| Oracle® Streams拡張例 11gリリース2 (11.2) B61356-02 |
|


 前 |
 次 |
この章では、Oracle Streamsを使用して構成できるn-wayレプリケーション環境の例を説明します。
この章の内容は次のとおりです。
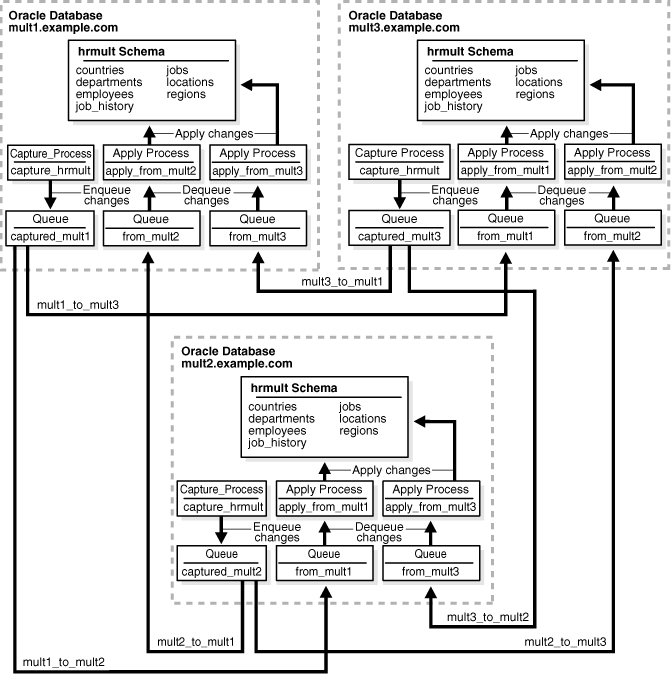
この例では、Oracle Streamsを使用して、3つのOracle Database間でスキーマのデータをレプリケートする方法について説明します。hrmultスキーマ内の表に対するDML変更とDDL変更が、この環境の全データベースで取得され、この環境の他の各データベースに伝播します。
この種の環境は、n-wayレプリケーション環境と呼ばれます。n-wayレプリケーション環境は、複数のソース・データベースで変更が取得およびレプリケートされる、複数ソース・レプリケーション環境の一種です。
図3-1に、この環境の概要を示します。
図3-1に示すように、この例が完了すると、すべてのデータベースにhrmultスキーマが含まれることになります。ただし、この例の開始時には、hrmultスキーマはmult1.example.comにのみ存在します。この例の実行中に、mult2.example.comとmult3.example.comでhrmultスキーマをインスタンス化します。
この例では、Oracle Streamsを使用して次の一連のアクションが実行されます。
インスタンス化の後に、各データベースの取得プロセスが、hrmultスキーマ内のすべての表に対するDML変更とDDL変更を取得し、それをローカル・キューにエンキューします。
各データベースの伝播が、これらの変更を環境内の他の全データベースに伝播します。
各データベースの適用プロセスが、環境内の他のデータベースから受信したhrmultスキーマ内の変更を適用します。
この例では、適用プロセスにデフォルトの適用タグを使用してソース・データベースに変更を戻すことは行いません。適用プロセスを作成すると、その適用プロセスによって適用された変更は、デフォルトで'00' (2つのゼロ)というタグが付いたREDOエントリ持ちます。DBMS_STREAMS_ADMパッケージによって作成されたルールにはis_null_tag()='Y'条件がデフォルトで設定されており、REDOエントリのタグがNULLの場合、この条件によって、各取得プロセスは確実にREDOログ・エントリの変更のみを取得するため、これらの変更が再取得されることはありません。
|
関連項目:
|
この章の例を開始する前に、前提条件となる次の作業を完了する必要があります。
Oracle Streams環境内の各データベースで、次の初期化パラメータを指定の値に設定します。
GLOBAL_NAMES: このパラメータはTRUEに設定する必要があります。データベースのグローバル名がmult1.example.com、mult2.example.comおよびmult3.example.comであることを確認してください。
COMPATIBLE: このパラメータは10.2.0以上に設定する必要があります。
PROCESSESおよびSESSIONS初期化パラメータが、この例で使用されるすべてのOracle Streamsクライアントに対して十分に大きい値に設定されていることを確認してください。この例では、各データベースで1つの取得プロセス、2つの伝播および2つの適用プロセスを構成します。
STREAMS_POOL_SIZE: オプションで、このパラメータを環境内の各データベースの適切な値に設定します。このパラメータでは、Oracle Streamsプールのサイズを指定します。Oracle Streamsプールは、バッファ・キューにメッセージを格納し、パラレル取得およびパラレル適用中の内部通信に使用されます。MEMORY_TARGET、MEMORY_MAX_TARGETまたはSGA_TARGET初期化パラメータを0 (ゼロ)以外の値に設定した場合、Oracle Streamsプールのサイズは自動的に管理されます。
|
注意: この例を正しく実行するには、他の初期化パラメータの設定を変更することが必要な場合もあります。 |
|
関連項目: Oracle Streams環境で重要なその他の初期化パラメータについては、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
取得される変更を生成するデータベースは、ARCHIVELOGモードで実行している必要があります。この例では、すべてのデータベースで変更が取得されるため、すべてのデータベースをARCHIVELOGモードで実行する必要があります。
|
関連項目: ARCHIVELOGモードでデータベースを実行する方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
ネットワークとOracle Netを、3つのデータベースすべてが相互に通信できるように構成します。
|
関連項目: 『Oracle Database Net Services管理者ガイド』 |
レプリケーション環境の各データベースでOracle Streams管理者を作成します。この例では、データベースmult1.example.com、mult2.example.comおよびmult3.example.comで作成します。この例では、Oracle Streams管理者のユーザー名がstrmadminであると想定しています。
|
関連項目: Oracle Streams管理者を作成する方法は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
この例のために、mult1.example.comデータベースに新しいスキーマhrmultを作成します。n-way環境では、この新しいスキーマがレプリケートされます。
次の手順を実行して、データ・ポンプ・エクスポート/インポートを使用し、hrスキーマのコピーであるhrmultスキーマを作成します。
SQL*Plusで、管理ユーザーとしてmult1.example.comデータベースに接続します。
SQL*Plusでデータベースに接続する手順については、『Oracle Database管理者ガイド』を参照してください。
エクスポート・ダンプ・ファイルおよびエクスポート・ログ・ファイルを保持するディレクトリ・オブジェクトを作成します。このディレクトリ・オブジェクトは、コンピュータ・システム上のアクセス可能な任意のディレクトリを指すことができます。たとえば、次の文を実行すると、/usr/tmpディレクトリを指すディレクトリ・オブジェクトdp_hrmult_dirが作成されます。
CREATE DIRECTORY dp_hrmult_dir AS '/usr/tmp';
コンピュータ・システム上の適切なディレクトリに置き換えてください。
ソース・データベースの現行のシステム変更番号(SCN)を判別します。
SELECT DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER FROM DUAL;
この問合せで戻されるSCN値を、手順5でFLASHBACK_SCNデータ・ポンプ・エクスポート・パラメータに指定します。hrスキーマには表間の外部キー制約が含まれるため、FLASHBACK_SCNエクスポート・パラメータ、または類似のエクスポート・パラメータは、エクスポート中に指定する必要があります。
SQL*Plusを終了します。
mult1.example.comデータベース・サイトのコマンドラインでデータ・ポンプを使用して、mult1.example.comデータベースのhrスキーマをエクスポートします。手順3で戻されたSCN値をFLASHBACK_SCNパラメータに指定してください。
expdp system SCHEMAS=hr DIRECTORY=dp_hrmult_dir
DUMPFILE=hrmult_schema.dmp FLASHBACK_SCN=flashback_scn_value
mult1.example.comデータベース・サイトのコマンドラインでデータ・ポンプを使用して、インポート・ダンプ・ファイルhrmult_schema.dmpをインポートします。
impdp system SCHEMAS=hr DIRECTORY=dp_hrmult_dir DUMPFILE=hrmult_schema.dmp REMAP_SCHEMA=hr:hrmult
SQL*Plusで、管理ユーザーとしてmult1.example.comデータベースに接続します。
ALTER USER文を使用して、mult1.example.comデータベースの新しいユーザーhrmultにパスワードを割り当てます。
将来hrmultユーザーとしてログインできるように、割り当てたパスワードを覚えておいてください。
この項では、3つのOracle Databaseを含むOracle Streamsレプリケーション環境にキューおよびデータベース・リンクを作成する方法について説明します。この章の残りの項は、この項で構成するキューおよびデータベース・リンクによって異なります。
次の手順を実行して、すべてのデータベースでキューおよびデータベース・リンクを作成します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_setup_mult.out /*
Oracle Streams管理者としてmult1.example.comに接続します。
*/ CONNECT strmadmin@mult1.example.com /*
SET_UP_QUEUEプロシージャを実行して、次のキューを作成します。
captured_mult1キュー: mult1.example.comデータベースで取得され、他のデータベースに伝播される変更を保持します。
from_mult2キュー: mult2.example.comデータベースで取得され、mult1.example.comデータベースに伝播されて適用される変更を保持します。
from_mult3キュー: mult3.example.comデータベースで取得され、mult1.example.comデータベースに伝播されて適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、各キューに次のアクションが実行されます。
Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用するキュー表の作成。
Oracle Streams管理者(strmadmin)が所有するANYDATAキューの作成。
キューの起動。
*/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.captured_mult1_table',
queue_name => 'strmadmin.captured_mult1');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult2_table',
queue_name => 'strmadmin.from_mult2');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult3_table',
queue_name => 'strmadmin.from_mult3');
END;
/
/*
現行データベースから環境内の他のデータベースへのデータベース・リンクを作成します。
*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE CREATE DATABASE LINK mult2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult2.example.com'; CREATE DATABASE LINK mult3.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult3.example.com'; /*
この例では、トランザクションの最新時刻に基づいて競合解消が行われるようにhrmultスキーマ内の表を構成します。
hrmultユーザーとしてmult1.example.comに接続します。
*/ CONNECT hrmult@mult1.example.com /*
hrmultスキーマ内の各表にtime列を追加します。
*/ ALTER TABLE hrmult.countries ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.departments ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.employees ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.job_history ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.jobs ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.locations ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hrmult.regions ADD (time TIMESTAMP WITH TIME ZONE); /*
hrmultスキーマ内の各表用のトリガーを作成し、トランザクションによって挿入または更新された各行のトランザクションの時刻を挿入します。
*/
CREATE OR REPLACE TRIGGER hrmult.insert_time_countries
BEFORE
INSERT OR UPDATE ON hrmult.countries FOR EACH ROW
BEGIN
-- Consider time synchronization problems. The previous update to this
-- row might have originated from a site with a clock time ahead of the
-- local clock time.
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_departments
BEFORE
INSERT OR UPDATE ON hrmult.departments FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_employees
BEFORE
INSERT OR UPDATE ON hrmult.employees FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_job_history
BEFORE
INSERT OR UPDATE ON hrmult.job_history FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_jobs
BEFORE
INSERT OR UPDATE ON hrmult.jobs FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_locations
BEFORE
INSERT OR UPDATE ON hrmult.locations FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
CREATE OR REPLACE TRIGGER hrmult.insert_time_regions
BEFORE
INSERT OR UPDATE ON hrmult.regions FOR EACH ROW
BEGIN
IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN
:NEW.TIME := SYSTIMESTAMP;
ELSE
:NEW.TIME := :OLD.TIME + 1 / 86400;
END IF;
END;
/
/*
Oracle Streams管理者としてmult2.example.comに接続します。
*/ CONNECT strmadmin@mult2.example.com /*
SET_UP_QUEUEプロシージャを実行して、次のキューを作成します。
captured_mult2キュー: mult2.example.comデータベースで取得され、他のデータベースに伝播される変更を保持します。
from_mult1キュー: mult1.example.comデータベースで取得され、mult2.example.comデータベースに伝播されて適用される変更を保持します。
from_mult3キュー: mult3.example.comデータベースで取得され、mult2.example.comデータベースに伝播されて適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、各キューに次のアクションが実行されます。
Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用するキュー表の作成。
Oracle Streams管理者(strmadmin)が所有するANYDATAキューの作成。
キューの起動。
*/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.captured_mult2_table',
queue_name => 'strmadmin.captured_mult2');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult1_table',
queue_name => 'strmadmin.from_mult1');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult3_table',
queue_name => 'strmadmin.from_mult3');
END;
/
/*
現行データベースから環境内の他のデータベースへのデータベース・リンクを作成します。
*/ CREATE DATABASE LINK mult1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult1.example.com'; CREATE DATABASE LINK mult3.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult3.example.com'; /*
Oracle Streams管理者としてmult3.example.comに接続します。
*/ CONNECT strmadmin@mult3.example.com /*
SET_UP_QUEUEプロシージャを実行して、次のキューを作成します。
captured_mult3キュー: mult3.example.comデータベースで取得され、他のデータベースに伝播される変更を保持します。
from_mult1キュー: mult1.example.comデータベースで取得され、mult3.example.comデータベースに伝播されて適用される変更を保持します。
from_mult2キュー: mult2.example.comデータベースで取得され、mult3.example.comデータベースに伝播されて適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、各キューに次のアクションが実行されます。
Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用するキュー表の作成。
Oracle Streams管理者(strmadmin)が所有するANYDATAキューの作成。
キューの起動。
*/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.captured_mult3_table',
queue_name => 'strmadmin.captured_mult3');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult1_table',
queue_name => 'strmadmin.from_mult1');
END;
/
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.from_mult2_table',
queue_name => 'strmadmin.from_mult2');
END;
/
/*
現行データベースから環境内の他のデータベースへのデータベース・リンクを作成します。
*/ CREATE DATABASE LINK mult1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult1.example.com'; CREATE DATABASE LINK mult2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'mult2.example.com'; /*
streams_setup_mult.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
次の手順を実行して、Oracle Streams n-wayレプリケーション環境を構成します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_mult.out /*
strmadminユーザーとしてmult1.example.comに接続します。
*/ CONNECT strmadmin@mult1.example.com /*
「mult1.example.comでの最新時刻に基づいた競合解消の構成」の指定に従って、各表の主キーおよび各表の列リストを含む無条件のサプリメンタル・ログ・グループを指定します。各表の列リストには、各表の主キー以外のすべての列が含まれているため、この手順では、表のすべての列を含む各表のサプリメンタル・ログ・グループを作成します。
|
注意:
|
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/ ALTER TABLE hrmult.countries ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.departments ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.employees ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.jobs ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.job_history ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.locations ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE hrmult.regions ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; /*
mult1.example.comでhrmultスキーマ全体に対する変更を取得するように取得プロセスを作成します。また、この手順では、mult1.example.comでhrmultスキーマをインスタンス化のために準備します。この手順の実行後、ユーザーはmult1.example.comでhrmultスキーマ内の表を変更できます。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'capture',
streams_name => 'capture_hrmult',
queue_name => 'strmadmin.captured_mult1',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
mult2.example.comのhrmultスキーマに変更を適用するようにmult1.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult2',
queue_name => 'strmadmin.from_mult2',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult2.example.com',
inclusion_rule => TRUE);
END;
/
/*
mult3.example.comのhrmultスキーマに変更を適用するようにmult1.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult3',
queue_name => 'strmadmin.from_mult3',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult3.example.com',
inclusion_rule => TRUE);
END;
/
/*
hrmultスキーマ内の各表に更新競合ハンドラを指定します。各表で、MAXIMUM競合ハンドラの解消列としてtime列を指定します。更新の競合が発生すると、このような競合ハンドラは最新(または最大)時刻のトランザクションを適用し、それより前の(または小さい)時刻のトランザクションを廃棄します。この例では、主キー値が更新されないと想定しているため、列リストには主キーを除く各表のすべての列が含まれます。
*/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'country_name';
cols(2) := 'region_id';
cols(3) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.countries',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'department_name';
cols(2) := 'manager_id';
cols(3) := 'location_id';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.departments',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'first_name';
cols(2) := 'last_name';
cols(3) := 'email';
cols(4) := 'phone_number';
cols(5) := 'hire_date';
cols(6) := 'job_id';
cols(7) := 'salary';
cols(8) := 'commission_pct';
cols(9) := 'manager_id';
cols(10) := 'department_id';
cols(11) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.employees',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'job_title';
cols(2) := 'min_salary';
cols(3) := 'max_salary';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.jobs',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'employee_id';
cols(2) := 'start_date';
cols(3) := 'end_date';
cols(4) := 'job_id';
cols(5) := 'department_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.job_history',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'street_address';
cols(2) := 'postal_code';
cols(3) := 'city';
cols(4) := 'state_province';
cols(5) := 'country_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.locations',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'region_name';
cols(2) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.regions',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
/*
mult1.example.comのキューからmult2.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult1_to_mult2',
source_queue_name => 'strmadmin.captured_mult1',
destination_queue_name => 'strmadmin.from_mult1@mult2.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
mult1.example.comのキューからmult3.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult1_to_mult3',
source_queue_name => 'strmadmin.captured_mult1',
destination_queue_name => 'strmadmin.from_mult1@mult3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
strmadminユーザーとしてmult2.example.comに接続します。
*/ CONNECT strmadmin@mult2.example.com /*
mult2.example.comでhrmultスキーマ全体に対する変更を取得するように取得プロセスを作成します。また、この手順では、mult2.example.comでhrmultスキーマをインスタンス化のために準備します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'capture',
streams_name => 'capture_hrmult',
queue_name => 'strmadmin.captured_mult2',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
この例では、すべてのデータベースにhrmultスキーマがすでに存在します。手順16でmult2.example.comおよびmult3.example.comでインスタンス化されるまで、スキーマ内の表はmult1.example.comにのみ存在します。インスタンス化は、mult1.example.comからの表のインポートを使用して実行されます。これらのインポート操作によって、mult2.example.comおよびmult3.example.comのmult1.example.comでのスキーマのインスタンス化SCNが自動的に設定されます。
ただし、mult2.example.comおよびmult3.example.comのインスタンス化SCNは、環境内の他のサイトでは自動的に設定されません。この手順では、mult1.example.comおよびmult3.example.comでmult2.example.comのスキーマのインスタンス化SCNを手動で設定します。mult2.example.comでの現行のSCNは、mult2.example.comでDBMS_FLASHBACKパッケージのGET_SYSTEM_CHANGE_NUMBERファンクションを使用して取得できます。このSCNは、mult1.example.comおよびmult3.example.comでDBMS_APPLY_ADMパッケージのSET_SCHEMA_INSTANTIATION_SCNプロシージャを実行するために使用されます。
SET_SCHEMA_INSTANTIATION_SCNプロシージャを使用すると、適用プロセスで無視されるスキーマのDDL LCRと、適用プロセスで適用されるスキーマのDDL LCRを制御できます。ソース・データベースからのスキーマ内のデータベース・オブジェクトに関するDDL LCRのコミットSCNが、一部の接続先データベースでそのデータベース・オブジェクトのインスタンス化SCN以下であれば、接続先データベースの適用プロセスではDDL LCRが無視されます。それ以外の場合は、適用プロセスによってDDL LCRが適用されます。
SET_SCHEMA_INSTANTIATION_SCNプロシージャは、mult2.example.comで表がインスタンス化される前に実行し、ローカルの取得プロセスがすでに構成されているため、インスタンス化後の表ごとにSET_TABLE_INSTANTIATION_SCNプロシージャを実行する必要はありません。この例では、mult1.example.comとmult3.example.comの両方の適用プロセスは、この手順で取得したSCNの後にコミットされたSCNを持つhrmultスキーマ内の表にトランザクションを適用します。
|
注意:
|
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT1.EXAMPLE.COM(
source_schema_name => 'hrmult',
source_database_name => 'mult2.example.com',
instantiation_scn => iscn);
DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT3.EXAMPLE.COM(
source_schema_name => 'hrmult',
source_database_name => 'mult2.example.com',
instantiation_scn => iscn);
END;
/
/*
mult1.example.comのhrmultスキーマに変更を適用するようにmult2.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult1',
queue_name => 'strmadmin.from_mult1',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult1.example.com',
inclusion_rule => TRUE);
END;
/
/*
mult3.example.comのhrmultスキーマに変更を適用するようにmult2.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult3',
queue_name => 'strmadmin.from_mult3',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult3.example.com',
inclusion_rule => TRUE);
END;
/
/*
mult2.example.comのキューからmult1.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult2_to_mult1',
source_queue_name => 'strmadmin.captured_mult2',
destination_queue_name => 'strmadmin.from_mult2@mult1.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult2.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
mult2.example.comのキューからmult3.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult2_to_mult3',
source_queue_name => 'strmadmin.captured_mult2',
destination_queue_name => 'strmadmin.from_mult2@mult3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult2.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
strmadminユーザーとしてmult3.example.comに接続します。
*/ CONNECT strmadmin@mult3.example.com /*
mult3.example.comでhrmultスキーマ全体に対する変更を取得するように取得プロセスを作成します。また、この手順では、mult3.example.comでhrmultスキーマをインスタンス化のために準備します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'capture',
streams_name => 'capture_hrmult',
queue_name => 'strmadmin.captured_mult3',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
この例では、すべてのデータベースにhrmultスキーマがすでに存在します。手順16でmult2.example.comおよびmult3.example.comでインスタンス化されるまで、スキーマ内の表はmult1.example.comにのみ存在します。インスタンス化は、mult1.example.comからの表のインポートを使用して実行されます。これらのインポート操作によって、mult2.example.comおよびmult3.example.comのmult1.example.comでのスキーマのインスタンス化SCNが自動的に設定されます。
ただし、mult2.example.comおよびmult3.example.comのインスタンス化SCNは、環境内の他のサイトでは自動的に設定されません。この手順では、mult1.example.comおよびmult2.example.comでmult3.example.comのスキーマのインスタンス化SCNを手動で設定します。mult3.example.comでの現行のSCNは、mult3.example.comでDBMS_FLASHBACKパッケージのGET_SYSTEM_CHANGE_NUMBERファンクションを使用して取得できます。このSCNは、mult1.example.comおよびmult2.example.comでDBMS_APPLY_ADMパッケージのSET_SCHEMA_INSTANTIATION_SCNプロシージャを実行するために使用されます。
SET_SCHEMA_INSTANTIATION_SCNプロシージャを使用すると、適用プロセスで無視されるスキーマのDDL LCRと、適用プロセスで適用されるスキーマのDDL LCRを制御できます。ソース・データベースからのスキーマ内のデータベース・オブジェクトに関するDDL LCRのコミットSCNが、一部の接続先データベースでそのデータベース・オブジェクトのインスタンス化SCN以下であれば、接続先データベースの適用プロセスではDDL LCRが無視されます。それ以外の場合は、適用プロセスによってDDL LCRが適用されます。
SET_SCHEMA_INSTANTIATION_SCNプロシージャは、mult3.example.comで表がインスタンス化される前に実行し、ローカルの取得プロセスがすでに構成されているため、インスタンス化後の表ごとにSET_TABLE_INSTANTIATION_SCNプロシージャを実行する必要はありません。この例では、mult1.example.comとmult2.example.comの両方の適用プロセスは、この手順で取得したSCNの後にコミットされたSCNを持つhrmultスキーマ内の表にトランザクションを適用します。
|
注意:
|
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT1.EXAMPLE.COM(
source_schema_name => 'hrmult',
source_database_name => 'mult3.example.com',
instantiation_scn => iscn);
DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT2.EXAMPLE.COM(
source_schema_name => 'hrmult',
source_database_name => 'mult3.example.com',
instantiation_scn => iscn);
END;
/
/*
mult1.example.comのhrmultスキーマに変更を適用するようにmult3.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult1',
queue_name => 'strmadmin.from_mult1',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult1.example.com',
inclusion_rule => TRUE);
END;
/
/*
mult2.example.comのhrmultスキーマに変更を適用するようにmult3.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hrmult',
streams_type => 'apply',
streams_name => 'apply_from_mult2',
queue_name => 'strmadmin.from_mult2',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult2.example.com',
inclusion_rule => TRUE);
END;
/
/*
mult3.example.comのキューからmult1.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult3_to_mult1',
source_queue_name => 'strmadmin.captured_mult3',
destination_queue_name => 'strmadmin.from_mult3@mult1.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult3.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
mult3.example.comのキューからmult2.example.comのキューへのhrmultスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hrmult',
streams_name => 'mult3_to_mult2',
source_queue_name => 'strmadmin.captured_mult3',
destination_queue_name => 'strmadmin.from_mult3@mult2.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'mult3.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
この例では、データ・ポンプを使用してmult1.example.comからmult2.example.comへのhrmultスキーマのネットワーク・インポートを実行します。ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでmult1.example.comからスキーマのデータベース・オブジェクトをインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてmult2.example.comに接続します。
*/ CONNECT strmadmin@mult2.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用してスキーマ・レベルのインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
mult2_instantscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a schema-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'SCHEMA',
remote_link => 'MULT1.EXAMPLE.COM',
job_name => 'dp_mult2');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HRMULT''');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects in the schema.
mult2_instantscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@mult1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => mult2_instantscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||mult2_instantscn);
END;
END;
/
/*
この例では、データ・ポンプを使用してmult1.example.comからmult3.example.comへのhrmultスキーマのネットワーク・インポートを実行します。ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでmult1.example.comからスキーマのデータベース・オブジェクトをインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてmult3.example.comに接続します。
*/ CONNECT strmadmin@mult3.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用して表のインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
mult3_instantscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a schema-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'SCHEMA',
remote_link => 'MULT1.EXAMPLE.COM',
job_name => 'dp_mult3');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HRMULT''');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects in the schema.
mult3_instantscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@mult1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => mult3_instantscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||mult3_instantscn);
END;
END;
/
/*
strmadminユーザーとしてmult2.example.comに接続します。
*/ CONNECT strmadmin@mult2.example.com /*
hrmultスキーマ内の各表に更新競合ハンドラを指定します。各表で、MAXIMUM競合ハンドラの解消列としてtime列を指定します。更新の競合が発生すると、このような競合ハンドラは最新(または最大)時刻のトランザクションを適用し、それより前の(または小さい)時刻のトランザクションを廃棄します。
*/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'country_name';
cols(2) := 'region_id';
cols(3) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.countries',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'department_name';
cols(2) := 'manager_id';
cols(3) := 'location_id';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.departments',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'first_name';
cols(2) := 'last_name';
cols(3) := 'email';
cols(4) := 'phone_number';
cols(5) := 'hire_date';
cols(6) := 'job_id';
cols(7) := 'salary';
cols(8) := 'commission_pct';
cols(9) := 'manager_id';
cols(10) := 'department_id';
cols(11) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.employees',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'job_title';
cols(2) := 'min_salary';
cols(3) := 'max_salary';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.jobs',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'employee_id';
cols(2) := 'start_date';
cols(3) := 'end_date';
cols(4) := 'job_id';
cols(5) := 'department_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.job_history',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'street_address';
cols(2) := 'postal_code';
cols(3) := 'city';
cols(4) := 'state_province';
cols(5) := 'country_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.locations',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'region_name';
cols(2) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.regions',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
/*
mult2.example.comで両方の適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult1');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult3');
END;
/
/*
strmadminユーザーとしてmult3.example.comに接続します。
*/ CONNECT strmadmin@mult3.example.com /*
hrmultスキーマ内の各表に更新競合ハンドラを指定します。各表で、MAXIMUM競合ハンドラの解消列としてtime列を指定します。更新の競合が発生すると、このような競合ハンドラは最新(または最大)時刻のトランザクションを適用し、それより前の(または小さい)時刻のトランザクションを廃棄します。
*/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'country_name';
cols(2) := 'region_id';
cols(3) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.countries',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'department_name';
cols(2) := 'manager_id';
cols(3) := 'location_id';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.departments',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'first_name';
cols(2) := 'last_name';
cols(3) := 'email';
cols(4) := 'phone_number';
cols(5) := 'hire_date';
cols(6) := 'job_id';
cols(7) := 'salary';
cols(8) := 'commission_pct';
cols(9) := 'manager_id';
cols(10) := 'department_id';
cols(11) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.employees',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'job_title';
cols(2) := 'min_salary';
cols(3) := 'max_salary';
cols(4) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.jobs',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'employee_id';
cols(2) := 'start_date';
cols(3) := 'end_date';
cols(4) := 'job_id';
cols(5) := 'department_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.job_history',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'street_address';
cols(2) := 'postal_code';
cols(3) := 'city';
cols(4) := 'state_province';
cols(5) := 'country_id';
cols(6) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.locations',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
DECLARE
cols DBMS_UTILITY.NAME_ARRAY;
BEGIN
cols(1) := 'region_name';
cols(2) := 'time';
DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER(
object_name => 'hrmult.regions',
method_name => 'MAXIMUM',
resolution_column => 'time',
column_list => cols);
END;
/
/*
mult3.example.comで両方の適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult1');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult2');
END;
/
/*
strmadminユーザーとしてmult1.example.comに接続します。
*/ CONNECT strmadmin@mult1.example.com /*
mult1.example.comで両方の適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult2');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_from_mult3');
END;
/
/*
mult1.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture_hrmult');
END;
/
/*
strmadminユーザーとしてmult2.example.comに接続します。
*/ CONNECT strmadmin@mult2.example.com /*
mult2.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture_hrmult');
END;
/
/*
strmadminユーザーとしてmult3.example.comに接続します。
*/ CONNECT strmadmin@mult3.example.com /*
mult3.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture_hrmult');
END;
/
SET ECHO OFF
/*
streams_mult.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
|
関連項目: データベース・オブジェクトまたはデータベースをレプリケーション環境に追加する方法の概要は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
環境内の任意のデータベースのhrmultスキーマ内の表に対して、DML変更およびDDL変更を行うことができます。これらの変更は、環境内の他のデータベースにレプリケートされ、問合せを実行してそれらのレプリケートされたデータを表示できます。
たとえば、次の手順を実行して、mult1.example.comおよびmult2.example.comのhrmult.employees表に対してDML変更を行います。前述の手順で構成した更新競合ハンドラで更新の競合が解消されることを確認するには、これらの2つのデータベースの同じ行を変更し、ほぼ同時に変更をコミットします。環境内の各データベースで変更された行を問い合せ、変更が適切に取得、伝播および適用されたことを確認できます。
また、mult3.example.comのhrmult.jobs表に対してDDL変更を行い、変更がmult3.example.comで取得され、環境内の他のデータベースに伝播され、これらのデータベースで適用されることも確認できます。
次の変更を行います。競合をシミュレートするため、これらをほぼ同時にコミット(ただし、mult1.example.comでの変更をコミットした直後にmult2.example.comでの変更をコミット)します。各データベースの更新競合ハンドラによって、競合が解消されます。
CONNECT hrmult@mult1.example.com Enter password: password UPDATE hrmult.employees SET salary=9000 WHERE employee_id=206; COMMIT; CONNECT hrmult@mult2.example.com Enter password: password UPDATE hrmult.employees SET salary=10000 WHERE employee_id=206; COMMIT;
job_title列の名前をjob_nameに変更して、hrmult.jobs表を変更します。
CONNECT hrmult@mult3.example.com
Enter password: password
ALTER TABLE hrmult.jobs RENAME COLUMN job_title TO job_name;
手順1で実行した変更が取得、伝播および適用されてから、次の問合せを実行して、UPDATE変更が各データベースで適用されていることを確認します。
CONNECT hrmult@mult1.example.com Enter password: password SELECT salary FROM hrmult.employees WHERE employee_id=206; CONNECT hrmult@mult2.example.com Enter password: password SELECT salary FROM hrmult.employees WHERE employee_id=206; CONNECT hrmult@mult3.example.com Enter password: password SELECT salary FROM hrmult.employees WHERE employee_id=206;
すべての問合せで、salaryの値が10000と表示されるはずです。各データベースの更新競合ハンドラによって、行に対する最新の変更を適用して競合が解消されています。ここでは、行に対する最新の変更は、手順1のmult2.example.comデータベースで行われました。
手順2で実行した変更が取得、伝播および適用されてから、各データベースでhrmult.jobs表の定義を表示し、ALTER TABLE変更が正常に伝播および適用されていることを確認します。
CONNECT hrmult@mult1.example.com Enter password: password DESC hrmult.jobs CONNECT hrmult@mult2.example.com Enter password: password DESC hrmult.jobs CONNECT hrmult@mult3.example.com Enter password: password DESC hrmult.jobs
各データベースでは、表の2列目にjob_nameが表示されているはずです。