| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、Oracleのデータ・ウェアハウス実装の概要について説明します。内容は次のとおりです。
データ・ウェアハウスからの情報の抽出
このマニュアルは、データ・ウェアハウスに関する標準テキストを補足するものです。Oracle固有の性能を中心に説明しており、データ・ウェアハウスの一般的な性能について詳細に説明するものではありません。標準テキストには、次の2冊があります。
『The Data Warehouse Toolkit』(Ralph Kimball著、John Wiley and Sons, 1996)
『Building the Data Warehouse』(William Inmon著、John Wiley and Sons, 1996)
データ・ウェアハウスとは、トランザクション処理ではなく、問合せおよび分析用に設計されたリレーショナル・データベースです。データ・ウェアハウスには、通常、トランザクション・データから導出された履歴データが含まれますが、他のソースからのデータを含めることもできます。データ・ウェアハウスは分析処理をトランザクション処理の負荷と分離し、組織で、様々なソースからのデータを整理統合できるようにします。これは、次のような場合に役立ちます。
履歴データのメンテナンス
ビジネスをよりよく理解し改善するためのデータの分析
データ・ウェアハウス環境には、リレーショナル・データベースに加えて、抽出、転送、変換、ロード(ETL)のソリューションや、統計分析、レポート、データ・マイニング機能、クライアント分析ツール、および、データ収集処理や有益かつ実用的な情報へのデータ変換処理、ビジネス・ユーザーへのデータ配信処理を管理するその他のアプリケーションが含まれます。
データ・ウェアハウスを導入する際は、William Inmon氏が提唱するデータ・ウェアハウスの次の特性を十分に理解する必要があります。
データ・ウェアハウスは、データの分析に役立つように設計されています。たとえば、会社の売上データの詳細が必要な場合は、売上を中心とするデータ・ウェアハウスを作成できます。このデータ・ウェアハウスでは、「昨年、この品目を最も多く購入した顧客は誰だったか」、「来年、この品目を最も多く購入しそうな顧客は誰か」のような質問に答えることができます。このようにデータ・ウェアハウスをサブジェクト(この場合は売上)別に定義できるため、データ・ウェアハウスの使用はサブジェクト指向となります。
統合化は、サブジェクト指向と密接な関係があります。データ・ウェアハウスでは、異なるソースのデータを、一貫したフォーマットに入れる必要があります。また、ネーミングの競合や単位の不整合などの問題を解決する必要があります。これが達成されれば、データ・ウェアハウスは統合化されたことになります。
データ・ウェアハウスでは、時系列という用語が意味する、時間経過に伴う変化に重点が置かれています。ビジネスの動向を見いだし、背後に潜むパターンおよび関係性を識別するには、アナリストは大量のデータを必要とします。これは、オンライン・トランザクション処理(OLTP)システムとは非常に対照的です。OLTPシステムでは、パフォーマンス要件のために、履歴データをアーカイブに移動させる必要があります。
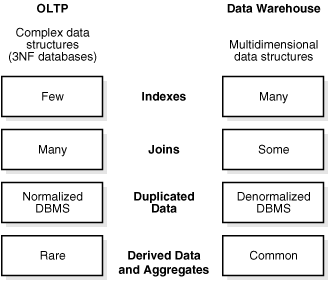
図1-1に、OLTPシステムとデータ・ウェアハウスの主な違いを示します。
この2つのシステムにおける大きな違いの1つは、OLTP環境での一般的なデータ正規化タイプは第3正規形(3NF)ですが、データ・ウェアハウスでは、通常そうではないということです。
データ・ウェアハウスおよびOLTPシステムの要件は、大きく異なります。次に、典型的なデータ・ウェアハウスとOLTPシステムのいくつかの違いの例を示します。
処理負荷
データ・ウェアハウスは、非定型の問合せおよびデータ分析に適応するように設計されています。データ・ウェアハウスの処理負荷は、事前には不明な場合があります。このため、データ・ウェアハウスは、様々な問合せ操作および分析操作を適切に実行できるように最適化する必要があります。
OLTPシステムは、事前に定義された操作のみサポートします。アプリケーションは、これらの操作のみサポートするようにチューニングまたは設計されている場合があります。
データ修正
データ・ウェアハウスのデータは、大量データ修正の技術を使用して、ETLプロセスによって定期的に(毎晩、毎週など)更新されます。データ・マイニングなどの分析ツールを使用して、関連する確率から予測を作成したり、顧客を市場セグメントに当てはめたり、顧客プロファイルを作成したりする場合を除き、データ・ウェアハウスのエンド・ユーザーは、データ・ウェアハウスを直接更新することはありません。
OLTPシステムでは、エンド・ユーザーが機械的に、個々のデータ修正の都度、修正文を発行します。OLTPデータベースは常に最新であり、各ビジネス・トランザクションの現在の状態が反映されます。
スキーマ設計
データ・ウェアハウスは、非正規化または部分的に非正規化されたスキーマ(スター・スキーマなど)を使用して、問合せおよび分析のパフォーマンスを最適化します。
OLTPシステムは、完全に正規化されたスキーマを使用して、更新/挿入/削除のパフォーマンスを最適化し、データ整合性を保証します。
典型的な操作
典型的なデータ・ウェアハウスの問合せでは、膨大な数の列がスキャンされる場合があります。たとえば、「先月のすべての顧客に対する合計売上の検索」などの場合です。
典型的なOLTP操作では、少数のレコードのみがアクセスされます。たとえば、「この顧客に対する現在の注文の取出し」などの場合です。
履歴データ
データ・ウェアハウスには、通常、長い年月分のデータが格納されています。これは、履歴の分析およびレポートをサポートするためです。
OLTPシステムには、通常、数週間または数か月分のデータのみが格納されています。OLTPシステムには、現行のトランザクション要件を満たすために必要な履歴データのみが格納されます。
データ・ウェアハウスおよびそのアーキテクチャは、組織の特定の状況に応じて変化します。一般的なアーキテクチャは、次の3つです。
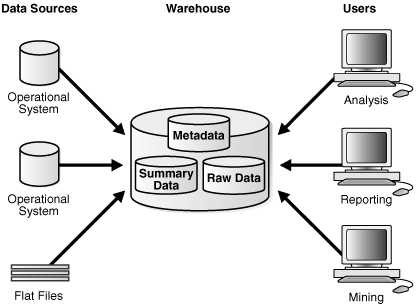
図1-2に、データ・ウェアハウスの単純なアーキテクチャを示します。エンド・ユーザーは、複数のソース・システムから導出されたデータに、データ・ウェアハウスを通じて直接アクセスします。
図1-2では、従来のOLTPシステムのメタデータと生データは、付加的なデータであるサマリー・データと同様に示されています。長時間かかる作業を事前計算するサマリーは、データ・ウェアハウスでは大変役立ちます。たとえば、典型的なデータ・ウェアハウス問合せとして、8月の売上などを取り出す問合せがあります。Oracleデータベースでは、サマリーをマテリアライズド・ビューと呼びます。
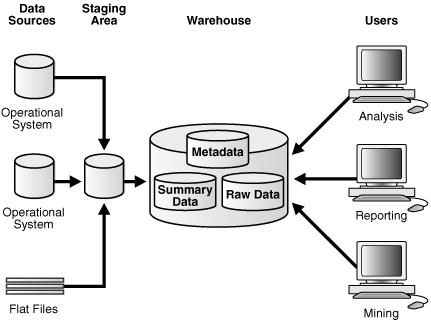
図1-3に示すように、業務系データはウェアハウスに格納する前にクレンジングして加工しておく必要があります。これはプログラムで処理できますが、ほとんどのデータ・ウェアハウスではステージング・エリアが使用されます。ステージング・エリアにより、サマリーの作成とウェアハウス管理全般が簡素化されます。図1-3に、この典型的なアーキテクチャを示します。
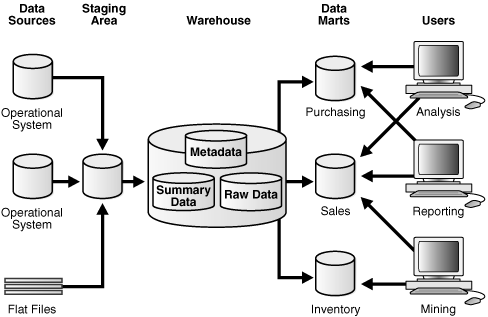
図1-3のアーキテクチャはきわめて一般的ですが、ウェアハウスのアーキテクチャを組織内のグループごとにカスタマイズすることもできます。そのためには、特定の業務に合せて設計されたデータ・マートを追加します。図1-4の例では、発注、受注、在庫が分離されています。この例で、ファイナンシャル・アナリストは発注と受注の履歴データを分析したり、履歴データをマイニングして顧客の行動の予測を作成できます。
図1-4 データ・ウェアハウス・アーキテクチャ(ステージング・エリアおよびデータ・マートを伴う)
|
注意: データ・マートは多くのデータ・ウェアハウスにおいて重要ですが、このマニュアルでは重点を置いていません。 |
データを分析することにより、データ・ウェアハウスに格納された大量のデータから情報を抽出できます。Oracle Databaseでは、いくつかの方法でデータを分析できます。
記述統計、仮説の検証、相関分析、分布の適合度の検証、カイ2乗統計によるクロス集計、および分散分析(ANOVA)などの、多様な統計関数(これらの関数については、『Oracle Database SQL言語リファレンス』を参照)
Oracle Databaseは、業界初で唯一の埋込みOLAPサーバーを提供します。Oracle OLAPにより、複数のディメンションにまたがってデータを分析する際に、固有の多次元格納および高速な応答時間を実現できます。データベースでは、時系列計算、予測、加算および非加算の演算子や割当て演算子による高度な集計など、多様な形で分析を行うことができます。こうした機能により、Oracleデータベースは、ビジネス・インテリジェンスや高度な分析アプリケーション全般をサポートできる、完全な分析プラットフォームとなります。
Oracle OLAPでは、多次元データ・モデルを使用して、リアルタイムで履歴データの複雑な統計分析、算術分析および財務分析を行います。Oracle OLAPはデータベースに完全に統合されているため、標準のSQL管理ツール、問合せツールおよびレポート・ツールを使用できます。
OLAPの詳細は、『Oracle OLAPユーザーズ・ガイド』を参照してください。
Oracleでは、多次元オブジェクトおよび分析をデータベースに統合することにより、両者の利点を活かし、Oracleデータベースの信頼性、可用性、セキュリティ、スケーラビリティとともに多次元分析機能を実現しています。
Oracle OLAPはOracle Databaseに完全に統合されています。これは、技術レベルでは次のことを意味します。
OLAPエンジンは、Oracle Databaseのカーネルで実行されます。
ディメンション・オブジェクトは、固有の多次元形式でOracle Databaseに格納されます。
キューブなどのディメンション・オブジェクトは、Oracleデータ・ディクショナリの主要なデータ・オブジェクトです。
データ・セキュリティは、Oracle Databaseのユーザーとロールに対して権限の付与および取消しを行う、標準的な方法で管理されます。
アプリケーションで、SQLを使用してディメンション・オブジェクトを問い合せることができます。
これは組織にとって非常に有益です。Oracle OLAPは、簡素化によるメリットをもたらします。つまり、1つのデータベース、標準の管理およびセキュリティ機能、標準のインタフェースや開発ツールを利用できるのです。
Oracle OLAPでは、特徴的な分析コンテンツでデータベースやアプリケーションを簡単に強化できます。Oracleの多次元オブジェクトや計算に対する固有のSQLアクセスによって、ダッシュボード、レポート、ビジネス・インテリジェンス(BI)、あらゆるタイプの分析アプリケーションの開発作業が、独自のインタフェースを提供するシステムと比較して非常に容易になります。また、SQLアクセスは、従来の限られたOLAPアプリケーションのみではなく、どのようなデータベース・アプリケーションでも、Oracle OLAPの分析機能が使用できることを意味します。
Oracle OLAPはOracleデータベースに完全に埋め込まれているため、通常スタンドアロンのOLAPサーバーに必須となる管理技術を習得する必要がありません。専門の管理スキルに投資することなく、既存のDBAスタッフを活用できます。
Oracleの埋込みOLAPテクノロジの主な管理上のメリットの1つは、キューブの自動的なメンテナンスです。スタンドアロンのOLAPサーバーでは、キューブのリフレッシュ作業の負担がすべて管理者にかかります。その結果、ジョブが複雑になり、エラーが発生しやすくなることがあります。管理者は、リレーショナル・ソースから変更済データを抽出し、そのデータをソース・システムからスタンドアロンOLAPサーバーを実行しているシステムに移動し、キューブのロードと再構築を行うプロシージャを作成する必要があります。また、このプロセスの間、DBAはデルタ(変更された値)のセキュリティについて責任を負わなければなりません。
その一方、Oracle OLAPでは、キューブのリフレッシュはすべてOracleデータベースで処理されます。データベースは、ディメンション・オブジェクトの失効を追跡し、ソース表のデルタの動きを自動的に記録して、リフレッシュ・プロセス中に変更された値のみを自動的に適用します。DBAはリフレッシュのスケジュールを適切な間隔で設定するだけで、他のことについてはすべてOracle Databaseが対処します。
Oracle OLAPでは、Oracle Databaseの標準のセキュリティ機能を使用して、多次元データを保護します。
これに対し、スタンドアロンのOLAPサーバーでは、管理者はリレーショナル・ソース・システムとOLAPサーバー・システムで、2回に渡ってセキュリティの管理を行う必要があります。また、リレーショナル・システムからスタンドアロンOLAPシステムにデータを移動する際のセキュリティを管理しなければなりません。
ビジネス・インテリジェンスおよび分析アプリケーションは主に、階層のドリルアップやドリルダウン、集計値の比較(前期比、親のシェア、将来の予測、多数の類似の計算など)といった操作に使用します。こうした操作は多くの場合、階層集計が可能な領域全体においてランダムに行われます。Oracle OLAPは、定義された多次元領域ですべての集計を事前計算するか、効率よく即時計算するため、典型的なビジネス・インテリジェンス・アプリケーションで優れたパフォーマンスを実現できます。
Oracle OLAPの問合せでは、Oracleの共有カーソルを利用することにより、メモリー要件を大幅に削減し、パフォーマンスを向上させます。
Oracle DatabaseとともにReal Application Clusters(Oracle RAC)オプションをインストールすると、OLAPアプリケーションにおいても、パフォーマンス、スケーラビリティ、フェイルオーバーおよびロード・バランシングについて、他のアプリケーションと同様の利点があります。
上述の機能はすべて、コストの削減につながります。既存のスタッフのスキルを利用できるため、管理費が減少します。また、Oracleデータベースでは、他のシステムにおいては管理者の負担となる複雑な作業である、ディメンション・オブジェクトのリフレッシュの管理が可能です。標準のセキュリティによっても、管理費が削減されます。SQLに精通した多数のアプリケーション開発者や豊富なSQLベースの開発ツールを活用できるため、アプリケーションの開発とデプロイを迅速に行うことができ、アプリケーション開発費が減少します。いずれのSQLベースの開発ツールでもOracle OLAPを利用できます。Oracle OLAPの効率的な集計の管理、共有カーソルの使用、低コストのコモディティ部品でスケーラブルなシステムを構築できるOracle RACによって、ハードウェア費が削減されます。
Oracle OLAPでは多数の分析コンテンツが用意されており、問合せに対する応答も高速なため、お使いのSQLアプリケーションを強化できます。SQL問合せのインタフェースにより、OLAPの知識がなくても、すべてのアプリケーションでキューブやディメンションへの問合せを実行できます。
OLAPオプションでは、キューブ、ディメンションおよび階層のリレーショナル・ビューを自動的に生成します。SQLアプリケーションでこれらのビューを問い合せることにより、分析担当者や意思決定者はこれらのオブジェクトの情報量に富んだ内容を表示できます。また、実表などのシステム生成ビューを使用して、お使いのアプリケーションが求める構造に適合するカスタム・ビューを作成できます。
分析者は、SQL問合せと分析ツールを選択して、データの選択、表示および分析を行うことができます。好みのツールやアプリケーション、またはOracle Databaseのツール(Oracle Application ExpressやBusiness Intelligence Publisherなど)を使用できます。
キューブ・マテリアライズド・ビューでは、詳細なリレーショナル表への問合せを行うアプリケーション、およびキューブに直接問合せを行うアプリケーションに対して、OLAPオプションの高速更新および高速問合せの機能が提供されます。
ファクト表に含まれるサマリーの多数のリレーショナル・マテリアライズド・ビューは、単一のキューブ・マテリアライズド・ビューに置き換えることができます。そのため、クエリー・リライトの間の全サマリー・データへの応答時間は均一になります。アプリケーションでは、優れた問合せパフォーマンスが得られます。
キューブ・マテリアライズド・ビューは、Oracle Databaseの自動リフレッシュ機能およびクエリー・リライト機能のために拡張されたキューブです。サマリー・データが生成され、キューブに格納されると、クエリー・リライト機能によって問合せがキューブ・マテリアライズド・ビューに自動的にリダイレクトされます。
リレーショナル・マテリアライズド・ビューをサポートするディクショナリ・ビューおよびPL/SQLパッケージでは、多くの場合、キューブ・マテリアライズド・ビューもサポートされます。さらに、DBMS_CUBEでPL/SQLサブプログラム・グループを使用すると、既存のリレーショナル・マテリアライズド・ビューからキューブ・マテリアライズド・ビューを迅速にデプロイできます。
データ・マイニングでは、大量のデータを使用してモデルを作成します。こうしたモデルにより、データに埋もれた重要かつ貴重な情報を見つけ出すことができます。たとえば、データ・マイニングを使用すると次のことが可能になります。
サービス業者を変更する見込みが高い顧客を予測する
病気に関係のある要素を発見する
不正行為を識別する
データ・マイニングにより、ビジネスの様々な問題が解決されます。たとえば、データ・マイニングを使用して、減少する可能性がある顧客層を予測できます。
Oracle Data Miningは、データ・マイニングをOracle Database内で実行します。Oracle Data Miningでは、データベースと外部マイニング・サーバー間でのデータ移動を必要としません。このことは、冗長性の排除、データの格納と処理の効率性向上、使用するデータの最新状態の維持、およびデータ・セキュリティの確保につながります。
Oracle Data Miningの詳細は、『Oracle Data Mining概要』を参照してください。
Oracle Data Miningは、主なデータ・マイニング機能をサポートしています。各マイニング機能には、少なくとも1つのアルゴリズムがあります。
Oracle Data Miningは、次のデータ・マイニング機能をサポートしています。
分類: 項目を個別のクラスにグループ化し、ある項目がどのクラスに属するかを予測します。分類に使用されるアルゴリズムは、Decision Tree、Naive Bayes、一般化線型モデル(2項ロジスティック回帰)、およびサポート・ベクター・マシンです。
回帰: 連続する数値の近似および予測を行います。回帰に使用されるアルゴリズムは、サポート・ベクター・マシンおよび一般化線型モデル(多変量線型回帰)です。
異常検出: 不正および侵入などの異常ケースを検出します。異常検出に使用されるアルゴリズムは、1クラス・サポート・ベクター・マシンです。
属性評価: ターゲット属性(たとえば、解約の可能性が高い顧客)と最も強い関係を持つ属性を識別します。属性評価に使用されるアルゴリズムは、最小記述長です。
クラスタリング: 顧客セグメントの識別に多く使用される、データ内の自然なグループを見つけます。クラスタリングに使用されるアルゴリズムは、k-MeansおよびO-Clusterです。
相関: 「マーケット・バスケット」、つまり同時に購入される可能性が高い商品群を分析します。相関に使用されるアルゴリズムは、a prioriです。
特徴抽出: 新しい属性(特徴)を元の属性の組合せとして作成します。特徴抽出に使用されるアルゴリズムは、Non-Negative Matrix Factorizationです。
Oracle Data Miningでは、構造化データのマイニングのみでなく、テキスト・データ(警察の報告や顧客のコメント、医師のメモなど)や空間データのマイニングも行えます。
Oracle Data MiningのAPIは、データ・マイニング結果の抽出および配布を自動化するアプリケーションの開発に関して、次のような幅広いサポートを提供しています。
モデルの作成、テストおよびスコアリングなどのデータ・マイニング・アクティビティは、PL/SQL API、Java APIおよびSQLデータ・マイニング関数を使用して実行できます。Java APIはデータ・マイニング規格のJSR 73に準拠しています。Java APIとPL/SQL APIの間には完全な相互運用性があります。
Oracle Data Miningでは、スーパーモデル、つまりデータ準備の手順を含むモデルを作成できます。埋め込まれたデータ準備は、自動と手動のどちらでも実装できます。埋込みデータ準備は、ユーザー指定のデータ変換をサポートします。自動データ準備は、アルゴリズムが必要とするデータ準備(ビニング、正規化、外れ値の処理など)をサポートします。
SQLデータ・マイニング関数は、分類モデル、回帰モデル、クラスタリング・モデル、および特徴抽出モデルのスコアリングをサポートしています。他のSQL問合せと同様、標準SQL文のコンテキスト内で、事前に作成したモデルを新しいデータや後続処理用に戻された結果へ適用できます。
予測分析により、データ・マイニングの処理を自動化します。ユーザーの介入なしに、予測分析ルーチンがデータ準備、アルゴリズムの選択、モデルの作成、およびモデルのスコアリングを管理するため、データ・マイニングの専門家でなくともデータ・マイニングを活用できます。
Oracle Data Minerは、Oracle Data Miningのグラフィカル・ユーザー・インタフェースです。Oracle Data Minerの画面に従って、データ準備、データ・マイニング、モデル評価およびモデル・スコアリングのすべての手順を実行できます。Oracle Data Miningインタフェースの詳細は、『Oracle Data Mining概要』を参照してください。