| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、データ・ウェアハウスのスキーマについて説明します。内容は次のとおりです。
スキーマとは、表、ビュー、索引およびシノニムを含むデータベース・オブジェクトのコレクションです。
データ・ウェアハウス用に設計されたスキーマ・モデルにスキーマ・オブジェクトを配置するためには、様々な方法があります。データ・ウェアハウス・スキーマ・モデルの1つは、スター・スキーマです。shサンプル・スキーマ(このマニュアルに記載するほとんどの例の基本)では、スター・スキーマを使用します。ただし、その他にも、データ・ウェアハウスによく使用されるスキーマ・モデルがあります。そのようなスキーマ・モデルのうち最も一般的なのは、第3正規形(3NF)スキーマです。また、スター・スキーマでも3NFスキーマでもなく、かわりにこの2つのスキーマの特性を兼ね備えたハイブリッド・スキーマ・モデルと呼ばれるスキーマもあります。
Oracle Databaseは、すべてのデータ・ウェアハウス・スキーマをサポートするよう設計されています。機能によっては、1つのスキーマ・モデルに固有のものもあります(たとえば、スター変換機能はスター・スキーマに固有です。これは、「スター型変換の使用」に記載されています)。ただし、Oracleのデータ・ウェアハウス機能の大多数は、スター・スキーマ、3NFスキーマおよびハイブリッド・スキーマに同じように適用できます。パーティション化(ローリング・ウィンドウのロード手法を含む)、パラレル化、マテリアライズド・ビュー、分析SQLなどの主なデータ・ウェアハウス機能は、すべてのスキーマ・モデルに実装されています。
データ・ウェアハウスにどのスキーマ・モデルを使用するかは、データ・ウェアハウス・プロジェクト・チームの要件と選択に基づいて決定されます。代替スキーマ・モデルの利点の比較は、本書の範囲外です。かわりに、この章では、各スキーマ・モデルを簡単に紹介し、それらの環境に対してOracle Databaseを最適化する方法を提示します。
本書では、例として主にスター・スキーマを使用していますが、データ・ウェアハウスの実装に第3正規形を使用することもできます。
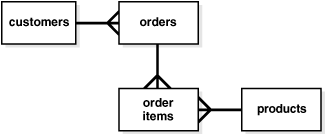
第3正規形モデルは、正規化を介してデータの冗長性を最小限に抑える古典的なリレーショナル・データベース・モデリング手法です。3NFスキーマでは通常、スター・スキーマと比べると、正規化処理のために表の数が多くなります。たとえば、図20-1で、orders表およびorder items表には、図20-2のスター・スキーマのsales表と同じ情報が含まれています。
通常、3NFスキーマは、大規模なデータ・ウェアハウス、特に、データのロード要求が多く、データ・マートへのデータの入力および長時間実行問合せの実行に使用される環境用として選択されます。
3NFスキーマの主なメリットは、次のとおりです。
アプリケーションやデータの使用方法の考慮事項とは独立した、中立的なスキーマ設計を提供します。
スター・スキーマのように正規化度の高いスキーマに比べて、データ変換が少なくて済みます。
図20-1に、第3正規形を示します。
3NFスキーマでは、多くの場合、問合せが非常に複雑になり、多数の表を必要とします。このため、大規模な表の結合のパフォーマンスが、3NFスキーマを使用する際の主な考慮事項になります。
3NFスキーマの特に重要な機能の1つは、パーティション・ワイズ結合です。3NFスキーマの最大の表は、パーティション・ワイズ結合を使用可能にするためにパーティション化する必要があります。こうした環境で最も一般的なパーティション化手法は、最大の表に対するコンポジット・レンジ-ハッシュ・パーティション化であり、最も一般的な結合キーがハッシュ・パーティション化キーとして選択されます。
3NF環境では、パラレル化が非常によく利用されるため、通常はパラレル化を使用可能にする必要があります。
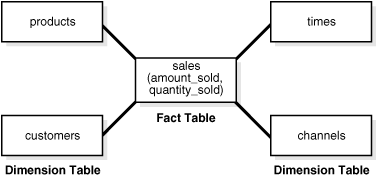
スター・スキーマは、おそらく最も単純なデータ・ウェアハウス・スキーマです。スター・スキーマをエンティティ関連図で表すと、星(スター)のように中央の表から点が放射状に広がっているため、スター・スキーマと呼ばれます。スターの中心は1つの大規模なファクト表で構成されており、スターの先端はディメンション表になっています。
スター・クエリーは、ファクト表といくつかのディメンション表を結合するものです。各ディメンション表は、主キーから外部キーへの結合を使用してファクト表に結合されますが、ディメンション表同士は結合されません。オプティマイザによってスター・クエリーが認識されると、スター・クエリーのための効率的な実行計画が生成されます。スター型変換を有効化するにあたり、ファクト表の外部キーは必須ではありません。
一般的なファクト表には、キーおよびメジャーが含まれます。たとえばshサンプル・スキーマの場合、ファクト表salesには、メジャーとしてquantity_sold、amountおよびcostが含まれ、キーとしてcust_id、time_id、prod_id、channel_idおよびpromo_idが含まれます。ディメンション表は、customers、times、products、channelsおよびpromotionsです。たとえば、productsディメンション表には、ファクト表に表示される各製品番号に関する情報があります。
スター型結合とは、ディメンション表とファクト表の主キーと外部キーの結合です。
スター・スキーマの主なメリットは、次のとおりです。
エンド・ユーザーによって分析されるビジネス・エンティティとスキーマ・デザイン間の直接的および直感的マッピングを提供します。
一般的なスター・クエリーに、高度に最適化されたパフォーマンスを提供します。
多数のビジネス・インテリジェンス・ツールで幅広くサポートされます。これらのツールは、データ・ウェアハウス・スキーマがディメンション表を含むことを想定または必須要件としている場合があります。
スター・スキーマは、単純なデータ・マートと非常に大規模なデータ・ウェアハウスの両方に使用されます。
図20-2に、スター・スキーマを示します。
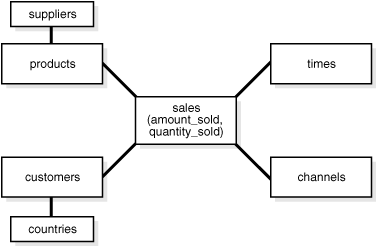
スノーフレーク・スキーマは、スター・スキーマより複雑なデータ・ウェアハウス・モデルであり、スター・スキーマの一種です。このスキーマの図がスノーフレーク(雪片)に似ているため、スノーフレーク・スキーマと呼ばれます。
スノーフレーク・スキーマでは、ディメンションが正規化され、冗長性が排除されます。つまり、ディメンション・データは1つの大規模な表ではなく複数の表にグルーピングされます。たとえば、スター・スキーマのproductディメンション表は、スノーフレーク・スキーマのproducts表、product_category表およびproduct_manufacturer表に正規化できます。これによって、領域が節約されますが、ディメンション表の数が増加し、より多くの外部キー結合が必要になります。その結果、問合せがより複雑になり、問合せのパフォーマンスが低下します。図20-3に、スノーフレーク・スキーマを示します。
|
注意: 特に理由がなければ、スノーフレーク・スキーマではなくスター・スキーマを選択することをお薦めします。 |
スター・クエリーを使用する場合は、次の点を考慮する必要があります。
スター・クエリーのパフォーマンスを最大限に向上させるためには、次の基本的なガイドラインに従う必要があります。
ビットマップ索引をファクト表の各外部キー列上に作成する必要があります。
初期化パラメータSTAR_TRANSFORMATION_ENABLEDをTRUEに設定する必要があります。これにより、スター・クエリーのための重要なオプティマイザ機能が使用可能になります。この機能は、下位互換性のためにデフォルトでFALSEに設定されています。
データ・ウェアハウスがこれらの条件を満たす場合、そのデータ・ウェアハウスで実行しているほとんどのスター・クエリーは、スター型変換と呼ばれる問合せ実行計画を使用します。スター型変換によって、スター・クエリーの問合せパフォーマンスが向上します。
スター型変換は、元のスター・クエリーのSQLを暗黙的にリライト(または変換)することによる、強力な最適化テクニックです。エンド・ユーザーがスター型変換の詳細を知る必要はありません。Oracle Databaseの問合せオプティマイザでは、該当する場合にスター型変換が自動的に選択されます。
スター型変換は、スター・クエリーを効率的に実行することを目的とした問合せ変換です。Oracle Databaseでは、2つの基本フェーズを使用してスター・クエリーが処理されます。第1フェーズでは、ファクト表から必要な行(結果セット)のみを取り出します。この取出しにはビットマップ索引が使用されるため、非常に効率的です。第2フェーズでは、この結果セットをディメンション表に結合します。たとえば、「西部および南西部販売地域における過去3四半期の食料品部門の売上および利益はどうであったか」というエンド・ユーザーの問合せがあるとします。これは、1つの単純なスター・クエリーです。
スター型変換の前提条件は、ファクト表の各結合列に単一列のビットマップ索引が存在することです。これらの結合列には、すべての外部キー列が含まれます。
たとえば、shサンプル・スキーマのsales表の場合、time_id列、channel_id列、cust_id列、prod_id列およびpromo_id列にビットマップ索引が定義されています。
次のスター・クエリーを考えてみます。
SELECT ch.channel_class, c.cust_city, t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc in ('Internet','Catalog')
AND t.calendar_quarter_desc IN ('1999-Q1','1999-Q2')
GROUP BY ch.channel_class, c.cust_city, t.calendar_quarter_desc;
この問合せは、2つのフェーズで処理されます。第1フェーズでは、Oracle Databaseは、ファクト表の外部キー列上のビットマップ索引を使用して、ファクト表から必要な行のみを識別し、取り出します。つまり、Oracle Databaseは、主に次の問合せを使用して、ファクト表から結果セットを取り出します。
SELECT ... FROM sales
WHERE time_id IN
(SELECT time_id FROM times
WHERE calendar_quarter_desc IN('1999-Q1','1999-Q2'))
AND cust_id IN
(SELECT cust_id FROM customers WHERE cust_state_province='CA')
AND channel_id IN
(SELECT channel_id FROM channels WHERE channel_desc IN('Internet','Catalog'));
元のスター・クエリーがこの副問合せ表現に変換されたことから、これがアルゴリズムの変換ステップになります。ファクト表にアクセスするこの方法は、ビットマップ索引の効果を高めます。ビットマップ索引は、リレーショナル・データベース内に集合ベースの処理方法を提供します。Oracleでは、AND(標準的な集合についての用語で共通部分の意味)、OR(集合の用語で和集合)、MINUS、COUNTなどの集合演算を実行するための非常に高速な方法が実装されています。
このスター・クエリーでは、time_idのビットマップ索引を使用して、1999年第1四半期(1999-Q1)の売上(sales)に対応するファクト表のすべての行集合が識別されます。この集合は、ビットマップ(ファクト表のどの行がこの集合のメンバーであるかを示す1および0(ゼロ)の文字列)として表されます。
同様のビットマップが、1999年第2四半期(1999-Q2)の売上に対応するファクト表の行に取り出されます。ビットマップOR演算を使用して、このQ1の売上集合をQ2の売上集合と組み合せます。
追加の集合演算が、customerディメンションおよびproductディメンションに対して実行されます。この時点で、スター・クエリー処理には3つのビットマップがあります。各ビットマップは、別々のディメンション表に対応し、それぞれ、個々のディメンションの絞込み条件を満たすファクト表の行集合を表します。
これらの3つのビットマップは、ビットマップAND演算を使用して単一ビットマップに結合されます。この最後のビットマップは、ファクト表のうちディメンション表上の絞込み条件をすべて満たす行集合を表します。これは結果セットであり、問合せの評価に必要なファクト表からの正確な行集合です。ここまでのところでは、ファクト表の実際のデータには、まだアクセスしていないことに注意してください。これらの演算はすべて、ビットマップ索引とディメンション表のみを基にしています。ビットマップ索引はデータを圧縮した形で表すため、ビットマップの集合ベース演算は非常に効率的です。
結果セットが識別されると、ビットマップはSALES表から実データへのアクセスに使用されます。エンド・ユーザーの問合せに必要な行のみが、ファクト表から取り出されます。この時点で、すべてのディメンション表が、ビットマップ索引を使用してファクト表に効率的に結合されています。Oracle Databaseでは、各ディメンション表をファクト表に個別に結合するのではなく、すべてのディメンション表を単一の論理結合演算でファクト表に結合しているため、この技法を使用すると優れたパフォーマンスが得られます。
この問合せの第2フェーズでは、ファクト表の行(結果セット)をディメンション表に結合します。Oracleは、最も効率的な方法を使用して、ディメンション表にアクセスおよび結合します。ほとんどのディメンションは非常に小規模なため、これらのディメンション表への最も効率的なアクセス方法は、通常、表スキャンです。大規模なディメンション表については、表スキャンは最も効率的なアクセス方法ではない場合があります。前述の例では、product.departmentのビットマップ索引を使用して、食料品部門のすべての製品が高速で識別されます。Oracle Databaseでは、各ディメンション表のサイズおよびデータ分散に関するオプティマイザの知識に基づいて、オプティマイザが、特定のディメンション表に最適のアクセス方法を自動的に判断します。
同様に、各ディメンション表用の特定の結合方法(および索引付け方法)も、オプティマイザによってインテリジェントに判断されます。多くの場合、ディメンション表を結合するための最も効率的なアルゴリズムはハッシュ結合です。すべてのディメンション表が結合されると、最終結果がユーザーに戻されます。1つの表から一致する行のみを取り出してから、別の表に結合する問合せテクニックは、一般にセミ結合と呼ばれます。
「ビットマップ索引を使用したスター型変換」から得られる典型的な実行計画は次のようになります。
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ITERATOR
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CUSTOMERS
BITMAP INDEX RANGE SCAN SALES_CUST_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
この計画では、ファクト表は、ビットマップ・アクセス・パスを介してアクセスされます。このパスは、3つのマージされたビットマップのビットマップANDに基づきます。この3つのビットマップは、下位の行ソース・ツリーからビットマップが提供されているBITMAP MERGE行ソースによって生成されます。このような行ソース・ツリーはそれぞれ、副問合せ行ソース・ツリーの値をフェッチするBITMAP KEY ITERATION行ソースで構成されています。この例では、副問合せ行ソース・ツリーは、1つの全表アクセスです。これらの各値について、BITMAP KEY ITERATION行ソースがビットマップをビットマップ索引から取り出します。関係するファクト表の行は、このアクセス・パスを使用して取り出された後に、問合せ結果を生成するためにディメンション表および一時表と結合されます。
スター型変換において、ビットマップ索引の他にビットマップ結合索引も使用できます。次に示すような追加の索引構造があるとします。
CREATE BITMAP INDEX sales_c_state_bjix ON sales(customers.cust_state_province) FROM sales, customers WHERE sales.cust_id = customers.cust_id LOCAL NOLOGGING COMPUTE STATISTICS;
同じスター・クエリーでビットマップ結合索引を使用した場合の処理は、前述の例に似ています。唯一の違いは、単一表のビットマップ索引のかわりに、結合インデックスを使用してスター・クエリーの第1フェーズで顧客データにアクセスすることです。
「ビットマップ結合索引を使用したスター型変換の実行計画」から得られる典型的な実行計画は次のようになります。
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ALL
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP INDEX SINGLE VALUE SALES_C_STATE_BJIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
この計画と前述の計画との唯一の違いは、customerディメンションのビットマップ索引スキャン内の選択のための処理がないことです。これは、customer.cust_state_provinceの結合述語情報を、ビットマップ結合索引sales_c_state_bjixで満たすことができるためです。
オプティマイザは、変換なしでも生成できる最適な計画を生成して保存します。変換が有効な場合、オプティマイザは問合せを変換し、必要に応じて、その変換された問合せを使用して最適な計画を生成します。オプティマイザは、この2つの問合せに対する最適な計画のコスト概算を比較して、変換または未変換のどちらの最適な計画を使用するかを決定します。
問合せがファクト表の行の大部分にアクセスする必要があるときは、変換ではなく、全表スキャンを使用する方がよい場合があります。ただし、ディメンション表について、選択による絞込み度合いが高く、ファクト表のわずかな部分のみを取り出す必要がある場合は、変換に基づく計画の方が適していることもあります。
オプティマイザは、多くの基準に基づいて適切であると判断した場合にのみ、ディメンション表に対して副問合せを生成します。副問合せは、すべてのディメンション表に対して生成されるわけではありません。また、オプティマイザが、表および問合せの性質に基づいて、問合せに変換を適用するメリットがないと判断することもあります。このような場合は、最適な通常の計画が使用されます。
スター型変換は、次の特性が1つでもある表ではサポートされません。
ビットマップ・アクセス・パスと非互換の表ヒントがある問合せ。
バインド変数を含む問合せ。
ビットマップ索引が少なすぎる表。オプティマイザが副問合せを生成するためには、ファクト表の列にビットマップ索引がある必要があります。
リモート・ファクト表。ただし、リモート・ディメンション表は、生成された副問合せでは有効です。
アンチ結合された表。
副問合せでディメンション表として使用済の表。
ビュー・パーティションではなく、実際はマージされていないビューである表。
ファクト表がマージされていないビューである表。
パーティション・ビューがファクト表として使用されている表。
次の場合には、オプティマイザではスター型変換が選択されないことがあります。
効率的な単一表アクセス・パスを持つ表
小さすぎて変換によるメリットがない表
さらに、次の条件下では、スター型変換で一時表は使用されません。
データベースが読取り専用モードの場合
スター・クエリーがシリアル化可能モードでのトランザクションの一部である場合