTSおよびPROMOTIONSを含むデータ・ソースについて検討します。次の情報があります。
CUSTOMERS表は、多くの重複エントリおよびエラーの可能性があるエントリを含むことが分かっており、マーケティング・キャンペーンの作成で使用されます。
ORDERS表には、手書きの書式や電話の注文から転写した発注データを含みます。
PRODUCTS表には、信頼できる仕入先からダウンロードしたデータが含まれており、自由書式のテキストを含むVARCHAR2(4000)列のDESCRIPTIONがあります。
ソース・システムのマニュアルにORDERS表とREGIONS表の間に外部キー関係があると記載されていても、このマニュアルは数年前のもので、ソース・システムが変わっている可能性があります。
このような場合、最初のプロファイリング・プロセスを次のように制限できます。
他の表の前にCUSTOMERS表をプロファイリングします。これは、この表がエラーを含むことが分かっているためです。
すべてのプロファイリングからPRODUCTS.DESCRIPTION列を除外します。これは、自由形式のテキストはプロファイリングで有効な情報を生成する可能性が低いためです。
ランダム・サンプリングを使用してすべての表から限定された数の行をプロファイリングします。
ORDERS表およびREGIONS表をプロファイリングし、外部キー関係をテストします。
その後は、最初の引渡しでの検出内容に基づいてその後のプロファイリングを実行できます。
Oracleデータベースに格納されているデータ、Oracle Gatewayにアクセス可能なデータ、SAPシステムのデータのみをプロファイリングできます。フラット・ファイルに格納されているデータをプロファイリングしてから、そのフラット・ファイルに基づいて外部表を作成する必要があります。
JDBCベース接続でアクセスするプロファイル・データを直接プロファイリングすることはできません。Oracleデータベースのこのデータを最初にステージングしてからプロファイリングする必要があります。
データ・プロファイリングでは必ずデフォルト構成を使用します。複数の構成を使用する顧客は、デフォルト構成にプロファイリング用の適切な設定が含まれていることを確認します。
プロファイリング・ワークスペース・ロケーションは、Oracle 10gデータベース以上である必要があります。
ソース・モジュールおよびデータ・プロファイルが異なるデータベース・インスタンス上にある場合は、複雑なデータ型を含むソース表をプロファイルできません。
データ・プロファイリングは各表、ビューまたはマテリアライズド・ビューの165列を超えるデータを一度に解析できません。165を超える列を含むオブジェクトをプロファイリングする場合は、属性セットを作成してプロファイリングする列のサブセットを選択する必要があります。詳細は、「属性セットを使用したデータ・オブジェクトの列のサブセットのプロファイル」を参照してください。
データ・オブジェクトをプロファイリングする前に、データ・プロファイリングを実行するソース・オブジェクトの正しいメタデータをプロジェクトが含むことを確認します。
プロファイリングするオブジェクトには、ソース・データが含まれている必要があります。たとえば、ステージング領域に格納されている表をプロファイリングする場合、プロファイルを実行する前にソースからステージング表をロードする必要があります。
データ・プロファイリングではマッピングを使用してプロファイリングを実行するため、使用するすべてのロケーションが登録されていることを確認する必要があります。データ・プロファイリングではロケーションの登録が試行されます。なんらかの理由で、データ・プロファイリングでロケーションを登録できない場合は、プロファイリングを開始する前にロケーションを明示的に登録する必要があります。
|
関連項目: メタデータのインポートの詳細は、『Oracle Warehouse Builderソースおよびターゲット・ガイド』を参照してください。 |
データ・プロファイリングを準備するには、プロジェクトに1つ以上のデータ・プロファイルを作成する必要があります。データ・プロファイル・オブジェクトはそれぞれプロジェクト内のメタデータ・オブジェクトです。データ・プロファイル・オブジェクトでは次を格納します。
プロファイリングするオブジェクトのセット
このオブジェクトのセットに対して実行するプロファイリングのタイプ
プロファイリング操作をコントロールするしきい値などの設定
これらの設定するデータ・プロファイリングの最新の実行で返される結果
プロファイリング結果から生成されるデータの修正に関するメタデータ
プロファイリングするオブジェクトを決定した後は、次のステップに従ってプロファイリング・プロセスを実行します。
プロジェクト・ナビゲータで、プロジェクト・ノードを開いてプロファイリングするすべてのオブジェクトをこのプロジェクトにインポートします。
「データ・プロファイリングの前提条件」を参照してください。
オブジェクトをインポートしたプロジェクトで、プロファイリングするオブジェクトを含むデータ・プロファイル・オブジェクトを作成します。
「データ・プロファイルの作成」を参照してください。
データ・プロファイルを構成し、プロファイリング対象データに対して実行する分析のタイプを指定します。
「データ・プロファイルの構成」を参照してください。
データをプロファイリングし、前のステップで指定した分析のタイプを実行します。
「データのプロファイリング」を参照してください。
データ・プロファイリングの結果を確認し、分析します。
「プロファイル結果の表示」を参照してください。
プロファイリング結果に基づいて、スキーマおよびデータの修正の生成を決定できます。これらの修正はOracle Warehouse Builderが自動的に生成します。スキーマの修正およびデータの修正の自動的な生成の詳細は、「データ・プロファイリングの結果からの修正マッピングの生成」を参照してください。
また、データ・プロファイリング結果に基づいて、データ・ルールを導出することもできます。プロファイリングの結果に基づくデータ・ルールの導出の詳細は、「データ・プロファイリング結果からのデータ・ルールの導出」を参照してください。
ロケーションの準備が完了し、データが使用可能になったら、デザイン・センターでデータ・プロファイル・オブジェクトを作成する必要があります。データ・プロファイルは、ワークスペース内のメタデータ・オブジェクトで、プロファイリングするデータ・オブジェクトのセット、プロファイル操作の管理の設定、データをプロファイリングした後に戻す結果、および修正情報(これらの修正を使用する場合)を指定します。
データ・プロファイルを作成する手順は、次のとおりです。
プロジェクト・ナビゲータで、データ・プロファイルを作成する「プロジェクト」ノードを開きます。
「データ・プロファイル」を右クリックして新規データ・プロファイルを選択します。
データ・プロファイルウィザードのようこそページが表示されます。
ようこそページで「次へ」をクリックします。
名前と説明ページで、データ・プロファイルの名前と説明(オプション)を入力します。「次へ」をクリックします。
オブジェクトの選択ページで、データ・プロファイルに含めるオブジェクトを選択し、矢印を使用してこれらを「選択済」リストに移動します。「次へ」をクリックします。
複数のオブジェクトを選択するには、オブジェクトの選択中に[Ctrl]キーを押し続けます。データ・プロファイルに表、ビュー、マテリアライズド・ビュー、外部表、ディメンションおよびキューブを含めることができます。
属性セットを含む表、ビューまたはマテリアライズド・ビューを選択した場合、「属性セットの選択」ダイアログ・ボックスが表示されます。このダイアログ・ボックスの最下部にあるリストに、データ・オブジェクトで定義した属性セットが表示されます。
属性セットに定義されている属性のみをプロファイリングするには、リストから属性セットを選択します。
データ・オブジェクトのすべての列をプロファイリングするには、リストから<すべての列>を選択します。
オブジェクトの選択ページでディメンション・オブジェクトを選択した場合、これらのディメンション・オブジェクトにバインドされるリレーショナル・オブジェクトもプロファイルに追加されることを示す警告が表示されます。次に進むには、「はい」をクリックします。
サマリー・ページで、前のウィザード・ページでの選択を確認します。「戻る」をクリックして、選択した値を変更します。データ・プロファイルを作成するには、「終了」をクリックします。
Oracle Warehouse Builderの「注意」ダイアログが表示されます。「OK」をクリックし、新しく作成したデータ・プロファイルのデータ・プロファイル・エディタを表示します。
ナビゲーション・ツリーの「データ・プロファイル」ノードに、この新規データ・プロファイルが追加されます。
特定のタイプを分析する場合または分析しない場合は、データ・プロファイルを実行する前に構成する必要があります。
データ・プロファイルは、次のいずれかのレベルで設定できます。
プロファイル全体(プロファイルに含まれるすべてのオブジェクト)
データ・プロファイルの個別オブジェクト
たとえば、データ・プロファイルには3つの表が含まれます。1つの表に対して特定のタイプの分析を実行する場合、この表のみを構成します。
オブジェクト内の属性
たとえば、表内の1つの列のみが問題となっており、ほとんどのレコードは特定ドメイン内の値に一致していることがわかっている場合です。プロファイリング・リソースをドメインの検出と分析に集中できます。必要なプロファイリングのタイプを絞り込むことによって、使用するリソースが減り、結果をより速く取得できます。
プロジェクト・ナビゲータで、データ・プロファイルを右クリックして「開く」を選択します。
データ・プロファイルに対するデータ・プロファイル・エディタが表示されます。
構成パラメータを設定するレベルを選択します。
データ・プロファイル全体を構成するには、「プロファイル・オブジェクト」タブで、データ・プロファイルを選択します。
「プロファイル・オブジェクト」タブで、データ・プロファイルの特定のオブジェクトを構成するには、データ・プロファイルを表すノードを開きます。データ・オブジェクト名をクリックしてデータ・オブジェクトを選択します。
データ・プロファイルのオブジェクトで属性を構成するには、「プロファイル・オブジェクト」タブで、データ・プロファイルを表すノードを開きます。属性が含まれるデータ・オブジェクトを開き、属性名をクリックして必要な属性を選択します。
「プロパティ・インスペクタ」パネルを使用して必要な構成パラメータを設定します。
構成パラメータはロード、集計、パターン検出、ドメイン検出、関係属性カウント、一意キー検出、関数従属性検出、行関係検出、冗長列検出、およびデータ・ルール・プロファイリングのタイプに分類されます。次の項では、各カテゴリのパラメータを説明します。
表18-1ではこのカテゴリのパラメータを説明します。
表18-1 ロード構成パラメータの説明
| 構成パラメータ名 | 説明 |
|---|---|
|
データ型検出を使用可能にする |
このパラメータをTRUEに設定すると、選択した表のデータ型検出が有効になります。 |
|
共通形式検出を使用可能にする |
このパラメータをTRUEに設定すると、選択した表の共通形式検出が有効になります。 |
|
データをワークスペースにコピー |
このパラメータをTRUEに設定すると、ソースからプロファイル・ワークスペースへのデータのコピーが有効になります。 |
|
ランダム・サンプル率 |
この値は、ロード時にランダムに選択される合計行のパーセントを表します。 |
|
プロファイルを常に強制実行する |
このパラメータをTRUEに設定すると、データ・プロファイラがデータ・オブジェクトの再リロードと再プロファイリングを強制実行します。 |
|
サンプル・セット・フィルタ |
データをプロファイル・ワークスペースにロードするときにソースに適用される |
|
NULL値表現 |
プロファイリング時にこの値はNULL値とみなされます。値は一重引用符で囲む必要があります。デフォルト値はNULLであり、データベースNULLとみなされます。 |
このカテゴリは、「NOT NULL推奨率」というパラメータ1つで構成されています。列内のNULL値の割合がこのしきい値の割合より低い場合、その列はNOT NULLの可能性がある列として検出されます。
パターン検出の有効化: このパラメータをTrueに設定すると、パターン検出が使用可能になります。
最大パターン数: プロファイラが属性に対して取得するパターンの最大数を表します。たとえば、このパラメータを10に設定すると、プロファイラは属性に対して上位10パターンを取得します。
表18-2ではこのカテゴリのパラメータを説明します。
表18-2 ドメイン検出構成パラメータの説明
| 構成パラメータ名 | 説明 |
|---|---|
|
ドメイン検出の有効化 |
このパラメータをTrueに設定すると、ドメイン検出が使用可能になります。 |
|
ドメイン検出最大個別値件数 |
列内の個別値の最大数で、その列がドメインによって定義されている可能性があると検出されるためのものです。その列内の個別値の数が最大の個別値カウント・プロパティと同じかそれ以下で、個別値の数の行数合計に占める割合が最大の個別値パーセント・プロパティと同じかそれ以下である場合、列のドメイン検出が発生します。 |
|
ドメイン検出最大個別値パーセント |
列内の個別値の最大数を表中の行数合計に対する割合で表したもので、その列がドメインによって定義されている可能性があると検出されるためのものです。その列内の個別値の数が最大の個別値カウント・プロパティと同じかそれ以下で、個別値の数の行数合計に占める割合が最大の個別値パーセント・プロパティと同じかそれ以下である場合、列のドメイン検出が発生します。 |
|
ドメイン値準拠最小行数 |
指定された個別値の行の最小数で、その個別値がドメインに準拠しているとみなされるための数値です。その値を持つ行の数が最小の行カウント・プロパティと同じかそれ以上で、その値を持つ行の数の行数合計に占める割合が最小の行パーセント・プロパティと同じかそれ以上である場合、値に対するドメイン値準拠が発生します。 |
|
ドメイン値準拠最小行パーセント |
指定された個別値の行の最小数を行数合計に対する割合で表したもので、その個別値がドメインに準拠しているとみなされるための数値です。その値を持つ行の数が最小の行カウント・プロパティと同じかそれ以上で、その値を持つ行の数の行数合計に占める割合が最小の行パーセント・プロパティと同じかそれ以上である場合、値に対するドメイン値準拠が発生します。 |
このカテゴリには、「最大属性カウント」パラメータが含まれています。これは、一意キー、外部キーおよび機能依存プロファイリングの属性の最大数です。
一意キー検出の有効化: このパラメータをTrueに設定すると、一意キー検出が使用可能になります。
最小一意性割合: これは、一意キー関係を満たすために必要な行の最小割合です。
関数従属性検出の有効化: このパラメータをTrueに設定すると、関数従属性検出が使用可能になります。
最小関数従属性割合: これは、関数従属性を満たすために必要な行の最小割合です。
関係検出の有効化: このパラメータをTrueに設定すると、外部キー検出が使用可能になります。
Soundex関係の検出を使用可能にする: このパラメータをTRUEに設定すると、文字列データ型を含む列でのsoundex関係の検出が有効になります。これらの属性は関係検出の一部であることを確認する必要があります。
最小関係割合: これは、外部キー関係を満たすために必要な行の最小割合です。
最小Soundex関係割合: これは、Soundex関係を満たすために必要な行の最小割合です。同じSoundexの値を含む値は同じであるとみなされます。
冗長列検出の有効化: このパラメータをTrueに設定すると、外部キーと一意キーのペアに対して冗長列検出が使用可能になります。
最小冗長性割合: これは、冗長な行の最小割合です。
このカテゴリには、マテリアライズド・ビューの作成を有効化パラメータが含まれます。このパラメータをTRUEに設定すると、データ・プロファイルのすべての表の各列にマテリアライズド・ビューを作成します。これによりドリルダウン中の問合せのパフォーマンスが強化されます。
このカテゴリには、「表のデータ・ルール・プロファイリングを使用可能にします。」パラメータが含まれています。このパラメータを「True」に設定すると、選択した表のデータ・ルール・プロファイリングが使用可能になります。この設定を適用できるのは表のみで、個別の属性には適用できません。
選択したオブジェクトのディープ・スキャンを実行すると、データ・プロファイリングが実行されます。実行するプロファイリングのオブジェクト数やタイプによって、時間がかかる場合があります。ただし、プロファイリングは非同期のジョブとして実行されるため、プロファイリング・プロセス中にデザイン・センター・クライアントを閉じることができます。ETLジョブと同様に、ジョブ・モニターで実行中のジョブを参照できます。プロファイリング・ジョブが完了すると、Oracle Warehouse Builderにより、ジョブが完了した旨が表示されます。
データ・プロファイルを作成した後、それをデータ・プロファイル・エディタで開いてデータをプロファイリングしたり、以前に実行したプロファイルの結果を確認できます。データ・プロファイル・エディタのオブジェクト・ツリーには、プロファイルの作成時に選択したオブジェクトが表示されます。「プロファイル」、「追加」の順に選択すると、プロファイルにオブジェクトを追加できます。
データ・プロファイルを使用してデータをプロファイリングするには:
プロジェクト・ナビゲータで「データ・プロファイル」ノードを開き、データ・プロファイルを右クリックして「開く」を選択します。
選択したデータ・プロファイルがデータ・プロファイル・エディタに開きます。
データ・プロファイルを構成していない場合は、「データ・プロファイルの構成」の説明に従ってデータ・プロファイルを構成します。
「プロファイル」メニューから「プロファイル」を選択します。
初めてデータをプロファイリングする場合は、「データ・プロファイル設定」ダイアログ・ボックスが表示されます。プロファイリング・ワークスペースの詳細を入力します。入力する情報の詳細は、「ヘルプ」をクリックしてください。
Oracle Warehouse Builderでは、プロファイリングに使用するメタデータの準備を開始します。進行状況ウィンドウには、データをプロファイリングするために作成されているオブジェクト名が表示されます。メタデータの準備が完了した後、「プロファイリングが開始されました」ダイアログ・ボックスで、プロファイリング・ジョブが開始したことが通知されます。
「プロファイリングが開始されました」ダイアログ・ボックスで、「OK」をクリックします。
プロファイリング・ジョブが開始すると、データ・プロファイリングは非同期ジョブとして実行されるため、処理を続行したり、設計センターを閉じることもできます。プロファイリング・プロセスは、完了するまで実行されます。
データ・プロファイル・エディタの「モニター」パネルでプロファイリング・ジョブのステータスを確認します。
プロファイリング・ジョブの進行状況は、「モニター」パネルで引き続きモニターできます。プロファイリング・ジョブが完了すると、ステータスが「完了」として表示されます。
プロファイリングが完了すると、「プロファイル結果の取得」ダイアログ・ボックスが表示され、結果のリフレッシュが要求されます。「はい」をクリックしてデータ・プロファイリング結果を取得し、これらをデータ・プロファイル・エディタに表示します。
|
注意: データ・プロファイリング結果は、以降にプロファイリングを実行すると上書きされます。 |
プロファイリング操作が完了した後、データ・プロファイル・エディタでデータ・プロファイルを開き、結果を確認および分析できます。プロファイリング結果には、プロファイリングされたデータに関する様々な分析情報および統計情報が含まれています。異常が発生している箇所にすぐにドリルダウンして、その原因を確認できます。その後、修正する必要のあるデータを特定できます。
プロファイル結果を表示する手順は、次のとおりです。
ナビゲーション・ツリーでデータ・プロファイルを選択し、右クリックして「開く」を選択します。
データ・プロファイル・エディタが開き、データ・プロファイルが表示されます。
前にデータ・プロファイル・エディタにデータ・プロファイリング結果を表示したことがある場合は、最新の結果が表示されるように、プロンプトが表示された時点で表示をリフレッシュします。
プロファイリングの結果がプロファイル結果キャンバスに表示されます。
「データ・ルール」パネルと「モニター」パネルの左上隅にある矢印記号をクリックし、この2つのパネルを最小化します。
これにより、画面領域が最大化されます。
オブジェクト・ツリーの「プロファイル・オブジェクト」タブでオブジェクトを選択し、特定のオブジェクトの結果にフォーカスを置きます。
選択したオブジェクトのプロファイリング結果は、プロファイル結果キャンバスの次のタブを使用して表示されます。
データ・プロファイル内の様々なオブジェクトを切り替えることができます。前のオブジェクトで選択したタブは選択されたまま残ります。
「データ・プロファイル」タブには、データ・プロファイルの一般情報が表示されます。このタブを使用して、データ・プロファイルに関するノートや情報を格納します。
「プロファイル・オブジェクト」タブには「オブジェクト・データ」および「オブジェクト・ノート」という2つのサブタブがあります。「オブジェクト・データ」タブには、オブジェクト・ツリーの「プロファイル・オブジェクト」タブで選択したオブジェクト内のデータ・レコードがリスト表示されます。サンプルで使用した行数がリストされます。タブの上部にあるボタンを使用すると、問合せの実行、データの追加取得またはWHERE句の追加ができます。
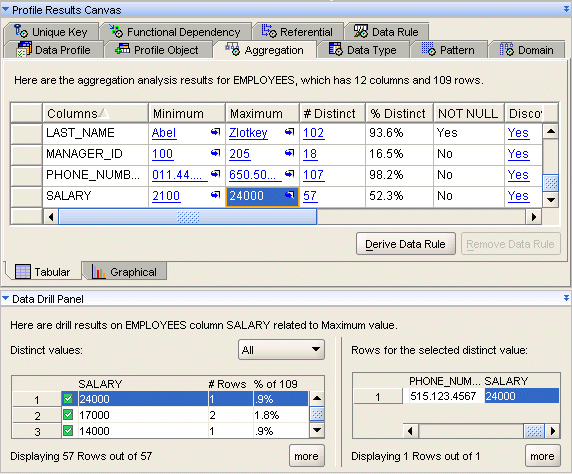
「集計」タブには、最小値、最大値、個別値の数およびNULL値など、各列の重要なメジャーがすべて表示されます。特定のデータ型の場合にのみ使用可能なメジャーがあります。たとえば、平均、中央値および標準偏差などのメジャーです。情報は、「表形式」サブタブまたは「グラフィカル」サブタブで参照できます。
表18-3に、「集計」タブで使用可能な測定結果を示します。
表18-3 集計結果
| メジャー | 説明 |
|---|---|
|
列 |
集計メジャーを特定するデータ・プロファイリング用のプロファイリング対象のデータ・オブジェクト内の列の名前。 |
|
最小 |
列のデータベース固有の順序付けに関する最小値 |
|
最大 |
列のデータベース固有の順序付けに関する最大値 |
|
個別数 |
列の個別値の合計数 |
|
%個別 |
行セット数全体に対する列の個別値の割合 |
|
NOT NULL |
列に対してNOT NULL制約がデータベースで定義されているかどうかを示す |
|
推奨NOT NULL |
データ・プロファイリング結果が列にNULL値を許可するよう推奨しているかどうかを示します。値が「はい」の場合、この列にNULL値を許可しないよう推奨しています。 |
|
NULL数 |
列のNULL値の合計数 |
|
% NULL |
行セット数全体に対する列のNULL値の割合 |
|
シックスシグマ |
表の合計行数(可能性)に対するNULL値(欠損)の数 |
|
平均 |
行セット数全体での列の平均値 |
|
中央値 |
行セット数全体での列の中間値 |
|
標準偏差 |
列の標準偏差 |
集計結果表の値にハイパーリンクが付いている場合、この値をクリックするとデータにドリルダウンできます。これにより、この結果を生成したサンプルのデータを分析できます。
たとえば、図18-2に示すように、SALARY列までスクロールして24000と表示されている「最大」セルの値をクリックすると、下部の「データ・ドリル・パネル」が変更され、この列のすべての個別値とカウントが左側に表示されます。右側のデータ・ドリルでは、個別値から選択した値にズームインして、これらの値が検出されたレコード全体を表示できます。
グラフィカル分析では結果がグラフ形式で表示されます。グラフィカル・ツールバーを使用して表示を変更できます。また、「列」および「プロパティ」メニューを使用して、表示されるデータ・オブジェクトを変更することもできます。
「データ型」タブにはデータ型のプロファイリング結果が表示されます。これには、文字データ型の長さや数値データ型の精度とスケールなどのメトリックが含まれます。検出された各データ型は、属性全体で検出された主要なデータ型と比較され、主要なメジャーに準拠する行の割合が表示されます。
データ型のプロファイリングの一例は、VARCHARとして定義されていて数値のみが格納されていた列を検出することです。この列のデータ型をNUMBERに変更すると、格納と処理の効率が向上します。
表18-4に、「データ型」タブで使用可能な測定結果を示します。
表18-4 データ型の結果
| メジャー | 説明 |
|---|---|
|
列 |
データ型分析を実行したデータ・オブジェクト内の列の名前 |
|
文書化されたデータ型 |
ソース・オブジェクト内の列のデータ型 |
|
主要なデータ型 |
データ・プロファイリングでは、列値の分析に基づいて、これが主要な(最も頻度の高い)データ型であることが判別されます。 |
|
%主要なデータ型 |
列値が主要なデータ型を持つ行の合計行数に対する割合 |
|
文書化された長さ |
ソース・オブジェクト内のデータ型の長さ |
|
最小長 |
列に格納されているデータの最大長 |
|
最大長 |
列に格納されているデータの最小長 |
|
主要な長さ |
データ・プロファイリングでは、列値の分析に基づいて、これが主要な(最も頻度の高い)長さであると判別されます。 |
|
%主要な長さ |
列値が主要な長さである行の合計行数に対する割合 |
|
文書化された精度 |
ソース・オブジェクト内のデータ型の精度 |
|
最小精度 |
ソース・オブジェクト内の列の最小精度 |
|
最大精度 |
ソース・オブジェクト内の列の最大精度 |
|
主要な精度 |
データ・プロファイリングでは、列値の分析に基づいて、これが主要な(最も頻度の高い)精度であると判別されます。 |
|
%主要な精度 |
列値が主要な精度を持つ行の合計行数に対する割合 |
|
文書化されたスケール |
ソース・オブジェクト内のデータ型に指定されているスケール |
|
最小スケール |
ソース・オブジェクト内のデータ型の最小スケール |
|
最大スケール |
ソース・オブジェクト内のデータ型の最大スケール |
|
主要なスケール |
データ・プロファイリングでは、列値の分析に基づいて、これが主要な(最も頻度の高い)スケールであると判別されます。 |
|
%主要なスケール |
列値が主要なスケールを持つ行の合計行数に対する割合 |
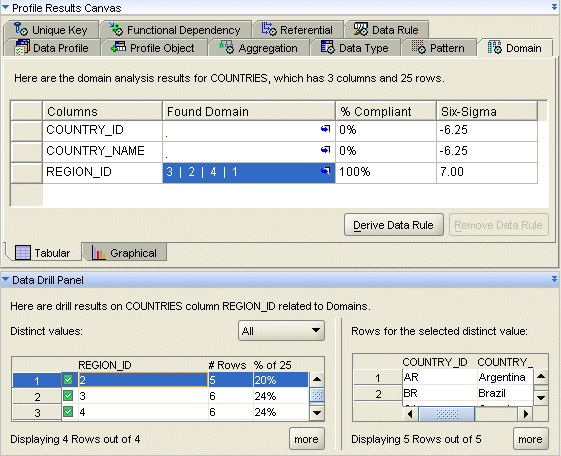
「ドメイン」タブには、特定の属性に存在する可能性のある値セットに関する結果が表示されます。情報は、「表形式」サブタブまたは「グラフィカル」サブタブで参照できます。
図18-3は、データ・プロファイル・エディタの「ドメイン」タブを示しています。
列のドメインを検出するプロセスには2つのフェーズがあります。最初に、列の個別値を使用して、その列がドメインで定義されている可能性があるかどうかが判別されます。通常、ドメインにはいくつか個別値が存在します。次に、可能性のあるドメインが識別され、個別値のカウントを使用して、その個別値がドメインに準拠しているかどうかが判別されます。ドメイン検出の両方のフェーズのしきい値を制御するプロパティは、プロパティ・インスペクタで設定できます。
詳細が必要な結果が見つかった場合は、ドリルダウンし、データ・ドリル・パネルを使用して、結果の原因に関する詳細を参照します。
たとえば、列REGION_IDについて4つの値3、2、4および1のドメインが検出されたとします。この検出結果に影響したレコードを調べるには、REGION_ID行を選択してデータ・ドリル・パネルで詳細を参照します。
表18-5に、「ドメイン」タブで使用可能な測定結果を示します。
「パターン」タブには、属性内のパターンに関して検出された情報が表示されます。パターン検出とは、プロファイラが特定の属性について検出したデータの正規表現の生成を試行することです。パターン検出プロセスでは、英語以外の文字はサポートされません。
表18-6に、「パターン」タブで使用可能な測定結果を示します。
表18-6 パターン結果
| メジャー | 説明 |
|---|---|
|
列 |
パターンの結果を検出した列の名前 |
|
主要な文字パターン |
最も検出頻度の高かった文字パターンまたはコンセンサス・パターン。 |
|
%準拠 |
データ・パターンが主要な文字パターンと一致した行の割合。 |
|
主要な単語パターン |
最も検出頻度の高かった単語パターンまたはコンセンサス・パターン。 |
|
%準拠 |
データ・パターンが主要な単語パターンと一致した行の割合。 |
|
共通形式 |
名前、アドレス、日付、ブール、社会保障番号、電子メール、URL。これは、プロファイラによる参照しているデータへのセマンティクス認識の追加試行です。パターンと他のなんらかのテクニックに基づいて、特定の属性のデータが属しているドメイン・バケットの特定が試行されます。 |
|
%準拠 |
データ・パターンがコンセンサス共通形式パターンと一致した行の割合。 |
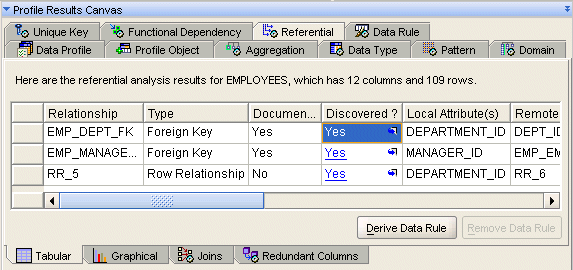
「一意キー」タブには、データ・ディクショナリに文書化された既存の一意キーおよびデータ・プロファイリング操作で検出された一意キーまたはキーの組合せの候補に関する情報が表示されます。それぞれについて一意性の割合が表示されます。文書化済列が「いいえ」の一意キーは、データ・プロファイリングで検出された一意キーです。
たとえば、電話番号は98%のレコードで一意です。これは一意キーの候補として使用でき、準拠しないレコードを整備できます。また、ドリルダウン機能を使用して、電話番号の重複の原因を「データ・ドリル・パネル」に表示することもできます。表18-7は、「一意キー」タブで使用可能な各種の測定結果を示しています。
表18-7 一意キーの結果
| メジャー | 説明 |
|---|---|
|
一意キー |
検出された一意キー |
|
文書化済 |
列の一意キーがデータ・ディクショナリに存在するかどうかを示します。 「はい」という値は、一意キーがデータ・ディクショナリに存在することを示します。「いいえ」という値は、その一意キーがデータ・プロファイリングによって検出されたことを示します。 |
|
検出済 |
データ・プロファイリングでは、列値の分析に基づいて、「ローカル属性」列に表示される列に一意キーを作成する必要があるかどうかが判別されます。 |
|
ローカル属性 |
プロファイルされたデータ・オブジェクトの列の名前 |
|
一意の数 |
ソース・オブジェクト内で、ローカル属性で表される属性が一意である行の数 |
|
%一意 |
ソース・オブジェクト内で、ローカル属性で表される属性が一意である行の割合 |
|
シックスシグマ |
表の合計行数(可能性)に対するNULL値(欠損)の数 |
「関数従属性」タブには、他の属性に依存するか他の属性を決定付けると思われる属性の情報が表示されます。情報は、「表形式」サブタブまたは「グラフィカル」サブタブで参照できます。「表示」リストを使用すると、レポートのフォーカスを変更できます。データ・プロファイリング中は、データベース内で定義されている一意キーは関数従属性として検出されません。
表18-8に、「関数従属性」タブで使用可能な測定結果を示します。
表18-8 関数従属性の結果
| メジャー | 説明 |
|---|---|
|
決定子 |
「依存」に表示される属性を決定するものと判明した属性の名前 |
|
依存 |
他の属性の値により決定されることが判明した属性の名前 |
|
欠陥数 |
決定子属性の値のうち、依存属性により決定されなかった値の数 |
|
%準拠 |
検出された従属性に準拠する値の割合 |
|
シックスシグマ |
シックスシグマの値 |
|
タイプ |
関数従属性のタイプ。指定できる値は単方向または双方向 |
たとえば、「表示」リストから「100%の依存性のみ」を選択すると、表示される情報は絶対依存性に限定されます。常に他の属性に依存する属性がある場合、その属性は参照表の候補として推奨されます。推奨事項は「タイプ」列に表示されます。属性を別の参照表に移動すると、スキーマが正規化されます。
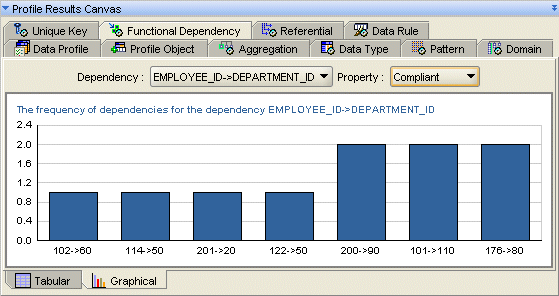
「関数従属性」タブには「グラフィカル」サブタブも表示されるため、情報をグラフ形式で表示できます。リストから依存性とプロパティを選択し、グラフ・データを表示できます。
たとえば、図18-4では、EMPLOYEE_IDがDEPARTMENT_IDを決定付けると思われる依存性(EMPLOYEE_ID->DEPARTMENT_ID)を選択しています。Oracle Warehouse Builderでは、ほとんどのEMPLOYEE_ID値がDEPARMENT_IDを決定付けるものと判断されます。プロパティを「非準拠」に切り替えると、この検出の例外を表示できます。
「参照」タブには、データ・ディクショナリに文書化されている外部キーとプロファイリング中に検出された関係に関する情報が表示されます。関係ごとに準拠レベルを表示できます。情報は、「表形式」サブタブと「グラフィカル」サブタブの両方で参照できます。また、他の2つのサブタブ「結合」サブタブおよび「冗長列」サブタブは、「参照」タブでのみ使用可能です。
表18-9に、「参照」タブで使用可能な測定結果を示します。
表18-9 参照の結果
| メジャー | 説明 |
|---|---|
|
関係 |
関係の名前 |
|
タイプ |
関係のタイプ。使用可能な値は、「行関係」および「外部キー」です。 |
|
文書化済 |
列の外部キーがデータ・ディクショナリに存在するかどうかを示します。 「はい」は列の外部キーがデータ・ディクショナリに存在することを示します。「いいえ」はデータ・プロファイリングによって外部キーが検出されたことを示します。 |
|
検出済 |
データ・プロファイリングでは、列値の分析に基づいて、「ローカル属性」に表示される列に外部キーを作成する必要があるかどうかが判別されます。 |
|
ローカル属性 |
ソース・オブジェクト内の属性の名前 |
|
リモート・キー |
ローカル属性の参照先オブジェクト内のキーの名前 |
|
リモート属性 |
参照先オブジェクト内の属性の名前 |
|
リモート・リレーション |
ソース・オブジェクトの参照先オブジェクトの名前 |
|
リモート・モジュール |
参照オブジェクトを含むモジュールの名前 |
|
カーディナリティ範囲 |
2つの属性間のカーディナリティの範囲 たとえば、 データ・プロファイリングでは、 |
|
親なしの子の数 |
ソース・オブジェクト内の親なしの子行の数 |
|
%準拠 |
検出された従属性に準拠する値の割合 |
|
シックスシグマ |
表の合計行数(可能性)に対するNULL値(欠損)の数 |
たとえば、EmployeesおよびDepartmentsという2つの表の参照関係を分析しているとします。図18-5に示した参照のデータ・プロファイリング結果を使用すると、Employees表のDEPARTMENT_ID列が、その時点でDepartments表の98%でDEPARTMENT_ID列に関連付けられていることがわかります。次に、「検出済」列でハイパーリンクとなっている「はい」をクリックすると、検出された外部キー関係に準拠していなかった行を表示できます。
また、「グラフィカル」サブタブを選択すると、情報をグラフ形式で表示できます。この表示は、親なしの子など非準拠レコードを表示する際に効率的です。「グラフィカル」サブタブを使用するには、「参照」および「プロパティ」リストから選択します。
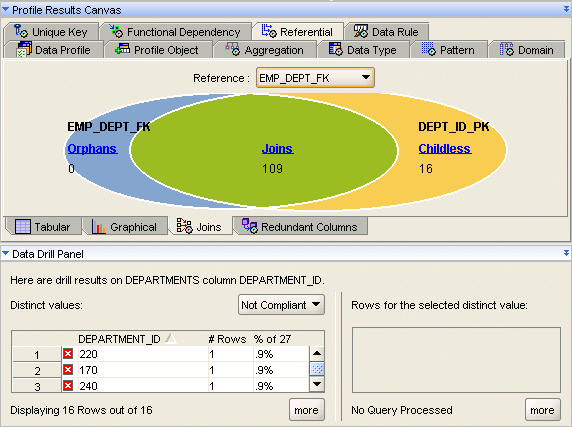
「結合」サブタブには、「参照」リストから選択した参照の結合分析が表示されます。結果は、参照関係に可能性のある3つの結果(結合、親なしの子、子なしのオブジェクト)の相対サイズと正確なカウントを示します。
たとえば、EMPLOYEES表とDEPARTMENTS表の両方にDEPARTMENT_ID列が含まれているとします。DEPARTMENTS表のDEPARTMENT_ID列とEMPLOYEES表のDEPARTMENT_ID列の間には、1対多の関係が存在します。「結合」は、両方の表に値を持つ値を表します。「親なしの子」は、EMPLOYEES表にのみ存在してDEPARTMENTS表には存在しない値を表します。すべての「子なし」の値は、DEPARTMENTS表には存在しますがEMPLOYEES表には存在しません。ダイアグラム上の値にドリルインして「データ・ドリル・パネル」に詳細を表示できます。
図18-6に、「参照」タブの「結合」サブタブを示します。
「冗長列」サブタブには、子表に含まれていて主表にも含まれている列に関する情報が表示されます。冗長列の結果を使用できるのは、プロファイリング中に完全に一意の列が検出された場合のみです。
たとえば、表18-10および表18-11に示すように、2つの表EMPおよびDEPTが、EMP.DEPTNO (fk) = DEPT.DEPTNO (uk)という外部キー関係を持つとします。
この例で、EMP表のLocation列は、結合から同じ情報を取得できるため冗長列です。
「データ・ルール」タブには、オブジェクト・ツリーで選択した表のデータ・プロファイリングによって定義されたデータ・ルールが表示されます。各データ・ルールには、次の詳細が含まれています。
ルール名: データ・ルール名を表します。
ルール・タイプ: データ・ルールのタイプの簡潔な説明を入力します。
元: データ・ルールの元を表します。たとえば、値「導出済」はデータ・ルールが導出されたことを示します。
%準拠: データ・ルールに準拠している行の割合。
欠陥数: データ・ルールに準拠しない行数。
このタブに表示されるデータ・ルールは、「データ・ルール」パネルでアクティブになっているデータ・ルールを反映しています。このタブでデータ・ルールを直接作成することはできません。
属性セットを使用すると、データ・プロファイリング操作の対象を、表、ビューまたはマテリアライズド・ビューの列のサブセットに制限できます。
属性セットを使用する理由は次のとおりです。
プロファイリング結果が必要でない列を除外することで、プロファイリングにかかる時間を短縮できます。
データ・プロファイリングでは、表、ビューまたはマテリアライズド・ビューの列を、一度に165までしかプロファイルできません。属性セットを使用して、オブジェクトから165以下の列を選択してプロファイルできます。
属性セットを使用したデータ・プロファイリングは、次の上位レベルの手順で構成されています。
データ・プロファイリングの実行
データのプロファイリングの詳細は、「データのプロファイリング」を参照してください。
データ・プロファイリングの結果の確認
プロファイリングの結果の詳細は、「プロファイル結果の表示」を参照してください。
次の手順で、表、ビューまたはマテリアライズド・ビューの属性セットを定義します。
プロジェクト・ナビゲータで、表、ビューまたはマテリアライズド・ビューをダブルクリックします。
選択したオブジェクトのエディタが開かれます。
「属性セット」タブを選択します。
「属性セット」セクションで「名前」列の空白領域をクリックし、作成する属性セットの名前を入力して、[Enter]キーを押してください。
手順3で作成した属性セットの名前を選択します。
選択した属性セットの「属性」セクションに、データ・オブジェクトの属性が表示されます。
属性セットに含めるすべての属性で、「挿入」を選択します。
ツールバーの「保存」をクリックして変更内容を保存します。
プロジェクト・ナビゲータで、「データ・プロファイル」ノードを右クリックして新規データ・プロファイルを選択します。
データ・プロファイルの作成ウィザードのようこそページが表示されます。
ようこそページで「次へ」をクリックします。
名前と説明ページで、データ・プロファイルの名前と説明(オプション)を入力します。「次へ」をクリックします。
オブジェクトの選択ページでプロファイリングするデータ・オブジェクトを選択し、シャトル矢印を使用して、データ・オブジェクトを「選択済」リストに移動します。
選択したデータ・オブジェクトに属性セットが含まれている場合は、「属性セットの選択」ダイアログ・ボックスが表示されます。
「属性セットの選択」ダイアログ・ボックスで、プロファイリングする属性セットを選択して「OK」をクリックします。
オブジェクトの選択ページで「次へ」をクリックします。
サマリー・ページで、ウィザードのこれまでのページで選択したオプションを確認し、「終了」をクリックします。
データ・プロファイルが作成され、ナビゲータ・ツリーに追加されます。
データ・プロファイルの作成後に、データ・プロファイル・エディタを使用してプロファイルの定義を変更できます。プロファイル設定を変更したり、データ・プロファイルにプロファイル設定を追加したり、これらを削除したりすることも可能です。オブジェクトを追加するには、メニュー・バーのオプションを使用する方法と「データ・プロファイルの編集」ダイアログの「オブジェクトの選択」タブを使用する方法があります。
データ・プロファイルを編集する手順は、次のとおりです。
プロジェクト・ナビゲータで、データ・プロファイルを右クリックして「開く」を選択します。
データ・プロファイル・エディタが表示されます。
「編集」メニューから「プロパティ」を選択します。
「データ・プロファイルの編集」ダイアログ・ボックスが表示されます。
「データ・プロファイルの編集」ダイアログ・ボックスで、データ・プロファイルの次のプロパティのいずれかを編集し、「OK」をクリックします。
データ・プロファイルの名前または説明を変更するには、「名前」タブで、名前または説明を選択し、新規値を入力します。
オブジェクトを追加または削除するには、「オブジェクトの選択」タブで、矢印を使用してデータ・プロファイルのオブジェクトを追加または削除します。
データ・プロファイリングのステージング領域の場所を変更するには、「データのロケーション」タブを使用します。
矢印を使用して、新規ロケーションを「選択されたロケーション」セクションに移動します。このロケーションをデータ・プロファイルのデフォルトのプロファイリング・ロケーションとして設定するために「新規構成デフォルト」が選択されていることを確認します。
|
注意: データ・プロファイリングを実行した後に、プロファイリングのロケーションを変更する場合、前のプロファイリング結果は失われます。 |
データ・プロファイルにデータ・オブジェクトを追加するには:
プロジェクト・ナビゲータで、データ・プロファイルを右クリックして「開く」を選択します。
データ・プロファイル・エディタが表示されます。
「プロファイル」メニューから「追加」を選択します。
「プロファイル表の追加」ダイアログ・ボックスが表示されます。
「プロファイル表の追加」ダイアログ・ボックスで、データ・プロファイルに追加するオブジェクトを選択します。矢印を使用してこれらを「選択済」セクションに移動します。
オブジェクトの選択時に、[Ctrl]キーを押し続けることで複数のファイルを選択できます。
データ・プロファイリングは、プロセッサおよびI/Oが集中するプロセスであり、プロファイリングの実行時間は数分から数日にわたります。次の条件が満たされていることを確認することで、最大限のデータ・プロファイリング・パフォーマンスを達成できます。
データベースがデータ・プロファイリング用に適切に設定されていること。
データ・プロファイリングの実行時に適切なデータ・プロファイリング構成パラメータを使用すること。
データ・プロファイルは、データ・プロファイリング結果を最適化するように構成できます。データ・プロファイルの構成には構成パラメータを使用します。
次のガイドラインに従うと、データ・プロファイリング・プロセスが高速になります。
必要なタイプの分析のみを実行します。
プロファイリング対象となるオブジェクトに特定のタイプの分析が不要であることがわかっている場合は、構成パラメータを使用して該当タイプのデータ・プロファイリングをオフにします。
プロファイリングするデータ量を制限します。
WHERE句とサンプル率構成パラメータを使用します。
プロファイリングのソース・データがOracle Databaseに格納されている場合は、ソース・スキーマをプロファイル・ワークスペースと同じデータベース・インスタンスに置くことをお薦めします。そのためには、プロファイリング・ワークスペースをソース・スキーマ・ロケーションと同じOracle Databaseインスタンスにインストールします。これにより、データベース・リンクを使用してデータをソースからプロファイリング・ワークスペースに移動する必要がなくなります。
データ・プロファイリング・パフォーマンスを向上させるには、Oracle Databaseを実行するコンピュータに特定のハードウェア機能が必要です。さらに、データ・プロファイリングを実行するOracle Databaseインスタンスを最適化する必要があります。
効率的なデータ・プロファイリングのための考慮事項は、次のとおりです。
Oracle Databaseを実行するコンピュータには、複数のプロセッサが必要です。データ・プロファイリングは、Oracle Databaseが提供する並列化を最大限に利用するように設計されチューニングされています。大きい表(1000万行以上)をプロファイリングする間は、マルチプロセッサ・コンピュータを使用することをお薦めします。
データ・プロファイリングの実行に必要な問合せには、ヒントが使用されます。これにより、Oracle Databaseの初期化パラメータ・ファイルからの並列度が使用されます。デフォルトの初期化パラメータ・ファイルには、並列度を利用するパラメータが含まれています。
データ・プロファイリング時には、高いメモリー・ヒット率を確保することが重要です。そのためには、システム・グローバル領域に割り当てるサイズを大きくします。システム・グローバル領域のサイズは500MB以上の値に構成することをお薦めします。可能であれば、2GBまたは3GBに構成してください。
上級データベース・ユーザーの場合は、バッファ・キャッシュ・ヒット率とライブラリ・キャッシュ・ヒット率を調べることをお薦めします。バッファ・キャッシュ・ヒット率は95%以上に、ライブラリ・キャッシュ・ヒット率は99%以上に設定してください。
I/Oシステムの処理能力は、データ・プロファイリングのパフォーマンスに直接影響します。データ・プロファイリング処理では、全表スキャンと大規模結合が頻繁に実行されます。現在のCPUではI/Oシステムの能力を容易に超えてしまう可能性があるため、I/Oサブシステムを慎重に設計して構成する必要があります。I/Oパフォーマンスの向上に役立つ考慮事項は、次のとおりです。
CPUとI/Oの中断なしの連携をサポートするには、多数のディスク・スピンドルが必要です。ディスクが少数しかなければ、I/Oシステムは高度な並列処理に適応しません。CPUごとに2枚以上のディスクを使用することをお薦めします。
ディスクを構成します。論理ストライプ・ボリュームを既存のディスク上に作成し、各ボリュームを使用可能な全ディスク間でストライプ化することをお薦めします。ストライプ幅の計算には、次の計算式を使用します。
MAX(1,DB_FILE_MULTIBLOCK_READ_COUNT/number_of_disks) X DB_BLOCK_SIZE
DB_FILE_MULTIBLOCK_SIZEおよびDB_BLOCK_SIZEは、データベース初期化パラメータ・ファイル内で設定するパラメータです。計算式で得られた値の倍数をストライプ幅として使用することもできます。
論理ボリュームを作成してメンテナンスするには、Veritas Volume ManagerまたはSun Storage Managerなどのボリューム管理ソフトウェアが必要です。Oracle Database 10g以上を使用していて、ボリューム管理ソフトウェアがない場合は、Oracle Databaseの自動記憶域管理機能を使用してワークロードをディスクに分散できます。
表領域ごとに異なるストライプ・ボリュームを作成します。いくつかの表領域に同じディスク・セットを使用することも可能です。
データ・プロファイリングの場合、通常はUSERS表領域とTEMP表領域が同時に使用されます。これらの表領域を別のディスクに配置してI/Oの競合を減らすことを検討できます。
データの監視および修復(DWR)は、Oracle Master Data Management(MDM)でのデータ管理を支援するために設計されたプロファイリングおよび修正ソリューションです。MDMアプリケーションは、統合された単一のデータ・ビューを提供する必要があります。最初にシステムのマスター・データをクリーンアップしてから、接続された複数のエンティティで共有する必要があります。
MDMアプリケーションがデータの整備および統合を実行できるように、Oracle Warehouse Builderには、データ・プロファイリングおよびデータ修正機能が用意されています。DWRは次のMDMアプリケーションに使用できます。
Customer Data Hub(CDH)
Product Information Management(PIM)
Universal Customer Master(UCH)
データの監視および修復(DWR)では、次の機能を使用してMDMデータベースに格納されたデータの分析、整備、統合を行うことができます。
データ・プロファイリング
データ・プロファイリングは、ソース・データの欠陥を検出および測定できるデータ分析方法です。
データ・プロファイリングの詳細は、「データ・プロファイリングの概要」を参照してください。
データ・ルール
データ・ルールにより、ソース・データ内の有効なデータと関係を判別し、データ品質を確保できます。MDM固有のデータ・ルールをインポートしたり、データ・プロファイリングを実行する前の独自のデータ・ルールを定義したり、データ・プロファイリングの結果からデータ・ルールを導出できます。
データ・ルールの詳細は、「データ・ルールの概要」を参照してください。
データ修正
データ修正により、データおよびメタデータの矛盾、冗長性、誤りを修正できます。修正マッピングを自動的に作成し、ソース・データを整備できます。
データ修正の詳細は、「ETLでのデータ・ルールおよび自動データ修正の概要」を参照してください。
DWRにより、重要なビジネス・ルールを定期的に測定できます。データに矛盾を検出した場合、新しいデータ・ルールを定義して適用し、データ品質を確保できます。
Oracle Warehouse Builderには、MDMアプリケーションでよく利用されるデータ・ルールのセットがあります。たとえば、次のカスタム・データ・ルールは、Customer Data Hub(CDH)およびUniversal Customer Master(UCM)の両方のアプリケーションで使用できます。
属性の完全性
連絡先の完全性
データ型
データ・ドメイン
制限値
一意キー検出
完全名の標準化
共通パターン
名前の大文字化
内線電話番号
国際電話番号
名前のみのアクセス・リストの禁止
名前またはSSNによるアクセス・リストを禁止
電子メール・リストの禁止
これらのデータ・ルールの詳細は、『Oracle Watch and Repair for MDMユーザーズ・ガイド』を参照してください。
データの監視および修復(DWR)を使用するには、次のソフトウェアが必要です。
Oracle Database 11gリリース1(11.1)以上
Oracle Warehouse Builder 11gリリース1 (11.1.0.7)以上
Customer Data Hub(CDH)、Product Information Management(PIM)またはUniversal Customer Master(UCH)のうち、1つ以上のMaster Data Management(MDM)アプリケーション。
Oracle Databaseで実行されるMDMアプリケーションの場合、DWRを直接使用できます。ただし、Oracle Databaseで実行されないMDMアプリケーションの場合には、サード・パーティのデータベースとのゲートウェイを設定する必要があります。
次の手順で、データの監視および修復(DWR)を実行します。
Master Data Management(MDM)アプリケーション・データベースに対応するロケーションを作成します。
ロケーション・ナビゲータの「データベース」ノードの下にある「Oracle」ノードを使用します。ユーザー名、パスワード、ホスト名、ポート、サービス名、データベースのリリースなど、MDMアプリケーションの詳細を指定します。
プロジェクト・ナビゲータで「アプリケーション」ノードを開き、MDMアプリケーションのノードを表示します。
「CDH」ノードはCustomer Data Hubアプリケーションを表します。「PIM」ノードはProduct Information Managementアプリケーションを表します。「UCM」ノードはUniversal Customer Masterを表します。
DWRを実行するMDMアプリケーションのタイプに対応するノードを右クリックし、「CMIモジュールの作成」を選択します。
モジュールの作成ウィザードを使用して、MDMメタデータ定義を格納するモジュールを作成します。モジュールの作成時の手順1で作成したロケーションを選択します。
手順3で作成したモジュールにMDMアプリケーションからメタデータをインポートします。モジュールを右クリックして、「インポート」を選択します。
MDMメタデータをインポートできるメタデータのインポート・ウィザードが表示されます。
「MDMデータ・ルールのインポート」の説明に従って、MDM固有のデータ・ルールをインポートします。
「データ・ルールのデータ・オブジェクトへの適用」の説明に従って、MDMアプリケーション表にデータ・ルールを適用します。
データ・ルールを表に適用すると、表データがデータ・ルールを使用して定義されたビジネス・ルールに準拠しているかどうかがわかります。手順5でインポートしたデータ・ルールまたは作成したその他のデータ・ルールを適用できます。データ・ルールの作成の詳細は、「データ・ルールの作成ウィザードを使用したデータ・ルールの作成」を参照してください。
プロファイリングするMDMアプリケーションのすべての表を含むデータ・プロファイルを作成します。
データ・プロファイルの作成の詳細は、「データ・プロファイルの作成」を参照してください。
「データのプロファイリング」の説明に従って、MDMアプリケーション・オブジェクトにデータ・プロファイリングを実行します。
「プロファイル結果の表示」の説明に従って、データ・プロファイリングの結果を表示します。
(オプション)「データ・プロファイリング結果からのデータ・ルールの導出」の説明に従って、データ・プロファイリングの結果に基づいてデータ・ルールを導出します。
データ・プロファイリングの結果から導出したデータ・ルールは、自動的に表に適用されます。
「修正オブジェクトの作成手順」の説明に従って、修正マッピングを作成します。
「スキーマ修正のデプロイ」および「修正マッピングのデプロイ」に従って、Oracle Warehouse Builderにより生成された修正マッピングでデータおよびメタデータを修正します。
「修正済データおよびメタデータのMDMアプリケーションへの書込み」の説明に従って、手順12で作成した修正オブジェクトに格納された修正済データをMDMアプリケーションに書き込みます。
Customer Data Hub(CDH)およびUniversal Customer Master(UCM)アプリケーションに必要なデータ・ルールは、OWB_HOME/owb/misc/dwr/customer_data_rules.mdlファイルに記述されています。これらのデータ・ルールをインポートするには、「ファイル」メニューから「インポート」、Oracle Warehouse Builderメタデータの順に選択します。「メタデータのインポート」ダイアログ・ボックスで、customer_data_rules.mdlを選択して「OK」をクリックします。「メタデータのインポート」ダイアログの詳細は、このページの「ヘルプ」をクリックします。
インポートされたデータ・ルールは、グローバル・ナビゲータで「パブリック・データ・ルール」ノードの「MDM Customer Data Rules」ノードの下に表示されます。
整備済および修正済のデータは、データ・プロファイリングによって作成される修正オブジェクトに保存されます。
より効果的に処理するために、修正が必要な行のみを書き込むことができます。これは、生成された修正マッピングを変更することで実現します。未変更の準拠行を通過するブランチを削除します(このブランチには、負のフィルタと集合演算子が含まれています)。修正マッピングでブランチを処理している修正済の行のみを保持します。
ソースのMDMアプリケーションに修正データを書き込むには、次の手順に従います。
マッピング・エディタを使用してマッピングを作成します。
修正済の表をマッピング・エディタにドラッグ・アンド・ドロップします。これがソース表になります。
UCMの場合は、作業する実表に対応するインタフェースをドラッグ・アンド・ドロップします。
MDMアプリケーション・ツールおよびドキュメントを使用して、特定のインタフェース表の実表を判別します。
修正済の表からインタフェース表に列をマッピングします。
マッピングをデプロイして実行し、修正済のデータをソースMDMアプリケーションに書き込みます。
インタフェース表に対する変更で実表を更新します。Siebel Enterprise Integration Manager(EIM)を使用できます。EIMはコマンドラインで実行することも、Graphical User Interface(GUI)からでも実行できます。
EIMの使用方法の詳細は、『Siebel Enterprise Integration Manager管理ガイド』を参照してください。