| Oracle® Streams拡張例 11gリリース2 (11.2) B61356-02 |
|


 前 |
 次 |
この章では、Oracle Streamsを使用して構成できる単一ソースの異機種間レプリケーション環境、およびこの環境に新しいオブジェクトおよびデータベースを追加する場合に必要となるタスクの例を説明します。
この章の内容は次のとおりです。
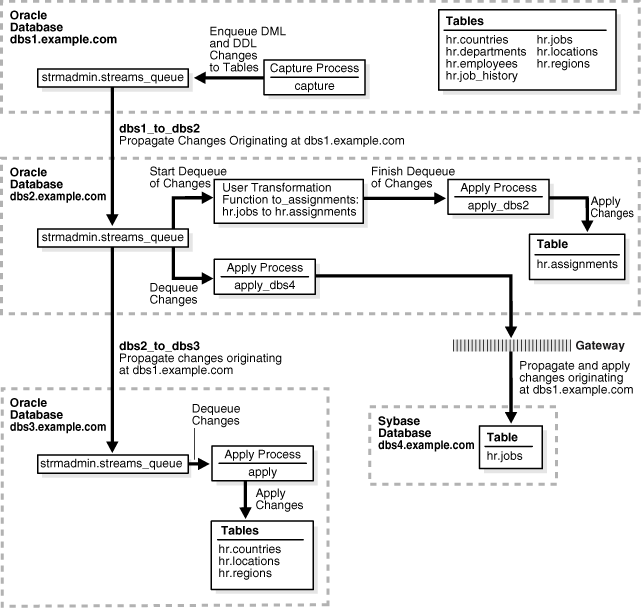
この例では、Oracle Streamsを使用して4つのデータベース間でデータをレプリケートする方法を説明します。データベースのうち3つがOracle Databaseで1つがSybaseデータベースであるため、異機種間環境です。dbs1.example.com Oracle Databaseで、hrスキーマ内の表に対して行われたDML変更とDDL変更が取得され、他の2つのOracle Databaseに伝播します。適用プロセスではOracle以外のデータベースにはDDL変更を適用できないため、DML変更のみが取得されてdbs4.example.comデータベースに伝播します。hrスキーマに対する変更は、dbs1.example.comでのみ発生します。hrスキーマは、環境内の他のデータベースでは読取り専用です。
図2-1に、この環境の概要を示します。
図2-1に示すように、dbs1.example.comのhrスキーマには次の表が含まれています。
countries
departments
employees
job_history
jobs
locations
regions
この例では、有向ネットワークを使用します(ソース・データベースで取得された変更は、1つ以上の中間データベースを介して、別のデータベースに伝播されることを意味します)。ここでは、dbs1.example.comデータベースがdbs3.example.comデータベースに、中間データベースdbs2.example.comを介して変更を伝播します。この構成は、有向ネットワークで前進するキューの一例です。また、dbs1.example.comデータベースは変更をdbs2.example.comデータベースに伝播し、このデータベースは、Oracle Database Gatewayを介して変更を直接dbs4.example.comデータベースに適用します。
この環境内の一部のデータベースには、特定の表がありません。データベースが表の中間データベースではなく、その表が含まれていない場合、そのデータベースには表に対する変更を伝播する必要はありません。たとえば、departments、employees、job_historyおよびjobsの各表は、dbs3.example.comには存在しません。したがって、これらの表に対する変更はdbs2.example.comからdbs3.example.comには伝播しません。
この例では、Oracle Streamsを使用して次の一連のアクションが実行されます。
取得プロセスは、dbs1.example.comデータベースでhrスキーマ内のすべての表に対するDML変更とDDL変更を取得し、その変更をエンキューします。この例では、7つの表のうち4つに対する変更のみが接続先データベースに伝播されますが、「既存のOracle Streamsレプリケーション環境へのオブジェクトの追加」を示す例では、hrスキーマ内の残りの表が接続先データベースに追加されます。
dbs1.example.comデータベースから、これらの変更がメッセージの形式でdbs2.example.comのキューに伝播します。
dbs2.example.comで、jobs表に対するDML変更がassignments表(jobsの直接のマッピング)に対するDML変更に変換されてから適用されます。hrスキーマ内の他の表に対する変更は、dbs2.example.comでは適用されません。
dbs3.example.comのキューは、dbs1.example.comのcountries、locationsおよびregions表で発生した変更をdbs2.example.comのキューから受信するため、これらの変更はdbs2.example.comからdbs3.example.comに伝播します。この構成は、有向ネットワークの一例です。
dbs3.example.comの適用プロセスは、countries、locationsおよびregionsの各表に変更を適用します。
dbs4.example.comはSybaseデータベースであり、dbs1.example.comで発生したjobs表に対する変更をdbs2.example.comのキューから受信するため、これらの変更はOracle Database Gateway経由でdbs4.example.comのデータベース・リンクを使用してdbs2.example.comからリモートで適用されます。この構成は、異機種間サポートの一例です。
この章の例を開始する前に、前提条件となる次の作業を完了する必要があります。
環境内のすべてのデータベースについて、次の初期化パラメータを指定の値に設定します。
GLOBAL_NAMES: Oracle Streams環境の各データベースで、このパラメータをTRUEに設定する必要があります。
COMPATIBLE: このパラメータは10.2.0以上に設定する必要があります。
STREAMS_POOL_SIZE: オプションで、このパラメータを環境内の各データベースの適切な値に設定します。このパラメータでは、Oracle Streamsプールのサイズを指定します。Oracle Streamsプールは、バッファ・キューにメッセージを格納し、パラレル取得およびパラレル適用中の内部通信に使用されます。MEMORY_TARGET、MEMORY_MAX_TARGETまたはSGA_TARGET初期化パラメータを0 (ゼロ)以外の値に設定した場合、Oracle Streamsプールのサイズは自動的に管理されます。
|
関連項目: Oracle Streams環境で重要なその他の初期化パラメータについては、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
取得される変更を生成するデータベースは、ARCHIVELOGモードで実行している必要があります。この例では、dbs1.example.comで変更が生成されるため、dbs1.example.comはARCHIVELOGモードで実行する必要があります。
|
関連項目: ARCHIVELOGモードでデータベースを実行する方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
dbs2.example.com上のOracle Database Gatewayを、Sybaseデータベースdbs4.example.comと通信するように構成します。
|
関連項目: 『Oracle Database Heterogeneous Connectivityユーザーズ・ガイド』 |
Sybaseデータベースdbs4.example.comでhrユーザーを設定します。
|
関連項目: Sybaseデータベース内でユーザーと表を作成する方法については、Sybaseマニュアルを参照してください。 |
dbs4.example.com Sybaseデータベースで、dbs1.example.com Oracle Databaseからhr.jobs表をインスタンス化します。
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
ネットワークとOracle Netを、次のデータベースが相互に通信できるように構成します。
dbs1.example.comとdbs2.example.com
dbs2.example.comとdbs3.example.com
dbs2.example.comとdbs4.example.com
dbs3.example.comとdbs1.example.com(オプションのデータ・ポンプ・ネットワークのインスタンス化のため)
|
関連項目: 『Oracle Database Net Services管理者ガイド』 |
レプリケーション環境の各Oracle DatabaseでOracle Streams管理者を作成します。この例では、データベースdbs1.example.com、dbs2.example.comおよびdbs3.example.comで作成します。この例では、Oracle Streams管理者のユーザー名がstrmadminであると想定しています。
|
関連項目: Oracle Streams管理者を作成する方法は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
次の手順を実行して、3つのOracle Databaseと1つのSybaseデータベースを含むOracle Streamsレプリケーション環境にキューおよびデータベース・リンクを作成します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_setup_single.out /*
変更を取得するデータベースにOracle Streams管理者として接続します。この例では、データベースdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
SET_UP_QUEUEプロシージャを実行して、dbs1.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、他のデータベースに伝播される取得された変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
変更が取得されるデータベースから変更が伝播されるデータベースにデータベース・リンクを作成します。この例では、変更が取得されるデータベースはdbs1.example.comで、これらの変更はdbs2.example.comに伝播されます。
*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE CREATE DATABASE LINK dbs2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs2.example.com'; /*
Oracle Streams管理者としてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
SET_UP_QUEUEプロシージャを実行して、dbs2.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、このデータベースに適用される変更および他のデータベースに伝播される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
変更が伝播されるデータベースへのデータベース・リンクを作成します。この例では、データベースdbs2.example.comからdbs3.example.com(別のOracle Database)およびdbs4.example.com(Sybaseデータベース)に変更が伝播されます。Sybaseデータベースへのデータベース・リンクが、Oracle Streams管理者ではなく表の所有者に接続されていることに注意してください。このデータベース・リンクは、そのデータベースのhr.jobs表を変更する権限を持つ、dbs4.example.comのいずれかのユーザーに接続できます。
|
注意: Sybaseなどの一部のOracle以外のデータベースでは、ユーザー名およびパスワードの大/小文字が正しいことを確認する必要があります。したがって、Sybaseデータベースのユーザー名およびパスワードは、二重引用符で指定します。 |
*/ CREATE DATABASE LINK dbs3.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs3.example.com'; CREATE DATABASE LINK dbs4.example.com CONNECT TO "hr" IDENTIFIED BY "&password" USING 'dbs4.example.com'; /*
この例では、dbs1.example.comのhr.jobs表に対する変更をdbs2.example.comのhr.assignments表に対する変更に変換するカスタム・ルールベースの変換について説明します。この例での変換を正常に実行するために、dbs2.example.comにhr.assignments表を作成する必要があります。
|
注意: カスタム・ルールベースの変換を使用して表の名前を変更するかわりに、RENAME_TABLE宣言ルールベースの変換を使用できます。『Oracle Streams概要および管理』を参照してください。 |
hrとしてdbs2.example.comに接続します。
*/ CONNECT hr@dbs2.example.com /*
dbs2.example.comデータベースにhr.assignments表を作成します。
*/ CREATE TABLE hr.assignments AS SELECT * FROM hr.jobs; ALTER TABLE hr.assignments ADD PRIMARY KEY (job_id); /*
Oracle Streams管理者としてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
SET_UP_QUEUEプロシージャを実行して、dbs3.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、このデータベースに適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
dbs3.example.comからdbs1.example.comへのデータベース・リンクを作成します。このデータベース・リンクは、この例の後半で、手順9で削除するデータベース・オブジェクトの一部をインスタンス化するために使用します。この例では、DBMS_DATAPUMPパッケージを使用して、dbs1.example.comデータベースから直接これらのデータベース・オブジェクトのネットワーク・インポートを実行します。この例ではネットワーク・インポートを実行するため、ダンプ・ファイルは不要です。
または、ソース・データベースdbs1.example.comでエクスポートを実行し、エクスポート・ダンプ・ファイルを接続先データベースdbs3.example.comに転送して、接続先データベースでエクスポート・ダンプ・ファイルをインポートすることもできます。この場合、この手順で作成するデータベース・リンクは不要です。
*/ CREATE DATABASE LINK dbs1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs1.example.com'; /*
この例では、データ・ポンプを使用してdbs1.example.comからdbs3.example.comに表をインポートすることによって、hrスキーマ内の表をインスタンス化する方法について説明します。この例でのインスタンス化を正常に実行するために、dbs3.example.comでこれらの表を削除する必要があります。
hrとしてdbs3.example.comに接続します。
*/ CONNECT hr@dbs3.example.com /*
dbs3.example.comデータベースのhrスキーマ内のすべての表を削除します。
|
注意: この手順を実行してhrスキーマ内のすべての表を削除した場合、この例の残りの項の手順を実行して、dbs3.example.comでhrスキーマを再インスタンス化する必要があります。hrスキーマがOracle Databaseに存在しない場合、Oracleマニュアル・セットの一部の例が失敗する可能性があります。 |
*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
streams_setup_single.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
この例では、Oracle Streamsを使用してhrスキーマ内の表のレプリケーションを行う2つの方法について説明します。
「1つのデータベースからのデータを共有する簡単な構成」では、簡単な方法での環境の構成を示します。この例では、DBMS_STREAMS_ADMパッケージを使用して、取得プロセス、伝播および適用プロセスと、それらに関連付けられたルール・セットを作成します。DBMS_STREAMS_ADMパッケージを使用すると、最も簡単にOracle Streams環境を構成できます。
「1つのデータベースからのデータを共有する柔軟な構成」では、より柔軟な方法でのこの環境の構成を示します。この例では、DBMS_CAPTURE_ADMパッケージを使用して取得プロセスを作成し、DBMS_PROPAGATION_ADMパッケージを使用して伝播を作成し、DBMS_APPLY_ADMパッケージを使用して適用プロセスを作成します。また、この例では、DBMS_RULES_ADMパッケージを使用して、これらの取得プロセス、伝播および適用プロセスに関連付けられたルール・セットを作成および移入します。DBMS_STREAMS_ADMパッケージのかわりにこれらのパッケージを使用すると、より多くの構成オプションを使用でき、柔軟性が向上します。
|
注意: これらの例では、同じOracle Streams環境を構成する2つの異なる方法を示します。したがって、特定の分散データベース・システムに、いずれかの例のみを実行する必要があります。両方の例を実行すると、オブジェクトがすでに存在することを示すエラーが発生します。 |
次の手順を実行して、主にDBMS_STEAMS_ADMパッケージを使用して、取得、伝播および適用の定義を指定します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_share_schema1.out /*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
dbs1.example.comのキューからdbs2.example.comのキューへのhrスキーマ内のDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hr',
streams_name => 'dbs1_to_dbs2',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs2.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
dbs1.example.comでhrスキーマ全体に対する変更を取得するように取得プロセスを構成します。この手順では、指定したスキーマ内の表に対する変更が取得プロセスによって取得され、指定したキューにエンキューされるように指定します。
また、この手順では、hrスキーマをインスタンス化のために準備し、このスキーマ内の表のすべての主キー列、一意キー列、ビットマップ索引列および外部キー列のサプリメンタル・ロギングを有効にします。サプリメンタル・ロギングによって、表に対する変更の追加の情報がREDOログに記録されます。適用プロセスでは、一意の行の識別や競合解消など、一部の操作を実行するために、この追加情報が必要です。この環境では、dbs1.example.comデータベースでのみ変更が取得されるため、hrスキーマ内の表に対してサプリメンタル・ロギングを指定する必要があるのはこのデータベースのみです。
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hr',
streams_type => 'capture',
streams_name => 'capture',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
この例では、dbs2.example.comおよびdbs4.example.comにhr.jobs表がすでに存在します。dbs2.example.comでは、この表の名前はassignmentsですが、この表はdbs1.example.comのjobs表と同じ形式で、同じデータを含んでいます。また、この例では、dbs4.example.comはSybaseデータベースです。Oracle Streams環境内の他のすべての表が、データ・ポンプ・インポートを使用して他の接続先データベースでインスタンス化されます。
hr.jobs表はdbs2.example.comおよびdbs4.example.comにすでに存在するため、この例ではdbs1.example.comでDBMS_FLASHBACKパッケージのGET_SYSTEM_CHANGE_NUMBERファンクションを使用して、データベースの現行のSCNを取得します。このSCNは、dbs2.example.comでDBMS_APPLY_ADMパッケージのSET_TABLE_INSTANTIATION_SCNプロシージャを実行するために使用されます。このプロシージャを2回実行して、dbs2.example.comおよびdbs4.example.comでhr.jobs表にインスタンス化SCNを設定します。
SET_TABLE_INSTANTIATION_SCNプロシージャを使用すると、適用プロセスで無視される表のLCRと、適用プロセスで適用される表のLCRを制御できます。ソース・データベースからの表に関するLCRのコミットSCNが、接続先データベースでその表のインスタンス化SCN以下であれば、接続先データベースの適用プロセスではLCRが廃棄されます。それ以外の場合は、適用プロセスによってLCRが適用されます。
この例では、dbs2.example.comの適用プロセスはいずれも、この手順で取得したSCNの後にコミットされたSCNを持つhr.jobs表にトランザクションを適用します。
|
注意: この例では、dbs1.example.com、dbs2.example.com(hr.assignments)およびdbs4.example.comのhr.jobs表の内容は、この手順が完了した時点で一貫性があると想定しています。一貫性を確保するために、この手順の実行中に各データベースの表をロックすることをお薦めします。 |
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'dbs1.example.com',
instantiation_scn => iscn);
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'dbs1.example.com',
instantiation_scn => iscn,
apply_database_link => 'dbs4.example.com');
END;
/
/*
この例では、データ・ポンプを使用して次の表のネットワーク・インポートを実行します。
hr.countries
hr.locations
hr.regions
ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでdbs1.example.comからこれらの表をインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用して表のインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
sscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a table-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'TABLE',
remote_link => 'DBS1.EXAMPLE.COM',
job_name => 'dp_sing1');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HR''');
-- A metadata filter is used to specify the tables that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'NAME_EXPR',
value => 'IN(''COUNTRIES'', ''REGIONS'', ''LOCATIONS'')');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects included in the import.
sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => sscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn);
END;
END;
/
/*
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
countries表、locations表およびregions表に変更を適用するようにdbs3.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.countries',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.locations',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.regions',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
この例では、hrユーザーが、このデータベースで適用プロセスによって変更が適用されるすべてのデータベース・オブジェクトを所有します。したがって、hrはこれらのデータベース・オブジェクトを変更するために必要な権限をすでに持っており、hrを適用ユーザーにすることが有効です。
前述の手順で適用プロセスを作成したときに、適用プロセスを作成したプロシージャをOracle Streams管理者strmadminが実行したため、デフォルトでは、strmadminが適用ユーザーとして指定されています。hrを適用ユーザーとして指定するかわりに、strmadminを適用ユーザーのままにしておくこともできますが、この場合、変更が適用されるすべてのデータベース・オブジェクトに対する権限、および適用プロセスで使用されるすべてのユーザー・プロシージャを実行する権限をstrmadminに付与する必要があります。適用プロセスが複数のスキーマ内のデータベース・オブジェクトに変更を適用する環境では、Oracle Streams管理者を適用ユーザーとして使用する方が有効な場合があります。
|
関連項目: Oracle Streams管理者を構成する方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
*/
BEGIN
DBMS_APPLY_ADM.ALTER_APPLY(
apply_name => 'apply',
apply_user => 'hr');
END;
/
/*
前述の手順でhrユーザーを適用ユーザーとして指定したため、hrユーザーには、適用プロセスで使用されるポジティブ・ルール・セットに対するEXECUTE権限が必要です。
*/
DECLARE
rs_name VARCHAR2(64); -- Variable to hold rule set name
BEGIN
SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME
INTO rs_name
FROM DBA_APPLY
WHERE APPLY_NAME='APPLY';
DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE(
privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET,
object_name => rs_name,
grantee => 'hr');
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、dbs3.example.comで適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply');
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
dbs2.example.comのキューからdbs3.example.comのキューへの伝播を構成およびスケジュールします。この伝播は、dbs3.example.comで変更を適用する表ごとに指定する必要があります。dbs2.example.comの変更はdbs1.example.comで発生したものであるため、この構成は、有向ネットワークの一例です。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.countries',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.locations',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.regions',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
hrユーザーとしてdbs2.example.comに接続します。
*/ CONNECT hr@dbs2.example.com /*
dbs1.example.comのjobs表に対するDML文によって発生する行変更をdbs2.example.comのassignments表に対する行変更に変換するカスタム・ルールベースの変換ファンクションを作成します。
次のファンクションを実行すると、jobs表のすべての行LCRがassignments表の行LCRに変換されます。
|
注意: assignments表にDDL変更も適用された場合、DDL LCR用に別の変換が必要になります。この変換では、オブジェクト名およびDDLテキストを変更する必要があります。 |
*/
CREATE OR REPLACE FUNCTION hr.to_assignments_trans_dml(
p_in_data in ANYDATA)
RETURN ANYDATA IS out_data SYS.LCR$_ROW_RECORD;
tc pls_integer;
BEGIN
-- Typecast AnyData to LCR$_ROW_RECORD
tc := p_in_data.GetObject(out_data);
IF out_data.GET_OBJECT_NAME() = 'JOBS'
THEN
-- Transform the in_data into the out_data
out_data.SET_OBJECT_NAME('ASSIGNMENTS');
END IF;
-- Convert to AnyData
RETURN ANYDATA.ConvertObject(out_data);
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
assignments表に変更を適用するようにdbs2.example.comを構成します。assignments表がdbs1.example.comのjobs表から変更を受信することに注意してください。
*/
DECLARE
to_assignments_rulename_dml VARCHAR2(30);
dummy_rule VARCHAR2(30);
BEGIN
-- DML changes to the jobs table from dbs1.example.com are applied
-- to the assignments table. The to_assignments_rulename_dml variable
-- is an out parameter in this call.
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs', -- jobs, not assignments, specified
streams_type => 'apply',
streams_name => 'apply_dbs2',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => FALSE,
source_database => 'dbs1.example.com',
dml_rule_name => to_assignments_rulename_dml,
ddl_rule_name => dummy_rule,
inclusion_rule => TRUE);
-- Modify the rule for the hr.jobs table to use the transformation function.
DBMS_STREAMS_ADM.SET_RULE_TRANSFORM_FUNCTION(
rule_name => to_assignments_rulename_dml,
transform_function => 'hr.to_assignments_trans_dml');
END;
/
/*
この例では、hrユーザーが、このデータベースで適用プロセスによって変更が適用されるすべてのデータベース・オブジェクトを所有します。したがって、hrはこれらのデータベース・オブジェクトを変更するために必要な権限をすでに持っており、hrを適用ユーザーにすることが有効です。
前述の手順で適用プロセスを作成したときに、適用プロセスを作成したプロシージャをOracle Streams管理者strmadminが実行したため、デフォルトでは、strmadminが適用ユーザーとして指定されています。hrを適用ユーザーとして指定するかわりに、strmadminを適用ユーザーのままにしておくこともできますが、この場合、変更が適用されるすべてのデータベース・オブジェクトに対する権限、および適用プロセスで使用されるすべてのユーザー・プロシージャを実行する権限をstrmadminに付与する必要があります。適用プロセスが複数のスキーマ内のデータベース・オブジェクトに変更を適用する環境では、Oracle Streams管理者を適用ユーザーとして使用する方が有効な場合があります。
|
関連項目: Oracle Streams管理者を構成する方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
*/
BEGIN
DBMS_APPLY_ADM.ALTER_APPLY(
apply_name => 'apply_dbs2',
apply_user => 'hr');
END;
/
/*
前述の手順でhrユーザーを適用ユーザーとして指定したため、hrユーザーには、適用プロセスで使用されるポジティブ・ルール・セットに対するEXECUTE権限が必要です。
*/
DECLARE
rs_name VARCHAR2(64); -- Variable to hold rule set name
BEGIN
SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME
INTO rs_name
FROM DBA_APPLY
WHERE APPLY_NAME='APPLY_DBS2';
DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE(
privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET,
object_name => rs_name,
grantee => 'hr');
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、dbs2.example.comでローカル適用を実行するために適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_dbs2',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_dbs2');
END;
/
/*
dbs4.example.com(Sybaseデータベース)の適用プロセスを構成します。dbs2.example.comデータベースは、dbs4.example.comへのゲートウェイとして機能しています。したがって、dbs4.example.comの適用プロセスは、dbs2.example.comで構成する必要があります。適用プロセスでDDL変更をOracle以外のデータベースに適用することはできません。したがって、ADD_TABLE_RULESプロシージャの実行時に、include_ddlパラメータがFALSEに設定されています。
*/
BEGIN
DBMS_APPLY_ADM.CREATE_APPLY(
queue_name => 'strmadmin.streams_queue',
apply_name => 'apply_dbs4',
apply_database_link => 'dbs4.example.com',
apply_captured => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'apply',
streams_name => 'apply_dbs4',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => FALSE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、データベース・リンクdbs4.example.comを使用してSybaseのリモート適用を開始します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_dbs4',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_dbs4');
END;
/
/*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
dbs1.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture');
END;
/
/*
streams_share_schema1.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*
ここで、dbs1.example.comの特定の表に対してDML変更およびDDL変更を行い、この環境内のOracle Streamsプロセスおよび伝播について構成したルールに基づいて、環境内の他のデータベースにこれらの変更がレプリケートされていることを確認できます。
/*************************** END OF SCRIPT ******************************/
次の手順を実行して、より柔軟な方法を使用して、取得、伝播および適用の定義を指定します。この方法では、DBMS_STREAMS_ADMパッケージを使用しません。かわりに、次のパッケージを使用します。
DBMS_CAPTURE_ADMパッケージ。取得プロセスを構成します。
DBMS_PROPAGATION_ADMパッケージ。伝播を構成します。
DBMS_APPLY_ADMパッケージ。適用プロセスを構成します。
DBMS_RULES_ADMパッケージ。取得プロセス、伝播および適用プロセスのルールおよびルール・セットを指定します。
|
注意: ALL_STREAMS_TABLE_RULESおよびDBA_STREAMS_TABLE_RULESデータ・ディクショナリ・ビューはいずれも、この例で作成するルールでは移入されません。この例で作成されるルールを表示するには、ALL_STREAMS_RULESまたはDBA_STREAMS_RULESデータ・ディクショナリ・ビューを問い合せます。 |
この例の手順は次のとおりです。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_share_schema2.out /*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
dbs1.example.comのキューからdbs2.example.comのキューへの伝播を構成およびスケジュールします。この構成では、hrスキーマへのすべての変更が伝播されることを指定しています。ルール・セットの指定を省略することもできますが、その場合はキュー内のすべてが伝播されます(これは、将来、複数の取得プロセスでstreams_queueを使用することになる場合には適していません)。
*/
BEGIN
-- Create the rule set
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.propagation_dbs1_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Create rules for all modifications to the hr schema
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_hr_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_hr_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Add rules to rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_hr_dml',
rule_set_name => 'strmadmin.propagation_dbs1_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_hr_ddl',
rule_set_name => 'strmadmin.propagation_dbs1_rules');
-- Create a propagation that uses the rule set as its positive rule set
DBMS_PROPAGATION_ADM.CREATE_PROPAGATION(
propagation_name => 'dbs1_to_dbs2',
source_queue => 'strmadmin.streams_queue',
destination_queue => 'strmadmin.streams_queue',
destination_dblink => 'dbs2.example.com',
rule_set_name => 'strmadmin.propagation_dbs1_rules');
END;
/
/*
dbs1.example.comでhrスキーマ全体を取得する取得プロセスおよびルールを作成します。
*/
BEGIN
-- Create the rule set
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.demo_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Create rules that specify the entire hr schema
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.schema_hr_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.schema_hr_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Add the rules to the rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.schema_hr_dml',
rule_set_name => 'strmadmin.demo_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.schema_hr_ddl',
rule_set_name => 'strmadmin.demo_rules');
-- Create a capture process that uses the rule set as its positive rule set
DBMS_CAPTURE_ADM.CREATE_CAPTURE(
queue_name => 'strmadmin.streams_queue',
capture_name => 'capture',
rule_set_name => 'strmadmin.demo_rules');
END;
/
/*
dbs1.example.comにOracle Streams管理者として接続したままで、dbs3.example.comでdbs1.example.comのhrスキーマをインスタンス化のために準備します。この手順では、インスタンス化のためにスキーマ内の表の最小SCNにマークが付けられます。最小SCNより後のSCNは、インスタンス化に使用できます。
また、この手順では、hrスキーマ内の表のすべての主キー列、一意キー列、ビットマップ索引列および外部キー列のサプリメンタル・ロギングを有効にします。サプリメンタル・ロギングによって、表に対する変更の追加の情報がREDOログに記録されます。適用プロセスでは、一意の行の識別や競合解消など、一部の操作を実行するために、この追加情報が必要です。この環境では、dbs1.example.comデータベースでのみ変更が取得されるため、hrスキーマ内の表に対してサプリメンタル・ロギングを指定する必要があるのはこのデータベースのみです。
|
注意: この手順は、「1つのデータベースからのデータを共有する簡単な構成」では不要です。簡単な構成の例では、手順3でDBMS_STREAMS_ADMパッケージのADD_SCHEMA_RULESプロシージャを実行するときに、DBMS_CAPTURE_ADMパッケージのPREPARE_SCHEMA_INSTANTIATIONプロシージャがhrスキーマに対して自動的に実行されます。 |
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_SCHEMA_INSTANTIATION(
schema_name => 'hr',
supplemental_logging => 'keys');
END;
/
/*
この例では、dbs2.example.comおよびdbs4.example.comにhr.jobs表がすでに存在します。dbs2.example.comでは、この表の名前はassignmentsですが、この表はdbs1.example.comのjobs表と同じ形式で、同じデータを含んでいます。また、この例では、dbs4.example.comはSybaseデータベースです。Oracle Streams環境内の他のすべての表が、データ・ポンプ・インポートを使用して他の接続先データベースでインスタンス化されます。
hr.jobs表はdbs2.example.comおよびdbs4.example.comにすでに存在するため、この例ではdbs1.example.comでDBMS_FLASHBACKパッケージのGET_SYSTEM_CHANGE_NUMBERファンクションを使用して、データベースの現行のSCNを取得します。このSCNは、dbs2.example.comでDBMS_APPLY_ADMパッケージのSET_TABLE_INSTANTIATION_SCNプロシージャを実行するために使用されます。このプロシージャを2回実行して、dbs2.example.comおよびdbs4.example.comでhr.jobs表にインスタンス化SCNを設定します。
SET_TABLE_INSTANTIATION_SCNプロシージャを使用すると、適用プロセスで無視される表のLCRと、適用プロセスで適用される表のLCRを制御できます。ソース・データベースからの表に関するLCRのコミットSCNが、接続先データベースでその表のインスタンス化SCN以下であれば、接続先データベースの適用プロセスではLCRが廃棄されます。それ以外の場合は、適用プロセスによってLCRが適用されます。
この例では、dbs2.example.comの適用プロセスはいずれも、この手順で取得したSCNの後にコミットされたSCNを持つhr.jobs表にトランザクションを適用します。
|
注意: この例では、dbs1.example.com、dbs2.example.com(hr.assignments)およびdbs4.example.comのhr.jobs表の内容は、この手順が完了した時点で一貫性があると想定しています。一貫性を確保するために、この手順の実行中に各データベースの表をロックすることをお薦めします。 |
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'dbs1.example.com',
instantiation_scn => iscn);
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'dbs1.example.com',
instantiation_scn => iscn,
apply_database_link => 'dbs4.example.com');
END;
/
/*
この例では、データ・ポンプを使用して次の表のネットワーク・インポートを実行します。
hr.countries
hr.locations
hr.regions
ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでdbs1.example.comからこれらの表をインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用して表のインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
sscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a table-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'TABLE',
remote_link => 'DBS1.EXAMPLE.COM',
job_name => 'dp_sing2');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HR''');
-- A metadata filter is used to specify the tables that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'NAME_EXPR',
value => 'IN(''COUNTRIES'', ''REGIONS'', ''LOCATIONS'')');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects included in the import.
sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => sscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn);
END;
END;
/
/*
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
countries表、locations表およびregions表にDML変更およびDDL変更を適用するようにdbs3.example.comを構成します。
*/
BEGIN
-- Create the rule set
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.apply_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Rules for hr.countries
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_countries_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''COUNTRIES'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_countries_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''COUNTRIES'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Rules for hr.locations
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_locations_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''LOCATIONS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_locations_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''LOCATIONS'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Rules for hr.regions
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_regions_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''REGIONS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_regions_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''REGIONS'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Add rules to rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_countries_dml',
rule_set_name => 'strmadmin.apply_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_countries_ddl',
rule_set_name => 'strmadmin.apply_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_locations_dml',
rule_set_name => 'strmadmin.apply_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_locations_ddl',
rule_set_name => 'strmadmin.apply_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_regions_dml',
rule_set_name => 'strmadmin.apply_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_regions_ddl',
rule_set_name => 'strmadmin.apply_rules');
-- Create an apply process that uses the rule set as its positive rule set
DBMS_APPLY_ADM.CREATE_APPLY(
queue_name => 'strmadmin.streams_queue',
apply_name => 'apply',
rule_set_name => 'strmadmin.apply_rules',
apply_user => 'hr',
apply_captured => TRUE,
source_database => 'dbs1.example.com');
END;
/
/*
前述の手順でhrユーザーを適用ユーザーとして指定したため、hrユーザーには、適用プロセスで使用されるポジティブ・ルール・セットに対するEXECUTE権限が必要です。
*/
BEGIN
DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE(
privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET,
object_name => 'strmadmin.apply_rules',
grantee => 'hr');
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、dbs3.example.comで適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply');
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
dbs2.example.comのキューからdbs3.example.comのキューへの伝播を構成およびスケジュールします。dbs2.example.comの変更はdbs1.example.comで発生したものであるため、この構成は、有向ネットワークの一例です。
*/
BEGIN
-- Create the rule set
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.propagation_dbs3_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Create rules for all modifications to the countries table
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_countries_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''COUNTRIES'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_countries_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''COUNTRIES'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Create rules for all modifications to the locations table
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_locations_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''LOCATIONS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_locations_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''LOCATIONS'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Create rules for all modifications to the regions table
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_regions_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''REGIONS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_regions_ddl',
condition => ' (:ddl.get_object_owner() = ''HR'' OR ' ||
' :ddl.get_base_table_owner() = ''HR'') AND ' ||
' :ddl.get_object_name() = ''REGIONS'' AND ' ||
' :ddl.is_null_tag() = ''Y'' AND ' ||
' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Add rules to rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_countries_dml',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_countries_ddl',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_locations_dml',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_locations_ddl',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_regions_dml',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_regions_ddl',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
-- Create a propagation that uses the rule set as its positive rule set
DBMS_PROPAGATION_ADM.CREATE_PROPAGATION(
propagation_name => 'dbs2_to_dbs3',
source_queue => 'strmadmin.streams_queue',
destination_queue => 'strmadmin.streams_queue',
destination_dblink => 'dbs3.example.com',
rule_set_name => 'strmadmin.propagation_dbs3_rules');
END;
/
/*
hrユーザーとしてdbs2.example.comに接続します。
*/ CONNECT hr@dbs2.example.com /*
dbs1.example.comのjobs表に対するDML文によって発生する行変更をdbs2.example.comのassignments表に対する行変更に変換するカスタム・ルールベースの変換ファンクションを作成します。
次のファンクションを実行すると、jobs表のすべての行LCRがassignments表の行LCRに変換されます。
|
注意: assignments表にDDL変更も適用された場合、DDL LCR用に別の変換が必要になります。この変換では、オブジェクト名およびDDLテキストを変更する必要があります。 |
*/
CREATE OR REPLACE FUNCTION hr.to_assignments_trans_dml(
p_in_data in ANYDATA)
RETURN ANYDATA IS out_data SYS.LCR$_ROW_RECORD;
tc pls_integer;
BEGIN
-- Typecast AnyData to LCR$_ROW_RECORD
tc := p_in_data.GetObject(out_data);
IF out_data.GET_OBJECT_NAME() = 'JOBS'
THEN
-- Transform the in_data into the out_data
out_data.SET_OBJECT_NAME('ASSIGNMENTS');
END IF;
-- Convert to AnyData
RETURN ANYDATA.ConvertObject(out_data);
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
ローカルのassignments表に変更を適用するようにdbs2.example.comを構成します。assignments表がdbs1.example.comのjobs表から変更を受信することに注意してください。この手順では、DBMS_STREAMS_ADMパッケージのSET_RULE_TRANSFORM_FUNCTIONプロシージャを使用せずにカスタム・ルールベースの変換を指定します。かわりに、名前/値ペアをルールのアクション・コンテキストに手動で追加します。名前/値ペアでは、名前にSTREAMS$_TRANSFORM_FUNCTION、値にhr.to_assignments_trans_dmlが指定されます。
*/
DECLARE
action_ctx_dml SYS.RE$NV_LIST;
action_ctx_ddl SYS.RE$NV_LIST;
ac_name VARCHAR2(30) := 'STREAMS$_TRANSFORM_FUNCTION';
BEGIN
-- Specify the name-value pair in the action context
action_ctx_dml := SYS.RE$NV_LIST(SYS.RE$NV_ARRAY());
action_ctx_dml.ADD_PAIR(
ac_name,
ANYDATA.CONVERTVARCHAR2('hr.to_assignments_trans_dml'));
-- Create the rule set strmadmin.apply_rules
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.apply_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Create a rule that transforms all DML changes to the jobs table into
-- DML changes for assignments table
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_jobs_dml',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''JOBS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ',
action_context => action_ctx_dml);
-- Add the rule to the rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_jobs_dml',
rule_set_name => 'strmadmin.apply_rules');
-- Create an apply process that uses the rule set as its positive rule set
DBMS_APPLY_ADM.CREATE_APPLY(
queue_name => 'strmadmin.streams_queue',
apply_name => 'apply_dbs2',
rule_set_name => 'strmadmin.apply_rules',
apply_user => 'hr',
apply_captured => TRUE,
source_database => 'dbs1.example.com');
END;
/
/*
前述の手順でhrユーザーを適用ユーザーとして指定したため、hrユーザーには、適用プロセスで使用されるポジティブ・ルール・セットに対するEXECUTE権限が必要です。
*/
BEGIN
DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE(
privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET,
object_name => 'strmadmin.apply_rules',
grantee => 'hr');
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、dbs2.example.comでローカル適用を実行するために適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_dbs2',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_dbs2');
END;
/
/*
dbs4.example.com(Sybaseデータベース)のjobs表にDML変更を適用するようにdbs2.example.comを構成します。この変更はdbs1.example.comで発生したことに注意してください。
*/
BEGIN
-- Create the rule set
DBMS_RULE_ADM.CREATE_RULE_SET(
rule_set_name => 'strmadmin.apply_dbs4_rules',
evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT');
-- Create rule strmadmin.all_jobs_remote for all modifications
-- to the jobs table
DBMS_RULE_ADM.CREATE_RULE(
rule_name => 'strmadmin.all_jobs_remote',
condition => ' :dml.get_object_owner() = ''HR'' AND ' ||
' :dml.get_object_name() = ''JOBS'' AND ' ||
' :dml.is_null_tag() = ''Y'' AND ' ||
' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ');
-- Add the rule to the rule set
DBMS_RULE_ADM.ADD_RULE(
rule_name => 'strmadmin.all_jobs_remote',
rule_set_name => 'strmadmin.apply_dbs4_rules');
-- Create an apply process that uses the rule set as its positive rule set
DBMS_APPLY_ADM.CREATE_APPLY(
queue_name => 'strmadmin.streams_queue',
apply_name => 'apply_dbs4',
rule_set_name => 'strmadmin.apply_dbs4_rules',
apply_database_link => 'dbs4.example.com',
apply_captured => TRUE,
source_database => 'dbs1.example.com');
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、データベース・リンクdbs4.example.comを使用してSybaseのリモート適用を開始します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_dbs4',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_dbs4');
END;
/
/*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
dbs1.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture');
END;
/
/*
streams_share_schema2.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*
ここで、dbs1.example.comの特定の表に対してDML変更およびDDL変更を行い、この環境内のOracle Streamsプロセスおよび伝播について構成したルールに基づいて、環境内の他のデータベースにこれらの変更がレプリケートされていることを確認できます。
/*************************** END OF SCRIPT ******************************/
「1つのデータベースからのデータを共有するスクリプトの例」で説明したいずれかの例を完了した後に、dbs1.example.comデータベースのhrスキーマ内の表に対してDML変更およびDDL変更を行うことができます。これらの変更は、Oracle Streamsプロセスおよび伝播について構成したルールに基づいて、環境内の他のデータベースにレプリケートされます。他のデータベースをチェックして、変更がレプリケートされていることを確認できます。
たとえば、次の手順を実行して、dbs1.example.comのhr.jobsおよびhr.locations表に対してDML変更を行います。また、dbs1.example.comのhr.locations表に対してDDL変更を行うこともできます。
これらの変更を行った後に、dbs2.example.comでhr.assignments表を問い合せて、dbs1.example.comのこの表に対して行ったDML変更がレプリケートされていることを確認できます。dbs2.example.comの適用プロセスに構成したカスタム・ルールベースの変換によって、hr.jobs表に対するDML変更がhr.assignments表に対するDML変更に変換されていることに注意してください。dbs3.example.comでhr.locations表を問い合せて、dbs1.example.comのこの表に対して行ったDML変更およびDDL変更がレプリケートされていることも確認できます。
次の変更を行います。
CONNECT hr@dbs1.example.com
Enter password: password
UPDATE hr.jobs SET max_salary=10000 WHERE job_id='MK_REP';
COMMIT;
INSERT INTO hr.locations VALUES(
3300, '521 Ralston Avenue', '94002', 'Belmont', 'CA', 'US');
COMMIT;
ALTER TABLE hr.locations RENAME COLUMN state_province TO state_or_province;
前述の手順で行った変更が取得、伝播および適用されてから、次の問合せを実行して、dbs1.example.comのhr.jobs表に対して行ったUPDATE変更がdbs2.example.comのhr.assignments表に適用されていることを確認します。
CONNECT hr@dbs2.example.com
Enter password: password
SELECT max_salary FROM hr.assignments WHERE job_id='MK_REP';
max_salaryの値が10000と表示されるはずです。
次の問合せを実行して、dbs1.example.comのhr.locations表に対して行ったINSERT変更がdbs3.example.comで適用されていることを確認します。
CONNECT hr@dbs3.example.com
Enter password: password
SELECT * FROM hr.locations WHERE location_id=3300;
前述の手順でdbs1.example.comのhr.locations表に挿入した行が表示されるはずです。
次に、hr.locations表の定義を表示して、ALTER TABLE変更が正常に伝播および適用されていることを確認します。
DESC hr.locations
表の5列目がstate_or_provinceであるはずです。
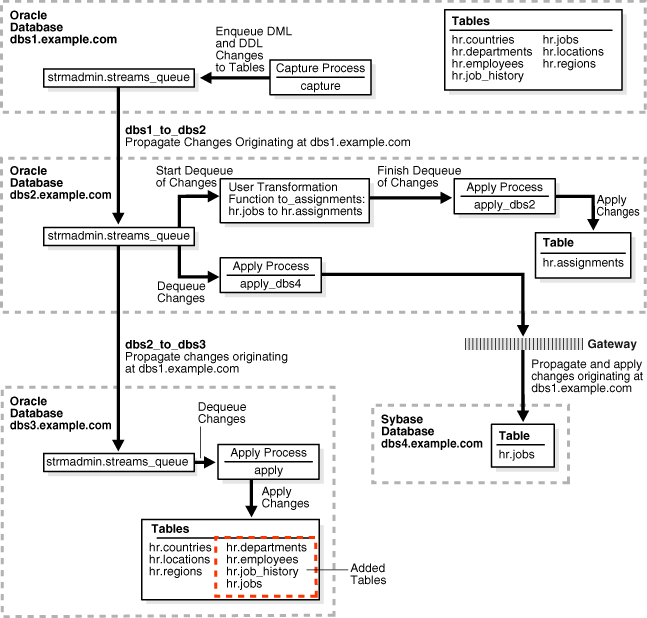
この例では、レプリケート・オブジェクトを既存のデータベースに追加して、前項で構成したOracle Streams環境を拡張します。この例を実行するには、前述の例のいずれか一方のタスクを完了している必要があります。
この例では、dbs3.example.comデータベースのhrスキーマに次の表を追加します。
departments
employees
job_history
jobs
この例を完了すると、Oracle Streamsでは、これらの表に対する変更が次の一連のアクションで処理されます。
取得プロセスがdbs1.example.comで変更を取得してエンキューします。
伝播によって、dbs1.example.comのキューからdbs2.example.comのキューに変更が伝播されます。
伝播によって、dbs2.example.comのキューからdbs3.example.comのキューに変更が伝播されます。
dbs3.example.comの適用プロセスが、変更をdbs3.example.comで適用します。
この例を完了すると、countries表、locations表およびregions表は前項でdbs3.example.comでインスタンス化されているため、dbs3.example.comデータベースのhrスキーマにはオリジナルの表がすべて含まれることになります。
図2-2に、表が追加された環境の概要を示します。
次の手順を実行して、前述の表をdbs3.example.comデータベースにレプリケートします。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_addobjs.out /*
dbs3.example.comへのオブジェクトの追加が完了するまで、追加するオブジェクトの適用プロセスによって、これらのオブジェクトの変更が適用されないようにする必要があります。そのために、ソース・データベースで取得プロセスを停止できます。または、dbs2.example.comからdbs3.example.comへの変更の伝播を停止できます。さらに、dbs3.example.comで適用プロセスを停止することもできます。この例では、dbs3.example.comで適用プロセスを停止します。
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
dbs3.example.comで適用プロセスを停止します。
*/
BEGIN
DBMS_APPLY_ADM.STOP_APPLY(
apply_name => 'apply');
END;
/
/*
追加する表に変更を適用するように、dbs3.example.comで適用プロセスを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.departments',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.employees',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.job_history',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
dbs2.example.comのキューからdbs3.example.comのキューへの伝播のルールに表を追加します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.departments',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.employees',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.job_history',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.jobs',
streams_name => 'dbs2_to_dbs3',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
表をインスタンス化のために準備します。これらの表は、dbs3.example.comでインスタンス化されます。この手順では、インスタンス化のために表の最小SCNにマークが付けられます。最小SCNより後のSCNは、インスタンス化に使用できます。この準備は、dbs3.example.comで関連する伝播および適用プロセスのOracle Streamsデータ・ディクショナリにこれらの表の情報を含めるためにも必要です。
|
注意: この手順でPREPARE_TABLE_INSTANTIATIONプロシージャを実行する際、supplemental_loggingパラメータは指定しません。したがって、このパラメータにはデフォルト値(keys)が使用されます。サプリメンタル・ロギングは、これらの表のすべての主キー列、一意キー列、ビットマップ索引列および外部キー列について、手順3ですでに有効化されています。 |
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION(
table_name => 'hr.departments');
END;
/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION(
table_name => 'hr.employees');
END;
/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION(
table_name => 'hr.job_history');
END;
/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION(
table_name => 'hr.jobs');
END;
/
/*
この例では、データ・ポンプを使用して次の表のネットワーク・インポートを実行します。
hr.departments
hr.employees
hr.job_history
hr.jobs
ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでdbs1.example.comからこれらの表をインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用して表のインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
sscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a table-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'TABLE',
remote_link => 'DBS1.EXAMPLE.COM',
job_name => 'dp_sing3');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HR''');
-- A metadata filter is used to specify the tables that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'NAME_EXPR',
value => 'IN(''DEPARTMENTS'', ''EMPLOYEES'',
''JOB_HISTORY'', ''JOBS'')');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects included in the import.
sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => sscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn);
END;
END;
/
/*
dbs3.example.comで適用プロセスを起動します。これは、手順2で停止した適用プロセスです。
strmadminユーザーとしてdbs3.example.comに接続します。
*/ CONNECT strmadmin@dbs3.example.com /*
dbs3.example.comで適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply');
END;
/
/*
streams_addobjs.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
「既存のOracle Streamsレプリケーション環境へのオブジェクトの追加」で説明した例を完了した後に、dbs1.example.comデータベースのhrスキーマ内の表に対してDML変更およびDDL変更を行うことができます。これらの変更は、dbs3.example.comにレプリケートされます。dbs3.example.comでこれらの表をチェックして、変更がレプリケートされていることを確認できます。
たとえば、次の手順を実行して、dbs1.example.comのhr.employees表に対してDML変更を行います。次に、dbs3.example.comでhr.employees表を問い合せて、変更がレプリケートされていることを確認します。
次の変更を行います。
CONNECT hr@dbs1.example.com
Enter password: password
UPDATE hr.employees SET job_id='ST_MAN' WHERE employee_id=143;
COMMIT;
前述の手順で行った変更が取得、伝播および適用されてから、次の問合せを実行して、dbs1.example.comのhr.employees表に対して行ったUPDATE変更がdbs3.example.comのhr.employees表に適用されていることを確認します。
CONNECT hr@dbs3.example.com
Enter password: password
SELECT job_id FROM hr.employees WHERE employee_id=143;
job_idの値がST_MANと表示されるはずです。
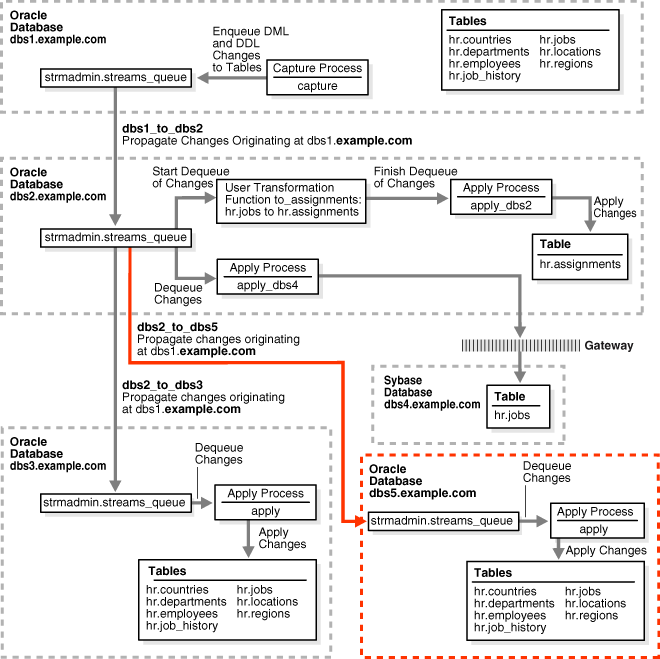
この例では、既存の構成にデータベースを追加して、前項で構成したOracle Streams環境を拡張します。この例では、dbs2.example.comのキューからhrスキーマ全体に対する変更を受信するために、既存のOracle Database dbs5.example.comを追加します。
図2-3に、データベースが追加された環境の概要を示します。
この例を完了するには、次の前提条件を満たしている必要があります。
dbs5.example.comデータベースが存在すること。
dbs2.example.comおよびdbs5.example.comデータベースがOracle Netを介して相互に通信できること。
dbs5.example.comおよびdbs1.example.comデータベースがOracle Netを介して相互に通信できること(オプションのデータ・ポンプ・ネットワークのインスタンス化のため)。
この章の前述の例のタスクを完了していること。
Oracle Streams環境全体を正常に機能させる場合は、「前提条件」を満たしていること。
この例では、dbs5.example.comデータベースで新規ユーザーがOracle Streams管理者(strmadmin)として作成され、このユーザーのデータに使用する表領域の指定を求めるプロンプトが表示されます。この例を開始する前に、dbs5.example.comデータベースでOracle Streams管理者用に新規の表領域を作成するか、または既存の表領域を識別してください。SYSTEM表領域は、Oracle Streams管理者用にしないでください。
次の手順を実行して、dbs5.example.comをOracle Streams環境に追加します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_adddb.out /*
この例では、データ・ポンプを使用してdbs1.example.comからdbs5.example.comに表をインポートすることによって、hrスキーマ内の表をインスタンス化する方法について説明します。この例でのインスタンス化を正常に実行するために、dbs5.example.comでこれらの表を削除する必要があります。
hrとしてdbs5.example.comに接続します。
*/ CONNECT hr@dbs5.example.com /*
dbs5.example.comデータベースのhrスキーマ内のすべての表を削除します。
|
注意: この手順を実行してhrスキーマ内のすべての表を削除した場合、この例の残りの項の手順を実行して、dbs5.example.comでhrスキーマを再インスタンス化する必要があります。hrスキーマがOracle Databaseに存在しない場合、Oracleマニュアル・セットの一部の例が失敗する可能性があります。 |
*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
SYSTEMユーザーとしてdbs5.example.comに接続します。
*/ CONNECT system@dbs5.example.com /*
Oracle Streams管理者strmadminを作成し、このユーザーに必要な権限を付与します。これらの権限によって、ユーザーは、キューの管理、Oracle Streamsに関連するパッケージのサブプログラムの実行、ルール・セットおよびルールの作成、データ・ディクショナリ・ビューおよびキュー表の問合せによるOracle Streams環境の監視を行うことができるようになります。このユーザーには、異なる名前を指定できます。
|
注意: ACCEPTコマンドを、スクリプト内の1行に指定する必要があります。 |
|
関連項目: Oracle Streams管理者を構成する方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
*/
ACCEPT password PROMPT 'Enter password for user: ' HIDE
GRANT DBA TO strmadmin IDENTIFIED BY &password;
ACCEPT streams_tbs PROMPT 'Enter Oracle Streams administrator tablespace on dbs5.example.com: ' HIDE
ALTER USER strmadmin DEFAULT TABLESPACE &streams_tbs
QUOTA UNLIMITED ON &streams_tbs;
/*
Oracle Streams管理者として追加するデータベースに接続します。この例では、データベースdbs5.example.comに接続します。
*/ CONNECT strmadmin@dbs5.example.com /*
SET_UP_QUEUEプロシージャを実行して、dbs5.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、このデータベースに適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
dbs5.example.comからdbs1.example.comへのデータベース・リンクを作成します。このデータベース・リンクは、この例の後半で、手順2で削除したデータベース・オブジェクトをインスタンス化するために使用します。この例では、DBMS_DATAPUMPパッケージを使用して、dbs1.example.comデータベースから直接これらのデータベース・オブジェクトのネットワーク・インポートを実行します。この例ではネットワーク・インポートを実行するため、ダンプ・ファイルは不要です。
または、ソース・データベースdbs1.example.comでエクスポートを実行し、エクスポート・ダンプ・ファイルを接続先データベースdbs5.example.comに転送して、接続先データベースでエクスポート・ダンプ・ファイルをインポートすることもできます。この場合、この手順で作成するデータベース・リンクは不要です。
*/ CREATE DATABASE LINK dbs1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs1.example.com'; /*
dbs5.example.comにOracle Streams管理者として接続したままで、hrスキーマに変更を適用するように適用プロセスを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
schema_name => 'hr',
streams_type => 'apply',
streams_name => 'apply',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE);
END;
/
/*
この例では、hrユーザーが、このデータベースで適用プロセスによって変更が適用されるすべてのデータベース・オブジェクトを所有します。したがって、hrはこれらのデータベース・オブジェクトを変更するために必要な権限をすでに持っており、hrを適用ユーザーにすることが有効です。
前述の手順で適用プロセスを作成したときに、適用プロセスを作成したプロシージャをOracle Streams管理者strmadminが実行したため、デフォルトでは、strmadminが適用ユーザーとして指定されています。hrを適用ユーザーとして指定するかわりに、strmadminを適用ユーザーのままにしておくこともできますが、この場合、変更が適用されるすべてのデータベース・オブジェクトに対する権限、および適用プロセスで使用されるすべてのユーザー・プロシージャを実行する権限をstrmadminに付与する必要があります。適用プロセスが複数のスキーマ内のデータベース・オブジェクトに変更を適用する環境では、Oracle Streams管理者を適用ユーザーとして使用する方が有効な場合があります。
|
関連項目: Oracle Streams管理者を構成する方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
*/
BEGIN
DBMS_APPLY_ADM.ALTER_APPLY(
apply_name => 'apply',
apply_user => 'hr');
END;
/
/*
前述の手順でhrユーザーを適用ユーザーとして指定したため、hrユーザーには、適用プロセスで使用されるポジティブ・ルール・セットに対するEXECUTE権限が必要です。
*/
DECLARE
rs_name VARCHAR2(64); -- Variable to hold rule set name
BEGIN
SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME
INTO rs_name
FROM DBA_APPLY
WHERE APPLY_NAME='APPLY';
DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE(
privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET,
object_name => rs_name,
grantee => 'hr');
END;
/
/*
strmadminユーザーとしてdbs2.example.comに接続します。
*/ CONNECT strmadmin@dbs2.example.com /*
変更が伝播されるデータベースへのデータベース・リンクを作成します。この例では、データベースdbs2.example.comがdbs5.example.comに変更を伝播します。
*/ CREATE DATABASE LINK dbs5.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs5.example.com'; /*
dbs2.example.comにOracle Streams管理者として接続したままで、dbs2.example.comのキューからdbs5.example.comのキューへの伝播を構成およびスケジュールします。hrスキーマに対する変更はdbs1.example.comで発生したことに注意してください。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
schema_name => 'hr',
streams_name => 'dbs2_to_dbs5',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@dbs5.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'dbs1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
strmadminユーザーとしてdbs1.example.comに接続します。
*/ CONNECT strmadmin@dbs1.example.com /*
hrスキーマをインスタンス化のために準備します。このスキーマ内の表は、dbs5.example.comでインスタンス化されます。この準備は、dbs5.example.comで関連する伝播および適用プロセスのOracle Streamsデータ・ディクショナリに、hrスキーマおよびそのスキーマ内のオブジェクトの情報を含めるために必要です。
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/
BEGIN
DBMS_CAPTURE_ADM.PREPARE_SCHEMA_INSTANTIATION(
schema_name => 'hr',
supplemental_logging => 'keys');
END;
/
/*
この例では、データ・ポンプを使用して次の表のネットワーク・インポートを実行します。
hr.countries
hr.departments
hr.employees
hr.job_history
hr.jobs
hr.locations
hr.regions
ネットワーク・インポートとは、エクスポート・ダンプ・ファイルを使用せずに、データ・ポンプでdbs1.example.comからこれらの表をインポートすることを意味します。
|
関連項目: インポートを実行する方法の詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
strmadminユーザーとしてdbs5.example.comに接続します。
*/ CONNECT strmadmin@dbs5.example.com /*
この例では、DBMS_DATAPUMPパッケージを使用して表のインポートを実行します。簡略化するために、どのAPIコールからの例外も捕捉されません。ただし、例外ハンドラを定義し、障害発生時にGET_STATUSをコールしてエラーの詳細情報を取得することをお薦めします。インポートを監視する場合は、インポート・データベースでDBA_DATAPUMP_JOBSデータ・ディクショナリ・ビューを問い合せます。
*/
SET SERVEROUTPUT ON
DECLARE
h1 NUMBER; -- Data Pump job handle
sscn NUMBER; -- Variable to hold current source SCN
job_state VARCHAR2(30); -- To keep track of job state
js ku$_JobStatus; -- The job status from GET_STATUS
sts ku$_Status; -- The status object returned by GET_STATUS
job_not_exist exception;
pragma exception_init(job_not_exist, -31626);
BEGIN
-- Create a (user-named) Data Pump job to do a table-level import.
h1 := DBMS_DATAPUMP.OPEN(
operation => 'IMPORT',
job_mode => 'TABLE',
remote_link => 'DBS1.EXAMPLE.COM',
job_name => 'dp_sing4');
-- A metadata filter is used to specify the schema that owns the tables
-- that will be imported.
DBMS_DATAPUMP.METADATA_FILTER(
handle => h1,
name => 'SCHEMA_EXPR',
value => '=''HR''');
-- Get the current SCN of the source database, and set the FLASHBACK_SCN
-- parameter to this value to ensure consistency between all of the
-- objects included in the import.
sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com();
DBMS_DATAPUMP.SET_PARAMETER(
handle => h1,
name => 'FLASHBACK_SCN',
value => sscn);
-- Start the job.
DBMS_DATAPUMP.START_JOB(h1);
-- The import job should be running. In the following loop, the job
-- is monitored until it completes.
job_state := 'UNDEFINED';
BEGIN
WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP
sts:=DBMS_DATAPUMP.GET_STATUS(
handle => h1,
mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR +
DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS +
DBMS_DATAPUMP.KU$_STATUS_WIP,
timeout => -1);
js := sts.job_status;
DBMS_LOCK.SLEEP(10);
job_state := js.state;
END LOOP;
-- Gets an exception when job no longer exists
EXCEPTION WHEN job_not_exist THEN
DBMS_OUTPUT.PUT_LINE('Data Pump job has completed');
DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn);
END;
END;
/
/*
Oracle Streams管理者としてdbs5.example.comに接続します。
*/ CONNECT strmadmin@dbs5.example.com /*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、dbs5.example.comで適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply');
END;
/
/*
streams_adddb.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
「既存のOracle Streamsレプリケーション環境へのデータベースの追加」で説明した例を完了した後に、dbs1.example.comデータベースのhrスキーマ内の表に対してDML変更およびDDL変更を行うことができます。これらの変更は、dbs5.example.comにレプリケートされます。dbs5.example.comでこれらの表をチェックして、変更がレプリケートされていることを確認できます。
たとえば、次の手順を実行して、dbs1.example.comのhr.departments表に対してDML変更を行います。次に、dbs5.example.comでhr.departments表を問い合せて、変更がレプリケートされていることを確認します。
次の変更を行います。
CONNECT hr@dbs1.example.com
Enter password: password
UPDATE hr.departments SET location_id=2400 WHERE department_id=270;
COMMIT;
前述の手順で行った変更が取得、伝播および適用されてから、次の問合せを実行して、dbs1.example.comのhr.departments表に対して行ったUPDATE変更がdbs5.example.comのhr.departments表に適用されていることを確認します。
CONNECT hr@dbs5.example.com
Enter password: password
SELECT location_id FROM hr.departments WHERE department_id=270;
location_idの値が2400と表示されるはずです。