9 Understanding Object Configuration Manager
This chapter contains the following topics:
Object Configuration Manager Overview
This section provides and overview of Object Configuration Manager functionality and discusses:
-
OCM Characteristics
-
OCM Information Requests
-
Object Mappings
OCM Functionality
The OCM provides the flexibility to map data, batch applications, and business functions to a data source, which enables you to coordinate the distributed processing. For example, you would map table objects to database data sources and logic objects to machine data sources
This table describes the minimum of two sets of the Object Configuration Master (F986101) and Data Source Master (F98611) tables that you must have:
- One for All Workstations
-
The Object Configuration Master and Data Source Master tables that the software uses for workstation processing are stored in the centralized system data source normally kept on an enterprise server. If the system data source is not available, the software looks to the workstation's jde.ini file for a secondary location.
- One per Logic Server
-
The Object Configuration Master and Data Source Master tables that the logic server uses are stored on that server in the server map data source. Each logic server type requires its own server map data source.
OCM Characteristics
OCM contains a large number of mappings that define where individual tables exist when looking for data. OCM also contains mappings that define where particular types of logic, specifically business functions or UBEs, will be processed. When a request for data or logic processing occurs, OCM directs it to the appropriate database or machine.
OCM has these characteristics:
-
Data and logic resources can be located on any machine, and JD Edwards EnterpriseOne must know where each resource is located.
-
OCM is the method of managing distributed data and distributed logic processing in a CNC configuration
-
OCM is a collection of data sources, or pointers, to databases and logic processing machines
OCM Information Requests
When an application requests data from a table or a logic object for processing, OCM points to the appropriate database data source.
This diagram illustrates an information request from OCM.
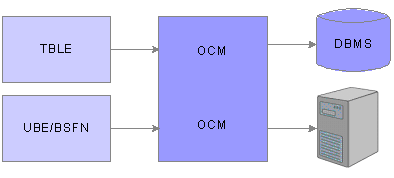
Object Mappings
In Oracle's JD Edwards EnterpriseOne, business objects are used to configure distributed processing and distributed data at runtime. The Object Configuration Master table defines this configuration. You can work with the server object map to modify the entries in this table.
Workstation mappings are stored in a centralized system data source. The F986101 table used by the enterprise server is stored on that server in the server map data source. Each enterprise server requires a separate server map data source.
Compared to a workstation, an enterprise server processing a logic object has a different perspective of where data should be retrieved. For a workstation that is requesting user defined codes, its F986101 table (in the system data source) points to the local database.
When an enterprise server requests user defined codes, it makes no sense for the enterprise server to look to a workstation for this information; therefore, the enterprise server should have unique mappings for user defined codes. These mappings are set up in the Object Configuration Master table (F986101) in the server map data source.
If you have changed table F986101 for the workstation, you should check it in the server maps to see if they should also be changed. For example, if you have new environments with unique mappings for the workstation, you should check to see if changes are required in the corresponding mappings for the enterprise server.
The Object Configuration Manager also provides batch processes to help with the administration of the object mappings. These processes perform such tasks as comparing, updating, copying, and deleting Object Configuration Manager records.
Mapping Alternatives
You map objects by environment. You select an environment that you have already created and map that environment's objects to the data sources you want those objects to use. You can set default mappings for all instances of an object type to one data source, and you can map individual objects to data sources.
This table describes mapping alternatives:
- Mapping Object Types: Default Maps
-
To create a default map for an object type, create a mapping whose object name is the literal value: DEFAULT. Then enter an object type (such as TBLE) and a data source. By creating a default map for the object type TBLE, any table objects not mapped individually point to the default data source.
- Mapping Individual Objects
-
You can map individual objects within an environment. For example, you can map a specific table, such as the Security Workbench Table (F00950), to a data source other than the default, such as to the system data source.
If you do not explicitly map an object by name in the Object Configuration Manager, the software uses the default map for that object's type.
Important:
Each environment must have a default map for TBLE (table) objects for the *PUBLIC user profile because there is no inherent default location for table objects. If table objects do not have a default map and are not explicitly mapped by name, the software produces a Select/Failed error message.Distributed Architecture
The software enables you to distribute data and logic in a manner that optimizes both the power of the workstation and the data integrity of the server. This optimization provides you with:
- Flexibility in determining your own partitioning schemes.
-
As requirements change, you can repartition the system quickly and easily to meet new needs.
- Independence in using the data and logic objects that you need.
-
For example, if you are a salesperson on the road, you can download only the data and logic you need to quote prices and availability. Later, you can connect to the server and place the orders in a batch process.
- Growth for your enterprise systems.
-
The system can be as large as you need because the software enables you to move objects around the system in practically endless combinations.
To keep track of where data resides and where logic processing occurs, the software uses a tool called the Object Configuration Manager. This tool enables users to specify data and logic processing locations.
Partitioning Application Logic on Servers
The logic for JD Edwards EnterpriseOne applications can be partitioned to run remotely by mapping individual or specified groups of business function components to run on an application server or enterprise server instead of on a workstation.
It has been found that redeploying certain business function components (including master business functions and business functions) can significantly increase the performance of a distributed JD Edwards EnterpriseOne workstation while simultaneously decreasing network traffic. This redeployment involves remapping objects using the JD Edwards EnterpriseOne standard Object Configuration Manager methodology.
Examples of such configurations are illustrated by the Windows light client/heavy server and the Java light client/heavy server models. Both models have applications specifications on the client and business function components on the server. The main difference is that the Windows model uses JDENet communication middleware, while the Java model uses JDENet/CORBA middleware.
While the software design enables you to partition all business function components, the biggest benefit is derived from partitioning Master Business Functions (MBFs).
JD Edwards EnterpriseOne transaction-oriented applications are built around the concept of MBFs, which are typically responsible for transaction edits and for committing transactions to the database. Most of the I/O services for transaction-oriented applications are performed by MBFs. By localizing the majority of business logic for transactions in MBFs and partitioning the MBFs to run on application servers, network traffic can be minimized, thus dramatically improving the performance of the application in distributed and WAN environments.
In a two-tier setup where MBFs are processed on the client, a lot of interaction occurs across the WAN between client and server. In a three-tier setup consisting of a client, a data server, and an application or enterprise server, transaction processing can occur across a LAN between the two servers. Interaction across the WAN between the client and server is thus reduced to entering input on the client and sending back results from the server. This three-tier configuration can result in a significant reduction in traffic across the WAN.
The following contrasts typical network traffic for a two-tier setup where MBFs are processed on the client versus network traffic segmentation for a three-tier setup where MBFs are processed on the server.
Two-Tier: Typical Network Traffic
In a two-tier configuration, the GUI, event rules, and MBFs are typically handled by the client, and data is stored on the server. Typically, this processing occurs across the WAN between client and server:
-
Fetch Record (client to server)
-
Return Record (server to client)
-
Validate Data Format (client to server)
-
Format OK (server to client)
-
Send Record Detail (client to server)
-
Detail OK (server to client)
-
End Transaction (client to server)
Three-Tier: Network Traffic Segmentation
In a three-tier configuration, the GUI and event rules are handled by the client, but an application server or enterprise server handles MBF processing. The database server stores data. This processing occurs across the WAN between client and application or enterprise server:
-
Input Processing Request or Data (client to server)
-
Return Processing Results (server to client)
This processing occurs locally across the LAN between the application or enterprise server and the database server:
-
Fetch Record
-
Return Record
-
Validate Data Format
-
Format OK
-
Send Record Detail
-
Detail OK
-
End Transaction
Master Business Function Operations
This series of events demonstrates how a typical application uses a Master Business Function (MBF). This example uses the Sales Order Entry application.
- End of Sales Order Line
-
The first event occurs when the end of a sales order line is reached, causing the JD Edwards EnterpriseOne client application to call the jdeCallObject API. This command sends a message to the MBF. Included with the message is data (in the form of a data structure) for the line. The application sends the message asynchronously with its associated data; that is, once the message is sent, the client application proceeds to the next line.
- MBF Receives Line Message
-
This event occurs when the MBF receives the JDENet message that includes the data for the line. The line data is cached in the server's shared memory.
- MBF Extends and Edits the Line
-
This event occurs when the MBF extends and edits the sales order line. The data necessary to extend and edit the line is typically accessed locally on a LAN. The data is requested by a database-dependent SQL call and is transported by the applicable Open Database Connectivity (ODBC) or Oracle Call Level Interface (OCI) mechanisms.
- MBF Sends a Return Message to the Client Application
-
This event, the fourth event, occurs after the MBF extends and edits the sales order line and returns the extended line, as well as any error codes, to the client. The return message is sent using JDENet. Events 1 through 4 are then repeated asynchronously for all of the lines associated with the sales order.
- End of Sales Order (OK Button)
-
This event indicates that the user has completed all sales order lines. The user triggers this event by clicking OK after all edited lines have been returned to the client. When the user clicks OK, an end of transaction message is sent to the MBF. The client is immediately released to enter the next transaction.
- MBF Processes the Full Transaction
-
The full transaction is processed when the MBF asynchronously reads the shared memory cache (where all transaction lines are stored) and begins the process of committing the transaction to the database.
- Transaction Commitment to the Database and MBF Cleanup
-
The MBF commits the entire transaction to the database, typically locally through ODBC and OCI, and cleans up the shared memory cache for the completed transaction.
Mapping the MBF to run on the server causes the bulk of the database and logic interaction to occur within a single server machine (enterprise server) or between LAN-attached machines (application server and data server). Thus the transaction has been processed with a minimum of network traffic. This type of application transaction is ideally suited for performance gains in distributed and WAN environments.