| Oracle® Database SQL言語リファレンス 11gリリース2 (11.2) B56299-08 |
|


 前 |
 次 |
用途
SELECT文または副問合せを使用すると、1つ以上の表、オブジェクト表、ビュー、オブジェクト・ビューまたはマテリアライズド・ビューからデータを取り出すことができます。
SELECT文の結果(またはその一部)が既存のマテリアライズド・ビューと同じ場合、そのマテリアライズド・ビューをSELECT文で指定した1つ以上の表のかわりに使用できます。この置き換えを、クエリー・リライトといいます。これが行われるのは、コスト最適化が有効であり、かつQUERY_REWRITE_ENABLEDパラメータがTRUEに設定されている場合のみです。クエリー・リライトが行われたかどうかを特定するには、EXPLAIN PLAN文を使用します。
|
関連項目:
|
前提条件
表またはマテリアライズド・ビューからデータを選択する場合、表またはマテリアライズド・ビューが自分のスキーマ内にある必要があります。自分のスキーマ内にない場合は、その表またはマテリアライズド・ビューに対するSELECT権限が必要です。
ビューの実表から行を選択する場合、次の条件を2つとも満たしている必要があります。
ビューに対するSELECT権限を持っている。
ビューを含むスキーマの所有者が、実表に対するSELECT権限を持っている。
SELECT ANY TABLEシステム権限を持っている場合、任意の表、マテリアライズド・ビューまたはビューの実表からデータを選択できます。
flashback_query_clauseを使用してOracleフラッシュバック問合せを発行する場合は、SELECT構文のリスト内のオブジェクトに対するSELECT権限が必要です。さらに、SELECT構文のリスト内のオブジェクトに対するFLASHBACKオブジェクト権限またはFLASHBACK ANY TABLEシステム権限のいずれかが必要です。
構文
select::=

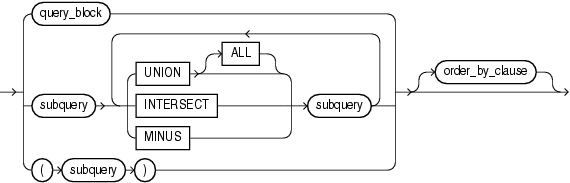
(query_block::=、order_by_clause ::=を参照)
query_block::=
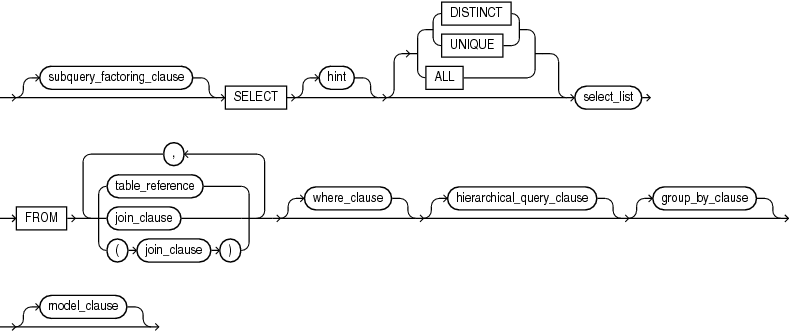
(subquery_factoring_clause::=、select_list::=、table_reference::=、join_clause ::=、where_clause::=、hierarchical_query_clause ::=、group_by_clause ::=、model_clause ::=を参照)

cycle_clause::=

select_list::=
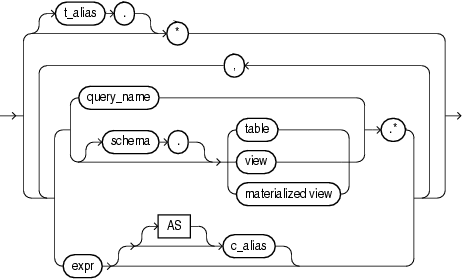
table_reference::=

(query_table_expression::=、flashback_query_clause ::=、pivot_clause::=、unpivot_clause::=を参照)

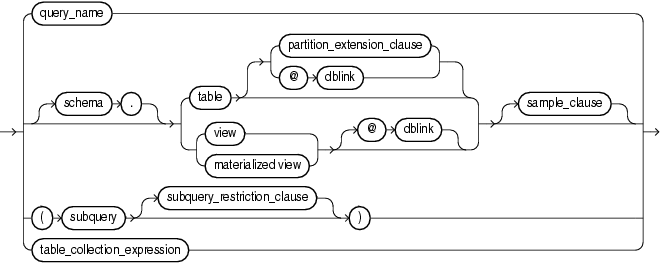
(subquery_restriction_clause::=、table_collection_expression ::=を参照)
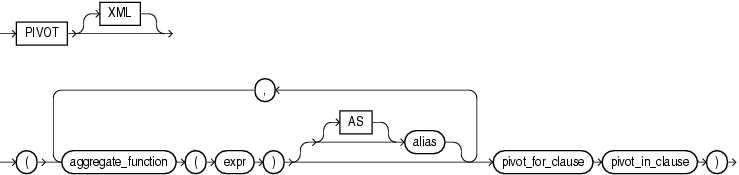
pivot_clause::=
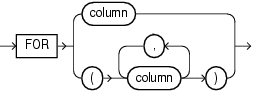
pivot_for_clause::=
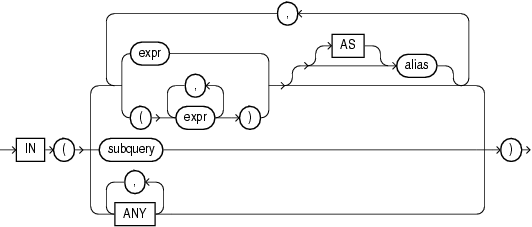
pivot_in_clause::=

unpivot_in_clause::=
sample_clause ::=
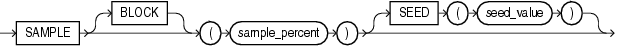
partition_extension_clause::=
subquery_restriction_clause::=

table_collection_expression::=

join_clause ::=

(table_reference::=を参照)

(query_partition_clause::=、outer_join_type::=、table_reference::=を参照)
where_clause::=

(conditionには、第7章「条件」で説明した任意の条件を使用できます)
group_by_clause ::=
(rollup_cube_clause::=、grouping_sets_clause::=を参照)
rollup_cube_clause::=
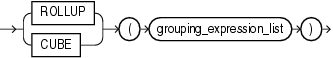
(grouping_expression_list::=を参照)
grouping_sets_clause::=
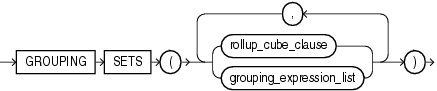
(rollup_cube_clause::=、grouping_expression_list::=を参照)
grouping_expression_list::=
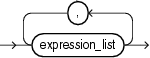
expression_list::=
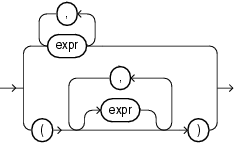
model_clause ::=

(cell_reference_options::=、return_rows_clause::=、reference_model::=、main_model::=を参照)


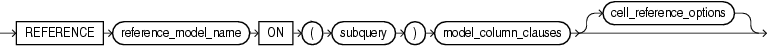
(model_column_clauses::=、cell_reference_options::=を参照)
main_model::=

(model_column_clauses::=、cell_reference_options::=、model_rules_clause::=を参照)
model_column::=
(model_iterate_clause::=、cell_assignment::=、order_by_clause ::=を参照)
model_iterate_clause::=
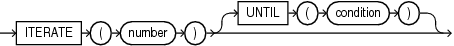
(single_column_for_loop::=、multi_column_for_loop::=を参照)
order_by_clause ::=

セマンティクス
WITH query_name句を使用すると、副問合せブロックに名前を割り当てることができます。query_nameを指定することによって、問合せに複数存在する副問合せブロックを参照することができます。問合せの名前をインライン・ビューまたは一時表として扱うことによって、問合せが最適化されます。
query_nameの後に続く列別名およびAS句内にある複数の副問合せを区切る集合演算子は有効ですが、再帰的副問合せのファクタリングを必要とします。search_clauseおよびcycle_clauseは、再帰的副問合せのファクタリングに対してのみ有効ですが、必須ではありません。「再帰的副問合せのファクタリング」を参照してください。
最上位のSELECT文およびほとんどの副問合せでこの句を指定できます。問合せの名前は、主問合せおよび後続のすべての副問合せから参照できます。再帰的副問合せのファクタリングの場合、問合せの名前は、自身の問合せ名を定義する副問合せからも参照できます。
自身の問合せ名を定義する副問合せからsubquery_factoring_clauseが自身のquery_nameを参照する場合、そのsubquery_factoring_clauseは再帰的であるといいます。再帰的subquery_factoring_clauseには、2つの問合せブロック(1つ目のアンカー・メンバーおよび2つ目の再帰的メンバー)が含まれている必要があります。アンカー・メンバーは、再帰的メンバーの前に指定する必要があり、このメンバーはquery_nameを参照できません。アンカー・メンバーは、集合演算子UNION ALL、UNION、INTERSECTまたはMINUSによって結合された1つ以上の問合せブロックで構成できます。再帰的メンバーは、アンカー・メンバーの後に指定し、query_nameの参照は1回のみにする必要があります。UNION ALL集合演算子を使用して、再帰的メンバーをアンカー・メンバーに結合する必要があります。
WITH query_nameの後に続く列別名の数、およびアンカーのSELECT構文のリストと再帰的問合せブロックの数は同じである必要があります。
再帰的メンバーには、次の要素を含めることができません。
DISTINCTキーワードまたはGROUP BY句
model_clause
集計ファンクション。ただし、SELECT構文のリスト内には分析ファンクションを含めることができます。
query_nameを参照する副問合せ。
query_nameを右側の表として参照する外部結合。
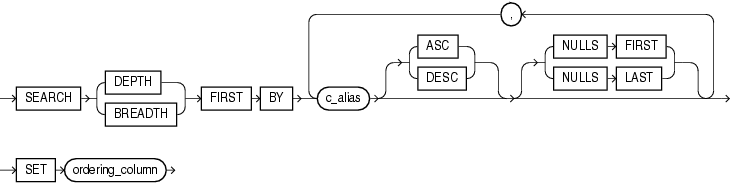
search_clause
行の順序付けを指定するには、SEARCH句を使用します。
子の行が戻される前に兄弟の行を戻す必要がある場合は、BREADTH FIRST BYを指定します。
兄弟の行が戻される前に子の行を戻す必要がある場合は、DEPTH FIRST BYを指定します。
兄弟の行は、BYキーワードの後にリストされる列によって順序付けされます。
SEARCHキーワードの後に続くc_aliasリストには、query_nameに対する列別名のリストからの列名を含める必要があります。
ordering_columnは、問合せ名の列リストに自動的に追加されます。query_nameから選択する問合せは、ordering_columnにORDER BYを含めて、SEARCH句によって指定された順序で行を戻すことができます。
cycle_clause
CYCLE句は、再帰型での繰返しをマーク付けするために使用します。
CYCLEキーワードの後に続くc_aliasリストには、query_nameに対する列別名のリストからの列名を含める必要があります。Oracle Databaseは、これらの列を使用して繰返しを検出します。
cycle_valueおよびno_cycle_valueは、長さが1の文字列です。
繰返しが検出されると、繰返しを引き起こしている行に対してcycle_mark_c_aliasによって指定されている繰返しマーク列に、cycle_valueとして指定されている値が設定されます。その後、この行への再帰は停止します。つまり、問題の行については、その子の行の検索は行われませんが、繰返しが発生していない行については、検索が継続されます。
繰返しが検出されない場合、no_cycle_valueとして指定されているデフォルト値が繰返しマーク列に設定されます。
この繰返しマーク列は、query_nameの列リストに自動的に追加されます。
祖先の行のいずれかの繰返し列に同じ値がある行は、繰返しを形成するとみなされます。
CYCLE句を指定しない場合に、繰返しが検出されると、再帰的WITH句はエラーを戻します。この場合、再帰的メンバーのWHERE句で参照されるquery_nameの列別名リストのすべての列について、祖先の行のいずれかに同じ値がある行は繰返しを形成します。
副問合せのファクタリングの制限事項: この句には、次の制限事項があります。
subquery_factoring_clauseは、1つのSQL文内に1つのみ指定できます。subquery_factoring_clauseで定義したquery_nameは、そのsubquery_factoring_clause内の後続の任意の名前付き問合せブロックで使用できます。
集合演算子を指定した複合問合せの場合、その問合せを構成する各問合せではquery_nameを使用できませんが、各問合せのFROM句ではquery_nameを使用できます。
query_nameに対する列別名のリストには重複した名前を指定できません。
ordering_columnの名前は、cycle_mark_c_aliasとは異なる名前を使用する必要があります。
ordering_columnおよび繰返しマーク列には、query_nameに対する列別名のリストに存在する名前を使用することはできません。
hint
文の実行計画を選択する場合に、オプティマイザに指示を与えるためのコメントを指定します。
DISTINCTまたはUNIQUEを指定すると、選択された重複行の1行のみを戻すことができます。これらの2つのキーワードは同義です。重複行とは、SELECT構文のリスト中のそれぞれの式で一致する値を持つ行のことです。
DISTINCTおよびUNIQUE問合せの制限事項: このタイプの問合せには、次の制限事項があります。
DISTINCTまたはUNIQUEを指定する場合、SELECT構文のリスト中の式すべての総バイト数は、データ・ブロックのサイズからオーバーヘッド分を引いたサイズに制限されます。このサイズは、初期化パラメータDB_BLOCK_SIZEによって指定されます。
select_listにLOB列が含まれている場合、DISTINCTは指定できません。
ALLを指定すると、重複行を含め、選択されたすべての行を戻すことができます。デフォルトはALLです。
*(全列ワイルド・カード)
全列ワイルド・カード(アスタリスク)を指定すると、疑似列を除いて、FROM句に指定されているすべての表、ビューまたはマテリアライズド・ビューのすべての列を選択できます。アスタリスクは、同じ副問合せのFROM句で指定される表の別名の前に付けることもできます。列は、表、ビューまたはマテリアライズド・ビューの*_TAB_COLUMNSデータ・ディクショナリ・ビューのCOLUMN_IDによって指定されている順序で戻されます。
ビューやマテリアライズド・ビューではなく表から選択する場合、ALTER TABLE SET UNUSED文によってUNUSEDのマークが付けられた列は選択されません。
select_list
select_listでは、データベースから取り出す列を指定できます。
query_name
query_nameには、subquery_factoring_clauseですでに指定されている名前を指定します。select_listでquery_nameを指定するには、subquery_factoring_clauseを指定する必要があります。select_listでquery_nameを指定するには、query_table_expression(FROM句)でもquery_nameを指定する必要があります。
table.* | view.* | materialized view.*
オブジェクト名の後にピリオドおよびアスタリスクを指定すると、指定した表、ビューまたはマテリアライズド・ビューのすべての列を選択できます。オブジェクトの作成時に指定された順序で列の集合が戻されます。2つ以上の表、ビューまたはマテリアライズド・ビューの行を選択する問合せを結合といいます。
他のユーザーのスキーマの表、ビューまたはマテリアライズド・ビューから選択する場合には、スキーマ修飾子を使用します。schemaを指定しない場合、この表、ビューおよびマテリアライズド・ビューは自分のスキーマ内にあるとみなされます。
expr
選択する情報を表す式を指定します。リスト中の列が含まれている表、ビューまたはマテリアライズド・ビューがFROM句でschema名で指定されている場合のみ、その列名をschema名で指定できます。オブジェクト型のメンバー・メソッドを指定するときは、メソッドが引数を取らない場合でも、カッコを使用するメソッド名に従う必要があります。
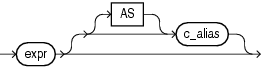
c_alias 列式の別名を指定します。この別名は、結果セットの列のヘッダーで使用されます。ASキーワードはオプションです。別名によって、問合せ中にSELECT構文のリストの項目名を効果的に変更できます。問合せにおいて、別名はorder_by_clauseで使用できますが、他の句では使用できません。
SELECT構文のリストの制限事項: SELECT構文のリストには、次の制限事項があります。
この文にgroup_by_clauseも指定している場合、このSELECT構文のリストには次の式のみ指定できます。
定数
集計ファンクション、USERファンクション、UIDファンクションおよびSYSDATEファンクション
group_by_clauseに指定されているものと同じ式。group_by_clauseが副問合せの中にある場合、その副問合せのSELECT構文のリストにあるすべての列が副問合せのGROUP BY列と対応する必要があります。SELECT構文のリストおよびトップレベル問合せまたは副問合せのGROUP BY列が対応しない場合、その文ではORA-00979が発生します。
グループ内のすべての行が同じ値に評価される前述の式を伴っている式
結合内のキー保存表が1つのみの場合、結合ビューからROWIDを選択することができます。表のROWIDがビューのROWIDになります。
|
関連項目: キー保存表の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
複数の表に同じ名前の列があり、FROM句で結合を指定した場合、表の名前または表の別名でその列名を修飾する必要があります。
FROM句
FROM句を指定すると、どのオブジェクトからデータを選択するかを指定できます。
query_table_expression
query_table_expression句を使用すると、表、ビュー、マテリアライズド・ビュー、パーティションまたはサブパーティションの識別、またはオブジェクトを識別する副問合せの指定を行うことができます。
ONLY ONLY句は、ビューのみに適用されます。FROM句のビューが階層に属し、サブビューの行を含めない場合は、ONLY句を使用します。
flashback_query_clauseを使用すると、表、ビューまたはマテリアライズド・ビューの過去のデータを問い合せることができます。
この句を指定すると、SQLによるフラッシュバックが実装され、SELECT構文のリスト内のオブジェクトごとに異なるシステム変更番号またはタイムスタンプを指定できるようになります。また、セッション・レベルのフラッシュバックをDBMS_FLASHBACKパッケージを使用して実装できます。
フラッシュバック問合せを使用すると、行に対して行った変更の履歴を取り出すことができます。VERSIONS_XID疑似列を使用して、変更を行ったトランザクションの対応する識別子を取り出すことができます。また、Oracle Flashback Transaction Queryを発行して、特定の行バージョンを生成したトランザクションの情報を取り出すこともできます。これを行うには、特定のトランザクションIDをFLASHBACK_TRANSACTION_QUERYデータ・ディクショナリ・ビューで問い合せます。
AS OF AS OFを指定すると、特定のシステム変更番号(SCN)またはタイムスタンプでの問合せによって戻された行の単一のバージョンを取り出すことができます。SCNを指定する場合、exprは数値に評価される必要があります。TIMESTAMPを指定する場合、exprはタイムスタンプ値に評価される必要があります。いずれの場合も、exprの評価結果がNULLであってはなりません。指定されたシステム変更番号または時刻に存在した行が戻されます。
VERSIONS
VERSIONSを指定すると、問合せによって戻された行の複数のバージョンを取り出すことができます。2つのSCNまたは2つのタイムスタンプ値の間に存在する、行のすべてのコミット済バージョンが戻されます。最初に指定されたSCNまたはタイムスタンプは、2番目に指定されたSCNまたはタイムスタンプよりも前でなければなりません。戻された行には、削除後に再度挿入された行のバージョンが含まれます。
BETWEEN SCN ...を指定すると、2つのSCNの間に存在する行のバージョンを取り出すことができます。どちらの式も、評価結果は数値でなければならず、評価結果がNULLであってはなりません。MINVALUEおよびMAXVALUEは、それぞれ使用可能な一番古いデータおよび最新のデータのSCNに解決されます。
BETWEEN TIMESTAMP ...を指定すると、2つのタイムスタンプの間に存在する行のバージョンを取り出すことができます。どちらの式も、評価結果はタイムスタンプ値でなければならず、評価結果がNULLであってはなりません。MINVALUEおよびMAXVALUEは、それぞれ使用可能な一番古いデータおよび最新のデータのタイムスタンプに解決されます。
Oracle Databaseでは、バージョン問合せ疑似列のグループを使用して、様々な行のバージョンに関する追加情報を取り出すことができます。詳細は、「バージョン問合せ疑似列」を参照してください。
両方の句を同時に使用する場合、AS OF句によって、SCNまたはデータベースが問合せを発行した時点が判断されます。VERSIONS句によって、AS OFで指定した時点を基準とした行のバージョンが判断されます。トランザクションが、BETWEENの最初の値より前に開始したり、AS OFで指定した時点より後に終了した場合は、行のバージョンとしてNULLが戻されます。
フラッシュバック問合せの注意事項 Oracle Databaseは、フラッシュバック問合せの実行時、他のタイプの問合せとは異なり、問合せ最適化を使用しない場合があります。ここで問合せ最適化を使用すると、パフォーマンスが低下する可能性があります。これは特に、階層問合せに複数のフラッシュバック問合せを指定した場合に発生します。
フラッシュバック問合せの制限事項: この問合せには、次の制限事項があります。
列式や副問合せをAS OF句の式で指定することはできません。
AS OF句を指定する場合、for_update_clause句は指定できません。
AS OF句は、マテリアライズド・ビューを定義する問合せの中では使用できません。
一時表、外部表またはクラスタの一部である表に対するフラッシュバック問合せでは、VERSIONS句を使用できません。
ビューに対するフラッシュバック問合せではVERSIONS句を使用できません。ただし、ビューを定義する問合せには、VERSIONS構文を使用できます。
すでにquery_nameがquery_table_expressionの中で指定されている場合は、flashback_query_clauseは指定できません。
|
関連項目:
|
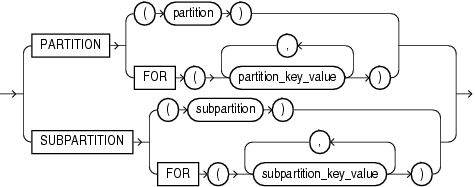
partition_extension_clause データを取り出す表のPARTITIONまたはSUBPARTITIONの名前を指定します。
レンジ・パーティション・データおよびリスト・パーティション・データでは、この句のかわりに、データの取出しをtableの1つ以上のパーティションに制限する条件をWHERE句に指定できます。Oracle Databaseは、この条件を解析して、そのパーティションからのデータのみをフェッチします。そのようなWHERE条件を、ハッシュ・パーティション・データに対して形成することは不可能です。
dblink 表、ビューまたはマテリアライズド・ビューが存在するリモート・データベースのデータベース・リンクの完全名または部分名を指定します。このデータベースは、Oracle Databaseである必要はありません。
|
関連項目:
|
dblinkを指定しない場合、その表、ビューまたはマテリアライズド・ビューは、ローカル・データベース内にあるものとみなされます。
データベース・リンクの制限事項: データベース・リンクには、次の制限事項があります。
リモート表のユーザー定義型またはオブジェクトREFを問い合せることはできません。
リモート表のANYTYPE型、ANYDATA型またはANYDATASET型の列を問い合せることはできません。
table | view | materialized view データを選択する表、ビューまたはマテリアライズド・ビューの名前を指定します。
sample_clauseを指定すると、表全体からではなく、表のランダムなサンプル・データから選択が行われます。
BLOCK BLOCKを指定すると、ランダムな行サンプリングのかわりに、ランダムなブロック・サンプリングを実行できます。
ブロック・サンプリングは、全表スキャン中または高速全索引スキャン中にのみ使用可能です。より効率的な実行パスが存在する場合、ブロック・サンプリングは実行されません。特定の表または索引に対するブロック・サンプリングを確実に実行する場合は、FULLまたはINDEX_FFSのヒントを使用します。
sample_percent sample_percentには、全体の行またはブロック数のうち、サンプルに入れる割合(%)を指定します。0.000001以上100未満の範囲の値を指定します。この割合は、各行(ブロック・サンプリングの場合は行の各クラスタ)が、サンプルの一部として選択される可能性を示します。sample_percentに指定した割合の行が表から正確に取り出されるわけではありません。
|
注意: 統計的に適切でない想定値でこの機能を使用した場合、不正確な、または望ましくない結果になります。 |
SEED seed_value この句を指定すると、今回の実行と次の実行で同じサンプルが戻されます。seed_valueには、0(ゼロ)から4294967295の整数を指定します。この句を省略した場合、戻されるサンプルは実行ごとに異なります。
sample_clauseの制限事項 SAMPLE句には、次の制限事項が適用されます。
SAMPLE句は、DML文の副問合せの中では指定できません。
SAMPLE句を問合せで指定できるのは、問合せの対象が実表、マテリアライズド・ビューのコンテナ表、またはキー保存であるビューである場合です。この句は、キー保存ではないビューに対しては指定できません。
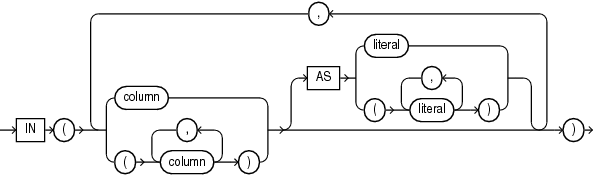
subquery_restriction_clause subquery_restriction_clauseを使用すると、次のいずれかの方法で副問合せを制限できます。
WITH READ ONLY WITH READ ONLYを指定すると、表またはビューを更新禁止にできます。
WITH CHECK OPTION WITH CHECK OPTIONを指定すると、副問合せに含まれない行を生成する表またはビューの変更を禁止できます。この句をDML文の副問合せ内で使用する場合、FROM句内の副問合せには指定できますが、WHERE句内の副問合せには指定できません。
CONSTRAINT constraint CHECK OPTION制約の名前を指定します。この識別子を省略した場合は、Oracleによって自動的にSYS_Cnという形式の制約名が割り当てられます(nはデータベース内で制約名を一意にするための整数)。
table_collection_expressionを使用すると、問合せおよびDML操作で、collection_expression値を表として扱うことができます。collection_expressionには、副問合せ、列、ファンクションまたはコレクション・コンストラクタのいずれかを指定できます。その形式にかかわらず、集合値(ネストした表型またはVARRAY型の値)を戻す必要があります。このようなコレクションの要素抽出プロセスをコレクション・ネスト解除といいます。
TABLEコレクション式を親表と結合する場合は、オプションのプラス(+)には大きな意味があります。+を指定すると、その2つの外部結合が作成され、コレクション式がNULLの場合でも、外部表の行が問合せで戻されるようになります。
|
注意: 以前のリリースのOracleでは、collection_expressionが副問合せの場合、table_collection_expressionをTHE subqueryと表現していました。現在、このような表現方法は非推奨になっています。 |
collection_expressionは、FROM句で左側に定義された表の列を参照できます。これを左相関といいます。左相関はtable_collection_expressionのみで行われます。その他の副問合せは、その副問合せ以外で定義された列を参照することはできません。
オプションの(+)を使用すると、コレクションがNULLまたは空である場合、すべてのフィールドにNULLが設定された行をtable_collection_expressionが戻すように指定できます。この(+)はcollection_expressionが左相関を使用する場合にのみ有効です。結果は、外部結合の結果と似ています。
UPDATEまたはDELETE操作で副問合せのWHERE句に(+)構文を使用する場合は、副問合せのFROM句に2つの表を指定する必要があります。副問合せに結合が存在しないかぎり、外部結合構文は無視されます。
相関名(表、ビュー、マテリアライズド・ビューまたは問合せを評価するための副問合せの別名)を指定します。SELECT構文のリストがオブジェクト型属性またはオブジェクト型メソッドを参照する場合、この別名が必要になります。相関名は、相関問合せ内で最も頻繁に使用されます。表、ビューまたはマテリアライズド・ビューを参照する問合せでは、この別名を参照する必要があります。
pivot_clauseを使用すると、行を列に変換し、変換処理中にデータを集計するクロス集計問合せを記述できます。ピボット演算の出力には、最初のデータセットよりも多くの列と少ない行が含まれています。pivot_clauseでは、次の手順が実行されます。
pivot_clauseの先頭で指定されている集計ファンクションが計算されます。集計ファンクションは、複数の値を戻すようにGROUP BY句を指定する必要がありますが、pivot_clauseには、明示的なGROUP BY句が含まれていません。かわりに、暗黙的なGROUP BYが実行されます。暗黙的なグループ化は、pivot_clauseで参照されていないすべての列、およびpivot_in_clauseで指定されている値セットに基づいています。
列のグループ化および手順1で計算された集計値は、次のクロス集計出力を生成するように構成されています。
最初に、pivot_clauseで参照されていないすべての暗黙的なグループ化列が出力されます。
pivot_in_clause内の値に対応する新しい列が出力されます。集計値はそれぞれ、クロス集計の中の該当する新しい列に移されます。XMLキーワードを指定した場合は、結果は新しい列1つだけとなり、データは1つのXML文字列として表現されます。
pivot_clauseの副次句のセマンティクスは、次のとおりです。
XML オプションのXMLキーワードは、問合せのXML出力を生成します。XMLキーワードを指定すると、pivot_in_clauseには、副問合せまたはワイルド・カード・キーワードANYを含めることができます。副問合せおよびANYワイルド・カードは、pivot_in_clause値が事前にわかっていない場合に有効です。XML出力では、ピボット列の値が実行時に評価されます。pivot_in_clauseで式を使用して明示的なピボット値を指定する場合は、XMLを指定することができません。
XML出力が生成される際、集計ファンクションが各ピボット値に適用され、データベースによって、値とメジャーのすべてのペアのXML文字列を含むXMLTypeの列が戻されます。
expr ピボット列の定数値への評価を行う式を指定します。オプションで、各ピボット列値の別名を指定できます。別名がない場合は、列ヘッダーが引用識別子となります。
subquery subqueryは、XMLキーワードとともにのみ使用されます。subqueryを指定すると、subqueryによって検出されたすべての値がピボットに使用されます。出力は、XML以外のピボット問合せによって戻されるクロス集計書式とは異なります。pivot_in_clauseで指定されている複数の列のかわりに、subqueryでは、XML文字列の列が1つ生成されます。各行のXML文字列は、その行の暗黙的なGROUP BY値に対応する集計データを保持します。入力データに対応する行がない場合でも、各出力行のXML文字列には、subqueryによって検出されたすべてのピボット値が含まれています。
subqueryは、ピボット問合せの実行時に、一意の値リストを戻します。subqueryが一意の値を戻さない場合、Oracle Databaseによってランタイム・エラーが生成されます。問合せが一意の値を戻すかどうかがわからない場合は、subqueryにDISTINCTキーワードを使用します。
ANY ANYキーワードは、XMLキーワードとともにのみ使用されます。ANYキーワードは、ワイルド・カードとして機能し、subqueryと同様に動作します。出力は、XML以外のピボット問合せによって戻されるクロス集計書式とは異なります。pivot_in_clauseで指定されている複数の列のかわりに、ANYキーワードでは、XML文字列の列が1つ生成されます。各行のXML文字列は、その行の暗黙的なGROUP BY値に対応する集計データを保持します。ただし、subqueryを指定した場合と比較すると、ANYワイルド・カードでは、各出力行について、行に対応する入力データで検出されたピボット値のみを含むXML文字列が生成されます。
unpivot_clauseは、列を行に変換します。
INCLUDE | EXCLUDE NULLS句を使用すると、NULL値の行を含めるか除外するかを選択できます。INCLUDE NULLSを指定すると、NULL値の行もアンピボット操作の対象となり、EXCLUDE NULLSを指定するとNULL値の行は戻り値のセットから除外されます。この句を省略した場合は、アンピボット操作からNULLが除外されます。
columnには、sales_quantityなどのメジャー値を保持する各出力列の名前を指定します。
pivot_for_clauseには、四半期または製品などの記述子値を保持する各出力列の名前を指定します。
unpivot_in_clauseには、名前がpivot_for_clauseの出力列の値となる入力データ列を指定します。これらの入力データ列には、Q1、Q2、Q3、Q4など、カテゴリ値を指定する名前が含まれています。任意指定のAS句を使用すると、入力データ列名を、出力列内の指定したliteral値にマッピングできます。
アンピボット操作は、複数の値列を単一の列に変更します。このため、値列のすべてのデータ型は、数値、文字などの同じデータ型グループに属している必要があります。
すべての値列がCHARの場合、アンピボットされる列はCHARになります。値列がVARCHAR2の場合、アンピボットされる列はVARCHAR2になります。
すべての値列がNUMBERの場合、アンピボットされる列はNUMBERになります。値列がBINARY_DOUBLEの場合、アンピボットされる列はBINARY_DOUBLEになります。BINARY_DOUBLEの値列はないが、いずれかの値列がBINARY_FLOATの場合、アンピボットされる列はBINARY_FLOATになります。
適切なjoin_clause構文を使用すると、データが選択され、結合の一部となる表を識別できます。inner_cross_join_clauseを使用すると、内部結合またはクロス結合を指定できます。outer_join_clauseを使用すると、外部結合を指定できます。
結合する行ソースが3つ以上ある場合は、カッコを使用してデフォルトの優先順位を無効にすることができます。たとえば、次のような構文があるとします。
SELECT ... FROM a JOIN (b JOIN c) ...
この場合、bとcが結合され、次にその結果とaが結合されます。
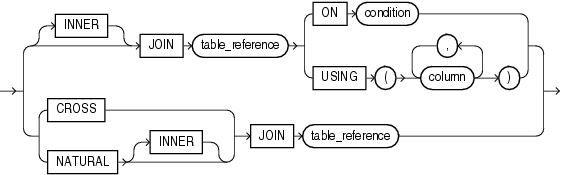
inner_cross_join_clause
内部結合は、結合条件を満たす行のみを戻します。
INNER INNERを指定すると、内部結合を明示的に指定できます。
JOIN JOINキーワードを使用すると、結合の実行を明示的に示すことができます。この構文を使用すると、WHERE句の結合で使用されている、カンマで区切られた表の式を、FROM句の結合構文に置き換えることができます。
ON condition ON句を使用すると、結合条件を指定できます。これによって、WHERE句の検索またはフィルタ条件とは分離して結合条件を指定できます。
USING (column) 両方の表で同じ名前の列同士を等価結合する場合、USING column句に使用する列を指定します。両方の表で同じ名前の列同士を結合する場合のみ、この句を使用できます。この句の中では、列名を表の名前および別名で修飾しないでください。
CROSS CROSSキーワードは、クロス結合を実行することを示します。クロス結合とは、2つの関係(リレーション)のクロス積を生成するものであり、実質的にはカンマ区切りのOracle Database表記法と同じです。
NATURAL NATURALキーワードは、自然結合を実行することを示します。この句のセマンティクスの詳細は、「NATURAL」を参照してください。
outer_join_clause
外部結合は、結合条件を満たすすべての行と、結合条件を満たす他方の表の行を除いた、一方の表のすべての行を戻します。指定可能な外部結合は、結合の両側にtable_reference構文を使用した従来の外部結合と、いずれかの側にquery_partition_clauseを使用したパーティション化された外部結合の2種類です。パーティション化された外部結合は、内部表の各パーティションと外部表の間で結合が行われるという点を除いて、従来の外部結合と同じです。この形式の結合では、対象のディメンションに沿って、選択的に疎データをより密にできます。このプロセスはデータの稠密化といいます。
query_partition_clause query_partition_clauseを使用すると、パーティション化された外部結合を定義できます。このような結合は、問合せによって戻されたパーティションに外部結合を適用し、従来の外部結合構文を拡張します。PARTITION BY句で指定した各式に対する行のパーティションが作成されます。問合せの各パーティションの行は、PARTITION BY式に対して同じ値を持ちます。
query_partition_clauseは、外部結合のいずれかの側で使用できます。パーティション化された外部結合の結果は、パーティション化された結果セットの各パーティションと結合の反対側の表との外部結合のUNIONになります。この形式の結果は、疎データの欠損の補完に役立つため、分析計算が簡単になります。
この句を省略した場合、表の式全体(table_referenceに指定したすべてのもの)が単一のパーティションとして扱われるため、従来型の外部結合となります。
分析ファンクションでquery_partition_clauseを使用するには、構文の上位ブランチ(カッコなし)を使用します。この句をモデルの問合せ(model_column_clauses内)またはパーティション化された外部結合(outer_join_clause内)で使用するには、構文の下位ブランチ(カッコ付き)を使用します。
パーティション化された外部結合の制限事項: パーティション化された外部結合には、次の制限事項があります。
query_partition_clauseは、結合の右側または左側に指定できますが、両方に指定することはできません。
パーティション化された完全外部結合(FULL)は指定できません。
ON句を使用して外部結合にquery_partition_clauseを指定した場合、ON条件内には副問合せを指定できません。
NATURAL NATURALキーワードは、自然結合を実行することを示します。自然結合は、2つの表の間で同じ名前のすべての列に基づきます。2つの表から関連する列の値が等しい行が選択されます。同じ名前の2つの列のデータ型の間に互換性がない場合は、エラーが発生します。自然結合で使用する列を指定する場合は、表の名前または別名で列名を修飾しないでください。
自然結合またはクロス結合の表の組合せが不明瞭な場合があります。たとえば、次のような結合構文があるとします。
a NATURAL LEFT JOIN b LEFT JOIN c ON b.c1 = c.c1
この例は、次のどちらにも解釈できます。
a NATURAL LEFT JOIN (b LEFT JOIN c ON b.c1 = c.c1) (a NATURAL LEFT JOIN b) LEFT JOIN c ON b.c1 = c.c1
このような不明瞭さをなくすため、カッコを使用して結合する表の組合せを明確にしてください。このようなカッコがないと、左から右へ表が組み合せられ、左の結合が使用されます。
自然結合の制限事項: LOB列、ANYTYPE列、ANYDATA列、ANYDATASET列またはコレクション列は、自然結合の一部として指定できません。
outer_join_type 実行する外部結合の種類を指定します。
RIGHTを指定すると、右側外部結合が実行されます。
LEFTを指定すると、左側外部結合が実行されます。
FULLを指定すると、完全な外部結合または両側外部結合が実行されます。内部結合に加え、内部結合の結果に戻されない両方の表からの行は、保持され、NULLで拡張されます。
RIGHT、LEFTまたはFULLの後にオプションのOUTERキーワードを指定し、外部結合の実行を明示的に示すことができます。
ON condition ON句を使用すると、結合条件を指定できます。これによって、WHERE句の検索またはフィルタ条件とは分離して結合条件を指定できます。
ON condition句の制限事項: NATURAL外部結合を使用してこの句を指定することはできません。
USING column USING句を含む外部結合の場合、問合せによって単一列が戻されます。この単一列は、結合内の一致する2つの列が結合したものです。この結合(coalesce)は、次のように機能します。
COALESCE (a, b) = a if a NOT NULL, else b.
したがって、次のことがいえます。
左側外部結合では、FROM句内の左側の表から共通するすべての列値が戻されます。
右側外部結合では、FROM句内の右側の表から共通するすべての列値が戻されます。
完全な外部結合では、結合された両方の表から共通するすべての列値が戻されます。
USING column句の制限事項:
この句の中では、列名を表の名前および別名で修飾しないでください。
LOB列またはコレクション列は、USING column句で指定できません。
NATURAL外部結合を使用してこの句を指定することはできません。
|
関連項目:
|
WHERE条件を指定すると、選択する行を1つ以上の条件を満たす行のみに制限できます。conditionには、有効なSQL条件を指定します。
この句を省略した場合、FROM句に指定されている表、ビューまたはマテリアライズド・ビューのすべての行が戻されます。
|
注意: この句がパーティション表またはパーティション索引のDATE列を参照している場合、データベースは、次の条件でのみパーティション・プルーニングを実行します。
|
hierarchical_query_clauseを使用すると、階層順序で行を選択できます。
階層問合せを含むSELECT文では、SELECT構文のリスト内のLEVEL疑似列を使用できます。LEVELは、ルート・ノードには1を、ルート・ノードの子であるノードには2を、孫であるノードには3を戻します(以下同様)。階層問合せによって戻されるレベルの数値は、使用可能なユーザー・メモリーによって制限されます。
Oracleは次のように階層問合せを処理します。
最初に、結合(指定されている場合)が、FROM句で指定されているか、またはWHERE句述語で指定されているかが評価されます。
CONNECT BY条件が評価されます。
残りのWHERE句述語が評価されます。
この句を指定する場合、ORDER BYおよびGROUP BYを指定すると、CONNECT BY結果の階層順序が破棄されるため、これらの句のどちらも指定しないでください。同じ親の兄弟である行を順序付ける場合は、ORDER SIBLINGS BY句を使用します。
階層問合せのルートとして使用される行を識別する場合の条件を指定します。conditionには、第7章「条件」で説明した任意の条件を使用できます。Oracle Databaseは、この条件を満たしているすべての行をルートとして使用します。この句を省略した場合、表内のすべての行がルート行として使用されます。
階層の親/子の行の関連を識別する条件を指定します。conditionには、第7章「条件」で説明した任意の条件を使用できます。ただし、親の行を参照するには、PRIOR演算子を使用する必要があります。
GROUP BY句を指定すると、選択した行を各行のexprの値に基づいてグループ化し、各グループのサマリー情報を1行戻すことができます。この句にCUBEまたはROLLUP拡張要素を指定した場合、標準グループ化の他に超集合グループ化が生成されます。
GROUP BY句の式には、SELECT構文のリストに指定されている列であるかどうかにかかわらず、FROM句の表、ビューおよびマテリアライズド・ビューの列を指定できます。
GROUP BY句は行をグループ化しますが、結果セットの順序は保証しません。グループ化の順序付けを行うには、ORDER BY句を使用します。
NLS_SORTパラメータがBINARY以外に設定され、NLS_COMPパラメータがLINGUISTICに設定されている場合、NLS_SORTで指定される言語定義に従って式の値が言語的に比較されて、値が等しく同じグループに属するかどうかが判断されます。GROUP BYの文字値が言語的に比較される場合、文字値はまず照合キーに変換されてから、RAW値のように比較されます。照合キーは、NLSSORTファンクションによって戻されるものと同じ値であり、「NLSSORT」で説明されているものと同じ制限事項があります。これらの制限事項により、照合キーの生成に使用された接頭辞に違いがない場合、その他の値に違いがあるとしても、2つの値は言語的に等しいものとしてグループ化されることがあります。
|
関連項目:
|
ROLLUP simple_grouping_clauseのROLLUP操作を使用すると、選択した行をGROUP BYで指定した式n、n-1、n-2、... 0の最初の値に基づいてグループ化し、各グループのサマリー情報を1行戻すことができます。ROLLUP操作をSUMファンクションとともに使用すると、小計値を出力できます。ROLLUPをSUMとともに使用すると、最も詳細なレベルの小計から総計までが生成されます。COUNTなどの集計ファンクションは、他の種類の超集合の出力に使用できます。
たとえば、simple_grouping_clauseのROLLUP句に式を3つ指定した場合(n=3)、操作の結果はn+1=3+1=4グループになります。
最初のn式の値でグループ化した行を標準行、その他を超集合行といいます。
|
関連項目: マテリアライズド・ビューでROLLUPを使用する場合の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』 |
CUBE CUBE操作をsimple_grouping_clauseの中で指定すると、選択された行は、指定された式のすべての可能な組合せの値に基づいてグループ化されます。グループごとに1つのサマリー情報行が戻されます。CUBE操作を使用すると、クロス集計値を出力できます。
たとえば、simple_grouping_clauseのCUBE句に式を3つ指定した場合(n=3)、操作の結果は2n = 23 = 8グループになります。n式の値でグループ化した行を標準行、その他を超集合行といいます。
GROUPING SETS GROUPING SETSは、データを複数にグループ化するGROUP BY句をさらに拡張したものです。これによって、不要な集計が排除され、効率的に集計できるようになります。必要なグループを指定すると、データベースがCUBEまたはROLLUPによって生成された集計のすべてを実行する必要がなくなります。GROUPING SETS句で指定したすべてのグループ化が計算され、UNION ALL操作で個々のグループ化の結果が組み合されます。UNION ALLは、結果セットが重複行を含むことを許可します。
GROUP BY句では、様々な方法で式を組み合せることができます。
複合列を指定するには、カッコで列をグループ化します。データベースは、ROLLUP操作またはCUBE操作の計算でこれらを1つの単位として処理します。
グルーピング・セットの連結を指定するには、複数のグルーピング・セット、ROLLUP操作およびCUBE操作をカンマで区切って指定すると、データベースによってこれらが結合されて1つのGROUP BY句になります。結果は、各グルーピング・セットからのグループ化のクロス積です。
HAVING句を使用すると、指定したconditionがTRUEであるグループの行のみを戻すように制限できます。この句を省略した場合、すべてのグループのサマリー行が戻されます。
where_clauseおよびhierarchical_query_clauseの後に、GROUP BYおよびHAVINGを指定します。GROUP BYおよびHAVING句を両方指定する場合は、どちらを先に指定してもかまいません。
GROUP BY句の制限事項: この句には、次の制限事項があります。
LOB列、ネストした表またはVARRAYをexprの一部として指定できません。
式には、スカラー副問合せ式を除くすべての形式が可能です。
group_by_clauseがオブジェクト型列を参照する場合、問合せはパラレル化されません。
model_clauseを使用すると、選択した行を多次元配列として表示して、その配列内のセルにランダムにアクセスできます。model_clauseを使用すると、一連のセル割当て(ルールと呼ばれます)を指定しておき、このルールによって個々のセルやセル範囲に対する計算を実行できます。このルールの操作の対象は問合せの結果であり、データベース表が更新されることはありません。
問合せでmodel_clauseを使用する場合、SELECT句およびORDER BY句は、model_column_clausesで定義された列のみを参照する必要があります。
|
関連項目:
|
main_model
main_model句を使用すると、選択した行を多次元配列内で表示する方法および配列内の各セルに適用するルールを定義できます。
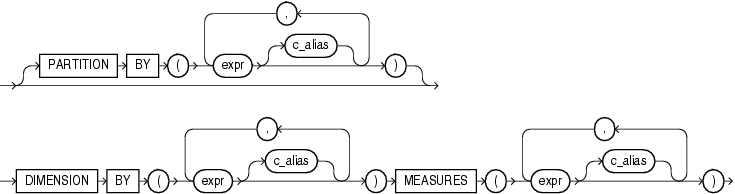
model_column_clauses
model_column_clausesを使用すると、問合せの列を、パーティション列、ディメンション列およびメジャー列の3つのグループに定義して分類できます。この3つの副次句内のexprがモデル列の場合、列の別名(c_alias)の指定は任意です。exprがモデル列でない場合、列の別名は必須です。
PARTITION BY PARTITION BY句を使用すると、選択した行を列の値に基づいてパーティションに分割するために使用する列を指定できます。
DIMENSION BY DIMENSION BY句を使用すると、パーティション内で行を識別する列を指定できます。ディメンション列およびパーティション列の値は、行のメジャー列に対する配列の索引として使用されます。
MEASURES MEASURES句を使用すると、計算が実行可能な列を識別できます。個々の行のメジャー列は、パーティション列およびディメンション列の値を指定することによる参照および更新が可能なセルと同様に扱われます。
model_column model_columnを使用すると、モデルの定義に使用する列を識別できます。exprが列名ではない場合、列の別名が必要です。モデル式の詳細は、「モデル式」を参照してください。
cell_reference_options
cell_reference_options句を使用すると、ルールでNULLまたは値なしを処理する方法および列の一意性を制約する方法を指定できます。
IGNORE NAV IGNORE NAVを指定すると、指定したデータ型のNULLまたは値なしに対して、次の値が戻されます。
数値データ型: 0(ゼロ)
日時データ型: 01-JAN-2000
文字データ型: 空の文字列
その他のデータ型: NULL
KEEP NAV KEEP NAVを指定すると、NULLまたは値なしのセル値に対してNULLが戻されます。KEEP NAVはデフォルトです。
UNIQUE SINGLE REFERENCE UNIQUE SINGLE REFERENCEを指定すると、問合せの結果セット全体ではなく、ルールの右側の単一セルの参照のみが一意性をチェックされます。
UNIQUE DIMENSION UNIQUE DIMENSIONを指定すると、PARTITION BYおよびDIMENSION BYで指定した列が、問合せに対する一意キーであるかどうかが確認されます。UNIQUE DIMENSIONはデフォルトです。
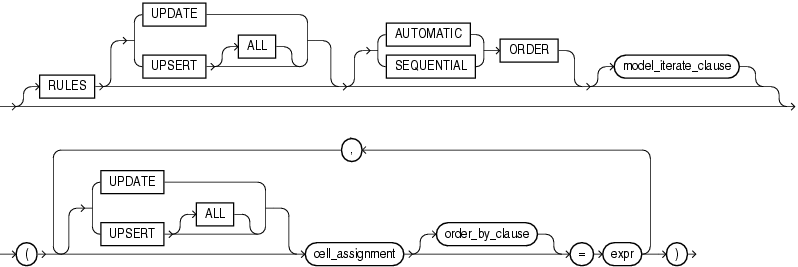
model_rules_clause
model_rules_clauseを使用すると、更新するセルおよびこれらのセルを更新するルールを指定できます。オプションで、ルールを適用および処理する方法も指定できます。
各ルールは割当てを表し、左側と右側にわかれています。ルールの左側は、ルールの右側によって更新されるセルを識別します。ルールの右側は、ルールの左側で指定されたセルに割り当てられる値を評価します。
UPSERT ALL UPSERT ALLを使用すると、ルールの左側に位置参照と記号参照の両方があるルールに対してUPSERT動作が可能になります。UPSERT ALLルールが評価されると、次の手順が実行され、アップサートするセル参照のリストが作成されます。
セル参照のすべてのシンボリック述語を満たす既存のセルを検索します。
記号参照があるディメンションのみを使用して、これらのセルの異なるディメンション値の組合せを検索します。
位置参照によって指定されたディメンション値を持つ、これらの値の組合せのクロス積が実行されます。
UPSERT ALLのセマンティクスの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
UPSERT UPSERTを指定すると、ルールの左側で参照されるセルが多次元配列内に存在している場合、セルにルールが適用され、多次元配列内に存在しないセルに対しては新しい行が挿入されます。UPSERT動作は、ルールの左側で位置参照が使用され、単一セルが参照されている場合にのみ適用されます。UPSERTはデフォルトです。位置参照および単一セル参照の詳細は、「cell_assignment」を参照してください。
UPDATEおよびUPSERTは、個々のルールに同様に指定できます。特定のルールにUPDATEまたはUPSERTのいずれかを指定した場合、その指定はRULES句に指定したその他のオプションより優先されます。
|
UPSERT [ALL]およびUPDATEに関する注意: UPSERT ALL、UPSERTまたはUPDATEルールに適切な条件が含まれていない場合は、別のタイプのルールに暗黙的に変換される場合があります。
|
UPDATE UPDATEを指定するとルールの左側で参照されるセルが多次元配列内に存在している場合、そのセルにルールが適用されます。セルが存在しない場合、割当ては無視されます。
AUTOMATIC ORDER AUTOMATIC ORDERを指定すると、依存順序に基づいてルールが評価されます。この場合、セルには値が1回のみ割り当てられます。
SEQUENTIAL ORDER SEQUENTIAL ORDERを指定すると、表示されている順序でルールが評価されます。この場合、セルには値が複数回割り当てられます。SEQUENTIAL ORDERはデフォルトです。
ITERATE ... [UNTIL] ITERATE ... [UNTIL]を使用すると、ルールを繰り返す回数を指定でき、さらに早期終了条件を指定することもできます。UNTILを囲むカッコの使用は任意です。
ITERATE ... [UNTIL]を指定した場合、ルールは表示されている順序で評価されます。model_rules_clauseでAUTOMATIC ORDERおよびITERATE ... [UNTIL]の両方が指定されている場合、エラーが戻されます。
cell_assignment
cell_assignment句は、ルールの左側に使用し、更新する1つ以上のセルを指定します。単一セルを参照するcell_assignmentは、単一セル参照といいます。複数のセルが参照される場合は、複数セル参照といいます。
model_clauseで定義したすべてのディメンション列は、cell_assignment句で修飾する必要があります。ディメンションは、記号参照または位置参照を使用して修飾できます。
記号参照は、dimension_column=constantなどのブール条件を使用して、単一のディメンション列を修飾します。位置参照では、DIMENSION BY句でディメンション列の位置が示されます。記号参照と位置参照の唯一の相違点は、NULLの処理です。
a[x=null,y=2000]のような単一セルの記号参照を使用すると、x=nullがFALSEと評価されるため、該当するセルは存在しません。ただし、a[null,2000]のような単一セルの位置参照を使用すると、null = nullがTRUEと評価されるため、xがNULL、yが2000のセルが該当します。単一セルの位置参照を使用すると、ディメンション列がNULLのセルを参照、更新および挿入できます。
ディメンション列の値を表す条件または式を指定するときは、記号参照と位置参照のどちらも使用できます。conditionに集計ファンクションやCVファンクションを含めることはできず、conditionが参照するのは単一のディメンション列でなければなりません。exprに副問合せを含めることはできません。モデル式の詳細は、「モデル式」を参照してください。
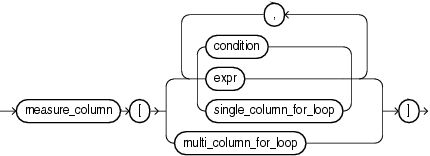
single_column_for_loop
single_column_for_loop句を使用すると、更新するセルの範囲を単一のディメンション列内で指定できます。
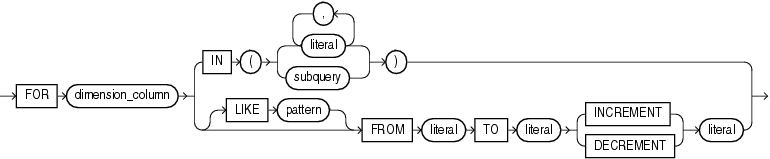
IN句を使用すると、ディメンション列の値を値のリストまたは副問合せとして指定できます。subqueryを使用するときは、次の制限事項があります。
相関問合せは使用できません。
10,000を超える行を戻すことはできません。
WITH句で定義された問合せを使用できません。
FROM句を使用すると、ディメンション列の値の範囲を指定できます(範囲内の増分は不連続でもかまいません)。FROM句を使用できるのは、列のデータ型が、加算および減算をサポートするものである場合のみです。INCREMENTおよびDECREMENTの値は、正の値である必要があります。
オプションで、FROM句内でLIKE句を指定することができます。LIKE句のpatternは、単一のパターン一致文字%を含む文字列です。この文字は、実行時にFROM句の現在の増分値または減分値で置き換えられます。
FORループで使用されるディメンション以外のすべてのディメンションが単一セル参照に関係する場合は、式で新しい行を挿入できます。FORループによって生成されたディメンション値の組合せの数は、MODEL句の行制限(10,000)の計算に含まれます。
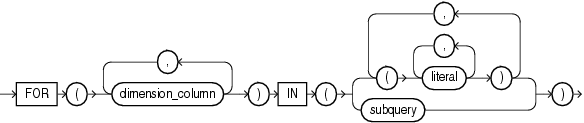
multi_column_for_loop
multi_column_for_loop句を使用すると、更新するセルの範囲を複数のディメンション列にまたがって指定できます。IN句を使用すると、ディメンション列の値を複数の値のリストまたは副問合せとして指定できます。subqueryを使用するときは、次の制限事項があります。
相関問合せは使用できません。
10,000を超える行を戻すことはできません。
WITH句で定義された問合せを使用できません。
FORループで使用されるディメンション以外のすべてのディメンションが単一セル参照に関係する場合は、式で新しい行を挿入できます。FORループによって生成されたディメンション値の組合せの数は、MODEL句の行制限(10,000)の計算に含まれます。
|
関連項目: MODEL句でFORループを使用する方法の詳細は、 |
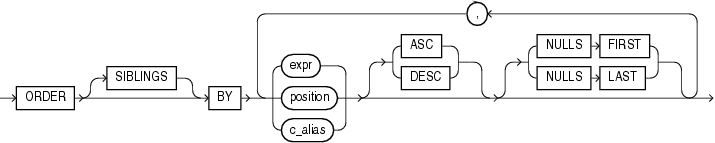
order_by_clause
ORDER BY句を使用すると、ルールの左側のセルを評価する順序を指定できます。exprは、ディメンションまたはメジャー列に変換される必要があります。ORDER BY句を指定しない場合、DIMENSION BY句で指定した列の順序がデフォルトで使用されます。詳細は、「order_by_clause」を参照してください。
order_by_clause句の制限事項: モデル・ルールでORDER BY句を使用する場合には、次の制限があります。
model_clause句のorder_by_clauseには、SIBLINGS、positionまたはc_aliasを指定できません。
モデル・ルールの左側にこの句を指定し、右側にFORループも指定することはできません。
expr
ルールの右側で指定されているセルの値を表す式を指定します。exprに副問合せを含めることはできません。モデル式の詳細は、「モデル式」を参照してください。
return_rows_clause
return_rows_clauseを使用すると、選択されたすべての行を戻すか、モデル・ルールによって更新された行のみを戻すかどうかを指定できます。ALLはデフォルトです。
reference_model
reference_modelは、model_clause内から複数の配列にアクセスする必要がある場合に使用します。この句は、問合せの結果に基づいて、読取り専用の多次元配列を定義します。
reference_model句の副次句は、main_model句と同じセマンティクスを持ちます。model_column_clausesおよびcell_reference_optionsを参照してください。
reference_model句の制限事項: この句には、次の制限事項があります。
PARTITION BY列を参照モデルに指定することはできません。
参照モデルの副問合せから外部副問合せの列を参照することはできません。
集合演算子: UNION、UNION ALL、INTERSECTおよびMINUS
集合演算子は、2つのSELECT文によって戻された行を1つの結果に結合します。それぞれのコンポーネント問合せで選択される列の数とデータ型は同じである必要がありますが、列の長さは異なってもかまいません。結果セット内の列の名前は、集合演算子の前にあるSELECT構文のリスト内の式の名前です。
集合演算子で3つ以上の問合せを結合する場合、隣接する問合せが左から右へ評価されます。副問合せを囲むカッコは任意指定です。この評価順序を変更する場合、カッコを使用します。
これらの演算子の詳細および使用方法の制限事項については、「UNION [ALL]、INTERSECTおよびMINUS演算子」を参照してください。
ORDER BY句を使用すると、文によって戻された行を順序付けることができます。order_by_clauseを指定しない場合、同じ問合せで取り出される行の順序が異なることがあります。
SIBLINGS SIBLINGSキーワードは、hierarchical_query_clause(CONNECT BY)を指定する場合のみに有効です。ORDER SIBLINGS BYは階層問合せ句で指定した任意の順序を保持し、兄弟関係にある階層にorder_by_clauseを適用します。
expr exprを使用すると、exprの値を基準にして行を順番付けることができます。式は、SELECT構文のリストの列、あるいはFROM句の表、ビューまたはマテリアライズド・ビューの列に基づきます。
position positionを使用すると、SELECT構文のリストの指定した位置にある式の値に基づいて行を順序付けることができます。positionには整数を指定する必要があります。
order_by_clauseには複数の式を指定できます。この場合、まず、最初の式の値に基づいて行がソートされます。次に、最初の式と同じ値を持つ行が2番目の式の値に基づいてソートされる、というように処理が行われます。NULL値は昇順では最後に、降順では先頭にソートされます。問合せ結果の順位付けの詳細は、「問合せ結果のソート」を参照してください。
ASC | DESC 昇順か降順かを指定します。デフォルトはASCです。
NULLS FIRST | NULLS LAST NULL値を含む戻された行が順序の最初にくるか、最後にくるかを指定します。
NULLS LASTは昇順のデフォルトで、NULLS FIRSTは降順のデフォルトです。
ORDER BY句の制限事項: ORDER BY句には次の制限事項があります。
この文中でDISTINCT演算子を指定した場合、SELECT構文のリストに指定された列でないかぎり、この句は列を参照することはできません。
order_by_clauseには最大255個の式を指定できます。
LOB列、LONG列、LONG RAW列、ネストした表またはVARRAYを使用して順位付けすることはできません。
同じ文中でgroup_by_clauseを指定する場合、このorder_by_clauseは次の式に制限されます。
定数
集計ファンクション
分析ファンクション
USERファンクション、UIDファンクションおよびSYSDATEファンクション
group_by_clauseに指定されているものと同じ式
グループ内のすべての行が同じ値に評価されるこれらの式を導出する式
FOR UPDATE句を使用すると、選択した行がロックされ、トランザクションが終了するまでは他のユーザーがその行をロックまたは更新することはできなくなります。この句を指定できるのは、最上位のSELECT文の中のみであり、副問合せでは指定できません。
|
注意: LOB値を更新する場合、そのLOBを含む行をロックしておく必要があります。行をロックする方法の1つに、埋込みSELECT ... FOR UPDATE文があります。この場合、プログラム言語の1つまたはDBMS_LOBパッケージを使用します。LOBの書込み前に行う行のロックの詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』を参照してください。 |
親表の行がロックされても、ネストした表の行はロックされません。ネストした表の行をロックする場合、ネストした表を明示的にロックする必要があります。
FOR UPDATE句の制限事項: この句には、次の制限事項があります。
この句をDISTINCT演算子またはCURSOR式、集合演算子、group_by_clause、または集計ファンクションの構造体とともに指定することはできません。
この句がロックした表は、同じ文で参照されたLONG列および順序と同じデータベース内にある必要があります。
ビューでのFOR UPDATE句の使用: 一般に、この句はビューではサポートされていません。ただし、ビューでSELECT ... FOR UPDATE問合せを実行してもエラーが発生しない場合もあります。これは、問合せオプティマイザによってビューが問合せブロックに内部的にマージされ、内部で変換された問合せに対してSELECT ... FOR UPDATEが行われる場合です。この項では、ビューに対してFOR UPDATE句を使用できる場合とできない場合の例を示します。
マージされたビューでのFOR UPDATE句の使用
次の条件が両方とも満たされている場合、マージされたビューに対してFOR UPDATE句を使用するとエラーが発生する可能性があります。
ビューの基礎となる列が式である
FOR UPDATE句が列リストに適用される
次の文は、ビューの基礎となる列が式ではないため、正常に実行されます。
SELECT employee_id FROM (SELECT * FROM employees) FOR UPDATE OF employee_id;
次の文は、ビューの基礎となる列は式ですが、FOR UPDATE句が列リストに適用されないため、正常に実行されます。
SELECT employee_id FROM (SELECT employee_id+1 AS employee_id FROM employees) FOR UPDATE;
次の文は、ビューの基礎となる列が式であり、FOR UPDATE句が列リストに適用されるため、失敗します。
SELECT employee_id FROM (SELECT employee_id+1 AS employee_id FROM employees)
FOR UPDATE OF employee_id;
*
Error at line 2:
ORA-01733: virtual column not allowed here
マージされていないビューでのFOR UPDATE句の使用
ビューではFOR UPDATE句がサポートされていないため、ビューのマージを回避する句(NO_MERGEヒントなど)、ビューのマージを禁止するパラメータ、またはビューのマージを回避する問合せ構造を使用すると、ORA-02014エラーが発生します。
次の例では、GROUP BY文によってビューのマージが回避されるため、エラーが発生します。
SELECT avgsal
FROM (SELECT AVG(salary) AS avgsal FROM employees GROUP BY job_id)
FOR UPDATE;
FROM (SELECT AVG(salary) AS avgsal FROM employees GROUP BY job_id)
*
ERROR at line 2:
ORA-02014: cannot select FOR UPDATE from view with DISTINCT, GROUP BY, etc.
|
注意: ビューのマージのメカニズムは複雑であるため、ビューではFOR UPDATE句を使用しないことをお薦めします。 |
OF ... column
OF ... column句を使用すると、結合内の特定の表またはビューで選択された行のみをロックできます。OF句の列は、どの表またはビューの行をロックするかを識別する場合にのみ使用します。指定する列は重要ではありません。ただし、列の別名ではなく、実際の列名を指定する必要があります。この句を省略した場合、問合せ内のすべての表の選択された行がロックされます。
NOWAIT | WAIT
NOWAITおよびWAIT句を使用すると、他のユーザーによってロックされている行をSELECT文がロックしようとする場合に処理する方法をデータベースに指示できます。
NOWAITを指定すると、ロックされている場合に制御がすぐに戻ります。
WAITを指定すると、行が使用可能になるまでinteger秒待機した後で制御が戻されます。
WAITおよびNOWAITのどちらも指定しない場合、行が使用可能になるまで待機した後でSELECT文の結果が戻されます。
SKIP LOCKED
SKIP LOCKEDは、競合するトランザクションを処理するもう1つの方法であり、対象の行のうち一部をロックするというものです。SKIP LOCKEDを指定すると、WHERE句で指定した行のロックが試行され、他のトランザクションによってすでにロックされている行はスキップされます。この機能は、Oracle Streams Advanced Queuingなどのマルチコンシューマ・キュー環境で使用するために設計されています。キュー・コンシューマは、他のコンシューマによってロックされた行はスキップして未ロックの行を取得できるので、他のコンシューマの操作が終了するまで待つ必要はなくなります。SKIP LOCKED機能を直接使用するかわりに、Oracle Streams Advanced Queuing APIを使用することをお薦めします。詳細は、『Oracle Streamsアドバンスト・キューイング・ユーザーズ・ガイド』を参照してください。
WAITまたはSKIP LOCKEDを指定したときに排他モードで表がロックされていると、表のロックが解除されるまではSELECT文の結果が戻りません。WAITでは、指定されている待機時間にかかわらず、SELECT FOR UPDATE句がブロックされます。
例
副問合せのファクタリング例: 次の文は、結合を含む初期問合せブロックに対する問合せの名前dept_costsおよびavg_costを作成し、主問合せの本体でその問合せの名前を使用します。
WITH
dept_costs AS (
SELECT department_name, SUM(salary) dept_total
FROM employees e, departments d
WHERE e.department_id = d.department_id
GROUP BY department_name),
avg_cost AS (
SELECT SUM(dept_total)/COUNT(*) avg
FROM dept_costs)
SELECT * FROM dept_costs
WHERE dept_total >
(SELECT avg FROM avg_cost)
ORDER BY department_name;
DEPARTMENT_NAME DEPT_TOTAL
------------------------------ ----------
Sales 304500
Shipping 156400
再帰的副問合せのファクタリング例: 次の文は、従業員101に直接的または間接的に報告する従業員とそのレポート・レベルを表示します。
WITH
reports_to_101 (eid, emp_last, mgr_id, reportLevel) AS
(
SELECT employee_id, last_name, manager_id, 0 reportLevel
FROM employees
WHERE employee_id = 101
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id, reportLevel+1
FROM reports_to_101 r, employees e
WHERE r.eid = e.manager_id
)
SELECT eid, emp_last, mgr_id, reportLevel
FROM reports_to_101
ORDER BY reportLevel, eid;
EID EMP_LAST MGR_ID REPORTLEVEL
---------- ------------------------- ---------- -----------
101 Kochhar 100 0
108 Greenberg 101 1
200 Whalen 101 1
203 Mavris 101 1
204 Baer 101 1
205 Higgins 101 1
109 Faviet 108 2
110 Chen 108 2
111 Sciarra 108 2
112 Urman 108 2
113 Popp 108 2
206 Gietz 205 2
次の文は、従業員101に直接的または間接的に報告する従業員、レポート・レベル、および管理チェーンを表示します。
WITH
reports_to_101 (eid, emp_last, mgr_id, reportLevel, mgr_list) AS
(
SELECT employee_id, last_name, manager_id, 0 reportLevel,
CAST(manager_id AS VARCHAR2(2000))
FROM employees
WHERE employee_id = 101
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id, reportLevel+1,
CAST(mgr_list || ',' || manager_id AS VARCHAR2(2000))
FROM reports_to_101 r, employees e
WHERE r.eid = e.manager_id
)
SELECT eid, emp_last, mgr_id, reportLevel, mgr_list
FROM reports_to_101
ORDER BY reportLevel, eid;
EID EMP_LAST MGR_ID REPORTLEVEL MGR_LIST
---------- ------------------------- ---------- ----------- --------
101 Kochhar 100 0 100
108 Greenberg 101 1 100,101
200 Whalen 101 1 100,101
203 Mavris 101 1 100,101
204 Baer 101 1 100,101
205 Higgins 101 1 100,101
109 Faviet 108 2 100,101,108
110 Chen 108 2 100,101,108
111 Sciarra 108 2 100,101,108
112 Urman 108 2 100,101,108
113 Popp 108 2 100,101,108
206 Gietz 205 2 100,101,205
次の文は、従業員101の直接的または間接的な部下である従業員とそのレポート・レベルを表示します。これは、レポート・レベル1で停止します。
WITH
reports_to_101 (eid, emp_last, mgr_id, reportLevel) AS
(
SELECT employee_id, last_name, manager_id, 0 reportLevel
FROM employees
WHERE employee_id = 101
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id, reportLevel+1
FROM reports_to_101 r, employees e
WHERE r.eid = e.manager_id
)
SELECT eid, emp_last, mgr_id, reportLevel
FROM reports_to_101
WHERE reportLevel <= 1
ORDER BY reportLevel, eid;
EID EMP_LAST MGR_ID REPORTLEVEL
---------- ------------------------- ---------- -----------
101 Kochhar 100 0
108 Greenberg 101 1
200 Whalen 101 1
203 Mavris 101 1
204 Baer 101 1
205 Higgins 101 1
次の文は、管理レベルごとにインデントを挿入して、組織全体を表示します。
WITH
org_chart (eid, emp_last, mgr_id, reportLevel, salary, job_id) AS
(
SELECT employee_id, last_name, manager_id, 0 reportLevel, salary, job_id
FROM employees
WHERE manager_id is null
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id,
r.reportLevel+1 reportLevel, e.salary, e.job_id
FROM org_chart r, employees e
WHERE r.eid = e.manager_id
)
SEARCH DEPTH FIRST BY emp_last SET order1
SELECT lpad(' ',2*reportLevel)||emp_last emp_name, eid, mgr_id, salary, job_id
FROM org_chart
ORDER BY order1;
EMP_NAME EID MGR_ID SALARY JOB_ID
-------------------- ---------- ---------- ---------- ----------
King 100 24000 AD_PRES
Cambrault 148 100 11000 SA_MAN
Bates 172 148 7300 SA_REP
Bloom 169 148 10000 SA_REP
Fox 170 148 9600 SA_REP
Kumar 173 148 6100 SA_REP
Ozer 168 148 11500 SA_REP
Smith 171 148 7400 SA_REP
De Haan 102 100 17000 AD_VP
Hunold 103 102 9000 IT_PROG
Austin 105 103 4800 IT_PROG
Ernst 104 103 6000 IT_PROG
Lorentz 107 103 4200 IT_PROG
Pataballa 106 103 4800 IT_PROG
Errazuriz 147 100 12000 SA_MAN
Ande 166 147 6400 SA_REP
. . .
次の文は組織全体を表示し、管理レベルごとにインデントを挿入します(各レベルの順序はhire_dateによって決定します)。is_cycleの値がYに設定されるのは、その従業員のhire_dateと同じ値を持つマネージャが管理チェーン内の上位にいる場合です。
WITH
dup_hiredate (eid, emp_last, mgr_id, reportLevel, hire_date, job_id) AS
(
SELECT employee_id, last_name, manager_id, 0 reportLevel, hire_date, job_id
FROM employees
WHERE manager_id is null
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id,
r.reportLevel+1 reportLevel, e.hire_date, e.job_id
FROM dup_hiredate r, employees e
WHERE r.eid = e.manager_id
)
SEARCH DEPTH FIRST BY hire_date SET order1
CYCLE hire_date SET is_cycle TO 'Y' DEFAULT 'N'
SELECT lpad(' ',2*reportLevel)||emp_last emp_name, eid, mgr_id,
hire_date, job_id, is_cycle
FROM dup_hiredate
ORDER BY order1;
EMP_NAME EID MGR_ID HIRE_DATE JOB_ID IS_CYCLE
-------------------- ---------- ---------- --------- ---------- --------
King 100 17-JUN-03 AD_PRES N
De Haan 102 100 13-JAN-01 AD_VP N
Hunold 103 102 03-JAN-06 IT_PROG N
Austin 105 103 25-JUN-05 IT_PROG N
. . .
Kochhar 101 100 21-SEP-05 AD_VP N
Mavris 203 101 07-JUN-02 HR_REP N
Baer 204 101 07-JUN-02 PR_REP N
Higgins 205 101 07-JUN-02 AC_MGR N
Gietz 206 205 07-JUN-02 AC_ACCOUNT Y
Greenberg 108 101 17-AUG-02 FI_MGR N
Faviet 109 108 16-AUG-02 FI_ACCOUNT N
Chen 110 108 28-SEP-05 FI_ACCOUNT N
. . .
次の文は、各マネージャの配下の従業員の人数をカウントします。
WITH
emp_count (eid, emp_last, mgr_id, mgrLevel, salary, cnt_employees) AS
(
SELECT employee_id, last_name, manager_id, 0 mgrLevel, salary, 0 cnt_employees
FROM employees
UNION ALL
SELECT e.employee_id, e.last_name, e.manager_id,
r.mgrLevel+1 mgrLevel, e.salary, 1 cnt_employees
FROM emp_count r, employees e
WHERE e.employee_id = r.mgr_id
)
SEARCH DEPTH FIRST BY emp_last SET order1
SELECT emp_last, eid, mgr_id, salary, sum(cnt_employees), max(mgrLevel) mgrLevel
FROM emp_count
GROUP BY emp_last, eid, mgr_id, salary
HAVING max(mgrLevel) > 0
ORDER BY mgr_id NULLS FIRST, emp_last;
EMP_LAST EID MGR_ID SALARY SUM(CNT_EMPLOYEES) MGRLEVEL
------------------ ---------- ---------- ---------- ------------------ ----------
King 100 24000 106 3
Cambrault 148 100 11000 7 2
De Haan 102 100 17000 5 2
Errazuriz 147 100 12000 6 1
Fripp 121 100 8200 8 1
Hartstein 201 100 13000 1 1
Kaufling 122 100 7900 8 1
. . .
単純問合せの例: 次の文は、部門番号30の従業員表employeesの行を選択します。
SELECT * FROM employees WHERE department_id = 30 ORDER BY last_name;
次の文は、部門番号30の購買係を除くすべての従業員の名前、職種、給与および部門番号を選択します。
SELECT last_name, job_id, salary, department_id FROM employees WHERE NOT (job_id = 'PU_CLERK' AND department_id = 30) ORDER BY last_name;
次の文は、FROM句の副問合せから、すべての従業員数と給与合計がすべての部門に対して占める割合を部門ごとに戻します。
SELECT a.department_id "Department", a.num_emp/b.total_count "%_Employees", a.sal_sum/b.total_sal "%_Salary" FROM (SELECT department_id, COUNT(*) num_emp, SUM(salary) sal_sum FROM employees GROUP BY department_id) a, (SELECT COUNT(*) total_count, SUM(salary) total_sal FROM employees) b ORDER BY a.department_id;
パーティションからの行の選択例: FROM句にキーワードPARTITIONを指定することによって、パーティション表の1つのパーティションから行を選択できます。次のSQL文は、サンプル表sh.salesのsales_q2_2000パーティションへ別名を割り当て、行を取り出します。
SELECT * FROM sales PARTITION (sales_q2_2000) s WHERE s.amount_sold > 1500 ORDER BY cust_id, time_id, channel_id;
次の文は、oe.orders表から、指定した日付より早い注文が含まれる行を選択します。
SELECT * FROM orders
WHERE order_date < TO_DATE('2006-06-15', 'YYYY-MM-DD');
サンプルの選択例: 次の問合せは、oe.orders表の注文数を推定します。
SELECT COUNT(*) * 10 FROM orders SAMPLE (10);
COUNT(*)*10
-----------
70
問合せでは推定値が戻されるため、実際の戻り値は問合せを行うたびに異なる場合があります。
SELECT COUNT(*) * 10 FROM orders SAMPLE (10);
COUNT(*)*10
-----------
80
次の問合せでは、前述の問合せにシード値を追加します。同じシード値では、常に同じ推定値が戻されます。
SELECT COUNT(*) * 10 FROM orders SAMPLE(10) SEED (1);
COUNT(*)*10
-----------
130
SELECT COUNT(*) * 10 FROM orders SAMPLE(10) SEED(4);
COUNT(*)*10
-----------
120
SELECT COUNT(*) * 10 FROM orders SAMPLE(10) SEED (1);
COUNT(*)*10
-----------
130
フラッシュバック問合せの使用例: 次の文は、サンプル表hr.employeesの現在の値を表示し、値を変更します。この例の目的はデモであるため、使用している時間隔が非常に短くなっています。実際の環境での時間隔は、これより長いのが一般的です。
SELECT salary FROM employees
WHERE last_name = 'Chung';
SALARY
----------
3800
UPDATE employees SET salary = 4000
WHERE last_name = 'Chung';
1 row updated.
SELECT salary FROM employees
WHERE last_name = 'Chung';
SALARY
----------
4000
更新前の値を確認するには、次のフラッシュバック問合せを使用します。
SELECT salary FROM employees
AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '1' MINUTE)
WHERE last_name = 'Chung';
SALARY
----------
3800
過去の特定の期間における値を確認するには、次のバージョン・フラッシュバック問合せを使用します。
SELECT salary FROM employees
VERSIONS BETWEEN TIMESTAMP
SYSTIMESTAMP - INTERVAL '10' MINUTE AND
SYSTIMESTAMP - INTERVAL '1' MINUTE
WHERE last_name = 'Chung';
元の値に戻すには、フラッシュバック問合せを別のUPDATE文の副問合せとして使用します。
UPDATE employees SET salary =
(SELECT salary FROM employees
AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '2' MINUTE)
WHERE last_name = 'Chung')
WHERE last_name = 'Chung';
1 row updated.
SELECT salary FROM employees
WHERE last_name = 'Chung';
SALARY
----------
3800
GROUP BY句の使用例: 次の文は、employees表の各部門について最低給与と最高給与を戻します。
SELECT department_id, MIN(salary), MAX (salary)
FROM employees
GROUP BY department_id
ORDER BY department_id;
次の文は、各部門の事務員について最高給与と最低給与を戻します。
SELECT department_id, MIN(salary), MAX (salary)
FROM employees
WHERE job_id = 'PU_CLERK'
GROUP BY department_id
ORDER BY department_id;
GROUP BY CUBE句の使用例: 部門および職種のすべての組合せについて、従業員数と平均年収を戻すには、サンプル表hr.employeesおよびhr.departmentsに次の問合せを発行します。
SELECT DECODE(GROUPING(department_name), 1, 'All Departments',
department_name) AS department_name,
DECODE(GROUPING(job_id), 1, 'All Jobs', job_id) AS job_id,
COUNT(*) "Total Empl", AVG(salary) * 12 "Average Sal"
FROM employees e, departments d
WHERE d.department_id = e.department_id
GROUP BY CUBE (department_name, job_id)
ORDER BY department_name, job_id;
DEPARTMENT_NAME JOB_ID Total Empl Average Sal
------------------------------ ---------- ---------- -----------
Accounting AC_ACCOUNT 1 99600
Accounting AC_MGR 1 144000
Accounting All Jobs 2 121800
Administration AD_ASST 1 52800
. . .
Shipping ST_CLERK 20 33420
Shipping ST_MAN 5 87360
GROUPING SETS句の使用例: 次の例は、指定した3つのグループで集計した販売の合計を示します。
(channel_desc, calendar_month_desc, country_id)
(channel_desc, country_id)
(calendar_month_desc, country_id)
GROUPING SETS構文を指定しない場合、SQLはより複雑になり、問合せの効果は低くなります。たとえば、3つの個別の問合せを実行し、UNION演算を行うか、またはCUBE(channel_desc, calendar_month_desc, country_id)操作を指定した問合せを実行し、生成される8つのグループから5つを除去します。
SELECT channel_desc, calendar_month_desc, co.country_id,
TO_CHAR(sum(amount_sold) , '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries co
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND sales.channel_id= channels.channel_id
AND customers.country_id = co.country_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND co.country_iso_code IN ('UK', 'US')
GROUP BY GROUPING SETS(
(channel_desc, calendar_month_desc, co.country_id),
(channel_desc, co.country_id),
(calendar_month_desc, co.country_id) );
CHANNEL_DESC CALENDAR COUNTRY_ID SALES$
-------------------- -------- ---------- ----------
Internet 2000-09 52790 124,224
Direct Sales 2000-09 52790 638,201
Internet 2000-10 52790 137,054
Direct Sales 2000-10 52790 682,297
2000-09 52790 762,425
2000-10 52790 819,351
Internet 52790 261,278
Direct Sales 52790 1,320,497
階層問合せの例 CONNECT BY句を指定した次の問合せは、親である行のemployee_id値が子である行のmanager_id値と等しいという階層関係を定義します。
SELECT last_name, employee_id, manager_id FROM employees CONNECT BY employee_id = manager_id ORDER BY last_name;
次のCONNECT BY句では、PRIOR演算子がemployee_id値のみに適用されます。この条件を評価するために、データベースは親である行に対してはemployee_idの値を評価し、子である行に対してはmanager_id、salaryおよびcommission_pctのそれぞれの値を評価します。
SELECT last_name, employee_id, manager_id FROM employees CONNECT BY PRIOR employee_id = manager_id AND salary > commission_pct ORDER BY last_name;
子である行を限定する場合、manager_idの値と親である行のemployee_idの値が等しく、salaryの値がcommission_pctの値より大きい必要があります。
HAVING条件の使用例: 次の文は、従業員の最低給与が$5,000未満の部門についての最高給与と最低給与を戻します。
SELECT department_id, MIN(salary), MAX (salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) < 5000
ORDER BY department_id;
DEPARTMENT_ID MIN(SALARY) MAX(SALARY)
------------- ----------- -----------
10 4400 4400
30 2500 11000
50 2100 8200
60 4200 9000
次の例は、HAVING句で相関副問合せを使用して、マネージャのいない部門および部門のないマネージャを結果セットから除外しています。
SELECT department_id, manager_id
FROM employees
GROUP BY department_id, manager_id HAVING (department_id, manager_id) IN
(SELECT department_id, manager_id FROM employees x
WHERE x.department_id = employees.department_id)
ORDER BY department_id;
ORDER BY句の使用例: 次の文は、employees表からすべての購買係のレコードを選択し、その給与によって降順にソートします。
SELECT * FROM employees WHERE job_id = 'PU_CLERK' ORDER BY salary DESC;
次の文は、employees表から情報を選択し、最初に部門番号で昇順にソートした後、給与で降順にソートします。
SELECT last_name, department_id, salary FROM employees ORDER BY department_id ASC, salary DESC, last_name;
次の文は、前述のSELECT文と同じ情報を選択し、ORDER BY位置表記法を使用します。ここでは、まずdepartment_idで昇順に、次にsalaryで降順に、最後にlast_nameでアルファベット順に順序付けします。
SELECT last_name, department_id, salary FROM employees ORDER BY 2 ASC, 3 DESC, 1;
MODEL句の例: ここで作成されたビューは、サンプル・スキーマshに基づいており、後述の例で使用されています。
CREATE OR REPLACE VIEW sales_view_ref AS
SELECT country_name country,
prod_name prod,
calendar_year year,
SUM(amount_sold) sale,
COUNT(amount_sold) cnt
FROM sales,times,customers,countries,products
WHERE sales.time_id = times.time_id
AND sales.prod_id = products.prod_id
AND sales.cust_id = customers.cust_id
AND customers.country_id = countries.country_id
AND ( customers.country_id = 52779
OR customers.country_id = 52776 )
AND ( prod_name = 'Standard Mouse'
OR prod_name = 'Mouse Pad' )
GROUP BY country_name,prod_name,calendar_year;
SELECT country, prod, year, sale
FROM sales_view_ref
ORDER BY country, prod, year;
COUNTRY PROD YEAR SALE
---------- ----------------------------------- -------- ---------
France Mouse Pad 1998 2509.42
France Mouse Pad 1999 3678.69
France Mouse Pad 2000 3000.72
France Mouse Pad 2001 3269.09
France Standard Mouse 1998 2390.83
France Standard Mouse 1999 2280.45
France Standard Mouse 2000 1274.31
France Standard Mouse 2001 2164.54
Germany Mouse Pad 1998 5827.87
Germany Mouse Pad 1999 8346.44
Germany Mouse Pad 2000 7375.46
Germany Mouse Pad 2001 9535.08
Germany Standard Mouse 1998 7116.11
Germany Standard Mouse 1999 6263.14
Germany Standard Mouse 2000 2637.31
Germany Standard Mouse 2001 6456.13
16 rows selected.
次の例では、国、製品、年および売上が格納されている列が存在するsales_view_refから多次元配列を作成します。さらに、次のことも行われます。
2001年のマウス・パッドの売上を含む行が存在する場合、1999年および2000年のマウス・パッドの売上を2001年のマウス・パッドの売上に割り当てます。
2002年のスタンダード・マウスの売上を含む行が存在しない場合、2001年のスタンダード・マウスの売上を2002年のスタンダード・マウスの売上に割り当てます。
SELECT country,prod,year,s
FROM sales_view_ref
MODEL
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale s)
IGNORE NAV
UNIQUE DIMENSION
RULES UPSERT SEQUENTIAL ORDER
(
s[prod='Mouse Pad', year=2001] =
s['Mouse Pad', 1999] + s['Mouse Pad', 2000],
s['Standard Mouse', 2002] = s['Standard Mouse', 2001]
)
ORDER BY country, prod, year;
COUNTRY PROD YEAR SALE
---------- ----------------------------------- -------- ---------
France Mouse Pad 1998 2509.42
France Mouse Pad 1999 3678.69
France Mouse Pad 2000 3000.72
France Mouse Pad 2001 6679.41
France Standard Mouse 1998 2390.83
France Standard Mouse 1999 2280.45
France Standard Mouse 2000 1274.31
France Standard Mouse 2001 2164.54
France Standard Mouse 2002 2164.54
Germany Mouse Pad 1998 5827.87
Germany Mouse Pad 1999 8346.44
Germany Mouse Pad 2000 7375.46
Germany Mouse Pad 2001 15721.9
Germany Standard Mouse 1998 7116.11
Germany Standard Mouse 1999 6263.14
Germany Standard Mouse 2000 2637.31
Germany Standard Mouse 2001 6456.13
Germany Standard Mouse 2002 6456.13
18 rows selected.
最初のルールでは、ルールの左側で記号参照が使用されているため、UPDATE動作が使用されます。ルールの左側で表される行が存在するため、メジャー列が更新されます。行が存在しない場合、何も実行されません。
2番目のルールでは、ルールの左側で位置参照が使用され、単一セルが参照されているため、UPSERT動作が使用されます。行が存在しないため、新しい行が追加され、関連するメジャー列が更新されます。行が存在する場合、メジャー列は更新されません。
|
関連項目: 詳細および例は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
次の例は、同じsales_view_refビューおよび分析ファンクションSUMを使用して、国および年ごとの累計(csum)を計算しています。
SELECT country, year, sale, csum
FROM
(SELECT country, year, SUM(sale) sale
FROM sales_view_ref
GROUP BY country, year
)
MODEL DIMENSION BY (country, year)
MEASURES (sale, 0 csum)
RULES (csum[any, any]=
SUM(sale) OVER (PARTITION BY country
ORDER BY year
ROWS UNBOUNDED PRECEDING)
)
ORDER BY country, year;
COUNTRY YEAR SALE CSUM
--------------- ---------- ---------- ----------
France 1998 4900.25 4900.25
France 1999 5959.14 10859.39
France 2000 4275.03 15134.42
France 2001 5433.63 20568.05
Germany 1998 12943.98 12943.98
Germany 1999 14609.58 27553.56
Germany 2000 10012.77 37566.33
Germany 2001 15991.21 53557.54
8 rows selected.
FOR UPDATE句の使用例: 次の文は、employees表中のオックスフォード勤務(location_idは2500)の購買係の行をロックし、departments表中の購買係が存在するオックスフォードの部門の行をロックします。
SELECT e.employee_id, e.salary, e.commission_pct FROM employees e, departments d WHERE job_id = 'SA_REP' AND e.department_id = d.department_id AND location_id = 2500 ORDER BY e.employee_id FOR UPDATE;
次の文は、employees表中のオックスフォード勤務の購買係の行のみをロックします。departments表中の行はロックされません。
SELECT e.employee_id, e.salary, e.commission_pct FROM employees e JOIN departments d USING (department_id) WHERE job_id = 'SA_REP' AND location_id = 2500 ORDER BY e.employee_id FOR UPDATE OF e.salary;
WITH CHECK OPTION句の使用例: 次の文は、3番目の値が副問合せwhere_clauseの条件に違反していても有効です。
INSERT INTO (SELECT department_id, department_name, location_id FROM departments WHERE location_id < 2000) VALUES (9999, 'Entertainment', 2500);
ただし、次の文はWITH CHECK OPTION句を含むため、無効になります。
INSERT INTO (SELECT department_id, department_name, location_id
FROM departments WHERE location_id < 2000 WITH CHECK OPTION)
VALUES (9999, 'Entertainment', 2500);
*
ERROR at line 2:
ORA-01402: view WITH CHECK OPTION where-clause violation
PIVOTおよびUNPIVOTの使用例: oe.orders表には、注文が発注された日時(order_date)、発注方法(order_mode)および注文の合計数(order_total)に関する情報とその他の情報が含まれています。次の例は、PIVOT句を使用して、order_mode値を列にピボットし、処理中にorder_totalデータを集計して発注モードごとの年間合計を取得する方法を示します。
CREATE TABLE pivot_table AS
SELECT * FROM
(SELECT EXTRACT(YEAR FROM order_date) year, order_mode, order_total FROM orders)
PIVOT
(SUM(order_total) FOR order_mode IN ('direct' AS Store, 'online' AS Internet));
SELECT * FROM pivot_table ORDER BY year;
YEAR STORE INTERNET
---------- ---------- ----------
2004 5546.6
2006 371895.5 100056.6
2007 1274078.8 1271019.5
2008 252108.3 393349.4
UNPIVOT句では、入力列ヘッダーが1つ以上の記述子列の値として出力され、入力列値が1つ以上のメジャー列の値として出力されるように、指定した列を変換します。次に示す最初の問合せでは、デフォルトでNULLが除外されています。2番目の問合せは、INCLUDE NULLS句を使用してNULLを組み込むことができることを示しています。
SELECT * FROM pivot_table
UNPIVOT (yearly_total FOR order_mode IN (store AS 'direct',
internet AS 'online'))
ORDER BY year, order_mode;
YEAR ORDER_ YEARLY_TOTAL
---------- ------ ------------
2004 direct 5546.6
2006 direct 371895.5
2006 online 100056.6
2007 direct 1274078.8
2007 online 1271019.5
2008 direct 252108.3
2008 online 393349.4
7 rows selected.
SELECT * FROM pivot_table
UNPIVOT INCLUDE NULLS
(yearly_total FOR order_mode IN (store AS 'direct', internet AS 'online'))
ORDER BY year, order_mode;
YEAR ORDER_ YEARLY_TOTAL
---------- ------ ------------
2004 direct 5546.6
2004 online
2006 direct 371895.5
2006 online 100056.6
2007 direct 1274078.8
2007 online 1271019.5
2008 direct 252108.3
2008 online 393349.4
8 rows selected.
結合問合せの使用例: 次の例は、問合せにおける様々な表の結合方法を示します。最初の例では、等価結合は、それぞれの従業員の名前と職種、およびその従業員が属する部門の番号と名前を戻します。
SELECT last_name, job_id, departments.department_id, department_name FROM employees, departments WHERE employees.department_id = departments.department_id ORDER BY last_name, job_id; LAST_NAME JOB_ID DEPARTMENT_ID DEPARTMENT_NAME ------------------- ---------- ------------- ---------------------- Abel SA_REP 80 Sales Ande SA_REP 80 Sales Atkinson ST_CLERK 50 Shipping Austin IT_PROG 60 IT . . .
従業員名およびジョブは部門名と異なる表に格納されているため、このデータを戻すには結合を使用する必要があります。Oracle Databaseでは、次の結合条件に従って2つの表の行が結合されます。
employees.department_id = departments.department_id
次の等価結合は、すべての販売マネージャの名前、職種、部門番号および部門名を戻します。
SELECT last_name, job_id, departments.department_id, department_name FROM employees, departments WHERE employees.department_id = departments.department_id AND job_id = 'SA_MAN' ORDER BY last_name; LAST_NAME JOB_ID DEPARTMENT_ID DEPARTMENT_NAME ------------------- ---------- ------------- ----------------------- Cambrault SA_MAN 80 Sales Errazuriz SA_MAN 80 Sales Partners SA_MAN 80 Sales Russell SA_MAN 80 Sales Zlotkey SA_MAN 80 Sales
この問合せは、次のwhere_clause条件を使用して'SA_MAN'というjob値を持つ行のみを戻すこと以外は、前述の例と同じです。
副問合せの使用例: 次の文は、従業員'Lorentz'と同じ部門で働く従業員を判断します。
SELECT last_name, department_id FROM employees
WHERE department_id =
(SELECT department_id FROM employees
WHERE last_name = 'Lorentz')
ORDER BY last_name, department_id;
次の文は、employees表の職種を変更した(job_history表に示される)すべての従業員の給与を10%上げます。
UPDATE employees
SET salary = salary * 1.1
WHERE employee_id IN (SELECT employee_id FROM job_history);
次の文は、departments表から3つの列のみを伴って新しい表new_departmentsを作成します。
CREATE TABLE new_departments (department_id, department_name, location_id) AS SELECT department_id, department_name, location_id FROM departments;
自己結合の使用例: 次の問合せは、自己結合を使用して、それぞれの従業員の名前およびその従業員の上司の名前を戻します。出力を短くするためにWHERE句が追加されています。
SELECT e1.last_name||' works for '||e2.last_name
"Employees and Their Managers"
FROM employees e1, employees e2
WHERE e1.manager_id = e2.employee_id
AND e1.last_name LIKE 'R%'
ORDER BY e1.last_name;
Employees and Their Managers
-------------------------------
Rajs works for Mourgos
Raphaely works for King
Rogers works for Kaufling
Russell works for King
この問合せの結合条件では、サンプル表employeesに対する別名e1およびe2を使用します。
e1.manager_id = e2.employee_id
外部結合の使用例: 次の例では、パーティション化された外部結合によって行のデータの欠損を補完し、分析ファンクションの指定および信頼性の高いレポートの書式設定を簡単にする方法を示します。この例では、結合で使用する小規模なデータ表を最初に作成します。
SELECT d.department_id, e.last_name FROM departments d LEFT OUTER JOIN employees e ON d.department_id = e.department_id ORDER BY d.department_id, e.last_name;
これは、次に示す以前のOracle Databaseの外部結合の構文と同じ問合せです。
SELECT d.department_id, e.last_name FROM departments d, employees e WHERE d.department_id = e.department_id(+) ORDER BY d.department_id, e.last_name;
この構文ではなく、前述の例で示した、より柔軟性が高いFROM句の結合構文を使用することをお薦めします。
左側外部結合では、従業員のいない部門を含むすべての部門が戻されます。右側外側結合が指定された同一文では、どの部門にも割り当てられていない従業員を含むすべての従業員が戻されます。
|
注意: 前述の例の従業員表には、従業員Zeussが追加されていますが、この従業員はサンプル・データには含まれません。 |
SELECT d.department_id, e.last_name
FROM departments d RIGHT OUTER JOIN employees e
ON d.department_id = e.department_id
ORDER BY d.department_id, e.last_name;
DEPARTMENT_ID LAST_NAME
------------- -------------------------
. . .
110 Gietz
110 Higgins
Grant
Zeuss
この結果からは、GrantとZeussという従業員のdepartment_idがNULLであるのか、department_idがdepartments表に存在しないのかは不明です。これを確認するには、完全な外部結合が必要です。
SELECT d.department_id as d_dept_id, e.department_id as e_dept_id,
e.last_name
FROM departments d FULL OUTER JOIN employees e
ON d.department_id = e.department_id
ORDER BY d.department_id, e.last_name;
D_DEPT_ID E_DEPT_ID LAST_NAME
---------- ---------- -------------------------
. . .
110 110 Gietz
110 110 Higgins
. . .
260
270
999 Zeuss
Grant
この例の列名は、結合状態にある両方の表で同じであるため、結合構文のUSING句を指定することで、共通列機能も使用できます。出力は、一致する2つのdepartment_id列がUSING句によって結合されることを除き、前述の例と同じです。
SELECT department_id AS d_e_dept_id, e.last_name
FROM departments d FULL OUTER JOIN employees e
USING (department_id)
ORDER BY department_id, e.last_name;
D_E_DEPT_ID LAST_NAME
----------- -------------------------
. . .
110 Higgins
110 Gietz
. . .
260
270
999 Zeuss
Grant
パーティション化された外部結合の使用例: 次の例では、パーティション化された外部結合によって行の欠損を補完し、分析計算の指定および信頼性の高いレポートの書式設定を簡単にする方法を示します。この例では、結合で使用する単純な表を最初に作成し、移入します。
CREATE TABLE inventory (time_id DATE,
product VARCHAR2(10),
quantity NUMBER);
INSERT INTO inventory VALUES (TO_DATE('01/04/01', 'DD/MM/YY'), 'bottle', 10);
INSERT INTO inventory VALUES (TO_DATE('06/04/01', 'DD/MM/YY'), 'bottle', 10);
INSERT INTO inventory VALUES (TO_DATE('01/04/01', 'DD/MM/YY'), 'can', 10);
INSERT INTO inventory VALUES (TO_DATE('04/04/01', 'DD/MM/YY'), 'can', 10);
SELECT times.time_id, product, quantity FROM inventory
PARTITION BY (product)
RIGHT OUTER JOIN times ON (times.time_id = inventory.time_id)
WHERE times.time_id BETWEEN TO_DATE('01/04/01', 'DD/MM/YY')
AND TO_DATE('06/04/01', 'DD/MM/YY')
ORDER BY 2,1;
TIME_ID PRODUCT QUANTITY
--------- ---------- ----------
01-APR-01 bottle 10
02-APR-01 bottle
03-APR-01 bottle
04-APR-01 bottle
05-APR-01 bottle
06-APR-01 bottle 10
01-APR-01 can 10
02-APR-01 can
03-APR-01 can
04-APR-01 can 10
05-APR-01 can
06-APR-01 can
12 rows selected.
これで、製品ディメンションの各パーティションのデータの密度は、時間ディメンションに沿ってより密になります。ただし、各パーティションに新しく追加された行のquantity列はそれぞれNULLです。さらに役立つようにするには、NULL値を、時間順でそれより前にあるNULL以外の値で置き換えます。このことを実現するには、分析ファンクションLAST_VALUEを問合せ結果に適用します。
SELECT time_id, product, LAST_VALUE(quantity IGNORE NULLS)
OVER (PARTITION BY product ORDER BY time_id) quantity
FROM ( SELECT times.time_id, product, quantity
FROM inventory PARTITION BY (product)
RIGHT OUTER JOIN times ON (times.time_id = inventory.time_id)
WHERE times.time_id BETWEEN TO_DATE('01/04/01', 'DD/MM/YY')
AND TO_DATE('06/04/01', 'DD/MM/YY'))
ORDER BY 2,1;
TIME_ID PRODUCT QUANTITY
--------- ---------- ----------
01-APR-01 bottle 10
02-APR-01 bottle 10
03-APR-01 bottle 10
04-APR-01 bottle 10
05-APR-01 bottle 10
06-APR-01 bottle 10
01-APR-01 can 10
02-APR-01 can 10
03-APR-01 can 10
04-APR-01 can 10
05-APR-01 can 10
06-APR-01 can 10
12 rows selected.
|
関連項目: 時系列計算における欠損補完の詳細および使用例については、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
アンチ結合の使用例: 次の例では、特定の部門の集合に所属していない従業員のリストを選択します。
SELECT * FROM employees
WHERE department_id NOT IN
(SELECT department_id FROM departments
WHERE location_id = 1700)
ORDER BY last_name;
セミ結合の使用例: 次の例では、副問合せに一致する行がemployees表に多数存在する場合でも、departments表から1つの行のみが戻されます。employeesのsalary列に索引が定義されていない場合、セミ結合を使用すると、問合せのパフォーマンスが向上します。
SELECT * FROM departments
WHERE EXISTS
(SELECT * FROM employees
WHERE departments.department_id = employees.department_id
AND employees.salary > 2500)
ORDER BY department_name;
表のコレクション例: DML操作は、表の列として定義された場合にのみ、ネストした表で実行できます。したがって、INSERT、DELETEまたはUPDATE文のquery_table_expr_clauseがtable_collection_expressionの場合、コレクション式は、TABLEコレクション式を使用して表のネストした表の列を選択する副問合せである必要があります。次の例は、次の使用例に基づいています。
データベースに、department_id列、location_id列、manager_id列を持つhr_info表と、マネージャごとのすべての従業員のlast_name列、department_id列およびsalary列を持つネストした表型peopleの列が含まれていると仮定します。
CREATE TYPE people_typ AS OBJECT ( last_name VARCHAR2(25), department_id NUMBER(4), salary NUMBER(8,2)); / CREATE TYPE people_tab_typ AS TABLE OF people_typ; / CREATE TABLE hr_info ( department_id NUMBER(4), location_id NUMBER(4), manager_id NUMBER(6), people people_tab_typ) NESTED TABLE people STORE AS people_stor_tab; INSERT INTO hr_info VALUES (280, 1800, 999, people_tab_typ());
次の例では、hr_info表の部門番号280のネストした表peopleの列に値を挿入します。
INSERT INTO TABLE(SELECT h.people FROM hr_info h
WHERE h.department_id = 280)
VALUES ('Smith', 280, 1750);
次の例では、部門番号280のネストした表peopleを更新します。
UPDATE TABLE(SELECT h.people FROM hr_info h WHERE h.department_id = 280) p SET p.salary = p.salary + 100;
次の例では、部門番号280のネストした表peopleを削除します。
DELETE TABLE(SELECT h.people FROM hr_info h WHERE h.department_id = 280) p WHERE p.salary > 1700;
コレクションのネスト解除例: ネストした表の列からデータを選択するには、TABLEコレクション式を使用して、ネストした表を表の列として処理します。このプロセスをコレクション・ネスト解除と呼びます。
次の文を使用すると、前述の例で作成したhr_infoからすべての行を取得し、hr_infoのネストした表peopleの列からすべての行を取得できます。
SELECT t1.department_id, t2.* FROM hr_info t1, TABLE(t1.people) t2 WHERE t2.department_id = t1.department_id;
peopleは、hr_infoのネストした表の列ではなく、last_name、department_id、address、hiredateおよびsalary列と別の表であると仮定します。次の文を使用して、前述の例と同じ行を抽出できます。
SELECT t1.department_id, t2.*
FROM hr_info t1, TABLE(CAST(MULTISET(
SELECT t3.last_name, t3.department_id, t3.salary
FROM people t3
WHERE t3.department_id = t1.department_id)
AS people_tab_typ)) t2;
最後に、peopleはhr_info表のネストした表の列でも、表そのものでもないと仮定します。かわりに、すべての従業員の名前、部門および給与を様々な情報から抽出するpeople_funcファンクションを作成しておきます。次の問合せを使用して、前述の例と同様の情報を得ることができます。
SELECT t1.department_id, t2.* FROM hr_info t1, TABLE(CAST (people_func( ... ) AS people_tab_typ)) t2;
|
関連項目: コレクション・ネスト解除の別の例は、『Oracle Databaseオブジェクト・リレーショナル開発者ガイド』を参照してください。 |
LEVEL疑似列の使用例: 次の文は、すべての従業員を階層順序で戻します。職種がAD_VPである従業員がルート行となるように定義されています。また、親である行の従業員番号が上司の従業員番号となるように、親である行の子である行が定義されています。
SELECT LPAD(' ',2*(LEVEL-1)) || last_name org_chart,
employee_id, manager_id, job_id
FROM employees
START WITH job_id = 'AD_VP'
CONNECT BY PRIOR employee_id = manager_id;
ORG_CHART EMPLOYEE_ID MANAGER_ID JOB_ID
------------------ ----------- ---------- ----------
Kochhar 101 100 AD_VP
Greenberg 108 101 FI_MGR
Faviet 109 108 FI_ACCOUNT
Chen 110 108 FI_ACCOUNT
Sciarra 111 108 FI_ACCOUNT
Urman 112 108 FI_ACCOUNT
Popp 113 108 FI_ACCOUNT
Whalen 200 101 AD_ASST
Mavris 203 101 HR_REP
Baer 204 101 PR_REP
Higgins 205 101 AC_MGR
Gietz 206 205 AC_ACCOUNT
De Haan 102 100 AD_VP
Hunold 103 102 IT_PROG
Ernst 104 103 IT_PROG
Austin 105 103 IT_PROG
Pataballa 106 103 IT_PROG
Lorentz 107 103 IT_PROG
次の文は、前述の例とほぼ同じですが、職種がFI_MGRである従業員を選択しません。
SELECT LPAD(' ',2*(LEVEL-1)) || last_name org_chart,
employee_id, manager_id, job_id
FROM employees
WHERE job_id != 'FI_MGR'
START WITH job_id = 'AD_VP'
CONNECT BY PRIOR employee_id = manager_id;
ORG_CHART EMPLOYEE_ID MANAGER_ID JOB_ID
------------------ ----------- ---------- ----------
Kochhar 101 100 AD_VP
Faviet 109 108 FI_ACCOUNT
Chen 110 108 FI_ACCOUNT
Sciarra 111 108 FI_ACCOUNT
Urman 112 108 FI_ACCOUNT
Popp 113 108 FI_ACCOUNT
Whalen 200 101 AD_ASST
Mavris 203 101 HR_REP
Baer 204 101 PR_REP
Higgins 205 101 AC_MGR
Gietz 206 205 AC_ACCOUNT
De Haan 102 100 AD_VP
Hunold 103 102 IT_PROG
Ernst 104 103 IT_PROG
Austin 105 103 IT_PROG
Pataballa 106 103 IT_PROG
Lorentz 107 103 IT_PROG
Greenbergが管理する従業員は戻されますが、マネージャGreenbergは戻されません。
次の文も、前述の例と同じですが、LEVEL疑似列を使用して管理階層の最初の2つのレベルのみを選択します。
SELECT LPAD(' ',2*(LEVEL-1)) || last_name org_chart,
employee_id, manager_id, job_id
FROM employees
START WITH job_id = 'AD_PRES'
CONNECT BY PRIOR employee_id = manager_id AND LEVEL <= 2;
ORG_CHART EMPLOYEE_ID MANAGER_ID JOB_ID
------------------ ----------- ---------- ----------
King 100 AD_PRES
Kochhar 101 100 AD_VP
De Haan 102 100 AD_VP
Raphaely 114 100 PU_MAN
Weiss 120 100 ST_MAN
Fripp 121 100 ST_MAN
Kaufling 122 100 ST_MAN
Vollman 123 100 ST_MAN
Mourgos 124 100 ST_MAN
Russell 145 100 SA_MAN
Partners 146 100 SA_MAN
Errazuriz 147 100 SA_MAN
Cambrault 148 100 SA_MAN
Zlotkey 149 100 SA_MAN
Hartstein 201 100 MK_MAN
分散問合せの使用例: 次の文は、ローカル・データベース上のdepartments表と、remoteデータベース上のemployees表を結合します。
SELECT last_name, department_name FROM employees@remote, departments WHERE employees.department_id = departments.department_id;
相関副問合せの使用例: 次に、相関副問合せの構文の一般的な例を示します。
SELECT select_list FROM table1 t_alias1 WHERE expr operator (SELECT column_list FROM table2 t_alias2 WHERE t_alias1.column operator t_alias2.column); UPDATE table1 t_alias1 SET column = (SELECT expr FROM table2 t_alias2 WHERE t_alias1.column = t_alias2.column); DELETE FROM table1 t_alias1 WHERE column operator (SELECT expr FROM table2 t_alias2 WHERE t_alias1.column = t_alias2.column);
次の文は、部門内の平均給与を超える給与を支給されている従業員の情報を戻します。給与情報が格納されているemployees表に別名を割り当て、相関副問合せではその別名を使用します。
SELECT department_id, last_name, salary
FROM employees x
WHERE salary > (SELECT AVG(salary)
FROM employees
WHERE x.department_id = department_id)
ORDER BY department_id;
親問合せでは、相関副問合せを使用して同一部門の従業員の平均給与を、employees表の行ごとに計算します。相関副問合せは、employees表の各行について次の手順を実行します。
行のdepartment_idを判断します。
department_idに基づいて親問合せが評価されます。
行の部門の平均給与より高い給与の行がある場合は、その行を戻します。
副問合せは、employees表の各行につき1回ずつ評価されます。
DUAL表からの選択例: 次の文は、現在の日付を戻します。
SELECT SYSDATE FROM DUAL;
employees表から簡単にSYSDATEを選択できますが、このとき、employees表のすべての行に対して1件ずつ14行の同じSYSDATEが戻ります。このため、DUALから選択する方が便利です。
順序値の選択例: 次の文は、employees_seq順序を増分し、新しい値を戻します。
SELECT employees_seq.nextval
FROM DUAL;
次の文は、employees_seqの現在値を選択します。
SELECT employees_seq.currval
FROM DUAL;
