| Oracle® Database VLDBおよびパーティショニング・ガイド 11g リリース2 (11.2) B56316-03 |
|



 前 |
 次 |
ここでは、SQL文のパラレル実行プロセスについて説明します。
この項の内容は次のとおりです。
各SQL文では、解析の際に最適化およびパラレル化のプロセスが行われます。パラレル実行が選択された場合、次の手順が実行されます。
ユーザー・セッションまたはシャドウ・プロセスが、コーディネータの役割を引き受けます。これは、問合せコーディネータと呼ばれることもあります。
問合せコーディネータは、必要な数のパラレル・サーバーを取得します。
SQL文は一連の操作(非索引列に対する結合を実行するための全表スキャン、ORDER BYなど)として実行されます。パラレル実行サーバーは可能な場合には各操作をパラレルで実行します。
パラレル・サーバーで文の実行が終了すると、問合せコーディネータは、パラレルで実行できない作業の部分を実行します。たとえば、SUM()演算を含むパラレル問合せでは、各パラレル・サーバーで計算された小計それぞれを合計する必要があります。
最後に問合せコーディネータが結果をユーザーに返します。
オプティマイザが文の実行計画を決定した後で、パラレル実行コーディネータが計画の各操作におけるパラレル実行の方法を決定します。たとえば、ブロック・レンジごとのパラレル全表スキャンの実行や、パーティションごとのパラレル索引レンジ・スキャンの実行です。コーディネータは、操作をパラレルで実行できるかどうかと、実行できる場合には使用するパラレル実行サーバーの数を決定する必要があります。1セットのパラレル実行サーバーの数が並列度(DOP)です。
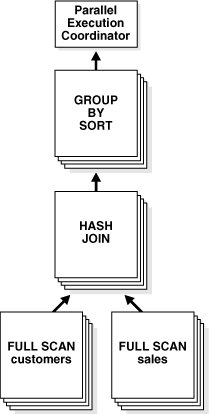
パラレル実行コーディネータは、SQL文の実行計画の各操作を調べて、操作によって処理される行をパラレル実行サーバー間で分割すなわち再分配する方法を決定します。イントラ・オペレーション並列化およびインター・オペレーション並列化を含むパラレル問合せの例として、例8-1に問合せを示します。
例8-1 CustomersおよびSalesに対する問合せの実行計画の実行
EXPLAIN PLAN FOR SELECT /*+ PARALLEL(4) */ customers.cust_first_name, customers.cust_last_name, MAX(QUANTITY_SOLD), AVG(QUANTITY_SOLD) FROM sales, customers WHERE sales.cust_id=customers.cust_id GROUP BY customers.cust_first_name, customers.cust_last_name; Explained.
表customersおよびsalesのDOPを指定するために、問合せでヒントが使用されていることに注意してください。
例8-2 CustomersおよびSalesに対する問合せの実行計画出力
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------
Plan hash value: 4060011603
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 925 | 25900 | | | |
| 1 | PX COORDINATOR | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 | 925 | 25900 | Q1,03 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 925 | 25900 | Q1,03 | PCWP | |
| 4 | PX RECEIVE | | 925 | 25900 | Q1,03 | PCWP | |
| 5 | PX SEND HASH | :TQ10002 | 925 | 25900 | Q1,02 | P->P | HASH |
|* 6 | HASH JOIN BUFFERED | | 925 | 25900 | Q1,02 | PCWP | |
| 7 | PX RECEIVE | | 630 | 12600 | Q1,02 | PCWP | |
| 8 | PX SEND HASH | :TQ10000 | 630 | 12600 | Q1,00 | P->P | HASH |
| 9 | PX BLOCK ITERATOR | | 630 | 12600 | Q1,00 | PCWC | |
| 10 | TABLE ACCESS FULL| CUSTOMERS | 630 | 12600 | Q1,00 | PCWP | |
| 11 | PX RECEIVE | | 960 | 7680 | Q1,02 | PCWP | |
| 12 | PX SEND HASH | :TQ10001 | 960 | 7680 | Q1,01 | P->P | HASH |
| 13 | PX BLOCK ITERATOR | | 960 | 7680 | Q1,01 | PCWC | |
| 14 | TABLE ACCESS FULL| SALES | 960 | 7680 | Q1,01 | PCWP | |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("SALES"."CUST_ID"="CUSTOMERS"."CUST_ID")
26 rows selected.
図8-1に示す問合せ計画に対して、2セットのパラレル実行サーバーSS1およびSS2がある場合、各サーバー・セット(SS1およびSS2)が4つの実行プロセスを使用して実行が行われます。問合せのPARALLELヒントでDOPが指定されているためです。
子セットSS1が最初に表customersをスキャンしてSS2に行を送り、SS2はその行に対してハッシュ表を構築します。つまり、SS2のコンシューマとSS1のプロデューサは同時に働きます。一方はcustomersをパラレルでスキャンし、もう一方は行を受け取って、パラレルでハッシュ結合を実行できるようにハッシュ表を構築します。インター・オペレーション並列処理の例を次に示します。
SS1はcustomers表全体のスキャンを終了すると、sales表をパラレルでスキャンします。SS1が行をSS2のサーバーに送り、SS2はプローブを実行してハッシュ結合をパラレルで完了します。SS1はsales表のパラレルでのスキャンと行のSS2への送信を終了すると、GROUP BYのパラレルでの実行に切り替わります。これは、2つのサーバー・セットを同時に実行して、問合せツリーの様々な演算子に対してインター・オペレーション並列化を実現する方法です。
パラレル実行のもう1つの重要な面は、サーバー・セット間でサーバーからサーバーに送信される際の行の再分配です。例8-2の問合せ計画で、SS1のサーバー・プロセスがcustomers表の行をスキャンした後、SS2のどのサーバー・プロセスに行を送信するでしょうか。行を受け取る演算子が、再分配を決定します。この例では、customersのパラレル・スキャンを実行するSS1から、パラレル・ハッシュ結合を実行するSS2に送られる行の再分配は、結合列に対するハッシュ・パーティション化によって行われます。つまり、customersをスキャンするサーバー・プロセスが、列customers.cust_idの値のハッシュ関数を計算して、送り先のSS2のサーバー・プロセスの数を決定します。パラレル問合せで使用される再分配方法は、問合せのEXPLAIN PLANのDistrib列に明示的に示されます。図8-1「表結合のためのデータ・フロー図」では、EXPLAIN PLANの5、8および12行目に示されています。
他の操作の出力を必要とする操作は、コンシューマ操作と呼ばれます。図8-1では、GROUP BY SORT操作はHASH JOIN操作のコンシューマです。GROUP BY SORTではHASH JOINの出力が必要なためです。
コンシューマ操作は、プロデューサ操作で行が生成されるとすぐに行の消費を開始できます。例8-2では、パラレル実行サーバーがsales表のFULL SCANで行を生成する間、別のパラレル実行サーバー・セットがHASH JOIN操作の実行を開始して、行を使用することができます。
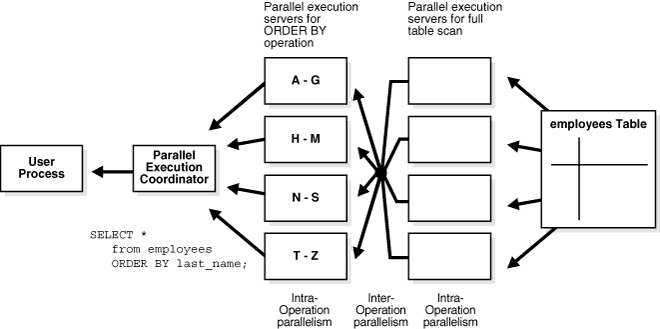
同時に実行される2つの操作それぞれには、独自のパラレル実行サーバー・セットが与えられます。したがって、問合せ操作とデータ・フロー・ツリーの両方でそれぞれの並列処理が行われます。個々の操作の並列処理はイントラ・オペレーション並列化と呼ばれます。データ・フロー・ツリーの操作間の並列処理はインター・オペレーション並列化と呼ばれます。Oracle Databaseの操作のプロデューサとコンシューマという形態のため、実行時間を最小限にするために同時に実行する必要があるのはツリー内の2つの操作のみです。次の文に関して、イントラ・オペレーション並列化とインター・オペレーション並列化を説明します。
SELECT * FROM employees ORDER BY last_name;
実行計画により、employees表の全体スキャンが実装されます。この操作の後で、取得された行がlast_name列の値に基づいてソートされます。この例では、last_name列には索引がないとします。また、問合せのDOPが4に設定されているとします。これは、どの操作に対しても4つのパラレル実行サーバーが使用できることを意味します。
図8-2は、この例の問合せのパラレル実行を示しています。
図8-2に示すように、この問合せのDOPは4ですが、実際は8つのパラレル実行サーバーが関係しています。これは、プロデューサ演算子とコンシューマ演算子が同時に実行できるためです(インター・オペレーション並列化)。
また、スキャン操作に関係するすべてのパラレル実行サーバーが、SORT操作を実行する適切なパラレル実行サーバーに行を送信することに注意してください。パラレル実行サーバーでスキャンされる行のlast_name列の値がAからGの場合、その行は最初のORDER BYパラレル実行サーバーに送信されます。スキャン操作が完了すると、ソート・プロセスはソート結果を問合せコーディネータに返し、コーディネータが完全な問合せ結果をユーザーに返します。
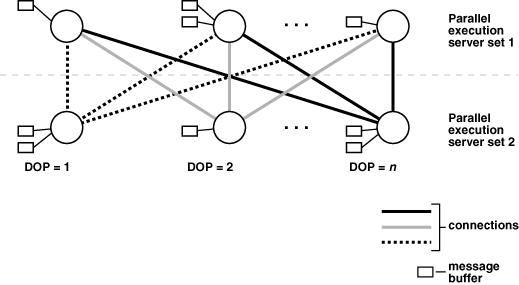
問合せをパラレルで実行するために、通常、Oracle Databaseはプロデューサ・パラレル実行サーバー・セットとコンシューマ・パラレル実行サーバー・セットを作成します。プロデューサ・サーバーは表から行を取得し、コンシューマ・サーバーはそれらの行に対して結合、ソート、DML、DDLなどの操作を実行します。プロデューサ・セットの各サーバーは、コンシューマ・セットの各サーバーに接続しています。パラレル実行サーバー間の仮想接続数は並列度の2乗で増加します。
各通信チャネルには、少なくとも1つ、最大で4つのメモリー・バッファがあり、共有プールから割り当てられます。複数のメモリー・バッファを使用すると、パラレル実行サーバー間の非同期通信が促進されます。
シングル・インスタンス環境では、各通信チャネルで最大3つのバッファを使用します。Oracle Real Application Clusters環境では、各チャネルで最大4つのバッファを使用します。図8-3は、メッセージ・バッファと、プロデューサ・パラレル実行サーバーがコンシューマ・パラレル実行サーバーにどのように接続するかを示します。
同一インスタンスで2つのプロセス間に接続が存在するとき、サーバーはメモリー内で(共有プールで)バッファを受け渡すことにより通信を行います。異なるインスタンスのプロセス間に接続が存在するとき、メッセージはインターコネクトを介して外部の高速ネットワーク・プロトコルを使用して送信されます。図8-3では、DOPはパラレル実行サーバーの数と同じです(この場合はn)。図8-3にはパラレル実行コーディネータは示されていません。実際には各パラレル実行サーバーはパラレル実行コーディネータとも接続しています。パラレル実行を使用する際は、共有プールのサイズを適切に設定することが重要です。共有プールに、パラレル・サーバーに必要なメモリー・バッファを割り当てるための十分な空き領域がない場合、開始することができません。
1つの操作に関連付けられるパラレル実行サーバーの数は、並列度(DOP)と呼ばれます。パラレル実行は複数のCPUを効率よく使用するためのものです。Oracle Databaseのパラレル実行フレームワークでは、特定の並列度をユーザーが明示的に選択することも、Oracleによって自動的に並列度を制御することもできます。
この項の内容は次のとおりです。
Oracle Databaseで特定のDOPをリクエストできます。たとえば、次のように表または索引レベルで固定DOPを設定できます。
ALTER TABLES sales PARALLEL 8; ALTER TABLE customers PARALLEL 4;
この場合、sales表のみにアクセスする問合せはリクエストされたDOPである8を使用し、customers表にアクセスする問合せはDOPとして4をリクエストします。sales表とcustomers表の両方にアクセスする問合せは、DOPが8として処理され、潜在的に16のパラレル・サーバー(プロデューサおよびコンシューマ)を割り当てます。異なるDOPが指定された場合は、高い方のDOPが使用されます。
PARALLEL句が指定されているが並列度の指定がない場合、オブジェクトのDOPはデフォルトになります。デフォルトの並列処理では、次に示すように、計算式が使用され、システム構成に基づいてDOPが決定されます。
シングル・インスタンスの場合、DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT
Oracle RAC構成の場合、DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT x INSTANCE_COUNT
デフォルトでは、INSTANCE_COUNTはクラスタ内の全ノードです。ただし、Oracle RACサービスを使用して1つのパラレル操作が実行できるノードの数を制限している場合は、関与するノード数はそのサービスに属するノード数になります。たとえば、4ノードのRACクラスタで、各ノードに8個のCPUコアがあり、Oracle RACサービスがない場合、デフォルトのDOPは2 x 8 x 4 = 64になります。
デフォルトのDOPアルゴリズムは、最大限のリソースを使用するように設計されており、操作で使用できるリソースが多いほど、操作は速く終了すると想定しています。デフォルトの並列処理は単一ユーザーのワークロードを対象にしています。複数ユーザー環境ではデフォルトの並列処理はお薦めしません。
SQL文のDOPは、リソース・マネージャで設定または制限することもできます。詳細は、『Oracle Database管理者ガイド』を参照してください。
パラメータPARALLEL_DEGREE_POLICYをAUTOに設定すると、Oracle Databaseでは文がパラレルで実行されるかどうかと使用するDOPが自動的に決定されます。また、文がただちに実行されるのか、あるいは使用可能なシステム・リソースが増えるまでキューに入れるのかも自動的に決定されます。さらに、文が集められたクラスタ・メモリーを利用できるかどうかも決定されます。
次に、並列度ポリシーを自動に設定した場合のパラレル文処理のサマリーを示します。
SQL文が発行されます。
文が解析され、オプティマイザが実行計画を決定します。
初期化パラメータPARALLEL_MIN_TIME_THRESHOLDによって指定されたしきい値がチェックされます。
実行時間がしきい値より短い場合は、SQL文はシリアルで実行されます。
実行時間がしきい値より長い場合は、オプティマイザが計算するDOPに基づいてSQL文はパラレルで実行されます。
詳細は、「並列度の決定」および「自動並列度の制御」を参照してください。
オプティマイザは、文のリソース要件に基づいて文のDOPを自動的に決定します。オプティマイザは実行計画内のすべてのスキャン操作(全表スキャン、索引の高速全スキャンなど)のコストを使用して、その文に必要なDOPを決定します。
ただし、オプティマイザは実際のDOPの上限を設定して、多数のパラレル・サーバー・プロセスによってシステムの障害が発生しないようにします。この上限値は、パラメータPARALLEL_DEGREE_LIMITで設定されます。このパラメータのデフォルト値はCPUで、プロセス数はシステム上のCPUの数(PARALLEL_THREADS_PER_CPU * CPU_COUNT * 使用可能なインスタンス数)によって制限されることを意味し、デフォルトDOPとも呼ばれます。このパラメータの設定を調整することによって、オプティマイザがSQL文に対して選択できるDOPの最大値を制御できます。
オプティマイザによって決定されたDOPは実行計画のNoteセクションに示され(次の実行計画出力を参照)、実行計画文すなわちV$SQL_PLANを使用して表示できます。
EXPLAIN PLAN FOR SELECT SUM(AMOUNT_SOLD) FROM SH.SALES; PLAN TABLE OUTPUT Plan hash value: 672559287 ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost(%CPU) | Time | Pstart | Pstop | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 4 | 5 (0) | 00:00:01 | | | | 1 | SORT AGGREGATE | | 1 | 4 | | | | | | 2 | PX COORDINATOR | | 1 | 4 | | | | | | 3 | PX SEND QC(RANDOM) |:TQ10000| 1 | 4 | 5 (0) | | | | | 4 | SORT AGGREGATE | | 1 | 4 | | | | | | 5 | PX BLOCK ITERATOR | | 960 | 3840 | 5 (0) | 00:00:01 | 1 | 16 | | 6 | TABLE ACCESS FULL | SALES | 960 | 3840 | 5 (0) | 00:00:01 | 1 | 16 | -------------------------------------------------------------------------------------------------- Note ----- - Computed Degree of Parallelism is 2 - Degree of Parallelism of 2 is derived from scan of object SH.SALES
PARALLEL_MIN_TIME_THRESHOLDは、自動DOPを制御する第2の初期化パラメータです。これは、文が自動DOPの対象とみなされるまでの最小実行時間を指定します。デフォルトでは、この値は10秒です。オプティマイザは最初にSQL文のシリアル実行計画を計算します。推定実行経過時間がPARALLEL_MIN_TIME_THRESHOLD (10秒)よりも大きい場合、文は自動DOPの候補になります。
自動DOPを制御する初期化パラメータには、PARALLEL_DEGREE_POLICYとPARALLEL_MIN_TIME_THRESHOLDの2つがあります。これらのパラメータについては、「自動並列度ポリシー」および「自動DOP、パラレル文のキューイングおよびメモリー内パラレル実行の制御」でも説明しています。並列度を制御するために使用できるヒントが2つあります。
次のようにALTER SESSION文を使用してDOPを設定できます。
ALTER SESSION SET parallel_degree_policy = limited; ALTER TABLE emp parallel (degree default);
PARALLELヒントを使用して並列処理を強制することができます。オプションのパラメータとして、文を実行すべきDOPを指定できます。また、NO_PARALLELヒントは、表を作成または変更したDDLのPARALLELパラメータよりも優先されます。次の例では、文のパラレル実行が強制されます。
SELECT /*+parallel */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
次の例では、文のパラレル実行が並列度10で強制されます。
SELECT /*+ parallel(10) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
次の例では、文のシリアル実行が強制されます。
SELECT /*+ no_parallel */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
次の例では、文で使用すべきDOPが計算されます。
SELECT /*+ parallel(auto) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
次の例では、文がOracle Database 11gリリース1(11.1)の動作を使用するように強制されます。
SELECT /*+ parallel(manual) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
パラメータPARALLEL_DEGREE_POLICYがAUTOに設定されている場合、パラレル実行を使用してアクセスされるオブジェクトがSGA(バッファ・キャッシュとも呼ばれる)にキャッシュされることにメリットがあるかどうかが判別されます。オブジェクトをキャッシュするかどうかの決定は、サイズやアクセス頻度などの明確な経験則に基づいて行われます。Oracle RAC環境では、オブジェクトのピースがアクティブ・インスタンスの各バッファ・キャッシュにマップされます。このマッピングを作成することで、オブジェクトの様々な部分もしくはピースを見つけるためにアクセスするバッファ・キャッシュが自動的にわかります。この情報を使用すると、複数のインスタンスが、ディスクから同じ情報を何度も繰り返して読み取ることがなくなり、オブジェクトをキャッシュできるメモリー容量を最大化することができます。オブジェクトのサイズが、バッファ・キャッシュ(シングル・インスタンス)のサイズよりも大きい場合、またはOracle RACクラスタでアクティブ・インスタンス数とバッファ・キャッシュ・サイズを掛けたものよりも大きい場合、オブジェクトはダイレクト・パス読取りを使用して読み取られます。
デフォルトで有効になっているマルチユーザー問合せ調整アルゴリズムにより、システムのロードが上昇すると並列度が低減されます。Oracle Databaseの問合せ調整並列処理を使用すると、データベースはSQL実行時にアルゴリズムを使用して、パラレル操作がリクエストどおりのDOPを受け取るか、低いDOPに下げてシステムのオーバーロードを回避するかを決定します。
高いDOPを使用してパラレル実行を積極的に利用するシステムでは、問合せ調整アルゴリズムによってDOPが下がるのは、ごく少数の操作がパラレルで実行する場合のみです。このアルゴリズムでは最適なリソース使用率が保証されますが、ユーザーによってレスポンス時間が一定しないことがあります。確定したレスポンス時間を必要とする環境では問合せ調整並列処理のみを使用することはお薦めしません。問合せ調整並列処理は、データベース初期化パラメータPARALLEL_ADAPTIVE_MULTI_USERを介して制御されます。
初期化パラメータPARALLEL_DEGREE_POLICYは、自動並列度(DOP)、パラレル文のキューイング、およびメモリー内パラレル実行を有効にするかどうかを制御します。このパラメータには、次の3つの値を指定できます。
MANUAL: 自動DOP、文のキューイングおよびメモリー内パラレル実行を無効にします。パラレル実行の動作をOracle Database 11g リリース2(11.2)よりも前の設定に戻します。これがデフォルトです。
LIMITED: 一部の文については自動DOPを有効にしますが、パラレル文のキューイングおよびメモリー内パラレル実行は無効にします。自動並列度は、PARALLEL句で明示的に宣言されている表または索引にアクセスする文に対してのみ適用されます。特定のDOPが指定された表および索引は、その明示的なDOP設定を使用します。
AUTO: 自動DOP、パラレル文のキューイングおよびメモリー内パラレル実行を有効にします。
デフォルトでは、並列度がオブジェクトに明示的に設定されている場合、またはパラレル・ヒントがSQL文に指定されている場合に限り、パラレル実行が使用されます。使用される並列度は、正確に指定されたものになります。パラレル文のキューイングは行われず、パラレル実行はバッファ・キャッシュを使用しません。パラレル文のキューイングの詳細は、「パラレル文のキューイング」を参照してください。
特定のオブジェクトのサブセットにアクセスするSQL文のサブセットに対してのみ、Oracle Databaseに並列度を自動的に決定させる場合は、PARALLEL_DEGREE_POLICYをLIMITEDに設定し、そのオブジェクトのサブセットにパラレル句を設定します。Oracle Databaseに並列度を自動的に決定させる場合は、PARALLEL_DEGREE_POLICYをAUTOに設定します。
PARALLEL_DEGREE_POLICYがAUTOに設定されている場合、実行計画とハードウェア特性における運用コストに基づいて、文をパラレルで実行すべきかどうかが判別されます。ハードウェア特性にはI/Oキャリブレーション統計が含まれており、自動並列度ポリシー機能を使用するには、この統計を収集する必要があります。
I/Oキャリブレーションを実行して必要な統計が収集されていないと、実行計画出力のNoteセクションに次のテキストが含められます。
automatic DOP: skipped because of IO calibrate statistics are missing
I/Oキャリブレーション統計は、PL/SQL DBMS_RESOURCE_MANAGER.CALIBRATE_IOプロシージャを使用して収集できます。I/Oキャリブレーションは、ハードウェアの物理的な交換を行わない限り、1回のみの処理です。
|
関連項目:
|
パラメータPARALLEL_DEGREE_POLICYをAUTOに設定すると、必要なパラレル・サーバー・プロセスが使用可能でない場合、パラレル実行を必要とするSQL文はキューに入ります。必要なリソースが使用可能になると、SQL文はデキューされ、実行が許可されます。デフォルトのデキュー順序は、文が発行された時刻に基づく単純な先入先出キューです。
次に、パラレル文処理のサマリーを示します。
SQL文が発行されます。
文が解析され、DOPが自動的に決定されます。
使用可能なパラレル・リソースがチェックされます。
十分なパラレル・リソースがあり、キューにリソース待ちの文がない場合は、そのSQL文が実行されます。
十分なパラレル・サーバーがない場合、SQL文は指定された条件に基づいてキューに入れられ、指定された条件が満たされたときにキューの先頭からデキューされます。
文を実行するとアクティブなパラレル・サーバーの数が初期化パラメータPARALLEL_SERVERS_TARGETの値を超える場合、そのパラレル文はキューに入れられます。たとえば、PARALLEL_SERVERS_TARGETが64に設定されており、現在アクティブなサーバーの数が60で、新しいパラレル文が16のパラレル・サーバーを必要とする場合、60に16を加えるとPARALLEL_SERVERS_TARGETの値である64より大きくなるため、そのパラレル文はキューに入れられます。
デフォルト値はPARALLEL_SERVERS_TARGETで指定されます。これはシステムで使用可能なパラレル・サーバー・プロセスの最大数ではなく、パラレル文のキューイングが使用されるまでにパラレル文の実行に使用できるパラレル・サーバー・プロセスの数です。各パラレル文に必要なパラレル・サーバー・プロセスをすべて確保するとともに、パラレル・サーバー・プロセスによるシステムのオーバーロードを回避するため、システムで許容されるパラレル・サーバー・プロセスの最大数(PARALLEL_MAX_SERVERS)未満に設定されます。ただし、文のキューイングがアクティブになっている場合でも、すべてのシリアル(非パラレル)文はただちに実行されます。
文がキューに入っているかどうかを確認するには、resmgr:pq queued待機イベントを使用します。
この項の内容は次のとおりです。
|
注意: この機能は、Oracle Database 11gリリース2(11.2.0.2)以降で使用可能です。 |
デフォルトでは、パラレル文のキューは先入先出キューとして動作します。リソース・プランを構成および設定して、パラレル文をデキューする順序と、各ワークロードまたはコンシューマ・グループが使用するパラレル・サーバーの数を管理できます。
リソース・プランとコンシューマ・グループは、DBMS_RESOURCE_MANAGER PL/SQLパッケージを使用して作成されます。リソース・プランは、各コンシューマ・グループに対するディレクティブのコレクションから構成され、パラレル・サーバーなどの各種データベース・リソースの管理と割当てを指定します。リソース・プランは、RESOURCE_MANAGER_PLANパラメータをリソース・プランの名前に設定すると有効になります。
次のセクションでは、並列度ポリシーをAUTOに設定した場合に、コンシューマ・グループのパラレル文処理を管理するために使用できるディレクティブについて説明します。
どのような場合でも、パラレル文のキューはOracle RACデータベース上の単一キューとして管理されます。各コンシューマ・グループに対する制限は、そのコンシューマ・グループに属するOracle RACデータベースのすべてのセッションに適用されます。パラレル文のキューイングは、データベース・インスタンス全体での初期化パラメータPARALLEL_SERVERS_TARGETの合計値に基づいて発生します。
|
関連項目:
|
リソース・マネージャを使用して、パラレル文がパラレル文キューからデキューされる順序を管理できます。特定のコンシューマ・グループのパラレル文は、常に先入先出の順序でデキューされます。ディレクティブmgmt_p1 ... mgmt_p8を使用して、どのコンシューマ・グループのパラレル文を次にデキューするかを決定します。これらのディレクティブは、DBMS_RESOURCE_MANAGER PL/SQLパッケージ内のCREATE_PLAN_DIRECTIVEプロシージャまたはUPDATE_PLAN_DIRECTIVEプロシージャを使用して構成されます。
たとえば、コンシューマ・グループPQ_HIGH、PQ_MEDIUMおよびPQ_LOWを作成し、優先順位に基づいてパラレル文セッションをこれらのコンシューマ・グループにマップします。次にリソース・プランを作成し、mgmt_p1をPQ_HIGHに70%、PQ_MEDIUMに25%、PQ_LOWに5%にそれぞれ設定します。これは、PQ_HIGHの文が次にデキューされる確率は70%、PQ_MEDIUMが次にデキューされる確率は25%、そしてPQ_LOWが次にデキューされる確率は5%であることを示しています。
リソース・マネージャを使用して、優先順位の低いコンシューマ・グループのパラレル文がパラレル文処理に使用できるパラレル・サーバーの数を制限できます。リソース・マネージャを使用してパラレル文セッションを異なるコンシューマ・グループにマップし、それぞれに使用できるパラレル・サーバーの数に特定の制限を持たせることができます。この制限を指定した場合、コンシューマ・グループのパラレル文は、この制限を超えるとキューに入れられます。
この制限は、データベースにコンシューマ・グループの優先順位が高いものと低いものがある場合に役立ちます。制限を設けないと、優先順位の低いコンシューマ・グループから大量のパラレル文が発行されて、すべてのパラレル・サーバーが使用される可能性があります。優先順位の高いコンシューマ・グループからパラレル文が発行されたときに、リソース割当てディレクティブにより、その優先順位の高いパラレル文を確実に最初にデキューすることができます。優先順位の低いコンシューマ・グループが使用できるパラレル・サーバーの数を制限することにより、優先順位の高いコンシューマ・グループが使用できるパラレル・サーバーを常に確保しておくことができます。
コンシューマ・グループが使用するパラレル・サーバーを制限するには、DBMS_RESOURCE_MANAGERパッケージで、CREATE_PLAN_DIRECTIVEプロシージャのparallel_target_percentageパラメータを使用するか、UPDATE_PLAN_DIRECTIVEプロシージャのnew_parallel_target_percentageパラメータを使用します。parallel_target_percentageおよびnew_parallel_target_percentageパラメータは、PARALLEL_SERVERS_TARGETで指定されるOracle RAC全体のパラレル・サーバー・プールのうち、コンシューマ・グループが使用できる最大パーセンテージを指定します。
たとえば、Oracle RACデータベース・システムでは、初期化パラメータPARALLEL_SERVERS_TARGETは2ノードで32に設定されるため、キューイングが開始されるまでに使用できるパラレル・サーバーの合計数は、32 x 2 = 64です。使用可能なパラレル・サーバーのうち50%をコンシューマ・グループPQ_LOWが使用するように設定し(parallel_target_percentage = 50)、優先順位の低い文をPQ_LOWコンシューマ・グループにマップできます。このシナリオでは、コンシューマ・グループPQ_LOWのパラレル文は、64 x 50% = 32のパラレル・サーバーに制限されます。これは、たとえ非アクティブなまたは未使用のパラレル・サーバーがこれより多くあったとしても同じです。このシナリオでは、コンシューマ・グループPQ_LOWの文は、32のパラレル・サーバーをすべて使用すると、キューに入れられます。
1つのデータベース内に並列度ポリシーをMANUALに設定したセッションとAUTOに設定したセッションを混在させることが可能です。このシナリオでは、並列度ポリシーをAUTOに設定したセッションのみキューに入れることができます。ただし、並列度ポリシーをMANUALに設定したセッションで使用されるパラレル・サーバーは、コンシューマ・グループで使用されるパラレル・サーバーの合計数に含まれます。
ユーザーに対するパラレル・リソースの制限の詳細は、「ユーザーのプロセスが多すぎる場合」および「コンシューマ・グループを使用したユーザーに対するリソース数の制限」を参照してください。
リソース・マネージャを使用してキューのタイムアウトの最大値を設定し、パラレル文がキューに長時間入ったままにならないようにすることができます。リソース・マネージャを使用して、リソース・プランでパラレル文セッションをそれぞれ特定のタイムアウト最大値を持つ異なるコンシューマ・グループにマップできます。
キューのタイムアウトを管理するには、DBMS_RESOURCE_MANAGERパッケージで、CREATE_PLAN_DIRECTIVEプロシージャのparallel_queue_timeoutパラメータを使用するか、UPDATE_PLAN_DIRECTIVEプロシージャのnew_parallel_queue_timeoutパラメータを使用します。parallel_queue_timeoutおよびnew_parallel_queue_timeoutパラメータは、文がコンシューマ・グループのパラレル文のキューに留まることのできる時間を秒単位で指定します。タイムアウト時間が経過すると、文はエラーORA-7454により停止され、パラレル文キューから削除されます。
リソース・マネージャを使用して、特定のコンシューマ・グループに対する並列度を制限できます。リソース・マネージャを使用して、リソース・プランでパラレル文セッションをそれぞれ特定の並列度制限を持つ異なるコンシューマ・グループにマップできます。
コンシューマ・グループの並列度制限を管理するには、DBMS_RESOURCE_MANAGERパッケージでCREATE_PLAN_DIRECTIVEプロシージャのparallel_degree_limit_p1パラメータを使用するか、DBMS_RESOURCE_MANAGERパッケージでUPDATE_PLAN_DIRECTIVEプロシージャのnew_parallel_degree_limit_p1パラメータを使用します。parallel_degree_limit_p1およびnew_parallel_degree_limit_p1パラメータは、任意の操作について並列度の制限を指定します。
たとえば、コンシューマ・グループPQ_HIGH、PQ_MEDIUMおよびPQ_LOWを作成し、優先順位に基づいてパラレル文セッションをこれらのコンシューマ・グループにマップします。それから並列度の制限を指定するリソース・プランを作成し、PQ_HIGHの制限値を16、PQ_MEDIUMの制限値を8、PQ_LOWの制限値を2に設定します。
このシナリオでは、リソース・マネージャを使用してコンシューマ・グループを設定してパラレル・キュー内の文を管理する方法について説明します。このシナリオでは、3種類のSQL文で構成されるデータ・ウェアハウスのワークロードについて考えます。
実行時間の短いSQL文
実行時間が短い文とは、実行時間が1分以内の文を指します。このような文はレスポンスが非常に良いことが予想されます。
実行時間が中程度のSQL文
実行時間が中程度の文とは、実行時間が1分より長く15分以内の短い文を指します。このような文はレスポンスがある程度良いことが予想されます。
実行時間の長いSQL文
実行時間の長い文とは、実行時間が15分より長い非定型の問合せや複雑な問合せを指します。このような文は長時間かかると予想されます。
このデータ・ウェアハウス・ワークロードでは、実行時間の短い文でより良いレスポンスが求められています。この目標を達成するには、次の点について確認する必要があります。
実行時間の長い文がパラレル・サーバー・リソースをすべて使用して、実行時間のより短い文がパラレル文のキューで待機させられることがないようにします。
実行時間の短い文と長い文の両方がキューに入っている場合は、実行時間の短い文を長い文よりも先にデキューするようにします。
実行時間の短い問合せのDOPを制限します。これはDOPを高くすることで得られる高速化は、多数のパラレル・サーバーの使用を正当化するほど重要ではないためです。
例8-3に、リソース・マネージャを使用してコンシューマ・グループを設定して、パラレル文キュー内の文に優先順位を設定する方法を示します。この例については、次の内容に注意してください。
デフォルトでは、ユーザーはコンシューマ・グループOTHER_GROUPSに割り当てられています。SQL文の推定実行時間が1分(60秒)より長い場合は、ユーザーはMEDIUM_SQL_GROUPに切り替わります。switch_for_callがTRUEに設定されている場合、その文の完了後、ユーザーはOTHER_GROUPSに戻ります。ユーザーがMEDIUM_SQL_GROUPにあり、文の推定実行時間が15分(900秒)より長い場合は、ユーザーはLONG_SQL_GROUPに切り替わります。同様に、switch_for_callがTRUEに設定されている場合は、問合せの完了後、ユーザーはOTHER_GROUPSに戻ります。切替え処理の実行に使用されるディレクティブは、switch_time、switch_estimate、switch_for_callおよびswitch_groupです。
アクティブなパラレル・サーバーの数が初期化パラメータPARALLEL_SERVERS_TARGETの値に達すると、それ以降のパラレル文はキューに入れられます。mgmt_p[1-8]ディレクティブは、パラレル・サーバーが使用可能になったときにパラレル文をデキューする順番を制御します。この例では、SYS_GROUPのmgmt_p1が100%に設定されているため、SYS_GROUPのパラレル文は常に最初にデキューされます。SYS_GROUPのパラレル文がキューにない場合、OTHER_GROUPSのパラレル文は70%、MEDIUM_SQL_GROUPの文は20%、LONG_SQL_GROUPの文は10%の確率でデキューされます。
OTHER_GROUPSから発行されるパラレル文は、parallel_degree_limit_p1ディレクティブの設定により、DOPが4に制限されます。
LONG_SQL_GROUPグループのパラレル文がパラレル・サーバーをすべて使用して、OTHER_GROUPSやMEDIUM_SQL_GROUPのパラレル文を長時間待機させることのないようにするには、そのparallel_target_percentageディレクティブを50%に設定します。つまり、LONG_SQL_GROUPが初期化パラメータPARALLEL_SERVERS_TARGETで設定したパラレル・サーバーの50%まで使用すると、それ以降はそのグループのパラレル文を強制的にキューで待機させます。
LONG_SQL_GROUPグループのパラレル文はかなり長い時間キューに留まる可能性があるため、14400秒(4時間)のタイムアウトが設定されます。LONG_SQL_GROUPのパラレル文は、キューで4時間待機すると、エラーORA-7454により停止されます。
例8-3 コンシューマ・グループを使用したパラレル文キュー内の優先順位の設定
BEGIN
DBMS_RESOURCE_MANAGER.CREATE_PENDING_AREA();
/* Create consumer groups.
* By default, users start in OTHER_GROUPS, which is automatically
* created for every database.
*/
DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
'MEDIUM_SQL_GROUP',
'Medium-running SQL statements, between 1 and 15 minutes. Medium priority.');
DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
'LONG_SQL_GROUP',
'Long-running SQL statements of over 15 minutes. Low priority.');
/* Create a plan to manage these consumer groups */
DBMS_RESOURCE_MANAGER.CREATE_PLAN(
'REPORTS_PLAN',
'Plan for daytime that prioritizes short-running queries');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'SYS_GROUP', 'Directive for sys activity',
mgmt_p1 => 100);
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'OTHER_GROUPS', 'Directive for short-running queries',
mgmt_p2 => 70,
parallel_degree_limit_p1 => 4,
switch_time => 60, switch_estimate => TRUE, switch_for_call => TRUE,
switch_group => 'MEDIUM_SQL_GROUP');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'MEDIUM_SQL_GROUP', 'Directive for medium-running queries',
mgmt_p2 => 20,
parallel_target_percentage => 80,
switch_time => 900, switch_estimate => TRUE, switch_for_call => TRUE,
switch_group => 'LONG_SQL_GROUP');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'LONG_SQL_GROUP', 'Directive for medium-running queries',
mgmt_p2 => 10,
parallel_target_percentage => 50,
parallel_queue_timeout => 14400);
DBMS_RESOURCE_MANAGER.SUBMIT_PENDING_AREA();
END;
/
/* Allow all users to run in these consumer groups */
EXEC DBMS_RESOURCE_MANAGER_PRIVS.GRANT_SWITCH_CONSUMER_GROUP(
'public', 'MEDIUM_SQL_GROUP', FALSE);
EXEC DBMS_RESOURCE_MANAGER_PRIVS.GRANT_SWITCH_CONSUMER_GROUP(
'public', 'LONG_SQL_GROUP', FALSE);
|
注意: この機能は、Oracle Database 11gリリース2(11.2.0.2)以降で使用可能です。 |
複数のパラレル文からなるレポートやバッチ・ジョブをできるだけ高速に完了することが重要な場合がよくあります。たとえば、多数のレポートを同時に開始した場合、すべてのレポートをできるだけすばやく完了させる必要があります。ただし、すべてのレポートを同時に終わらせるのではなく、特定のレポートを最初に完了させたい場合もあります。
レポートに複数のパラレル文が含まれており、PARALLEL_DEGREE_POLICYがAUTOに設定されている場合、それぞれのパラレル文がビジー状態のデータベース上でキューに待機する可能性があります。たとえば、次の手順では、SQL文の処理でのシナリオについて説明します。
serial statement parallel query - dop 8 -> wait in queue serial statement parallel query - dop 32 -> wait in queue parallel query - dop 4 -> wait in queue
レポートをすばやく完了させるには、パラレル文が次のように動作するようグループ化する必要があります。
start SQL block serial statement parallel query - dop 8 -> first parallel query: ok to wait in queue serial statement parallel query - dop 32 -> avoid or minimize wait parallel query - dop 4 -> avoid or minimize wait end SQL block
パラレル文をグループ化するには、DBMS_RESOURCE_MANAGER PL/SQLパッケージでBEGIN_SQL_BLOCKおよびEND_SQL_BLOCKプロシージャを使用します。各コンシューマ・グループに対して、コンシューマ・グループの各パラレル文に関連付けられた時間によってパラレル文キューの順序付けを行います。通常は、パラレル文に関連付けられた時間は、その文がエンキューされた時間で、つまりキューは先入先出(FIFO)であることを意味します。BEGIN_SQL_BLOCKおよびEND_SQL_BLOCKプロシージャを使用してパラレル文をSQLブロックにグループ化する場合、最初にキューイングされたパラレル文は同様にエンキューされた時間を使用します。ただし、2番目とその後続のパラレル文はすべて特別な扱いを受け、SQLブロック内の最初にキューイングされたパラレル文のエンキュー時間を使用してエンキューされます。この機能により、文がパラレル文キューの前方に移動することがよくあります。この優先的な扱いにより、待機時間を最小限に抑えられます。
|
関連項目: DBMS_RESOURCE_MANAGERパッケージの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
SQL文でNO_STATEMENT_QUEUINGおよびSTATEMENT_QUEUINGヒントを使用して、パラレル文のキューイングを管理できます。
NO_STATEMENT_QUEUING
PARALLEL_DEGREE_POLICYをAUTOに設定すると、このヒントにより文がパラレル文キューに入らないようにすることができます。次に例を示します。
SELECT /*+ NO_STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;
STATEMENT_QUEUING
PARALLEL_DEGREE_POLICYをAUTOに設定しない場合は、このヒントにより文を遅延させ、リクエストされたDOPでパラレス処理を実行できる場合にのみ実行させることができます。次に例を示します。
SELECT /*+ STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;
インスタンスが起動すると、Oracle Databaseによって、パラレル操作に使用可能なパラレル実行サーバーのプールが作成されます。 初期化パラメータPARALLEL_MIN_SERVERSによって、Oracle Databaseがインスタンス起動時に作成するパラレル実行サーバーの数が指定されます。
パラレル操作を実行するとき、パラレル実行コーディネータは、パラレル実行サーバーをプールから獲得して操作に割り当てます。必要であれば、Oracle Databaseは操作のためにパラレル実行サーバーを追加作成することもできます。これらのパラレル実行サーバーは、実行の間は操作とともにあります。文が完全に処理されると、パラレル実行サーバーはプールに戻ります。
パラレル操作の数が増えると、着信リクエストを扱うためにOracle Databaseによって追加のパラレル実行サーバーが作成されます。ただし、初期化パラメータPARALLEL_MAX_SERVERSで指定された値を超えるパラレル実行サーバーが、1つのインスタンスに対して作成されることはありません。
パラレル操作の数が減ると、一定期間アイドル状態になっていたパラレル実行サーバーがOracle Databaseによって停止されます。パラレル実行サーバーのアイドル状態が長く続いても、プールのサイズがPARALLEL_MIN_SERVERSの値よりも小さくなることはありません。
Oracle Databaseでは、リクエストよりも少ないプロセス数でパラレル操作を処理することができます。プールのすべてのパラレル実行サーバーが占有され、最大数のパラレル実行サーバーが起動されている場合、パラレル実行コーディネータはシリアル処理に切り替えます。
初期化パラメータPARALLEL_MIN_PERCENTの使用方法の詳細は『Oracle Databaseリファレンス』、PARALLEL_MIN_PERCENTおよびPARALLEL_MAX_SERVERS初期化パラメータの詳細は「パラレル実行のための一般的なパラメータのチューニング」を参照してください。
並列処理の基本作業ユニットはグラニュルと呼ばれます。Oracle Databaseによって、パラレル化対象の操作(表のスキャン、表の更新、索引の作成など)がグラニュル単位に分割されます。パラレル実行プロセスは操作を1回に1グラニュルずつ実行します。グラニュルの数とサイズは並列度(DOP)と相関関係があります。また、問合せサーバー・プロセス間で作業を適切に均衡できるかどうかに影響します。
ブロック・レンジ・グラニュルは、ほとんどのパラレル操作の基本ユニットです。パーティション表の場合でも同様です。このため、Oracle Databaseの観点では、並列度はパーティション数に関係しません。
ブロック・レンジ・グラニュルは、表の物理ブロックのレンジです。グラニュルの数とサイズは、関連するすべてのパラレル実行サーバーにおいて作業の分散を最適化して均衡させるように、実行時にOracle Databaseによって計算されます。グラニュルの数とサイズは、オブジェクトのサイズとDOPによって決まります。ブロック・レンジ・グラニュルは、表または索引の静的な事前割当てには影響を受けません。グラニュルの計算の際に、Oracle DatabaseはDOPを考慮に入れて、可能な場合には競合を避けるために、異なるデータファイルのグラニュルを各パラレル実行サーバーに割り当てようとします。また、Oracle Databaseは、パラレル実行サーバーとディスクの物理的な近接性を利用するために、超並列処理(MPP)システム上のグラニュルのディスク・アフィニティを考慮します。
パーティション・グラニュルが使用されるとき、パラレル・サーバー・プロセスは表または索引のパーティションまたはサブパーティション全体を処理します。パーティション・グラニュルは表または索引の作成時の構造によって静的に決まるため、パーティション・グラニュルではブロック・グラニュルのように操作を柔軟にパラレル実行することはできません。使用可能な最大のDOPはパーティション数です。このため、システムの使用率とパラレル実行サーバー間のロード・バランシングが制限されることがあります。
表または索引に対するパラレル・アクセスにパーティション・グラニュルが使用されるときは、比較的多数のパーティション(理想的にはDOPの3倍)を使用することをお薦めします。これによって、Oracle Databaseでは作業を問合せサーバー・プロセス間で効率よく均衡化できます。
パーティション・グラニュルは、パラレル索引レンジ・スキャン、2つの同一レベル・パーティション表の結合(問合せオプティマイザがパーティション・ワイズ結合を選択した場合)、およびパーティション・オブジェクトの複数パーティションを変更するパラレル操作の基本ユニットです。これらの操作には、パーティション索引のパラレル作成やパーティション表のパラレル作成も含まれます。
文の実行計画を調べることによって、どのタイプのグラニュルが使用されたかがわかります。表または索引アクセスの上の行PX BLOCK ITERATORは、ブロック・レンジ・グラニュルが使用されたことを示しています。次の例では、SALES表のTABLE FULL ACCESSのすぐ上の実行計画出力の7行目に示されています。
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - filter("CUST_ID"<=22810 AND "CUST_ID">=22300)
パーティション・グラニュルが使用された場合、実行計画出力の表または索引アクセスの上に行PX PARTITION RANGEが表示されます。次の例では、この文が表内の16個のパーティションすべてにアクセスするため、計画の6行目にPX PARTITION RANGE ALLと示されています。すべてのパーティションにアクセスするのでない場合は、単にPX PARTITION RANGEと表示されます。
---------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000| 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES| 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST|26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - access("CUST_ID"<=22810 AND "CUST_ID">=22300)
パフォーマンスを最適化するには、すべてのパラレル実行サーバーのワークロードを均等にする必要があります。ブロック・レンジまたはパラレル実行サーバーによってパラレルで実行されるSQL文では、ワークロードはパラレル実行サーバー間で動的に分割されます。この方法では、一部のパラレル実行サーバーで実行する作業が他のプロセスよりも大幅に多くなる、ワークロードの偏りが最小限に抑えられます。
パーティション単位でパラレル実行される比較的少数のSQL文では、ワークロードがパーティションで均等に分散されていれば、パラレル実行サーバーの数とパーティションの数を一致させるか、パーティション数がプロセス数の倍数になるようにDOPを選択することで、パフォーマンスを最適化できます。これは、Oracle9iよりも前に作成された表に対するパーティション・ワイズ結合とパラレルDMLに適用されます。詳細は、「並列度の制限」を参照してください。
たとえば、表に16個のパーティションがあり、パラレル操作の処理がそれらのパーティション間で均等に分割されるとします。16個のパラレル実行サーバー(DOPが16)を使用すると、1プロセスの場合のおよそ10分の1の時間で作業を行うことができます。また、5プロセスを使用すると5分の1の時間、2プロセスを使用すると2分の1の時間になります。
ただし、16個のパーティションで作業を行うために15個のプロセスを使用した場合は、1つのパーティションの作業を最初に終了したプロセスが16番目のパーティションの作業を開始し、それ以外のプロセスは作業を終了してアイドルになります。この構成では、作業をパーティション間で均等に分割しても、優れたパフォーマンスは得られません。作業の分割が不均等な場合、最後に残ったパーティションの作業が他のパーティションに比べて多いか少ないかによってパフォーマンスが変わります。
同様に、6個のプロセスを使用して16個のパーティションを処理し、作業を均等に分割するとします。この場合、各プロセスは最初のパーティションを終了してから2番目のパーティションを処理しますが、3番目のパーティションを処理するのは4つのプロセスのみで、残りの2つはアイドルになります。
一般的に、P個のパラレル実行サーバーを使用したN個のパーティションに対するパラレル操作の実行時間がN/Pになると想定することはできません。この計算式は、最後のパーティションを処理する間に待機する必要のあるプロセスが存在する可能性を考慮に入れていません。ただし、適切なDOPを選択すると、ワークロードの偏りを最小にしてパフォーマンスを最適化することができます。
デフォルトでは、Oracle RAC環境で、パラレルで実行されるSQL文はクラスタ内のすべてのノードで実行できます。このクロスノードまたはノード間パラレル実行を実現するには、ノード間パラレル実行によってインターコネクト・トラフィックが増大する可能性があるため、Oracle RAC環境でのインターコネクトのサイズが適切である必要があります。サーバーからストレージ・サブシステムへのI/O帯域幅に比べてインターコネクトの帯域幅がかなり小さい場合、パラレル実行を単一ノードまたは限られたノード数に制限した方がよい場合があります。ノード間パラレル実行は、インターコネクトのサイズが小さいと対応できません。
ノード間パラレル実行を制限するには、初期化パラメータPARALLEL_FORCE_LOCALを使用してOracle RAC環境でパラレル実行を制御します。このパラメータをTRUEに設定することによって、パラレル・サーバーはSQL文が開始されたのと同じOracle RACノードでのみ実行されます。
Oracle Real Application Clustersでは、パラレルSQL操作に参加するインスタンス数を制限するためにサービスが使用されます。デフォルトのサービスには使用可能なすべてのインスタンスが含まれます。それぞれが1つ以上のインスタンスを含むサービスを必要な数のみ作成できます。パラレル実行サーバーがインスタンスで使用されるのは、そのインスタンスが指定サービスのメンバーである場合のみです。
|
関連項目: インスタンス・グループの詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』を参照してください。 |