| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、SQLモデリングの使用方法について説明します。次の内容が含まれます。
MODEL句によって、SQL計算の機能性と柔軟性が向上します。MODEL句を使用すると、問合せ結果から多次元配列を作成し、この配列に(ルールと呼ばれる)式を適用して新しい値を計算できます。ルールは、基本的な算術式から再帰型を使用した連立方程式まで様々です。一部のアプリケーションでは、MODEL句の機能をPCベースのスプレッドシートと置き換えることができます。SQLのモデルには、Oracle Databaseが持つスケーラビリティ、管理性、コラボレーション機能、セキュリティ機能などの長所が生かされています。問合せのコア・エンジンは、無制限の量のデータを処理できます。データベース内でモデルを定義および実行することにより、別個のモデリング環境間で大規模なデータセットを転送する必要がなくなります。モデルはワークグループ間で簡単に共有できるため、すべてのアプリケーションで計算の一貫性を維持できます。モデルの共有と同様に、アクセスもOracleのセキュリティ機能を使用して厳密に制御できます。豊富な機能を備えたMODEL句を使用することで、あらゆるタイプのアプリケーションを強化できます。
MODEL句を使用すると、パーティション列、ディメンション列およびメジャー列の3つのグループに問合せの列を対応付けることによって、多次元配列を作成できます。これらの要素は、次のタスクを実行します。
パーティション列では、第22章「分析計算およびレポート用SQL関数」で説明した分析関数のパーティションと同様の方法で結果セットの論理ブロックを定義します。MODEL句のルールは、他のパーティションとは別個にパーティションごとに適用されます。したがって、パーティションは、MODEL句での計算をパラレル化するための境界点となります。
ディメンション列では、多次元配列を定義します。この列は、パーティション内のセルの識別に使用します。デフォルトでは、ディメンションの1つの完全な組合せはパーティション内の1つのセルのみを識別する必要があります。デフォルト・モードの場合、リレーショナル表のキーと同様のものとみなされます。
メジャーは、スター・スキーマのファクト表のメジャーと等価です。通常、メジャーには販売単位やコストなどの数値が格納されています。各セルにアクセスするには、各セルのディメンションの完全な組合せを指定します。各パーティションには、特定のディメンションの組合せと一致するセルが含まれることがあります。
MODEL句ではルールを指定して、パーティション列およびディメンション列で定義された多次元配列内のセルのメジャー値を操作できます。ルールは、ディメンション値を直接指定して、メジャー列値へのアクセスおよび更新を行います。ルールで参照を使用することにより、モデルの可読性が向上します。ルールは簡潔かつ柔軟なもので、表現力を最大限に高めるためにワイルド・カードおよびループ・コンストラクトを使用できます。Oracle Databaseでは、効率的にルールを評価し、可能なかぎりモデル計算をパラレル化し、MODEL句を他のSQL句とシームレスに統合します。したがって、データベースのビジネス・モデルを計算する上でMODEL句はスケーラブルで管理性に優れた方法であるといえます。
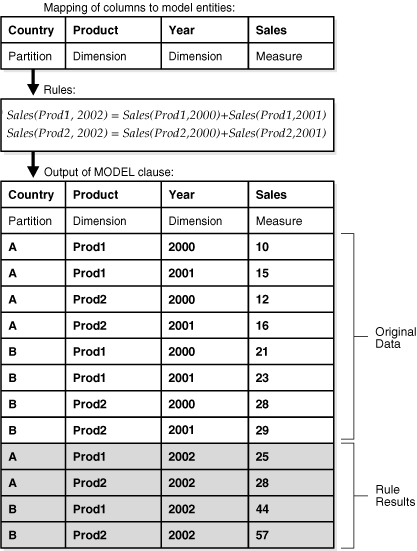
図23-1に、SQLのモデリング機能の概要を示します。図は3つの部分から構成されています。最上部では、一般的な表をパーティション列、ディメンション列およびメジャー列に分割する概念を示しています。中央の部分では、2002年のProd1およびProd2の値を計算する2つのルールを示しています。最下部では、仮想データを含む表にルールを適用した問合せの出力を示しています。白の部分の出力はデータベースから取得した元のデータを表し、グレーの部分の出力はルールで計算された行を表します。パーティションAの結果はパーティションBの結果とは独立して計算されていることに注目してください。
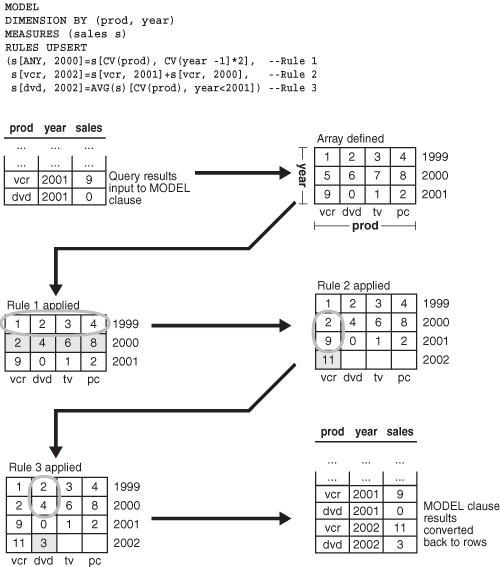
図23-2に、単純なMODEL句における処理フローを示します。ここでは、3つのルールを含んだMODEL句を通してデータの処理を理解していきます。ルールの1つでは既存の値を更新し、残りの2つのルールでは予測用に新しい値を作成します。図では、問合せで取得したデータの行がMODEL句に入力され、配列に再配置されていることが示されています。配列が定義されると、ルールが1つずつデータに適用されます。図23-2のグレーのセルはルールによって作成された新しいデータを表し、楕円で囲まれたセルは新しい値のソース・データを表しています。最後に、更新された値と新規に作成された値の両方を含むデータが行形式に再配置され、問合せの結果として表されます。この問合せでは、表へのデータの挿入はまったく行われていないことに注目してください。
Oracleのモデリングでは、高度な計算をデータに対して実行できます。通常は、ビジネス・ルールをデータに適用してレポートを生成する場合などに使用します。Oracle Databaseでは、モデリングの計算をデータベースに統合しているため、パフォーマンスと管理性が飛躍的に向上します。次の問合せを考えてみます。
SELECT SUBSTR(country, 1, 20) country,
SUBSTR(product, 1, 15) product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL
PARTITION BY (country) DIMENSION BY (product, year)
MEASURES (sales sales)
RULES
(sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001],
sales['All_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002])
ORDER BY country, product, year;
この問合せでは、「ベース・スキーマ」に示すように、sales_viewのデータをcountryでパーティション化して、3つのルールで定義されたモデル計算を国ごとに実行します。このモデルでは、2002年のBounceの売上を2000年と2001年の売上の合計として計算し、2002年のY Boxの売上を2001年の売上と同じ値に設定します。また、2002年については、同年のBounceとY Boxの売上の合計となる、新製品カテゴリAll_Productsを導入しています(sales_viewには、製品All_Productsはありません)。この問合せの出力を次に示します。この中で太字は新しい値を示します。
COUNTRY PRODUCT YEAR SALES -------------------- --------------- ---------- ---------- Italy Bounce 1999 2474.78 Italy Bounce 2000 4333.69 Italy Bounce 2001 4846.3 Italy Bounce 2002 9179.99 ... Italy Y Box 1999 15215.16 Italy Y Box 2000 29322.89 Italy Y Box 2001 81207.55 Italy Y Box 2002 81207.55 ... Italy All_Products 2002 90387.54 ... Japan Bounce 1999 2961.3 Japan Bounce 2000 5133.53 Japan Bounce 2001 6303.6 Japan Bounce 2002 11437.13 ... Japan Y Box 1999 22161.91 Japan Y Box 2000 45690.66 Japan Y Box 2001 89634.83 Japan Y Box 2002 89634.83 ... Japan All_Products 2002 101071.96 ...
BounceとY Boxの売上値は入力データ内に存在するのに対し、All_Productsの値は導出されていることに注目してください。
Oracle DatabaseのMODEL句の機能を次に示します。
ディメンション値を使用したセルのアドレッシング
個々の行のメジャー列は、多次元配列のセルのように処理され、ディメンション値を使用して参照および更新できます。たとえば、ファクト表ft(country, year, sales)では、countryおよびyearをディメンション列に、salesをメジャーに指定し、特定の国および年の売上をsales[country='Spain', year=1999]として参照できます。この場合、1999年のSpainの売上値を取得できます。また、同じ内容を短縮形式で表したsales['Spain', 1999]を使用することもできます。ただし、両者の表記には、わずかな意味の違いがあります。詳細は、「セル参照」を参照してください。
シンボリック配列の計算
データの処理に、ルールと呼ばれる一連の式を指定できます。ルールでは、個々のセル、セルの集合または範囲で関数を呼び出すことができます。個々のセルを対象にした例を次に示します。
sales[country='Spain',year=2001] = sales['Spain',2000]+ sales['Spain',1999]
この場合、2001年のSpainの売上は、1999年と2000年におけるSpainの売上の合計に設定されています。次に、セルの範囲を対象とした例を示します。
sales[country='Spain',year=2001] = MAX(sales)['Spain',year BETWEEN 1997 AND 2000]
この場合、2001年のSpainの売上は、1997年から2000年のSpainにおける最高の売上と等しくなるよう設定されています。
UPSERT、UPSERT ALLおよびUPDATEオプション
UPSERTオプション(デフォルト)を使用すると、入力データに存在しないセルの値を作成できます。参照先のセルがデータに存在する場合、セルが更新されます。参照先のセルがデータに存在せず、なおかつルールが適切な表記法を使用している場合は、セルが挿入されます。UPSERT ALLオプションでは、より幅広い種類のルールに対してUPSERTの動作を適用できます。反対に、UPDATEオプションでは、新しいセルは一切挿入されません。
これらのオプションは、グローバルに指定(すべてのルールに適用)することも、ルールごとに指定することもできます。ルール・レベルでオプションを指定すると、グローバル・オプションはオーバーライドされます。次のルールを考えてみます。
UPDATE sales['Spain', 1999] = 3567.99, UPSERT sales['Spain', 2001] = sales['Spain', 2000]+ sales['Spain', 1999]
最初のルールでは、1999年のSpainにおける売上のセルを更新します。2番目のルールでは、2001年のSpainにおける売上のセルが存在する場合は更新し、存在しない場合は新しいセルを作成します。
ディメンションのワイルド・カード指定
ANYおよびIS ANYを使用すると、ディメンションの値をすべて指定できます。たとえば、次の文があるとします。
sales[ANY, 2001] = sales['Japan', 2000]
このルールでは、2001年のすべての国の売上を2000年のJapanの売上値と同じに設定しています。この場合、ディメンションの値はNULLも含め、すべてANYの指定を満たしています。次のように、IS ANY述語を使用して同じ処理を指定することもできます。
sales[country IS ANY, 2001] = sales['Japan', 2000]
CV関数を使用したディメンション値へのアクセス
ルールの右辺でCV関数を使用すると、ルールの左辺で参照されるセルのディメンション列の値にアクセスできます。これによって、類似した計算を実行する複数のルールを単一のルールに結合できるため、指定が簡潔になります。たとえば、次のルールを結合できます。
sales[country='Spain', year=2002] = 1.2 * sales['Spain', 2001], sales[country='Italy', year=2002] = 1.2 * sales['Italy', 2001], sales[country='Japan', year=2002] = 1.2 * sales['Japan', 2001]
これらは、次の単一のルールに結合できます。
sales[country IN ('Spain', 'Italy', 'Japan'), year=2002] = 1.2 *
sales[CV(country), 2001]
この場合、CV関数は、左辺のcountryディメンションの値をルールの右辺に渡します。
順序付け計算
セルの集合を更新するルールでは、結果はディメンション値の順序に依存する場合があります。ルールでORDER BYを指定すると、ディメンション値を特定の順序に強制できます。たとえば、次のルールを考えてみます。
sales[country IS ANY, year BETWEEN 2000 AND 2003] ORDER BY year = 1.05 * sales[CV(country), CV(year)-1]
これによって、yearは時系列的に昇順で参照されます。
ルールの自動順序付け
AUTOMATIC ORDERキーワードを使用すると、セル間の依存関係に基づいてMODEL句のルールを自動的に順序付けできます。たとえば、次の割当ての場合、2番目と3番目のルールが最初のルールよりも先に処理されます。これは、最初のルールが最後の2つのルールに依存しているためです。
RULES AUTOMATIC ORDER
{sales[c='Spain', y=2001] = sales[c='Spain', y=2000]
+ sales[c='Spain', y=1999]
sales[c='Spain', y=2000] = 50000,
sales[c='Spain', y=1999] = 40000}
反復ルール評価
反復ルール評価を指定すると、終了条件が満たされるまで、反復的にルールが評価されます。次の指定を考えてみます。
MODEL DIMENSION BY (x) MEASURES (s) RULES ITERATE (4) (s[x=1] = s[x=1]/2)
この文では、式s[x=1] = s[x=1]/2の評価を4回繰り返すように指定しています。反復回数は、MODEL句のITERATEオプションで指定しています。また、UNTIL句を使用すると、終了条件も指定できます。
反復ルール評価は、ビジネス・アプリケーションのエンティティ間の再帰的関係をモデル化する場合に重要な機能です。たとえば、ローンの総額が金利によって異なる一方で、金利はローンの額に応じて異なります。
参照モデル
1つのモデルには、読取り専用の配列である参照モデルを複数含めることができます。ルールは、複数の参照モデルのセルを参照できます。ルールでセルを更新または挿入できるのは、メイン・モデルと呼ばれる1つの多次元配列のみです。参照モデルを使用すると、異なるディメンションにモデルを関係付けることができます。たとえば、ファクト表ft(country, year, sales)の他に、通貨の換算率の表cr(country, ratio)があるとします。この表には、ディメンション列としてcountry、メジャーとしてratioがあります。この表の各行は、当該国の通貨のUSドルへの換算率を示します。この2つの表は、次のルールで使用できます。
dollar_sales['Spain',2001] = sales['Spain',2000] * ratio['Spain']
スケーラブルな計算
データをパーティション化して、他のパーティションとは関係なく各パーティション内のルールを評価できます。これにより、パーティションに基づいてモデル計算をパラレル化できます。たとえば、次のモデルがあるとします。
MODEL PARTITION BY (country) DIMENSION BY (year) MEASURES (sales) (sales[year=2001] = AVG(sales)[year BETWEEN 1990 AND 2000]
データはcountryでパーティション化されています。各パーティション内では、2001年の売上高は1990年から2000年の平均売上高になるよう計算されます。パーティションはパラレルに処理できるため、スケーラブルなモデルの実行が実現します。
この項では、モデルの基本的な概念および使用方法について説明します。次の内容が含まれます。
この章の例は、shサンプル・スキーマから導出される次のビューsales_viewをベースにしています。
CREATE VIEW sales_view AS SELECT country_name country, prod_name product, calendar_year year, SUM(amount_sold) sales, COUNT(amount_sold) cnt, MAX(calendar_year) KEEP (DENSE_RANK FIRST ORDER BY SUM(amount_sold) DESC) OVER (PARTITION BY country_name, prod_name) best_year, MAX(calendar_year) KEEP (DENSE_RANK LAST ORDER BY SUM(amount_sold) DESC) OVER (PARTITION BY country_name, prod_name) worst_year FROM sales, times, customers, countries, products WHERE sales.time_id = times.time_id AND sales.prod_id = products.prod_id AND sales.cust_id =customers.cust_id AND customers.country_id=countries.country_id GROUP BY country_name, prod_name, calendar_year;
この問合せでは、country、productおよびyearでグルーピングされた売上データのSUMおよびCOUNT集計を計算します。また、対象国で各製品の売上高が最も高かった年をレポートします。これを製品のbest_yearと呼びます。また、worst_yearは、売上高が最も低かった年を示します。
MODEL句を使用すると、SQL問合せブロックでデータの多次元計算を定義できます。多次元アプリケーションでは、ファクト表は、従属メジャーまたは属性として機能する列とともに各行を一意に識別する列から構成されます。MODEL句では、多次元配列を定義するPARTITION、DIMENSIONおよびMEASUREの各列、この多次元配列を処理するルール、および処理オプションを指定できます。
MODEL句は、パーティション内の配列計算を表す更新のリストを含み、SQL問合せブロックの一部となります。この句の構造を次に示します。
MODEL
[<global reference options>]
[<reference models>]
[MAIN <main-name>]
[PARTITION BY (<cols>)]
DIMENSION BY (<cols>)
MEASURES (<cols>)
[<reference options>]
[RULES] <rule options>
(<rule>, <rule>,.., <rule>)
<global reference options> ::= <reference options> <ret-opt>
<ret-opt> ::= RETURN {ALL|UPDATED} ROWS
<reference options> ::=
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
<rule options> ::=
[UPDATE | UPSERT | UPSERT ALL]
[AUTOMATIC ORDER | SEQUENTIAL ORDER]
[ITERATE (<number>) [UNTIL <condition>]]
<reference models> ::= REFERENCE ON <ref-name> ON (<query>)
DIMENSION BY (<cols>) MEASURES (<cols>) <reference options>
各ルールは割当てを表します。ルールの左辺は、セルまたはセルの集合を参照します。ルールの右辺には、定数、ホスト変数、個々のセルまたはセルの範囲による集計を含む式を指定できます。次に、例23-1を考えてみます。
例23-1 MODEL句を使用した単純な問合せ
SELECT SUBSTR(country,1,20) country, SUBSTR(product,1,15) product, year, sales
FROM sales_view
WHERE country in ('Italy', 'Japan')
MODEL
RETURN UPDATED ROWS
MAIN simple_model
PARTITION BY (country)
DIMENSION BY (product, year)
MEASURES (sales)
RULES
(sales['Bounce', 2001] = 1000,
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001])
ORDER BY country, product, year;
この問合せでは、国ItalyおよびJapanのsales_viewの行についてモデル計算を定義しています。このモデルには、simple_modelという名前が付いています。countryでデータをパーティション化し、各パーティション内にproductとyearで2次元配列を定義しています。この配列の各セルは、salesメジャーの値を保持します。このモデルの最初のルールでは、2001年のBounceの売上を1000に設定しています。残りの2つのルールでは、2002年のBounceの売上は2001年と2000年の売上の合計であり、2002年のY Boxの売上は前年の売上と同じであることを定義しています。
RETURN UPDATED ROWSを指定すると、前述の問合せは、モデル計算によって更新または挿入された行のみを戻します。デフォルトのRETURN ALL ROWSを使用した場合、MODEL句によって更新または挿入された行のみでなく、すべての行を取得します。問合せの出力は次のようになります。
COUNTRY PRODUCT YEAR SALES -------------------- --------------- ---------- ---------- Italy Bounce 2001 1000 Italy Bounce 2002 5333.69 Italy Y Box 2002 81207.55 Japan Bounce 2001 1000 Japan Bounce 2002 6133.53 Japan Y Box 2002 89634.83
MODEL句は、データベース表に対して行の更新または挿入を行っていないことに注目してください。次の問合せで、sales_viewが変更されていないことを示し、このことを確認します。
SELECT SUBSTR(country,1,20) country, SUBSTR(product,1,15) product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan');
COUNTRY PRODUCT YEAR SALES
-------------------- --------------- ---------- ----------
Italy Bounce 1999 2474.78
Italy Bounce 2000 4333.69
Italy Bounce 2001 4846.3
...
MODEL句で行った2001年のBounceの売上値の更新は、データベースに反映されていません。データベース表の行を更新または挿入するには、INSERT、UPDATEまたはMERGE文を使用する必要があります。
前述の例では、PARTITION BY、DIMENSION BYおよびMEASURESリストで列を指定しています。パーティション・キー、ディメンション・キーおよびメジャーとして、定数、ホスト変数、単一行関数、集計関数、分析関数またはこれらを含む式を指定することもできます。ただし、これらはPARTITION BY、DIMENSION BYおよびMEASURESリスト内で別名化する必要があります。ルール、SELECTリストおよびORDER BY問合せ内の式を参照するには、別名を使用する必要があります。次の例では、式および別名の使用方法を示します。
SELECT country, p product, year, sales, profits
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL
RETURN UPDATED ROWS
PARTITION BY (SUBSTR(country,1,20) AS country)
DIMENSION BY (product AS p, year)
MEASURES (sales, 0 AS profits)
RULES
(profits['Bounce', 2001] = sales['Bounce', 2001] * 0.25,
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
profits['Bounce', 2002] = sales['Bounce', 2002] * 0.35)
ORDER BY country, year;
COUNTRY PRODUCT YEAR SALES PROFITS
------- --------- ---- -------- --------
Italy Bounce 2001 4846.3 1211.575
Italy Bounce 2002 9179.99 3212.9965
Japan Bounce 2001 6303.6 1575.9
Japan Bounce 2002 11437.13 4002.9955
別名「0 AS profits」は、profitsメジャーのすべてのセルを0に初期化します。MODEL句の構文の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
この項では、SQLモデリングで使用されるキーワードの定義について説明します。
UPSERT
既存のセルのメジャー値を更新します。目的のセルが存在せず、なおかつルールが適切な表記法を使用している場合は、そのセルが挿入されます。セル参照にシンボリック参照が1つでも含まれる場合、セルの挿入は行われません。
UPSERT ALL
UPSERTと似ていますが、より幅広いルール表記法で新しいセルを挿入できる点が異なります。
UPDATE
既存のセルの値を更新します。セルの値が存在しない場合、更新は行われません。
IGNORE NAV
数値セルの場合、使用できない値を0として処理します。つまり、問合せ結果セットによってMODEL句に指定されていないセルは、計算でゼロとして処理されます。これは、モデルのすべてのメジャーに対してグローバル・レベルで使用できます。
KEEP NAV
使用できないセルの値を変更せずにそのまま維持します。これは、グローバル・レベルでIGNORE NAVを指定した場合に例外を設けるのに役立ちます。これはデフォルトなので、省略可能です。
MEASURES
モデルで変更または作成される値の集合です。
RULES
値をメジャーに割り当てる式です。
AUTOMATIC ORDER
すべてのルールが、論理的な依存関係に基づいた順序で評価されます。
SEQUENTIAL ORDER
ルールが、記述された順序で評価されます。これがデフォルトです。
UNIQUE DIMENSION
これがデフォルトです。MODEL句のPARTITION BYおよびDIMENSION BYの列の組合せが、モデル内のあらゆるセルを一意に識別する必要があることを意味します。この一意性は、必要に応じて、問合せの実行時に明示的に検証されます。その場合、処理速度低下の原因となることがあります。
UNIQUE SINGLE REFERENCE
PARTITION BYおよびDIMENSION BY句は、ルールの右辺のシングル・ポイント参照を一意に識別します。これは、問合せの実行時に一意性の明示的なチェックを行わないため、処理時間を短縮できる場合があります。
RETURN [ALL|UPDATED] ROWS
選択した行すべてを戻すか、ルールによって更新された行のみを戻すかを指定できます。デフォルト値は、ALLです。UPDATED ROWSも指定可能です。
MODEL句では、リレーションはセルの多次元配列として扱われます。多次元配列のセルにはメジャー値が含まれ、このセルは、PARTITION BYキーによって定義された各パーティション内でDIMENSION BYキーを使用して索引付けされます。次の例を考えてみます。
SELECT country, product, year, sales, best_year, best_year FROM sales_view MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales, best_year) (<rules> ..) ORDER BY country, product, year;
この例では、countryでデータをパーティション化し、各パーティション内にproductとyearで2次元配列を定義しています。この配列のセルには、salesおよびbest_yearという2つのメジャーが格納されます。
DIMENSION BYキーを指定してセルのメジャー値にアクセスすることを、セル参照といいます。セル参照の例を次に示します。
sales[product= 'Bounce', year=2000]
この例では、製品Bounceおよび年2000で参照されるセルのsales値にアクセスしています。セル参照では、DIMENSION BYキーを、前述のセル参照のようにシンボリックに指定するか、sales['Bounce', 2000]のように位置ベースで指定できます。
シンボリック・ディメンション参照(シンボリック参照)では、DIMENSION BYキーの値をブール式で指定します。たとえば、セル参照sales[year >= 2001]の場合、DIMENSION BYキーyearのシンボリック参照があり、yearの値が2001以上のセルをすべて指定します。また、sales[product = 'Bounce', year >= 2001]も、productおよびyearディメンションのシンボリック参照の一例です。
位置ベースのディメンション参照(位置参照)は、定数、またはディメンションに対して指定された定数式です。たとえば、セル参照sales['Bounce']の場合、productディメンションの位置参照があり、製品Bounceのsales値にアクセスします。セル参照の定数(または定数式)は、DIMENSION BYキーに対して指定された列の順序と比較されます。次に、ディメンションの位置参照の使用例を示します。
sales['Bounce', 2001]
DIMENSION BYキーがproductとyearで両者の順序が同じ場合、Bounceと2001のsales値にアクセスします。
指定方法に応じて、セル参照はシングル・セル参照とマルチセル参照に分類されます。
モデル計算はルールで記述します。このルールに基づいて、PARTITION BY、DIMENSION BYおよびMEASURES句で定義された多次元配列のセルの操作が行われます。ルールは、左辺が1つのセルまたはセルの範囲を表し、右辺が定数、バインド変数、個々のセル、セルの範囲の集計関数を含む式になっている代入文です。ルールでは、表現力を最大限に高めるためにワイルド・カードおよびループ・コンストラクトを使用できます。次に、ルールの例を示します。
sales['Bounce', 2003] = 1.2 * sales['Bounce', 2002]
このルールは、製品Bounceの2003年の売上は2002年の売上より20%増加するということを表しています。
このルールは、左辺と右辺がともにシングル・セル参照であるため比較的単純です。マルチセル参照、集計、ネステッド・セル参照を使用した複雑なルールも記述できます。以降の項では、これらについて説明します。
このタイプのルールには、左辺に定数によるシングル・セル参照があり、右辺にシングル・セル参照があるものが含まれます。次に、例をいくつか示します。
sales[product='Finding Fido', year=2003] = 100000 sales['Bounce', 2003] = 1.2 * sales['Bounce', 2002] sales[product='Finding Fido', year=2004] = 0.8 * sales['Standard Mouse Pad', year=2003] + sales['Finding Fido', 2003]
マルチセル参照は、ルールの右辺で使用できます。この場合、集計関数を適用して単一値に変換する必要があります。分析集計関数(逆パーセンタイル関数、仮説ランク関数、仮説分布関数など)や統計集計関数(CORRELATION関数、REGR_SLOPE関数など)など既存のすべての集計関数、およびユーザー定義の集計関数を使用できます。RANKやMOVING_AVGなどのウィンドウ関数も使用可能です。たとえば、次のルールでは、2003年のBounceの売上は、1998年から2002年の期間における最高の売上より100増加すると計算します。
sales['Bounce', 2003] = 100 + MAX(sales)['Bounce', year BETWEEN 1998 AND 2002]
次に、逆パーセンタイル関数PERCENTILE_DISCの使用例を示します。ここでは、2003年のFinding Fidoの売上高は、2003年より前のすべての年におけるFinding Fido、Standard Mouse PadおよびBoatの売上の中央値より30%増加すると想定しています。
sales[product='Finding Fido', year=2003] = 1.3 *
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY sales) [product IN ('Finding
Fido','Standard Mouse Pad','Boat'), year < 2003]
集計関数は、ルールの右辺でのみ使用できます。集計関数の引数には、MODEL句のメジャー、バインド変数、定数、またはこれらを含む式を指定できます。たとえば、次のルールでは、2003年のBounceの売上は、1998年から2002年の売上の加重平均になると計算します。
sales['Bounce', 2003] = AVG(sales * weight)['Bounce', year BETWEEN 1998 AND 2002]
ルールでは、次のように左辺にマルチセル参照を指定できます。
sales['Standard Mouse Pad', year > 2000] = 0.2 * sales['Finding Fido', year=2000]
このルールでは、左辺のセルの範囲(製品Standard Mouse Padのセルおよび2001年以降のyearのセル)にアクセスして、これらのセルのsalesメジャーを右辺の式で計算される値に割り当てます。前述のルールによる計算は、「2001年以降のStandard Mouse Padの売上は、2000年のFinding Fidoの売上の20%になる」ということを表しています。この計算は、右辺のセル参照(右辺の式)が左辺で参照されるすべてのセルと同じである点で単純です。
CV関数を使用すると相対索引付けが可能です。相対索引付けでは、左辺で参照されるセルのディメンション値が右辺のセル参照で使用されます。CV関数は、引数にディメンション・キーを取り、左辺で現在参照されているセルのDIMENSION BYキーの値を提供します。次の例を考えてみます。
sales[product='Standard Mouse Pad', year>2000] = sales[CV(product), CV(year)] + 0.2 * sales['Finding Fido', 2000]
左辺がセルStandard Mouse Padおよび2001を参照する場合、右辺の式は次のようになります。
sales['Standard Mouse Pad', 2001] + 0.2 * sales['Finding Fido', 2000]
同様に、左辺がセルStandard Mouse Padおよび2002を参照する場合、右辺の式は次のようになります。
sales['Standard Mouse Pad', 2002] + 0.2 * sales['Finding Fido', 2000]
また、CV()のように引数を指定せずにCVを使用することもできます。この場合、位置参照となります。CV()は、セル参照の外部で使用することもできます。ただし、この場合は、引数に対象のディメンション名を指定する必要があります。前述のルールは、次のように記述することもできます。
sales[product='Standard Mouse Pad', year>2000] = sales[CV(), CV()] + 0.2 * sales['Finding Fido', 2000]
最初のCV()参照はCV(product)に対応し、2番目の参照はCV(year)に対応します。CV関数は、右辺のセル参照でのみ使用できます。別のCV関数の使用例を次に示します。
sales[product IN ('Finding Fido','Standard Mouse Pad','Bounce'), year
BETWEEN 2002 AND 2004] = 2 * sales[CV(product), CV(year)-10]
このルールは、「Finding Fido、Standard Mouse Pad、Bounceの各製品について、2002年から2004年の売上は10年前の2倍になる」という意味です。
セル参照でワイルド・カードANYを使用すると、NULLを含むすべてのディメンション値に一致させることができます。ANYは、ルールの左辺と右辺の両方で使用できます。たとえば、「2003年の全製品の売上は、2002年の売上より10%増加する」という計算を行う場合、ルールは次のようになります。
sales[product IS ANY, 2003] = 1.1 * sales[CV(product), 2002]
位置参照を使用する場合は、次のようになります。
sales[ANY, 2003] = 1.1 * sales[CV(), 2002]
ANYは、位置ベースで指定した場合でも、シンボリック参照として扱われます。これは、ANYの実際の意味が(dimension IS NOT NULL OR dimension IS NULL)であるためです。
セル参照はネストできます。つまり、ディメンション値を指定するセル参照をセル参照内で使用できます。たとえば、ネステッド・セル参照のメジャーがbest_yearの場合、次のようになります。
sales[product='Bounce', year = best_year['Bounce', 2003]]
ネステッド・セル参照best_year['Bounce', 2003]は、ディメンション・キーyearに値を提供し、yearのシンボリック参照で使用されます。メジャーbest_yearおよびworst_yearは、年(y)と製品(p)の組合せごとに、製品pの売上が最高または最低だった年を示します。次のルールでは、2003年のStandard Mouse Padの売上高が、Finding Fidoの売上が最高および最低だった年のStandard Mouse Padの平均売上高となるものとして計算します。
sales['Standard Mouse Pad', 2003] = (sales[CV(), best_year['Finding Fido', CV(year)]] + sales[CV(), worst_year['Finding Fido', CV(year)]]) / 2
Oracle Databaseで許容されるネストのレベルは1つのみです。また、ネステッド・セル参照として使用できるのは、シングル・セル参照のみです。マルチセル参照の集計は、ネステッド・セル参照で使用できません。
デフォルトでは、ルールはMODEL句内での出現順に評価されます。MODEL句でオプションのキーワードSEQUENTIAL ORDERを指定すると、評価順序を明示できます。ルールの評価順序が順次的になっているSQLモデルを、順次順序モデルと呼びます。たとえば、次のRULESの指定では、指定した順序でルールが評価されます。
RULES SEQUENTIAL ORDER
(sales['Bounce', 2001] =
sales['Bounce', 2000] + sales['Bounce', 1999], --Rule R1
sales['Bounce', 2000] = 50000, --Rule R2
sales['Bounce', 1999] = 40000) --Rule R3
また、AUTOMATIC ORDERオプションを使用すると、Oracle Databaseによってルールの評価順序が自動的に決定されます。Oracleは、各ルール内のセル参照を調べ、ルール間の依存関係を確認します。ルールR1の左辺で参照されるセルが、別のルールR2の右辺で参照される場合、R2はR1に依存しているとみなされます。したがって、ルールR1は、ルールR2より先に評価される必要があります。前述の例にAUTOMATIC ORDERを指定すると、次のようになります。
RULES AUTOMATIC ORDER (sales['Bounce', 2001] = sales['Bounce', 2000] + sales['Bounce', 1999], sales['Bounce', 2000] = 50000, sales['Bounce', 1999] = 40000)
ルール2とルール3は、ルール1より先に任意の順序で評価されます。これは、ルール1がルール2とルール3に依存しており、ルール2とルール3より後に評価される必要があるためです。ルール2とルール3は相互に依存していないため、評価順序は任意になります。相互に独立したルールの場合、任意の順序で評価できます。前述の例のように、評価順序が自動になっているSQLモデルを自動順序モデルと呼びます。
自動順序モデルの場合、同一セルへの複数の割当ては禁止されています。つまり、セルのメジャーを割り当てることができるのは1回のみです。結果が不確定的となる場合は、エラーが戻されます。たとえば、次のルール指定の場合、sales['Bounce', 2001]が複数回割り当てられているため、エラーが生成されます。
RULES AUTOMATIC ORDER (sales['Bounce', 2001] = sales['Bounce', 2000] + sales['Bounce', 1999], sales['Bounce', 2001] = 50000, sales['Bounce', 2001] = 40000)
2001年の製品Bounceの売上を割り当てるルールは相互に依存していないため、ルール間で特定の評価順序が決まりません。この場合、sales['Bounce', 2001]は、40000、50000、1999年と2000年のBounceの合計売上のいずれにもなり得るため、評価順序が無原則となり、不確定的な結果になります。Oracle Databaseでは、これを防止するために、AUTOMATIC ORDERが指定された場合は複数の割当てを禁止しています。ただし、順次順序モデルでは、複数の割当ては可能です。前述の例でAUTOMATIC ORDERのかわりにSEQUENTIAL ORDERを指定した場合、sales['Bounce', 2001]の結果は40000になります。
UPDATE、UPSERT、UPSERT ALL、IGNORE NAVおよびKEEP NAVオプションは、RULES句の中でグローバル・レベルで指定できます。この場合、すべてのルールが指定のモードで処理されます。これらのオプションは、ルールごとにローカル・レベルで指定することもできます。この場合、グローバルな動作はオーバーライドされます。たとえば、次の指定を考えてみます。
RULES UPDATE (UPDATE s['Bounce',2001] = sales['Bounce',2000] + sales['Bounce',1999], UPSERT s['Y Box', 2001] = sales['Y Box', 2000] + sales['Y Box', 1999], sales['Mouse Pad', 2001] = sales['Mouse Pad', 2000] + sales['Mouse Pad',1999])
UPDATEオプションをグローバル・レベルで指定しているため、最初と3番目のルールは更新モードで処理されます。2番目のルールは、UPSERTキーワードを指定しているため、アップサート・モードで処理されます。3番目のルールは、オプションが未指定のため、グローバル・オプションの更新動作を継承します。
UPDATE、UPSERTまたはUPSERT ALLのいずれかを選択することで、ルールで指定されたセルの処理方法を指定できます。MODEL句のルールは、デフォルトでUPSERTとして処理されますが、アップサートであることを明確にするために、明示的にUPSERTキーワードを指定してもかまいません。
次の各項で、これら3つのオプションの動作について説明します。
UPDATEオプションを指定すると、完全な更新モードが強制されます。このモードでは、左辺の参照先のセルが存在しない場合、ルールは無視されます。ルールの左辺で参照されるセルが存在する場合、そのメジャーが右辺の式の値で更新されます。それ以外の場合でセル参照が位置ベースの場合は、右辺の式の値に等しいメジャー値で新しいセルが作成され、多次元配列に挿入されます。セル参照が位置ベースでない場合、セルは挿入されません。セルの指定にシンボリック参照が1つでも含まれる場合は、アップサートのルールでも挿入はできないことに注意してください。たとえば、次のルールがあるとします。
sales['Bounce', 2003] = sales['Bounce', 2001] + sales ['Bounce', 2002]
製品Bounceと2003年のセルが存在する場合、2001年と2002年のBounceの合計売上でセルが更新され、存在しない場合はセルが作成されます。次のように、シンボリック参照を使用して同じルールを作成した場合、更新は行われません。
sales[prod= 'Bounce', year= 2003] = sales['Bounce', 2001] + sales ['Bounce', 2002]
UPSERTを使用すると、セルが存在せず、セル参照に含まれているのが定数で修飾された位置参照のみである場合に、ルールの左辺で参照されているセルに対応する新しいセルが作成されます。FORループで作成されるセル参照(「SQLモデリングの高度なトピック」を参照)は、位置参照として扱われることに注意してください。このため、FORループで作成される値は、新しいセルの挿入に使用されます。たとえば、2004年以降の年のセルがないとします。この場合、次のルールを考えてみます。
UPSERT sales['Bounce', year = 2004] = 1.1 * sales['Bounce', 2002]
この場合、シンボリック参照year = 2004があるため、新しいセルは作成されません。さらに、次の例を考えてみます。
UPSERT sales['Bounce', 2004] = 1.1 * sales['Bounce', 2002]
この場合、2004年の製品Bounceのセルが新規作成されます。ただし、いずれかの参照がANYの場合、新しいセルは作成されません。これは、ANYが、NULLを含むすべてのディメンション値を許可する述語であるためです。たとえば、ディメンションdに対する参照ANYは、(d IS NOT NULL OR d IS NULL)という述語と同じ意味になります。
UPSERTルールの左辺のセル参照でFORループが使用されている場合、アップサート対象のセルのリストは、各ディメンションのすべての個別値のクロス積を計算することで生成されます。FORループを含むUPSERTを使用してディメンションの稠密化(「レポート用のデータの稠密化」を参照)を行うことは可能ですが、稠密化にはパーティション外部結合操作を使用するのが一般的です。
UPSERT ALLを使用すると、存在述語(比較、IN、ANYなど)を左辺に含むモデル・ルールにUPSERTの動作を適用できます。たとえば次のルールでは、ANYを使用して、San Francisco、San JoseおよびOaklandの組合せであるBay Areaを作成しています。
SELECT product, time, city, s sales
FROM cube_subquery
MODEL PARTITION BY (product)
DIMENSION BY (time, city) MEASURES(sales s
RULES UPSERT ALL
(s[ANY, 'Bay Area'] =
s[CV(), 'San Francisco'] + s[CV(), 'San Jose'] + s[CV(), 'Oakland']
s['2004', ANY] = s['2002', CV()] + s['2003', CV()]);
この例の最初のルールでは、単純に、個別の各time値用のBay Areaセルを挿入しています。2番目のルールでは、Bay Areaを含む個別の各city値用の2004セルを挿入しています。この例は、左辺で使用されている存在述語がANY述語であるという比較的単純なものですが、UPSERT ALLはより複雑な計算で使用することも可能です。
UPSERT ALLを使用する場合(特に、複数のシンボリック・ディメンション参照がある場合)は、その動作を正確に理解しておく必要があります。その動作は、FORループを使用するUPSERTルールとは異なります。Oracle Databaseでは、UPSERT ALLルールの評価の際、次の手順が実行され、アップサート対象となるセル参照のリストが作成されます。
手順3の結果を使用して、新しいセルを配列にアップサートします。
これらの4つの手順を説明するために、3つのディメンションを持つ抽象的なデータおよびモデルを使用した簡単な例を示します。このモデルは、(product, time, city)でディメンション化され、salesというメジャーを持つものとします。この例では、都市zに新しい売上値をアップサートしますが、この売上値は都市yからコピーしてきます。
UPSERT ALL sales[ANY, ANY, 'z']= sales[CV(product),CV(time),'y']
ソースのデータセットには、次の4つの行があります。
PROD TIME CITY SALES 1 2002 x 10 1 2003 x 15 2 2002 y 21 2 2003 y 24
次に、前述の4つの手順を、このデータに当てはめて詳しく説明します。
ルールのシンボリック述語はANYなので、前述の行すべてが対象になります。
条件に合致する、シンボリック述語で参照されたセルの重複しないディメンションの組合せは、(1, 2002)、(1, 2003)、(2, 2002)および(2, 2003)です。
これらのディメンションの組合せと、位置参照で指定されたセルのクロス積を求めます。この例では、単純に値zとのクロス積となり、結果のセル参照は(1, 2002, z)、(1, 2003, z)、(2, 2002, z)および(2, 2003, z)となります。
手順3で求めたセルが、都市yに基づいて計算された売上でアップサートされます。都市yの製品1には値がないので、製品1用に作成されたセルの売上値はNULLになります。当然のことながら、ルールが異なる場合には、新しいすべてのセルに非NULLの結果が生成されることもあります。結果セットには、元の4つの行に加えて、次のように新しい4つの行が追加されます。
PROD TIME CITY SALES 1 2002 x 10 1 2003 x 15 2 2002 y 21 2 2003 y 24 1 2002 z NULL 1 2003 z NULL 2 2002 z 21 2 2003 z 24
この結果は、すべてのディメンションの値をすべて使用したクロス積ではないことに注意してください。すべてのディメンションの値をすべて使用した場合は、(1,2002, y)、(2,2003, x)などのセルも生成されます。これは、あくまでも既存の行で見つかったディメンションの組合せを使用して生成された結果です。
モデルを使用するアプリケーションでは、NULLによるセル・メジャーの不確定値のみでなく、欠損セルによる不確定性にも対応する必要があります。シングル・セル参照で参照されるセルがデータ内で欠損している場合、このようなセルを欠損セルと呼びます。MODEL句では、NULLのセルおよび欠損セルについてANSI SQL規格に準拠したデフォルトの処理方法があり、ビジネス・ロジックに応じて適切な方法でこうしたセルを処理するオプションも用意されています。たとえば、NULLを算術演算でゼロとして処理するオプションなどがあります。
デフォルトでは、NULLのセル・メジャー値は、SQLの他の箇所と同じ方法で処理されます。たとえば、次のルールがあるとします。
sales['Bounce', 2001] = sales['Bounce', 1999] + sales['Bounce', 2000]
1999年と2000年のBounceの売上値のいずれかがNULLの場合、右辺の式はNULLと評価されます。同様に、ルール内の集計関数でも、通常の動作と同じ方法でNULL値を処理します。つまり、NULL値は集計処理時に無視されます。
欠損セルは、NULLメジャー値を含むセルとして処理されます。たとえば、前述のルールでは、Bounceと2000のセルがない場合、NULL値として処理され、右辺の式はNULLと評価されます。
PRESENTV関数およびPRESENTNNV関数を使用すると、欠損セルの識別およびNULL値との区別が可能です。これらの関数の引数には、PRESENTV(cell, expr1, expr2)のようにシングル・セル参照および2つの式を指定します。PRESENTV関数は、セルcellがMODEL句に入力されたデータに存在する場合、最初の式expr1を戻します。それ以外の場合は、2番目の式expr2を戻します。次の例を考えてみます。
PRESENTV(sales['Bounce', 2000], 1.1*sales['Bounce', 2000], 100)
製品Bounceおよび2000年のセルが存在する場合、対応する売上値に1.1を掛けて戻します。これに該当しない場合は100を戻します。製品Bounceおよび2000年のセルがNULLの場合、前述の指定ではNULLが戻されます。
PRESENTNNV関数は、セルの有無のチェックに加えて、セルがNULLかどうかのチェックも行います。セルが存在してNULLでない場合は最初の式expr1を、それ以外の場合は2番目の式expr2を戻します。次の例を考えてみます。
PRESENTNNV(sales['Bounce', 2000], 1.1*sales['Bounce', 2000], 100)
この例では、sales['Bounce', 2000]が存在し、NULLでない場合、1.1*sales['Bounce', 2000]を戻します。それ以外の場合は100を戻します。
アプリケーションでは、モデルにIS PRESENT述語を使用して、セルの有無を明示的にチェックできます。この述語は、セルが存在する場合はTRUEを、存在しない場合はFALSEを戻します。PRESENTNNVを使用した前述の例を、IS PRESENTを使用して記述すると次のようになります。
CASE WHEN sales['Bounce', 2000] IS PRESENT AND sales['Bounce', 2000] IS NOT NULL THEN 1.1 * sales['Bounce', 2000] ELSE 100 END
PRESENTVおよびPRESENTNNV関数と同様に、IS PRESENT述語は、入力データ(MODEL句の実行前に存在していたデータ)にセルが存在するかどうかをチェックします。これを使用すると、UPSERTルールで新規に挿入されたセルの複数のメジャーを初期化できます。たとえば、製品Bounceと2003年のセルがデータに存在しない場合、セルのsales値とprofit値をそれぞれ1000と500に初期化するには、次のように記述します。
RULES
(UPSERT sales['Bounce', 2003] =
PRESENTV(sales['Bounce', 2003], sales['Bounce', 2003], 1000),
UPSERT profit['Bounce', 2003] =
PRESENTV(profit['Bounce', 2003], profit['Bounce', 2003], 500))
この例で使用されているPRESENTV関数は、入力データ内のセルの有無に応じて、TRUEまたはFALSEを戻します。評価順序に基づいて一方のルールでBounceと2003のセルが挿入される場合でも、他方のルールのPRESENTV関数は、引き続きFALSEと評価します。この動作は、ルール評価の事前処理手順とみなすことができます。この手順では、PRESENTV関数、PRESENTNNV関数およびIS PRESENT述語のすべてを評価し、対応する値ですべて置き換えます。
MODEL句では、デフォルトで欠損セルを、NULLメジャー値を含むセルとして処理します。この動作にするには、オプションのKEEP NAVキーワードをMODEL句で指定します。アプリケーションのデフォルトとして、欠損セルおよびNULLをなんらかの値にするには、IS PRESENT述語、IS NULL述語、PRESENTV関数およびPRESENTNNV関数を使用します。ただし、シングル・セル参照およびルールが多い場合は、処理が複雑になる場合があります。デフォルトのKEEP NAVオプションのかわりに、IGNORE NAVオプションを使用すると、NULLおよび欠損セルを次のデフォルト値に設定できます。
数値データの場合は0
文字/文字列データの場合は空の文字列
日付型のデータの場合は01-JAN-2001
前述以外のデータ型の場合はNULL
次の問合せを考えてみます。
SELECT product, year, sales FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales) IGNORE NAV RULES UPSERT (sales['Bounce', 2003] = sales['Bounce', 2002] + sales['Bounce', 2001]);
この例では、MODEL句の入力データに、製品Bounceおよび2002年のセルがありません。IGNORE NAVオプションが指定されていることにより、sales['Bounce', 2002]のデフォルト値はNULLではなく、0になります(salesが数値型のため)。したがって、sales['Bounce', 2003]の値は、sales['Bounce', 2001]の値と同じになります。
セル参照でNULL値を使用するには、次のいずれかの方法を使用します。
ワイルド・カードANYを使用した位置参照(たとえば、sales[ANY])
IS ANY述語を使用したシンボリック参照(たとえば、sales[product IS ANY])
NULLの位置参照(たとえば、sales[NULL])
IS NULL述語を使用したシンボリック参照(たとえば、sales[product IS NULL])
シンボリック参照sales[product = NULL]では、productディメンションのNULLのチェックは行われません。この場合の動作は、SQLによるNULLの標準の取扱いに準拠します。
ルールが処理される多次元配列の他に、1つ以上の読取り専用の多次元配列があります。前者は、メイン・モデル、後者は参照モデルと呼ばれます。参照モデルは、MODEL句で作成および参照でき、メイン・モデルの参照表のように機能します。参照モデルは、メイン・モデルと同様に問合せブロックで定義されます。また、参照モデルには、ディメンションとメジャーを示すDIMENSION BY句およびMEASURES句があります。参照モデルは、次の副次句で作成されます。
REFERENCE model_name ON (query) DIMENSION BY (cols) MEASURES (cols) [reference options]
メイン・モデルと同様、参照モデルの多次元配列は、ルールの評価前に作成されます。ただし、メイン・モデルとは異なり、参照モデルは読取り専用のため、作成した後にセルの更新や新しいセルの挿入を行うことはできません。したがって、メイン・モデルのルールは、参照モデルに対して、セルへのアクセスは可能ですが、セルの更新や新しいセルの挿入はできません。次に、参照モデルとして通貨の換算表を使用した例を示します。
CREATE TABLE dollar_conv_tbl(country VARCHAR2(30), exchange_rate NUMBER);
INSERT INTO dollar_conv_tbl VALUES('Poland', 0.25);
INSERT INTO dollar_conv_tbl VALUES('France', 0.14);
...
2003年のPolandとFranceの算出売上をUSドルに換算するには、次のようにドル換算表を参照モデルとして使用できます。
SELECT country, year, sales, dollar_sales
FROM sales_view
GROUP BY country, year
MODEL
REFERENCE conv_ref ON (SELECT country, exchange_rate FROM dollar_conv_tbl)
DIMENSION BY (country) MEASURES (exchange_rate) IGNORE NAV
MAIN conversion
DIMENSION BY (country, year)
MEASURES (SUM(sales) sales, SUM(sales) dollar_sales) IGNORE NAV
RULES
(dollar_sales['France', 2003] = sales[CV(country), 2002] * 1.02 *
conv_ref.exchange_rate['France'],
dollar_sales['Poland', 2003] =
sales['Poland', 2002] * 1.05 * exchange_rate['Poland']);
この例の要点を次に示します。
1つのディメンション参照モデルconv_refが表dollar_conv_tblの行に作成され、そのメジャーexchange_rateは、メイン・モデルのルールで参照されています。
メイン・モデルconversionには、countryとyearの2つのディメンションがあり、参照モデルconv_refには、ディメンションcountryが1つあります。
参照モデルのメジャーexchange_rateへのアクセス方法に違いがあります。Franceの場合、model_name.measure_nameの表記法に準拠したconv_ref.exchange_rateを使用しているため明示的です。Polandの場合、単純なmeasure_nameの表記法に準拠した参照exchange_rateを使用しています。メイン・モデルと参照モデル間での列名の曖昧性を解決するには、前者の表記法を使用する必要があります。
次の例では、増加率がルールでハードコード化されています。Franceの増加率は2%、Polandは5%です。ただし、これらは別個の表に存在するため、各表の上位に参照モデルを定義できます。表growth_rate(country, year, rate)を次のように定義するとします。
CREATE TABLE growth_rate_tbl(country VARCHAR2(30),
year NUMBER, growth_rate NUMBER);
INSERT INTO growth_rate_tbl VALUES('Poland', 2002, 2.5);
INSERT INTO growth_rate_tbl VALUES('Poland', 2003, 5);
...
INSERT INTO growth_rate_tbl VALUES('France', 2002, 3);
INSERT INTO growth_rate_tbl VALUES('France', 2003, 2.5);
次の問合せでは、すべての国を対象とした2003年のドルでの算出売上高を計算します。
SELECT country, year, sales, dollar_sales
FROM sales_view
GROUP BY country, year
MODEL
REFERENCE conv_ref ON
(SELECT country, exchange_rate FROM dollar_conv_tbl)
DIMENSION BY (country c) MEASURES (exchange_rate) IGNORE NAV
REFERENCE growth_ref ON
(SELECT country, year, growth_rate FROM growth_rate_tbl)
DIMENSION BY (country c, year y) MEASURES (growth_rate) IGNORE NAV
MAIN projection
DIMENSION BY (country, year) MEASURES (SUM(sales) sales, 0 dollar_sales)
IGNORE NAV
RULES
(dollar_sales[ANY, 2003] = sales[CV(country), 2002] *
growth_rate[CV(country), CV(year)] *
exchange_rate[CV(country)]);
この問合せでは、異なるディメンションのオブジェクトを処理および関連付ける、MODEL句の機能を示しています。参照モデルconv_refにはディメンションが1つあり、参照モデルgrowth_refとメイン・モデルにはディメンションが2つあります。参照モデルでのシングル・セル参照のディメンションは、CV関数を使用して指定されているので、メイン・モデルのセルと参照モデルが関連付けられます。この指定により、メイン・モデルと参照モデル間でリレーショナル結合が実行されます。
参照モデルは、キーを順序番号に変換し、順序番号を使用した計算(たとえば、減算に前期を使用する場合など)を実行してから、順序番号をキーに再変換する場合にも有効です。たとえば、順序番号を年に割り当てる次のビューがあるとします。
CREATE or REPLACE VIEW year_2_seq (i, year) AS SELECT ROW_NUMBER() OVER (ORDER BY calendar_year), calendar_year FROM (SELECT DISTINCT calendar_year FROM TIMES);
このビューで、参照表を2つ定義できます。1つは、整数から年に変換するi2yです。これは、順序番号を整数にマップします。もう1つは、年から整数に変換するy2iで、逆のマッピングを行います。参照y2i.i[year]およびy2i.i[year] - 1は、それぞれ今年と昨年の順序番号を戻します。参照i2y.y[y2i.i[year]-1]は、昨年のyearキーの値を戻します。次の問合せでは、参照モデルのこのような使用方法を示します。
SELECT country, product, year, sales, prior_period FROM sales_view MODEL REFERENCE y2i ON (SELECT year, i FROM year_2_seq) DIMENSION BY (year y) MEASURES (i) REFERENCE i2y ON (SELECT year, i FROM year_2_seq) DIMENSION BY (i) MEASURES (year y) MAIN projection2 PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales, CAST(NULL AS NUMBER) prior_period) (prior_period[ANY, ANY] = sales[CV(product), i2y.y[y2i.i[CV(year)]-1]]) ORDER BY country, product, year;
前述の例では、参照モデルのセル参照がネストされていることがわかります。参照モデルy2iのセル参照は、i2yのセル参照内でネストされ、これがさらにメインSQLモデルのセル参照内でネストされています。参照モデルのセル参照は、無制限のレベルでネストできます。ただし、メインSQLモデルのセル参照の場合は、2つのレベルまでしかネストできません。
最後に、参照モデルの指定および使用方法に関する制限を次に示します。
参照モデルでは、PARTITION BY句は指定できません。
参照モデルが定義された問合せブロックは、他の問合せと相関させることができません。
参照モデルには、一意の名前を付ける必要があります。
参照モデルのセルへの参照は、すべてシングル・セル参照である必要があります。
この項では、SQLモデリングのより高度なトピックについて説明します。
MODEL句では、ルール内でFORコンストラクトを使用して、計算をよりコンパクトに表現できます。これは、ルールの左辺と右辺の両方で使用できます。FORループは、ルールの左辺に指定された場合は位置参照として扱われます。たとえば、次の計算を考えてみます。この計算では、2004年の製品の売上高は、2003年の売上高より10%増加すると見積ります。
RULES UPSERT (sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003], sales['Standard Mouse Pad', 2004] = 1.1 * sales['Standard Mouse Pad', 2003], ... sales['Y Box', 2004] = 1.1 * sales['Y Box', 2003])
この計算では、UPSERTオプションが使用されているため、これらの製品および2004年のセルが多次元配列にない場合、これらのセルが挿入されます。この場合、製品の数と同じ数のルールを指定する必要があるため、処理が困難になります。次のように、FORコンストラクトを使用すると、この計算をコンパクトかつ完全に同じセマンティックで表現できます。
RULES UPSERT
(sales[FOR product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'), 2004] =
1.1 * sales[CV(product), 2003])
この例と同様の指定をFORキーワードを使用せずに記述すると、次のようになります。
RULES UPSERT
(sales[product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'), 2004] =
1.1 * sales[CV(product), 2003])
この場合、UPSERTを指定していても、UPDATEの処理方法が適用されます。つまり、既存のセルは更新されますが、この指定では新しいセルは作成されません。その理由は、productに対するマルチセル参照がシンボリック参照であり、シンボリック参照では新しいセルを挿入できないためです。FORコンストラクトは、1つのルールから位置参照で複数のルールを生成するマクロとみなすことができます。これによりUPSERTの処理方法が保持されます。概念上、次のルールがあるとします。
sales[FOR product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'),
FOR year IN (2004, 2005)] = 1.1 * sales[CV(product), CV(year)-1]
これは、次のルールの順序付きコレクションとして扱うことができます。
sales['Bounce', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Bounce', 2005] = 1.1 * sales[CV(product), CV(year)-1], sales['Standard Mouse Pad', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Standard Mouse Pad', 2005] = 1.1 * sales[CV(product), CV(year)-1], ... sales['Y Box', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Y Box', 2005] = 1.1 * sales[CV(product), CV(year)-1]
前述の例の場合、FORコンストラクトの形式は、FOR ディメンション IN (値のリスト)となっています。リスト内の値は、定数の式やシングル・セル参照など、単一値の式でなければなりません。前述の例では、FORコンストラクトは、productとyearに別々にあります。単一のFORコンストラクトですべてのディメンションを指定し、複数列のINリストを使用して値を指定することも可能です。たとえば、2004年のBounceの売上高、2005年のStandard Mouse Padの売上高、2004年と2005年のY Boxの売上高のみを見積る場合、次のように記述できます。これは、次のように記述できます。
sales[FOR (product, year) IN (('Bounce', 2004), ('Standard Mouse Pad', 2005),
('Y Box', 2004), ('Y Box', 2005))] =
1.1 * sales[CV(product), CV(year)-1]
n個のディメンションd1, ..., dnがあり、リスト内にm個の値がある場合、このFORコンストラクトの形式は、FOR (d1, ..., dn) IN ((d1_val1, ..., dn_val1), ..., (d1_valm, ..., dn_valm)]とする必要があります。
FOR内のディメンションの値のリストは、表または副問合せから取得することもできます。このようなケースに対応するためにOracle Databaseでは、FOR ディメンション IN (副問合せ)などの形式のFORコンストラクトが用意されています。たとえば、対象の製品が表interesting_productsに格納されるとします。この場合、次のルールでは、2004年と2005年の製品の売上高を見積ります。
sales[FOR product IN (SELECT product_name FROM interesting_products)
FOR year IN (2004, 2005)] = 1.1 * sales[CV(product), CV(year)-1]
別の例として、new_countryという新しいcountryを導入し、その売上高を、Polandにおいて売上高が存在するすべての製品および年から流用するシナリオを考えてみます。これを実現するために、次の文を発行します。
SELECT country, product, year, s
FROM sales_view
MODEL
DIMENSION BY (country, product, year)
MEASURES (sales s) IGNORE NAV
RULES UPSERT
(s[FOR (country, product, year) IN
(SELECT DISTINCT 'new_country', product, year
FROM sales_view
WHERE country = 'Poland')] = s['Poland',CV(),CV()])
ORDER BY country, year, product;
この指定に含まれている、副問合せを評価することで生成される複数列のINリストに注目してください。INリストの取得に使用される副問合せは、外部の問合せブロックと相関させることはできません。
このルールで作成されるアップサートのリストは、各ディメンションの個別値のクロス積です。たとえば、countryの値が10個、yearの値が5個、productの値が3個ある場合は、150個のセルを含むアップサートのリストが生成されます。
対象の値が不連続な領域の値であるとわかっている場合は、FORコンストラクトのFOR dimension FROM value1 TO value2 [INCREMENT | DECREMENT] value3を使用できます。これを指定すると、value1からvalue2の範囲内にあり、value1から始まり、value3ずつ増加(または減少)する値を取得できます。value1、value2およびvalue3の各値には、単一値の式を指定する必要があります。たとえば、次のルールがあるとします。
sales['Bounce', FOR year FROM 2001 TO 2005 INCREMENT 1] = sales['Bounce', year=CV(year)-1] * 1.2
これは、意味的および順序的に次のルールと同等です。
sales['Bounce', 2001] = sales['Bounce', 2000] * 1.2, sales['Bounce', 2002] = sales['Bounce', 2001] * 1.2, ... sales['Bounce', 2005] = sales['Bounce', 2004] * 1.2
このタイプのFORコンストラクトは、数値、日付および日時データ型のディメンションに使用できます。増加/減少式のvalue3の型には、数値型のディメンションの場合は数値を、日付または日時型のディメンションの場合は数値またはインターバルを指定する必要があります。また、value3は、正の値である必要があります。FOR year FROM 2005 TO 2001 INCREMENT -1を使用した場合、エラーが戻されます。この場合、FOR year FROM 2005 TO 2001 DECREMENT 1またはFOR year FROM 2001 TO 2005 INCREMENT 1を使用する必要があります。
文字列値を生成する場合は、FORコンストラクトのFOR dimension LIKE string FROM value1 TO value2 [INCREMENT | DECREMENT] value3を使用できます。文字列stringには、%文字を1つ含める必要があります。これを指定すると、value1からvalue2の範囲内にありvalue3の値ごとに増減する値で%を置き換えた文字列を取得できます。たとえば、次のルールがあるとします。
sales[FOR product LIKE 'product-%' FROM 1 TO 3 INCREMENT 1, 2003] = sales[CV(product), 2002] * 1.2
これは、次のルールと同等です。
sales['product-1', 2003] = sales['product-1', 2002] * 1.2, sales['product-2', 2003] = sales['product-2', 2002] * 1.2, sales['product-3', 2003] = sales['product-3', 2002] * 1.2
SEQUENTIAL ORDERモデルの場合、FORコンストラクトで表されるルールは、生成された順に評価されます。一方、AUTOMATIC ORDERを指定した場合、ルールの評価順序は依存関係に基づいて決定されます。たとえば、次のようにルールで複数のルールが表される場合の評価順序を考えてみます。
sales['Bounce', FOR year FROM 2004 TO 2001 DECREMENT 1] = 1.1 * sales['Bounce', CV(year)-1]
SEQUENTIAL ORDERモデルの場合、ルールは次の順序で生成されます。
sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003], sales['Bounce', 2003] = 1.1 * sales['Bounce', 2002], sales['Bounce', 2002] = 1.1 * sales['Bounce', 2001], sales['Bounce', 2001] = 1.1 * sales['Bounce', 2000]
一方、AUTOMATIC ORDERモデルの場合、次と同等の順序になります。
sales['Bounce', 2001] = 1.1 * sales['Bounce', 2000], sales['Bounce', 2002] = 1.1 * sales['Bounce', 2001], sales['Bounce', 2003] = 1.1 * sales['Bounce', 2002], sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003]
FORループ・コンストラクトは、1つのディメンション、またはすべてのディメンション(INリストで複数列を指定する場合)の単一値参照を生成するための反復の仕組みを提供します。左辺にFORループを含む式を評価するプロセスでは、基本的に、これらのFORループによって生成される各単一値参照について式の右辺を評価し、この単一値参照で指定されたセルにその結果を割り当てるという処理が行われます。これらの単一参照値の生成は、「FORループの展開」と呼ばれます。これら展開されたセルは、展開プロセス時の生成順で評価されます。
展開がどのように行われるかは、ルールに指定されたUPSERT、UPDATEまたはUPDATE ALLの動作と、そのルール固有の特性によって異なります。これを理解するためには、問合せの処理に伴う、問合せ計画の作成と問合せの実行という2つのステップを理解する必要があります。問合せ計画の作成では、効率的な問合せ実行計画を作成するために、特定のルール参照が解決されます。問合せの実行では、残りの未解決の参照がすべて解決されます。FORループの展開は、問合せ計画の作成時に行われる場合もあれば、問合せの実行時に行われる場合もあります。以降の各項で、展開方法がどのように決定されるかを詳しく説明します。
UPDATEルールまたはUPSERTルールでは、ルールの左辺の展開でシングル・セル参照が生成されることが保証される場合、展開は問合せの実行時に行われます。展開プロセスでシングル・セル参照を生成できない場合、展開は問合せ計画の作成時に行われ、展開プロセスで生成される参照ごとに同じ式のコピーが作成されます。たとえば、次の式では、展開によってシングル・セル参照が生成されるので、展開は問合せの実行時に行われます。
sales[FOR product IN ('prod1', 'prod2'), 2003] = sales[CV(product), 2002] * 1.2
一方、次の式では、別のディメンションに対する述語が使用されているため、参照値の展開で単一値参照は生成されません。
sales[FOR product in ('prod1', 'prod2'), year >= 2003]
= sales[CV(product), 2002] * 1.2
この式には、yearディメンションに対する単一値参照がありません。そのため、たとえFORループがproductディメンションで展開されるとしても、式の左辺に単一値参照は存在しないことになります。これは、展開が問合せ計画の作成時に行われ、元の式は物理的に次の式に置き換えられることを意味します。
sales['prod1', year >= 2003] = sales[CV(product), 2002] * 1.2, sales['prod2', year >= 2003] = sales[CV(product), 2002] * 1.2
MODEL句内で実行される分析と最適化は、問合せ計画の作成時における展開の後(展開がこのタイミングで行われる場合)に行われます。したがって、これ以降のすべての処理は、あたかも複数のルールが明示的にMODEL句に指定されているかのように行われます。これらのケースでは、問合せ計画の作成時に展開を行うことによって、より正確な分析と、より効果的な式の評価の最適化が可能になります。ただし、この場合は式の数が増加する可能性があり、それによって式の合計数が上限を超えるとエラーが発生するので注意が必要です。
UPSERT ALLを使用するルールでは、FORループは様々な方法で展開されます。UPSERT ALLルールのFORループは、使用されている述語に関係なく、常に問合せの実行時に展開されます。この動作によって、次の項で説明するFORループのいくつかの制限が回避されます。ただし、制限が少なくなることと、問合せ計画がより効果的に最適化されるようになることは、トレードオフの関係にあります。UPSERT ALLルールは、一般的に、同じような内容のUPSERTルールまたはUPDATEルールよりも処理が低速です。モデルを設計する際は、この点を考慮する必要があります。
FORループ・コンストラクトの使用に関する制限事項は、展開処理が問合せ計画の作成時に行われるか、問合せの実行時に行われるかによって異なります。FORループを左辺に含む式が(前項で説明した理由によって)問合せ計画の作成時に展開される場合、展開するうえで評価する必要のある式は、問合せ計画の作成時に使用可能な値を持つ定数の式でなければなりません。たとえば、次の文を考えてみます。
sales[For product like 'prod%' from ITERATION_NUMBER to ITERATION_NUMBER+1, year >= 2003] = sales[CV(product), 2002]*1.2
UPSERT ALLが指定されていない場合、このルールは問合せ計画の作成時に展開されます。開始式と終了式を評価するために必要なITERATION_NUMBERの値は、問合せ計画の作成時には不明であるため、このルールが問合せの実行時に展開されない場合には、エラーが発生します。しかし、次のルールであれば、問合せ計画の作成時にエラーなしで展開できます。ITERATION_NUMBERがFORループ内の式として指定されていますが、このルールの場合、その値は展開するために必要ではありません。
sales[For product in ('prod'||ITERATION_NUMBER, 'prod'||(ITERATION_NUMBER+1)),
year >= 2003] = sales[CV(product), 2002]*1.2
次のいずれかを含む式は、問合せ計画の作成時に評価できません。
ネステッド・セル参照
参照モデルの参照
ITERATION_NUMBER参照
このような式の結果を必要とするFORループを含むルールを問合せ計画の作成時に展開すると、エラーが発生します。問合せの実行時に展開する場合には、これらの式によってエラーが発生することはありません。
FORループ・コンストラクトに副問合せを含む式で、コンパイル時の展開が必要な場合、その副問合せは、展開を行えるようにするため、問合せ計画の作成時に評価されます。副問合せを問合せ計画の作成時に評価すると、カーソルを共有できなくなる場合があります。これは、同じ問合せであっても発行のたびに再コンパイルが必要になる可能性があることを意味します。このような式の展開を問合せの実行時まで遅延させると、コンパイル時の評価は不要になり、式がカーソルの共有性に影響を与えることもなくなります。
式のFORループに含まれる副問合せは、式が問合せの実行時に展開される場合には、WITH句内の表を参照できます。その式が問合せ計画の作成時に展開される場合は、エラーが発生します。
MODEL句のITERATEオプションを使用すると、ルールを特定の回数で反復的に評価できます。回数は、ITERATE句の引数として指定できます。ITERATEは、SEQUENTIAL ORDERモデルにのみ指定できます。このようなモデルは、反復モデルと呼ばれます。次の例を考えてみます。
SELECT x, s FROM DUAL MODEL DIMENSION BY (1 AS x) MEASURES (1024 AS s) RULES UPDATE ITERATE (4) (s[1] = s[1]/2);
表DUALにある行はただ1つです。したがって、このモデルでは、xでディメンション化され、メジャーsおよび単一の要素s[1] = 1024を持つ1次元配列を定義します。ルールs[1] = s[1]/2の評価は、4回繰り返されます。この問合せの結果は、列xと列sにそれぞれ値1と値64を持つ単一の行になります。ITERATE句の反復回数の引数には、正の整定数を指定する必要があります。オプションで早期終了条件を指定して、最大反復回数に達する前にルールの評価を停止することもできます。この条件は、ITERATEのUNTIL副次句で指定し、反復の終了時にチェックされます。したがって、ITERATEを指定した場合、最低1回は反復が行われます。ITERATE句の構文を次に示します。
ITERATE (number_of_iterations) [ UNTIL (condition) ]
反復評価は、指定の反復回数が終了した後または終了条件の評価がTRUEになった時点のいずれか早い時点で停止します。
場合によっては、反復の過程でのセル値の変更に基づいた終了条件が必要になることもあります。Oracle Databaseでは、このような条件を指定するためのメカニズムを備えています。この場合、UNTIL条件で現行の反復の前後におけるセルの値にアクセスできます。OracleのPREVIOUS関数は、引数にシングル・セル参照を取り、前の反復の後に存在するようになったセルのメジャー値を戻します。また、システム変数ITERATION_NUMBERを使用すると、現行の反復回数を取得できます。反復回数は、値0から開始し、1回の反復が終了するたびに増加します。PREVIOUSおよびITERATION_NUMBERを使用することにより、複雑な終了条件を作成できます。
次の反復モデルを考えてみます。この反復モデルでは、最大1000回までの継続的な反復の過程でs[1]の値が1未満に変化するまで、ルールを反復するよう指定しています。
SELECT x, s, iterations FROM DUAL MODEL DIMENSION BY (1 AS x) MEASURES (1024 AS s, 0 AS iterations) RULES ITERATE (1000) UNTIL ABS(PREVIOUS(s[1]) - s[1]) < 1 (s[1] = s[1]/2, iterations[1] = ITERATION_NUMBER);
最新の値は正か負かわからない場合があるため、終了条件の指定には絶対値関数(ABS)が役立ちます。このモデルのルールは11回反復されます。これは、11回目の反復後にs[1]の値が0.5になるためです。この問合せの結果は、x、sおよび繰返し回数に対して、それぞれ1、0.5および10の値を持つ単一行になります。
PREVIOUS関数は、UNTIL条件でのみ使用できます。ただし、ITERATION_NUMBERは、メイン・モデルの任意の場所に指定できます。次の例では、ITERATION_NUMBERをセル参照で使用しています。
SELECT country, product, year, sales FROM sales_view MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales sales) IGNORE NAV RULES ITERATE(3) (sales['Bounce', 2002 + ITERATION_NUMBER] = sales['Bounce', 1999 + ITERATION_NUMBER]);
この文では、Bounceの売上を配列1999-2001のセルから配列2002-2005にコピーします。
Oracle Databaseでは、ルールの依存関係に基づいて、AUTOMATIC ORDERモデルでのルールの評価順序を決定します。ルールは、依存対象のルールが評価された後でのみ評価されます。ルールを評価するためのアルゴリズムは、依存関係分析およびモデルのルール間に循環依存があるかどうかに基づきます。循環依存には、「ルールAはルールBに依存し、ルールBはルールAに依存する」形式と「ルールがそのルール自身に依存する」自己循環の形式があります。前者の例を次に示します。
sales['Bounce', 2002] = 1.5 * sales['Y Box', 2002], sales['Y Box', 2002] = 100000 / sales['Bounce', 2002
後者の例を次に示します。
sales['Bounce', 2002] = 25000 / sales['Bounce', 2002]
ただし、次のルールの場合、左辺と右辺で異なるメジャーにアクセスしているため、自己循環はありません。
projected_sales['Bounce', 2002] = 25000 / sales['Bounce', 2002]
Oracle Databaseでは、AUTOMATIC ORDERモデルの分析でルールに循環依存がないと判断した場合、依存関係の順序でルールを評価します。たとえば、次のAUTOMATIC ORDERモデルを考えてみます。
MODEL DIMENSION BY (prod, year) MEASURES (sale sales) IGNORE NAV
RULES AUTOMATIC ORDER
(sales['SUV', 2001] = 10000,
sales['Standard Mouse Pad', 2001] = sales['Finding Fido', 2001]
* 0.10 + sales['Boat', 2001] * 0.50,
sales['Boat', 2001] = sales['Finding Fido', 2001]
* 0.25 + sales['SUV', 2001]* 0.75,
sales['Finding Fido', 2001] = 20000)
ルール2はルール3と4に依存し、ルール3はルール1と4に依存し、ルール1と4はどのルールにも依存していません。この場合、Oracleではルールの依存関係が非循環であると判断して、有効な評価順序(1、4、3、2)または(4、1、3、2)のいずれかでルールを評価します。このタイプのルール評価は、ACYCLICアルゴリズムと呼ばれます。
Oracle Databaseでは、ルール間に循環依存がなくても、モデルが非循環であることを確認できない場合があります。これは、セル参照内に複雑な式がある場合などで発生します。このような場合、Oracle Databaseではルールが循環依存になっていると仮定し、CYCLICアルゴリズムを使用して、ルールおよびデータに基づいて反復的にモデルを評価します。収束に達した時点で反復は終了し、結果が戻されます。収束とは、これ以上モデルを実行しても、モデルのどのセルの値も変化しない状態のことをいいます。循環依存がない場合、必ず収束に達します。
AUTOMATIC ORDERモデルに循環依存のルールがある場合、Oracle Databaseでは前述のCYCLICアルゴリズムを使用します。アルゴリズムが試行される反復回数内で収束に達した場合、結果が生成されます。それ以外の場合は、循環検出エラーがレポートされます。この問題を回避するには、ルールを手動で順序付け、SEQUENTIAL ORDERを指定します。
順序付きルールは、左辺にORDER BYが指定されているルールです。このルールは、ORDER BYで指定された順序でセルにアクセスし、右辺の計算を適用します。ルールの左辺にANYまたはシンボリック参照がある場合、ORDER BY句を指定しないと、ルールの結果はセルのアクセス順序に依存しているため不確定的であるという内容のエラーが戻される可能性があります。次のSEQUENTIAL ORDERモデルを考えてみます。
SELECT t, s FROM sales, times WHERE sales.time_id = times.time_id GROUP BY calendar_year MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES SEQUENTIAL ORDER (s[ANY] = s[CV(t)-1]);
この問合せでは、すべての年tについて、ある年の売上高の値sを前年の売上高の値に設定するよう試みます。ただし、このルールの結果は、セルのアクセス順序に依存しています。年の昇順でセルにアクセスする場合、結果は表23-1の3列目に示す結果になります。降順でセルにアクセスする場合、結果は4列目に示す結果になります。
表23-1 順序付きルール
| t | s | 昇順の場合 | 降順の場合 |
|---|---|---|---|
|
1998 |
1210000982 |
NULL |
NULL |
|
1999 |
1473757581 |
NULL |
1210000982 |
|
2000 |
2376222384 |
NULL |
1473757581 |
|
2001 |
1267107764 |
NULL |
2376222384 |
セルを降順で考慮する場合、表の4列目の結果を取得するには、次のように指定する必要があります。
SELECT t, s FROM sales, times WHERE sales.time_id = times.time_id GROUP BY calendar_year MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES SEQUENTIAL ORDER (s[ANY] ORDER BY t DESC = s[CV(t)-1]);
一般的に、左辺のセル参照と一致するセル間で順序が一意となるかぎり、任意のORDER BY指定を使用できます。ルールのORDER BYの式には、定数、メジャー、ディメンション・キーを含めることができます。また、順序付けオプション[ASC | DESC] [NULLS FIRST | NULLS LAST]を指定すると、目的の順序を取得できます。
AUTOMATIC ORDERモデルのルールにORDER BYを指定することもできます。この場合、ルールの評価時に特定の順序でセルが考慮されます。ルールにORDER BYを指定した場合、そのルールが自己循環とみなされることはありません。たとえば、自己循環の式を使用した次のAUTOMATIC ORDERモデルを非循環にするとします。
MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES AUTOMATIC ORDER (s[ANY] = s[CV(t)-1])
この場合、ORDER BYを使用して、アクセスする評価対象のセルの順序を指定する必要があります。次に例を示します。
s[ANY] ORDER BY t = s[CV(t) - 1]
これにより、Oracleは式の評価にACYCLICアルゴリズムを使用して、結果を確実に生成します。
分析関数(ウィンドウ関数とも呼ばれる)は、ルールの右辺で使用できます。分析関数を使用すると、MODEL句で、より複雑な式を柔軟に計算できるようになります。次の例では、分析関数とMODEL句を組み合せて使用します。まず、GROUPING_ID関数を使用して集計の各レベルの識別子を計算するビューsales_rollup_timeを作成します。次に、quarterレベルとyearレベルの両方で売上高の累積合計を計算する問合せの中で、このビューを使用します。
CREATE OR REPLACE VIEW sales_rollup_time
AS
SELECT country_name country, calendar_year year, calendar_quarter_desc quarter,
GROUPING_ID(calendar_year, calendar_quarter_desc) gid, SUM(amount_sold) sale,
COUNT(amount_sold) cnt
FROM sales, times, customers, countries
WHERE sales.time_id = times.time_id AND sales.cust_id = customers.cust_id
AND customers.country_id = countries.country_id
GROUP BY country_name, calendar_year, ROLLUP(calendar_quarter_desc)
ORDER BY gid, country, year, quarter;
SELECT country, year, quarter, sale, csum
FROM sales_rollup_time
WHERE country IN ('United States of America', 'United Kingdom')
MODEL DIMENSION BY (country, year, quarter)
MEASURES (sale, gid, 0 csum)
(
csum[any, any, any] =
SUM(sale) OVER (PARTITION BY country, DECODE(gid,0,year,null)
ORDER BY year, quarter
ROWS UNBOUNDED PRECEDING)
)
ORDER BY country, gid, year, quarter;
COUNTRY YEAR QUARTER SALE CSUM
------------------------------ ---------- ------- ---------- ----------
United Kingdom 1998 1998-01 484733.96 484733.96
United Kingdom 1998 1998-02 386899.15 871633.11
United Kingdom 1998 1998-03 402296.49 1273929.6
United Kingdom 1998 1998-04 384747.94 1658677.54
United Kingdom 1999 1999-01 394911.91 394911.91
United Kingdom 1999 1999-02 331068.38 725980.29
United Kingdom 1999 1999-03 383982.61 1109962.9
United Kingdom 1999 1999-04 398147.59 1508110.49
United Kingdom 2000 2000-01 424771.96 424771.96
United Kingdom 2000 2000-02 351400.62 776172.58
United Kingdom 2000 2000-03 385137.68 1161310.26
United Kingdom 2000 2000-04 390912.8 1552223.06
United Kingdom 2001 2001-01 343468.77 343468.77
United Kingdom 2001 2001-02 415168.32 758637.09
United Kingdom 2001 2001-03 478237.29 1236874.38
United Kingdom 2001 2001-04 437877.47 1674751.85
United Kingdom 1998 1658677.54 1658677.54
United Kingdom 1999 1508110.49 3166788.03
United Kingdom 2000 1552223.06 4719011.09
United Kingdom 2001 1674751.85 6393762.94
... /*and similar output for the US*/
分析関数を使用する際は、いくつかの固有の制限事項が適用されます。詳細は、「モデリング用SQLを使用する場合の規則および制限事項」を参照してください。
MODEL句のデフォルトの動作では、モデルへの入力で各行を一意に識別するために、PARTITION BYおよびDIMENSION BYキーが必要です。Oracleは、データの一意性を検証し、データが一意でない場合はエラーを戻します。PARTITION BYおよびDIMENSION BYキーでの入力行セットの一意性によって、シングル・セル参照がアクセスするモデル内のセルが1つに限定されることが保証されます。MODEL句でオプションのキーワードUNIQUE DIMENSIONを指定すると、この動作を明示できます。たとえば、次の問合せを考えてみます。
SELECT country, product, sales
FROM sales_view
WHERE country IN ('France', 'Poland')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (product) MEASURES (sales sales)
IGNORE NAV RULES UPSERT
(sales['Bounce'] = sales['All Products'] * 0.24);
この問合せは、モデルに入力された行セットがcountryおよびproductでは一意でないため(yearも必要)、次の一意性違反エラーを戻します。
ERROR at line 2:ORA-32638: Non unique addressing in MODEL dimensions
ただし、次の問合せの場合、このようなエラーは戻されません。
SELECT country, product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales sales)
RULES UPSERT
(sales['Bounce', 2003] = sales['All Products', 2002] * 0.24);
この場合、MODEL句への入力は、次に示すようにcountry、productおよびyearで一意です。
COUNTRY PRODUCT YEAR SALES ------- ----------------------------- ---- -------- Italy 1.44MB External 3.5" Diskette 1998 3141.84 Italy 1.44MB External 3.5" Diskette 1999 3086.87 Italy 1.44MB External 3.5" Diskette 2000 3440.37 Italy 1.44MB External 3.5" Diskette 2001 855.23 ...
UNIQUE SINGLE REFERENCEキーワードを指定すると、一意性を簡単にチェックできます。これにより、処理時間を節約できます。この場合、MODEL句は、ルールの右辺に現れるシングル・セル参照のみの一意性をチェックします。したがって、一意性違反エラーを戻した問合せでUNIQUE DIMENSIONのかわりにUNIQUE SINGLE REFERENCEを指定すると、エラーが発生しなくなります。
UNIQUE DIMENSIONとUNIQUE SINGLE REFERENCEのもう1つの違いは、左辺にシングル・セル参照があるルールで更新できるセルの数です。UNIQUE DIMENSIONの場合、左辺のシングル・セル参照に1つのセルのみが一致するようなルールで更新できる行は最大でも1つです。これは、入力行セットがPARTITION BYおよびDIMENSION BYキーで一意であるためです。UNIQUE SINGLE REFERENCEの場合、左辺のシングル・セル参照に一致するすべてのセルがルールで更新されます。
MODEL句を使用する場合は、次の一般規則および制限事項が適用されます。
更新可能な列は、メインSQLモデルのMEASURES副次句で指定された列のみです。参照モデルのメジャーは更新できません。
MODEL句が評価されるのは、SELECT DISTINCT句を除く問合せブロック内のすべての句およびORDER BY句が評価された後です。SELECT構文のリスト内の句および式は、MODEL句の後に評価されます。
問合せにMODEL句がある場合、問合せのSELECTおよびORDER BYリストに集計関数または分析関数は指定できません。これらの関数が必要な場合は、PARTITION BY、DIMENSION BYおよびMEASURESリストで指定可能であり、別名化する必要があります。これにより、SELECTまたはORDER BY句で別名を使用できるようになります。次の例では、分析関数RANKをMODEL句のMEASURESリストで指定および別名化し、その別名をSELECT構文のリストで使用して、外部の問合せがランクに基づいて結果の行を順序付けできるようにしています。
SELECT country, product, year, s, RNK
FROM (SELECT country, product, year, s, rnk
FROM sales_view
MODEL
PARTITION BY (country) DIMENSION BY (product, year)
MEASURES (sales s, year y, RANK() OVER (ORDER BY sales) rnk)
RULES UPSERT
(s['Bounce Increase 90-99', 2001] =
REGR_SLOPE(s, y) ['Bounce', year BETWEEN 1990 AND 2000],
s['Bounce', 2001] = s['Bounce', 2000] *
(1+s['Bounce increase 90-99', 2001])))
WHERE product <> 'Bounce Increase 90-99'
ORDER BY country, year, rnk, product;
ルールの右辺にマルチセル参照がある場合、集計関数を適用して、マルチセル参照の複数のメジャー値を単一値に変換する必要があります。これには、通常の集計関数、分析集計関数(逆パーセンタイル関数、仮説ランク関数、仮説分布関数)、ユーザー定義の集計関数など、任意の種類の集計関数を使用できます。
UPSERTを指定できるのは、左辺に位置ベースのシングル・セル参照があるルールのみです。それ以外のルールはすべて、UPSERTオプションを指定した場合でも、UPDATEになります。
FORループでは、負の値の増加は禁止されています。また、空のFORループも禁止されています。たとえば、FOR d FROM 2005 TO 2001 INCREMENT -1は無効です。かわりに、FOR d FROM 2005 TO 2001 DECREMENT 1を使用する必要があります。FOR d FROM 2005 TO 2001 INCREMENT 1は、空のループを指定しているため無効です。
FORコンストラクト内を除き、ルールではネストした問合せ式(副問合せ)は使用できません。たとえば、次の文を発行した場合は無効になります。
SELECT * FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales) RULES UPSERT (sales['Bounce', 2003] = sales['Bounce', 2002] + (SELECT SUM(sales) FROM sales_view));
これは、ルールの右辺に副問合せがあるためです。前述の問合せは、次の有効な方法で記述しなおすことができます。
SELECT * FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales, (SELECT SUM(sales) FROM sales_view) AS grand_total) RULES UPSERT (sales['Bounce', 2003] =sales['Bounce', 2002] + grand_total['Bounce', 2002]);
ルールの左辺に指定されたFORコンストラクトにも副問合せを使用できます。ただし、次の制限があります。
相関させることはできません。
戻り値の行数は10,000行未満に制限する必要があります。
WITH句で定義した問合せにすることはできません。
カーソルは共有できません。
ネステッド・セル参照には、次の制限事項があります。
ネステッド・セル参照は、シングル・セル参照である必要があります。ネステッド・セル参照での集計はサポートされていません。したがって、s['Bounce', MAX(best_year)['Bounce', ANY]]のような指定は無効になります。
メイン・モデルのネステッド・セル参照の場合、サポートされているネストのレベルは1レベルのみです。たとえば、s['Bounce', best_year['Bounce', 2001]]は有効ですが、s['Bounce', best_year['Bounce', best_year['Bounce', 2001]]]は無効になります。
AUTOMATIC ORDERモデルでは、ルールの左辺にあるネステッド・セル参照をモデルのルールで更新しないようにしてください。この制限によって、参照メジャーの更新が原因でルールの依存関係が無原則に変更される(そのため、結果が不確定的になる)のを防止できます。
SEQUENTIAL ORDERモデルのネステッド・セル参照の場合、このような制限はありません。また、SEQUENTIALまたはAUTOMATIC ORDERのどちらのモデルでも、ルールの右辺にあるネステッド・セル参照には、この制限は適用されません。
参照モデルには、次の制限事項があります。
参照モデルを定義する問合せは、外部の問合せと相関させることはできません。ただし、副問合せやビューなどを持つ問合せにすることはできます。
参照モデルでは、PARTITION BY句は指定できません。
参照モデルは更新できません。
ウィンドウ関数には、次の制限事項があります。
OVER句に指定できる式は、定数の式、メジャー、MODEL句のPARTITION BYとDIMENSION BYのキー、および単一のセルの式です。集計は、OVER句の内部には指定できません。次の式は許容されます。
rnk[ANY, ANY, ANY] = RANK() (PARTITION BY prod, country ORDER BY sale)
次の式は許容されません。
rnk[ANY, ANY, ANY] = RANK() (PARTITION BY prod, country ORDER BY SUM(sale))
ルールの右辺にウィンドウ関数が含まれる場合、同じルールの左辺にはORDER BY句を指定できません。
ウィンドウ関数と集計関数の両方を同じルールの右辺には指定できません。
ウィンドウ関数は、UPDATEルールの右辺でのみ使用できます。
ルールの左辺にFORループがある場合、ウィンドウ関数は同じルールの右辺で使用できません。
以降の項では、MODEL句を使用する場合のパフォーマンスに影響するトピックについて説明します。
MODEL句の計算のスケーラビリティは、使用するプロセッサの数に応じて向上します。また、スケーラビリティは、PARTITION BY句で定義したパーティション間でMODEL計算をパラレルに実行することにより実現します。データは、PARTITION BYキーの値に基づいて(パラレル問合せスレーブと呼ばれる)処理要素に分散されます。これにより、PARTITION BYキーの値が同じ行は、すべて同じスレーブに配置されます。この場合、パーティションの内部処理では、論理的に処理されるパーティションと内部的に処理されるパーティションは1対1の一致とはなりません。これにより、各スレーブは、他のスレーブとは関係なくMODEL句の計算を終了できます。データは、ハッシュ・ベースまたはレンジ・ベースでパーティション化できます。次のMODEL句を考えてみます。
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sales) RULES UPDATE (sales['Bounce', 2002] = 1.2 * sales['Bounce', 2001], sales['Car', 2002] = 0.8 * sales['Car', 2001])
ここで、入力データは、PARTITION BYキーcountryに基づいてスレーブ間でパーティション化されます。このパーティション化は、ハッシュ・ベースまたはレンジ・ベースで行うことができます。各スレーブは、受け取ったデータのルールを評価します。
モデル計算のパラレル化は、MODEL句の指定方法によって制御または制限されます。MODEL句にPARTITION BYキーがない場合、(後述の例外を除き)計算はパラレル化できません。PARTITION BYキーのカーディナリティが非常に低い場合、並列度は制限されます。このような場合、Oracleでは、パーティション化に使用可能なDIMENSION BYキーを識別します。たとえば、前述の例とほぼ同等だがPARTITION BYキーがない、次のようなMODEL句があるとします。
MODEL DIMENSION BY (country, product, time) MEASURES (sales) RULES UPDATE (sales[ANY, 'Bounce', 2002] = 1.2 * sales[CV(country), 'Bounce', 2001], sales[ANY, 'Car', 2002] = 0.8 * sales[CV(country), 'Car', 2001])
この場合、Oracle Databaseでは、DIMENSION BYキーcountryがパーティション化に使用可能であると識別し、内部のパーティション化の処理にregionを使用します。データは、countryのスレーブ間でパーティション化され、パラレル実行が行われます。
MODEL句の集計の処理には2通りの方法があります。1つはパーティション内のデータをスキャンして集計する一般的な方法、もう1つはウィンドウ形式の集計を行う効率的な方法です。最初の方法の例を次に示します。ここでは、新しいディメンション・メンバーALL_2002_productsを導入し、その値が全製品の2002年の合計売上になるよう計算します。
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sale sales) RULES UPSERT (sales['ALL_2002_products', 2002] = SUM(sales)[ANY, 2002])
この場合、集計の合計を評価するために、各パーティションをスキャンして、全製品の2002年のセルを検索して集計します。ルールの左辺が複数のセルを参照する場合は、左辺で参照されるセルごとにパーティションがスキャンされ、右辺の集計が計算されます。たとえば、次の例を考えてみます。
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sale sales, 0 avg_exclusive) RULES UPDATE (avg_exclusive[ANY, 2002] = AVG(sales)[product <> CV(product), CV(time)])
このルールは、2002年の全製品を対象にメジャーavg_exclusiveを計算します。メジャーavg_exclusiveは、現行の製品を除外したすべての製品の平均売上として定義されています。この場合、2002年の全製品についてパーティションのデータがスキャンされ集計が計算されるため、コストが高くなる可能性があります。
Oracle Databaseでは、このような集計の評価を最適化するために、集計関数で使用される、ウィンドウ形式の計算のシナリオが複数用意されています。これらのシナリオでは、左辺にマルチセル参照を持つルールを指定し、移動平均や累積合計などのウィンドウ計算を実行します。次の例を考えてみます。
MODEL PARTITION BY (country) DIMENSION BY (product, time)
MEASURES (sale sales, 0 mavg)
RULES UPDATE
(mavg[product IN ('Bounce', 'Y Box', 'Mouse Pad'), ANY] =
AVG(sales)[CV(product), time BETWEEN CV(time)
AND CV(time) - 2])
この例では、3年間にわたる製品Bounce、Y BoxおよびMouse Padの売上の移動平均を計算します。左辺で参照されるすべてのセルについてパーティションがスキャンされると、集計の評価が非常に非効率的になります。Oracleでは、ウィンドウ形式で計算が識別され、効率的に評価されます。この場合、productおよびtimeの入力をソートしてから、データを1回スキャンして移動平均を計算します。このルールは、次のように製品Bounce、Y BoxおよびMouse Padの売上データに適用する集計関数として表すことができます。
AVG(sales) OVER (PARTITION BY product ORDER BY time RANGE BETWEEN 2 PRECEDING AND CURRENT ROW)
この計算形式は、WINDOW (IN MODEL) SORTと呼ばれます。この形式の集計を適用できるのは、ルールの左辺にORDER BYが指定されていないマルチセル参照があり、ルールの右辺に単純な集計(SUM、COUNT、MIN、MAX、STDEV、VAR)があり、右辺のいずれか1つのディメンションにブール型の述語(<、<=、>、>=、BETWEEN)があり、右辺のその他のディメンションがすべてCVで修飾されている場合です。
OracleのEXPLAIN PLAN機能は、モデルに完全対応しています。問合せに対するEXPLAIN PLANのメインの出力では、モデルおよび使用されたアルゴリズムを示す行が表示されます。参照モデルの場合、EXPLAIN PLANの出力ではキーワードREFERENCEでタグ付けられます。また、いずれかのルールでウィンドウ形式の集計計算を許可する場合、EXPLAIN PLANにWINDOW (IN MODEL) SORTという注釈が付けられます。
EXPLAIN PLANを調べることにより、モデルの評価で使用されたアルゴリズムを確認できます。モデルにSEQUENTIAL ORDERが指定されている場合、ORDEREDが表示されます。AUTOMATIC ORDERモデルの場合は、評価用のアルゴリズムがACYCLICかCYCLICかに応じて、ACYCLICまたはCYCLICが表示されます。さらに、左辺のすべてのセル参照がシングル・セル参照であり、ルールの右辺の集計が単純で非個別的な算術集計(SUM、COUNT、AVGなど)の場合、アルゴリズムがORDEREDおよびACYCLICだと、EXPLAIN PLANの出力に注釈FASTが付けられます。この場合、ルールの評価が非常に効率的になるため、注釈FASTが付きます。したがって、EXPLAIN PLANの出力では、MODEL {ORDERED [FAST] | ACYCLIC [FAST] | CYCLIC}と表示されます。
このモデルでは、ルールの左辺にシングル・セル参照のみがあり、最初のルールの右辺にある集計AVGは単純で非個別的な集計になっています。
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT
(sales['Bounce', 2003] = AVG(sales)[ANY, 2002] * 1.24,
sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25);
次の例の場合、2番目のルールの左辺がマルチセル参照になっているため、FASTは選択されません。
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT
(sales['Bounce', 2003] = AVG(sales)[ANY, 2002] * 1.24,
sales[prod <> 'Bounce', 2003] = sales['Bounce', 2003] * 0.25);
このモデルのルールは非循環になっているため、EXPLAIN PLANではACYCLICが表示されます。この場合、FASTも選択されます。
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT AUTOMATIC ORDER
(sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce', 2003] = sales['Bounce', 2002] / SUM(sales)[ANY, 2002] * 2 *
sales['All Products', 2003],
sales['All Products', 2003] = 200000);
このモデルのルールは非循環です。2番目のルールでは、2002年の売上高の中央値を示すPERCENTILE_DISC集計があります。この集計は、単純な集計関数ではありません。そのため、FASTは選択されず、EXPLAIN PLANではACYCLICのみが表示されます。
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT AUTOMATIC ORDER
(sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce',2003] = PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY
sales)[ANY,2002] / SUM(sales)[ANY, 2002] * 2 * sales['All Products', 2003],
sales['All Products', 2003] = 200000);
2番目と3番目のルールは循環依存になっているため、このモデルではCYCLICアルゴリズムが選択されます。
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
IGNORE NAV RULES UPSERT AUTOMATIC ORDER
(sales['All Products', 2003] = 200000,
sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce', 2003] = sales['Y Box', 2003] +
(sales['Bounce', 2002] / SUM(sales)[ANY, 2002] * 2 *
sales['All Products', 2003]));
この項の各例では、sales_viewに加え、次のビューが定義されていると想定します。このビューは、製品別および国別の月単位による合計売上高と販売数量を示します。
CREATE VIEW sales_view2 AS
SELECT country_name country, prod_name product, calendar_year year,
calendar_month_name month, SUM(amount_sold) sale, COUNT(amount_sold) cnt
FROM sales, times, customers, countries, products
WHERE sales.time_id = times.time_id AND
sales.prod_id = products.prod_id AND
sales.cust_id = customers.cust_id AND
customers.country_id = countries.country_id
GROUP BY country_name, prod_name, calendar_year, calendar_month_name;
ItalyとSpainの売上高および両国の売上高の差を製品別に示します。差は、country = 'Diff Italy-Spain'を使用して新しい行に配置されます。
SELECT product, country, sales
FROM sales_view
WHERE country IN ('Italy', 'Spain')
GROUP BY product, country
MODEL
PARTITION BY (product) DIMENSION BY (country) MEASURES (SUM(sales) AS sales)
RULES UPSERT
(sales['DIFF ITALY-SPAIN'] = sales['Italy'] - sales['Spain']);
2000年10月から11月と同年11月から12月のそれぞれの期間において、各国での各製品の売上高が同じ月間変化率で増加(または減少)した場合、会社全体および国ごとの第4四半期の売上高を計算します。
SELECT country, SUM(sales)
FROM (SELECT product, country, month, sales
FROM sales_view2
WHERE year=2000 AND month IN ('October','November')
MODEL
PARTITION BY (product, country) DIMENSION BY (month) MEASURES (sale sales)
RULES
(sales['December']=(sales['November'] /sales['October']) *sales['November']))
GROUP BY GROUPING SETS ((),(country));
一連の定期的なキャッシュ・フローの正味現在価値(NPV)を計算するとします。シナリオには、2つのプロジェクトがあります。それぞれ、時間0での負のキャッシュ・フローで表される初期投資から開始します。初期投資以降の3年間のキャッシュ・フローは正の値になります。最初に、次の文で表(cash_flow)を作成し、データを移入します。
CREATE TABLE cash_flow (year DATE, i INTEGER, prod VARCHAR2(3), amount NUMBER);
INSERT INTO cash_flow VALUES (TO_DATE('1999', 'YYYY'), 0, 'vcr', -100.00);
INSERT INTO cash_flow VALUES (TO_DATE('2000', 'YYYY'), 1, 'vcr', 12.00);
INSERT INTO cash_flow VALUES (TO_DATE('2001', 'YYYY'), 2, 'vcr', 10.00);
INSERT INTO cash_flow VALUES (TO_DATE('2002', 'YYYY'), 3, 'vcr', 20.00);
INSERT INTO cash_flow VALUES (TO_DATE('1999', 'YYYY'), 0, 'dvd', -200.00);
INSERT INTO cash_flow VALUES (TO_DATE('2000', 'YYYY'), 1, 'dvd', 22.00);
INSERT INTO cash_flow VALUES (TO_DATE('2001', 'YYYY'), 2, 'dvd', 12.00);
INSERT INTO cash_flow VALUES (TO_DATE('2002', 'YYYY'), 3, 'dvd', 14.00);
割引率を0.14としてNPVを計算する場合、次の文を発行します。
SELECT year, i, prod, amount, npv
FROM cash_flow
MODEL PARTITION BY (prod)
DIMENSION BY (i)
MEASURES (amount, 0 npv, year)
RULES
(npv[0] = amount[0],
npv[i !=0] ORDER BY i =
amount[CV()]/ POWER(1.14,CV(i)) + npv[CV(i)-1]);
YEAR I PRO AMOUNT NPV
--------- ---------- --- ---------- ----------
01-AUG-99 0 dvd -200 -200
01-AUG-00 1 dvd 22 -180.70175
01-AUG-01 2 dvd 12 -171.46814
01-AUG-02 3 dvd 14 -162.01854
01-AUG-99 0 vcr -100 -100
01-AUG-00 1 vcr 12 -89.473684
01-AUG-01 2 vcr 10 -81.779009
01-AUG-02 3 vcr 20 -68.279579
利子負担率を純所得(純所得=給与-税金-利子)の30%にするとします。利子は総所得から控除できます。税率は給与の38%、資産売却益の28%です。給与は100,000ドル、資産売却益は15,000ドルとします。純所得、税額および利子負担率は不明です。純所得は利子に依存し、利子は純所得に依存していることから、これは連立方程式であるため、ITERATE句が含まれていることに注目してください。
最初に、表ledgerを作成します。
CREATE TABLE ledger (account VARCHAR2(20), balance NUMBER(10,2) );
次の5つの行を挿入します。
INSERT INTO ledger VALUES ('Salary', 100000);
INSERT INTO ledger VALUES ('Capital_gains', 15000);
INSERT INTO ledger VALUES ('Net', 0);
INSERT INTO ledger VALUES ('Tax', 0);
INSERT INTO ledger VALUES ('Interest', 0);
続いて、次の文を発行します。
SELECT s, account FROM ledger MODEL DIMENSION BY (account) MEASURES (balance s) RULES ITERATE (100) (s['Net']=s['Salary']-s['Interest']-s['Tax'], s['Tax']=(s['Salary']-s['Interest'])*0.38 + s['Capital_gains']*0.28, s['Interest']=s['Net']*0.30);
出力は次のようになります(端数は切り捨てられています)。
S ACCOUNT
---------- --------------------
100000 Salary
15000 Capital_gains
48735.2445 Net
36644.1821 Tax
14620.5734 Interest
2001年のBounceの売上高は、過去3年(1998年から2000年)と同様、2000年と比べて増加する見通しです。この増加額を計算するには、次のように回帰関数REGR_SLOPEを使用します。ここでは、次の期間の値を計算するため、傾きを2000年の値に追加すれば十分です。
SELECT * FROM
(SELECT country, product, year, projected_sale, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan') AND product IN ('Bounce')
MODEL
PARTITION BY (country) DIMENSION BY (product, year)
MEASURES (sales sales, year y, CAST(NULL AS NUMBER) projected_sale) IGNORE NAV
RULES UPSERT
(projected_sale[FOR product IN ('Bounce'), 2001] =
sales[CV(), 2000] +
REGR_SLOPE(sales, y)[CV(), year BETWEEN 1998 AND 2000]))
ORDER BY country, product, year;
出力は次のようになります。
COUNTRY PRODUCT YEAR PROJECTED_SALE SALES ------- ------- ---- -------------- ------- Italy Bounce 1999 2474.78 Italy Bounce 2000 4333.69 Italy Bounce 2001 6192.6 4846.3 Japan Bounce 1999 2961.3 Japan Bounce 2000 5133.53 Japan Bounce 2001 7305.76 6303.6
この例では、貸付金のファクト表から選択した住宅ローンに関する情報を使用して、任意の数の顧客を対象とした貸付金の割賦償還額の表を作成します。最初に、次の2つの表を作成し、必要なデータを挿入します。
mortgage_facts
顧客名など個々の顧客のローンに関する情報、行に格納されているローンに関するファクト、およびそのファクトの値を保持します。この例で格納されるファクトには、ローン(Loan)、年間利子率(Annual_Interest)およびローンの支払回数(Payments)があります。また、2名の顧客(SmithとJones)の値も挿入されます。
CREATE TABLE mortgage_facts (customer VARCHAR2(20), fact VARCHAR2(20),
amount NUMBER(10,2));
INSERT INTO mortgage_facts VALUES ('Smith', 'Loan', 100000);
INSERT INTO mortgage_facts VALUES ('Smith', 'Annual_Interest', 12);
INSERT INTO mortgage_facts VALUES ('Smith', 'Payments', 360);
INSERT INTO mortgage_facts VALUES ('Smith', 'Payment', 0);
INSERT INTO mortgage_facts VALUES ('Jones', 'Loan', 200000);
INSERT INTO mortgage_facts VALUES ('Jones', 'Annual_Interest', 12);
INSERT INTO mortgage_facts VALUES ('Jones', 'Payments', 180);
INSERT INTO mortgage_facts VALUES ('Jones', 'Payment', 0);
mortgage
計算の出力情報を保持します。これには、顧客、支払回数(pmt_num)、支払に適用される元本金額(principalp)、支払に適用される利子(interestp)、ローンの残高(mort_balance)の列があります。新しいセルをパーティションにアップサートするには、事前に各パーティションに少なくとも1つの行を作成しておく必要があります。したがって、2名の顧客が支払を行う前に、顧客の値を貸付金の表に入力します。このシード情報は、表mortgage_factsに基づいてSQLのINSERT文を使用すると、簡単に生成できます。
CREATE TABLE mortgage_facts (customer VARCHAR2(20), fact VARCHAR2(20),
amount NUMBER(10,2));
INSERT INTO mortgage_facts VALUES ('Smith', 'Loan', 100000);
INSERT INTO mortgage_facts VALUES ('Smith', 'Annual_Interest', 12);
INSERT INTO mortgage_facts VALUES ('Smith', 'Payments', 360);
INSERT INTO mortgage_facts VALUES ('Smith', 'Payment', 0);
INSERT INTO mortgage_facts VALUES ('Jones', 'Loan', 200000);
INSERT INTO mortgage_facts VALUES ('Jones', 'Annual_Interest', 12);
INSERT INTO mortgage_facts VALUES ('Jones', 'Payments', 180);
INSERT INTO mortgage_facts VALUES ('Jones', 'Payment', 0);
CREATE TABLE mortgage (customer VARCHAR2(20), pmt_num NUMBER(4),
principalp NUMBER(10,2), interestp NUMBER(10,2), mort_balance NUMBER(10,2));
INSERT INTO mortgage VALUES ('Jones',0, 0, 0, 200000);
INSERT INTO mortgage VALUES ('Smith',0, 0, 0, 100000);
次のSQL文は複雑であるため、必要に応じて個々の行に注釈を付けています。これらの行の詳細については後述します。
SELECT c, p, m, pp, ip
FROM MORTGAGE
MODEL --See 1
REFERENCE R ON
(SELECT customer, fact, amt --See 2
FROM mortgage_facts
MODEL DIMENSION BY (customer, fact) MEASURES (amount amt) --See 3
RULES
(amt[any, 'PaymentAmt']= (amt[CV(),'Loan']*
Power(1+ (amt[CV(),'Annual_Interest']/100/12),
amt[CV(),'Payments']) *
(amt[CV(),'Annual_Interest']/100/12)) /
(Power(1+(amt[CV(),'Annual_Interest']/100/12),
amt[CV(),'Payments']) - 1)
)
)
DIMENSION BY (customer cust, fact) measures (amt) --See 4
MAIN amortization
PARTITION BY (customer c) --See 5
DIMENSION BY (0 p) --See 6
MEASURES (principalp pp, interestp ip, mort_balance m, customer mc) --See 7
RULES
ITERATE(1000) UNTIL (ITERATION_NUMBER+1 =
r.amt[mc[0],'Payments']) --See 8
(ip[ITERATION_NUMBER+1] = m[CV()-1] *
r.amt[mc[0], 'Annual_Interest']/1200, --See 9
pp[ITERATION_NUMBER+1] = r.amt[mc[0], 'PaymentAmt'] - ip[CV()], --See 10
m[ITERATION_NUMBER+1] = m[CV()-1] - pp[CV()] --See 11
)
ORDER BY c, p;
次の番号は、例で示した番号と対応しています。
1: これは、メイン・モデル定義の開始です。
2から4: これらの行では、参照モデルRの開始と終了をマークしています。このモデルは、各顧客のローンについて月々の支払額を計算するSELECT文を定義します。このSELECT文では、3のラベルが付けられた行で開始し、ルールが1つ指定された独自のMODEL句を使用します。このルールでは、表mortgage_factsの情報に基づいてamtの値を定義します。4のラベルが付けられた行で定義した、顧客名custおよびファクトの値factによってディメンション化されている、参照モデルRによって戻されるメジャーはamtです。
参照モデルが計算されると、メイン・モデルでは、その値を使用して他の計算を実行します。参照モデルが計算されると、メイン・モデルでは、その値を使用して他の計算を実行します。参照モデルRは、mortgage_factの既存の各行の1行を戻し、さらに顧客ごとに新規に計算された行を戻します。この場合、ファクト・タイプはPaymentでamtが月々の支払額です。Rの出力から特定の金額を使用する場合は、式r.amt[<customer_name>,<fact_name>]で指定します。
5: これは、メイン・モデル定義の続きです。cに別名化したcustomerで出力をパーティション化します。
6: メイン・モデルを定数値0でディメンション化し、pに別名化します。これは、行の支払回数を表します。
7: メジャーを4つ定義しています。principalp (pp)は月々のローンに適用される元本金額、interestp (ip)は月々に支払われる利子、mort_balance (m)はローンの支払後における貸付金の残高値を示します。customer (mc)はパーティション化をサポートするために使用されます。
8: ルールのブロックを開始します。ルールの計算は、最大1000回実行されます。計算は顧客ごとに各月につき1回実行されるため、ローンに指定できる最大の月数は1000です。反復処理は、ITERATION_NUMBER+1が参照Rから導出される支払額に等しくなった時点で停止します。参照Rの値は、REFERENCE句で定義したamt(金額)メジャーであることに注意してください。この参照値は、r.amt[<customer_name>,<fact>]として処理されます。反復行で使用される式"r.amt[mc[0], 'Payments']"は、参照Rからの金額に解決し、この場合、顧客名はmc[0]で解決される値です。各パーティションに含まれる顧客は1つのみのため、mc[0]が持つことができる値は1つのみです。これにより、"r.amt[mc[0], 'Payments']"から、REFERENCE句の現行の顧客に関する支払回数の値が得られます。つまり、顧客の支払回数と同じ回数でルールが実行されます。
9から11: このブロックの最初の2つのルールは、8で説明したr.amt参照と同じタイプです。違いは、ルールipがファクトの値をAnnual_Interestとして定義している点です。各ルールは、他のいずれかのメジャー値を参照することに注意してください。各ルールの左辺で使用されている式"[ITERATION_NUMBER+1]"によって、新しいディメンション値が作成され、メジャーが結果セットにアップサートされます。これにより、各顧客のすべての支払について月々の割賦償還額を示す行が結果に含まれるようになります。
この例の最終行によって、顧客別およびローンの支払回数別に結果がソートされます。