| Oracle® Textアプリケーション開発者ガイド 11gリリース2 (11.2) B61358-04 |
|


 前 |
 次 |
次の項目について説明します。
今日、企業をはじめ様々な組織が直面している主要な問題の1つが情報過多です。不要なドキュメントの中から役立つドキュメントを選別するために、個人も組織も、創意工夫し、リソースを費やす必要に迫られています。
莫大な数のドキュメントを選別する1つの方法が、キーワード検索エンジンの使用です。ただし、キーワード検索には限界があります。キーワード検索のデメリットの1つが、文脈による識別ができないことです。多くの言語で、1つのワードまたは1つのフレーズに複数の意味があるため、検索すると必要でないトピックに多数一致する可能性があります。たとえば、bankというワードには2つの意味があるため、river bankというフレーズに対して問い合せると、Hudson River Bank & Trust Companyに関するドキュメントが戻されることがあります。
代替案として考えられるのは、人間がドキュメントを選び出し、内容によって分類することですが、これも大量のドキュメントがある場合は現実的ではありません。
Oracle Textは、ドキュメント分類の様々な方法を提供します。ルールベース分類では、ユーザー自身が分類ルールを作成します。管理型分類では、ユーザーが事前に分類したサンプル・ドキュメント・セットに基づいて、Oracle Textにより分類ルールが作成されます。非管理型分類(またはクラスタリング)では、分類ルールの記述からドキュメントの分類に至るすべての手順がOracle Textで自動的に実行されます。
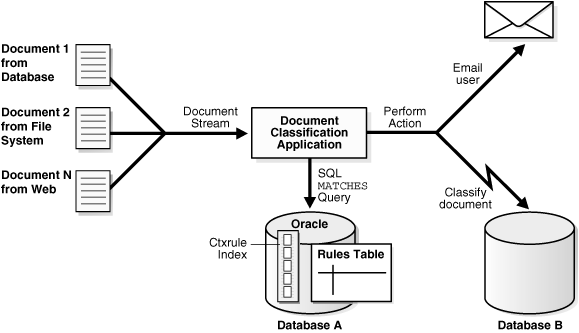
Oracle Textを使用すると、ドキュメント分類アプリケーションを作成できます。ドキュメント分類アプリケーションでは、ドキュメントの内容に基づき、いくつかのアクションを実行します。この処理には、将来の検索で使用するカテゴリIDのドキュメントへの割当てや、ユーザーへのドキュメントの送信などが含まれます。これにより、カテゴリ化されたドキュメントのセットまたはストリームができます。図6-1に、分類プロセスの流れを示します。
Oracle Textを使用すると、ドキュメント分類アプリケーションを様々な方法で作成できます。この章では、典型的な分類方法を定義し、Oracle Textを使用したソリューションの構築方法を説明します。
Oracle Textを使用すると、次の方法でドキュメントを分類できます。
ルールベース分類。ルールベース分類では、ドキュメントをグループ化し、カテゴリを決定し、そのカテゴリを定義する(実際には問合せフレーズとなる)ルールを作成します。次に、そのルールに索引を付け、MATCHES演算子を使用してドキュメントを分類します。
メリット: ルールベース分類は、小さなドキュメント・セットに対しては非常に正確です。ユーザーがルールを作成しているため、常にユーザーの定義に基づいた結果が出ます。
デメリット: カテゴリが多数である大きなドキュメント・セットに対してルールを定義する作業は、冗長になる可能性があります。ドキュメント・セットが大きくなるにつれ、対応するルールをさらに作成する必要があります。
管理型分類。このメソッドはルールベース分類に類似していますが、ルール作成の手順はCTX_CLS.TRAINによって自動化されます。CTX_CLS.TRAINにより、ユーザーが提供する事前分類済のサンプル・ドキュメント・セットから、一連の分類ルールが形成されます。ルールベース分類と同様に、MATCHES演算子を使用してドキュメントを分類します。
Oracle Textには、2つのバージョンの管理型分類があります。1つはRULE_CLASSIFIERプリファレンスを使用したもので、もう1つはSVM_CLASSIFIERプリファレンスを使用したものです。これらについては、「管理型分類」で説明しています。
メリット: ルールが自動的に作成されます。これは、大きなドキュメント・セットに対して役立ちます。
デメリット:
ルールを生成する前にドキュメントをカテゴリに割り当てる必要があります。
ルールは、ユーザーが自分で作成したものには、特定的または正確ではない場合があります。
非管理型分類(クラスタ化分類)。ドキュメントのグループ化からカテゴリ・ルール作成までのすべての手順がCTX_CLS.CLUSTERINGによって自動化されます。Oracle Textでは、ドキュメント・セットを統計的に分析し、その内容に応じてそれらをクラスタと相関付けます。
メリット:
ユーザーが分類ルールや参考用のサンプル・ドキュメントを提供する必要はありません。
ユーザーが見すごす可能性がある、ドキュメント・セットのパターンおよび内容の類似性を検出できます。
実際には、ルールまたは分類の方法を見出せない場合に、非管理型分類を使用できます。また、非管理型分類を使用して最初のカテゴリ・セットを作成し、それを基にして管理型分類を行う方法もあります。
デメリット:
クラスタ化処理はユーザー定義ではなく内部アルゴリズムに基づいているため、クラスタ化によって予期しないグループ化となる可能性があります。
クラスタを作成するルールは表示できません。
クラスタ化はCPU集中型の処理であり、少なくとも索引付けと同じ時間がかかります。
ルールベース分類(「単純な分類」とも呼ばれます)は、Oracle Text分類アプリケーションを作成する基本的な方法です。
ルールベース分類の基本的な手順は、次のとおりです。手順の詳細は、例で説明します。
分類するドキュメント用の表を作成し、それにドキュメントを移入します。
ルール表(カテゴリ表ともいう)を作成します。ルール表は、開発者がネーミングしたカテゴリ(「medicine(医学)」または「finance(会計)」など)、およびドキュメントをこれらのカテゴリにソートするルールで構成されます。
これらのルールが実際の問合せとなります。たとえば、「medicine(医学)」カテゴリを、「hospital(病院)」、「doctor(医者)」または「disease(病気)」などのワードを含むドキュメントで構成すると定義した場合、「hospital OR doctor OR disease」というルールを設定することになります。問合せに使用できる演算子の詳細は、「CTXRULEパラメータおよび制限事項」を参照してください。
ルール表でCTXRULE索引を作成します。
ドキュメントを分類します。
この例では、様々な主題に関する新しい記事を収集し、分類します。
独自のルールが作成されると、それを索引付けし、MATCHES文を使用してドキュメントを分類できます。その手順は次のとおりです。
データを格納する表を作成します。news_tableに、分類するドキュメントが格納されます。news_categories表に、カテゴリおよびカテゴリを定義するルールが格納されます。news_id_cat表に、分類後のドキュメントIDおよび関連するカテゴリが格納されます。
create table news_table (
tk number primary key not null,
title varchar2(1000),
text clob);
create table news_categories (
queryid number primary key not null,
category varchar2(100),
query varchar2(2000));
create table news_id_cat (
tk number,
category_id number);
この手順では、SQLLDRプログラムを使用して、news_tableにHTMLの新しい記事をロードします。ファイル名およびタイトルはloader.datから読み取ります。
LOAD DATA
INFILE 'loader.dat'
INTO TABLE news_table
REPLACE
FIELDS TERMINATED BY ';'
(tk INTEGER EXTERNAL,
title CHAR,
text_file FILLER CHAR,
text LOBFILE(text_file) TERMINATED BY EOF)
この手順では、カテゴリを定義し、各カテゴリのルールを作成します。
| 定義済カテゴリ: | ||
|---|---|---|
| United States(米国) | Europe(ヨーロッパ) | Middle East(中東) |
| Asia(アジア) | Africa(アフリカ) | Conflicts(紛争) |
| Finance(会計) | Technology(科学技術) | Consumer Electronics(家庭用電化製品) |
| Latin America(ラテン・アメリカ) | World Politics(国際政治) | U.S. Politics(米国政治) |
| Astronomy(天文学) | Paleontology(古生物学) | Health(健康) |
| Natural Disasters(自然災害) | Law(法律) | Music News(ミュージック・ニュース) |
ルールとは、カテゴリに対するドキュメントを選択する問合せのことです。たとえば、カテゴリ「Asia(アジア)」には、「China or Pakistan or India or Japan」というルールがあります。news_categories表に次のようにルールを挿入します。
insert into news_categories values (1,'United States','Washington or George Bush or Colin Powell'); insert into news_categories values (2,'Europe','England or Britain or Germany'); insert into news_categories values (3,'Middle East','Israel or Iran or Palestine'); insert into news_categories values(4,'Asia','China or Pakistan or India or Japan'); insert into news_categories values(5,'Africa','Egypt or Kenya or Nigeria'); insert into news_categories values (6,'Conflicts','war or soliders or military or troops'); insert into news_categories values(7,'Finance','profit or loss or wall street'); insert into news_categories values (8,'Technology','software or computer or Oracle or Intel or IBM or Microsoft'); insert into news_categories values (9,'Consumer electronics','HDTV or electronics'); insert into news_categories values (10,'Latin America','Venezuela or Colombia or Argentina or Brazil or Chile'); insert into news_categories values (11,'World Politics','Hugo Chavez or George Bush or Tony Blair or Saddam Hussein or United Nations'); insert into news_categories values (12,'US Politics','George Bush or Democrats or Republicans or civil rights or Senate or White House'); insert into news_categories values (13,'Astronomy','Jupiter or Earth or star or planet or Orion or Venus or Mercury or Mars or Milky Way or Telescope or astronomer or NASA or astronaut'); insert into news_categories values (14,'Paleontology','fossils or scientist or paleontologist or dinosaur or Nature'); insert into news_categories values (15,'Health','stem cells or embryo or health or medical or medicine or World Health Organization or AIDS or HIV or virus or centers for disease control or vaccination'); insert into news_categories values (16,'Natural Disasters','earthquake or hurricane or tornado'); insert into news_categories values (17,'Law','abortion or Supreme Court or illegal or legal or legislation'); insert into news_categories values (18,'Music News','piracy or anti-piracy or Recording Industry Association of America or copyright or copy-protection or CDs or music or artist or song'); commit;
この手順では、news_categories問合せ列でCTXRULE索引を作成します。
create index news_cat_idx on news_categories(query) indextype is ctxsys.ctxrule;
ドキュメントを分類するには、PL/SQLプロシージャCLASSIFIER.THIS(この例のために設計された簡単なプロシージャ)を使用します。このプロシージャはnews_tableをスクロールして、各ドキュメントをカテゴリに照合し、カテゴリに分類した結果をnews_id_cat表に書き込みます。
create or replace package classifier asprocedure this;end;/
show errors
create or replace package body classifier as
procedure this
is
v_document clob;
v_item number;
v_doc number;
begin
for doc in (select tk, text from news_table)
loop
v_document := doc.text;
v_item := 0;
v_doc := doc.tk;
for c in (select queryid, category from news_categories
where matches(query, v_document) > 0 )
loop
v_item := v_item + 1;
insert into news_id_cat values (doc.tk,c.queryid);
end loop;
end loop;
end this;
end;
/
show errors
exec classifier.this
次の考慮事項は、CTXRULE索引の索引付けに適用されます。
SVM_CLASSIFIER分類が使用される場合は、BASIC_LEXER、CHINESE_LEXER、JAPANESE_LEXERまたはKOREAN_MORPH_LEXERレクサーを使用できます。SVM_CLASSIFIERが使用されない場合、問合せセットの索引付けに使用できるのはBASIC_LEXERレクサー・タイプのみです。(レクサーおよび分類のプリファレンスの詳細は、『Oracle Textリファレンス』を参照してください。)
filter、memory、datastoreおよび[no]populateの各パラメータは、索引タイプCTXRULEには適用できません。
CREATE INDEXのSTORAGE句は、問合せでCTXRULE索引を作成するためにサポートされています。
ワードリストは、問合せセットに対するステミング操作でサポートされています。
CTXRULEに対する問合せは、CONTAINS問合せと類似しています。CONTAINS演算子(ABOUT、AND、NEAR、NOT、OR、STEM、WITHINおよびTHESAURUS)とともに、基本的なフレーズ(dog house)がサポートされています。MATCHES演算子を使用してドキュメントを分類する場合、セクション・グループがサポートされています。フィールド・セクションもサポートされていますが、CTXRULEではフィールド問合せが直接サポートされないため、CONTEXT問合せに対しては問合せリライトを使用する必要があります。
管理型分類では、CTX_CLS.TRAINプロシージャを使用してルール記述の手順を自動化します。CTX_CLS.TRAINでは、サンプル・ドキュメントのトレーニング・セットを使用して分類ルールが推定されます。この点が、ユーザー自身が分類ルールを作成する必要があるルールベース分類と比較して大きなメリットとなります。
ただし、CTX_CLS.TRAINプロシージャを実行する前に、カテゴリを手動で作成し、サンプル・トレーニング・セットの各ドキュメントをカテゴリに割り当てる必要があります。CTX_CLS.TRAINの詳細は、『Oracle Textリファレンス』を参照してください。
ルールが生成されると、ユーザーがそれを索引付けし、CTXRULE索引を作成します。次に、MATCHES演算子を使用して、新規ドキュメントの着信ストリームを分類できます。
管理型分類の場合、2つの異なる分類アルゴリズムを選択できます。
意思決定ツリー分類。意思決定ツリー分類のメリットは、生成したルールを簡単に監視(または変更)できる点です。
SVMベース分類。このメソッドでは、サポート・ベクター・マシン(SVM)・アルゴリズムを使用してルールを作成します。SVMベース分類のメリットは、通常、意思決定ツリー分類より正確である点です。デメリットは、バイナリ・ルールが生成されるため、ルール自体が不明瞭になる点です。
意思決定ツリー分類を使用するには、RULE_CLASSIFIERに対して、プリファレンス引数をCTX_CLS.TRAINに設定します。
この分類形式では、ルールの作成に意思決定ツリー・アルゴリズムが使用されます。一般的には、意思決定ツリーは2つ(あるいは3つ以上だが、通常は2つ)の選択肢の間で決定するメソッドです。ドキュメント分類では、選択肢は「トレーニング・セットに一致するドキュメント」か「トレーニング・セットに一致しないドキュメント」です。
意思決定ツリーには、テストできる属性のセットがあります。この場合、次が含まれます。
ドキュメントのワード
ドキュメントのワードのステム(たとえば、「running」のステムは「run」)
ドキュメントのテーマ(テーマが使用されている言語でサポートされている場合)
Oracle Textの学習アルゴリズムにより、トレーニング・セットで提供される各カテゴリに対して、1つ以上の意思決定ツリーが作成されます。これらの意思決定ツリーは、CTXRULE索引で適切に使用できるように、問合せにコード化されます。通常は、「Japanese beetle」で構成されたトレーニング・ドキュメントを含む、あるカテゴリおよび「Japanese currency」に関するドキュメントを含む別のカテゴリが提供された場合、アルゴリズムにより、ワード「Japanese」、「beetle」および「currency」に基づいて意思決定ツリーが作成され、それに応じてドキュメントが分類されます。
意思決定ツリーには、信頼度という概念が含まれます。生成された各ルールには、現行のトレーニング・セットのルールの正確さを表す、パーセンテージ値が割り当てられます。通常、この正確さは常にほぼ100%ですが、これは単にトレーニング・セットの限界を表しています。同様に、通常のトレーニング・セットで生成されたルールの数がユーザーが予想した数よりも少ない場合がありますが、これは、現行のトレーニング・セットの様々なカテゴリを識別するには十分な数です。
意思決定ツリー・メソッドのメリットは、人間が簡単に検査したり変更できるルールを生成できる点です。コンピュータでルールを生成し、その後でルール・セットを編集してユーザーがルールを微調整する場合に、意思決定ツリー分類は役立ちます。
次のSQL例では、ドキュメントおよび分類表の作成、ドキュメントの分類、およびルールの生成の手順を示します。次に、CTX_CLS.TRAINを使用してルールを生成します。
ルールが索引付けされるとCTXRULE索引が作成され、新規ドキュメントはMATCHESを使用して分類されます。
管理型分類の一般的な手順は、次のようになります。
CTX_CLS.TRAINプロシージャでは、入力トレーニング・ドキュメント・セットが必要です。トレーニング・セットとは、すでにカテゴリに割り当てられたドキュメントのセットです。
トレーニング・ドキュメントの表を作成してロードします。次の例では、単純なセットを使用します。ファスト・フード関連が3つとコンピュータ関連が2つです。
create table docs ( doc_id number primary key, doc_text clob); insert into docs values (1, 'MacTavishes is a fast-food chain specializing in burgers, fries and - shakes. Burgers are clearly their most important line.'); insert into docs values (2, 'Burger Prince are an up-market chain of burger shops, who sell burgers - and fries in competition with the likes of MacTavishes.'); insert into docs values (3, 'Shakes 2 Go are a new venture in the low-cost restaurant arena, specializing in semi-liquid frozen fruit-flavored vegetable oil products.'); insert into docs values (4, 'TCP/IP network engineers generally need to know about routers, firewalls, hosts, patch cables networking etc'); insert into docs values (5, 'Firewalls are used to protect a network from attack by remote hosts, generally across TCP/IP');
----------------------------------------------------------------------------
-- Create category tables -- Note that "category_descriptions" isn't really needed for this demo - -- it just provides a descriptive name for the category numbers in -- doc_categories ---------------------------------------------------------------------------- create table category_descriptions ( cd_category number, cd_description varchar2(80)); create table doc_categories ( dc_category number, dc_doc_id number, primary key (dc_category, dc_doc_id)) organization index; -- descriptons for categories insert into category_descriptions values (1, 'fast food'); insert into category_descriptions values (2, 'computer networking');
この場合、ファスト・フードのドキュメントはすべてカテゴリ1に、コンピュータのドキュメントはカテゴリ2になります。
insert into doc_categories values (1, 1); insert into doc_categories values (1, 2); insert into doc_categories values (1, 3); insert into doc_categories values (2, 4); insert into doc_categories values (2, 5);
索引用にOracle Textプリファレンスを作成します。これにより、次のように、テーマをオンにした場合とオフにした場合の効果を実験できます。
exec ctx_ddl.create_preference('my_lex', 'basic_lexer');
exec ctx_ddl.set_attribute ('my_lex', 'index_themes', 'no');
exec ctx_ddl.set_attribute ('my_lex', 'index_text', 'yes');
create index docsindex on docs(doc_text) indextype is ctxsys.context
parameters ('lexer my_lex');
生成したルールに移入する表を作成します。
create table rules( rule_cat_id number, rule_text varchar2(4000), rule_confidence number );
ここで、CTX_CLS.TRAINプロシージャをコールしてルールの一部を生成します。すべての引数が、表、列またはこの例で以前に作成された索引の名前であることに注意してください。これにより、rules表にルールが含まれ、ユーザーが表示できるようになります。
begin
ctx_cls.train(
index_name => 'docsindex',
docid => 'doc_id',
cattab => 'doc_categories',
catdocid => 'dc_doc_id',
catid => 'dc_category',
restab => 'rules',
rescatid => 'rule_cat_id',
resquery => 'rule_text',
resconfid => 'rule_confidence'
);
end;
/
生成済のルールをフェッチします。便宜上、rules表はcategory_descriptionsと結合され、各ルールが適用されるカテゴリを表示できるようになります。
select cd_description, rule_confidence, rule_text from rules, category_descriptions where cd_category = rule_cat_id;
ルールが生成されると、ユーザーは最初の索引付けでルールをテストし、次にMATCHESを使用して新規ドキュメントを分類できます。そのプロセスは、次のとおりです。
CREATE INDEXを使用し、以前に生成したルールにCTXRULE索引を作成します。
create index rules_idx on rules (rule_text) indextype is ctxsys.ctxrule;
set serveroutput on;
declare
incoming_doc clob;
begin
incoming_doc
:= 'I have spent my entire life managing restaurants selling burgers';
for c in
( select distinct cd_description from rules, category_descriptions
where cd_category = rule_cat_id
and matches (rule_text, incoming_doc) > 0) loop
dbms_output.put_line('CATEGORY: '||c.cd_description);
end loop;
end;
/
トレーニング目的に使用できる2番目のメソッドは、サポート・ベクター・マシン(SVM)分類です。SVMは、統計学習理論から派生した、学習アルゴリズム・タイプのマシンです。SVM分類の特徴は、非常に小さいサンプル・セットから学習する機能です。
SVM分類を使用すると、意思決定ツリー分類を使用した場合とほぼ同じ結果が得られますが、次の違いがあります。
CTX_CLS.TRAINのコールで使用するプリファレンスは、RULE_CLASSIFIERではなくSVM_CLASSIFIERと同じタイプになります。(属性を変更しない場合、事前定義済のプリファレンスCTXSYS.SVM_CLASSIFIERを使用できます。)
表のCONTEXT索引を移入する必要がないため、NOPOPULATEキーワードを使用できます。これは、データソースおよびフィルタのプリファレンスによってテキストのソースを検索し、レクサーおよびセクショナのプリファレンスを介してテキストの処理方法を決定する場合にのみ使用されます。
生成済ルールの表には、(最小限)次の列がある必要があります。
cat_id number, type number, rule blob );
見てわかるように、生成されたルールはBLOB列に書き込まれます。そのため、これはユーザーにはわかりにくく、意思決定ツリー分類ルールの場合とは異なり、編集も変更もできません。ここでのトレードオフは、通常、SVMを使用すると、意思決定ツリー分類を使用した場合よりもはるかに高い正確性が得られる点です。
SVM分類では、割当てメモリーはSVMモデルをロードするのに十分な大きさである必要があります。十分でない場合は、SVMに基づいて作成されたアプリケーションでメモリー不足エラーが発生します。メモリー割当ての計算方法は次のとおりです。
Minimum memory request (in bytes) = number of unique categories x number of features example: (value of MAX_FEATURES attributes) x 8
最小限のメモリー要件と一致させる必要がある場合は、次のいずれかを行います。
SGAメモリーの増加(共有サーバー・モードの場合)
PGAメモリーの増加(専用サーバー・モードの場合)
次の例ではSVMベース分類を使用します。基本的には意思決定ツリーの例と同じ手順を使用しています。ただし、次の違いがあります。
この例では、CTX_CLS.TRAINではなくCTX_DDL.CREATE_PREFERENCEを使用して、SVM_CLASSIFIERプリファレンスを設定します。(どちらでも可能です。)
この例では、意思決定ツリーの例のカテゴリ表とは異なり、カテゴリ表にはカテゴリ説明が含まれます。(どちらでも可能です。)
ユーザーにとってルールがわかりにくいため、CTX_CLS.TRAINは、意思決定ツリーの例より少ない引数を取ります。
create table doc (id number primary key, text varchar2(2000)); insert into doc values(1,'1 2 3 4 5 6'); insert into doc values(2,'3 4 7 8 9 0'); insert into doc values(3,'a b c d e f'); insert into doc values(4,'g h i j k l m n o p q r'); insert into doc values(5,'g h i j k s t u v w x y z');
create table testcategory (
doc_id number,
cat_id number,
cat_name varchar2(100)
);
insert into testcategory values (1,1,'number');
insert into testcategory values (2,1,'number');
insert into testcategory values (3,2,'letter');
insert into testcategory values (4,2,'letter');
insert into testcategory values (5,2,'letter');
この場合、移入せずに索引を作成します。
create index docx on doc(text) indextype is ctxsys.context
parameters('nopopulate');
これは、CTX.CLS_TRAINでも可能です。
exec ctx_ddl.create_preference('my_classifier','SVM_CLASSIFIER');
exec ctx_ddl.set_attribute('my_classifier','MAX_FEATURES','100');
create table restab ( cat_id number, type number(3) not null, rule blob );
exec ctx_cls.train('docx', 'id','testcategory','doc_id','cat_id',
'restab','my_classifier');
exec ctx_ddl.create_preference('my_filter','NULL_FILTER');
create index restabx on restab (rule)
indextype is ctxsys.ctxrule
parameters ('filter my_filter classifier my_classifier');
ここで、2つの未知のドキュメントを分類できます。
select cat_id, match_score(1) from restab
where matches(rule, '4 5 6',1)>50;
select cat_id, match_score(1) from restab
where matches(rule, 'f h j',1)>50;
drop table doc;
drop table testcategory;
drop table restab;
exec ctx_ddl.drop_preference('my_classifier');
exec ctx_ddl.drop_preference('my_filter');
ルールベース分類の場合は、ユーザー自身がドキュメントを分類するルールを作成します。管理型分類の場合は、Oracle Textによりルールが作成されますが、事前分類したトレーニング・ドキュメント・セットを提供する必要があります。非管理型分類(またはクラスタリング)では、では、トレーニング・ドキュメント・セットを提供する必要がありません。
CTX_CLS.CLUSTERINGプロシージャを使用して、クラスタ化が行われます。CTX_CLS.CLUSTERINGにより、クラスタと呼ばれるドキュメント・グループの階層が作成され、ドキュメントごとに全リーフ・クラスタの関連性のスコアが戻されます。
たとえば、動物に関するドキュメントの膨大なコレクションがあるとします。CTX_CLS.CLUSTERINGでは、犬、猫、魚、熊に関するリーフ・クラスタを個別に作成できます。(最初の3つのリーフ・クラスタをペットに関するノード・クラスタの下位にグループ化できます。)さらに、チワワなど、特定の犬種に関するドキュメントがあるとします。CTX_CLS.CLUSTERINGでは、関連性スコアの高いドキュメントに犬のクラスタが割り当てられ、猫のクラスタにはそれより低いスコアが割り当てられ、魚と熊のクラスタにはさらに低いスコアが割り当てられます。すべてのクラスタのスコアがすべてのドキュメントに割り当てられる場合、アプリケーションではスコアに基づいて処理を実行できます。
「意思決定ツリー管理型分類」に示したように、クラスタの決定に使用される属性は単純なワード(またはトークン)、ワードのステムおよびテーマ(サポートされている場合)で構成されます。
CTX_CLS.CLUSTERINGにより、出力は2つの表(メモリー内表)に割り当てられます。
ドキュメント割当て表は、各リーフ・クラスタに対するドキュメントの類似性を示します。この情報は、ドキュメント識別、クラスタ識別およびドキュメントとクラスタ間の類似性のスコアで表されます。
クラスタ説明表には、生成されたクラスタに関する情報が含まれます。この表には、クラスタ識別、クラスタ説明テキスト、提示されたクラスタ・ラベル、およびクラスタの品質スコアが含まれます。
CTX_CLS.CLUSTERINGでは、K-MEANアルゴリズムを使用して、クラスタ化を実行します。KMEAN_CLUSTERINGプリファレンスを使用して、CTX_CLS.CLUSTERINGの操作方法を決定します。
|
関連項目: クラスタ・タイプおよび階層的クラスタ化の詳細は、『Oracle Textリファレンス』を参照してください。 |
次のSQL例では、コレクション表でドキュメントの小さなコレクションを作成し、CONTEXT索引を作成します。次に、ドキュメント割当て表およびクラスタ記述表を作成しますが、これらはCLUSTERINGプロシージャに対するコールを使用して移入されます。出力は、SELECT文を使用して表示されます。
set serverout on
/* collect document into a table */
create table collection (id number primary key, text varchar2(4000));
insert into collection values (1, 'Oracle Text can index any document or textual content.');
insert into collection values (2, 'Ultra Search uses a crawler to access documents.');
insert into collection values (3, 'XML is a tag-based markup language.');
insert into collection values (4, 'Oracle Database 11g XML DB treats XML
as a native datatype in the database.');
insert into collection values (5, 'There are three Text index types to cover
all text search needs.');
insert into collection values (6, 'Ultra Search also provides API
for content management solutions.');
create index collectionx on collection(text)
indextype is ctxsys.context parameters('nopopulate');
/* prepare result tables, if you omit this step, procedure will create table automatically */
create table restab (
docid NUMBER,
clusterid NUMBER,
score NUMBER);
create table clusters (
clusterid NUMBER,
descript varchar2(4000),
label varchar2(200),
sze number,
quality_score number,
parent number);
/* set the preference */
exec ctx_ddl.drop_preference('my_cluster');
exec ctx_ddl.create_preference('my_cluster','KMEAN_CLUSTERING');
exec ctx_ddl.set_attribute('my_cluster','CLUSTER_NUM','3');
/* do the clustering */
exec ctx_output.start_log('my_log');
exec ctx_cls.clustering('collectionx','id','restab','clusters','my_cluster');
exec ctx_output.end_log;
|
関連項目 CTX_CLS.CLUSTERING構文および例の詳細は、『Oracle Textリファレンス』を参照してください。 |