| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、データ・ウェアハウスでパフォーマンスを向上させることのできるパラレル実行の概念について説明します。次の内容が含まれます。
今日のデータベースには、それがウェアハウスや運用データ・ストア、またはOLTPシステムのどれであるかに限らず、大量の情報が格納されています。しかし、含まれるデータの量が膨大であるため、正しい情報をタイムリーに検索し、提示することは容易ではありません。
パラレル実行は、この課題に対処するための機能です。パラレル実行(パラレル化とも呼ばれます)では、複数のプロセスを使用して単一のタスクを完了させることで、テラバイトのデータを数時間や数日ではなく、数分で処理できます。これにより、通常意思決定支援システム(DSS)およびデータ・ウェアハウスに関連付けられているサイズの大きなデータベース上で、データ集中型の操作のレスポンス時間を大幅に削減できます。また、OLTPシステム上で、索引の作成などのバッチ処理またはスキーマ・メンテナンス操作のためにパラレル実行を実装することもできます。パラレル化の概念は、タスクへの分解であり、これにより1つのプロセスで問合せに関するすべての処理を実行するのではなく、多くのプロセスが同時に各処理を実行します。たとえば、1年の合計売上げを4つのプロセスで計算するのに、1つのプロセスですべての四半期を処理するのではなく、各プロセスが1年の四半期それぞれを処理する場合です。これを使用するとパフォーマンスの大幅な向上が見込めます。
パラレル実行では、次のプロセスのパフォーマンスを向上できます。
サイズの大きな表のスキャン、結合またはパーティション化された索引のスキャンを要求する問合せ
大規模な索引の作成
サイズの大きな表の作成(マテリアライズド・ビューを含む)
バルク挿入、更新、マージ、削除
また、パラレル実行を使用して、Oracleデータベース内のオブジェクト型にアクセスできます。たとえば、パラレル実行により、ラージ・オブジェクト(LOB)にアクセスできます。
大規模なデータ・ウェアハウスでは、優れたパフォーマンスを得るために、常にパラレル実行を使用する必要があります。OLTPアプリケーションの特定の処理(バッチ処理など)も、パラレル実行を行うことでパフォーマンスが大幅に向上します。
通りにある車の台数を数えるというタスクがあるとします。このタスクを実行するには2つの方法があります。1つは、自分が通りまで行き、車の台数を数えます。もう1つは、友人に協力してもらい、それぞれ通りの反対側から車の台数を数え始め、2人が落ち合ったところでそれぞれの台数を足します。
友人が車を数える速さがあなたと同じだとした場合、通りにあるすべての車を数えるタスクは、自分一人で行う場合と比べて半分の時間で終えることができます。このような場合、処理は直線的に測定できます。つまりリソースの数を2倍にすると、全体の処理時間は半分になります。
データベースの場合も、車を数える例とさほど変わりません。リソースの数を2倍にすることで、処理時間が最初の半分になれば、その処理は直線的に測定できます。直線的に測定できることが、車を数える場合でも、データベース問合せからの応答を配信する場合でも、パラレル処理の最終的な目標です。
|
関連項目:
|
パラレル実行は、次のすべての特性を持つシステム上で有効です。
対称型マルチプロセッサ(SMP)、クラスタ、または大規模なパラレル・システム
十分なI/Oバンド幅
稼働中でないCPUまたは断続的に使用されているCPU(CPUの使用率が通常30%未満のシステムなど)
ソート、ハッシュおよびI/Oバッファなどの追加のメモリー集中処理をサポートする十分なメモリー
これらの特性を持たないシステムでは、パラレル実行を使用しても大幅にパフォーマンスが向上しない場合があります。実際に、大容量を使用しているシステムまたはI/Oバンド幅の少ないシステム上では、システムのパフォーマンスが低下する可能性があります。
パラレル実行のメリットは、DSSおよびデータ・ウェアハウス環境でわかります。OLTPシステムでも、索引の作成などのスキーマ・メンテナンス操作中やバッチ処理中に、パラレル実行によるメリットを得ることができます。OLTPアプリケーションを特徴づける通常の単純なDMLまたはSELECT文では、パラレルで実行することによるメリットはありません。
パラレル実行は、次の場合では通常有効ではありません。
標準的な問合せまたはトランザクションが非常に短い(数秒またはそれ以下)環境。これには、ほとんどのオンライン・トランザクション・システムが含まれます。パラレル実行サーバーの調整にはコストがかかり、短いトランザクションでは、このような調整のコストがパラレル化のメリットよりも上回る可能性があるため、パラレル実行はこのような環境では有効ではありません。
CPU、メモリーまたはI/Oリソースが大量に使用されている環境。パラレル実行は追加の使用可能なハードウェア・リソースを利用するように設計されています。そのようなリソースが使用できない場合、パラレル実行はなんのメリットももたらさず、パフォーマンスに悪影響をおよぼす可能性があります。
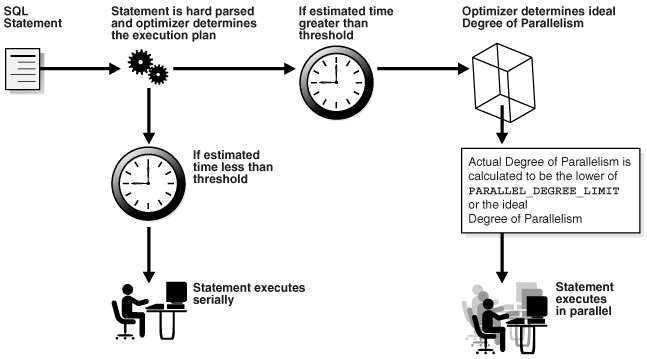
名前が示すとおり、自動並列度では、オプティマイザにより決定された最速と考えられるプランに基づき、Oracle Databaseが文(DML、DDLおよび問合せ)を実行する並列度(DOP)を決定します。つまり、データベースが問合せを解析し、コストを計算してから、実行に使用するDOPを計算します。コストの最も低い計画がシリアルに実行される可能性もオプションの1つとしてあります。図6-1「オプティマイザの計算: シリアルかパラレルか」に、この決定プロセスを示します。
自動DOPの使用を選択する場合、特にしきい値が比較的低い場合は、多くの文がパラレルに実行している可能性があります。この場合の低いというのはシステムに対する相対的なものであり、絶対的な数量ではありません。
自動DOPを使用して多くの文がパラレルに実行しているという動作が予想されるため、使用可能なパラレル・プロセスの使用量を管理することはより重要になります。つまり、システムは、文をいつ実行するかについてインテリジェントであり、要求されたパラレル・プロセスの数が使用可能かどうかを検証する必要があります。この要求されたプロセスの数というのが、その文のDOPです。
この管理上の課題への答は、データベース・リソース・マネージャを使用した文のパラレル・キューイングです。文のパラレル・キューイングでは、文が要求したDOPが使用可能な場合に文が実行されます。たとえば、文が64のDOPを要求したときに、この顧客への支援に現在使用できるのが32プロセスのみである場合は、この文はキューに入れられます。
データベース・リソース・マネージャを使用すると、文を消費者グループを介してワークロードに分類できます。各消費者グループには適切な優先度およびパラレル・プロセスの適切なレベルが与えられます。また、各消費者グループはシステム・ロードに基づきパラレル文を格納する固有のキューを持ちます。
|
関連項目:
|
従来、ほとんどの操作に対するパラレル処理では、データベース・バッファ・キャッシュがバイパスされ、ディスクから(ダイレクト・パスI/O経由で)パラレル実行サーバーのプライベート作業領域に直接読み込まれていました。DB_CACHE_SIZEの約2%よりも小さいオブジェクトのみがインスタンスのデータベース・バッファ・キャッシュに入れられますが、パラレルにアクセスされるオブジェクトはこの制限よりも大きいものがほとんどです。つまりこの動作は、そのプライベート処理以外では、使用可能なメモリが利用されることがほとんどないことを示します。しかし、この10年で、ハードウェア・システムはきわめて劇的に進化し、一般的なデータベース・サーバーのメモリ容量は2桁または3桁のギガバイトの領域に達しています。このことが、Oracleの圧縮技術と、Oracle Real Application Clustersの集計されたデータベース・バッファ・キャッシュを利用するOracle Database 11gリリース2の機能とともに、テラバイトの領域でのオブジェクトのキャッシュを可能にしました。
メモリ内パラレル実行は、この大きな集計されたデータベース・バッファ・キャッシュを利用します。パラレル実行サーバーはデータベース・バッファ・キャッシュを使用してオブジェクトにアクセスすることにより、ディスク上よりも少なくとも10倍は高速でスキャンできます。
メモリ内パラレル実行を使用して、SQL文がパラレルに発行されるとき、チェックが実行されて、文がアクセスするオブジェクトをシステムの集計されたバッファ・キャッシュに入れる必要があるかどうかが決定されます。この状況で、オブジェクトは表、索引またはパーティション・オブジェクトの場合には1つまたは複数のパーティションのいずれかです。
|
関連項目:
|