| Oracle® Database管理者ガイド 11gリリース2 (11.2) B56301-08 |
|


 前 |
 次 |
この章の内容は、次のとおりです。
索引は表およびクラスタと関連付けられているオプション構造で、これにより表に対するSQL問合せをより迅速に実行できます。このマニュアルで、索引の使用により、索引がない場合よりも高速に情報を検索できるように、Oracle Databaseの索引は、表データへのより高速なアクセス・パスを提供します。索引は問合せをリライトすることなく使用できます。結果は同じですが、より高速に得られます。
Oracle Databaseは、補完的なパフォーマンス機能を持つ複数の索引付け方法を提供します。それらは次のとおりです。
Bツリー索引: デフォルトの設定で、最も一般的です。
Bツリー・クラスタ索引: 特にクラスタ用に定義します。
ハッシュ・クラスタ索引: 特にハッシュ・クラスタ用に定義します。
グローバル索引とローカル索引: パーティション表とパーティション索引に関連します。
逆キー索引: Oracle Real Application Clustersアプリケーションに最も役立ちます。
ビットマップ索引: サイズが小さいので、小さい値の集合を持つ列に効果的です。
ファンクション索引: 事前計算された関数や式の値を含みます。
ドメイン索引: アプリケーションまたはカートリッジに固有の索引です。
索引は、対応付けられた表内のデータから論理的にも物理的にも独立しています。索引は独立した構造体であり、記憶域を必要とします。索引は、実表、データベース・アプリケーションまたはその他の索引に影響を与えることなく、作成または削除できます。索引に対応する表に対して行の挿入、更新および削除が発生すると、データベースは索引を自動的にメンテナンスします。索引を削除しても、すべてのアプリケーションは引き続き動作可能です。ただし、それまで索引が付けられていたデータへのアクセスが遅くなります。
ここでは、索引管理のガイドラインについて説明します。この項の内容は、次のとおりです。
|
関連項目:
|
データは、通常、SQL*Loaderまたはインポート・ユーティリティを使用して表に挿入またはロードされます。データの挿入またはロードの後に表の索引を作成すると効率がよくなります。データのロード前に1つ以上の索引を作成すると、データベースに行が挿入されるたびに索引を更新する必要があります。
すでにデータが格納されている表に索引を作成するには、ソート領域が必要です。索引の作成ユーザーに割り当てられているメモリーから確保されるソート領域もあります。各ユーザーのソート領域の大きさは、初期化パラメータSORT_AREA_SIZEによって決まります。また、データベースでは、索引作成のときにのみユーザーの一時表領域に割り当てられる一時セグメントとの間でソート情報のスワップが行われます。
特定の条件下では、SQL*Loaderのダイレクト・パス・ロードを使用してデータを表にロードし、データがロードされたときに索引が作成されるようにすることも可能です。
|
関連項目: SQL*Loaderを使用したダイレクト・パス・ロードの詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
索引を作成するかどうか判断する際は、次のガイドラインを参考にしてください。
大きな表で頻繁に検索される行の割合が15%未満の場合は索引を作成してください。割合は、表スキャンの相対速度、および索引キーに対する行データの分散度によって大きく異なります。表スキャンが高速であるほど割合は低くなり、クラスタ化されている行データが多いほど割合は高くなります。
複数の表を結合するパフォーマンスを改善するには、結合に使用する列に索引を付けます。
|
注意: 主キーおよび一意キーには自動的に索引が作成されますが、外部キーには必要に応じて索引を作成できます。 |
小さい表に索引は不要です。問合せに時間がかかる場合は、表のサイズが大きくなっていることが考えられます。
索引付けに適した列
列のタイプによっては、索引を付ける方が望ましいものがあります。次のような特性を1つ以上持つ列には、索引の作成を検討してください。
一意の値が比較的多い。
値の範囲が広い(通常の索引が適している)。
値の範囲が狭い(ビットマップ索引が適している)。
列に多くのNULLが含まれているが、通常の問合せでは必ず値を持つ列を選択する。この場合は次の句を使用します。
WHERE COL_X > -9.99 * power(10,125)
この句は、次の句よりも適しています。
WHERE COL_X IS NOT NULL
これは、最初の句ではCOL_Xの索引を使用しているためです(COL_Xは数値列とします)。
索引付けに適さない列
次のような特性を持つ列は、索引付けには適していません。
列にNULLが多く含まれていて、NULL以外の値を検索することがない。
LONG列およびLONG RAW列には索引を作成できません。
仮想列
仮想列には、一意索引または非一意索引を作成できます。仮想列に定義された表の索引は、表のファンクション索引と同じです。
CREATE INDEX文の列の順序は、問合せのパフォーマンスに影響を与えます。一般的には、最も頻繁に使用する列を最初に指定します。
たとえば、col1、col2およびcol3の各列にアクセスする問合せを高速にするために、列にまたがる単一の索引を作成すると、col1のみにアクセスする問合せ、またはcol1とcol2にアクセスする問合せが速くなります。しかし、col2のみにアクセスする問合せ、col3のみにアクセスする問合せ、およびcol2とcol3にアクセスする問合せは速くなりません。
|
注意: 先頭列のカーディナリティが非常に低い場合などには、データベースでは、このタイプの索引が使用されることがあります。索引スキップ・スキャンの詳細は、『Oracle Database概要』を参照してください。 |
表は、多数の索引を持つことができます。ただし、索引の数が多いほど、表を変更するときに発生するオーバーヘッドが増加します。特に、行を挿入したり削除したりするときは、その表の索引もすべて更新する必要があります。また、列を更新するときには、その列を含む索引もすべて更新する必要があります。
このように、表からデータを検索する速度とその表を更新する速度は二律背反的です。たとえば、表が主に読取り専用である場合、索引を増やすと有効ですが、表が頻繁に更新される場合は、索引を少なくすることをお薦めします。
次のような状況では、索引の削除を検討してください。
問合せを高速化しない。これには、たとえば表が非常に小さい場合や、表の行数は多いものの、索引エントリが非常に少ない場合などがあります。
アプリケーションの問合せが索引を使用しない場合。
索引を再作成する前にいったん削除する必要がある場合。
索引を作成する前にそのサイズを見積っておくと、ディスク領域の計画と管理がいっそう容易になります。索引の見積りサイズの合計と、表、UNDO表領域およびREDOログ・ファイルの見積りを使用して、作成するデータベースを格納するために必要なディスク容量を決定できます。この見積りを利用して適切なハードウェアを購入できます。
個々の索引の見積りサイズを使用することで、索引が使用するディスク領域をより適切に管理できます。索引を作成するときに、適切な記憶域パラメータを設定し、その索引を使用するアプリケーションのI/Oパフォーマンスを改善できます。たとえば、索引を作成する前に最大サイズを予測したとします。次に索引の作成時に記憶域パラメータを設定すると、表データ・セグメントに対して割り当てられるエクステントが少なくなり、すべての索引データはディスク領域の比較的連続したセクションに格納されます。これにより、この索引に関するディスクのI/O操作にかかる時間が削減されます。
単一の索引エントリの最大サイズは、データ・ブロック・サイズのおよそ2分の1です。
索引を主キー制約または一意キー制約を規定するために使用する場合、その索引のために作成する索引セグメントの記憶域パラメータは、次のどちらかの方法で設定できます。
ENABLE ... CREATE TABLE文またはALTER TABLE文のUSING INDEX句
ALTER INDEX文のSTORAGE句
索引はどの表領域にも作成できます。索引は、その索引を付けた表と同じ表領域にも、異なる表領域にも作成できます。表とその索引に対して同じ表領域を使用すると、(表領域やファイルのバックアップなどの)データベースのメンテナンスやアプリケーションの可用性確保の面で便利です。これは、すべての関連するデータが常にまとまってオンラインになっているためです。
表とその索引に対して(異なるディスク上にある)異なる表領域を使用すると、表と索引を同じ表領域に格納するよりも、パフォーマンスが向上します。これは、ディスクの競合が解消されるためです。表とその索引に対して異なる表領域を使用し、一方の(データまたは索引のいずれかを含む)表領域がオフラインになっている場合には、その表を参照している文が動作する保証はありません。
表作成をパラレル化できるのと同様に、索引の作成もパラレル化できます。複数のプロセスが同時に動作して索引を作成するため、1つのサーバー・プロセスが順に索引を作成する場合よりも高速に索引を作成できます。
索引を並行して作成する場合、問合せサーバー・プロセスごとに別々の記憶域パラメータが使用されます。したがって、INITIAL値を5MB、並行度を12で索引を作成する場合は、作成時に60MB以上の記憶域を使用します。
|
関連項目: パラレル実行の使用に関する詳細は、『Oracle Database VLDBおよびパーティショニング・ガイド』を参照してください。 |
CREATE INDEX文でNOLOGGINGを指定すると、索引の作成時に最小限のREDOログ・レコードしか生成されません。
|
注意: NOLOGGINGを使用して作成された索引はアーカイブされないため、索引作成後にバックアップを実行してください。 |
NOLOGGINGを使用して索引を作成すると、次のような利点があります。
REDOログ・ファイルの領域を節約できます。
索引の作成に要する時間が削減できます。
大規模な索引のパラレル作成のパフォーマンスが向上します。
一般に、LOGGINGを指定しないで索引を作成した場合、小規模な索引より大規模な索引の方が相対的にパフォーマンスの向上が大きくなります。小規模な索引をLOGGINGを指定しないで作成しても、索引作成に要する時間にはほとんど影響しません。一方、大規模な索引では、特に索引作成のパラレル化もあわせて指定したときに、パフォーマンスが著しく向上します。
使用禁止または不可視索引は、バルク・ロードのパフォーマンスを向上させる場合、索引を削除する前に削除によって発生する影響をテストする場合、またはオプティマイザによるその索引の使用を停止する場合に使用します。
使用禁止索引
使用禁止索引は、オプティマイザで無視され、DMLではメンテナンスされません。索引を使用禁止にする理由の1つに、バルク・ロードのパフォーマンス向上があります。(行の挿入時にデータベースで索引のメンテナンスを実行する必要がないため、バルク・ロードが速くなります。)索引を削除した後に再度作成する場合はCREATE INDEX文のパラメータを正確に覚えておく必要がありますが、この方法では索引を使用禁止にした後に再構築できます。
使用禁止状態の索引を作成することも、既存の索引または索引パーティションに使用禁止のマークを付けることもできます。場合によっては、データベースで索引の構築中に障害が発生したときなどに、索引に使用禁止のマークが付けられることがあります。パーティション化された索引のパーティションのうちの1つを使用禁止にした場合、その索引の他のパーティションは有効なままです。
使用禁止の索引または索引パーティションを使用するには、再構築するか、または削除して再作成する必要があります。表を切り捨てると、使用禁止の索引が有効になります。
Oracle Database 11g リリース2以降、既存の索引を使用禁止にすると、その索引セグメントが削除されます。
使用禁止の索引の機能は、SKIP_UNUSABLE_INDEXESの初期化パラメータの設定により異なります。SKIP_UNUSABLE_INDEXESがTRUE(デフォルト)の場合は、次のようになります。
表に対するDML文は続行されますが、使用禁止索引のメンテナンスは実行されません。
UNIQUE制約を規定する使用禁止索引がある場合は、DML文はエラーで終了します。
パーティション化されていない索引では、オプティマイザはSELECT文のアクセス計画の作成時に使用禁止索引を考慮しません。唯一の例外は、索引がINDEX()のヒントで明示的に指定された場合です。
パーティション化された索引に使用禁止のパーティションが1つ以上あるとき、削除可能な索引パーティションがあるかどうかを問合せのコンパイル時に判断できない場合は、オプティマイザではその索引を処理しません。これは、表がパーティション化されているかどうかにかかわらず同様です。唯一の例外は、索引がINDEX()のヒントで明示的に指定された場合です。
SKIP_UNUSABLE_INDEXESがFALSEの場合は、次のようになります。
使用禁止の索引または索引パーティションがある場合は、これらの索引または索引パーティションを更新するDML文はエラーで終了します。
SELECT文は、使用禁止索引または使用禁止索引パーティションが存在しても、オプティマイザでアクセス計画に使用されない場合は、通常どおり実行されます。ただし、オプティマイザが使用禁止索引または使用禁止索引パーティションを使用する場合は、この文はエラーで終了します。
不可視索引
Oracle Database 11gリリース1以降、不可視索引を作成したり、既存の索引を不可視にできます。不可視索引は、セッションまたはシステム・レベルでOPTIMIZER_USE_INVISIBLE_INDEXES初期化パラメータを明示的にTRUEに設定しないかぎり、オプティマイザで無視されます。使用禁止索引と異なり、不可視索引はDML文中でも維持されます。パーティション化された索引は不可視にできますが、個別の索引パーティションを不可視にし、残りのパーティションを可視のままにすることはできません。不可視索引を使用して、次のことを実行できます。
索引を削除する前に、削除した状態をテストできます。
アプリケーション全体に影響を与えずに、アプリケーションの特定の操作またはモジュールに対して一時的な索引構造を使用できます。
不適切な索引サイズの設定やサイズの拡大によって、索引の断片化が生じることがあります。断片化を解消または低減するには、索引を再作成するか、索引を結合します。ただし、どちらの作業を行う場合も、事前に各選択肢のコストと利点を分析し、状況に最も有効な方法を選択してください。表21-1は、索引を再作成する場合と結合する場合のコストと利点を示しています。
表21-1 索引の結合と再作成に関するコストと利点
| 索引の再作成 | 索引の結合 |
|---|---|
|
索引を別の表領域に迅速に移動できる。 |
索引を別の表領域に移動することはできない。 |
|
多くのディスク領域を必要とし、コストが高い。 |
必要なディスク領域が少ないため、コストが低い。 |
|
新しいツリーを作成して、可能であればその高さを縮小する。 |
ツリーの同じブランチ内のリーフ・ブロックを結合する。 |
|
オリジナルの索引を削除せずに、記憶域パラメータと表領域パラメータを迅速に変更できる。 |
索引のリーフ・ブロックを迅速に解放できる。 |
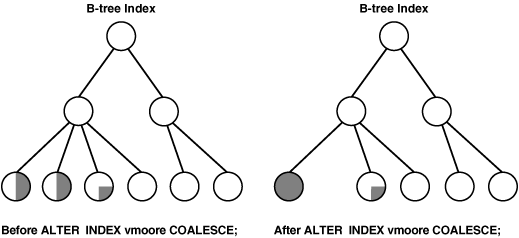
再利用のために解放できるBツリー索引のリーフ・ブロックがある場合は、次の文を使用してそのようなリーフ・ブロックをマージできます。
ALTER INDEX vmoore COALESCE;
図21-1は、ALTER INDEX COALESCEが索引vmooreに与える影響を示しています。操作を実行する前は、最初の2つのリーフ・ブロックは50%使用されています。したがって、フラグメンテーションを削減して最初のブロック全体を使用しながら、2番目のブロックを解放することが可能になります。
|
注意: これらの操作は、索引統計も収集します。 |
自分のスキーマ内に索引を作成する場合は、次のいずれかの条件のうち、少なくとも1つが満たされている必要があります。
索引を付ける表またはクラスタが、自分のスキーマに格納されている。
索引を付ける表に対するINDEX権限を持っている。
CREATE ANY INDEXシステム権限を持っている。
別のスキーマ内に索引を作成する場合は、次のすべての条件が満たされている必要があります。
CREATE ANY INDEXシステム権限を持っている。
目的のスキーマの所有者が、索引または索引パーティションを作成する表領域への割当て制限を持っているか、UNLIMITED TABLESPACEシステム権限を持っている。
この項の内容は次のとおりです。
SQL文CREATE INDEXを使用して、索引を明示的に(整合性制約の他に)作成できます。次の文は、emp表のename列に対してemp_enameという名前の索引を作成します。
CREATE INDEX emp_ename ON emp(ename)
TABLESPACE users
STORAGE (INITIAL 20K
NEXT 20k);
索引に対して、複数の記憶域設定および1つの表領域が明示的に指定されています。索引に記憶域オプション(INITIALやNEXTなど)を指定しない場合、デフォルトの表領域または指定された表領域のデフォルトの記憶域オプションが自動的に使用されます。
|
関連項目: CREATE INDEX文の構文と制限事項については、『Oracle Database SQL言語リファレンス』 |
索引は、一意にすることも、重複を許可することもできます。一意索引を使用すると、表の複数行のキー列に重複した値が入らないことが保証されます。非一意索引では、列の値にこのような制限はありません。
一意索引を作成するには、CREATE UNIQUE INDEX文を使用します。次の例では、一意索引を作成しています。
CREATE UNIQUE INDEX dept_unique_index ON dept (dname)
TABLESPACE indx;
別の方法として、目的の列にUNIQUE整合性制約を定義することもできます。データベースでは、一意のキーに対して自動的に一意索引を定義することによって、UNIQUE整合性制約を規定します。この詳細は次の項に記載されています。ただし、問合せのパフォーマンス向上のために必要な索引は、一意索引も含め、明示的に作成することをお薦めします。
|
関連項目: パフォーマンス向上のための索引作成の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
Oracle Databaseは、表にUNIQUEキー整合性制約またはPRIMARY KEY整合性制約を規定するために、一意キーまたは主キーの一意索引を作成します。この索引は、制約を使用可能にしたときに、データベースによって自動的に作成されます。CREATE TABLE文またはALTER TABLE文を発行して索引を作成する場合は、それ以外に必要なアクションはありませんが、必要に応じて、USING INDEX句を指定して索引作成を制御できます。これは、制約を定義して使用可能にする場合、および定義したが使用禁止にしていた制約を使用可能にする場合のどちらでも可能です。
UNIQUE制約またはPRIMARY KEY制約を使用可能にし、対応する索引を作成するには、表の所有者が索引を格納する表領域の割当て制限またはUNLIMITED TABLESPACEシステム権限を持っている必要があります。特に指定しないかぎり、制約に対応付けられた索引には、常に制約と同じ名前が付けられます。
USING INDEX句を使用すると、 UNIQUE制約またはPRIMARY KEY制約に対応する索引の記憶域オプションを設定できます。次のCREATE TABLE文は、PRIMARY KEY制約を使用可能にして、対応する索引の記憶域オプションを指定します。
CREATE TABLE emp (
empno NUMBER(5) PRIMARY KEY, age INTEGER)
ENABLE PRIMARY KEY USING INDEX
TABLESPACE users;
UNIQUE制約およびPRIMARY KEY制約に対応付けられた索引をより明示的に制御する場合、データベースでは次のことが可能です。
制約を規定するために使用する既存の索引の指定
索引の作成と制約の規定に使用するCREATE INDEX文の指定
これらのオプションは、USING INDEX句を使用して指定します。次にいくつかの例を示します。
例1:
CREATE TABLE a (
a1 INT PRIMARY KEY USING INDEX (create index ai on a (a1)));
例2:
CREATE TABLE b(
b1 INT,
b2 INT,
CONSTRAINT bu1 UNIQUE (b1, b2)
USING INDEX (create unique index bi on b(b1, b2)),
CONSTRAINT bu2 UNIQUE (b2, b1) USING INDEX bi);
例3:
CREATE TABLE c(c1 INT, c2 INT); CREATE INDEX ci ON c (c1, c2); ALTER TABLE c ADD CONSTRAINT cpk PRIMARY KEY (c1) USING INDEX ci;
単一の文で制約とともに索引を作成し、同じ文でその索引を別の制約にも使用する場合、Oracleでは、索引を再使用する前に索引を作成するための句の再編成を試みます。
極端に大きい索引を作成するときは、次の手順を使用して、索引の作成に大きな一時表領域を割り当てることを検討してください。
CREATE TABLESPACE文またはCREATE TEMPORARY TABLESPACE文を使用して、新しい一時表領域を作成します。
ALTER USER文でTEMPORARY TABLESPACEオプションを指定して、この一時表領域を自分の新しい一時表領域として割り当てます。
CREATE INDEX文を使用して、索引を作成します。
DROP TABLESPACE文を使用して、この表領域を削除します。次にALTER USER文を使用して、自分の一時表領域を元の一時表領域に再設定します。
この手順により、通常使用している一時表領域(ほとんどの場合、共有されている)が極度に肥大化して今後のパフォーマンスに影響を及ぼす問題を回避できます。
索引をオンラインで作成および再作成できます。そのため、実表の索引を作成または再作成する際に、同時に実表も更新できます。索引の作成中にDML操作を実行できますが、DDL操作はできません。索引をオンラインで作成または再作成している最中のパラレル実行はサポートされません。
次の文は、オンラインでの索引作成操作を示しています。
CREATE INDEX emp_name ON emp (mgr, emp1, emp2, emp3) ONLINE;
|
注意: オンライン索引ビルドが完了するまでの時間は、表のサイズおよび同時に実行しているDML文の数に比例することに注意してください。したがって、オンライン索引ビルドはDMLアクティビティが低いときに開始することをお薦めします。 |
ファンクション索引を使用すると、関数や式から返される値を修飾する問合せが可能です。関数や式の値は、事前に計算されて索引に格納されます。
ユーザー定義のファンクションに基づく索引の場合は、従来型の索引を作成するための前提条件に加えて、これらのファンクションにDETERMINISTICのマークが設定されている必要があります。さらに、これらのファンクションを別のユーザーが所有している場合は、ファンクション索引で使用するすべてのユーザー定義ファンクションに対するEXECUTEオブジェクト権限を持っている必要があります。
|
注意: CREATE INDEXでは、ファンクション索引で最後に使用された関数のタイムスタンプが格納されます。このタイムスタンプは、索引の妥当性チェック時に更新されます。ファンクション索引について表領域のPoint-in-Timeリカバリを実行する場合、索引で最後に使用された関数のタイムスタンプが索引に格納されたタイムスタンプより新しい場合は、その索引には無効を示すマークが設定されます。ANALYZE INDEX...VALIDATE STRUCTURE文を使用して、この索引の妥当性をチェックする必要があります。 |
ファンクション索引の具体例として、ファンクションarea(geo)に定義されているファンクション索引(area_index)を定義する次の文を示します。
CREATE INDEX area_index ON rivers (area(geo));
次のSQL文では、area(geo)がWHERE句で参照されているため、オプティマイザは索引area_indexの使用を考慮します。
SELECT id, geo, area(geo), desc
FROM rivers
WHERE Area(geo) >5000;
表の所有者は、ファンクション索引で使用されるファンクションに対してEXECUTE権限を持つ必要があります。
ファンクション索引は使用するファンクションに依存するため、ファンクションの変更時に無効にできます。ファンクションが有効な場合は、ALTER INDEX...ENABLE文を使用して、使用禁止になっているファンクション索引を使用可能にすることができます。ALTER INDEX...DISABLE文では、ファンクション索引を使用禁止にすることができます。ファンクションの本体で作業をする場合は、ファンクション索引を使用禁止にするか検討してください。
|
関連項目:
|
キー圧縮を使用して索引を作成すると、キー列の接頭辞が同じ値で繰り返し格納されることを回避できます。
キー圧縮によって、索引キーは接頭辞および接尾辞エントリに分割されます。圧縮するために、接頭辞エントリは索引ブロック内のすべての接尾辞エントリ間で共有されます。このような共有によって、領域が大幅に節約され、各索引ブロックに格納できるキー数が増え、パフォーマンスが向上します。
キー圧縮は、次のような状況で役立ちます。
ROWIDを追加してキーを一意にしている非一意索引がある場合。このような状況でキー圧縮を使用すると、重複キーは接頭辞エントリとして索引ブロックにROWIDなしで格納されます。残りの行は、ROWIDのみからなる接尾辞エントリとなります。
一意の複数列索引がある場合。
キー圧縮を使用可能にするには、COMPRESS句を使用します。また、接頭辞の長さをキー列の数で指定して、キー列が接頭辞および接尾辞エントリにどのように分割されるかを識別できます。たとえば、次の文は、索引リーフ・ブロックの重複するキーを圧縮します。
CREATE INDEX emp_ename ON emp(ename) TABLESPACE users COMPRESS 1;
索引の再作成中にCOMPRESS句を指定することもできます。たとえば、次のようにして、再作成中に圧縮を使用禁止にすることができます。
ALTER INDEX emp_ename REBUILD NOCOMPRESS;
|
関連項目: キー圧縮の詳細は、『Oracle Database概要』を参照してください。 |
UNUSABLE状態の索引を作成した場合、オプティマイザで無視され、DMLではメンテナンスされません。使用禁止の索引を使用可能にする場合、再構築するか、または削除して再作成する必要があります。
索引がパーティション化されている場合、索引パーティションはすべてUNUSABLEとしてマークされます。
Oracle Database 11g リリース2以降、データベースは使用禁止索引の作成時に索引セグメントを作成しません。
次の手順では、使用禁止の索引を作成する方法と、データベースに索引に関する詳細を問い合せる方法を示します。
使用禁止索引を作成する手順は、次のとおりです。
必要に応じて、索引を付ける表を作成します。
たとえば、次のように、hr.employees_partという名前でハッシュ・パーティション表を作成します。
sh@PROD> CONNECT hr
Enter password: **
Connected.
hr@PROD> CREATE TABLE employees_part
2 PARTITION BY HASH (employee_id) PARTITIONS 2
3 AS SELECT * FROM employees;
Table created.
hr@PROD> SELECT COUNT(*) FROM employees_part;
COUNT(*)
----------
107
キーワードUNUSABLEで索引を作成します。
次の例では、employees_partにローカル・パーティション索引を作成し、索引パーティションにp1_i_emp_enameおよびp2_i_emp_enameという名前を付け、p1_i_emp_enameを使用禁止にしています。
hr@PROD> CREATE INDEX i_emp_ename ON employees_part (employee_id) 2 LOCAL (PARTITION p1_i_emp_ename UNUSABLE, PARTITION p2_i_emp_ename); Index created.
オプションで、データ・ディクショナリに問い合せて索引が使用禁止になっていることを確認できます。
次の例では、索引i_emp_enameとその2つのパーティションのステータスを問い合せて、パーティションp2_i_emp_enameのみが使用禁止になっていることを示しています。
hr@PROD> SELECT INDEX_NAME AS "INDEX OR PARTITION NAME", STATUS 2 FROM USER_INDEXES 3 WHERE INDEX_NAME = 'I_EMP_ENAME' 4 UNION ALL 5 SELECT PARTITION_NAME AS "INDEX OR PARTITION NAME", STATUS 6 FROM USER_IND_PARTITIONS 7 WHERE PARTITION_NAME LIKE '%I_EMP_ENAME%'; INDEX OR PARTITION NAME STATUS ------------------------------ -------- I_EMP_ENAME N/A P1_I_EMP_ENAME UNUSABLE P2_I_EMP_ENAME USABLE
オプションで、データ・ディクショナリに問い合せて、パーティションの記憶域が存在するかどうかを確認できます。
たとえば、次の問合せは索引パーティションp2_i_emp_enameのみがセグメントを占有していることを示しています。p1_i_emp_enameは使用禁止として作成したため、セグメントが割り当てられませんでした。
hr@PROD> COL PARTITION_NAME FORMAT a14 hr@PROD> COL SEG_CREATED FORMAT a11 hr@PROD> SELECT p.PARTITION_NAME, p.STATUS AS "PART_STATUS", 2 p.SEGMENT_CREATED AS "SEG_CREATED", 3 FROM USER_IND_PARTITIONS p, USER_SEGMENTS s 4 WHERE s.SEGMENT_NAME = 'I_EMP_ENAME'; PARTITION_NAME PART_STA SEG_CREATED -------------- -------- ----------- P2_I_EMP_ENAME USABLE YES P1_I_EMP_ENAME UNUSABLE NO
|
関連項目:
|
不可視索引とは、セッションまたはシステム・レベルでOPTIMIZER_USE_INVISIBLE_INDEXES初期化パラメータを明示的にTRUEに設定しないかぎり、オプティマイザで無視される索引です。
不可視索引を作成する手順は、次のとおりです。
CREATE INDEX文をINVISIBLEキーワードとともに指定します。
次の文は、emp表のename列に対してemp_enameという名前の不可視索引を作成します。
CREATE INDEX emp_ename ON emp(ename)
TABLESPACE users
STORAGE (INITIAL 20K
NEXT 20k)
INVISIBLE;
索引を変更するには、その索引が自分のスキーマに含まれているか、またはALTER ANY INDEXシステム権限を持っている必要があります。ALTER INDEX文では、次の操作を実行できます。
既存の索引の再作成または結合
未使用領域の割当て解除または新規エクステントの割当て
パラレル実行の指定(または指定解除)およびその並列度の変更
記憶域パラメータまたは物理属性の変更
LOGGINGまたはNOLOGGINGの指定
キー圧縮の使用可能または使用禁止の設定
索引へのUNUSABLEマークの設定
索引の不可視化
索引の名前変更
索引使用状況の監視の開始または停止
索引の列構造は変更できません。
これらの操作のいくつかについて、次の項で詳しく説明します。
|
関連項目:
|
主キーと一意キーの整合性制約を規定するためにデータベースによって作成される索引も含めて、どの索引の記憶域パラメータも、ALTER INDEX文を使用して変更できます。たとえば、次の文はemp_ename索引を変更します。
ALTER INDEX emp_ename
STORAGE (NEXT 40);
パラメータINITIALとMINEXTENTSは変更できません。他の記憶域パラメータの新しい設定はすべて、その後に索引に割り当てられるエクステントにのみ影響します。
整合性制約を実装する索引では、ENABLE句のUSING INDEX副次句を指定したALTER TABLE文を発行することによって、記憶域パラメータを調整できます。たとえば、次の文は、表empに作成された索引の記憶域オプションを変更して、主キー制約を規定します。
ALTER TABLE emp
ENABLE PRIMARY KEY USING INDEX;
|
関連項目: ALTER INDEX文の構文と制限事項については、『Oracle Database SQL言語リファレンス』 |
既存の索引を再作成する前に、表21-1の説明に従って、索引を再作成する方法と結合する方法のコストと利点を比較してください。
索引を再作成するときは、既存の索引をデータソースとして使用できます。このようにして索引を作成すると、記憶特性の変更や新しい表領域への移動ができます。既存のデータソースに基づいて索引を再作成すると、ブロック内の断片化も解消されます。索引を削除してからCREATE INDEX文を使用するよりも、既存の索引を再構築する方がパフォーマンスに優れています。
次の文は、既存の索引emp_nameを再作成します。
ALTER INDEX emp_name REBUILD;
REBUILD句は索引名の直後に使用し、他のオプションの前に置く必要があります。DEALLOCATE UNUSED句とともに使用することはできません。
索引はオンラインで再作成できます。オンラインで再作成することにより、再作成と同時に実表を更新できます。次の文は、emp_name索引をオンラインで再作成します。
ALTER INDEX emp_name REBUILD ONLINE;
別のユーザーのスキーマにオンラインで索引を再作成するには、さらに次のシステム権限が必要です。
CREATE ANY TABLE
CREATE ANY INDEX
|
注意: オンラインでの索引の再作成には、別の方式による索引の再作成に比べ、処理できるキーの最大長に関して、より厳しい制限があります。オンラインでの再構築中にORA-1450(最大キー長を超過)エラーが発生した場合は、索引のオフラインでの再構築または結合を行うか、索引を削除してから再作成してください。 |
索引の再作成に必要な大きさの領域がない場合、かわりに索引を結合する方法が使用できます。索引の結合はオンライン操作です。
索引を使用禁止にした場合、オプティマイザで無視され、DMLではメンテナンスされません。パーティション化された索引のパーティションのうちの1つを使用禁止にした場合、その索引の他のパーティションは有効なままです。
使用禁止の索引または索引パーティションを使用する場合は、事前に索引または索引パーティションを再作成するか、または削除した後再作成する必要があります。
次の手順では、索引および索引パーティションを使用禁止にする方法と、オブジェクトのステータスを問い合せる方法を示します。
索引を使用禁止にする手順は、次のとおりです。
データ・ディクショナリに問い合せて、既存の索引または索引パーティションが使用可能であるか、使用禁止であるかを確認します。
たとえば、次の問合せを発行します(スペースの節約のため出力を切り捨てています)。
hr@PROD> SELECT INDEX_NAME AS "INDEX OR PART NAME", STATUS, SEGMENT_CREATED 2 FROM USER_INDEXES 3 UNION ALL 4 SELECT PARTITION_NAME AS "INDEX OR PART NAME", STATUS, SEGMENT_CREATED 5 FROM USER_IND_PARTITIONS; INDEX OR PART NAME STATUS SEG ------------------------------ -------- --- I_EMP_ENAME N/A N/A JHIST_EMP_ID_ST_DATE_PK VALID YES JHIST_JOB_IX VALID YES JHIST_EMPLOYEE_IX VALID YES JHIST_DEPARTMENT_IX VALID YES EMP_EMAIL_UK VALID NO . . . COUNTRY_C_ID_PK VALID YES REG_ID_PK VALID YES P2_I_EMP_ENAME USABLE YES P1_I_EMP_ENAME UNUSABLE NO 22 rows selected.
前述の出力は、索引パーティションp1_i_emp_enameのみが使用禁止であることを示しています。
索引または索引パーティションを使用禁止にするには、UNUSABLEキーワードを指定します。
次の例では、索引emp_email_ukを使用禁止にしています。
hr@PROD> ALTER INDEX emp_email_uk UNUSABLE; Index altered.
次の例では、索引パーティションp2_i_emp_enameを使用禁止にしています。
hr@PROD> ALTER INDEX i_emp_ename MODIFY PARTITION p2_i_emp_ename UNUSABLE; Index altered.
オプションで、データ・ディクショナリに問い合せて、ステータス変更を確認できます。
たとえば、次の問合せを発行します(スペースの節約のため出力を切り捨てています)。
hr@PROD> SELECT INDEX_NAME AS "INDEX OR PARTITION NAME", STATUS, 2 SEGMENT_CREATED 3 FROM USER_INDEXES 4 UNION ALL 5 SELECT PARTITION_NAME AS "INDEX OR PARTITION NAME", STATUS, 6 SEGMENT_CREATED 7 FROM USER_IND_PARTITIONS; INDEX OR PARTITION NAME STATUS SEG ------------------------------ -------- --- I_EMP_ENAME N/A N/A JHIST_EMP_ID_ST_DATE_PK VALID YES JHIST_JOB_IX VALID YES JHIST_EMPLOYEE_IX VALID YES JHIST_DEPARTMENT_IX VALID YES EMP_EMAIL_UK UNUSABLE NO . . . COUNTRY_C_ID_PK VALID YES REG_ID_PK VALID YES P2_I_EMP_ENAME UNUSABLE NO P1_I_EMP_ENAME UNUSABLE NO 22 rows selected.
i_emp_enameセグメントとemp_email_ukセグメントが消費している領域を問い合せると、どちらのセグメントも存在しなくなったことが示されます。
hr@PROD> SELECT SEGMENT_NAME, BYTES
2 FROM USER_SEGMENTS
3 WHERE SEGMENT_NAME IN ('I_EMP_ENAME', 'EMP_EMAIL_UK');
no rows selected
|
関連項目:
|
不可視索引は、セッションまたはシステム・レベルでOPTIMIZER_USE_INVISIBLE_INDEXES初期化パラメータを明示的にTRUEに設定しないかぎり、オプティマイザで無視されます。索引を非表示にするのは、使用禁止または削除の代替手段です。個別の索引パーティションは不可視にできません。試みた場合はエラーとなります。
索引を不可視にする手順は、次のとおりです。
次のSQL文を発行します。
ALTER INDEX index INVISIBLE;
不可視状態の索引を可視にする手順は、次のとおりです。
次のSQL文を発行します。
ALTER INDEX index VISIBLE;
索引が可視か不可視かを判別する手順は、次のとおりです。
USER_INDEXES、ALL_INDEXESまたはDBA_INDEXESディクショナリ・ビューの問合せを行います。
たとえば、索引ind1が不可視かどうかを判別するには、次の問合せを発行します。
SELECT INDEX_NAME, VISIBILITY FROM USER_INDEXES WHERE INDEX_NAME = 'IND1'; INDEX_NAME VISIBILITY ---------- ---------- IND1 VISIBLE
Oracle Databaseには、索引を監視し、それらが使用されているかどうかを判別する手段が用意されています。未使用の索引がある場合は、それを削除して不要な文によるオーバーヘッドを解消できます。
索引の使用状況の監視を開始するには、次の文を発行します。
ALTER INDEX index MONITORING USAGE;
その後、監視を停止するには、次の文を発行します。
ALTER INDEX index NOMONITORING USAGE;
監視中の索引について、それが使用されているかどうか確認するには、ビューV$OBJECT_USAGEを問い合せます。このビューにはUSED列があり、監視期間中に索引が使用されたかどうかによってYESまたはNOの値を持ちます。また、このビューには監視の開始時間と停止時間も記録され、MONITORING列(YES/NO)には使用状況の監視が現在アクティブであるかどうかが示されます。
MONITORING USAGEを指定するたびに、指定した索引のV$OBJECT_USAGEビューはリセットされます。前回の使用方法の情報はクリアまたはリセットされ、新しい開始時間が記録されます。NOMONITORING USAGEを指定すると、これ以上の監視は実行されず、監視期間の終了時間が記録されます。次にALTER INDEX...MONITORING USAGE文が発行されるまで、ビューの情報は変更されずに保持されます。
索引のキー値が頻繁に挿入、更新および削除されると、時間が経つにつれて領域の効率性が失われることがあります。索引の領域の使用状況の効率性を定期的に監視するには、まずANALYZE INDEX...VALIDATE STRUCTURE文を使用し、次にINDEX_STATSビューを問い合せて索引構造を分析します。
SELECT PCT_USED FROM INDEX_STATS WHERE NAME = 'index';
索引の領域使用の割合は、どれくらい頻繁に索引キーが挿入、更新または削除されるかによって変化します。次の一連の操作を何度か実行し、索引の平均的な領域使用効率の履歴を作成してください。
統計分析
索引の検証
PCT_USEDのチェック
索引の削除および再作成(または結合)
索引の領域使用がその平均を下回っているときは、索引を削除してから再作成または結合することによって、索引の領域を圧縮できます。
索引を削除するには、その索引が自分のスキーマに含まれているか、またはDROP ANY INDEXシステム権限を持っている必要があります。
索引が不要になった場合。
対応する表に対して発行した問合せで、索引が予想されたパフォーマンスの改善を達成していない場合。たとえば、表が非常に小さい、または表には多くの行があるものの、索引エントリが非常に少ないなどがこれに該当します。
アプリケーションに索引を使用するデータ問合せが含まれない場合。
索引が無効になり、再作成する前に削除する必要がある場合。
索引がかなり断片化し、再作成する前に削除する必要がある場合。
索引が削除されると、その索引のセグメントのエクステントはすべて、索引を含んでいる表領域に戻され、表領域内の他のオブジェクトで利用できます。
索引を削除する方法は、索引の作成方法、つまりCREATE INDEX文によって索引を明示的に作成したか、または表にキー制約を定義することによって索引を暗黙的に作成したかによって異なります。CREATE INDEX文を使用して明示的に作成した索引は、DROP INDEX文で削除できます。次の文は、emp_ename索引を削除します。
DROP INDEX emp_ename;
使用可能になっているUNIQUEキー制約やPRIMARY KEY制約に対応付けられた索引のみを削除することはできません。制約に対応付けられた索引を削除するには、制約自体を使用禁止にするかまたは削除します。
|
注意: 表を削除すると、対応する索引はすべて自動的に削除されます。 |
|
関連項目:
|
次のビューには、索引に関する情報が表示されます。
| ビュー | 説明 |
|---|---|
DBA_INDEXES
|
DBAビューには、データベース内にあるすべての表の索引が表示されます。ALLビューには、ユーザーがアクセス可能なすべての表の索引が表示されます。USERビューは、ユーザーが所有する索引のみに制限されます。これらのビューの一部の列には、DBMS_STATSパッケージまたはANALYZE文によって生成される統計が含まれます。 |
DBA_IND_COLUMNS
|
これらのビューには、表の索引の列が表示されます。これらのビューの一部の列には、DBMS_STATSパッケージまたはANALYZE文によって生成される統計が含まれます。 |
DBA_IND_EXPRESSIONS
|
これらのビューには、表のファンクション索引の式が表示されます。 |
DBA_IND_PARTITIONS
|
これらのビューには、各索引パーティションのパーティションレベルのパーティション化情報、パーティションの記憶域パラメータ、DBMS_STATSパッケージよって生成された様々なパーティション統計情報が表示されます。 |
DBA_IND_STATISTICS
|
これらのビューには、索引のオプティマイザ統計が含まれています。 |
INDEX_STATS |
最後に発行されたANALYZE INDEX...VALIDATE STRUCTURE文の情報が格納されています。 |
INDEX_HISTOGRAM |
最後に発行されたANALYZE INDEX...VALIDATE STRUCTURE文の情報が格納されています。 |
V$OBJECT_USAGE |
ALTER INDEX...MONITORING USAGE機能で生成された索引使用状況の情報が含まれます。 |
|
関連項目: これらのビューの詳細は、『Oracle Databaseリファレンス』を参照してください。 |