| Oracle® Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド 11gリリース2 (11.2) B61350-02 |
|



 前 |
 次 |
この章では、Oracle Warehouse Builderの照合、マージおよびデータ重複機能について説明します。
この章の内容は次のとおりです。
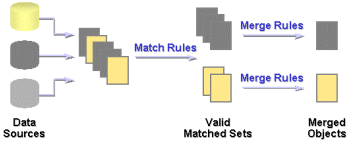
Oracle Warehouse Builderは、あらゆるデータ・タイプに適用可能な汎用性のあるデータの照合およびマージ機能を備えています。
アルゴリズムに一致する行のリストをターゲット表に書き出すことができます。また、再度幅広い組込みのマージ・ルールを使用し、マージ・ルールを実装して生成されたマージ済レコードに複雑な重複除外ロジックを実装することもできます。
Oracle Warehouse Builderの照合およびマージでは次の機能を提供します。
「Jaro-Winkler」アルゴリズム、Levenshtein edit distanceアルゴリズムなどの組込みアルゴリズムを使用したり、実装するカスタム・アルゴリズムを使用して、一致を識別します。
重みを使用して、レコード間の一致を識別します。
既存のマスター・データ管理アプリケーションなどその他のマージ・ロジックへの入力として一致候補を含む表を生成します。
組込みのマージ・ルール、カスタム実装のマージ・ロジックまたはパッケージとカスタム・ルールを組み合せた複雑なマージ・ルールに基づくマージ・ロジックを使用して、マージ・データ・レコードの表を生成します。
データを相互参照して、一致を追跡および監査します。
個人、企業およびアドレス・データ用の高度な照合ルールが組み込まれています。
Oracle Warehouse Builderの照合およびマージ機能をOracle Warehouse Builderの名前とアドレスのクレンジング機能と組み合せることで、ハウスホールディングをサポートできます。これは、名前とアドレスのデータから一意のハウスホールドを識別するプロセスです。
Name and Addressデータのクレンジングの詳細は、第22章「Name and Addressのクレンジング」を参照してください。
|
注意: Oracle Warehouse Builderは、Oracle Warehouse Builder ETLマッピングで使用されるMatch-Merge演算子を通じて、その照合およびマージ機能を公開します。サード・パーティのETL製品のユーザーは、既存のETLソリューションを保持したまま、Oracle Warehouse Builderの照合およびマージ機能を使用できます。
マッピング用のデプロイされるコードは、照合およびマージを実行するデータベースにロードされるPL/SQLパッケージのみであるので、この技術はPL/SQパッケージからロジックを呼び出すことのできるELTツールから使用できます。 |
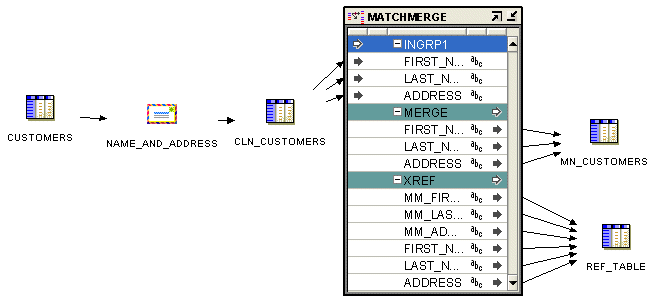
図23-1に、Match-Merge演算子を使用するマッピングを示します。Match-Merge演算子の前にName and Address演算子NAMEADDRとステージング表CLN_CUSTOMERSがあることがわかります。多くのシナリオで、名前とアドレスのクレンジングおよび重複除外を行うときは、マッピングでMatch-Merge演算子をName and Address演算子と組み合せることをお薦めします。ソース・データにアドレス・クレンジングを実行すると、一致およびマージ用のエラーのない標準化されたデータが得られます。これにより、結果の品質が向上し、整備済データを照合としてより容易に識別できるため、パフォーマンスが向上します。
この単純なマッピングは照合およびマージ・プロセスのデータ・フローを表します。
顧客表では、Name and Address演算子への入力を提供します。この演算子の出力はCLN_CUSTOMERS表に格納されます。
CLN_CUSTOMERS表では、FIRST、LASTおよびADDRESS列がMatch-Merge演算子の入力として提供されます。
Match-Merge演算子では、MM_CUSTOMERS表(実際の重複除外済の行)へのFIRST、LASTおよびADDRESS入力が提供されるとともに、REF_TABLE表へのFIRST、LAST、ADDRESS、MM_FIRST、MM_LASTおよびMM_ADDRESS入力が提供されます。これは、入力からの照合済の行のグループを特定します。
この一致プロセスの詳細は、「照合およびマージ・プロセスの概要」で説明しています。
照合により、同じ論理データを参照するレコードが判別されます。Oracle Warehouse Builderでは、レコードを比較するための様々な一致ルールが提供されます。一致ルールの範囲は、単純な完全一致から、共通のデータ入力エラーを検出して修正できる高度なアルゴリズムまでおよびます。
マージは、各列のマージ済の値を作成するために選択または定義するマージ・ルールというサバイバーシップ・ルールに基づく一致した複数のレコードを単一の一元化された「ゴールデン」レコードに一元化します。
パッケージされているMDMなど、重複したレコードをマージするためのロジックがあるその他のツールがある場合でも、Oracle Warehouse Builderを使用して一致する行の候補のセットを生成したり、中間表にそれらを格納できます。
次の概念と用語は、照合およびマージ・プロセスを理解するうえで重要です。
一致bin
一致binは、類似するレコードのためのコンテナで、潜在的な一致を識別するために使用されます。一致bin属性は、レコードが一致bin内に分類される方法を判別するために使用されます。照合の実行中は、Oracle Warehouse Builderでは同じ一致bin内のレコードのみを比較します。一致binによりデータ・セット内の潜在的な一致の数が制限されるので、一致アルゴリズムのパフォーマンスが向上します。
一致bin属性
照合を実行する前に、Oracle Warehouse Builderによりソース・レコードが分割され、より小規模な類似するレコードのグループになります。一致bin属性はソース属性で、レコードの分類方法の決定に使用されます。同じ一致bin属性を持つレコードは、同じ一致bin内に存在します。また一致bin属性により、管理可能なセットになるように一致binが制限されます。
次の競合するニーズを満たすように、慎重に一致bin属性を選択します。
一致する可能性のあるすべてのレコードが必ず同じ一致bin内に存在するようにします。
一致binサイズをできるかぎり小規模にします。
一致を識別するには、binに含まれるレコード同士を照合する必要があるため、一致binのサイズは小さいほうが効率的です。binが大きければ大きいほど、パフォーマンスは低下します。
一致レコードのセット
一致レコードのセットは、一致bin内で1つ以上の類似するレコードで構成されています。照合の後、各一致binには1つ以上の一致レコードのセットが含まれます。2つのレコードが類似する場合に判別する一致ルールを定義できます。
マージ済レコード
マージ済レコードには、一致レコードのセット内の複数のレコードを使用してマージされたデータが含まれています。各一致レコードのセットにより、独自のマージ済レコードが生成されます。
Match-Merge演算子を使用してレコードの照合およびマージを行います。この演算子では、入力ソースからレコードを受け入れ、論理的に同一であるレコードを判別し、一致したレコードから新規のマージ済レコードを構成します。
一致およびマージ・プロセスの概要を示します。次のプロセスがあります。
図23-2に、一致およびマージ・プロセスの概要を示します。
一致binは、一致bin属性を使用して構成されています。一致bin属性値が同じレコードは、同じ一致binに存在します。小さな一致binの使用は効率的ではありません。
一致ルールは、各一致bin内のすべてのレコードに適用され、一致レコードのセットが1つ以上生成されます。一致ルールでは、2つのレコードが一致するかどうかが判別されます。一致アルゴリズムは、一致bin内のすべてのレコードを比較するn X nアルゴリズムです。
このアルゴリズムは推移的な照合という点で重要です。レコードA、レコードBおよびレコードCの3つのレコードについて考えてみます。レコードAがレコードBと等しく、レコードBがレコードCと等しい場合、レコードAはレコードCと等しくなります。
1つのマージ・レコードは、1つの照合レコード・セットから作成されます。固有のルールを作成し、マージ・ルールとして使用することで、マージ属性を定義できます。
一致ルールは、2つのレコードが論理的に同じかどうかの判別に使用されます。Oracle Warehouse Builderを使用すると、様々なタイプのルールを使用してソース・レコードを照合できます。Match-MergeウィザードまたはMatchMergeエディタを使用して一致ルールを定義できます。このエディタを使用して、既存の一致ルールを編集するか、新しいルールを追加します。
一致ルールはアクティブまたは受動の可能性があります。アクティブなルールが生成された場合、指定された順序で実行されます。受動ルールは生成されても自動的には実行されません。受動ルールはカスタム・ルールによって実行できます。
表23-1に、一致ルールのタイプを説明します。
表23-1 一致ルールのタイプ
| 一致ルール | 説明 |
|---|---|
|
すべて一致 |
一致bin内の行がすべて照合されます。 |
|
一致なし |
照合がオフになります。一致bin内の行は照合されません。 |
|
条件付き |
設定したアルゴリズムに基づいて行が照合されます。条件付き一致ルールの詳細および作成方法は、「条件付き一致ルール」を参照してください。 |
|
重み |
属性に割り当てるスコアに基づいて行が照合されます。重み一致ルールの詳細および作成方法は、「重み一致ルール」を参照してください。 |
|
人名 |
人名に基づいてレコードが照合されます。人名一致ルールの詳細および作成方法は、「人名一致ルール」を参照してください。 |
|
会社 |
組織または会社の名前に基づいてレコードが照合されます。会社一致ルールの詳細および作成方法は、「会社一致ルール」を参照してください。 |
|
アドレス |
郵便アドレスに基づいてレコードが照合されます。アドレス一致ルールの詳細および作成方法は、「アドレス一致ルール」を参照してください。 |
|
カスタム |
定義するカスタム比較アルゴリズムに基づいてレコードが照合されます。カスタム一致ルールの詳細および作成方法は、「カスタム一致ルール」を参照してください。 |
条件付き一致ルールにより、レコードの一致条件が指定されます。
条件付き一致ルールを使用すると、複数の属性の比較を組み合せて1つの複合ルールにできます。複数の属性が1つのルールに関与する場合、すべての比較がtrueの場合にのみ2つのレコードは一致するとみなされます。Oracle Warehouse Builderでは、2番目以降の条件の左端の列に「AND」アイコンが表示されます。
比較アルゴリズムを使用して属性を比較する方法を指定できます。
属性
特定の条件のテスト対象となる属性を識別します。任意の入力属性(INGRP1)から選択できます。
位置
実行順序。行ヘッダーをクリックし、その行を新規の位置にドラッグすると、ルールの位置を変更できます。行ヘッダーは、「属性」列の左側にあるボックスです。
アルゴリズム
方法のリストを使用して一致を判別します。各アルゴリズムについては、表23-2を参照してください。
類似度のスコア
「Edit Distance」、「標準化されたEdit Distance」、「Jaro-Winkler」または「標準化したJaro-Winkler」アルゴリズムにより計算された、2つの文字列の一致に必要な類似度の最小値。0(ゼロ)から100の値を入力します。値100は完全一致を示し、値0(ゼロ)は類似度がないことを示します。
空白の一致
照合時の空の文字列の処理オプションを示します。
条件付き一致ルールの各属性に比較アルゴリズムを割り当て、属性値を比較する方法を指定します。複数の属性が、それぞれに選択した固有の比較アルゴリズムを持つ1つのルールで比較される場合があります。
表23-2に、比較のタイプを示します。
表23-2 条件付き一致ルールに対する比較アルゴリズムのタイプ
| アルゴリズム | 説明 |
|---|---|
|
Exact |
属性の値が同じ場合にその属性は一致します。たとえば、「Dog」と「dog!」は、2番目の文字列が大文字始まりでなく、余分な文字が含まれているため、両者は一致しません。
|
|
標準化されたExact |
完全一致の比較前に、属性の値が標準化されます。標準化すると、比較時に大/小文字区別、空白および非英数字は無視されます。このアルゴリズムを使用すると「Dog」と「dog!」は一致となります。 |
|
Soundex |
データがSoundex表示に変換された後、テキスト文字列と比較されます。Soundex表示が一致する場合、2つの属性値は一致するとみなされます。 |
|
Edit Distance |
「類似度のスコア」に0から100を入力します。2つの属性の類似度が指定した値以上の場合、この属性値は一致するとみなされます。 類似度のアルゴリズムでは、2つの文字列のEdit Distanceが計算されます。値が100の場合、2つの値が同一であることを示し、値が0の場合はまったく類似していないことを示します。 たとえば、文字列「tootle」が文字列「tootles」と比較される場合、Edit Distanceは1です。文字列「tootles」の長さは7です。したがって、類似度の値は、(6/7)*100つまり85となります。 ここで使用するアルゴリズムはLevenshtein edit distanceアルゴリズムです。 |
|
標準化されたEdit Distance |
類似度のアルゴリズムを使用して一致が判別される前に、属性の値が標準化されます。標準化すると、比較時に大/小文字区別、空白および非英数字は無視されます。 |
|
不完全な名前 |
ある属性の値全体が、同じ単語で始まる他の属性内に含まれる場合、文字列の属性の値は一致するとみなされます。たとえば、「Midtown Power」は「Midtown Power and Light」とは一致しますが、「Northern Midtown Power」とは一致しません。比較時に大/小文字区別および非英数字は無視されます。 |
|
略称 |
ある文字列内で一致する単語の略称が、他の文字列に含まれている場合、文字列の属性の値は一致するとみなされます。このアルゴリズムでは、略称の検出前に、標準化されたExact比較が文字列全体で実行されます。比較時に大/小文字区別および非英数字は無視されます。一致ルールでは、各単語に対して略称が検索されます。比較対象となる長い方の単語に、短い方の単語の文字がすべて含まれる場合、また、その文字が短い方の単語と出現順序が同じ場合、その単語は一致するとみなされます。 たとえば、「Intl.Business Products」は「International Bus Prd」と一致します。 |
|
頭文字 |
ある文字列が他の文字列の頭字語の場合、文字列の属性の値は一致するとみなされます。このアルゴリズムでは、頭字語を識別する前に、標準化されたExact比較が文字列全体で実行されます。一致しない場合は、ある文字列の各単語が、他の文字列内で一致する単語と比較されます。単語全体で一致しない場合、その文字列に含まれる単語の各文字が、他の文字列内の一致していない単語の最初の文字と比較されます。その文字が同じ場合、その名前は一致するとみなされます。 たとえば、「Chase Manhattan Bank NA」は「CMB North America」と一致します。比較時に大/小文字区別および非英数字は無視されます。 |
|
Jaro-Wrinkler |
「Edit Distance」アルゴリズムをさらに改良した比較システムを使用して、類似度の値に基づいて文字列を一致させます。「Jaro-Winkler」アルゴリズムでは、文字列の長さが考慮され、先頭にあるエラーほど大きなペナルティが適用されます。また、一般的な誤植も認識されます。 その文字列は、類似度の値が指定する「類似度のスコア」のスコア以上の場合に一致します。類似度が100の場合、2つの文字列が同一であることを示します。類似度が0の場合は、まったく類似していないことを示します。実際にアルゴリズムにより計算された値(0.0から1.0)を100倍すると「Edit Distance」のスコアと対応します。 |
|
標準化したJaro-Wrinkler |
大/小文字区別、空白および非英数字が排除されてから、「Jaro-Winkler」アルゴリズムを使用して一致が判別されます。 |
|
Double Metaphone |
「Soundex」アルゴリズムをさらに改良したコーディング・システムを使用して、発音の類似する文字列を一致させます。複数の方法で発音可能な文字列に対して2つのコードを生成します。最初のコードが2つの文字列と一致しているか、2番目のコードが2つの文字列と一致している場合、その文字列は一致しています。「Double Metaphone」アルゴリズムでは他に、イタリア語、スペイン語、フランス語、ゲルマンおよびスラブ系言語の発音が考慮されています。「Soundex」アルゴリズムとは異なり、「Double Metaphone」アルゴリズムでは1文字目がエンコードされるため、「Kathy」と「Cathy」は同じ表音コードとして評価されます。 |
条件付き一致ルールを定義する手順は、次のとおりです。
「一致ルール」タブまたは一致ルール・ページの最上位で、「ルール・タイプ」列の「条件付き」を選択します。
「詳細」セクションが表示されます。
「追加」をクリックして新規の1行を追加します。
「属性」列の属性を選択します。
「アルゴリズム」列で、比較アルゴリズムを選択します。説明は、表23-2を参照してください。
「Edit Distance」、「標準化されたEdit Distance」、「Jaro-Winkler」または「標準化したJaro-Winkler」アルゴリズムの類似度のスコアを指定します。
空白の処理方法を選択します。
次の説明では、一部の基本の一致ルールを実際のデータに適用する方法と、複数の一致ルールを相互にやり取りできるようにする方法について示します。
Match-Merge演算子を使用して顧客の郵送先リストを管理する方法を考えてみます。照合を使用して、10,000行ある顧客データの表内の同じ人物を参照するレコードを検出します。
たとえば、類似する名前および姓を持つレコードを選別する一致ルールを定義できます。照合を使用して、5つの行が同じ人物を参照していることが判明したとします。その場合、これらのレコードを1つの新規レコードにマージできます。たとえば、マージ・ルールを作成して、一致した5つのレコードの中で一番長いアドレスを持つレコードの値を保持できます。新しくマージされた表には、各顧客につき1つのレコードが含まれています。
表23-3に、Match-Merge演算子を使用する前の、同じ人物を参照している各レコードを示します。
表23-3 サンプル・レコード
| 行 | 名 | 姓 | SSN | アドレス | 単位 | 郵便番号 |
|---|---|---|---|---|---|---|
|
1 |
Jane |
Doe |
NULL |
123 Main Street |
NULL |
22222 |
|
2 |
Jane |
Doe |
111111111 |
NULL |
NULL |
22222 |
|
3 |
J. |
Doe |
NULL |
123 Main Street |
Apt 4 |
22222 |
|
4 |
NULL |
Smith |
111111111 |
123 Main Street |
Apt 4 |
22222 |
|
5 |
Jane |
Smith-Doe |
111111111 |
NULL |
NULL |
22222 |
表23-4に、Match-Merge演算子を使用した後のJane Doeに関する単一レコードを示します。新規レコードでは、サンプルの様々な行のデータが含まれていることがわかります。
複数の一致ルールを作成すると、Oracle Warehouse Builderでは2つの行がいずれかの一致ルールを満たしている場合に、両者が一致しているものと判別されます。つまり、Oracle Warehouse Builderでは複数の一致ルールがOR論理を使用して評価されます。
次の例は、Oracle Warehouse Builderで複数の一致ルールがどのように評価されるかを示しています。
「一致ルール」タブの最上部で、表23-5で説明した2つの一致ルールを作成します。
タブの下部で、表23-6で説明するようにRule_1に詳細を割り当てます。
Rule_2について、表23-7に示す詳細を割り当てます。
表23-7 Rule_2の詳細
| 属性 | 位置 | アルゴリズム | 類似度のスコア | 空白の一致 |
|---|---|---|---|---|
|
姓 |
1 |
Exact |
0 |
いずれかが空白の場合は一致しない |
|
PHN |
2 |
Exact |
0 |
いずれかが空白の場合は一致しない |
表23-8に示すデータがあるとします。
表23-8 サンプル・データ
| 行 | 名 | 姓 | PHN | SSN |
|---|---|---|---|---|
|
A |
John |
Doe |
650-123-1111 |
NULL |
|
B |
Jonathan |
Doe |
650-123-1111 |
555-55-5555 |
|
C |
John |
Dough |
650-123-1111 |
555-55-5555 |
Rule_1に従って、行BおよびCは一致します。Rule_2に従って行AおよびBは一致します。したがって、Oracle Warehouse Builderでは一致ルールがOR論理を使用して処理されるため、3つのレコードはすべて一致することになります。
一般ルールでは、AがBと一致し、BがCと一致する場合、AはCと一致することになります。表23-9で説明するような類似性に基づいて、条件付き一致ルールを割り当てます。
表23-10に示すデータがあるとします。
表23-10 サンプル・データ
| 行 | 名 | 姓 | PHN | SSN |
|---|---|---|---|---|
|
A |
John |
Jones |
650-123-1111 |
NULL |
|
B |
Jonathan |
James |
650-123-1111 |
555-55-5555 |
|
C |
John |
Jamos |
650-123-1111 |
555-55-5555 |
JonesはJamesと類似度80で一致し、JamesはJamosと類似度80で一致します。Jonesは、類似度が60でしきい値の80より低いため、Jamosとは一致しません。ただし、JonesはJamesと一致し、JamesはJamosと一致するため、3つのレコード(Jones、JamesおよびJamos)はすべて一致することになります。
重み付けされた一致ルールにより、ルールに含まれる各属性に整数の重みを割り当てることができます。また、しきい値を指定する必要があります。各属性について、Match-Merge演算子により、その重みに類似度のスコアが乗算されてスコアの合計が計算されます。その合計がしきい値以上である場合、比較している2つのレコードは一致するとみなされます。
重み一致ルールは、多数の属性を比較する必要がある場合に非常に便利で、異なる単一の属性が存在しなければ、条件付きルールで発生する可能性のある不一致が発生します。
重みルールは、暗黙的に類似度のアルゴリズムを呼び出し、2つの属性値を比較します。このアルゴリズムでは整数(0から100の間の割合値)を戻します。これは、2つの値の類似度を表します。値が100の場合、2つの値が同一であることを示し、値が0の場合はまったく類似していないことを示します。
類似度アルゴリズム
一致の判別に使用する方法。次のアルゴリズムから選択します。
Edit Distance: ある文字列から別の文字列への変換に必要な削除、挿入または置換の数が計算されます。
Jaro-Winkler: 「Edit Distance」アルゴリズムよりも改善された比較システムが使用されます。文字列の長さが考慮され、先頭にあるエラーほど大きなペナルティが適用されます。また、一般的な誤植も認識されます。
属性
特定の条件のテスト対象となる属性を識別します。任意の入力属性(INGRP1)から選択できます。
最大スコア
属性の重み値。「一致のための必須スコア」よりも大きい値を指定する必要があります。
空白の場合にスコア
レコードの1つが空の場合の類似度の値。
一致のための必須スコア
一致に必要な類似度を表す値。値が100の場合、2つの値が同一であることを示します。値0(ゼロ)は類似性がないことを示します。
表23-11は、2つの異なるレコードに含まれる属性値を示しており、レコードは次の順序で読み込まれます。
一致ルールを「Edit Distance」類似度のアルゴリズムを使用するように定義します。「一致のための必須スコア」は120です。名およびモジュール名の属性には、「最大スコア」を50、「空白の場合にスコア」を20と定義します。姓の属性は、「最大スコア」は80、「空白の場合にスコア」は0です。
重み一致ルールを使用したレコード1とレコード2の比較の例を考えてみます。
レコード2の名は空白のため、空白のスコア = 20です。
2つのレコードのミドル・ネームの類似度は0.83です。この属性に割り当てられた重みは50であるため、この属性の類似度のスコアは41.5です(0.83 X 50)。
属性の姓は同一であるため、姓の類似度のスコアは1です。重み付けスコアは80です(1 X 80)。
この比較の合計スコアは143です(20+43+80)。この値は「一致のための必須スコア」に定義した値よりも大きいため、このレコードは一致するとみなされます。
重み一致ルールを使用する手順は、次のとおりです。
「一致ルール」タブまたは一致ルール・ページで、「ルール・タイプ」として「重み」を選択します。
ページの最下部に「詳細」タブが表示されます。
ページの最下部にある「追加」を選択して新規の1行を追加します。
各行について、「属性」列を使用して属性を選択し、ルールに追加します。
「最大スコア」で、各属性に重みを割り当てます。Oracle Warehouse Builderでは、各属性が類似度のアルゴリズムを使用して比較されます。このアルゴリズムは、2つの行の類似度を表す0から100までのスコアを戻します。
「空白の場合にスコア」で、レコードのいずれかの属性が空白の場合に使用する値を割り当てます。
「一致のための必須スコア」で、一致全体のスコアを割り当てます。
2つの行が一致すると考えられる場合、合計数は「一致のための必須スコア」パラメータで指定した値より大きいはずです。
組込み人名ルールは、個々の名前を照合する容易で便利な方法です。人名一致ルールは、最初にName and Address演算子を使用してデータが修正された場合に最も効果的です。
人名一致ルールを使用する場合、レコード内で、人名を表すデータを指定する必要があります。データは複数の列から取得できます。各列には、データが何を表すかを指定する「入力」ロールを割り当てる必要があります。
人名一致ルールを定義するには、ルールの一部である「人名属性」を定義する必要があります。たとえば、「人名属性」の名と姓を比較に使用する人名一致ルールを作成できます。各「人名属性」について、その属性に使用する人名ロールを定義する必要があります。次に、比較に使用するルール・オプションを定義します。たとえば、姓を比較する場合に、ハイフンで連結された姓は一致するとみなすように指定することもできます。
表23-12は、照合に使用する名前の各部分のロールを示しています。一致ルール・ページまたは「一致ルール」タブで、「人名属性」タブの「ロール」列を使用して人名詳細を定義します。
表23-12 人名一致ルールの名前ロール
| ロール | 説明 |
|---|---|
|
プリネーム |
プリネームは、次の条件に当てはまる場合にのみ比較されます。
|
|
標準化された名前 |
名を比較します。デフォルトでは、名が一致する必要がありますが、他の比較オプションも指定できます。 名は、両方が空白の場合に一致します。「プリネーム」ロールが割り当てられ、「"Mrs"の一致」オプションが設定されていなければ、空白の名は空白以外の名と一致しません。「姓」ロールが割り当てられていない場合、First_name_stdのロールを割り当てる必要があります。 |
|
標準化されたミドル・ネーム、標準化されたミドル・ネーム2、標準化されたミドル・ネーム3 |
ミドル・ネームを比較します。デフォルトでは、ミドル・ネームが一致する必要がありますが、他の比較オプションも指定できます。複数の「ミドル・ネーム」ロールが割り当てられている場合、異なるロールに割り当てられた属性はクロス比較されます。 たとえば、Middle_name_stdの値は、「Middle_name_2_std」ロールも割り当てられている場合、他のMiddle_name_std値に対してだけでなく、Middle_name_2_stdに対しても比較されます。いずれかまたは両方が空白の場合、ミドル・ネームは一致します。いずれかの「ミドル・ネーム」ロールが割り当てられている場合、「First_name_std」ロールも割り当てられている必要があります。 |
|
姓 |
姓を比較します。デフォルトでは、姓が一致する必要がありますが、他の比較オプションも指定できます。両方が空白の場合、姓は一致しますが、いずれか一方が空白の場合は一致しません。 |
|
ポストネーム |
「Jr.」や「III」などのポストネームを比較します。値が同一である場合またはいずれかの値が空白の場合に、ポストネームは一致します。 |
表23-13は、人名一致ルールの一致を判別するオプションを示しています。「一致ルール」タブまたは一致ルール・ページの「詳細」タブを使用して人名詳細を定義します。
表23-13 人名一致ルールのオプション
| オプション | 説明 |
|---|---|
|
姓名の順序の変更を検出 |
「Elmer Fudd」を「Fudd Elmer」と一致させるなど、姓名の順序の変更が検出されます。このオプションを選択できるのは、「人名属性」タブで属性に「名」および「姓」ロールを選択した場合です。 |
|
イニシャルの一致 |
「R.」と「Robert」など、イニシャルを名前と一致させます。このオプションは、「名」および「ミドル・ネーム」ロール用に選択できます。 |
|
部分文字列の一致 |
「Rob」と「Robert」など、部分文字列を名前と一致させます。このオプションは、「名」および「ミドル・ネーム」ロール用に選択できます。 |
|
類似度のスコア |
類似度がスコア以上の場合、レコードは一致するとみなされます。たとえば、スコアが80以下の場合、「Susan」と「Susen」は一致となります。 「Edit Distance」または「Jaro-Winkler」アルゴリズムにより計算された類似度のスコアを使用して、一致が判別されます。値100を入力すると完全一致が要求され、値0(ゼロ)を入力すると類似度は要求されません。 |
|
表音コードの一致 |
「Soundex」または「Double Metaphone」アルゴリズムを使用して一致を判別します。 |
|
複合名の検出 |
「De Anne」と「Deanne」など、複合名と名前を一致させます。このオプションは、「名」ロール用に選択できます。 |
|
"""Mrs""の一致" |
「Mrs.Washington」と「George Washington」など、プリネームと姓名を一致させます。このオプションは「プリネーム」ロール用に選択できます。 |
|
ハイフンで連結された一致名 |
「Reese-Jones」と「Reese」など、ハイフンで連結された名前とハイフンなしの名前を一致させます。このオプションは「姓」ロール用に選択できます。 |
|
欠落したハイフンの検出 |
演算子では、「Hillary Rodham Clinton」と「Hillary Rodham-Clinton」を一致させるなど、欠落したハイフンが検出されます。このオプションは「姓」ロール用に選択できます。 |
組込み会社ルールは、ビジネス名を照合する容易で便利な方法です。会社一致ルールは、データが、最初にName and Address演算子を使用してデータが修正された場合に最も効果的です。人名ルールと同様に、このルールでは、レコード内で、どのデータが会社の名前を表すかを設定する必要があります。データは複数の列から取得でき、指定した各列には、データが何を表すかを指定する「入力」ロールを割り当てる必要があります。
すべての属性に対して「会社」ロールを割り当てる必要はなく、また、すべてのロールを属性に割り当てる必要もありません。「会社」ロールに割り当てられた属性は、レコードを比較するために一致ルールで使用されます。割り当てたロールおよび設定した他の比較オプションに基づいて属性が比較されます。各ロールを会社一致ルールで処理する方法の一覧は、「会社ロール」を参照してください。
「会社」ロールでは、照合に使用される会社名の一部を定義します。「会社」ロールに対して選択できるオプションは、会社1または会社2です。属性を1つ選択する場合、会社名に対して、ロールとして会社1を選択します。属性を2つ選択した場合は、いずれか1つを会社1とし、残りを会社2と指定します。
会社1: このロールを割り当てる場合、会社1が表すビジネス名が比較されます。「会社1と会社2のクロス一致」ボックスが選択されていなければ、会社1の名前は会社2の名前と比較されません。デフォルトでは、会社名が一致する必要がありますが、他の比較オプションも指定できます。いずれかまたは両方の名前が空白の場合、会社1の名前は一致しません。
会社2: このロールを割り当てる場合、会社2に割り当てられた属性の値が比較されます。「会社1と会社2のクロス一致」ボックスが選択されていなければ、会社2の名前は会社1の名前と比較されません。デフォルトでは、会社名が一致する必要がありますが、他の比較オプションも指定できます。いずれかまたは両方の名前が空白の場合、会社2の名前は一致しません。「会社1」ロールが割り当てられていない場合、「会社2」ロールが割り当てられることはありません。
表23-14に、一致を確認するために会社名の各コンポーネントに設定可能なルール・オプションを示します。
表23-14 会社ルールのオプション
| オプション | 説明 |
|---|---|
|
ストライプ・ノイズ・ワード |
照合する前に会社1および会社2からTHE、AND、CORP、CORPORATION、CO、COMPANY、INC、INCORPORATED、LTD、TO、OFおよびBYを削除します。 |
|
会社1と会社2のクロス一致 |
照合する2つのレコードを比較する場合、会社1と会社1および会社2と会社2のレコードをそれぞれ照合し、さらに会社1と会社2のレコードを照合します。 |
|
会社名の不完全一致 |
「不完全な名前」アルゴリズムを使用して、一致が判別されます。たとえば、Midtown PowerとMidtown Power and Lightは一致します。 |
|
略称の一致 |
「略称」アルゴリズムを使用して、一致が判別されます。たとえば、International Business MachinesとIBMは一致します。 |
|
頭文字の一致 |
「頭文字」アルゴリズムを使用して、一致が判別されます。たとえば、CMB, North AmericaとChase Manhattan Bank, NAは一致します。 |
|
類似度のスコア |
「Edit Distance」または「Jaro-Winkler」アルゴリズムにより計算された類似度のスコアを使用して、一致が判別されます。一致に必要な最小類似度として0(ゼロ)から100の値を入力します。値100を入力すると完全一致が要求され、値0(ゼロ)を入力すると類似度は要求されません。 類似度が類似度のスコアの値以上の場合、2つのレコードは一致とみなされます。 |
会社一致ルールを定義する手順は、次のとおりです。
「一致ルール」タブまたは一致ルール・ページで、「ルール・タイプ」として「会社」を選択します。
ページの下部に「会社属性」タブと「詳細」タブが表示されます。
「会社属性」タブの左パネルで、会社名を表す属性を1つまたは2つ選択して右シャトル・ボタンをクリックします。
選択した属性が「会社ロール」ボックスに移動します。
属性ごとに「ロール」をクリックします。リストから第1の属性について「会社1」を選択し、存在する場合は第2の属性について「会社2」を選択します。
「詳細」タブで、使用可能なオプションを選択します。詳細は、「会社の詳細」を参照してください。
アドレス一致ルールは、郵便アドレスに基づいてレコードを照合する方法です。アドレス一致ルールは、データが、最初にName and Address演算子を使用して修正された場合に最も効果的です。
アドレス一致ルールは、処理されているアドレスがName and Address演算子を使用して修正されたかどうかによって異なる働きをします。一般に、修正されたアドレスは、郵便照合データベース内で識別されているため、そのアドレスのある国の郵政公社に準拠した既存のアドレスであり、構文的に正しく正当です。一致ルールはそれらの形式について推測を行うため、修正されたアドレスはより迅速に処理できます。
未修正のアドレスは、構文的に正しい場合もありますが、郵便照合データベースでは検出できません。データベース内にないか、アドレスのある国に郵便照合データベースがインストールされていないため、検出されない場合があります。アドレス一致ルールでは、「検出済」ロールに基づいて修正されたアドレスかどうかが判別されます。「検出済」ロールが割り当てられていない場合、一致ルールは、修正されたアドレスと未修正のアドレスの両方に対して比較を実行します。
アドレス一致ルールを作成するには、「アドレス」ロールを様々な属性に割り当てます。「アドレス」ロールに割り当てられた属性は、レコードを比較するために一致ルールで使用されます。属性は、属性が割り当てられたロールおよび他の比較オプションの設定に基づいて比較されます。
表23-15は、アドレスの各部分に対して選択できる「アドレス」ロールを示しています。
表23-15 アドレス・ロール
| ロール | 説明 |
|---|---|
|
第1アドレス |
第1アドレスが比較されます。第1アドレスは、番地(100 Main Street)または私書箱(PO Box 100)などです。デフォルトでは、第1アドレスが一致する必要がありますが、類似度のオプションも指定できます。 「第1アドレス」ロールを割り当てる必要があります。 |
|
区画番号 |
第1アドレスが一致した場合に、区画番号(部屋番号、階、棟番号など)が比較されます。「空白の第2アドレスの一致」オプションが設定されていないかぎり、いずれか一方のみでなく、両方が空白の場合に区画番号は一致します。「異なる第2アドレスの許可」オプションが設定されている場合は、区画番号は無視されます。 |
|
私書箱 |
私書箱が比較されます。第1アドレスが私書箱(PO Box 100)を表す場合、私書箱は、私書箱の数字部分(100)のみで、第1アドレスのサブセットです。第1アドレスが番地を表す場合、私書箱は空白になります。 |
|
二重第1アドレス |
二重第1アドレスは他のレコードの二重第1アドレスおよび第1アドレスと比較され、一致が判別されます。 |
|
二重区画番号 |
二重区画番号アドレスは、他のレコードの二重区画番号および区画番号と比較されます。一方または両方が空白の場合、この区画番号は一致します。「二重区画番号」ロールを割り当てるには、「二重第1アドレス」ロールも割り当てられている必要があります。 |
|
二重私書箱 |
あるレコードの二重私書箱アドレスは、他のレコードの二重私書箱および私書箱と比較されます。「二重私書箱」ロールを割り当てるには、「二重第1アドレス」ロールも割り当てられている必要があります。 |
|
市区町村 |
未修正のアドレスの場合、市区町村が比較されます。修正されたアドレスの場合、郵便番号が一致していない場合にのみ市区町村が比較されます。「市区町村」ロールと「都道府県」ロールの両方が一致している場合は、第1アドレスなどの「アドレス行」ロールが比較されます。 デフォルトでは、市区町村が一致する必要があります。ただし、最終行の類似度のオプションを指定することもできます。両方が空白の場合、市区町村は一致しますが、いずれか一方が空白の場合は一致しません。「市区町村」ロールが割り当てられている場合、「都道府県」ロールも割り当てられている必要があります。 |
|
都道府県 |
このロールを割り当てるのは、「市区町村」ロールも割り当てる場合のみです。 未修正のアドレスの場合、都道府県が比較されます。修正されたアドレスの場合、郵便番号が一致していない場合にのみ都道府県が比較されます。「市区町村」ロールと「都道府県」ロールの両方が一致している場合は、第1アドレスなどの「アドレス行」ロールが比較されます。デフォルトでは、都道府県が一致する必要があります。ただし、最終行の類似度のオプションを指定することもできます。両方が空白の場合、都道府県は一致しますが、いずれか一方が空白の場合は一致しません。「都道府県」ロールが割り当てられている場合、「市区町村」ロールも割り当てられている必要があります。 |
|
郵便番号 |
未修正のアドレス・データの場合、演算子では「郵便番号」は使用されません。 修正されたアドレスの場合、郵便番号が比較されます。未修正のアドレスの場合、「郵便番号」ロールは使用されません。一致するには、郵便番号が同一である必要があります。一方または両方が空白の場合、郵便番号は一致するとみなされます。郵便番号が一致する場合、第1アドレスなどの「アドレス行」ロールが比較されます。郵便番号が一致しない場合、「市区町村」ロールおよび「都道府県」ロールが比較されて、「アドレス行」ロールを比較する必要があるかどうかが判別されます。 |
|
検出済 |
「Is_found_flag」属性は比較されませんが、そのかわりにこの属性を使用して、アドレスが郵便照合データベース内で検出されたかどうかを判別します。したがって、そのアドレスがある国の郵政公社に従った正当なアドレスです。この判別が重要なのは、照合時に行われた比較のタイプは、そのアドレスが郵便データベースで検出されたかどうかによって異なるからです。 |
表23-16は、アドレス・ルールを使用した場合の一致を判別するオプションを示します。
表23-16 アドレス・ロールのオプション
| オプション | 説明 |
|---|---|
|
異なる第2アドレスの許可 |
区画番号がNULL値でなく、異なる場合でもアドレスの一致を許可します。 |
|
空白の第2アドレスの一致 |
一方の区画番号がNULL値の場合でもアドレスの一致を許可します。 |
|
番地または私書箱の一致 |
番地または私書箱が一致する場合にレコードが一致します。 |
|
アドレス行の類似度 |
アドレス行の類似度>=スコアの場合に一致します。すべての空白および非英数字文字が削除されてから類似度が計算されます。 |
|
最終行の類似度 |
最終行の類似度>=スコアの場合に一致します。最終行は市区町村および都道府県で構成されています。すべての空白および非英数字文字が削除されてから類似度が計算されます。 |
アドレス一致ルールを定義する手順は、次のとおりです。
「一致ルール」タブまたは一致ルール・ページで、「ルール・タイプ」として「アドレス」を選択します。
ページの下部に「アドレス属性」タブと「詳細」タブが表示されます。
「アドレス属性」タブの左パネルで、第1アドレスを表す属性を選択します。右シャトル・キーを使用して、選択した属性をアドレス・ロール属性の列に移動します。
「ロールが必要です」をクリックし、その属性を第1アドレスとして指定します。
第1アドレスとして属性を1つ指定する必要があります。「第1アドレス」ロールを割り当てない場合、一致ルールは無効です。
他の属性を追加し、そのロールを必要に応じて指定します。割当て可能なロールのタイプは、表23-15を参照してください。
「詳細」タブを選択し、表23-16に示す適用可能なオプションを選択します。
カスタム一致ルールを使用すると、独自の比較アルゴリズムを記述してレコードを照合できます。入力属性を使用したり、この比較内のファンクションを照合できます。アクティブなカスタム・ルールを使用して受動ルールの実行を制御できます。
次の3つの受動組込みルールがあります。
NAME_MATCH: 組込み名前ルール
ADDRESS_MATCH: 組込みアドレス・ルール
TN_MATCH: 組込み条件付きルール
カスタム・ルールを作成して、これらの2つのルールを満たす場合に2つのレコードが一致するとみなされるように指定できます。例23-1は、この例を実装するカスタム一致ルールの作成に使用されるPL/SQLコードを示しています。
例23-1 既存の受動ルールを使用したカスタム・ルールの作成
BEGIN
RETURN(
(NAME_MATCH(THIS_,THAT_) AND ADDRESS_MATCH(THIS_,THAT_))
OR
(NAME_MATCH(THIS_,THAT_) AND TN_MATCH(THIS_,THAT_))
OR
(ADDRESS_MATCH(THIS_,THAT_) AND TN_MATCH(THIS_,THAT_))
);
END;
カスタム一致ルールを定義する手順は、次のとおりです。
「一致ルール」タブまたは一致ルール・ページで、「ルール・タイプ」として「カスタム」を選択します。
ページの下部に、PL/SQLプログラムのスケルトンとともに「詳細」フィールドが表示されます。
「編集」をクリックしてカスタム一致ルール・エディタを開きます。
エディタの使用の詳細は、「ヘルプ」メニューから「ヘルプ・トピック」を選択してください。
PL/SQLコードを入力するには、次の任意の手順を組み合せて使用します。
ファイルを読み取るには、「コード」メニューから「ファイルを開く」を選択します。
テキストを入力するには、マウスまたは矢印キーを使用してカーソルを置いてから入力を開始します。「編集」メニューと「検索」メニューのコマンドを使用することもできます。
ナビゲーション・ツリーでファンクション、パラメータまたは変換を参照するには、カーソルを置いてからオブジェクトをダブルクリックするか、「実装」フィールドにドラッグ・アンド・ドロップします。
コードを検証するには、「テスト」メニューから「検証」を選択します。
検証結果が「メッセージ」タブに表示されます。
コードを保存するには、「コード」メニューから「保存」を選択します。
カスタム一致ルール・エディタを閉じるには、「コード」メニューから「閉じる」を選択します。
一致は、論理的に同じレコードのセットを生成します。マージは、一致する一連のレコードから1つのレコードを作成するプロセスです。マージ・ルールは、一致するレコードのセットの属性に適用され、マージ済レコードの属性の単一の値を取得されます。
マージ済レコードの全属性に対してルールを1つ定義する方法と、属性ごとにルールを定義する方法があります。たとえば、マージ済レコードが顧客レコードの場合は、ADDRESS1、ADDRESS2、CITY、STATEおよびZIPなどの属性を持っている可能性があります。各属性の値を最大5つの異なるレコードから選択する5つのルールを記述するか、5つの属性の値をすべて1つのレコードから選択するレコード・ルールを1つ記述できます。レコード・ルールを使用するのは、複数の属性が住所などの論理単位を構成している場合です。たとえば、「市区町村」、「都道府県」および「郵便番号」は3つの異なる属性ですが、これらの属性のデータはすべて同じレコードから取り込まれます。
表23-17に、マージ・ルールのタイプを示します。
表23-17 マージ・ルールのタイプ
| マージ・ルール | 説明 |
|---|---|
|
すべて |
空白以外の最初の値が使用されます。 |
|
一致ID |
別のMatch-Merge演算子から出力されたレコードがマージされます。 |
|
ランク |
一致セットのレコードをランク付けします。最上位にランク付けされたレコードの関連する属性は、マージ属性値の移入に使用されます。 |
|
順序 |
このルールにデータベースの順序を指定します。値には、この順序での次の値が使用されます。 |
|
最小/最大 |
属性およびリレーションを指定して、マージ属性のソースとして使用するレコードを選択します。 |
|
コピー |
以前にマージした値とは異なる値を選択します。 |
|
カスタム |
PL/SQLパッケージ・ファンクションを作成して、マージ値を選択します。その演算子によって、このファンクションのシグネチャが提供されます。ユーザーは、BEGINとENDの間にルールを実装する必要があります。一致したレコードおよびマージ・レコードはこのファンクションのパラメータです。 |
|
任意のレコード |
「すべて」ルールと同じですが、「任意のレコード」ルールは複数の属性に適用されます。 |
|
レコードのランク |
「ランク」ルールと同じですが、「レコードのランク」ルールは複数の属性に適用されます。 |
|
最小/最大レコード |
「最小/最大」ルールと同じですが、「最小/最大レコード」ルールは複数の属性に適用されます。 |
|
カスタム・レコード |
「カスタム」ルールと同じですが、「カスタム・レコード」ルールは複数の属性に適用されます。 |
「一致ID」マージ・ルールを使用して、別のMatch-Merge演算子からのXREFグループ内で出力済のレコードをマージします。このタイプの入力には、他の演算子は無効です。詳細は、「例: ハウスホールディング用の2つのMatch-Merge演算子の使用」を参照してください。
順序の次の値
ルールで使用される順序を識別します。
「順序」リスト
現行のプロジェクトで定義済の順序がすべて表示されます。
順序の選択
ルールの順序がリストで現在選択されている順序に設定されます。「順序」リストから「順序の選択」に順序を移動します。
「ランク」および「レコードのランク」ルールを使用するのは、複数のソースからデータをマージする場合です。この2つのルールを使用すると、特定のソースのプリファレンスを識別できます。データには、ルールの基礎となる第2入力属性が必要です。
たとえば、第2属性でデータ・ソースを識別し、これらのデータ・ソースを信頼度順にランク付けするとします。最も信頼度の高い値がマージ済レコードで使用されます。このマージ・ルールは次のようになります。
INGRP1.SOURCE = 'Order Entry'
名前
ルールの任意名。Oracle Warehouse Builderでは、ランク・マージ・ルールごとにRULE_0などのデフォルト名が作成されます。これらの名前は意味のある名前で置き換えることができます。
位置
実行順序。行ヘッダーをクリックし、その行を新規の位置にドラッグすると、ルールの位置を変更できます。行ヘッダーは、「名前」列の左側にあるボックスです。
式のレコードの選択
ランキングに使用されるカスタムSQL式。省略記号ボタンをクリックすると、「ランク・ルール・エディタ」(「式ビルダー」ユーザー・インタフェース)が表示されます。このエディタを使用してランキング式を作成します。
「順序」ルールでは、順序の次の値が使用されます。
順序の次の値
ルールで使用される順序を識別します。
「順序」リスト
現行のプロジェクトで定義済の順序がすべて表示されます。
順序の選択
ルールの順序がリストで現在選択されている順序に設定されます。
「最小/最大」および「最小/最大レコード」ルールを使用して、レコード内の別の属性値のサイズに基づいて属性値を選択します。
たとえば、最大の「姓」値を含む各bin内のレコードから「名」値を選択できます。
属性の選択
すべての入力属性が表示されます。値で順序を指定する属性を選択します。
属性リレーション
選択した属性の値を選択するための特性を選択します。
最小: 最小の数値または最も古い日付値が選択されます。
最大: 最大の数値または最も新しい日付値が選択されます。
最短: 最も短い文字値が選択されます。
最長: 最も長い文字値が選択されます。
「カスタム」および「カスタム・レコード」ルールでは、レコードのマージ用に提供したPL/SQLコードが使用されます。次のコードに、レコード1のTAXID属性の値を戻す「カスタム」マージ・ルールの例を示します。
BEGIN RETURN M_MATCHES(1)."TAXID"; END;
次のコードは、レコード1のレコードを戻す「カスタム・レコード」マージ・ルールの例です。
BEGIN RETURN M_MATCHES(1); END;
マージ・ルール詳細
カスタム・アルゴリズムを構成するPL/SQLコードが表示されます。このフィールドでコードを直接編集するか、カスタム・マージ・ルール・エディタを使用できます。
編集
カスタム・マージ・ルール・エディタが表示されます。
Match-Merge演算子を使用すると、データ・ソース内の一致レコードを識別し、単一のレコードにマージできます。
Match-Merge演算子には、1つの入力グループと2つの出力グループ(MergeグループおよびXrefグループ)があります。ソース・データは入力グループにマップされます。Mergeグループには、プロセスの照合が完了した後にマージしたレコードが含まれます。Xrefグループでは、マージ・プロセスのレコードが提供されます。入力グループのすべてのレコードには、Xrefグループ内に対応するレコードがあります。このレコードには元の属性値およびマージ済属性が含まれる場合があります。
Match-Merge演算子には、順序付けされたレコード・ストリームが入力として使用されます。このストリームから一致binが構成されます。各一致binから、一致したセットが構成されます。一致した各セットから、マージ済レコードが作成されます。最初の問合せには、一致bin属性で構成されたORDER BY句が含まれます。
Match-Merge演算子を使用してソース・データを照合およびマージする手順は、次のとおりです。
ソース・データを表す演算子およびマージしたデータを表す演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
たとえば、ソース・データがある表に格納され、マージしたデータが別の表に格納される場合、その表にバインドされる2つの表演算子をキャンバスにドラッグ・アンド・ドロップします。
Match-Merge演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
Match-Mergeウィザードが表示されます。
名前・ページの「名前」フィールドには、その演算子のデフォルト名が含まれます。この名前を変更するか、デフォルト名を使用できます。
その演算子の説明を入力できます(オプション)。
グループ・ページで、グループ名を変更したり、グループの説明を追加できます。
このページには、次の3つのグループが含まれます。
INGRP1: 入力属性が含まれます。
MERGE: マージ済レコードが含まれます(通常INGRP1よりレコードが少ないことを意味します)。
XREF: 元のデータ・セットおよびマージ済データ・セットのリンクが含まれます。マージの実行時に使用される追跡メカニズムです。
接続の入力ページで、照合およびマージする属性を「使用可能な属性」セクションから「マップ済属性」セクションに移動します。「次へ」をクリックします。
このページの「使用可能な属性」セクションで、各演算子のノードがキャンバスに表示されます。ノードを展開して演算子に含まれる属性を表示し、属性を選択して、選択した属性をシャトル矢印を使用して「マップ済属性」セクションに移動します。
|
注意: Match-Merge演算子には、順序付けされた入力データ・セットが必要です。複数の演算子のソース・データがある場合、集合演算演算子を使用してデータを結合し、順序付けされたデータ・セットを取得します。 |
入力属性ページで、属性のデータ型と長さを確認します。
通常、このウィザードを使用する場合は、これらの値をすべて変更する必要はありません。Oracle Warehouse Builderは、出力属性に基づいてこれらの値を移入します。
マージ出力ページで、入力属性からマージする属性を選択します。
これらの属性は、Merge出力グループ(整備されたグループ)に表示されます。このグループの属性に、入力属性の名前およびプロパティが保持されます。
相互参照出力ページで、XREF出力グループの属性を選択します。
「ソース属性」セクションには、マージ出力ページで選択したすべての入力属性およびマージ済属性が含まれます。Mergeグループの属性には、接頭辞MM_が付きます。他の属性では、変更されていない属性値を定義します。Mergeグループから属性を1つ以上選択して、入力グループおよびMergeグループをリンクします。
一致binページで、一致bin属性を指定します。これらの属性は、ソース・データを一致binにグループ化する場合に使用されます。
最初のデプロイメントの後に、すべてのレコードまたは新しいレコードのみを照合またはマージするかどうかを選択できます。新しいレコードのみを一致およびマージさせるには「新規レコードのみ一致」を選択します。
新しいレコードの識別条件を指定する必要があります。Match-Merge演算子は、新しいレコードを次の方法で処理します。
一致binに新しいレコードが含まれないかぎり、一致bin内のレコードの照合は実行されません。
古いレコード同士は比較されません。
一致するレコード・セットは、新しいレコードが含まれないかぎり、マージ・プロセスに表示されません。
古いレコードは、新しいレコードと一致しないかぎり、Xref出力には表示されません。
一致bin属性および一致binの詳細は、「照合およびマージ・プロセスの概要」を参照してください。
一致ルールの定義ページで、ソース・データの照合に使用する一致ルールを定義します。
一致ルールはアクティブまたは受動の可能性があります。受動一致ルールは生成されますが、自動的には起動しません。1つ以上のアクティブ一致ルールを定義する必要があります。
一致ルール、定義できる一致ルールのタイプおよび一致ルールを定義するために使用する手順の詳細は、「一致ルール」を参照してください。
マージ・ルール・ページで、ソース・データから作成した、一致するレコードのセットをマージする場合に使用するルールを定義します。
レコード内の各属性に対してまたはレコード全体に対して一致ルールを定義できます。Oracle Warehouse Builderでは、様々なタイプのマージ・ルールを使用できます。
一致ルールのタイプおよび一致ルールを作成する手順の詳細は、「マージ・ルール」を参照してください。
サマリー・ページで、選択した項目を確認します。「戻る」をクリックして、選択した項目を変更します。「次へ」をクリックして、Match-Merge演算子の作成を完了します。
Match-Merge演算子のMatchグループを、マージ済データを格納する演算子の入力グループにマッピングします。
マッピングの設計時には、次の考慮事項に注意してください。
オペレーティング・モード: Match-Merge演算子を含むマッピングを実行できるのは、セット・ベース・モードの場合のみです。演算子は、セット・ベースまたは行ベースの入力を受け入れて、セット・ベースまたは行ベースの出力を生成できます。SQLはセット・ベースのため、一連のレコードが処理されます。PL/SQLは行ベースのため、各行が個別に処理されます。Match-Merge演算子は、レコードの照合時に各行をソース内の後続行と比較して行ベースのコードのみを生成します。
Match-Merge前のSQLベースの演算子: Match-Merge演算子はセット・ベースのSQL入力を受け入れますが、生成するのは行ベースのPL/SQL出力のみです。SQLコードのみを生成する演算子の場合は、いずれもその前にMatch-Merge演算子を使用する必要があります。たとえば、ジョイナ演算子、参照演算子および集合演算子はセット・ベースのSQL出力を生成するため、前にMatch-Merge演算子を使用する必要があります。セット・ベースの演算子がMatch-Merge演算子よりも後にあるマッピングは無効です。セット・ベースのSQL演算子を使用してMatch-Mergeマッピングの出力を処理する場合は、中間表の出力をステージングします。
PL/SQL入力: Match-Merge演算子には、他のMatch-Merge演算子以外からのSQL入力が必要です。「例: ハウスホールディング用の2つのMatch-Merge演算子の使用」を参照してください。Match-Merge演算子の前に、PL/SQL出力のみを生成する演算子を使用するには、最初にデータをステージング表にロードする必要があります。
Match-Merge演算子からのデータの詳細化: データを大幅に詳細化するには、あるMatch-Merge演算子からのXREF出力を別のMatch-Merge演算子にマップします。このシナリオは、Match-Merge演算子のSQL入力ルールに対する1つの例外です。追加の設計要素を使用すると、第2のMatch-Merge演算子はPL/SQLを受け入れます。詳細は、「例: ハウスホールディング用の2つのMatch-Merge演算子の使用」を参照してください。
ほとんどのMatch-Merge操作は、1つのMatch-Merge演算子で実行できます。ただし、出力を2つの異なるターゲットに送る場合は、2つのMatch-Merge演算子の連続使用が必要です。
たとえば、名前とアドレスのデータをハウスホールドする際に、最初にアドレス・データ、次に名前データという順序によるマージが必要です。MERGE出力をターゲット表にマップすると仮定すれば、XREFグループをもう1つのMatch-Merge演算子にマップできます。
|
注意: XREFグループをステージング表にマップすることもできますが、この方法ではパフォーマンスが大幅に低下する可能性があります。Match-Merge機能は、この項で説明するように、2つのMatch-Merge演算子を使用して最大のパフォーマンスに対応できるように設計されています。 |
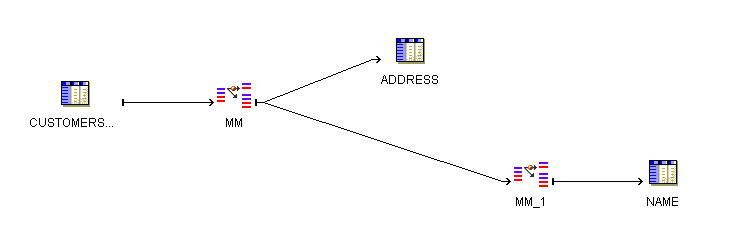
図23-3は、2つのMatch-Merge演算子を使用するマッピングを示しています。MMからのXREFグループはMM_1に直接マップされています。このマッピングを有効にするには、第1のXREFグループ用に生成された一致IDを、第2のMatch-Merge演算子の一致binルールとして割り当てる必要があります。
図23-3 データのハウスホールディング: 第2のMatch-Merge演算子にマージされたXREFグループ
|
注意: ハウスホールディングに関する問題のより完全なソリューションでは、照合とマージを実行して、顧客をハウスホールドにグループ分けする前に個別のレコードに名前およびアドレスのクレンジングを適用する場合があります。 |