| Oracle® Textアプリケーション開発者ガイド 11gリリース2 (11.2) B61358-04 |
|


 前 |
 次 |
この章では、Oracle Textの索引付け機能について説明します。次の項目について説明します。
この項では、Oracle Textの索引のタイプ、索引の構造、索引付け処理および制限について説明します。次の項目について説明します。
Oracle Textでは、CREATE INDEXを使用して複数のタイプの索引を作成できます。表3-1は、各索引タイプ、その用途およびサポートしている機能を示しています。
表3-1 Oracle Textの索引タイプ
| 索引タイプ | 説明 | サポートされるプリファレンスとパラメータ | 問合せ演算子 | 注意 |
|---|---|---|---|---|
|
テキストが大量のまとまったドキュメントで構成されている場合、テキスト検索アプリケーションを作成するには、この索引を使用します。MS Word、HTMLまたはプレーン・テキストなどの多様な形式のドキュメントを索引付けできます。 様々な方法で索引をカスタマイズできます。 この索引タイプでは、元表のDMLの後に |
このサポート対象のパラメータには、索引パーティション句、形式列、キャラクタ・セット列および言語列が含まれます。 |
文法は
|
すべてのドキュメント・サービスと問合せサービスがサポートされています。 パーティション・テキスト表の索引付けがサポートされています。
|
|
|
複合問合せのパフォーマンスを改善するには、この索引タイプを使用します。通常は、この索引タイプを使用して、小さいドキュメントやテキスト断片を索引付けします。複合問合せのパフォーマンスを改善するために、項目名、価格および説明などの元表の他の列を索引に組み込むことができます。 この索引タイプはトランザクションに基づき、元表に対するDMLの後に自動的に更新されます。 |
形式列、キャラクタ・セット列および言語列はサポートされていません。 表のパーティション化および索引のパーティション化はサポートされていません。 |
文法は
テーマ問合せがサポートされています。 |
この索引は大きいため、
|
|
|
ドキュメント分類アプリケーションまたはルーティング・アプリケーションの作成には、 |
「CTXRULEパラメータおよび制限事項」を参照してください。 |
|
単一のドキュメント(プレーン・テキスト、HTMLまたはXML)は、 |
|
|
|
|
|
この索引タイプは非推奨であり、 この索引を作成できるのは、 この索引タイプは |
Oracle Textの索引は、Oracle Databaseのドメイン索引です。問合せアプリケーションを作成するには、テキスト列と構造化データ列の組合せを持つCONTEXTタイプの索引を作成し、CONTAINS演算子を使用してその索引を問い合せます。
索引は、移入済のテキスト表から作成します。問合せアプリケーションでは、テキスト表にテキストまたはテキストの格納場所へのポインタが含まれている必要があります。テキストは通常ドキュメントの集まりですが、小さいテキスト断片の場合もあります。
複合問合せのパフォーマンスを向上させるために、FILTER BY句またはORDER BY句(またはその両方)を持つCONTEXT索引を作成して、複合問合せの構造化基準に使用するリレーショナル列を指定できます。この索引は、CONTAINS演算子で問い合せます。
使用しているアプリケーションが、日付や価格などの関連基準に基づいて、小さいドキュメントや記述的なテキスト断片を検索する複合問合せを利用する回数が多い場合は、CTXCAT索引タイプを使用します。この索引は、CATSEARCH演算子で問い合せます。
単純な分類またはルールベースの分類を使用して、ドキュメント分類アプリケーションを作成するには、CTXRULEタイプの索引を作成します。この索引は、MATCHES演算子を使用してプレーン・テキスト、HTMLまたはXMLドキュメントを分類します。定義する問合せセットは、索引付け対象のテキスト表に格納します。
XMLtype列を使用している場合は、XMLIndex索引によりexistsNode問合せを高速に実行できます。
|
注意: 索引タイプCTXXPATHは非推奨となっています。これは、XMLIndexを使用できない古いリリースのOracle Databaseとの下位互換性のためにのみサポートされています。新しいアプリケーションを作成する場合は、XMLIndexを使用することをお薦めします。 |
テキスト索引は、標準SQLを使用して、Oracle Databaseの拡張索引の1タイプとして作成します。つまり、Oracle Textの索引は、Oracle Databaseの索引と同じように機能します。この索引には参照名があり、標準SQL文を使用して操作できます。
Oracle Textの索引を作成するメリットは、CONTAINS、CATSEARCHおよびMATCHESなどのOracle Textの演算子を使用したテキスト問合せの応答時間が短縮されることです。これらの演算子は、それぞれCONTEXT、CTXCATおよびCTXRULEの各索引タイプを問い合せます。
|
注意: 透過的データ暗号化が可能な列ではドメイン索引はサポートされないため、Oracle Textでドメイン索引を使用することはできません。ただし、TDEが可能な表領域に格納される表の列にはOracle Text索引を作成できます。 |
Oracle Textでは、すべてのワードをトークンに変換してテキストを索引付けします。Oracle TextのCONTEXT索引の一般的な構造は、逆向きの索引であり、各トークンにそのトークンを含むドキュメント(行)のリストが格納されています。
たとえば、初期の索引付け操作が1つ終了すると、ワードDOGのエントリは次のようになります。
| ワード | ドキュメント内の表示 |
|---|---|
| DOG | DOC1 DOC3 DOC5 |
つまり、ワードDOGは、ドキュメント1、3および5を格納する行に含まれています。
この項では、Oracle Textの索引付け処理について説明します。CREATE INDEX文を使用して索引付け処理を開始します。CREATE INDEX文を使用して索引付け処理を開始し、指定したパラメータとプリファレンスに基づいて、トークンに対してOracle Textの索引を作成します。
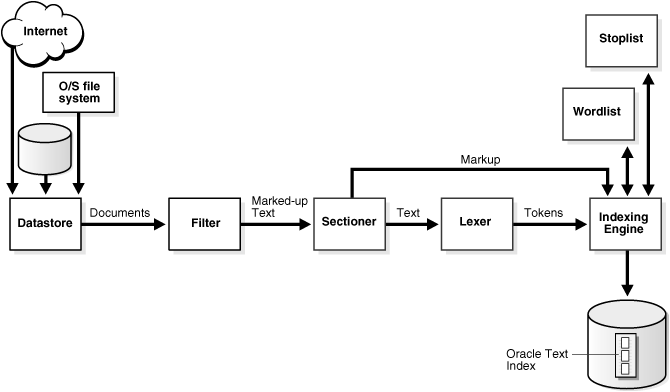
図3-1は、索引付け処理を示しています。データは、様々な索引付けオブジェクトによって操作されます。各オブジェクトは、CREATE INDEXまたはALTER INDEXのパラメータ文字列で指定した索引付けプリファレンス型またはセクション・グループにそれぞれ対応しています。次の項では、これらの各オブジェクトについて説明します。
ストリームはデータストアから始まり、データストアでは、指定したデータストア・プリファレンスに従って、システムに格納されているとおりにドキュメントが読み込まれます。たとえば、データストアをFILE_DATASTOREと定義した場合、ストリームは、オペレーティング・システムからのファイルの読込みで開始されます。ドキュメントは、インターネット上またはOracle Databaseに格納することもできます。ファイルが物理的にどこに存在していても、Oracle Databaseにはそのファイルを指すテキスト表が必要です。
次に、ストリームはフィルタ内を通過します。フィルタで行われる処理の内容は、指定したFILTERプリファレンスによって決定されます。次のいずれかの処理がストリームに対して行われます。
フィルタ処理後、マークアップされたテキストはセクショナを通過し、ストリームはテキスト情報とセクション情報に分割されます。セクション情報には、テキスト・ストリーム内でセクションが開始する場所と終了する場所の情報が含まれています。抽出されるセクションのタイプは、セクション・グループのタイプによって決定されます。
セクション情報は、直接索引付けエンジンに渡され、後で使用されます。テキストはレクサーに渡されます。
Oracle Textのレクサー・タイプのいずれかを使用してレクサー・プリファレンスを作成し、索引付けをするテキストの言語を指定します。レクサーは、使用言語に基づいて、テキストをトークンに分解します。通常、分解されたトークンはワードです。レクサーは、トークンの抽出に、レクサー・プリファレンスに定義されたパラメータを使用します。これらのパラメータには、トークンの分割に使用する空白などの文字の定義や、テキストをすべて大文字に変換するか、あるいは大/小文字混合のままで残すかなどの定義が含まれています。
テーマの索引付けが使用可能の場合、レクサーはテキストを分析してテーマ・トークンを作成し、索引付けを行います。
パーティション・テキスト表にCONTEXTパーティション索引を作成できます。パーティション表は、レンジでパーティション化する必要があります。ハッシュ・パーティション、コンポジット・パーティションおよびリスト・パーティションは、サポートされていません。
日付でデータをパーティション化したパーティション・テキスト表を作成できます。たとえば、使用しているアプリケーションで日付付きのニュース記事の大規模なライブラリをメンテナンスしている場合は、月別または年度別に情報をパーティション化できます。パーティション化によって、問合せ、DMLおよびバックアップとリカバリの操作を単一のパーティションに対して行うことができるため、大規模データベースが管理しやすくなります。
複数の表セットを持つローカルのCONTEXT索引では、Oracle TextはOracle Databaseがサポートする数のパーティションをサポートします。
|
注意: Oracle Textでサポートされるパーティションの数は約1024K-1です。この制限は十分すぎるため、パーティション化された表のCONTEXT索引には適用できません。 |
|
関連項目: パーティション化の詳細は、『Oracle Database概要』を参照してください。 |
継続的に更新が発生し、索引付けのために元表をロックすることが実用的でない場合は、CREATE INDEXのONLINEパラメータを使用して、オンラインで索引を作成できます。この方法を使用すると、DML操作が頻繁に発生するアプリケーションで、索引のために元表の更新を一時停止する必要がありません。
ただし、索引付け処理の最初と最後に元表が短時間ロックされます。
|
関連項目: オンラインでの索引の作成の詳細は、『Oracle Textリファレンス』を参照してください。 |
Oracle Textでは、CREATE INDEXを使用したパラレル索引付けがサポートされています。
非パーティション表にパラレル索引付け文を入力すると、元表が一時パーティションに分割され、子プロセスが起動し、パーティションに子が割り当てられます。その後、子ごとに、それぞれのパーティションの行が索引付けされます。元表をパーティションに分割する方法はOracleによって判断され、ユーザーが直接制御することはありません。また、実際に起動される子プロセス数もOracleによって判断され、マシンの性能、システム負荷、init.ora設定およびその他の要因に依存します。これらの変数により、実際の並列度は、要求された並列度に一致しない可能性があります。
索引付けはI/O集中型の操作であるため、分散ディスク・アクセスと複数CPUを使用する場合は、パラレル索引付けが索引付けに要する時間を短縮するための最も効果的な操作となります。パラレル索引付けは、CREATE INDEXを使用した初期索引のパフォーマンスにのみ影響します。ALTER INDEXを使用したDMLのパフォーマンスには影響せず、問合せパフォーマンスにもほとんど影響しません。
パラレル索引付けは、初期の索引付け時間を短縮するため、次の状況で役立ちます。
データ・ステージング。使用している製品にOracle Textの索引が組み込まれている場合に有効です。
アプリケーションの高速な初期起動。大規模なデータ・コレクションを対象にする場合に有効です。
アプリケーションのテスト。アプリケーションの開発時に多様な索引パラメータやスキーマのテストが必要な場合に有効です。
Oracle SQLの標準では、ビューに対する索引の作成はサポートされていません。複数の表にコンテンツを含むドキュメントの索引付けが必要な場合は、USER_DATASTOREオブジェクトを使用してデータ記憶域プリファレンスを作成できます。このオブジェクトを使用して、索引時に複数の表のドキュメントを合成するプロシージャを定義できます。
|
関連項目: USER_DATASTOREの詳細は、『Oracle Textリファレンス』を参照してください。 |
Oracle Textでは、マテリアライズド・ビュー(MVIEW)に対するCONTEXT、CTXCAT、CTXRULEおよびCTXXPATHの各索引の作成がサポートされています。
Oracle Textの索引を作成するには、CREATE INDEX文を使用します。索引の作成時にパラメータ文字列を指定しないと、索引は、デフォルトのパラメータを使用して作成されます。CONTEXT、CTXCATまたはCTXRULEの各索引を作成できます。ここでは、次の項目について説明します。
また、デフォルトを変更し、問合せアプリケーションにあわせて索引をカスタマイズできます。CREATE INDEXで索引をカスタマイズするために使用するパラメータとプリファレンスのタイプは、次の一般的なカテゴリに分類されます。
Oracle Text問合せアプリケーションの基本的な前提条件は、移入されたテキスト表があることです。テキスト表は、ドキュメント・コレクションに関する情報が格納される場所であり、索引付けをする際に必要です。
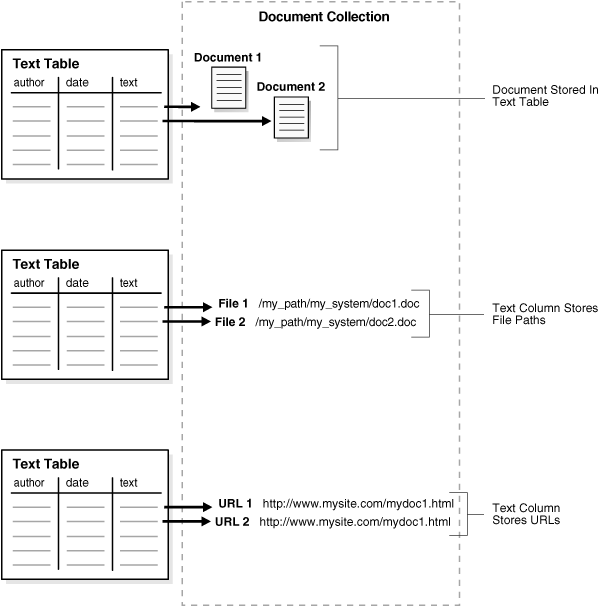
CONTEXT索引を作成する場合、次の要素のいずれかを使用して、テキスト表に行を移入できます。
テキスト情報(ドキュメントまたはテキスト断片)
ファイル・システムにあるドキュメントのパス名
World Wide Webのドキュメントを指定するURL
図3-2は、これらの方法を示しています。
CTXCATまたはCTXRULE索引を作成する場合は、最初に示した方法のみがサポートされます。
デフォルトでは、索引付け操作は、ドキュメント・テキストが直接テキスト表にロードされているものとして動作します。これが、前述の1番目の方法です。
CONTEXT索引を作成する場合、ファイル名やURLからなるドキュメントについては、それぞれに対応するデータ記憶域索引プリファレンスを使用することにより、識別方法を変更できます。
Oracle Textでは、VARCHAR2、CLOB、BLOB、CHAR、BFILE、XMLTypeおよびURIType型の列を使用して、CONTEXT索引を作成できます。
|
注意: NCLOB、DATEおよびNUMBERの列型は索引付けできません。 |
この項では、異なる索引を持つ表にテキストを直接格納する方法について説明します。
ドキュメントは様々な方法でテキスト表に格納できます。
DIRECT_DATASTOREデータ格納タイプを使用すると、1つの列にドキュメントを格納できます。また、MULTI_COLUMN_DATASTOREタイプを使用すると、複数の列にドキュメントを格納できます。複数の列にテキストが格納されている場合、Oracle Textは索引付けを行うためにこれらの列を連結して仮想ドキュメントを作成します。
また、ドキュメントのマスター/ディテール関係を作成し、1つのドキュメントを複数の行に格納することもできます。マスター/ディテール索引を作成するには、DETAIL_DATASTOREデータ格納タイプを使用します。
また、NESTED_DATASTOREタイプを使用して、ネストした表にテキストを格納できます。
Oracle Textでは、XMLドキュメントの格納に使用できるXMLTypeデータ型の索引付けをサポートしています。
テキスト表には、ファイル・システムに格納されているファイルのパス名を格納できます。ファイルのパス名を格納する場合は、索引付け時に、FILE_DATASTOREプリファレンス型を使用します。このデータ格納方法は、CONTEXT索引でのみサポートされています。
URL名を格納して、Webサイトを索引付けできます。URL名を格納する場合は、索引付け時に、URL_DATASTOREプリファレンス型を使用します。このデータ格納方法は、CONTEXT索引でのみサポートされています。
ドキュメントが複合形式または複合キャラクタ・セットの場合は、次の列を追加できます。
索引付け時のフィルタ処理に必要な形式(TEXTまたはBINARY)を記録する形式列。形式列をIGNOREに設定すると、索引付け時に無視する行を指定できます。この機能は、テキスト索引付けと互換性のないイメージなどのデータが含まれた行をバイパスする場合に役立ちます。
行ごとにドキュメントのキャラクタ・セットを記録するキャラクタ・セット列。
索引の作成時に、形式列またはキャラクタ・セット列の名前を、CREATE INDEXのPARAMETERS句に指定する必要があります。
キャラクタ・セット列または言語列にキーワードAUTOまたはAUTOMATICが含まれるすべての行について、Oracle Textは統計的手法を適用して、ドキュメントのキャラクタ・セットおよび言語をそれぞれ判断し、ドキュメントの索引付けを適切に変更します。
システムでは、HTML、PDF、Microsoft Wordおよびプレーン・テキストを含むほとんどのドキュメント形式を索引付けできるため、ユーザーはサポートされている任意のドキュメント・タイプをテキスト列にロードできます。
テキスト列に複合形式がある場合は、必要に応じて、索引付け時のフィルタ処理に役立つ形式列をオプションで組み込むことができます。その形式列を使用して、ドキュメントをBINARY (形式設定済)またはTEXT (形式未設定、HTMLなど)のいずれかに指定できます。HTMLドキュメントとXMLドキュメントを1つの索引に使用する場合、ニーズに合せて索引を構成できない場合があります。スタイルシート情報が索引に追加されないようにすることはできません。
|
関連項目: サポートされているドキュメント形式の詳細は、『Oracle Textリファレンス』を参照してください。 |
CREATE INDEXで索引付けするときに、データストア・プリファレンスを使用してその場所を指定します。使用しているアプリケーションに従って適切なデータストアを使用します。
表3-2は、データストア・プリファレンス型を使用してテキストを格納するすべての方法を説明しています。
表3-2 DATASTOREタイプの要約
| データストア型 | 使用する場合 |
|---|---|
|
データをテキスト列に内部的に格納する場合。各行は単一のドキュメントとして索引付けされます。 テキスト列には、 |
|
|
データをテキスト表の複数の列に格納する場合。列が連結され、各行に1つずつ仮想ドキュメントが作成されます。 |
|
|
データをテキスト列に内部的に格納する場合。ドキュメントがディテール表のテキスト列にある1つ以上の行で構成され、ヘッダー情報はマスター表に格納されます。 |
|
|
データをオペレーティング・システム・ファイルに外部的に格納する場合。ファイル名が、テキスト列の各行に1つずつ格納されます。 |
|
|
データをネストした表に格納する場合。 |
|
|
データをイントラネットまたはインターネット上にあるファイルに外部的に格納する場合。URLはテキスト列に格納されます。 |
|
|
ドキュメントが、索引付け時にユーザー定義ストアド・プロシージャによって合成されます。 |
URLの索引付けの場合、索引付け時間とドキュメントの取出し時間が長くなります。これは、システムがネットワークからドキュメントを取り出す必要があるためです。
Microsoft WordやPDFなどの書式設定されたドキュメントを索引付けするには、テキストにフィルタ処理する必要があります。システムで使用されるフィルタ処理のタイプは、FILTERプリファレンス型によって決まります。デフォルトでは、ドキュメントの形式を自動的に検出し、そのドキュメントをテキストにフィルタ処理するAUTO_FILTERフィルタ型が使用されます。
Oracle Textでは、ほとんどの形式を索引付けできます。また、複合形式を持つドキュメントを含む列も索引付けできます。
HTMLやプレーン・テキストのファイルを索引付けする場合は、AUTO_FILTER型を使用しないでください。最も効率のよい方法として、NULL_FILTERプリファレンス型を使用します。
Microsoft Word、プレーン・テキストおよびHTMLのドキュメントを含む列などの複合形式列がある場合は、テキスト表に形式列を組み込んで、プレーン・テキストやHTMLのフィルタ処理をバイパスできます。形式列では、各行にTEXTまたはBINARYのタグを付けることができます。TEXTタグを付けた行は、フィルタ処理されません。
たとえば、HTMLおよびプレーン・テキストの行にTEXTタグを付け、Microsoft Wordの行にBINARYタグを付けることができます。その形式列をCREATE INDEXのPARAMETERS句で指定します。
第3の形式列の型IGNOREは、ドキュメントに索引を付ける必要がない場合のために用意されています。これは、英語と日本語の両方によるプレーン・テキスト・ドキュメントを含む複合形式の表があり、英語のドキュメントのみを処理する場合や、プレーン・テキスト・ドキュメントとイメージの両方を含む複合形式の表などに役立ちます。IGNOREはデータストア・レベルで実装されるため、すべてのフィルタとともに使用できます。
テキスト表内の索引付け対象外の行(イメージ・データなどを含む行)はバイパスできます。バイパスする場合は、表に形式列を作成し、IGNOREに設定します。その形式列の名前を、CREATE INDEXのPARAMETERS句で指定します。
索引付けエンジンは、フィルタ処理済のテキストを、データベース・キャラクタ・セットであるとみなします。AUTO_FILTERフィルタ型を使用すると、書式設定されたドキュメントは、データベース・キャラクタ・セットでテキストに変換されます。
ソースがテキストで、ドキュメント・キャラクタ・セットがデータベース・キャラクタ・セットでない場合は、AUTO_FILTERフィルタ型またはCHARSET_FILTERフィルタ型を使用すると、テキストを索引付け用に変換できます。
Oracle Textでは、ほとんどの言語を索引付けできます。デフォルトでは、索引付けするテキストの言語は、データベース設定で指定した言語であるとみなされます。ドキュメントの言語によって、次のいずれかのレクサー型を使用します。
英語、フランス語、ドイツ語およびスペイン語のような空白で区切られた言語の索引付けには、BASIC_LEXERプリファレンス型を使用します。これらの言語の中には、代替スペル、複合語の索引付けおよび基本文字変換を使用できるものがあります。
英語、ドイツ語および日本語などの異なる言語のドキュメントを含む表を索引付けするには、MULTI_LEXERプリファレンス型を使用します。
特定の言語を索引付けするために独自のレクサーを作成するには、USER_LEXERプリファレンス型を使用します。
異なる言語のドキュメントを含む表を索引付けし、またドキュメント内の言語を自動検出するには、WORLD_LEXERプリファレンス型を使用します。
日本語、中国語および韓国語のトークン化および索引付け用に特別に設計された他のレクサー型も使用できます。
|
関連項目: 言語の索引付けおよびレクサー型の詳細は、『Oracle Textリファレンス』を参照してください。 |
BASIC_LEXER、日本語、中国語および韓国語の各レクサーを使用して、Oracle Textではほとんどの言語にレクサー・ソリューションを提供しています。他の言語の場合は、ユーザー定義のレクサー・インタフェースを使用して、独自のレクサー・ソリューションを作成できます。このインタフェースを使用すると、索引付けまたは問合せ中にドキュメントを処理するPL/SQLプロシージャまたはJavaプロシージャを作成できます。
さらに、ユーザー定義レクサーを使用して、独自のテーマ・レクサー・ソリューションまたは言語処理エンジンを作成することもできます。
|
関連項目: ユーザー定義レクサーの詳細は、『Oracle Textリファレンス』を参照してください。 |
BASIC_LEXERプリファレンス型を使用する場合は、ハイフンやピリオドなど英数字以外の文字を索引付けでどのように扱うかを、それらの文字を含むトークンに対して指定できます。たとえば、web-siteのようなワードを索引付けする場合、ハイフン文字(-)を組み込むかまたは除外するかを指定できます。
これらの文字は、索引付け時に要求する動作に基づいて、BASIC_LEXERカテゴリに分類されます。索引付け用に設定したレクサーの動作は、問合せ解析用のレクサーの動作と同じです。
次に、設定できる特殊文字をいくつか示します。
索引付け時に英数字以外の文字をトークンに組み込む場合は、その文字をprintjoinとして定義します。
たとえば、索引にハイフンやアンダースコアの文字を組み込む場合は、その文字をprintjoinとして定義します。この場合、web-siteのようなワードは、web-siteとして索引付けされます。websiteを問い合せても、web-siteは検索されません。
英数字以外の文字を含むトークンを使用して索引付けしない場合は、その文字をskipjoinとして定義します。
たとえば、ハイフン(-)文字をskipjoinとして定義した場合、ワードweb-site は、websiteとして索引付けされます。web-siteを問い合せると、websiteとweb-siteを含むドキュメントが検索されます。
その他の文字は、トークン分割(startjoin、endjoin、whitespace)、句読点識別(punctuation)、数値トークン化(numjoin)、改行後のワード継続(continuation)などの別のトークン化動作を制御する文字として指定できます。これらのカテゴリの文字にはデフォルトがありますが、変更できます。
|
関連項目: BASIC_LEXERの詳細は、『Oracle Textリファレンス』を参照してください。 |
デフォルトでは、すべてのテキスト・トークンが大文字に変換された後で索引付けされます。つまり、大/小文字を区別しない問合せになります。たとえば、3つのワードcat、CATおよびCatをそれぞれ個別に問い合せても、すべて同じドキュメントが戻ります。
デフォルトを変更し、索引レコード・トークンをテキストの表示どおりに設定できます。大/小文字を区別する索引を作成した場合は、ドキュメントに一致するように大/小文字を正確に区別して問合せを指定する必要があります。たとえば、ドキュメントにCatが含まれている場合は、このドキュメントに一致するように、問合せをCatと指定する必要があります。catまたはCATと指定すると、ドキュメントは戻りません。
大/小文字を区別する索引付けを使用可能または使用禁止にするには、BASIC_LEXERプリファレンスのmixed_case属性を使用します。
|
関連項目: BASIC_LEXERの詳細は、『Oracle Textリファレンス』を参照してください。 |
索引付け時に、次の各国語別の機能を使用可能にできます。
英語とフランス語の場合は、ドキュメントのテーマ情報を索引付けできます。ドキュメント・テーマは、ドキュメント内で詳しく展開されている概念のことです。テーマは、ABOUT演算子で問い合せることができます。
他の言語のナレッジ・ベースがロードされ、コンパイルされている場合は、その言語でテーマ情報を索引付けできます。
デフォルトでは、テーマは英語とフランス語で索引付けされます。テーマの索引付けは、BASIC_LEXERプリファレンス型のindex_themes属性を使用して、使用可能および使用禁止にできます。
一部の言語には、ティルデ、ウムラウトおよびアクセントなどの発音区別記号を持つ文字が含まれています。索引付け操作で、発音区別記号を含むワードが基本文字書式に変換された場合は、一致のスコアを取得するために、問合せに発音区別記号を含める必要はありません。たとえば、スペイン語の基本文字索引を使用すると、energíaの問合せでは、索引内のenergíaおよびenergiaが一致します。
ただし、基本文字の索引付けが使用禁止になっていると、energíaを問い合せても、一致するのはenergíaのみです。
言語の基本文字の索引付けは、BASIC_LEXERプリファレンス型のbase_letter属性を使用して、使用可能および使用禁止にできます。
|
関連項目: BASIC_LEXERの詳細は、『Oracle Textリファレンス』を参照してください。 |
ドイツ語、デンマーク語およびスウェーデン語などの言語には、複数のスペルが容認されているワードがあります。たとえば、ドイツ語では、äという文字は、aeという文字で代替できます。ae文字は、代替書式と呼ばれます。
これらの言語の場合、デフォルトでは代替書式のワードが索引付けされます。問合せ語句もそれぞれの代替書式に変換されます。その結果、これらのワードをいずれのスペルでも問い合せることができます。
言語の代替スペルは、BASIC_LEXERプリファレンス型のalternate_spelling属性を使用して、使用可能および使用禁止にできます。
|
関連項目: BASIC_LEXERの詳細は、『Oracle Textリファレンス』を参照してください。 |
ドイツ語とオランダ語のテキストには、複合語が含まれています。これらの言語の場合、デフォルトではコンポジット索引が作成されます。その結果、ある語句を問い合せると、その語句を複合語の要素として含むワードが戻ります。
たとえば、ドイツ語で、語句Bahnhof(列車の駅)を問い合せると、Bahnhofを含むドキュメント、あるいはHauptbahnhof、NordbahnhofまたはOstbahnhofなど、Bahnhofが複合語の要素として含まれているワードを含むドキュメントが戻ります。
コンポジット索引の作成は、BASIC_LEXERプリファレンス型のcomposite属性を使用して、使用可能および使用禁止にできます。
|
関連項目: BASIC_LEXERの詳細は、『Oracle Textリファレンス』を参照してください。 |
問合せでファジー・マッチングを使用すると、類似するスペルのワードが一致します。
ステミングを使用すると、同じ語幹を持つワードが一致します。たとえば、$speakを問い合せると、speak、speaks、spokeおよびspokenを含むすべてのドキュメントに検索が拡張されます。
ファジー・マッチングとステミングは、Oracle Textが使用言語に対してこの機能をサポートしている場合は、索引で自動的に使用可能になります。
ファジー・マッチングはデフォルトのパラメータで有効になっていますが、類似度スコアの下限および拡張される語句の最大数が指定されています。索引時にこのデフォルト・パラメータを変更できます。
ステミング問合せのパフォーマンスを改善するには、BASIC_LEXERのindex_stems属性を使用可能にして、ステミング索引を作成します。
|
関連項目: 『Oracle Textリファレンス』 |
ワイルド・カード問合せを使用すると、%ing、cos%または%benz%のような後方一致、前方一致および中間一致の各問合せを入力できます。通常の索引付けでは、これらの問合せは、問合せパフォーマンスを無視して、大きなワード・リストに拡張されることがあります。
ワイルド・カード問合せでは、トークン・プリフィックスとサブストリングが索引に記録されていると、応答時間が短縮されます。
デフォルトでは、トークン・プリフィックスとサブストリングは、Oracle Textの索引に記録されません。使用している問合せアプリケーションがワイルド・カード問合せを頻繁に使用する場合は、トークン・プリフィックスとサブストリングの索引付けを考慮してください。この索引付けを実行するには、wordlistプリファレンス型を使用します。ワイルド・カード検索のパフォーマンスを向上させるために必要なトレードオフは、索引が大きくなることです。
HTMLやXMLのように、内部構造を持つドキュメントの場合は、ドキュメントのセクションを定義および索引付けできます。ドキュメントのセクションを索引付けすると、問合せの範囲を事前定義したセクションに絞り込むことができます。たとえば、問合せに対して、Headingsとして定義したセクション内の語句dogを含むドキュメントすべてを検索するように指定できます。
セクションは、索引付け前に定義し、セクション・グループ・プリファレンスを使用して指定する必要があります。
Oracle Textには、システム定義のHTMLおよびXML用のセクションが定義されたセクション・グループが用意されています。また、索引付け時に、XMLドキュメントからセクションをシステムで自動的に作成するように指定できます。
ストップワードは、索引付け対象外のワードです。通常、ストップワードは、特定の言語で下位レベルの情報を提供するワードを指します。英語では、thisやthatのようなワードです。
デフォルトでは、特定言語の索引付け用に、ストップリストと呼ばれるストップワードのリストが用意されています。CTX_DDLパッケージを使用してこのリストを変更したり、独自のリストを作成できます。ストップリストは、CREATE INDEXのパラメータ文字列に指定します。
ストップテーマは、テーマ索引またはテーマの構成要素に使用できないワードです。ストップテーマは、CTX_DDLパッケージを使用して追加できます。
ドキュメントのテーマは、ABOUT演算子を使用して問い合せることができます。また、PL/SQLパッケージCTX_DOCを使用して、プログラムで取り出すこともできます。
索引のパフォーマンスに影響する要因には、メモリー割当て、ドキュメント形式、並列度およびパーティション表などがあります。
問合せで頻繁にアクセスされるが、ほとんど更新されないLOB構造化列を含む表の場合は、このような列を表外に格納することで問合せのパフォーマンスを向上させることができます。
|
注意: 属性をリモートLOB列にマップすることはできません。 |
CONTAINS()問合せでテキスト以外の列に構造化述語も含まれている場合は、テキスト索引でそれらの列の値も索引付けすることも検討できます。そのようにする場合は、CREATE INDEX文のFILTER BY句でそれらの列を指定します。これにより、パフォーマンス向上のためにOracle Textで構造化述語もまたテキスト索引によって処理するかどうかを決定できます。
また、CONTAINS()問合せで1つ以上の構造化列にORDER BY基準が含まれている場合、テキスト索引はそれらの列の値も索引付けできます。CREATE INDEX文のORDER BY句でそれらの列を指定します。これにより、問合せ応答時間の向上のためにOracle Textでテキスト索引にソートを入れるかどうかを決定できます。
Oracle Textでは、CONTEXT、CTXCAT、CTXRULEおよびCTXXPATHという4つのタイプの索引を作成できます。ここでは、次の項目について説明します。
デフォルトでは、システムはドキュメントがテキスト列に格納されるとみなします。この要件が満たされている場合は、プリファレンスを明示的に指定せずに、SQL文CREATE INDEXを使用して、テキスト索引を拡張可能な索引タイプCONTEXTとして作成できます。システムでは、言語、テキスト列のデータ型およびドキュメントの形式を自動的に検出し、それに従って索引プリファレンスを設定します。
Oracle Textの索引を作成する手順は、次のとおりです。
デフォルトを使用しない場合は、必要に応じて、カスタムの索引プリファレンス、セクション・グループまたはストップリストを指定します。次の表は、これらの索引クラスを説明しています。
必要に応じて、独自のカスタム・プリファレンス、セクション・グループまたはストップリストを作成します。「プリファレンスの作成」を参照してください。
SQL文CREATE INDEXを使用してテキスト索引を作成し、索引名を指定し、必要に応じてプリファレンスを指定します。「CONTEXT索引の作成」を参照してください。
必要に応じて、独自のカスタム索引プリファレンスを作成し、デフォルトを変更できます。ファイルの格納場所やドキュメントのフィルタ処理方法などの索引情報を指定するには、プリファレンスを使用します。プリファレンスを作成した後、属性を設定します。
次の各項では、ダイレクト、複数列、URLおよびファイルのデータストアの設定例を示します。
|
関連項目: データ記憶域の詳細は、『Oracle Textリファレンス』を参照してください。 |
次の例では、テキスト・データを格納するCLOB列がある表を作成します。その後、2行のテキスト・データを移入し、DIRECT_DATASTOREプリファレンス型を使用するシステム定義プリファレンスCTXSYS.DEFAULT_DATASTOREを使用して表を索引付けします。
create table mytable(id number primary key, docs clob);
insert into mytable values(111555,'this text will be indexed');
insert into mytable values(111556,'this is a default datastore example');
commit;
create index myindex on mytable(docs)
indextype is ctxsys.context
parameters ('DATASTORE CTXSYS.DEFAULT_DATASTORE');
次の例では、これらのテキスト列は、連結されて索引付けされます。3つのテキスト列にmy_multiという複数列のデータストア・プリファレンスを作成します。
begin
ctx_ddl.create_preference('my_multi', 'MULTI_COLUMN_DATASTORE');
ctx_ddl.set_attribute('my_multi', 'columns', 'column1, column2, column3');
end;
この例では、my_urlというURL_DATASTOREプリファレンスを作成し、http_proxy、no_proxyおよびtimeoutの各属性を設定します。timeout属性は300秒に設定されます。属性を設定しない場合は、デフォルトが使用されます。
begin
ctx_ddl.create_preference('my_url','URL_DATASTORE');
ctx_ddl.set_attribute('my_url','HTTP_PROXY','www-proxy.us.oracle.com');
ctx_ddl.set_attribute('my_url','NO_PROXY','us.oracle.com');
ctx_ddl.set_attribute('my_url','Timeout','300');
end;
次の例では、FILE_DATASTOREを使用してデータ記憶域プリファレンスを作成します。このプリファレンスによって、索引付け対象のファイルがオペレーティング・システムに格納されていることをシステムに知らせます。この例では、CTX_DDL.SET_ATTRIBUTEを使用して、PATH属性をディレクトリ/docsに設定します。
begin
ctx_ddl.create_preference('mypref', 'FILE_DATASTORE');
ctx_ddl.set_attribute('mypref', 'PATH', '/docs');
end;
ドキュメント・セット全体がHTMLである場合は、フィルタ・プリファレンスにNULL_FILTERを使用する(フィルタ処理を行わない)ことをお薦めします。
たとえば、HTMLドキュメント・セットを索引付けするには、NULL_FILTERおよびHTML_SECTION_GROUPに対するシステム定義プリファレンスを次のように指定できます。
create index myindex on docs(htmlfile) indextype is ctxsys.context
parameters('filter ctxsys.null_filter
section group ctxsys.html_section_group');
次のシグネチャを使用して定義するフィルタ・プロシージャCTXSYS.NORMALIZEを考えてみます。
PROCEDURE NORMALIZE(id IN ROWID, charset IN VARCHAR2, input IN CLOB, output IN OUT NOCOPY VARCHAR2);
このプロシージャをフィルタとして使用するには、次のようにフィルタ・プリファレンスを設定します。
begin
ctx_ddl.create_preference('myfilt', 'procedure_filter');
ctx_ddl.set_attribute('myfilt', 'procedure', 'normalize');
ctx_ddl.set_attribute('myfilt', 'input_type', 'clob');
ctx_ddl.set_attribute('myfilt', 'output_type', 'varchar2');
ctx_ddl.set_attribute('myfilt', 'rowid_parameter', 'TRUE');
ctx_ddl.set_attribute('myfilt', 'charset_parameter', 'TRUE');
end;
printjoin文字は、索引トークンに組み込まれる英数字以外の文字を指します。web-siteのようなワードを、web-siteとして索引付けする場合に使用します。
次の例では、BASIC_LEXERを使用して、printjoin文字をハイフンとアンダースコアに設定します。
begin
ctx_ddl.create_preference('mylex', 'BASIC_LEXER');
ctx_ddl.set_attribute('mylex', 'printjoins', '_-');
end;
前述のように、printjoin文字を設定した索引を作成するには、次の文を入力します。
create index myindex on mytable ( docs ) indextype is ctxsys.context parameters ( 'LEXER mylex' );
異なる言語のドキュメントを含む列を索引付けするには、MULTI_LEXERプリファレンス型を使用します。たとえば、テキスト列に英語、ドイツ語およびフランス語のドキュメントが格納されている場合は、このプリファレンス型を使用できます。
最初に、次のように、主キー、テキスト列および言語列を持つマルチ言語表を作成します。
create table globaldoc ( doc_id number primary key, lang varchar2(3), text clob );
表に格納されているドキュメントのほとんどが英語で、ドイツ語または日本語のドキュメントがいくつかあるとします。この3つの言語を処理するには、英語、ドイツ語および日本語に対して1つずつの、3つのサブレクサーを作成する必要があります。
ctx_ddl.create_preference('english_lexer','basic_lexer');
ctx_ddl.set_attribute('english_lexer','index_themes','yes');
ctx_ddl.set_attribute('english_lexer','theme_language','english');
ctx_ddl.create_preference('german_lexer','basic_lexer');
ctx_ddl.set_attribute('german_lexer','composite','german');
ctx_ddl.set_attribute('german_lexer','mixed_case','yes');
ctx_ddl.set_attribute('german_lexer','alternate_spelling','german');
ctx_ddl.create_preference('japanese_lexer','japanese_vgram_lexer');
マルチレクサー・プリファレンスを作成します。
ctx_ddl.create_preference('global_lexer', 'multi_lexer');
格納されているドキュメントのほとんどが英語であるため、CTX_DDL.ADD_SUB_LEXERを使用して、英語のレクサーをデフォルトに設定します。
ctx_ddl.add_sub_lexer('global_lexer','default','english_lexer');
ここで、CTX_DDL.ADD_SUB_LEXERプロシージャを使用して、ドイツ語および日本語のレクサーをそれぞれの言語に追加します。また、言語列がISO標準言語コード639-2で表現されている場合は、これらを代替値として追加します。
ctx_ddl.add_sub_lexer('global_lexer','german','german_lexer','ger');
ctx_ddl.add_sub_lexer('global_lexer','japanese','japanese_lexer','jpn');
次のように、PARAMETERS句にマルチレクサー・プリファレンスおよび言語列を指定して、索引globalxを作成します。
create index globalx on globaldoc(text) indextype is ctxsys.context
parameters ('lexer global_lexer language column lang');
次の例では、プリフィックスとサブストリングの索引付けに対してワードリスト・プリファレンスを設定します。プリフィックスとサブストリングのコンポーネントを索引に設定すると、ワイルド・カード問合せのパフォーマンスが向上します。
プリフィックス索引付けに対して、3から4文字の長さのトークン・プリフィックスを作成するように指定します。
begin
ctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST');
ctx_ddl.set_attribute('mywordlist','PREFIX_INDEX','TRUE');
ctx_ddl.set_attribute('mywordlist','PREFIX_MIN_LENGTH', '3');
ctx_ddl.set_attribute('mywordlist','PREFIX_MAX_LENGTH', '4');
ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX', 'YES');
end;
HTMLやXMLのように、ドキュメントに内部構造がある場合は、索引付け操作前に埋込みタグを使用してドキュメントのセクションを定義できます。この定義によって、WITHIN演算子を使用してセクション内で問合せができます。セクションは、セクション・グループの構成要素として定義します。
ストップワードは、索引付け対象外のワードです。ストップワードは、通常、英語のthisやthatのような下位レベルの情報を提供するワードを指します。
システムには、すべての言語に対してストップリストというストップワードのリストが用意されています。デフォルトでは、索引付け時に使用言語に対して、Oracle Textのデフォルトのストップリストが使用されます。
デフォルトのストップリストCTXSYS.DEFAULT_STOPLISTを編集するか、次のPL/SQLプロシージャを使用して独自のリストを作成できます。
CREATE INDEXのPARAMETERS句に、カスタムのストップリストを指定します。
また、索引を作成した後で、ALTER INDEX文でストップワードを動的に追加することもできます。
各言語固有のストップワードを保持するマルチ言語ストップリストを作成できます。マルチ言語のストップリストは、英語、ドイツ語および日本語などの異なる言語のドキュメントを含む表を索引付けするためにMULTI_LEXERを使用している場合に有効です。
マルチ言語ストップリストを作成するには、CTX_DLL.CREATE_STOPLISTプロシージャを使用し、MULTI_STOPLISTというストップリスト・タイプを指定します。CTX_DDL.ADD_STOPWORDを使用して言語固有のストップワードを追加します。
独自のストップワードの定義に加えて、ストップテーマ(索引付け対象外のテーマ)も定義できます。この機能が使用できるのは、英語およびフランス語のみです。
数値が索引付け対象外であることも指定できます。索引付け対象外の数値のような英数字のクラスは、ストップクラスと呼ばれます。
独自のストップワード、ストップテーマおよびストップクラスを記録するには、それらを追加するためのストップリストを1つ作成します。そのストップリストをCREATE INDEXのPARAMETERS句で指定します。
CONTEXT索引タイプは、Microsoft Word、HTMLまたはプレーン・テキストのような形式の大量のまとまったドキュメントを索引付けする場合に最適です。CONTEXT索引では、様々な方法で索引をカスタマイズすることもできます。ドキュメントはテキスト表にロードする必要があります。
CONTEXT索引は、トランザクション・ベースでは更新されません。レコードが削除される場合、索引の変更はただちに行われます。つまり、変更を行った瞬間から独自のセッションはレコードを検索しなくなり、他のユーザーはコミット後すぐにレコードを検索しません。挿入と更新の場合、索引の同期化が行われるまで、新しい情報はテキスト検索には表示されません。したがって、元表で挿入または更新を行う場合、CTX_DDL.SYNC_INDEXを使用して明示的に索引を同期化する必要があります。
次の文によって、docs表内のtext列にmyindexというデフォルトのCONTEXT索引を作成します。
CREATE INDEX myindex ON docs(text) INDEXTYPE IS CTXSYS.CONTEXT;
パラメータを明示的に指定せずにCREATE INDEXを使用すると、すべての言語に対してシステムのデフォルト動作が次のようになります。
索引付けされるテキストは、テキスト列に直接格納されるとみなします。テキスト列の型は、CLOB、BLOB、BFILE、VARCHAR2またはCHARになります。
列型を検出し、バイナリの列型(BLOBおよびBFILE)に対してフィルタ処理を使用します。ほとんどのドキュメント形式がフィルタ処理でサポートされています。列がプレーン・テキストの場合、システムはフィルタ処理を使用しません。
|
注意: システムで正しくドキュメントをフィルタ処理するために、使用している環境がAUTO_FILTERフィルタをサポートするように正しく設定されていることを確認してください。
|
データベース設定で指定した言語に対するデフォルトのストップリストを使用します。ストップリストは、索引付け時にシステムが無視するワードを識別します。
デフォルトの索引付け動作は、ユーザー独自のプリファレンスを作成し、このカスタム・プリファレンスをCREATE INDEXのパラメータ文字列に指定することによって、いつでも変更できます。
ALTER INDEX文およびCREATE INDEX文は、CONTEXTグローバル索引の追加的な作成をサポートします。
グローバル索引を作成するために、CREATE INDEXは、REBUILD句のNOPOPULATEキーワードをサポートしています。REPLACEパラメータ内のNOPOPULATEキーワードを使用すると、索引を追加的に作成できます。これは、索引付け処理を連続的に実行するのが困難な大規模なインストールでテキスト索引を作成する場合に便利です。
ローカル索引パーティションを作成するために、ALTER INDEX ... REBUILD partition ... parameters('REPLACE ...')パラメータ文字列は、NOPOPULATEキーワードをサポートするように修正されています。
ローカル索引パーティションを作成するために、CREATE INDEX ... LOCAL ... (partition ... parameters ('NOPOPULATE'))がサポートされています。パーティション・レベルのPOPULATEキーワードまたはNOPOPULATEキーワードは、索引レベルで指定されたPOPULATEまたはNOPOPULATEを上書きします。
|
関連項目: ALTER INDEX文およびCREATE INDEX文の構文の詳細は、『Oracle Textリファレンス』を参照してください。 |
索引付け処理を連続的に実行するのが困難な大規模なインストールの場合、CTX_DDL.POPULATE_PENDINGプロシージャを使用できます。これにより、索引の作成をより細かく制御できます。空の索引を作成し、保留中のキューにすべてのROWIDを配置し、その後CTX_DDL.SYNC_INDEXによって索引を作成する方法をお薦めします。
このプロシージャにより、元表および表パーティション内のすべてのROWIDが保留中のキューに移入されます。
|
関連項目: CTX.DDL.POPULATE_PENDINGの詳細は、『Oracle Textリファレンス』を参照してください。 |
URLで指定されたHTMLドキュメント・セットを索引付けする場合は、CREATE INDEX文でシステム定義プリファレンスであるNULL_FILTERを指定できます。
HTML_SECTION_GROUPを使用するセクション・グループhtmgroupおよびURL_DATASTOREを使用するデータストアmy_urlを次のように指定できます。
begin
ctx_ddl.create_preference('my_url','URL_DATASTORE');
ctx_ddl.set_attribute('my_url','HTTP_PROXY','www-proxy.us.oracle.com');
ctx_ddl.set_attribute('my_url','NO_PROXY','us.oracle.com');
ctx_ddl.set_attribute('my_url','Timeout','300');
end;
begin
ctx_ddl.create_section_group('htmgroup', 'HTML_SECTION_GROUP');
ctx_ddl.add_zone_section('htmgroup', 'heading', 'H1');
end;
ドキュメントを次のように索引付けできます。
CREATE INDEX myindex on docs(htmlfile) indextype is ctxsys.context parameters( 'datastore my_url filter ctxsys.null_filter section group htmgroup' );
複合問合せで問合せ処理を効率化し応答時間を短縮するため、次の例に示すようにFILTER BY句およびORDER BY句を使用できます。
CREATE INDEX myindex on docs(text) INDEXTYPE is CTXSYS.CONTEXT FILTER BY category, publisher, pub_date ORDER BY pub_date desc;
この例では、問合せ処理を効率化するため、問合せ時にFILTER BY category, publisher, pub_date句を指定することで、これらの列上に関連の述語があった場合に、Oracle Textがそれらをテキスト索引の行ソースに入れることを考慮しています。
また、問合せに一致するORDER BY条件がある場合、応答時間を短縮するために、ORDER BY pub_date descを指定することで、Oracle Textにより、SORTをテキスト索引の行ソースに入れるかどうかが決定されます。
CTXCAT索引タイプは、小さなテキスト断片や関連情報の索引付けに最適です。適切に作成されている場合は、この索引タイプを使用するほうが、CONTEXT索引に比べて構造化問合せのパフォーマンスが向上します。
CTXCAT索引は、トランザクション・ベースで更新されます。元表でDML(挿入、更新および削除)を実行すると、索引が自動的に同期化されます。CONTEXT索引と異なり、CTX_DDL.SYNC_INDEXは不要です。
|
注意: トリガーを起動せずに挿入を実行するアプリケーション(SQL*Loaderなど)では、前述の索引の自動同期化は行われません。 |
CTXCAT索引には、索引セットの構成要素として定義したサブ索引が含まれます。1つ以上の列にサブ索引を作成すると、複合問合せのパフォーマンスが向上します。ただし、索引セットにサブ索引を追加すると、コストがかかります。CTXCAT索引の作成に要する時間は、その総サイズによって異なります。CTXCAT索引の総サイズに直接関係する要因は、次のとおりです。
索引付け対象の総テキスト
索引セットに含まれるサブ索引の数
サブ索引を構成する元表の列数
索引セットに多数のコンポーネント索引がある場合、更新が必要な索引が増えるため、DMLのパフォーマンスは低下します。
CTXCAT索引の作成には追加の索引付け時間とディスク領域が必要になるため、索引セットにコンポーネント索引を追加する前に、それぞれのコンポーネント索引によってアプリケーションに提供される問合せパフォーマンス上のメリットを慎重に考慮する必要があります。
オンライン・オークション・サイトでは、品目の説明、価格、入札終了日などの情報を格納し、参照する必要があるため、CTXCAT索引作成のよい例です。
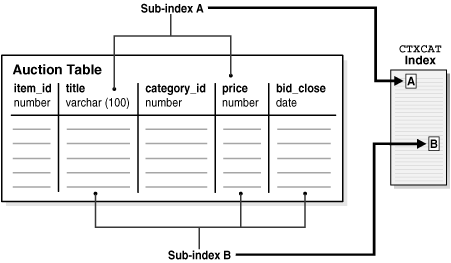
図3-3は、次のスキーマを使用したAUCTIONという表を示しています。
create table auction(
item_id number, title varchar2(100), category_id number, price number, bid_close date);
サブ索引を作成するには、サブ索引を格納する索引セットを作成します。
begin
ctx_ddl.create_index_set('auction_iset');
end;
次に、アプリケーションが入力する可能性がある構造化問合せを特定します。CATSEARCH問合せ演算子では、必須のテキスト句とオプションの構造化句を使用します。
この例では、すべての問合せにテキスト列であるtitle列の句が組み込まれています。
構造化句は、次のカテゴリに分類されるとします。
| 構造化句 | 問合せを満たすサブ索引の定義 | カテゴリ |
|---|---|---|
| 'price < 200'
'price = 150' 'order by price' |
'price' | A |
| 'price = 100 order by bid_close'
'order by price, bid_close' |
'price, bid_close' | B |
構造化問合せ句には、次のように、価格列のみの式が含まれています。
SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'price < 200')> 0; SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'price = 150')> 0; SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'order by price')> 0;
これらの問合せは、サブ索引Bを使用して満たすことができます。しかし、効率を上げるために、priceのみにサブ索引を作成することもできます。それをここではサブ索引Aとします。
begin
ctx_ddl.add_index('auction_iset','price'); /* sub-index A */
end;
構造化問合せ句には、priceについての等式にbid_closeでのソートの条件が付与されたもの、およびpriceとbid_closeの両方で(この順に)ソートの条件が付与されたものが含まれます。
SELECT FROM auction WHERE CATSEARCH( title, 'camera','price = 100 ORDER BY bid_close')> 0; SELECT FROM auction WHERE CATSEARCH( title, 'camera','order by price, bid_close')> 0;
これらの問合せは、次のように定義したサブ索引で満たすことができます。
begin
ctx_ddl.add_index('auction_iset','price, bid_close'); /* sub-index B */
end;
結合されたBツリー索引と同様に、CTX_DDL.ADD_INDEXを使用して指定する列の順序は、特定の問合せを満たすために使用される索引スキャンの効率性および実行可能性に影響します。たとえば、2つの構造化列pとqにBツリー索引が'p,q'として指定されている場合、Oracle Textでは、この索引をスキャンして'ORDER BY q,p'をソートできません。
次の例では、前述の例を結合し、2つのサブ索引を持つ索引セット・プリファレンスを作成します。
begin
ctx_ddl.create_index_set('auction_iset');
ctx_ddl.add_index('auction_iset','price'); /* sub-index A */
ctx_ddl.add_index('auction_iset','price, bid_close'); /* sub-index B */
end;
図3-3は、サブ索引AおよびBをAUCTION表から作成する方法を示しています。各サブ索引はそれぞれテキスト列と名前付き構造化列のBツリー索引です。たとえば、サブ索引Aは、title列とbid_close列の索引です。
結合されたカタログ索引は、CREATE INDEXを使用して次のように作成します。
CREATE INDEX auction_titlex ON AUCTION(title)
INDEXTYPE IS CTXSYS.CTXCAT
PARAMETERS ('index set auction_iset')
;
|
関連項目: CREATEINDEXを使用したCTXCAT索引の作成方法の詳細は、『Oracle Textリファレンス』を参照してください。 |
ドキュメント分類アプリケーションの作成には、CTXRULE索引を使用します。ドキュメント分類アプリケーションでは、ドキュメントの内容に基づいて着信ドキュメントのストリームが分類されます。表または問合せでCTXRULE索引を作成すると、ドキュメント・ルーティングが実行されます。問合せによりカテゴリが定義されます。単一ドキュメントの分類には、MATCHES演算子を使用できます。
この項では、CTXRULE索引および単一のドキュメント分類アプリケーションを作成するための次の手順について説明します。
最初に、分類を定義する問合せ表を作成します。ここでは、カテゴリ名と問合せテキストを保持する表myqueriesを次のように作成します。
CREATE TABLE myqueries (
queryid NUMBER PRIMARY KEY, category VARCHAR2(30), query VARCHAR2(2000)
);
表に分類と各分類を定義する問合せを移入します。たとえば、US Politics、MusicおよびSoccerなどの主題の分類を考えます。
INSERT INTO myqueries VALUES(1, 'US Politics', 'democrat or republican'); INSERT INTO myqueries VALUES(2, 'Music', 'ABOUT(music)'); INSERT INTO myqueries VALUES(3, 'Soccer', 'ABOUT(soccer)');
CREATE INDEXを使用して、CTXRULE索引を作成します。必要に応じて、次のように、lexer、storage、section groupおよびwordlistの各パラメータを指定できます。
CREATE INDEX myruleindex ON myqueries(query)
INDEXTYPE IS CTXRULE PARAMETERS
('lexer lexer_pref
storage storage_pref
section group section_pref
wordlist wordlist_pref');
問合せセットに作成されたCTXRULE索引を使用すれば、MATCHES演算子を使用したドキュメント分類が可能です。
着信ドキュメントは表newsに格納されるとします。
CREATE TABLE news (
newsid NUMBER, author VARCHAR2(30), source VARCHAR2(30), article CLOB);
MATCHESでBEFORE INSERTトリガーを作成すると、各ドキュメントをそれぞれの分類に基づいて、別の表news_routeにルーティングできます。
BEGIN
-- find matching queries
FOR c1 IN (select category
from myqueries
where MATCHES(query, :new.article)>0)
LOOP
INSERT INTO news_route(newsid, category)
VALUES (:new.newsid, c1.category);
END LOOP;
END;
この項では、エラーや索引付け時の障害が発生した場合の索引のメンテナンスについて説明します。次の項目について説明します。
索引付け操作は失敗したり、正常に完了しないことがあります。行の索引付け操作でエラーが発生すると、システムはそのエラーをOracle Textのビューに記録します。
索引のエラーは、CTX_USER_INDEX_ERRORSを使用して表示できます。すべての索引のエラーを表示するには、CTXSYSとしてCTX_INDEX_ERRORSを使用します。
たとえば、索引に最後に発生したエラーを表示するには、次の文を入力します。
SELECT err_timestamp, err_text FROM ctx_user_index_errors ORDER BY err_timestamp DESC;
エラーのビューをクリアするには、次のように入力します。
DELETE FROM ctx_user_index_errors;
このビューは、新しい索引を作成したときに、自動的にクリアされます。
|
関連項目: これらのビューの詳細は、『Oracle Textリファレンス』を参照してください。 |
CREATE INDEXを使用して索引を再作成する前に、既存の索引を削除する必要があります。
索引を削除するには、SQLのDROP INDEX文を使用します。
無効なPARAMETERS文字列を使用して索引を作成する場合は、索引を再作成する前に削除する必要があります。
たとえば、newsindexという索引を削除するには、次のSQL文を入力します。
DROP INDEX newsindex;
索引付け操作が異常終了したときなど、Oracle Textが索引の状態を判断できない場合は、前述のコマンドでは索引を削除できません。この場合は、次のコマンドを使用します。
DROP INDEX newsindex FORCE;
|
関連項目: この文の詳細は、『Oracle Textリファレンス』を参照してください。 |
ALTER INDEX文を使用すると、失敗した索引作成操作を再開できます。通常は、失敗した索引を調査して修正した後、その索引作成を再開します。ただし、失敗した索引をすべて再開できるとはかぎりません。
索引の最適化は定期的にコミットされます。したがって、最適化操作が失敗しても、コミット・ポイントまでのすべての最適化作業は保存されています。
|
関連項目: ALTER INDEX文の構文の詳細は、『Oracle Textリファレンス』を参照してください。 |
例: 失敗した索引の再開
次の文は、10MBのメモリーを使用してnewsindexの索引付け操作を再開します。
ALTER INDEX newsindex REBUILD PARAMETERS('resume memory 10M');
この項では、索引設定の変更を可能にする、索引の再作成に使用できるプロシージャについて説明します。再作成のプロセス中、通常、索引を問い合せることができます。
Oracle Textでは、RECREATE_INDEX_ONLINEを提供して新規プリファレンスによるCONTEXT索引を再作成できる一方、再作成処理中の元表DMLおよび問合せ機能が保持されています。RECREATE_INDEX_ONLINEを単一手順のプロシージャで使用して、グローバル索引用のCONTEXT索引をオンラインで作成できます。既存の索引を残したまま新規索引が作成されるため、この操作には既存の索引とほぼ同じサイズの記憶域が必要です。また、RECREATE_INDEX_ONLINE操作はオンラインで実行されるため、操作中に元表でDMLを発行できます。再作成中に発行されるすべてのDMLは、オンラインの保留中のキューに記録されます。
索引の再作成操作の完了後、再作成プロセス中のDMLによる新しい情報がすぐに反映されない場合があります。オンラインでの索引の作成の場合と同様に、索引の再作成操作の完了後は、索引を完全に最新にするために、それを同期化する必要があります。
再作成中に索引に対して発行される同期化は、既存の古いデータに対して処理されます。この期間中、問合せがエラーを戻す場合、同期化はブロックされます。
再作成中に索引に対して発行される最適化コマンドは、エラーも処理もなく、すぐに戻ります。
RECREATE_INDEX_ONLINEの間は、ほとんど常に、索引を問い合せることができます。問合せは、最後のスワップが終わるまで、既存の索引およびポリシーに基づいて結果を戻します。また、DML文を発行してそれを同期化した場合は、既存の索引の問合せ時に新しい行を表示できます。
|
関連項目: RECREATE_INDEX_ONLINEプロシージャの詳細は、『Oracle Textリファレンス』を参照してください。 |
|
注意: RECREATE_INDEX_ONLINEでは、トランザクション・ベースの問合せはサポートされていません。 |
索引がローカルにパーティション化されている場合は、1回の手順で索引を再作成できません。最初にシャドウ・ポリシーを作成してから、すべてのパーティションに対してRECREATE_INDEX_ONLINEプロシージャを実行する必要があります。パーティションの索引の再作成で索引パーティション・データおよび索引パーティション・メタデータをスワップするかどうかを示すSWAPまたはNOSWAPを指定できます。
パラメータ文字列でNOPOPULATEを指定した場合、このプロシージャを使用して、各パーティションのメタデータ(記憶域プリファレンスなど)を更新できます。これは、時間が限定された同期化によってシャドウ索引を追加的に構築する場合に便利です。NOPOPULATEが指定されている場合は、NOSWAPが警告なしで強制されます。
すべてのパーティションでNOSWAPが使用されている場合、既存の索引とほぼ同じサイズの記憶域が必要です。索引パーティションの再作成中にスワッピングは実行されないため、パーティションに対する問合せは通常処理されます。複数のパーティションにわたる問合せは、スワッピングの段階に到達するまで、パーティションをまたがって一貫した結果を戻します。
SWAPを指定してパーティションを再構築する場合、その操作に必要な記憶域は、既存の索引パーティションとほぼ同じサイズです。索引パーティション・データおよび索引パーティション・メタデータは再作成後にスワッピングされるため、複数のパーティションにわたる問合せはパーティション間で一貫した結果を戻しませんが、各索引パーティションに関しては常に正しい結果となります。
SWAPが指定されている場合、パーティションに対するDMLおよび同期化は、スワッピング・プロセス中にブロックされます。
|
関連項目: RECREATE_INDEX_ONLINEの詳細は、『Oracle Textリファレンス』を参照してください。 |
時間制限付き同期化によるグローバル索引の再作成
索引の再作成を制御して、営業時間外にSYNC_INDEXの時間制限を設定し、索引を追加的に再作成できます。CREATE_SHADOW_INDEXプロシージャをPOPULATE_PENDINGおよびmaxtimeとともに使用します。
|
関連項目: CREATE_SHADOW_INDEXの例については、『Oracle Textリファレンス』を参照してください。 |
スケジュールされたスワッピングによるグローバル索引の再作成
問合せの失敗およびDMLブロックを許容できる場合は、CTX_DDL.EXCHANGE_SHADOW_INDEXを使用して、営業時間外に索引の再作成を実行できます。
|
関連項目: CTX_DDL.EXCHANGE_SHADOW_INDEXの例については、『Oracle Textリファレンス』を参照してください。 |
同時スワッピングによるローカル索引の再作成
ローカル・パーティション索引をオンラインで再作成して、プリファレンスを作成または変更できます。索引およびパーティションのメタデータのスワッピングは、この処理の最後に実行されます。複数のパーティションにわたる問合せは、最後にEXCHANGE_SHADOW_INDEXが実行されているときを除く再作成の処理中、パーティションをまたがって一貫した結果を戻します。
同時スワッピングによるローカル索引再作成のスケジューリング
CTX.DDLパッケージのRECREATE_INDEX_ONLINEにより、ローカル・パーティション索引を追加的に再作成できます。ここで、パーティションは最後にすべてスワッピングされます。
|
関連項目: RECREATE_INDEX_ONLINEを使用したこの処理の詳細および例は、『Oracle Textリファレンス』を参照してください。 |
パーティションごとのスワッピングによるローカル索引の再作成
同時にすべてのパーティションをスワッピングするかわりに、各パーティションをその完了時にスワッピングすることによって、新しいプリファレンスを使用して索引をオンラインで再作成できます。すべてのパーティションにわたる問合せは、その処理中に一貫性のない結果を戻す場合があります。このプロシージャでは、CREATE_SHADOW_INDEXがRECREATE_INDEX_ONLINEとともに使用されます。
|
関連項目: RECREATE_INDEX_ONLINEを使用した索引パーティションのスワッピングの例は、『Oracle Textリファレンス』を参照してください。 |
ALTER INDEXを使用すると、有効な索引を再構築できます。索引の再構築では、索引のほとんどの設定は変更できません。新しいプリファレンスを使用して索引付けする場合に、索引を再構築することがあります。一般的に、索引を削除して、CREATE INDEXを使用して再作成した後に、索引を再構築するメリットはありません。
例: 索引の再構築
次の文は、索引を再構築し、レクサー・プリファレンスをmy_lexerで置き換えます。
ALTER INDEX newsindex REBUILD PARAMETERS('replace lexer my_lexer');
カスタム索引プリファレンスが不要になった場合は、そのプリファレンスを削除できます。
索引プリファレンスの削除には、プロシージャCTX_DDL.DROP_PREFERENCEを使用します。
プリファレンスを削除しても、そのプリファレンスから作成された索引は影響を受けません。
|
関連項目: CTX_DDL.DROP_PREFERENCEプロシージャの構文の詳細は、『Oracle Textリファレンス』を参照してください。 |
例: プリファレンスの削除
次のコードは、プリファレンスmy_lexerを削除します。
begin
ctx_ddl.drop_preference('my_lexer');
end;
元表のDML操作とは、元表に対するドキュメントの挿入、更新または削除操作のことです。この項では、DML操作時にOracle TextのCONTEXT索引を監視、同期化および最適化する方法を説明します。この項の内容は次のとおりです。
|
注意: CTXCAT索引はトランザクション・ベースで更新されるため、元表を変更すると即時に更新されます。この項で説明する手動同期化は、CTXCAT索引には不要です。 |
元表のドキュメントを挿入、更新または削除すると、そのROWIDは、その索引が同期化されるまでDMLキューに保持されます。このキューを表示するには、CTX_USER_PENDINGビューを使用します。
たとえば、すべての索引で保留中のDMLを表示するには、次の文を入力します。
SELECT pnd_index_name, pnd_rowid, to_char(
pnd_timestamp, 'dd-mon-yyyy hh24:mi:ss'
) timestamp FROM ctx_user_pending;
この文によって、次の形式の出力結果が戻されます。
PND_INDEX_NAME PND_ROWID TIMESTAMP ------------------------------ ------------------ -------------------- MYINDEX AAADXnAABAAAS3SAAC 06-oct-1999 15:56:50
|
関連項目: このビューの詳細は、『Oracle Textリファレンス』を参照してください。 |
索引を同期化すると、元表に対する保留中のすべての更新および挿入が処理されます。同期化は、PL/SQLでCTX_DDL.SYNC_INDEXプロシージャを使用して実行します。次の項では、索引の同期化で継続期間およびロック動作を制御する方法を説明します。
次の例では、2MBのメモリーを使用して索引を同期化します。
begin
ctx_ddl.sync_index('myindex', '2M');
end;
|
関連項目: CTX_DDL.SYNC_INDEX文の構文の詳細は、『Oracle Textリファレンス』を参照してください。 |
sync_indexプロシージャには、optimize_indexのように、操作に対し分単位の提示された時間制限を指定するmaxtimeパラメータが含まれます。sync_indexは、指定の時間制限内に、キュー内のできるかぎり多くのドキュメントを処理します。
maxtimeがNULLの場合は、CTX_DDL.MAXTIME_UNLIMITEDの場合と同じです。
時間制限は、概算です。実際にかかる時間が指定した時間より短いかまたは長い場合があります。
非推奨となっているALTER INDEX... syncコマンドには、変更はありません。
sync_indexが索引名なしに起動された場合、maxtimeパラメータは無視されます。
maxtimeパラメータは、自動同期化(sync on commitやsync everyなど)には反映されません。
sync_indexのロック・パラメータにより、索引に対してすでに他の同期化が実行中の場合に同期化がどのような処理をするかを構成できます。
sync_indexが索引名なしに起動された場合、ロック・パラメータは無視されます。
ロック・パラメータは、自動同期化(sync on commitまたはsync everyなど)には反映されません。
ロック・モードがLOCK_WAITの場合、ロックが取得できない場合には永久に待機され、maxtimeの設定は無視されます。
オプションは次のとおりです。
| オプション | 説明 |
|---|---|
CTX_DDL.LOCK_WAIT |
別の同期化が実行されている場合、実行中の同期化が完了するまで待機してから新規の同期化を開始します。 |
CTX_DDL.LOCK_NOWAIT |
別の同期化が実行されている場合、すぐにエラーなしで戻ります。 |
CTX_DDL.LOCK_NOWAIT_ERROR |
別の同期化が実行されている場合、すぐにエラーが発生します(DRG-51313: DMLまたは最適化ロックの待機中にタイムアウトになりました)。 |
索引の同期化を頻繁に行うと、最終的にCONTEXT索引が断片化します。索引の断片化は、問合せ応答時間に悪影響を与える場合があります。したがって、索引の断片化を減少させ、最善の問合せパフォーマンスを実現するために、時間をおいてCONTEXT索引を最適化する必要があります。索引の最適化を理解するには、索引の構造と同期化の内容を理解する必要があります。
CONTEXTCONTEXT索引は、各ワードにそのワードを含むドキュメントのリストが格納された逆向きの索引です。たとえば、初期の索引付け操作が1つ終了すると、ワードDOGのエントリは次のようになります。
DOG DOC1 DOC3 DOC5
新しいドキュメントが元表に追加されると、索引は新しい行の追加によって同期化されます。たとえば、ワードdogを含む新しいドキュメント(DOC 7など)を元表に追加し、索引を同期化すると、次のようになります。
DOG DOC1 DOC3 DOC5 DOG DOC7
続くDML操作によって、新しい行が次のように作成されるとします。
DOG DOC1 DOC3 DOC5 DOG DOC7 DOG DOC9 DOG DOC11
新しいドキュメントの追加と索引の同期化は、索引の断片化の原因になります。特に、バックグラウンドDMLの場合は索引を頻繁に同期化するため、一般的に、バッチ・モードでの同期化に比べて断片化が増加します。
バッチ処理の頻度を少なくすると、ドキュメント・リストが長くなり、索引内の行数も減ります。したがって、断片化も減少します。
CTX_DDL.OPTIMIZE_INDEXを使用して、FULL(完全)またはFAST(高速)モードで索引を最適化すると、索引の断片化を減少させることができます。
ドキュメントを元表から削除すると、Oracle Textでは、そのドキュメントに削除済のマークが設定されます。ただし、索引は即時に変更されません。
古い情報が領域を占有していると問合せ時に余分なオーバーヘッドが発生するため、索引をFULLモードで最適化して古い情報を削除する必要があります。この処理はガベージ・コレクションと呼ばれます。元表に対する更新または削除を頻繁に行う場合は、ガベージ・コレクションのためにFULLモードで最適化を行う必要があります。
索引全体の最適化以外に、単一のトークンも最適化できます。トークン・モードを使用すると、参照頻度の低いトークンの最適化に時間をかけずに、検索頻度の高い索引トークンを最適化できます。
たとえば、トークンDOGの更新と問合せが頻繁に行われる場合、索引内のこのトークンのみの最適化を指定できます。
トークンを最適化すると、そのトークンの問合せ応答時間が短縮できます。
索引の最適化を単一のトークンで行うには、CTX_DDL.OPTIMIZE_INDEXを使用します。